프로그래밍 및 C++ 소개
고급 개념에 대한 자세한 내용은 온라인 자습서를 참조하십시오. 3부를 읽으시기 바랍니다. 이 모듈에서는 포인터 사용과 객체 시작하기에 중점을 둡니다.
예시로 배우기 #2
이 모듈에서는 분해를 통해 더 많은 연습을 얻고, 포인터를 이해하고, 객체와 클래스를 시작하는 데 중점을 둡니다. 다음 예를 살펴보세요. 요청이 있을 경우 직접 프로그램을 작성하거나 실험을 수행합니다. 좋은 프로그래머가 되기 위한 핵심은 연습, 연습, 연습이라는 사실은 아무리 강조해도 지나치지 않습니다.
예 1: 추가적인 분해 연습
간단한 게임에서 다음과 같은 출력을 살펴보세요.
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
첫 번째 관찰은 소개 텍스트로, 프로그램당 한 번씩 표시됩니다. 실행할 수 있습니다 각 행성에 대한 적의 거리를 정의하려면 랜덤 숫자 생성기가 필요합니다. 라운딩입니다. 플레이어의 각도 입력을 가져오는 메커니즘이 필요하며 적에게 공격할 때까지 반복되기 때문에 반복 구조로 되어 있습니다. 또한 거리와 각도를 계산하는 함수가 필요합니다. 마지막으로, 적을 공격하는 데 걸린 총 샷 수와 히트가 발생할 수 있습니다. 다음은 기본 프로그램에 대해 가능한 개요입니다.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
화재 절차는 게임 플레이를 처리합니다. 이 함수에서 적의 거리를 구하기 위해 랜덤 숫자 생성기를 사용한 다음, 루프를 설정하여 플레이어의 입력을 받아 상대를 공격했는지 여부를 계산합니다. 이 루프의 감시 조건은 우리가 적에게 얼마나 가까이 접근했는지입니다.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
cos() 및 sin()을 호출하므로 math.h를 포함해야 합니다. 사용해 보기 이는 문제 분해와 학습에 도움이 되는 기본 C++에 대해 알아봅니다. 각 함수에서 하나의 태스크만 실행해야 합니다. 이것은 지금까지 작성한 프로그램 중 가장 정교한 프로그램이므로, 해야 합니다.여기에서 솔루션을 확인하실 수 있습니다.
예 2: 포인터로 연습
포인터를 사용할 때 기억해야 할 네 가지 사항이 있습니다. <ph type="x-smartling-placeholder">- </ph>
- 포인터는 메모리 주소를 보유하는 변수입니다. 프로그램이 실행되는 동안
모든 변수는 각각 고유한 주소 또는 위치에 메모리에 저장됩니다.
포인터는 메모리 주소가 아닌 메모리 주소를 포함하는 특수한 유형의 변수입니다.
데이터 값보다 더 적을 수 있습니다. 일반 변수가 사용될 때 데이터가 수정되는 것처럼
포인터에 저장된 주소의 값이 포인터 변수로 수정됨
조작할 수 있습니다 예를 들면 다음과 같습니다.
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - 일반적으로 포인터는 배포가 저장 중인 위치로
('포인트') 따라서 위의 예에서 intptr은 포인터를 가리킵니다.
5.
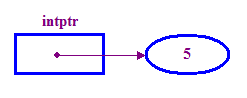
'new'는 정수를 위한 메모리를 할당하는 연산자 Pointee. 이 작업은 포인트에 액세스하기 전에 해야 하는 작업입니다.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.* 연산자는 C에서 역참조에 사용됩니다. 가장 일반적인 오류 중 하나는 C/C++ 프로그래머가 포인터로 작업하면 초기화를 잊어버림 정의합니다. 그로 인해 가끔씩 런타임 비정상 종료가 발생할 수 있습니다. 알 수 없는 데이터가 포함된 메모리 내 특정 위치입니다. 이 텍스트를 수정하려고 하면 미세한 메모리 손상을 일으켜 추적하기 어려운 버그가 될 수 있습니다.
- 두 포인터 간의 포인터 할당은 포인터가 동일한 포인터를 가리키게 합니다.
즉, y = x;는 y는 x와 같은 점(pointee)을 가리키게 합니다. 포인터 할당
터치 포인트에 닿지 않습니다. 포인터 한 개가 동일한 위치를 갖도록 변경됩니다.
다른 포인터로 볼 수 있습니다. 포인터 할당 후 두 개의 포인터는
Pointee.
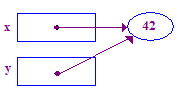
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
이 코드의 트레이스는 다음과 같습니다.
| 1. 두 개의 포인터 x 및 y를 할당합니다. 포인터를 할당하면 어떤 포인트도 할당하지 않습니다. | 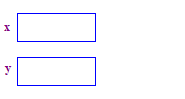 |
| 2. Pointee를 할당하고 x를 설정하여 가리킵니다. | 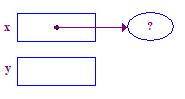 |
| 3. x를 역참조하여 포인트에 42를 저장합니다. 이 것은 기본적인 예로서 역참조 작업의 값을 반환합니다. x에서 시작한 다음 화살표를 따라가면 액세스할 수 있습니다. 있습니다. | 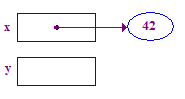 |
| 4. 포인트에 13을 저장하기 위해 역참조를 시도합니다. 이는 비정상 종료로 인해 포인트가 할당되지 않았습니다. | 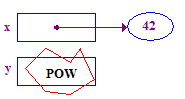 |
| 5. y = x;를 y가 x의 포인트를 가리키도록 합니다. 이제 x와 y가 '공유'하는 것이죠. | 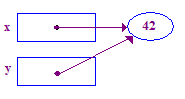 |
| 6. 포인트에 13을 저장하기 위해 역참조를 시도합니다. 이번에는 작동합니다. 이전 과제가 점점을 주었기 때문에 | 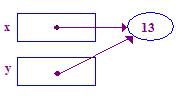 |
보시다시피 사진은 포인터 사용을 이해하는 데 매우 유용합니다. 다음은 또 다른 예입니다.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
이 예에서는 'new' 연산자와 같습니다. 일반 정수 변수를 선언하고 포인터를 통해 조작했습니다.
이 예에서는 힙 메모리에 대해 알아보고 더 복잡한 구조에 할당하는 방법을 알아봅니다. 이 모듈에서 다룰 내용은 메모리 구성 (힙 및 런타임 스택)에 관해서는 다른 강의에서 살펴보겠습니다. 지금은 힙을 실행 중인 프로그램에 사용할 수 있는 무료 메모리 저장소로 생각하세요.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
이 마지막 예에서는 포인터를 사용하여 값을 참조로 전달하는 방법을 보여줍니다. 추가합니다. 이는 함수 내에서 변수 값을 수정하는 방법입니다.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
중복 함수 정의에서 &를 인수를 사용하지 않도록 하려면 '값별' 변수를 전달합니다. 즉, 있습니다. 함수에서 변수를 변경하면 사본이 수정됩니다. 원본 변수는 수정되지 않습니다.
변수가 참조를 통해 전달될 때는 그 값의 사본이 전달되지 않습니다. 변수의 주소를 함수에 전달합니다. 전달된 원래 변수가 실제로 수정됩니다.
C 프로그래머라면 이 방식이 색다른 선택입니다. C에서도 동일한 작업을 할 수 있습니다. Duplicate() 선언 Duplicate(int *x), 이 경우 x 가 정수에 대한 포인터이고 인수 &x(주소: x)를 사용하여 Duplicate()를 호출하고 x 내 중복() (아래 참고) 그러나 C++는 다음을 통해 함수에 값을 전달하는 더 간단한 방법을 제공합니다. 비록 이전 'C'가 여전히 효과가 있습니다.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
C++ 참조에서는 변수의 주소를 전달할 필요가 없고 호출된 함수 내에서 변수를 역참조해야 합니다.
다음 프로그램은 무엇을 출력하나요? 기억의 그림을 그려서 파악해 보세요.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} 정답을 맞추었는지 확인하려면 프로그램을 실행하세요.
예 3: 참조로 값 전달
차량의 속도와 양을 입력으로 취하는 가속()이라는 함수를 작성합니다. 이 함수는 속도에 양을 더하여 차량을 가속합니다. 속도 매개변수는 참조로, 양으로 값을 전달해야 합니다. Google Cloud의 솔루션은 여기에서 확인하세요.
예시 #4: 클래스 및 객체
다음 클래스를 살펴보세요.
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
클래스 멤버 변수에는 뒤에 밑줄이 있습니다. 이는 로컬 변수와 클래스 변수를 구분하기 위해 수행됩니다.
이 클래스에 decrement 메서드를 추가합니다. Google Cloud의 솔루션은 여기에서 확인하세요.
과학의 경이로움: 컴퓨터 공학
연습
이 과정의 첫 번째 모듈에서와 마찬가지로, 연습이나 프로젝트에 대한 솔루션은 제공하지 않습니다.
좋은 프로그램이란 점을 기억하세요...
하나의 함수가 한 개라도 있는 함수로 논리적으로 분해됨 한 가지 작업만 수행합니다.
... 프로그램의 개요와 같은 기본 프로그램이 있습니다.
... 설명적인 함수, 상수, 변수 이름이 있습니다.
... 상수를 사용하여 '마법'을 피합니다. 도움이 될 수 있습니다.
사용자 인터페이스가 친숙해야 합니다.
워밍업 연습
- 실습 1
정수 36은 완전한 제곱이고 1과 8 사이의 정수의 합입니다. 그다음 숫자는 1225이며 1부터 49까지 정수의 합을 나타냅니다. 다음 번호 찾기 이는 완전 제곱이고 1...n 계열의 합입니다. 이 다음 번호 32,767보다 클 수 있습니다. 여러분이 알고 있는 라이브러리 함수를 사용할 수도 있습니다. 또는 수학 공식)을 사용하여 프로그램을 더 빠르게 실행할 수 있습니다. 또한 숫자가 완전한지 판단하는 데 for 루프를 사용하여 이 프로그램을 작성합니다. 제곱 또는 급수의 합으로 표현됩니다. (참고: 컴퓨터 및 프로그램에 따라 이 숫자를 찾는 데 시간이 오래 걸릴 수 있습니다.)
- 실습 2
대학교 서점에서 다음 학기의 매출을 예측하는 데 있습니다. 경험에 따르면 책이 필요한지 여부에 따라 판매가 크게 좌우됩니다. 선택사항이며 수업에서 사용되었는지 여부 있습니다. 새로운 필수 교과서는 예비 등록자의 90% 에게 판매될 것입니다. 그러나 이전에 수업에서 사용한 적이 있다면 65% 만 구매합니다. 마찬가지로 예비 등록자의 40% 가 새로운 교과서(선택 사항)를 구입하게 되지만 20% 만 구매하기 전에 수업에서 사용한 적이 있다고 합니다. (여기서 '중고품'이란 중고책을 의미하지 않습니다.)
사용자가 입력할 때까지 일련의 도서를 입력으로 받는 프로그램을 작성합니다. 감시병). 각 도서 요청: 도서 코드, 단일 사본 구매 비용 책, 현재 소장 중인 책 권수, 입학 예정 도서가 필수/선택사항인지, 신간/중고품인지를 나타내는 데이터입니다. 따라서 출력은 깔끔한 형식으로 모든 입력 정보를 화면에 몇 권의 책을 주문해야 하는지 (있는 경우 새 책만 주문됨), 총 비용을 나타냅니다
그런 다음 모든 입력이 완료되면 모든 도서 주문의 총비용을 표시합니다. 매장이 정가의 80% 를 지불할 경우 예상되는 이익 아직 프로그램에 들어오는 대량의 데이터를 처리하는 모든 방법( 한 번에 한 권씩만 처리하고 해당 도서의 출력 화면을 표시합니다. 그런 다음 사용자가 모든 데이터 입력을 마치면 프로그램은 합쳐집니다.
코드 작성을 시작하기 전에 이 프로그램의 설계에 대해 생각해 보세요. 함수 집합으로 분해하고 다음과 같은 main() 함수를 만듭니다. 문제 해결 방법의 개요를 제공합니다 각 함수가 하나의 작업을 실행해야 합니다.
다음은 샘플 출력입니다.
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
데이터베이스 프로젝트
이 프로젝트에서는 간단한 코드 블록을 구현하는 완전한 기능을 갖춘 C++ 프로그램을 만듭니다. 데이터베이스 애플리케이션입니다
본 프로그램을 통해 작곡가의 데이터베이스 및 관련 정보를 관리할 수 있습니다. 확인할 수 있습니다 이 프로그램의 기능은 다음과 같습니다.
- 새 작곡가를 추가하는 기능
- 작곡가의 순위 (예: 좋아요 또는 싫어요 표시) 작곡가의 음악)
- 데이터베이스의 모든 작곡가를 볼 수 있는 기능
- 순위별로 모든 작곡가를 볼 수 있는 기능
"데이터 레이크를 구성하는 방법에는 소프트웨어 설계: 한 가지 방법은 매우 단순해서 또 다른 방법은 문제를 너무나 복잡하게 만들어 명확한 결점이 없다는 것입니다 첫 번째 방법은 훨씬 더 어렵습니다."라고 말합니다. - C.A.R. Hoare
많은 사람이 데이터 레이크에서 '절차적'인 접근하는 것입니다. 가장 먼저 해야 할 일은 "프로그램이 무엇을 해야 하는가?"입니다. 문제에 대한 솔루션을 작업으로 분해하며, 각 작업은 있습니다. 이러한 작업은 순차적으로 호출되는 프로그램의 함수에 매핑됩니다. 다른 함수에서 삭제할 수 있습니다. 이 단계별 접근 방식은 우리가 해결해야 할 문제들입니다. 그러나 대부분의 경우 Google 프로그램은 선형적이 아니라 일련의 작업 또는 이벤트의 시퀀스입니다.
객체 지향 (OO) 접근 방식의 경우 '실제 세상은 무엇을 모델링해야 하나요?" 설명된 대로 프로그램을 태스크로 나누는 대신 물리적 물체의 모델로 나뉩니다. 이러한 물리적 물체는 속성 집합으로 정의되는 상태 및 수행할 수 있습니다. 작업이 객체의 상태를 변경하거나 다른 객체의 작업을 호출할 수 있습니다 기본 전제는 객체가 '알고 있다'는 것입니다. 어떻게 스스로의 작업을 수행할 수 있습니다.
OO 디자인에서는 클래스와 객체를 기준으로 물리적 객체를 정의합니다. 속성 파악할 수 있습니다 일반적으로 OO 프로그램에는 많은 객체가 있습니다. 그러나 이러한 객체의 대부분은 본질적으로 동일합니다. 다음 사항을 고려하세요.
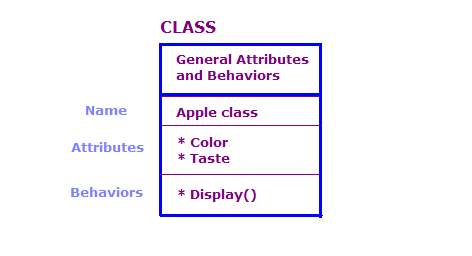
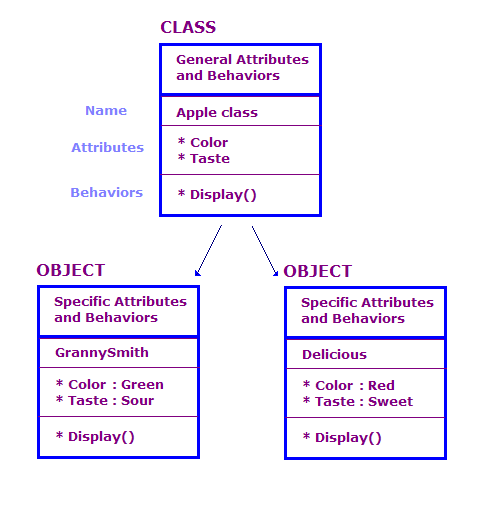
이 다이어그램에서는 Apple 클래스의 두 객체를 정의했습니다. 각 객체에는 클래스와 동일한 속성과 작업이 있지만 는 특정 유형의 사과에 대한 속성을 정의합니다. 또한 디스플레이 액션은 해당 특정 객체에 대한 속성을 표시합니다. 예: "녹색" 그리고 '새콤'입니다.
OO 디자인은 일련의 클래스, 이러한 클래스와 관련된 데이터, 클래스가 수행할 수 있는 작업 집합을 정의합니다. 또한 공격 대상이 될 수 있는 상호작용하는 방식을 보여줍니다. 이러한 상호작용은 인코더-디코더 아키텍처를 다른 클래스의 객체 작업을 호출하는 클래스의 클래스입니다. 예를 들어 배열의 색상과 맛을 출력하는 AppleOutputer 클래스가 있을 수 있습니다. 각 Apple 객체의 Display() 메서드를 호출하여 Apple 객체의 해상도를 지원합니다.
다음은 OO 디자인에서 수행하는 단계입니다.
- 클래스를 식별하고 일반적으로 각 클래스의 객체 정의 객체가 할 수 있는 작업을 살펴보겠습니다
- 각 클래스의 데이터 요소 정의
- 각 클래스의 작업 및 한 클래스의 일부 작업이 어떻게 정의될 수 있는지 정의
다른 관련 클래스의 작업을 사용하여 구현됩니다.
대규모 시스템의 경우 이러한 단계는 다양한 세부정보 수준에서 반복적으로 발생합니다.
컴포저 데이터베이스 시스템에는 모든 구성 요소를 캡슐화하는 Composer 클래스가 개별 작곡가에 저장할 데이터를 지정합니다. 이 클래스의 객체는 순위를 변경하고 해당 속성을 표시할 수 있습니다.
Composer 객체 컬렉션도 필요합니다. 이를 위해 Database 클래스 개별 레코드를 관리합니다 이 클래스의 객체는 추가하거나 가져올 수 있습니다. Composer 객체의 표시 작업을 호출하여 개별 객체를 Composer 객체입니다.
마지막으로, 대화형 작업을 제공하려면 일종의 사용자 인터페이스가 필요합니다. 생성합니다. 이 클래스는 자리표시자 클래스입니다. 즉, 어떤 클래스인지 사용자 인터페이스의 형태는 아직 없을 것이지만, 우리는 그것이 필요하다는 것을 알고 있습니다. 미정 그래픽일 수도 있고 텍스트 기반일 수도 있습니다. 지금은 나중에 채울 수 있습니다.
이제 Composer 데이터베이스 애플리케이션의 클래스를 확인했으므로 다음 단계는 클래스의 속성과 작업을 정의하는 것입니다. 더 연필과 종이를 가지고 앉아서 UML 또는 CRC 카드 또는 OOD 클래스 계층 구조와 객체가 상호작용하는 방식을 매핑합니다.
작곡가 데이터베이스의 경우 관련 작업이 포함된 Composer 클래스를 정의합니다. 선택해야 합니다. 또한 인코더-디코더 아키텍처를 데이터 표시가 있습니다.
Database 클래스에는 Composer 객체를 보관하기 위한 일종의 구조가 필요합니다. 새 Composer 객체를 구조에 추가하고 특정 Composer 객체를 가져올 수 있습니다. 또한 이 객체의 순위를 지정할 수 있습니다.
사용자 인터페이스 클래스는 메뉴 기반 인터페이스를 구현하고 데이터베이스 클래스의 호출 작업
클래스를 쉽게 이해할 수 있고 해당 속성과 작업이 명확하다면 Composer 애플리케이션에서와 같이 클래스를 설계하는 것은 비교적 쉽습니다. 하지만 수업의 관계와 상호작용 방식에 대해 생각하고 있다면 먼저 그림을 그리고 세부사항을 살피고 살펴보겠습니다
디자인을 확실히 파악하고 평가한 후에는 곧) 각 클래스의 인터페이스를 정의합니다. 자동 태그 구현과 관련해서도 속성과 작업이 무엇인지 그리고 수업의 다른 클래스에서 사용할 수 있습니다.
C++에서는 일반적으로 각 클래스에 헤더 파일을 정의하여 이를 수행합니다. 작곡가 클래스에는 작성기에 저장하려는 모든 데이터에 대한 비공개 데이터 멤버가 있습니다. 접근자 (“get” 메서드)와 변형자 (“set” 메서드), 그리고 수업의 기본 작업을 표시합니다.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
Database 클래스도 간단합니다.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
작곡가별 데이터를 별도의 클래스에 대해 자세히 알아보세요. Database 클래스에 구조체 또는 클래스를 넣어 Composer 레코드에서 데이터를 저장하고 거기에서 직접 액세스했습니다. 하지만 그것은 '목표화 미달', 즉 '객체'로 모델링하지 않는 경우가 많음 할 수 있습니다.
Composer 및 Database의 구현 작업을 시작하면서 보게 됩니다. 별도의 Composer 클래스가 있는 것이 훨씬 더 깔끔하다는 것을 알 수 있습니다. 특히 Composer 객체에 별도의 원자적 연산이 있으면 구현이 크게 간소화됨 Display() 메서드의 한 수준입니다.
물론 '과도한 목표화'도 있습니다. 각 항목의 의미는 다음과 같습니다. 모든 것을 클래스로 만들거나 필요한 것보다 더 많은 클래스가 있습니다. 연습해야 하며, 개별 프로그래머는 다른 의견을 가질 수 있습니다
목표를 과도하거나 과소화하는지 여부를 신중하게 판단할 수 있음 살펴보겠습니다 앞서 언급했듯이, 한 가지 특정 주제나 설계할 수 있으며 이는 접근 방식을 분석하는 데 도움이 될 수 있습니다. 일반적인 이 용도로 사용되는 표기법은 UML (통합 모델링 언어) 이제 Composer 및 Database 객체에 클래스를 정의했으니 사용자가 데이터베이스와 상호 작용할 수 있는 인터페이스입니다. 간단한 메뉴를 통해 다음과 같이 할 수 있습니다.
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
사용자 인터페이스를 클래스로 또는 절차적 프로그램으로 구현할 수 있습니다. 비 C++ 프로그램의 모든 것은 클래스여야 합니다. 실제로 처리가 순차적으로 이루어지면 또는 작업 지향의 경우, 이 메뉴 프로그램에서처럼, 절차상으로 구현하는 것이 좋습니다. '자리표시자'로 유지되도록 구현하는 것이 중요합니다. 즉, 그래픽 사용자 인터페이스를 만들고 싶다면 사용자 인터페이스 외에 시스템에서 아무것도 변경할 필요가 없습니다.
신청을 완료하기 위해 마지막으로 필요한 것은 클래스를 테스트하는 프로그램입니다. Composer 클래스의 경우 입력을 받아 데이터 캡션을 채우는 main() 프로그램이 composer 객체를 만든 다음 표시하여 클래스가 제대로 작동하는지 확인합니다. 또한 Composer 클래스의 모든 메서드를 호출하려고 합니다.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
Database 클래스에도 비슷한 테스트 프로그램이 필요합니다.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
이 간단한 테스트 프로그램은 좋은 첫 단계이지만 출력을 수동으로 검사하여 프로그램이 올바르게 작동하는지 확인합니다. 따라서 시스템이 커지면 결과를 수동으로 검사하는 것이 실용적이지 않게 됩니다. 다음 강의에서는 자가 진단 테스트 프로그램을 살펴보겠습니다
이제 애플리케이션의 설계가 완료되었습니다. 다음 단계는 클래스 및 사용자 인터페이스의 .cpp 파일시작하려면 위의 .h 및 테스트 드라이버 코드를 복사하여 파일에 붙여넣고 컴파일합니다.사용 테스트 드라이버를 사용하여 클래스를 테스트할 수 있습니다. 그런 다음 아래 인터페이스를 구현합니다.
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Database 클래스에 정의한 메서드를 사용하여 사용자 인터페이스를 구현합니다. 메서드에 오류가 없도록 합니다. 예를 들어 순위는 항상 범위 내에 있어야 합니다. 1~10. 101명의 작곡가를 추가하지 마세요. 데이터베이스 클래스의 데이터 구조입니다.
모든 코드는 Google의 코딩 규칙을 따라야 한다는 점을 기억하세요. 확인하시기 바랍니다.
- 우리가 작성하는 모든 프로그램은 헤더 주석으로 시작하며, 헤더 코멘트는 정보 (작성자, 연락처 정보, 간단한 설명, 사용) 모든 함수와 메서드는 연산 및 사용법에 대한 주석으로 시작합니다.
- 코드가 실행될 때마다 전체 문장을 사용하여 설명 주석을 추가합니다. 처리가 까다롭거나 명확하지 않거나 흥미로울 수도 있고 중요할 수도 있습니다.
- 항상 알아보기 쉬운 이름을 사용하세요. 변수는 _). 함수/메서드 이름은 대문자를 사용하여 MyExcitingFunction()에서처럼 작동합니다. 상수는 'k'로 시작합니다. 및 kDaysInWeek와 같이 대문자를 사용하여 단어를 표시합니다.
- 들여쓰기는 2의 배수입니다. 첫 번째 수준은 두 개의 공백입니다. 추가적으로 들여쓰기가 필요하며 공백 4개, 공백 6개 등을 사용합니다.
현실 세계에 오신 것을 환영합니다!
이 모듈에서는 대부분의 소프트웨어 엔지니어링에 사용되는 두 가지 매우 중요한 도구를 소개합니다. 액세스할 수 있습니다 첫 번째는 빌드 도구이고 두 번째는 구성 관리입니다 있습니다. 이 두 도구 모두 많은 엔지니어가 종종 하나의 대형 시스템에서 작업합니다. 이러한 도구는 코드베이스의 변경사항을 제어하고 효율적인 컴파일 수단 제공 많은 프로그램 및 헤더 파일에서 시스템을 연결하는 것입니다.
Makefile
프로그램 빌드 프로세스는 일반적으로 필요한 파일을 올바른 순서로 연결합니다. 종종 C++ 파일에는 예를 들어 한 프로그램에서 호출된 함수는 다른 프로그램에 상주하고 있습니다. 또는 헤더 파일이 여러 다른 .cpp 파일에 필요할 수 있습니다. 가 빌드 도구는 이러한 종속성에서 올바른 컴파일 순서를 파악합니다. 데이터 커리큘럼 내의 마지막 빌드 이후에 변경된 파일만 컴파일합니다. 이렇게 하면 수백 또는 수천 개의 파일로 구성된 시스템에서 많은 시간을 소비하게 됩니다.
make라는 오픈소스 빌드 도구가 흔히 사용됩니다. 자세한 내용은 이를 통해 도움말을 참조하세요. Composer 데이터베이스 애플리케이션의 종속 항목 그래프를 만들 수 있는지 확인합니다. 이를 makefile로 변환합니다.여기에서 확인하세요. 솔루션을 제공합니다
구성 관리 시스템
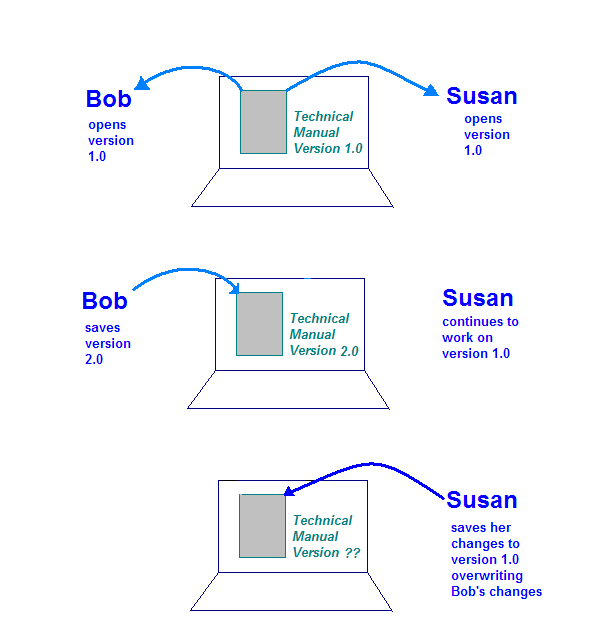
산업용 소프트웨어 엔지니어링에서 두 번째로 사용되는 도구는 구성 관리입니다. (CM). 변경사항을 관리하는 데 사용됩니다. Bob과 Susan이 둘 다 테크니컬 라이터이고 두 회사 모두 기술 매뉴얼 업데이트를 진행하고 있습니다 회의 중에 관리자가 각 사용자에게 업데이트할 동일한 문서의 섹션을 할당합니다.
기술 설명서는 Bob과 Susan이 액세스할 수 있는 컴퓨터에 저장되어 있습니다. CM 도구나 프로세스가 없으면 여러 문제가 발생할 수 있습니다. 1개 가능한 시나리오는 문서를 저장하는 컴퓨터가 밥과 수잔은 동시에 매뉴얼 작업을 할 수 없습니다. 이렇게 하면 줄일 수 있습니다.
스토리지 컴퓨터에서 문서를 허용하면 더 위험한 상황이 발생합니다. 열어 볼 수 있습니다. 발생할 수 있는 상황은 다음과 같습니다.
- 밥은 컴퓨터에서 문서를 열고 해당 섹션에서 작업합니다.
- 수잔은 컴퓨터에서 문서를 열고 섹션에서 작업합니다.
- 밥은 변경을 완료하고 스토리지 컴퓨터에 문서를 저장합니다.
- 수잔이 변경을 완료하고 문서를 스토리지 컴퓨터에 저장합니다.
이 그림은 컨트롤이 없는 경우 발생할 수 있는 문제를 보여줍니다. 참조하세요. 수잔이 변경사항을 저장하면 Bob이 만든 항목을 덮어씁니다.
이것이 바로 CM 시스템이 제어할 수 있는 상황 유형입니다. CM과 함께 모두 '체크아웃'하고 자체 기술 사본을 수동으로 작업해야 합니다 철수씨가 변경사항을 다시 확인하면 시스템은 확인해 보겠습니다. 수잔이 광고 문구를 확인하자 시스템은 밥과 수잔이 함께 변경한 내용을 분석하고 는 두 변경사항 집합을 병합합니다.
CM 시스템에는 설명된 대로 동시 변경을 관리하는 것 이상의 기능이 있습니다. 참조하세요. 많은 시스템은 문서의 모든 버전에 대한 보관 파일을 생성된 시간 동안 표시됩니다. 기술 매뉴얼의 경우 이것은 매우 유용할 수 있습니다 사용자가 이전 버전의 매뉴얼을 사용 중이고 테크니컬 라이터에게 질문할 때 CM 시스템은 기술 작성자가 이전 버전에 액세스하고 사용자가 무엇을 보고 있는지 확인할 수 있습니다
CM 시스템은 특히 소프트웨어 변경사항을 제어하는 데 유용합니다. 이러한 소프트웨어 구성 관리 (SCM) 시스템이라고 합니다 다음을 고려한다면 대규모 소프트웨어 엔지니어링에 사용되는 수많은 개별 소스 코드 파일을 변경해야 하는 수많은 엔지니어가 SCM 시스템이 중요하다는 것은 분명합니다.
소프트웨어 구성 관리
SCM 시스템은 파일의 최종 사본이라는 단순한 아이디어에 기반합니다. 중앙 저장소에 저장됩니다 사용자는 저장소에서 파일 사본을 체크아웃하고, 해당 사본에서 작업한 다음, 작업이 완료되면 다시 체크인하세요. SCM 시스템은 단일 마스터에 대해 여러 사람의 수정 사항을 관리하고 추적합니다. 설정합니다.
모든 SCM 시스템은 다음과 같은 필수 기능을 제공합니다.
- 동시 실행 관리
- 버전 관리
- 동기화
각 기능에 대해 자세히 살펴보겠습니다.
동시 실행 관리
동시 실행은 둘 이상의 사용자가 동시에 파일을 수정하는 것을 의미합니다. 대규모 저장소는 사용자가 이러한 작업을 수행할 수 있도록 하고 싶지만 몇 가지 문제에 대처할 수 있습니다.
엔지니어링 분야의 간단한 예를 들어 보겠습니다. 엔지니어가 소스 코드의 중앙 저장소에서 동시에 같은 파일을 수정할 수 있습니다. Client1과 Client2 모두 동시에 파일을 변경해야 합니다.
- 클라이언트1이 bar.cpp를 엽니다.
- 클라이언트2가 bar.cpp를 엽니다.
- Client1이 파일을 변경하고 저장합니다.
- Client2가 파일을 변경하고 Client1의 변경사항을 덮어씁니다.
이런 일이 일어나지 않았으면 좋겠어요. 우리가 그것으로 상황을 통제했더라도 두 엔지니어가 마스터에서 직접 작업하지 않고 별도의 사본에서 작업하도록 함 (아래 그림에서와 같이) 사본은 어떻게든 조정되어야 합니다. 대부분 SCM 시스템은 여러 엔지니어가 하나의 파일을 확인할 수 있도록 허용하여 동기화하고 필요에 따라 변경합니다. SCM 파일이 다시 체크인되면 시스템에서 알고리즘을 실행하여 변경사항을 병합합니다. ('submit' 또는 'commit') 저장소에 전달됩니다.
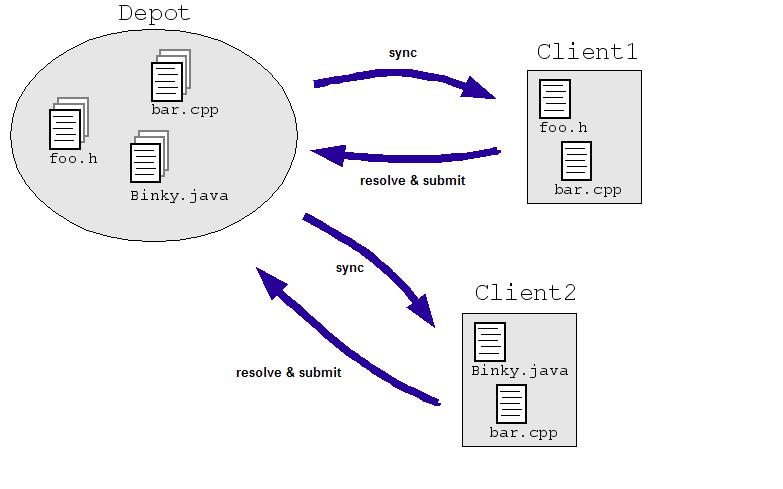
알고리즘은 단순함 (엔지니어에게 변경사항 충돌 해결을 요청) 또는 간단하지 않은 부분 (충돌하는 변경사항을 지능적으로 병합하는 방법 결정) 시스템이 실제로 중단되는 경우에만 엔지니어에게 문의하세요).
버전 관리
버전 관리는 파일 버전을 추적하는 것을 의미하며, 이를 통해 파일의 이전 버전을 다시 만들거나 이전 버전으로 롤백합니다. 이 작업은 리포지토리에 체크인하면 모든 파일의 아카이브 사본을 만들어 또는 파일의 모든 변경사항을 저장하여 저장하는 것입니다 사용자는 언제든지 정보를 변경하여 이전 버전을 만들 수 있습니다. 버전 관리 시스템은 또한 누가 변경사항을 체크인했는지, 언제 체크인했는지, 무엇을 변경했는지에 대한 로그 보고서를 확인할 수 있습니다
동기화
일부 SCM 시스템에서는 개별 파일이 저장소에서 체크인 및 체크아웃됩니다. 시스템이 더 강력하면 한 번에 두 개 이상의 파일을 확인할 수 있습니다. 엔지니어 저장소 (또는 저장소 일부)의 전체 사본을 확인하고 작업 할 수 있습니다 그런 다음 변경사항을 마스터 저장소에 다시 커밋합니다. 정기적으로 업데이트하고 변경 사항을 최신 상태로 유지하기 위해 자신의 개인 사본을 업데이트합니다. 만들 수 있다는 것입니다. 이 과정을 동기화 또는 업데이트라고 합니다.
하위 버전
Subversion (SVN)은 오픈소스 버전 제어 시스템입니다. Kubernetes는 기능을 사용할 수 있습니다.
SVN은 충돌이 발생할 때 간단한 방법론을 사용합니다. 충돌은 또는 그 이상의 엔지니어가 코드베이스의 동일한 영역을 다르게 변경하고 둘 다 변경사항을 제출합니다. SVN은 엔지니어에게 해당 문제에 대한 엔지니어의 몫입니다.
이 과정 전반에서는 SVN을 사용해 구성 관리입니다. 이러한 시스템은 업계에서 매우 일반적입니다.
첫 번째 단계는 시스템에 SVN을 설치하는 것입니다. 클릭 여기에서 참조하세요. 운영 체제를 찾아 적절한 바이너리를 다운로드합니다.
일부 SVN 용어
- 버전: 파일 또는 파일 집합의 변경사항입니다. 버전 1은 '스냅샷' 매우 중요한 역할을 할 수 있습니다
- 저장소: SVN이 프로젝트의 전체 업데이트 기록을 저장하는 마스터 사본입니다. 각 프로젝트에는 저장소가 하나씩 있습니다.
- 작업 사본: 엔지니어가 프로젝트를 변경하는 사본입니다. 거기 각각 개별 엔지니어가 소유한 특정 프로젝트의 작업 복사본 여러 개일 수 있습니다.
- 체크아웃: 저장소에서 작업 중인 사본을 요청합니다. 작업용 사본 체크아웃할 때의 프로젝트 상태입니다.
- 커밋: 작업 중인 사본의 변경사항을 중앙 저장소로 전송합니다. 체크인 또는 제출이라고도 합니다.
- 업데이트: 다른 사람의 작업 사본으로 변경하면 작업 사본에 커밋되지 않은 변경사항이 있는지 나타낼 수 있습니다. 이것은 동기화와 동일해야 합니다. 업데이트/동기화하면 작업 사본이 저장소 사본으로 업데이트합니다
- 충돌: 두 엔지니어가 변경사항을 동일한 작업에 커밋하려고 하는 상황 영역만 나타냅니다. SVN은 충돌을 나타내지만 엔지니어가 해결해야 합니다.
- 로그 메시지: 수정할 때 버전에 첨부하는 댓글로, 변경사항에 대해 설명합니다. 로그는 현재 진행 중인 작업을 요약하여 역할을 합니다
SVN이 설치되었으니 이제 몇 가지 기본 명령어를 실행해 보겠습니다. 이 가장 먼저 해야 할 일은 지정된 디렉터리에 저장소를 설정하는 것입니다. 사용 가능한 명령어:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
import 명령어는 mytree 디렉터리 콘텐츠를 디렉터리 프로젝트에 있어야 합니다 디렉터리에서 list 명령어로 저장소 생성
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
가져오기를 수행해도 작업 사본이 생성되지 않습니다. 이렇게 하려면 svn 결제 명령어를 사용합니다. 이렇게 하면 디렉터리 트리의 작업 복사본이 생성됩니다. 자, 지금 실행합니다.
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
이제 작업 사본이 생성되었으므로 파일과 디렉터리를 변경할 수 있습니다. 있습니다. 작업 사본은 다른 파일 및 디렉터리 컬렉션과 똑같습니다. - 새 사진을 추가하거나 수정할 수 있으며, 항목을 이동할 수도 있습니다. 전체 작업 사본입니다. 작업 사본에서 파일을 복사하고 이동하는 경우 svn copy 및 svn move를 실행할 수 있습니다 새 파일을 추가하려면 svn add를 사용하고 삭제하려면 파일은 svn delete를 사용합니다. 편집만 하고 싶다면 파일을 수정할 수 있습니다.
Subversion에는 자주 사용되는 몇 가지 표준 디렉터리 이름이 있습니다. '트렁크' 디렉터리 프로젝트의 주요 개발 라인을 담당합니다. A '브랜치' 디렉터리 작업 중일 수 있는 모든 브랜치 버전을 보관합니다.
$ svn list file:///usr/local/svn/repos /trunk /branches
작업 사본에 필요한 모든 변경을 완료했고 선택해야 합니다 많은 다른 엔지니어들이 작업 복사본을 최신 상태로 유지하는 것이 중요합니다. svn status 명령어를 사용하면 현재 변경사항을 확인할 수 있습니다. 있습니다.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
status 명령어에는 이 출력을 제어하는 다수의 플래그가 있습니다. 수정된 파일의 구체적인 변경사항을 보려면 svn diff를 사용하세요.
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...마지막으로 저장소에서 작업 사본을 업데이트하려면 svn update 명령어를 사용합니다.
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
여기에서 갈등이 발생할 수 있습니다. 위의 출력에서 'U'는 는 이 파일의 저장소 버전은 변경되지 않았고 되었습니다. 'G' 는 병합이 발생했음을 의미합니다. 저장소 버전에는 변경사항이 내 변경사항과 충돌하지 않았습니다. 'C' 는 갈등이 있을 수 있습니다. 즉, 저장소의 변경사항이 내 변경사항과 겹쳤습니다. 둘 중 하나를 선택해야 합니다
Subversion은 충돌이 발생한 모든 파일에 대해 작업 파일에 세 개의 파일을 저장합니다. 카피:
- file.mine: 이전에 작업 사본에 있던 파일입니다. 작업 사본을 업데이트했습니다.
- file.rOLDREV: 이전에 저장소에서 체크아웃한 파일입니다. 확인할 수 있습니다
- file.rNEWREV: 이 파일은 저장소의 현재 버전입니다.
다음 세 가지 중 한 가지 방법으로 충돌을 해결할 수 있습니다.
- 파일을 살펴보고 수동으로 병합을 수행합니다.
- SVN에서 만든 임시 파일 중 하나를 작업 중인 사본 버전에 복사합니다.
- 모든 변경사항을 삭제하려면 svn undo를 실행합니다.
충돌을 해결하면 svnresolve를 실행하여 SVN에 알립니다. 이렇게 하면 임시 파일 3개가 삭제되고 SVN은 더 이상 충돌 상태가 됩니다.
마지막으로 할 일은 최종 버전을 저장소에 커밋하는 것입니다. 이 svn commit 명령어를 사용하면 됩니다. 변경사항을 커밋할 때는 다음이 필요합니다. 변경사항을 설명하는 로그 메시지가 제공됩니다. 이 로그 메시지가 첨부되었습니다. 업데이트할 수 있습니다
svn commit -m "Update files to include new headers."
SVN 및 SVN이 대규모 소프트웨어를 지원하는 방법에 관해 알아야 할 내용이 아주 많습니다. 프로젝트를 맡길 수 있습니다. 웹에는 광범위한 리소스가 있습니다. Google에서 'Subversion'을 검색합니다.
연습 삼아 Composer 데이터베이스 시스템용 저장소를 만들고 모든 파일이 포함됩니다 그런 다음 작업 사본을 확인하고 설명된 명령어를 사용해 보세요. 참조하세요.
참조
응용 사례: 해부학 연구
The University의 eSkeletons를 확인해 보세요 텍사스 오스틴