關於這份文件
閱讀這篇文章後,您將:
- 先瞭解應建立哪些策略,再產生摘要報表。
- 認識 Noise Lab,這項工具可以協助你瞭解各種雜訊參數的效果,並能快速探索及評估各種雜訊管理策略。
提供意見
雖然本文總結了使用摘要報表的幾項原則,但雜訊管理方法有很多,但可能未在這裡反映。歡迎提出建議、補充內容和問題!
- 如要針對雜訊管理策略、API 公用性或隱私權 (Psilon) 提供公開意見回饋,並在使用雜訊研究室模擬時分享觀察結果:針對這個問題留言
- 如要針對 Noise Lab 提供公開意見回饋 (提出問題、回報錯誤、要求新功能):按這裡建立新問題
- 如要提供對 API 其他面向的公開意見回饋:在這裡建立新問題
事前準備
- 如需相關簡介,請參閱「歸因報表:摘要報表」和「歸因報表完整系統總覽」一文。
- 請參閱「瞭解雜訊」和「瞭解匯總鍵」這兩篇文章,充分運用本指南。
設計決策
核心設計原則
第三方 Cookie 和摘要報表運作方式的基本差異。主要差異在於,在摘要報表的評估資料中加入「雜訊」。另一個方式是排定報表。
如要使用高雜訊比率較高的信號比率、需求端平台 (DSP) 和廣告評估服務供應商,以便存取摘要報表評估資料,必須與廣告客戶合作制定雜訊管理策略。為了製定這些策略,需求端平台和評估服務供應商必須做出設計決策。這些決定與一個基本概念有關:
雖然分佈「雜訊值」的來源是絕對的,但僅取決於兩個參數⏤epsilon 和捐款預算⏤,您有更多其他控制選項,會影響輸出評估資料的訊號雜訊比率。
雖然我們預期反覆式程序能做出最佳決策,但這些決定的每個變化版本都會稍微改變導入方式,因此這些決定在逐一撰寫程式碼前 (以及放送廣告前) 都必須做決定。
決策:維度精細程度
在噪音研究室中試用
- 前往進階模式。
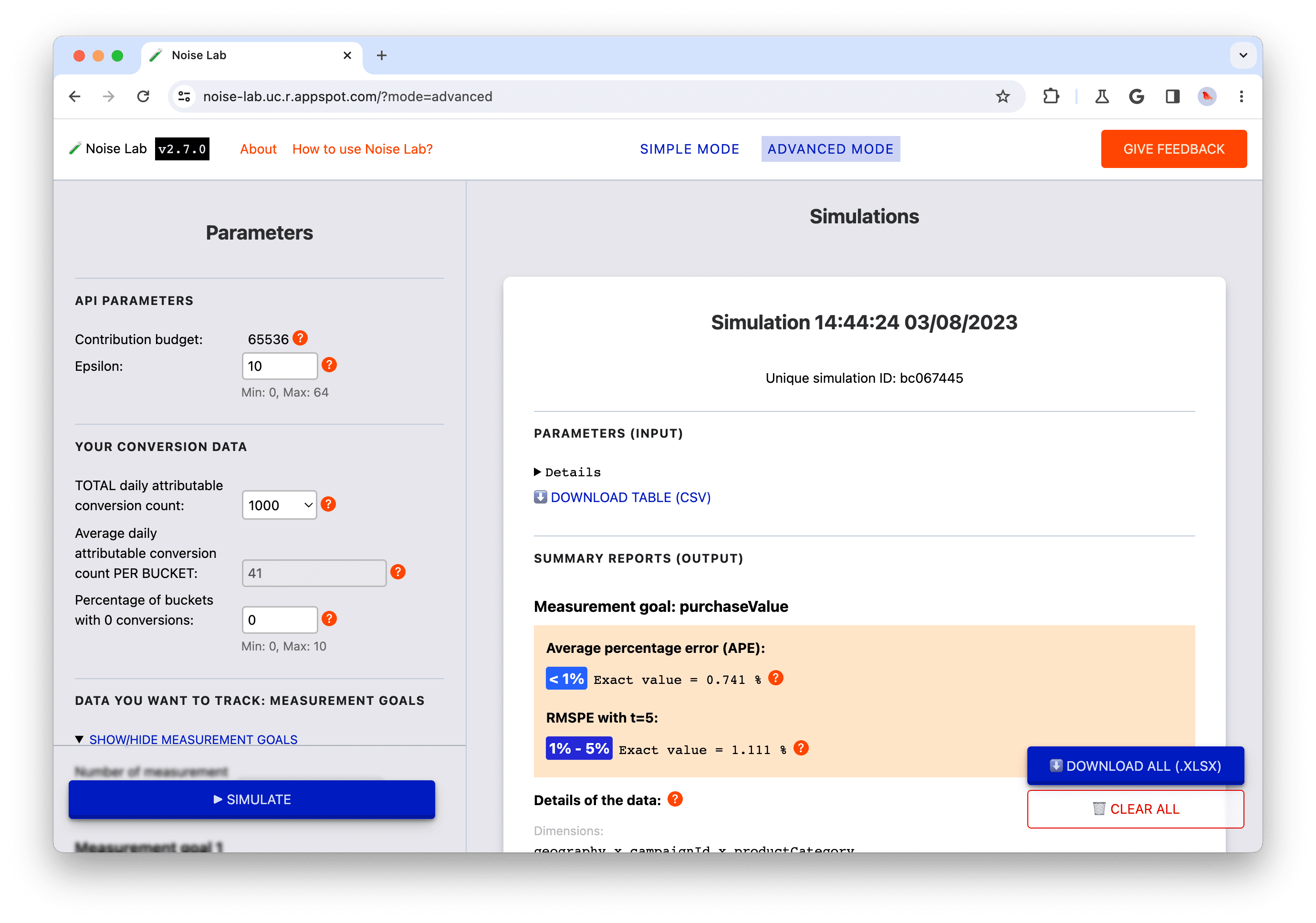
- 在「參數」側邊面板中找出「您的轉換資料」。
- 觀察預設參數。根據預設,共 TOTAL 的可歸因轉換次數為 1000 次。如果您使用預設設定,這個數值約為每個值區 40 的平均值 (預設維度、每個維度的預設可能不同值數量、「鍵策略 A」)。您會發現在「每個值區」的輸入平均每日可歸因轉換次數中,這個值為 40。
- 點選「模擬」即可使用預設參數執行模擬作業。
- 在「參數」側邊面板中,找出「尺寸」。將「Geography」重新命名為「City」,並將不同值的數量變更為 50。
- 觀察這項變更,變更每個值區的平均每日可歸因轉換次數。現在超級低了。這是因為如果您在不變更任何其他項目的情況下增加這個維度中可能的值數量,您就會增加值區總數,而不會變更各值區中的轉換事件數量。
- 按一下「模擬」。
- 觀察產生的模擬的雜訊比:雜訊比現在高於上一個模擬作業的雜訊比率。
基於核心設計原則,小型摘要值可能比大型匯總值更大。因此,您的設定選項會影響每個值區中最終有多少歸因轉換事件 (否則稱為匯總鍵),而數量會影響最終輸出摘要報表中的雜訊。
一項設計決策會影響單一值區中的歸因轉換事件數量,也就是維度精細程度。請參考以下匯總鍵及其維度示例:
- 方法 1:一個維度為粗略的鍵結構:國家/地區 x 廣告活動 (或最大的廣告活動匯總值區) x 產品類型 (共 10 種產品類型中)
- 方法 2:採用精細維度的一個主要結構:「城市」x「廣告素材 ID」x「產品」 (共 100 項可行產品)
「City」是比「Country」(國家/地區) 更精細的維度,「廣告素材 ID」更比「Campaign」更精細,而「Product」則是比「產品類型」更加精細。因此,方法 2 在摘要報表輸出中,每個值區的事件 (轉換) 數量 (每個鍵 = 數量) 會比方法 1 少。由於輸出的雜訊與值區中的事件數量無關,因此摘要報表中的評估資料會因為方法 2 而變得更為雜訊。針對每個廣告主,嘗試在金鑰設計中多方取捨,以獲得最廣泛的結果。
決策:主要結構
在噪音研究室中試用
在簡易模式中,系統會使用預設金鑰結構。在進階模式中,您可以嘗試不同的鍵結構。其中已包含一些尺寸範例,但您也可以修改這些維度。
- 前往進階模式。
- 在「參數」側邊面板中,找出「鍵」策略。您會發現此工具中的預設策略 (名稱為 A) 使用一個精細的鍵結構,其中包含所有維度:地理位置 x 廣告活動 ID x 產品類別。
- 按一下「模擬」。
- 觀察產生的模擬的雜訊比。
- 將鑰匙策略變更為 B。畫面上會顯示其他控制項,供您設定金鑰結構。
- 設定金鑰結構,例如:
- 主要結構數量:2
- 鍵結構 1 = 地理位置 x 產品類別。
- 主要結構 2 = 廣告活動 ID x 產品類別。
- 按一下「模擬」。
- 您會發現,由於使用的是兩種不同的主要結構,因此每個評估目標類型現在會取得兩份摘要報表 (兩個代表購買次數,兩份為購買價值)。觀察雜訊比。
- 你也可以使用自己的自訂維度試試這項功能。方法很簡單,請找出 您想追蹤的資料:維度。建議您移除範例維度,並使用最後一個維度下方的「新增/移除/重設」按鈕來自行建立維度。
另一個設計決策將會影響單一值區中的歸因轉換事件數量,也就是您要使用的主要結構。請參考以下匯總鍵的範例:
- 一種主要結構,包含所有維度;我們將這個主要策略 A 稱為「主要策略 A」。
- 有兩個主要結構,每個結構都有部分維度,稱為「關鍵策略 B」。
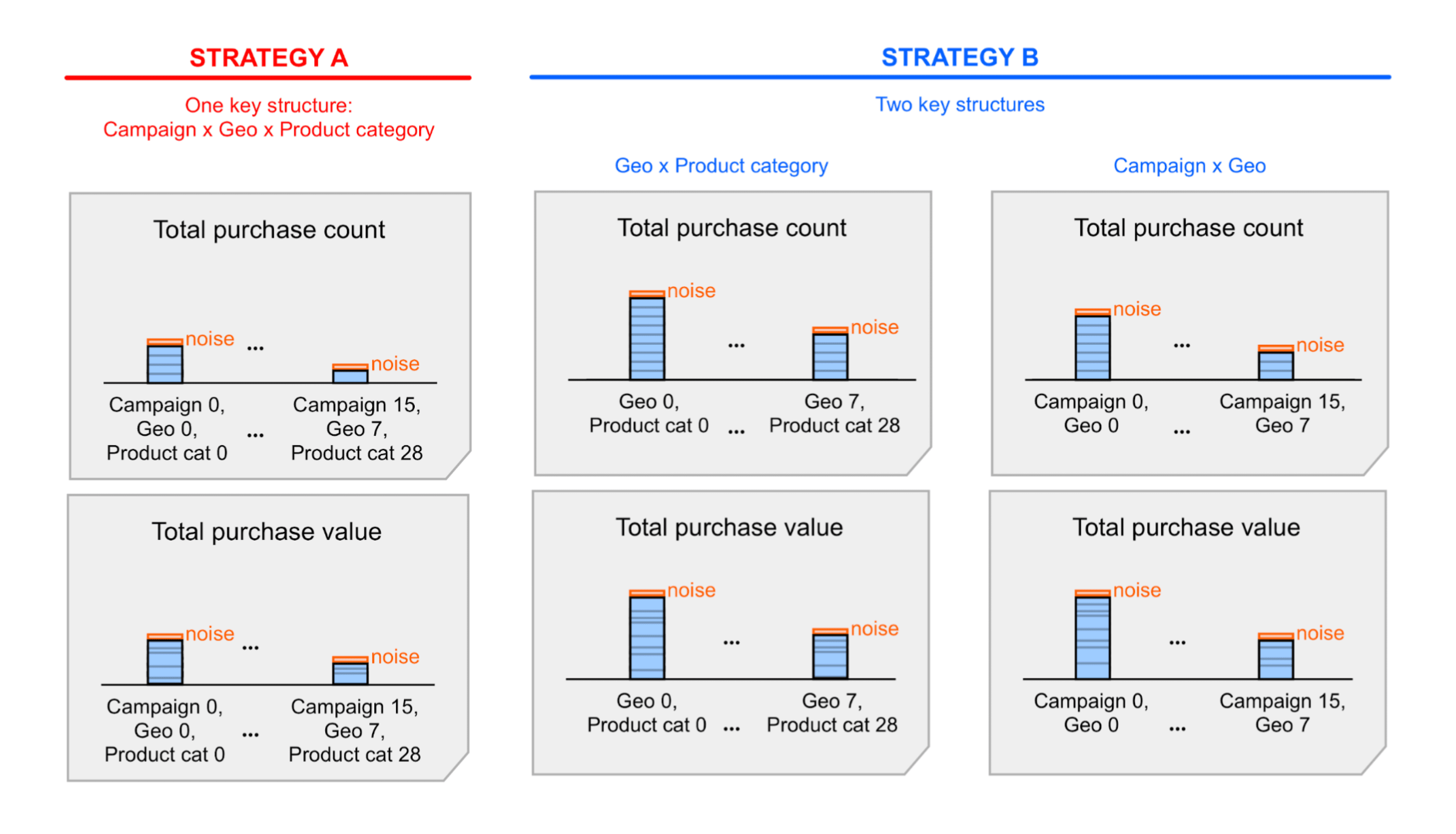
策略 A 會比較簡單,但您可能需要匯總 (總和) 包含摘要報表的雜訊摘要值,才能存取特定洞察資料。將這些數值加總後,系統就能一併加總雜訊。採用策略 B 時,摘要報表中顯示的摘要值可能已能提供您所需的資訊。這表示策略 B 可能比策略 A 的信號雜訊比更佳。然而,策略 A 或許能夠接受雜訊,因此建議您採用 A 策略來簡化作業。歡迎參考這兩種策略的詳細範例。
金鑰管理是深厚的主題。可以考慮使用許多精密的技術,改善訊號雜訊比。其中一項請參閱進階金鑰管理一文。
決策:批次處理頻率
在噪音研究室中試用
- 前往簡易模式 (或進階模式;在批次處理頻率方面,這兩種模式的運作方式都相同)
- 在「參數」側邊面板中,找出您的匯總策略 >「批次頻率」。這是指在單一工作中使用匯總服務處理可匯總報表的批次處理頻率。
- 觀察預設批次處理頻率:根據預設,系統會模擬每日批次處理頻率。
- 按一下「模擬」。
- 觀察產生的模擬的雜訊比。
- 將批次處理頻率變更為每週。
- 觀察產生的模擬的雜訊比:雜訊比現在比上一個模擬作業低 (更好)。
另一項設計決策會影響單一值區中的歸因轉換事件數量,也就是您要使用的批次處理頻率。批次頻率是指您處理可匯總報表的頻率。
相較於匯總時間表 (例如每週) 的同一報表,排定匯總頻率的報表會更少納入轉換事件。因此,每小時報表會包含更多雜訊。與匯總時間表 (例如每週) 的同一報表相比,納入的轉換事件數量少於同一份報表。因此,每小時報表的信號雜訊率會比每週報表低,在其他方面相等。測試不同頻率的報表要求,並評估每個要求的信號雜訊比率。
決策:影響可歸因轉換的廣告活動變數
在噪音研究室中試用
雖然這可能難以預測,加上季節性影響也可能會產生重大變化,但請試著預估每日單次接觸點可歸因轉換次數,並估算出最接近的 10:10、100、1,000 或 10,000 次。
- 前往進階模式。
- 在「參數」側邊面板中找出「您的轉換資料」。
- 觀察預設參數。根據預設,共 TOTAL 的可歸因轉換次數為 1000 次。如果您使用預設設定,這個數值約為每個值區 40 的平均值 (預設維度、每個維度的預設可能不同值數量、「鍵策略 A」)。您會發現在「每個值區」的輸入平均每日可歸因轉換次數中,這個值為 40。
- 點選「模擬」即可使用預設參數執行模擬作業。
- 觀察產生的模擬的雜訊比。
- 現在將 TOTAL 的每日可歸因轉換次數設為 100。 您會發現,這會降低每個值區的平均每日可歸因轉換次數。
- 按一下「模擬」。
- 您會發現雜訊比現在較高:這是因為每個值區的轉換量較少,系統就套用更多雜訊來保護隱私權。
重要的差異在於廣告客戶可能獲得的轉換總數,以及可能的「歸因」轉換總數。後者最終會影響摘要報表中的雜訊。歸因轉換是指容易產生廣告活動變數 (例如廣告預算和廣告指定目標) 的轉換總數。舉例來說,相較於 $10, 000 美元的廣告活動,$1, 000 萬美元的廣告活動可獲得較多的歸因轉換次數,在所有其他條件相同的情況下。
注意事項:
- 針對單一觸控和同一種裝置歸因模式評估歸因轉換,因為這些轉換位於透過 Attribution Reporting API 收集的摘要報表範圍內。
- 您可以針對歸因轉換考慮最壞的情況,以及最佳情況計數。舉例來說,在所有其他條件都相同的情況下,廣告客戶應盡可能為單一廣告客戶設定最低和最高廣告活動預算,然後在模擬時將這兩項結果的可歸因轉換都列入計算。
- 如果您考慮使用 Android Privacy Sandbox,請在計算跨平台歸因轉換時考慮採用。
決策:使用資源調度功能
在噪音研究室中試用
- 前往進階模式。
- 在「參數」側邊面板中,找出您的匯總策略 >「縮放」。預設設定為「是」。
- 為了瞭解資源調度對雜訊比帶來的正面影響,請先將「資源調度」設為「否」。
- 按一下「模擬」。
- 觀察產生的模擬的雜訊比。
- 將「Scaling」設為「Yes」。請注意,Noise Lab 會根據您的情況評估目標的範圍 (平均值和最大值),自動計算要使用的縮放比例係數。在實際的系統或來源試用設定中,您會想要自行計算資源調度因數。
- 按一下「模擬」。
- 您會發現在第二次模擬中,雜訊比現在較低 (較佳)。這是因為您正在使用縮放功能。
基於核心設計原則,加入的雜訊是貢獻預算的函式。
因此,如要提高信號雜訊比,您可以決定轉換轉換事件期間收集的值,方法是根據貢獻預算「縮放」,然後在匯總後調整這些值。使用縮放功能增加信號雜訊比。
決策:評估目標數量和隱私預算分配
這與資源調度相關;請務必參閱「使用資源調度」一節。
在噪音研究室中試用
評估目標是在轉換事件中收集的不同資料點。
- 前往進階模式。
- 在「參數」側邊面板中,尋找您想追蹤的資料: 評估目標。根據預設,您有兩個評估目標:購買價值和購買次數。
- 按一下「模擬」即可執行採用預設目標的模擬作業。
- 按一下「移除」。這麼做會移除最後一個評估目標 (在這種情況下,也就是購買次數)。
- 按一下「模擬」。
- 您會發現在這次的第二次模擬中,購物價值的雜訊比現在較低 (較佳)。這是因為您的評估目標較少,因此您現在只建立一個評估目標,就可以獲得所有貢獻預算。
- 按一下「重設」。您現在又擁有「購物價值」和「購買次數」這兩個評估目標。請注意,Noise Lab 會根據您的情況評估目標的範圍 (平均值和最大值),自動計算要使用的縮放比例係數。根據預設,Noise Lab 會將預算平均分配給各個評估目標。
- 按一下「模擬」。
- 觀察系統產生模擬的雜訊比。記下模擬結果顯示的縮放比例係數。
- 現在,讓我們自訂隱私預算分配比例,取得更佳的信號雜訊比。
- 調整指派給每個評估目標的預算百分比。以預設參數來說,評估目標 1 (也就是購買價值) 遠比評估目標 2 更大 (介於 1 和 1 之間,即一律等於 1)。因此,需要「擴大規模」需要「擴充規模」:與評估目標 2 相比,應該分配較多貢獻預算給評估目標 1,這樣才能更有效率地擴大規模 (請參閱「資源調度」)。
- 將 70% 的預算指派給評估目標 1. 將 30% 指派至評估目標 2。
- 按一下「模擬」。
- 觀察系統產生模擬的雜訊比。針對購買價值,雜訊比現在明顯低於先前的模擬作業 (更佳)。購買次數幾乎沒有變化。
- 持續調整各指標的預算分配比例。觀察這對於雜訊的影響。
請注意,您可以使用「新增/移除/重設」按鈕自訂評估目標。
如果您為某個轉換事件 (例如轉換次數) 評估一個資料點 (評估目標),該資料點就能取得所有貢獻預算 (65536)。如果您為轉換事件設定了多個評估目標 (例如轉換次數和購物價值),這些資料點就必須共用貢獻預算。這表示您可以減少向上擴充值的方法。
因此,您的評估目標越多,訊號雜訊比就越低 (雜訊越多)。
另一項成效評估目標的決策就是分配預算。如果您將貢獻預算平均分配給兩個資料點,則每個資料點都會獲得 65536/2 = 32768 的預算。這未必是最佳項目,視每個資料點的最大可能值而定。舉例來說,如果您要評估購買次數 (值為 1 時) 且購買價值至少為 1 至 120,則隨著「更多空間」向上擴充 (也就是提高這筆貢獻預算的比例),就比較有利於購買價值。您將瞭解,在套用雜訊的影響下,某些評估目標是否應優先於其他評估目標。
決策:離群值管理
在噪音研究室中試用
評估目標是在轉換事件中收集的不同資料點。
- 前往進階模式。
- 在「參數」側邊面板中,找出您的匯總策略 >「縮放」。
- 確認「Scaling」已設為「Yes」。請注意,Noise Lab 會根據您為測量目標指定的範圍 (平均值和最大值),自動計算要使用的縮放比例係數。
- 我們假設史上最大的交易金額是 $2, 000 美元,但多數購買交易的發生價格介於 $10 至 $120 美元之間。首先,我們來看看使用常值調整方法時會發生什麼情況 (不建議使用):輸入 $2000 做為 purchaseValue 最大值。
- 按一下「模擬」。
- 觀察雜訊比偏高。這是因為縮放比例係數目前是根據 $2, 000 美元計算,但實際上大部分的購買價值更不會低於這個值。
- 現在,讓我們以實際的縮放方法進行操作。將最高購買價值變更為 $120 美元。
- 按一下「模擬」。
- 您會發現在第二次模擬中,雜訊比較低 (較佳)。
一般來說,如要實作資源調度,您通常會根據特定轉換事件的可能最高值計算縮放比例係數 (詳情請參閱本範例)。
不過,請避免使用常值最大值來計算這個縮放比例係數,因為這會導致訊號雜訊比惡化。您應改為移除離群值,並使用實用的最大值。
離群值管理是很深的議題。可以考慮使用許多精密的技術,改善訊號雜訊比。一請參閱進階離群值管理一文。
後續步驟
現在您已針對自身用途評估各種雜訊管理策略,現在可以透過來源試用收集實際測量資料,開始測試摘要報表。查看試用 API 的指南和提示。
附錄
噪音研究室快速導覽
Noise Lab 可協助您快速評估和比較雜訊管理策略。用途:
- 瞭解會影響雜訊的主要參數及其效果。
- 根據不同的設計決策,模擬雜訊對輸出評估資料的影響。調整設計參數,直到達到適合用途的信號雜訊比。
- 請針對摘要報告的實用性提供意見:哪些是 epsilon 和雜訊參數的值適合你,哪些值不適合?觀察點在哪裡?
您可以將此視為準備步驟。Noise Lab 會產生評估資料,並根據您輸入的內容模擬摘要報表輸出結果。不會保存或分享任何資料。
噪音研究室提供兩種不同的模式:
- 簡易模式:瞭解用於套用雜訊的控制項基礎知識。
- 進階模式:測試不同的雜訊管理策略,評估哪種策略可針對您的用途獲得最佳訊號雜訊比。
按一下頂端選單中的按鈕,即可在兩種模式之間切換 (下方螢幕截圖中的#1.)。
簡易模式
- 透過簡易模式,您可以控制參數 (可在左側找到,或下方螢幕截圖中的#2),例如 Epsilon,看看它們如何影響雜訊。
- 每個參數都有一個工具提示 (「?」按鈕)。點選這些圖示即可查看每個參數的說明 (下方螢幕截圖中的#3.)
- 首先,請按一下「Simulate」按鈕,並觀察輸出內容的外觀 (下方螢幕截圖中的#4.)
- 您可以在「輸出」區塊查看各種詳細資料。部分元素旁邊有「?」符號。請花點時間點選各個「?」圖示,查看各項資訊的說明。
- 如要查看展開後的資料表版本,請在「Output」(輸出) 部分中按一下「Details」(詳細資料) 切換按鈕 (下方螢幕截圖中的#5.)。
- 在輸出區段的每個資料表下方,有一個選項可下載資料表供離線使用。此外,右下角也有下載所有資料表格的選項 (下方螢幕截圖中的#6.)
- 在「參數」部分中測試不同參數的設定,然後按一下「模擬」,即可查看這些參數對輸出內容的影響:
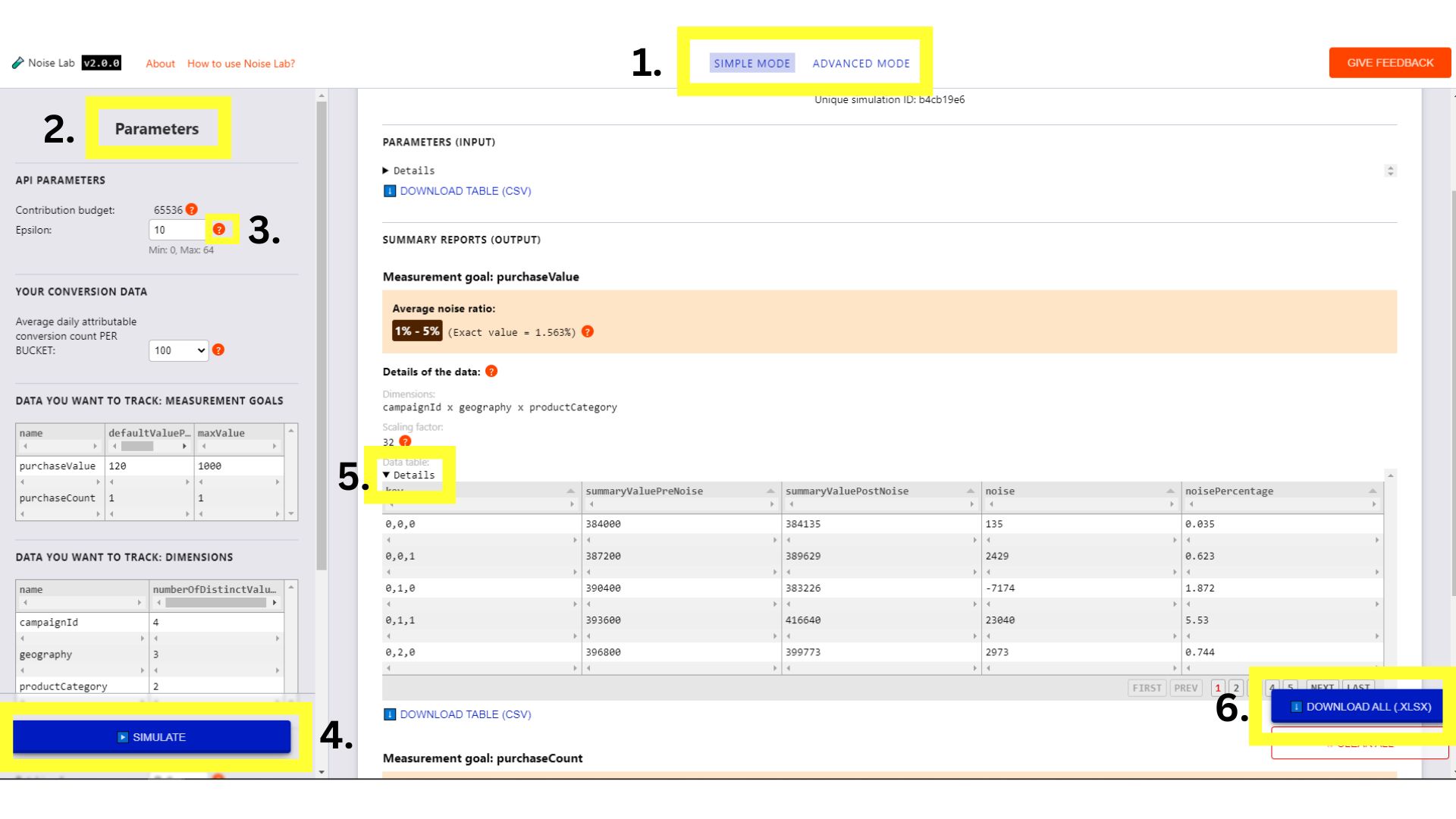
簡易模式的 Noise Lab 介面。
進階模式
- 在進階模式中,您可以進一步控制參數。 您可以新增自訂評估目標和維度 (下方螢幕截圖中的#1. 和 #2.)
- 在「參數」部分中向下捲動,並查看「金鑰策略」選項。這可用於測試不同的金鑰結構 (下方螢幕截圖中的#3.)
- 若要測試不同的主要結構,請將關鍵策略切換為「B」
- 輸入要使用的不同金鑰結構數量 (預設為「2」)
- 按一下「產生金鑰結構」
- 在您要加入各金鑰結構的鍵旁邊按一下核取方塊,畫面就會顯示指定金鑰結構的選項。
- 點選「模擬」即可查看輸出內容。
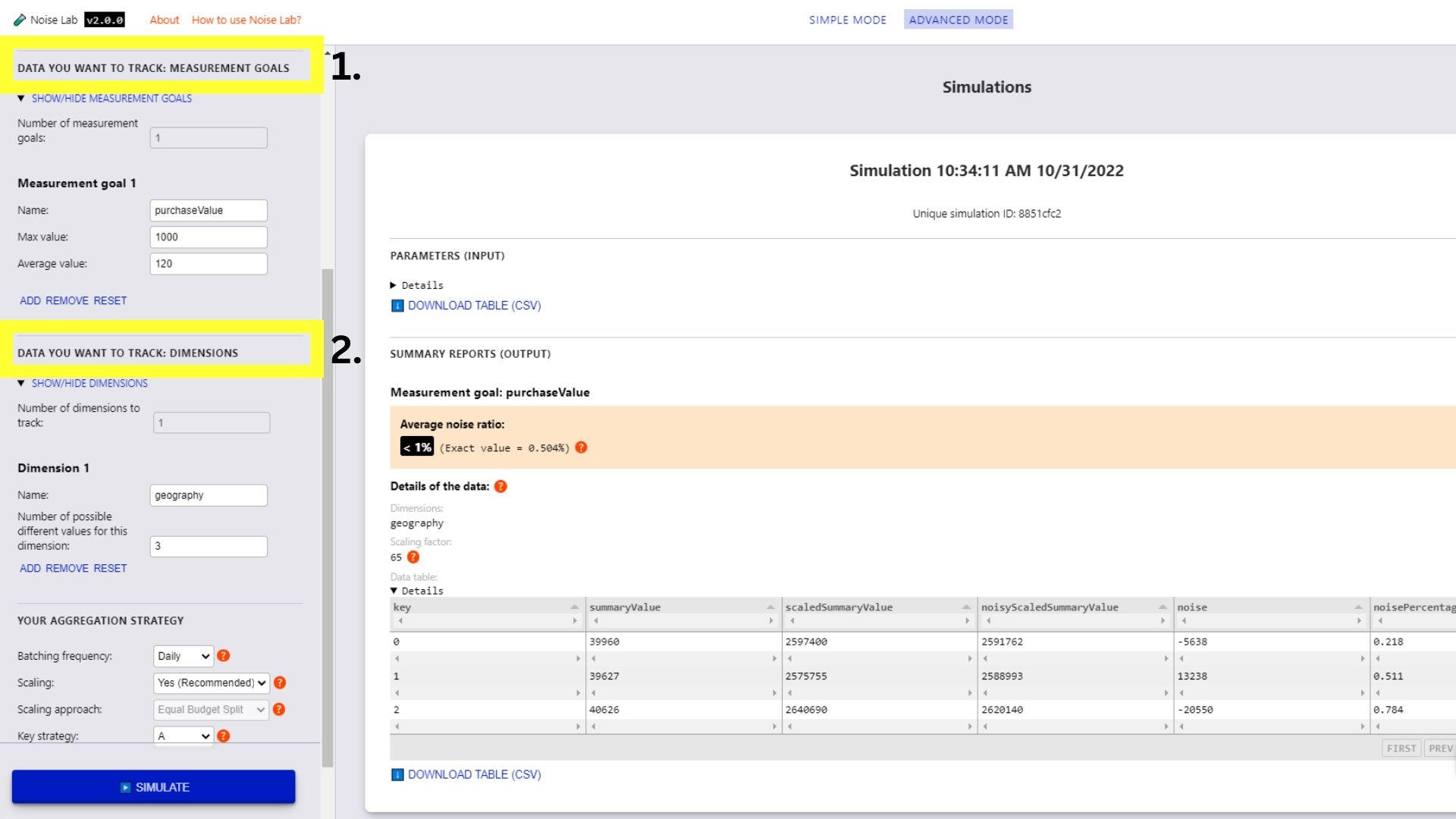
進階模式的 Noise Lab 介面。 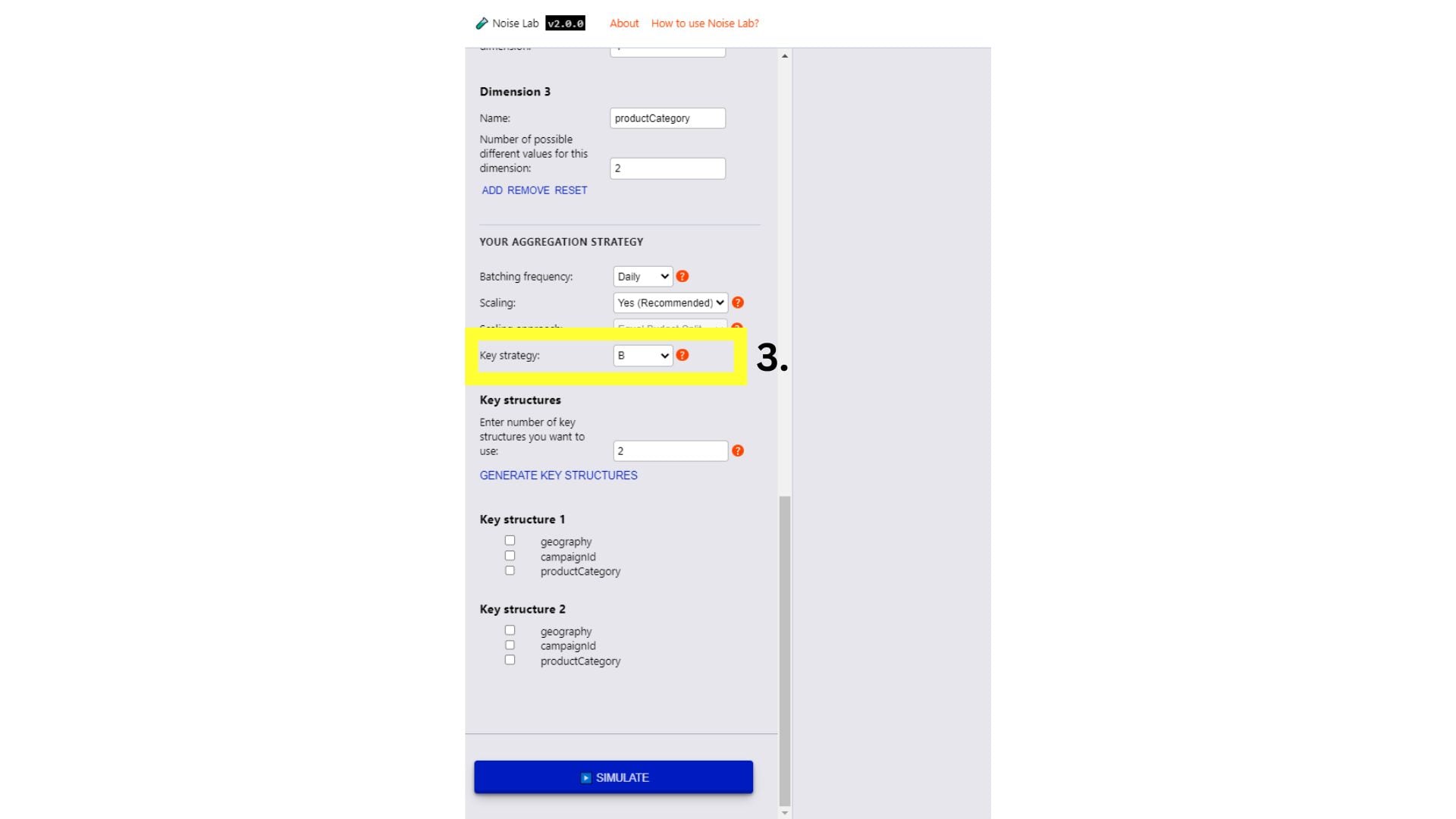
進階模式的 Noise Lab 介面。
噪音指標
核心概念
為保護個別使用者隱私,手機會加入雜訊。
雜訊值越高,代表值區/索引鍵的稀疏度不足,且包含少數敏感事件帶來的貢獻。Noise Lab 會自動執行這項作業,讓他人「隱藏在人群中」。換句話說,我們希望使用者能「大量加入雜訊」來保護受限對象的隱私權。
如果雜訊值較低,表示此資料設定的設計方式允許個別使用者「隱藏在人群中」。這表示值區會包含來自足夠事件的貢獻,確保個別使用者隱私受到保護。
這個陳述式同時適用於平均百分比誤差 (APE) 和 RMSRE_T (設有門檻的超級方位誤差)。
APE (平均錯誤百分比)
APE 是指雜訊在信號上的比率,也就是真正的摘要值。p> APE 值越低表示訊號雜訊比越高。
公式
對於特定摘要報表,APE 的計算方式如下:

True 是指實際的摘要值。APE 是每個真實匯總值在摘要報表中所有項目的雜訊平均值。在噪音研究室中,這個數字會乘以 100 所得的百分比。
優缺點
大小較小的值區會對 APE 的最終值產生不成比例的影響。這在評估雜訊時可能會產生誤導。因此,我們新增了另一個指標 RMSRE_T,以減輕這項 APE 限制。詳情請參閱示例。
程式碼
查看 APE 計算的原始碼。
RMSRE_T (設有門檻的均方根誤差)
RMSRE_T (根層級均值的相對誤差) 是雜訊的另一種評估方式。
如何解讀 RMSRE_T
RMSRE_T 值越低表示訊號雜訊比越高。
舉例來說,如果用途可接受的雜訊比為 20%,而 RMSRE_T 為 0.2,代表雜訊量落在可接受的範圍內。
公式
對於特定摘要報表,RMSRE_T 的計算方式如下:
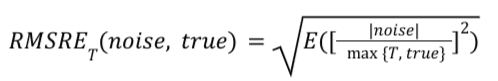
優缺點
相較於 APE,RMSRE_T 較為複雜。不過,它有幾個優點,因此在某些情況下比 APE 更適合在摘要報表中分析雜訊:
- RMSRE_T 較穩定。「T」是閾值,使用「T」即可在 RMSRE_T 計算時降低轉換的權重,導致轉換次數較少的值區因規模較小而較為敏感。與 T 相比,指標不會因轉換次數偏低的值區遽增。如果 T 等於 5,在轉換為 0 次的值區中如果雜訊值小為 1,就不會顯示為超過 1 次。而上限是 0.2,相當於 1/5,因為 T 等於 5。藉由調降較小型值區 (因此對雜訊較敏感) 的權重,這項指標會更加穩定,因此更容易比較兩項模擬結果。
- RMSRE_T 可進行簡單的匯總作業。瞭解多個區塊的 RMSRE_T 及其真正的計數,可讓您計算其總和的 RMSRE_T。這樣一來,您就能針對這些合併值進行最佳化的 RMSRE_T。
雖然 APE 可以匯總匯總資料,但公式非常複雜,因為它涉及 Laplace 雜訊總和的絕對值。導致 APE 更難最佳化。
程式碼
查看 RMSRE_T 計算的原始碼。
示例
含有三個值區的摘要報表:
- bucket_1 = 雜訊:10,trueSummaryValue:100
- bucket_2 = 雜訊:20,trueSummaryValue:100
- bucket_3 = 雜訊:20,trueSummaryValue:200
APE = (0.1 + 0.2 + 0.1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
含有三個值區的摘要報表:
- bucket_1 = 雜訊:10,trueSummaryValue:100
- bucket_2 = 雜訊:20,trueSummaryValue:100
- bucket_3 = 雜訊:20,trueSummaryValue:20
APE = (0.1 + 0.2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
含有三個值區的摘要報表:
- bucket_1 = 雜訊:10,trueSummaryValue:100
- bucket_2 = 雜訊:20,trueSummaryValue:100
- bucket_3 = 雜訊:20,trueSummaryValue:0
APE = (0.1 + 0.2 + Infinity) / 3 = Infinity
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
進階金鑰管理
DSP 或廣告評估公司可能有數千位全球廣告客戶,範圍遍及多種產業、貨幣和潛在購買價格。這表示為每位廣告客戶建立及管理一個匯總鍵,可能非常不切實際。此外,要選取最大可匯總值和匯總預算,這將會限制全球數千名廣告主產生雜訊的影響。我們改為考量下列情境:
重點策略 A
廣告技術供應商決定為所有廣告客戶建立及管理一個金鑰。所有廣告主和幣別的購買範圍,從低量、高額購買,到高量購買、低階購買都有不同。這會產生以下金鑰:
| 鍵 (多種貨幣) | |
|---|---|
| 可匯總值上限 | 5,000,000 |
| 購物價值範圍 | [120 至 5000000] |
重點策略 B
廣告技術供應商決定為所有廣告客戶建立及管理兩個金鑰。他們決定依貨幣分隔鍵。所有廣告主和貨幣的購買範圍,都不盡相同,從低量、高額購買,到高購買量和低階購買都有。他們是依貨幣區隔,會建立 2 個鍵:
| 鍵 1 (美元) | 鍵 2 (¥) | |
|---|---|---|
| 可匯總值上限 | $40,000 美元 | ¥5,000,000 日圓 |
| 購物價值範圍 | [120 到 40,000] | [15,000 到 5,000,000] |
由於貨幣值無法統一分配給各個貨幣,因此重點策略 B 的結果中的雜訊會比主要策略 A 少。舉例來說,請考量以美元計價的購買交易,以 ¥ 日圓做為交易依據,會改變基本資料並產生雜訊。
主要策略 C
廣告技術供應商決定為所有廣告主建立和管理四組鍵,並依據幣別 x 廣告主產業區隔:
| 鍵 1 (美元 x 高級珠寶廣告客戶) |
鍵 2 (¥ x 高級珠寶廣告客戶) |
索引鍵 3 (美元 x 服飾零售商廣告主) |
主要 4 (¥ x 服飾零售商廣告客戶) |
|
|---|---|---|---|---|
| 可匯總值上限 | $40,000 美元 | ¥5,000,000 日圓 | $500 美元 | ¥65,000 日圓 |
| 購物價值範圍 | [10,000 到 40,000 人] | [1,250,000 至 5,000,000 人] | [120 到 500] | [15,000 到 65,000 人] |
主要策略 C 的結果雜訊比主要策略 B 更少,因為廣告主的購物價值並未統一分配給各個廣告主。舉例來說,不妨試想一下,同時購買高級珠寶和棒球帽後,會如何改變基礎資料,並產生的雜訊。
建議您針對多個廣告主的共通性,建立共用的最高匯總值和共用縮放比例係數,以減少輸出中的雜訊。例如,您可以針對廣告客戶進行以下不同策略進行實驗:
- 以貨幣 (例如美元、¥、加幣等) 區隔的策略
- 按廣告客戶產業 (例如保險、汽車、零售業等) 區隔的策略
- 按類似購物價值範圍 ([100]、[1000]、[10000] 等) 區隔的策略
透過針對廣告主的共通性建立主要策略,鍵和對應程式碼便能更輕鬆地管理,信號雜訊的比率也會提高。根據不同的廣告客戶常見做法進行不同策略,找出最大程度提升的雜訊影響,而不是程式碼管理得宜的轉折點。
進階離群值管理
假設有兩位廣告客戶,我們設了一個情境:
- 廣告客戶 A:
- 就廣告客戶 A 網站上的所有產品,購買價格的可能性介於 [$120 - $1,000] 之間,範圍介於 $880 美元。
- 購買價格均平均分配到 $880 美元的範圍內,且不會超出購買價格中位數的標準差。
- 廣告客戶 B:
- 在廣告客戶 B 網站上的所有產品中,購買價格可能介於 [$120 - $1,000] 之間,範圍介於 $880 美元。
- 購買價格極有偏向 $120 至 $500 美元的範圍內,只有 5% 的購買發生在 $500 至 $1,000 美元之間。
考量到貢獻預算需求以及 [套用雜訊] 的方法](/privacy-sandbox/relevance/attribution-reporting/understanding-noise/#how-noise-is-applied),根據預設,廣告客戶 B 的輸出結果較廣告客戶 A 有較多的雜訊,因為廣告客戶 B 較有可能影響基礎計算結果。
只要設定特定金鑰,即可緩解這種情況。測試有助於管理離群資料的重要策略,並將購物價值平均分配給鍵的購買範圍。
針對廣告客戶 B,您可以建立兩個不同的鍵來擷取兩個不同的購買價值範圍。在本例中,廣告技術指出離群值所在的購買價值高於 $500 美元。嘗試為這個廣告客戶導入兩個不同的鍵:
- 主要結構 1:只擷取介於 $120 至 $500 美元 (涵蓋總購買量的 95%) 範圍內的購買行為。
- 主要結構 2:只吸引超過 $500 美元的購買行為 (涵蓋總購買量的 5% 左右)
執行這項關鍵策略應更有效地管理廣告客戶 B 的雜訊,並盡可能提高摘要報表的實用性。考量到新的較小範圍,鍵 A 和鍵 B 現在應能針對前一個鍵,在各個索引鍵上更一致的資料分佈。因此,對於前一個鍵,每個鍵輸出內容中的雜訊影響較低。