C++ 언어 튜토리얼
이 시리즈의 초기 섹션은 튜토리얼 이미 발표된 기본 자료를 다루고 복습하고 고급 개념에 대한 자세한 정보를 제공합니다. Google의 동적 메모리에 대해 알아보고 객체와 클래스에 대해 자세히 알아봅니다. 또한 상속, 다형성, 템플릿, 네임스페이스가 있습니다 나중에 고급 C++ 과정에서 학습할 것입니다.
객체 지향 디자인
아주 훌륭합니다. 튜토리얼에서 살펴볼 수 있습니다. Google은 자세히 알아보겠습니다
예시로 배우기 #3
이 모듈에서는 포인터, 객체 지향, 다차원 배열 및 클래스/객체입니다. 다음 단계를 따르세요. 예로 들 수 있습니다 좋은 프로그래머가 되는 비결은 아무리 강조해도 지나치지 않습니다. 연습, 연습, 연습입니다!연습문제 #1: 포인터를 사용한 더 많은 연습
포인터에 관한 추가 연습이 필요한 경우 다음을 참고하세요. 이 리소스를 참조하시기 바랍니다.
다음 프로그램은 어떻게 출력되나요? 프로그램을 실행하지 마세요. 메모리 사진을 그려 출력을 결정합니다.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}직접 출력을 결정했다면 프로그램을 실행하여 맞습니다.
연습 #2: 클래스와 객체를 사용한 더 많은 연습
클래스와 객체에 대한 추가 연습이 필요한 경우 여기 은 두 개의 작은 클래스의 구현을 거치는 리소스입니다. 가져오기 운동하는 시간
연습 #3: 다차원 배열
다음 프로그램을 고려해 보세요.
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}이 프로그램에는 '이 선은 어떻게 작동하나요?'라고 표시된 줄이 있습니다. - 알아낼 수 있나요? 여기에서 설명을 확인하세요.
희미한 3차원 배열을 초기화하고 3차원을 채우는 프로그램 작성 값을 세 가지 색인 모두의 합으로 바꿉니다. 여기에서 솔루션을 확인하실 수 있습니다.
연습 #4: 광범위한 OO 디자인 예
자세한 내용은 객체 지향 설계 예를 살펴보겠습니다. 모든 프로세스와 관련이 있습니다 최종 코드는 Java, Python, 얼마나 멀리 가야 하는지에 따라 읽을 수 있을 것입니다. 새로운 기능이 출시되었습니다.
시간을 내어 이 예제를 전부 살펴보시기 바랍니다. 정말 훌륭합니다. 프로세스와 이를 지원하는 설계 도구를 보여주는 그림입니다.
단위 테스트
소개
테스트는 소프트웨어 엔지니어링 프로세스에서 중요한 부분입니다. 단위 테스트 는 특정 종류의 테스트로, 단일, 작은 단일 호출의 기능을 점검하고 모듈을 마칩니다단위 테스트는 항상 엔지니어가 수행하며 보통 모듈을 코딩하는 동시에 실행됩니다. 테스트 드라이버는 Composer 및 Database 클래스를 테스트하는 데 사용되는 요소가 단위 테스트의 예입니다.
단위 테스트에는 다음과 같은 특성이 있습니다. 그들은...
- 격리된 구성 요소 테스트
- 결정론적임
- 일반적으로 단일 클래스에 매핑됩니다.
- 외부 리소스에 대한 종속 항목을 방지합니다. 데이터베이스, 파일, 네트워크
- 빠르게 실행
- 임의의 순서로 실행 가능
이를 뒷받침하는 자동화된 프레임워크와 방법론이 대규모 소프트웨어 엔지니어링 조직의 단위 테스트에 일관성이 있어야 합니다. 몇 가지 정교한 오픈소스 단위 테스트 프레임워크가 있습니다. 더 자세히 알아보도록 하겠습니다.
단위 테스트의 일부로 발생하는 테스트는 아래에 나와 있습니다.
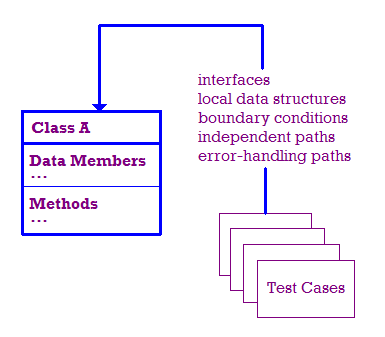
이상적인 환경에서는 다음을 테스트합니다.
- 모듈 인터페이스는 정보가 들어오고 나가는지 확인하기 위해 테스트됩니다. 있습니다.
- 데이터를 제대로 저장하는지 확인하기 위해 로컬 데이터 구조를 검사합니다.
- 모듈이 올바르게 작동하는지 확인하기 위해 경계 조건 테스트 처리를 제한하거나 제한하는 경계에 있을 수 있습니다.
- 모듈을 통과하는 독립적인 경로를 테스트하여 각 경로가 제대로 작동하는지 확인합니다.
따라서 모듈의 각 문은 최소 한 번 실행됩니다.
- 마지막으로 오류가 제대로 처리되고 있는지 확인해야 합니다.
코드 적용 범위
실제로는 완전한 '코드 범위'를 확보할 수 없습니다. 살펴보겠습니다 코드 적용 범위는 소프트웨어의 어떤 부분을 사용할지 결정하는 분석 방법입니다. 시스템이 실행 (커버링됨)되었는지, 그리고 어떤 부분이 테스트 사례 모음에 의해 실행되었는지 없습니다. 만약 우리가 100% 커버리지를 달성하려고 하면 더 많은 시간을 더 많은 시간이 필요하게 됩니다. 단위를 떠올려 보세요 다음의 모든 독립 경로를 테스트합니다. 이것은 빠르게 지수 문제입니다.
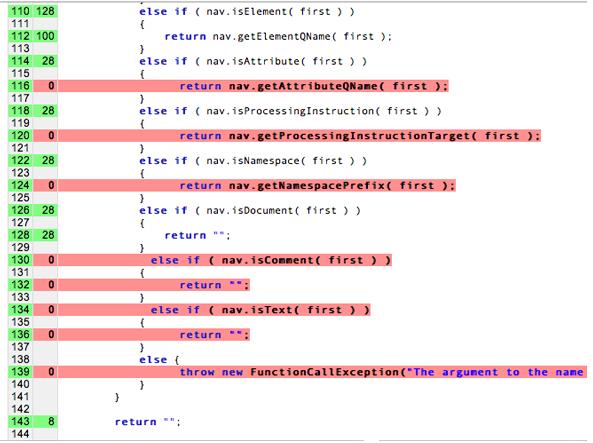
이 다이어그램에서 빨간색 선은 테스트되지 않지만 색이 없는 선은 테스트되지 않습니다. 있습니다
100% 적용 범위를 시도하는 대신 신뢰도를 높이는 테스트에 집중합니다. 모듈이 제대로 작동하는지 확인합니다 다음을 테스트합니다.
- null 사례
- 범위 테스트(예: 양성/음성 값 테스트)
- 특이 사례
- 실패 사례
- 대부분의 경우 실행될 가능성이 가장 높은 경로 테스트
단위 테스트 프레임워크
대부분의 단위 테스트 프레임워크는 경로 어설션은 조건이 참인지 확인하는 문입니다. 이 결과는 성공, 치명적이지 않은 실패 또는 치명적인 실패일 수 있습니다. 후(After) 어설션이 수행되면, 결과가 다음 중 하나에 해당하면 프로그램은 정상적으로 계속됩니다. 심각하지 않은 오류입니다 치명적인 실패가 발생하는 경우 현재 함수는 중단됩니다.
테스트는 상태를 설정하거나 모듈을 조작하는 코드로 구성되며 예상되는 결과를 확인하는 다수의 어설션으로 구성됩니다. 모든 어설션이 즉, true를 반환하면 테스트가 성공합니다. 그렇지 않은 경우 실패합니다
테스트 사례에는 하나 이상의 테스트가 포함됩니다. 테스트는 테스트 사례로 그룹화됩니다. 테스트된 코드의 구조를 반영합니다. 이 과정에서는 CPPUnit을 단위 테스트 프레임워크로 사용합니다. 이 프레임워크를 사용하여 단위 테스트를 작성할 수 있고 자동으로 실행하여 성공 또는 실패에 대한 보고서를 제공 매우 유용합니다
CPPUnit 설치
다음에서 CPPUnit 코드를 다운로드합니다. SourceForge를 사용하세요. 적절한 디렉터리를 찾아 tar.gz 파일을 배치합니다. 그런 다음 다음 명령어 (Linux, Unix)를 적절한 cppunit 파일로 대체합니다. 이름:
gunzip filename.tar.gz tar -xvf filename.tar
Windows에서 작업하는 경우 tar.gz를 추출하는 유틸리티를 찾아야 할 수도 있습니다. 할 수 있습니다. 다음 단계는 라이브러리를 컴파일하는 것입니다. cppunit 디렉터리로 변경합니다. 특정 지침을 제공하는 INSTALL 파일이 있습니다. 일반적으로 다음을 실행해야 합니다.
./configure make install
문제가 발생하면 INSTALL 파일을 참고하세요. 라이브러리는 일반적으로 cppunit/src/cppunit 디렉터리에서 찾을 수 있습니다. 컴파일이 작동하는지 확인하려면 cppunit/examples/simple 디렉터리로 이동하여 'make'를 입력합니다. 만약 컴파일이 완료되면 모든 준비가 완료된 것입니다.
훌륭한 튜토리얼이 있고 여기에서 확인할 수 있습니다. 이 튜토리얼을 진행하면서 복소수 클래스 및 이와 연결된 클래스를 만드세요. 단위 테스트와 유사합니다. cppunit/examples 디렉터리에 몇 가지 추가 예가 있습니다.
이렇게 해야 하는 이유는 무엇인가요?
단위 테스트는 여러 가지 이유로 업계에서 매우 중요합니다. 여러분은 한 가지 이유는 이미 잘 알고 있습니다. 하나는 작업을 확인하는 동안 살펴봤습니다 아주 작은 프로그램을 개발하더라도 본능적으로 일종의 검사기 또는 드라이버를 작성하여 프로그램이 예상대로 작동하는지 확인합니다.
엔지니어들은 오랜 경험을 통해 프로그램이 제대로 작동할 가능성을 알고 매우 작습니다. 단위 테스트는 이 아이디어를 바탕으로 프로그램 자체 검사 및 반복 가능. 어설션은 배웠습니다 또한 결과를 해석하기 쉽기 때문입니다 (테스트 테스트를 계속 실행할 수 있으므로 안전망을 구축해야 합니다.
구체적으로 설명해 보겠습니다. 완성된 코드를 CVS, 완벽하게 작동합니다. 한동안은 계속해서 완벽하게 작동합니다. 그런 다음 어느 날 다른 사람이 코드를 변경합니다. 머지않아 누군가가 생성합니다. 그들이 스스로 알아차릴 거라고 생각하나요? 그럴 가능성은 없습니다. 하지만 매일 자동으로 실행할 수 있는 시스템이 있습니다. 이러한 시스템을 지속적 통합 시스템이라고 합니다. 엔지니어가 X가 코드를 깨뜨리면 문제가 해결될 때까지 시스템에서 악성 이메일을 보냅니다. 있습니다. 엔지니어 X가 나라면!
소프트웨어 개발을 지원하고 소프트웨어를 안전하게 보호하는 것 외에도 단위 테스트:
- 실행 가능한 사양 및 동기화 상태를 유지하는 문서를 만듭니다. 코드를 사용합니다. 즉, 단위 테스트를 읽고 어떤 작업을 처리할지 모듈이 지원하는 동작입니다.
- 요구사항을 구현으로부터 분리하는 데 도움이 됩니다. 다음을 주장하고 있으므로 명시적으로 생각할 수 있는 기회를 얻게 됩니다. 동작을 구현하는 방법에 대한 아이디어를 혼합하는 대신
- 실험을 지원합니다. 경보를 받을 수 있는 안전망이 있다면 모듈의 동작을 깨뜨린 경우 시도해 볼 가능성이 큽니다. 설계를 재구성할 수 있습니다
- 디자인을 개선합니다. 철저한 단위 테스트를 작성하려면 다음을 수행해야 함 코드를 더 쉽게 테스트할 수 있습니다. 테스트 가능한 코드가 테스트할 수 없는 코드보다 모듈식에 더 가까운 경우가 많음 있습니다.
- 높은 품질을 유지합니다. 중대한 시스템의 사소한 버그로 인해 어쩌면 사용자의 행복이나 신뢰를 잃는 것일 수도 있습니다. 이 안전망이 있습니다. 벌레를 잡기 때문에 또한 품질 보증팀이 더 정교하고 어려운 작업에 시간을 할애할 수 있어 장애 시나리오에 대비하는 것이 좋습니다
Composer 데이터베이스 애플리케이션에 CPPUnit을 사용하여 단위 테스트를 작성해 봅니다. 자세한 내용은 cppunit/examples/ 디렉토리를 참조하세요.
Google의 작동 방식
소개중세 시대의 한 수도사가 수도원의 기록 보관소였습니다.“아리스토텔레스의 작품이 어디 있지...”

다행히 원고가 내용별로 정리되어 있고 포함되어 있는 정보를 검색할 수 있도록 특수 기호로 있습니다 이러한 조직이 없으면 적절한 조직이 있는 사람을 찾기가 매우 어려울 것입니다. 원고입니다.
대규모 컬렉션에서 작성된 정보를 저장하고 가져오는 활동 정보 검색 (IR)이라고 합니다. 이러한 활동은 특히 종이나 인쇄물과 같은 발명품에서 누릅니다. 예전에는 소수의 사람만 사는 곳이었지만 이제 그러나 매일 수억 명의 사람들이 정보 검색에 참여합니다. 검색엔진을 사용하거나 데스크톱에서 검색하는 날입니다.
정보 검색 시작하기

닥터 수스는 30년 동안 46권의 아동용 도서를 저술했습니다. 그의 책은 고양이, 소, 코끼리, 주인공, 으스스한 표정, 악어가 있습니다. 기억나? 어떤 생물이 어떤 스토리에 등장했나요? 부모가 아닌 경우 자녀만 닥터 수스 생명체가 등장하는 스토리를 알려주세요.
(COW 및 BEE) 또는 CROWS
이러한 문제를 해결하기 위해 몇 가지 기본적인 정보 검색 모델을 적용할 것입니다. 있습니다.
무작위 대입은 분명합니다. 닥터 수스의 이야기 46개를 모두 모으고 있습니다. 각 책에서 COW와 BEE라는 단어가 어떤 책에 포함되어 있는지 확인하세요. 동시에 CROWS라는 단어가 포함된 책을 찾습니다. 컴퓨터는 훨씬 빠릅니다. 닥터 수스 책에 나오는 텍스트를 전부 가지고 있다면 텍스트 파일과 같은 디지털 형식의 경우 파일을 grep할 수 있습니다. Dr. Seuss의 책과 같은 작은 컬렉션에서는 이 기법이 효과적입니다.
그러나 더 많은 상황이 필요한 경우도 있습니다. 예를 들어 grep이 처리하기에 너무 큽니다. 또한 우리는 조건과 일치하는 문서를 원하기 때문에 관련성에 따라 순위를 매기는 것이 좋습니다.
grep 외의 또 다른 접근 방식은 컬렉션의 문서 색인을 생성하는 것입니다. 검색할 수 있습니다. IR의 지수는 다음의 지수와 유사하다. 교과서 뒷면에 있습니다. Google은 각 단어 (또는 용어)의 목록을 만듭니다. 닥터 수스의 이야기에서 'the', 'and', 기타 연결어는 빼고 전치사(중지 단어라고 함) 등). 그런 다음 쉽게 식별할 수 있는 방식으로 확인할 수 있습니다
가능한 표현 중 하나는 스토리가 상단에 있는 행렬이며 확인할 수 있습니다 열에 '1'이 있으면 해당 용어가 확인할 수 있습니다.
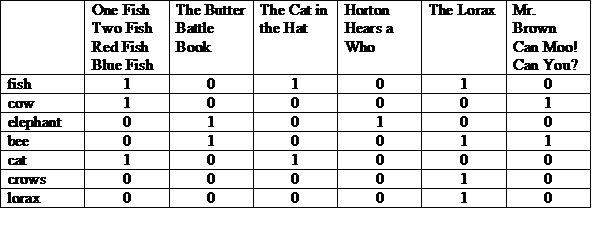
각 행이나 열을 비트 벡터로 볼 수 있습니다. 행의 비트 벡터는 어떤 뉴스가 등장하는지 알 수 있습니다. 열의 비트 벡터는 어떤 항이 확인할 수 있습니다.
원래 문제로 돌아가기:
(COW 및 BEE) 또는 CROWS
이 용어에 대한 비트 벡터를 가져와서 먼저 비트 단위 AND를 수행한 다음 결과에 대해 비트별 OR을 반환합니다.
(100001 및 010011) 또는 000010 = 000011
답변: “Mr. Brown Can Moo! 괜찮으신가요?” '로렉스'가 있습니다. 삽화 '일치검색' 모델인 불리언 검색 모델의 인프라를 활용합니다.
닥터 수스의 이야기와 관련 용어에 대해 배웠습니다. 매트릭스가 상당히 커질 것이고 대부분의 항목은 0이 됩니다. 행렬은 아마도 최상의 나타냅니다. 1의 지표만 저장할 방법을 찾아야 합니다.
일부 개선사항
이 문제를 해결하기 위해 IR에서 사용되는 구조를 반전 색인이라고 합니다. Google은 용어 사전을 보관하고 있으며 각 용어의 목록을 제공합니다. 해당 용어가 등장하는 문서를 기록한 문서입니다. 이 목록을 게시물 목록이라고 합니다. 목록에 추가합니다. 이와 같이 구조를 나타내려면 단일 연결 목록으로 사용하는 것이 좋습니다. 참조하세요.
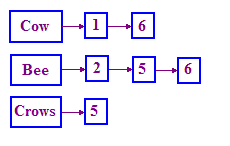
연결된 목록에 대해 잘 모르는 경우 Google 검색에서 "연결됨
만드는 방법을 설명하는 많은 리소스를 찾을 수 있습니다.
사용할 수 있습니다. 이 내용은 이후 모듈에서 자세히 다루겠습니다.
문서 ID (DocIDs)를 있습니다. 또한 쿼리 처리를 용이하게 하기 때문에 이러한 DocID를 정렬합니다.
쿼리는 어떻게 처리하나요? 원래 문제의 경우 먼저 COW 게시물을 찾아 BEE 게시물 목록을 클릭합니다. 그런 다음 이를 '병합'합니다.
- 마커를 두 목록에 유지하고 두 게시물 목록을 살펴봅니다. 동시에 사용할 수 있습니다.
- 각 단계에서 두 포인터가 가리키는 DocID를 비교합니다.
- 동일하면 해당 DocID를 결과 목록에 넣고 그렇지 않으면 포인터를 앞으로 이동합니다. 더 작은 docID를 가리키게 됩니다.
반전 색인을 빌드하는 방법은 다음과 같습니다.
- 관심 있는 각 문서에 DocID를 할당합니다.
- 각 문서에 대해 관련 용어를 식별합니다 (토큰화).
- 각 용어에 대해 용어, 해당 용어의 DocID로 구성된 레코드를 만듭니다. 해당 문서의 빈도를 나타냅니다. 여러 개의 해당 검색어가 여러 문서에 나타날 경우 해당 용어에 대한 기록이 표시됩니다.
- 검색어를 기준으로 레코드를 정렬합니다.
- 다음에 대한 단일 레코드를 처리하여 사전 및 게시물 목록을 만듭니다. 검색어에 대한 여러 레코드를 결합하여 문서 여러 개를 업로드할 수 있습니다 DocID의 연결 목록을 만듭니다 (정렬된 순서). 각 또한 검색어에는 모든 레코드의 주파수 합계인 빈도가 있습니다. 표시됩니다.
프로젝트
실험할 수 있는 몇 가지 긴 일반 텍스트 문서를 찾습니다. 이 프로젝트에서 반전 색인을 생성하는 것입니다. 설명됩니다. 쿼리 입력을 위한 인터페이스도 만들어야 합니다. 이를 처리하는 엔진이 필요합니다 포럼에서 프로젝트 파트너를 찾아볼 수 있습니다.
이 프로젝트를 완료하는 과정은 다음과 같습니다.
- 가장 먼저 해야 할 일은 문서에서 용어를 식별하기 위한 전략을 정의하는 것입니다. 생각할 수 있는 모든 불용어의 목록을 만들고, 모든 단어를 읽고, 용어를 저장하고, 불용어를 제거합니다. 키워드 목록을 검토할 때 불용어를 목록에 더 추가해야 할 수도 있습니다. 단어를 추출하는 것입니다
- CPPUnit 테스트 사례를 작성하여 함수를 테스트하고 makefile을 작성하여 모든 것을 가져옵니다. 함께 사용할 수 있습니다. 파일을 CVS에 체크인하세요. 협업하고 있습니다. CVS 인스턴스를 여는 방법을 알아보는 것이 좋습니다. 원격 엔지니어에게 맡기세요.
- 위치 데이터를 포함하도록 처리를 추가합니다. 즉, 파일에 검색어가 있는지 확인할 수 있습니다 계산을 통해 페이지 번호 또는 단락 번호입니다.
- CPPUnit 테스트 사례를 작성하여 이 추가 기능을 테스트합니다.
- 반전 색인을 만들고 각 용어의 레코드에 위치 데이터를 저장합니다.
- 더 많은 테스트 사례를 작성합니다.
- 사용자가 쿼리를 입력할 수 있는 인터페이스를 설계합니다.
- 위에서 설명한 검색 알고리즘을 사용하여 반전 색인을 처리하고 사용자에게 위치 데이터를 반환합니다.
- 이 마지막 부분의 테스트 사례도 포함해야 합니다.
모든 프로젝트에서 그랬던 것처럼 포럼과 채팅을 통해 프로젝트 파트너를 찾아보세요. 아이디어를 공유할 수 있죠
추가 기능
많은 IR 시스템에서 일반적인 처리 단계를 어간 추출이라고 합니다. 이 파생어 생성의 주된 아이디어는 사용자가 '검색'에 대한 정보를 검색한다는 것입니다. '검색', 'retrieved', 'retrieving' 등입니다. 시스템은 여러 가지 이유로 인해 어간이 잘못된 것이기 때문에 이 작업은 조금 까다롭습니다. 예를 들어 '정보 검색'이라는 제목의 문서가 리트리버'라고 합니다. 어간 추출에 유용한 알고리즘은 포터 알고리즘.