Page Summary
-
This document answers frequently asked questions about Health AI Foundation models.
-
HAI-DEF models are open-weight, not open-source, allowing developers to download and use the model under specific terms.
-
HAI-DEF models aim to accelerate AI development in healthcare by providing tools that require less data and compute.
-
Developers are responsible for ensuring their use of HAI-DEF models complies with relevant regulations, such as those for medical applications.
-
HAI-DEF models can be used on various systems and infrastructure, including locally or on different cloud platforms.
This document provides answers to frequently asked questions (FAQs) about the Health AI Foundations (HAI-DEF) building blocks.
You can also ask questions interactively using our chatbot, which has full context on this FAQ and the rest of our documentation. To open the chatbot from any page, click the tab on the right side of your screen.
General
The main target audience of HAI-DEF are app developers, machine learning engineers, data scientists, and clinical researchers in the healthcare and life sciences sectors who are researching the role of AI in healthcare and building AI-enabled applications.
Models are mathematical functions that process input data to produce a useful output. For example, a model to determine if an image is of a cat or dog takes the image pixels as input and uses mathematical functions to produce a probability score indicating the likelihood of the image being a cat or a dog.
HAI-DEF models are focused on "understanding" healthcare data. To explore the unique capabilities of each model, visit its overview page. For example, see the MedGemma overview.
A model is considered foundational if it is trained on broad range of data and can be adapted to perform a wide variety of downstream tasks, rather than being built for a single, specific task.
An embedding is a compact list of numbers (a multidimensional vector) that captures the essential semantic meaning and underlying features of complex data, such as medical images or clinical audio.
By converting raw, high-dimensional input data into rich numerical embeddings, HAI-DEF embedding models such as MedSigLip or HeAR allow developers to build task-specific models using significantly less training data and computational resources than building models from scratch.
HAI-DEF is rooted in Google's Health AI research, with the mandate to "catalyze the adoption of human-centered AI in healthcare". Success is measured by real-world impact that is otherwise not possible by Google alone.
The purpose of the HAI-DEF models is to provide the businesses/developer community with extensible building blocks to accelerate the application of AI in healthcare.
Although Google Cloud customers benefit from prebuilt integrations and a shorter path to production at scale, our models are offered on a non-exclusive basis, meaning you are free to deploy and run them anywhere across any cloud, local server, or edge infrastructure.
HAI-DEF models are open-weight, not open-source. While the weights (learned parameters of the neural network) are openly released, not all of the supporting code that was used to produce those weights is open. With open-weight models, you as the developer can download, adapt and use the model, subject to HAI-DEF's Terms of use and Prohibited use.
All the accompanying code in each model's GitHub repository are open-source under an Apache 2.0 license.
Consult the Shortcuts page for a compact list of available models and related links. You can refer to each model's dedicated model card to learn about its intended use, limitations, required data formats, and evaluation benchmarks.
You can also use our interactive chatbot to help you with model details. It has all our model cards and technical reports in context.
If you choose to deploy any of our foundation models, you are responsible for evaluating them on your specific data and tasks, and should be prepared to fine-tune and re-evaluate the models until they meet your performance requirements.
Unfortunately not. MedGemma and other HAI-DEF models are tools for developers and are not designed to be used as standalone applications. Users are responsible for deploying HAI-DEF models in their own environments, which ensures complete operational sovereignty and facilitates adaptation and evaluation in the same setting in which the models will be used.
Choosing the right model involves more than evaluating raw performance, and it is rarely an either-or decision. Use the following decision guide to evaluate your deployment requirements:
| Decision Check | If YES → Recommended
Approach |
|---|---|
| Regulated Product: Are you building a regulated clinical product or medical device where strict change control is paramount to clinical safety? |
Self-host open HAI-DEF models Provides full operational sovereignty, edge data residency, deep weight customization, and offline capability. |
| Deployment Environment: Do you have strict deployment constraints on where the model runs? For example, directly on an imaging scanner, within a mobile clinic with sporadic internet access or on an offline mobile device? | |
| Deep Customization: Do you need to substantially customize the model to meet your needs? | |
| Sovereignty: Do you require full operational sovereignty or edge data residency? | |
| None of the above? |
Use managed Gemini models Excellent choices for cloud-based applications. Gemini Enterprise Agent Platform (formerly Vertex AI) is covered under the Google Cloud Business Associate Agreement (BAA), supporting your compliance with Health Insurance Portability and Accountability Act (HIPAA) regulations. |
Model characteristics
Each HAI-DEF model has a different intended purpose, and performance varies across tasks. For example, see MedGemma's intended use. Our baseline evaluations will give you a sense of which tasks each model is likely to perform best on; however, you can often improve baseline performance using your own data and a variety of techniques, such as fine-tuning or Retrieval-Augmented Generation (RAG). For more details, see the question How can I improve the baseline performance of HAI-DEF models?.
Consult each model card's "Performance and validation" section to learn more. For example, see the baseline performance evaluations for MedGemma 1.5.
The answer varies per model. Consult each model card's "Limitations" section to learn more. For example, see MedGemma 1.5 limitations.
Performance metrics and evaluation results are available in both the individual model cards and our technical reports, with the latter offering a deeper dive into our scientific methodology. Because the Health AI landscape evolves rapidly, we recommend evaluating models against those of a similar size and function. Ultimately, you are responsible for conducting thorough evaluations tailored to your specific use cases prior to production deployment. You can find all model cards and technical reports in the compact Shortcuts page.
You can adapt HAI-DEF models to your application using your own datasets and domain-relevant runtime instructions. The optimal strategy depends on the model architecture and your specific goals, with distinct approaches for generative large language models (LLMs) versus embedding models:
| Model Type | Adaptation Strategy | When to Use & How It Works |
|---|---|---|
|
LLMs Examples: MedGemma, TxGemma |
Teach the model |
If the information consists of fundamental terminology, clinical reasoning patterns, or reporting styles that are universally and enduringly true across your domain, fine-tune the model's weights to internalize the information. When fine-tuning is appropriate, you can adopt different training paradigms such as Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL). Either paradigm can be executed using full-parameter adaptation or parameter-efficient methods like LoRA (Low-Rank Adaptation) to reduce compute and memory requirements. References: MedGemma SFT notebook and MedGemma RL notebook. |
| Augment at runtime |
If the information is fluid, institutional, or rapidly evolving (such as dynamic clinical guidelines, patient records, or local protocols), don't rely on weight memorization. Instead, supply the knowledge at runtime through in-context prompting, Retrieval-Augmented Generation (RAG), or agentic orchestration and tool calling. By coupling models with external tools, such as web search, FHIR generator/interpreter functions, or general reasoning models like Gemini, you can execute complex multi-step workflows without modifying base model weights. Reference: Demo application for an EHR navigator agent with MedGemma. |
|
|
Embedding models Examples: MedSigLIP, HeAR |
Train an embedding classifier |
To categorize clinical data (such as identifying normal versus abnormal X-rays), keep HAI-DEF embedding model weights frozen and use the model to convert your raw data into compact embedding vectors. You then train a lightweight classifier directly on those vectors, which is much faster and requires significantly less training data than processing the raw data. Reference: Notebook on training a data-efficient classifier with MedSigLIP. |
| Train encoder + classifier |
For complex classification tasks where training an embedding classifier is insufficient, you can attach a classification head to the HAI-DEF embedding model and train the entire neural network directly on your proprietary datasets to specialize the underlying embedding space for your taxonomy. Reference: Notebook on fine-tuning MedSigLIP for image classification. |
|
| Fine-tune the encoder |
For vector analysis tasks (like semantic retrieval or clustering), when HAI-DEF embedding models out-of-the-box don't achieve your performance goals, you can fine-tune the encoders on your proprietary datasets to optimize vector alignment without training a classification head. Reference: Notebook on fine-tuning MedSigLIP. |
HAI-DEF models are trained on a diverse variety of datasets from different sources, as documented in every model card. For example, see the MedGemma 1.5 data card section. Commercial users are responsible for ensuring the HAI-DEF base models comply with their specific anti-bias requirements. This may involve fine-tuning the models to meet the requirements. Mitigating bias also requires ongoing vigilance, including monitoring performance across diverse patient populations, auditing for inequitable outcomes, and ensuring that a human-in-the-loop workflow is in place to catch and correct biased outputs.
HAI-DEF models are trained on de-identified data. For more details, refer to the respective model cards. Note that institutions using HAI-DEF models for further model or application development remain responsible for preserving patient privacy.
We have provided an example of how to reproduce results on open benchmarks in our tutorial on evaluating MedGemma on MedQA. In addition, all of our fine-tuning tutorials start by calculating baseline model performance on the target task prior to training. For an example, see our guide on fine-tuning MedGemma for a multimodal histopathology image classification task.
MedGemma is a Gemma 3 variant and as such preserves much of the multilingual capabilities of Gemma. We have seen several examples in the community of MedGemma being tested and fine-tuned on various languages. You should conduct thorough evaluations for your use case and be prepared to fine-tune the base model for the purpose.
Technical infrastructure
You can run HAI-DEF models in three primary ways depending on the nature of your workload. To evaluate the cost implications and optimization strategies, see the question What are the best practices for optimizing infrastructure costs?.
| Execution Mode | When to Use | References |
|---|---|---|
| Local execution |
Best for early experimentation or deploying in air-gapped or offline environments such as processing highly sensitive data for vulnerable populations, mobile clinics with sporadic connectivity, or disconnected local devices. |
|
| Managed batch jobs |
Best for bulk processing over large datasets without low latency requirements. |
Our Model Garden quick start tutorials (such as MedGemma's) show you how to use Gemini Enterprise Agent Platform (formerly Vertex AI) batch inference service to run offline inference jobs at scale. |
|
Online service endpoints |
Best for low-latency, real-time inference in backend services behind user-facing applications. |
You can deploy HAI-DEF models and their accompanying Docker containers as highly available, scalable HTTPS service endpoints with options for automatic scaling and managed infrastructure on your platform of choice. For your convenience, we provide one-click deployment presets on Hugging Face and Google Cloud Model Garden, each bridging into underlying deployment options. Use Hugging Face Inference Endpoints for rapid experimentation, community sharing, and building concept demos. When ready for production deployments, evaluate Google Cloud options such as Agent Platform (formerly Vertex AI) Endpoints and Google Kubernetes Engine. See the question What are the advantages of using the models with Google Cloud?. |
Optimizing infrastructure costs is a balancing act between provisioning compute that is powerful enough for the task without sacrificing quality and staying within budget. This section compiles some of the possible optimization levers available to you. The following guidance uses MedGemma and MedSigLIP as examples, but most strategies apply to other similar models.
| Optimization Category | Strategy | Implementation Guidance & References |
|---|---|---|
| Model type | Use generative power only when needed | Don't deploy an LLM for its novelty. Most clinical workflows are predictive in nature, where generative models add unnecessary compute overhead. Use smaller, specialized embedding models or targeted classifiers instead. For example, if you are classifying medical images, finding similar patient cases, or retrieving images based on captions, use an embedding model like MedSigLIP. If your input data is structured and coded, treat it as tabular data analysis where standard relational databases and Structured Query Language (SQL) or a rule-based engine could do the job. |
| Consider managed Gemini | Before self-hosting the most capable open-weight LLM (for example, MedGemma 27B at full precision), evaluate whether managed Gemini models can meet your needs. Given the total cost of self-hosting (infrastructure plus engineering, DevOps, and ongoing maintenance), using a managed service is often the most cost-effective approach for enterprise workloads. See the question Gemini does a great job on my use case; why would I choose to self-host a HAI-DEF model instead?. | |
| LLM variant | Select the smallest viable size | Select the LLM variant with the fewest parameters that satisfies your needs (for example, MedGemma 4B versus 27B). Remember that larger is not always better; instead of paying the compute cost for a heavy model, you can often achieve acceptable performance on a smaller variant using adaptation techniques. See the question How can I improve the baseline performance of HAI-DEF models?. |
| Quantize to lower precision | Apply model quantization (such as 8-bit or 4-bit precision) or leverage pre-quantized community variants (like medgemma-27b-it from Unsloth) to reduce GPU memory footprint and inference latency. | |
| Distill knowledge to a smaller model | Apply knowledge distillation techniques to compress larger base models (for example, MedGemma 27B) into smaller, specialized student models tailored to your task. While many distillation tools and frameworks are available in the open-source community, representative examples to explore include Hugging Face's MiniLLM Trainer and Generalized Knowledge Distillation Trainer. | |
| Deployment pattern | Select the right hardware | Provision the smallest accelerator that satisfies your memory, latency, and concurrency constraints. In fact, if your workload can tolerate higher latency, you often don't need a hardware accelerator at all and can run inference directly on standard CPUs. When using accelerators, select a smaller machine type and GPU instance to process requests sequentially if high concurrent throughput is not required. For sizing guidance on your MedGemma deployments, see the question What are the minimum hardware requirements to run MedGemma?. |
| Leverage batch inference when possible | If your workflow does not require real-time, low-latency responses (such as when analyzing retrospective patient cohorts, generating embeddings for an image archive, or running overnight quality audits), don't deploy a dedicated online service endpoint. Run the model in a batch job instead. If using our models on Google Cloud, you can take advantage of Agent Platform (formerly Vertex AI) batch inference jobs, as demonstrated in our Model Garden quick start tutorials (such as MedGemma's), to bulk process large datasets and pay only for the duration of the job. | |
| Configure as online service endpoints |
When real-time, low-latency responses are required, then you should deploy our models as online service endpoints. Our Model Garden one-click deployment presets provide a convenient starting point configured for low latency, high throughput, and always-on service deployments. If your selected hardware is available among the presets, then click to deploy. However, if you're not expecting steady traffic, select scale-to-zero during the deployment process (shown below) to avoid paying for idle compute. Also consider sharing endpoint instances across applications to pool your organizational resources. 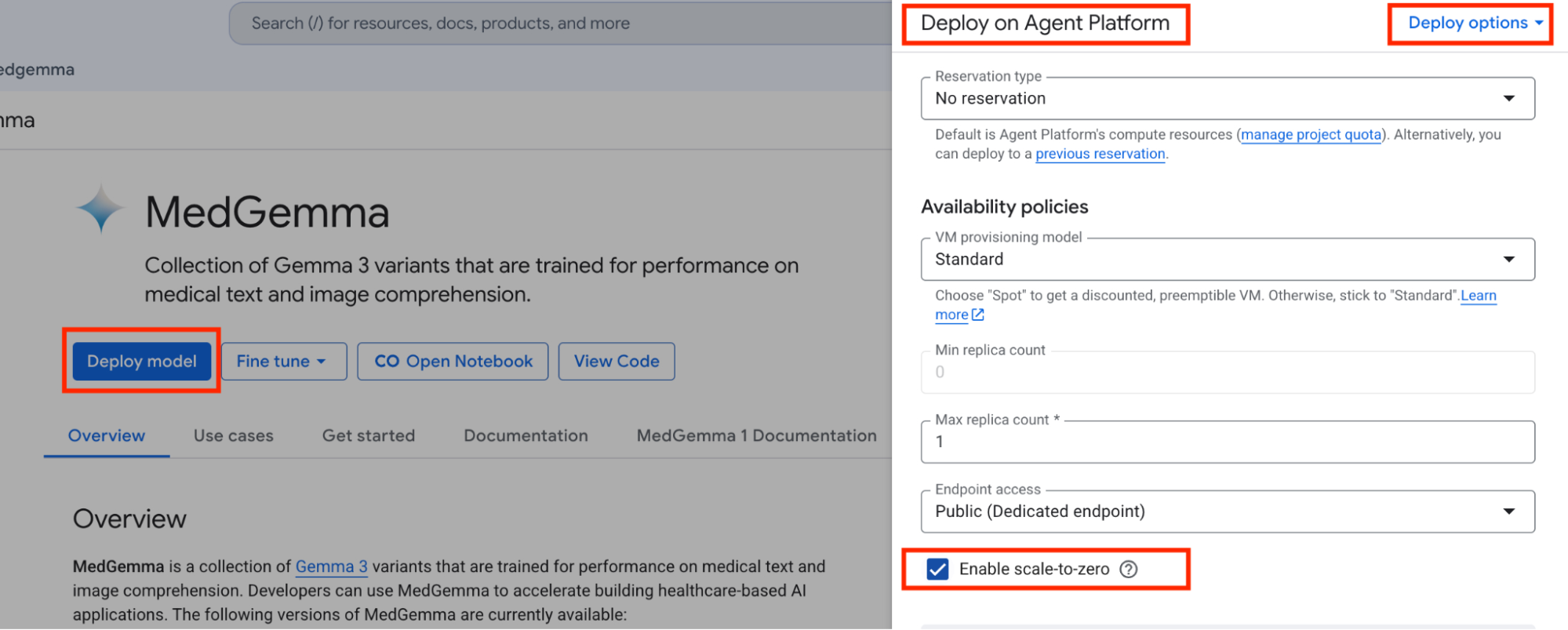
Alternatively, if your selected hardware is not among the preset options or you want full control over serving parameters, you can self-deploy to Agent Platform endpoints using a prebuilt container. When self-deploying an LLM, like MedGemma, you can use the prebuilt vLLM container for Agent Platform, or build your own custom vLLM container. For total infrastructure control, if you are comfortable with Kubernetes management, you can deploy on Google Kubernetes Engine (GKE) to take charge of fine-grained optimizations. Explore these advanced GKE strategies:
|
|
| Evaluate TPUs at scale | For production training and serving workloads, evaluate Google Cloud TPUs (Tensor Processing Units). Designed specifically for AI acceleration, TPUs deliver high price-to-performance efficiency and higher throughput at scale compared to GPUs. We offer Model Garden one-click deployment presets for some variants of MedGemma. You can also self-deploy on TPUs. |
Using Google Cloud to host HAI-DEF models paves the way to production by offloading engineering overhead without taking away your control. Key advantages include:
- Production-grade agent platform: We containerize our models and make them one-click deployable as endpoints on Google Cloud's Gemini Enterprise Agent Platform (formerly Vertex AI) to expedite your entry into the end-to-end framework for designing, deploying, governing, and optimizing production-grade multi-agent applications.
- Healthcare data integration: We actively solve for enterprise workflows with clinical data already hosted in Cloud Healthcare API, including DICOM Stores and FHIR Stores. See our publication on how to integrate MedGemma into clinical workflows.
- Security and data governance: Our open models run within your virtual private cloud perimeters, enabling you to take advantage of Google Cloud's security, protecting data both at rest and in transit, while keeping data governance controls in your own hands.
- Enterprise SLAs and compliance: For your highly available, low-latency, scalable, and compliant applications, you can rely on Google Cloud's Service Level Agreements (SLAs) and enterprise compliance support, including Business Associate Agreements (BAAs) for Health Insurance Portability and Accountability Act (HIPAA) compliance.
Refer to the Google Cloud website for more details, and talk to your Google Cloud account representative to understand how your unique requirements can be met.
Yes, you can. Since HAI-DEF models are open-weight, you can download the weights from Hugging Face, adapt them, and run them on your infrastructure of choice.
Because HAI-DEF models are open-weight, you can download and run them locally or on your own servers without any data ever leaving your environment. If you choose to deploy HAI-DEF models on Google Cloud, the models process your data entirely within your own Google Cloud project. This ensures your data adheres to your organization's data privacy policies; Google does not access or log your patient information, and never uses it to train its foundation models. Read more about the Google Cloud Privacy Notice.
The following table details the approximate GPU or TPU memory requirements for loading model weights for each size of the MedGemma 1.0 or 1.5 model versions. Note that these figures reflect static weight footprints and vary by inference framework.
| Parameters | BF16 (16-bit) | SFP8 (8-bit) | Q4_0 (4-bit) |
|---|---|---|---|
| MedGemma 4B | 6.4 GB | 4.4 GB | 3.4 GB |
| MedGemma 27B | 46.4 GB | 29.1 GB | 21 GB |
When deploying with inference engines like vLLM,
your total GPU High Bandwidth Memory (HBM) requirement equals model
weights plus runtime overhead and the Key-Value (KV)
cache. To size memory beyond static weights, consider how
context window size (--max-model-len) and concurrent
request throughput (--max-num-seqs) dynamically expand your
cache buffer. You can practice calculating your exact runtime memory
buffer and max concurrency limits across different scenarios using the
interactive vLLM HBM Calculator Colab notebook. Here
is how to size specific Google Cloud GPU models and machine types for two
representative scenarios:
-
Scenario 1: MedGemma 4B at Full Precision (BF16):
Assuming an 8,192-token context window and moderate
batch concurrency, a single NVIDIA L4 GPU (24 GB
VRAM) on a
g2-standard-4org2-standard-8machine type is optimal. The 16-bit model weights consume ~6.4–8 GB, leaving over 15 GB of High Bandwidth Memory for the KV cache and vLLM runtime overhead without needing tensor parallelism. -
Scenario 2: MedGemma 27B at Lower Precision (4-bit or
8-bit): Assuming a 16,384-token context window for
longitudinal patient records, model weights consume ~21 GB (for
4-bit Q4_0) to ~29 GB (for 8-bit SFP8). You can serve this using
two architectural approaches:
-
Multiple Small GPUs (Cost & Availability
Optimized): Provision 2x NVIDIA L4 GPUs (48
GB total VRAM) on a
g2-standard-24machine type using tensor parallelism (--tensor-parallel-size 2). This splits the weights (~10.5–14.5 GB per GPU) and KV cache across both processors, providing an economical and widely available serving tier. -
One Big GPU (Simplicity & Latency Optimized):
Provision a single NVIDIA A100 (40 GB or 80 GB VRAM)
on an
a2-highgpu-1gora2-ultragpu-1gmachine. Keeping the model on one GPU avoids inter-GPU communication overhead, simplifying deployment and minimizing latency.
-
Multiple Small GPUs (Cost & Availability
Optimized): Provision 2x NVIDIA L4 GPUs (48
GB total VRAM) on a
Resources and support
Sign up to our newsletter.
The HAI-DEF developer forum is the best place to post your technical questions. We actively staff the forum and respond to community inquiries. By asking questions publicly, you not only get the assistance you need, but also help build a shared knowledge base that benefits all developers in the HAI-DEF community.
If you run into specific bugs or issues with our open-source code, you can also file them directly in our GitHub repositories.
Yes! We welcome your help in building the HAI-DEF community. Contributions can come in different ways:
- Contribute code: To contribute code to any HAI-DEF GitHub repository, submit a pull request. For detailed instructions, review the Community Guidelines on contributing. Note that all contributors must sign a Contributor License Agreement (CLA).
- Join the discussion: Play an active role in the HAI-DEF developer forum. Start new topics or contribute your expertise to ongoing discussions.
- Inspire others: If you are building something great, apply to be featured in the HAI-DEF Showcase using the intake form.
- Shape our roadmap: Help shape our future engineering efforts by sharing your input using our feedback form.
HAI-DEF's goal is to enable the community at large without formal partnership agreements. If you believe there is a unique and impactful opportunity to uplift the community that requires close collaboration with your organization, please let us know using our feedback form.
We appreciate your interest in working on HAI-DEF! All open positions are listed on Google Careers. In the meantime, you don't need to be a Google employee to collaborate with us; to see how you can get involved right now, check out the FAQ Can I contribute to HAI-DEF?
The following table compiles some of the available free tiers, cloud credits, and academic research grants for Google Cloud and Colab:
| Platform | Program / Tier Name | Benefits & Value | Key Eligibility Criteria | Official Portal / Link |
|---|---|---|---|---|
| Colab | Always-Free Dynamic Tier | Free access to CPUs and basic GPUs (NVIDIA T4). | Anyone with a Google Account; usage limits fluctuate based on demand. | Google Colab Workspace |
| Colab | Academic Pro Upgrade | Free 1-Year Colab Pro Subscription (100 Compute Units/month, priority GPUs, high RAM). | Active students, researchers, or faculty at accredited higher education institutions. | Google Colab Signup (Select Academic Offer) |
| Google Cloud | Introductory Free Trial | $300 cloud credits valid for 90 days. | First-time Google Cloud billing account configuration. | Google Cloud Free Program Guide |
| Google Cloud | Academic Research Grants | $1,000 (PhD students) to $5,000 (Faculty/Postdocs) in cloud credits. Can fund Colab Enterprise. | Requires formal research proposal and estimated budget calculation. | Google Cloud Higher Education Research Guidelines |
| Google Cloud | Teaching & Coursework Credits | Course-wide credit pools ($50–$100 per student) for lab tracks. | Active faculty members at accredited teaching institutions. | Google Cloud Higher Education Course Guidelines |
| Google Cloud | Startups Cloud Program (Start) | $2,000 cloud credits valid for 1 year. | Tech startups founded within 24 months, pre-funding, seeking venture track. | Google Cloud Startup Program |
| Google Cloud | Startups Cloud Program (Scale) | Up to $200,000 (or $350,000 for verified AI-first startups) over 2 years. | Founded within 5 years; raised a Pre-Seed, Seed, or early Series A round. | Google Cloud Startup Program |
| Google Cloud | Google for Nonprofits | Discounted cloud tiers, complimentary Workspace infrastructure, and Ad Grants. | Verified 501(c)(3) organizations or local charitable equivalents. | Google for Nonprofits Portal |
Terms, licensing, and regulation
Yes, you can. Refer to HAI-DEF's Terms of use and Prohibited use for more details.
Yes, you can. Our goal with the HAI-DEF Showcase is to inspire app development. While the showcased clinical applications and technical solutions and tools are entirely owned and operated by the third party organizations, most community prototypes and all of our own demo apps come with open-source implementation code. You are free to use the code to expedite your app development, but it's your responsibility to adapt the code and conduct extensive evaluation to ensure it works for your intended use case and comply with all applicable legal and regulatory requirements in the locality where you are developing and deploying it.
The HAI-DEF program doesn't provide regulatory advice. You are responsible for ensuring your use of HAI-DEF models complies with all applicable regulations. HAI-DEF open-weight models give you the full control over downstream development, evaluation, change control and deployment.
Subject to the terms of the HAI-DEF license, your use of the HAI-DEF models gives you freedom to use the models on any approved infrastructure that's covered under your BAA. Read more about Health Insurance Portability and Accountability Act (HIPAA) compliance on Google Cloud.
The model card associated with each model outlines its specific citation requirements. For example, see citation requirement for MedGemma 1.5.
Software in each respective GitHub repository may depend on other open source software with their own license terms.
For compliance when distributing prebuilt Docker images of our model
service, each GitHub repository has a THIRD_PARTY_LICENSES file
that aggregates the licenses of all direct and transitive dependencies
involved in the service implementation. The source code for those
dependencies is pulled into the image as part of the Docker image building
process.