Intended to be implemented in the Android Open Source Project (AOSP), this technical explainer discusses the motivation behind On-Device Personalization (ODP), the design principles that guide its development, its privacy via confidentiality model, and how it helps to ensure a verifiably private experience.
We plan to achieve this by simplifying the data access model and making certain that all user data which leaves the security boundary is differentially private at a per- (user, adopter, model_instance) level (sometimes shortened to user-level in this document).
All code related to potential end user data egress from the end users' devices will be open source and verifiable by external entities. In the early stages of our proposal, we seek to generate interest and gather feedback for a platform that facilitates On-Device Personalization opportunities. We invite stakeholders such as privacy experts, data analysts, and security practitioners to engage with us.
Vision
On-Device Personalization is designed to protect end users' information from businesses with whom they have not interacted. Businesses may continue to customize their products and services for end users (for example using appropriately anonymized and differentially private machine learning models), but they won't be able to see the exact customizations made for an end user (that depends not only on the customization rule generated by the business owner, but also on the individual end user preference) unless there are direct interactions between the business and the end user. If a business produces any machine learning models or statistical analyses, ODP will seek to ensure that they are properly anonymized using the appropriate Differential Privacy mechanisms.
Our current plan is to explore ODP in multiple milestones, covering the following features and functionalities. We also invite interested parties to constructively suggest any additional features or workflows to further this exploration:
- A sandboxed environment wherein all business logic is contained and executed, permitting a multitude of end user signals to enter the sandbox while limiting outputs.
End-to-end encrypted data stores for:
- User controls, and other user related data. This could be end user-provided or gathered and inferred by businesses, along with time to live (TTL) controls, wipe out policies, privacy policies, and more.
- Business configurations. ODP provides algorithms to compress or obfuscate these data.
- Business processing results. These results can be:
- Consumed as inputs in later rounds of processing,
- Noised per appropriate Differential Privacy mechanisms and uploaded to qualifying endpoints.
- Uploaded using the trusted uploading flow to Trusted Execution Environments (TEE) running Open Sourced workloads with appropriate central Differential Privacy mechanisms
- Shown to end users.
APIs designed to:
- Update 2(a), batch or incrementally.
- Update 2(b) periodically, either batch or incrementally.
- Upload 2(c), with appropriate noising mechanisms in trusted aggregation environments. Such results may become 2(b) for the next processing rounds.
Design principles
There are three pillars ODP seeks to balance: privacy, fairness, and utility.
Towered data model for enhanced privacy protection
ODP follows Privacy by Design, and is designed with the protection of end user privacy as the default.
ODP explores moving personalization processing to an end user's device. This approach balances privacy and utility by keeping data on the device as much as possible and only processing it outside of the device when necessary. ODP focuses on:
- Device control of end user data, even when it leaves the device. Destinations have to be attested Trusted Execution Environments offered by public cloud providers running ODP authored code.
- Device verifiability of what happens to the end user data if it leaves the device. ODP provides Open Source, Federated Compute workloads to coordinate cross-device machine learning and statistical analysis for its adopters. An end user's device will attest that such workloads are executed in Trusted Execution Environments unmodified.
- Guaranteed technical privacy (for example, aggregation, noise, Differential Privacy) of outputs that leave the device-controlled/verifiable boundary.
Consequently, personalization will be device-specific.
Moreover, businesses also require privacy measures, which the platform should address. This entails maintaining raw business data in their respective servers. To achieve this, ODP adopts the following data model:
- Each raw data source will be stored either on the device or server-side, enabling local learning and inference.
- We will supply algorithms to facilitate decision-making across multiple data sources, such as filtering between two disparate data locations or training or inference across various sources.
In this context, there could be a business tower and an end-user tower:
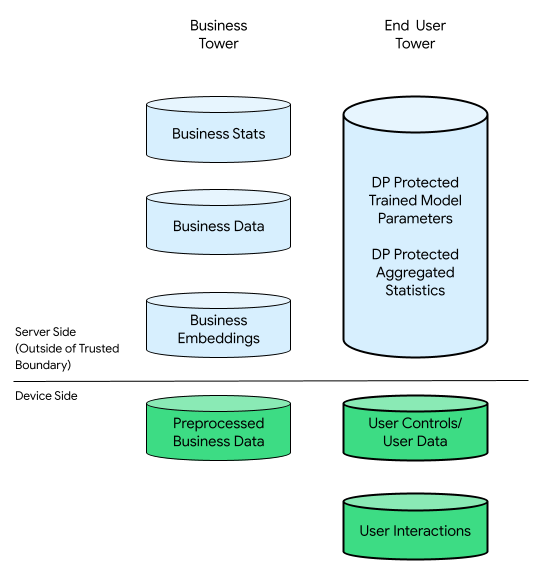
The end-user tower consists of data provided by the end-user (for example, account information and controls), collected data related to an end user's interactions with their device, and derivative data (for example, interests and preferences) inferred by the business. Inferred data does not overwrite any user's direct declarations.
For comparison, in a cloud-centric infrastructure, all raw data from the end-user tower is transferred to the businesses' servers. Conversely, in a device-centric infrastructure, all raw data from the end-user tower remains at its origin, while the business's data remains stored on servers.
On-Device Personalization combines the best of both worlds by only enabling attested, open sourced code to process data that has any potential to relate to end users in TEEs using more private output channels.
Inclusive public engagement for equitable solutions
ODP aims to ensure a balanced environment for all participants within a diverse ecosystem. We recognize the intricacy of this ecosystem, which consists of various players offering distinct services and products.
To inspire innovation, ODP offers APIs that can be implemented by developers and the businesses they represent. On-Device personalization facilitates seamless integration of these implementations while managing releases, monitoring, developer tools, and feedback tools. On-Device Personalization does not create any concrete business logic; rather, it serves as a catalyst for creativity.
ODP could offer more algorithms over time. Collaboration with the ecosystem is essential in determining the right level of features and potentially establishing a reasonable device resource cap for each participating business. We anticipate feedback from the ecosystem to help us recognize and prioritize new use cases.
Developer utility for improved user experiences
With ODP there's no loss of event data or observation delays, as all events are recorded locally at the device level. There are no joining errors and all events are associated with a specific device. As a result, all observed events naturally form a chronological sequence reflecting the user's interactions.
This simplified process eliminates the need for joining or rearranging data, allowing for near real-time and non-lossy user data accessibility. In turn, this may enhance the utility that end users perceive when engaging with data-driven products and services, potentially leading to higher satisfaction levels and more meaningful experiences. With ODP, businesses can effectively adapt to their users' needs.
The privacy model: privacy via confidentiality
The following sections discuss the consumer-producer model as the basis of this privacy analysis, and computation environment privacy versus output accuracy.
Consumer-producer model as the basis of this privacy analysis
We'll employ the consumer-producer model to examine the privacy assurances of privacy via confidentiality. Computations in this model are represented as nodes within a Directed Acyclic Graph (DAG) that consists of nodes and subgraphs. Each computation node has three components: inputs consumed, outputs produced, and computation mapping inputs to outputs.

In this model, privacy protection applies to all three components:
- Input privacy. Nodes can have two types of inputs. If an input is generated by a predecessor node, it already has the output privacy guarantees of that predecessor. Otherwise, inputs must clear data ingress policies using the policy engine.
- Output privacy. The output may need to be privatized, such as that provided by Differential Privacy (DP).
- Computation environment confidentiality. Computation must occur in a
securely sealed environment, ensuring that no one has access to
intermediary states within a node. Technologies that enable this include
Federated Computations (FC), hardware-based Trusted Execution Environments
(TEE), secure Multi-Party Computation (sMPC), homomorphic encryption (HPE),
and more. It's worth noting that privacy via confidentiality safeguards
intermediary states and all outputs egressing the confidentiality boundary
still need to be protected by Differential Privacy mechanisms. Two required
claims are:
- Environments confidentiality, ensuring only declared outputs leave the environment and
- Soundness, enabling accurate deductions of output privacy claims from input privacy claims. Soundness allows privacy property propagation down a DAG.
A private system maintains input privacy, computation environment confidentiality and output privacy. However, the number of applications of Differential Privacy mechanisms can be decreased by sealing more processing inside a confidential computation environment.
This model offers two main advantages. First, most systems, large and small, can be represented as a DAG. Second, DP's Post-Processing [Section 2.1] and composition Lemma 2.4 in The Complexity of Differential Privacy properties lend powerful tools to analyze the (worst-case) privacy and accuracy tradeoff for an entire graph:
- Post-Processing guarantees that once a quantity is privatized, it can't be "un-privatized," if the original data is not used again. As long as all inputs for a node are private, its output is private, regardless of its computations.
- Advanced Composition guarantees that if each graph part is DP, the overall graph is as well, effectively bounding the ε and δ of a graph's final output by approximately ε√κ, respectively, assuming a graph has κ units and each unit's output is (ε, δ)-DP.
These two properties translate into two design principles for each node:
- Property 1 (From Post-Processing) if a node's inputs are all DP, its output is DP, accommodating any arbitrary business logic executed in the node, and supporting businesses' "secret sauces."
- Property 2 (From Advanced Composition) if a node's inputs are not all DP, its output must be made DP compliant. If a computation node is one that runs on Trusted Execution Environments and is executing open sourced, On-Device Personalization-supplied workloads and configurations, then tighter DP bounds are possible. Otherwise, On-Device Personalization may need to use worst-case DP bounds. Due to resource constraints Trusted Execution Environments offered by a public cloud provider will be prioritized initially.
Computation environment privacy versus output accuracy
Henceforth, On-Device Personalization will focus on enhancing the security of confidential computation environments and ensuring that intermediate states remain inaccessible. This security process, known as sealing, will be applied at the subgraph level, allowing multiple nodes to be made DP compliant together. This means that property 1 and property 2 mentioned earlier apply at the subgraph level.

Of course the final graph output, Output 7, is DP'ed per composition. This means there will be 2 DP altogether for this graph; compared with 3 total (local) DP if no sealing was used.
Essentially, by securing the computation environment and eliminating opportunities for adversaries to access a graph or subgraph's inputs and intermediate states, this enables the implementation of Central DP (that is, the output of a sealed environment is DP compliant), which can improve accuracy compared with Local DP (that is, the individual inputs are DP compliant). This principle underlies the consideration of FC, TEEs, sMPCs, and HPEs as privacy technologies. Refer to Chapter 10 in The Complexity of Differential Privacy.
A good, practical example is model training and inference. Discussions below assume that (1), the training population and the inference population overlap, and (2), both features and labels constitute private user data. We can apply DP to all inputs:

On-Device Personalization can apply local DP to user labels and features before sending them to servers. This approach does not impose any requirements on the server's execution environment or its business logic.



This is the current On-Device Personalization design.
Verifiably private
On-Device Personalization aims to be verifiably private. It puts the focus on verifying what happens off the user devices. ODP will author the code that processes the data leaving end users' devices and will use NIST's RFC 9334 Remote ATtestation procedureS (RATS) Architecture to attest that such code is running unmodified in a Confidential Computing Consortium-compliant, instance admin de-privileged server. These codes will be open sourced and accessible for transparent verification to build trust. Such measures can give individuals confidence that their data is protected, and businesses can establish reputations based on a strong foundation of privacy assurance.
Reducing the amount of private data collected and stored is another critical aspect of On-Device Personalization. It adheres to this principle by adopting technologies like Federated Compute and Differential Privacy, enabling revelation of valuable data patterns without exposing sensitive individual details or identifiable information.
Maintaining an audit trail that logs activities related to data processing and sharing is another key aspect of verifiable privacy. This enables the creation of audit reports and identification of vulnerabilities, showcasing our commitment to privacy.
We ask for constructive collaborations from privacy experts, authorities, industries, and individuals to help us continuously improve the design and implementations.
The graph below shows the code path for cross-device aggregation and noising per Differential Privacy.
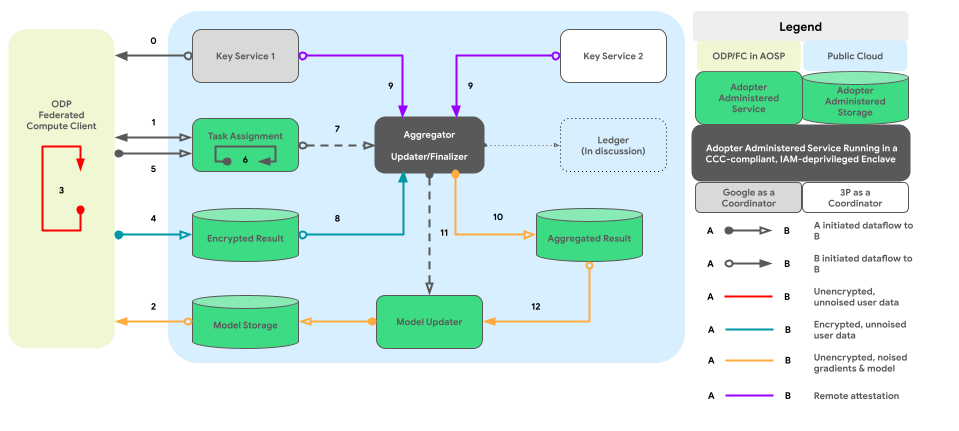
High-level design
How can privacy via confidentiality be implemented? At a high level, a policy engine authored by ODP that runs in a sealed environment serves as the core component overseeing each node/subgraph while tracking the DP status of their inputs and outputs:
- From the policy engine's perspective, devices and servers are treated the same. Devices and servers running the identical policy engine are considered logically identical, once their policy engines have been mutually attested.
- On devices, isolation is achieved through AOSP isolated processes (or pKVM in the long run once availability becomes high). On servers, the isolation relies on a "trusted party," which is either a TEE plus other technical sealing solutions that is preferred, a contractual agreement, or both.
In other words, all sealed environments installing and running the platform policy engine are considered part of our Trusted Computing Base (TCB). Data can propagate without additional noise with the TCB. DP needs to be applied when data leaves the TCB.
The high-level design of On-Device Personalization effectively integrates two essential elements:
- A paired-process architecture for business logic execution
- Policies and a policy engine for managing data Ingress, egress and permitted operations.
This cohesive design offers businesses a level playing field where they can run their proprietary code in a trusted execution environment, and access user data that has cleared appropriate policy checks.
The following sections will expand on these two key aspects.
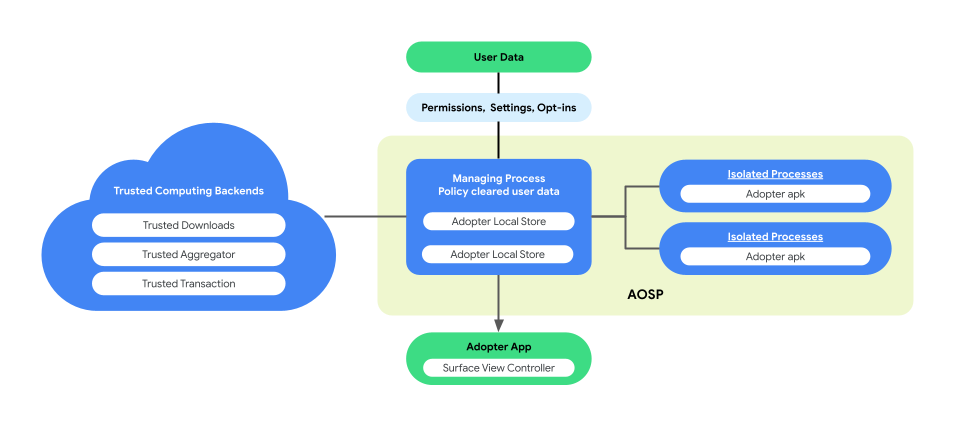
Paired-process architecture for business logic execution
On-Device Personalization introduces a paired-process architecture in AOSP to enhance user privacy and data security during business logic execution. This architecture consists of:
ManagingProcess. This process creates and manages IsolatedProcesses, ensuring they remain process-level isolated with access limited to allow-listed APIs and no network or disk permissions. The ManagingProcess handles the collection of all business data, all end user data and policy clear them for the business code, pushing them into the IsolatedProcesses for execution. In addition, it mediates the interaction between IsolatedProcesses and other processes, such as system_server.
IsolatedProcess. Designated as isolated (
isolatedprocess=truein the manifest), this process receives business data, policy-cleared end-user data, and business code from the ManagingProcess. They allow the business code to operate on its data and policy-cleared end-user data. The IsolatedProcess communicates exclusively with the ManagingProcess for both ingress and egress, with no additional permissions.
The paired-process architecture provides the opportunity for independent verification of end-user data privacy policies without requiring businesses to open-source their business logic or code. With the ManagingProcess maintaining the independence of IsolatedProcesses, and the IsolatedProcesses efficiently executing the business logic, this architecture ensures a more secure and efficient solution for preserving user privacy during personalization.
The following figure shows this paired process architecture.
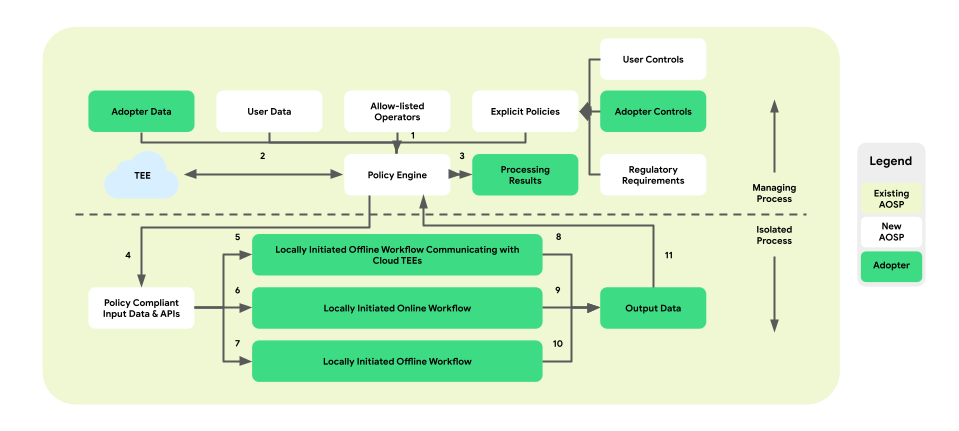
Policies and policy engines for data operations
On-Device Personalization introduces a policy enforcement layer between the platform and the business logic. The goal is to provide a set of tools that map end-user and business controls into centralized and actionable policy decisions. These policies are then comprehensively and reliably enforced across flows and businesses.
In the paired-process architecture, the policy engine resides within the ManagingProcess, overseeing ingress and egress of end-user and business data. It will also supply allow-listed operations to the IsolatedProcess. Sample coverage areas include end-user control honoring, child protection, prevention of unconsented data sharing, and business privacy.
This policy enforcement architecture comprises three types of workflows that can be leveraged:
- Locally initiated, offline workflows with Trusted Execution Environment
(TEE) communications:
- Data downloading flows: trusted downloads
- Data uploading flows: trusted transactions
- Locally initiated, online workflows:
- Real-time serving flows
- Inference flows
- Locally initiated, offline workflows:
- Optimization flows: on-device model training implemented via Federated Learning (FL)
- Reporting flows: cross-device aggregation implemented via Federated Analytics (FA)
The following figure shows the architecture from the perspective of policies and policy engines.
- Download: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- Serving: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- Optimization: 2 (provides training plan) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- Reporting: 3 (provides aggregation plan) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
Overall, the introduction of the policy enforcement layer and the policy engine within On-Device Personalization's paired-process architecture ensures an isolated and privacy-preserving environment for executing business logic while providing controlled access to necessary data and operations.
Layered API surfaces
On-Device Personalization provides a layered API architecture for interested businesses. The top layer consists of applications built for specific use cases. Potential businesses can connect their data to these applications, known as Top-Layer APIs. Top-layer APIs are built on the Mid-layer APIs.
Over time, we expect to add more Top-layer APIs. When a Top-layer API is not available for a particular use case, or when existing Top-layer APIs are not flexible enough, businesses can directly implement the Mid-Layer APIs, which provide power and flexibility through programming primitives.
Conclusion
On-Device Personalization is an early stage research proposal to solicit interest and feedback on a long-term solution that addresses end user privacy concerns with the latest and best technologies that are expected to bring high utility.
We'd like to engage with stakeholders such as privacy experts, data analysts, and potential end users to ensure that ODP meets their needs and addresses their concerns.