
コネクテッド シート を使用すると、Google スプレッドシート内でペタバイト単位のデータを直接分析できます。スプレッドシートを BigQuery データ ウェアハウスまたはLookerに接続し、使い慣れたスプレッドシートのツール(ピボット テーブル、グラフ、数式など)を使用して分析できます。
BigQuery データソースを管理する
このセクションでは、BigQuery
Shakespeare
の一般公開データセットを使用して、コネクテッド シートの使用方法を説明します。このデータセットには次の情報が含まれています。
| フィールド | タイプ | 説明 |
|---|---|---|
| word | STRING |
コーパスから抽出された一意の単語(空白文字が区切り文字)。 |
| word_count | INTEGER |
この単語がこのコーパスに出現する回数。 |
| corpus | STRING |
この単語が抽出された作品。 |
| corpus_date | INTEGER |
このコーパスが公開された年。 |
アプリケーションが BigQuery コネクテッド シートのデータをリクエストする場合は、通常の Google Sheets API リクエストに必要な他のスコープに加えて、bigquery.readonly スコープを付与する OAuth 2.0 トークンを提供する必要があります。詳細については、Google Sheets API のスコープを選択する
をご覧ください。
データソースは、データが見つかる外部ロケーションを指定します。データソースはスプレッドシートに接続されます。
BigQuery データソースを追加する
データソースを追加するには、
AddDataSourceRequest
を使用して
spreadsheets.batchUpdate
メソッドを指定します。リクエストの本文では、dataSource フィールドをタイプ
DataSource
オブジェクトとして指定する必要があります。
"addDataSource":{
"dataSource":{
"spec":{
"bigQuery":{
"projectId":"PROJECT_ID",
"tableSpec":{
"tableProjectId":"bigquery-public-data",
"datasetId":"samples",
"tableId":"shakespeare"
}
}
}
}
}
PROJECT_ID は、有効な Google Cloud プロジェクト ID に置き換えます。
データソースが作成されると、関連する
DATA_SOURCE
シートが作成され、最大 500 行のプレビューが表示されます。プレビューはすぐには使用できません。BigQuery データをインポートするために、実行が非同期でトリガーされます。
AddDataSourceResponse
には次のフィールドが含まれます。
dataSource: 作成されたDataSourceオブジェクト。dataSourceIdは、 スプレッドシート スコープの一意の ID です。データソースから各DataSourceオブジェクトを作成するために、入力され、参照されます。dataExecutionStatus: BigQuery データをプレビュー シートにインポートする実行のステータス。詳細については、データの実行 ステータスをご覧ください。
BigQuery データソースを更新または削除する
spreadsheets.batchUpdate
メソッドを使用し、
UpdateDataSourceRequest
リクエストまたは
DeleteDataSourceRequest
リクエストを適宜指定します。
BigQuery データソース オブジェクトを管理する
データソースがスプレッドシートに追加されると、データソース オブジェクトを作成できます。データソース オブジェクトは、ピボット テーブル、グラフ、数式などの通常の Sheets ツールで、コネクテッド シートと統合してデータ分析を強化します。
オブジェクトには次の 4 種類があります。
DataSourceテーブルDataSourcepivotTableDataSourceグラフDataSource数式
BigQuery データソース テーブルを追加する
スプレッドシート エディタでは「抽出」と呼ばれます。テーブル オブジェクトは、データソースから Sheets にデータの静的ダンプをインポートします。 ピボット テーブルと同様に、テーブルは指定され、左上のセルに固定されます。
次のコードサンプルは、
spreadsheets.batchUpdate
メソッドと
UpdateCellsRequest
を使用して、2 列(word と
word_count)の最大 1,000 行のデータソース テーブルを作成する方法を示しています。
"updateCells":{
"rows":{
"values":[
{
"dataSourceTable":{
"dataSourceId":"DATA_SOURCE_ID",
"columns":[
{
"name":"word"
},
{
"name":"word_count"
}
],
"rowLimit":{
"value":1000
},
"columnSelectionType":"SELECTED"
}
}
]
},
"fields":"dataSourceTable"
}
DATA_SOURCE_ID は、データソースを識別するスプレッドシート スコープの一意の ID に 置き換えます。
データソース テーブルが作成されても、データはすぐには使用できません。スプレッドシート エディタでは、プレビューとして表示されます。BigQuery データを取得するには、データソース テーブルを更新する必要があります。同じ batchUpdate 内で
RefreshDataSourceRequest
を指定できます。すべてのデータソース オブジェクトは同様に機能します。
詳細については、データソース
オブジェクトを更新するをご覧ください。
更新が完了して BigQuery データが取得されると、データソース テーブルは次のように入力されます。
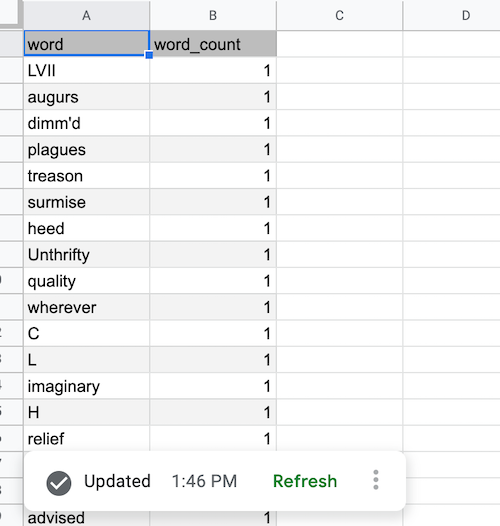
BigQuery データソース ピボット テーブルを追加する
従来のピボット テーブルとは異なり、データソース ピボット テーブルはデータソースによってバックアップされ、列名でデータを参照します。次のコードサンプルは、spreadsheets.batchUpdate メソッドと UpdateCellsRequest を使用して、コーパス別の単語数の合計を示すピボット テーブルを作成する方法を示しています。
"updateCells":{
"rows":{
"values":[
{
"pivotTable":{
"dataSourceId":"DATA_SOURCE_ID",
"rows":{
"dataSourceColumnReference":{
"name":"corpus"
},
"sortOrder":"ASCENDING"
},
"values":{
"summarizeFunction":"SUM",
"dataSourceColumnReference":{
"name":"word_count"
}
}
}
}
]
},
"fields":"pivotTable"
}
DATA_SOURCE_ID は、データソースを識別するスプレッドシート スコープの一意の ID に 置き換えます。
BigQuery データが取得されると、データソース ピボット テーブルは次のように入力されます。
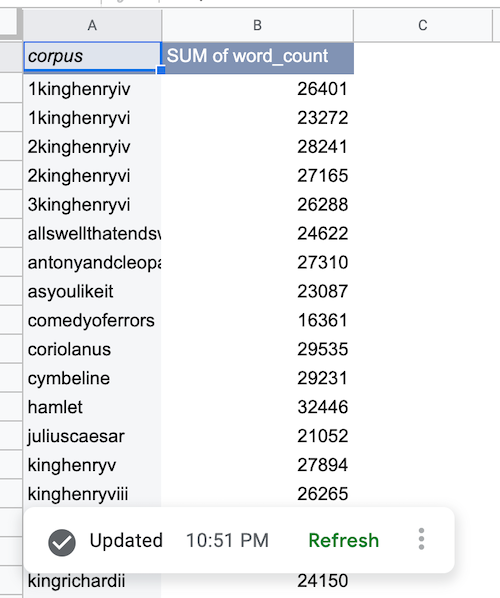
BigQuery データソース グラフを追加する
次のコードサンプルは、spreadsheets.batchUpdate メソッド
と
AddChartRequest
を使用して、chartType が COLUMN のデータソース グラフを作成し、コーパス別の単語数の合計を表示する方法を示しています。
"addChart":{
"chart":{
"spec":{
"title":"Corpus by word count",
"basicChart":{
"chartType":"COLUMN",
"domains":[
{
"domain":{
"columnReference":{
"name":"corpus"
}
}
}
],
"series":[
{
"series":{
"columnReference":{
"name":"word_count"
},
"aggregateType":"SUM"
}
}
]
}
},
"dataSourceChartProperties":{
"dataSourceId":"DATA_SOURCE_ID"
}
}
}
DATA_SOURCE_ID は、データソースを識別するスプレッドシート スコープの一意の ID に 置き換えます。
BigQuery データが取得されると、データソース グラフは次のようにレンダリングされます。
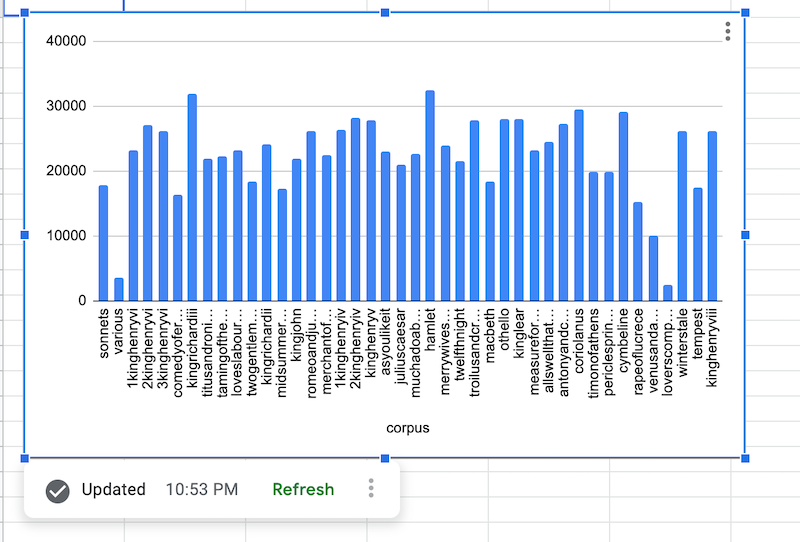
BigQuery データソースの数式を追加する
次のコードサンプルは、spreadsheets.batchUpdate メソッドと UpdateCellsRequest を使用して、単語数の平均を計算するデータソースの数式を作成する方法を示しています。
"updateCells":{
"rows":[
{
"values":[
{
"userEnteredValue":{
"formulaValue":"=AVERAGE(shakespeare!word_count)"
}
}
]
}
],
"fields":"userEnteredValue"
}
BigQuery データが取得されると、データソースの数式は次のように入力されます。
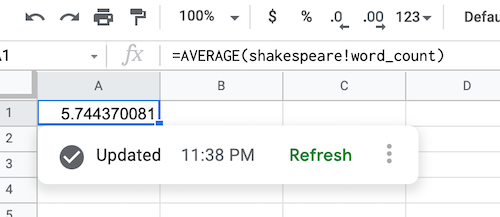
BigQuery データソース オブジェクトを更新する
データソース オブジェクトを更新して、現在のデータソースの仕様とオブジェクト構成に基づいて BigQuery から最新のデータを取得できます。メソッドを使用して
RefreshDataSourceRequestを呼び出すことができます。spreadsheets.batchUpdate次に、
DataSourceObjectReferences
オブジェクトを使用して、更新するオブジェクト参照を 1 つ以上指定します。
1 つの batchUpdate リクエスト内でデータソース オブジェクトを作成して更新できます。
Looker データソースを管理する
このガイドでは、Looker データソースを追加、更新、削除し、ピボット テーブルを作成して更新する方法について説明します。
Looker コネクテッド シートのデータをリクエストするアプリケーションは、Looker との既存の Google アカウント リンクを再利用します。
Looker データソースを追加する
データソースを追加するには、
AddDataSourceRequest
を使用して
spreadsheets.batchUpdate
メソッドを指定します。リクエストの本文では、dataSource フィールドをタイプ
DataSource
オブジェクトとして指定する必要があります。
"addDataSource":{
"dataSource":{
"spec":{
"looker":{
"instance_uri":"INSTANCE_URI",
"model":"MODEL",
"explore":"EXPLORE"
}
}
}
}
INSTANCE_URI、MODEL、 EXPLORE は、有効な Looker インスタンス URI、モデル名、 Explore 名に置き換えます。
データソースが作成されると、関連する
DATA_SOURCE
シートが作成され、選択した Explore の構造(ビュー、ディメンション、メジャー、フィールドの説明など)のプレビューが表示されます。
AddDataSourceResponse
には次のフィールドが含まれます。
dataSource: 作成されたDataSourceオブジェクト。dataSourceIdは、スプレッドシート スコープの一意の ID です。データソースから各DataSourceオブジェクトを作成するために、入力され、参照されます。dataExecutionStatus: BigQuery データをプレビュー シートにインポートする実行のステータス。詳細については、データの実行 ステータスをご覧ください。
Looker データソースを更新または削除する
spreadsheets.batchUpdate
メソッドを使用し、
UpdateDataSourceRequest
リクエストまたは
DeleteDataSourceRequest
リクエストを適宜指定します。
Looker データソース オブジェクトを管理する
データソースがスプレッドシートに追加されると、データソース オブジェクトを作成できます。Looker データソースの場合、DataSource ピボット テーブル オブジェクトのみを作成できます。
Looker データソースから DataSource の数式、抽出、グラフを作成することはできません。
Looker データソース オブジェクトを更新する
データソース オブジェクトを更新して、現在のデータソースの仕様とオブジェクト構成に基づいて Looker から最新のデータを取得できます。メソッドを使用して
RefreshDataSourceRequestを呼び出すことができます。spreadsheets.batchUpdate次に、
DataSourceObjectReferences
オブジェクトを使用して、更新するオブジェクト参照を 1 つ以上指定します。
1 つの batchUpdate リクエスト内でデータソース オブジェクトを作成して更新できます。
データの実行ステータス
データソースを作成するか、データソース オブジェクトを更新すると、BigQuery または Looker からデータを取得し、
DataExecutionStatus を含む
レスポンスを返すバックグラウンド実行が作成されます。実行が正常に開始されると、
DataExecutionState
は通常、RUNNING状態になります。
このプロセスは非同期であるため、アプリケーションはポーリング モデルを実装して、データソース オブジェクトのステータスを定期的に取得する必要があります。ステータスが SUCCEEDED または FAILED 状態を返すまで、
spreadsheets.get
メソッドを使用します。
ほとんどの場合、実行はすぐに完了しますが、データソースの複雑さによって異なります。通常、実行時間は 10 分を超えません。
関連トピック
- Google Sheets API のスコープを選択する
- Google スプレッドシートで BigQuery データを使ってみる
- BigQuery ドキュメント
- BigQuery: コネクテッド シートを使用する
- コネクテッド シートの動画チュートリアル
- Looker 向けコネクテッド シートの使用
- Looker の概要