האלגוריתמים לסיווג טקסט נמצאים בלב מגוון מערכות תוכנה שמעבדות נתוני טקסט בקנה מידה נרחב. תוכנות אימייל משתמשות בסיווג טקסט כדי לקבוע אם הודעות נכנסות נשלחות לתיבת הדואר הנכנס או כשהן מסוננות בתיקיית הספאם. פורומים לדיונים משתמשים בסיווג טקסט כדי לקבוע אם צריך לסמן תגובות כלא הולמות.
אלה שתי דוגמאות לסיווג נושאים, שמסווגות מסמך טקסט בסדרה אחת של נושאים מוגדרים מראש. בבעיות רבות הקשורות לסיווג נושאים, הסיווג הזה מבוסס בעיקר על מילות מפתח בטקסט.
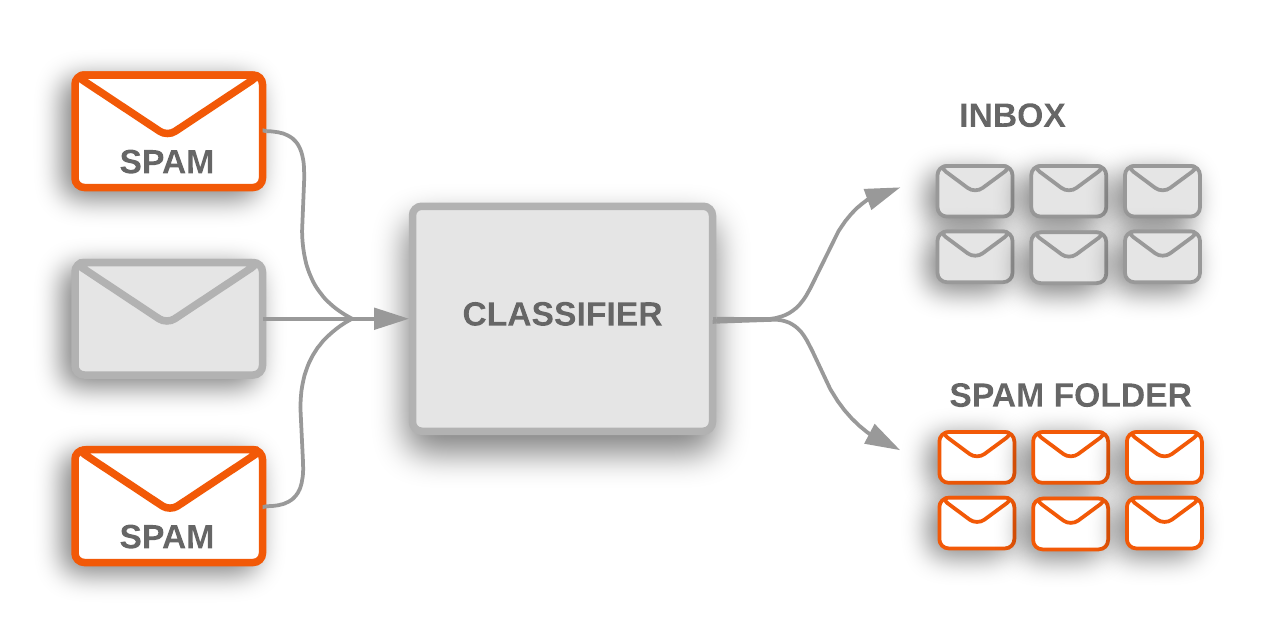
איור 1: סיווג לפי נושא משמש לסימון אימיילים זדוניים כספאם, שמסוננים לתיקיית הספאם.
סוג נפוץ נוסף של סיווג טקסט הוא ניתוח סנטימנט, שהמטרה שלו היא לזהות את הקוטביות של תוכן הטקסט: סוג הדעה שהוא מבטא. זה יכול להיות דירוג בינארי של 'לייק' או 'דיסלייק', או קבוצת אפשרויות מפורטת יותר, כמו דירוג של 1 עד 5. דוגמאות לניתוח סנטימנט כוללות ניתוח פוסטים ב-Twitter כדי לקבוע אם אנשים אהבו את הסרט השחור השחור, או כדי לגבש את דעתו של הציבור הרחב על מותג חדש של נעלי Nike מביקורות של Walmart.
במדריך הזה נפרט כמה שיטות מומלצות ללמידה חישובית לפתרון בעיות שקשורות לסיווג טקסט. מה נלמד אתכם:
- תהליך העבודה מקצה לקצה לפתרון בעיות בסיווג טקסט באמצעות למידה חישובית
- איך לבחור את המודל המתאים לבעיה של סיווג טקסט
- איך להטמיע את המודל הרצוי באמצעות TensorFlow
תהליך העבודה של סיווג הטקסט
לפניכם סקירה כללית של תהליך העבודה המשמש לפתרון בעיות בלמידת מכונה:
- שלב 1: אוספים נתונים
- שלב 2: מעיינים בנתונים
- שלב 2.5: בחירת דגם*
- שלב 3: הכנת הנתונים
- שלב 4: בניית המודל, הדרכה והערכה של המודל
- שלב 5: כוונון של פרמטרים מותאמים אישית
- שלב 6: פריסת המודל

איור 2: תהליך העבודה לפתרון בעיות בלמידת מכונה
הקטעים הבאים מסבירים בפירוט כל שלב ומוסבר איך ליישם אותם עבור נתוני טקסט.