
গুগল ডক্স এপিআই আপনাকে ডকুমেন্টের যেকোনো ট্যাব থেকে কন্টেন্ট অ্যাক্সেস করার সুযোগ দেয়।
ট্যাব বলতে কী বোঝায়?
গুগল ডকস-এ ট্যাব নামে একটি সাংগঠনিক স্তর রয়েছে। বর্তমানে শীটস-এ যেভাবে ট্যাব রয়েছে, ঠিক সেভাবেই ডকস ব্যবহারকারীদের একটি ডকুমেন্টের মধ্যে এক বা একাধিক ট্যাব তৈরি করার সুযোগ দেয়। প্রতিটি ট্যাবের নিজস্ব শিরোনাম এবং আইডি থাকে (যা ইউআরএল-এ যুক্ত করা হয়)। একটি ট্যাবের চাইল্ড ট্যাবও থাকতে পারে, যেগুলো হলো এমন ট্যাব যা অন্য একটি ট্যাবের নিচে অবস্থিত থাকে।
ডকুমেন্ট রিসোর্সে ডকুমেন্টের বিষয়বস্তু উপস্থাপনের পদ্ধতিতে কাঠামোগত পরিবর্তন
অতীতে, ডকুমেন্টগুলিতে ট্যাবের কোনো ধারণা ছিল না, তাই Document রিসোর্স সরাসরি নিম্নলিখিত ফিল্ডগুলির মাধ্যমে সমস্ত টেক্সট কন্টেন্ট ধারণ করত:
-
document.body -
document.headers -
document.footers -
document.footnotes -
document.documentStyle -
document.suggestedDocumentStyleChanges -
document.namedStyles -
document.suggestedNamedStylesChanges -
document.lists -
document.namedRanges -
document.inlineObjects -
document.positionedObjects
ট্যাবের অতিরিক্ত কাঠামোগত স্তরবিন্যাসের কারণে, এই ফিল্ডগুলো এখন আর ডকুমেন্টের সমস্ত ট্যাবের টেক্সট কন্টেন্টকে অর্থগতভাবে প্রতিনিধিত্ব করে না। টেক্সট-ভিত্তিক কন্টেন্ট এখন একটি ভিন্ন স্তরে উপস্থাপিত হয়। গুগল ডকস-এ ট্যাবের প্রোপার্টি এবং কন্টেন্ট document.tabs এর মাধ্যমে অ্যাক্সেস করা যায়, যা হলো Tab অবজেক্টের একটি তালিকা, এবং এর প্রতিটিতে পূর্বে উল্লিখিত সমস্ত টেক্সট কন্টেন্ট ফিল্ড থাকে। পরবর্তী বিভাগগুলোতে একটি সংক্ষিপ্ত বিবরণ দেওয়া হয়েছে; ট্যাবের JSON উপস্থাপনা আরও বিস্তারিত তথ্য প্রদান করে।
ট্যাব বৈশিষ্ট্য অ্যাক্সেস করুন
tab.tabProperties ব্যবহার করে ট্যাবের বৈশিষ্ট্যগুলো অ্যাক্সেস করা যায়, যার মধ্যে ট্যাবের আইডি, শিরোনাম এবং অবস্থানের মতো তথ্য অন্তর্ভুক্ত থাকে।
একটি ট্যাবের মধ্যে থাকা টেক্সট কন্টেন্ট অ্যাক্সেস করুন
ট্যাবের ভেতরের প্রকৃত ডকুমেন্ট কন্টেন্ট tab.documentTab হিসেবে প্রকাশিত হয়। উপরে উল্লিখিত সমস্ত টেক্সট কন্টেন্ট ফিল্ড tab.documentTab ব্যবহার করে অ্যাক্সেস করা যায়। উদাহরণস্বরূপ, document.body ব্যবহার করার পরিবর্তে, আপনার document.tabs[indexOfTab].documentTab.body ব্যবহার করা উচিত।
ট্যাব শ্রেণিবিন্যাস
এপিআই-তে চাইল্ড ট্যাবগুলোকে Tab এর ` tab.childTabs ফিল্ড হিসেবে দেখানো হয়। একটি ডকুমেন্টের সমস্ত ট্যাব অ্যাক্সেস করার জন্য চাইল্ড ট্যাবগুলোর "ট্রি"-কে ট্র্যাভার্স করতে হয়। উদাহরণস্বরূপ, এমন একটি ডকুমেন্ট বিবেচনা করুন যেখানে নিম্নলিখিত ট্যাব হায়ারার্কি রয়েছে:
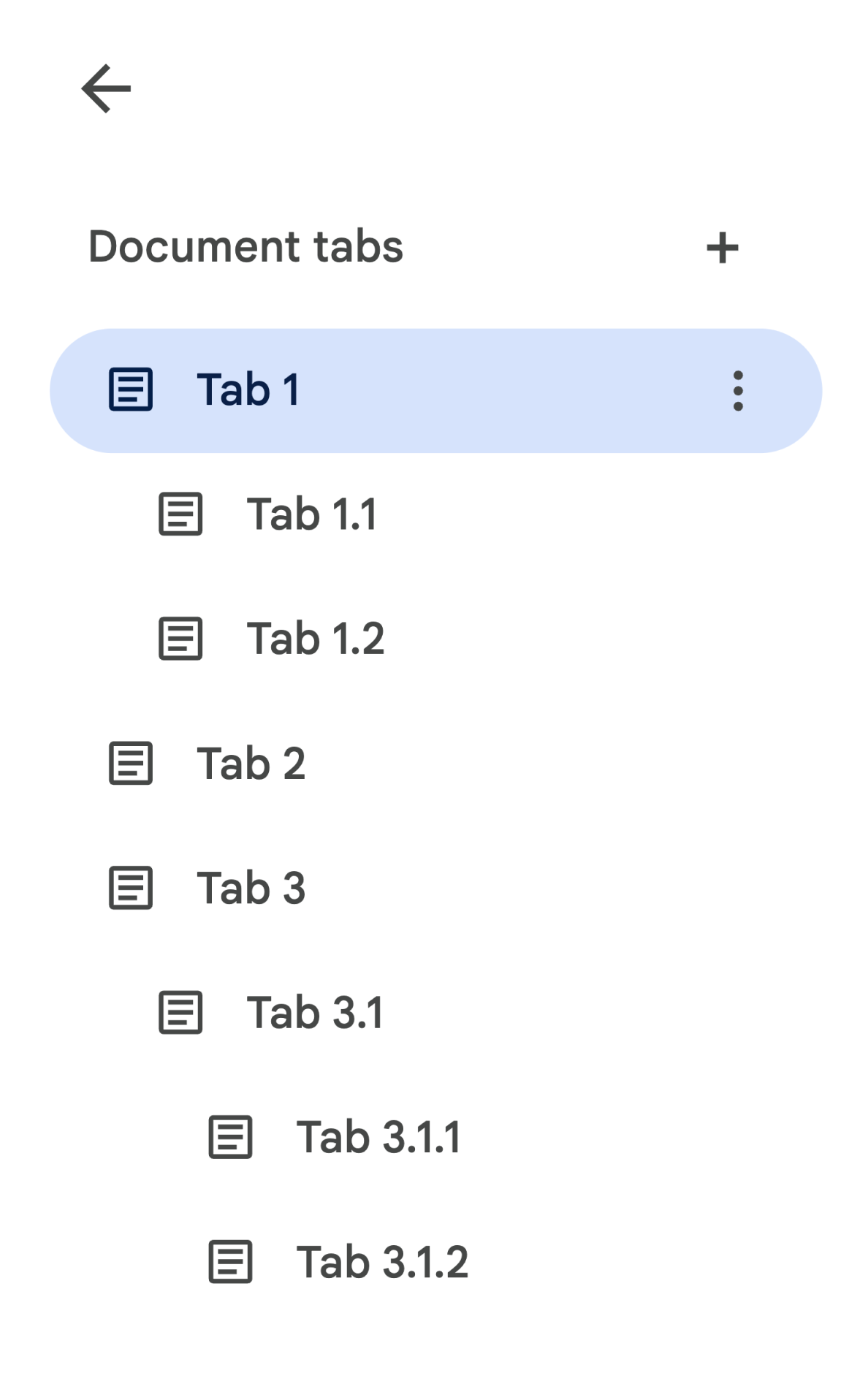
ট্যাব 3.1.2 থেকে Body পুনরুদ্ধার করতে, আপনাকে document.tabs[2].childTabs[0].childTabs[1].documentTab.body অ্যাক্সেস করতে হবে। পরবর্তী বিভাগে নমুনা কোড ব্লকগুলি দেখুন, যেখানে একটি ডকুমেন্টের সমস্ত ট্যাবের মধ্যে পুনরাবৃত্তি করার জন্য নমুনা কোড দেওয়া আছে।
পদ্ধতিতে পরিবর্তন
ট্যাব চালু হওয়ার ফলে প্রতিটি ডকুমেন্ট মেথডে কিছু পরিবর্তন এসেছে, যার জন্য আপনার কোড আপডেট করার প্রয়োজন হতে পারে।
নথিগুলি পান
ডিফল্টরূপে, সব ট্যাবের বিষয়বস্তু ফেরত দেওয়া হয় না। সব ট্যাব অ্যাক্সেস করার জন্য ডেভেলপারদের তাদের কোড আপডেট করা উচিত। documents.get মেথডটিতে একটি includeTabsContent প্যারামিটার রয়েছে, যা রেসপন্সে সব ট্যাবের বিষয়বস্তু দেওয়া হবে কিনা তা কনফিগার করার সুযোগ দেয়।
- যদি
includeTabsContentমানtrueসেট করা থাকে, তাহলেdocuments.getমেথডটি এমন একটিDocumentResource রিটার্ন করবে যারdocument.tabsফিল্ডটি ডেটা দিয়ে পূর্ণ থাকবে।documentসরাসরি উপরের সমস্ত টেক্সট ফিল্ড (যেমনdocument.body) খালি থাকবে। - যদি
includeTabsContentপ্রদান করা না হয়, তাহলেDocumentরিসোর্সের (যেমনdocument.body) টেক্সট ফিল্ডগুলো শুধুমাত্র প্রথম ট্যাবের কন্টেন্ট দিয়ে পূরণ হবে।document.tabsফিল্ডটি খালি থাকবে এবং অন্য ট্যাবগুলোর কন্টেন্ট ফেরত আসবে না।
নথি তৈরি করুন
documents.create মেথডটি তৈরি হওয়া খালি ডকুমেন্টটির প্রতিনিধিত্বকারী একটি Document Resource রিটার্ন করে। রিটার্ন করা Document Resource-টি ডকুমেন্টের টেক্সট কন্টেন্ট ফিল্ড এবং document.tabs উভয় জায়গাতেই খালি ডকুমেন্টের বিষয়বস্তু দিয়ে পূরণ করে দেবে।
ডকুমেন্ট.ব্যাচআপডেট
প্রতিটি Request কোন ট্যাবগুলিতে আপডেটটি প্রয়োগ করা হবে তা নির্দিষ্ট করার একটি উপায় থাকে। ডিফল্টরূপে, যদি কোনো ট্যাব নির্দিষ্ট করা না থাকে, তাহলে বেশিরভাগ ক্ষেত্রে Request ডকুমেন্টের প্রথম ট্যাবে প্রয়োগ করা হবে। ReplaceAllTextRequest , DeleteNamedRangeRequest , এবং ReplaceNamedRangeContentRequest হলো তিনটি বিশেষ রিকোয়েস্ট, যেগুলো এর পরিবর্তে ডিফল্টরূপে সমস্ত ট্যাবে প্রয়োগ করা হয়।
বিস্তারিত তথ্যের জন্য Request ডকুমেন্টেশন দেখুন।
অভ্যন্তরীণ লিঙ্কগুলিতে পরিবর্তন
ব্যবহারকারীরা একটি ডকুমেন্টের ট্যাব, বুকমার্ক এবং হেডিং-এ অভ্যন্তরীণ লিঙ্ক তৈরি করতে পারেন। ট্যাব ফিচারটি চালু হওয়ার ফলে, Link রিসোর্সের link.bookmarkId এবং link.headingId ফিল্ডগুলো এখন আর ডকুমেন্টের কোনো নির্দিষ্ট ট্যাবের বুকমার্ক বা হেডিং-কে নির্দেশ করতে পারবে না।
ডেভেলপারদের রিড এবং রাইট অপারেশনে link.bookmark এবং link.heading ব্যবহার করার জন্য তাদের কোড আপডেট করা উচিত। এগুলি BookmarkLink এবং HeadingLink অবজেক্ট ব্যবহার করে অভ্যন্তরীণ লিঙ্ক প্রকাশ করে, যার প্রতিটিতে বুকমার্ক বা হেডিং-এর আইডি এবং এটি যে ট্যাবে অবস্থিত তার আইডি থাকে। এছাড়াও, link.tabId ট্যাবগুলির অভ্যন্তরীণ লিঙ্ক প্রকাশ করে।
includeTabsContent প্যারামিটারের উপর নির্ভর করে documents.get রেসপন্সের লিঙ্কের বিষয়বস্তুও ভিন্ন হতে পারে:
- যদি
includeTabsContentমানtrueসেট করা থাকে, তাহলে সমস্ত অভ্যন্তরীণ লিঙ্কlink.bookmarkএবংlink.headingহিসেবে প্রদর্শিত হবে। পুরোনো ফিল্ডগুলো আর ব্যবহার করা হবে না। - যদি
includeTabsContentপ্রদান করা না হয়, তাহলে একটিমাত্র ট্যাবযুক্ত ডকুমেন্টে, সেই একক ট্যাবের ভেতরের বুকমার্ক বা হেডিং-এর যেকোনো অভ্যন্তরীণ লিঙ্কlink.bookmarkIdএবংlink.headingIdহিসেবেই প্রদর্শিত হতে থাকবে। একাধিক ট্যাবযুক্ত ডকুমেন্টে, অভ্যন্তরীণ লিঙ্কগুলোlink.bookmarkএবংlink.headingহিসেবে প্রদর্শিত হবে।
document.batchUpdate এ, যদি লিগ্যাসি ফিল্ডগুলোর কোনো একটি ব্যবহার করে একটি অভ্যন্তরীণ লিঙ্ক তৈরি করা হয়, তাহলে বুকমার্ক বা হেডিংটি Request এ নির্দিষ্ট করা ট্যাব আইডি থেকে এসেছে বলে গণ্য করা হবে। যদি কোনো ট্যাব নির্দিষ্ট করা না থাকে, তবে এটি ডকুমেন্টের প্রথম ট্যাব থেকে এসেছে বলে গণ্য করা হবে।
লিঙ্ক JSON উপস্থাপনাটি আরও বিস্তারিত তথ্য প্রদান করে।
ট্যাবের সাধারণ ব্যবহারের ধরণ
নিম্নলিখিত কোড নমুনাগুলিতে ট্যাবের সাথে ইন্টারঅ্যাক্ট করার বিভিন্ন উপায় বর্ণনা করা হয়েছে।
ডকুমেন্টের সমস্ত ট্যাবের বিষয়বস্তু পড়ুন।
ট্যাব ফিচারের আগে যে বিদ্যমান কোড এই কাজটি করত, সেটিকে ` includeTabsContent প্যারামিটারটি ` true সেট করে, ট্যাব ট্রি হায়ারার্কি ট্র্যাভার্স করে এবং Document এর পরিবর্তে Tab ও DocumentTab এর গেটার মেথড কল করার মাধ্যমে ট্যাব সাপোর্ট করার জন্য মাইগ্রেট করা যেতে পারে। নিম্নলিখিত আংশিক কোড স্যাম্পলটি `Extract the text from a document`-এর কোড স্নিপেটের উপর ভিত্তি করে তৈরি। এটি দেখায় কিভাবে একটি ডকুমেন্টের প্রতিটি ট্যাব থেকে সমস্ত টেক্সট কন্টেন্ট প্রিন্ট করতে হয়। এই ট্যাব ট্র্যাভার্সাল কোডটি আরও অনেক ব্যবহারের ক্ষেত্রে অভিযোজিত করা যেতে পারে, যেখানে ট্যাবের প্রকৃত কাঠামো নিয়ে মাথা ঘামানোর প্রয়োজন নেই।
জাভা
/** Prints all text contents from all tabs in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from each tab in the document. for (Tab tab: allTabs) { // Get the DocumentTab from the generic Tab. DocumentTab documentTab = tab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); } } /** * Returns a flat list of all tabs in the document in the order they would * appear in the UI (top-down ordering). Includes all child tabs. */ private List<Tab> getAllTabs(Document doc) { List<Tab> allTabs = new ArrayList<>(); // Iterate over all tabs and recursively add any child tabs to generate a // flat list of Tabs. for (Tab tab: doc.getTabs()) { addCurrentAndChildTabs(tab, allTabs); } return allTabs; } /** * Adds the provided tab to the list of all tabs, and recurses through and * adds all child tabs. */ private void addCurrentAndChildTabs(Tab tab, List<Tab> allTabs) { allTabs.add(tab); for (Tab tab: tab.getChildTabs()) { addCurrentAndChildTabs(tab, allTabs); } } /** * Recurses through a list of Structural Elements to read a document's text * where text may be in nested elements. * * <p>For a code sample, see * <a href="https://developers.google.com/workspace/docs/api/samples/extract-text">Extract * the text from a document</a>. */ private static String readStructuralElements(List<StructuralElement> elements) { ... }
ডকুমেন্টের প্রথম ট্যাব থেকে ট্যাবের বিষয়বস্তু পড়ুন।
এটি সব ট্যাব পড়ার মতোই।
জাভা
/** Prints all text contents from the first tab in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from the first tab in the document. Tab firstTab = allTabs.get(0); // Get the DocumentTab from the generic Tab. DocumentTab documentTab = firstTab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); }
প্রথম ট্যাব আপডেট করার জন্য একটি অনুরোধ করুন
নিম্নলিখিত আংশিক কোড নমুনাটি দেখায় কিভাবে একটি Request মধ্যে একটি নির্দিষ্ট ট্যাবকে টার্গেট করতে হয়। এই কোডটি Insert, delete, and move text গাইডের নমুনার উপর ভিত্তি করে তৈরি।
জাভা
/** Inserts text into the first tab of the document. */ static void insertTextInFirstTab(Docs service, String documentId) throws IOException { // Get the first tab's ID. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); Tab firstTab = doc.getTabs().get(0); String tabId = firstTab.getTabProperties().getTabId(); List<Request>requests = new ArrayList<>(); requests.add(new Request().setInsertText( new InsertTextRequest().setText(text).setLocation(new Location() // Set the tab ID. .setTabId(tabId) .setIndex(25)))); BatchUpdateDocumentRequest body = new BatchUpdateDocumentRequest().setRequests(requests); BatchUpdateDocumentResponse response = docsService.documents().batchUpdate(<var>DOCUMENT_ID</var>, body).execute(); }