
Les feuilles connectées vous permettent d'analyser des pétaoctets de données directement dans Google Sheets. Vous pouvez connecter vos feuilles de calcul à un entrepôt de données BigQuery ou à Looker, puis effectuer l'analyse à l'aide d'outils Sheets que vous connaissez bien, comme les tableaux croisés dynamiques, les graphiques et les formules.
Gérer une source de données BigQuery
Cette section utilise l'ensemble de données
Shakespeare
public de BigQuery pour montrer comment utiliser les feuilles connectées. L'ensemble de données contient les informations suivantes :
| Champ | Type | Description |
|---|---|---|
| word | STRING |
Un seul mot unique (où l'espace est le délimiteur) extrait d'un corpus. |
| word_count | INTEGER |
Le nombre de fois que ce mot apparaît dans ce corpus. |
| corpus | STRING |
L'œuvre à partir de laquelle ce mot a été extrait. |
| corpus_date | INTEGER |
L'année de publication de ce corpus. |
Si votre application demande des données de feuilles connectées BigQuery, elle doit fournir un jeton OAuth 2.0 qui accorde le champ d'application bigquery.readonly, en plus des autres champs d'application requis pour une requête d'API Google Sheets standard. Pour
en savoir plus, consultez Choisir les champs d'application de l'API Google Sheets.
Une source de données spécifie un emplacement externe où les données sont trouvées. La source de données est ensuite connectée à la feuille de calcul.
Ajouter une source de données BigQuery
Pour ajouter une source de données, fournissez un
AddDataSourceRequest
à l'aide de la
spreadsheets.batchUpdate
méthode. Le corps de la requête doit spécifier un dataSource champ de type
DataSource
objet.
"addDataSource":{
"dataSource":{
"spec":{
"bigQuery":{
"projectId":"PROJECT_ID",
"tableSpec":{
"tableProjectId":"bigquery-public-data",
"datasetId":"samples",
"tableId":"shakespeare"
}
}
}
}
}
Remplacez PROJECT_ID par un ID de projet Google Cloud valide.
Une fois la source de données créée, une feuille associée
DATA_SOURCE
est créée pour fournir un aperçu de 500 lignes maximum. L'aperçu n'est pas disponible immédiatement. Une exécution est déclenchée de manière asynchrone pour importer les données BigQuery.
AddDataSourceResponse
contient les champs suivants :
dataSource: objetDataSourcecréé. ThedataSourceIdest un ID unique limité à la feuille de calcul. Il est renseigné et référencé pour créer chaque objetDataSourceà partir de la source de données.dataExecutionStatus: état d'une exécution qui importe des données BigQuery dans la feuille d'aperçu. Pour en savoir plus, consultez la section État d'exécution des données.
Mettre à jour ou supprimer une source de données BigQuery
Utilisez la
spreadsheets.batchUpdate
méthode et fournissez une
UpdateDataSourceRequest
ou
DeleteDataSourceRequest
requête, selon le cas.
Gérer les objets de source de données BigQuery
Une fois qu'une source de données est ajoutée à la feuille de calcul, un objet de source de données peut être créé à partir de celle-ci. Un objet de source de données est un outil Sheets standard, tel que des tableaux croisés dynamiques, des graphiques et des formules, qui est intégré aux feuilles connectées pour optimiser votre analyse de données.
Il existe quatre types d'objets :
- Tableau
DataSource DataSourcepivotTable- Graphique
DataSource - Formule
DataSource
Ajouter un tableau de source de données BigQuery
Également appelé "extraction" dans l'éditeur Sheets, l'objet de tableau importe un vidage statique des données de la source de données dans Sheets. Comme un tableau croisé dynamique, le tableau est spécifié et ancré dans la cellule en haut à gauche.
L'exemple de code suivant montre comment utiliser la
spreadsheets.batchUpdate
méthode et un
UpdateCellsRequest
pour créer un tableau de source de données contenant jusqu'à 1 000 lignes de deux colonnes (word et
word_count).
"updateCells":{
"rows":{
"values":[
{
"dataSourceTable":{
"dataSourceId":"DATA_SOURCE_ID",
"columns":[
{
"name":"word"
},
{
"name":"word_count"
}
],
"rowLimit":{
"value":1000
},
"columnSelectionType":"SELECTED"
}
}
]
},
"fields":"dataSourceTable"
}
Remplacez DATA_SOURCE_ID par un ID unique limité à la feuille de calcul qui identifie la source de données.
Une fois le tableau de source de données créé, les données ne sont pas disponibles immédiatement. Dans l'éditeur Sheets, elles s'affichent sous forme d'aperçu. Vous devez actualiser le tableau de source de données pour extraire les données BigQuery. Vous pouvez spécifier un
RefreshDataSourceRequest
dans le même batchUpdate. Notez que tous les objets de source de données fonctionnent de la même manière.
Pour en savoir plus, consultez Actualiser un objet de source de données.
Une fois l'actualisation terminée et les données BigQuery extraites, le tableau de source de données est rempli comme suit :
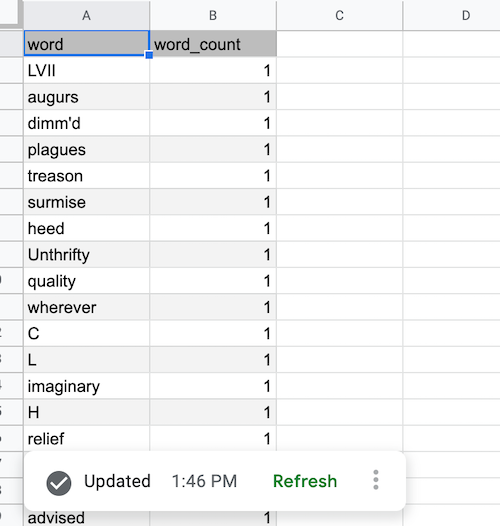
Ajouter un tableau croisé dynamique de source de données BigQuery
Contrairement à un tableau croisé dynamique classique, un tableau croisé dynamique de source de données est basé sur une source de données et référence les données par nom de colonne. L'exemple de code suivant montre comment utiliser la méthode spreadsheets.batchUpdate et un UpdateCellsRequest pour créer un tableau croisé dynamique affichant le nombre total de mots par corpus.
"updateCells":{
"rows":{
"values":[
{
"pivotTable":{
"dataSourceId":"DATA_SOURCE_ID",
"rows":{
"dataSourceColumnReference":{
"name":"corpus"
},
"sortOrder":"ASCENDING"
},
"values":{
"summarizeFunction":"SUM",
"dataSourceColumnReference":{
"name":"word_count"
}
}
}
}
]
},
"fields":"pivotTable"
}
Remplacez DATA_SOURCE_ID par un ID unique limité à la feuille de calcul qui identifie la source de données.
Une fois les données BigQuery extraites, le tableau croisé dynamique de source de données est rempli comme suit :
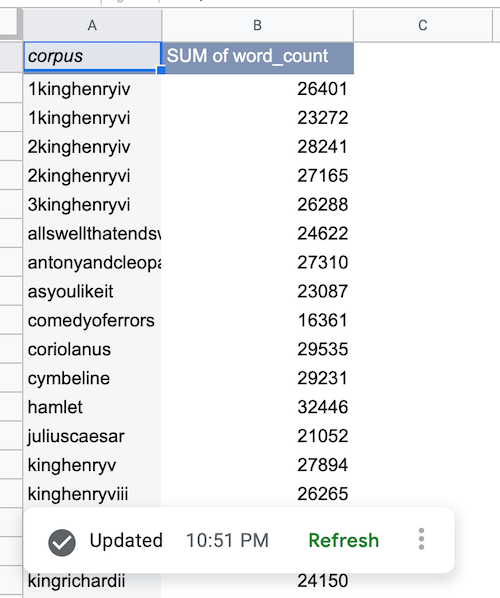
Ajouter un graphique de source de données BigQuery
L'exemple de code suivant montre comment utiliser la méthode spreadsheets.batchUpdate
et un
AddChartRequest
pour créer un graphique de source de données avec un chartType de type COLUMN, affichant le nombre total
de mots par corpus.
"addChart":{
"chart":{
"spec":{
"title":"Corpus by word count",
"basicChart":{
"chartType":"COLUMN",
"domains":[
{
"domain":{
"columnReference":{
"name":"corpus"
}
}
}
],
"series":[
{
"series":{
"columnReference":{
"name":"word_count"
},
"aggregateType":"SUM"
}
}
]
}
},
"dataSourceChartProperties":{
"dataSourceId":"DATA_SOURCE_ID"
}
}
}
Remplacez DATA_SOURCE_ID par un ID unique limité à la feuille de calcul qui identifie la source de données.
Une fois les données BigQuery extraites, le graphique de source de données s'affiche comme suit :
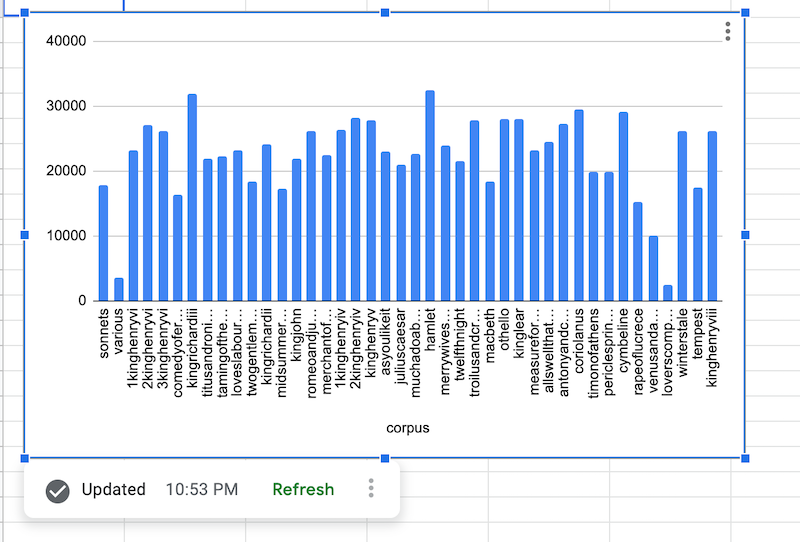
Ajouter une formule de source de données BigQuery
L'exemple de code suivant montre comment utiliser la méthode spreadsheets.batchUpdate et un UpdateCellsRequest pour créer une formule de source de données permettant de calculer le nombre moyen de mots.
"updateCells":{
"rows":[
{
"values":[
{
"userEnteredValue":{
"formulaValue":"=AVERAGE(shakespeare!word_count)"
}
}
]
}
],
"fields":"userEnteredValue"
}
Une fois les données BigQuery extraites, la formule de source de données est remplie comme suit :
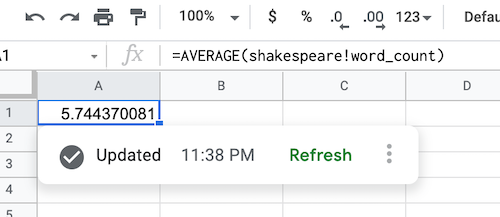
Actualiser un objet de source de données BigQuery
Vous pouvez actualiser un objet de source de données pour extraire les dernières données de BigQuery en fonction des spécifications de la source de données et des configurations d'objet actuelles. Vous pouvez utiliser
la
spreadsheets.batchUpdate
méthode pour appeler la
RefreshDataSourceRequest.
Spécifiez ensuite une ou plusieurs références d'objet à actualiser à l'aide de l'
DataSourceObjectReferences
objet.
Notez que vous pouvez à la fois créer et actualiser des objets de source de données dans une seule requête batchUpdate.
Gérer une source de données Looker
Ce guide explique comment ajouter une source de données Looker, la mettre à jour ou la supprimer, créer un tableau croisé dynamique et l'actualiser.
Votre application demandant des données de feuilles connectées Looker réutilisera votre association de compte Google existante avec Looker.
Ajouter une source de données Looker
Pour ajouter une source de données, fournissez un
AddDataSourceRequest
à l'aide de la
spreadsheets.batchUpdate
méthode. Le corps de la requête doit spécifier un dataSource champ de type
DataSource
objet.
"addDataSource":{
"dataSource":{
"spec":{
"looker":{
"instance_uri":"INSTANCE_URI",
"model":"MODEL",
"explore":"EXPLORE"
}
}
}
}
Remplacez INSTANCE_URI, MODEL et EXPLORE par un URI d'instance Looker, un nom de modèle et un nom d'exploration valides, respectivement.
Une fois la source de données créée, une feuille associée
DATA_SOURCE
est créée pour fournir un aperçu de la structure de l'exploration sélectionnée,
y compris les vues, les dimensions, les mesures et les descriptions de champ.
AddDataSourceResponse
contient les champs suivants :
dataSource: objetDataSourcecréé. ThedataSourceIdest un ID unique limité à la feuille de calcul. Il est renseigné et référencé pour créer chaque objetDataSourceà partir de la source de données.dataExecutionStatus: état d'une exécution qui importe des données BigQuery dans la feuille d'aperçu. Pour en savoir plus, consultez la section État d'exécution des données.
Mettre à jour ou supprimer une source de données Looker
Utilisez la
spreadsheets.batchUpdate
méthode et fournissez une
UpdateDataSourceRequest
ou
DeleteDataSourceRequest
requête, selon le cas.
Gérer les objets de source de données Looker
Une fois qu'une source de données est ajoutée à la feuille de calcul, un objet de source de données peut être créé à partir de celle-ci. Pour les sources de données Looker, vous ne pouvez créer qu'un objet DataSource pivotTable.
Il n'est pas possible de créer des formules, des extractions et des graphiques DataSource à partir de sources de données Looker.
Actualiser un objet de source de données Looker
Vous pouvez actualiser un objet de source de données pour extraire les dernières données de Looker en fonction des spécifications de la source de données et des configurations d'objet actuelles. Vous pouvez utiliser
la
spreadsheets.batchUpdate
méthode pour appeler la
RefreshDataSourceRequest.
Spécifiez ensuite une ou plusieurs références d'objet à actualiser à l'aide de l'
DataSourceObjectReferences
objet.
Notez que vous pouvez à la fois créer et actualiser des objets de source de données dans une seule requête batchUpdate.
État d'exécution des données
Lorsque vous créez des sources de données ou actualisez des objets de source de données, une exécution en arrière-plan
est créée pour extraire les données de BigQuery ou de Looker et renvoyer une
réponse contenant le
DataExecutionStatus.
Si l'exécution démarre correctement, le
DataExecutionState
est généralement à l'état RUNNING.
Comme le processus est asynchrone, votre application doit implémenter un modèle d'interrogation pour récupérer régulièrement l'état des objets de source de données. Utilisez la
spreadsheets.get
méthode jusqu'à ce que l'état renvoie l'état SUCCEEDED ou FAILED.
L'exécution se termine rapidement dans la plupart des cas, mais cela dépend de la complexité de votre source de données. En règle générale, l'exécution ne dépasse pas 10 minutes.
Articles associés
- Choisir les champs d'application de l'API Google Sheets
- Premiers pas avec les données BigQuery dans Google Sheets
- Documentation BigQuery
- BigQuery : utiliser les feuilles connectées
- Tutoriel vidéo sur les feuilles connectées
- Utiliser les feuilles connectées pour Looker
- Présentation de Looker