پس از تأیید اینکه مشکل شما با استفاده از یک رویکرد ML پیشبینیکننده یا یک رویکرد هوش مصنوعی مولد به بهترین شکل حل میشود، آماده هستید تا مشکل خود را در قالب ML چارچوببندی کنید. شما با انجام وظایف زیر یک مشکل را در قالب ML قاب بندی می کنید:
- نتیجه ایده آل و هدف مدل را تعریف کنید.
- خروجی مدل را شناسایی کنید.
- معیارهای موفقیت را تعریف کنید.
نتیجه ایده آل و هدف مدل را تعریف کنید
مستقل از مدل ML، نتیجه ایده آل چیست؟ به عبارت دیگر، دقیقاً وظیفه ای که می خواهید محصول یا ویژگی شما انجام دهد چیست؟ این همان عبارتی است که قبلاً در قسمت State the goal تعریف کردید.
با تعریف صریح آنچه می خواهید مدل انجام دهد، هدف مدل را به نتیجه ایده آل متصل کنید. جدول زیر نتایج ایده آل و هدف مدل را برای برنامه های فرضی بیان می کند:
| برنامه | نتیجه ایده آل | هدف مدل |
|---|---|---|
| اپلیکیشن آب و هوا | بارش را با افزایش شش ساعته برای یک منطقه جغرافیایی محاسبه کنید. | پیش بینی میزان بارش شش ساعته برای مناطق جغرافیایی خاص. |
| اپلیکیشن مد | ایجاد انواع طرح های پیراهن. | سه نوع طرح پیراهن را از متن و تصویر ایجاد کنید، که در آن متن سبک و رنگ و تصویر نوع پیراهن (تیشرت، دکمهدار، پولو) را بیان میکند. |
| برنامه ویدیویی | ویدیوهای مفید را توصیه کنید. | پیش بینی کنید که آیا کاربر روی یک ویدیو کلیک می کند یا خیر. |
| برنامه ایمیل | شناسایی هرزنامه | پیش بینی کنید که آیا ایمیل هرزنامه است یا خیر. |
| اپلیکیشن مالی | خلاصه اطلاعات مالی از چندین منبع خبری. | خلاصه 50 کلمه ای از روندهای مالی اصلی هفت روز گذشته ایجاد کنید. |
| برنامه نقشه | محاسبه زمان سفر | پیش بینی کنید که چقدر طول می کشد تا بین دو نقطه سفر کنید. |
| اپلیکیشن بانکی | تراکنش های تقلبی را شناسایی کنید. | پیش بینی کنید که آیا معامله ای توسط دارنده کارت انجام شده است. |
| برنامه غذاخوری | آشپزی را با منوی رستوران شناسایی کنید. | نوع رستوران را پیش بینی کنید. |
| اپلیکیشن تجارت الکترونیک | پاسخ های پشتیبانی مشتری در مورد محصولات شرکت ایجاد کنید. | پاسخها را با استفاده از تحلیل احساسات و پایگاه دانش سازمان ایجاد کنید. |
خروجی مورد نیاز خود را شناسایی کنید
انتخاب نوع مدل شما به زمینه و محدودیت های مشکل شما بستگی دارد. خروجی مدل باید وظیفه تعریف شده در نتیجه ایده آل را انجام دهد. بنابراین، اولین سوالی که باید پاسخ داد این است که "برای حل مشکلم به چه نوع خروجی نیاز دارم؟"
اگر نیاز دارید چیزی را طبقه بندی کنید یا یک پیش بینی عددی انجام دهید، احتمالاً از ML پیش بینی کننده استفاده خواهید کرد. اگر نیاز به تولید محتوای جدید یا تولید خروجی مرتبط با درک زبان طبیعی دارید، احتمالاً از هوش مصنوعی مولد استفاده خواهید کرد.
جداول زیر خروجی های ML پیش بینی و هوش مصنوعی مولد را فهرست می کنند:
| سیستم ML | خروجی نمونه | |
|---|---|---|
| طبقه بندی | باینری | ایمیل را به عنوان هرزنامه یا غیر هرزنامه طبقه بندی کنید. |
| چند کلاسه تک برچسب | یک حیوان را در یک تصویر طبقه بندی کنید. | |
| چند کلاسه چند برچسبی | همه حیوانات را در یک تصویر طبقه بندی کنید. | |
| عددی | رگرسیون یک بعدی | تعداد بازدیدهای یک ویدیو را پیش بینی کنید. |
| رگرسیون چند بعدی | فشار خون، ضربان قلب و سطح کلسترول را برای یک فرد پیش بینی کنید. |
| نوع مدل | خروجی نمونه |
|---|---|
| متن | یک مقاله را خلاصه کنید به نظرات مشتریان پاسخ دهید. اسناد را از انگلیسی به ماندارین ترجمه کنید. توضیحات محصول را بنویسید اسناد قانونی را تجزیه و تحلیل کنید. |
| تصویر | تولید تصاویر بازاریابی اعمال جلوه های بصری بر روی عکس ها ایجاد تنوع در طراحی محصول |
| صوتی | دیالوگ را با لهجه خاصی ایجاد کنید. یک آهنگ کوتاه موسیقی در یک ژانر خاص مانند جاز ایجاد کنید. |
| ویدیو | ویدیوهایی با ظاهر واقعی ایجاد کنید. فیلم های ویدئویی را تجزیه و تحلیل کنید و جلوه های بصری را اعمال کنید. |
| چند وجهی | چندین نوع خروجی تولید کنید، مانند یک ویدیو با شرح متن. |
طبقه بندی
یک مدل طبقهبندی پیشبینی میکند که دادههای ورودی به چه دستهای تعلق دارند، برای مثال، آیا ورودی باید بهعنوان A، B یا C طبقهبندی شود.
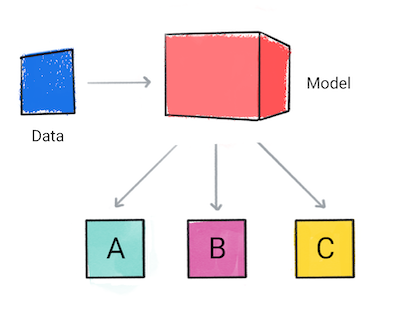
شکل 1. یک مدل طبقه بندی که پیش بینی می کند.
بر اساس پیشبینی مدل، برنامه شما ممکن است تصمیم بگیرد. برای مثال، اگر پیشبینی رده A است، X را انجام دهید. اگر پیش بینی رده B است، انجام دهید، Y; اگر پیشبینی رده C است، Z را انجام دهید. در برخی موارد، پیشبینی خروجی برنامه است .
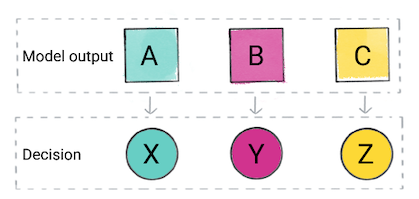
شکل 2. خروجی مدل طبقه بندی که در کد محصول برای تصمیم گیری استفاده می شود.
رگرسیون
یک مدل رگرسیون یک مقدار عددی را پیش بینی می کند.
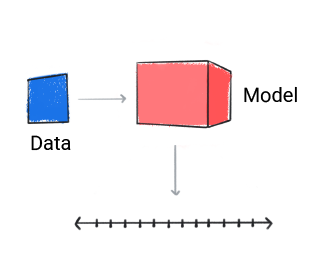
شکل 3. یک مدل رگرسیون که یک پیش بینی عددی را انجام می دهد.
بر اساس پیشبینی مدل، برنامه شما ممکن است تصمیم بگیرد. برای مثال، اگر پیشبینی در محدوده A قرار میگیرد، X را انجام دهید. اگر پیش بینی در محدوده B قرار گرفت، Y را انجام دهید. اگر پیشبینی در محدوده C قرار گرفت، Z را انجام دهید. در برخی موارد، پیشبینی خروجی برنامه است .
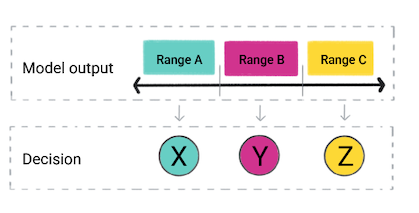
شکل 4. خروجی یک مدل رگرسیون در کد محصول برای تصمیم گیری استفاده می شود.
سناریوی زیر را در نظر بگیرید:
میخواهید ویدیوها را بر اساس محبوبیت پیشبینیشدهشان در حافظه پنهان ذخیره کنید . به عبارت دیگر، اگر مدل شما پیشبینی میکند که ویدیویی محبوب خواهد بود، میخواهید آن را به سرعت به کاربران ارائه دهید. برای انجام این کار، از کش موثرتر و گرانتر استفاده میکنید. برای ویدیوهای دیگر، از حافظه پنهان دیگری استفاده خواهید کرد. معیارهای ذخیره شما به شرح زیر است:
- اگر پیشبینی میشود که ویدیویی ۵۰ بازدید یا بیشتر داشته باشد، از کش گران قیمت استفاده خواهید کرد.
- اگر پیش بینی می شود که یک ویدیو بین 30 تا 50 بازدید داشته باشد، از حافظه پنهان ارزان قیمت استفاده خواهید کرد.
- اگر پیشبینی میشود ویدیو کمتر از 30 بازدید داشته باشد، ویدیو را در حافظه پنهان ذخیره نمیکنید.
شما فکر می کنید یک مدل رگرسیون رویکرد درستی است زیرا یک مقدار عددی - تعداد بازدیدها را پیش بینی می کنید. با این حال، هنگام آموزش مدل رگرسیون، متوجه میشوید که برای ویدیوهایی که 30 بازدید دارند، همان ضرر را برای پیشبینی 28 و 32 ایجاد میکند. به عبارت دیگر، اگرچه اگر پیشبینی 28 در مقابل 32 باشد، برنامه شما رفتار بسیار متفاوتی خواهد داشت، مدل هر دو پیشبینی را به یک اندازه خوب در نظر میگیرد.
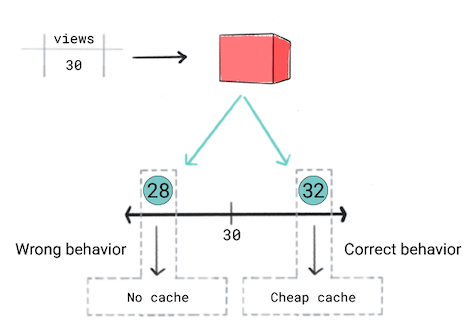
شکل 5. آموزش یک مدل رگرسیون.
مدل های رگرسیون از آستانه های تعریف شده توسط محصول بی اطلاع هستند. بنابراین، اگر رفتار برنامه شما بهدلیل تفاوتهای کوچک در پیشبینیهای مدل رگرسیون بهطور قابلتوجهی تغییر میکند، باید به جای آن یک مدل طبقهبندی را پیادهسازی کنید.
در این سناریو، یک مدل طبقهبندی رفتار صحیحی را ایجاد میکند، زیرا یک مدل طبقهبندی برای پیشبینی 28 از 32 ضرر بیشتری ایجاد میکند. به یک معنا، مدلهای طبقهبندی به طور پیشفرض آستانه تولید میکنند.
این سناریو دو نکته مهم را برجسته می کند:
تصمیم را پیش بینی کنید . در صورت امکان، تصمیمی که برنامه شما خواهد گرفت را پیش بینی کنید. در مثال ویدیویی، یک مدل طبقهبندی تصمیم را پیشبینی میکند که دستههایی که ویدیوها را در آنها طبقهبندی میکند «بدون کش»، «حافظه پنهان ارزان» و «حافظه پنهان گران قیمت» باشند. پنهان کردن رفتار برنامه شما از مدل می تواند باعث شود برنامه شما رفتار اشتباهی ایجاد کند.
محدودیت های مشکل را درک کنید . اگر برنامه شما بر اساس آستانه های مختلف اقدامات متفاوتی انجام می دهد، مشخص کنید که آیا این آستانه ها ثابت هستند یا پویا.
- آستانه های پویا: اگر آستانه ها پویا هستند، از مدل رگرسیون استفاده کنید و محدودیت های آستانه را در کد برنامه خود تنظیم کنید. این به شما امکان میدهد به راحتی آستانهها را بهروزرسانی کنید، در حالی که مدل همچنان پیشبینیهای معقولی را انجام میدهد.
- آستانه های ثابت: اگر آستانه ها ثابت هستند، از یک مدل طبقه بندی استفاده کنید و مجموعه داده های خود را بر اساس محدودیت های آستانه برچسب گذاری کنید.
به طور کلی، بیشتر تأمین حافظه پنهان پویا است و آستانه ها در طول زمان تغییر می کنند. بنابراین، از آنجا که این به طور خاص یک مشکل حافظه پنهان است، مدل رگرسیون بهترین انتخاب است. با این حال، برای بسیاری از مشکلات، آستانه ها ثابت خواهند شد و یک مدل طبقه بندی بهترین راه حل است.
بیایید به مثال دیگری نگاهی بیندازیم. اگر در حال ساختن یک برنامه هواشناسی هستید که نتیجه ایدهآل آن این است که به کاربران بگویید در شش ساعت آینده چقدر باران خواهد بارید، میتوانید از یک مدل رگرسیونی استفاده کنید که برچسب precipitation_amount.
| نتیجه ایده آل | برچسب ایده آل |
|---|---|
| به کاربران بگویید در شش ساعت آینده چقدر باران در منطقه آنها خواهد بارید. | precipitation_amount |
در مثال برنامه آب و هوا، برچسب مستقیماً به نتیجه ایده آل می پردازد. با این حال، در برخی موارد، یک رابطه یک به یک بین نتیجه ایده آل و برچسب مشخص نیست. به عنوان مثال، در برنامه ویدیویی، نتیجه ایده آل توصیه ویدیوهای مفید است. با این حال، هیچ برچسبی در مجموعه داده به نام useful_to_user.
| نتیجه ایده آل | برچسب ایده آل |
|---|---|
| ویدیوهای مفید را توصیه کنید. | ? |
بنابراین، شما باید یک برچسب پروکسی پیدا کنید.
برچسب های پروکسی
برچسبهای پراکسی جایگزین برچسبهایی میشوند که در مجموعه داده نیستند. وقتی نمیتوانید مستقیماً آنچه را که میخواهید پیشبینی کنید اندازهگیری کنید، برچسبهای پروکسی ضروری هستند. در اپلیکیشن ویدیو، نمیتوانیم مستقیماً اندازهگیری کنیم که آیا کاربر یک ویدیو را مفید میبیند یا خیر. اگر مجموعه داده دارای یک ویژگی useful باشد، و کاربران همه ویدیوهایی را که مفید میدانند علامتگذاری کنند، بسیار عالی خواهد بود، اما چون مجموعه داده اینطور نیست، به یک برچسب پراکسی نیاز داریم که جایگزین مفید بودن شود.
یک برچسب پراکسی برای مفید بودن ممکن است این باشد که آیا کاربر ویدیو را به اشتراک میگذارد یا دوست دارد.
| نتیجه ایده آل | برچسب پروکسی |
|---|---|
| ویدیوهای مفید را توصیه کنید. | shared OR liked |
در مورد برچسب های پروکسی محتاط باشید زیرا آنها مستقیماً آنچه را که می خواهید پیش بینی کنید اندازه نمی گیرند. برای مثال، جدول زیر مشکلات مربوط به برچسبهای پراکسی بالقوه را برای ویدیوهای مفید توصیه میکند :
| برچسب پروکسی | موضوع |
|---|---|
| پیش بینی کنید که آیا کاربر روی دکمه "پسندیدن" کلیک می کند یا خیر. | اکثر کاربران هرگز روی "پسندیدن" کلیک نمی کنند. |
| پیش بینی کنید که آیا یک ویدیو محبوب خواهد بود یا خیر. | شخصی نیست. ممکن است برخی از کاربران ویدیوهای محبوب را دوست نداشته باشند. |
| پیش بینی کنید که آیا کاربر ویدیو را به اشتراک می گذارد یا خیر. | برخی از کاربران ویدیوها را به اشتراک نمی گذارند. گاهی اوقات، مردم به دلیل اینکه ویدیوها را دوست ندارند به اشتراک می گذارند. |
| پیش بینی کنید که آیا کاربر روی play کلیک می کند یا خیر. | طعمه کلیک را به حداکثر می رساند. |
| پیش بینی کنید که چه مدت ویدیو را تماشا می کنند. | ویدیوهای طولانی را به طور متفاوتی نسبت به ویدیوهای کوتاه ترجیح می دهد. |
| پیش بینی کنید که کاربر چند بار ویدیو را دوباره تماشا خواهد کرد. | ویدیوهای «قابل تماشا» را به ژانرهای ویدیویی که قابل تماشا نیستند ترجیح می دهد. |
هیچ برچسب پروکسی نمی تواند جایگزین مناسبی برای نتیجه ایده آل شما باشد. همه مشکلات احتمالی خواهند داشت. موردی را که کمترین مشکل را دارد را برای مورد استفاده خود انتخاب کنید.
درک خود را بررسی کنید
نسل
در بیشتر موارد، شما مدل تولیدی خود را آموزش نمیدهید، زیرا انجام این کار به حجم عظیمی از دادههای آموزشی و منابع محاسباتی نیاز دارد. در عوض، یک مدل مولد از پیش آموزش دیده را سفارشی خواهید کرد. برای به دست آوردن یک مدل مولد برای تولید خروجی مورد نظر خود، ممکن است لازم باشد از یک یا چند تکنیک زیر استفاده کنید:
تقطیر . برای ایجاد یک نسخه کوچکتر از یک مدل بزرگتر، یک مجموعه داده با برچسب مصنوعی از مدل بزرگتر تولید می کنید که برای آموزش مدل کوچکتر استفاده می کنید. مدل های مولد معمولاً غول پیکر هستند و منابع قابل توجهی (مانند حافظه و برق) را مصرف می کنند. تقطیر به مدل کوچکتر و کم مصرفتر اجازه می دهد تا عملکرد مدل بزرگتر را تقریبی کند.
تنظیم دقیق یا تنظیم با پارامتر کارآمد . برای بهبود عملکرد یک مدل در یک کار خاص، باید مدل را بر روی مجموعه داده ای که شامل نمونه هایی از نوع خروجی می خواهید تولید کنید، آموزش دهید.
مهندسی سریع برای اینکه مدل یک کار خاص را انجام دهد یا خروجی در یک فرمت خاص تولید کند، به مدل میگویید که چه کاری را میخواهید انجام دهد یا توضیح میدهید که چگونه میخواهید خروجی را قالببندی کند. به عبارت دیگر، اعلان می تواند شامل دستورالعمل های زبان طبیعی برای نحوه انجام کار یا مثال های گویا با خروجی های مورد نظر باشد.
برای مثال، اگر میخواهید خلاصهای از مقالات داشته باشید، میتوانید موارد زیر را وارد کنید:
Produce 100-word summaries for each article.اگر می خواهید مدل برای یک سطح خواندن خاص متن تولید کند، می توانید موارد زیر را وارد کنید:
All the output should be at a reading level for a 12-year-old.اگر میخواهید مدل خروجی خود را در قالب خاصی ارائه دهد، میتوانید نحوه قالببندی خروجی را توضیح دهید - مثلاً «نتایج را در یک جدول قالببندی کنید» - یا میتوانید کار را با مثالهایی برای آن نشان دهید. به عنوان مثال، می توانید موارد زیر را وارد کنید:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
تقطیر و تنظیم دقیق پارامترهای مدل را به روز می کند. مهندسی سریع پارامترهای مدل را به روز نمی کند. درعوض، مهندسی سریع به مدل کمک میکند تا یاد بگیرد که چگونه خروجی دلخواه را از متن اعلان تولید کند.
در برخی موارد، شما همچنین به یک مجموعه داده آزمایشی برای ارزیابی خروجی یک مدل تولیدی در برابر مقادیر شناخته شده نیاز دارید، به عنوان مثال، بررسی اینکه خلاصههای مدل شبیه خلاصههای تولید شده توسط انسان هستند یا اینکه انسانها خلاصههای مدل را خوب ارزیابی میکنند.
هوش مصنوعی مولد همچنین میتواند برای پیادهسازی یک راهحل پیشبینیکننده ML، مانند طبقهبندی یا رگرسیون استفاده شود. به عنوان مثال، به دلیل دانش عمیق خود از زبان طبیعی، مدلهای زبان بزرگ (LLMs) اغلب میتوانند وظایف طبقهبندی متن را بهتر از ML پیشبینیشده برای کار خاص انجام دهند.
معیارهای موفقیت را تعریف کنید
معیارهایی را که برای تعیین موفقیت آمیز بودن یا نبودن اجرای ML استفاده می کنید، تعریف کنید. معیارهای موفقیت آنچه را که برای شما مهم است مشخص می کند، مانند تعامل یا کمک به کاربران برای انجام اقدامات مناسب، مانند تماشای ویدیوهایی که برای آنها مفید است. معیارهای موفقیت با معیارهای ارزیابی مدل، مانند دقت ، دقت ، یادآوری یا AUC متفاوت است.
برای مثال، معیارهای موفقیت و شکست برنامه آب و هوا ممکن است به صورت زیر تعریف شود:
| موفقیت | کاربران "آیا باران خواهد آمد؟" را باز می کنند. این ویژگی 50 درصد بیشتر از قبل است. |
|---|---|
| شکست | کاربران "آیا باران خواهد آمد؟" را باز می کنند. بیشتر از قبل مشخص نمی شود. |
معیارهای برنامه ویدیویی ممکن است به صورت زیر تعریف شود:
| موفقیت | کاربران به طور متوسط 20 درصد زمان بیشتری را در سایت صرف می کنند. |
|---|---|
| شکست | کاربران به طور متوسط زمان بیشتری نسبت به قبل در سایت صرف نمی کنند. |
توصیه می کنیم معیارهای موفقیت بلندپروازانه را تعریف کنید. با این حال، جاه طلبی های بالا می تواند باعث ایجاد شکاف بین موفقیت و شکست شود. به عنوان مثال، کاربرانی که به طور متوسط 10 درصد بیشتر از قبل در سایت وقت صرف می کنند نه موفقیت است و نه شکست. شکاف تعریف نشده آن چیزی نیست که مهم است.
آنچه مهم است ظرفیت مدل شما برای نزدیکتر یا فراتر رفتن از تعریف موفقیت است. به عنوان مثال، هنگام تجزیه و تحلیل عملکرد مدل، سؤال زیر را در نظر بگیرید: آیا بهبود مدل شما را به معیارهای موفقیت تعریف شده نزدیکتر می کند؟ به عنوان مثال، یک مدل ممکن است معیارهای ارزیابی عالی داشته باشد، اما شما را به معیارهای موفقیت نزدیکتر نمیکند، که نشان میدهد حتی با یک مدل کامل، معیارهای موفقیتی را که تعریف کردهاید برآورده نمیکنید. از سوی دیگر، یک مدل ممکن است معیارهای ارزیابی ضعیفی داشته باشد، اما شما را به معیارهای موفقیت نزدیکتر میکند، که نشان میدهد بهبود مدل شما را به موفقیت نزدیکتر میکند.
هنگام تعیین اینکه آیا مدل ارزش بهبود دارد یا خیر، ابعاد زیر باید در نظر گرفته شود:
به اندازه کافی خوب نیست، اما ادامه دهید . این مدل نباید در محیط تولید استفاده شود، اما با گذشت زمان ممکن است به طور قابل توجهی بهبود یابد.
به اندازه کافی خوب است و ادامه دهید . این مدل می تواند در یک محیط تولید استفاده شود و ممکن است بیشتر بهبود یابد.
به اندازه کافی خوب است، اما نمی توان آن را بهتر کرد . این مدل در یک محیط تولید قرار دارد، اما احتمالاً تا آنجا که می تواند خوب است.
به اندازه کافی خوب نیست و هرگز نخواهد بود . این مدل نباید در محیط تولید مورد استفاده قرار گیرد و احتمالاً هیچ آموزشی آن را به آنجا نمی رساند.
هنگام تصمیمگیری برای بهبود مدل، مجدداً ارزیابی کنید که آیا افزایش منابع، مانند زمان مهندسی و هزینههای محاسبهشده، بهبود پیشبینیشده مدل را توجیه میکند یا خیر.
پس از تعریف معیارهای موفقیت و شکست، باید تعیین کنید که چقدر آنها را اندازه گیری می کنید. به عنوان مثال، می توانید معیارهای موفقیت خود را شش روز، شش هفته یا شش ماه پس از اجرای سیستم اندازه گیری کنید.
هنگام تجزیه و تحلیل معیارهای شکست، سعی کنید علت شکست سیستم را مشخص کنید. برای مثال، این مدل ممکن است پیشبینی کند که کاربران روی کدام ویدیوها کلیک خواهند کرد، اما مدل ممکن است شروع به توصیه عناوین طعمه کلیکی کند که باعث کاهش تعامل کاربر میشود. در مثال برنامه هواشناسی، این مدل ممکن است به دقت پیشبینی کند که چه زمانی باران میبارد، اما برای یک منطقه جغرافیایی بسیار بزرگ.
درک خود را بررسی کنید
یک شرکت مد می خواهد لباس های بیشتری بفروشد. شخصی استفاده از ML را برای تعیین لباس هایی که شرکت باید تولید کند پیشنهاد می کند. آنها فکر می کنند می توانند یک مدل تربیت کنند تا مشخص کند کدام نوع لباس مد است. پس از آموزش مدل، آنها می خواهند آن را در کاتالوگ خود اعمال کنند تا تصمیم بگیرند کدام لباس را بسازند.
آنها چگونه باید مشکل خود را در قالب ML تنظیم کنند؟
نتیجه ایده آل : تعیین کنید کدام محصولات را تولید کنید.
هدف مدل : پیشبینی کنید که کدام لباسها مد هستند.
خروجی مدل : طبقه بندی باینری، in_fashion ، not_in_fashion
معیارهای موفقیت : هفتاد درصد یا بیشتر از لباس های ساخته شده را بفروشید.
نتیجه ایده آل : تعیین کنید چه مقدار پارچه و لوازم سفارش دهید.
هدف مدل : پیش بینی کنید که چه مقدار از هر کالا باید تولید شود.
خروجی مدل : طبقه بندی باینری، make , do_not_make
معیارهای موفقیت : هفتاد درصد یا بیشتر از لباس های ساخته شده را بفروشید.