Einführung
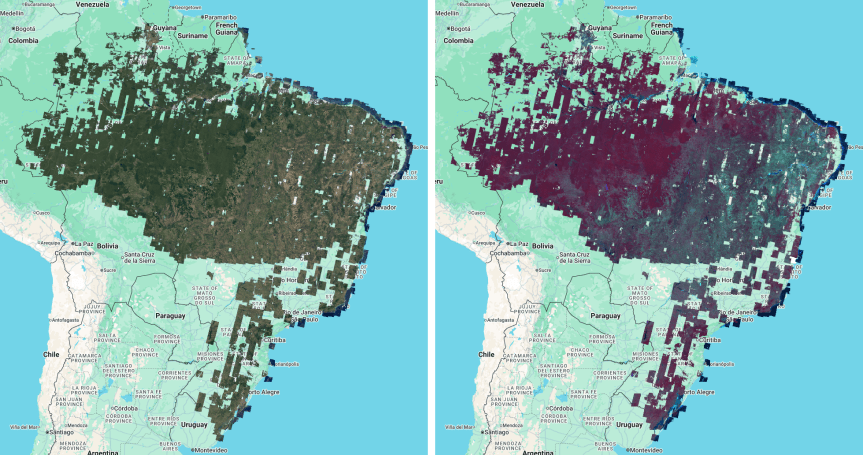
Zur Unterstützung der Bemühungen der brasilianischen Regierung, das brasilianische Waldschutzgesetz (Código Florestal brasileiro) umzusetzen und Wälder auf Privatgrundstücken zu schützen, hat Google zwei Basiskarten erstellt, die auf SPOT-Satellitenbeobachtungen basieren: eine visuelle Basiskarte und eine analytische Basiskarte (G-BFID v1.0).
Diese mosaikierten Bildprodukte bilden eine Grundlage für den 22. Juli 2008, ein wichtiges Datum im brasilianischen Waldschutzgesetz, um „konsolidierte Gebiete“ zu identifizieren – Regionen mit bestehender menschlicher Besiedlung oder landwirtschaftlicher Nutzung. Diese Mosaik-Datasets, die aus dem SPOT-Satellitenarchiv abgeleitet wurden, bieten eine Alternative mit höherer Auflösung zu den 30‑Meter-Landsat-Daten, die traditionell zur Festlegung dieser Baseline verwendet werden.
Um Tausende von SPOT-Bildern zu einheitlichen Basiskarten zusammenzufügen, wurden die Bilder in einem Verarbeitungsvorgang bearbeitet, der Folgendes umfasste:
- Kantenoptimierung, um Komprimierungsartefakte zu entfernen.
- Radiometrische Normalisierung anhand einer Landsat-Baseline.
- Cloud-Maskierung (konservativ, manuell).
- Korrektur von Registrierungsfehlern (Koregistrierung mit einem Landsat-Composite).
Für das endgültige Compositing wurde eine deterministische Mosaikmethode anstelle einer statistischen Reduktion verwendet. Die Pixel wurden nach räumlicher Auflösung und Chronologie der Satellitenmissionen geschichtet, wobei Beobachtungen von neueren Satelliten Vorrang hatten. Diese Hierarchie wurde mit dem Nearest-Neighbor-Resampling kombiniert, um eine strenge Datenherkunft zu gewährleisten. Folglich behielt jedes Pixel auf der endgültigen Grundkarte seinen diskreten Ursprung und blieb direkt auf eine bestimmte Quellbeobachtung und ihre Metadaten zurückzuführen.
Quelldaten
Spezifikationen von Satelliten und Sensoren
Die Basiskarten für G-BFID v1.0 basieren auf Bilddaten von SPOT (Satellite pour l’Observation de la Terre). Die SPOT-Missionen, die von CNES betrieben und von Airbus vertrieben werden, liefern hochauflösende optische Bilder mit einer Breite von 60 km. Für dieses Projekt wird ein Archiv mit Bildern von drei bestimmten Satelliten verwendet, um die Baseline für 2008 festzulegen:
- SPOT 2 und 4:Mit HRV/HRVIR-Sensoren ausgestattet, die multispektrale Daten mit einer Auflösung von 20 Metern und panchromatische Daten mit einer Auflösung von 10 Metern liefern.
- SPOT 5:Mit dem HRG-Sensor ausgestattet, der eine deutlich verbesserte räumliche Auflösung mit multispektralen Daten mit einer Auflösung von 10 Metern und panchromatischen Daten mit einer Auflösung von 5 Metern bietet.
| SPOT 2 | SPOT 4 | SPOT 5 | |
|---|---|---|---|
| Multispektral | 20 m | 20 m | 10 m |
| Panchromatisch | 10 m | 10 m | 5 m |
| Spektralbänder | Grün, Rot, NIR | Grün, Rot, NIR, SWIR | Grün, Rot, NIR, SWIR |
Tabelle 1 Technische Daten für SPOT-Missionen 2, 4 und 5.
Hinweis: Airbus bietet ein panchromatisches „Supermode“-Produkt an, mit dem SPOT 5-Bilder auf eine Auflösung von 2,5 Metern geschärft werden können. Die Verfügbarkeit dieser Daten ist für die Spezifikationen dieses Projekts sehr begrenzt und sie wurden nicht berücksichtigt.
Earth Engine-Sammlungen eingeben
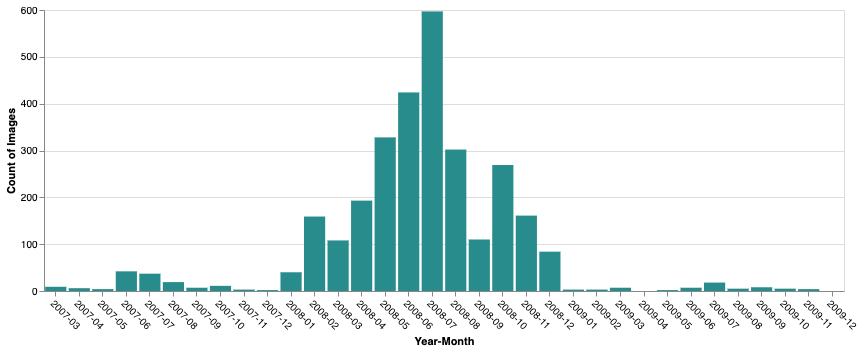
Es wurden drei verschiedene SPOT-Datenprodukte aufgenommen und verarbeitet, um die endgültigen Grundkarten zu erstellen. Diese Sammlungen umfassen den Zeitraum vom 9. Januar 2007 bis zum 26. November 2009 und bieten die erforderliche zeitliche Tiefe, um Einschränkungen durch die Wolkendecke zu überwinden und gleichzeitig eine hochauflösende Baseline beizubehalten.
Szenenauswahl
Um den Schutz von Wäldern auf Privatgrundstücken zu unterstützen, die im Rural Environmental Registry (CAR) registriert sind, wurde die geografische Abdeckung für das Amazonas-Biom und die fünf Bundesstaaten des „Arc of Deforestation“ (Entwaldungsbogen) priorisiert: Maranhão, Mato Grosso, Pará, Rondônia und Tocantins.
Um den Anforderungen des brasilianischen Waldgesetzes zu entsprechen, wurde ein Zeitfenster Mitte 2008 anvisiert. Anhand dieser Kriterien für den Zeitraum und die Wolkendecke (<50%) wurden insgesamt 10.072 Bilder von SPOT 2, 4 und 5 identifiziert und zur Verarbeitung in den Earth Engine-Datenkatalog aufgenommen.
Hinweis zur spektralen Zusammensetzung:SPOT 2-, 4- und 5-Sensoren erfassen kein blaues Spektralband. Für die Produkte in natürlichen Farben wird vom Datenvertrieb ein synthetisches blaues Band bereitgestellt, das aus vorhandenen Spektralbändern abgeleitet wird, um eine Darstellung in echten Farben zu ermöglichen.
1. Pansharpened multispectral natural color (Pansharpened multispectral natural color)
- Earth Engine-Asset:
AIRBUS/SPOT_2_4_5/BRAZIL/2007_2009/PMS_NC/V1 - Anzahl der Bilder:2.977
- Zeitraum:1. März 2007 bis 26. November 2009
- Beschreibung:Bei diesem Produkt wird das hochauflösende panchromatische Band mit den multispektralen Bändern kombiniert, um ein scharfes RGB-Bild mit drei Bändern zu erzeugen. Dies ist die bevorzugte Quelle für die visuelle Basiskarte.
2. Multispektral – natürliche Farben
- Earth Engine-Asset:
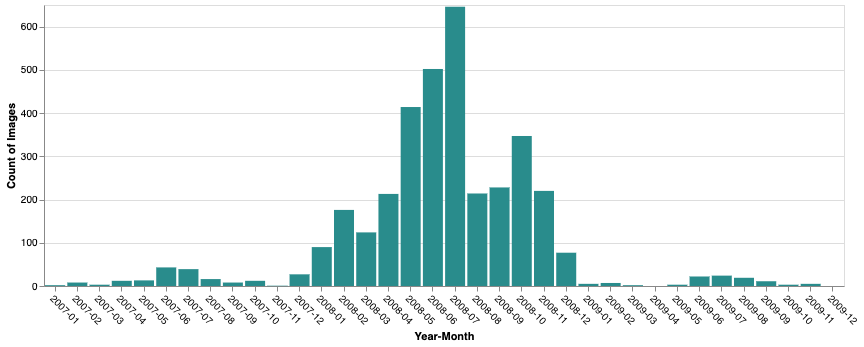
AIRBUS/SPOT_2_4_5/BRAZIL/2007_2009/MS_NC/V1 - Anzahl der Bilder:3.536
- Zeitraum:9. Januar 2007 bis 26. November 2009
- Beschreibung:Ein 3-Band-Produkt in Pseudonaturfarben (simuliertes RGB) in der nativen multispektralen Auflösung. Diese Sammlung wird in der visuellen Grundkarte als sekundäre Quelle verwendet, wenn keine pansharpened Daten verfügbar sind.
3. Multispektral
- Earth Engine-Asset:
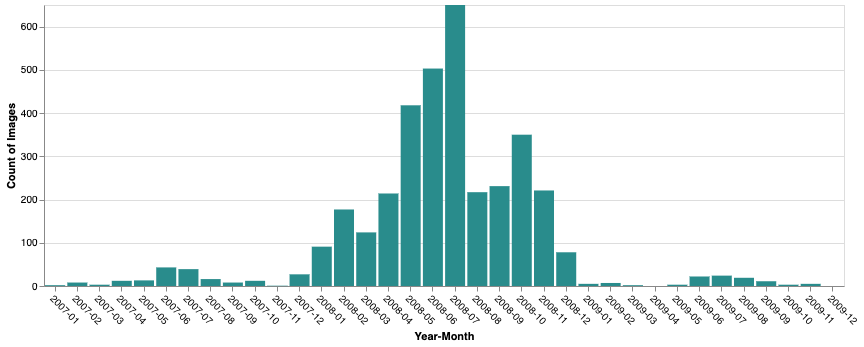
AIRBUS/SPOT_2_4_5/BRAZIL/2007_2009/MS/V1 - Anzahl der Bilder:3.559
- Zeitraum:9. Januar 2007 bis 26. November 2009
- Beschreibung:Die Quelle für die analytische Grundkarte. Diese Sammlung enthält die ursprünglichen Spektralbänder (einschließlich Nah- und Kurzwellen-Infrarot, sofern verfügbar), die für die Berechnung von Vegetationsindizes (z.B. NDVI) und die Durchführung der Klassifizierung der Bodenbedeckung erforderlich sind.
Geografische Abdeckung und Lücken
Das Hauptziel der G-BFID v1.0-Basiskarten ist es, eine hochauflösende Baseline für das Verwaltungsgebiet von Brasilien aus dem Jahr 2008 zu erstellen. Durch die Beibehaltung eines strengen Zeitfensters (2007–2009) beim Filtern nach hochwertigen Bildern mit geringer Bewölkung entstanden jedoch räumliche Lücken, insbesondere in Regionen mit anhaltender Bewölkung.
Szenenauswahl und Qualitätsfilterung
Um die Datenintegrität zu gewährleisten, wurde ein Kandidatenpool aus den Jahren 2007 bis 2009 mit einer anfänglichen Wolkendecke von unter 50% ermittelt. Insgesamt wurden so etwas mehr als 10.000 Bilder aufgenommen und weiter gefiltert, um Bilder mit erheblichen Qualitätsproblemen auszuschließen:
- Prüfung auf Diskontinuität: Bilder mit manuell identifizierten Telemetrie- oder geometrischen Artefakten, einschließlich diskontinuierlicher Szenen, die vom Datenanbieter zusammengefasst wurden, wurden ausgeschlossen.
- Cloud QA: Szenen, die von professionellen Bildanalysten abgelehnt wurden, weil sie vollständig von Wolken bedeckt sind oder aus anderen Gründen.
- Datendichte: Nur Bilder mit >10% gültigen Pixeln (visuelle Grundkarte), die nach der Wolkenmaskierung verblieben sind, wurden beibehalten (>5% für die analytische Grundkarte).
Räumliche Verteilung
Wie in Abbildung 5 dargestellt, erreichen die Mosaike die höchste Dichte im „Arc of Deforestation“ und in den nord- und zentralwestlichen Regionen. Transparente Bereiche stellen Regionen dar, in denen keine SPOT 2-, 4- oder 5-Bilder die oben aufgeführten Qualitätsfilter innerhalb des Zielzeitraums bestanden haben oder durch Wolken verdeckt wurden.
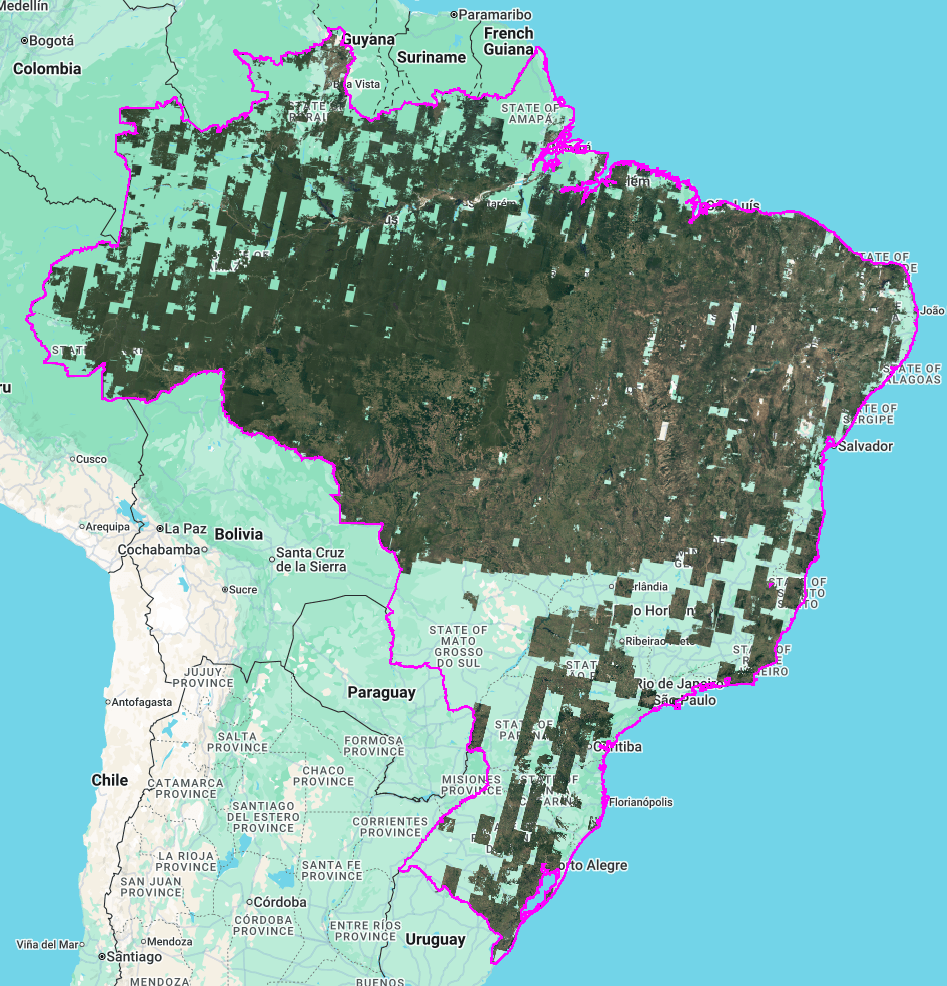
Abdeckung nach Bundesstaat
Abbildung 6 zeigt eine Aufschlüsselung der gültigen Pixelabdeckung nach Bundesstaat. Die Abdeckung ist für Bundesstaaten wie Rondônia und Mato Grosso nahezu vollständig (> 95%), während Bundesstaaten im Süden und Teile des Nordosten aufgrund der Einschränkungen des Archivs und der Cloud-Maskierung eine geringere Dichte aufweisen.
Das Diagramm zeigt auch, dass die visuelle Grundkarte in fast allen Bundesstaaten durchgehend eine etwas höhere Abdeckung mit gültigen Pixeln als die analytische Grundkarte bietet. Dieser Unterschied besteht, weil für das visuelle Produkt sowohl die pansharpened- als auch die multispektralen Natural Color-Sammlungen verwendet werden können, während das Analyseprodukt ausschließlich aus der multispektralen Sammlung abgeleitet wird.
Verarbeitungsmethodik
Bei der Verarbeitungsmethodik für die G-BFID v1.0-Grundkarten werden Datenherkunft und radiometrische Integrität priorisiert, um die Einhaltung des Forest Code zu unterstützen. In diesem Abschnitt werden zuerst die übergeordnete Mosaikarchitektur und die Layering-Logik definiert, die verwendet werden, um diese Integrität zu wahren. Anschließend werden die chronologischen Vorverarbeitungs- und Normalisierungsschritte beschrieben, die auf einzelne Quellbilder angewendet werden, bevor sie endgültig zusammengesetzt werden.
Mosaikmethode
Die endgültigen Grundkarten wurden mit einer Mosaikmethode und nicht mit statistischen Reduzierern (z. B. Mittelwert- oder Median-Composites) erstellt. So wird sichergestellt, dass die Endprodukte die ursprünglichen Spektralwerte und räumlichen Texturen des Quellbildmaterials beibehalten. Da keine Mittelung mehrerer Beobachtungen erfolgt, bleibt die diskrete Herkunft jedes Pixels erhalten.
Logik für die Schichtbildung
Die Eingabebilder wurden in einer Hierarchie geschichtet, die eine höhere räumliche Auflösung und spätere Satellitenmissionen bevorzugt:
- Visuelle Basiskarte:Das Bildmaterial wurde nach Pixelgröße sortiert (wobei Daten mit der höchsten verfügbaren Auflösung priorisiert wurden) und dann nach Satellitenmission (wobei Daten von neueren SPOT-Satelliten priorisiert wurden).
- Analytische Basiskarte:Die Bilder wurden nach Satellitenmissionen geschichtet, wobei Beobachtungen aus späteren SPOT-Missionen priorisiert wurden, um die bestmöglichen Daten zu erhalten.
Integrität und Rückverfolgbarkeit
Neu berechnen: Bei allen internen Neuberechnungen wurde die Methode „Nächster Nachbar“ verwendet. So werden die interpolativen Glättungseffekte anderer Methoden vermieden und die ursprünglichen radiometrischen und räumlichen Eigenschaften der Quellpixel werden nicht durch ihre Nachbarn beeinflusst.
Datenrückverfolgbarkeit:In beiden Produkten ist ein
date-Metadatenband pro Pixel enthalten. So können Nutzer das genaue Beobachtungsdatum für einen bestimmten Ort ermitteln und so für vollständige Transparenz bei der Bewertung der Einhaltung des Forest Code sorgen.
Optimierung von Bildrändern
Um saubere Grenzen zwischen sich überschneidenden Szenen zu gewährleisten, wurde ein Verfahren zur Kantenverfeinerung angewendet, um Artefakte in den Quellbildern zu entfernen. Diese Artefakte, die als gesprenkelte oder „verrauschte“ Pixel entlang der Bildränder auftreten, waren ein Merkmal der verlustbehafteten Komprimierung in den vom Anbieter gelieferten Daten. Um dieses Problem zu beheben, wurde eine minimale Erosion von 2,5 Pixeln auf die Bildmasken angewendet, wodurch die Artefakte an den Rändern mit geringer Qualität entfernt wurden.So wird sichergestellt, dass nur gültige Daten in den endgültigen Mosaiken verwendet werden (Abbildung 7).

Wolkenmaskierung
Um die höchstmögliche Datenintegrität für G-BFID v1.0 zu gewährleisten, wurde im gesamten Bildarchiv ein manuelles Maskierungsverfahren implementiert. Diese Methode wurde gegenüber automatisierten Methoden gewählt, um einen konservativeren Ausschluss von Pixeln zu ermöglichen, die von Wolken oder anderen atmosphärischen Störungen betroffen sind.
Maskierungsverfahren
Geschulte Analysten haben Bereiche mit Wolken und zugehörigen atmosphärischen Artefakten identifiziert. Um sicherzustellen, dass diese problematischen Pixel vollständig erfasst wurden, wurde eine konservative Maskierungsstrategie mit vereinfachten, groben Geometrien angewendet. Anstatt einzelne Wolkenränder genau nachzuzeichnen, wurden größere rechteckige Bereiche maskiert, um sicherzustellen, dass das resultierende Mosaik so klar wie möglich bleibt.
Dieser Ansatz ist bewusst aggressiv und entfernt oft gültige Pixel, die an Wolken angrenzen. Er wurde jedoch als notwendig erachtet, um ein Produkt mit hoher Integrität für die Baseline von 2008 zu liefern.
Richtlinie zur Maskierung und Integration
Manuelle Masken wurden ausschließlich für die multispektralen und pansharpened-Sammlungen mit natürlichen Farben erstellt. Da das multispektrale Produkt in natürlicher Farbe aus den multispektralen Daten abgeleitet wird, wurden diese Masken während der Verarbeitung auf die übereinstimmenden multispektralen Bilder übertragen.
Alle multispektralen Bilder, die kein entsprechendes, manuell maskiertes Gegenstück in natürlichen Farben hatten, wurden aus dem endgültigen Mosaik ausgeschlossen. So wird sichergestellt, dass bei jedem Pixel, das in der G-BFID v1.0-Suite enthalten ist, unabhängig vom Produkttyp, Wolken entfernt wurden.
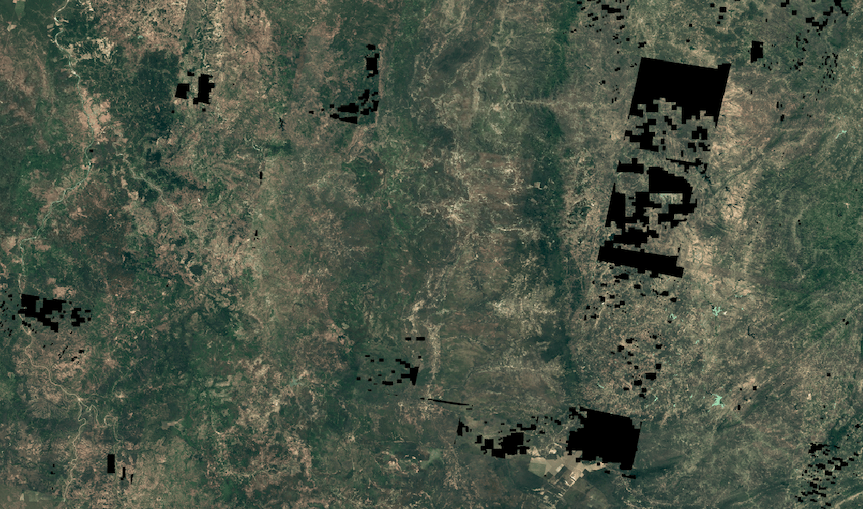
Interpretation von Datenlücken
Transparente Lücken in den endgültigen Mosaiken stellen Bereiche dar, in denen im Zeitraum 2007–2009 keine gültigen, hochwertigen Daten verfügbar sind. Diese Lücken sind das Ergebnis einer Kombination aus der oben beschriebenen konservativen manuellen Maskierung, der anfänglichen Ablehnung von Szenen mit hoher Wolkendecke (>50%) oder dem vollständigen Fehlen von verfügbaren Quellbildern des Anbieters für eine bestimmte Region. Größere regionale Lücken sind in der Regel auf einen Mangel an Bildern aus dem Jahr 2008 zurückzuführen. Die deutlichen „blockartigen“ Muster in Abbildung 9 sind eine Folge der Wolkenmaskierung.
Korrektur von Registrierungsfehlern
Es wurde ein automatisierter Coregistrierungs-Workflow implementiert, um erhebliche Registrierungsfehler in den SPOT-Quellbildern im Vergleich zu einer geografischen Baseline zu beheben, die aus Landsat Collection 2-Daten abgeleitet wurde.
Referenz-Baseline
Ein wolkenfreies Landsat Collection 2-Referenzmosaik wurde als Referenzbild für die Koregistrierung erstellt. Dieses Referenzbild wurde mithilfe eines Median-Reducers für Landsat 7- und 8-Bilder erstellt, die sich für den Zeitraum 2006–2010 mit Brasilien überschneiden. Das rote Band von Landsat wurde als primäres Registrierungsziel ausgewählt, um dem roten Band von SPOT zu entsprechen.
Schätzung der Umrüstung
Der ee.Image.displacement-Algorithmus wurde verwendet, um den Offset auf Pixelebene zwischen den SPOT-Quelldaten und der Landsat-Referenz zu berechnen.
- Suchparameter:Für das Verschiebungsmodell wurden ein maximaler Offset von 500 m und ein Steifigkeitsparameter von 5 angewendet.
- Statistische Aggregation:Delta x ($dx$) und Delta y ($dy$) sowie die Konfidenzwerte wurden mit einem Mean-Reducer über den gesamten Bildbereich aggregiert.
- Berechnung der Größenordnung:Aus diesen aggregierten Statistiken wurde eine Schätzung des gesamten Größenordnungs-Offsets $M = \sqrt{dx^2 + dy^2}$ berechnet, um die durchschnittliche Verschiebung der Szene darzustellen.
Richtlinie für Korrekturen
Szenen wurden anhand der berechneten Statistiken zur Verschiebung kategorisiert und korrigiert, um wichtige Verbesserungen zu priorisieren und gleichzeitig die Einführung neuer Artefakte zu vermeiden:
- Automatische Korrektur: Bilder mit einer Verschiebung von $M > 30$ m und einem Konfidenzwert von $C > 0,3$ wurden automatisch mithilfe der geschätzten $dx$- und $dy$-Werte verschoben.
- Manuelle Bewertung: Bei Szenen mit sehr hoher geschätzter Verschiebung ($M > 100$ m), aber geringer Konfidenz ($C \le 0,3$) wurde eine manuelle Überprüfung durchgeführt. Korrekturen wurden nur akzeptiert, wenn die resultierende Koregistrierung eine deutliche Verbesserung gegenüber der ursprünglichen Platzierung darstellte.
- Ausschluss: Szenen, die nach dem Korrekturversuch weiterhin deutlich falsch registriert waren oder nicht genügend Merkmale für einen zuverlässigen Abgleich aufwiesen, wurden aus dem Mosaik ausgeschlossen.
Implementierung und Qualitätskontrolle
Die korrigierten Bilder wurden mit der Nearest-Neighbor-Methode neu projiziert, um die ursprünglichen radiometrischen Werte beizubehalten und die Glättungseffekte der bilinearen oder kubischen Interpolation zu vermeiden.
Um die räumliche Rückverfolgbarkeit zu gewährleisten, wurde jedem Bild ein boolesches coregistered-Band angehängt, das im endgültigen Mosaik erhalten blieb. Mithilfe dieser Metadaten können Nutzer zwischen Pixeln, die räumlich angepasst wurden, und Pixeln, die in ihrer ursprünglichen Position beibehalten wurden, unterscheiden.
Radiometrische Normalisierung
Um unterschiedliche atmosphärische Bedingungen und Sensordifferenzen in den SPOT-Quellsammlungen zu berücksichtigen, wurde eine radiometrische Normalisierung auf die Bilder angewendet, aus denen die Mosaikprodukte bestehen. Sowohl die visuellen als auch die analytischen Grundkarten verwenden den Histogrammabgleich mit einer konsistenten Landsat-Ziel-Baseline von 2008.
Landsat wurde als Referenz gegenüber gröberen Alternativen wie MODIS ausgewählt, da seine Auflösung von 30 Metern besser mit den SPOT-Daten mit einer Auflösung von 5 bis 20 Metern übereinstimmt. Durch diese Ähnlichkeit sind die Spektralhistogramme gleichmäßiger repräsentativ, was einen genaueren radiometrischen Transfer während des Abgleichs ermöglicht. Die genaue Methodik für diese Harmonisierung variiert je nachdem, ob der endgültige Anwendungsfall visuell oder analytisch ist.
Visuelle Basiskarte
Um radiometrische Diskontinuitäten zwischen benachbarten Bildern zu minimieren und ein nahezu nahtloses Erscheinungsbild zu gewährleisten, wurde ein Workflow für den Farbabgleich mithilfe von Histogrammabgleich implementiert. Die Pixelwerte wurden angepasst, um einer einheitlichen Landsat-Mosaik-Ziel-Baseline von 2008 zu entsprechen.
Der Prozess umfasst die folgenden Schritte:
- Analysemaskierung: Damit die Statistiken beim Histogrammabgleich stabil sind, wird eine temporäre Analysemaske generiert, um Bereiche auszuschließen, die die Daten verzerren könnten. Die Maskierung zielt auf zwei primäre Funktionen ab:
- Bereiche mit starken Veränderungen: Pixel, die das 95. Perzentil des absoluten Unterschieds zwischen dem SPOT-Bild und dem Landsat-Referenzmosaik überschreiten, werden ausgeschlossen.
- Gewässer: Hohe Reflexionsvariabilität über Wasser wird mithilfe des JRC Yearly Water Classification History-Datasets ausgeschlossen. Das Dataset wird auf das Jahr 2008 gefiltert und eine inverse Maske wird angewendet, um sicherzustellen, dass für die statistische Analyse nur nicht wasserbezogene Klassen beibehalten werden.
- Generierung von Nachschlagetabellen (Look-Up Tables, LUTs): Anhand der maskierten Daten werden kumulative Histogramme sowohl für die SPOT-Quellbänder als auch für die Landsat-Zielbänder berechnet.
- Interpolation: Die Quellpixelwerte werden mithilfe der generierten LUT den Zielwerten zugeordnet. So wird das radiometrische Profil der SPOT-Daten an die Landsat-Referenz von 2008 angepasst.

Analytische Basiskarte
Die Verarbeitung der Analytic Basemap entspricht der Visual Basemap, umfasst aber auch die Umwandlung von DN-Werten in Reflexionsdaten aus der obersten Schicht der Atmosphäre:
1. Umrechnung der Reflexion am oberen Rand der Atmosphäre (Top-Of-Atmosphere, TOA)
Die digitalen Rohwerte (DN) von SPOT werden in TOA-Reflektanz umgewandelt, um physikalische Sensoreigenschaften und die solare Geometrie zu berücksichtigen:
- Berechnung der Strahlung: Anwendung der bandspezifischen Metadaten für physische Verstärkung und Bias des Anbieters.
- Normalisierung des Reflexionsgrads: Die Strahlung wird durch die solare Bestrahlungsstärke, den Kosinus des Sonnenzenitwinkels und den Abstand zwischen Erde und Sonne für den jeweiligen Aufnahmetag normalisiert.
2. Histogramm-Abgleich
Um die radiometrischen Unterschiede zwischen verschiedenen SPOT-Bildern weiter zu minimieren, wird ein Workflow für den Histogrammabgleich angewendet:
Analysemaskierung: In diesem Schritt wird dieselbe Analysemaskierung verwendet, die oben im Abschnitt „Visuelle Basiskarte“ beschrieben wird: Pixel mit Änderungen im oberen 5. Prozentil werden ausgeschlossen und Wasserpixel werden über die invertierte JRC-Klassifizierungsmaske von 2008 herausgefiltert.
Harmonisierung: Ähnlich wie bei der visuellen Grundkarte werden die Pixelwerte über eine Nachschlagetabelle neu zugeordnet, um das radiometrische Profil an eine Landsat-TOA-Referenz anzugleichen. So wird eine mosaikweite radiometrische Konsistenz für das Training von Machine-Learning-Modellen im großen Maßstab und für zuverlässige Inferenzen erreicht.
Beschränkungen und bekannte Probleme
G-BFID v1.0 bietet zwar eine hochauflösende Baseline aus dem Jahr 2008, Nutzer sollten sich jedoch der Einschränkungen bewusst sein, die mit dem historischen SPOT-Archiv und den verwendeten Verarbeitungsmethoden einhergehen.
Räumliche Vollständigkeit und Lücken
Die Basiskarten decken nicht das gesamte Gebiet von Brasilien ab. Es gibt Lücken, weil kein Bildmaterial den strengen Zeitrahmen des Projekts von 2008 (2007–2009), die Grenzwerte für die Wolkendecke oder die Qualitätsstandards erfüllt hat. Diese Lücken treten am häufigsten in Regionen mit anhaltender Wolkendecke oder einer geringeren Häufigkeit historischer Satellitenaufnahmen auf. Weitere Informationen finden Sie im Abschnitt Geografische Abdeckung und Lücken.
Variable native Auflösung
Die endgültigen Produkte werden mit einer nominellen Pixelgröße von 5 Metern (visuell) und 10 Metern (analytisch) geliefert. Das Quellbildmaterial besteht jedoch aus einer Mischung aus nativen Pixeln mit 5 m, 10 m und 20 m. Da das Resampling des nächsten Nachbarn verwendet wurde, um die spektrale Integrität zu bewahren, sind die Grenzen zwischen den verschiedenen Auflösungen möglicherweise sichtbar.

Restliche Falschregistrierung
Trotz des automatisierten Coregistrierungs-Workflows können in einigen Bereichen räumliche Verschiebungen auftreten. Restliche Registrierungsfehler treten am wahrscheinlichsten in Regionen mit extremen Geländehöhenunterschieden oder in dichten, homogenen Waldgebieten auf, in denen der Algorithmus nicht genügend Landmarken hatte, um Verschiebungsvektoren mit hoher Konfidenz zu berechnen.
Atmosphärische und Cloud-Artefakte
Die manuelle Cloud-Maskierung war bewusst konservativ und aggressiv, aber nicht vollständig. Nutzer können gelegentlich auf Restartefakte stoßen, z. B. sehr dünnen Cirrus-Schleier oder kleine Wolkenschatten.

Radiometrische Inkonsistenz und ML-Leistung
Obwohl der Histogrammabgleich verwendet wurde, um radiometrische Diskontinuitäten zu minimieren, bleibt eine restliche spektrale Variation zwischen benachbarten Bildern bestehen. Bei der automatischen Klassifizierung der Landbedeckung oder Anwendungen für maschinelles Lernen erhöht diese Variabilität die spektrale Varianz für einen bestimmten Landbedeckungstyp im gesamten Mosaik. Dieser breitere Datenbereich kann die Genauigkeit der Klassentrennung während der Inferenz verringern, was möglicherweise zu höheren Fehlerraten führt.

Spektrale Sättigung
In Bereichen mit extremer Helligkeit, z. B. auf stark reflektierenden städtischen Oberflächen, bestimmten Bodentypen oder hellem Sand, können Pixel die maximal erkennbare Grenze des Sensors erreichen. Diese „Sättigung“ führt zu einem Verlust von Textur und Details an diesen Stellen.

Geänderte Bandverhältnisse und Vegetationsindizes
Um ein nahezu nahtloses Mosaik zu erhalten, wurde Histogrammabgleich auf jedes Spektralband einzeln angewendet, wodurch sich die ursprünglichen physischen Verhältnisse zwischen den Bändern ändern. Daher werden bei der Berechnung gängiger Indexe wie NDVI oder anderer Bandverhältnis-Messwerte Werte erzeugt, die sich von unveränderten Quelldatasets unterscheiden. Diese abgeleiteten Indexwerte können zwar weiterhin relative räumliche Muster im Mosaik erfassen, sollten aber nicht für absolute Zwecke, sensorübergreifende Vergleiche oder Analysen verwendet werden, die auf starren Indexschwellenwerten beruhen.