本番環境の ML では、単一のモデルを構築してデプロイすることが目標ではありません。目標は、モデルの開発、テスト、デプロイを自動化するパイプラインを構築することです。その理由は、世の中が変化すると、データの傾向が変化し、本番環境のモデルが古くなります。通常、モデルは最新のデータで再トレーニングして、長期にわたって高品質の予測を提供し続ける必要があります。つまり、古いモデルを新しいモデルに置き換える方法が必要になります。
パイプラインがない場合、古いモデルの置き換えはエラーが発生しやすいプロセスです。たとえば、モデルが不適切な予測を開始すると、新しいデータを手動で収集して処理し、新しいモデルをトレーニングして品質を検証し、最終的にデプロイする必要があります。ML パイプラインは、これらの反復プロセスの多くを自動化し、モデルの管理とメンテナンスをより効率的かつ信頼性の高いものにします。
パイプラインの構築
ML パイプラインは、モデルの構築とデプロイの手順を明確に定義されたタスクに整理します。パイプラインには、予測の配信またはモデルの更新のいずれかの機能があります。
予測の配信
サービング パイプラインは予測を配信します。モデルを現実世界に公開し、ユーザーがアクセスできるようにします。たとえば、ユーザーが予測(明日の天気、空港までの所要時間、おすすめ動画のリストなど)を求めている場合、サービング パイプラインはユーザーのデータを受け取って処理し、予測を行って、その結果をユーザーに配信します。
モデルの更新
モデルは、本番環境に移行するとすぐに古くなる傾向があります。つまり、古い情報を使用して予測を行っています。トレーニング データセットは、1 日前、場合によっては 1 時間前の世界の状況をキャプチャしています。世界は必然的に変化します。ユーザーがより多くの動画を視聴し、新しいおすすめリストが必要になったり、雨で交通が遅くなり、ユーザーが到着予定時刻の更新を必要としたり、人気のあるトレンドにより、小売業者が特定のアイテムの在庫予測の更新をリクエストしたりします。
通常、チームは本番環境モデルが古くなる前に新しいモデルをトレーニングします。場合によっては、チームは継続的なトレーニングとデプロイのサイクルで、新しいモデルを毎日トレーニングしてデプロイします。理想的には、本番環境モデルが古くなる前に、新しいモデルのトレーニングを行う必要があります。
次のパイプラインが連携して新しいモデルをトレーニングします。
- データ パイプライン。データ パイプラインはユーザーデータを処理して、トレーニング用とテスト用のデータセットを作成します。
- トレーニング パイプライン。トレーニング パイプラインは、データ パイプラインの新しいトレーニング データセットを使用してモデルをトレーニングします。
- 検証パイプライン。検証パイプラインは、データ パイプラインによって生成されたテスト データセットを使用して、トレーニング済みモデルを本番環境モデルと比較することで検証します。
図 4 は、各 ML パイプラインの入力と出力を示しています。
ML パイプライン

図 4. ML パイプラインは、モデルの開発とメンテナンスの多くのプロセスを自動化します。各パイプラインには、入力と出力が表示されます。
パイプラインが本番環境で最新のモデルを維持する仕組みの概要は次のとおりです。
まず、モデルが本番環境に移行し、サービング パイプラインが予測の配信を開始します。
データ パイプラインは、新しいトレーニング データセットとテスト データセットを生成するために、データの収集を直ちに開始します。
スケジュールまたはトリガーに基づいて、トレーニング パイプラインと検証パイプラインは、データ パイプラインによって生成されたデータセットを使用して新しいモデルをトレーニングして検証します。
検証パイプラインで新しいモデルが本番環境モデルよりも劣っていないことが確認されると、新しいモデルがデプロイされます。
このプロセスは継続的に繰り返されます。
モデルの未更新とトレーニング頻度
ほとんどのモデルは古くなります。モデルによっては、他のモデルよりも早く古くなることがあります。たとえば、衣料品を推奨するモデルは、消費者の好みが頻繁に変化することで知られているため、通常はすぐに古くなります。一方、花を識別するモデルは古くならない可能性があります。花の特徴は安定した状態を保ちます。
ほとんどのモデルは、本番環境に導入された直後から古くなり始めます。データの性質を反映したトレーニング頻度を設定する必要があります。データが動的な場合は、頻繁にトレーニングします。動的でない場合は、頻繁にトレーニングする必要がない可能性があります。
モデルが古くなる前にトレーニングします。早期トレーニングは、データやトレーニング パイプラインが失敗した場合や、モデルの品質が低い場合など、潜在的な問題を解決するためのバッファを提供します。
ベスト プラクティスとして、新しいモデルを毎日トレーニングしてデプロイすることをおすすめします。毎日のビルドとリリース プロセスがある通常のソフトウェア プロジェクトと同様に、トレーニングと検証用の ML パイプラインは、毎日実行すると最適な結果が得られることがよくあります。
理解度チェック
サービング パイプライン
サービング パイプラインは、オンラインまたはオフラインのいずれかの方法で予測を生成して配信します。
オンライン予測。オンライン予測はリアルタイムで行われます。通常は、オンライン サーバーにリクエストを送信し、予測を返します。たとえば、ユーザーが予測を必要とする場合、ユーザーのデータがモデルに送信され、モデルが予測を返します。
オフライン予測。オフライン予測は事前計算されてキャッシュに保存されます。予測を配信するために、アプリはデータベースでキャッシュに保存された予測を見つけて返します。たとえば、サブスクリプション ベースのサービスでは、サブスクライバーの離脱率を予測できます。モデルは、すべてのサブスクライバーの解約の可能性を予測してキャッシュに保存します。アプリで予測が必要になった場合(たとえば、離脱しそうなユーザーにインセンティブを付与する場合)、事前計算された予測を検索するだけです。
図 5 は、オンライン予測とオフライン予測が生成されて配信される仕組みを示しています。
オンライン予測とオフライン予測

図 5. オンライン予測では、リアルタイムで予測が提供されます。オフライン予測はキャッシュに保存され、サービング時にルックアップされます。
予測の後処理
通常、予測は配信前に後処理されます。たとえば、予測を後処理して、有害なコンテンツや偏見のあるコンテンツを削除できます。分類結果は、モデルの未加工の出力を表示する代わりに、結果の順序を変更するプロセスを経る場合があります。たとえば、より信頼性の高いコンテンツを上位に表示したり、多様な結果を表示したり、特定の検索結果(クリックベイトなど)の順位を下げたり、法的理由で検索結果を削除したりするために、結果の順序を変更するプロセスを経る場合があります。
図 6 は、サービング パイプラインと、予測の配信に関連する一般的なタスクを示しています。
後処理の予測

図 6. 予測を提供する一般的なタスクを示すサービング パイプライン。
特徴量エンジニアリングのステップは通常、モデル内に構築され、独立したスタンドアロン プロセスではありません。サービング パイプラインのデータ処理コードは、データ パイプラインがトレーニング データセットとテスト データセットの作成に使用するデータ処理コードとほぼ同じであることがよくあります。
アセットとメタデータの保存
サービング パイプラインには、モデル予測と(可能であれば)正解をロギングするリポジトリを組み込む必要があります。
モデルの予測をロギングすると、モデルの品質をモニタリングできます。予測を集計することで、モデルの一般的な品質をモニタリングし、品質が低下し始めているかどうかを判断できます。一般に、本番環境モデルの予測の平均は、トレーニング データセットのラベルの平均と同じである必要があります。詳細については、予測バイアスをご覧ください。
グラウンド トゥルースのキャプチャ
場合によっては、グラウンド トゥルースがずっと後になってからしか利用できないことがあります。たとえば、天気予報アプリが 6 週間先の天気を予測する場合、グラウンド トゥルース(実際の天気)は 6 週間利用できません。
可能であれば、アプリにフィードバック メカニズムを追加して、ユーザーにグラウンド トゥルースを報告してもらうようにします。メールアプリでは、ユーザーが受信トレイから迷惑メール フォルダにメールを移動したときに、ユーザー フィードバックが暗黙的にキャプチャされます。ただし、これはユーザーがメールを正しく分類した場合にのみ機能します。ユーザーが迷惑メールを受信トレイに残しておくと(迷惑メールだとわかっていて開かない場合)、トレーニング データが不正確になります。そのメールは「スパム」であるべきなのに「スパムではない」とラベル付けされます。つまり、常にグラウンド トゥルースをキャプチャして記録する方法を見つけるように努める必要がありますが、フィードバック メカニズムに存在する可能性のある欠点にも注意する必要があります。
図 7 は、ユーザーに配信され、リポジトリにロギングされる予測を示しています。
予測のロギング
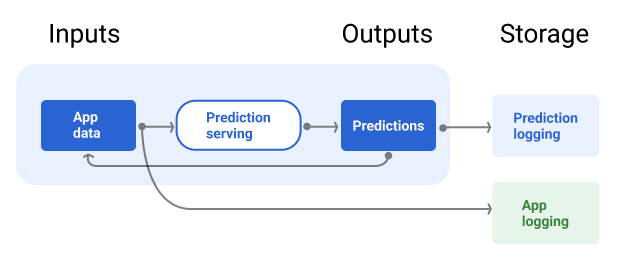
図 7. 予測をロギングして、モデルの品質をモニタリングします。
データ パイプライン
データ パイプラインは、アプリケーション データからトレーニング データセットとテスト データセットを生成します。トレーニング パイプラインと検証パイプラインは、データセットを使用して新しいモデルをトレーニングして検証します。
データ パイプラインは、モデルのトレーニングに元々使用されたものと同じ特徴とラベルを使用して、新しい情報を含むトレーニング データセットとテスト データセットを作成します。たとえば、地図アプリは、数百万人のユーザーの地点間の最近の移動時間と、天気などの関連データからトレーニング データセットとテスト データセットを生成します。
動画のおすすめアプリは、ユーザーがおすすめリストからクリックした動画(クリックしなかった動画も含む)と、視聴履歴などの他の関連データを含むトレーニング データセットとテスト データセットを生成します。
図 8 は、アプリケーション データを使用してトレーニング データセットとテスト データセットを生成するデータ パイプラインを示しています。
データ パイプライン

図 8. データ パイプラインは、アプリケーション データを処理して、トレーニング パイプラインと検証パイプラインのデータセットを作成します。
データの収集と処理
データ パイプラインでデータを収集して処理するタスクは、実験フェーズ(ソリューションが実現可能であることを確認したフェーズ)とは異なる可能性があります。
データ収集。テスト中、データの収集には通常、保存されたデータへのアクセスが必要です。データ パイプラインの場合、データの収集には、ストリーミング ログデータにアクセスするための検出と承認が必要になることがあります。
ヒューマン ラベリングが行われたデータ(医療画像など)が必要な場合は、そのデータを収集して更新するプロセスも必要になります。
データ処理。テストでは、テスト データセットのスクレイピング、結合、サンプリングによって適切な特徴が抽出されました。データ パイプラインの場合、同じ特徴量を生成するためにまったく異なるプロセスが必要になることがあります。ただし、特徴とラベルに同じ数学演算を適用して、テストフェーズのデータ変換を複製してください。
アセットとメタデータの保存
トレーニング データセットとテスト データセットの保存、バージョン管理、管理を行うプロセスが必要です。バージョン管理されたリポジトリには、次の利点があります。
再現性。モデル トレーニング環境を再作成して標準化し、さまざまなモデルの予測品質を比較します。
コンプライアンス。監査可能性と透明性に関する規制コンプライアンス要件を遵守します。
保持。データを保存する期間のデータ保持値を設定します。
アクセス管理。きめ細かい権限を使用して、データにアクセスできるユーザーを管理します。
データの整合性。データセットの経時的な変化を追跡して把握することで、データやモデルの問題を簡単に診断できます。
検出可能性。他のユーザーがデータセットと特徴を簡単に見つけられるようにします。他のチームは、その機能が自分たちの目的に役立つかどうかを判断できます。
データを文書化する
適切なドキュメントを作成すると、データの種類、ソース、サイズなどの重要なメタデータに関する情報を他のユーザーが理解しやすくなります。ほとんどの場合、設計ドキュメント でデータを文書化すれば十分です。データを共有または公開する予定がある場合は、 データカード を使用して情報を構造化します。データカードを使用すると、他のユーザーがデータセットを見つけて理解しやすくなります。
トレーニング パイプラインと検証パイプライン
トレーニング パイプラインと検証パイプラインは、本番環境モデルが古くなる前に、本番環境モデルを置き換える新しいモデルを生成します。新しいモデルを継続的にトレーニングして検証することで、常に最適なモデルが本番環境にデプロイされます。
トレーニング パイプラインはトレーニング データセットから新しいモデルを生成し、検証パイプラインはテスト データセットを使用して、新しいモデルの品質を本番環境のモデルと比較します。
図 9 は、トレーニング データセットを使用して新しいモデルをトレーニングするトレーニング パイプラインを示しています。
トレーニング パイプライン

図 9. トレーニング パイプラインは、最新のトレーニング データセットを使用して新しいモデルをトレーニングします。
モデルのトレーニング後、検証パイプラインはテスト データセットを使用して、本番環境モデルの品質とトレーニング済みモデルの品質を比較します。
一般に、トレーニング済みモデルが本番環境モデルよりも大幅に劣っていない場合は、トレーニング済みモデルが本番環境に移行されます。トレーニング済みモデルのパフォーマンスが低下した場合は、モニタリング インフラストラクチャでアラートを作成する必要があります。予測品質が低いトレーニング済みモデルは、データまたは検証パイプラインに問題がある可能性を示している可能性があります。このアプローチは、最新のデータでトレーニングされた最適なモデルが常に本番環境にあることを保証します。
アセットとメタデータの保存
モデルとそのメタデータは、モデルのデプロイを整理して追跡するために、バージョン管理されたリポジトリに保存する必要があります。モデル リポジトリには、次のようなメリットがあります。
追跡と評価。本番環境のモデルを追跡し、評価と予測の品質指標を把握します。
モデルのリリース プロセス。モデルの審査、承認、リリース、ロールバックを簡単に行うことができます。
再現性とデバッグ。モデルの結果を再現し、デプロイ全体でモデルのデータセットと依存関係をトレースすることで、問題をより効果的にデバッグします。
検出可能性。他のユーザーがモデルを見つけやすいようにします。他のチームは、モデル(またはその一部)を自社の目的に使用できるかどうかを判断できます。
図 10 は、モデル リポジトリに保存された検証済みモデルを示しています。
モデル ストレージ

図 10. 検証済みのモデルは、追跡と検出可能性のためにモデル リポジトリに保存されます。
モデルカード を使用して、モデルの目的、アーキテクチャ、ハードウェア要件、評価指標などのモデルに関する重要な情報を文書化して共有します。
理解度チェック
パイプラインの構築に関する課題
パイプラインの構築時に、次の問題が発生することがあります。
必要なデータへのアクセス権を取得する。データアクセスには、その必要性を正当化することが求められる場合があります。たとえば、データの使用方法を説明したり、個人情報(PII)の問題を解決する方法を明確にする必要がある場合があります。特定の種類のデータにアクセスすることで、モデルの予測精度が向上することを実証する概念実証を提示できるように準備してください。
適切な機能を取得する。場合によっては、試験運用フェーズで使用される特徴がリアルタイム データから利用できないことがあります。そのため、テストを行う際は、本番環境でも同じ機能を利用できることを確認してください。
データの収集方法と表示方法を理解する。データの収集方法、収集者、収集方法(その他の問題を含む)を把握するには、時間と労力がかかることがあります。データを十分に理解することが重要です。本番環境に移行する可能性のあるモデルのトレーニングに、信頼できないデータを使用しないでください。
労力、費用、モデルの品質のトレードオフを理解する。データ パイプラインに新機能を組み込むには、多くの労力が必要になることがあります。ただし、追加された特徴量によってモデルの品質がわずかに向上するだけの場合もあります。場合によっては、新機能の追加が容易なこともあります。ただし、特徴を取得して保存するためのリソースが非常に高価になる可能性があります。
コンピューティングを取得する。再トレーニングに TPU が必要な場合、必要な割り当てを取得することは困難な場合があります。また、TPU の管理は複雑です。たとえば、モデルやデータの一部を複数の TPU チップに分割して、TPU 専用に設計する必要がある場合があります。
適切なゴールデン データセットを見つける。データが頻繁に変更される場合、一貫性のある正確なラベルを含むゴールデン データセットを取得することは困難です。
テスト中にこのような問題を検出することで、時間を節約できます。たとえば、最適な特徴とモデルを開発した後に、本番環境で実現可能でないことが判明するのは避けたいところです。そのため、ソリューションが本番環境の制約内で動作することをできるだけ早く確認してください。パイプライン フェーズで解決できない問題が明らかになり、実験フェーズに戻る必要が生じるよりも、ソリューションが機能することを検証する時間を費やす方が望ましいです。