
When you build a community connector, each field that you define in the
schema
requires a data type. The data type defines the field's primitive type such as
BOOLEAN, STRING, NUMBER, etc.
In addition to data types, Data Studio also makes use of semantic types.
Semantic types help to describe the kind of information the data represents. For
example, a field with a NUMBER data type may semantically represent a currency
amount or percentage and a field with a STRING data type may semantically
represent a city. To see which semantic types are available, please consult the
semantic types documentation
Community Connector schema and Data Studio fields
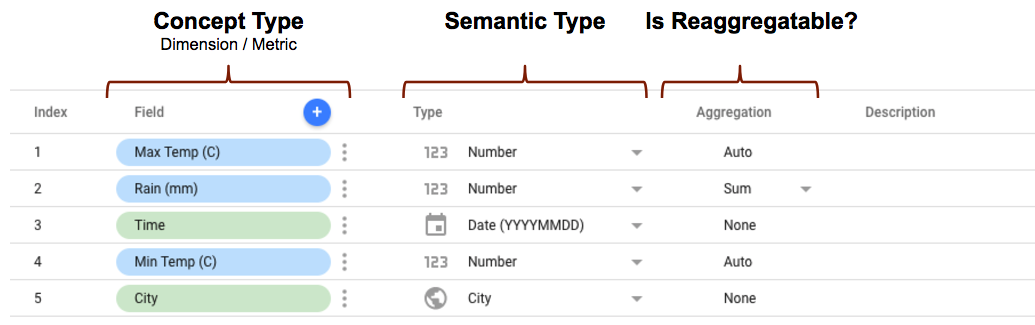
When you define the schema for your community connector, there are various properties for each field that will determine how the field is represented and used in Data Studio. For example:
- The conceptType is
defined in your connector schema using the
conceptTypeproperty. This property determines whether the field is treated as a dimension or metric. An explanation on the difference between metrics and dimensions can be found at Dimensions and metrics. - The semantic type can either be defined in the connector schema, or can be automatically detected by Data Studio based on the data type property defined in your connector and the data values returned by your connector. See Automatic semantic type detection for details on how this works.
- The aggregation type determines whether the metric values (dimensions
are ignored) can be reaggregated. Setting the
semantics.isReaggregatableproperty totruewill default to theSUMaggregation, otherwise it is set toAuto. You can also manually set default aggregation type for reaggregatable fields using thedefaultAggregationTypeproperty.
When you configure and connect using a connector in Data Studio, the fields
editor shows the complete schema for the connector based on how you've defined
the properties above. If you have included the semantic types, then they will
show as you have defined them. If you are using
automatic semantic type detection, then the fields
will show as they were detected.
Setting semantic information
There are two ways to set semantic information. You can either set field semantics manually or rely on Data Studio to automatically detect.
For example, if you have a Number that semantically represents US Dollars, Data Studio will not be able to automatically detect this semantic type. Additionally, automatic semantic detection requires Data Studio to make data fetch calls for each field of your schema. If you manually specify the schema instead, then no data fetch calls will be made. In the case that you know the semantic type (E.g. currency, percent, date, etc.) for your data, then we recommend explicitly setting this in the schema for accuracy and performance reasons.
Manually setting semantic types (Recommended)
If you know your semantic types, you can manually define semantics for each
schema field. The full details on what properties available to you can be found
in the field reference page. If you
choose to define manual semantic types, it is recommend that you define
semanticType and semanticGroup for every field. By manually providing these
properties, the automatic semantic type detection process will not run. If you
manually set some of your fields, but not all, then the ones that you do not
specify default to Text, Number, or Boolean depending on the dataType
specified for the field.
The following is an example of a simple schema that manually sets semantic
types. Income is set as a Currency, and Filing Year is set as a date.
Troubleshooting Manual Semantic Types
If you set your semantic types incorrectly for the underlying data, they will not work properly. This can be difficult to test, but there are a few things you can do to help find issues.
- Return 2 or 3 rows from your data instead of all of it, then manually inspect it.
- Make a table in Data Studio that only uses the field you are trying to check.
- Pay close attention to
GeoandDatefields since they have the most stringent format.
Understanding the "Semantic configuration changed" warning
Symptom: When you edit a data source and change its connection (e.g., to a table in a different dataset or project), you might see a warning "Semantic configuration changed" for some fields. This can occur even if the new table or view seems to have the same schema (field names and types).
Cause: Data Studio re-analyzes fields when the underlying connection changes. This warning often appears because Data Studio detects a change in the source's internal metadata, even if the field names, types, and your settings appear the same.
What to do:
- Review affected fields: Note the fields mentioned in the warning.
- Check key settings: In the data source fields list, carefully verify that the Type (e.g., Number, Text, Date) and the Default Aggregation (e.g., SUM, NONE) are still correct for each affected field. Data Studio can sometimes reset these to defaults.
- Correct if needed: Adjust the Type or Default Aggregation if they have been changed unexpectedly.
- If settings are correct: If you confirm that the Type and Default Aggregation for the flagged fields are still accurate, the warning is likely due to internal changes in how Data Studio references the new source and does not negatively impact your report. You can proceed.
- Save changes: Once you've confirmed or corrected the settings, save the data source.
Always double-check field settings after changing a data source connection to ensure your reports function as expected.
Automatic semantic type detection
If you have not defined any semantic types in your schema, then Data Studio will attempt to automatically detect them based on the data type property and the format of the data values returned by your connector.
The steps of the automatic detection process are as follows:
- Request the schema by executing the
getSchemafunction of your community connector. - Iterate through batches of fields defined in the connector schema and issue
getDatarequests the fields. ThegetDatarequests are executed with thesampleExtractionparameter set totrueto indicate the data requests are for the purposes of semantic detection. - Based on the field data type and the format of the value returned from the
getDatarequest, identify the semantic type of the field.
Options for handling automatic semantic type detection
When Data Studio executes the getData function of a community connector for
the purpose of semantic detection, the incoming request will contain a
sampleExtraction property which will be set to true. The data returned by
your connector is only used by Data Studio to identify the semantic type of
the field. Since the value will not be used for any other purpose, it does not
require actual data from your external source.
There are several ways to improve semantic type detection in your code:
Recommended: Pass predefined values
Return a predefined value for each field that best represents the semantic type for the field and is known to be properly be detected by Data Studio. For example, if the semantic type for a field is Country then return a value such asITfor Italy. The other benefit of this approach is that it is much quicker since it does not require you to make HTTP requests to the third-party service for data.Return only n number of records
If the third-party service from which you're fetching data supports row limits when requesting data then return a small subset of rows to Data Studio instead of the full data set. This will limit the amount of data you need to pass to Data Studio for each semantic detection request.Request all columns and cache the response
If it's possible to request all columns for the third-party service from which you're fetching data then on the first semantic detection request received from Data Studio fetch all columns and cache the results. For subsequent semantic detection requests fetch column values from the cache instead of making additional HTTP requests to the third-party service.Do nothing different
You can choose to not implement any specific accommodation for requests wheresampleExtractionis set totrue. This will cause the Semantic Detection process to be slower since Data Studio will have to fetch all data for the Semantic Detection process. In addition, this will affect the request rate to your external data source since many semantic detection requests will be executed in parallel.
Recognized formats for automatic semantic type detection
Date & Time
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- Time: epoch for second, micro, milli, and nano.
Geo
- Continent name or code
- Sub continent name or code
- Region name or code
- Country name or code. Also see ISO_3166-1.
- City Name
- Comma separated latitude and longitude value
- Designated Marketing Area (DMA) Name and code