머신러닝 (ML)은 번역 앱부터 자율 주행 차량에 이르기까지 우리가 사용하는 가장 중요한 기술을 지원합니다. 이 과정에서는 ML의 핵심 개념을 설명합니다.
ML은 문제를 해결하고, 복잡한 질문에 답하고, 새로운 콘텐츠를 만드는 새로운 방법을 제공합니다. ML은 날씨를 예측하고, 이동 시간을 추정하고, 노래를 추천하고, 문장을 자동 완성하고, 기사를 요약하고, 이전에 본 적 없는 이미지를 생성할 수 있습니다.
기본적으로 ML은 모델이라는 소프트웨어를 학습시켜 유용한 예측을 하거나 데이터로부터 콘텐츠(예: 텍스트, 이미지, 오디오, 동영상)를 생성하는 프로세스입니다.
예를 들어 강수량을 예측하는 앱을 만들고 싶다고 가정해 보겠습니다. 기존 접근 방식이나 ML 접근 방식을 사용할 수 있습니다. 기존 방식을 사용하면 지구 대기와 표면의 물리 기반 표현을 만들어 엄청난 양의 유체 역학 방정식을 계산합니다. 이 작업은 매우 어렵습니다.
ML 접근 방식을 사용하면 ML 모델이 다양한 양의 비를 생성하는 날씨 패턴 간의 수학적 관계를 결국 학습할 때까지 ML 모델에 엄청난 양의 날씨 데이터를 제공합니다. 그런 다음 모델에 현재 날씨 데이터를 제공하면 강우량을 예측합니다.
이해도 확인
ML 시스템 유형
ML 시스템은 예측을 하거나 콘텐츠를 생성하는 방법을 학습하는 방식에 따라 다음 카테고리 중 하나 이상에 속합니다.
- 지도 학습
- 비지도 학습
- 강화 학습
- 생성형 AI
지도 학습
지도 학습 모델은 정답이 있는 많은 데이터를 확인한 후 정답을 생성하는 데이터의 요소 간 연결을 발견하여 예측할 수 있습니다. 이는 학생이 질문과 답변이 모두 포함된 이전 시험을 공부하여 새로운 자료를 학습하는 것과 같습니다. 학생이 충분한 이전 시험을 학습하면 새로운 시험을 치를 준비가 잘 된 것입니다. 이러한 ML 시스템은 사람이 ML 시스템에 알려진 올바른 결과가 포함된 데이터를 제공한다는 의미에서 '감독'됩니다.
지도 학습의 가장 일반적인 사용 사례 두 가지는 회귀와 분류입니다.
회귀
회귀 모델은 숫자 값을 예측합니다. 예를 들어 강수량을 인치 또는 밀리미터로 예측하는 날씨 모델은 회귀 모델입니다.
회귀 모델의 더 많은 예는 아래 표를 참고하세요.
| 시나리오 | 가능한 입력 데이터 | 숫자 예측 |
|---|---|---|
| 향후 주택 가격 | 면적, 우편번호, 침실 및 욕실 수, 부지 크기, 주택담보대출 이자율, 재산세율, 건설 비용, 해당 지역의 판매용 주택 수 | 주택 가격입니다. |
| 향후 이동 시간 | 이전 교통상황 (스마트폰, 교통 센서, 차량 호출 및 기타 탐색 애플리케이션에서 수집), 목적지까지의 거리, 날씨 | 목적지에 도착하는 데 걸리는 시간(분 및 초)입니다. |
분류
분류 모델은 항목이 카테고리에 속할 가능성을 예측합니다. 출력이 숫자인 회귀 모델과 달리 분류 모델은 특정 카테고리에 속하는지 여부를 나타내는 값을 출력합니다. 예를 들어 분류 모델은 이메일이 스팸인지 또는 사진에 고양이가 포함되어 있는지 예측하는 데 사용됩니다.
분류 모델은 이진 분류와 다중 클래스 분류의 두 그룹으로 나뉩니다. 이진 분류 모델은 값이 두 개만 포함된 클래스의 값을 출력합니다(예: rain 또는 no rain을 출력하는 모델). 다중 클래스 분류 모델은 두 개 이상의 값을 포함하는 클래스의 값을 출력합니다. 예를 들어 rain, hail, snow, sleet 중 하나를 출력할 수 있는 모델이 있습니다.
이해도 확인
비지도 학습
비지도 학습 모델은 데이터 세트에서 의미 있는 패턴을 식별하는 것을 목표로 합니다. 예를 들어 많은 비지도 학습 모델은 클러스터링이라는 기법을 사용하여 유사한 데이터를 그룹 ('클러스터')으로 정리합니다.
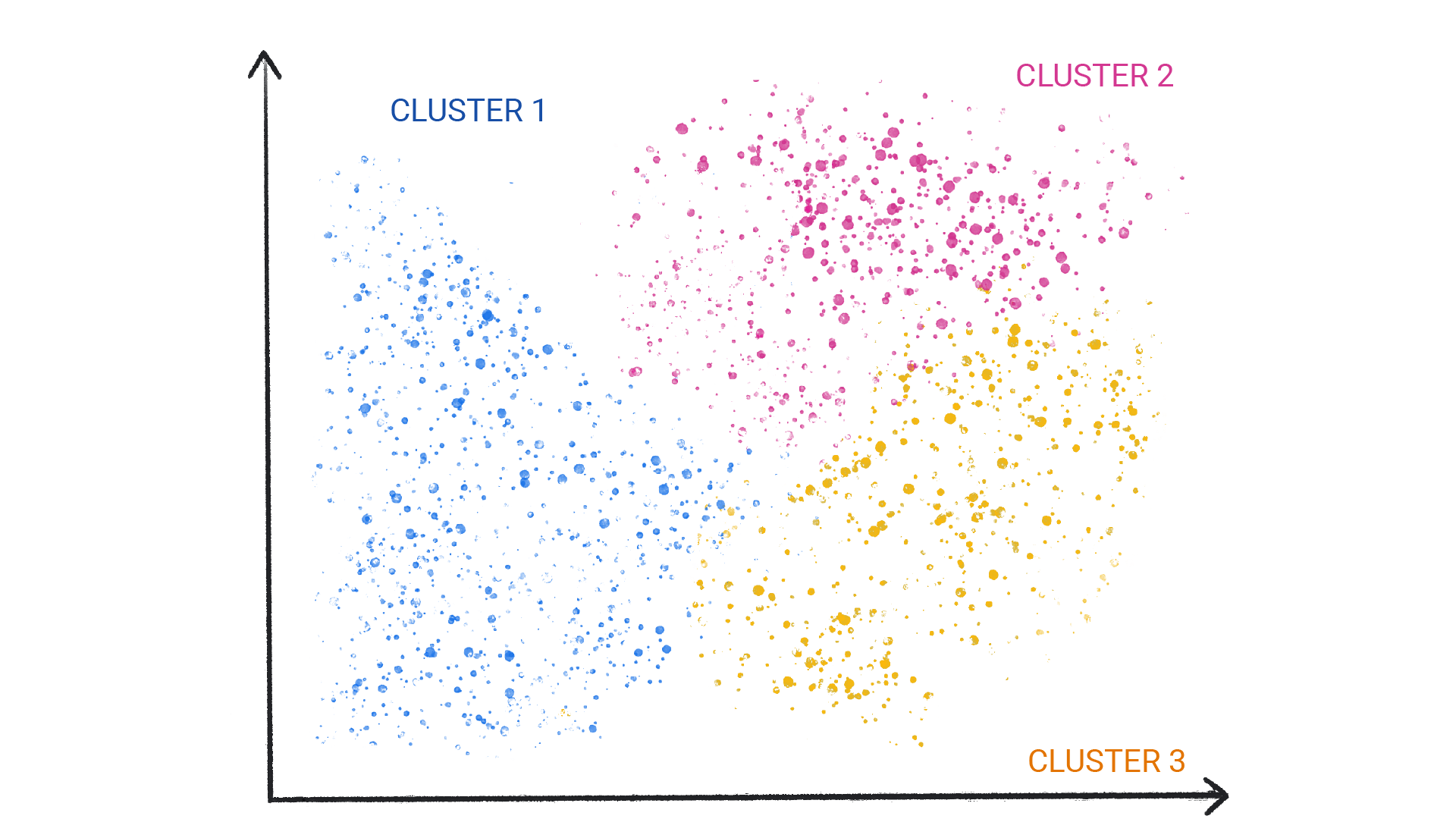
그림 1. 유사한 데이터 포인트를 클러스터링하는 ML 모델
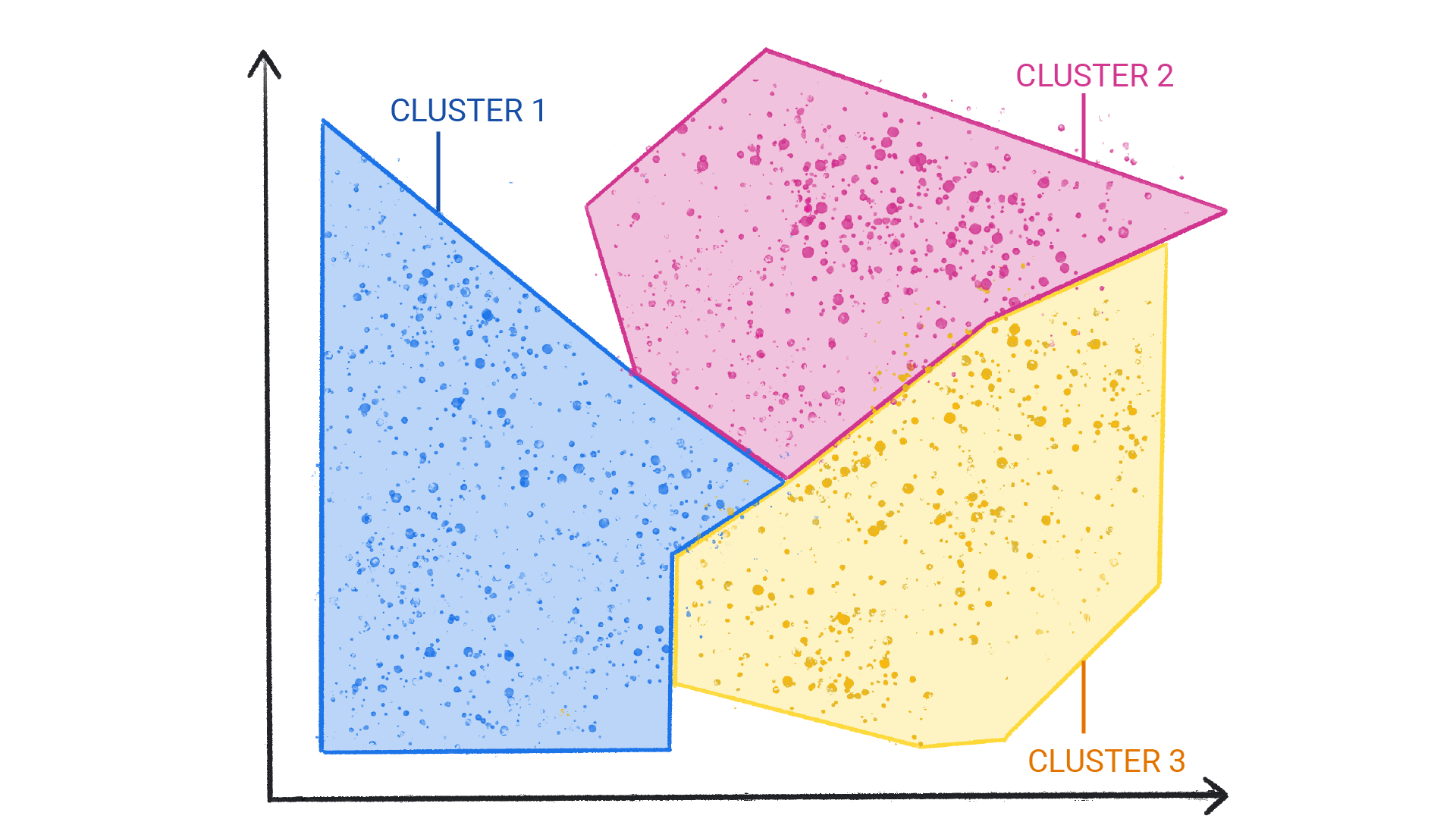
그림 2. 자연스러운 경계가 있는 클러스터 그룹입니다.
클러스터링은 분류와 다릅니다. 카테고리가 사용자에 의해 정의되지 않기 때문입니다. 예를 들어 비지도 모델은 온도를 기반으로 날씨 데이터 세트를 클러스터링하여 계절을 정의하는 세분화를 표시할 수 있습니다. 그런 다음 데이터 세트에 대한 이해를 바탕으로 이러한 클러스터의 이름을 지정할 수 있습니다.
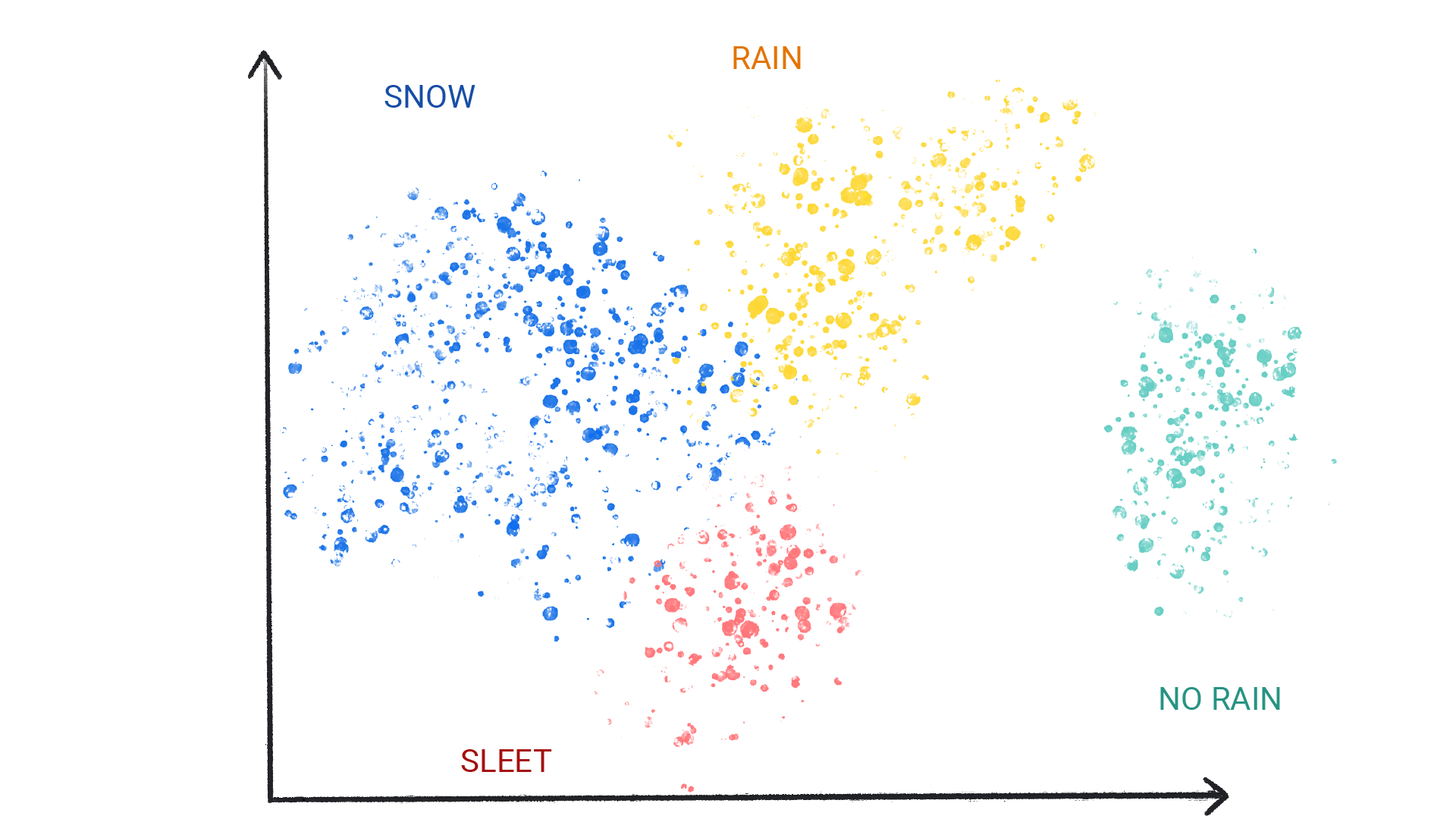
그림 3. 유사한 날씨 패턴을 클러스터링하는 ML 모델
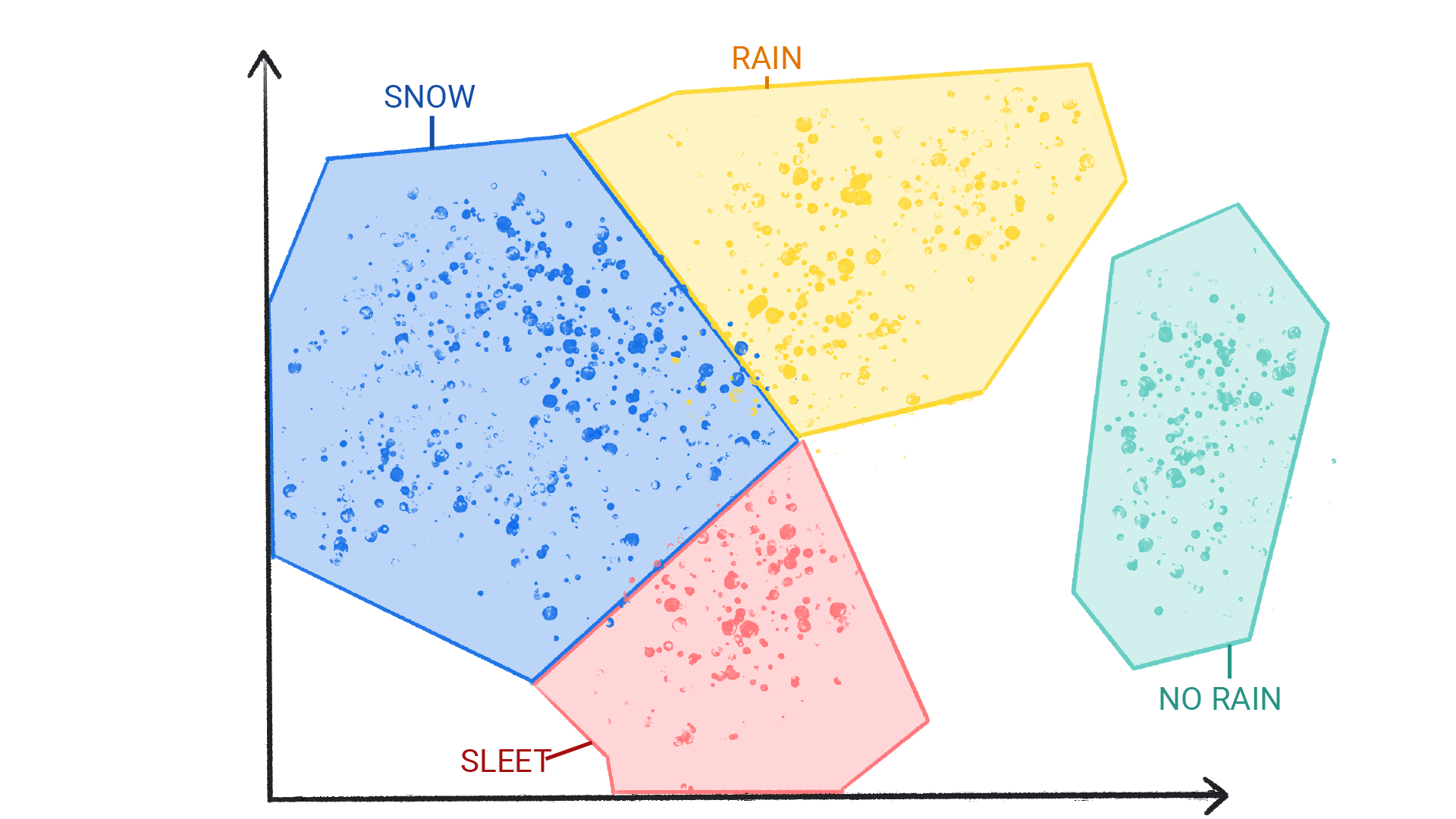
그림 4. 눈, 진눈깨비, 비, 비 없음으로 라벨이 지정된 기상 패턴 클러스터
이해도 확인
강화 학습
강화 학습 모델은 환경 내에서 수행된 작업을 기반으로 보상 또는 불이익을 받아 예측합니다. 강화 학습 시스템은 가장 많은 보상을 얻기 위한 최적의 전략을 정의하는 정책을 생성합니다.
강화 학습은 로봇이 방을 돌아다니는 것과 같은 작업을 수행하도록 학습시키고 AlphaGo와 같은 소프트웨어 프로그램이 바둑을 두도록 학습시키는 데 사용됩니다.
생성형 AI
생성형 AI는 사용자 입력에서 콘텐츠를 생성하는 모델 클래스입니다. 예를 들어 생성형 AI는 고유한 이미지, 음악, 농담을 만들 수 있고, 기사를 요약하거나, 작업을 수행하는 방법을 설명하거나, 사진을 수정할 수 있습니다.
생성형 AI는 다양한 입력을 받아 텍스트, 이미지, 오디오, 동영상과 같은 다양한 출력을 생성할 수 있습니다. 이러한 요소를 조합하여 만들 수도 있습니다. 예를 들어 모델은 이미지를 입력으로 받아 이미지와 텍스트를 출력으로 생성하거나 이미지와 텍스트를 입력으로 받아 동영상을 출력으로 생성할 수 있습니다.
생성형 모델은 입력과 출력에 따라 논의할 수 있으며, 일반적으로 '입력 유형'에서 '출력 유형'으로 작성됩니다. 예를 들어 생성 모델의 입력 및 출력의 일부 목록은 다음과 같습니다.
- 텍스트 간 변환
- 텍스트 이미지 변환
- 텍스트 동영상 변환
- 텍스트-코드
- 텍스트 음성 변환
- 이미지 및 텍스트 이미지 변환
다음 표에는 생성형 모델, 입력, 가능한 출력의 예가 나와 있습니다.
| 모델 | 입력 | 출력 예 |
|---|---|---|
| 텍스트 간 변환 | 르망 레이스는 누가 발명했나요? |
르망 24시 레이스는 1906년에 설립된 자동차 단체인 Automobile Club de l'Ouest(ACO)에 의해 설립되었습니다. 첫 번째 경주는 1923년 5월 26일과 27일에 프랑스 르망 마을 근처에 있는 13.426km(8.345마일) 길이의 도로 서킷인 사르트 서킷에서 개최되었습니다.
이 레이스는 원래 ACO와 사르트 지역을 홍보하기 위한 방법으로 고안되었습니다. 출처: Bard |
| 텍스트 이미지 변환 | 외계인 문어가 신문을 읽으며 포털을 통과합니다. |
 출처: Imagen |
| 텍스트 동영상 변환 | 포토리얼리스틱 테디베어가 샌프란시스코 바다에서 수영하고 있습니다. 곰 인형이 물속으로 들어갑니다. 테디베어는 다채로운 물고기와 함께 물속에서 계속 헤엄칩니다. 판다곰이 물속에서 헤엄치고 있습니다. |
 소스: Phenaki |
| 텍스트-코드 | 숫자 목록을 반복하고 소수를 출력하는 Python 루프를 작성하세요. |
for number in numbers: # Check if the number is prime. is_prime = True for i in range(2, number): if number % i == 0: is_prime = False break # If the number is prime, print it. if is_prime: print(number) 출처: Bard |
| 이미지 텍스트 변환 |  |
이것은 플라밍고입니다. 카리브해에서 발견됩니다. 출처: Google DeepMind |
생성형 AI는 어떻게 작동하나요? 개략적으로 생성형 모델은 새로운 유사 데이터를 생성하기 위해 데이터의 패턴을 학습합니다. 생성형 모델은 다음과 같습니다.
- 사람들의 행동과 말투를 관찰하여 다른 사람을 모방하는 방법을 배우는 코미디언
- 특정 스타일의 그림을 많이 연구하여 해당 스타일로 그림을 그리는 방법을 배우는 화가
- 특정 음악 그룹의 음악을 많이 들어 해당 그룹과 비슷한 소리를 내는 방법을 배우는 커버 밴드
고유하고 창의적인 출력을 생성하기 위해 생성 모델은 모델이 학습된 데이터를 모방하도록 학습하는 비지도 접근 방식을 사용하여 초기 학습됩니다. 모델은 때때로 모델이 수행하도록 요청받을 수 있는 작업(예: 기사 요약 또는 사진 수정)과 관련된 특정 데이터에 대해 지도 학습 또는 강화 학습을 사용하여 추가로 학습됩니다.
생성형 AI는 새로운 사용 사례가 끊임없이 발견되는 빠르게 발전하는 기술입니다. 예를 들어 생성형 모델은 비즈니스가 주의를 산만하게 하는 배경을 자동으로 삭제하거나 해상도가 낮은 이미지의 품질을 개선하여 전자상거래 제품 이미지를 개선하는 데 도움이 됩니다.