وظایف یادگیری تحت نظارت به خوبی تعریف شده است و می تواند در بسیاری از سناریوها اعمال شود - مانند شناسایی هرزنامه یا پیش بینی بارش.
مفاهیم یادگیری با نظارت بنیادی
یادگیری ماشینی نظارت شده بر اساس مفاهیم اصلی زیر است:
- داده ها
- مدل
- آموزش
- در حال ارزیابی
- استنتاج
داده ها
داده ها نیروی محرکه ML هستند. داده ها به شکل کلمات و اعداد ذخیره شده در جداول یا مقادیر پیکسل ها و شکل موج های ثبت شده در تصاویر و فایل های صوتی می آیند. ما داده های مرتبط را در مجموعه داده ها ذخیره می کنیم. به عنوان مثال، ممکن است مجموعه داده ای از موارد زیر داشته باشیم:
- تصاویری از گربه ها
- قیمت مسکن
- اطلاعات آب و هوا
مجموعه داده ها از نمونه های مجزا تشکیل شده اند که حاوی ویژگی ها و یک برچسب هستند. می توانید مثالی را مشابه یک ردیف در یک صفحه گسترده در نظر بگیرید. ویژگی ها مقادیری هستند که یک مدل نظارت شده برای پیش بینی برچسب استفاده می کند. برچسب "پاسخ" یا مقداری است که ما می خواهیم مدل پیش بینی کند. در یک مدل آب و هوایی که بارندگی را پیش بینی می کند، ویژگی ها می توانند عرض جغرافیایی ، طول جغرافیایی ، دما ، رطوبت ، پوشش ابر ، جهت باد و فشار اتمسفر باشند. برچسب مقدار بارندگی خواهد بود.
به نمونه هایی که دارای هر دو ویژگی و برچسب هستند، نمونه های برچسب دار گفته می شود.
دو نمونه برچسب گذاری شده

در مقابل، نمونههای بدون برچسب دارای ویژگیهایی هستند، اما فاقد برچسب هستند. پس از ایجاد یک مدل، مدل برچسب را از روی ویژگی ها پیش بینی می کند.
دو نمونه بدون برچسب
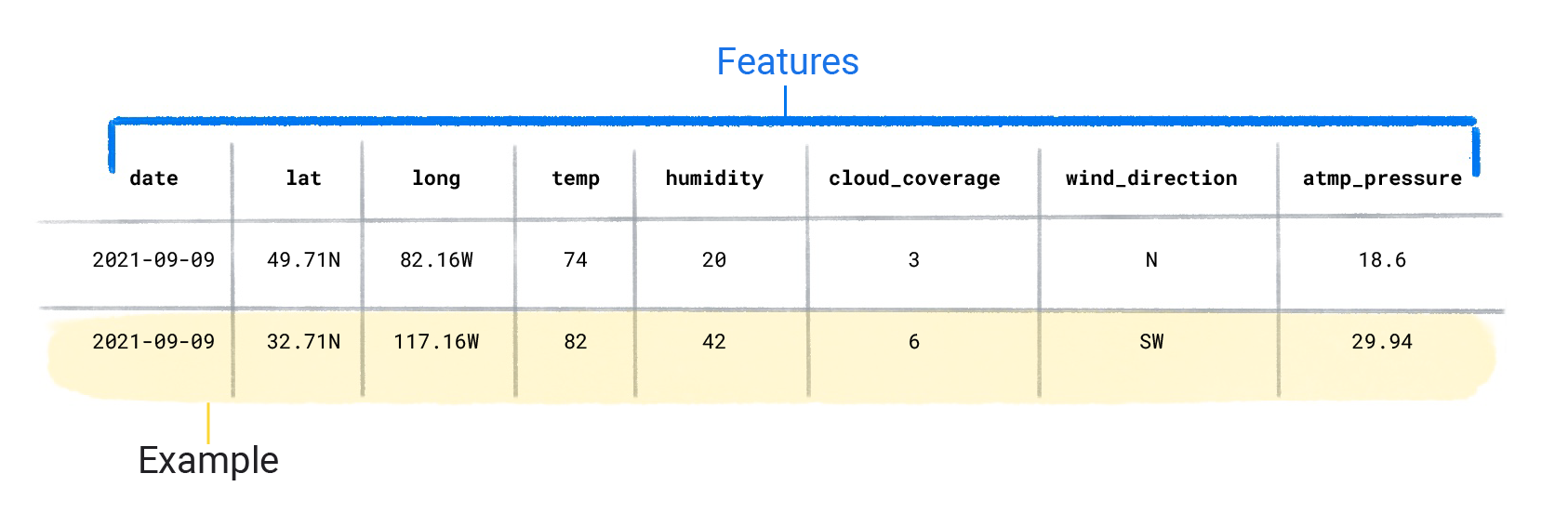
ویژگی های مجموعه داده
یک مجموعه داده با اندازه و تنوع آن مشخص می شود. اندازه تعداد نمونه ها را نشان می دهد. تنوع محدوده ای را که نمونه ها پوشش می دهند نشان می دهد. مجموعه داده های خوب هم بزرگ و هم بسیار متنوع هستند.
مجموعه داده ها می توانند بزرگ و متنوع، یا بزرگ اما متنوع نباشند، یا کوچک اما بسیار متنوع باشند. به عبارت دیگر، یک مجموعه داده بزرگ تنوع کافی را تضمین نمی کند و مجموعه داده ای که بسیار متنوع است، نمونه های کافی را تضمین نمی کند.
به عنوان مثال، یک مجموعه داده ممکن است حاوی داده های 100 ساله باشد، اما فقط برای ماه جولای. استفاده از این مجموعه داده برای پیشبینی بارندگی در ژانویه پیشبینی ضعیفی ایجاد میکند. برعکس، یک مجموعه داده ممکن است فقط چند سال را پوشش دهد اما هر ماه را شامل شود. این مجموعه داده ممکن است پیشبینیهای ضعیفی ایجاد کند زیرا شامل سالهای کافی برای محاسبه تنوع نیست.
درک خود را بررسی کنید
یک مجموعه داده را می توان با تعداد ویژگی های آن نیز مشخص کرد. به عنوان مثال، برخی از مجموعه داده های آب و هوا ممکن است شامل صدها ویژگی باشد، از تصاویر ماهواره ای گرفته تا مقادیر پوشش ابر. سایر مجموعههای داده ممکن است فقط شامل سه یا چهار ویژگی مانند رطوبت، فشار اتمسفر و دما باشند. مجموعههای داده با ویژگیهای بیشتر میتوانند به مدل کمک کنند تا الگوهای اضافی را کشف کند و پیشبینیهای بهتری انجام دهد. با این حال، مجموعه دادههایی با ویژگیهای بیشتر، همیشه مدلهایی تولید نمیکنند که پیشبینیهای بهتری انجام دهند، زیرا ممکن است برخی از ویژگیها هیچ رابطه علّی با برچسب نداشته باشند.
مدل
در یادگیری نظارت شده، یک مدل مجموعه پیچیده ای از اعداد است که رابطه ریاضی را از الگوهای مشخصه ورودی خاص تا مقادیر برچسب خروجی خاص تعریف می کند. مدل از طریق آموزش این الگوها را کشف می کند.
آموزش
قبل از اینکه یک مدل تحت نظارت بتواند پیش بینی کند، باید آموزش داده شود. برای آموزش یک مدل، یک مجموعه داده با نمونه های برچسب دار به مدل می دهیم. هدف این مدل یافتن بهترین راه حل برای پیش بینی برچسب ها از روی ویژگی ها است. مدل با مقایسه مقدار پیش بینی شده خود با مقدار واقعی برچسب بهترین راه حل را پیدا می کند. بر اساس تفاوت بین مقادیر پیش بینی شده و واقعی - که به عنوان ضرر تعریف می شود - مدل به تدریج راه حل خود را به روز می کند. به عبارت دیگر، مدل رابطه ریاضی بین ویژگی ها و برچسب را یاد می گیرد تا بتواند بهترین پیش بینی ها را روی داده های دیده نشده انجام دهد.
برای مثال، اگر مدل 1.15 inches باران را پیشبینی کرده بود، اما مقدار واقعی .75 inches بود، مدل راهحل خود را تغییر میدهد تا پیشبینی آن به .75 inches نزدیکتر شود. پس از اینکه مدل به هر نمونه در مجموعه داده نگاه کرد - در برخی موارد، چندین بار - به راه حلی می رسد که به طور متوسط بهترین پیش بینی ها را برای هر یک از نمونه ها انجام می دهد.
موارد زیر آموزش یک مدل را نشان می دهد:
این مدل یک مثال برچسب گذاری شده را می گیرد و یک پیش بینی ارائه می دهد.
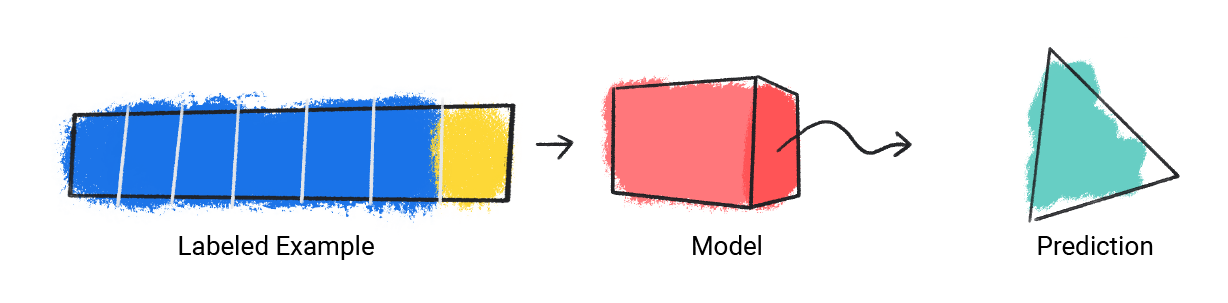
شکل 1 . یک مدل ML که از یک مثال برچسبدار پیشبینی میکند.
مدل مقدار پیش بینی شده خود را با مقدار واقعی مقایسه می کند و راه حل خود را به روز می کند.
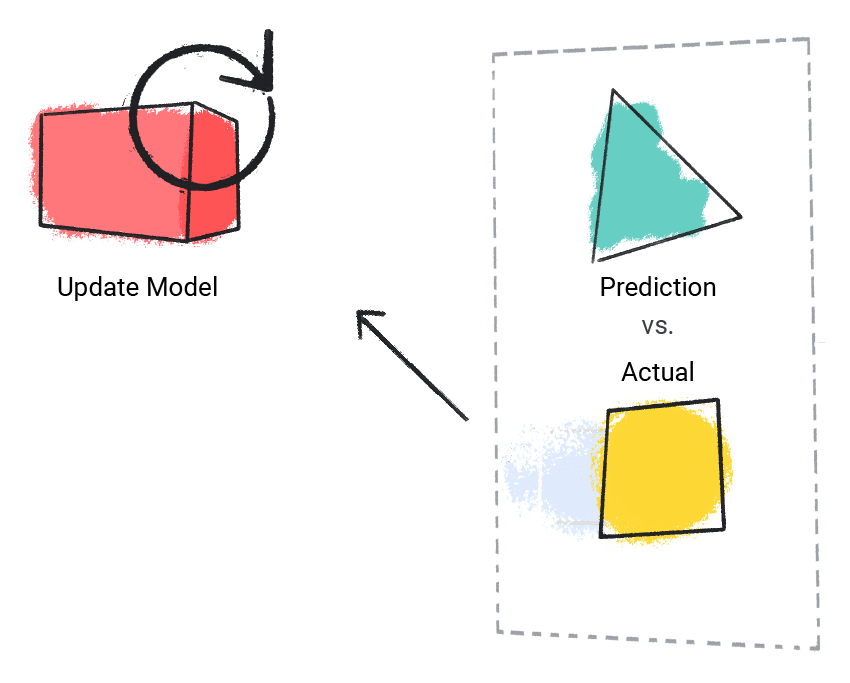
شکل 2 . یک مدل ML که مقدار پیش بینی شده خود را به روز می کند.
مدل این فرآیند را برای هر نمونه برچسب گذاری شده در مجموعه داده تکرار می کند.
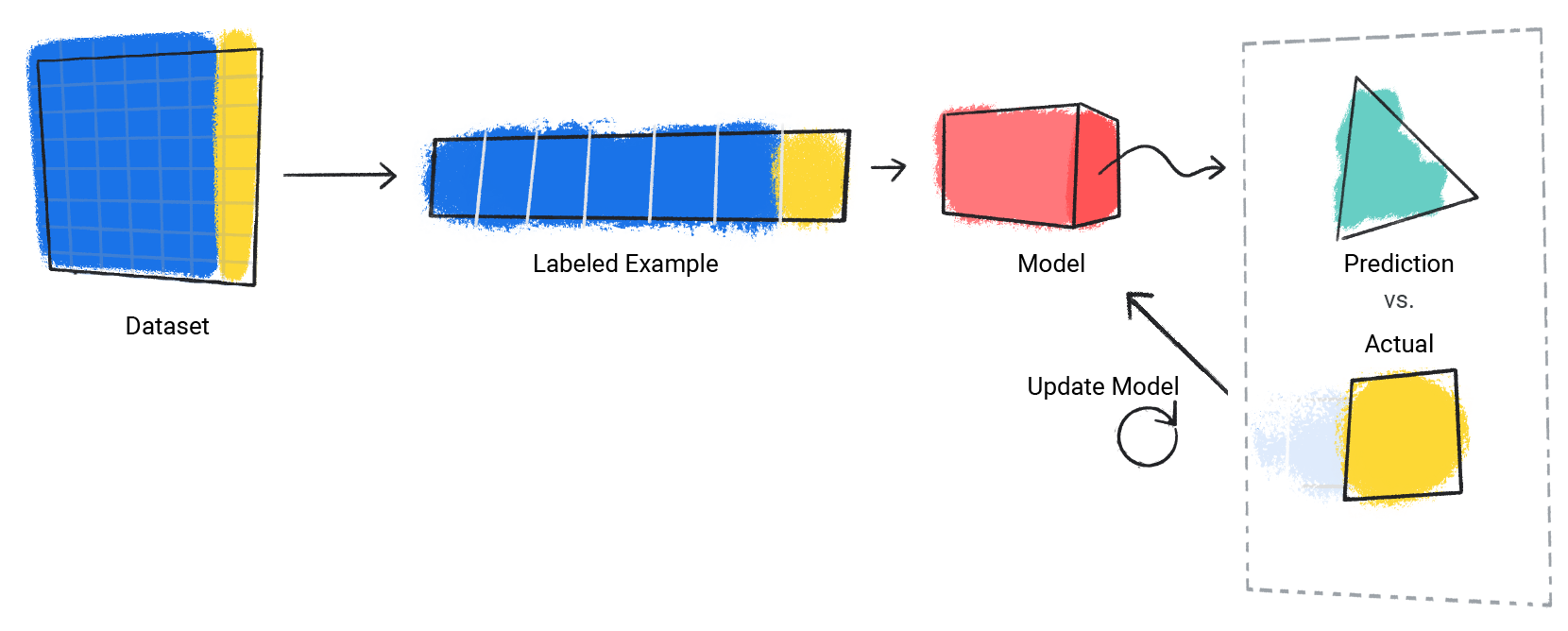
شکل 3 . یک مدل ML که پیش بینی های خود را برای هر نمونه برچسب گذاری شده در مجموعه داده آموزشی به روز می کند.
به این ترتیب مدل به تدریج رابطه صحیح بین ویژگی ها و برچسب را یاد می گیرد. این درک تدریجی همچنین به این دلیل است که مجموعه داده های بزرگ و متنوع مدل بهتری را تولید می کند. مدل دادههای بیشتری را با طیف وسیعتری از مقادیر دیده است و درک خود را از رابطه بین ویژگیها و برچسب اصلاح کرده است.
در طول آموزش، تمرینکنندگان ML میتوانند تنظیمات و ویژگیهایی را که مدل برای پیشبینی استفاده میکند، تنظیمات ظریفی انجام دهند. به عنوان مثال، برخی از ویژگی ها قدرت پیش بینی بیشتری نسبت به سایرین دارند. بنابراین، تمرینکنندگان ML میتوانند انتخاب کنند که مدل از کدام ویژگی در طول آموزش استفاده میکند. برای مثال، فرض کنید یک مجموعه داده آب و هوا شامل time_of_day به عنوان یک ویژگی باشد. در این مورد، یک متخصص ML میتواند در طول آموزش time_of_day اضافه یا حذف کند تا ببیند آیا مدل با آن یا بدون آن پیشبینیهای بهتری انجام میدهد.
در حال ارزیابی
ما یک مدل آموزش دیده را ارزیابی می کنیم تا مشخص کنیم که چقدر خوب یاد گرفته است. وقتی یک مدل را ارزیابی می کنیم، از یک مجموعه داده برچسب دار استفاده می کنیم، اما فقط ویژگی های مجموعه داده را به مدل می دهیم. سپس پیشبینیهای مدل را با مقادیر واقعی برچسب مقایسه میکنیم.

شکل 4 . ارزیابی یک مدل ML با مقایسه پیشبینیهای آن با مقادیر واقعی.
بسته به پیشبینیهای مدل، ممکن است قبل از استقرار مدل در یک برنامه واقعی، آموزش و ارزیابی بیشتری انجام دهیم.
درک خود را بررسی کنید
استنتاج
هنگامی که از نتایج ارزیابی مدل راضی شدیم، میتوانیم از مدل برای پیشبینیهایی که استنتاج نامیده میشود، در نمونههای بدون برچسب استفاده کنیم. در مثال برنامه آب و هوا، ما به مدل شرایط آب و هوای فعلی -مانند دما، فشار اتمسفر و رطوبت نسبی- را میدهیم و میزان بارندگی را پیشبینی میکند.