予測モデルか予測モデルのいずれかを使用して ML や生成 AI のアプローチを採用している場合、問題を ML の用語で組み立てることができます。 次のタスクを実行して、問題を ML の観点で捉えます。
- 理想的な結果とモデルの目標を定義します。
- モデルの出力を特定する。
- 成功指標を定義する。
理想的な結果とモデルの目標を定義する
ML モデルに関係なく、理想的な結果は何ですか。つまり、 どのようなタスクに同じ 目標を定めるで定義したステートメントを 。
行うべきことを明示的に定義することで、モデルの目標を理想的な結果に結び付ける 指示を与えます。次の表に、理想的な結果と、 モデルの目標は次のとおりです。
| アプリ | 理想的な結果 | モデルの目標 |
|---|---|---|
| 天気アプリ | 地域の降水量を 6 時間単位で計算します。 | 特定の地域の 6 時間の降水量を予測する。 |
| ファッション アプリ | さまざまなデザインのシャツを生成します。 | テキストと画像から、3 種類のシャツのデザインを生成します。 テキストはスタイルと色を示し、画像は シャツ(T シャツ、ボタンアップ、ポロ)。 |
| 動画アプリ | 役に立つ動画をおすすめする。 | ユーザーが動画をクリックするかどうかを予測します。 |
| メールアプリ | スパムを検出する。 | メールが迷惑メールであるかどうかを予測します。 |
| 金融アプリ | 複数のニュース提供元の財務情報を要約します。 | 分析の結果に基づいて、主要な金融動向を 50 語の要約で生成 確認できます |
| 地図アプリ | 移動時間を計算します。 | 2 点間の移動にかかる時間を予測する。 |
| バンキング アプリ | 不正な取引を特定する。 | カード所有者によって取引が行われたかどうかを予測します。 |
| ダイニング アプリ | レストランのメニューで料理を識別する。 | レストランのタイプを予測します。 |
| e コマースアプリ | 会社の製品に関するカスタマー サポートの返信を生成する。 | 感情分析と組織の質問文を使用して、返信を生成する 説明します。 |
必要な出力を特定する
どのモデルタイプを選択するかは、インフラストラクチャの具体的なコンテキストと制約によって 困難です。モデルの出力は、 予測します。したがって、最初に回答する質問は、 「問題を解決するためにどのようなアウトプットが必要か?」
何かを分類したり、数値の予測を行ったりする必要がある場合は、 予測 ML を使用します。新しいコンテンツを生成したり、出力を生成したりする必要がある場合 生成 AI を使用するでしょう。
次の表に、予測 ML と生成 AI の出力を示します。
| ML システム | 出力例 | |
|---|---|---|
| 分類 | バイナリ | メールを迷惑メールまたは迷惑メール以外に分類。 |
| マルチクラスの単一ラベル | 画像内の動物を分類します。 | |
| マルチクラス マルチラベル | 画像内のすべての動物を分類します。 | |
| 数値 | 一次元回帰 | 動画の視聴回数を予測します。 |
| 多次元回帰 | 血圧、心拍数、コレステロール値を予測し、 できます。 |
| モデルタイプ | 出力例 |
|---|---|
| テキスト |
記事を要約します。 ユーザーのクチコミに返信する。 ドキュメントを英語から標準中国語に翻訳します。 商品の説明を作成します。 法的文書を分析する。
|
| 画像 |
マーケティング画像を作成する。 写真に視覚効果を適用できます。 製品デザインのバリエーションを生成する。
|
| オーディオ |
特定のアクセントで会話を生成します。
特定のジャンルの短い楽曲を生成します。たとえば、
ジャズ。
|
| 動画 |
リアルな動画を生成できます。
動画映像を分析し、視覚効果を適用する。
|
| マルチモーダル | テキスト キャプション付きの動画など、複数の種類の出力を生成する。 |
分類
分類モデル 入力データが属するカテゴリを予測します。たとえば、入力データが A、B、C のいずれかに分類します
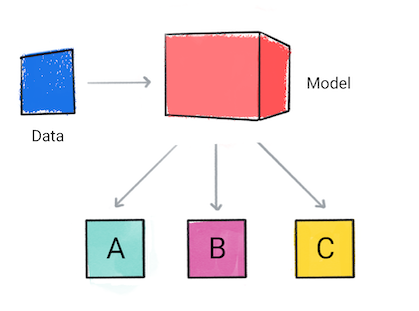
図 1. 予測を行う分類モデル。
アプリは、モデルの予測に基づいて決定を下すことがあります。たとえば 予測がカテゴリ A ならば X を行う。予測がカテゴリ B の場合 do、Y、予測がカテゴリ C の場合は Z を行います。場合によっては 予測は がアプリの出力です。
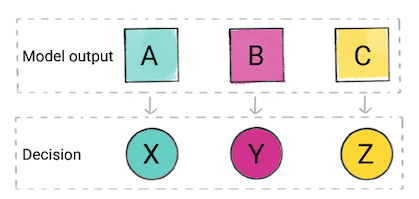
図 2. 分類モデルの出力を製品コード内で使用して、 決定を下します。
回帰
回帰モデルは、 数値を返します
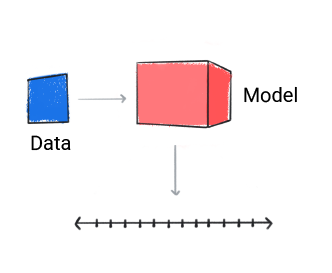
図 3. 数値予測を行う回帰モデル。
アプリは、モデルの予測に基づいて決定を下すことがあります。たとえば 予測が範囲 A 内にあり、X を行う。予測が範囲内にある場合 B、Y を行います。予測が範囲 C に該当する場合は、Z を行います。場合によって、 アプリの出力です。
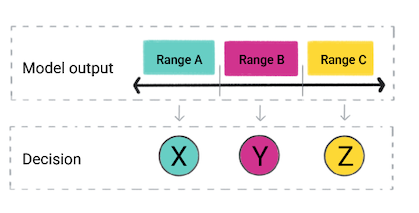
図 4. 回帰モデルの出力を製品コードで使用して します。
次のシナリオを考えてみます。
キャッシュに保存する 動画が表示されます。言い換えると、モデルがトレーニング 動画の人気が出ると予測した場合、すぐにユーザーに配信する必要がある。宛先 より効果的でコストのかかるキャッシュを使用します。その他の動画については 別のキャッシュを使用しますキャッシュ保存の条件は次のとおりです。
- 動画の視聴回数が 50 回以上になると予測された場合、 作成します。
- 動画の視聴回数が 30 ~ 50 回になると予測される場合は、低価格の 作成します。
- 視聴回数が 30 回未満と予測される場合、 動画をご覧ください。
あなたは、予測を行うので、回帰モデルが正しいアプローチだと考えます。 数値(表示回数)です。ただし、回帰をトレーニングするときは、 モデルに対して、同じ内容の 28 と 32 の予測の loss 視聴回数が 30 回の動画を対象に指定できます。言い換えれば、アプリの開発にかなりの時間を要しても、 では、予測が 28 と 32 の場合は、両方の 同等です
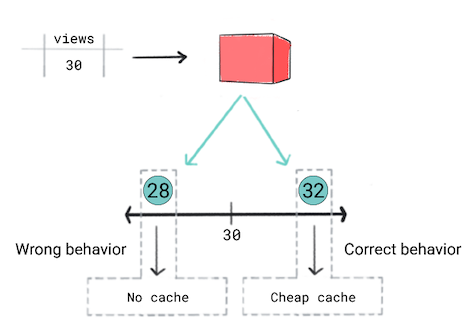
図 5. 回帰モデルをトレーニングする。
回帰モデルでは、プロダクトで定義されたしきい値が認識されません。そのため、 アプリケーションのわずかな違いによって、動作が 使用する場合は、事前トレーニング済み回帰モデルの 使用します。
このシナリオでは、分類モデルによって正しい動作が生成されます 分類モデルでは 32 よりも 28 です。ある意味、分類モデルはデフォルトでしきい値を生成します。
このシナリオでは、2 つの重要なポイントを強調しています。
決定を予測します。可能であれば、アプリが実行する決定を 要点をまとめますこの動画の例では、分類モデルによって 分類したカテゴリが「キャッシュなし」の場合、"格安 あります。「高価なキャッシュ」などですアプリの動作をモデルから隠すことで、 アプリが誤った動作を起こす原因になります
問題の制約を理解する。アプリの依存関係が 基づいて、それらのしきい値が 固定または動的のいずれかです
- 動的しきい値: しきい値が動的な場合は、回帰モデルを使用する しきい値の制限もアプリのコードで設定します。これにより、 モデルの妥当性を保ちながらしきい値を更新する 説明します。
- 固定しきい値: しきい値が固定されている場合は、分類モデルを使用する しきい値制限に基づいてデータセットにラベル付けします
一般に、ほとんどのキャッシュのプロビジョニングは動的であり、しきい値は変化します。 学習します。これは明らかにキャッシュの問題であるため、 回帰モデルが最適な選択ですただし 多くの問題では 決定されるため、分類モデルが最適なソリューションになります。
別の例を見てみましょう。作成する天気アプリには、
今後 6 時間の降水量をユーザーに知らせるのが理想的です
ラベル precipitation_amount. を予測する回帰モデルを使用できます。
| 理想的な結果 | 理想的なラベル |
|---|---|
| お住まいの地域の降水量をユーザーに伝えましょう わかります | precipitation_amount
|
天気情報アプリの例では、ラベルが理想的な結果に直接対処しています。
ただし、場合によっては、両者の間に 1 対 1 の関係が
ラベルが生成されます。たとえば、動画アプリでは、
役立つ動画をおすすめしています。ただし、このデータセットには「
useful_to_user.
| 理想的な結果 | 理想的なラベル |
|---|---|
| 役に立つ動画をおすすめする。 | ? |
そのため、プロキシラベルを見つける必要があります。
プロキシラベル
プロキシラベル:
データセットに含まれないラベルだけを抽出できます。プロキシラベルは、
予測対象を直接測定できます動画アプリでは、
ユーザーがその動画が役に立つかどうかを測定する。もし、
データセットに useful 特徴があり、ユーザーが見つけたすべての動画をマークした
ただし、このデータセットには含まれていないため、Google Cloud の
有用性の代わりになるからです。
有用性を表すプロキシラベルは、ユーザーが共有または高評価するかどうかです。 できます。
| 理想的な結果 | プロキシラベル |
|---|---|
| 役に立つ動画をおすすめする。 | shared OR liked |
プロキシラベルは必要なデータを直接測定できないため、慎重に使用する 生成します。たとえば、次の表は潜在的な問題の概要を示しています。 有益な動画をおすすめするのプロキシラベル:
| プロキシラベル | 問題 |
|---|---|
| ユーザーが「高評価」をクリックするかどうかを予測します] ボタンを離します。 | ほとんどのユーザーは「高評価」をクリックしません。 |
| 動画の人気が出るかどうかを予測する。 | パーソナライズされていません。人気の動画は好みでないユーザーもいます。 |
| ユーザーが動画を共有するかどうかを予測します。 | 動画を共有しないユーザーもいます。動画を共有する理由 好まれないことを示します。 |
| ユーザーが再生をクリックするかどうかを予測します。 | クリックベイトを最大化する。 |
| 視聴者が動画を視聴する時間を予測します。 | 短い動画よりも長い動画を差分で優先します。 |
| ユーザーが動画を再視聴する回数を予測します。 | 「再視聴したくなる」動画を好みます。再視聴できない動画ジャンルで視聴できない動画の割合。 |
プロキシラベルは、理想的な結果を完全に置き換えることはできません。すべての人は 潜在的な問題がありますテスト環境で問題が最も少ないものを選んで 構築できます
理解度をチェックする
生成
ほとんどの場合、独自の生成モデルのトレーニングは行いません。これは、独自の生成モデルを 膨大なトレーニング データと計算リソースが必要です。代わりに 事前トレーニング済みの生成モデルをカスタマイズします。生成モデルを取得して、 必要な出力を生成するには、次のいずれか 1 つ以上を使用する必要があります。 手法:
抽出。新しい P-MAX キャンペーンを 大規模なモデルの小さいバージョンを 1 つ作成し、 使用するモデルを比較します生成 モデルは通常、巨大で、相当なリソース(メモリや 。抽出を使用すると、より小規模でリソース消費量が抑えられる 大規模なモデルの性能を近似できます。
ファインチューニングまたは パラメータ効率チューニング。 特定のタスクに対するモデルのパフォーマンスを改善するには、 トレーニングする出力タイプの例を含むデータセットでモデルをトレーニングする。 指定します。
プロンプト エンジニアリング。宛先 モデルに特定のタスクを実行させるか、 特定の形式で出力を生成する場合、 出力の形式を指定するかの説明になります。つまり、 プロンプトにタスクの実行方法を自然言語で指示できる 出力の例を示しています。
たとえば、記事を短く要約したい場合は、 次のとおりです。
Produce 100-word summaries for each article.モデルに特定の読解レベルのテキストを生成させたい場合は、 次のように入力します。
All the output should be at a reading level for a 12-year-old.モデルから特定の形式で出力を生成したい場合は、 出力の形式を指定します(例: 「 するか、タスクのデモを行うこともできます。 例を与えてあげる。たとえば、次のように入力します。
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
抽出とファインチューニングにより、モデルの パラメータ。プロンプト エンジニアリング モデルのパラメータは更新されませんその代わり、プロンプト エンジニアリングは、 プロンプトのコンテキストから目的の出力を生成する方法を学習する。
場合によっては テスト データセットを使用して、 生成モデルの出力を既知の値と比較します。たとえば、 モデルの要約は人間が生成した要約と モデルの要約の品質を評価します
生成 AI を使用して予測 ML を実装することもできます。 分類や回帰のようなものです たとえば、自然言語に対する深い知識から、 大規模言語モデル(LLM) 予測 ML よりも優れたテキスト分類タスクが頻繁に実行される 特定のタスク向けにトレーニングできます。
成功指標を定義する
ML が実装されているかどうかを判断するために使用する指標を定義する 成功です。成功指標では、エンゲージメントや 表示される動画の視聴など、ユーザーが適切な行動を取れるようにする 便利です。成功指標はモデルの評価指標とは異なります accuracy、 precision、 再現率 AUC。
たとえば、天気アプリの成功と失敗の指標は次のように定義できます。 次のとおりです。
| 成功 | ユーザーは [雨の降る?]50% 高い確率で 大幅に向上しました |
|---|---|
| 失敗 | ユーザーは [雨の降る?]最大 100 個 おすすめします |
動画アプリの指標は、次のように定義されます。
| 成功 | ユーザーのサイト滞在時間は平均 20% 長くなっています。 |
|---|---|
| 失敗 | ユーザーがサイトに時間を費やす時間は平均で以前より減っています。 |
意欲的な成功指標を定義することをおすすめします。野心的な願望はギャップを引き起こす可能性がある 成功か失敗かは関係ありませんたとえば平均して 24 時間 365 日という サイト滞在時間が以前と比べて 10% 増加したのは成功でも失敗でもない。 定義されていないギャップは重要ではありません。
重要なのは、モデルが近づく能力、つまり 成功の定義です。たとえば、モデルの予測結果を 次の質問を考えてみましょう。モデルを改善しても 達成基準にどれだけ近いかたとえば、予測された単語が 成功基準に近づくことはありません。 たとえ完璧なモデルであっても 定義します。一方、モデルの評価指標は低いものの、 成功基準に近づきます。つまり、モデルを改善することで、 成功に近づきます
モデルに価値があるかどうかを判断する際に考慮すべき要素 改善:
不十分だが、続行する。このモデルは、 時間の経過とともに大幅に改善される可能性があります。
十分に理解して続行:このモデルは、本番環境での 改善の余地があります。
これで十分だが、これ以上改善できない。モデルが本番環境にある 考えてみましょう
不十分で、今後もそうならないでしょう。このモデルは、 トレーニングを一切行わずに済むようになります
モデルの改善を決定する際には、リソースの増加、 たとえばエンジニアリング時間やコンピューティング費用など 行います。
成功と失敗の指標を定義したら、次は成功と失敗の 測定しますたとえば 6 つのステップで成功指標を測定できます。 システム導入後 数日、6 週間、6 か月のいずれかです。
失敗の指標を分析する際は、システムが失敗した理由を特定しようとします。対象 モデルはユーザーがクリックする動画を予測しますが クリックベイト タイトルが推奨され始めると、 減少します天気情報アプリの例では、モデルは正確な予測を 雨が降るでしょうが、地域が大きすぎます。
理解度をチェックする
ファッション会社が、洋服の売り上げを伸ばしたいと考えています。ML を使用して どの服を製造するかを決めます彼らは、 ファッションの種類を判断するためにモデルをトレーニングします。変更後 モデルをトレーニングしたら、それをカタログに適用し、 考えています
この問題を ML の用語でどのように組み立てればよいでしょうか。
理想的な結果: 製造する製品を決定します。
モデルの目標: どの衣服が含まれるかを予測します。 考えています
モデル出力: バイナリ分類、in_fashion
not_in_fashion
成功指標: 洋服の 70% 以上を販売する できます。
理想的な結果: 注文する生地と備品の量を決定します。
モデルの目標: 製造する各商品の数量を予測します。
モデル出力: バイナリ分類、make
do_not_make
成功指標: 洋服の 70% 以上を販売する できます。