از آنجایی که خوشه بندی بدون نظارت است، هیچ «حقیقتی» برای تأیید نتایج در دسترس نیست. فقدان حقیقت، ارزیابی کیفیت را پیچیده می کند. علاوه بر این، مجموعه داده های دنیای واقعی معمولاً در خوشه های واضحی از نمونه ها مانند مجموعه داده نشان داده شده در شکل 1 قرار نمی گیرند.
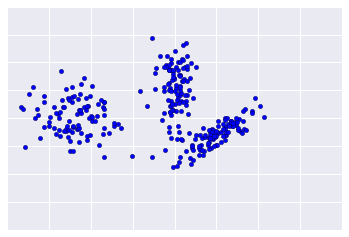
متأسفانه، داده های دنیای واقعی بیشتر شبیه شکل 2 هستند و ارزیابی بصری کیفیت خوشه بندی را دشوار می کند.
فلوچارت زیر نحوه بررسی کیفیت خوشه بندی خود را خلاصه می کند. خلاصه را در بخشهای بعدی توضیح میدهیم.

مرحله اول: کیفیت خوشه بندی
بررسی کیفیت خوشهبندی فرآیند دقیقی نیست زیرا خوشهبندی فاقد «حقیقت» است. در اینجا دستورالعمل هایی وجود دارد که می توانید به طور مکرر برای بهبود کیفیت خوشه بندی خود اعمال کنید.
ابتدا، یک بررسی بصری انجام دهید که خوشهها همانطور که انتظار میرود به نظر میرسند و نمونههایی که شما مشابه آنها را در نظر میگیرید در همان خوشه ظاهر میشوند. سپس این معیارهای رایج مورد استفاده را همانطور که در بخش های زیر توضیح داده شده است بررسی کنید:
- کاردینالیته خوشه
- قدر خوشه
- عملکرد سیستم پایین دستی
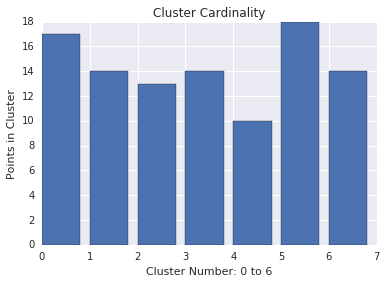
کاردینالیته خوشه
کاردینالیته خوشه تعداد نمونه در هر خوشه است. کاردینالیته خوشه را برای همه خوشه ها ترسیم کنید و خوشه هایی را که نقاط پرت اصلی هستند بررسی کنید. به عنوان مثال، در شکل 2، خوشه شماره 5 را بررسی کنید.
قدر خوشه
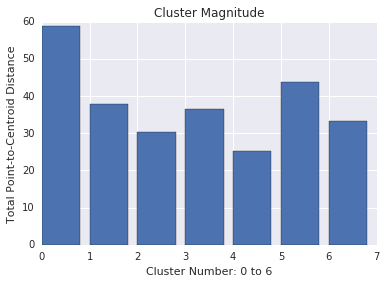
قدر خوشه مجموع فواصل تمام مثال ها تا مرکز خوشه است. مشابه کاردینالیته، بررسی کنید که چگونه بزرگی در میان خوشهها متفاوت است و ناهنجاریها را بررسی کنید. به عنوان مثال، در شکل 3، خوشه شماره 0 را بررسی کنید.
بزرگی در مقابل کاردینالیته
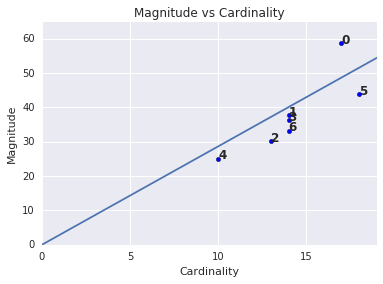
توجه داشته باشید که کاردینالیته خوشه ای بالاتر منجر به بزرگی خوشه بالاتری می شود که به طور شهودی منطقی است. خوشه ها زمانی غیرعادی هستند که کاردینالیته با بزرگی نسبت به خوشه های دیگر همبستگی نداشته باشد. خوشه های غیرعادی را با ترسیم قدر در برابر کاردینالیته پیدا کنید. به عنوان مثال، در شکل 4، برازش یک خط به معیارهای خوشه نشان می دهد که خوشه شماره 0 غیرعادی است.
عملکرد سیستم پایین دستی
از آنجایی که خروجی خوشهبندی اغلب در سیستمهای ML پاییندستی استفاده میشود، بررسی کنید که آیا عملکرد سیستم پاییندست با تغییر فرآیند خوشهبندی شما بهبود مییابد. تأثیر بر عملکرد پایین دستی شما یک آزمون واقعی برای کیفیت خوشه بندی شما فراهم می کند. اشکال این است که انجام این بررسی پیچیده است.
سوالاتی برای بررسی اگر مشکلی پیدا شد
اگر مشکلی پیدا کردید، آماده سازی داده ها و معیار تشابه خود را بررسی کنید و سوالات زیر را از خود بپرسید:
- آیا داده های شما مقیاس بندی شده است؟
- آیا معیار تشابه شما درست است؟
- آیا الگوریتم شما عملیات معنایی معنی داری روی داده ها انجام می دهد؟
- آیا مفروضات الگوریتم شما با داده ها مطابقت دارد؟
مرحله دوم: اجرای معیار تشابه
الگوریتم خوشه بندی شما به اندازه معیار شباهت شما خوب است. اطمینان حاصل کنید که معیار تشابه شما نتایج معقولی را به دست می دهد. سادهترین بررسی، شناسایی جفتهایی از نمونههایی است که کم و بیش شبیه به جفتهای دیگر شناخته شدهاند. سپس، معیار تشابه را برای هر جفت مثال محاسبه کنید. اطمینان حاصل کنید که معیار شباهت برای نمونههای مشابه بیشتر از معیار تشابه برای نمونههای مشابه کمتر است.
مثال هایی که برای بررسی دقیق اندازه گیری شباهت خود استفاده می کنید باید معرف مجموعه داده باشد. اطمینان حاصل کنید که معیار تشابه شما برای همه مثال های شما صادق است. راستیآزمایی دقیق تضمین میکند که اندازهگیری شباهت شما، چه به صورت دستی و چه تحت نظارت، در کل مجموعه داده شما سازگار است. اگر معیار تشابه شما برای برخی از مثالها ناسازگار باشد، آن مثالها با نمونههای مشابه خوشهبندی نمیشوند.
اگر نمونههایی با شباهتهای نادرست پیدا کردید، احتمالاً اندازهگیری شباهت شما دادههای ویژگیای را که آن نمونهها را متمایز میکند، ثبت نمیکند. اندازه گیری شباهت خود را آزمایش کنید و تعیین کنید که آیا شباهت های دقیق تری دارید یا خیر.
مرحله سوم: تعداد بهینه خوشه ها
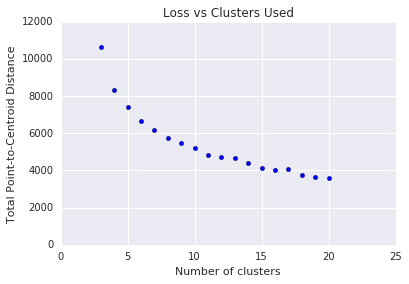
k-means از شما می خواهد که تعداد خوشه های \(k\) را از قبل تعیین کنید. چگونه مقدار بهینه \(k\)را تعیین می کنید؟ سعی کنید الگوریتم افزایش \(k\) را اجرا کنید و مجموع بزرگی های خوشه را یادداشت کنید. با افزایش \(k\)، خوشه ها کوچکتر می شوند و فاصله کل کاهش می یابد. این فاصله را در برابر تعداد خوشه ها ترسیم کنید.
همانطور که در شکل 4 نشان داده شده است، در یک \(k\)مشخص، کاهش ضرر با افزایش \(k\)حاشیه ای می شود. از نظر ریاضی، این تقریباً همان \(k\)که در آن شیب از -1 (\(\theta > 135^{\circ}\)) عبور می کند. این دستورالعمل یک مقدار دقیق را برای \(k\) بهینه مشخص نمی کند، بلکه فقط یک مقدار تقریبی را مشخص می کند. برای نمودار نشان داده شده، \(k\) بهینه تقریباً 11 است. اگر خوشه های دانه دار بیشتری را ترجیح می دهید، می توانید با استفاده از این نمودار به عنوان راهنما، یک \(k\) بالاتر انتخاب کنید.