इस शब्दावली में, आर्टिफ़िशियल इंटेलिजेंस से जुड़े शब्दों की परिभाषाएं दी गई हैं.
A
ऐब्लेशन
यह मॉडल से किसी फ़ीचर या कॉम्पोनेंट को कुछ समय के लिए हटाकर, उसकी अहमियत का आकलन करने का तरीका है. इसके बाद, उस सुविधा या कॉम्पोनेंट के बिना मॉडल को फिर से ट्रेन करें. अगर फिर से ट्रेन किया गया मॉडल पहले से काफ़ी खराब परफ़ॉर्म करता है, तो इसका मतलब है कि हटाई गई सुविधा या कॉम्पोनेंट ज़रूरी था.
उदाहरण के लिए, मान लें कि आपने 10 सुविधाओं के आधार पर क्लासिफ़िकेशन मॉडल को ट्रेन किया है. साथ ही, टेस्ट सेट पर 88% सटीकता हासिल की है. पहली सुविधा की अहमियत का पता लगाने के लिए, सिर्फ़ नौ अन्य सुविधाओं का इस्तेमाल करके मॉडल को फिर से ट्रेन किया जा सकता है. अगर फिर से ट्रेन किया गया मॉडल, पहले से काफ़ी खराब परफ़ॉर्म करता है (उदाहरण के लिए, 55% सटीक), तो इसका मतलब है कि हटाई गई सुविधा शायद ज़रूरी थी. इसके उलट, अगर फिर से ट्रेन किया गया मॉडल भी उतना ही अच्छा परफ़ॉर्म करता है, तो इसका मतलब है कि वह सुविधा शायद उतनी ज़रूरी नहीं थी.
एब्लेशन की मदद से, यह भी पता लगाया जा सकता है कि ये कितने ज़रूरी हैं:
- बड़े कॉम्पोनेंट, जैसे कि बड़े एमएल सिस्टम का पूरा सबसिस्टम
- प्रोसेस या तकनीकें, जैसे कि डेटा प्रीप्रोसेसिंग का चरण
दोनों ही मामलों में, आपको यह पता चलेगा कि कॉम्पोनेंट हटाने के बाद, सिस्टम की परफ़ॉर्मेंस में क्या बदलाव हुआ है या कोई बदलाव नहीं हुआ है.
A/B टेस्टिंग
यह आंकड़ों की मदद से, दो या उससे ज़्यादा तकनीकों की तुलना करने का तरीका है. जैसे, A और B. आम तौर पर, A एक मौजूदा तकनीक होती है और B एक नई तकनीक होती है. A/B टेस्टिंग से न सिर्फ़ यह पता चलता है कि कौनसी तकनीक बेहतर परफ़ॉर्म करती है, बल्कि यह भी पता चलता है कि क्या परफ़ॉर्मेंस में अंतर, आंकड़ों के हिसाब से अहम है.
A/B टेस्टिंग में आम तौर पर, दो तकनीकों के लिए एक मेट्रिक की तुलना की जाती है. उदाहरण के लिए, दो तकनीकों के लिए मॉडल की सटीकता की तुलना कैसे की जाती है? हालांकि, A/B टेस्टिंग में मेट्रिक की किसी भी सीमित संख्या की तुलना भी की जा सकती है.
ऐक्सलरेटर चिप
यह खास हार्डवेयर कॉम्पोनेंट की एक कैटगरी है. इसे डीप लर्निंग एल्गोरिदम के लिए ज़रूरी मुख्य कंप्यूटेशन करने के लिए डिज़ाइन किया गया है.
ऐक्सलरेटर चिप (या सिर्फ़ ऐक्सलरेटर) की मदद से, ट्रेनिंग और अनुमान लगाने के टास्क की स्पीड और क्षमता को सामान्य सीपीयू की तुलना में काफ़ी हद तक बढ़ाया जा सकता है. ये न्यूरल नेटवर्क को ट्रेनिंग देने और कंप्यूटेशनल इंटेंसिव टास्क के लिए सबसे सही हैं.
ऐक्सलरेटर चिप के उदाहरणों में ये शामिल हैं:
- डीप लर्निंग के लिए, Google की टेंसर प्रोसेसिंग यूनिट (TPU) के साथ-साथ खास हार्डवेयर.
- NVIDIA के जीपीयू. इन्हें शुरुआत में ग्राफ़िक्स प्रोसेसिंग के लिए डिज़ाइन किया गया था. हालांकि, अब इन्हें पैरलल प्रोसेसिंग के लिए डिज़ाइन किया गया है. इससे प्रोसेसिंग की स्पीड काफ़ी बढ़ सकती है.
सटीक
सही क्लासिफ़िकेशन अनुमानों की संख्या को अनुमानों की कुल संख्या से भाग देने पर यह स्कोर मिलता है. यानी:
उदाहरण के लिए, अगर किसी मॉडल ने 40 अनुमान सही लगाए और 10 अनुमान गलत लगाए, तो उसकी सटीकता इस तरह से कैलकुलेट की जाएगी:
बाइनरी क्लासिफ़िकेशन में, सही अनुमानों और गलत अनुमानों की अलग-अलग कैटगरी के लिए खास नाम दिए गए हैं. इसलिए, बाइनरी क्लासिफ़िकेशन के लिए सटीक नतीजे का फ़ॉर्मूला यह है:
कहां:
- टीपी, ट्रू पॉज़िटिव (सही अनुमान) की संख्या है.
- TN, ट्रू नेगेटिव (सही अनुमान) की संख्या है.
- एफ़पी, फ़ॉल्स पॉज़िटिव (गलत अनुमान) की संख्या होती है.
- FN, फ़ॉल्स निगेटिव (गलत अनुमान) की संख्या है.
प्रिसिज़न और रीकॉल के साथ, सटीकता की तुलना करें और इनके बीच अंतर बताएं.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: सटीकता, रीकॉल, प्रेसिज़न, और इनसे जुड़ी मेट्रिक देखें.
ऐक्शन गेम
रीइन्फ़ोर्समेंट लर्निंग में, एजेंट के एनवायरमेंट की स्टेट के बीच ट्रांज़िशन करने का तरीका. एजेंट, नीति का इस्तेमाल करके कार्रवाई चुनता है.
ऐक्टिवेशन फ़ंक्शन
यह एक ऐसा फ़ंक्शन है जो न्यूरल नेटवर्क को सुविधाओं और लेबल के बीच नॉनलीनियर (जटिल) संबंधों को समझने में मदद करता है.
लोकप्रिय ऐक्टिवेशन फ़ंक्शन में ये शामिल हैं:
ऐक्टिवेशन फ़ंक्शन के प्लॉट कभी भी सीधी लाइनें नहीं होते. उदाहरण के लिए, ReLU ऐक्टिवेशन फ़ंक्शन के प्लॉट में दो सीधी लाइनें होती हैं:

सिगमॉइड ऐक्टिवेशन फ़ंक्शन का प्लॉट ऐसा दिखता है:

उदाहरण देखने के लिए, आइकॉन पर क्लिक करें.
न्यूरल नेटवर्क में, ऐक्टिवेशन फ़ंक्शन, न्यूरॉन के सभी इनपुट के वेटेड सम में बदलाव करते हैं. वेटेड सम का हिसाब लगाने के लिए, न्यूरॉन काम की वैल्यू और वेट के प्रॉडक्ट को जोड़ता है. उदाहरण के लिए, मान लें कि किसी न्यूरॉन के लिए ज़रूरी इनपुट में यह जानकारी शामिल है:
| इनपुट वैल्यू | इनपुट वज़न |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
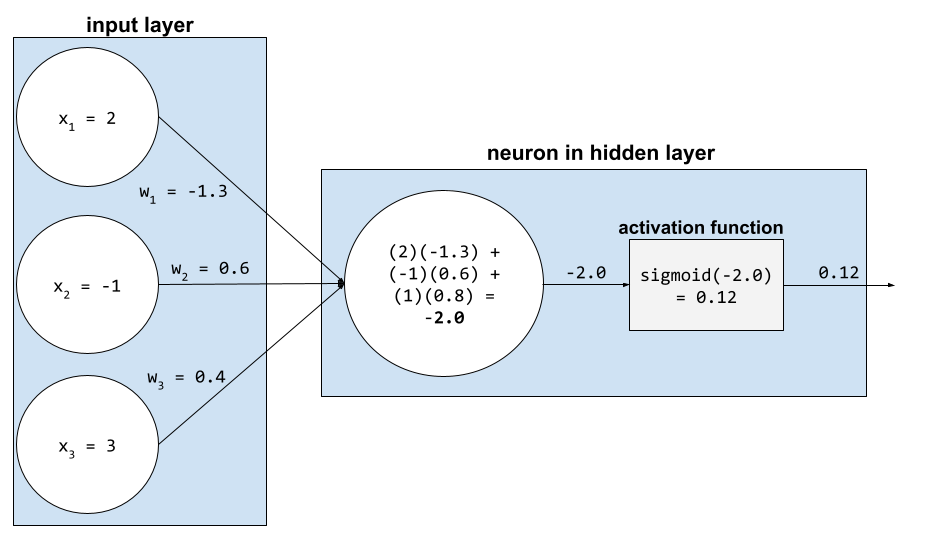
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: ऐक्टिवेशन फ़ंक्शन देखें.
ऐक्टिव लर्निंग
ट्रेनिंग का ऐसा तरीका जिसमें एल्गोरिदम, सीखने के लिए कुछ डेटा चुनता है. एक्टिव लर्निंग, खास तौर पर तब फ़ायदेमंद होती है, जब लेबल किए गए उदाहरण कम हों या उन्हें पाना महंगा हो. ऐक्टिव लर्निंग एल्गोरिदम, लेबल किए गए अलग-अलग उदाहरणों को खोजने के बजाय, सिर्फ़ उन उदाहरणों को खोजता है जिनकी उसे सीखने के लिए ज़रूरत होती है.
AdaGrad
यह एक बेहतर ग्रेडिएंट डिसेंट एल्गोरिदम है. यह हर पैरामीटर के ग्रेडिएंट को फिर से स्केल करता है. इससे हर पैरामीटर को एक अलग लर्निंग रेट मिलता है. पूरी जानकारी के लिए, Adaptive Subgradient Methods for Online Learning and Stochastic Optimization देखें.
अडैप्टेशन
ट्यूनिंग या फ़ाइन-ट्यूनिंग के लिए इस्तेमाल किया जाने वाला दूसरा शब्द.
एजेंट
ऐसा सॉफ़्टवेयर जो मल्टीमॉडल इनपुट के आधार पर, उपयोगकर्ता की ओर से कार्रवाइयां करने के लिए प्लान बना सकता है और उन्हें लागू कर सकता है.
रीइन्फ़ोर्समेंट लर्निंग में, एजेंट वह इकाई होती है जो नीति का इस्तेमाल करके, एनवायरमेंट की स्टेट के बीच ट्रांज़िशन से मिलने वाले अनुमानित फ़ायदे को ज़्यादा से ज़्यादा करती है.
एजेंटिक
agent का विशेषण रूप. एजेंटिक का मतलब उन क्वालिटी से है जो एजेंटों में होती हैं. जैसे, स्वायत्तता.
एजेंटिक वर्कफ़्लो
यह एक डाइनैमिक प्रोसेस है. इसमें एजेंट, किसी लक्ष्य को हासिल करने के लिए अपने-आप प्लान बनाता है और कार्रवाइयां करता है. इस प्रोसेस में, वजह बताना, बाहरी टूल इस्तेमाल करना, और अपने प्लान को खुद ठीक करना शामिल हो सकता है.
एगलोमेरेटिव क्लस्टरिंग
हैरारिकल क्लस्टरिंग देखें.
एआई स्लोप
जनरेटिव एआई सिस्टम से मिला ऐसा जवाब जिसमें क्वालिटी के बजाय क्वांटिटी पर ज़्यादा ध्यान दिया गया हो. उदाहरण के लिए, एआई स्लोप वाले वेब पेज पर, एआई से जनरेट किया गया और खराब क्वालिटी वाला कॉन्टेंट मौजूद होता है.
गड़बड़ी की पहचान करना
आउटलायर की पहचान करने की प्रोसेस. उदाहरण के लिए, अगर किसी सुविधा के लिए औसत 100 है और स्टैंडर्ड डेविएशन 10 है, तो गड़बड़ी का पता लगाने वाली सुविधा को 200 की वैल्यू को संदिग्ध के तौर पर फ़्लैग करना चाहिए.
AR
ऑगमेंटेड रिएलिटी का संक्षिप्त नाम.
पीआर कर्व के नीचे का एरिया
पीआर एयूसी (पीआर कर्व के नीचे का हिस्सा) देखें.
आरओसी कर्व के नीचे का क्षेत्र
एयूसी (आरओसी कर्व के नीचे का हिस्सा) देखें.
आर्टिफ़िशियल जनरल इंटेलिजेंस
यह एक ऐसा सिस्टम है जो इंसानों की तरह काम करता है. इसमें समस्याओं को अलग-अलग तरीकों से हल करने, क्रिएटिविटी दिखाने, और अडैप्ट करने की क्षमता होती है. उदाहरण के लिए, आर्टिफ़िशियल जनरल इंटेलिजेंस (एजीआई) वाला कोई प्रोग्राम, टेक्स्ट का अनुवाद कर सकता है, सिम्फ़नी बना सकता है, और ऐसे गेम में महारत हासिल कर सकता है जो अब तक बनाए नहीं गए हैं.
आर्टिफ़िशियल इंटेलिजेंस
ऐसा प्रोग्राम या मॉडल जो इंसानों की तरह काम करता है और मुश्किल टास्क को हल कर सकता है. उदाहरण के लिए, टेक्स्ट का अनुवाद करने वाला प्रोग्राम या मॉडल या रेडियोलॉजिकल इमेज से बीमारियों का पता लगाने वाला प्रोग्राम या मॉडल, दोनों में आर्टिफ़िशियल इंटेलिजेंस का इस्तेमाल किया जाता है.
आधिकारिक तौर पर, मशीन लर्निंग, आर्टिफ़िशियल इंटेलिजेंस का एक उप-क्षेत्र है. हालांकि, हाल के वर्षों में कुछ संगठन, आर्टिफ़िशियल इंटेलिजेंस और मशीन लर्निंग शब्दों का इस्तेमाल एक-दूसरे की जगह कर रहे हैं.
ध्यान देना
यह न्यूरल नेटवर्क में इस्तेमाल होने वाला एक ऐसा तरीका है जो किसी शब्द या शब्द के हिस्से की अहमियत के बारे में बताता है. अटेंशन, मॉडल को अगले टोकन/शब्द का अनुमान लगाने के लिए ज़रूरी जानकारी को छोटा कर देता है. आम तौर पर, अटेंशन मैकेनिज़्म में इनपुट के सेट पर वेटेड सम शामिल होता है. इसमें हर इनपुट के लिए वज़न की गिनती, न्यूरल नेटवर्क के किसी दूसरे हिस्से से की जाती है.
सेल्फ़-अटेंशन और मल्टी-हेड सेल्फ़-अटेंशन के बारे में भी जानें. ये ट्रांसफ़ॉर्मर के बुनियादी ब्लॉक हैं.
सेल्फ़-अटेंशन के बारे में ज़्यादा जानने के लिए, मशीन लर्निंग क्रैश कोर्स में एलएलएम: लार्ज लैंग्वेज मॉडल क्या होता है? देखें.
एट्रिब्यूट
feature के लिए समानार्थी शब्द.
मशीन लर्निंग में निष्पक्षता के लिए, एट्रिब्यूट का मतलब अक्सर लोगों की विशेषताओं से होता है.
एट्रिब्यूट सैंपलिंग
यह डिसिज़न फ़ॉरेस्ट को ट्रेन करने की एक रणनीति है. इसमें हर डिसिज़न ट्री, शर्त के बारे में सीखते समय, संभावित सुविधाओं के सिर्फ़ एक रैंडम सबसेट पर विचार करता है. आम तौर पर, हर नोड के लिए, सुविधाओं का अलग सबसेट सैंपल किया जाता है. इसके उलट, एट्रिब्यूट सैंपलिंग के बिना किसी फ़ैसले वाले ट्री को ट्रेन करते समय, हर नोड के लिए सभी संभावित सुविधाओं पर विचार किया जाता है.
AUC (आरओसी कर्व के नीचे का हिस्सा)
यह 0.0 से 1.0 के बीच की एक संख्या होती है. यह बाइनरी क्लासिफ़िकेशन मॉडल की, पॉज़िटिव क्लास को नेगेटिव क्लास से अलग करने की क्षमता को दिखाती है. एयूसी की वैल्यू 1.0 के जितनी ज़्यादा करीब होगी, मॉडल की परफ़ॉर्मेंस उतनी ही बेहतर होगी.
उदाहरण के लिए, इस इमेज में एक वर्गीकरण मॉडल दिखाया गया है. यह पॉज़िटिव क्लास (हरे रंग के ओवल) को नेगेटिव क्लास (बैंगनी रंग के आयत) से पूरी तरह अलग करता है. इस मॉडल का एयूसी 1.0 है, जो कि काफ़ी अच्छा है:

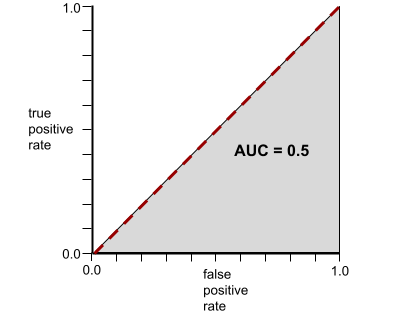
इसके उलट, यहां दिए गए उदाहरण में, क्लासिफ़िकेशन मॉडल के नतीजे दिखाए गए हैं. इस मॉडल ने रैंडम नतीजे जनरेट किए हैं. इस मॉडल का एयूसी 0.5 है:

हां, पिछले मॉडल का एयूसी 0.5 है, न कि 0.0.
ज़्यादातर मॉडल, इन दोनों के बीच में कहीं होते हैं. उदाहरण के लिए, यहां दिया गया मॉडल, पॉज़िटिव और नेगेटिव वैल्यू को कुछ हद तक अलग करता है. इसलिए, इसका एयूसी 0.5 और 1.0 के बीच है:

एयूसी, क्लासिफ़िकेशन थ्रेशोल्ड के लिए सेट की गई किसी भी वैल्यू को अनदेखा करता है. इसके बजाय, एयूसी, क्लासिफ़िकेशन के सभी संभावित थ्रेशोल्ड पर विचार करता है.
एयूसी और आरओसी कर्व के बीच के संबंध के बारे में जानने के लिए, आइकॉन पर क्लिक करें.
AUC, ROC कर्व के नीचे के क्षेत्र को दिखाता है. उदाहरण के लिए, किसी ऐसे मॉडल के लिए आरओसी कर्व यहां दिया गया है जो पॉज़िटिव और नेगेटिव को पूरी तरह से अलग करता है:
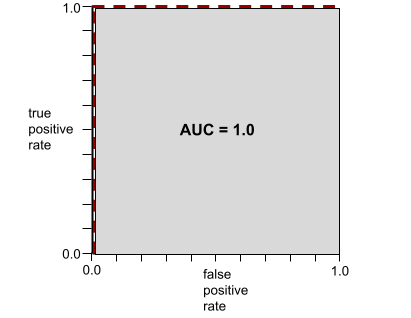
एयूसी, ऊपर दिए गए इलस्ट्रेशन में ग्रे रंग वाला हिस्सा है. इस खास मामले में, क्षेत्रफल निकालने के लिए ग्रे रंग वाले हिस्से की लंबाई (1.0) को ग्रे रंग वाले हिस्से की चौड़ाई (1.0) से गुणा किया जाता है. इसलिए, 1.0 और 1.0 के प्रॉडक्ट से, एयूसी का स्कोर ठीक 1.0 मिलता है. यह एयूसी का सबसे ज़्यादा स्कोर है.
इसके उलट, क्लासिफ़िकेशन मॉडल के लिए आरओसी कर्व, क्लास को अलग नहीं कर सकता. यह इस तरह दिखता है. इस ग्रे रंग के क्षेत्र का क्षेत्रफल 0.5 है.
आम तौर पर, आरओसी कर्व कुछ ऐसा दिखता है:
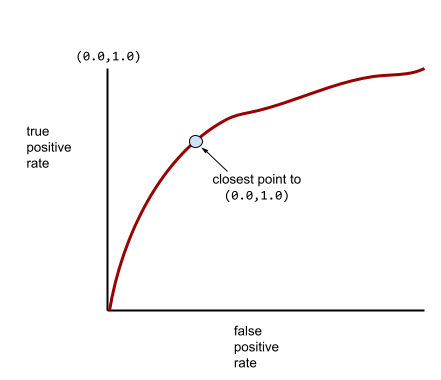
इस कर्व के नीचे के एरिया का हिसाब मैन्युअल तरीके से लगाना मुश्किल होता है. इसलिए, आम तौर पर कोई प्रोग्राम ज़्यादातर एयूसी वैल्यू का हिसाब लगाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: आरओसी और एयूसी देखें.
संवर्धित वास्तविकता
यह एक ऐसी टेक्नोलॉजी है जो कंप्यूटर से जनरेट की गई इमेज को, उपयोगकर्ता को दिखने वाली असली दुनिया के ऊपर दिखाती है. इस तरह, यह कंपोज़िट व्यू उपलब्ध कराती है.
ऑटोएन्कोडर
यह एक ऐसा सिस्टम है जो इनपुट से सबसे ज़रूरी जानकारी निकालने के बारे में सीखता है. ऑटोएन्कोडर, एन्कोडर और डिकोडर का कॉम्बिनेशन होते हैं. ऑटोएनकोडर, दो चरणों वाली इस प्रोसेस पर काम करते हैं:
- एनकोडर, इनपुट को (आम तौर पर) लॉसलेस लोअर-डाइमेंशनल (इंटरमीडिएट) फ़ॉर्मैट में मैप करता है.
- डीकोडर, कम डाइमेंशन वाले फ़ॉर्मैट को ज़्यादा डाइमेंशन वाले ओरिजनल इनपुट फ़ॉर्मैट में मैप करके, ओरिजनल इनपुट की लॉस वाली वर्शन बनाता है.
ऑटोएनकोडर को शुरू से आखिर तक ट्रेन किया जाता है. इसमें डिकोडर, एनकोडर के इंटरमीडिएट फ़ॉर्मैट से ओरिजनल इनपुट को फिर से बनाने की कोशिश करता है. इंटरमीडिएट फ़ॉर्मैट, ओरिजनल फ़ॉर्मैट से छोटा (कम डाइमेंशन वाला) होता है. इसलिए, ऑटोएन्कोडर को यह सीखना पड़ता है कि इनपुट में कौनसी जानकारी ज़रूरी है. साथ ही, आउटपुट, इनपुट से पूरी तरह मेल नहीं खाएगा.
उदाहरण के लिए:
- अगर इनपुट डेटा कोई ग्राफ़िक है, तो पूरी तरह से मेल न खाने वाली कॉपी, ओरिजनल ग्राफ़िक से मिलती-जुलती होगी. हालांकि, इसमें कुछ बदलाव किए गए होंगे. ऐसा हो सकता है कि ओरिजनल ग्राफ़िक की हूबहू कॉपी न होने की वजह से, उसमें मौजूद नॉइज़ हट गया हो या कुछ छूटे हुए पिक्सल भर गए हों.
- अगर इनपुट डेटा टेक्स्ट है, तो ऑटोएनकोडर एक नया टेक्स्ट जनरेट करेगा. यह टेक्स्ट, ओरिजनल टेक्स्ट की तरह होगा, लेकिन उससे अलग होगा.
वेरिएशनल ऑटोएनकोडर के बारे में भी जानें.
अपने-आप होने वाला आकलन
सॉफ़्टवेयर का इस्तेमाल करके, मॉडल के आउटपुट की क्वालिटी का आकलन करना.
जब मॉडल का आउटपुट काफ़ी आसान हो, तब कोई स्क्रिप्ट या प्रोग्राम, मॉडल के आउटपुट की तुलना गोल्डन रिस्पॉन्स से कर सकता है. इस तरह के अपने-आप होने वाले आकलन को कभी-कभी प्रोग्रामैटिक आकलन कहा जाता है. ROUGE या BLEU जैसी मेट्रिक, प्रोग्राम के हिसाब से आकलन करने के लिए अक्सर काम की होती हैं.
जब मॉडल का आउटपुट मुश्किल होता है या कोई एक सही जवाब नहीं होता, तो कभी-कभी ऑटोरेटर नाम का एक अलग एमएल प्रोग्राम, अपने-आप आकलन करता है.
इसकी तुलना मानवीय आकलन से करें.
ऑटोमेशन बायस
जब फ़ैसला लेने वाला कोई व्यक्ति, ऑटोमेटेड फ़ैसले लेने वाले सिस्टम की ओर से दिए गए सुझावों को, बिना ऑटोमेशन के तैयार की गई जानकारी के मुकाबले ज़्यादा अहमियत देता है. ऐसा तब भी होता है, जब ऑटोमेटेड फ़ैसले लेने वाला सिस्टम गलतियां करता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: पूर्वाग्रह के टाइप देखें.
AutoML
मशीन लर्निंग मॉडल बनाने की कोई भी ऑटोमेटेड प्रोसेस. AutoML, अपने-आप ये टास्क कर सकता है:
- सबसे सही मॉडल खोजें.
- हाइपरपैरामीटर को ट्यून करें.
- डेटा तैयार करना. इसमें फ़ीचर इंजीनियरिंग करना भी शामिल है.
- इसके बाद, मॉडल को डिप्लॉय करें.
AutoML, डेटा वैज्ञानिकों के लिए फ़ायदेमंद है. इसकी मदद से, वे मशीन लर्निंग पाइपलाइन को कम समय और मेहनत में डेवलप कर सकते हैं. साथ ही, अनुमान लगाने की सटीकता को बेहतर बना सकते हैं. यह उन लोगों के लिए भी फ़ायदेमंद है जो मशीन लर्निंग के विशेषज्ञ नहीं हैं. यह मशीन लर्निंग के मुश्किल कामों को उनके लिए आसान बना देता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ऑटोमेटेड मशीन लर्निंग (AutoML) देखें.
ऑटोरेटर की परफ़ॉर्मेंस का आकलन
यह जनरेटिव एआई मॉडल के आउटपुट की क्वालिटी का आकलन करने का एक हाइब्रिड तरीका है. इसमें मैन्युअल तरीके से आकलन और ऑटोमैटिक तरीके से आकलन, दोनों शामिल होते हैं. ऑटोरेटर, एक एमएल मॉडल है. इसे मैन्युअल तरीके से किए गए आकलन से बनाए गए डेटा पर ट्रेन किया जाता है. आदर्श रूप से, ऑटोमेटेड रेटिंग देने वाला सिस्टम, मैन्युअल तरीके से रेटिंग देने वाले व्यक्ति की तरह काम करता है.पहले से तैयार किए गए ऑटोरेटर उपलब्ध हैं. हालांकि, सबसे अच्छे ऑटोरेटर को खास तौर पर उस टास्क के लिए फ़ाइन-ट्यून किया जाता है जिसका आकलन किया जा रहा है.
ऑटो-रिग्रेसिव मॉडल
ऐसा मॉडल जो अपने पिछले अनुमानों के आधार पर अनुमान लगाता है. उदाहरण के लिए, ऑटो-रिग्रेसिव भाषा मॉडल, पहले से अनुमानित किए गए टोकन के आधार पर अगले टोकन का अनुमान लगाते हैं. ट्रांसफ़ॉर्मर पर आधारित सभी लार्ज लैंग्वेज मॉडल, ऑटो-रिग्रेसिव होते हैं.
इसके उलट, GAN पर आधारित इमेज मॉडल आम तौर पर ऑटो-रिग्रेसिव नहीं होते. ऐसा इसलिए, क्योंकि वे एक ही फ़ॉरवर्ड-पास में इमेज जनरेट करते हैं, न कि चरणों में बार-बार. हालांकि, कुछ इमेज जनरेट करने वाले मॉडल ऑटो-रिग्रेसिव होते हैं, क्योंकि वे इमेज को चरणों में जनरेट करते हैं.
सहायक नुकसान
लॉस फ़ंक्शन—इसका इस्तेमाल न्यूरल नेटवर्क मॉडल के मुख्य लॉस फ़ंक्शन के साथ किया जाता है. इससे शुरुआती इटरेशन के दौरान, ट्रेनिंग की प्रोसेस को तेज़ करने में मदद मिलती है. ऐसा तब होता है, जब वेट को रैंडम तरीके से शुरू किया जाता है.
सहायक लॉस फ़ंक्शन, शुरुआती लेयर को असरदार ग्रेडिएंट देते हैं. यह वैनिशिंग ग्रेडिएंट की समस्या को कम करके, ट्रेनिंग के दौरान कन्वर्जेंस को बेहतर बनाता है.
k पर औसत प्रीसिज़न
यह एक ऐसी मेट्रिक है जो किसी एक प्रॉम्प्ट पर मॉडल की परफ़ॉर्मेंस की खास जानकारी देती है. यह मेट्रिक, रैंक किए गए नतीजे जनरेट करती है. जैसे, किताबों के सुझावों की नंबर वाली सूची. k पर औसत सटीक नतीजे, हर काम के नतीजे के लिए k पर सटीक नतीजे वैल्यू का औसत होता है. इसलिए, k पर औसत सटीक स्कोर का फ़ॉर्मूला यह है:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
कहां:
- \(n\) सूची में मौजूद काम के आइटम की संख्या है.
इसकी तुलना k पर वापस मंगाना से करें.
ऐक्सिस के साथ अलाइन होने की शर्त
डिसिज़न ट्री में, शर्त सिर्फ़ एक फ़ीचर से जुड़ी होती है. उदाहरण के लिए, अगर area
एक सुविधा है, तो ऐक्सिस के साथ अलाइन की गई शर्त यह है:
area > 200
तिरछी स्थिति के साथ कंट्रास्ट.
B
बैकप्रॉपैगेशन
यह एल्गोरिदम, न्यूरल नेटवर्क में ग्रेडिएंट डिसेंट को लागू करता है.
न्यूरल नेटवर्क को ट्रेन करने में, दो पास वाले साइकल के कई इटरेशन शामिल होते हैं. ये इटरेशन इस तरह से होते हैं:
- फ़ॉरवर्ड पास के दौरान, सिस्टम उदाहरणों के बैच को प्रोसेस करता है, ताकि अनुमान लगाया जा सके. सिस्टम, हर अनुमान की तुलना हर लेबल वैल्यू से करता है. अनुमानित वैल्यू और लेबल की वैल्यू के बीच के अंतर को उस उदाहरण के लिए लॉस कहा जाता है. सिस्टम, सभी उदाहरणों के लिए नुकसान को इकट्ठा करता है, ताकि मौजूदा बैच के लिए कुल नुकसान का हिसाब लगाया जा सके.
- बैकवर्ड पास (बैकप्रॉपैगेशन) के दौरान, सिस्टम सभी हिडन लेयर में मौजूद सभी न्यूरॉन के वेट को अडजस्ट करके, नुकसान को कम करता है.
न्यूरल नेटवर्क में, अक्सर कई हिडन लेयर में कई न्यूरॉन होते हैं. उनमें से हर न्यूरॉन, कुल नुकसान में अलग-अलग तरीके से योगदान देता है. बैकप्रॉपैगेशन से यह तय किया जाता है कि किसी न्यूरॉन पर लागू किए गए वेट को बढ़ाना है या घटाना है.
लर्निंग रेट एक मल्टीप्लायर होता है. यह कंट्रोल करता है कि हर बैकवर्ड पास, हर वेट को किस हद तक बढ़ाता या घटाता है. ज़्यादा लर्निंग रेट होने पर, हर वेट में बढ़ोतरी या गिरावट, कम लर्निंग रेट की तुलना में ज़्यादा होगी.
कैलकुलस के हिसाब से, बैकप्रॉपैगेशन में कैलकुलस का चेन रूल लागू होता है. इसका मतलब है कि बैकप्रॉपैगेशन, हर पैरामीटर के हिसाब से गड़बड़ी के आंशिक अवकलज का हिसाब लगाता है.
कुछ साल पहले, एमएल प्रैक्टिशनर को बैकप्रॉपैगेशन लागू करने के लिए कोड लिखना पड़ता था. Keras जैसे आधुनिक एमएल एपीआई, अब आपके लिए बैकप्रोपैगेशन लागू करते हैं. वाह!
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क देखें.
बैगिंग
यह एन्सेम्बल को ट्रेन करने का एक तरीका है. इसमें हर मॉडल, ट्रेनिंग के उदाहरणों के रैंडम सबसेट पर ट्रेन होता है. इन उदाहरणों को रिप्लेसमेंट के साथ सैंपलिंग करके चुना जाता है. उदाहरण के लिए, रैंडम फ़ॉरेस्ट, बैगिंग की मदद से ट्रेन किए गए डिसिज़न ट्री का कलेक्शन होता है.
बैगिंग शब्द, बूटस्ट्रैप ऐग्रीगेटिंग का छोटा रूप है.
ज़्यादा जानकारी के लिए, फ़ैसले लेने में मदद करने वाले फ़ॉरेस्ट कोर्स में रैंडम फ़ॉरेस्ट देखें.
बैग ऑफ़ वर्ड्स
किसी वाक्यांश या पैसेज में मौजूद शब्दों को किसी भी क्रम में दिखाया गया हो. उदाहरण के लिए, शब्दों का बैग इन तीन वाक्यांशों को एक जैसा दिखाता है:
- कुत्ता कूदता है
- कुत्ते को कूदते हुए
- dog jumps the
हर शब्द को स्पार्स वेक्टर में मौजूद इंडेक्स पर मैप किया जाता है. इस वेक्टर में, शब्दावली के हर शब्द के लिए एक इंडेक्स होता है. उदाहरण के लिए, कुत्ता कूदता है वाक्यांश को एक ऐसे फ़ीचर वेक्टर में मैप किया जाता है जिसमें कुत्ता, कूदता, और है शब्दों से जुड़े तीन इंडेक्स पर शून्य से अलग वैल्यू होती हैं. शून्य से अलग वैल्यू इनमें से कोई भी हो सकती है:
- किसी शब्द के मौजूद होने की जानकारी देने के लिए 1.
- बैग में कोई शब्द कितनी बार दिखता है, इसकी संख्या. उदाहरण के लिए, अगर वाक्यांश मरून रंग का कुत्ता, मरून रंग के फ़र वाला कुत्ता है, तो मरून और कुत्ता, दोनों को 2 के तौर पर दिखाया जाएगा. वहीं, अन्य शब्दों को 1 के तौर पर दिखाया जाएगा.
- कोई अन्य वैल्यू, जैसे कि बैग में किसी शब्द के दिखने की संख्या का लॉगरिदम.
आधारभूत
मॉडल का इस्तेमाल, रेफ़रंस पॉइंट के तौर पर किया जाता है. इससे यह तुलना की जाती है कि कोई दूसरा मॉडल (आम तौर पर, ज़्यादा जटिल मॉडल) कैसा परफ़ॉर्म कर रहा है. उदाहरण के लिए, लॉजिस्टिक रिग्रेशन मॉडल, डीप मॉडल के लिए एक अच्छा बेसलाइन मॉडल हो सकता है.
किसी समस्या के लिए, बेसलाइन से मॉडल डेवलपर को यह तय करने में मदद मिलती है कि नए मॉडल को कम से कम कितनी परफ़ॉर्मेंस देनी चाहिए, ताकि वह उपयोगी हो सके.
बेस मॉडल
यह पहले से ट्रेन किया गया मॉडल है. इसका इस्तेमाल, फ़ाइन-ट्यूनिंग के लिए शुरुआती पॉइंट के तौर पर किया जा सकता है. इससे खास टास्क या ऐप्लिकेशन को पूरा किया जा सकता है.
प्री-ट्रेन मॉडल और फ़ाउंडेशन मॉडल के बारे में भी जानें.
बैच
एक ट्रेनिंग इटरेशन में इस्तेमाल किए गए उदाहरणों का सेट. बैच साइज़ से यह तय होता है कि किसी बैच में कितने उदाहरण होंगे.
बैच का युग से क्या संबंध है, यह जानने के लिए युग देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
बैच इन्फ़रेंस
यह एक ऐसी प्रोसेस है जिसमें कई बिना लेबल वाले उदाहरणों के आधार पर अनुमान लगाया जाता है. इन उदाहरणों को छोटे-छोटे सबसेट ("बैच") में बांटा जाता है.
बैच इन्फ़रेंस, ऐक्सलरेटर चिप की पैरललाइज़ेशन सुविधाओं का फ़ायदा उठा सकता है. इसका मतलब है कि एक साथ कई ऐक्सलरेटर, बिना लेबल वाले उदाहरणों के अलग-अलग बैच के लिए अनुमान लगा सकते हैं. इससे हर सेकंड में अनुमानों की संख्या में काफ़ी बढ़ोतरी होती है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में प्रोडक्शन एमएल सिस्टम: स्टैटिक बनाम डाइनैमिक इन्फ़रेंस देखें.
बैच नॉर्मलाइज़ेशन
हिडन लेयर में ऐक्टिवेशन फ़ंक्शन के इनपुट या आउटपुट को नॉर्मलाइज़ करना. बैच नॉर्मलाइज़ेशन से ये फ़ायदे मिल सकते हैं:
- आउटलायर वेट से सुरक्षित रखकर, न्यूरल नेटवर्क को ज़्यादा स्टेबल बनाता है.
- इससे लर्निंग रेट बढ़ जाता है. इससे ट्रेनिंग की प्रोसेस तेज़ हो सकती है.
- ओवरफ़िटिंग को कम करें.
बैच का आकार
किसी बैच में उदाहरणों की संख्या. उदाहरण के लिए, अगर बैच का साइज़ 100 है, तो मॉडल हर इटरेशन में 100 उदाहरणों को प्रोसेस करता है.
बैच के साइज़ के लिए, यहां कुछ लोकप्रिय रणनीतियां दी गई हैं:
- स्टोकास्टिक ग्रेडिएंट डिसेंट (एसजीडी), जिसमें बैच का साइज़ 1 होता है.
- पूरा बैच, जिसमें बैच का साइज़ पूरे ट्रेनिंग सेट में मौजूद उदाहरणों की संख्या होती है. उदाहरण के लिए, अगर ट्रेनिंग सेट में 10 लाख उदाहरण शामिल हैं, तो बैच का साइज़ 10 लाख उदाहरणों का होगा. पूरे बैच को प्रोसेस करना, आम तौर पर एक असरदार रणनीति नहीं होती.
- मिनी-बैच, जिसमें बैच का साइज़ आम तौर पर 10 से 1,000 के बीच होता है. मिनी-बैच, आम तौर पर सबसे असरदार रणनीति होती है.
ज़्यादा जानकारी के लिए, यहां देखें:
- प्रोडक्शन एमएल सिस्टम: मशीन लर्निंग क्रैश कोर्स में स्टैटिक बनाम डाइनैमिक इन्फ़रेंस.
- डीप लर्निंग ट्यूनिंग प्लेबुक.
बेज़ियन न्यूरल नेटवर्क
यह एक संभाव्यता वाला न्यूरल नेटवर्क है. यह वज़न और आउटपुट में अनिश्चितता को ध्यान में रखता है. स्टैंडर्ड न्यूरल नेटवर्क रिग्रेशन मॉडल आम तौर पर, स्केलर वैल्यू का अनुमान लगाता है. उदाहरण के लिए, स्टैंडर्ड मॉडल से घर की कीमत 8,53,000 का अनुमान लगाया जाता है. इसके उलट, बेज़ियन न्यूरल नेटवर्क, वैल्यू के डिस्ट्रिब्यूशन का अनुमान लगाता है. उदाहरण के लिए, बेज़ियन मॉडल, घर की कीमत का अनुमान 8,53,000 रुपये लगाता है. इसका स्टैंडर्ड डेविएशन 67,200 रुपये है.
बेज़ियन न्यूरल नेटवर्क, वज़न और अनुमानों में अनिश्चितताओं का हिसाब लगाने के लिए, बेज़ थ्योरम पर निर्भर करता है. बेज़ियन न्यूरल नेटवर्क तब फ़ायदेमंद हो सकता है, जब अनिश्चितता को मेज़र करना ज़रूरी हो. जैसे, फ़ार्मास्यूटिकल्स से जुड़े मॉडल में. बायेसियन न्यूरल नेटवर्क, ओवरफ़िटिंग को रोकने में भी मदद कर सकते हैं.
बेज़ियन ऑप्टिमाइज़ेशन
संभाव्यता रिग्रेशन मॉडल, कंप्यूटेशनल तौर पर मुश्किल ऑब्जेक्टिव फ़ंक्शन को ऑप्टिमाइज़ करने की एक तकनीक है. इसमें, बेज़ियन लर्निंग तकनीक का इस्तेमाल करके अनिश्चितता को मापने वाले सरोगेट को ऑप्टिमाइज़ किया जाता है. बेज़ियन ऑप्टिमाइज़ेशन खुद ही बहुत महंगा होता है. इसलिए, इसका इस्तेमाल आम तौर पर उन टास्क को ऑप्टिमाइज़ करने के लिए किया जाता है जिनका आकलन करना महंगा होता है और जिनमें पैरामीटर की संख्या कम होती है. जैसे, हाइपरपैरामीटर चुनना.
बेलमैन इक्वेशन
रीइन्फ़ोर्समेंट लर्निंग में, ऑप्टिमल Q-फ़ंक्शन के लिए यह आइडेंटिटी पूरी होती है:
\[Q(s, a) = r(s, a) + \gamma \mathbb{E}_{s'|s,a} \max_{a'} Q(s', a')\]
रीइन्फ़ोर्समेंट लर्निंग एल्गोरिदम, इस आइडेंटिटी को लागू करते हैं. इससे अपडेट करने के इस नियम का इस्तेमाल करके, Q-लर्निंग बनाई जाती है:
\[Q(s,a) \gets Q(s,a) + \alpha \left[r(s,a) + \gamma \displaystyle\max_{\substack{a_1}} Q(s',a') - Q(s,a) \right] \]
रीइन्फ़ोर्समेंट लर्निंग के अलावा, बेलमैन समीकरण का इस्तेमाल डाइनैमिक प्रोग्रामिंग में भी किया जाता है. बेलमैन समीकरण के बारे में Wikipedia की जानकारी देखें.
BERT (बाईडायरेक्शनल एन्कोडर रिप्रज़ेंटेशन्स फ़्रॉम ट्रांसफ़ॉर्मर्स)
टेक्स्ट रिप्रेज़ेंटेशन के लिए मॉडल आर्किटेक्चर. ट्रेन किए गए BERT मॉडल का इस्तेमाल, टेक्स्ट क्लासिफ़िकेशन या एमएल से जुड़े अन्य कामों के लिए, बड़े मॉडल के हिस्से के तौर पर किया जा सकता है.
BERT की ये विशेषताएं हैं:
- यह Transformer आर्किटेक्चर का इस्तेमाल करता है. इसलिए, यह सेल्फ़-अटेंशन पर निर्भर करता है.
- यह Transformer के encoder हिस्से का इस्तेमाल करता है. एनकोडर का काम, टेक्स्ट को अच्छी तरह से समझना है. इसका काम, क्लासिफ़िकेशन जैसे किसी खास टास्क को पूरा करना नहीं है.
- दोतरफ़ा है.
- बिना निगरानी वाली ट्रेनिंग के लिए, मास्किंग का इस्तेमाल करता है.
BERT के वैरिएंट में ये शामिल हैं:
BERT के बारे में खास जानकारी पाने के लिए, Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing लेख पढ़ें.
पूर्वाग्रह (नीतिशास्त्र/निष्पक्षता)
1. किसी चीज़, व्यक्ति या ग्रुप को दूसरों से बेहतर बताना या उनके बारे में पूर्वाग्रह रखना. इन पूर्वाग्रहों से, डेटा को इकट्ठा करने और उसकी व्याख्या करने, सिस्टम के डिज़ाइन, और उपयोगकर्ताओं के सिस्टम से इंटरैक्ट करने के तरीके पर असर पड़ सकता है. इस तरह के पूर्वाग्रह के उदाहरणों में ये शामिल हैं:
- ऑटोमेशन बायस
- कंफ़र्मेशन बायस
- एक्सपेरिमेंटर का पूर्वाग्रह
- ग्रुप एट्रिब्यूशन बायस
- अनजाने में भेदभाव करना
- इन-ग्रुप बायस
- आउट-ग्रुप होमोजेनिटी बायस
2. सैंपलिंग या रिपोर्टिंग की प्रोसेस की वजह से हुई सिस्टमैटिक गड़बड़ी. इस तरह के पूर्वाग्रह के उदाहरणों में ये शामिल हैं:
- कवरेज से जुड़ा पूर्वाग्रह
- नॉन-रिस्पॉन्स बायस
- सर्वे में हिस्सा लेने से जुड़ा पूर्वाग्रह
- रिपोर्टिंग बायस
- सैंपलिंग बायस
- सैंपल चुनने में होने वाला पक्षपात
इसे मशीन लर्निंग मॉडल में मौजूद बायस टर्म या पूर्वानुमान में पक्षपात से भ्रमित न करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: पूर्वाग्रह के टाइप देखें.
बायस (गणित) या बायस टर्म
किसी मूल बिंदु से इंटरसेप्ट या ऑफ़सेट. गड़बड़ी, मशीन लर्निंग मॉडल में एक पैरामीटर होता है. इसे इनमें से किसी भी तरीके से दिखाया जाता है:
- b
- w0
उदाहरण के लिए, इस फ़ॉर्मूले में b, बायस है:
आसान शब्दों में कहें, तो दो डाइमेंशन वाली लाइन में बायस का मतलब "y-इंटरसेप्ट" होता है. उदाहरण के लिए, इस इलस्ट्रेशन में लाइन का झुकाव 2 है.
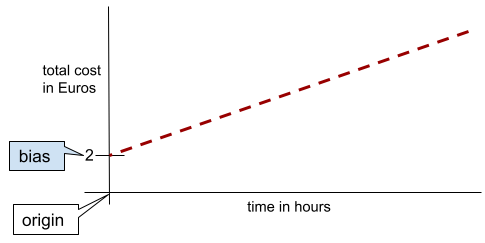
बायस इसलिए मौजूद है, क्योंकि सभी मॉडल ओरिजिन (0,0) से शुरू नहीं होते. उदाहरण के लिए, मान लें कि किसी अम्यूज़मेंट पार्क में जाने का शुल्क 200 रुपये है.इसके अलावा, हर घंटे के लिए 50 रुपये का अतिरिक्त शुल्क लगता है. इसलिए, कुल लागत को मैप करने वाले मॉडल में 2 का पूर्वाग्रह होता है, क्योंकि सबसे कम लागत 2 यूरो है.
पूर्वाग्रह को नैतिकता और निष्पक्षता में पूर्वाग्रह या अनुमान में पूर्वाग्रह से भ्रमित नहीं होना चाहिए.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन देखें.
दोनों दिशाओं में काम करने वाला
इस शब्द का इस्तेमाल ऐसे सिस्टम के लिए किया जाता है जो टेक्स्ट के उस हिस्से का आकलन करता है जो टेक्स्ट के टारगेट सेक्शन से पहले और बाद में आता है. इसके उलट, यूनिडायरेक्शनल सिस्टम सिर्फ़ उस टेक्स्ट का आकलन करता है जो टेक्स्ट के टारगेट सेक्शन से पहले आता है.
उदाहरण के लिए, मास्क किए गए लैंग्वेज मॉडल पर विचार करें. इसे इस सवाल में अंडरलाइन किए गए शब्द या शब्दों की संभावनाओं का पता लगाना है:
आपको _____ क्या है?
एकतरफ़ा भाषा मॉडल को अपनी संभावनाओं को सिर्फ़ "What", "is", और "the" शब्दों से मिले कॉन्टेक्स्ट के आधार पर तय करना होगा. इसके उलट, दोनों दिशाओं में काम करने वाला भाषा मॉडल, "with" और "you" से भी कॉन्टेक्स्ट हासिल कर सकता है. इससे मॉडल को बेहतर अनुमान लगाने में मदद मिल सकती है.
दोनों भाषाओं में काम करने वाला लैंग्वेज मॉडल
यह एक लैंग्वेज मॉडल है. यह इस बात की संभावना का पता लगाता है कि किसी टेक्स्ट के चुने गए हिस्से में, कोई टोकन किसी जगह पर मौजूद है या नहीं. यह पहले और बाद के टेक्स्ट के आधार पर काम करता है.
bigram
यह एक N-ग्राम है, जिसमें N=2 है.
बाइनरी क्लासिफ़िकेशन
यह क्लासिफ़िकेशन टास्क का एक टाइप है. इसमें, दो में से किसी एक क्लास के बारे में अनुमान लगाया जाता है:
उदाहरण के लिए, यहां दिए गए दोनों मशीन लर्निंग मॉडल, बाइनरी क्लासिफ़िकेशन करते हैं:
- यह मॉडल यह तय करता है कि ईमेल मैसेज स्पैम (पॉज़िटिव क्लास) हैं या स्पैम नहीं हैं (नेगेटिव क्लास).
- एक ऐसा मॉडल जो चिकित्सा से जुड़े लक्षणों का आकलन करता है. इससे यह पता चलता है कि किसी व्यक्ति को कोई खास बीमारी (पॉज़िटिव क्लास) है या नहीं (नेगेटिव क्लास).
इसकी तुलना मल्टी-क्लास क्लासिफ़िकेशन से करें.
लॉजिस्टिक रिग्रेशन और क्लासिफ़िकेशन थ्रेशोल्ड भी देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में वर्गीकरण देखें.
बाइनरी कंडीशन
डिसिज़न ट्री में, शर्त ऐसी होती है जिसके सिर्फ़ दो संभावित नतीजे होते हैं. आम तौर पर, हां या नहीं. उदाहरण के लिए, यहां दी गई शर्त बाइनरी शर्त है:
temperature >= 100
नॉन-बाइनरी स्थिति से अलग.
ज़्यादा जानकारी के लिए, Decision Forests कोर्स में शर्तों के टाइप देखें.
बिनिंग
बकेटिंग के लिए समानार्थी शब्द.
ब्लैक बॉक्स मॉडल
ऐसा मॉडल जिसकी "वजह" को इंसानों के लिए समझना मुश्किल हो या नामुमकिन हो. इसका मतलब है कि इंसान यह देख सकते हैं कि प्रॉम्प्ट से जवाबों पर क्या असर पड़ता है. हालांकि, इंसान यह नहीं जान सकते कि ब्लैक बॉक्स मॉडल, जवाब का फ़ैसला कैसे करता है. दूसरे शब्दों में कहें, तो ब्लैक बॉक्स मॉडल में व्याख्या करने की क्षमता नहीं होती.
ज़्यादातर डीप मॉडल और लार्ज लैंग्वेज मॉडल ब्लैक बॉक्स होते हैं.
ब्लू (बायलिंग्वल इवैल्युएशन अंडरस्टडी)
यह मेट्रिक, मशीन ट्रांसलेशन का आकलन करने के लिए 0.0 से 1.0 के बीच होती है. उदाहरण के लिए, स्पैनिश से जापानी में अनुवाद.
स्कोर का हिसाब लगाने के लिए, BLEU आम तौर पर एमएल मॉडल के अनुवाद (जनरेट किया गया टेक्स्ट) की तुलना, किसी विशेषज्ञ के अनुवाद (रेफ़रंस टेक्स्ट) से करता है. जनरेट किए गए टेक्स्ट और रेफ़रंस टेक्स्ट में N-ग्राम कितने मिलते-जुलते हैं, इससे BLEU स्कोर तय होता है.
इस मेट्रिक पर मूल पेपर BLEU: a Method for Automatic Evaluation of Machine Translation है.
BLEURT भी देखें.
BLEURT (ट्रांसफ़ॉर्मर से बाइलिंग्वल इवैलुएशन अंडरस्टडी)
यह एक मेट्रिक है. इसका इस्तेमाल, एक भाषा से दूसरी भाषा में किए गए मशीन ट्रांसलेशन का आकलन करने के लिए किया जाता है. खास तौर पर, अंग्रेज़ी से दूसरी भाषा में और दूसरी भाषा से अंग्रेज़ी में किए गए ट्रांसलेशन का आकलन करने के लिए.
अंग्रेज़ी से दूसरी भाषाओं में और दूसरी भाषाओं से अंग्रेज़ी में अनुवाद करने के लिए, BLEURT, BLEU की तुलना में, लोगों की रेटिंग के ज़्यादा करीब होता है. BLEU के उलट, BLEURT में सिमैंटिक (मतलब) समानता पर ज़ोर दिया जाता है. साथ ही, इसमें पैराफ़्रेज़िंग को शामिल किया जा सकता है.
BLEURT, पहले से ट्रेन किए गए लार्ज लैंग्वेज मॉडल (BERT) पर आधारित है. इसके बाद, इसे इंसानों की ओर से किए गए अनुवाद के टेक्स्ट के आधार पर फ़ाइन-ट्यून किया जाता है.
इस मेट्रिक पर मूल पेपर, BLEURT: Learning Robust Metrics for Text Generation है.
बूलियन सवाल (BoolQ)
एलएलएम के 'हां' या 'नहीं' में जवाब देने की क्षमता का आकलन करने के लिए डेटासेट. डेटासेट में मौजूद हर चुनौती के तीन कॉम्पोनेंट होते हैं:
- क्वेरी
- क्वेरी के जवाब के बारे में जानकारी देने वाला पैसेज.
- सही जवाब, जो हां या नहीं में से कोई एक होता है.
उदाहरण के लिए:
- सवाल: क्या मिशिगन में कोई न्यूक्लियर पावर प्लांट है?
- पैसेज: ...तीन न्यूक्लियर पावर प्लांट, मिशिगन को करीब 30% बिजली की आपूर्ति करते हैं.
- सही जवाब: हां
रिसर्च करने वालों ने, पहचान छिपाकर इकट्ठा की गई Google Search क्वेरी से सवाल इकट्ठा किए. इसके बाद, जानकारी को सही ठहराने के लिए Wikipedia पेजों का इस्तेमाल किया.
ज़्यादा जानकारी के लिए, BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions देखें.
BoolQ, SuperGLUE का एक कॉम्पोनेंट है.
BoolQ
बूलियन सवाल के लिए संक्षिप्त नाम.
बूस्टिंग
यह एक मशीन लर्निंग तकनीक है. इसमें, क्लासिफ़िकेशन मॉडल के एक सेट को बार-बार मिलाकर, ज़्यादा सटीक क्लासिफ़िकेशन मॉडल बनाया जाता है. इस सेट में, सामान्य और कम सटीक मॉडल शामिल होते हैं. इन्हें "कमज़ोर क्लासिफ़ायर" कहा जाता है. ज़्यादा सटीक क्लासिफ़िकेशन मॉडल को "मज़बूत क्लासिफ़ायर" कहा जाता है. इसके लिए, उन उदाहरणों को ज़्यादा अहमियत दी जाती है जिन्हें मॉडल फ़िलहाल गलत तरीके से क्लासिफ़ाई कर रहा है.
ज़्यादा जानकारी के लिए, फ़ैसले लेने वाले फ़ॉरेस्ट कोर्स में ग्रैडिएंट बूस्टेड डिसिज़न ट्री क्या होते हैं? देखें.
बाउंडिंग बॉक्स
किसी इमेज में, दिलचस्पी वाली जगह के आस-पास मौजूद रेक्टैंगल के (x, y) कोऑर्डिनेट. जैसे, यहां दी गई इमेज में कुत्ते के आस-पास मौजूद रेक्टैंगल के कोऑर्डिनेट.

ब्रॉडकास्ट करना
मैट्रिक्स की गणितीय संक्रिया में, ऑपरेंड के शेप को इस तरह से बढ़ाना कि वह संक्रिया के साथ काम करने वाले डाइमेंशन के साथ काम कर सके. उदाहरण के लिए, लीनियर अलजेब्रा के हिसाब से, मैट्रिक्स जोड़ने की कार्रवाई में शामिल दो ऑपरेंड के डाइमेंशन एक जैसे होने चाहिए. इसलिए, m x n डाइमेंशन वाली मैट्रिक्स को n लंबाई वाले वेक्टर में नहीं जोड़ा जा सकता. ब्रॉडकास्टिंग की मदद से, इस ऑपरेशन को इस तरह से किया जा सकता है: n लंबाई वाले वेक्टर को (m, n) शेप वाले मैट्रिक्स में वर्चुअली बड़ा किया जाता है. इसके लिए, हर कॉलम में एक ही वैल्यू को दोहराया जाता है.
ज़्यादा जानकारी के लिए, NumPy में ब्रॉडकास्टिंग के बारे में यहां दिया गया ब्यौरा देखें.
बकेटिंग
किसी एक फ़ीचर को कई बाइनरी फ़ीचर में बदलना. इन्हें आम तौर पर, वैल्यू रेंज के आधार पर बकेट या बिन कहा जाता है. आम तौर पर, काटी गई सुविधा एक लगातार चलने वाली सुविधा होती है.
उदाहरण के लिए, तापमान को एक फ़्लोटिंग-पॉइंट फ़ीचर के तौर पर दिखाने के बजाय, तापमान की रेंज को अलग-अलग बकेट में बांटा जा सकता है. जैसे:
- <= 10 डिग्री सेल्सियस को "ठंडा" बकेट में रखा जाएगा.
- 11 से 24 डिग्री सेल्सियस के बीच के तापमान को "सामान्य" बकेट में रखा जाएगा.
- >= 25 डिग्री सेल्सियस को "गर्म" बकेट में रखा जाएगा.
मॉडल, एक ही बकेट में मौजूद हर वैल्यू को एक जैसा मानेगा. उदाहरण के लिए, 13 और 22, दोनों वैल्यू को सामान्य बकेट में रखा गया है. इसलिए, मॉडल इन दोनों वैल्यू को एक जैसा मानता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: बिनिंग देखें.
C
कैलिब्रेशन लेयर
अनुमान लगाने के बाद किया गया अडजस्टमेंट. आम तौर पर, इसका इस्तेमाल अनुमान में होने वाली गड़बड़ी को ठीक करने के लिए किया जाता है. एडजस्ट किए गए अनुमान और संभावितताएं, लेबल के देखे गए सेट के डिस्ट्रिब्यूशन से मेल खानी चाहिए.
उम्मीदवार जनरेट करना
सुझावों का शुरुआती सेट, जिसे सुझाव देने वाले सिस्टम ने चुना है. उदाहरण के लिए, एक ऐसी किताबों की दुकान के बारे में सोचें जो 1,00,000 किताबें उपलब्ध कराती है. उम्मीदवार जनरेट करने के चरण में, किसी उपयोगकर्ता के लिए काम की किताबों की एक छोटी सूची बनाई जाती है. जैसे, 500 किताबें. हालांकि, किसी उपयोगकर्ता को 500 किताबों के सुझाव देना भी बहुत ज़्यादा है. सुझाव देने वाले सिस्टम के बाद के चरणों (जैसे कि स्कोरिंग और फिर से रैंक करना) में, इन 500 सुझावों को कम करके, ज़्यादा काम के सुझावों का एक छोटा सेट तैयार किया जाता है.
ज़्यादा जानकारी के लिए, Recommendation Systems कोर्स में Candidate generation overview देखें.
उम्मीदवारों का सैंपल
यह ट्रेनिंग के दौरान किया जाने वाला ऑप्टिमाइज़ेशन है. इसमें सभी पॉज़िटिव लेबल की संभावना का हिसाब लगाया जाता है. इसके लिए, उदाहरण के तौर पर सॉफ़्टमैक्स का इस्तेमाल किया जाता है. हालांकि, यह सिर्फ़ नेगेटिव लेबल के रैंडम सैंपल के लिए होता है. उदाहरण के लिए, बीगल और कुत्ता के तौर पर लेबल किए गए उदाहरण के लिए, कैंडिडेट सैंपलिंग, अनुमानित संभावनाओं और इनसे जुड़े नुकसान की शर्तों का हिसाब लगाती है. ये शर्तें इनके लिए होती हैं:
- बीगल
- dog
- बची हुई नेगेटिव क्लास का रैंडम सबसेट (उदाहरण के लिए, बिल्ली, लॉलीपॉप, बाड़).
इसका मतलब यह है कि नेगेटिव क्लास को कम बार मिलने वाले नेगेटिव रीइन्फ़ोर्समेंट से सीखा जा सकता है. हालांकि, इसके लिए यह ज़रूरी है कि पॉज़िटिव क्लास को हमेशा सही पॉज़िटिव रीइन्फ़ोर्समेंट मिले. यह बात अनुभव के आधार पर भी देखी गई है.
कैंडिडेट सैंपलिंग, ट्रेनिंग एल्गोरिदम की तुलना में ज़्यादा कंप्यूटेशनल तौर पर असरदार होती है. ट्रेनिंग एल्गोरिदम, सभी नेगेटिव क्लास के लिए अनुमान का हिसाब लगाते हैं. खास तौर पर, जब नेगेटिव क्लास की संख्या बहुत ज़्यादा होती है.
कैटगोरिकल डेटा
सुविधाएं, जिनमें संभावित वैल्यू का कोई खास सेट होता है. उदाहरण के लिए, traffic-light-state नाम की कैटगरी वाली सुविधा पर विचार करें. इसकी सिर्फ़ तीन वैल्यू हो सकती हैं:
redyellowgreen
traffic-light-state को कैटगरी के हिसाब से तय की गई सुविधा के तौर पर दिखाने से, मॉडल यह जान सकता है कि ड्राइवर के व्यवहार पर red, green, और yellow का क्या असर पड़ता है.
कैटगोरिकल फ़ीचर को कभी-कभी डिसक्रीट फ़ीचर भी कहा जाता है.
संख्यात्मक डेटा से तुलना करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटगरी में बांटे गए डेटा का इस्तेमाल करना लेख पढ़ें.
कैज़ल लैंग्वेज मॉडल
यह एक दिशा में काम करने वाले लैंग्वेज मॉडल का समानार्थी शब्द है.
भाषा मॉडलिंग में अलग-अलग दिशाओं वाले तरीकों की तुलना करने के लिए, दोनों दिशाओं में काम करने वाला भाषा मॉडल देखें.
CB
CommitmentBank का छोटा नाम.
सेंट्रॉइड
k-मीन्स या k-मीडियन एल्गोरिदम से तय किया गया क्लस्टर का सेंटर. उदाहरण के लिए, अगर k की वैल्यू 3 है, तो k-मीन्स या k-मीडियन एल्गोरिदम, तीन सेंट्रॉइड ढूंढता है.
ज़्यादा जानकारी के लिए, क्लस्टरिंग कोर्स में क्लस्टरिंग एल्गोरिदम देखें.
सेंट्रॉइड पर आधारित क्लस्टरिंग
यह क्लस्टरिंग एल्गोरिदम की एक कैटगरी है. यह डेटा को नॉनहायरार्किकल क्लस्टर में व्यवस्थित करता है. k-मीन्स, सेंट्रॉइड पर आधारित सबसे ज़्यादा इस्तेमाल किया जाने वाला क्लस्टरिंग एल्गोरिदम है.
हायरार्किकल क्लस्टरिंग एल्गोरिदम से तुलना करें.
ज़्यादा जानकारी के लिए, क्लस्टरिंग कोर्स में क्लस्टरिंग एल्गोरिदम देखें.
सिलसिलेवार तरीके से जवाब देने के लिए प्रॉम्प्ट तैयार करना
यह प्रॉम्प्ट इंजीनियरिंग की एक ऐसी तकनीक है जो लार्ज लैंग्वेज मॉडल (एलएलएम) को, जवाब देने के पीछे की वजह को क्रम से बताने के लिए बढ़ावा देती है. उदाहरण के लिए, इस प्रॉम्प्ट को देखें. इसमें दूसरे वाक्य पर खास ध्यान दें:
अगर कोई कार 7 सेकंड में 0 से 60 मील प्रति घंटे की रफ़्तार पकड़ लेती है, तो ड्राइवर को कितने G फ़ोर्स का अनुभव होगा? जवाब में, सभी ज़रूरी कैलकुलेशन दिखाएं.
एलएलएम का जवाब ऐसा हो सकता है:
- फ़िज़िक्स के फ़ॉर्मूलों का क्रम दिखाएं. साथ ही, सही जगहों पर 0, 60, और 7 वैल्यू डालें.
- यह भी बताएं कि उन फ़ॉर्मूलों को क्यों चुना गया और अलग-अलग वैरिएबल का क्या मतलब है.
चेन-ऑफ़-थॉट प्रॉम्प्टिंग से, एलएलएम को सभी कैलकुलेशन करनी पड़ती हैं. इससे ज़्यादा सही जवाब मिल सकता है. इसके अलावा, चेन-ऑफ़-थॉट प्रॉम्प्टिंग की मदद से उपयोगकर्ता, एलएलएम के जवाब देने के तरीके की जांच कर सकता है. इससे यह पता चलता है कि जवाब सही है या नहीं.
कैरेक्टर एन-ग्राम F-स्कोर (ChrF)
यह मशीन ट्रांसलेशन मॉडल का आकलन करने के लिए एक मेट्रिक है. वर्ण N-ग्राम F-स्कोर से यह पता चलता है कि रेफ़रंस टेक्स्ट में मौजूद N-ग्राम, एमएल मॉडल के जनरेट किए गए टेक्स्ट में मौजूद N-ग्राम से कितने मिलते-जुलते हैं.
कैरेक्टर एन-ग्राम एफ़-स्कोर, ROUGE और BLEU फ़ैमिली की मेट्रिक के जैसा ही होता है. हालांकि, इसमें ये अंतर होते हैं:
- वर्ण N-ग्राम F-स्कोर, वर्ण N-ग्राम पर काम करता है.
- ROUGE और BLEU, शब्द N-ग्राम या टोकन पर काम करते हैं.
चैट
किसी एमएल सिस्टम के साथ बातचीत का कॉन्टेंट. आम तौर पर, यह लार्ज लैंग्वेज मॉडल होता है. चैट में पिछली बातचीत (आपने क्या टाइप किया और लार्ज लैंग्वेज मॉडल ने कैसे जवाब दिया) को चैट के बाद के हिस्सों के लिए कॉन्टेक्स्ट माना जाता है.
चैटबॉट, लार्ज लैंग्वेज मॉडल का एक ऐप्लिकेशन है.
COVID-19 की जांच के लिए बनी चेकपोस्ट
ऐसा डेटा जो मॉडल के पैरामीटर की स्थिति को कैप्चर करता है. यह स्थिति, ट्रेनिंग के दौरान या ट्रेनिंग पूरी होने के बाद की हो सकती है. उदाहरण के लिए, ट्रेनिंग के दौरान ये काम किए जा सकते हैं:
- ट्रेनिंग को रोकना. ऐसा जान-बूझकर या कुछ गड़बड़ियों की वजह से किया जा सकता है.
- चेकपॉइंट कैप्चर करें.
- बाद में, चेकपॉइंट को फिर से लोड करें. ऐसा हो सकता है कि आपको अलग हार्डवेयर पर ऐसा करना पड़े.
- ट्रेनिंग को फिर से शुरू करें.
मिलते-जुलते विकल्पों का चुनाव (कोपा)
यह डेटासेट, इस बात का आकलन करने के लिए है कि एलएलएम, किसी आधार के लिए दो विकल्पों में से बेहतर जवाब की पहचान कितनी अच्छी तरह से कर सकता है. डेटासेट में मौजूद हर चुनौती में तीन कॉम्पोनेंट होते हैं:
- कोई आधार वाक्य, जो आम तौर पर एक ऐसा वाक्य होता है जिसके बाद कोई सवाल पूछा जाता है
- आधार वाक्य में पूछे गए सवाल के दो संभावित जवाब, जिनमें से एक सही है और दूसरा गलत
- सही जवाब
उदाहरण के लिए:
- आधार: आदमी के पैर की उंगली टूट गई. इसकी वजह क्या थी?
- संभावित जवाब:
- उसकी मोज़े में छेद हो गया.
- उसके पैर पर हथौड़ा गिर गया.
- सही जवाब: 2
COPA, SuperGLUE का एक कॉम्पोनेंट है.
क्लास
वह कैटगरी जिससे कोई लेबल जुड़ा हो सकता है. उदाहरण के लिए:
- स्पैम का पता लगाने वाले बाइनरी क्लासिफ़िकेशन मॉडल में, दो क्लास स्पैम और स्पैम नहीं है हो सकती हैं.
- मल्टी-क्लास क्लासिफ़िकेशन मॉडल में, कुत्ते की नस्लों की पहचान की जाती है. इसमें क्लास पूडल, बीगल, पग वगैरह हो सकती हैं.
क्लासिफ़िकेशन मॉडल किसी क्लास का अनुमान लगाता है. इसके उलट, रिग्रेशन मॉडल, क्लास के बजाय किसी संख्या का अनुमान लगाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में वर्गीकरण देखें.
क्लास-बैलेंस किया गया डेटासेट
ऐसा डेटासेट जिसमें कैटगोरिकल लेबल शामिल हों और हर कैटगरी के इंस्टेंस की संख्या लगभग बराबर हो. उदाहरण के लिए, वनस्पति विज्ञान के किसी डेटासेट पर विचार करें. इसके बाइनरी लेबल, स्थानीय पौधा या विदेशी पौधा हो सकते हैं:
- 515 स्थानीय पौधों और 485 बाहरी पौधों वाला डेटासेट, क्लास-बैलेंस वाला डेटासेट होता है.
- 875 स्थानीय पौधों और 125 बाहरी पौधों वाला डेटासेट, क्लास-इंबैलेंस वाला डेटासेट होता है.
क्लास के हिसाब से संतुलित डेटासेट और क्लास के हिसाब से असंतुलित डेटासेट के बीच कोई औपचारिक अंतर नहीं होता. इनके बीच का अंतर सिर्फ़ तब अहम हो जाता है, जब क्लास के हिसाब से बहुत ज़्यादा असंतुलित डेटासेट पर ट्रेन किया गया मॉडल, कन्वर्ज नहीं हो पाता. ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: असंतुलित डेटासेट देखें.
क्लासिफ़िकेशन मॉडल
ऐसा मॉडल जिसका अनुमान, क्लास होता है. उदाहरण के लिए, यहां दिए गए सभी क्लासिफ़िकेशन मॉडल हैं:
- ऐसा मॉडल जो इनपुट किए गए वाक्य की भाषा का अनुमान लगाता है (क्या यह फ़्रेंच है? स्पैनिश? इटैलियन?).
- ऐसा मॉडल जो पेड़ की प्रजातियों का अनुमान लगाता है (मेपल? ओक? बेओबैब?).
- ऐसा मॉडल जो किसी खास बीमारी के लिए पॉज़िटिव या नेगेटिव क्लास का अनुमान लगाता है.
इसके उलट, रिग्रेशन मॉडल क्लास के बजाय संख्याओं का अनुमान लगाते हैं.
आम तौर पर, क्लासिफ़िकेशन मॉडल दो तरह के होते हैं:
श्रेणी में बाँटने की सीमा
बाइनरी क्लासिफ़िकेशन में, 0 से 1 के बीच की कोई संख्या होती है. यह लॉजिस्टिक रिग्रेशन मॉडल के रॉ आउटपुट को पॉज़िटिव क्लास या नेगेटिव क्लास के अनुमान में बदलती है. ध्यान दें कि क्लासिफ़िकेशन थ्रेशोल्ड एक ऐसी वैल्यू होती है जिसे कोई व्यक्ति चुनता है. यह मॉडल ट्रेनिंग के दौरान चुनी गई वैल्यू नहीं होती.
लॉजिस्टिक रिग्रेशन मॉडल, 0 और 1 के बीच की रॉ वैल्यू दिखाता है. इसके बाद:
- अगर यह रॉ वैल्यू, क्लासिफ़िकेशन थ्रेशोल्ड से ज़्यादा है, तो पॉज़िटिव क्लास का अनुमान लगाया जाता है.
- अगर यह रॉ वैल्यू, क्लासिफ़िकेशन थ्रेशोल्ड से कम है, तो नेगेटिव क्लास का अनुमान लगाया जाता है.
उदाहरण के लिए, मान लें कि क्लासिफ़िकेशन थ्रेशोल्ड 0.8 है. अगर रॉ वैल्यू 0.9 है, तो मॉडल पॉज़िटिव क्लास का अनुमान लगाता है. अगर रॉ वैल्यू 0.7 है, तो मॉडल नेगेटिव क्लास का अनुमान लगाता है.
क्लासिफ़िकेशन थ्रेशोल्ड चुनने से, फ़ॉल्स पॉज़िटिव और फ़ॉल्स नेगेटिव की संख्या पर काफ़ी असर पड़ता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में थ्रेशोल्ड और कन्फ़्यूज़न मैट्रिक्स देखें.
डेटा की कैटगरी तय करने वाला
क्लासिफ़िकेशन मॉडल के लिए इस्तेमाल किया जाने वाला सामान्य शब्द.
क्लास-इंबैलेंस वाला डेटासेट
क्लासिफ़िकेशन के लिए डेटासेट, जिसमें हर क्लास के लेबल की कुल संख्या में काफ़ी अंतर होता है. उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन वाले किसी डेटासेट पर विचार करें. इसके दो लेबल इस तरह बांटे गए हैं:
- 10,00,000 नेगेटिव लेबल
- 10 पॉज़िटिव लेबल
नेगेटिव और पॉज़िटिव लेबल का अनुपात 100,000 से 1 है. इसलिए, यह क्लास-इंबैलेंस वाला डेटासेट है.
इसके उलट, यहां दिया गया डेटासेट क्लास-बैलेंस है, क्योंकि नेगेटिव लेबल और पॉज़िटिव लेबल का अनुपात 1 के आस-पास है:
- 517 नेगेटिव लेबल
- 483 पॉज़िटिव लेबल
मल्टी-क्लास डेटासेट में क्लास का बैलेंस भी बिगड़ा हो सकता है. उदाहरण के लिए, यहां दिया गया मल्टी-क्लास क्लासिफ़िकेशन डेटासेट भी क्लास के असंतुलन वाला है. ऐसा इसलिए, क्योंकि एक लेबल के उदाहरण, अन्य दो लेबल के मुकाबले काफ़ी ज़्यादा हैं:
- "green" क्लास वाले 10,00,000 लेबल
- "purple" क्लास वाले 200 लेबल
- "ऑरेंज" क्लास वाले 350 लेबल
ट्रेनिंग के लिए, क्लास-इंबैलेंस वाले डेटासेट में खास चुनौतियां आ सकती हैं. ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट में क्लास का असंतुलित डिस्ट्रिब्यूशन देखें.
एंट्रॉपी, मेजर क्लास}, और माइनर क्लास के बारे में भी जानें.
क्लिपिंग
यह आउटलायर को मैनेज करने का एक तरीका है. इसके तहत, इनमें से कोई एक या दोनों काम किए जाते हैं:
- सुविधा की उन वैल्यू को कम करना जो ज़्यादा से ज़्यादा थ्रेशोल्ड से ज़्यादा हैं. इन वैल्यू को ज़्यादा से ज़्यादा थ्रेशोल्ड तक कम किया जाता है.
- सुविधा की उन वैल्यू को बढ़ाना जो कम से कम थ्रेशोल्ड से कम हैं, ताकि वे कम से कम थ्रेशोल्ड तक पहुंच सकें.
उदाहरण के लिए, मान लें कि किसी सुविधा के लिए, 0.5% से कम वैल्यू, 40 से 60 के बीच की सीमा से बाहर हैं. इस मामले में, ये काम किए जा सकते हैं:
- 60 से ज़्यादा की सभी वैल्यू को 60 पर सेट करें. यह ज़्यादा से ज़्यादा थ्रेशोल्ड है.
- 40 से कम (कम से कम थ्रेशोल्ड) वाली सभी वैल्यू को 40 पर सेट करें.
आउटलायर, मॉडल को नुकसान पहुंचा सकते हैं. कभी-कभी, ट्रेनिंग के दौरान वज़न ज़्यादा हो जाते हैं. कुछ आउटलायर, सटीकता जैसी मेट्रिक को भी काफ़ी हद तक खराब कर सकते हैं. क्लिपिंग, नुकसान को कम करने का एक सामान्य तरीका है.
ग्रेडिएंट क्लिपिंग, ट्रेनिंग के दौरान ग्रेडिएंट की वैल्यू को तय की गई रेंज में रखती है.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में संख्यात्मक डेटा: नॉर्मलाइज़ेशन देखें.
Cloud TPU
यह एक खास हार्डवेयर एक्सेलरेटर है. इसे Google Cloud पर मशीन लर्निंग के वर्कलोड को तेज़ी से प्रोसेस करने के लिए डिज़ाइन किया गया है.
क्लस्टरिंग
मिलते-जुलते उदाहरणों को ग्रुप करना. खास तौर पर, बिना निगरानी वाली लर्निंग के दौरान. सभी उदाहरणों को ग्रुप करने के बाद, कोई व्यक्ति हर क्लस्टर का मतलब बता सकता है.
क्लस्टरिंग के कई एल्गोरिदम मौजूद हैं. उदाहरण के लिए, k-means एल्गोरिदम, उदाहरणों को उनके सेंट्रॉइड से दूरी के आधार पर क्लस्टर करता है. जैसा कि इस डायग्राम में दिखाया गया है:

इसके बाद, रिसर्च करने वाला व्यक्ति क्लस्टर की समीक्षा कर सकता है. उदाहरण के लिए, वह क्लस्टर 1 को "छोटे पेड़" और क्लस्टर 2 को "बड़े पेड़" के तौर पर लेबल कर सकता है.
एक और उदाहरण के तौर पर, किसी सेंटर पॉइंट से उदाहरण की दूरी के आधार पर क्लस्टरिंग एल्गोरिदम पर विचार करें. इसे इस तरह दिखाया गया है:

ज़्यादा जानकारी के लिए, क्लस्टरिंग कोर्स देखें.
को-अडैप्टेशन
यह एक ऐसी समस्या है जिसमें न्यूरॉन, ट्रेनिंग डेटा में पैटर्न का अनुमान लगाते हैं. इसके लिए, वे पूरे नेटवर्क के व्यवहार पर भरोसा करने के बजाय, खास तौर पर अन्य न्यूरॉन के आउटपुट पर भरोसा करते हैं. जब पुष्टि करने के लिए इस्तेमाल किए गए डेटा में, को-अडैप्टेशन की वजह बनने वाले पैटर्न मौजूद नहीं होते हैं, तब को-अडैप्टेशन की वजह से ओवरफ़िटिंग होती है. ड्रॉपआउट रेगुलराइज़ेशन से को-अडैप्टेशन कम हो जाता है, क्योंकि ड्रॉपआउट यह पक्का करता है कि न्यूरॉन सिर्फ़ कुछ अन्य न्यूरॉन पर भरोसा न करें.
कोलैबोरेटिव फ़िल्टरिंग
कई अन्य उपयोगकर्ताओं की दिलचस्पी के आधार पर, किसी एक उपयोगकर्ता की दिलचस्पी के बारे में अनुमान लगाना. कोलैबोरेटिव फ़िल्टरिंग का इस्तेमाल अक्सर सुझाव देने वाले सिस्टम में किया जाता है.
ज़्यादा जानकारी के लिए, Recommendation Systems कोर्स में Collaborative filtering देखें.
कमिटमेंटबैंक (सीबी)
यह एक ऐसा डेटासेट है जिसका इस्तेमाल यह आकलन करने के लिए किया जाता है कि कोई एलएलएम, किसी पैसेज के लेखक के बारे में यह पता लगाने में कितना माहिर है कि वह पैसेज में मौजूद किसी टारगेट क्लॉज़ पर भरोसा करता है या नहीं. डेटासेट की हर एंट्री में यह जानकारी शामिल होती है:
- एक पैसेज
- उस पैसेज में मौजूद टारगेट क्लॉज़
- बूलियन वैल्यू, जिससे यह पता चलता है कि पैसेज के लेखक का मानना है कि टारगेट क्लॉज़
उदाहरण के लिए:
- पैसेज: अर्टमिस की हंसी सुनकर बहुत अच्छा लगा. वह बहुत गंभीर बच्ची है. मुझे नहीं पता था कि वह इतनी मज़ेदार है.
- टारगेट क्लॉज़: वह मज़ेदार थी
- बूलियन: सही है. इसका मतलब है कि लेखक का मानना है कि टारगेट क्लॉज़
CommitmentBank, SuperGLUE का एक कॉम्पोनेंट है.
कॉम्पैक्ट मॉडल
ऐसा कोई भी छोटा मॉडल जिसे कम कंप्यूटेशनल संसाधनों वाले छोटे डिवाइसों पर चलाने के लिए डिज़ाइन किया गया हो. उदाहरण के लिए, कॉम्पैक्ट मॉडल को मोबाइल फ़ोन, टैबलेट या एम्बेड किए गए सिस्टम पर चलाया जा सकता है.
कंप्यूट
(संज्ञा) किसी मॉडल या सिस्टम के लिए इस्तेमाल किए जाने वाले कंप्यूटेशनल संसाधन. जैसे, प्रोसेसिंग पावर, मेमोरी, और स्टोरेज.
ऐक्सलरेटर चिप देखें.
कॉन्सेप्ट ड्रिफ़्ट
सुविधाओं और लेबल के बीच संबंध में बदलाव. समय के साथ, कॉन्सेप्ट ड्रिफ्ट की वजह से मॉडल की क्वालिटी कम हो जाती है.
ट्रेनिंग के दौरान, मॉडल ट्रेनिंग सेट में मौजूद सुविधाओं और उनके लेबल के बीच के संबंध को समझता है. अगर ट्रेनिंग सेट में मौजूद लेबल, असल दुनिया के लिए अच्छे प्रॉक्सी हैं, तो मॉडल को असल दुनिया के लिए अच्छे अनुमान लगाने चाहिए. हालांकि, कॉन्सेप्ट ड्रिफ़्ट की वजह से, समय के साथ मॉडल के अनुमानों की क्वालिटी कम हो जाती है.
उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल पर विचार करें. यह मॉडल अनुमान लगाता है कि कोई कार मॉडल "ईंधन की कम खपत करने वाला" है या नहीं. इसका मतलब है कि ये सुविधाएं:
- कार का वज़न
- इंजन कंप्रेस करना
- ट्रांसमिशन का टाइप
जब लेबल इनमें से कोई एक हो:
- ईंधन की कम खपत
- ईंधन की खपत ज़्यादा होती है
हालांकि, "ईंधन की कम खपत करने वाली कार" की परिभाषा लगातार बदलती रहती है. साल 1994 में, जिस कार मॉडल को कम ईंधन खपत करने वाला लेबल किया गया था उसे साल 2024 में ज़्यादा ईंधन खपत करने वाला लेबल किया जाएगा. कॉन्सेप्ट ड्रिफ्ट की समस्या से जूझ रहा मॉडल, समय के साथ कम से कम काम के अनुमान लगाता है.
नॉनस्टेशनैरिटी से इसकी तुलना करें और इनके बीच अंतर बताएं.
शर्त
डिसिज़न ट्री में, कोई भी नोड जो टेस्ट करता है. उदाहरण के लिए, इस फ़ैसले के ट्री में दो शर्तें शामिल हैं:
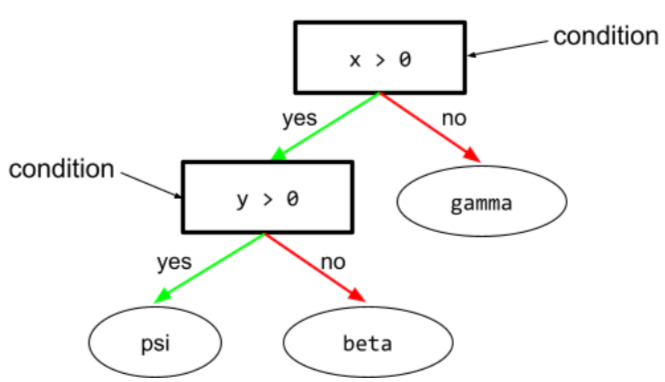
कंडीशन को स्प्लिट या टेस्ट भी कहा जाता है.
पत्ती के साथ कंट्रास्ट की स्थिति.
यह भी देखें:
ज़्यादा जानकारी के लिए, Decision Forests कोर्स में शर्तों के टाइप देखें.
झूठी बातें बनाना
गलत जानकारी के लिए समानार्थी शब्द.
तकनीकी तौर पर, 'भ्रम' शब्द की तुलना में 'झूठी जानकारी देना' ज़्यादा सटीक शब्द है. हालांकि, सबसे पहले हैलुसिनेशन की समस्या के बारे में लोगों को पता चला.
कॉन्फ़िगरेशन
मॉडल को ट्रेन करने के लिए इस्तेमाल की गई शुरुआती प्रॉपर्टी वैल्यू असाइन करने की प्रोसेस. इसमें ये शामिल हैं:
- मॉडल की कंपोज़िंग लेयर
- डेटा की जगह
- हाइपरपैरामीटर, जैसे कि:
मशीन लर्निंग प्रोजेक्ट में, कॉन्फ़िगरेशन को किसी खास कॉन्फ़िगरेशन फ़ाइल के ज़रिए किया जा सकता है. इसके अलावा, यहां दी गई कॉन्फ़िगरेशन लाइब्रेरी का इस्तेमाल करके भी कॉन्फ़िगरेशन किया जा सकता है:
कंफ़र्मेशन बायस
किसी जानकारी को इस तरह से खोजना, समझना, उसके पक्ष में तर्क देना, और उसे याद रखना कि वह पहले से मौजूद मान्यताओं या अनुमानों की पुष्टि करे. मशीन लर्निंग डेवलपर, अनजाने में डेटा को इस तरह से इकट्ठा या लेबल कर सकते हैं जिससे उनके मौजूदा विचारों के मुताबिक नतीजे मिलें. कंफ़र्मेशन बायस, अचेतन पूर्वाग्रह का एक रूप है.
एक्सपेरिमेंट करने वाले व्यक्ति का पूर्वाग्रह, पुष्टि करने वाले पूर्वाग्रह का एक रूप है. इसमें एक्सपेरिमेंट करने वाला व्यक्ति, मॉडल को तब तक ट्रेनिंग देता रहता है, जब तक कि पहले से मौजूद किसी हाइपोथेसिस की पुष्टि न हो जाए.
कन्फ़्यूज़न मैट्रिक्स
यह NxN टेबल होती है. इसमें क्लासिफ़िकेशन मॉडल के सही और गलत अनुमानों की संख्या के बारे में खास जानकारी दी जाती है. उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल के लिए, यहां दी गई कन्फ़्यूज़न मैट्रिक्स देखें:
| ट्यूमर (अनुमानित) | नॉन-ट्यूमर (अनुमानित) | |
|---|---|---|
| ट्यूमर (ग्राउंड ट्रुथ) | 18 (TP) | 1 (FN) |
| ट्यूमर नहीं है (असल डेटा) | 6 (FP) | 452 (TN) |
ऊपर दी गई कन्फ़्यूज़न मैट्रिक्स में यह जानकारी दिखती है:
- ट्यूमर के 19 अनुमानों में से, मॉडल ने 18 अनुमानों को सही तरीके से और 1 अनुमान को गलत तरीके से क्लासिफ़ाई किया.
- 458 अनुमानों में से, मॉडल ने 452 अनुमानों को सही तरीके से और 6 अनुमानों को गलत तरीके से क्लासिफ़ाई किया. इन अनुमानों में, ग्राउंड ट्रुथ के तौर पर नॉन-ट्यूमर की जानकारी दी गई थी.
मल्टी-क्लास क्लासिफ़िकेशन की समस्या के लिए कन्फ़्यूज़न मैट्रिक्स की मदद से, गलतियों के पैटर्न की पहचान की जा सकती है. उदाहरण के लिए, तीन क्लास वाले मल्टी-क्लास क्लासिफ़िकेशन मॉडल के लिए, यहां दी गई कन्फ़्यूज़न मैट्रिक्स देखें. यह मॉडल, आइरिस की तीन अलग-अलग प्रजातियों (वर्जिनिका, वर्सीकलर, और सेटोसा) को कैटगरी में बांटता है. जब ग्राउंड ट्रुथ वर्जिनिका था, तब कन्फ़्यूज़न मैट्रिक्स से पता चलता है कि मॉडल ने सेटोसा के मुकाबले वर्सिकलर का अनुमान ज़्यादा गलत तरीके से लगाया:
| सेटोज़ा (अनुमानित) | वर्सीकलर (अनुमानित) | वर्जिनिका (अनुमानित) | |
|---|---|---|---|
| सेटोज़ा (ग्राउंड ट्रूथ) | 88 | 12 | 0 |
| वर्सीकलर (ग्राउंड ट्रुथ) | 6 | 141 | 7 |
| वर्जिनिका (ग्राउंड ट्रुथ) | 2 | 27 | 109 |
एक और उदाहरण के तौर पर, कन्फ़्यूज़न मैट्रिक्स से पता चल सकता है कि हाथ से लिखे गए अंकों को पहचानने के लिए ट्रेन किए गए मॉडल में, 4 की जगह 9 या 7 की जगह 1 का अनुमान लगाने की गड़बड़ी होती है.
कन्फ़्यूज़न मैट्रिक्स में, परफ़ॉर्मेंस की अलग-अलग मेट्रिक का हिसाब लगाने के लिए ज़रूरी जानकारी होती है. इनमें सटीकता और रिकॉल शामिल हैं.
चुनावी क्षेत्र की जानकारी को पार्स करना
किसी वाक्य को छोटे-छोटे व्याकरण के स्ट्रक्चर ("कॉन्स्टिट्यूएंट") में बांटना. एमएल सिस्टम का बाद वाला हिस्सा, जैसे कि नैचुरल लैंग्वेज अंडरस्टैंडिंग मॉडल, ओरिजनल वाक्य के मुकाबले कॉम्पोनेंट को ज़्यादा आसानी से पार्स कर सकता है. उदाहरण के लिए, इस वाक्य पर ध्यान दें:
मेरे दोस्त ने दो बिल्लियां गोद ली हैं.
निर्वाचन क्षेत्र के पार्सर की मदद से, इस वाक्य को इन दो हिस्सों में बांटा जा सकता है:
- My friend एक संज्ञा वाक्यांश है.
- दो बिल्लियां गोद लीं एक क्रिया वाक्यांश है.
इन कॉम्पोनेंट को छोटे-छोटे कॉम्पोनेंट में बांटा जा सकता है. उदाहरण के लिए, क्रिया का वाक्यांश
दो बिल्लियां गोद ली हैं
इन्हें और उप-विभाजित किया जा सकता है:
- adopted एक क्रिया है.
- दो बिल्लियां एक और संज्ञा वाक्यांश है.
संदर्भ के हिसाब से भाषा को एंबेड करना
एम्बेडिंग, शब्दों और वाक्यांशों को "समझने" के लिए, इंसानों की तरह काम करती है. कॉन्टेक्स्ट के हिसाब से भाषा के एम्बेडिंग, मुश्किल सिंटैक्स, सिमैंटिक, और कॉन्टेक्स्ट को समझ सकते हैं.
उदाहरण के लिए, अंग्रेज़ी शब्द cow के एम्बेडिंग पर विचार करें. word2vec जैसे पुराने एम्बेडिंग, अंग्रेज़ी शब्दों को इस तरह से दिखा सकते हैं कि एम्बेडिंग स्पेस में गाय से बैल की दूरी, भेड़ी (मादा भेड़) से भेड़ा (नर भेड़) या महिला से पुरुष की दूरी के बराबर हो. संदर्भ के हिसाब से भाषा को एंबेड करने की प्रोसेस, एक कदम आगे बढ़कर यह पहचान सकती है कि अंग्रेज़ी बोलने वाले लोग कभी-कभी cow शब्द का इस्तेमाल, गाय या बैल के लिए करते हैं.
कॉन्टेक्स्ट विंडो
किसी मॉडल के लिए, दिए गए प्रॉम्प्ट में प्रोसेस किए जा सकने वाले टोकन की संख्या. कॉन्टेक्स्ट विंडो जितनी बड़ी होगी, मॉडल उतनी ही ज़्यादा जानकारी का इस्तेमाल करके, प्रॉम्प्ट के लिए जवाब दे पाएगा.
लगातार काम करने वाली सुविधा
फ़्लोटिंग-पॉइंट सुविधा, जिसमें वैल्यू की रेंज इनफ़िनिट होती है. जैसे, तापमान या वज़न.
इसकी तुलना डिस्क्रीट फ़ीचर से करें.
आसानी से इकट्ठा किया जाने वाला सैंपल
जल्दी एक्सपेरिमेंट करने के लिए, ऐसे डेटासेट का इस्तेमाल करना जिसे वैज्ञानिक तरीके से इकट्ठा नहीं किया गया है. बाद में, वैज्ञानिक तरीके से इकट्ठा किए गए डेटासेट पर स्विच करना ज़रूरी है.
कन्वर्जेंस
यह ऐसी स्थिति होती है, जब हर इटरेशन के साथ नुकसान की वैल्यू में बहुत कम बदलाव होता है या कोई बदलाव नहीं होता. उदाहरण के लिए, यहां दिया गया लॉस कर्व, 700 इटरेशन के आस-पास कन्वर्जेंस का सुझाव देता है:
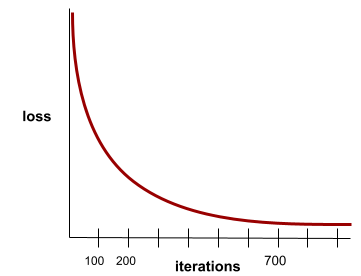
जब ज़्यादा ट्रेनिंग देने से मॉडल में सुधार नहीं होता, तो मॉडल कन्वर्ज हो जाता है.
डीप लर्निंग में, लॉस वैल्यू कभी-कभी कई इटरेशन के लिए स्थिर रहती हैं या आखिर में कम होने से पहले लगभग स्थिर रहती हैं. लंबे समय तक नुकसान की वैल्यू में लगातार बढ़ोतरी होने पर, आपको कुछ समय के लिए कन्वर्जेंस का गलत अनुमान मिल सकता है.
अर्ली स्टॉपिंग के बारे में भी जानें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में मॉडल कन्वर्जेंस और लॉस कर्व देखें.
बातचीत करके कोडिंग करना
सॉफ़्टवेयर बनाने के मकसद से, जनरेटिव एआई मॉडल और आपके बीच बार-बार होने वाली बातचीत. आपने किसी सॉफ़्टवेयर के बारे में जानकारी देने वाला कोई प्रॉम्प्ट दिया हो. इसके बाद, मॉडल उस ब्यौरे का इस्तेमाल करके कोड जनरेट करता है. इसके बाद, पिछले प्रॉम्प्ट या जनरेट किए गए कोड में मौजूद कमियों को ठीक करने के लिए, एक नया प्रॉम्प्ट दिया जाता है. इसके बाद, मॉडल अपडेट किया गया कोड जनरेट करता है. जब तक जनरेट किया गया सॉफ़्टवेयर सही नहीं हो जाता, तब तक दोनों के बीच बातचीत जारी रहती है.
बातचीत कोडिंग का मतलब, वाइब कोडिंग का मूल मतलब है.
इसे स्पेसिफ़िकेशनल कोडिंग से अलग माना जाता है.
कॉन्वेक्स फ़ंक्शन
ऐसा फ़ंक्शन जिसमें फ़ंक्शन के ग्राफ़ के ऊपर का क्षेत्र, कॉन्वेक्स सेट होता है. प्रोटोटाइपिकल कॉन्वेक्स फ़ंक्शन, U अक्षर की तरह दिखता है. उदाहरण के लिए, यहां दिए गए सभी फ़ंक्शन कॉन्वेक्स फ़ंक्शन हैं:
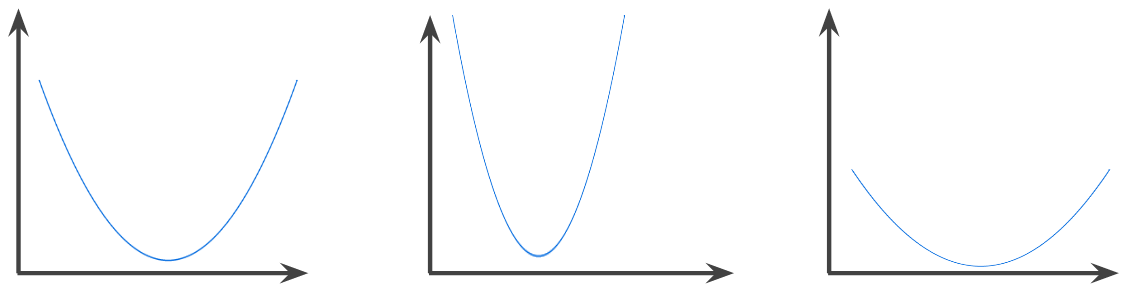
इसके उलट, यह फ़ंक्शन कॉन्वेक्स नहीं है. ध्यान दें कि ग्राफ़ के ऊपर वाला क्षेत्र, कॉन्वेक्स सेट नहीं है:

स्ट्रिक्टली कॉन्वेक्स फ़ंक्शन में सिर्फ़ एक लोकल मिनिमम पॉइंट होता है, जो ग्लोबल मिनिमम पॉइंट भी होता है. क्लासिक यू-शेप वाले फ़ंक्शन, स्ट्रिक्टली कॉन्वेक्स फ़ंक्शन होते हैं. हालांकि, कुछ कॉन्वेक्स फ़ंक्शन (उदाहरण के लिए, सीधी लाइनें) U-आकार के नहीं होते.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कन्वर्जेंस और कॉन्वेक्स फ़ंक्शन देखें.
कॉन्वेक्स ऑप्टिमाइज़ेशन
कॉन्वेक्स फ़ंक्शन के सबसे छोटे मान का पता लगाने के लिए, ग्रेडिएंट डिसेंट जैसी गणितीय तकनीकों का इस्तेमाल करने की प्रोसेस. मशीन लर्निंग में, ज़्यादातर रिसर्च में अलग-अलग समस्याओं को कॉन्वेक्स ऑप्टिमाइज़ेशन की समस्याओं के तौर पर फ़ॉर्म्युलेट करने और उन समस्याओं को ज़्यादा असरदार तरीके से हल करने पर फ़ोकस किया गया है.
पूरी जानकारी के लिए, बॉयड और वैनडेनबर्गहे का कॉन्वेक्स ऑप्टिमाइज़ेशन देखें.
कॉन्वेक्स सेट
यह इयूक्लिडियन स्पेस का एक सबसेट है. इसमें सबसेट के किसी भी दो पॉइंट के बीच खींची गई लाइन, पूरी तरह से सबसेट के अंदर ही रहती है. उदाहरण के लिए, यहां दी गई दो आकृतियां कॉन्वेक्स सेट हैं:

इसके उलट, यहां दी गई दो शेप कॉन्वेक्स सेट नहीं हैं:

कनवोल्यूशन
गणित में, आम तौर पर दो फ़ंक्शन का मिश्रण. मशीन लर्निंग में, कनवोल्यूशन, कनवोल्यूशनल फ़िल्टर और इनपुट मैट्रिक्स को मिलाकर वज़न को ट्रेन करता है.
मशीन लर्निंग में "कनवोल्यूशन" शब्द का इस्तेमाल, अक्सर कनवोल्यूशनल ऑपरेशन या कनवोल्यूशनल लेयर के लिए किया जाता है.
कन्वलूशन के बिना, मशीन लर्निंग एल्गोरिदम को बड़े टेंसर में मौजूद हर सेल के लिए अलग-अलग वेट असाइन करने होंगे. उदाहरण के लिए, 2K x 2K इमेज पर ट्रेनिंग देने वाले मशीन लर्निंग एल्गोरिदम को 40 लाख अलग-अलग वेट का पता लगाना होगा. कनवोल्यूशन की वजह से, मशीन लर्निंग एल्गोरिदम को सिर्फ़ कनवोल्यूशनल फ़िल्टर के हर सेल के लिए वज़न का पता लगाना होता है. इससे मॉडल को ट्रेन करने के लिए ज़रूरी मेमोरी काफ़ी कम हो जाती है. कनवोल्यूशनल फ़िल्टर लागू होने पर, इसे सभी सेल में कॉपी कर दिया जाता है. इससे हर सेल को फ़िल्टर से गुणा किया जाता है.
कनवोल्यूशनल फ़िल्टर
कनवोल्यूशनल ऑपरेशन में शामिल दो ऐक्टर में से एक. (दूसरा ऐक्टर, इनपुट मैट्रिक्स का एक स्लाइस है.) कनवोल्यूशनल फ़िल्टर एक मैट्रिक्स होता है. इसकी रैंक, इनपुट मैट्रिक्स के बराबर होती है, लेकिन इसका आकार छोटा होता है. उदाहरण के लिए, अगर इनपुट मैट्रिक्स 28x28 है, तो फ़िल्टर कोई भी 2D मैट्रिक्स हो सकता है. हालांकि, यह 28x28 से छोटा होना चाहिए.
फ़ोटोग्राफ़िक मैनिपुलेशन में, कनवोल्यूशनल फ़िल्टर की सभी सेल को आम तौर पर एक जैसे पैटर्न में सेट किया जाता है. इसमें एक और शून्य का इस्तेमाल किया जाता है. मशीन लर्निंग में, कनवोल्यूशनल फ़िल्टर में आम तौर पर रैंडम नंबर डाले जाते हैं. इसके बाद, नेटवर्क सबसे सही वैल्यू को ट्रेन करता है.
कनवोल्यूशनल लेयर
डीप न्यूरल नेटवर्क की एक लेयर, जिसमें कनवोल्यूशनल फ़िल्टर, इनपुट मैट्रिक्स से होकर गुज़रता है. उदाहरण के लिए, यहां दिए गए 3x3 कनवोल्यूशनल फ़िल्टर को देखें:
![यह 3x3 मैट्रिक्स है. इसकी वैल्यू ये हैं: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=1&hl=hi)
इस ऐनिमेशन में, 5x5 इनपुट मैट्रिक्स वाली नौ कनवोल्यूशनल कार्रवाइयों से बनी कनवोल्यूशनल लेयर दिखाई गई है. ध्यान दें कि हर कनवोल्यूशनल ऑपरेशन, इनपुट मैट्रिक्स के अलग-अलग 3x3 स्लाइस पर काम करता है. इसके बाद, 3x3 मैट्रिक्स (दाईं ओर) मिलता है. इसमें नौ कनवोल्यूशनल ऑपरेशन के नतीजे शामिल होते हैं:
![इस ऐनिमेशन में दो मैट्रिक्स दिखाए गए हैं. पहला मैट्रिक्स 5x5 मैट्रिक्स है: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
दूसरी मैट्रिक्स, 3x3 मैट्रिक्स है:
[[181,303,618], [115,338,605], [169,351,560]].
दूसरी मैट्रिक्स का हिसाब लगाने के लिए, 5x5 मैट्रिक्स के अलग-अलग 3x3 सबसेट पर कनवोल्यूशनल फ़िल्टर [[0, 1, 0], [1, 0, 1], [0, 1, 0]] लागू किया जाता है.](https://developers.google.com/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=1&hl=hi)
कन्वलूशनल न्यूरल नेटवर्क
एक न्यूरल नेटवर्क, जिसमें कम से कम एक लेयर कनवोल्यूशनल लेयर होती है. आम तौर पर, कनवोल्यूशनल न्यूरल नेटवर्क में यहां दी गई लेयर का कोई कॉम्बिनेशन होता है:
कनवोल्यूशनल न्यूरल नेटवर्क, इमेज की पहचान जैसी कुछ तरह की समस्याओं को हल करने में काफ़ी कारगर साबित हुए हैं.
कन्वलूशनल ऑपरेशन
गणित की यह दो चरणों वाली प्रक्रिया:
- कनवोल्यूशनल फ़िल्टर और इनपुट मैट्रिक्स के स्लाइस का एलिमेंट-वाइज़ गुणन. (इनपुट मैट्रिक्स के स्लाइस की रैंक और साइज़, कनवोल्यूशनल फ़िल्टर के बराबर होता है.)
- प्रॉडक्ट मैट्रिक्स में मौजूद सभी वैल्यू का जोड़.
उदाहरण के लिए, यहां दी गई 5x5 इनपुट मैट्रिक्स देखें:
![5x5 मैट्रिक्स: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=1&hl=hi)
अब इस 2x2 कनवोल्यूशनल फ़िल्टर के बारे में सोचें:
![2x2 मैट्रिक्स: [[1, 0], [0, 1]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=1&hl=hi)
हर कनवोल्यूशनल ऑपरेशन में, इनपुट मैट्रिक्स का एक 2x2 स्लाइस शामिल होता है. उदाहरण के लिए, मान लें कि हम इनपुट मैट्रिक्स के ऊपर-बाएं कोने पर मौजूद 2x2 स्लाइस का इस्तेमाल करते हैं. इसलिए, इस स्लाइस पर कनवोल्यूशन ऑपरेशन ऐसा दिखता है:
![इनपुट मैट्रिक्स के सबसे ऊपर बाईं ओर मौजूद 2x2 सेक्शन पर, कनवोल्यूशनल फ़िल्टर [[1, 0], [0, 1]] लागू किया गया है. यह सेक्शन [[128,97], [35,22]] है.
कनवोल्यूशनल फ़िल्टर, 128 और 22 को पहले जैसा ही रखता है. हालांकि, यह 97 और 35 को शून्य कर देता है. इसलिए, कनवोल्यूशन ऑपरेशन से 150 (128+22) वैल्यू मिलती है.](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=1&hl=hi)
कन्वलूशनल लेयर में, कन्वलूशनल कार्रवाइयों की एक सीरीज़ होती है. इनमें से हर कार्रवाई, इनपुट मैट्रिक्स के अलग-अलग स्लाइस पर काम करती है.
COPA
संभावित विकल्पों का चुनाव के लिए छोटा नाम.
लागत
loss के लिए समानार्थी शब्द.
को-ट्रेनिंग
सेमी-सुपरवाइज़्ड लर्निंग का तरीका, खास तौर पर तब काम आता है, जब ये सभी शर्तें पूरी होती हैं:
- डेटासेट में, बिना लेबल वाले उदाहरणों का अनुपात, लेबल वाले उदाहरणों के मुकाबले ज़्यादा है.
- यह एक क्लासिफ़िकेशन समस्या है (बाइनरी या मल्टी-क्लास).
- डेटासेट में अनुमान लगाने वाली सुविधाओं के दो अलग-अलग सेट होते हैं. ये एक-दूसरे से अलग होते हैं और एक-दूसरे के पूरक होते हैं.
को-ट्रेनिंग, अलग-अलग सिग्नल को मिलाकर एक बेहतर सिग्नल बनाती है. उदाहरण के लिए, कैटगरी तय करने वाले मॉडल पर विचार करें. यह मॉडल, इस्तेमाल की गई अलग-अलग कारों को अच्छी या खराब के तौर पर कैटगरी में बांटता है. अनुमान लगाने वाली सुविधाओं का एक सेट, कार की कुल विशेषताओं पर फ़ोकस कर सकता है. जैसे, कार का साल, ब्रैंड, और मॉडल. अनुमान लगाने वाली सुविधाओं का दूसरा सेट, पिछले मालिक के ड्राइविंग रिकॉर्ड और कार के रखरखाव के इतिहास पर फ़ोकस कर सकता है.
को-ट्रेनिंग पर सबसे अहम पेपर, ब्लम और मिशेल का Combining Labeled and Unlabeled Data with Co-Training है.
काउंटरफ़ैक्चुअल फ़ेयरनेस
यह एक निष्पक्षता मेट्रिक है. इससे यह पता चलता है कि क्या क्लासिफ़िकेशन मॉडल, एक व्यक्ति के लिए वही नतीजा देता है जो वह दूसरे व्यक्ति के लिए देता है. हालांकि, दूसरा व्यक्ति पहले व्यक्ति जैसा ही होता है. इसमें एक या उससे ज़्यादा संवेदनशील एट्रिब्यूट को छोड़कर, बाकी सभी एट्रिब्यूट एक जैसे होते हैं. क्लासिफ़िकेशन मॉडल का आकलन करके, यह पता लगाया जा सकता है कि मॉडल में पक्षपात के संभावित सोर्स कौनसे हैं.
ज़्यादा जानकारी के लिए, इनमें से कोई एक लेख पढ़ें:
- मशीन लर्निंग क्रैश कोर्स में, निष्पक्षता: काउंटरफ़ैक्चुअल निष्पक्षता के बारे में जानें.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
कवरेज बायस
चुने जाने का पूर्वाग्रह देखें.
क्रैश ब्लॉसम
ऐसा वाक्य या वाक्यांश जिसका मतलब साफ़ तौर पर समझ में न आ रहा हो. क्रैश ब्लॉसम, नैचुरल लैंग्वेज अंडरस्टैंडिंग में एक बड़ी समस्या पैदा करते हैं. उदाहरण के लिए, लाल फ़ीता गगनचुंबी इमारत को रोक देता है हेडलाइन, क्रैश ब्लॉसम है. ऐसा इसलिए, क्योंकि एनएलयू मॉडल इस हेडलाइन का शाब्दिक या लाक्षणिक अर्थ निकाल सकता है.
आलोचक
डीप क्यू-नेटवर्क का समानार्थी शब्द.
क्रॉस-एंट्रॉपी
यह लॉग लॉस का सामान्यीकरण है. इसका इस्तेमाल एक से ज़्यादा क्लास वाले क्लासिफ़िकेशन की समस्याओं को हल करने के लिए किया जाता है. क्रॉस-एंट्रॉपी, दो प्रायिकता बंटनों के बीच के अंतर को मेज़र करती है. perplexity भी देखें.
क्रॉस-वैलिडेशन
यह एक ऐसा तरीका है जिससे यह अनुमान लगाया जा सकता है कि मॉडल नए डेटा के लिए कितना सही काम करेगा. इसके लिए, मॉडल को एक या उससे ज़्यादा ऐसे डेटा सबसेट के ख़िलाफ़ टेस्ट किया जाता है जो ट्रेनिंग सेट से अलग होते हैं.
क्यूमुलेटिव डिस्ट्रीब्यूशन फ़ंक्शन (सीडीएफ़)
यह फ़ंक्शन, टारगेट वैल्यू से कम या उसके बराबर सैंपल की फ़्रीक्वेंसी तय करता है. उदाहरण के लिए, लगातार वैल्यू के सामान्य डिस्ट्रिब्यूशन पर विचार करें. सीडीएफ़ से पता चलता है कि लगभग 50% सैंपल, औसत से कम या उसके बराबर होने चाहिए. साथ ही, लगभग 84% सैंपल, औसत से एक स्टैंडर्ड डेविएशन से कम या उसके बराबर होने चाहिए.
D
डेटा का विश्लेषण
सैंपल, मेज़रमेंट, और विज़ुअलाइज़ेशन की मदद से डेटा को समझना. डेटा विश्लेषण, खास तौर पर तब काम आ सकता है, जब पहली बार कोई डेटासेट मिलता है. ऐसा पहली मॉडल बनाने से पहले किया जाता है. यह सिस्टम से जुड़ी समस्याओं को डीबग करने और एक्सपेरिमेंट को समझने में भी अहम भूमिका निभाता है.
डेटा बढ़ाना
मौजूदा उदाहरणों को बदलकर, ट्रेनिंग के उदाहरणों की रेंज और संख्या को बढ़ाना. उदाहरण के लिए, मान लें कि इमेज आपकी सुविधाओं में से एक है, लेकिन आपके डेटासेट में इमेज के ऐसे उदाहरण मौजूद नहीं हैं जिनसे मॉडल को काम के असोसिएशन के बारे में जानकारी मिल सके. हमारा सुझाव है कि आप अपने डेटासेट में, ज़रूरत के मुताबिक लेबल की गई इमेज जोड़ें, ताकि आपके मॉडल को सही तरीके से ट्रेन किया जा सके. अगर ऐसा नहीं होता है, तो डेटा ऑगमेंटेशन की मदद से, हर इमेज को घुमाया, स्ट्रेच किया, और पलटा जा सकता है. इससे ओरिजनल इमेज के कई वैरिएंट बनाए जा सकते हैं. इससे शायद लेबल किया गया इतना डेटा मिल जाए कि मॉडल को बेहतर तरीके से ट्रेन किया जा सके.
DataFrame
यह pandas का एक लोकप्रिय डेटा टाइप है. इसका इस्तेमाल मेमोरी में डेटासेट को दिखाने के लिए किया जाता है.
डेटाफ़्रेम, टेबल या स्प्रेडशीट की तरह होता है. डेटाफ़्रेम के हर कॉलम का एक नाम (हेडर) होता है. साथ ही, हर लाइन की पहचान एक यूनीक नंबर से होती है.
डेटाफ़्रेम में मौजूद हर कॉलम को 2D ऐरे की तरह स्ट्रक्चर किया जाता है. हालांकि, हर कॉलम को उसका डेटा टाइप असाइन किया जा सकता है.
आधिकारिक pandas.DataFrame रेफ़रंस पेज भी देखें.
डेटा पैरललिज़्म
यह ट्रेनिंग या अनुमान को स्केल करने का एक तरीका है. इसमें पूरे मॉडल को कई डिवाइसों पर कॉपी किया जाता है. इसके बाद, इनपुट डेटा के सबसेट को हर डिवाइस पर भेजा जाता है. डेटा पैरललिज़्म की मदद से, बहुत बड़े बैच साइज़ पर ट्रेनिंग और अनुमान लगाया जा सकता है. हालांकि, डेटा पैरललिज़्म के लिए ज़रूरी है कि मॉडल इतना छोटा हो कि वह सभी डिवाइसों पर फ़िट हो जाए.
डेटा पैरललिज़्म से, आम तौर पर ट्रेनिंग और अनुमान लगाने की प्रोसेस तेज़ हो जाती है.
मॉडल पैरललिज़्म के बारे में भी जानें.
Dataset API (tf.data)
यह डेटा को पढ़ने और उसे ऐसे फ़ॉर्म में बदलने के लिए, TensorFlow का हाई-लेवल एपीआई है जिसकी ज़रूरत मशीन लर्निंग एल्गोरिदम को होती है.
tf.data.Dataset ऑब्जेक्ट, एलिमेंट के क्रम को दिखाता है. इसमें हर एलिमेंट में एक या उससे ज़्यादा टेंसर होते हैं. tf.data.Iterator ऑब्जेक्ट, Dataset के एलिमेंट का ऐक्सेस देता है.
डेटा सेट या डेटासेट
रॉ डेटा का कलेक्शन. आम तौर पर (लेकिन सिर्फ़) इसे इनमें से किसी एक फ़ॉर्मैट में व्यवस्थित किया जाता है:
- स्प्रेडशीट
- CSV (कॉमा लगाकर अलग की गई वैल्यू) फ़ॉर्मैट वाली फ़ाइल
डिसिज़न बाउंड्री
यह बाइनरी क्लास या मल्टी-क्लास क्लासिफ़िकेशन की समस्याओं में, मॉडल से सीखी गई क्लास के बीच का सेपरेटर होता है. उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन की समस्या को दिखाने वाली इस इमेज में, फ़ैसले की सीमा, ऑरेंज क्लास और नीली क्लास के बीच की सीमा है:

डिसीज़न फ़ॉरेस्ट
यह मॉडल, कई डिसिज़न ट्री से बनाया जाता है. डिसिज़न फ़ॉरेस्ट, अपने डिसिज़न ट्री की मदद से अनुमान लगाता है. फ़ैसले लेने वाले फ़ॉरेस्ट के लोकप्रिय टाइप में, रैंडम फ़ॉरेस्ट और ग्रेडिएंट बूस्टेड ट्री शामिल हैं.
ज़्यादा जानकारी के लिए, Decision Forests कोर्स में Decision Forests सेक्शन देखें.
फ़ैसले का थ्रेशोल्ड
क्लासिफ़िकेशन थ्रेशोल्ड के लिए समानार्थी शब्द.
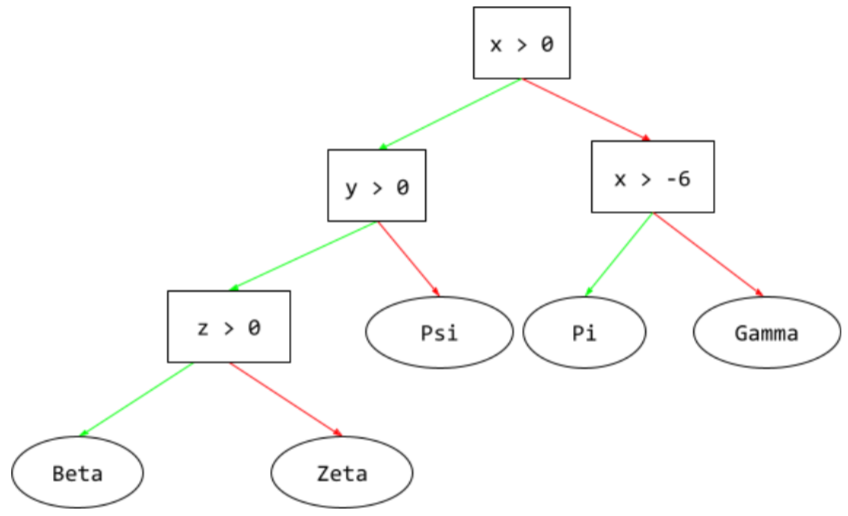
डिसीज़न ट्री
यह एक सुपरवाइज़्ड लर्निंग मॉडल है. इसमें शर्तों और लीफ़ का एक सेट होता है, जिसे क्रम से व्यवस्थित किया जाता है. उदाहरण के लिए, यहां एक फ़्लोचार्ट दिया गया है:
डिकोडर
आम तौर पर, कोई भी एमएल सिस्टम जो प्रोसेस किए गए, डेंस या इंटरनल रिप्रेजेंटेशन को ज़्यादा रॉ, स्पार्स या एक्सटर्नल रिप्रेजेंटेशन में बदलता है.
डिकोडर अक्सर किसी बड़े मॉडल का हिस्सा होते हैं. इनमें अक्सर एन्कोडर का इस्तेमाल किया जाता है.
सीक्वेंस-टू-सीक्वेंस टास्क में, डिकोडर, एन्कोडर से जनरेट की गई इंटरनल स्टेट से शुरू होता है, ताकि अगले सीक्वेंस का अनुमान लगाया जा सके.
ट्रांसफ़ॉर्मर आर्किटेक्चर में डिकोडर की परिभाषा के लिए, ट्रांसफ़ॉर्मर देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लार्ज लैंग्वेज मॉडल देखें.
डीप मॉडल
एक न्यूरल नेटवर्क, जिसमें एक से ज़्यादा हिडन लेयर होती हैं.
डीप मॉडल को डीप न्यूरल नेटवर्क भी कहा जाता है.
वाइड मॉडल से तुलना करें.
डीप न्यूरल नेटवर्क
डीप मॉडल के लिए समानार्थी शब्द.
डीप क्यू-नेटवर्क (डीक्यूएन)
Q-लर्निंग में, डीप न्यूरल नेटवर्क Q-फ़ंक्शन का अनुमान लगाता है.
Critic, Deep Q-Network का दूसरा नाम है.
डेमोग्राफ़िक पैरिटी
यह एक निष्पक्षता मेट्रिक है. यह तब पूरी होती है, जब मॉडल के क्लासिफ़िकेशन के नतीजे, दिए गए संवेदनशील एट्रिब्यूट पर निर्भर न हों.
उदाहरण के लिए, अगर ग्लबडबड्रिब यूनिवर्सिटी में लिलीपुटियन और ब्रॉबडिंगनैगियन, दोनों आवेदन करते हैं, तो डेमोग्राफ़िक पैरिटी तब हासिल होती है, जब यूनिवर्सिटी में भर्ती किए गए लिलीपुटियन का प्रतिशत, भर्ती किए गए ब्रॉबडिंगनैगियन के प्रतिशत के बराबर हो. भले ही, एक ग्रुप औसतन दूसरे ग्रुप से ज़्यादा क्वालिफ़ाइड हो.
इसकी तुलना समान अवसर और समान संभावना से करें. ये दोनों सिद्धांत, क्लासिफ़िकेशन के कुल नतीजों को संवेदनशील एट्रिब्यूट पर निर्भर रहने की अनुमति देते हैं. हालांकि, ये सिद्धांत, ग्राउंड ट्रुथ के कुछ खास लेबल के लिए, क्लासिफ़िकेशन के नतीजों को संवेदनशील एट्रिब्यूट पर निर्भर रहने की अनुमति नहीं देते. डेमोग्राफ़िक समानता के लिए ऑप्टिमाइज़ करते समय, फ़ायदे और नुकसान के बारे में जानने के लिए, "स्मार्ट मशीन लर्निंग की मदद से भेदभाव को खत्म करना" लेख में दिया गया विज़ुअलाइज़ेशन देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: डेमोग्राफ़िक समानता देखें.
डिनॉइज़िंग
सेल्फ़-सुपरवाइज़्ड लर्निंग का एक सामान्य तरीका, जिसमें:
- डेटासेट में नॉइज़ को आर्टिफ़िशियली जोड़ा जाता है.
- मॉडल, ग़ैर-ज़रूरी आवाज़ें कम करने की कोशिश करता है.
डीनॉइज़िंग की मदद से, बिना लेबल वाले उदाहरणों से सीखा जा सकता है. ओरिजनल डेटासेट को टारगेट या लेबल के तौर पर इस्तेमाल किया जाता है. वहीं, नॉइज़ी डेटा को इनपुट के तौर पर इस्तेमाल किया जाता है.
कुछ मास्क किए गए लैंग्वेज मॉडल, इस तरह से डीनॉइज़िंग का इस्तेमाल करते हैं:
- बिना लेबल वाले वाक्य में, कुछ टोकन को मास्क करके आर्टिफ़िशियल नॉइज़ जोड़ा जाता है.
- मॉडल, ओरिजनल टोकन का अनुमान लगाने की कोशिश करता है.
डेंस फ़ीचर
यह एक सुविधा है, जिसमें ज़्यादातर या सभी वैल्यू शून्य नहीं होती हैं. आम तौर पर, यह फ़्लोटिंग-पॉइंट वैल्यू का टेंसर होता है. उदाहरण के लिए, नीचे दिया गया 10 एलिमेंट वाला टेंसर डेंस है, क्योंकि इसकी 9 वैल्यू शून्य नहीं हैं:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
इसकी तुलना विरल सुविधा से करें.
डेंस लेयर
पूरी तरह से कनेक्ट की गई लेयर के लिए समानार्थी शब्द.
गहराई
न्यूरल नेटवर्क में, इन वैल्यू का योग:
- छिपी हुई लेयर की संख्या
- आउटपुट लेयर की संख्या, जो आम तौर पर 1 होती है
- किसी भी embedding layers की संख्या
उदाहरण के लिए, पांच छिपी हुई लेयर और एक आउटपुट लेयर वाले न्यूरल नेटवर्क की डेप्थ 6 होती है.
ध्यान दें कि इनपुट लेयर से डेप्थ पर कोई असर नहीं पड़ता.
डेप्थवाइज़ सेपरेबल कॉन्वोलूशनल न्यूरल नेटवर्क (sepCNN)
यह कन्वलूशनल न्यूरल नेटवर्क आर्किटेक्चर, Inception पर आधारित है. हालांकि, इसमें Inception मॉड्यूल को डेप्थवाइज़ सेपरेबल कन्वलूशन से बदल दिया गया है. इसे Xception के नाम से भी जाना जाता है.
डेप्थवाइज़ सेपरेबल कनवोल्यूशन (इसे सेपरेबल कनवोल्यूशन भी कहा जाता है) एक स्टैंडर्ड 3D कनवोल्यूशन को दो अलग-अलग कनवोल्यूशन ऑपरेशन में बदल देता है. ये ऑपरेशन, कंप्यूटेशनल तौर पर ज़्यादा असरदार होते हैं: पहला, डेप्थवाइज़ कनवोल्यूशन, जिसकी डेप्थ 1 (n ✕ n ✕ 1) होती है. दूसरा, पॉइंटवाइज़ कनवोल्यूशन, जिसकी लंबाई और चौड़ाई 1 (1 ✕ 1 ✕ n) होती है.
ज़्यादा जानने के लिए, Xception: Deep Learning with Depthwise Separable Convolutions लेख पढ़ें.
डिराइव किया गया लेबल
प्रॉक्सी लेबल के लिए समानार्थी शब्द.
डिवाइस
एक ऐसा शब्द जिसके कई मतलब होते हैं. इसके दो मतलब हो सकते हैं:
- यह हार्डवेयर की एक कैटगरी है, जो TensorFlow सेशन चला सकती है. इसमें सीपीयू, जीपीयू, और TPU शामिल हैं.
- ऐक्सलरेटर चिप (GPU या TPU) पर एमएल मॉडल को ट्रेन करते समय, सिस्टम का वह हिस्सा जो टेंसर और एम्बेडिंग को मैनेज करता है. डिवाइस, ऐक्सलरेटर चिप पर काम करता है. इसके उलट, होस्ट आम तौर पर सीपीयू पर चलता है.
डिफ़रेंशियल प्राइवसी
मशीन लर्निंग में, किसी मॉडल के ट्रेनिंग सेट में शामिल किसी भी संवेदनशील डेटा (उदाहरण के लिए, किसी व्यक्ति की निजी जानकारी) को सुरक्षित रखने के लिए, पहचान छिपाने का तरीका. इस तरीके से यह पक्का किया जाता है कि मॉडल को किसी व्यक्ति के बारे में ज़्यादा जानकारी न मिले और न ही वह उसे याद रखे. मॉडल ट्रेनिंग के दौरान, सैंपलिंग और नॉइज़ जोड़ने की प्रोसेस से ऐसा किया जाता है. इससे अलग-अलग डेटा पॉइंट को छिपाने में मदद मिलती है. साथ ही, ट्रेनिंग के लिए इस्तेमाल किए गए संवेदनशील डेटा के लीक होने का जोखिम कम हो जाता है.
डिफ़रेंशियल प्राइवसी का इस्तेमाल, मशीन लर्निंग के अलावा भी किया जाता है. उदाहरण के लिए, डेटा साइंटिस्ट कभी-कभी अलग-अलग डेमोग्राफ़िक के लिए प्रॉडक्ट के इस्तेमाल के आंकड़े कैलकुलेट करते समय, व्यक्तिगत निजता को सुरक्षित रखने के लिए डिफ़रेंशियल प्राइवसी का इस्तेमाल करते हैं.
डाइमेंशन कम करना
किसी फ़ीचर वेक्टर में, किसी फ़ीचर को दिखाने के लिए इस्तेमाल किए गए डाइमेंशन की संख्या को कम करना. आम तौर पर, ऐसा एंबेडिंग वेक्टर में बदलकर किया जाता है.
आयाम
ओवरलोड किए गए ऐसे शब्द जिनकी परिभाषाएं इनमें से कोई एक हो:
किसी Tensor में कोऑर्डिनेट के लेवल की संख्या. उदाहरण के लिए:
- स्केलर में कोई डाइमेंशन नहीं होता. उदाहरण के लिए,
["Hello"]. - वेक्टर में एक डाइमेंशन होता है. उदाहरण के लिए,
[3, 5, 7, 11]. - मैट्रिक्स में दो डाइमेंशन होते हैं. उदाहरण के लिए,
[[2, 4, 18], [5, 7, 14]]. एक डाइमेंशन वाले वेक्टर में किसी सेल को यूनीक तरीके से तय करने के लिए, एक कोऑर्डिनेट की ज़रूरत होती है. वहीं, दो डाइमेंशन वाले मैट्रिक्स में किसी सेल को यूनीक तरीके से तय करने के लिए, दो कोऑर्डिनेट की ज़रूरत होती है.
- स्केलर में कोई डाइमेंशन नहीं होता. उदाहरण के लिए,
फ़ीचर वेक्टर में मौजूद एंट्री की संख्या.
एम्बेडिंग लेयर में मौजूद एलिमेंट की संख्या.
सीधे तौर पर प्रॉम्प्ट देना
ज़ीरो-शॉट प्रॉम्प्ट के लिए समानार्थी शब्द.
डिस्क्रीट सुविधा
ऐसी सुविधा जिसमें संभावित वैल्यू का एक सीमित सेट होता है. उदाहरण के लिए, ऐसी सुविधा जिसकी वैल्यू सिर्फ़ animal, vegetable या mineral हो सकती है, वह डिसक्रीट (या कैटगरी वाली) सुविधा होती है.
लगातार चलने वाली सुविधा से तुलना करें.
भेदभाव करने वाला मॉडल
यह एक मॉडल है. यह एक या उससे ज़्यादा विशेषताओं के सेट से लेबल का अनुमान लगाता है. ज़्यादा औपचारिक तौर पर, डिसक्रिमिनेटिव मॉडल, सुविधाओं और वज़न के आधार पर किसी आउटपुट की शर्त वाली संभावना को तय करते हैं. इसका मतलब है कि:
p(output | features, weights)
उदाहरण के लिए, ऐसा मॉडल जो सुविधाओं और वज़न के आधार पर यह अनुमान लगाता है कि कोई ईमेल स्पैम है या नहीं, एक भेदभाव करने वाला मॉडल है.
ज़्यादातर सुपरवाइज़्ड लर्निंग मॉडल, डिसक्रिमिनेटिव मॉडल होते हैं. इनमें क्लासिफ़िकेशन और रिग्रेशन मॉडल शामिल हैं.
इसकी तुलना जनरेटिव मॉडल से करें.
डिस्क्रिमिनेटर
यह सिस्टम यह तय करता है कि उदाहरण असली हैं या नकली.
इसके अलावा, जनरेटिव एडवर्सैरियल नेटवर्क में मौजूद वह सबसिस्टम जो यह तय करता है कि जनरेटर से बनाए गए उदाहरण असली हैं या नकली.
ज़्यादा जानकारी के लिए, GAN कोर्स में डिसक्रिमिनेटर देखें.
अलग-अलग असर
लोगों के बारे में ऐसे फ़ैसले लेना जिनसे जनसंख्या के अलग-अलग उपसमूहों पर काफ़ी असर पड़ता है. आम तौर पर, इसका मतलब ऐसी स्थितियों से होता है जहां एल्गोरिदम के आधार पर लिए गए फ़ैसले से, कुछ उपसमूहों को दूसरों की तुलना में ज़्यादा फ़ायदा या नुकसान होता है.
उदाहरण के लिए, मान लें कि एक एल्गोरिदम, किसी बौने व्यक्ति के छोटे घर के लिए लिए जाने वाले होम लोन के लिए ज़रूरी शर्तें पूरी करने की स्थिति का पता लगाता है. अगर उसके पते में कोई खास पिन कोड है, तो एल्गोरिदम उसे "ज़रूरी शर्तें पूरी नहीं करता" के तौर पर क्लासिफ़ाई कर सकता है. अगर बिग-एंडियन लिलिपुटियन के पास लिटिल-एंडियन लिलिपुटियन की तुलना में इस पिन कोड वाले ज़्यादा पते हैं, तो इस एल्गोरिदम का असर अलग-अलग हो सकता है.
अलग-अलग तरह से व्यवहार करना, इस बात पर फ़ोकस करता है कि जब एल्गोरिदम के फ़ैसले लेने की प्रोसेस में, सबग्रुप की विशेषताओं को साफ़ तौर पर इनपुट के तौर पर इस्तेमाल किया जाता है, तब असमानताएं कैसे पैदा होती हैं.
अलग-अलग तरह का व्यवहार
एल्गोरिदम के आधार पर फ़ैसला लेने की प्रोसेस में, विषयों के संवेदनशील एट्रिब्यूट को ध्यान में रखा जाता है. इससे लोगों के अलग-अलग सबग्रुप के साथ अलग-अलग व्यवहार किया जाता है.
उदाहरण के लिए, मान लें कि कोई एल्गोरिदम, बौने लोगों के लिए छोटे घर के लिए क़र्ज़ पाने की ज़रूरी शर्तें तय करता है. यह एल्गोरिदम, क़र्ज़ के लिए किए गए आवेदन में दिए गए डेटा के आधार पर यह फ़ैसला लेता है. अगर एल्गोरिदम, इनपुट के तौर पर Lilliputian के अफ़िलिएशन का इस्तेमाल Big-Endian या Little-Endian के तौर पर करता है, तो वह उस डाइमेंशन के हिसाब से अलग-अलग तरह से काम कर रहा है.
यह अलग-अलग असर से अलग है. इसमें, एल्गोरिदम के फ़ैसलों से समाज के अलग-अलग ग्रुप पर पड़ने वाले असर में अंतर पर फ़ोकस किया जाता है. भले ही, वे ग्रुप मॉडल के इनपुट हों या न हों.
डिस्टिलेशन
किसी मॉडल (जिसे टीचर कहा जाता है) के साइज़ को कम करके, उसे छोटे मॉडल (जिसे छात्र कहा जाता है) में बदलना. यह छोटा मॉडल, ओरिजनल मॉडल के अनुमानों को ज़्यादा से ज़्यादा सटीक तरीके से दोहराता है. डिस्टिलेशन फ़ायदेमंद है, क्योंकि छोटे मॉडल को बड़े मॉडल (टीचर) के मुकाबले दो मुख्य फ़ायदे मिलते हैं:
- जवाब देने में कम समय लगता है
- मेमोरी और बैटरी की खपत कम होती है
हालांकि, छात्र या छात्रा के अनुमान आम तौर पर शिक्षक के अनुमानों जितने सटीक नहीं होते.
डिस्टिलेशन, छात्र मॉडल को इस तरह से ट्रेन करता है कि वह लॉस फ़ंक्शन को कम कर सके. यह छात्र और शिक्षक मॉडल की अनुमानित वैल्यू के बीच के अंतर पर आधारित होता है.
आसवन की तुलना इन शब्दों से करें:
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में एलएलएम: फ़ाइन-ट्यूनिंग, डिस्टिलेशन, और प्रॉम्प्ट इंजीनियरिंग देखें.
डिस्ट्रिब्यूशन
किसी विशेषता या लेबल के लिए, अलग-अलग वैल्यू कितनी बार और किस रेंज में दी गई हैं. डेटा डिस्ट्रिब्यूशन से पता चलता है कि किसी वैल्यू के होने की कितनी संभावना है.
इस इमेज में, दो अलग-अलग डिस्ट्रिब्यूशन के हिस्टोग्राम दिखाए गए हैं:
- बाईं ओर, धन और उसे रखने वाले लोगों की संख्या का पावर लॉ डिस्ट्रिब्यूशन दिखाया गया है.
- दाईं ओर, लंबाई के हिसाब से लोगों की संख्या का सामान्य डिस्ट्रिब्यूशन दिखाया गया है.
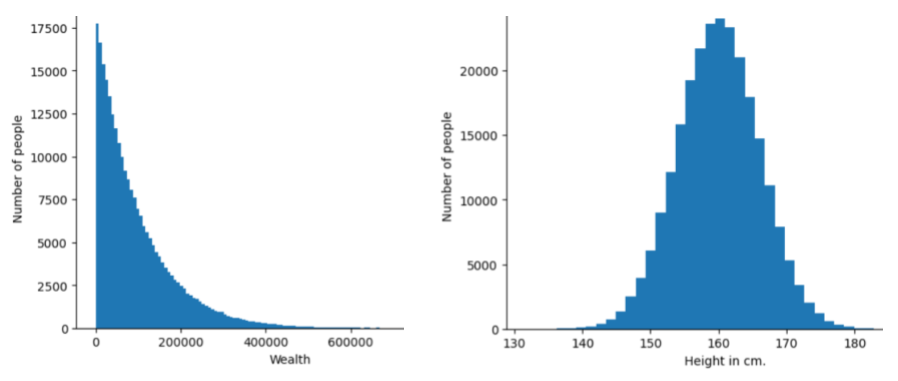
हर सुविधा और लेबल के डिस्ट्रिब्यूशन को समझने से, आपको वैल्यू को नॉर्मलाइज़ करने और आउटलायर का पता लगाने में मदद मिल सकती है.
आउट ऑफ़ डिस्ट्रिब्यूशन वाक्यांश का मतलब ऐसी वैल्यू से है जो डेटासेट में नहीं दिखती या बहुत कम दिखती है. उदाहरण के लिए, अगर किसी डेटासेट में सिर्फ़ बिल्ली की इमेज हैं, तो उसमें शनि ग्रह की इमेज को डिस्ट्रिब्यूशन से बाहर माना जाएगा.
डिविज़िव क्लस्टरिंग
हैरारिकल क्लस्टरिंग देखें.
डाउनसैंपलिंग
यह एक ऐसा शब्द है जिसके कई मतलब हो सकते हैं. इसका मतलब इनमें से कोई भी हो सकता है:
- मॉडल को ज़्यादा असरदार तरीके से ट्रेन करने के लिए, किसी सुविधा में मौजूद जानकारी को कम करना. उदाहरण के लिए, इमेज पहचानने वाले मॉडल को ट्रेनिंग देने से पहले, ज़्यादा रिज़ॉल्यूशन वाली इमेज को कम रिज़ॉल्यूशन वाले फ़ॉर्मैट में डाउनसैंपल करना.
- जिन क्लास के उदाहरण ज़्यादा मौजूद हैं उनके बहुत कम प्रतिशत पर ट्रेनिंग दी जाती है, ताकि जिन क्लास के उदाहरण कम मौजूद हैं उनके लिए मॉडल की ट्रेनिंग को बेहतर बनाया जा सके. उदाहरण के लिए, क्लास-इंबैलेंस वाले डेटासेट में, मॉडल मेजोरिटी क्लास के बारे में ज़्यादा सीखते हैं और माइनॉरिटी क्लास के बारे में कम सीखते हैं. डाउनसैंपलिंग से, ज़्यादातर और कम संख्या वाली क्लास के लिए ट्रेनिंग के डेटा को बैलेंस करने में मदद मिलती है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: असंतुलित डेटासेट देखें.
DQN
डीप क्यू-नेटवर्क का संक्षिप्त नाम.
ड्रॉपआउट रेगुलराइज़ेशन
यह रेगुलराइज़ेशन का एक तरीका है, जो न्यूरल नेटवर्क को ट्रेन करने में मददगार होता है. ड्रॉपआउट रेगुलराइज़ेशन, किसी नेटवर्क लेयर में यूनिट की तय संख्या को एक ग्रेडिएंट स्टेप के लिए हटा देता है. जितनी ज़्यादा यूनिट हटाई जाती हैं, रेगुलराइज़ेशन उतना ही ज़्यादा होता है. यह छोटे नेटवर्क के एन्सेम्बल की नकल करने के लिए नेटवर्क को ट्रेन करने जैसा है. पूरी जानकारी के लिए, ड्रॉपआउट: न्यूरल नेटवर्क को ओवरफ़िटिंग से रोकने का आसान तरीका देखें.
डाइनैमिक
कोई काम जो अक्सर या लगातार किया जाता है. मशीन लर्निंग में, डाइनैमिक और ऑनलाइन शब्द एक-दूसरे के समानार्थी हैं. मशीन लर्निंग में, डाइनैमिक और ऑनलाइन का इस्तेमाल आम तौर पर इन कामों के लिए किया जाता है:
- डाइनैमिक मॉडल (या ऑनलाइन मॉडल) एक ऐसा मॉडल होता है जिसे बार-बार या लगातार फिर से ट्रेन किया जाता है.
- डाइनैमिक ट्रेनिंग (या ऑनलाइन ट्रेनिंग) का मतलब है कि ट्रेनिंग को बार-बार या लगातार दिया जाता है.
- डाइनैमिक इन्फ़रेंस (या ऑनलाइन इन्फ़रेंस) एक ऐसी प्रोसेस है जिसमें मांग के आधार पर अनुमान जनरेट किए जाते हैं.
डाइनैमिक मॉडल
ऐसा मॉडल जिसे बार-बार (ऐसा हो सकता है कि लगातार) फिर से ट्रेन किया जाता है. डाइनैमिक मॉडल एक "लाइफ़लॉन्ग लर्नर" होता है, जो लगातार बदलते डेटा के हिसाब से खुद को ढालता रहता है. डाइनैमिक मॉडल को ऑनलाइन मॉडल भी कहा जाता है.
इसकी तुलना स्टैटिक मॉडल से करें.
E
ईगर एक्ज़ीक्यूशन
यह TensorFlow का प्रोग्रामिंग एनवायरमेंट है, जिसमें ऑपरेशन तुरंत पूरे होते हैं. इसके उलट, ग्राफ़ एक्ज़ीक्यूशन में कॉल किए गए ऑपरेशन तब तक नहीं चलते, जब तक उनका साफ़ तौर पर आकलन नहीं किया जाता. ईगर एक्ज़ीक्यूशन, इंपरेटिव इंटरफ़ेस है. यह ज़्यादातर प्रोग्रामिंग भाषाओं के कोड की तरह होता है. ईगर एक्ज़ीक्यूशन प्रोग्राम को, ग्राफ़ एक्ज़ीक्यूशन प्रोग्राम की तुलना में डीबग करना ज़्यादा आसान होता है.
अर्ली स्टॉपिंग
यह रेगुलराइज़ेशन का एक तरीका है. इसमें ट्रेनिंग को पहले ही रोक दिया जाता है, ताकि ट्रेनिंग लॉस कम हो सके. अर्ली स्टॉपिंग में, मॉडल को ट्रेनिंग देना जान-बूझकर तब बंद कर दिया जाता है, जब मान्य डेटासेट पर नुकसान बढ़ने लगता है. इसका मतलब है कि जब सामान्यीकरण की परफ़ॉर्मेंस खराब होने लगती है.
जल्दी बाहर निकलना से तुलना करें.
अर्थ मूवर की दूरी (ईएमडी)
यह दो डिस्ट्रीब्यूशन के बीच की समानता को मेज़र करता है. अर्थ मूवर की दूरी जितनी कम होगी, डिस्ट्रिब्यूशन उतने ही मिलते-जुलते होंगे.
एडिट डिस्टेंस
इससे यह पता चलता है कि दो टेक्स्ट स्ट्रिंग एक-दूसरे से कितनी मिलती-जुलती हैं. मशीन लर्निंग में, एडिट डिस्टेंस इन वजहों से काम का होता है:
- एडिट डिस्टेंस का हिसाब लगाना आसान होता है.
- एडिट डिस्टेंस की मदद से, एक-दूसरे से मिलती-जुलती दो स्ट्रिंग की तुलना की जा सकती है.
- एडिट डिस्टेंस से यह पता लगाया जा सकता है कि अलग-अलग स्ट्रिंग, किसी दी गई स्ट्रिंग से कितनी मिलती-जुलती हैं.
एडिट डिस्टेंस की कई परिभाषाएं मौजूद हैं. हर परिभाषा में अलग-अलग स्ट्रिंग ऑपरेशन का इस्तेमाल किया जाता है. उदाहरण के लिए, लेवेंश्टाइन दूरी देखें.
Einsum नोटेशन
यह एक असरदार नोटेशन है. इससे यह बताया जाता है कि दो टेंसर को कैसे जोड़ा जाना है. टेंसर को इस तरह से जोड़ा जाता है: एक टेंसर के एलिमेंट को दूसरे टेंसर के एलिमेंट से गुणा किया जाता है. इसके बाद, प्रॉडक्ट को जोड़ा जाता है. Einsum नोटेशन में, हर टेंसर के ऐक्सिस की पहचान करने के लिए सिंबल का इस्तेमाल किया जाता है. साथ ही, उन सिंबल को फिर से व्यवस्थित करके, नतीजे के तौर पर मिले नए टेंसर के आकार के बारे में बताया जाता है.
NumPy, Einsum को लागू करने का एक सामान्य तरीका उपलब्ध कराता है.
एंबेडिंग लेयर
यह एक खास हिडन लेयर होती है. यह ज़्यादा डाइमेंशन वाली कैटेगरी सुविधा पर ट्रेनिंग देती है, ताकि कम डाइमेंशन वाले एंबेड किए जा रहे वेक्टर को धीरे-धीरे सीखा जा सके. एम्बेडिंग लेयर की मदद से, न्यूरल नेटवर्क को ट्रेनिंग देने में कम समय लगता है. ऐसा सिर्फ़ हाई-डाइमेंशनल कैटगरी वाली सुविधा के आधार पर ट्रेनिंग देने की तुलना में होता है.
उदाहरण के लिए, Earth में फ़िलहाल करीब 73,000 तरह के पेड़ों की प्रजातियों की जानकारी उपलब्ध है. मान लें कि आपके मॉडल में पेड़ की प्रजाति एक फ़ीचर है. इसलिए, आपके मॉडल की इनपुट लेयर में 73,000 एलिमेंट वाला वन-हॉट वेक्टर शामिल है.
उदाहरण के लिए, शायद baobab को इस तरह दिखाया जाएगा:

73,000 एलिमेंट वाला ऐरे बहुत लंबा होता है. अगर मॉडल में एम्बेडिंग लेयर नहीं जोड़ी जाती है, तो ट्रेनिंग में बहुत ज़्यादा समय लगेगा. ऐसा इसलिए होगा, क्योंकि 72,999 शून्य को गुणा करना होगा. ऐसा हो सकता है कि आपने एम्बेडिंग लेयर को 12 डाइमेंशन से मिलकर बनाने का विकल्प चुना हो. इसलिए, एम्बेडिंग लेयर धीरे-धीरे हर पेड़ की प्रजाति के लिए एक नया एम्बेडिंग वेक्टर सीखेगी.
कुछ स्थितियों में, हैशिंग, एम्बेडिंग लेयर का एक बेहतर विकल्प है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में एम्बेडिंग देखें.
डेटा को एंबेड करने की प्रोसेस
यह d-डाइमेंशनल वेक्टर स्पेस होता है, जिसमें ज़्यादा डाइमेंशन वाले वेक्टर स्पेस की सुविधाओं को मैप किया जाता है. एम्बेड किए जा रहे स्पेस को इस तरह से ट्रेन किया जाता है कि वह स्ट्रक्चर को कैप्चर कर सके. यह स्ट्रक्चर, ऐप्लिकेशन के लिए काम का होता है.
दो एम्बेडिंग का डॉट प्रॉडक्ट, उनकी समानता का मेज़रमेंट होता है.
वेक्टर को एम्बेड करना
आसान शब्दों में कहें, तो फ़्लोटिंग-पॉइंट नंबर का एक ऐसा कलेक्शन जो किसी भी हिडन लेयर से लिया गया हो और उस हिडन लेयर के इनपुट के बारे में बताता हो. आम तौर पर, एंबेडिंग वेक्टर, फ़्लोटिंग-पॉइंट नंबर का ऐसा कलेक्शन होता है जिसे एंबेडिंग लेयर में ट्रेन किया जाता है. उदाहरण के लिए, मान लें कि किसी एम्बेडिंग लेयर को पृथ्वी पर मौजूद 73,000 तरह के पेड़ों के लिए, एम्बेडिंग वेक्टर के बारे में जानना है. ऐसा हो सकता है कि नीचे दिया गया ऐरे, बेओबैब ट्री के लिए एम्बेड किया जा रहा वेक्टर हो:

एम्बेडिंग वेक्टर, रैंडम नंबर का बंच नहीं होता है. एंबेड करने की प्रोसेस को स्टोर करने के लिए बनी लेयर, ट्रेनिंग के दौरान इन वैल्यू का पता लगाती है. यह प्रोसेस, न्यूरल नेटवर्क की ट्रेनिंग के दौरान अन्य वैल्यू का पता लगाने की प्रोसेस जैसी ही होती है. ऐरे का हर एलिमेंट, पेड़ की किसी प्रजाति की किसी विशेषता के हिसाब से रेटिंग होती है. कौनसा एलिमेंट, पेड़ की किस प्रजाति की खासियत को दिखाता है? इंसानों के लिए यह तय करना बहुत मुश्किल है.
गणित के हिसाब से, किसी एम्बेडिंग वेक्टर का सबसे अहम हिस्सा यह होता है कि मिलते-जुलते आइटम में फ़्लोटिंग-पॉइंट नंबर के मिलते-जुलते सेट होते हैं. उदाहरण के लिए, एक जैसी पेड़ की प्रजातियों में, अलग-अलग पेड़ की प्रजातियों की तुलना में फ़्लोटिंग-पॉइंट नंबर का ज़्यादा मिलता-जुलता सेट होता है. रेडवुड और सीक्वाइया, पेड़ों की मिलती-जुलती प्रजातियां हैं. इसलिए, इनमें रेडवुड और नारियल के पेड़ों की तुलना में, फ़्लोटिंग-पॉइंट नंबर का ज़्यादा मिलता-जुलता सेट होगा. मॉडल को फिर से ट्रेन करने पर, एम्बेडिंग वेक्टर में मौजूद नंबर बदल जाएंगे. भले ही, मॉडल को एक जैसे इनपुट के साथ फिर से ट्रेन किया गया हो.
अनुभवजन्य संचयी बंटन फ़ंक्शन (ईसीडीएफ़ या ईडीएफ़)
किसी असल डेटासेट से अनुभवजन्य मेज़रमेंट के आधार पर, क्यूमुलेटिव डिस्ट्रीब्यूशन फ़ंक्शन. x-ऐक्सिस पर किसी भी पॉइंट पर फ़ंक्शन की वैल्यू, डेटासेट में मौजूद उन ऑब्ज़र्वेशन का फ़्रैक्शन होती है जो तय की गई वैल्यू से कम या उसके बराबर होती हैं.
अनुभवजन्य जोखिम कम करना (ईआरएम)
ट्रेनिंग सेट पर नुकसान को कम करने वाले फ़ंक्शन को चुनना. स्ट्रक्चरल रिस्क मिनिमाइज़ेशन से तुलना करें.
एन्कोडर
आम तौर पर, ऐसा कोई भी एमएल सिस्टम जो रॉ, स्पार्स या बाहरी डेटा को प्रोसेस करके, ज़्यादा डेंस या इंटरनल डेटा में बदलता है.
एनकोडर अक्सर किसी बड़े मॉडल का हिस्सा होते हैं. इनमें से ज़्यादातर को डिकोडर के साथ जोड़ा जाता है. कुछ ट्रांसफ़ॉर्मर, एन्कोडर के साथ डिकोडर का इस्तेमाल करते हैं. हालांकि, अन्य ट्रांसफ़ॉर्मर सिर्फ़ एन्कोडर या सिर्फ़ डिकोडर का इस्तेमाल करते हैं.
कुछ सिस्टम, एन्कोडर के आउटपुट को क्लासिफ़िकेशन या रिग्रेशन नेटवर्क के इनपुट के तौर पर इस्तेमाल करते हैं.
सीक्वेंस-टू-सीक्वेंस टास्क में, एक एनकोडर इनपुट सीक्वेंस लेता है और एक इंटरनल स्टेट (एक वेक्टर) दिखाता है. इसके बाद, डिकोडर उस इंटरनल स्टेट का इस्तेमाल करके, अगले क्रम का अनुमान लगाता है.
ट्रांसफ़ॉर्मर आर्किटेक्चर में एन्कोडर की परिभाषा के लिए, ट्रांसफ़ॉर्मर देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में एलएलएम: लार्ज लैंग्वेज मॉडल क्या होता है लेख पढ़ें.
एंडपॉइंट
नेटवर्क से ऐक्सेस की जा सकने वाली जगह (आम तौर पर, यूआरएल), जहां सेवा को ऐक्सेस किया जा सकता है.
ensemble
यह अलग-अलग ट्रेन किए गए मॉडल का कलेक्शन होता है. इन मॉडल के अनुमानों का औसत निकाला जाता है या उन्हें एग्रीगेट किया जाता है. ज़्यादातर मामलों में, एक मॉडल की तुलना में कई मॉडल मिलकर बेहतर अनुमान लगाते हैं. उदाहरण के लिए, रैंडम फ़ॉरेस्ट एक ऐसा एनसेंबल है जिसे कई डिसिज़न ट्री से बनाया जाता है. ध्यान दें कि सभी डिसिज़न फ़ॉरेस्ट, एनसेंबल नहीं होते.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में रैंडम फ़ॉरेस्ट देखें.
एन्ट्रॉपी
सूचना सिद्धांत में, यह बताया जाता है कि किसी संभावना वितरण का अनुमान लगाना कितना मुश्किल है. इसके अलावा, एन्ट्रापी को इस तरह भी परिभाषित किया जाता है कि हर उदाहरण में कितनी जानकारी शामिल है. किसी डिस्ट्रिब्यूशन की एंट्रॉपी सबसे ज़्यादा तब होती है, जब रैंडम वैरिएबल की सभी वैल्यू की संभावना बराबर होती है.
दो संभावित वैल्यू "0" और "1" वाले सेट की एंट्रॉपी (उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन की समस्या में लेबल) का फ़ॉर्मूला यह है:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
कहां:
- H एन्ट्रॉपी है.
- p, "1" उदाहरणों का फ़्रैक्शन है.
- q, "0" उदाहरणों का फ़्रैक्शन है. ध्यान दें कि q = (1 - p)
- लॉग आम तौर पर log2 होता है. इस मामले में, एंट्रॉपी यूनिट एक बिट है.
उदाहरण के लिए, मान लें कि:
- 100 उदाहरणों में "1" वैल्यू मौजूद है
- 300 उदाहरणों में वैल्यू "0" मौजूद है
इसलिए, एंट्रॉपी की वैल्यू यह है:
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81 बिट प्रति उदाहरण
पूरी तरह से संतुलित सेट (उदाहरण के लिए, 200 "0" और 200 "1") में, हर उदाहरण के लिए एंट्रॉपी 1.0 बिट होगी. सेट जितना ज़्यादा इंबैलेंस होता है, उसकी एंट्रॉपी 0.0 की ओर बढ़ती है.
डिसिज़न ट्री में, एंट्रॉपी सूचना लाभ को फ़ॉर्म्युलेट करने में मदद करती है, ताकि स्प्लिटर, क्लासिफ़िकेशन डिसिज़न ट्री के बढ़ने के दौरान शर्तें चुन सके.
एंट्रॉपी की तुलना इससे करें:
- गिनी इंप्योरिटी
- क्रॉस-एंट्रॉपी लॉस फ़ंक्शन
एंट्रॉपी को अक्सर शैनन की एंट्रॉपी कहा जाता है.
ज़्यादा जानकारी के लिए, फ़ैसले लेने वाले फ़ॉरेस्ट कोर्स में संख्यात्मक सुविधाओं के साथ बाइनरी क्लासिफ़िकेशन के लिए सटीक स्प्लिटर देखें.
वातावरण
रीइन्फ़ोर्समेंट लर्निंग में, एजेंट मौजूद होता है. साथ ही, एजेंट को दुनिया की स्थिति देखने की अनुमति मिलती है. उदाहरण के लिए, दिखाया गया जगत शतरंज जैसा कोई गेम या भूलभुलैया जैसी कोई भौतिक दुनिया हो सकती है. जब एजेंट, एनवायरमेंट पर कोई कार्रवाई करता है, तो एनवायरमेंट के स्टेटस में बदलाव होता है.
एपिसोड
रीइन्फ़ोर्समेंट लर्निंग में, एजेंट, एनवायरमेंट के बारे में जानने के लिए बार-बार कोशिश करता है.
epoch
पूरे ट्रेनिंग सेट पर ट्रेनिंग पास की जाती है, ताकि हर उदाहरण को एक बार प्रोसेस किया जा सके.
एक इपॉक, N/बैच साइज़
ट्रेनिंग इटरेशन को दिखाता है. इसमें N, उदाहरणों की कुल संख्या है.
उदाहरण के लिए, मान लें कि:
- इस डेटासेट में 1,000 उदाहरण शामिल हैं.
- बैच का साइज़ 50 उदाहरणों का है.
इसलिए, एक इपॉक के लिए 20 बार दोहराना ज़रूरी है:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
एप्सिलॉन ग्रीडी नीति
रीइन्फ़ोर्समेंट लर्निंग में, एक नीति होती है. इसमें, इप्सिलॉन की संभावना के साथ रैंडम नीति का पालन किया जाता है. इसके अलावा, ग्रीडी नीति का पालन किया जाता है. उदाहरण के लिए, अगर इप्सिलॉन 0.9 है, तो नीति 90% समय में रैंडम नीति और 10% समय में लालची नीति का पालन करती है.
लगातार एपिसोड के दौरान, एल्गोरिदम, इप्सिलॉन की वैल्यू को कम करता है, ताकि रैंडम नीति को फ़ॉलो करने के बजाय, लालची नीति को फ़ॉलो किया जा सके. नीति में बदलाव करके, एजेंट पहले रैंडम तरीके से एनवायरमेंट को एक्सप्लोर करता है. इसके बाद, रैंडम एक्सप्लोरेशन के नतीजों का इस्तेमाल करता है.
समान अवसर
निष्पक्षता मेट्रिक का इस्तेमाल यह आकलन करने के लिए किया जाता है कि कोई मॉडल, संवेदनशील एट्रिब्यूट की सभी वैल्यू के लिए, एक जैसा और सही नतीजा दे रहा है या नहीं. दूसरे शब्दों में कहें, तो अगर किसी मॉडल के लिए पॉज़िटिव क्लास सबसे अच्छा नतीजा है, तो सभी ग्रुप के लिए ट्रू पॉज़िटिव रेट एक जैसा होना चाहिए.
अवसर की समानता, समान ऑड्स से जुड़ी होती है. इसके लिए, यह ज़रूरी है कि सभी ग्रुप के लिए, दोनों ट्रू पॉज़िटिव रेट और फ़ॉल्स पॉज़िटिव रेट एक जैसे हों.
मान लें कि ग्लबडबड्रिब यूनिवर्सिटी, गणित के एक मुश्किल प्रोग्राम में लिलीपुटियन और ब्रॉबडिंगनैगियन, दोनों को शामिल करती है. लिलिपुटियन के सेकंडरी स्कूलों में, गणित की क्लास के लिए एक मज़बूत पाठ्यक्रम उपलब्ध कराया जाता है. साथ ही, ज़्यादातर छात्र-छात्राएं यूनिवर्सिटी प्रोग्राम के लिए ज़रूरी शर्तें पूरी करते हैं. ब्रॉबडिंगनैग के सेकंडरी स्कूलों में गणित की क्लास नहीं होती हैं. इसलिए, वहां के बहुत कम छात्र-छात्राएं गणित की परीक्षा पास कर पाते हैं. अगर ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं को उनकी राष्ट्रीयता (लिलिपुटियन या ब्रॉबडिंगनैगियन) के आधार पर भेदभाव किए बिना बराबर मौके मिलते हैं, तो राष्ट्रीयता के हिसाब से "स्वीकार किया गया" लेबल के लिए, अवसरों की समानता की शर्त पूरी होती है.
उदाहरण के लिए, मान लें कि ग्लबडबड्रिब यूनिवर्सिटी में 100 बौने और 100 विशालकाय लोगों ने आवेदन किया है. इसके बाद, एडमिशन के फ़ैसले इस तरह लिए जाते हैं:
पहली टेबल. छोटे कारोबारों के लिए आवेदन करने वाले लोग या कंपनियां (इनमें से 90% ने ज़रूरी शर्तें पूरी की हैं)
| क्वालिफ़ाई हुई | अयोग्य | |
|---|---|---|
| स्वीकार किया गया | 45 | 3 |
| नामंजूर | 45 | 7 |
| कुल | 90 | 10 |
|
ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं में से चुने गए छात्र-छात्राओं का प्रतिशत: 45/90 = 50% ज़रूरी शर्तें पूरी न करने वाले छात्र-छात्राओं में से अस्वीकार किए गए छात्र-छात्राओं का प्रतिशत: 7/10 = 70% लिलिपुटियन स्कूल में चुने गए छात्र-छात्राओं का कुल प्रतिशत: (45+3)/100 = 48% |
||
टेबल 2. बहुत ज़्यादा आवेदन करने वाले लोग (इनमें से 10% लोग ज़रूरी शर्तें पूरी करते हैं):
| क्वालिफ़ाई हुई | अयोग्य | |
|---|---|---|
| स्वीकार किया गया | 5 | 9 |
| नामंजूर | 5 | 81 |
| कुल | 10 | 90 |
|
ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं में से दाखिला पाने वालों का प्रतिशत: 5/10 = 50% ज़रूरी शर्तें पूरी न करने वाले छात्र-छात्राओं में से दाखिला न पाने वालों का प्रतिशत: 81/90 = 90% ब्रॉबडिंगनैगियन छात्र-छात्राओं में से दाखिला पाने वालों का कुल प्रतिशत: (5+9)/100 = 14% |
||
ऊपर दिए गए उदाहरणों में, ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं को बराबर का मौका दिया गया है. ऐसा इसलिए, क्योंकि ज़रूरी शर्तें पूरी करने वाले Lilliputians और Brobdingnagians, दोनों के पास 50% संभावना है कि उन्हें दाखिला मिल जाए.
अवसर की समानता की शर्त पूरी होती है, लेकिन निष्पक्षता से जुड़ी ये दो मेट्रिक पूरी नहीं होती हैं:
- जनसांख्यिकी समानता: Lilliputians और Brobdingnagians को अलग-अलग दरों पर यूनिवर्सिटी में दाखिला मिलता है; Lilliputians के 48% छात्र-छात्राओं को दाखिला मिलता है, लेकिन Brobdingnagian के सिर्फ़ 14% छात्र-छात्राओं को दाखिला मिलता है.
- समान अवसर: ज़रूरी शर्तें पूरी करने वाले Lilliputian और Brobdingnagian, दोनों तरह के छात्र-छात्राओं को दाखिला मिलने की संभावना बराबर होती है. हालांकि, ज़रूरी शर्तें पूरी न करने वाले Lilliputian और Brobdingnagian, दोनों तरह के छात्र-छात्राओं को दाखिला न मिलने की संभावना बराबर होने की अतिरिक्त शर्त पूरी नहीं होती. ज़रूरी शर्तें पूरी न करने वाले Lilliputians के लिए, अस्वीकार किए जाने की दर 70% है. वहीं, ज़रूरी शर्तें पूरी न करने वाले Brobdingnagians के लिए, अस्वीकार किए जाने की दर 90% है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: अवसर की समानता देखें.
देखेंऑड बराबर करना
यह निष्पक्षता से जुड़ी मेट्रिक है. इससे यह आकलन किया जाता है कि कोई मॉडल, संवेदनशील एट्रिब्यूट की सभी वैल्यू के लिए, एक जैसे नतीजे दे रहा है या नहीं. साथ ही, यह भी आकलन किया जाता है कि मॉडल, पॉज़िटिव क्लास और नेगेटिव क्लास, दोनों के लिए एक जैसे नतीजे दे रहा है या नहीं. ऐसा नहीं होना चाहिए कि मॉडल, सिर्फ़ एक क्लास के लिए नतीजे दे रहा हो. दूसरे शब्दों में कहें, तो सभी ग्रुप के लिए ट्रू पॉज़िटिव रेट और फ़ॉल्स नेगेटिव रेट एक जैसा होना चाहिए.
इक्वल ऑड्स, अवसर की समानता से जुड़ा है. यह सिर्फ़ एक क्लास (पॉज़िटिव या नेगेटिव) के लिए गड़बड़ी की दरों पर फ़ोकस करता है.
उदाहरण के लिए, मान लें कि ग्लबडबड्रिब यूनिवर्सिटी, गणित के एक मुश्किल प्रोग्राम में लिलीपुटियन और ब्रॉबडिंगनैगियन, दोनों को दाखिला देती है. लिलिपुटियन के सेकंडरी स्कूलों में, गणित की क्लास के लिए एक मज़बूत पाठ्यक्रम उपलब्ध कराया जाता है. साथ ही, ज़्यादातर छात्र-छात्राएं यूनिवर्सिटी प्रोग्राम के लिए ज़रूरी शर्तें पूरी करते हैं. ब्रोबडिंगनैग के सेकंडरी स्कूलों में गणित की क्लास नहीं होती हैं. इसलिए, वहां के बहुत कम छात्र-छात्राएं इस परीक्षा को पास कर पाते हैं. अगर कोई व्यक्ति बौना है या बहुत लंबा, इससे कोई फ़र्क़ नहीं पड़ता. अगर वह ज़रूरी शर्तें पूरी करता है, तो उसे प्रोग्राम में शामिल होने का उतना ही मौका मिलेगा जितना किसी और व्यक्ति को. इसी तरह, अगर वह ज़रूरी शर्तें पूरी नहीं करता है, तो उसे प्रोग्राम में शामिल होने का उतना ही मौका मिलेगा जितना किसी और व्यक्ति को.
मान लें कि ग्लबडबड्रिब यूनिवर्सिटी में 100 लिलिपुटियन और 100 ब्रॉबडिंगनैगियन ने आवेदन किया है. साथ ही, एडमिशन के फ़ैसले इस तरह लिए गए हैं:
तीसरी टेबल. छोटे कारोबारों के लिए आवेदन करने वाले लोग या कंपनियां (इनमें से 90% ने ज़रूरी शर्तें पूरी की हैं)
| क्वालिफ़ाई हुई | अयोग्य | |
|---|---|---|
| स्वीकार किया गया | 45 | 2 |
| नामंजूर | 45 | 8 |
| कुल | 90 | 10 |
|
ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं में से, दाखिला पाने वाले छात्र-छात्राओं का प्रतिशत: 45/90 = 50% ज़रूरी शर्तें पूरी न करने वाले छात्र-छात्राओं में से, दाखिला न पाने वाले छात्र-छात्राओं का प्रतिशत: 8/10 = 80% लिलिपुटियन स्कूल में दाखिला पाने वाले छात्र-छात्राओं का कुल प्रतिशत: (45+2)/100 = 47% |
||
चौथी टेबल. बहुत ज़्यादा आवेदन करने वाले लोग (इनमें से 10% लोग ज़रूरी शर्तें पूरी करते हैं):
| क्वालिफ़ाई हुई | अयोग्य | |
|---|---|---|
| स्वीकार किया गया | 5 | 18 |
| नामंजूर | 5 | 72 |
| कुल | 10 | 90 |
|
ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं में से चुने गए छात्र-छात्राओं का प्रतिशत: 5/10 = 50% ज़रूरी शर्तें पूरी न करने वाले छात्र-छात्राओं में से अस्वीकार किए गए छात्र-छात्राओं का प्रतिशत: 72/90 = 80% ब्रॉबडिंगनैगियन स्कूल में चुने गए छात्र-छात्राओं का कुल प्रतिशत: (5+18)/100 = 23% |
||
'समान अवसर' सिद्धांत का पालन किया गया है, क्योंकि परीक्षा पास करने वाले लिलिपुटियन और ब्रॉबडिंग्नैगियन, दोनों छात्रों को 50% संभावना के साथ दाखिला मिल सकता है. वहीं, परीक्षा पास न करने वाले लिलिपुटियन और ब्रॉबडिंग्नैगियन, दोनों छात्रों को 80% संभावना के साथ अस्वीकार किया जा सकता है.
"Equality of Opportunity in Supervised Learning" में, समान अवसर को इस तरह से औपचारिक तौर पर परिभाषित किया गया है: "अगर Ŷ और A, Y के आधार पर एक-दूसरे से अलग हैं, तो अनुमान लगाने वाला Ŷ, सुरक्षित एट्रिब्यूट A और नतीजे Y के हिसाब से समान अवसर की शर्त पूरी करता है."
Estimator
यह एक पुराना TensorFlow API है. Estimators के बजाय tf.keras का इस्तेमाल करें.
आकलन
इसका इस्तेमाल मुख्य रूप से, एलएलएम के आकलन के लिए किया जाता है. मोटे तौर पर, इवैल, इवैलुएशन का संक्षिप्त रूप है.
आकलन
किसी मॉडल की क्वालिटी को मेज़र करने या अलग-अलग मॉडल की तुलना करने की प्रोसेस.
सुपरवाइज़्ड मशीन लर्निंग मॉडल का आकलन करने के लिए, आम तौर पर इसकी तुलना मान्य डेटा सेट और टेस्ट डेटा सेट से की जाती है. एलएलएम का आकलन करने में आम तौर पर, क्वालिटी और सुरक्षा से जुड़े बड़े पैमाने पर आकलन शामिल होते हैं.
पूरा मैच
यह एक ऐसी मेट्रिक है जिसमें मॉडल का आउटपुट, ग्राउंड ट्रुथ या रेफ़रंस टेक्स्ट से पूरी तरह मेल खाता है या नहीं खाता. उदाहरण के लिए, अगर ग्राउंड ट्रुथ orange है, तो मॉडल का सिर्फ़ orange आउटपुट, सटीक मिलान की शर्त को पूरा करता है.
सटीक मैच, उन मॉडल का भी आकलन कर सकता है जिनका आउटपुट एक क्रम (आइटम की रैंक की गई सूची) होता है. आम तौर पर, एग्ज़ैक्ट मैच के लिए यह ज़रूरी है कि रैंक की गई जनरेट की गई सूची, ग्राउंड ट्रुथ से पूरी तरह मेल खाती हो. इसका मतलब है कि दोनों सूचियों में मौजूद हर आइटम एक ही क्रम में होना चाहिए. हालांकि, अगर ग्राउंड ट्रुथ में एक से ज़्यादा सही क्रम शामिल हैं, तो पूरी तरह मेल खाने वाले जवाब के लिए, यह ज़रूरी है कि मॉडल का आउटपुट, सही क्रम में से किसी एक से मेल खाता हो.
उदाहरण
features की एक लाइन की वैल्यू और शायद label की वैल्यू. सुपरवाइज़्ड लर्निंग के उदाहरणों को दो सामान्य कैटगरी में बाँटा जा सकता है:
- लेबल किए गए उदाहरण में एक या उससे ज़्यादा सुविधाएं और एक लेबल होता है. ट्रेनिंग के दौरान, लेबल किए गए उदाहरणों का इस्तेमाल किया जाता है.
- बिना लेबल वाले उदाहरण में एक या उससे ज़्यादा सुविधाएं होती हैं, लेकिन कोई लेबल नहीं होता. अनुमान लगाने के दौरान, बिना लेबल वाले उदाहरणों का इस्तेमाल किया जाता है.
उदाहरण के लिए, मान लें कि आपको एक ऐसे मॉडल को ट्रेन करना है जो यह पता लगा सके कि मौसम की स्थितियों का छात्र-छात्राओं के टेस्ट स्कोर पर क्या असर पड़ता है. यहां लेबल किए गए तीन उदाहरण दिए गए हैं:
| सुविधाएं | लेबल | ||
|---|---|---|---|
| तापमान | नमी | दबाव | टेस्ट का स्कोर |
| 15 | 47 | 998 | अच्छा |
| 19 | 34 | 1020 | बहुत बढ़िया |
| 18 | 92 | 1012 | खराब |
यहां बिना लेबल वाले तीन उदाहरण दिए गए हैं:
| तापमान | नमी | दबाव | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
किसी उदाहरण के लिए, डेटासेट की लाइन आम तौर पर रॉ सोर्स होती है. इसका मतलब है कि उदाहरण में आम तौर पर, डेटासेट में मौजूद कॉलम का सबसेट शामिल होता है. इसके अलावा, उदाहरण में दी गई सुविधाओं में सिंथेटिक सुविधाएं भी शामिल हो सकती हैं. जैसे, फ़ీचर क्रॉस.
ज़्यादा जानकारी के लिए, मशीन लर्निंग के बारे में जानकारी देने वाले कोर्स में सुपरवाइज़्ड लर्निंग देखें.
एक्सपीरियंस रीप्ले
रीइन्फ़ोर्समेंट लर्निंग में, DQN तकनीक का इस्तेमाल किया जाता है. इसका मकसद, ट्रेनिंग डेटा में समय के साथ होने वाले बदलावों के बीच के संबंध को कम करना है. एजेंट, स्टेट ट्रांज़िशन को रिप्ले बफ़र में सेव करता है. इसके बाद, ट्रेनिंग डेटा बनाने के लिए रिप्ले बफ़र से ट्रांज़िशन के सैंपल लेता है.
एक्सपेरिमेंट करने वाले व्यक्ति का पूर्वाग्रह
कंफ़र्मेशन बायस लेख पढ़ें.
एक्सप्लोडिंग ग्रेडिएंट की समस्या
डीप न्यूरल नेटवर्क (खास तौर पर, रीकरंट न्यूरल नेटवर्क) में ग्रेडिएंट के अचानक बहुत ज़्यादा (हाई) हो जाने की समस्या. स्टीप ग्रेडिएंट की वजह से, डीप न्यूरल नेटवर्क के हर नोड के वज़न में अक्सर बहुत बड़े अपडेट होते हैं.
एक्सप्लोडिंग ग्रेडिएंट की समस्या वाले मॉडल को ट्रेन करना मुश्किल हो जाता है या उन्हें ट्रेन नहीं किया जा सकता. ग्रेडिएंट क्लिपिंग से इस समस्या को कम किया जा सकता है.
इसकी तुलना वैनिशिंग ग्रेडिएंट की समस्या से करें.
एक्सट्रीम समराइज़ेशन (xsum)
यह एक ऐसा डेटासेट है जिसका इस्तेमाल, किसी एक दस्तावेज़ की खास जानकारी देने की एलएलएम की क्षमता का आकलन करने के लिए किया जाता है. डेटासेट की हर एंट्री में ये शामिल होते हैं:
- ब्रिटिश ब्रॉडकास्टिंग कॉर्पोरेशन (बीबीसी) का लिखा हुआ दस्तावेज़.
- उस दस्तावेज़ की एक वाक्य में खास जानकारी.
ज़्यादा जानकारी के लिए, मुझे ज़्यादा जानकारी नहीं चाहिए, सिर्फ़ खास जानकारी चाहिए! Topic-Aware Convolutional Neural Networks for Extreme Summarization.
F
F1
यह एक "रोल-अप" बाइनरी क्लासिफ़िकेशन मेट्रिक है. यह प्रिसिज़न और रीकॉल, दोनों पर निर्भर करती है. यहां फ़ॉर्मूला दिया गया है:
तथ्यों का सही होना
मशीन लर्निंग की दुनिया में, यह एक ऐसी प्रॉपर्टी है जो किसी ऐसे मॉडल के बारे में बताती है जिसका आउटपुट, असलियत पर आधारित होता है. तथ्यों का सही होना, एक मेट्रिक के बजाय एक सिद्धांत है. उदाहरण के लिए, मान लें कि आपने लार्ज लैंग्वेज मॉडल को यह प्रॉम्प्ट भेजा है:
खाने के नमक का केमिकल फ़ॉर्मूला क्या है?
तथ्यों को सही रखने के लिए ऑप्टिमाइज़ किया गया मॉडल, इस तरह जवाब देगा:
NaCl
यह मान लेना आसान है कि सभी मॉडल, तथ्यों पर आधारित होने चाहिए. हालांकि, कुछ प्रॉम्प्ट ऐसे होने चाहिए जिनसे जनरेटिव एआई मॉडल, तथ्यों के सही होने के बजाय क्रिएटिविटी पर ज़्यादा ध्यान दे. जैसे, यहां दिए गए प्रॉम्प्ट.
मुझे एक अंतरिक्ष यात्री और एक कैटरपिलर के बारे में लिमरिक सुनाओ.
इस बात की संभावना कम है कि जवाब में मिली कविता, असल जानकारी पर आधारित हो.
भरोसेमंद स्रोतों से जानकारी लेने के सिद्धांत के साथ कंट्रास्ट.
निष्पक्षता से जुड़ी शर्त
निष्पक्षता की एक या उससे ज़्यादा परिभाषाओं को पूरा करने के लिए, किसी एल्गोरिदम पर कोई शर्त लागू करना. निष्पक्षता से जुड़ी शर्तों के उदाहरण:- अपने मॉडल के आउटपुट की पोस्ट-प्रोसेसिंग करें.
- निष्पक्षता मेट्रिक का उल्लंघन करने पर जुर्माना लगाने के लिए, लॉस फ़ंक्शन में बदलाव करना.
- ऑप्टिमाइज़ेशन की समस्या में सीधे तौर पर गणितीय बाधा जोड़ना.
निष्पक्षता मेट्रिक
"निष्पक्षता" की गणितीय परिभाषा, जिसे मापा जा सकता है. आम तौर पर इस्तेमाल की जाने वाली निष्पक्षता मेट्रिक में ये शामिल हैं:
निष्पक्षता से जुड़ी कई मेट्रिक एक-दूसरे से अलग होती हैं. निष्पक्षता से जुड़ी मेट्रिक का एक-दूसरे के साथ काम न करना लेख पढ़ें.
फ़ॉल्स नेगेटिव (FN)
इस उदाहरण में, मॉडल ने गलती से नेगेटिव क्लास का अनुमान लगाया है. उदाहरण के लिए, मॉडल का अनुमान है कि कोई ईमेल मैसेज स्पैम नहीं है (नेगेटिव क्लास), लेकिन वह ईमेल मैसेज असल में स्पैम है.
खतरे को कम आंकने की दर
यह असल पॉज़िटिव उदाहरणों का अनुपात है जिनके लिए मॉडल ने गलती से नेगेटिव क्लास का अनुमान लगाया. यहां दिया गया फ़ॉर्मूला, फ़ॉल्स नेगेटिव रेट का हिसाब लगाता है:
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में थ्रेशोल्ड और कन्फ़्यूज़न मैट्रिक्स देखें.
फ़ॉल्स पॉज़िटिव (FP)
ऐसा उदाहरण जिसमें मॉडल, पॉज़िटिव क्लास के बारे में गलत अनुमान लगाता है. उदाहरण के लिए, मॉडल का अनुमान है कि कोई ईमेल मैसेज स्पैम (पॉज़िटिव क्लास) है, लेकिन वह ईमेल मैसेज असल में स्पैम नहीं है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में थ्रेशोल्ड और कन्फ़्यूज़न मैट्रिक्स देखें.
फ़ॉल्स पॉज़िटिव रेट (एफ़पीआर)
यह असल नेगेटिव उदाहरणों का अनुपात है जिनके लिए मॉडल ने गलती से पॉज़िटिव क्लास का अनुमान लगाया. यहां दिए गए फ़ॉर्मूले से, फ़ॉल्स पॉज़िटिव रेट का पता लगाया जाता है:
फ़ॉल्स पॉज़िटिव रेट, आरओसी कर्व में x-ऐक्सिस होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: आरओसी और एयूसी देखें.
तेज़ी से कम होना
एलएलएम की परफ़ॉर्मेंस को बेहतर बनाने के लिए, ट्रेनिंग की एक तकनीक. फ़ास्ट डिके में, ट्रेनिंग के दौरान लर्निंग रेट को तेज़ी से कम किया जाता है. इस रणनीति से, मॉडल को ट्रेनिंग डेटा के हिसाब से ओवरफ़िट होने से रोकने में मदद मिलती है. साथ ही, सामान्यीकरण को बेहतर बनाया जा सकता है.
सुविधा
मशीन लर्निंग मॉडल के लिए इनपुट वैरिएबल. उदाहरण में एक या उससे ज़्यादा सुविधाएं होती हैं. उदाहरण के लिए, मान लें कि आपको किसी मॉडल को इस तरह से ट्रेन करना है कि वह मौसम की स्थितियों का छात्र-छात्राओं के टेस्ट स्कोर पर पड़ने वाले असर का पता लगा सके. यहां दी गई टेबल में तीन उदाहरण दिए गए हैं. इनमें से हर उदाहरण में तीन सुविधाएं और एक लेबल शामिल है:
| सुविधाएं | लेबल | ||
|---|---|---|---|
| तापमान | नमी | दबाव | टेस्ट का स्कोर |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
लेबल से कंट्रास्ट.
ज़्यादा जानकारी के लिए, मशीन लर्निंग के बारे में जानकारी देने वाले कोर्स में सुपरवाइज़्ड लर्निंग देखें.
सुविधा क्रॉस
सिंथेटिक फ़ीचर, कैटगोरिकल या बकेटेड फ़ीचर को "क्रॉस" करके बनाई जाती है.
उदाहरण के लिए, "मूड का अनुमान लगाने वाले" मॉडल पर विचार करें. यह मॉडल, तापमान को इन चार बकेट में से किसी एक में दिखाता है:
freezingchillytemperatewarm
साथ ही, हवा की रफ़्तार को इन तीन बकेट में से किसी एक में दिखाता है:
stilllightwindy
फ़्रीक्वेंसी कैपिंग की सुविधा के बिना, लीनियर मॉडल पिछले सात अलग-अलग बकेट में से हर एक पर अलग से ट्रेन होता है. इसलिए, मॉडल को freezing के उदाहरणों से ट्रेनिंग मिलती है. यह ट्रेनिंग, windy के उदाहरणों से मिलने वाली ट्रेनिंग से अलग होती है.
इसके अलावा, तापमान और हवा की रफ़्तार को मिलाकर भी कोई नई सुविधा बनाई जा सकती है. इस सिंथेटिक फ़ीचर की ये 12 संभावित वैल्यू होंगी:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
फ़ीचर क्रॉस की वजह से, मॉडल को freezing-windy दिन और freezing-still दिन के मूड में अंतर का पता चल सकता है.
अगर आपने दो ऐसी सुविधाओं से कोई सिंथेटिक सुविधा बनाई है जिनमें अलग-अलग बकेट की संख्या बहुत ज़्यादा है, तो सुविधा क्रॉस में संभावित कॉम्बिनेशन की संख्या बहुत ज़्यादा होगी. उदाहरण के लिए, अगर किसी सुविधा में 1,000 बकेट हैं और दूसरी सुविधा में 2,000 बकेट हैं, तो दोनों सुविधाओं को मिलाकर बनने वाली सुविधा में 20,00,000 बकेट होंगी.
आसान शब्दों में कहें, तो क्रॉस एक कार्टीज़ियन प्रॉडक्ट है.
फ़्रीक्वेंसी क्रॉस का इस्तेमाल ज़्यादातर लीनियर मॉडल के साथ किया जाता है. इनका इस्तेमाल न्यूरल नेटवर्क के साथ बहुत कम किया जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटेगरी के हिसाब से डेटा: फ़ीचर क्रॉस देखें.
फ़ीचर इंजीनियरिंग
यह एक ऐसी प्रोसेस है जिसमें ये चरण शामिल होते हैं:
- यह तय करना कि मॉडल को ट्रेन करने के लिए, कौनसी सुविधाएं काम की हो सकती हैं.
- डेटासेट से मिले रॉ डेटा को उन सुविधाओं के असरदार वर्शन में बदलना.
उदाहरण के लिए, आपको लग सकता है कि temperature एक काम की सुविधा है. इसके बाद, बकेटिंग का इस्तेमाल करके यह ऑप्टिमाइज़ किया जा सकता है कि मॉडल, अलग-अलग temperature रेंज से क्या सीख सकता है.
फ़ीचर इंजीनियरिंग को कभी-कभी फ़ीचर एक्सट्रैक्शन या फ़ीचरराइज़ेशन भी कहा जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: कोई मॉडल, फ़ीचर वेक्टर का इस्तेमाल करके डेटा को कैसे प्रोसेस करता है लेख पढ़ें.
फ़ीचर एक्सट्रैक्शन
ओवरलोड किए गए शब्द की परिभाषा इनमें से कोई एक होनी चाहिए:
- किसी बिना लेबल वाले डेटा या पहले से ट्रेन किए गए मॉडल से कैलकुलेट किए गए इंटरमीडिएट फ़ीचर रिप्रेजेंटेशन को वापस पाना. उदाहरण के लिए, किसी न्यूरल नेटवर्क में हिडन लेयर की वैल्यू. इनका इस्तेमाल किसी दूसरे मॉडल में इनपुट के तौर पर किया जाता है.
- फ़ीचर इंजीनियरिंग के लिए समानार्थी शब्द.
सुविधाओं की अहमियत
यह वैरिएबल के महत्व का समानार्थी शब्द है.
सुविधाओं का सेट
सुविधाओं का वह ग्रुप जिस पर आपका मशीन लर्निंग मॉडल ट्रेन होता है. उदाहरण के लिए, घर की कीमतों का अनुमान लगाने वाले मॉडल के लिए, सामान्य फ़ीचर सेट में पिन कोड, प्रॉपर्टी का साइज़, और प्रॉपर्टी की स्थिति शामिल हो सकती है.
सुविधा की खास जानकारी
इसमें tf.Example प्रोटोकॉल बफ़र से features डेटा निकालने के लिए ज़रूरी जानकारी दी गई है. tf.Example प्रोटोकॉल बफ़र सिर्फ़ डेटा के लिए कंटेनर होता है. इसलिए, आपको यह जानकारी देनी होगी:
- एक्सट्रैक्ट किया जाने वाला डेटा (यानी कि सुविधाओं के लिए कुंजियां)
- डेटा टाइप (उदाहरण के लिए, फ़्लोट या इंट)
- लंबाई (तय की गई या जिसमें बदलाव किया जा सकता है)
फ़ीचर वेक्टर
feature वैल्यू की वह सरणी जिसमें example शामिल है. फ़ेचर वेक्टर को ट्रेनिंग और इनफ़रेंस के दौरान इनपुट किया जाता है. उदाहरण के लिए, दो डिस्क्रीट फ़ीचर वाले मॉडल के लिए फ़ीचर वेक्टर ऐसा हो सकता है:
[0.92, 0.56]
हर उदाहरण में, फ़ीचर वेक्टर के लिए अलग-अलग वैल्यू दी गई हैं. इसलिए, अगले उदाहरण के लिए फ़ीचर वेक्टर कुछ इस तरह का हो सकता है:
[0.73, 0.49]
फ़ीचर इंजीनियरिंग से यह तय होता है कि फ़ीचर वेक्टर में फ़ीचर को कैसे दिखाया जाए. उदाहरण के लिए, पांच संभावित वैल्यू वाली बाइनरी कैटगोरिकल सुविधा को वन-हॉट एन्कोडिंग की मदद से दिखाया जा सकता है. इस मामले में, किसी उदाहरण के लिए फ़ीचर वेक्टर में चार शून्य और तीसरी पोज़िशन पर एक 1.0 होगा. यह इस तरह दिखेगा:
[0.0, 0.0, 1.0, 0.0, 0.0]
एक और उदाहरण के तौर पर, मान लें कि आपके मॉडल में तीन सुविधाएं शामिल हैं:
- पांच संभावित वैल्यू वाली बाइनरी कैटगरी की सुविधा, जिसे वन-हॉट एन्कोडिंग के साथ दिखाया गया है. उदाहरण के लिए:
[0.0, 1.0, 0.0, 0.0, 0.0] - एक और बाइनरी कैटगरी वाली सुविधा, जिसकी तीन संभावित वैल्यू हैं. इन्हें वन-हॉट एन्कोडिंग की मदद से दिखाया गया है. उदाहरण के लिए:
[0.0, 0.0, 1.0] - फ़्लोटिंग-पॉइंट फ़ीचर; उदाहरण के लिए:
8.3.
इस मामले में, हर उदाहरण के लिए फ़ीचर वेक्टर को नौ वैल्यू से दिखाया जाएगा. ऊपर दी गई सूची में मौजूद उदाहरण वैल्यू के हिसाब से, फ़ीचर वेक्टर यह होगा:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: कोई मॉडल, फ़ीचर वेक्टर का इस्तेमाल करके डेटा को कैसे प्रोसेस करता है लेख पढ़ें.
फ़ीचर बनाना
किसी इनपुट सोर्स, जैसे कि दस्तावेज़ या वीडियो से सुविधाएं निकालने की प्रोसेस. साथ ही, उन सुविधाओं को सुविधा वेक्टर में मैप करना.
कुछ एमएल विशेषज्ञ, फ़ीचरइज़ेशन को फ़ीचर इंजीनियरिंग या फ़ीचर एक्सट्रैक्शन के लिए इस्तेमाल करते हैं.
फ़ेडरेटेड लर्निंग
यह मशीन लर्निंग का एक डिस्ट्रिब्यूटेड तरीका है. इसमें मशीन लर्निंग मॉडल को ट्रेन किया जाता है. इसके लिए, स्मार्टफ़ोन जैसे डिवाइसों पर मौजूद डिसेंट्रलाइज़्ड उदाहरणों का इस्तेमाल किया जाता है. फ़ेडरेटेड लर्निंग में, डिवाइसों का एक सबसेट, सेंट्रल कोऑर्डिनेटिंग सर्वर से मौजूदा मॉडल डाउनलोड करता है. डिवाइसों पर सेव किए गए उदाहरणों का इस्तेमाल करके, मॉडल को बेहतर बनाया जाता है. इसके बाद, डिवाइस मॉडल में हुए सुधारों को कोऑर्डिनेटिंग सर्वर पर अपलोड करते हैं. हालांकि, ट्रेनिंग के उदाहरणों को अपलोड नहीं किया जाता. कोऑर्डिनेटिंग सर्वर पर, इन सुधारों को अन्य अपडेट के साथ इकट्ठा किया जाता है, ताकि बेहतर ग्लोबल मॉडल तैयार किया जा सके. डेटा इकट्ठा होने के बाद, डिवाइसों से मिले मॉडल अपडेट की ज़रूरत नहीं होती. इसलिए, उन्हें खारिज किया जा सकता है.
ट्रेनिंग के उदाहरण कभी अपलोड नहीं किए जाते. इसलिए, फ़ेडरेटेड लर्निंग में डेटा इकट्ठा करने और डेटा को कम से कम इस्तेमाल करने के सिद्धांतों का पालन किया जाता है.
ज़्यादा जानकारी के लिए, फ़ेडरेटेड लर्निंग कॉमिक (हाँ, एक कॉमिक) देखें.
फ़ीडबैक लूप
मशीन लर्निंग में, ऐसी स्थिति जिसमें किसी मॉडल के अनुमान, उसी मॉडल या किसी दूसरे मॉडल के ट्रेनिंग डेटा पर असर डालते हैं. उदाहरण के लिए, फ़िल्मों का सुझाव देने वाला मॉडल, लोगों को दिखने वाली फ़िल्मों पर असर डालेगा. इसके बाद, यह फ़िल्मों का सुझाव देने वाले अन्य मॉडल पर असर डालेगा.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में प्रोडक्शन एमएल सिस्टम: पूछने लायक सवाल देखें.
फ़ीडफ़ॉरवर्ड न्यूरल नेटवर्क (एफ़एफ़एन)
एक ऐसा न्यूरल नेटवर्क जिसमें साइक्लिक या रिकर्सिव कनेक्शन नहीं होते हैं. उदाहरण के लिए, पारंपरिक डीप न्यूरल नेटवर्क, फ़ीडफ़ॉरवर्ड न्यूरल नेटवर्क होते हैं. यह बार-बार इस्तेमाल होने वाले न्यूरल नेटवर्क से अलग है, जो साइक्लिक होते हैं.
कुछ उदाहरणों के साथ सीखना
यह मशीन लर्निंग का एक तरीका है. इसका इस्तेमाल अक्सर ऑब्जेक्ट क्लासिफ़िकेशन के लिए किया जाता है. इसे सिर्फ़ कुछ ट्रेनिंग उदाहरणों से, असरदार क्लासिफ़िकेशन मॉडल को ट्रेन करने के लिए डिज़ाइन किया गया है.
एक बार में सीखना और बिना किसी उदाहरण के सीखना के बारे में भी जानें.
उदाहरण के साथ डाले गए प्रॉम्प्ट
ऐसा प्रॉम्प्ट जिसमें एक से ज़्यादा ("कुछ") उदाहरण शामिल हों. इनसे यह पता चलता है कि बड़े भाषा मॉडल को कैसे जवाब देना चाहिए. उदाहरण के लिए, यहां दिए गए लंबे प्रॉम्प्ट में दो उदाहरण दिए गए हैं. इनमें बताया गया है कि लार्ज लैंग्वेज मॉडल को किसी क्वेरी का जवाब कैसे देना चाहिए.
| एक प्रॉम्ट के हिस्से | नोट |
|---|---|
| चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब आपको एलएलएम से चाहिए. |
| फ़्रांस: EUR | एक उदाहरण. |
| यूनाइटेड किंगडम: GBP | एक और उदाहरण. |
| भारत: | असल क्वेरी. |
आम तौर पर, फ़्यू-शॉट प्रॉम्प्ट से ज़ीरो-शॉट प्रॉम्प्ट और वन-शॉट प्रॉम्प्ट की तुलना में बेहतर नतीजे मिलते हैं. हालांकि, फ़्यू-शॉट प्रॉम्प्ट (उदाहरण के साथ डाले गए प्रॉम्प्ट) के लिए, लंबा प्रॉम्प्ट डालना ज़रूरी होता है.
उदाहरण के साथ डाले गए प्रॉम्प्ट, उदाहरण के साथ सीखने का एक तरीका है. इसका इस्तेमाल प्रॉम्प्ट के आधार पर सीखने के लिए किया जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में प्रॉम्प्ट इंजीनियरिंग देखें.
वायलिन
यह Python-first configuration लाइब्रेरी है. यह बिना किसी कोड या इन्फ़्रास्ट्रक्चर के, फ़ंक्शन और क्लास की वैल्यू सेट करती है. Pax और अन्य एमएल कोडबेस के मामले में, ये फ़ंक्शन और क्लास, मॉडल और ट्रेनिंग हाइपरपैरामीटर को दिखाते हैं.
Fiddle यह मानता है कि मशीन लर्निंग के कोडबेस को आम तौर पर इन हिस्सों में बांटा जाता है:
- लाइब्रेरी कोड, जो लेयर और ऑप्टिमाइज़र तय करता है.
- डेटासेट "ग्लू" कोड, जो लाइब्रेरी को कॉल करता है और सभी चीज़ों को एक साथ जोड़ता है.
Fiddle, ग्लू कोड के कॉल स्ट्रक्चर को ऐसी फ़ॉर्म में कैप्चर करता है जिसका आकलन नहीं किया गया है और जिसमें बदलाव किया जा सकता है.
फ़ाइन-ट्यूनिंग
किसी खास टास्क के लिए, पहले से ट्रेन किए गए मॉडल पर ट्रेनिंग का दूसरा चरण. इसका इस्तेमाल, किसी खास टास्क के लिए मॉडल के पैरामीटर को बेहतर बनाने के लिए किया जाता है. उदाहरण के लिए, कुछ लार्ज लैंग्वेज मॉडल के लिए ट्रेनिंग का पूरा क्रम इस तरह है:
- प्री-ट्रेनिंग: किसी लार्ज लैंग्वेज मॉडल को सामान्य डेटासेट के बड़े हिस्से पर ट्रेन करें. जैसे, अंग्रेज़ी भाषा के सभी Wikipedia पेज.
- फ़ाइन-ट्यूनिंग: पहले से ट्रेन किए गए मॉडल को किसी खास टास्क को पूरा करने के लिए ट्रेन करें. जैसे, चिकित्सा से जुड़ी क्वेरी के जवाब देना. फ़ाइन-ट्यूनिंग में आम तौर पर, किसी खास टास्क पर फ़ोकस करने वाले सैकड़ों या हज़ारों उदाहरण शामिल होते हैं.
एक अन्य उदाहरण के तौर पर, किसी बड़े इमेज मॉडल के लिए ट्रेनिंग का पूरा क्रम इस तरह है:
- प्री-ट्रेनिंग: किसी बड़े इमेज मॉडल को सामान्य इमेज के बड़े डेटासेट पर ट्रेन करें. जैसे, Wikimedia Commons में मौजूद सभी इमेज.
- फ़ाइन-ट्यूनिंग: पहले से ट्रेन किए गए मॉडल को किसी खास टास्क को पूरा करने के लिए ट्रेन करना. जैसे, किलर व्हेल की इमेज जनरेट करना.
फ़ाइन-ट्यूनिंग में, यहां दी गई रणनीतियों का कोई भी कॉम्बिनेशन शामिल हो सकता है:
- पहले से ट्रेन किए गए मॉडल के सभी मौजूदा पैरामीटर में बदलाव करना. इसे कभी-कभी फ़ुल फ़ाइन-ट्यूनिंग भी कहा जाता है.
- प्री-ट्रेन किए गए मॉडल के मौजूदा पैरामीटर में से सिर्फ़ कुछ में बदलाव करना. आम तौर पर, आउटपुट लेयर के सबसे नज़दीक वाली लेयर में बदलाव किया जाता है. वहीं, अन्य मौजूदा पैरामीटर में कोई बदलाव नहीं किया जाता. आम तौर पर, इनपुट लेयर के सबसे नज़दीक वाली लेयर में बदलाव नहीं किया जाता. पैरामीटर-इफ़िशिएंट ट्यूनिंग देखें.
- ज़्यादा लेयर जोड़ना. आम तौर पर, ये लेयर आउटपुट लेयर के सबसे करीब मौजूद लेयर के ऊपर जोड़ी जाती हैं.
फ़ाइन-ट्यूनिंग, ट्रांसफ़र लर्निंग का एक तरीका है. इसलिए, फ़ाइन-ट्यूनिंग में, पहले से ट्रेन किए गए मॉडल को ट्रेन करने के लिए इस्तेमाल किए गए लॉस फ़ंक्शन या मॉडल टाइप से अलग लॉस फ़ंक्शन या मॉडल टाइप का इस्तेमाल किया जा सकता है. उदाहरण के लिए, पहले से ट्रेन किए गए बड़े इमेज मॉडल को फ़ाइन-ट्यून करके, रिग्रेशन मॉडल बनाया जा सकता है. यह मॉडल, इनपुट इमेज में मौजूद पक्षियों की संख्या दिखाता है.
फ़ाइन-ट्यूनिंग की तुलना इन शब्दों से करें और इनके बीच अंतर बताएं:
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में फ़ाइन-ट्यूनिंग देखें.
फ़्लैश मॉडल
यह Gemini मॉडल का एक छोटा परिवार है. इसे तेज़ गति और कम लेटेंसी के लिए ऑप्टिमाइज़ किया गया है. Flash मॉडल को कई तरह के ऐप्लिकेशन के लिए डिज़ाइन किया गया है. इनमें तेज़ी से जवाब देना और ज़्यादा थ्रूपुट ज़रूरी होता है.
Flax
यह डीप लर्निंग के लिए, JAX पर आधारित एक हाई-परफ़ॉर्मेंस ओपन-सोर्स लाइब्रेरी है. Flax, न्यूरल नेटवर्क को ट्रेन करने के लिए फ़ंक्शन उपलब्ध कराता है. साथ ही, उनकी परफ़ॉर्मेंस का आकलन करने के तरीके भी उपलब्ध कराता है.
Flaxformer
यह एक ओपन-सोर्स Transformer लाइब्रेरी> है. इसे Flax पर बनाया गया है. इसे मुख्य रूप से नैचुरल लैंग्वेज प्रोसेसिंग और मल्टीमॉडल रिसर्च के लिए डिज़ाइन किया गया है.
गेट को भूल जाओ
लॉन्ग शॉर्ट-टर्म मेमोरी सेल का वह हिस्सा जो सेल के ज़रिए जानकारी के फ़्लो को कंट्रोल करता है. फ़ॉरगेट गेट, सेल की स्थिति से किस जानकारी को हटाना है, यह तय करके कॉन्टेक्स्ट को बनाए रखते हैं.
फ़ाउंडेशन मॉडल
यह एक बहुत बड़ा पहले से ट्रेन किया गया मॉडल है. इसे अलग-अलग तरह के ट्रेनिंग सेट पर ट्रेन किया गया है. फ़ाउंडेशन मॉडल, यहां दिए गए दोनों काम कर सकता है:
- अलग-अलग तरह के अनुरोधों का सही जवाब दे सकता है.
- इसे अन्य फ़ाइन-ट्यूनिंग या पसंद के मुताबिक बनाने के लिए, बेसिक मॉडल के तौर पर इस्तेमाल किया जा सकता है.
दूसरे शब्दों में, फ़ाउंडेशन मॉडल सामान्य तौर पर पहले से ही बहुत कुछ कर सकता है. हालांकि, इसे किसी खास काम के लिए और भी ज़्यादा उपयोगी बनाने के लिए, अपनी पसंद के मुताबिक बनाया जा सकता है.
सफलताओं का फ़्रैक्शन
यह एमएल मॉडल के जनरेट किए गए टेक्स्ट का आकलन करने के लिए इस्तेमाल की जाने वाली मेट्रिक है. सफलता की दर, जनरेट किए गए "सफल" टेक्स्ट आउटपुट की संख्या को जनरेट किए गए टेक्स्ट आउटपुट की कुल संख्या से भाग देने पर मिलती है. उदाहरण के लिए, अगर किसी बड़े भाषा मॉडल ने कोड के 10 ब्लॉक जनरेट किए, जिनमें से पांच सही थे, तो सही कोड जनरेट होने का फ़्रैक्शन 50% होगा.
हालांकि, सफलता का फ़्रैक्शन, आंकड़ों के लिए काफ़ी हद तक फ़ायदेमंद होता है. एमएल में, यह मेट्रिक मुख्य रूप से ऐसे कामों का आकलन करने के लिए फ़ायदेमंद होती है जिनकी पुष्टि की जा सकती है. जैसे, कोड जनरेट करना या गणित की समस्याएं हल करना.
फ़ुल सॉफ़्टमैक्स
यह softmax का समानार्थी शब्द है.
उम्मीदवार के सैंपल से तुलना करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: मल्टी-क्लास क्लासिफ़िकेशन देखें.
पूरी तरह से कनेक्ट की गई लेयर
यह एक छिपी हुई लेयर होती है. इसमें हर नोड, अगली छिपी हुई लेयर के हर नोड से जुड़ा होता है.
पूरी तरह से कनेक्टेड लेयर को डेंस लेयर भी कहा जाता है.
फ़ंक्शन ट्रांसफ़ॉर्मेशन
ऐसा फ़ंक्शन जो किसी फ़ंक्शन को इनपुट के तौर पर लेता है और बदले गए फ़ंक्शन को आउटपुट के तौर पर दिखाता है. JAX, फ़ंक्शन ट्रांसफ़ॉर्मेशन का इस्तेमाल करता है.
G
GAN
जनरेटिव ऐडवर्सैरियल नेटवर्क का संक्षिप्त नाम.
Gemini
यह Google के सबसे ऐडवांस एआई से बना नेटवर्क है. इस इकोसिस्टम में ये शामिल हैं:
- कई Gemini मॉडल.
- Gemini मॉडल के साथ बातचीत करने के लिए इंटरैक्टिव इंटरफ़ेस. उपयोगकर्ता प्रॉम्प्ट टाइप करते हैं और Gemini उन प्रॉम्प्ट के जवाब देता है.
- Gemini के अलग-अलग एपीआई.
- Gemini मॉडल पर आधारित कई कारोबारी प्रॉडक्ट. उदाहरण के लिए, Google Cloud के लिए Gemini.
Gemini के मॉडल
Google के सबसे बेहतरीन ट्रांसफ़ॉर्मर पर आधारित मल्टीमॉडल. Gemini मॉडल को खास तौर पर एजेंट के साथ इंटिग्रेट करने के लिए डिज़ाइन किया गया है.
उपयोगकर्ता, Gemini मॉडल के साथ कई तरह से इंटरैक्ट कर सकते हैं. जैसे, इंटरैक्टिव डायलॉग इंटरफ़ेस और एसडीके के ज़रिए.
जेमा
यह एक लाइटवेट ओपन मॉडल है. इसे Gemini मॉडल में इस्तेमाल की गई रिसर्च और तकनीक का इस्तेमाल करके बनाया गया है. Gemma के कई अलग-अलग मॉडल उपलब्ध हैं. हर मॉडल में अलग-अलग सुविधाएं मिलती हैं. जैसे, विज़न, कोड, और निर्देशों का पालन करना. ज़्यादा जानकारी के लिए, Gemma देखें.
GenAI या genAI
जनरेटिव एआई का संक्षिप्त नाम.
सामान्यीकरण
मॉडल की ऐसी क्षमता जिससे वह नए और पहले कभी न देखे गए डेटा के आधार पर सही अनुमान लगा सके. सामान्यीकरण करने वाला मॉडल, ओवरफ़िटिंग करने वाले मॉडल से अलग होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में सामान्यीकरण देखें.
सामान्यीकरण कर्व
इटरेशन की संख्या के आधार पर, ट्रेनिंग लॉस और वैलडेशन लॉस, दोनों का प्लॉट.
सामान्यीकरण कर्व से, ओवरफ़िटिंग का पता लगाया जा सकता है. उदाहरण के लिए, यहां दिया गया सामान्यीकरण कर्व, ओवरफ़िटिंग के बारे में बताता है. ऐसा इसलिए, क्योंकि आखिर में पुष्टि करने के दौरान होने वाला नुकसान, ट्रेनिंग के दौरान होने वाले नुकसान से काफ़ी ज़्यादा हो जाता है.
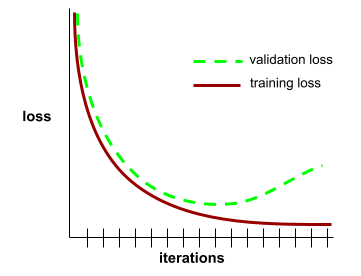
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में सामान्यीकरण देखें.
जनरलाइज़्ड लीनियर मॉडल
यह लीस्ट स्क्वेयर रिग्रेशन मॉडल का सामान्यीकरण है. ये मॉडल गॉसियन नॉइज़ पर आधारित होते हैं. इन्हें अन्य तरह के नॉइज़, जैसे कि पॉइज़न नॉइज़ या कैटगरी के हिसाब से नॉइज़ पर आधारित अन्य तरह के मॉडल के लिए इस्तेमाल किया जाता है. सामान्यीकृत लीनियर मॉडल के उदाहरणों में ये शामिल हैं:
- लॉजिस्टिक रिग्रेशन
- मल्टी-क्लास रिग्रेशन
- लीस्ट स्क्वेयर रिग्रेशन
सामान्यीकृत लीनियर मॉडल के पैरामीटर, कॉन्वेक्स ऑप्टिमाइज़ेशन की मदद से पता लगाए जा सकते हैं.
जनरलाइज़्ड लीनियर मॉडल में ये प्रॉपर्टी होती हैं:
- ऑप्टिमल लीस्ट स्क्वेयर रिग्रेशन मॉडल की औसत भविष्यवाणी, ट्रेनिंग डेटा पर मौजूद औसत लेबल के बराबर होती है.
- सबसे सही लॉजिस्टिक रिग्रेशन मॉडल से अनुमानित औसत संभावना, ट्रेनिंग डेटा पर मौजूद औसत लेबल के बराबर होती है.
किसी सामान्यीकृत लीनियर मॉडल की परफ़ॉर्मेंस, उसकी सुविधाओं पर निर्भर करती है. डीप मॉडल के उलट, सामान्यीकृत लीनियर मॉडल "नई सुविधाओं के बारे में नहीं जान सकता."
जनरेट किया गया टेक्स्ट
आम तौर पर, एमएल मॉडल से मिलने वाला टेक्स्ट. लार्ज लैंग्वेज मॉडल का आकलन करते समय, कुछ मेट्रिक जनरेट किए गए टेक्स्ट की तुलना रेफ़रंस टेक्स्ट से करती हैं. उदाहरण के लिए, मान लें कि आपको यह पता लगाना है कि कोई एमएल मॉडल, फ़्रेंच से डच में कितनी अच्छी तरह से अनुवाद करता है. इस मामले में:
- जनरेट किया गया टेक्स्ट, डच भाषा में किया गया अनुवाद है. यह अनुवाद, एमएल मॉडल ने किया है.
- रेफ़रंस टेक्स्ट, डच भाषा में किया गया वह अनुवाद होता है जिसे कोई व्यक्ति या सॉफ़्टवेयर करता है.
ध्यान दें कि कुछ आकलन रणनीतियों में रेफ़रंस टेक्स्ट शामिल नहीं होता है.
जनरेटिव ऐडवर्सल नेटवर्क (जीएएन)
यह एक ऐसा सिस्टम है जिसमें नया डेटा बनाया जाता है. इसमें जनरेटर डेटा बनाता है और डिसक्रिमिनेटर यह तय करता है कि बनाया गया डेटा मान्य है या अमान्य.
ज़्यादा जानकारी के लिए, जनरेटिव ऐडवर्सैरियल नेटवर्क कोर्स देखें.
जनरेटिव एआई
यह एक ऐसा क्षेत्र है जिसमें बदलाव हो रहा है और इसकी कोई औपचारिक परिभाषा नहीं है. हालांकि, ज़्यादातर विशेषज्ञ इस बात से सहमत हैं कि जनरेटिव एआई मॉडल, ऐसा कॉन्टेंट बना सकते हैं ("जनरेट" कर सकते हैं) जो इन सभी शर्तों को पूरा करता हो:
- जटिल
- समझ में आने वाला
- मूल
जनरेटिव एआई के उदाहरणों में ये शामिल हैं:
- लार्ज लैंग्वेज मॉडल, जो ओरिजनल टेक्स्ट जनरेट कर सकते हैं और सवालों के जवाब दे सकते हैं.
- इमेज जनरेट करने वाला मॉडल, जो यूनीक इमेज जनरेट कर सकता है.
- ऑडियो और संगीत जनरेट करने वाले मॉडल. ये मॉडल, ओरिजनल संगीत कंपोज़ कर सकते हैं या बिलकुल असली जैसी आवाज़ जनरेट कर सकते हैं.
- वीडियो जनरेट करने वाले मॉडल, जो ओरिजनल वीडियो जनरेट कर सकते हैं.
एलएसटीएम और आरएनएन जैसी कुछ पुरानी टेक्नोलॉजी भी ओरिजनल और समझ में आने वाला कॉन्टेंट जनरेट कर सकती हैं. कुछ विशेषज्ञों का मानना है कि ये पुरानी टेक्नोलॉजी, जनरेटिव एआई हैं. वहीं, अन्य विशेषज्ञों का मानना है कि जनरेटिव एआई को इन पुरानी टेक्नोलॉजी के मुकाबले ज़्यादा जटिल आउटपुट की ज़रूरत होती है.
इसकी तुलना अनुमान लगाने वाली एमएल से करें.
जनरेटिव मॉडल
असल में, ऐसा मॉडल जो इनमें से कोई काम करता है:
- यह ट्रेनिंग डेटासेट से नए उदाहरण बनाता है (जनरेट करता है). उदाहरण के लिए, जनरेटिव मॉडल को कविताओं के डेटासेट पर ट्रेनिंग देने के बाद, वह कविताएं लिख सकता है. जनरेटिव ऐडवर्सैरियल नेटवर्क का जनरेटर हिस्सा, इस कैटगरी में आता है.
- यह तय करता है कि किसी नए उदाहरण के ट्रेनिंग सेट से आने या ट्रेनिंग सेट बनाने वाले तरीके से बनाए जाने की संभावना कितनी है. उदाहरण के लिए, अंग्रेज़ी के वाक्यों वाले डेटासेट पर ट्रेनिंग देने के बाद, कोई जनरेटिव मॉडल यह तय कर सकता है कि नया इनपुट, अंग्रेज़ी का मान्य वाक्य है या नहीं.
सैद्धांतिक तौर पर, जनरेटिव मॉडल किसी डेटासेट में उदाहरणों या खास सुविधाओं के डिस्ट्रिब्यूशन का पता लगा सकता है. यानी:
p(examples)
अनसुपरवाइज़्ड लर्निंग मॉडल, जनरेटिव होते हैं.
भेदभाव करने वाले मॉडल से तुलना करें.
जेनरेटर
जनरेटिव एडवर्सरियल नेटवर्क में मौजूद ऐसा सबसिस्टम जो नए उदाहरण बनाता है.
भेदभाव करने वाले मॉडल से तुलना करें.
गिनी अशुद्धता
एंट्रॉपी से मिलती-जुलती मेट्रिक. स्प्लिटर, क्लासिफ़िकेशन डिसिज़न ट्री के लिए शर्तें बनाने के लिए, गिनी इंप्योरिटी या एंट्रॉपी से मिली वैल्यू का इस्तेमाल करते हैं. सूचना लाभ, एंट्रॉपी से मिलता है. गिनी अशुद्धता से मिली मेट्रिक के लिए, कोई भी ऐसा शब्द नहीं है जिसे दुनिया भर में स्वीकार किया गया हो. हालांकि, बिना नाम वाली यह मेट्रिक, सूचना के फ़ायदे जितनी ही अहम होती है.
Gini अशुद्धता को Gini इंडेक्स या सिर्फ़ Gini भी कहा जाता है.
गोल्डन डेटासेट
मैन्युअल तरीके से तैयार किया गया डेटा सेट, जिसमें ग्राउंड ट्रूथ शामिल होता है. टीम, मॉडल की क्वालिटी का आकलन करने के लिए एक या उससे ज़्यादा गोल्डन डेटासेट का इस्तेमाल कर सकती हैं.
कुछ गोल्डन डेटासेट, ग्राउंड ट्रुथ के अलग-अलग सबडোমेन कैप्चर करते हैं. उदाहरण के लिए, इमेज क्लासिफ़िकेशन के लिए गोल्डन डेटासेट में, रोशनी की स्थिति और इमेज का रिज़ॉल्यूशन कैप्चर किया जा सकता है.
गोल्डन रिस्पॉन्स
ऐसा जवाब जो अच्छा माना जाता है. उदाहरण के लिए, यहां दिए गए प्रॉम्प्ट के लिए:
2 + 2
हमें उम्मीद है कि सबसे अच्छा जवाब यह होगा:
4
Google AI Studio
यह Google का एक टूल है. यह Google के लार्ज लैंग्वेज मॉडल का इस्तेमाल करके, ऐप्लिकेशन बनाने और उन्हें आज़माने के लिए, उपयोगकर्ता के लिए आसान इंटरफ़ेस उपलब्ध कराता है. ज़्यादा जानकारी के लिए, Google AI Studio का होम पेज देखें.
GPT (जनरेटिव प्री-ट्रेन्ड ट्रांसफ़ॉर्मर)
यह OpenAI ने बनाया है. यह Transformer पर आधारित लार्ज लैंग्वेज मॉडल का एक ग्रुप है.
GPT के वैरिएंट, कई मोडेलिटी पर लागू हो सकते हैं. जैसे:
- इमेज जनरेट करने की सुविधा (उदाहरण के लिए, ImageGPT)
- टेक्स्ट से इमेज जनरेट करने की सुविधा (उदाहरण के लिए, DALL-E).
ग्रेडिएंट
सभी इंडिपेंडेंट वैरिएबल के हिसाब से, आंशिक अवकलज का वेक्टर. मशीन लर्निंग में, ग्रेडिएंट, मॉडल फ़ंक्शन के आंशिक अवकलजों का वेक्टर होता है. ग्रेडिएंट पॉइंट, सबसे ज़्यादा ढलान वाली दिशा में होता है.
ग्रेडिएंट एक्युमुलेशन
यह बैकप्रॉपैगेशन की एक ऐसी तकनीक है जो पैरामीटर को हर इटरेशन में अपडेट करने के बजाय, सिर्फ़ हर युग में एक बार अपडेट करती है. हर मिनी-बैच को प्रोसेस करने के बाद, ग्रेडिएंट एक्युमुलेशन, ग्रेडिएंट के रनिंग टोटल को अपडेट करता है. इसके बाद, सिस्टम हर युग में आखिरी मिनी-बैच को प्रोसेस करता है. इसके बाद, सभी ग्रेडिएंट में हुए बदलावों के आधार पर पैरामीटर को अपडेट करता है.
ग्रेडिएंट एक्युमुलेशन तब काम आता है, जब ट्रेनिंग के लिए उपलब्ध मेमोरी की तुलना में बैच साइज़ बहुत बड़ा होता है. जब मेमोरी की समस्या होती है, तो बैच साइज़ को कम करने की सलाह दी जाती है. हालांकि, सामान्य बैकप्रॉपैगेशन में बैच का साइज़ कम करने से, पैरामीटर अपडेट की संख्या बढ़ जाती है. ग्रेडिएंट एक्युमुलेशन की मदद से, मॉडल को मेमोरी से जुड़ी समस्याओं से बचने में मदद मिलती है. हालांकि, इससे मॉडल को ट्रेनिंग देने में कोई रुकावट नहीं आती.
ग्रेडिएंट बूस्टेड (डिसिज़न) ट्री (जीबीटी)
यह डिसिज़न फ़ॉरेस्ट का एक टाइप है. इसमें:
- ट्रेनिंग, ग्रेडिएंट बूस्टिंग पर निर्भर करती है.
- कमज़ोर मॉडल एक डिसिज़न ट्री है.
ज़्यादा जानकारी के लिए, फ़ैसले लेने वाले फ़ॉरेस्ट कोर्स में ग्रेडिएंट बूस्टेड डिसिज़न ट्री देखें.
ग्रेडिएंट बूस्टिंग
यह एक ट्रेनिंग एल्गोरिदम है. इसमें कमज़ोर मॉडल को बार-बार ट्रेन किया जाता है, ताकि वे किसी मज़बूत मॉडल की क्वालिटी को बेहतर बना सकें (नुकसान को कम कर सकें). उदाहरण के लिए, कमज़ोर मॉडल, लीनियर या छोटा डिसिज़न ट्री मॉडल हो सकता है. इस तरह, पहले से ट्रेन किए गए सभी कमज़ोर मॉडल को मिलाकर एक मज़बूत मॉडल तैयार किया जाता है.
ग्रेडिएंट बूस्टिंग के सबसे आसान तरीके में, हर बार एक कमज़ोर मॉडल को ट्रेन किया जाता है, ताकि वह मज़बूत मॉडल के लॉस ग्रेडिएंट का अनुमान लगा सके. इसके बाद, अनुमानित ग्रेडिएंट को घटाकर, मॉडल के आउटपुट को अपडेट किया जाता है. यह ग्रेडिएंट डिसेंट की तरह होता है.
कहां:
- $F_{0}$ एक ऐसा मॉडल है जो अच्छी परफ़ॉर्मेंस से शुरू होता है.
- $F_{i+1}$ अगला स्ट्रॉन्ग मॉडल है.
- $F_{i}$ मौजूदा स्ट्रॉन्ग मॉडल है.
- $\xi$ की वैल्यू 0.0 और 1.0 के बीच होती है. इसे श्रिंकेज कहा जाता है. यह ग्रेडिएंट डिसेंट में लर्निंग रेट के जैसा होता है.
- $f_{i}$ एक ऐसा मॉडल है जिसे $F_{i}$ के लॉस ग्रेडिएंट का अनुमान लगाने के लिए ट्रेन किया गया है.
ग्रेडिएंट बूस्टिंग के आधुनिक वर्शन में, कंप्यूटेशन के दौरान नुकसान के दूसरे डेरिवेटिव (Hessian) को भी शामिल किया जाता है.
डिसिज़न ट्री का इस्तेमाल, आम तौर पर ग्रेडिएंट बूस्टिंग में कमज़ोर मॉडल के तौर पर किया जाता है. ग्रेडिएंट बूस्टेड (डिसिज़न) ट्री देखें.
ग्रेडिएंट क्लिपिंग
यह एक ऐसा तरीका है जिसका इस्तेमाल आम तौर पर, एक्सप्लोडिंग ग्रेडिएंट की समस्या को कम करने के लिए किया जाता है. इसमें ग्रेडिएंट डिसेंट का इस्तेमाल करके, मॉडल को ट्रेन करते समय, ग्रेडिएंट की ज़्यादा से ज़्यादा वैल्यू को आर्टिफ़िशियली तौर पर सीमित (क्लिप) किया जाता है.
ग्रेडिएंट डिसेंट
यह नुकसान को कम करने की एक गणितीय तकनीक है. ग्रेडिएंट डिसेंट, वज़न और बायस को बार-बार अडजस्ट करता है. इससे, नुकसान को कम करने के लिए सबसे सही कॉम्बिनेशन धीरे-धीरे मिल जाता है.
ग्रेडिएंट डिसेंट, मशीन लर्निंग से बहुत पुराना है.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में लीनियर रिग्रेशन: ग्रेडिएंट डिसेंट देखें.
ग्राफ़
TensorFlow में, कंप्यूटेशन की खास जानकारी. ग्राफ़ में मौजूद नोड, कार्रवाइयों को दिखाते हैं. किनारों को डायरेक्ट किया जाता है. ये किसी ऑपरेशन (Tensor) के नतीजे को किसी दूसरे ऑपरेशन के लिए ऑपरेंड के तौर पर पास करने के बारे में बताते हैं. ग्राफ़ को विज़ुअलाइज़ करने के लिए, TensorBoard का इस्तेमाल करें.
ग्राफ़ एक्ज़ीक्यूशन
यह TensorFlow का प्रोग्रामिंग एनवायरमेंट है. इसमें प्रोग्राम पहले ग्राफ़ बनाता है. इसके बाद, उस ग्राफ़ के पूरे या कुछ हिस्से को एक्ज़ीक्यूट करता है. TensorFlow 1.x में, ग्राफ़ एक्ज़ीक्यूशन डिफ़ॉल्ट एक्ज़ीक्यूशन मोड होता है.
इसकी तुलना ईगर एक्ज़ीक्यूशन से करें.
लालच दिखाने वाली नीति
रीइन्फ़ोर्समेंट लर्निंग में, एक नीति होती है. यह हमेशा उस कार्रवाई को चुनती है जिससे सबसे ज़्यादा रिटर्न मिलने की उम्मीद होती है.
भरोसेमंद स्रोतों से जानकारी लेना
यह किसी मॉडल की ऐसी प्रॉपर्टी होती है जिसका आउटपुट, किसी खास सोर्स मटीरियल पर आधारित होता है. उदाहरण के लिए, मान लें कि आपने पूरी फ़िज़िक्स की टेक्स्टबुक को लार्ज लैंग्वेज मॉडल को इनपुट ("कॉन्टेक्स्ट") के तौर पर दिया है. इसके बाद, उस लार्ज लैंग्वेज मॉडल को भौतिक विज्ञान से जुड़ा कोई सवाल पूछा जाता है. अगर मॉडल का जवाब, उस किताब में मौजूद जानकारी के हिसाब से है, तो इसका मतलब है कि मॉडल का जवाब, उस किताब पर आधारित है.ध्यान दें कि ग्राउंडेड मॉडल हमेशा तथ्यों पर आधारित नहीं होता. उदाहरण के लिए, इनपुट की गई फ़िज़िक्स की टेक्स्टबुक में गलतियां हो सकती हैं.
ग्राउंड ट्रूथ
रियलिटी.
असल में क्या हुआ.
उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल पर विचार करें. यह मॉडल अनुमान लगाता है कि यूनिवर्सिटी के पहले साल में पढ़ने वाला छात्र/छात्रा, छह साल के अंदर ग्रेजुएट हो पाएगा या नहीं. इस मॉडल के लिए, ग्राउंड ट्रुथ यह है कि छात्र-छात्रा ने छह साल के अंदर वाकई में ग्रेजुएशन की है या नहीं.
ग्रुप एट्रिब्यूशन बायस
यह मान लेना कि किसी व्यक्ति के लिए जो सही है वह उस ग्रुप के सभी लोगों के लिए भी सही है. अगर डेटा इकट्ठा करने के लिए, सुविधा के हिसाब से सैंपलिंग का इस्तेमाल किया जाता है, तो ग्रुप एट्रिब्यूशन बायस के असर और बढ़ सकते हैं. प्रतिनिधि सैंपल न होने पर, ऐसे एट्रिब्यूशन किए जा सकते हैं जो असलियत को नहीं दिखाते.
आउट-ग्रुप होमोजेनिटी बायस और इन-ग्रुप बायस भी देखें. ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: पूर्वाग्रह के टाइप भी देखें.
H
गलत जानकारी
जनरेटिव एआई मॉडल से ऐसा आउटपुट मिलना जो देखने में सही लगे, लेकिन उसमें दी गई जानकारी गलत हो. साथ ही, यह दावा किया गया हो कि यह जानकारी असल दुनिया के बारे में है. उदाहरण के लिए, अगर कोई जनरेटिव एआई मॉडल यह दावा करता है कि बराक ओबामा की मौत 1865 में हुई थी, तो यह भ्रामक जानकारी दे रहा है.
हैशिंग
मशीन लर्निंग में, बकेटिंग एक ऐसा तरीका है जिससे कैटगोरिकल डेटा को बकेट में बांटा जाता है. खास तौर पर, ऐसा तब किया जाता है, जब कैटगरी की संख्या ज़्यादा हो, लेकिन डेटासेट में दिखने वाली कैटगरी की संख्या तुलनात्मक रूप से कम हो.
उदाहरण के लिए, पृथ्वी पर करीब 73,000 तरह के पेड़ पाए जाते हैं. आपके पास 73,000 तरह के पेड़ों को 73,000 अलग-अलग कैटगरी वाले बकेट में दिखाने का विकल्प है. इसके अलावा, अगर डेटासेट में सिर्फ़ 200 तरह के पेड़ दिखते हैं, तो पेड़ की प्रजातियों को 500 बकेट में बांटने के लिए हैशिंग का इस्तेमाल किया जा सकता है.
एक बकेट में, कई तरह के पेड़ हो सकते हैं. उदाहरण के लिए, हैशिंग की वजह से, बाओबाब और रेड मेपल को एक ही बकेट में रखा जा सकता है. ये दोनों प्रजातियां, जेनेटिक तौर पर अलग-अलग होती हैं. हालांकि, हैशिंग अब भी कैटगरी वाले बड़े डेटा सेट को चुनी गई बकेट की संख्या में मैप करने का एक अच्छा तरीका है. हैशिंग की मदद से, कैटगरी वाली ऐसी सुविधा को कम वैल्यू में बदला जाता है जिसमें संभावित वैल्यू की संख्या ज़्यादा होती है. ऐसा, वैल्यू को एक तय तरीके से ग्रुप करके किया जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटेगरी के हिसाब से डेटा: शब्दावली और वन-हॉट एन्कोडिंग देखें.
अनुमान से जुड़ा
किसी समस्या का आसान और तुरंत लागू किया जा सकने वाला समाधान. उदाहरण के लिए, "हमने अनुमानित तरीके से 86% सटीकता हासिल की. डीप न्यूरल नेटवर्क का इस्तेमाल करने पर, सटीकता 98% तक बढ़ गई."
छिपी हुई लेयर
यह न्यूरल नेटवर्क में एक लेयर होती है. यह इनपुट लेयर (सुविधाएं) और आउटपुट लेयर (अनुमान) के बीच होती है. हर छिपी हुई लेयर में एक या उससे ज़्यादा न्यूरॉन होते हैं. उदाहरण के लिए, यहां दिए गए न्यूरल नेटवर्क में दो हिडन लेयर हैं. पहली लेयर में तीन न्यूरॉन और दूसरी लेयर में दो न्यूरॉन हैं:
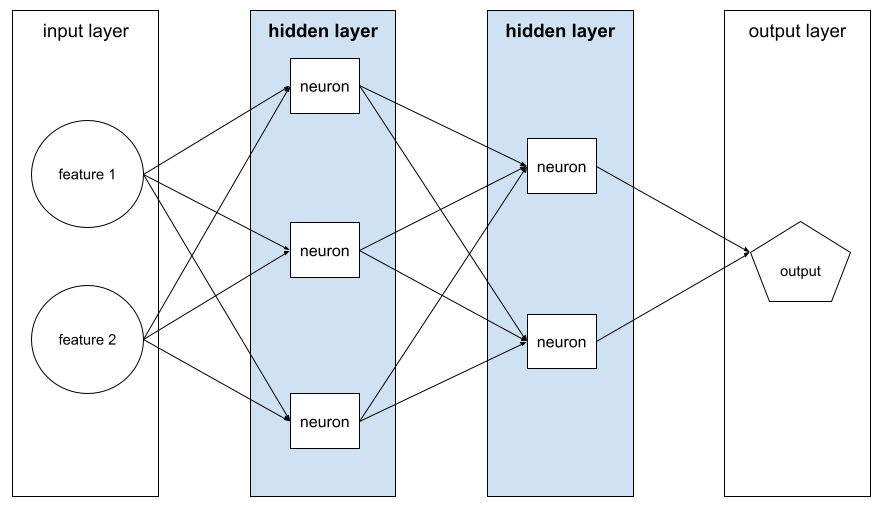
डीप न्यूरल नेटवर्क में एक से ज़्यादा हिडन लेयर होती हैं. उदाहरण के लिए, ऊपर दी गई इमेज एक डीप न्यूरल नेटवर्क है, क्योंकि मॉडल में दो हिडन लेयर शामिल हैं.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: नोड और हिडन लेयर देखें.
हैरारकीकल क्लस्टरिंग
क्लस्टरिंग एल्गोरिदम की एक कैटगरी, जो क्लस्टर का ट्री बनाती है. सबसे ज़रूरी कॉन्टेंट को पहले दिखाने वाला क्लस्टरिंग तरीका, सबसे ज़रूरी कॉन्टेंट को पहले दिखाने वाले डेटा के लिए सबसे सही होता है. जैसे, वनस्पति विज्ञान की टैक्सोनॉमी. हायरार्किकल क्लस्टरिंग एल्गोरिदम दो तरह के होते हैं:
- एगलोमेरेटिव क्लस्टरिंग में, सबसे पहले हर उदाहरण को उसके अपने क्लस्टर में असाइन किया जाता है. इसके बाद, सबसे नज़दीकी क्लस्टर को बार-बार मर्ज करके, एक हैरारिकल ट्री बनाया जाता है.
- डिविज़िव क्लस्टरिंग में, सबसे पहले सभी उदाहरणों को एक ग्रुप में रखा जाता है. इसके बाद, क्लस्टर को हैरारकी वाले ट्री में बार-बार बांटा जाता है.
इसकी तुलना सेंट्रॉइड पर आधारित क्लस्टरिंग से करें.
ज़्यादा जानकारी के लिए, क्लस्टरिंग कोर्स में क्लस्टरिंग ऐल्गोरिदम देखें.
पहाड़ी पर चढ़ना
यह एक ऐसा एल्गोरिदम है जो एमएल मॉडल को बार-बार बेहतर बनाता है ("वॉकिंग अपहिल"). ऐसा तब तक होता है, जब तक मॉडल बेहतर होना बंद नहीं हो जाता ("पहाड़ी के ऊपर पहुंच जाता है"). एल्गोरिदम का सामान्य फ़ॉर्म इस तरह है:
- शुरुआती मॉडल बनाएं.
- ट्रेन या फ़ाइन-ट्यून करने के तरीके में कुछ बदलाव करके, नए कैंडिडेट मॉडल बनाएँ. इसके लिए, आपको ट्रेनिंग सेट या अलग-अलग हाइपरपैरामीटर का इस्तेमाल करना पड़ सकता है.
- नए कैंडिडेट मॉडल का आकलन करें और इनमें से कोई एक कार्रवाई करें:
- अगर कोई कैंडिडेट मॉडल, शुरुआती मॉडल से बेहतर परफ़ॉर्म करता है, तो वह कैंडिडेट मॉडल, नया शुरुआती मॉडल बन जाता है. इस स्थिति में, पहले, दूसरे, और तीसरे चरण को दोहराएं.
- अगर कोई भी मॉडल, शुरुआती मॉडल से बेहतर परफ़ॉर्म नहीं करता है, तो इसका मतलब है कि आपने सबसे अच्छा मॉडल बना लिया है. इसलिए, आपको मॉडल में बदलाव करना बंद कर देना चाहिए.
हाइपरपैरामीटर ट्यूनिंग के बारे में दिशा-निर्देश पाने के लिए, डीप लर्निंग ट्यूनिंग प्लेबुक देखें. फ़ीचर इंजीनियरिंग के बारे में दिशा-निर्देश पाने के लिए, मशीन लर्निंग क्रैश कोर्स के डेटा मॉड्यूल देखें.
हिंज लॉस
यह loss फ़ंक्शन का एक फ़ैमिली है. इसे classification के लिए डिज़ाइन किया गया है. इसका मकसद, decision boundary को हर ट्रेनिंग उदाहरण से ज़्यादा से ज़्यादा दूरी पर रखना है. इससे उदाहरणों और बाउंड्री के बीच मार्जिन बढ़ जाता है. KSVM, हिंज लॉस (या इससे जुड़ा कोई फ़ंक्शन, जैसे कि स्क्वेयर्ड हिंज लॉस) का इस्तेमाल करते हैं. बाइनरी क्लासिफ़िकेशन के लिए, हिंज लॉस फ़ंक्शन को इस तरह से परिभाषित किया गया है:
यहां y, सही लेबल है. यह -1 या +1 हो सकता है. साथ ही, y', क्लासिफ़िकेशन मॉडल का रॉ आउटपुट है:
इसलिए, हिंज लॉस बनाम (y * y') का प्लॉट इस तरह दिखता है:

पुराने डेटा के आधार पर भेदभाव
यह एक तरह का पूर्वाग्रह है, जो दुनिया में पहले से मौजूद है और डेटासेट में शामिल हो गया है. इन पूर्वाग्रहों में, मौजूदा सांस्कृतिक रूढ़ियों, जनसांख्यिकी असमानताओं, और कुछ सामाजिक समूहों के ख़िलाफ़ पूर्वाग्रहों को दिखाने की प्रवृत्ति होती है.
उदाहरण के लिए, क्लासिफ़िकेशन मॉडल पर विचार करें. यह मॉडल, क़र्ज़ के लिए आवेदन करने वाले व्यक्ति के डिफ़ॉल्ट होने की संभावना का अनुमान लगाता है. इसे 1980 के दशक के क़र्ज़ के डिफ़ॉल्ट डेटा पर ट्रेन किया गया था. यह डेटा, दो अलग-अलग समुदायों के स्थानीय बैंकों से मिला था. अगर कम्यूनिटी A के पिछले आवेदकों के, कम्यूनिटी B के आवेदकों की तुलना में छह गुना ज़्यादा डिफ़ॉल्ट करने की संभावना थी, तो मॉडल को ऐतिहासिक पूर्वाग्रह का पता चल सकता है. इससे कम्यूनिटी A में मॉडल के ज़रिए लोन को मंज़ूरी मिलने की संभावना कम हो सकती है. भले ही, कम्यूनिटी A में डिफ़ॉल्ट रेट ज़्यादा होने की ऐतिहासिक स्थितियां अब लागू न हों.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: पूर्वाग्रह के टाइप देखें.
होल्डआउट डेटा
उदाहरण को ट्रेनिंग के दौरान जान-बूझकर इस्तेमाल नहीं किया गया ("होल्ड आउट"). पुष्टि करने के लिए इस्तेमाल किया जाने वाला डेटासेट और टेस्ट डेटासेट, होल्डआउट डेटा के उदाहरण हैं. होल्डआउट डेटा से, यह आकलन करने में मदद मिलती है कि आपका मॉडल, उस डेटा के अलावा किसी दूसरे डेटा के लिए सामान्य तौर पर काम कर सकता है या नहीं जिस पर उसे ट्रेन किया गया था. होल्डआउट सेट में हुए नुकसान से, ट्रेनिंग सेट में हुए नुकसान की तुलना में, ऐसे डेटासेट में हुए नुकसान का बेहतर अनुमान मिलता है जिसे पहले कभी नहीं देखा गया.
होस्ट
ऐक्सेलरेटर चिप (जीपीयू या टीपीयू) पर एमएल मॉडल को ट्रेनिंग देते समय, सिस्टम का वह हिस्सा जो इन दोनों को कंट्रोल करता है:
- कोड का पूरा फ़्लो.
- इनपुट पाइपलाइन से डेटा निकालने और उसे बदलने की प्रोसेस.
होस्ट आम तौर पर सीपीयू पर चलता है, न कि ऐक्सलरेटर चिप पर. डिवाइस, ऐक्सलरेटर चिप पर टेंसर में बदलाव करता है.
लोगों के सुझाव, शिकायत या राय
यह एक ऐसी प्रोसेस है जिसमें लोग, मशीन लर्निंग मॉडल के आउटपुट की क्वालिटी का आकलन करते हैं. उदाहरण के लिए, दो भाषाओं का ज्ञान रखने वाले लोगों से, मशीन लर्निंग ट्रांसलेशन मॉडल की क्वालिटी का आकलन कराना. मैन्युअल तरीके से आकलन करना, उन मॉडल का आकलन करने के लिए खास तौर पर फ़ायदेमंद होता है जिनके एक से ज़्यादा सही जवाब होते हैं.
इसकी तुलना अपने-आप होने वाले आकलन और ऑटोरेटर के आकलन से करें.
ह्यूमन इन द लूप (एचआईटीएल)
यह एक मुहावरा है, जिसका मतलब इनमें से कोई भी हो सकता है:
- जनरेटिव एआई के आउटपुट को गंभीरता से या संदेह की नज़र से देखने की नीति.
- यह एक रणनीति या सिस्टम है. इससे यह पक्का किया जाता है कि लोग, मॉडल के व्यवहार को बेहतर बनाने, उसका आकलन करने, और उसे बेहतर बनाने में मदद करें. इंसान को लूप में रखने से, एआई को मशीन इंटेलिजेंस और ह्यूमन इंटेलिजेंस, दोनों से फ़ायदा मिलता है. उदाहरण के लिए, एक ऐसा सिस्टम जिसमें एआई कोड जनरेट करता है और सॉफ़्टवेयर इंजीनियर उसकी समीक्षा करते हैं, वह ह्यूमन-इन-द-लूप सिस्टम है.
हाइपर पैरामीटर
ये ऐसे वैरिएबल होते हैं जिन्हें मॉडल को ट्रेन करने के दौरान, आपने या हाइपरपैरामीटर ट्यूनिंग सेवाने अडजस्ट किया है. उदाहरण के लिए, लर्निंग रेट एक हाइपरपैरामीटर है. ट्रेनिंग सेशन से पहले, लर्निंग रेट को 0.01 पर सेट किया जा सकता है. अगर आपको लगता है कि 0.01 बहुत ज़्यादा है, तो अगले ट्रेनिंग सेशन के लिए लर्निंग रेट को 0.003 पर सेट किया जा सकता है.
इसके उलट, पैरामीटर अलग-अलग वज़न और बायस होते हैं. मॉडल, ट्रेनिंग के दौरान इन्हें सीखता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
हाइपरप्लेन
ऐसी सीमा जो किसी स्पेस को दो सबस्पेस में बांटती है. उदाहरण के लिए, दो डाइमेंशन में एक लाइन, हाइपरप्लेन होती है. वहीं, तीन डाइमेंशन में एक प्लेन, हाइपरप्लेन होता है. मशीन लर्निंग में, हाइपरप्लेन एक ऐसी सीमा होती है जो ज़्यादा डाइमेंशन वाले स्पेस को अलग करती है. कर्नेल सपोर्ट वेक्टर मशीनें, पॉज़िटिव क्लास को नेगेटिव क्लास से अलग करने के लिए हाइपरप्लेन का इस्तेमाल करती हैं. ऐसा अक्सर बहुत ज़्यादा डाइमेंशन वाले स्पेस में किया जाता है.
I
i.i.d.
इंडिपेंडेंटली ऐंड आइडेंटिकली डिस्ट्रिब्यूटेड का संक्षिप्त रूप.
इमेज पहचानने की सुविधा
यह एक ऐसी प्रोसेस है जो किसी इमेज में मौजूद ऑब्जेक्ट, पैटर्न या कॉन्सेप्ट को कैटगरी में बांटती है. इमेज पहचानने की सुविधा को इमेज क्लासिफ़िकेशन भी कहा जाता है.
इंबैलेंस डेटासेट
यह क्लास-इम्बैलेंस डेटासेट का समानार्थी शब्द है.
अनजाने में भेदभाव करना
किसी व्यक्ति के दिमाग़ी मॉडल और यादों के आधार पर, अपने-आप कोई अनुमान लगाना या किसी चीज़ को जोड़ना. अचेतन पूर्वाग्रह की वजह से, इन पर असर पड़ सकता है:
- डेटा को कैसे इकट्ठा और कैटगरी में बांटा जाता है.
- मशीन लर्निंग सिस्टम को कैसे डिज़ाइन और डेवलप किया जाता है.
उदाहरण के लिए, शादी की फ़ोटो की पहचान करने के लिए क्लासिफ़िकेशन मॉडल बनाते समय, कोई इंजीनियर फ़ोटो में सफ़ेद रंग के कपड़े की मौजूदगी को एक सुविधा के तौर पर इस्तेमाल कर सकता है. हालांकि, सफ़ेद रंग की ड्रेस पहनने की परंपरा सिर्फ़ कुछ समय पहले शुरू हुई है और यह कुछ ही संस्कृतियों में है.
पुष्टि करने का पूर्वाग्रह के बारे में भी जानें.
इंप्यूटेशन
वैल्यू का अनुमान का छोटा फ़ॉर्म.
निष्पक्षता से जुड़ी मेट्रिक का साथ में काम न करना
इस सिद्धांत के मुताबिक, निष्पक्षता के कुछ सिद्धांत एक-दूसरे के साथ काम नहीं करते और उन्हें एक साथ लागू नहीं किया जा सकता. इस वजह से, निष्पक्षता का आकलन करने के लिए कोई एक मेट्रिक नहीं है, जिसे एमएल से जुड़ी सभी समस्याओं पर लागू किया जा सके.
हालांकि, यह निराशाजनक लग सकता है, लेकिन निष्पक्षता की मेट्रिक के काम न करने का मतलब यह नहीं है कि निष्पक्षता के लिए की गई कोशिशें बेकार हैं. इसके बजाय, इसमें यह सुझाव दिया गया है कि एमएल से जुड़ी किसी समस्या के लिए, निष्पक्षता को कॉन्टेक्स्ट के हिसाब से तय किया जाना चाहिए. साथ ही, इसका मकसद इस्तेमाल के उदाहरणों से होने वाले नुकसान को रोकना होना चाहिए.
निष्पक्षता की मेट्रिक के मेल न खाने के बारे में ज़्यादा जानकारी के लिए, "On the (im)possibility of fairness" लेख पढ़ें.
कॉन्टेक्स्ट के हिसाब से सीखने की सुविधा
उदाहरण के साथ डाले गए प्रॉम्प्ट के लिए समानार्थी शब्द.
स्वतंत्र और समान रूप से डिस्ट्रिब्यूट किया गया (आई.आई.डी.)
यह ऐसे डिस्ट्रिब्यूशन से लिया गया डेटा होता है जिसमें कोई बदलाव नहीं होता. साथ ही, इसमें ली गई हर वैल्यू, पहले ली गई वैल्यू पर निर्भर नहीं करती. आई.आई.डी., मशीन लर्निंग का आदर्श गैस है. यह एक उपयोगी गणितीय कॉन्सेप्ट है, लेकिन असल दुनिया में यह कभी भी पूरी तरह से नहीं मिलता. उदाहरण के लिए, किसी वेब पेज पर आने वाले लोगों का डिस्ट्रिब्यूशन, कुछ समय के लिए i.i.d. हो सकता है. इसका मतलब है कि उस अवधि के दौरान डिस्ट्रिब्यूशन में कोई बदलाव नहीं होता. साथ ही, आम तौर पर एक व्यक्ति की विज़िट, दूसरे व्यक्ति की विज़िट से अलग होती है. हालांकि, अगर इस समय अवधि को बढ़ाया जाता है, तो वेब पेज पर आने वाले लोगों की संख्या में सीज़न के हिसाब से अंतर दिख सकता है.
नॉनस्टेशनैरिटी के बारे में भी जानें.
व्यक्तिगत निष्पक्षता
यह निष्पक्षता से जुड़ी मेट्रिक है. इससे यह पता चलता है कि क्या एक जैसे लोगों को एक ही कैटगरी में रखा गया है. उदाहरण के लिए, Brobdingnagian Academy यह पक्का करके, व्यक्तिगत निष्पक्षता के सिद्धांत का पालन करना चाहेगी कि एक जैसे ग्रेड और स्टैंडर्ड टेस्ट स्कोर वाले दो छात्र-छात्राओं को एडमिशन मिलने की संभावना बराबर हो.
ध्यान दें कि किसी व्यक्ति के साथ निष्पक्षता से व्यवहार करना, पूरी तरह से इस बात पर निर्भर करता है कि आपने "समानता" को कैसे परिभाषित किया है. इस मामले में, ग्रेड और टेस्ट स्कोर. अगर समानता की मेट्रिक में ज़रूरी जानकारी (जैसे, छात्र-छात्रा के पाठ्यक्रम की मुश्किल का स्तर) शामिल नहीं है, तो निष्पक्षता से जुड़ी नई समस्याएं पैदा हो सकती हैं.
व्यक्तिगत निष्पक्षता के बारे में ज़्यादा जानकारी के लिए, "Fairness Through Awareness" देखें.
अनुमान
ट्रेडिशनल मशीन लर्निंग में, बिना लेबल वाले उदाहरणों पर ट्रेन किए गए मॉडल को लागू करके अनुमान लगाने की प्रोसेस. ज़्यादा जानने के लिए, एमएल के बारे में जानकारी देने वाले कोर्स में निगरानी में की जाने वाली लर्निंग सेक्शन देखें.
लार्ज लैंग्वेज मॉडल में, अनुमान लगाने की प्रोसेस का इस्तेमाल, ट्रेनिंग दिए गए मॉडल का इस्तेमाल करके, इनपुट प्रॉम्प्ट के लिए जवाब जनरेट करने के लिए किया जाता है.
आंकड़ों में अनुमान का मतलब कुछ अलग होता है. ज़्यादा जानकारी के लिए, सांख्यिकीय अनुमान के बारे में Wikipedia लेख पढ़ें.
अनुमान लगाने का तरीका
डिसिज़न ट्री में, इनफ़रेंस के दौरान, कोई उदाहरण, रूट से लेकर अन्य शर्तों तक जाता है. इसके बाद, यह लीफ पर खत्म होता है. उदाहरण के लिए, यहां दिए गए फ़ैसले के ट्री में, मोटे ऐरो से ऐसे उदाहरण के लिए अनुमान लगाने का पाथ दिखाया गया है जिसमें ये फ़ीचर वैल्यू मौजूद हैं:
- x = 7
- y = 12
- z = -3
नीचे दिए गए इलस्ट्रेशन में, अनुमान लगाने का पाथ तीन शर्तों से होकर गुज़रता है. इसके बाद, यह लीफ़ (Zeta) तक पहुंचता है.
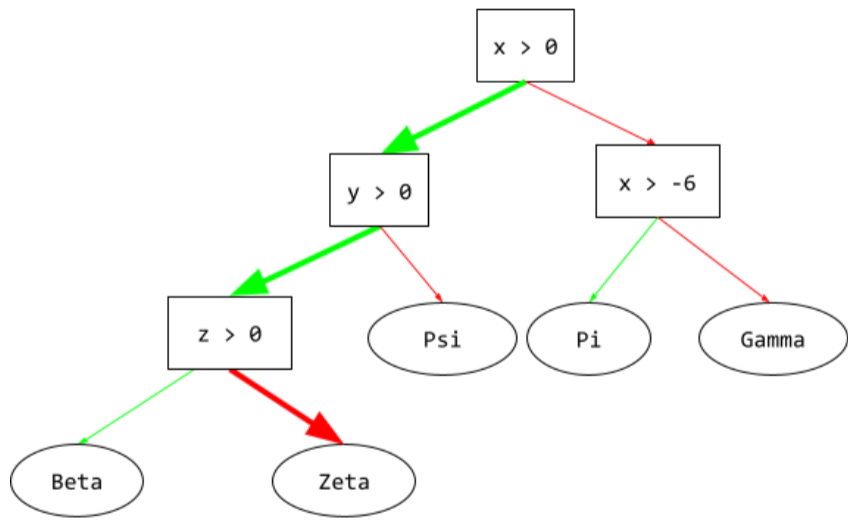
तीन मोटे ऐरो, अनुमान लगाने का तरीका दिखाते हैं.
ज़्यादा जानकारी के लिए, फ़ैसले लेने के लिए फ़ॉरेस्ट कोर्स में डिसिज़न ट्री देखें.
सूचना का फ़ायदा
डिसिज़न फ़ॉरेस्ट में, किसी नोड की एंट्रॉपी और उसके चाइल्ड नोड की एंट्रॉपी के वज़न (उदाहरणों की संख्या के हिसाब से) के योग के बीच का अंतर. किसी नोड की एंट्रॉपी, उस नोड में मौजूद उदाहरणों की एंट्रॉपी होती है.
उदाहरण के लिए, यहां दी गई एंट्रॉपी वैल्यू देखें:
- पैरंट नोड की एन्ट्रॉपी = 0.6
- काम के 16 उदाहरणों वाले एक चाइल्ड नोड की एंट्रॉपी = 0.2
- 24 काम के उदाहरणों वाले दूसरे चाइल्ड नोड की एंट्रॉपी = 0.1
इसलिए, 40% उदाहरण एक चाइल्ड नोड में हैं और 60% उदाहरण दूसरे चाइल्ड नोड में हैं. इसलिए:
- चाइल्ड नोड के वेटेड एन्ट्रॉपी का योग = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
इसलिए, जानकारी में हुई बढ़ोतरी यह है:
- सूचना लाभ = पैरंट नोड की एन्ट्रॉपी - चाइल्ड नोड की वज़न के हिसाब से एन्ट्रॉपी का योग
- सूचना में बढ़ोतरी = 0.6 - 0.14 = 0.46
ज़्यादातर स्प्लिटर, शर्तें बनाने की कोशिश करते हैं, ताकि ज़्यादा से ज़्यादा जानकारी मिल सके.
इन-ग्रुप बायस
अपने ग्रुप या अपनी विशेषताओं को ज़्यादा अहमियत देना. अगर टेस्टर या रेटर, मशीन लर्निंग डेवलपर के दोस्त, परिवार या सहकर्मी हैं, तो इन-ग्रुप बायस की वजह से, प्रॉडक्ट की टेस्टिंग या डेटासेट अमान्य हो सकता है.
इन-ग्रुप बायस, ग्रुप एट्रिब्यूशन बायस का एक टाइप है. आउट-ग्रुप होमोजेनिटी बायस के बारे में भी जानें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: पूर्वाग्रह के टाइप देखें.
इनपुट जनरेटर
यह एक ऐसा तरीका है जिससे डेटा को न्यूरल नेटवर्क में लोड किया जाता है.
इनपुट जनरेटर को एक ऐसे कॉम्पोनेंट के तौर पर देखा जा सकता है जो रॉ डेटा को टेंसर में प्रोसेस करने के लिए ज़िम्मेदार होता है. इन टेंसर को ट्रेनिंग, आकलन, और अनुमान के लिए बैच जनरेट करने के लिए दोहराया जाता है.
इनपुट लेयर
न्यूरल नेटवर्क की वह लेयर जिसमें फ़ीचर वेक्टर होता है. इसका मतलब है कि इनपुट लेयर, ट्रेनिंग या अनुमान के लिए उदाहरण देती है. उदाहरण के लिए, यहां दिए गए न्यूरल नेटवर्क की इनपुट लेयर में दो सुविधाएं शामिल हैं:
सेट में मौजूद होने की शर्त
डिसिज़न ट्री में, शर्त यह जांच करती है कि आइटम के सेट में कोई आइटम मौजूद है या नहीं. उदाहरण के लिए, यहां दी गई शर्त, सेट में मौजूद होने की शर्त है:
house-style in [tudor, colonial, cape]
अनुमान के दौरान, अगर हाउस-स्टाइल feature की वैल्यू tudor या colonial या cape है, तो यह शर्त 'हां' के तौर पर तय की जाती है. अगर हाउस-स्टाइल फ़ीचर की वैल्यू कुछ और है (उदाहरण के लिए, ranch), तो यह शर्त 'नहीं' के तौर पर तय होती है.
आम तौर पर, इन-सेट की गई शर्तों से, वन-हॉट एन्कोड की गई सुविधाओं की जांच करने वाली शर्तों की तुलना में, ज़्यादा असरदार फ़ैसले लेने वाले ट्री मिलते हैं.
इंस्टेंस
example के लिए समानार्थी शब्द.
निर्देशों के मुताबिक मॉडल को फ़ाइन-ट्यून करना
यह फ़ाइन-ट्यूनिंग का एक तरीका है. इससे जनरेटिव एआई मॉडल को निर्देशों का पालन करने में मदद मिलती है. निर्देशों के हिसाब से मॉडल को ट्यून करने के लिए, उसे निर्देशों वाले कई प्रॉम्प्ट पर ट्रेन किया जाता है. आम तौर पर, इसमें अलग-अलग तरह के टास्क शामिल होते हैं. इसके बाद, निर्देशों के मुताबिक काम करने वाला मॉडल, अलग-अलग टास्क के लिए ज़ीरो-शॉट प्रॉम्प्ट के जवाब जनरेट करता है.
इनके साथ तुलना करें:
व्याख्या करने की क्षमता
मशीन लर्निंग मॉडल के फ़ैसले के पीछे की वजह को आसान शब्दों में किसी इंसान को समझाना.
उदाहरण के लिए, ज़्यादातर लीनियर रिग्रेशन मॉडल को आसानी से समझा जा सकता है. (आपको सिर्फ़ हर सुविधा के लिए, ट्रेनिंग के दौरान तय किए गए वेट देखने हैं.) डिसिज़न फ़ॉरेस्ट को आसानी से समझा जा सकता है. हालांकि, कुछ मॉडल को समझने के लिए, बेहतर विज़ुअलाइज़ेशन की ज़रूरत होती है.
एमएल मॉडल को समझने के लिए, Learning Interpretability Tool (LIT) का इस्तेमाल किया जा सकता है.
इंटर-रेटर एग्रीमेंट
यह मेज़रमेंट बताता है कि किसी टास्क को पूरा करते समय, ह्यूमन रेटर कितनी बार एक-दूसरे से सहमत होते हैं. अगर रेटिंग देने वाले लोग सहमत नहीं हैं, तो टास्क के निर्देशों में सुधार करना पड़ सकता है. इसे कभी-कभी इंटर-एनोटेटर एग्रीमेंट या इंटर-रेटर रिलायबिलिटी भी कहा जाता है. यह भी देखें कोहेन का कप्पा, जो दो लोगों के बीच सहमति का आकलन करने के सबसे लोकप्रिय तरीकों में से एक है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटेगरी के हिसाब से डेटा: सामान्य समस्याएं देखें.
इंटरसेक्शन ओवर यूनियन (IoU)
दो सेट के इंटरसेक्शन को उनके यूनियन से भाग दिया जाता है. मशीन लर्निंग की मदद से इमेज का पता लगाने के टास्क में, IoU का इस्तेमाल मॉडल के अनुमानित बाउंडिंग बॉक्स की सटीक जानकारी का आकलन करने के लिए किया जाता है. यह आकलन, ग्राउंड-ट्रुथ बाउंडिंग बॉक्स के हिसाब से किया जाता है. इस मामले में, दो बॉक्स के लिए IoU, ओवरलैप होने वाले एरिया और कुल एरिया के बीच का अनुपात होता है. इसकी वैल्यू 0 (अनुमानित बाउंडिंग बॉक्स और ग्राउंड-ट्रुथ बाउंडिंग बॉक्स का कोई ओवरलैप नहीं) से लेकर 1 (अनुमानित बाउंडिंग बॉक्स और ग्राउंड-ट्रुथ बाउंडिंग बॉक्स के कोऑर्डिनेट एक जैसे हैं) तक होती है.
उदाहरण के लिए, नीचे दी गई इमेज में:
- अनुमानित बाउंडिंग बॉक्स (ऐसे कोऑर्डिनेट जो यह तय करते हैं कि पेंटिंग में नाइट टेबल कहां है) को बैंगनी रंग से हाइलाइट किया गया है.
- ग्राउंड-ट्रुथ बाउंडिंग बॉक्स (ऐसे निर्देशांक जो पेंटिंग में नाइटस्टैंड की सटीक जगह बताते हैं) को हरे रंग से हाइलाइट किया गया है.
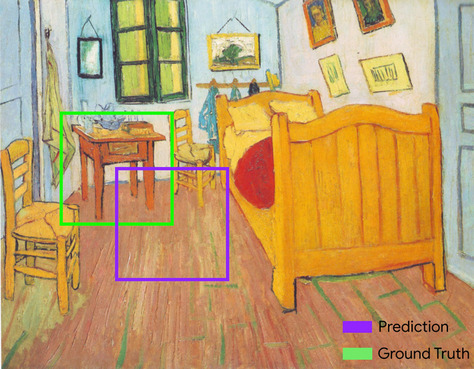
यहां, अनुमानित और असल वैल्यू के बाउंडिंग बॉक्स (नीचे बाईं ओर) का इंटरसेक्शन 1 है. साथ ही, अनुमानित और असल वैल्यू के बाउंडिंग बॉक्स (नीचे दाईं ओर) का यूनीयन 7 है. इसलिए, IoU \(\frac{1}{7}\)है.
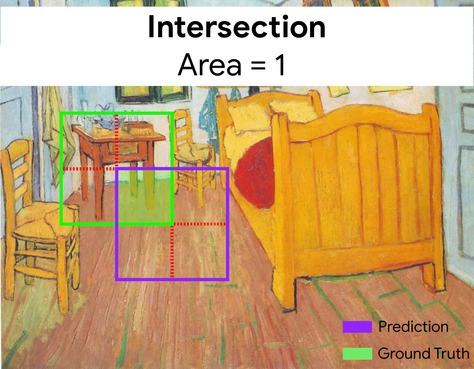
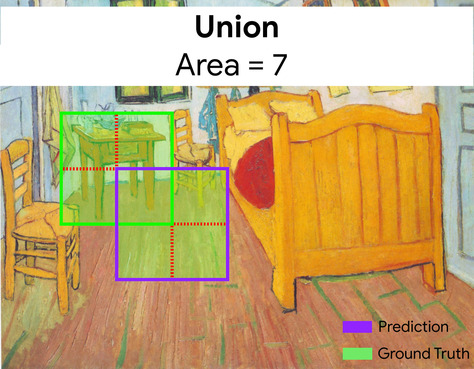
IoU
इंटरसेक्शन ओवर यूनियन के लिए छोटा नाम.
आइटम मैट्रिक्स
सुझाव देने वाले सिस्टम में, मैट्रिक्स फ़ैक्टराइज़ेशन से जनरेट की गई एंबेड किए जा रहे वेक्टर की मैट्रिक्स होती है. इसमें हर आइटम के बारे में छिपे हुए सिग्नल होते हैं. आइटम मैट्रिक्स की हर लाइन में, सभी आइटम के लिए एक लेटेंट फ़ीचर की वैल्यू होती है. उदाहरण के लिए, फ़िल्म का सुझाव देने वाले सिस्टम पर विचार करें. आइटम मैट्रिक्स के हर कॉलम में एक फ़िल्म के बारे में जानकारी होती है. लेटेंट सिग्नल, शैलियों को दिखा सकते हैं. इसके अलावा, ये ऐसे सिग्नल भी हो सकते हैं जिन्हें समझना मुश्किल हो. इनमें शैली, स्टार, फ़िल्म की उम्र या अन्य फ़ैक्टर के बीच जटिल इंटरैक्शन शामिल होते हैं.
आइटम मैट्रिक्स में उतने ही कॉलम होते हैं जितने टारगेट मैट्रिक्स में होते हैं. उदाहरण के लिए, अगर फ़िल्मों का सुझाव देने वाला कोई सिस्टम 10,000 फ़िल्मों के टाइटल का आकलन करता है, तो आइटम मैट्रिक्स में 10,000 कॉलम होंगे.
आइटम
सुझाव देने वाले सिस्टम में, वे इकाइयां जिनके बारे में सिस्टम सुझाव देता है. उदाहरण के लिए, वीडियो स्टोर में वीडियो का सुझाव दिया जाता है, जबकि किताबों की दुकान में किताबों का सुझाव दिया जाता है.
फिर से करें
ट्रेनिंग के दौरान, मॉडल के पैरामीटर—मॉडल के वज़न और बायस—को एक बार अपडेट करना. बैच साइज़ से यह तय होता है कि मॉडल एक बार में कितने उदाहरणों को प्रोसेस करेगा. उदाहरण के लिए, अगर बैच का साइज़ 20 है, तो मॉडल पैरामीटर को अडजस्ट करने से पहले, 20 उदाहरणों को प्रोसेस करता है.
न्यूरल नेटवर्क को ट्रेन करते समय, एक बार में ये दो पास शामिल होते हैं:
- किसी एक बैच पर नुकसान का आकलन करने के लिए फ़ॉरवर्ड पास.
- मॉडल के पैरामीटर को नुकसान और लर्निंग रेट के आधार पर अडजस्ट करने के लिए, बैकवर्ड पास (बैकप्रॉपैगेशन) का इस्तेमाल किया जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ग्रेडिएंट डिसेंट देखें.
J
JAX
यह एक ऐरे कंप्यूटिंग लाइब्रेरी है. इसमें XLA (ऐक्सलरेटेड लीनियर अलजेब्रा) और ऑटोमैटिक डिफ़रेंशिएशन को एक साथ लाया गया है, ताकि हाई-परफ़ॉर्मेंस न्यूमेरिकल कंप्यूटिंग की जा सके. JAX, कंपोज़ेबल ट्रांसफ़ॉर्मेशन के साथ तेज़ी से काम करने वाले न्यूमेरिक कोड लिखने के लिए, एक आसान और असरदार एपीआई उपलब्ध कराता है. JAX में ये सुविधाएं मिलती हैं:
grad(अपने-आप अंतर करने की सुविधा)jit(जस्ट-इन-टाइम कंपाइलेशन)vmap(अपने-आप वेक्टर बनाने या बैच बनाने की सुविधा)pmap(पैरललाइज़ेशन)
JAX, संख्या वाले कोड में बदलाव करने और उन्हें कंपोज़ करने के लिए इस्तेमाल की जाने वाली एक भाषा है. यह Python की NumPy लाइब्रेरी की तरह ही है, लेकिन इसका दायरा बहुत बड़ा है. (दरअसल, JAX के तहत .numpy लाइब्रेरी, Python NumPy लाइब्रेरी की तरह ही काम करती है. हालांकि, इसे पूरी तरह से फिर से लिखा गया है.)
JAX, मशीन लर्निंग से जुड़े कई टास्क को तेज़ी से पूरा करने के लिए खास तौर पर सही है. यह मॉडल और डेटा को ऐसे फ़ॉर्म में बदलता है जो GPU और TPU ऐक्सलरेटर चिप पर पैरलल प्रोसेसिंग के लिए सही होता है.
Flax, Optax, Pax, और कई अन्य लाइब्रेरी, JAX इंफ़्रास्ट्रक्चर पर बनाई गई हैं.
K
Keras
यह Python का एक लोकप्रिय मशीन लर्निंग एपीआई है. Keras, डीप लर्निंग के कई फ़्रेमवर्क पर काम करता है. इनमें TensorFlow भी शामिल है. TensorFlow में यह tf.keras के तौर पर उपलब्ध है.
कर्नेल सपोर्ट वेक्टर मशीनें (केएसवीएम)
यह एक क्लासिफ़िकेशन एल्गोरिदम है. यह इनपुट डेटा वेक्टर को ज़्यादा डाइमेंशन वाले स्पेस पर मैप करके, पॉज़िटिव और नेगेटिव क्लास के बीच मार्जिन को ज़्यादा से ज़्यादा करने की कोशिश करता है. उदाहरण के लिए, क्लासिफ़िकेशन की किसी समस्या पर विचार करें. इसमें इनपुट डेटासेट में 100 सुविधाएं हैं. पॉज़िटिव और नेगेटिव क्लास के बीच मार्जिन को ज़्यादा से ज़्यादा करने के लिए, KSVM उन सुविधाओं को इंटरनल तौर पर, एक मिलियन डाइमेंशन वाले स्पेस में मैप कर सकता है. KSVM, हिंज लॉस नाम के लॉस फ़ंक्शन का इस्तेमाल करता है.
मुख्य बातें
किसी इमेज में मौजूद खास सुविधाओं के निर्देशांक. उदाहरण के लिए, इमेज रिकॉग्निशन मॉडल, फूलों की प्रजातियों की पहचान करता है. इसमें मुख्य बिंदु, हर पंखुड़ी का केंद्र, तना, पुंकेसर वगैरह हो सकते हैं.
के-फ़ोल्ड क्रॉस वैलिडेशन
यह एक ऐसा एल्गोरिदम है जो नए डेटा के लिए, मॉडल की सामान्यीकरण करने की क्षमता का अनुमान लगाता है. के-फ़ोल्ड में k का मतलब है कि डेटासेट के उदाहरणों को बराबर के कितने ग्रुप में बांटा गया है. इसका मतलब है कि मॉडल को k बार ट्रेन और टेस्ट किया जाता है. ट्रेनिंग और टेस्टिंग के हर राउंड के लिए, एक अलग ग्रुप को टेस्ट सेट के तौर पर इस्तेमाल किया जाता है. बाकी सभी ग्रुप, ट्रेनिंग सेट बन जाते हैं. ट्रेनिंग और टेस्टिंग के k राउंड के बाद, चुनी गई टेस्ट मेट्रिक का औसत और स्टैंडर्ड डेविएशन कैलकुलेट किया जाता है.
उदाहरण के लिए, मान लें कि आपके डेटासेट में 120 उदाहरण हैं. मान लें कि आपने k को 4 पर सेट करने का फ़ैसला किया है. इसलिए, उदाहरणों को शफ़ल करने के बाद, डेटासेट को 30 उदाहरणों के चार बराबर ग्रुप में बांटा जाता है. इसके बाद, ट्रेनिंग और टेस्टिंग के चार राउंड किए जाते हैं:
उदाहरण के लिए, मीन स्क्वेयर्ड एरर (एमएसई), लीनियर रिग्रेशन मॉडल के लिए सबसे अहम मेट्रिक हो सकती है. इसलिए, आपको चारों राउंड में MSE का औसत और स्टैंडर्ड डेविएशन मिलेगा.
के-मीन्स
यह एक लोकप्रिय क्लस्टरिंग एल्गोरिदम है. यह बिना निगरानी वाली लर्निंग में उदाहरणों को ग्रुप करता है. के-मीन्स एल्गोरिदम, मुख्य रूप से ये काम करता है:
- यह सबसे अच्छे k सेंटर पॉइंट (जिन्हें सेंट्रॉइड कहा जाता है) का पता लगाता है.
- हर उदाहरण को सबसे नज़दीकी सेंट्रॉइड असाइन करता है. जो उदाहरण एक ही सेंट्रॉइड के सबसे करीब होते हैं उन्हें एक ही ग्रुप में रखा जाता है.
के-मीन्स एल्गोरिदम, सेंट्रॉइड की ऐसी जगहें चुनता है जिनसे हर उदाहरण और उसके सबसे पास के सेंट्रॉइड के बीच की दूरी का कुल स्क्वेयर कम से कम हो.
उदाहरण के लिए, कुत्ते की लंबाई और चौड़ाई के इस प्लॉट पर ध्यान दें:

अगर k=3 है, तो k-मीन्स एल्गोरिदम तीन सेंट्रॉइड तय करेगा. हर उदाहरण को उसके सबसे पास के सेंट्रॉइड को असाइन किया जाता है. इससे तीन ग्रुप मिलते हैं:

मान लें कि कोई मैन्युफ़ैक्चरर, कुत्तों के लिए छोटे, मीडियम, और बड़े साइज़ के स्वेटर बनाना चाहता है. तीनों सेंट्रॉइड, उस क्लस्टर में मौजूद हर कुत्ते की औसत ऊंचाई और औसत चौड़ाई की पहचान करते हैं. इसलिए, मैन्युफ़ैक्चरर को स्वेटर के साइज़, इन तीन सेंट्रॉइड के आधार पर तय करने चाहिए. ध्यान दें कि किसी क्लस्टर का सेंट्रॉइड, आम तौर पर क्लस्टर में मौजूद किसी उदाहरण से अलग होता है.
ऊपर दिए गए उदाहरणों में, सिर्फ़ दो सुविधाओं (ऊंचाई और चौड़ाई) के लिए k-मीन्स दिखाया गया है. ध्यान दें कि के-मीन्स, कई सुविधाओं के हिसाब से उदाहरणों को ग्रुप कर सकता है.
ज़्यादा जानकारी के लिए, क्लस्टरिंग कोर्स में के-मीन्स क्लस्टरिंग क्या होती है? देखें.
k-मीडियन
यह क्लस्टरिंग एल्गोरिदम, k-means से मिलता-जुलता है. इन दोनों के बीच का अंतर यहां दिया गया है:
- के-मीन्स में, सेंट्रॉइड इस तरह तय किए जाते हैं कि सेंट्रॉइड के संभावित उम्मीदवार और उसके हर उदाहरण के बीच की दूरी के स्क्वेयर का योग कम से कम हो.
- के-मीडियन में, सेंट्रॉइड का पता लगाने के लिए, सेंट्रॉइड के संभावित उम्मीदवार और उसके हर उदाहरण के बीच की दूरी के योग को कम किया जाता है.
ध्यान दें कि दूरी की परिभाषाएं भी अलग-अलग हैं:
- के-मीन्स, किसी उदाहरण के लिए सेंट्रॉइड से इयूक्लिडीन दूरी पर निर्भर करता है. (दो डाइमेंशन में, यूक्लिडियन दूरी का मतलब है कि कर्ण की लंबाई का पता लगाने के लिए, पाइथागोरस प्रमेय का इस्तेमाल करना.) उदाहरण के लिए, (2,2) और (5,-2) के बीच की k-means दूरी यह होगी:
- के-मीडियन, सेंट्रॉइड से किसी उदाहरण की मैनहैटन दूरी पर निर्भर करता है. यह दूरी, हर डाइमेंशन में मौजूद अंतर का कुल योग होती है. उदाहरण के लिए, (2,2) और (5,-2) के बीच k-मीडियन दूरी यह होगी:
L
L0 रेगुलराइज़ेशन
यह रेगुलराइज़ेशन का एक टाइप है. यह मॉडल में, शून्य से अलग वज़न की कुल संख्या को कम करता है. उदाहरण के लिए, 11 नॉन-ज़ीरो वेट वाले मॉडल पर, 10 नॉन-ज़ीरो वेट वाले मॉडल की तुलना में ज़्यादा जुर्माना लगाया जाएगा.
L0 रेगुलराइज़ेशन को कभी-कभी L0-नॉर्म रेगुलराइज़ेशन भी कहा जाता है.
L1 नुकसान
यह एक लॉस फ़ंक्शन है. यह लेबल की असल वैल्यू और मॉडल की अनुमानित वैल्यू के बीच के अंतर की ऐब्सलूट वैल्यू का हिसाब लगाता है. उदाहरण के लिए, यहां पांच उदाहरणों के बैच के लिए, L1 लॉस की गणना दी गई है:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | डेल्टा की ऐब्सलूट वैल्यू |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 नुकसान | ||
L1 लॉस, L2 लॉस की तुलना में आउटलायर के लिए कम संवेदनशील होता है.
कुल गड़बड़ी का मध्यमान, हर उदाहरण के लिए औसत L1 लॉस होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: लॉस देखें.
L1 रेगुलराइज़ेशन
यह एक तरह का रेगुलराइज़ेशन है. इसमें वेट को, वेट की ऐब्सलूट वैल्यू के योग के अनुपात में दंडित किया जाता है. L1 रेगुलराइज़ेशन से, काम की नहीं या बहुत कम काम की सुविधाओं के वेट को शून्य पर सेट करने में मदद मिलती है. वज़न के तौर पर 0 वैल्यू वाली सुविधा को मॉडल से हटा दिया जाता है.
इसकी तुलना L2 रेगुलराइज़ेशन से करें.
L2 नुकसान
यह एक लॉस फ़ंक्शन है. यह लेबल की असल वैल्यू और मॉडल की अनुमानित वैल्यू के बीच के अंतर का स्क्वेयर कैलकुलेट करता है. उदाहरण के लिए, यहां पांच उदाहरणों के बैच के लिए, L2 लॉस की गणना दी गई है:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | डेल्टा का स्क्वेयर |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 लॉस | ||
स्क्वेयर करने की वजह से, L2 लॉस, आउटलायर के असर को बढ़ा देता है. इसका मतलब है कि L1 लॉस की तुलना में, L2 लॉस, खराब अनुमानों पर ज़्यादा असर डालता है. उदाहरण के लिए, पिछले बैच के लिए L1 लॉस, 16 के बजाय 8 होगा. ध्यान दें कि एक आउटलायर, 16 में से 9 के लिए ज़िम्मेदार है.
रिग्रेशन मॉडल, आम तौर पर लॉस फ़ंक्शन के तौर पर L2 लॉस का इस्तेमाल करते हैं.
मीन स्क्वेयर्ड एरर, हर उदाहरण के लिए औसत L2 लॉस होता है. स्क्वेयर्ड लॉस को L2 लॉस भी कहा जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लॉजिस्टिक रिग्रेशन: लॉस और रेगुलराइज़ेशन देखें.
L2 रेगुलराइज़ेशन
यह रेगुलराइज़ेशन का एक टाइप है. इसमें वज़न को, वज़न के स्क्वेयर के योग के अनुपात में दंडित किया जाता है. L2 रेगुलराइज़ेशन, आउटलायर वेट (ज़्यादा पॉज़िटिव या कम नेगेटिव वैल्यू वाले) को 0 के करीब लाने में मदद करता है, लेकिन पूरी तरह से 0 नहीं करता है. जिन सुविधाओं की वैल्यू 0 के बहुत करीब होती है वे मॉडल में बनी रहती हैं, लेकिन मॉडल के अनुमान पर इनका ज़्यादा असर नहीं पड़ता.
L2 रेगुलराइज़ेशन, लीनियर मॉडल में हमेशा सामान्यीकरण को बेहतर बनाता है.
L1 रेगुलराइज़ेशन से तुलना करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग: L2 रेगुलराइज़ेशन देखें.
लेबल
सुपरवाइज़्ड मशीन लर्निंग में, उदाहरण का "जवाब" या "नतीजा" वाला हिस्सा.
हर लेबल किए गए उदाहरण में एक या उससे ज़्यादा विशेषताएं और एक लेबल होता है. उदाहरण के लिए, स्पैम का पता लगाने वाले डेटासेट में, लेबल शायद "स्पैम" या "स्पैम नहीं" होगा. बारिश के डेटासेट में, लेबल यह हो सकता है कि किसी समयावधि के दौरान कितनी बारिश हुई.
ज़्यादा जानकारी के लिए, मशीन लर्निंग के बारे में जानकारी में सुपरवाइज़्ड लर्निंग देखें.
लेबल किया गया उदाहरण
ऐसा उदाहरण जिसमें एक या उससे ज़्यादा सुविधाएं और एक लेबल शामिल हो. उदाहरण के लिए, यहां दी गई टेबल में घर की कीमत का अनुमान लगाने वाले मॉडल के तीन लेबल किए गए उदाहरण दिखाए गए हैं. इनमें से हर उदाहरण में तीन सुविधाएं और एक लेबल है:
| कमरों की संख्या | बाथरूम की संख्या | घर की उम्र | घर की कीमत (लेबल) |
|---|---|---|---|
| 3 | 2 | 15 | $345,000 |
| 2 | 1 | 72 | $179,000 |
| 4 | 2 | 34 | $3,92,000 |
सुपरवाइज़्ड मशीन लर्निंग में, मॉडल को लेबल किए गए उदाहरणों के आधार पर ट्रेन किया जाता है. साथ ही, वे बिना लेबल वाले उदाहरणों के आधार पर अनुमान लगाते हैं.
लेबल किए गए उदाहरण की तुलना, लेबल नहीं किए गए उदाहरणों से करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग के बारे में जानकारी में सुपरवाइज़्ड लर्निंग देखें.
लेबल लीक होना
मॉडल डिज़ाइन में मौजूद एक ऐसी गड़बड़ी जिसमें feature, label के लिए प्रॉक्सी के तौर पर काम करता है. उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल पर विचार करें. यह मॉडल अनुमान लगाता है कि संभावित खरीदार कोई खास प्रॉडक्ट खरीदेगा या नहीं.
मान लें कि मॉडल की किसी सुविधा का नाम SpokeToCustomerAgent है और यह बूलियन है. मान लें कि किसी ग्राहक एजेंट को सिर्फ़ तब असाइन किया जाता है, जब संभावित ग्राहक ने वाकई में प्रॉडक्ट खरीद लिया हो. ट्रेनिंग के दौरान, मॉडल SpokeToCustomerAgent और लेबल के बीच के संबंध को तुरंत समझ लेगा.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में पाइपलाइन की निगरानी करना देखें.
lambda
रेगुलराइज़ेशन रेट के लिए समानार्थी शब्द.
Lambda एक ओवरलोडेड शब्द है. यहां हम रेगुलराइज़ेशन के तहत, शब्द की परिभाषा पर फ़ोकस कर रहे हैं.
LaMDA (Language Model for Dialogue Applications)
यह Google का बनाया हुआ ट्रांसफ़ॉर्मर पर आधारित लार्ज लैंग्वेज मॉडल है. इसे बातचीत के बड़े डेटासेट पर ट्रेन किया गया है. यह बातचीत के दौरान, असल जैसे जवाब जनरेट कर सकता है.
LaMDA: हमारी बातचीत की नई टेक्नोलॉजी के बारे में खास जानकारी देता है.
लैंडमार्क
मुख्य बातें के लिए समानार्थी शब्द.
लैंग्वेज मॉडल
यह एक मॉडल है. यह टोकन या टोकन के किसी क्रम के, टोकन के लंबे क्रम में आने की संभावना का अनुमान लगाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लैंग्वेज मॉडल क्या होता है? लेख पढ़ें.
लार्ज लैंग्वेज मॉडल
कम से कम, एक लैंग्वेज मॉडल, जिसमें बहुत ज़्यादा संख्या में पैरामीटर हों. आसान शब्दों में कहें, तो ट्रांसफ़ॉर्मर पर आधारित कोई भी भाषा मॉडल, जैसे कि Gemini या GPT.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लार्ज लैंग्वेज मॉडल (एलएलएम) देखें.
प्रतीक्षा अवधि
किसी मॉडल को इनपुट प्रोसेस करने और जवाब जनरेट करने में लगने वाला समय. ज़्यादा समय में जनरेट होने वाले जवाब को जनरेट होने में, कम समय में जनरेट होने वाले जवाब की तुलना में ज़्यादा समय लगता है.
लार्ज लैंग्वेज मॉडल की लेटेन्सी पर इन बातों का असर पड़ता है:
- इनपुट और आउटपुट टोकन की लंबाई
- मॉडल की जटिलता
- वह इन्फ़्रास्ट्रक्चर जिस पर मॉडल काम करता है
तेज़ी से काम करने वाले और लोगों के लिए इस्तेमाल में आसान ऐप्लिकेशन बनाने के लिए, लेटेन्सी को ऑप्टिमाइज़ करना ज़रूरी है.
लेटेंट स्पेस
एंबेड किए जा रहे स्पेस के लिए समानार्थी शब्द.
लेयर
न्यूरल नेटवर्क में न्यूरॉन का एक सेट. आम तौर पर, तीन तरह की लेयर इस्तेमाल की जाती हैं. इनके बारे में यहां बताया गया है:
- इनपुट लेयर, जो सभी सुविधाओं के लिए वैल्यू देती है.
- एक या उससे ज़्यादा छिपी हुई लेयर, जो सुविधाओं और लेबल के बीच नॉनलीनियर संबंध ढूंढती हैं.
- आउटपुट लेयर, जो अनुमान देती है.
उदाहरण के लिए, इस इमेज में एक इनपुट लेयर, दो छिपी हुई लेयर, और एक आउटपुट लेयर वाला न्यूरल नेटवर्क दिखाया गया है:
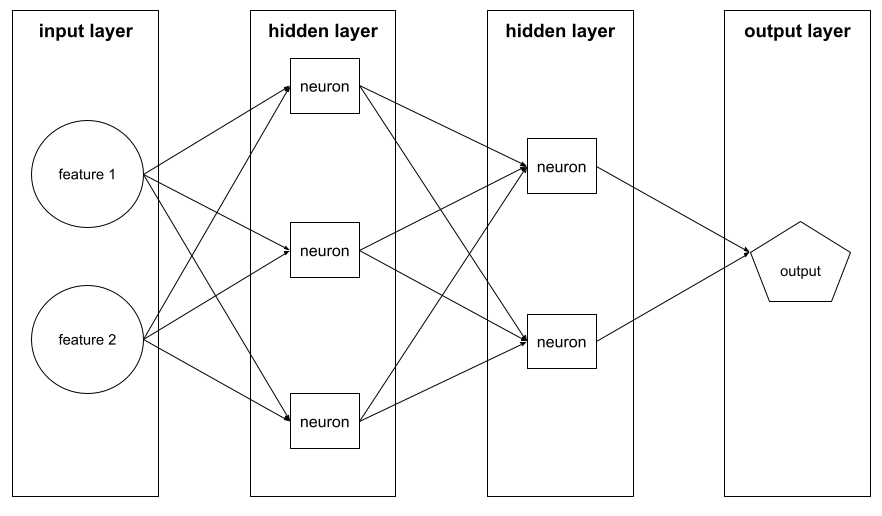
TensorFlow में, लेयर भी Python फ़ंक्शन होती हैं. ये टेंसर और कॉन्फ़िगरेशन के विकल्पों को इनपुट के तौर पर लेती हैं और आउटपुट के तौर पर अन्य टेंसर जनरेट करती हैं.
Layers API (tf.layers)
यह TensorFlow API, लेयर के कंपोज़िशन के तौर पर डीप न्यूरल नेटवर्क बनाने के लिए होता है. Layers API की मदद से, अलग-अलग तरह की लेयर बनाई जा सकती हैं. जैसे:
tf.layers.Dense, पूरी तरह से कनेक्ट की गई लेयर के लिए.tf.layers.Conv2D, कनवोल्यूशनल लेयर के लिए.
Layers API, Keras लेयर्स एपीआई के नियमों का पालन करता है. इसका मतलब है कि अलग प्रीफ़िक्स के अलावा, Layers API में मौजूद सभी फ़ंक्शन के नाम और सिग्नेचर, Keras layers API में मौजूद फ़ंक्शन के नाम और सिग्नेचर के जैसे ही होते हैं.
पत्ती
डिसिज़न ट्री में मौजूद कोई भी एंडपॉइंट. शर्त के उलट, लीफ़ कोई टेस्ट नहीं करती. हालांकि, पत्ता एक संभावित अनुमान है. कोई लीफ़, इनफ़रेंस पाथ का टर्मिनल नोड भी होता है.
उदाहरण के लिए, यहां दिए गए फ़ैसले के ट्री में तीन पत्तियां हैं:
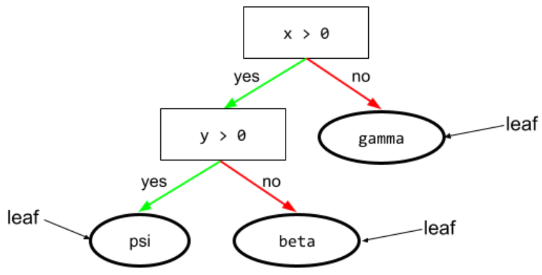
ज़्यादा जानकारी के लिए, फ़ैसले लेने के लिए फ़ॉरेस्ट कोर्स में डिसिज़न ट्री देखें.
Learning Interpretability Tool (LIT)
यह एक विज़ुअल और इंटरैक्टिव टूल है. इसकी मदद से, मॉडल को समझा जा सकता है और डेटा को विज़ुअलाइज़ किया जा सकता है.
मॉडल को समझने या टेक्स्ट, इमेज, और टेबल के डेटा को विज़ुअलाइज़ करने के लिए, ओपन-सोर्स LIT का इस्तेमाल किया जा सकता है.
सीखने की दर
यह एक फ़्लोटिंग-पॉइंट नंबर होता है. इससे ग्रेडिएंट डिसेंट एल्गोरिदम को यह पता चलता है कि हर इटरेशन पर, वज़न और बायस को कितना अडजस्ट करना है. उदाहरण के लिए, 0.3 का लर्निंग रेट, 0.1 के लर्निंग रेट की तुलना में वज़न और पूर्वाग्रहों को तीन गुना ज़्यादा असरदार तरीके से अडजस्ट करेगा.
लर्निंग रेट, एक मुख्य हाइपरपैरामीटर है. अगर लर्निंग रेट बहुत कम सेट किया जाता है, तो ट्रेनिंग में बहुत ज़्यादा समय लगेगा. अगर लर्निंग रेट को बहुत ज़्यादा पर सेट किया जाता है, तो ग्रेडिएंट डिसेंट को अक्सर कन्वर्जेंस तक पहुंचने में समस्या होती है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
लीस्ट स्क्वेयर रिग्रेशन
लीनियर रिग्रेशन मॉडल को L2 लॉस को कम करके ट्रेन किया जाता है.
लेवेंश्टाइन दूरी
एडिट डिस्टेंस मेट्रिक, जो एक शब्द को दूसरे शब्द में बदलने के लिए, सबसे कम संख्या में मिटाने, डालने, और बदलने की कार्रवाइयों का हिसाब लगाती है. उदाहरण के लिए, "heart" और "darts" शब्दों के बीच लेवेंश्टाइन दूरी तीन है, क्योंकि एक शब्द को दूसरे शब्द में बदलने के लिए, ये तीन बदलाव सबसे कम बदलाव हैं:
- heart → deart ("h" की जगह "d" का इस्तेमाल किया गया है)
- deart → dart (delete "e")
- dart → darts (insert "s")
ध्यान दें कि ऊपर दी गई सीक्वेंस में, तीन बदलावों का सिर्फ़ एक तरीका बताया गया है.
रेखीय
दो या उससे ज़्यादा वैरिएबल के बीच का ऐसा संबंध जिसे सिर्फ़ जोड़ और गुणा करके दिखाया जा सकता है.
लीनियर रिलेशनशिप का प्लॉट एक लाइन होती है.
नॉनलीनियर विज्ञापन से तुलना करें.
लीनियर मॉडल
यह एक ऐसा मॉडल है जो पूर्वानुमान लगाने के लिए, हर फ़ीचर को एक वज़न असाइन करता है. (लीनियर मॉडल में भी बायस शामिल होता है.) इसके उलट, डीप मॉडल में, सुविधाओं और अनुमानों के बीच का संबंध आम तौर पर नॉनलीनियर होता है.
लीनियर मॉडल को आम तौर पर ट्रेन करना आसान होता है. साथ ही, डीप मॉडल की तुलना में इन्हें समझना ज़्यादा आसान होता है. हालांकि, डीप मॉडल, सुविधाओं के बीच जटिल संबंधों को समझ सकते हैं.
लीनियर रिग्रेशन और लॉजिस्टिक रिग्रेशन, दो तरह के लीनियर मॉडल होते हैं.
लीनियर रिग्रेशन
यह एक तरह का मशीन लर्निंग मॉडल है. इसमें ये दोनों बातें सही होती हैं:
- यह मॉडल, लीनियर मॉडल है.
- अनुमान, फ़्लोटिंग-पॉइंट वैल्यू होती है. (यह लीनियर रिग्रेशन का रिग्रेशन हिस्सा है.)
लॉजिस्टिक रिग्रेशन की तुलना में लीनियर रिग्रेशन के बारे में जानकारी. साथ ही, रिग्रेशन की तुलना क्लासिफ़िकेशन से करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन देखें.
LIT
यह Learning Interpretability Tool (LIT) का संक्षिप्त नाम है. इसे पहले Language Interpretability Tool के नाम से जाना जाता था.
LLM
लार्ज लैंग्वेज मॉडल का संक्षिप्त नाम.
एलएलएम के आकलन (इवैल)
यह लार्ज लैंग्वेज मॉडल (एलएलएम) की परफ़ॉर्मेंस का आकलन करने के लिए, मेट्रिक और बेंचमार्क का एक सेट है. एलएलएम के आकलन के लिए, ये काम किए जाते हैं:
- शोधकर्ताओं को उन क्षेत्रों की पहचान करने में मदद करना जहां एलएलएम को बेहतर बनाने की ज़रूरत है.
- ये अलग-अलग एलएलएम की तुलना करने और किसी टास्क के लिए सबसे अच्छे एलएलएम की पहचान करने में मददगार होते हैं.
- यह पक्का करने में मदद करना कि एलएलएम का इस्तेमाल सुरक्षित और ज़िम्मेदारी से किया जा रहा है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लार्ज लैंग्वेज मॉडल (एलएलएम) देखें.
लॉजिस्टिक रिग्रेशन
यह एक तरह का रिग्रेशन मॉडल है, जो संभावना का अनुमान लगाता है. लॉजिस्टिक रिग्रेशन मॉडल में ये विशेषताएं होती हैं:
- लेबल कैटगरिकल है. लॉजिस्टिक रिग्रेशन शब्द का इस्तेमाल आम तौर पर बाइनरी लॉजिस्टिक रिग्रेशन के लिए किया जाता है. इसका मतलब है कि यह एक ऐसा मॉडल है जो दो संभावित वैल्यू वाले लेबल के लिए संभावनाओं का हिसाब लगाता है. मल्टीनोमियल लॉजिस्टिक रिग्रेशन, एक कम इस्तेमाल किया जाने वाला वैरिएंट है. यह दो से ज़्यादा संभावित वैल्यू वाले लेबल के लिए, संभावनाओं का हिसाब लगाता है.
- ट्रेनिंग के दौरान लॉस फ़ंक्शन लॉग लॉस होता है. (दो से ज़्यादा संभावित वैल्यू वाले लेबल के लिए, एक साथ कई लॉग लॉस यूनिट रखी जा सकती हैं.)
- मॉडल में लीनियर आर्किटेक्चर है, न कि डीप न्यूरल नेटवर्क. हालांकि, इस परिभाषा का बाकी हिस्सा डीप मॉडल पर भी लागू होता है. ये मॉडल, कैटगरी के हिसाब से लेबल की संभावनाओं का अनुमान लगाते हैं.
उदाहरण के लिए, लॉजिस्टिक रिग्रेशन मॉडल पर विचार करें. यह मॉडल, किसी इनपुट ईमेल के स्पैम होने या न होने की संभावना का हिसाब लगाता है. मान लें कि अनुमान लगाने के दौरान, मॉडल 0.72 का अनुमान लगाता है. इसलिए, मॉडल अनुमान लगा रहा है कि:
- ईमेल के स्पैम होने की 72% संभावना है.
- ईमेल के स्पैम न होने की संभावना 28% है.
लॉजिस्टिक रिग्रेशन मॉडल, दो चरणों वाले इस आर्किटेक्चर का इस्तेमाल करता है:
- यह मॉडल, इनपुट सुविधाओं पर लीनियर फ़ंक्शन लागू करके, अनुमान (y') जनरेट करता है.
- मॉडल, उस रॉ अनुमान का इस्तेमाल सिग्मॉइड फ़ंक्शन के इनपुट के तौर पर करता है. यह फ़ंक्शन, रॉ अनुमान को 0 से 1 के बीच की वैल्यू में बदलता है. इसमें 0 और 1 शामिल नहीं होते.
किसी भी रिग्रेशन मॉडल की तरह, लॉजिस्टिक रिग्रेशन मॉडल भी किसी संख्या का अनुमान लगाता है. हालांकि, आम तौर पर इस संख्या को बाइनरी क्लासिफ़िकेशन मॉडल का हिस्सा बनाया जाता है. ऐसा इस तरह किया जाता है:
- अगर अनुमानित संख्या, वर्गीकरण थ्रेशोल्ड से ज़्यादा है, तो बाइनरी क्लासिफ़िकेशन मॉडल, पॉज़िटिव क्लास का अनुमान लगाता है.
- अगर अनुमानित संख्या, क्लासिफ़िकेशन थ्रेशोल्ड से कम है, तो बाइनरी क्लासिफ़िकेशन मॉडल, नेगेटिव क्लास का अनुमान लगाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लॉजिस्टिक रिग्रेशन देखें.
लॉजेट
यह रॉ (नॉन-नॉर्मलाइज़्ड) अनुमानों का वेक्टर होता है, जिसे क्लासिफ़िकेशन मॉडल जनरेट करता है. आम तौर पर, इसे नॉर्मलाइज़ेशन फ़ंक्शन को पास किया जाता है. अगर मॉडल, मल्टी-क्लास क्लासिफ़िकेशन की समस्या हल कर रहा है, तो लॉजिट आम तौर पर सॉफ़्टमैक्स फ़ंक्शन के लिए इनपुट बन जाते हैं. इसके बाद, सॉफ़्टमैक्स फ़ंक्शन, (सामान्य की गई) प्रायिकताओं का एक वेक्टर जनरेट करता है. इसमें हर संभावित क्लास के लिए एक वैल्यू होती है.
लॉग लॉस
बाइनरी लॉजिस्टिक रिग्रेशन में इस्तेमाल किया गया लॉस फ़ंक्शन.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लॉजिस्टिक रिग्रेशन: लॉस और रेगुलराइज़ेशन देखें.
लॉग-ऑड्स
यह किसी इवेंट के होने की संभावना का लॉगरिद्म होता है.
लॉन्ग शॉर्ट-टर्म मेमोरी (एलएसटीएम)
यह रीकरंट न्यूरल नेटवर्क में एक तरह की सेल होती है. इसका इस्तेमाल, ऐप्लिकेशन में डेटा के क्रम को प्रोसेस करने के लिए किया जाता है. जैसे, हाथ से लिखे गए टेक्स्ट को पहचानना, मशीन ट्रांसलेशन, और इमेज के लिए कैप्शन जनरेट करना. एलएसटीएम, वैनिशिंग ग्रेडिएंट की समस्या को हल करते हैं. यह समस्या, लंबे डेटा सीक्वेंस की वजह से आरएनएन को ट्रेनिंग देते समय होती है. एलएसटीएम, आरएनएन में मौजूद पिछली सेल से मिले नए इनपुट और कॉन्टेक्स्ट के आधार पर, इंटरनल मेमोरी की स्थिति में इतिहास को बनाए रखते हैं.
LoRA
लो-रैंक अडैप्टेबिलिटी का संक्षिप्त नाम.
हार की वजह से
निगरानी वाले मॉडल की ट्रेनिंग के दौरान, यह मेज़रमेंट किया जाता है कि मॉडल का अनुमान, उसके लेबल से कितना अलग है.
लॉस फ़ंक्शन, लॉस का हिसाब लगाता है.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में लीनियर रिग्रेशन: लॉस देखें.
ऐप्लिकेशन हटाने का तरीका
यह एक तरह का मशीन लर्निंग एल्गोरिदम है. यह कई मॉडल के अनुमानों को मिलाकर, मॉडल की परफ़ॉर्मेंस को बेहतर बनाता है. साथ ही, उन अनुमानों का इस्तेमाल करके एक अनुमान लगाता है. इस वजह से, लॉस एग्रीगेटर, अनुमानों के वैरिएंस को कम कर सकता है. साथ ही, अनुमानों की सटीकता को बेहतर बना सकता है.
ऐप्लिकेशन हटाने का कर्व
ट्रेनिंग के इटरेशन की संख्या के फ़ंक्शन के तौर पर, नुकसान का प्लॉट. नीचे दिए गए प्लॉट में, सामान्य लॉस कर्व दिखाया गया है:
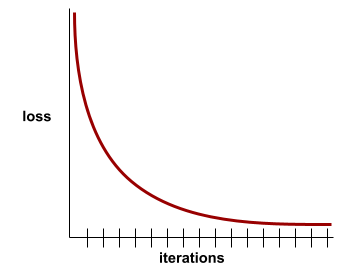
लॉस कर्व से यह पता लगाया जा सकता है कि आपका मॉडल कब कन्वर्ज हो रहा है या ओवरफ़िट हो रहा है.
लॉस कर्व में, यहां दिए गए सभी तरह के लॉस को प्लॉट किया जा सकता है:
जनरलाइज़ेशन कर्व भी देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग: लॉस कर्व की व्याख्या करना देखें.
लॉस फ़ंक्शन
ट्रेनिंग या टेस्टिंग के दौरान, यह एक गणितीय फ़ंक्शन होता है. यह उदाहरणों के बैच के नुकसान की गणना करता है. लॉस फ़ंक्शन, अच्छी परफ़ॉर्मेंस वाले मॉडल के लिए कम लॉस दिखाता है. वहीं, खराब परफ़ॉर्मेंस वाले मॉडल के लिए ज़्यादा लॉस दिखाता है.
ट्रेनिंग का मकसद आम तौर पर, लॉस फ़ंक्शन से मिलने वाले नुकसान को कम करना होता है.
कई तरह के लॉस फ़ंक्शन मौजूद होते हैं. बनाए जा रहे मॉडल के हिसाब से, सही लॉस फ़ंक्शन चुनें. उदाहरण के लिए:
- L2 लॉस या मीन स्क्वेयर्ड एरर, लीनियर रिग्रेशन के लिए लॉस फ़ंक्शन होता है.
- लॉग लॉस, लॉजिस्टिक्स रिग्रेशन के लिए लॉस फ़ंक्शन है.
लॉस सरफ़ेस
वज़न और वज़न कम होने की जानकारी देने वाला ग्राफ़. ग्रेडिएंट डिसेंट का मकसद, ऐसे वज़न का पता लगाना है जिनके लिए लॉस सर्फ़ेस, लोकल मिनिमम पर हो.
लॉस्ट-इन-द-मिडल इफ़ेक्ट
एलएलएम की यह टेंडेंसी होती है कि वह लंबी कॉन्टेक्स्ट विंडो की शुरुआत और आखिर में मौजूद जानकारी का इस्तेमाल, बीच में मौजूद जानकारी के मुकाबले ज़्यादा असरदार तरीके से करता है. इसका मतलब है कि लंबे कॉन्टेक्स्ट के लिए, बीच में मौजूद जानकारी को भूल जाने की वजह से, जवाब के सटीक होने की संभावना:
- अगर जवाब बनाने के लिए ज़रूरी जानकारी, कॉन्टेक्स्ट की शुरुआत या आखिर में मौजूद है, तो स्कोर काफ़ी ज़्यादा होता है.
- जब जवाब देने के लिए ज़रूरी जानकारी, कॉन्टेक्स्ट के बीच में होती है, तब स्कोर थोड़ा कम होता है.
यह शब्द, लॉस्ट इन द मिडल: हाउ लैंग्वेज मॉडल्स यूज़ लॉन्ग कॉन्टेक्स्ट से लिया गया है.
लो-रैंक अडैप्टेबिलिटी (LoRA)
यह पैरामीटर-इफ़िशिएंट तकनीक है. इसका इस्तेमाल फ़ाइन ट्यूनिंग के लिए किया जाता है. यह मॉडल के पहले से ट्रेन किए गए वेट को "फ़्रीज़" कर देती है, ताकि उन्हें बदला न जा सके. इसके बाद, यह मॉडल में ट्रेनिंग के लिए उपलब्ध वेट का एक छोटा सेट डालती है. ट्रेन किए जा सकने वाले वज़न का यह सेट (इसे "अपडेट मैट्रिक्स" भी कहा जाता है), बेस मॉडल से काफ़ी छोटा होता है. इसलिए, इसे ट्रेन करने में कम समय लगता है.
LoRA से ये फ़ायदे मिलते हैं:
- इससे उस डोमेन के लिए मॉडल के अनुमानों की क्वालिटी बेहतर होती है जहां फ़ाइन ट्यूनिंग लागू की जाती है.
- यह उन तकनीकों की तुलना में ज़्यादा तेज़ी से फ़ाइन-ट्यून होता है जिनके लिए, मॉडल के सभी पैरामीटर को फ़ाइन-ट्यून करने की ज़रूरत होती है.
- यह अनुमान लगाने की कंप्यूटेशनल लागत को कम करता है. ऐसा इसलिए होता है, क्योंकि यह एक ही बेस मॉडल को शेयर करने वाले कई खास मॉडल को एक साथ सेवा देने की सुविधा चालू करता है.
LSTM
यह Long Short-Term Memory का संक्षिप्त नाम है.
M
मशीन लर्निंग
यह एक प्रोग्राम या सिस्टम है, जो इनपुट डेटा की मदद से मॉडल को ट्रेन करता है. ट्रेन किया गया मॉडल, नए (पहले कभी न देखे गए) डेटा से काम के अनुमान लगा सकता है. यह डेटा, मॉडल को ट्रेन करने के लिए इस्तेमाल किए गए डेटा के डिस्ट्रिब्यूशन से लिया जाता है.
मशीन लर्निंग, पढ़ाई के उस फ़ील्ड को भी कहा जाता है जो इन प्रोग्राम या सिस्टम से जुड़ा है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग के बारे में जानकारी कोर्स देखें.
मशीनी अनुवाद
किसी सॉफ़्टवेयर (आम तौर पर, मशीन लर्निंग मॉडल) का इस्तेमाल करके, टेक्स्ट को एक भाषा से दूसरी भाषा में बदलना. उदाहरण के लिए, अंग्रेज़ी से जापानी में बदलना.
मेजर क्लास
क्लास-इंबैलेंस वाले डेटासेट में सबसे ज़्यादा बार दिखने वाला लेबल. उदाहरण के लिए, अगर किसी डेटासेट में 99% नेगेटिव लेबल और 1% पॉज़िटिव लेबल हैं, तो नेगेटिव लेबल मेजॉरिटी क्लास हैं.
माइनॉरिटी क्लास से तुलना करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: असंतुलित डेटासेट देखें.
मार्कोव डिसिज़न प्रोसेस (एमडीपी)
यह फ़ैसले लेने वाले मॉडल को दिखाने वाला ग्राफ़ है. इसमें फ़ैसले (या कार्रवाइयां) इस तरह से लिए जाते हैं कि स्टेट के क्रम को नेविगेट किया जा सके. ऐसा इस आधार पर किया जाता है कि मार्कोव प्रॉपर्टी लागू होती है. रीइन्फ़ोर्समेंट लर्निंग में, राज्यों के बीच होने वाले इन ट्रांज़िशन से, संख्या के तौर पर इनाम मिलता है.
मार्कोव प्रॉपर्टी
यह कुछ एनवायरमेंट की एक प्रॉपर्टी है. इसमें, स्टेट ट्रांज़िशन पूरी तरह से मौजूदा स्टेट और एजेंट की कार्रवाई में मौजूद जानकारी से तय होते हैं.
मास्क किया गया लैंग्वेज मॉडल
यह एक लैंग्वेज मॉडल है. यह किसी सीक्वेंस में मौजूद खाली जगहों को भरने के लिए, कैंडिडेट टोकन की संभावना का अनुमान लगाता है. उदाहरण के लिए, मास्क किए गए शब्दों का अनुमान लगाने वाला कोई भाषा मॉडल, नीचे दिए गए वाक्य में अंडरलाइन किए गए शब्द की जगह इस्तेमाल किए जा सकने वाले शब्दों की संभावनाओं का हिसाब लगा सकता है:
टोपी में मौजूद ____ वापस आ गया.
आम तौर पर, साहित्य में अंडरलाइन के बजाय "MASK" स्ट्रिंग का इस्तेमाल किया जाता है. उदाहरण के लिए:
हैट में "MASK" वापस आ गया.
मास्क किए गए ज़्यादातर आधुनिक भाषा मॉडल, दोनों दिशाओं में काम करने वाले होते हैं.
math-pass@k
यह एक मेट्रिक है. इससे यह पता चलता है कि एलएलएम, गणित के किसी सवाल को K बार में कितने सटीक तरीके से हल कर सकता है. उदाहरण के लिए, math-pass@2 से यह पता चलता है कि कोई एलएलएम, गणित के सवालों को दो बार में हल कर सकता है या नहीं. math-pass@2 पर 0.85 की सटीकता का मतलब है कि एलएलएम, दो बार कोशिश करने पर 85% बार गणित के सवालों को हल कर सका.
math-pass@k, pass@k मेट्रिक की तरह ही होती है. हालांकि, math-pass@k शब्द का इस्तेमाल खास तौर पर गणित के सवालों का आकलन करने के लिए किया जाता है.
matplotlib
यह एक ओपन-सोर्स Python 2D प्लॉटिंग लाइब्रेरी है. matplotlib की मदद से, मशीन लर्निंग के अलग-अलग पहलुओं को विज़ुअलाइज़ किया जा सकता है.
मैट्रिक्स फ़ैक्टराइज़ेशन
गणित में, यह एक ऐसा तरीका है जिससे उन मैट्रिक्स का पता लगाया जाता है जिनका डॉट प्रॉडक्ट, टारगेट मैट्रिक्स के करीब होता है.
सुझाव देने वाले सिस्टम में, टारगेट मैट्रिक्स में अक्सर आइटम के लिए उपयोगकर्ताओं की रेटिंग होती है. उदाहरण के लिए, किसी फ़िल्म के सुझाव देने वाले सिस्टम के लिए टारगेट मेट्रिक कुछ इस तरह दिख सकती है. इसमें पॉज़िटिव पूर्णांक, उपयोगकर्ता की रेटिंग हैं और 0 का मतलब है कि उपयोगकर्ता ने फ़िल्म को रेटिंग नहीं दी है:
| कैसाब्लांका | The Philadelphia Story | Black Panther | Wonder Woman | पल्प फ़िक्शन | |
|---|---|---|---|---|---|
| उपयोगकर्ता 1 | 5.0 | 3.0 | 0.0 | 2.0 | 0.0 |
| उपयोगकर्ता 2 | 4.0 | 0.0 | 0.0 | 1.0 | 5.0 |
| उपयोगकर्ता 3 | 3.0 | 1.0 | 4.0 | 5.0 | 0.0 |
फ़िल्मों के सुझाव देने वाले सिस्टम का मकसद, उन फ़िल्मों के लिए उपयोगकर्ता की रेटिंग का अनुमान लगाना है जिनकी रेटिंग नहीं दी गई है. उदाहरण के लिए, क्या उपयोगकर्ता 1 को ब्लैक पैंथर पसंद आएगी?
सुझाव देने वाले सिस्टम के लिए, मैट्रिक्स फ़ैक्टराइज़ेशन का इस्तेमाल करके ये दो मैट्रिक्स जनरेट किए जाते हैं:
- यह उपयोगकर्ता मैट्रिक्स है. इसका आकार, उपयोगकर्ताओं की संख्या X एम्बेडिंग डाइमेंशन की संख्या के बराबर होता है.
- आइटम मैट्रिक्स, जिसे एम्बेडिंग डाइमेंशन की संख्या X आइटम की संख्या के तौर पर बनाया जाता है.
उदाहरण के लिए, हमारे तीन उपयोगकर्ताओं और पांच आइटम पर मैट्रिक्स फ़ैक्टराइज़ेशन का इस्तेमाल करने से, हमें उपयोगकर्ता मैट्रिक्स और आइटम मैट्रिक्स मिल सकता है:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
उपयोगकर्ता मैट्रिक्स और आइटम मैट्रिक्स के डॉट प्रॉडक्ट से, सुझाव देने वाली मैट्रिक्स मिलती है. इसमें न सिर्फ़ उपयोगकर्ता की ओर से दी गई ओरिजनल रेटिंग शामिल होती हैं, बल्कि उन फ़िल्मों के लिए अनुमान भी शामिल होते हैं जिन्हें हर उपयोगकर्ता ने नहीं देखा है. उदाहरण के लिए, उपयोगकर्ता 1 की कैसाब्लांका को दी गई रेटिंग 5.0 है. सुझाव मैट्रिक्स में उस सेल से जुड़ा डॉट प्रॉडक्ट, उम्मीद है कि 5.0 के आस-पास होगा. यह है:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9सबसे अहम बात यह है कि क्या उपयोगकर्ता 1 को ब्लैक पैंथर पसंद आएगी? पहली लाइन और तीसरे कॉलम के डॉट प्रॉडक्ट से, अनुमानित रेटिंग 4.3 मिलती है:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3मैट्रिक्स फ़ैक्टराइज़ेशन से आम तौर पर, उपयोगकर्ता मैट्रिक्स और आइटम मैट्रिक्स मिलता है. ये दोनों मैट्रिक्स, टारगेट मैट्रिक्स की तुलना में काफ़ी छोटे होते हैं.
MBPP
Mostly Basic Python Problems का छोटा नाम.
मीन ऐब्सॉल्यूट एरर (MAE)
L1 लॉस का इस्तेमाल करने पर, हर उदाहरण के लिए औसत लॉस. कुल गड़बड़ी का मध्यमान इस तरह कैलकुलेट करें:
- किसी बैच के लिए L1 लॉस कैलकुलेट करें.
- बैच में मौजूद उदाहरणों की संख्या से L1 लॉस को भाग दें.
उदाहरण के लिए, पांच उदाहरणों के इस बैच पर L1 नुकसान का हिसाब लगाने पर विचार करें:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | नुकसान (असल और अनुमानित वैल्यू के बीच का अंतर) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 नुकसान | ||
इसलिए, L1 लॉस 8 है और उदाहरणों की संख्या 5 है. इसलिए, कुल गड़बड़ी का मध्यमान यह है:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
मीन स्क्वेयर्ड एरर और रूट मीन स्क्वेयर्ड एरर के साथ, कॉन्ट्रास्ट मीन ऐब्सलूट एरर की तुलना करें.
के पर औसत सटीक दर (एमएपी@के)
यह पुष्टि करने वाले डेटासेट में, सभी k पर औसत सटीक स्कोर का सांख्यिकीय माध्य होता है. के पर औसत सटीक दर का इस्तेमाल, सुझाव देने वाले सिस्टम से जनरेट किए गए सुझावों की क्वालिटी का आकलन करने के लिए किया जाता है.
हालांकि, "औसत" शब्द का इस्तेमाल दो बार किया गया है, लेकिन मेट्रिक का नाम सही है. आखिरकार, यह मेट्रिक कई के पर औसत सटीक वैल्यू का औसत निकालती है.
मीन स्क्वेयर्ड एरर (एमएसई)
L2 लॉस का इस्तेमाल करने पर, हर उदाहरण के लिए औसत लॉस. मीन स्क्वेयर्ड एरर की गणना इस तरह करें:
- किसी बैच के लिए L2 लॉस की गणना करता है.
- L2 लॉस को बैच में मौजूद उदाहरणों की संख्या से भाग दें.
उदाहरण के लिए, पांच उदाहरणों के इस बैच में हुए नुकसान पर विचार करें:
| वास्तविक मान | मॉडल का अनुमान | हार | स्क्वेयर्ड लॉस |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 लॉस | |||
इसलिए, वर्ग में गड़बड़ी का माध्य यह है:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
वर्ग में गड़बड़ी का माध्य, ट्रेनिंग के लिए इस्तेमाल किया जाने वाला एक लोकप्रिय ऑप्टिमाइज़र है. इसका इस्तेमाल खास तौर पर लीनियर रिग्रेशन के लिए किया जाता है.
मीन ऐब्सलूट एरर और रूट मीन स्क्वेयर्ड एरर के साथ कंट्रास्ट मीन स्क्वेयर्ड एरर की तुलना करें.
TensorFlow Playground, नुकसान की वैल्यू का हिसाब लगाने के लिए, माध्य वर्ग त्रुटि का इस्तेमाल करता है.
मेश
एमएल पैरलल प्रोग्रामिंग में, यह शब्द टीपीयू चिप को डेटा और मॉडल असाइन करने से जुड़ा है. साथ ही, यह तय करता है कि इन वैल्यू को कैसे शार्ड या रेप्लिकेट किया जाएगा.
मेश एक ऐसा शब्द है जिसके कई मतलब हो सकते हैं. इसका मतलब इनमें से कोई भी हो सकता है:
- टीपीयू चिप का फ़िज़िकल लेआउट.
- यह एक ऐब्स्ट्रैक्ट लॉजिकल कंस्ट्रक्ट है. इसका इस्तेमाल, डेटा और मॉडल को टीपीयू चिप पर मैप करने के लिए किया जाता है.
दोनों ही मामलों में, मेश को आकार के तौर पर तय किया जाता है.
मेटा-लर्निंग
यह मशीन लर्निंग का एक सबसेट है. यह लर्निंग एल्गोरिदम का पता लगाता है या उसे बेहतर बनाता है. मेटा-लर्निंग सिस्टम का मकसद, मॉडल को इस तरह से ट्रेन करना भी हो सकता है कि वह कम डेटा या पिछले टास्क से मिले अनुभव के आधार पर, नए टास्क को तुरंत सीख सके. मेटा-लर्निंग एल्गोरिदम आम तौर पर ये काम करते हैं:
- हाथ से तैयार की गई सुविधाओं को बेहतर बनाना या उनके बारे में जानना. जैसे, इनिशियलाइज़र या ऑप्टिमाइज़र.
- डेटा और कंप्यूटिंग के लिए ज़्यादा असरदार हो.
- सामान्यीकरण को बेहतर बनाना.
मेटा-लर्निंग, फ़्यू-शॉट लर्निंग से जुड़ी है.
मीट्रिक
वह आंकड़े जो आपके लिए अहम हैं.
मकसद एक ऐसी मेट्रिक होती है जिसे मशीन लर्निंग सिस्टम ऑप्टिमाइज़ करने की कोशिश करता है.
Metrics API (tf.metrics)
मॉडल का आकलन करने के लिए, TensorFlow API. उदाहरण के लिए, tf.metrics.accuracy
से यह तय होता है कि मॉडल के अनुमान, लेबल से कितनी बार मेल खाते हैं.
मिनी-बैच
यह बैच का एक छोटा सबसेट होता है. इसे रैंडम तरीके से चुना जाता है और एक इटरेशन में प्रोसेस किया जाता है. मिनी-बैच का बैच साइज़ आम तौर पर 10 से 1,000 उदाहरणों के बीच होता है.
उदाहरण के लिए, मान लें कि पूरे ट्रेनिंग सेट (पूरे बैच) में 1,000 उदाहरण शामिल हैं. मान लें कि आपने हर मिनी-बैच का बैच साइज़ 20 पर सेट किया है. इसलिए, हर इटरेशन में 1,000 उदाहरणों में से 20 उदाहरणों के नुकसान का पता लगाया जाता है. इसके बाद, वेट और बायस में बदलाव किया जाता है.
पूरे बैच के सभी उदाहरणों के नुकसान की तुलना में, मिनी-बैच के नुकसान का हिसाब लगाना ज़्यादा आसान होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
मिनी-बैच स्टोकेस्टिक ग्रेडिएंट डिसेंट
यह ग्रेडिएंट डिसेंट एल्गोरिदम है, जो मिनी-बैच का इस्तेमाल करता है. दूसरे शब्दों में कहें, तो मिनी-बैच स्टोकास्टिक ग्रेडिएंट डिसेंट, ट्रेनिंग डेटा के छोटे सबसेट के आधार पर ग्रेडिएंट का अनुमान लगाता है. रेगुलर स्टोकास्टिक ग्रेडिएंट डिसेंट, साइज़ 1 के मिनी-बैच का इस्तेमाल करता है.
मिनिमैक्स लॉस
यह जनरेटिव ऐडवर्सैरियल नेटवर्क के लिए एक लॉस फ़ंक्शन है. यह जनरेट किए गए डेटा और असली डेटा के डिस्ट्रिब्यूशन के बीच क्रॉस-एंट्रॉपी पर आधारित होता है.
मिनिमैक्स लॉस का इस्तेमाल पहले पेपर में, जनरेटिव ऐडवर्सैरियल नेटवर्क के बारे में बताने के लिए किया गया था.
ज़्यादा जानकारी के लिए, जनरेटिव ऐडवर्सैरियल नेटवर्क कोर्स में लॉस फ़ंक्शन देखें.
माइनॉरिटी क्लास
क्लास-इम्बैलेंस वाले डेटासेट में सबसे कम बार दिखने वाला लेबल. उदाहरण के लिए, अगर किसी डेटासेट में 99% नेगेटिव लेबल और 1% पॉज़िटिव लेबल हैं, तो पॉज़िटिव लेबल माइनॉरिटी क्लास में आते हैं.
ज़्यादातर क्लास के साथ कंट्रास्ट.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: असंतुलित डेटासेट देखें.
मिश्रण मॉडल
यह एक ऐसी स्कीम है जिसकी मदद से, न्यूरल नेटवर्क की परफ़ॉर्मेंस को बेहतर बनाया जाता है. इसके लिए, नेटवर्क के सिर्फ़ कुछ पैरामीटर (जिन्हें एक्सपर्ट कहा जाता है) का इस्तेमाल करके, दिए गए इनपुट टोकन या उदाहरण को प्रोसेस किया जाता है. गेटेड नेटवर्क, हर इनपुट टोकन या उदाहरण को सही विशेषज्ञ(ओं) तक पहुंचाता है.
ज़्यादा जानकारी के लिए, इनमें से कोई एक पेपर देखें:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- एक्सपर्ट चॉइस राउटिंग के साथ मिक्सचर-ऑफ़-एक्सपर्ट
ML
मशीन लर्निंग का संक्षिप्त नाम.
एमएमआईटी
मल्टीमॉडल इंस्ट्रक्शन-ट्यूनिंग का संक्षिप्त नाम.
MNIST
यह एक सार्वजनिक डोमेन वाला डेटासेट है. इसे LeCun, Cortes, और Burges ने तैयार किया है. इसमें 60,000 इमेज हैं. हर इमेज में यह दिखाया गया है कि किसी व्यक्ति ने मैन्युअल तरीके से 0 से 9 तक के किसी अंक को कैसे लिखा है. हर इमेज को पूर्णांकों के 28x28 ऐरे के तौर पर सेव किया जाता है. इसमें हर पूर्णांक, 0 से 255 के बीच की ग्रेस्केल वैल्यू होती है.
MNIST, मशीन लर्निंग के लिए एक स्टैंडर्ड डेटासेट है. इसका इस्तेमाल अक्सर, मशीन लर्निंग के नए तरीकों को टेस्ट करने के लिए किया जाता है. ज़्यादा जानकारी के लिए, हाथ से लिखे गए अंकों का MNIST डेटाबेस देखें.
मोडेलिटी
डेटा की टॉप-लेवल कैटगरी. उदाहरण के लिए, संख्याएं, टेक्स्ट, इमेज, वीडियो, और ऑडियो, पांच अलग-अलग मोडैलिटी हैं.
मॉडल
आम तौर पर, कोई भी ऐसा गणितीय फ़ंक्शन जो इनपुट डेटा को प्रोसेस करता है और आउटपुट देता है. दूसरे शब्दों में कहें, तो मॉडल, पैरामीटर और स्ट्रक्चर का ऐसा सेट होता है जिसकी मदद से कोई सिस्टम अनुमान लगाता है. सुपरवाइज़्ड मशीन लर्निंग में, मॉडल उदाहरण को इनपुट के तौर पर लेता है और अनुमान को आउटपुट के तौर पर दिखाता है. सुपरवाइज़्ड मशीन लर्निंग में, मॉडल कुछ हद तक अलग-अलग होते हैं. उदाहरण के लिए:
- लीनियर रिग्रेशन मॉडल में वज़न और बायस का सेट होता है.
- न्यूरल नेटवर्क मॉडल में ये शामिल होते हैं:
- छिपी हुई लेयर का एक सेट. हर लेयर में एक या उससे ज़्यादा न्यूरॉन होते हैं.
- हर न्यूरॉन से जुड़े वेट और बायस.
- डिसिज़न ट्री मॉडल में ये शामिल होते हैं:
- ट्री का आकार. इसका मतलब है कि शर्तें और पत्तियां किस पैटर्न में जुड़ी हैं.
- के आने और जाने की सूचना.
आपके पास किसी मॉडल को सेव करने, वापस लाने या उसकी कॉपी बनाने का विकल्प होता है.
बिना निगरानी वाली मशीन लर्निंग भी मॉडल जनरेट करती है. आम तौर पर, यह एक ऐसा फ़ंक्शन होता है जो इनपुट उदाहरण को सबसे सही क्लस्टर से मैप कर सकता है.
मॉडल की क्षमता
समस्याओं की जटिलता, जिसे मॉडल सीख सकता है. कोई मॉडल जितनी मुश्किल समस्याओं को हल करना सीख सकता है उसकी क्षमता उतनी ही ज़्यादा होती है. मॉडल के पैरामीटर की संख्या बढ़ने पर, आम तौर पर मॉडल की क्षमता बढ़ जाती है. क्लासिफ़िकेशन मॉडल की क्षमता की औपचारिक परिभाषा के लिए, वीसी डाइमेंशन देखें.
मॉडल कैस्केडिंग
यह एक ऐसा सिस्टम है जो किसी खास अनुमान लगाने वाली क्वेरी के लिए, सबसे सही मॉडल चुनता है.
मान लीजिए कि आपके पास मॉडल का एक ग्रुप है. इसमें बहुत बड़े मॉडल (बहुत सारे पैरामीटर) से लेकर बहुत छोटे मॉडल (बहुत कम पैरामीटर) तक शामिल हैं. बहुत बड़े मॉडल, छोटे मॉडल की तुलना में अनुमान लगाने के समय ज़्यादा कंप्यूटेशनल संसाधनों का इस्तेमाल करते हैं. हालांकि, बहुत बड़े मॉडल, छोटे मॉडल की तुलना में ज़्यादा जटिल अनुरोधों का अनुमान लगा सकते हैं. मॉडल कैस्केडिंग से, अनुमान लगाने के लिए की गई क्वेरी की जटिलता का पता चलता है. इसके बाद, अनुमान लगाने के लिए सही मॉडल चुना जाता है. मॉडल कैस्केडिंग का मुख्य मकसद, अनुमान लगाने की लागत को कम करना है. इसके लिए, आम तौर पर छोटे मॉडल चुने जाते हैं. साथ ही, ज़्यादा मुश्किल क्वेरी के लिए ही बड़े मॉडल चुने जाते हैं.
मान लें कि कोई छोटा मॉडल किसी फ़ोन पर काम करता है और उस मॉडल का बड़ा वर्शन किसी रिमोट सर्वर पर काम करता है. मॉडल कैस्केडिंग की मदद से, लागत और लेटेंसी को कम किया जा सकता है. ऐसा इसलिए, क्योंकि छोटे मॉडल को सामान्य अनुरोधों को हैंडल करने की अनुमति दी जाती है. साथ ही, जटिल अनुरोधों को हैंडल करने के लिए सिर्फ़ रिमोट मॉडल को कॉल किया जाता है.
मॉडल राउटर के बारे में भी जानें.
मॉडल पैरललिज़्म
ट्रेनिंग या अनुमान लगाने की प्रोसेस को बढ़ाने का एक तरीका, जिसमें एक मॉडल के अलग-अलग हिस्सों को अलग-अलग डिवाइसों पर रखा जाता है. मॉडल पैरललिज़्म की मदद से, ऐसे मॉडल इस्तेमाल किए जा सकते हैं जो एक डिवाइस पर फ़िट नहीं होते.
मॉडल पैरललिज़्म को लागू करने के लिए, सिस्टम आम तौर पर ये काम करता है:
- यह मॉडल को छोटे-छोटे हिस्सों में बांटता है.
- इन छोटे हिस्सों की ट्रेनिंग को कई प्रोसेसर में बांटता है. हर प्रोसेसर, मॉडल के अपने हिस्से को ट्रेन करता है.
- यह नतीजों को मिलाकर एक मॉडल बनाता है.
मॉडल पैरललिज़्म से ट्रेनिंग की प्रोसेस धीमी हो जाती है.
डेटा पैरललिज़्म के बारे में भी जानें.
मॉडल राऊटर
यह एल्गोरिदम, मॉडल कैस्केडिंग में अनुमान के लिए सबसे सही मॉडल तय करता है. मॉडल राउटर, आम तौर पर एक मशीन लर्निंग मॉडल होता है. यह धीरे-धीरे यह सीखता है कि किसी इनपुट के लिए सबसे अच्छा मॉडल कैसे चुना जाए. हालांकि, मॉडल राउटर कभी-कभी एक आसान, नॉन-मशीन लर्निंग एल्गोरिदम हो सकता है.
मॉडल की ट्रेनिंग
सबसे अच्छे मॉडल का पता लगाने की प्रोसेस.
MOE
यह मिक्सचर ऑफ़ एक्सपर्ट का संक्षिप्त नाम है.
दिलचस्पी बढ़ाना
यह एक बेहतर ग्रेडिएंट डिसेंट एल्गोरिदम है. इसमें लर्निंग का कोई चरण, न सिर्फ़ मौजूदा चरण के डेरिवेटिव पर निर्भर करता है, बल्कि उससे ठीक पहले के चरण के डेरिवेटिव पर भी निर्भर करता है. मोमेंटम में, समय के साथ ग्रेडिएंट के एक्सपोनेंशियल वेटेड मूविंग ऐवरेज का हिसाब लगाया जाता है. यह फ़िज़िक्स में मोमेंटम के जैसा होता है. मोमेंटम की वजह से, लर्निंग कभी-कभी लोकल मिनिमल में अटक जाती है.
Mostly Basic Python Problems (MBPP)
यह एक ऐसा डेटासेट है जिससे यह पता लगाया जा सकता है कि कोई एलएलएम, Python कोड जनरेट करने में कितना माहिर है. Mostly Basic Python Problems में, क्राउडसोर्सिंग के ज़रिए इकट्ठा की गई करीब 1,000 प्रोग्रामिंग समस्याएं दी गई हैं. डेटासेट में मौजूद हर समस्या में यह जानकारी शामिल होती है:
- टास्क के बारे में जानकारी
- समस्या का हल करने से जुड़ा कोड
- अपने-आप होने वाले तीन टेस्ट केस
MT
मशीन से अनुवाद के लिए इस्तेमाल किया जाने वाला संक्षिप्त नाम.
मल्टी-क्लास क्लासिफ़िकेशन
यह सुपरवाइज़्ड लर्निंग में क्लासिफ़िकेशन की समस्या है. इसमें डेटासेट में लेबल की दो से ज़्यादा क्लास होती हैं. उदाहरण के लिए, आइरिस डेटासेट में मौजूद लेबल, इन तीन क्लास में से कोई एक होना चाहिए:
- आइरिस सेटोसा
- आइरिस वर्जिनिका
- आइरिस वर्सिकलर
आइरिस डेटासेट पर ट्रेन किया गया मॉडल, नए उदाहरणों के आधार पर आइरिस टाइप का अनुमान लगाता है. यह मल्टी-क्लास क्लासिफ़िकेशन करता है.
इसके उलट, क्लासिफ़िकेशन की ऐसी समस्याएं जिनमें सिर्फ़ दो क्लास के बीच अंतर किया जाता है उन्हें बाइनरी क्लासिफ़िकेशन मॉडल कहा जाता है. उदाहरण के लिए, ईमेल मॉडल यह अनुमान लगाता है कि ईमेल स्पैम है या स्पैम नहीं है. यह एक बाइनरी क्लासिफ़िकेशन मॉडल है.
क्लस्टरिंग की समस्याओं में, मल्टी-क्लास क्लासिफ़िकेशन का मतलब दो से ज़्यादा क्लस्टर से होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: मल्टी-क्लास क्लासिफ़िकेशन देखें.
मल्टी-क्लास लॉजिस्टिक रिग्रेशन
मल्टी-क्लास क्लासिफ़िकेशन की समस्याओं में, लॉजिस्टिक रिग्रेशन का इस्तेमाल करना.
मल्टी-हेड सेल्फ-अटेंशन
यह सेल्फ़-अटेंशन का एक्सटेंशन है. यह इनपुट सीक्वेंस में मौजूद हर पोज़िशन के लिए, सेल्फ़-अटेंशन मेकेनिज़्म को कई बार लागू करता है.
ट्रांसफ़ॉर्मर ने मल्टी-हेड सेल्फ़-अटेंशन की सुविधा पेश की.
मल्टीमॉडल इंस्ट्रक्शन-ट्यूनिंग
यह निर्देशों के हिसाब से काम करने वाला मॉडल है. यह टेक्स्ट के अलावा, इमेज, वीडियो, और ऑडियो जैसे इनपुट को भी प्रोसेस कर सकता है.
मल्टीमॉडल मॉडल
ऐसा मॉडल जिसके इनपुट, आउटपुट या दोनों में एक से ज़्यादा मोडेलिटी शामिल हों. उदाहरण के लिए, ऐसे मॉडल पर विचार करें जो इमेज और टेक्स्ट कैप्शन (दो मोडेलिटी) को सुविधाओं के तौर पर लेता है. साथ ही, एक स्कोर आउटपुट करता है. यह स्कोर बताता है कि इमेज के लिए टेक्स्ट कैप्शन कितना सही है. इसलिए, इस मॉडल के इनपुट मल्टीमोडल हैं और आउटपुट यूनिमोडल है.
मल्टीनोमियल क्लासिफ़िकेशन
यह मल्टी-क्लास क्लासिफ़िकेशन का समानार्थी शब्द है.
मल्टीनोमियल रिग्रेशन
मल्टी-क्लास लॉजिस्टिक रिग्रेशन का समानार्थी शब्द.
एक से ज़्यादा वाक्यों को पढ़कर सवालों के जवाब देने की क्षमता (MultiRC)
यह एक डेटासेट है. इसका इस्तेमाल, यह आकलन करने के लिए किया जाता है कि एलएलएम, कई विकल्पों वाले सवालों के जवाब दे सकता है या नहीं. डेटासेट में मौजूद हर उदाहरण में यह जानकारी शामिल होती है:
- कॉन्टेक्स्ट पैराग्राफ़
- उस पैराग्राफ़ के बारे में एक सवाल
- सवाल के एक से ज़्यादा जवाब. हर जवाब को 'सही' या 'गलत' के तौर पर लेबल किया जाता है. एक से ज़्यादा जवाब सही हो सकते हैं.
उदाहरण के लिए:
कॉन्टेक्स्ट पैराग्राफ़:
सुज़न को जन्मदिन की पार्टी करनी थी. उसने अपने सभी दोस्तों को फ़ोन किया. उसके पांच दोस्त हैं. उसकी माँ ने कहा कि सुज़ैन उन सभी को पार्टी में न्योता दे सकती है. उसकी पहली दोस्त पार्टी में नहीं जा सकी, क्योंकि वह बीमार थी. उसकी दूसरी दोस्त शहर से बाहर जा रही थी. उसकी तीसरी दोस्त को पक्का नहीं था कि उसके माता-पिता उसे अनुमति देंगे या नहीं. चौथे दोस्त ने कहा कि वह शायद आ पाए. पांचवां दोस्त पार्टी में ज़रूर आ सकता है. सुज़ैन थोड़ी उदास थी. पार्टी के दिन, पांचों दोस्त आ गए. हर दोस्त के पास सुज़ैन के लिए एक तोहफ़ा था. सुज़न बहुत खुश हुई और उसने अगले हफ़्ते अपने हर दोस्त को धन्यवाद कार्ड भेजा.
सवाल: क्या सुज़ैन का बीमार दोस्त ठीक हो गया?
एक से ज़्यादा जवाब:
- हां, वह ठीक हो गई. (सही)
- नहीं. (गलत)
- हां. (सही)
- नहीं, वह ठीक नहीं हुई. (गलत)
- हाँ, वह सुज़ैन की पार्टी में थी. (सही)
MultiRC, SuperGLUE का एक हिस्सा है.
ज़्यादा जानकारी के लिए, Looking Beyond the Surface: A Challenge Set for Reading Comprehension over Multiple Sentences देखें.
एक साथ कई काम करना
मशीन लर्निंग की एक ऐसी तकनीक जिसमें एक मॉडल को कई टास्क पूरे करने के लिए ट्रेन किया जाता है.
मल्टीटास्क मॉडल को ऐसे डेटा पर ट्रेनिंग देकर बनाया जाता है जो अलग-अलग टास्क के लिए सही हो. इससे मॉडल को अलग-अलग टास्क के बीच जानकारी शेयर करने के बारे में जानने में मदद मिलती है. इससे मॉडल को ज़्यादा असरदार तरीके से सीखने में मदद मिलती है.
एक मॉडल को कई टास्क के लिए ट्रेन किया जाता है. इससे, वह अलग-अलग तरह के डेटा को बेहतर तरीके से हैंडल कर पाता है.
नहीं
Nano
यह Gemini का छोटा मॉडल है. इसे डिवाइस पर इस्तेमाल करने के लिए डिज़ाइन किया गया है. ज़्यादा जानकारी के लिए, Gemini Nano लेख पढ़ें.
Pro और Ultra के बारे में भी जानें.
एनएएन ट्रैप
ट्रेनिंग के दौरान, जब आपके मॉडल में मौजूद कोई नंबर NaN बन जाता है, तब आपके मॉडल में मौजूद कई या सभी नंबर आखिर में NaN बन जाते हैं.
एनएएन, Nॉट अ Nंबर का संक्षिप्त रूप है.
नैचुरल लैंग्वेज प्रोसेसिंग
यह कंप्यूटर को भाषा के नियमों का इस्तेमाल करके, उपयोगकर्ता के कहे या टाइप किए गए शब्दों को प्रोसेस करने की ट्रेनिंग देने का फ़ील्ड है. नैचुरल लैंग्वेज प्रोसेसिंग की आधुनिक तकनीकों में से ज़्यादातर, मशीन लर्निंग पर आधारित होती हैं.नैचुरल लैंग्वेज अंडरस्टैंडिंग
यह नैचुरल लैंग्वेज प्रोसेसिंग का एक सबसेट है. यह बोले या टाइप किए गए किसी कॉन्टेंट के मकसद का पता लगाता है. नैचुरल लैंग्वेज अंडरस्टैंडिंग, नैचुरल लैंग्वेज प्रोसेसिंग से आगे बढ़कर भाषा के मुश्किल पहलुओं को समझ सकती है. जैसे, संदर्भ, व्यंग्य, और भावनाएं.
नेगेटिव क्लास
बाइनरी क्लासिफ़िकेशन में, एक क्लास को पॉज़िटिव और दूसरी क्लास को नेगेटिव कहा जाता है. पॉज़िटिव क्लास, वह चीज़ या इवेंट होता है जिसके लिए मॉडल की टेस्टिंग की जा रही है. वहीं, नेगेटिव क्लास, दूसरी संभावना होती है. उदाहरण के लिए:
- मेडिकल टेस्ट में नेगेटिव क्लास "ट्यूमर नहीं है" हो सकती है.
- ईमेल के क्लासिफ़िकेशन मॉडल में नेगेटिव क्लास "स्पैम नहीं है" हो सकती है.
पॉज़िटिव क्लास से तुलना करें.
नेगेटिव सैंपलिंग
यह उम्मीदवारों के सैंपल का समानार्थी शब्द है.
न्यूरल आर्किटेक्चर सर्च (एनएएस)
यह न्यूरल नेटवर्क के आर्किटेक्चर को अपने-आप डिज़ाइन करने की एक तकनीक है. NAS एल्गोरिदम, न्यूरल नेटवर्क को ट्रेन करने में लगने वाले समय और ज़रूरी संसाधनों की संख्या को कम कर सकते हैं.
NAS आम तौर पर इनका इस्तेमाल करता है:
- सर्च स्पेस, जो संभावित आर्किटेक्चर का एक सेट होता है.
- फ़िटनेस फ़ंक्शन, जिससे यह मेज़र किया जाता है कि कोई आर्किटेक्चर, दिए गए टास्क को कितनी अच्छी तरह से पूरा करता है.
NAS एल्गोरिदम, अक्सर संभावित आर्किटेक्चर के छोटे सेट से शुरू होते हैं. साथ ही, जैसे-जैसे एल्गोरिदम को यह पता चलता है कि कौनसे आर्किटेक्चर असरदार हैं वैसे-वैसे खोज के दायरे को धीरे-धीरे बढ़ाया जाता है. फ़िटनेस फ़ंक्शन आम तौर पर, ट्रेनिंग सेट पर आर्किटेक्चर की परफ़ॉर्मेंस पर आधारित होता है. साथ ही, एल्गोरिदम को आम तौर पर रीइन्फ़ोर्समेंट लर्निंग तकनीक का इस्तेमाल करके ट्रेन किया जाता है.
NAS एल्गोरिदम, कई तरह के कामों के लिए बेहतर परफ़ॉर्म करने वाले आर्किटेक्चर ढूंढने में असरदार साबित हुए हैं. इनमें इमेज क्लासिफ़िकेशन, टेक्स्ट क्लासिफ़िकेशन, और मशीन ट्रांसलेशन शामिल हैं.
न्यूरल नेटवर्क
एक मॉडल, जिसमें कम से कम एक हिडन लेयर हो. डीप न्यूरल नेटवर्क, न्यूरल नेटवर्क का एक टाइप है. इसमें एक से ज़्यादा हिडन लेयर होती हैं. उदाहरण के लिए, इस डायग्राम में दो हिडन लेयर वाला डीप न्यूरल नेटवर्क दिखाया गया है.
न्यूरल नेटवर्क में मौजूद हर न्यूरॉन, अगली लेयर के सभी नोड से कनेक्ट होता है. उदाहरण के लिए, ऊपर दिए गए डायग्राम में देखें कि पहली हिडन लेयर में मौजूद तीनों न्यूरॉन, दूसरी हिडन लेयर में मौजूद दोनों न्यूरॉन से अलग-अलग तरीके से कनेक्ट होते हैं.
कंप्यूटर पर लागू किए गए न्यूरल नेटवर्क को कभी-कभी आर्टिफ़िशियल न्यूरल नेटवर्क कहा जाता है. ऐसा इसलिए, ताकि इन्हें दिमाग़ और अन्य नर्वस सिस्टम में मौजूद न्यूरल नेटवर्क से अलग किया जा सके.
कुछ न्यूरल नेटवर्क, अलग-अलग सुविधाओं और लेबल के बीच बेहद जटिल नॉनलीनियर रिलेशनशिप की नकल कर सकते हैं.
कन्वलूशनल न्यूरल नेटवर्क और रीकरंट न्यूरल नेटवर्क के बारे में भी जानें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क देखें.
न्यूरॉन
मशीन लर्निंग में, न्यूरल नेटवर्क की हिडन लेयर में मौजूद एक अलग यूनिट. हर न्यूरॉन, दो चरणों में यह कार्रवाई करता है:
- यह नोड, इनपुट वैल्यू को उनके वेट से गुणा करके, वेटेड सम की कैलकुलेशन करता है.
- वेटेड सम को ऐक्टिवेशन फ़ंक्शन के इनपुट के तौर पर पास करता है.
पहली हिडन लेयर में मौजूद न्यूरॉन, इनपुट लेयर में मौजूद फ़ीचर वैल्यू से इनपुट स्वीकार करता है. पहली हिडन लेयर के बाद की किसी भी हिडन लेयर में मौजूद न्यूरॉन, पिछली हिडन लेयर में मौजूद न्यूरॉन से इनपुट स्वीकार करता है. उदाहरण के लिए, दूसरी हिडन लेयर में मौजूद न्यूरॉन, पहली हिडन लेयर में मौजूद न्यूरॉन से इनपुट स्वीकार करता है.
नीचे दिए गए इलस्ट्रेशन में, दो न्यूरॉन और उनके इनपुट को हाइलाइट किया गया है.
न्यूरल नेटवर्क में मौजूद न्यूरॉन, दिमाग और नर्वस सिस्टम के अन्य हिस्सों में मौजूद न्यूरॉन की तरह काम करता है.
एन-ग्राम
N शब्दों का क्रम से लगाया गया सेट. उदाहरण के लिए, truly madly एक 2-ग्राम है. शब्दों का क्रम मायने रखता है. इसलिए, madly truly, truly madly से अलग 2-ग्राम है.
| नहीं | इस तरह के N-ग्राम के नाम | उदाहरण |
|---|---|---|
| 2 | बाइग्राम या 2-ग्राम | जाना, जाना, दोपहर का खाना खाना, रात का खाना खाना |
| 3 | ट्रायग्राम या 3-ग्राम | पेट भर खाना, शुभ विवाह, मौत की घंटी |
| 4 | 4-ग्राम | वॉक इन द पार्क, डस्ट इन द विंड, द बॉय एट लेंटिल्स |
नैचुरल लैंग्वेज अंडरस्टैंडिंग के कई मॉडल, N-ग्राम पर भरोसा करते हैं. इससे यह अनुमान लगाया जा सकता है कि उपयोगकर्ता अगला शब्द क्या टाइप करेगा या बोलेगा. उदाहरण के लिए, मान लें कि किसी उपयोगकर्ता ने happily ever टाइप किया. ट्रायग्राम पर आधारित कोई एनएलयू मॉडल, इस बात का अनुमान लगा सकता है कि उपयोगकर्ता इसके बाद after शब्द टाइप करेगा.
एन-ग्राम की तुलना बैग ऑफ़ वर्ड्स से करें. ये शब्दों के ऐसे सेट होते हैं जिनमें शब्दों का क्रम मायने नहीं रखता.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लार्ज लैंग्वेज मॉडल देखें.
एनएलपी
नैचुरल लैंग्वेज प्रोसेसिंग का संक्षिप्त नाम.
एनएलयू
नैचुरल लैंग्वेज अंडरस्टैंडिंग का संक्षिप्त नाम.
नोड (डिसिज़न ट्री)
डिसिज़न ट्री में, कोई भी शर्त या लीफ.
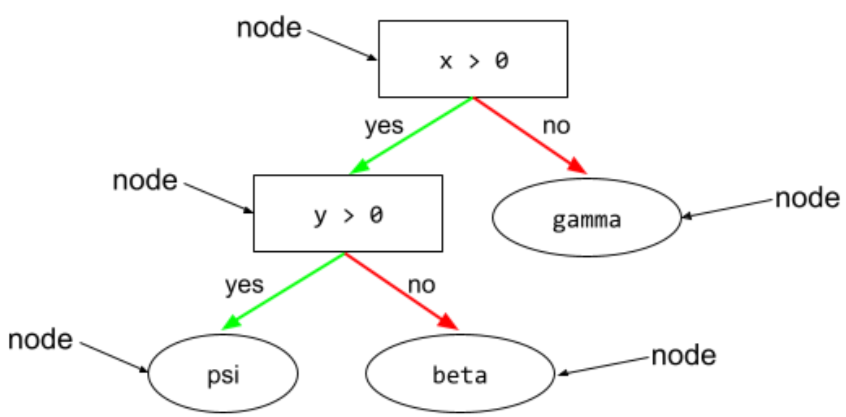
ज़्यादा जानकारी के लिए, फ़ैसले लेने के लिए फ़ॉरेस्ट कोर्स में डिसिज़न ट्री देखें.
नोड (न्यूरल नेटवर्क)
छिपी हुई लेयर में मौजूद न्यूरॉन.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क देखें.
नोड (TensorFlow ग्राफ़)
TensorFlow ग्राफ़ में कोई ऑपरेशन.
शोर
आसान शब्दों में कहें, तो डेटासेट में मौजूद किसी भी तरह की ऐसी जानकारी जो सिग्नल को धुंधला करती है. डेटा में नॉइज़ कई तरह से आ सकता है. उदाहरण के लिए:
- ह्यूमन रेटर, लेबलिंग में गलतियां करते हैं.
- लोग और इंस्ट्रूमेंट, सुविधाओं की वैल्यू को गलत तरीके से रिकॉर्ड करते हैं या उन्हें छोड़ देते हैं.
अन्य शर्त
ऐसी शर्त जिसमें दो से ज़्यादा संभावित नतीजे होते हैं. उदाहरण के लिए, यहां दी गई नॉन-बाइनरी शर्त में तीन संभावित नतीजे शामिल हैं:
ज़्यादा जानकारी के लिए, Decision Forests कोर्स में शर्तों के टाइप देखें.
नॉनलीनियर
दो या उससे ज़्यादा वैरिएबल के बीच ऐसा संबंध जिसे सिर्फ़ जोड़ और गुणा करके नहीं दिखाया जा सकता. लीनियर संबंध को लाइन के तौर पर दिखाया जा सकता है. वहीं, नॉनलीनियर संबंध को लाइन के तौर पर नहीं दिखाया जा सकता. उदाहरण के लिए, ऐसे दो मॉडल पर विचार करें जिनमें से हर मॉडल, एक सुविधा को एक लेबल से जोड़ता है. बाईं ओर मौजूद मॉडल लीनियर है और दाईं ओर मौजूद मॉडल नॉनलीनियर है:

अलग-अलग तरह के नॉनलीनियर फ़ंक्शन आज़माने के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: नोड और हिडन लेयर देखें.
नॉन-रिस्पॉन्स बायस
चुने जाने का पूर्वाग्रह देखें.
नॉनस्टेशनैरिटी
ऐसी सुविधा जिसकी वैल्यू एक या उससे ज़्यादा डाइमेंशन के हिसाब से बदलती हैं. आम तौर पर, यह समय के हिसाब से बदलती है. उदाहरण के लिए, नॉनस्टेशनैरिटी के ये उदाहरण देखें:
- किसी स्टोर पर बेचे गए स्विमसूट की संख्या, सीज़न के हिसाब से अलग-अलग होती है.
- किसी खास इलाके में, किसी खास फल की फ़सल साल के ज़्यादातर समय में शून्य होती है, लेकिन कुछ समय के लिए यह बहुत ज़्यादा होती है.
- क्लाइमेट चेंज की वजह से, सालाना औसत तापमान में बदलाव हो रहा है.
स्टेशनैरिटी से तुलना करें.
कोई भी जवाब सही नहीं है (नोरा)
एक ऐसा प्रॉम्प्ट जिसके कई सही जवाब हों. उदाहरण के लिए, इस प्रॉम्प्ट का कोई एक सही जवाब नहीं है:
मुझे हाथियों के बारे में कोई मज़ेदार चुटकुला सुनाओ.
एक सही जवाब वाले सवालों के जवाबों की जांच करने की तुलना में, कोई सही जवाब नहीं वाले सवालों के जवाबों की जांच करना ज़्यादा मुश्किल होता है. उदाहरण के लिए, हाथी के बारे में किसी चुटकुले का आकलन करने के लिए, यह तय करने का एक व्यवस्थित तरीका होना चाहिए कि चुटकुला कितना मज़ेदार है.
नोरा
कोई एक सही जवाब नहीं है के लिए इस्तेमाल किया जाने वाला छोटा नाम.
नॉर्मलाइज़ेशन
सामान्य तौर पर, किसी वैरिएबल की वैल्यू की असल रेंज को वैल्यू की स्टैंडर्ड रेंज में बदलने की प्रोसेस को नॉर्मलाइज़ेशन कहते हैं. जैसे:
- -1 से +1
- 0 से 1
- ज़ेड-स्कोर (लगभग -3 से +3)
उदाहरण के लिए, मान लें कि किसी सुविधा की वैल्यू की असल रेंज 800 से 2,400 है. फ़ीचर इंजीनियरिंग के तहत, असल वैल्यू को स्टैंडर्ड रेंज में नॉर्मलाइज़ किया जा सकता है. जैसे, -1 से +1.
नॉर्मलाइज़ेशन, फ़ीचर इंजीनियरिंग में एक सामान्य टास्क है. जब फ़ीचर वेक्टर में मौजूद हर संख्यात्मक फ़ीचर की रेंज लगभग एक जैसी होती है, तो मॉडल आम तौर पर तेज़ी से ट्रेन होते हैं और बेहतर अनुमान लगाते हैं.
ज़ेड-स्कोर नॉर्मलाइज़ेशन भी देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: सामान्य बनाना देखें.
Notebook LM
यह Gemini पर आधारित एक टूल है. इसकी मदद से लोग दस्तावेज़ अपलोड कर सकते हैं. इसके बाद, वे प्रॉम्प्ट का इस्तेमाल करके, उन दस्तावेज़ों के बारे में सवाल पूछ सकते हैं, उनकी खास जानकारी पा सकते हैं या उन्हें व्यवस्थित कर सकते हैं. उदाहरण के लिए, कोई लेखक कई छोटी कहानियां अपलोड कर सकता है. इसके बाद, वह NotebookLM से इन कहानियों में मौजूद सामान्य थीम ढूंढने या यह पता लगाने के लिए कह सकता है कि इनमें से कौनसी कहानी पर सबसे अच्छी फ़िल्म बनाई जा सकती है.
नई चीज़ों का पता लगाने की सुविधा
यह तय करने की प्रोसेस कि क्या कोई नया उदाहरण, ट्रेनिंग सेट के डिस्ट्रिब्यूशन से मिलता-जुलता है. दूसरे शब्दों में कहें, तो ट्रेनिंग सेट पर ट्रेनिंग के बाद, नॉवेल्टी डिटेक्शन यह तय करता है कि नया उदाहरण (अनुमान के दौरान या अतिरिक्त ट्रेनिंग के दौरान) आउटलायर है या नहीं.
आउटलायर डिटेक्शन से तुलना करें.
न्यूमेरिकल डेटा
विशेषताएं, जिन्हें पूर्णांक या असल वैल्यू वाली संख्याओं के तौर पर दिखाया जाता है. उदाहरण के लिए, घर की कीमत का अनुमान लगाने वाला मॉडल, घर के साइज़ (स्क्वेयर फ़ीट या स्क्वेयर मीटर में) को संख्या के तौर पर दिखाएगा. किसी सुविधा को संख्यात्मक डेटा के तौर पर दिखाने का मतलब है कि सुविधा की वैल्यू का लेबल से गणितीय संबंध है. इसका मतलब है कि घर के स्क्वेयर मीटर की संख्या का, घर की कीमत से कुछ गणितीय संबंध हो सकता है.
सभी पूर्णांक डेटा को संख्या के तौर पर नहीं दिखाया जाना चाहिए. उदाहरण के लिए, दुनिया के कुछ हिस्सों में पिन कोड पूर्णांक होते हैं. हालांकि, पूर्णांक वाले पिन कोड को मॉडल में संख्यात्मक डेटा के तौर पर नहीं दिखाया जाना चाहिए. ऐसा इसलिए है, क्योंकि 20000 का पिन कोड, 10000 के पिन कोड से दोगुना (या आधा) नहीं है. इसके अलावा, अलग-अलग पिन कोड के हिसाब से प्रॉपर्टी की वैल्यू अलग-अलग होती है. हालांकि, हम यह नहीं मान सकते कि पिन कोड 20000 के हिसाब से प्रॉपर्टी की वैल्यू, पिन कोड 10000 के हिसाब से प्रॉपर्टी की वैल्यू से दोगुनी है.
पिन कोड को कैटेगरी के हिसाब से बंटे डेटा के तौर पर दिखाया जाना चाहिए.
संख्यात्मक सुविधाओं को कभी-कभी कंटीन्यूअस फ़ीचर कहा जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा के साथ काम करना लेख पढ़ें.
NumPy
यह ओपन-सोर्स मैथ लाइब्रेरी है. यह Python में ऐरे से जुड़े ऑपरेशन को आसानी से पूरा करने में मदद करती है. pandas को NumPy पर बनाया गया है.
O
कैंपेन का मकसद
मेट्रिक, जिसे एल्गोरिदम ऑप्टिमाइज़ करने की कोशिश कर रहा है.
ऑब्जेक्टिव फ़ंक्शन
गणित का फ़ॉर्मूला या मेट्रिक जिसे मॉडल ऑप्टिमाइज़ करने की कोशिश करता है. उदाहरण के लिए, लीनियर रिग्रेशन के लिए ऑब्जेक्टिव फ़ंक्शन, आम तौर पर मीन स्क्वेयर्ड लॉस होता है. इसलिए, लीनियर रिग्रेशन मॉडल को ट्रेन करते समय, ट्रेनिंग का मकसद औसत स्क्वेयर्ड लॉस को कम करना होता है.
कुछ मामलों में, मकसद फ़ंक्शन को बढ़ाने का होता है. उदाहरण के लिए, अगर ऑब्जेक्टिव फ़ंक्शन सटीक होना है, तो लक्ष्य सटीक होने की संभावना को बढ़ाना है.
नुकसान के बारे में भी जानें.
तिरछी स्थिति
डिसिज़न ट्री में, एक ऐसी शर्त जिसमें एक से ज़्यादा सुविधाएं शामिल हों. उदाहरण के लिए, अगर ऊंचाई और चौड़ाई, दोनों सुविधाएं हैं, तो यहां दी गई शर्त, अप्रत्यक्ष शर्त है:
height > width
इसकी तुलना ऐक्सिस के साथ अलाइन की गई शर्त से करें.
ज़्यादा जानकारी के लिए, Decision Forests कोर्स में शर्तों के टाइप देखें.
अॉफ़लाइन
static का समानार्थी शब्द.
ऑफ़लाइन इन्फ़रेंस
किसी मॉडल के अनुमानों का एक बैच जनरेट करने और फिर उन अनुमानों को कैश मेमोरी में सेव करने की प्रोसेस. इसके बाद, ऐप्लिकेशन मॉडल को फिर से चलाने के बजाय, कैश मेमोरी से अनुमानित पूर्वानुमान को ऐक्सेस कर सकते हैं.
उदाहरण के लिए, एक ऐसे मॉडल पर विचार करें जो हर चार घंटे में एक बार, स्थानीय मौसम के पूर्वानुमान (अनुमान) जनरेट करता है. हर मॉडल रन के बाद, सिस्टम स्थानीय मौसम के सभी अनुमानों को कैश मेमोरी में सेव करता है. मौसम की जानकारी देने वाले ऐप्लिकेशन, कैश मेमोरी से पूर्वानुमान की जानकारी पाते हैं.
ऑफ़लाइन अनुमान को स्टैटिक अनुमान भी कहा जाता है.
इसकी तुलना ऑनलाइन इन्फ़रेंस से करें. ज़्यादा जानकारी के लिए, Machine Learning Crash Course में Production ML systems: Static versus dynamic inference देखें.
वन-हॉट एन्कोडिंग
कैटगरी वाले डेटा को ऐसे वेक्टर के तौर पर दिखाया जाता है जिसमें:
- एक एलिमेंट को 1 पर सेट किया गया है.
- अन्य सभी एलिमेंट को 0 पर सेट किया जाता है.
आम तौर पर, वन-हॉट एन्कोडिंग का इस्तेमाल उन स्ट्रिंग या आइडेंटिफ़ायर को दिखाने के लिए किया जाता है जिनकी वैल्यू सीमित होती हैं.
उदाहरण के लिए, मान लें कि कैटगरी के हिसाब से तय की गई किसी सुविधा का नाम Scandinavia है और इसकी पांच संभावित वैल्यू हैं:
- "डेनमार्क"
- "स्वीडन"
- "नॉर्वे"
- "फ़िनलैंड"
- "आइसलैंड"
वन-हॉट एन्कोडिंग, पांचों वैल्यू को इस तरह दिखा सकती है:
| देश | वेक्टर | ||||
|---|---|---|---|---|---|
| "डेनमार्क" | 1 | 0 | 0 | 0 | 0 |
| "स्वीडन" | 0 | 1 | 0 | 0 | 0 |
| "नॉर्वे" | 0 | 0 | 1 | 0 | 0 |
| "फ़िनलैंड" | 0 | 0 | 0 | 1 | 0 |
| "आइसलैंड" | 0 | 0 | 0 | 0 | 1 |
वन-हॉट एन्कोडिंग की मदद से, मॉडल पांचों देशों के आधार पर अलग-अलग कनेक्शन के बारे में जान सकता है.
किसी फ़ीचर को न्यूमेरिकल डेटा के तौर पर दिखाना, वन-हॉट एन्कोडिंग का एक विकल्प है. माफ़ करें, स्कैंडिनेवियन देशों को संख्या के हिसाब से दिखाना सही नहीं है. उदाहरण के लिए, यहां दिए गए संख्यात्मक फ़ॉर्मैट पर ध्यान दें:
- "डेनमार्क" के लिए 0
- "स्वीडन" 1 है
- "नॉर्वे" की वैल्यू 2 है
- "फ़िनलैंड" की वैल्यू 3 है
- "आइसलैंड" 4 है
न्यूमेरिक एन्कोडिंग की मदद से, मॉडल रॉ नंबर को गणित के हिसाब से समझता है और उन नंबरों के आधार पर ट्रेनिंग लेता है. हालांकि, आइसलैंड में नॉर्वे की तुलना में किसी चीज़ की कीमत दोगुनी (या आधी) नहीं है. इसलिए, मॉडल कुछ अजीब नतीजे देगा.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटेगरी के हिसाब से डेटा: शब्दावली और वन-हॉट एन्कोडिंग देखें.
एक सही जवाब (ओआरए)
ऐसा प्रॉम्प्ट जिसका एक ही सही जवाब हो. उदाहरण के लिए, यहां दिया गया प्रॉम्प्ट देखें:
सही या गलत: शनि, मंगल से बड़ा है.
सिर्फ़ सही जवाब सही है.
कोई एक सही जवाब नहीं होता से अलग.
वन-शॉट लर्निंग
यह मशीन लर्निंग का एक तरीका है. इसका इस्तेमाल अक्सर ऑब्जेक्ट क्लासिफ़िकेशन के लिए किया जाता है. इसे एक ट्रेनिंग उदाहरण से, असरदार क्लासिफ़िकेशन मॉडल सीखने के लिए डिज़ाइन किया गया है.
फ़्यू-शॉट लर्निंग और ज़ीरो-शॉट लर्निंग के बारे में भी जानें.
वन-शॉट प्रॉम्प्ट
ऐसा प्रॉम्प्ट जिसमें एक उदाहरण दिया गया हो. इससे यह पता चलता है कि लार्ज लैंग्वेज मॉडल को किस तरह से जवाब देना चाहिए. उदाहरण के लिए, यहां दिए गए प्रॉम्प्ट में एक उदाहरण शामिल है. इसमें लार्ज लैंग्वेज मॉडल को यह बताया गया है कि उसे किसी क्वेरी का जवाब कैसे देना चाहिए.
| एक प्रॉम्ट के हिस्से | नोट |
|---|---|
| चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब आपको एलएलएम से चाहिए. |
| फ़्रांस: EUR | एक उदाहरण. |
| भारत: | असल क्वेरी. |
एक बार में जवाब पाने के लिए प्रॉम्प्ट लिखना की तुलना इन शब्दों से करें और इनमें अंतर बताएं:
वन-वर्सेज़-ऑल
अगर क्लासिफ़िकेशन की समस्या में N क्लास हैं, तो N अलग-अलग बाइनरी क्लासिफ़िकेशन मॉडल का इस्तेमाल किया जाता है. हर संभावित नतीजे के लिए एक बाइनरी क्लासिफ़िकेशन मॉडल होता है. उदाहरण के लिए, अगर कोई मॉडल उदाहरणों को जानवर, सब्ज़ी या खनिज के तौर पर कैटगरी में बांटता है, तो वन-वर्सेज़-ऑल (एक बनाम सभी) समाधान, बाइनरी क्लासिफ़िकेशन (दो कैटगरी में बांटने वाला) के ये तीन अलग-अलग मॉडल उपलब्ध कराएगा:
- जानवर बनाम जानवर नहीं
- सब्ज़ी है या नहीं
- मिनरल है या नहीं
online
डाइनैमिक के लिए समानार्थी शब्द.
ऑनलाइन अनुमान
मांग के आधार पर अनुमान जनरेट करना. उदाहरण के लिए, मान लें कि कोई ऐप्लिकेशन, मॉडल को इनपुट देता है और अनुमान लगाने का अनुरोध करता है. ऑनलाइन इन्फ़्रेंस का इस्तेमाल करने वाला सिस्टम, मॉडल को चलाकर अनुरोध का जवाब देता है. साथ ही, ऐप्लिकेशन को अनुमानित नतीजे दिखाता है.
इसकी तुलना ऑफ़लाइन इन्फ़रेंस से करें.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में Production ML systems: Static versus dynamic inference देखें.
ऑपरेशन (ओपी)
TensorFlow में, ऐसी कोई भी प्रोसेस जो Tensor बनाती है, उसमें बदलाव करती है या उसे मिटाती है. उदाहरण के लिए, मैट्रिक्स मल्टिप्लाई एक ऐसी कार्रवाई है जिसमें दो टेंसर को इनपुट के तौर पर लिया जाता है और एक टेंसर को आउटपुट के तौर पर जनरेट किया जाता है.
Optax
यह JAX के लिए, ग्रेडिएंट प्रोसेसिंग और ऑप्टिमाइज़ेशन लाइब्रेरी है. Optax, रिसर्च को आसान बनाता है. इसके लिए, यह ऐसे बिल्डिंग ब्लॉक उपलब्ध कराता है जिन्हें पैरामीट्रिक मॉडल को ऑप्टिमाइज़ करने के लिए, अपनी पसंद के मुताबिक फिर से जोड़ा जा सकता है. जैसे, डीप न्यूरल नेटवर्क. अन्य लक्ष्यों में ये शामिल हैं:
- कोर कॉम्पोनेंट के ऐसे वर्शन उपलब्ध कराना जिन्हें आसानी से पढ़ा जा सके, जिनकी अच्छी तरह से जांच की गई हो, और जो बेहतर तरीके से काम करते हों.
- कम लेवल वाले कॉम्पोनेंट को कस्टम ऑप्टिमाइज़र (या अन्य ग्रेडिएंट प्रोसेसिंग कॉम्पोनेंट) में मिलाकर, प्रॉडक्टिविटी को बेहतर बनाया जा सकता है.
- नए आइडिया को आसानी से लागू करने के लिए, हर किसी को योगदान करने का मौका देना.
ऑप्टिमाइज़र
ग्रेडिएंट डिसेंट एल्गोरिदम को लागू करने का एक तरीका. लोकप्रिय ऑप्टिमाइज़र में ये शामिल हैं:
- AdaGrad, जिसका मतलब है ADAptive GRADient descent.
- Adam, जिसका मतलब है ADAptive with Momentum.
ओआरए
यह एक सही जवाब का संक्षिप्त रूप है.
आउट-ग्रुप होमोजेनिटी बायस
जब किसी व्यक्ति के रवैये, मूल्यों, व्यक्तित्व की विशेषताओं, और अन्य विशेषताओं की तुलना की जाती है, तो वह अपने ग्रुप के सदस्यों की तुलना में, दूसरे ग्रुप के सदस्यों को ज़्यादा एक जैसा मानता है. इन-ग्रुप का मतलब उन लोगों से है जिनसे आप नियमित तौर पर बातचीत करते हैं; आउट-ग्रुप का मतलब उन लोगों से है जिनसे आप नियमित तौर पर बातचीत नहीं करते. अगर लोगों से आउट-ग्रुप के बारे में एट्रिब्यूट देने के लिए कहा जाता है, तो हो सकता है कि वे एट्रिब्यूट, इन-ग्रुप के लोगों के लिए बताए गए एट्रिब्यूट की तुलना में कम बारीकी से बताए गए हों और उनमें ज़्यादा स्टीरियोटाइप शामिल हों.
उदाहरण के लिए, लिलिपुटियन, दूसरे लिलिपुटियन के घरों के बारे में काफ़ी जानकारी दे सकते हैं. वे आर्किटेक्चर के स्टाइल, खिड़कियों, दरवाज़ों, और साइज़ में छोटे-छोटे अंतरों के बारे में बता सकते हैं. हालांकि, बौने लोग यह कह सकते हैं कि सभी दानव एक जैसे घरों में रहते हैं.
आउट-ग्रुप होमोजेनिटी बायस, ग्रुप एट्रिब्यूशन बायस का एक रूप है.
इन-ग्रुप बायस के बारे में भी जानें.
आउटलायर का पता लगाना
ट्रेनिंग सेट में आउटलायर की पहचान करने की प्रोसेस.
इसकी तुलना नई चीज़ों का पता लगाने से करें.
जिसकी परफ़ॉर्मेंस सामान्य से अलग रही
ऐसी वैल्यू जो अन्य वैल्यू से बहुत अलग होती हैं. मशीन लर्निंग में, इनमें से कोई भी आउटलायर हो सकता है:
- इनपुट डेटा की वैल्यू, औसत से करीब तीन स्टैंडर्ड डेविएशन से ज़्यादा होती हैं.
- ज़्यादा ऐब्सलूट वैल्यू वाले वज़न.
- अनुमानित वैल्यू, असल वैल्यू से काफ़ी अलग हैं.
उदाहरण के लिए, मान लें कि widget-price किसी मॉडल की सुविधा है.
मान लें कि औसत widget-price 7 यूरो है और स्टैंडर्ड डेविएशन 1 यूरो है. इसलिए, 1200 रुपये या 200 रुपये की widget-price वाले उदाहरणों को आउटलायर माना जाएगा, क्योंकि इनमें से हर कीमत, औसत से पांच स्टैंडर्ड डेविएशन दूर है.
टाइपिंग की गलतियों या इनपुट से जुड़ी अन्य गलतियों की वजह से, अक्सर आउटलायर दिखते हैं. कुछ मामलों में, आउटलायर कोई गलती नहीं होते. आखिर, माध्य से पांच स्टैंडर्ड डेविएशन दूर की वैल्यू बहुत कम होती हैं, लेकिन ऐसा होना नामुमकिन नहीं है.
आउटलायर की वजह से, मॉडल ट्रेनिंग में अक्सर समस्याएं आती हैं. क्लिपिंग, आउटलायर को मैनेज करने का एक तरीका है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा के साथ काम करना लेख पढ़ें.
आउट-ऑफ़-बैग इवैल्यूएशन (OOB इवैल्यूएशन)
यह डिसिज़न फ़ॉरेस्ट की क्वालिटी का आकलन करने का एक तरीका है. इसमें हर डिसिज़न ट्री की जांच, उन उदाहरणों के आधार पर की जाती है जिनका इस्तेमाल, उस डिसिज़न ट्री की ट्रेनिंग के दौरान नहीं किया गया था. उदाहरण के लिए, इस डायग्राम में देखें कि सिस्टम, हर फ़ैसले के ट्री को करीब दो-तिहाई उदाहरणों पर ट्रेन करता है. इसके बाद, बाकी एक-तिहाई उदाहरणों के आधार पर उसका आकलन करता है.
आउट-ऑफ़-बैग आकलन, क्रॉस-वैलिडेशन के तरीके का अनुमान लगाने का एक ऐसा तरीका है जो कम समय में सटीक नतीजे देता है. क्रॉस-वैलिडेशन में, हर क्रॉस-वैलिडेशन राउंड के लिए एक मॉडल को ट्रेन किया जाता है. उदाहरण के लिए, 10-फ़ोल्ड क्रॉस-वैलिडेशन में 10 मॉडल को ट्रेन किया जाता है. OOB आकलन में, सिर्फ़ एक मॉडल को ट्रेन किया जाता है. बैगिंग की वजह से, ट्रेनिंग के दौरान हर ट्री से कुछ डेटा अलग रखा जाता है. इसलिए, ओओबी आकलन इस डेटा का इस्तेमाल करके क्रॉस-वैलिडेशन का अनुमान लगा सकता है.
ज़्यादा जानकारी के लिए, Decision Forests कोर्स में आउट-ऑफ़-बैग आकलन देखें.
आउटपुट लेयर
न्यूरल नेटवर्क की "आखिरी" लेयर. आउटपुट लेयर में अनुमान शामिल होता है.
इस इलस्ट्रेशन में, इनपुट लेयर, दो छिपी हुई लेयर, और आउटपुट लेयर वाला एक छोटा डीप न्यूरल नेटवर्क दिखाया गया है:
ओवरफ़िटिंग
ऐसा मॉडल बनाना जो ट्रेनिंग डेटा से इतना मिलता-जुलता हो कि मॉडल नए डेटा के आधार पर सही अनुमान न लगा पाए.
रेगुलराइज़ेशन से ओवरफ़िटिंग कम हो सकती है. बड़े और अलग-अलग तरह के ट्रेनिंग सेट पर ट्रेनिंग देने से भी ओवरफ़िटिंग की समस्या कम हो सकती है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग देखें.
ओवरसैंपलिंग
क्लास के असंतुलित डेटासेट में, माइनॉरिटी क्लास के उदाहरणों का फिर से इस्तेमाल करना, ताकि ज़्यादा संतुलित ट्रेनिंग सेट बनाया जा सके.
उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन की समस्या पर विचार करें. इसमें मेजोरिटी क्लास और माइनॉरिटी क्लास का अनुपात 5,000:1 है. अगर डेटासेट में 10 लाख उदाहरण हैं, तो इसमें माइनॉरिटी क्लास के सिर्फ़ 200 उदाहरण शामिल होंगे. ये उदाहरण, मॉडल को बेहतर तरीके से ट्रेन करने के लिए काफ़ी नहीं हो सकते. इस कमी को पूरा करने के लिए, उन 200 उदाहरणों को कई बार फिर से इस्तेमाल किया जा सकता है. इससे ट्रेनिंग के लिए ज़रूरी उदाहरण मिल सकते हैं.
ओवरसैंपलिंग करते समय, आपको ओवरफ़िटिंग के बारे में सावधान रहना होगा.
इसकी तुलना अंडरसैंपलिंग से करें.
P
पैक किया गया डेटा
डेटा को ज़्यादा असरदार तरीके से सेव करने का तरीका.
पैक किए गए डेटा में, डेटा को कंप्रेस किए गए फ़ॉर्मैट में सेव किया जाता है. इसके अलावा, इसे किसी ऐसे तरीके से सेव किया जाता है जिससे इसे ज़्यादा आसानी से ऐक्सेस किया जा सके. पैक किए गए डेटा को ऐक्सेस करने के लिए, कम मेमोरी और कंप्यूटेशन की ज़रूरत होती है. इससे ट्रेनिंग तेज़ी से होती है और मॉडल का अनुमान ज़्यादा असरदार होता है.
पैक किए गए डेटा का इस्तेमाल अक्सर अन्य तकनीकों के साथ किया जाता है. जैसे, डेटा ऑगमेंटेशन और रेगुलराइज़ेशन. इससे मॉडल की परफ़ॉर्मेंस और बेहतर हो जाती है.
PaLM
Pathways Language Model का संक्षिप्त नाम.
पांडा
यह कॉलम के हिसाब से डेटा का विश्लेषण करने वाला एपीआई है. इसे numpy के आधार पर बनाया गया है. TensorFlow जैसे कई मशीन लर्निंग फ़्रेमवर्क, pandas डेटा स्ट्रक्चर को इनपुट के तौर पर इस्तेमाल करते हैं. ज़्यादा जानकारी के लिए, pandas का दस्तावेज़ देखें.
पैरामीटर
वज़न और बायस, जो मॉडल ट्रेनिंग के दौरान सीखता है. उदाहरण के लिए, लीनियर रिग्रेशन मॉडल में, पैरामीटर में बायस (b) और इस फ़ॉर्मूले में मौजूद सभी वेट (w1, w2 वगैरह) शामिल होते हैं:
इसके उलट, हाइपरपैरामीटर वे वैल्यू होती हैं जिन्हें आप (या हाइपरपैरामीटर ट्यूनिंग सेवा) मॉडल को उपलब्ध कराती हैं. उदाहरण के लिए, लर्निंग रेट एक हाइपरपैरामीटर है.
पैरामीटर-इफ़िशिएंट ट्यूनिंग
यह एक ऐसी तकनीक है जिसकी मदद से, फ़ुल फ़ाइन-ट्यूनिंग की तुलना में, लार्ज प्री-ट्रेन किए गए लैंग्वेज मॉडल (पीएलएम) को ज़्यादा असरदार तरीके से फ़ाइन-ट्यून किया जा सकता है. पैरामीटर-इफ़िशिएंट ट्यूनिंग में, आम तौर पर फ़ुल फ़ाइन-ट्यूनिंग की तुलना में बहुत कम पैरामीटर फ़ाइन-ट्यून किए जाते हैं. हालांकि, इससे आम तौर पर एक ऐसा लार्ज लैंग्वेज मॉडल तैयार होता है जो फ़ुल फ़ाइन-ट्यूनिंग से बनाए गए लार्ज लैंग्वेज मॉडल की तरह ही (या लगभग उतना ही) परफ़ॉर्म करता है.
पैरामीटर-इफ़िशिएंट फ़ाइन-ट्यूनिंग की तुलना इनके साथ करें:
पैरामीटर-इफ़िशिएंट ट्यूनिंग को पैरामीटर-इफ़िशिएंट फ़ाइन-ट्यूनिंग भी कहा जाता है.
पैरामीटर सर्वर (पीएस)
यह एक ऐसा जॉब है जो डिस्ट्रिब्यूटेड सेटिंग में, मॉडल के पैरामीटर को ट्रैक करता है.
पैरामीटर अपडेट करना
ट्रेनिंग के दौरान, मॉडल के पैरामीटर को अडजस्ट करने की प्रोसेस. आम तौर पर, यह प्रोसेस ग्रेडिएंट डिसेंट के एक ही इटरेशन में होती है.
पार्शियल डेरिवेटिव
ऐसा डेरिवेटिव जिसमें एक को छोड़कर बाकी सभी वैरिएबल को कॉन्स्टेंट माना जाता है. उदाहरण के लिए, x के हिसाब से f(x, y) का आंशिक डेरिवेटिव, f का डेरिवेटिव होता है. इसे सिर्फ़ x के फ़ंक्शन के तौर पर माना जाता है. इसका मतलब है कि y को स्थिर रखा जाता है. x के हिसाब से f के पार्शियल डेरिवेटिव से सिर्फ़ यह पता चलता है कि x में क्या बदलाव हो रहा है. साथ ही, यह समीकरण के अन्य सभी वैरिएबल को अनदेखा करता है.
भागीदारी से जुड़ा पूर्वाग्रह
यह नॉन-रिस्पॉन्स बायस का समानार्थी शब्द है. चुने जाने का पूर्वाग्रह देखें.
पार्टिशनिंग की रणनीति
वह एल्गोरिदम जिसके ज़रिए वैरिएबल को पैरामीटर सर्वर में बांटा जाता है.
k पर पास (pass@k)
यह मेट्रिक, लार्ज लैंग्वेज मॉडल से जनरेट किए गए कोड (उदाहरण के लिए, Python) की क्वालिटी का पता लगाने के लिए इस्तेमाल की जाती है. खास तौर पर, k पर पास होने की संभावना से पता चलता है कि जनरेट किए गए k कोड ब्लॉक में से कम से कम एक कोड ब्लॉक, यूनिट की सभी जांचों में पास हो जाएगा.
लार्ज लैंग्वेज मॉडल को अक्सर, प्रोग्रामिंग से जुड़ी मुश्किल समस्याओं के लिए अच्छा कोड जनरेट करने में परेशानी होती है. सॉफ़्टवेयर इंजीनियर इस समस्या को हल करने के लिए, लार्ज लैंग्वेज मॉडल को एक ही समस्या के कई (k) समाधान जनरेट करने के लिए प्रॉम्प्ट करते हैं. इसके बाद, सॉफ़्टवेयर इंजीनियर हर समाधान की यूनिट टेस्ट करते हैं. k पर पास होने की दर की कैलकुलेशन, यूनिट टेस्ट के नतीजे पर निर्भर करती है:
- अगर उन समाधानों में से एक या उससे ज़्यादा समाधान यूनिट टेस्ट पास कर लेते हैं, तो एलएलएम, कोड जनरेट करने से जुड़ी उस चुनौती को पास कर लेता है.
- अगर कोई भी समाधान यूनिट टेस्ट पास नहीं करता है, तो एलएलएम, कोड जनरेट करने की इस चुनौती में फ़ेल हो जाता है.
k पर पास होने का फ़ॉर्मूला यहां दिया गया है:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
आम तौर पर, k की वैल्यू जितनी ज़्यादा होगी, पास ऐट k स्कोर उतना ही ज़्यादा होगा. हालांकि, k की वैल्यू ज़्यादा होने पर, बड़े लैंग्वेज मॉडल और यूनिट टेस्टिंग के लिए ज़्यादा संसाधनों की ज़रूरत होती है.
पाथवेज़ लैंग्वेज मॉडल (PaLM)
यह एक पुराना मॉडल है और Gemini मॉडल का पूर्ववर्ती है.
Pax
यह एक प्रोग्रामिंग फ़्रेमवर्क है. इसे बड़े पैमाने पर न्यूरल नेटवर्क मॉडल को ट्रेन करने के लिए डिज़ाइन किया गया है. ये मॉडल इतने बड़े होते हैं कि ये कई टीपीयू ऐक्सलरेटर चिप स्लाइस या पॉड तक फैले होते हैं.
Pax को Flax पर बनाया गया है. वहीं, Flax को JAX पर बनाया गया है.
परसेप्ट्रॉन
यह एक ऐसा सिस्टम (हार्डवेयर या सॉफ़्टवेयर) होता है जो एक या उससे ज़्यादा इनपुट वैल्यू लेता है. इसके बाद, इनपुट के वेटेड सम पर एक फ़ंक्शन चलाता है और एक आउटपुट वैल्यू का हिसाब लगाता है. मशीन लर्निंग में, यह फ़ंक्शन आम तौर पर नॉनलीनियर होता है. जैसे, ReLU, sigmoid या tanh. उदाहरण के लिए, यहां दिया गया परसेप्ट्रॉन, तीन इनपुट वैल्यू को प्रोसेस करने के लिए, सिग्मॉइड फ़ंक्शन पर निर्भर करता है:
नीचे दिए गए उदाहरण में, परसेप्ट्रॉन तीन इनपुट लेता है. परसेप्ट्रॉन में शामिल होने से पहले, हर इनपुट को वेट के हिसाब से बदला जाता है:

परसेप्ट्रॉन, न्यूरल नेटवर्क में मौजूद न्यूरॉन होते हैं.
प्रदर्शन
इस शब्द के कई मतलब हैं:
- सॉफ़्टवेयर इंजीनियरिंग में इसका स्टैंडर्ड मतलब. जैसे: यह सॉफ़्टवेयर कितनी तेज़ी से (या बेहतर तरीके से) काम करता है?
- मशीन लर्निंग में इसका मतलब. यहां परफ़ॉर्मेंस से इस सवाल का जवाब मिलता है: यह मॉडल कितना सही है? इसका मतलब है कि मॉडल के अनुमान कितने सटीक हैं?
पर्म्यूटेशन वैरिएबल के महत्व
यह वैरिएबल के महत्व का एक टाइप है. यह किसी मॉडल की अनुमान लगाने से जुड़ी गड़बड़ी में हुई बढ़ोतरी का आकलन करता है. ऐसा, फ़ीचर की वैल्यू को क्रम बदलने के बाद किया जाता है. परम्यूटेशन वैरिएबल इंपोर्टेंस, मॉडल से जुड़ी मेट्रिक नहीं है.
परप्लेक्सिटी
यह इस बात का आकलन करता है कि मॉडल अपने टास्क को कितनी अच्छी तरह से पूरा कर रहा है. उदाहरण के लिए, मान लें कि आपको किसी शब्द के पहले कुछ अक्षरों को पढ़ना है. यह शब्द, कोई उपयोगकर्ता फ़ोन के कीबोर्ड पर टाइप कर रहा है. इसके बाद, आपको उस शब्द को पूरा करने के लिए संभावित शब्दों की सूची दिखानी है. इस टास्क के लिए परप्लेक्सिटी, P, का मतलब है कि आपको अनुमानित तौर पर इतने विकल्प देने होंगे, ताकि आपकी सूची में वह शब्द शामिल हो जो उपयोगकर्ता टाइप करने की कोशिश कर रहा है.
परप्लेक्सिटी, क्रॉस-एंट्रॉपी से इस तरह जुड़ी होती है:
पाइपलाइन
मशीन लर्निंग एल्गोरिदम के आस-पास का इन्फ़्रास्ट्रक्चर. पाइपलाइन में, डेटा इकट्ठा करना, डेटा को ट्रेनिंग डेटा फ़ाइलों में डालना, एक या उससे ज़्यादा मॉडल को ट्रेनिंग देना, और मॉडल को प्रोडक्शन में एक्सपोर्ट करना शामिल है.
ज़्यादा जानकारी के लिए, एमएल प्रोजेक्ट मैनेज करने से जुड़े कोर्स में एमएल पाइपलाइन देखें.
पाइपलाइनिंग
यह मॉडल पैरललिज़्म का एक तरीका है. इसमें मॉडल की प्रोसेसिंग को लगातार चरणों में बांटा जाता है और हर चरण को अलग-अलग डिवाइस पर एक्ज़ीक्यूट किया जाता है. जब कोई स्टेज एक बैच को प्रोसेस कर रही होती है, तब पिछली स्टेज अगले बैच पर काम कर सकती है.
स्टेज के हिसाब से ट्रेनिंग भी देखें.
pjit
यह एक JAX फ़ंक्शन है. यह कोड को कई ऐक्सलरेटर चिप पर चलाने के लिए कोड को अलग-अलग हिस्सों में बाँटता है. उपयोगकर्ता, pjit को एक फ़ंक्शन पास करता है. यह फ़ंक्शन, एक ऐसा फ़ंक्शन दिखाता है जिसका सिमैंटिक एक जैसा होता है. हालांकि, इसे XLA कंप्यूटेशन में कंपाइल किया जाता है. यह कंप्यूटेशन, कई डिवाइसों (जैसे कि जीपीयू या TPU कोर) पर चलता है.
pjit की मदद से, उपयोगकर्ता SPMD पार्टीशनर का इस्तेमाल करके, कंप्यूटेशन को फिर से लिखे बिना उन्हें शार्ड कर सकते हैं.
मार्च 2023 से, pjit को jit के साथ मर्ज कर दिया गया है. ज़्यादा जानकारी के लिए, डिस्ट्रिब्यूटेड ऐरे और अपने-आप होने वाला पैरललाइज़ेशन देखें.
PLM
प्री-ट्रेन किए गए लैंग्वेज मॉडल के लिए छोटा नाम.
pmap
यह एक JAX फ़ंक्शन है. यह अलग-अलग इनपुट वैल्यू के साथ, कई हार्डवेयर डिवाइसों (सीपीयू, जीपीयू या टीपीयू)) पर, इनपुट फ़ंक्शन की कॉपी को एक्ज़ीक्यूट करता है. pmap, SPMD पर निर्भर करता है.
नीति
रीइन्फ़ोर्समेंट लर्निंग में, एजेंट की प्रोबेबिलिस्टिक मैपिंग, स्टेट से कार्रवाइयों तक होती है.
पूलिंग
पहले की कन्वलूशनल लेयर से बनाई गई मैट्रिक्स (या मैट्रिक्स) को छोटी मैट्रिक्स में बदलना. पूलिंग में आम तौर पर, पूल किए गए क्षेत्र में ज़्यादा से ज़्यादा या औसत वैल्यू ली जाती है. उदाहरण के लिए, मान लें कि हमारे पास यह 3x3 मैट्रिक्स है:
![3x3 मैट्रिक्स [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingStart.svg?authuser=1&hl=hi)
पूलिंग ऑपरेशन, कनवोल्यूशनल ऑपरेशन की तरह ही मैट्रिक्स को स्लाइस में बांटता है. इसके बाद, कनवोल्यूशनल ऑपरेशन को स्ट्राइड से स्लाइड करता है. उदाहरण के लिए, मान लें कि पूलिंग ऑपरेशन, कनवोल्यूशनल मैट्रिक्स को 2x2 स्लाइस में बांटता है. साथ ही, इसमें 1x1 स्ट्राइड का इस्तेमाल किया जाता है. नीचे दिए गए डायग्राम में दिखाया गया है कि चार तरह की पूलिंग की जाती है. मान लें कि हर पूलिंग ऑपरेशन, उस स्लाइस में मौजूद चार वैल्यू में से सबसे बड़ी वैल्यू चुनता है:
![इनपुट मैट्रिक्स 3x3 है. इसकी वैल्यू ये हैं: [[5,3,1], [8,2,5], [9,4,3]].
इनपुट मैट्रिक्स का टॉप-लेफ़्ट 2x2 सबमैट्रिक्स [[5,3], [8,2]] है. इसलिए, टॉप-लेफ़्ट पूलिंग ऑपरेशन से वैल्यू 8 मिलती है. यह 5, 3, 8, और 2 में से सबसे ज़्यादा है. इनपुट मैट्रिक्स का सबसे ऊपर दाईं ओर मौजूद 2x2 सबमैट्रिक्स [[3,1], [2,5]] है. इसलिए, सबसे ऊपर दाईं ओर मौजूद पूलिंग ऑपरेशन से वैल्यू 5 मिलती है. इनपुट मैट्रिक्स का सबसे नीचे बाईं ओर मौजूद 2x2 सबमैट्रिक्स [[8,2], [9,4]] है. इसलिए, सबसे नीचे बाईं ओर मौजूद पूलिंग ऑपरेशन से वैल्यू 9 मिलती है. इनपुट मैट्रिक्स का सबसे नीचे दाईं ओर मौजूद 2x2 सबमैट्रिक्स [[2,5], [4,3]] है. इसलिए, सबसे नीचे दाईं ओर मौजूद पूलिंग ऑपरेशन से वैल्यू 5 मिलती है. कुल मिलाकर, पूलिंग ऑपरेशन से 2x2 मैट्रिक्स [[8,5], [9,5]] मिलता है.](https://developers.google.com/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=1&hl=hi)
पूलिंग से, इनपुट मैट्रिक्स में ट्रांसलेशनल इनवेरियंस लागू करने में मदद मिलती है.
विज़न ऐप्लिकेशन के लिए पूलिंग को ज़्यादा औपचारिक तौर पर स्पेशल पूलिंग कहा जाता है. टाइम-सीरीज़ ऐप्लिकेशन में, पूलिंग को आम तौर पर टेंपोरल पूलिंग कहा जाता है. आसान शब्दों में, पूलिंग को अक्सर सबसैंपलिंग या डाउनसैंपलिंग कहा जाता है.
पोज़िशनल एन्कोडिंग
यह किसी टोकन की एम्बेडिंग में, क्रम में टोकन की जगह के बारे में जानकारी जोड़ने की एक तकनीक है. ट्रांसफ़ॉर्मर मॉडल, पोज़िशनल एन्कोडिंग का इस्तेमाल करते हैं. इससे उन्हें सीक्वेंस के अलग-अलग हिस्सों के बीच के संबंध को बेहतर तरीके से समझने में मदद मिलती है.
पोज़िशनल एन्कोडिंग को लागू करने के लिए, आम तौर पर साइन फ़ंक्शन का इस्तेमाल किया जाता है. (खास तौर पर, साइन फ़ंक्शन की फ़्रीक्वेंसी और ऐम्प्लिट्यूड, क्रम में टोकन की पोज़िशन से तय होते हैं.) इस तकनीक की मदद से, ट्रांसफ़ॉर्मर मॉडल को यह सीखने में मदद मिलती है कि सीक्वेंस के अलग-अलग हिस्सों पर उनकी पोज़िशन के आधार पर ध्यान कैसे दिया जाए.
पॉज़िटिव क्लास
वह क्लास जिसके लिए आपको टेस्ट करना है.
उदाहरण के लिए, कैंसर के मॉडल में पॉज़िटिव क्लास "ट्यूमर" हो सकती है. ईमेल क्लासिफ़िकेशन मॉडल में पॉज़िटिव क्लास "स्पैम" हो सकती है.
नेगेटिव क्लास से तुलना करें.
प्रोसेस होने के बाद
मॉडल के चलने के बाद, उसके आउटपुट में बदलाव करना. पोस्ट-प्रोसेसिंग का इस्तेमाल, मॉडल में बदलाव किए बिना निष्पक्षता से जुड़ी शर्तों को लागू करने के लिए किया जा सकता है.
उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन मॉडल पर पोस्ट-प्रोसेसिंग लागू की जा सकती है. इसके लिए, क्लासिफ़िकेशन थ्रेशोल्ड को इस तरह से सेट किया जाता है कि किसी एट्रिब्यूट के लिए अवसर की समानता बनी रहे. इसके लिए, यह जांच की जाती है कि उस एट्रिब्यूट की सभी वैल्यू के लिए ट्रू पॉज़िटिव रेट एक जैसा है.
पोस्ट-ट्रेनिंग मॉडल
यह एक ऐसा शब्द है जिसे आम तौर पर पहले से ट्रेन किए गए मॉडल के लिए इस्तेमाल किया जाता है. इस मॉडल को पोस्ट-प्रोसेसिंग के बाद इस्तेमाल किया जाता है. जैसे, इनमें से एक या एक से ज़्यादा काम किए जाते हैं:
PR AUC (PR कर्व के नीचे का हिस्सा)
इंटरपोलेट किए गए सटीकता-वापसी वक्र के नीचे का क्षेत्र. इसे वर्गीकरण थ्रेशोल्ड की अलग-अलग वैल्यू के लिए, (वापसी, सटीकता) पॉइंट को प्लॉट करके हासिल किया जाता है.
Praxis
Pax की कोर, हाई-परफ़ॉर्मेंस एमएल लाइब्रेरी. Praxis को अक्सर "लेयर लाइब्रेरी" कहा जाता है.
Praxis में, Layer क्लास की परिभाषाएं ही नहीं, बल्कि इसके ज़्यादातर साथ काम करने वाले कॉम्पोनेंट भी शामिल हैं. जैसे:
- डेटा इनपुट
- कॉन्फ़िगरेशन लाइब्रेरी (HParam और Fiddle)
- ऑप्टिमाइज़र
Praxis, Model क्लास के लिए परिभाषाएं उपलब्ध कराता है.
प्रीसिज़न
यह वर्गीकरण मॉडल के लिए एक मेट्रिक है. इससे इस सवाल का जवाब मिलता है:
जब मॉडल ने पॉज़िटिव क्लास का अनुमान लगाया, तो कितने प्रतिशत अनुमान सही थे?
यहां फ़ॉर्मूला दिया गया है:
कहां:
- ट्रू पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का सही अनुमान लगाया है.
- फ़ॉल्स पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का गलत अनुमान लगाया है.
उदाहरण के लिए, मान लें कि किसी मॉडल ने 200 पॉज़िटिव अनुमान लगाए. इन 200 पॉज़िटिव अनुमानों में से:
- इनमें से 150 सही पॉज़िटिव थे.
- इनमें से 50 फ़ॉल्स पॉज़िटिव थे.
इस मामले में:
इसकी तुलना सटीकता और रीकॉल से करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: सटीकता, रीकॉल, प्रेसिज़न, और इनसे जुड़ी मेट्रिक देखें.
के पर सटीक (precision@k)
यह मेट्रिक, रैंक की गई (क्रम से लगाई गई) आइटम की सूची का आकलन करने के लिए होती है. k पर सटीक होने का मतलब है कि सूची के पहले k आइटम में से कितने आइटम "काम के" हैं. यानी:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
k की वैल्यू, दिखाई गई सूची की लंबाई से कम या इसके बराबर होनी चाहिए. ध्यान दें कि जवाब में मिली सूची की लंबाई, कैलकुलेशन का हिस्सा नहीं होती.
'काम का होना' अक्सर व्यक्तिपरक होता है. यहां तक कि विशेषज्ञ मानव समीक्षक भी इस बात पर सहमत नहीं होते कि कौनसे आइटम काम के हैं.
इसके साथ तुलना करें:
प्रीसिज़न-रिकॉल कर्व
यह अलग-अलग क्लासिफ़िकेशन थ्रेशोल्ड पर, सटीकता बनाम रिकॉल का कर्व होता है.
अनुमान
मॉडल का आउटपुट. उदाहरण के लिए:
- बाइनरी क्लासिफ़िकेशन मॉडल का अनुमान, पॉज़िटिव क्लास या नेगेटिव क्लास होता है.
- मल्टी-क्लास क्लासिफ़िकेशन मॉडल का अनुमान, एक क्लास होता है.
- लीनियर रिग्रेशन मॉडल का अनुमान एक संख्या होती है.
पूर्वानुमान में पक्षपात
यह वैल्यू बताती है कि डेटासेट में, अनुमानों का औसत, लेबल के औसत से कितना अलग है.
इसे मशीन लर्निंग मॉडल में पक्षपात की अवधि या नैतिकता और निष्पक्षता में पक्षपात से भ्रमित नहीं होना चाहिए.
अनुमान लगाने वाली एमएल
कोई भी स्टैंडर्ड ("क्लासिक") मशीन लर्निंग सिस्टम.
अनुमान लगाने वाली एमएल की कोई औपचारिक परिभाषा नहीं है. इसके बजाय, यह शब्द एमएल सिस्टम की एक ऐसी कैटगरी को अलग करता है जो जनरेटिव एआई पर आधारित नहीं है.
अनुमानित समानता
यह निष्पक्षता मेट्रिक है. इससे यह पता चलता है कि दिए गए क्लासिफ़िकेशन मॉडल के लिए, विचाराधीन उपसमूहों के लिए सटीकता की दरें बराबर हैं या नहीं.
उदाहरण के लिए, अगर कॉलेज में दाखिले का अनुमान लगाने वाले मॉडल का सटीक अनुमान लगाने का रेट, लिलिपुटियन और ब्रॉबडिंगनैगियन के लिए एक जैसा है, तो यह राष्ट्रीयता के लिए प्रेडिक्टिव पैरिटी की शर्त पूरी करेगा.
कभी-कभी, अनुमानित कीमत की समानता को अनुमानित कीमत की समानता भी कहा जाता है.
अनुमानित समानता के बारे में ज़्यादा जानकारी के लिए, "निष्पक्षता की परिभाषाएं समझाई गईं" (सेक्शन 3.2.1) देखें.
किराये की समानता के लिए अनुमानित दर
अनुमानित समानता का दूसरा नाम.
प्रीप्रोसेसिंग
डेटा को प्रोसेस करना, ताकि उसका इस्तेमाल मॉडल को ट्रेन करने के लिए किया जा सके. प्रीप्रोसेसिंग, अंग्रेज़ी के टेक्स्ट कॉर्पस से ऐसे शब्दों को हटाने जैसी आसान हो सकती है जो अंग्रेज़ी की डिक्शनरी में नहीं हैं. इसके अलावा, यह डेटा पॉइंट को इस तरह से फिर से दिखाने जैसी मुश्किल भी हो सकती है कि संवेदनशील एट्रिब्यूट से जुड़े ज़्यादा से ज़्यादा एट्रिब्यूट हटा दिए जाएं. प्रीप्रोसेसिंग से, निष्पक्षता से जुड़ी शर्तों को पूरा करने में मदद मिल सकती है.पहले से ट्रेन किया गया मॉडल
हालांकि, इस शब्द का इस्तेमाल किसी भी ट्रेन किए गए मॉडल या ट्रेन किए गए एम्बेडिंग वेक्टर के लिए किया जा सकता है. फ़िलहाल, प्री-ट्रेन किए गए मॉडल का मतलब आम तौर पर, ट्रेन किए गए लार्ज लैंग्वेज मॉडल या ट्रेन किए गए जनरेटिव एआई मॉडल से होता है.
बेस मॉडल और फ़ाउंडेशन मॉडल के बारे में भी जानें.
प्री-ट्रेनिंग
किसी मॉडल को बड़े डेटासेट पर ट्रेन करना. पहले से ट्रेन किए गए कुछ मॉडल, बहुत ज़्यादा डेटा पर काम करते हैं. इसलिए, आम तौर पर उन्हें बेहतर बनाने के लिए, अतिरिक्त ट्रेनिंग देनी पड़ती है. उदाहरण के लिए, एमएल विशेषज्ञ, टेक्स्ट के बड़े डेटासेट पर लार्ज लैंग्वेज मॉडल को पहले से ही ट्रेन कर सकते हैं. जैसे, Wikipedia के सभी अंग्रेज़ी पेज. प्री-ट्रेनिंग के बाद, मॉडल को बेहतर बनाने के लिए इनमें से किसी भी तकनीक का इस्तेमाल किया जा सकता है:
- डिस्टिलेशन
- फ़ाइन-ट्यूनिंग
- निर्देशों के मुताबिक जवाब देने की सुविधा
- पैरामीटर-इफ़िशिएंट ट्यूनिंग
- प्रॉम्प्ट-ट्यूनिंग
प्रायर बिलीफ़
डेटा पर ट्रेनिंग शुरू करने से पहले, आपको डेटा के बारे में क्या लगता है. उदाहरण के लिए, L2 रेगुलराइज़ेशन इस बात पर निर्भर करता है कि वज़न कम होने चाहिए और आम तौर पर शून्य के आस-पास डिस्ट्रिब्यूट होने चाहिए.
Pro
यह Gemini मॉडल है, जिसमें Ultra से कम पैरामीटर हैं, लेकिन Nano से ज़्यादा पैरामीटर हैं. ज़्यादा जानकारी के लिए, Gemini Pro देखें.
संभावित रिग्रेशन मॉडल
यह एक रिग्रेशन मॉडल है. यह हर फ़ीचर के लिए, न सिर्फ़ वज़न का इस्तेमाल करता है, बल्कि उन वज़न की अनिश्चितता का भी इस्तेमाल करता है. संभाव्यता पर आधारित रिग्रेशन मॉडल, अनुमान और उस अनुमान के सटीक न होने की संभावना जनरेट करता है. उदाहरण के लिए, एक संभावित रिग्रेशन मॉडल, 12 के स्टैंडर्ड डेविएशन के साथ 325 का अनुमान दे सकता है. संभावित रिग्रेशन मॉडल के बारे में ज़्यादा जानने के लिए, tensorflow.org पर मौजूद यह Colab देखें.
प्रोबैबिलिटी डेंसिटी फ़ंक्शन
यह फ़ंक्शन, ठीक किसी वैल्यू वाले डेटा सैंपल की फ़्रीक्वेंसी का पता लगाता है. जब किसी डेटासेट की वैल्यू लगातार फ़्लोटिंग-पॉइंट नंबर होती हैं, तो एग्ज़ैक्ट मैच बहुत कम होते हैं. हालांकि, वैल्यू x से वैल्यू y तक प्रोबैबिलिटी डेंसिटी फ़ंक्शन को इंटिग्रेट करने पर, x और y के बीच डेटा सैंपल की अनुमानित फ़्रीक्वेंसी मिलती है.
उदाहरण के लिए, मान लें कि किसी नॉर्मल डिस्ट्रिब्यूशन का औसत 200 और स्टैंडर्ड डेविएशन 30 है. 211.4 से 218.7 की सीमा में आने वाले डेटा सैंपल की अनुमानित फ़्रीक्वेंसी का पता लगाने के लिए, सामान्य डिस्ट्रिब्यूशन के लिए प्रायिकता घनत्व फ़ंक्शन को 211.4 से 218.7 तक इंटिग्रेट किया जा सकता है.
prompt
किसी लार्ज लैंग्वेज मॉडल में इनपुट के तौर पर डाला गया कोई भी टेक्स्ट, ताकि मॉडल को किसी खास तरीके से काम करने के लिए तैयार किया जा सके. प्रॉम्प्ट, एक छोटे से वाक्यांश से लेकर काफ़ी लंबे भी हो सकते हैं. उदाहरण के लिए, किसी उपन्यास का पूरा टेक्स्ट. प्रॉम्प्ट को कई कैटगरी में बांटा गया है. इनमें से कुछ कैटगरी यहां दी गई टेबल में दिखाई गई हैं:
| प्रॉम्प्ट कैटगरी | उदाहरण | नोट |
|---|---|---|
| सवाल | कबूतर कितनी तेज़ गति से उड़ सकता है? | |
| निर्देश | आर्बिट्राज के बारे में एक मज़ेदार कविता लिखो. | ऐसा प्रॉम्प्ट जिसमें लार्ज लैंग्वेज मॉडल को कोई काम करने के लिए कहा गया हो. |
| उदाहरण | मार्कडाउन कोड को एचटीएमएल में बदलें. उदाहरण के लिए:
मार्कडाउन: * सूची का आइटम एचटीएमएल: <ul> <li>सूची का आइटम</li> </ul> |
इस उदाहरण प्रॉम्प्ट में पहला वाक्य, निर्देश है. प्रॉम्प्ट का बाकी हिस्सा उदाहरण है. |
| भूमिका | फ़िज़िक्स में पीएचडी करने वाले व्यक्ति को बताओ कि मशीन लर्निंग ट्रेनिंग में ग्रेडिएंट डिसेंट का इस्तेमाल क्यों किया जाता है. | वाक्य के पहले हिस्से में निर्देश दिया गया है. "भौतिक विज्ञान में पीएचडी करने वाले व्यक्ति" वाक्यांश में भूमिका के बारे में बताया गया है. |
| मॉडल को पूरा करने के लिए कुछ हद तक इनपुट | यूनाइटेड किंगडम के प्रधानमंत्री का आधिकारिक निवास | इनपुट प्रॉम्प्ट का कुछ हिस्सा अचानक खत्म हो सकता है. जैसे, इस उदाहरण में हुआ है. इसके अलावा, यह अंडरस्कोर से भी खत्म हो सकता है. |
जनरेटिव एआई मॉडल, प्रॉम्प्ट का जवाब टेक्स्ट, कोड, इमेज, एम्बेडिंग, वीडियो…किसी भी फ़ॉर्मैट में दे सकता है.
प्रॉम्प्ट के आधार पर लर्निंग
यह कुछ मॉडल की एक ऐसी सुविधा है जिसकी मदद से वे किसी भी टेक्स्ट इनपुट (प्रॉम्प्ट) के हिसाब से अपने व्यवहार में बदलाव कर सकते हैं. प्रॉम्प्ट के आधार पर सीखने के सामान्य पैराडाइम में, लार्ज लैंग्वेज मॉडल, टेक्स्ट जनरेट करके किसी प्रॉम्प्ट का जवाब देता है. उदाहरण के लिए, मान लें कि कोई उपयोगकर्ता यह प्रॉम्प्ट डालता है:
न्यूटन के गति के तीसरे नियम के बारे में खास जानकारी दो.
प्रॉम्प्ट के आधार पर सीखने की क्षमता रखने वाले मॉडल को, खास तौर पर पिछले प्रॉम्प्ट का जवाब देने के लिए ट्रेन नहीं किया जाता है. इसके बजाय, मॉडल को फ़िज़िक्स के बारे में कई तथ्यों की जानकारी होती है. साथ ही, उसे भाषा के सामान्य नियमों के बारे में भी काफ़ी कुछ पता होता है. इसके अलावा, उसे यह भी पता होता है कि आम तौर पर किस तरह के जवाब मददगार होते हैं. यह जानकारी, (उम्मीद है कि) काम का जवाब देने के लिए काफ़ी है. लोगों से मिले सुझाव, शिकायत या राय ("जवाब बहुत मुश्किल था." या "रिएक्शन क्या होता है?") की मदद से, प्रॉम्प्ट पर आधारित कुछ लर्निंग सिस्टम, अपने जवाबों को धीरे-धीरे बेहतर बना पाते हैं.
प्रॉम्प्ट डिज़ाइन
प्रॉम्प्ट इंजीनियरिंग के लिए समानार्थी शब्द.
प्रॉम्प्ट इंजीनियरिंग
प्रॉम्प्ट बनाने की कला, ताकि लार्ज लैंग्वेज मॉडल से मनमुताबिक जवाब मिल सकें. प्रॉम्प्ट इंजीनियरिंग का काम इंसान करते हैं. लार्ज लैंग्वेज मॉडल से काम के जवाब पाने के लिए, अच्छी तरह से स्ट्रक्चर किए गए प्रॉम्प्ट लिखना ज़रूरी है. प्रॉम्प्ट इंजीनियरिंग कई बातों पर निर्भर करती है. जैसे:
- लार्ज लैंग्वेज मॉडल को प्री-ट्रेन करने के लिए इस्तेमाल किया गया डेटासेट. साथ ही, शायद इसे फ़ाइन-ट्यून करने के लिए भी इस्तेमाल किया गया हो.
- temperature और अन्य डिकोडिंग पैरामीटर, जिनका इस्तेमाल मॉडल जवाब जनरेट करने के लिए करता है.
प्रॉम्प्ट डिज़ाइन, प्रॉम्प्ट इंजीनियरिंग का दूसरा नाम है.
मददगार प्रॉम्प्ट लिखने के बारे में ज़्यादा जानने के लिए, प्रॉम्प्ट डिज़ाइन के बारे में बुनियादी जानकारी देखें.
प्रॉम्प्ट सेट
लार्ज लैंग्वेज मॉडल का आकलन करने के लिए, प्रॉम्प्ट का ग्रुप. उदाहरण के लिए, इस इमेज में तीन प्रॉम्प्ट वाला एक प्रॉम्प्ट सेट दिखाया गया है:

अच्छे प्रॉम्प्ट सेट में, प्रॉम्प्ट का "बड़ा" कलेक्शन होता है. इससे लार्ज लैंग्वेज मॉडल की सुरक्षा और मददगार होने का पूरी तरह से आकलन किया जा सकता है.
जवाबों का सेट के बारे में भी जानें.
प्रॉम्प्ट ट्यूनिंग
पैरामीटर के हिसाब से बेहतर तरीके से ट्यून करने का तरीका. यह एक "प्रीफ़िक्स" सीखता है, जिसे सिस्टम, असल प्रॉम्प्ट से पहले जोड़ता है.
प्रॉम्प्ट ट्यूनिंग के एक वैरिएशन को कभी-कभी प्रीफ़िक्स ट्यूनिंग कहा जाता है. इसमें प्रीफ़िक्स को हर लेयर में जोड़ा जाता है. इसके उलट, ज़्यादातर प्रॉम्प्ट ट्यूनिंग में सिर्फ़ इनपुट लेयर में प्रीफ़िक्स जोड़ा जाता है.
प्रॉक्सी (संवेदनशील एट्रिब्यूट)
इस एट्रिब्यूट का इस्तेमाल, संवेदनशील एट्रिब्यूट के विकल्प के तौर पर किया जाता है. उदाहरण के लिए, किसी व्यक्ति के पिन कोड का इस्तेमाल उसकी आय, जाति या नस्ल के प्रॉक्सी के तौर पर किया जा सकता है.प्रॉक्सी लेबल
लेबल का अनुमान लगाने के लिए इस्तेमाल किया गया डेटा, डेटासेट में सीधे तौर पर उपलब्ध नहीं है.
उदाहरण के लिए, मान लें कि आपको किसी मॉडल को कर्मचारी के तनाव के स्तर का अनुमान लगाने के लिए ट्रेन करना है. आपके डेटासेट में अनुमान लगाने वाली कई सुविधाएं हैं, लेकिन इसमें तनाव का स्तर नाम का कोई लेबल नहीं है. आपने "काम की जगह पर होने वाली दुर्घटनाएं" को तनाव के लेवल के लिए प्रॉक्सी लेबल के तौर पर चुना. आखिरकार, ज़्यादा तनाव में रहने वाले कर्मचारियों के साथ, शांत रहने वाले कर्मचारियों की तुलना में ज़्यादा दुर्घटनाएं होती हैं. या फिर ऐसा होता है? ऐसा हो सकता है कि काम की जगह पर होने वाली दुर्घटनाओं की संख्या में कई वजहों से उतार-चढ़ाव होता हो.
दूसरे उदाहरण के तौर पर, मान लें कि आपको अपने डेटासेट के लिए, क्या बारिश हो रही है? को बूलियन लेबल के तौर पर इस्तेमाल करना है, लेकिन आपके डेटासेट में बारिश का डेटा मौजूद नहीं है. अगर फ़ोटोग्राफ़ उपलब्ध हैं, तो क्या बारिश हो रही है? के लिए, छाता लिए हुए लोगों की तस्वीरों को प्रॉक्सी लेबल के तौर पर इस्तेमाल किया जा सकता है क्या यह एक अच्छा प्रॉक्सी लेबल है? ऐसा हो सकता है. हालांकि, कुछ संस्कृतियों में लोग बारिश से बचने के बजाय, धूप से बचने के लिए छतरी का इस्तेमाल ज़्यादा करते हैं.
प्रॉक्सी लेबल अक्सर सही नहीं होते. जब भी संभव हो, प्रॉक्सी लेबल के बजाय असली लेबल चुनें. हालांकि, अगर कोई असल लेबल मौजूद नहीं है, तो प्रॉक्सी लेबल को बहुत सोच-समझकर चुनें. साथ ही, सबसे कम खराब प्रॉक्सी लेबल कैंडिडेट को चुनें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: लेबल देखें.
प्योर फ़ंक्शन
ऐसा फ़ंक्शन जिसके आउटपुट सिर्फ़ उसके इनपुट पर आधारित होते हैं और जिसका कोई साइड इफ़ेक्ट नहीं होता. खास तौर पर, प्योर फ़ंक्शन किसी ग्लोबल स्टेट का इस्तेमाल नहीं करता है और न ही उसे बदलता है. जैसे, किसी फ़ाइल का कॉन्टेंट या फ़ंक्शन के बाहर मौजूद किसी वैरिएबल की वैल्यू.
प्योर फ़ंक्शन का इस्तेमाल, थ्रेड-सेफ़ कोड बनाने के लिए किया जा सकता है. यह कई ऐक्सलरेटर चिप में मॉडल कोड को शार्ड करने के दौरान फ़ायदेमंद होता है.
JAX के फ़ंक्शन ट्रांसफ़ॉर्मेशन के तरीकों के लिए, यह ज़रूरी है कि इनपुट फ़ंक्शन प्योर फ़ंक्शन हों.
Q
Q-फ़ंक्शन
रीइन्फ़ोर्समेंट लर्निंग में, यह फ़ंक्शन किसी स्टेट में कार्रवाई करने और फिर दी गई नीति का पालन करने से मिलने वाले अनुमानित फ़ायदे का अनुमान लगाता है.
Q-फ़ंक्शन को स्टेट-ऐक्शन वैल्यू फ़ंक्शन भी कहा जाता है.
Q-लर्निंग
रीइन्फ़ोर्समेंट लर्निंग में, एक ऐसा एल्गोरिदम होता है जो एजेंट को बेलमैन समीकरण लागू करके, मार्कोव डिसिज़न प्रोसेस का सबसे सही Q-फ़ंक्शन सीखने की अनुमति देता है. मार्कोव डिसिज़न प्रोसेस मॉडल, एनवायरमेंट को मॉडल करता है.
क्वेनटाइल
क्वांटाइल बकेटिंग में मौजूद हर बकेट.
क्वेंटाइल बकेटिंग
किसी सुविधा की वैल्यू को बकेट में इस तरह से बांटना कि हर बकेट में उदाहरणों की संख्या एक जैसी हो या लगभग एक जैसी हो. उदाहरण के लिए, यहां दिए गए फ़िगर में 44 पॉइंट को चार बकेट में बांटा गया है. हर बकेट में 11 पॉइंट हैं. आंकड़े में मौजूद हर बकेट में एक ही संख्या में पॉइंट शामिल करने के लिए, कुछ बकेट में x-वैल्यू की चौड़ाई अलग-अलग होती है.

ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: बिनिंग देखें.
क्वांटाइज़ेशन
ओवरलोड किया गया ऐसा शब्द जिसका इस्तेमाल इनमें से किसी भी तरीके से किया जा सकता है:
- किसी सुविधा पर क्वांटाइल बकेटिंग लागू करना.
- डेटा को ज़ीरो और वन में बदलकर, उसे तेज़ी से सेव किया जाता है, ट्रेन किया जाता है, और अनुमान लगाया जाता है. बूलियन डेटा, अन्य फ़ॉर्मैट की तुलना में नॉइज़ और गड़बड़ियों से ज़्यादा सुरक्षित होता है. इसलिए, क्वांटाइज़ेशन से मॉडल की सटीकता को बेहतर बनाया जा सकता है. क्वांटाइज़ेशन की तकनीकों में राउंडिंग, ट्रंकेटिंग, और बिनिंग शामिल हैं.
मॉडल के पैरामीटर को सेव करने के लिए इस्तेमाल की जाने वाली बिट की संख्या कम करना. उदाहरण के लिए, मान लें कि किसी मॉडल के पैरामीटर, 32-बिट फ़्लोटिंग-पॉइंट नंबर के तौर पर सेव किए जाते हैं. क्वांटाइज़ेशन, उन पैरामीटर को 32 बिट से घटाकर 4, 8 या 16 बिट में बदल देता है. क्वांटाइज़ेशन से, इन चीज़ों को कम किया जा सकता है:
- कंप्यूट, मेमोरी, डिस्क, और नेटवर्क के इस्तेमाल से जुड़ी जानकारी
- पूर्वानुमान लगाने में लगने वाला समय
- ऊर्जा की खपत
हालांकि, कभी-कभी क्वानटाइज़ेशन की वजह से, मॉडल के अनुमानों की सटीकता कम हो जाती है.
सूची
यह एक TensorFlow Operation है, जो एक कतार डेटा स्ट्रक्चर को लागू करता है. आम तौर पर, इसका इस्तेमाल I/O में किया जाता है.
R
RAG
रिट्रीवल-ऑगमेंटेड जनरेशन का संक्षिप्त नाम.
रैंडम फ़ॉरेस्ट
यह डिसिज़न ट्री का ग्रुप होता है. इसमें हर डिसिज़न ट्री को खास रैंडम नॉइज़ के साथ ट्रेन किया जाता है. जैसे, बैगिंग.
रैंडम फ़ॉरेस्ट, डिसिज़न फ़ॉरेस्ट का एक टाइप है.
ज़्यादा जानकारी के लिए, फ़ैसले लेने वाले फ़ॉरेस्ट कोर्स में रैंडम फ़ॉरेस्ट देखें.
रेनडम नीति
रीइन्फ़ोर्समेंट लर्निंग में, एक नीति होती है, जो कार्रवाई को रैंडम तरीके से चुनती है.
रैंक (ऑर्डिनैलिटी)
मशीन लर्निंग की समस्या में किसी क्लास की क्रमसूचक पोज़िशन. यह क्लास को सबसे ज़्यादा से सबसे कम के हिसाब से कैटगरी में बांटती है. उदाहरण के लिए, व्यवहार के आधार पर रैंकिंग करने वाला सिस्टम, कुत्ते को मिलने वाले इनामों को सबसे ज़्यादा (स्टेक) से लेकर सबसे कम (सूखा केल) तक रैंक कर सकता है.
rank (Tensor)
Tensor में डाइमेंशन की संख्या. उदाहरण के लिए, स्केलर की रैंक 0 होती है, वेक्टर की रैंक 1 होती है, और मैट्रिक्स की रैंक 2 होती है.
इसे रैंक (क्रम) से भ्रमित न करें.
रैंकिंग
यह निगरानी में की जाने वाली लर्निंग का एक टाइप है. इसका मकसद, आइटम की सूची को क्रम से लगाना है.
रेटिंग देने वाला
एक ऐसा व्यक्ति जो उदाहरणों के लिए लेबल देता है. "एनोटेटर", रेटर का दूसरा नाम है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटेगरी के हिसाब से बंटा हुआ डेटा: सामान्य समस्याएं देखें.
रीडिंग कॉम्प्रिहेंशन विद कॉमनसेंस रीज़निंग डेटासेट (ReCoRD)
यह एक डेटासेट है. इससे यह आकलन किया जाता है कि एलएलएम, सामान्य समझ के आधार पर तर्क करने की क्षमता रखता है या नहीं. डेटासेट में मौजूद हर उदाहरण में तीन कॉम्पोनेंट होते हैं:
- किसी समाचार लेख से एक या दो पैराग्राफ़
- ऐसी क्वेरी जिसमें पैसेज में साफ़ तौर पर या किसी दूसरे तरीके से बताई गई किसी एंटिटी को मास्क किया गया हो.
- जवाब (मास्क में मौजूद इकाई का नाम)
उदाहरणों की पूरी सूची के लिए, ReCoRD देखें.
ReCoRD, SuperGLUE का एक कॉम्पोनेंट है.
RealToxicityPrompts
ऐसा डेटासेट जिसमें वाक्यों की शुरुआत के ऐसे सेट शामिल हैं जिनमें आपत्तिजनक कॉन्टेंट हो सकता है. इस डेटासेट का इस्तेमाल करके, यह आकलन करें कि एलएलएम, वाक्य को पूरा करने के लिए आपत्तिजनक कॉन्टेंट से बचा हुआ टेक्स्ट जनरेट कर सकता है या नहीं. आम तौर पर, इस टास्क में एलएलएम ने कैसा परफ़ॉर्म किया, यह पता लगाने के लिए Perspective API का इस्तेमाल किया जाता है.
ज़्यादा जानकारी के लिए, RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models देखें.
रीकॉल
यह वर्गीकरण मॉडल के लिए एक मेट्रिक है. इससे इस सवाल का जवाब मिलता है:
जब ग्राउंड ट्रुथ, पॉज़िटिव क्लास थी, तब मॉडल ने कितने प्रतिशत अनुमानों को सही तरीके से पॉज़िटिव क्लास के तौर पर पहचाना?
यहां फ़ॉर्मूला दिया गया है:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
कहां:
- ट्रू पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का सही अनुमान लगाया है.
- फ़ॉल्स नेगेटिव का मतलब है कि मॉडल ने गलती से नेगेटिव क्लास का अनुमान लगाया है.
उदाहरण के लिए, मान लें कि आपके मॉडल ने उन उदाहरणों के लिए 200 अनुमान लगाए जिनके लिए ग्राउंड ट्रुथ पॉज़िटिव क्लास था. इन 200 अनुमानों में से:
- इनमें से 180 ट्रू पॉज़िटिव थे.
- इनमें से 20 फ़ॉल्स नेगेटिव थे.
इस मामले में:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
ज़्यादा जानकारी के लिए, क्लासिफ़िकेशन: सटीकता, रिकॉल, सटीक और इससे जुड़ी मेट्रिक देखें.
k पर रीकॉल (recall@k)
यह मेट्रिक, उन सिस्टम का आकलन करने के लिए इस्तेमाल की जाती है जो आइटम की रैंक की गई (क्रम से लगाई गई) सूची दिखाते हैं. k पर रीकॉल से पता चलता है कि जवाब में मिले कुल काम के आइटम में से, सूची में मौजूद पहले k आइटम में कितने काम के आइटम हैं.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
k पर सटीक जानकारी के साथ कंट्रास्ट करें.
टेक्स्ट से जुड़ी जानकारी को समझना (आरटीई)
यह एक डेटासेट है. इसका इस्तेमाल, यह आकलन करने के लिए किया जाता है कि कोई एलएलएम, किसी टेक्स्ट पैसेज से किसी अनुमान को तार्किक तौर पर निकाल सकता है या नहीं. आरटीई के आकलन में दिए गए हर उदाहरण में तीन हिस्से होते हैं:
- कोई पैसेज, आम तौर पर खबरों या Wikipedia के लेखों से लिया गया
- हाइपोथीसिस
- सही जवाब, जो इनमें से कोई एक होता है:
- सही है. इसका मतलब है कि हाइपोथेसिस को पैसेज से निकाला जा सकता है
- गलत. इसका मतलब है कि पैसेज से हाइपोथेसिस नहीं निकाला जा सकता
उदाहरण के लिए:
- पैसेज: यूरो, यूरोपियन यूनियन की मुद्रा है.
- हाइपोथेसिस: फ़्रांस में मुद्रा के तौर पर यूरो का इस्तेमाल किया जाता है.
- निहितार्थ: सही है, क्योंकि फ़्रांस, यूरोपियन यूनियन का हिस्सा है.
आरटीई, SuperGLUE ensemble का एक कॉम्पोनेंट है.
सुझाव देने वाला सिस्टम
यह एक ऐसा सिस्टम है जो हर उपयोगकर्ता के लिए, बड़े कॉर्पस से आइटम का एक छोटा सेट चुनता है. उदाहरण के लिए, वीडियो के सुझाव देने वाला सिस्टम, 1,00,000 वीडियो के कॉर्पस में से दो वीडियो का सुझाव दे सकता है. जैसे, एक उपयोगकर्ता के लिए कैसाब्लांका और फ़िलाडेल्फ़िया स्टोरी को चुना जा सकता है. वहीं, दूसरे उपयोगकर्ता के लिए वंडर वुमन और ब्लैक पैंथर को चुना जा सकता है. वीडियो का सुझाव देने वाला सिस्टम, इन बातों के आधार पर सुझाव दे सकता है:
- ऐसी फ़िल्में जिन्हें आपकी तरह के उपयोगकर्ताओं ने रेटिंग दी है या देखा है.
- शैली, निर्देशक, अभिनेता, टारगेट डेमोग्राफ़िक...
ज़्यादा जानकारी के लिए, सुझाव देने वाले सिस्टम का कोर्स देखें.
ReCoRD
यह रीडिंग कॉम्प्रिहेंशन विद कॉमनसेंस रीज़निंग डेटासेट का संक्षिप्त नाम है.
रेक्टिफ़ाइड लीनियर यूनिट (आरईएलयू)
ऐक्टिवेशन फ़ंक्शन, जो इस तरह काम करता है:
- अगर इनपुट नेगेटिव या शून्य है, तो आउटपुट 0 होता है.
- अगर इनपुट पॉज़िटिव है, तो आउटपुट इनपुट के बराबर होता है.
उदाहरण के लिए:
- अगर इनपुट -3 है, तो आउटपुट 0 होगा.
- अगर इनपुट +3 है, तो आउटपुट 3.0 होगा.
यहां ReLU का प्लॉट दिया गया है:
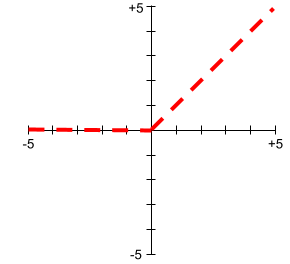
ReLU, एक बहुत लोकप्रिय ऐक्टिवेशन फ़ंक्शन है. आसान तरीके से काम करने के बावजूद, ReLU की मदद से न्यूरल नेटवर्क, विशेषताओं और लेबल के बीच नॉनलीनियर संबंधों को सीख पाता है.
रिकरंट न्यूरल नेटवर्क
यह एक न्यूरल नेटवर्क होता है, जिसे जान-बूझकर कई बार चलाया जाता है. इसमें हर बार के नतीजे, अगली बार के नतीजे तय करने में मदद करते हैं. खास तौर पर, पिछली बार के रन की छिपी हुई लेयर, अगली बार के रन की उसी छिपी हुई लेयर को इनपुट का कुछ हिस्सा देती हैं. रिकरंट न्यूरल नेटवर्क, खास तौर पर सीक्वेंस का आकलन करने के लिए काम आते हैं. इससे हिडन लेयर, सीक्वेंस के पिछले हिस्सों पर न्यूरल नेटवर्क के पिछले रन से सीख सकती हैं.
उदाहरण के लिए, यहां दिए गए डायग्राम में एक रिकरंट न्यूरल नेटवर्क दिखाया गया है, जो चार बार चलता है. ध्यान दें कि पहले रन में छिपी हुई लेयर से सीखी गई वैल्यू, दूसरे रन में छिपी हुई लेयर के इनपुट का हिस्सा बन जाती हैं. इसी तरह, दूसरे रन में छिपी हुई लेयर में सीखी गई वैल्यू, तीसरे रन में उसी छिपी हुई लेयर के इनपुट का हिस्सा बन जाती हैं. इस तरह, रिकरंट न्यूरल नेटवर्क धीरे-धीरे ट्रेन होता है और सिर्फ़ अलग-अलग शब्दों के मतलब के बजाय, पूरे सीक्वेंस के मतलब का अनुमान लगाता है.

रेफ़रंस टेक्स्ट
किसी विशेषज्ञ का प्रॉम्प्ट के जवाब में दिया गया सुझाव. उदाहरण के लिए, यह प्रॉम्प्ट दिया गया है:
"आपका नाम क्या है?" सवाल का अंग्रेज़ी से फ़्रेंच में अनुवाद करो.
किसी विशेषज्ञ का जवाब ऐसा हो सकता है:
आपका नाम क्या है?
अलग-अलग मेट्रिक (जैसे, ROUGE) से यह पता चलता है कि रेफ़रंस टेक्स्ट, एमएल मॉडल के जनरेट किए गए टेक्स्ट से कितना मेल खाता है.
गंभीर
यह एजेंटिक वर्कफ़्लो की क्वालिटी को बेहतर बनाने की एक रणनीति है. इसमें किसी चरण के आउटपुट की जांच की जाती है. इसके बाद, उस आउटपुट को अगले चरण में भेजा जाता है.
जवाब की जांच करने वाला LLM अक्सर वही होता है जिसने जवाब जनरेट किया है. हालांकि, यह कोई दूसरा एलएलएम भी हो सकता है. जिस एलएलएम ने जवाब जनरेट किया है वह अपने जवाब का सही आकलन कैसे कर सकता है? "ट्रिक" यह है कि एलएलएम को आलोचनात्मक (सोचने-समझने वाला) माइंडसेट में रखा जाए. यह प्रोसेस, किसी लेखक की प्रोसेस से मिलती-जुलती है. लेखक, पहला ड्राफ़्ट लिखते समय क्रिएटिव माइंडसेट का इस्तेमाल करता है. इसके बाद, वह ड्राफ़्ट में बदलाव करते समय आलोचनात्मक माइंडसेट का इस्तेमाल करता है.
उदाहरण के लिए, मान लें कि एक एजेंटिक वर्कफ़्लो है. इसका पहला चरण, कॉफ़ी मग के लिए टेक्स्ट बनाना है. इस चरण के लिए प्रॉम्प्ट यह हो सकता है:
आप एक क्रिएटिव हैं. कॉफ़ी मग के लिए, 50 से कम वर्णों वाला मज़ेदार और ओरिजनल टेक्स्ट जनरेट करो.
अब इस तरह के सवाल के बारे में सोचें:
आप कॉफ़ी पीने वाले व्यक्ति हैं. क्या आपको ऊपर दिया गया जवाब मज़ेदार लगा?
इसके बाद, वर्कफ़्लो सिर्फ़ ऐसे टेक्स्ट को अगले चरण में भेज सकता है जिसे रिफ़्लेक्शन स्कोर ज़्यादा मिला हो.
रिग्रेशन मॉडल
आसान शब्दों में कहें, तो यह एक ऐसा मॉडल है जो संख्या के तौर पर अनुमान जनरेट करता है. (इसके उलट, क्लासिफ़िकेशन मॉडल, क्लास के बारे में अनुमान लगाता है.) उदाहरण के लिए, ये सभी रिग्रेशन मॉडल हैं:
- ऐसा मॉडल जो किसी घर की कीमत का अनुमान यूरो में लगाता है. जैसे, 4,23,000.
- ऐसा मॉडल जो किसी पेड़ की उम्र का अनुमान लगाता है. जैसे, 23.2 साल.
- यह मॉडल, अगले छह घंटों में किसी शहर में होने वाली बारिश का अनुमान लगाता है. यह अनुमान इंच में होता है. जैसे, 0.18.
आम तौर पर, दो तरह के रिग्रेशन मॉडल इस्तेमाल किए जाते हैं:
- लीनियर रिग्रेशन, जो ऐसी लाइन ढूंढता है जो लेबल वैल्यू को सुविधाओं के हिसाब से सबसे सही तरीके से फ़िट करती है.
- लॉजिस्टिक रिग्रेशन, जो 0.0 और 1.0 के बीच की संभावना जनरेट करता है. आम तौर पर, सिस्टम इस संभावना को क्लास के अनुमान पर मैप करता है.
संख्यात्मक अनुमान देने वाला हर मॉडल, रिग्रेशन मॉडल नहीं होता. कुछ मामलों में, संख्यात्मक अनुमान लगाने वाला मॉडल सिर्फ़ एक क्लासिफ़िकेशन मॉडल होता है. हालांकि, इसमें क्लास के नाम संख्यात्मक होते हैं. उदाहरण के लिए, पिन कोड का अनुमान लगाने वाला मॉडल, क्लासिफ़िकेशन मॉडल होता है, न कि रिग्रेशन मॉडल.
रेगुलराइज़ेशन
ऐसा कोई भी मेकैनिज़्म जो ओवरफ़िटिंग को कम करता है. रेगुलराइज़ेशन के लोकप्रिय टाइप में ये शामिल हैं:
- L1 रेगुलराइज़ेशन
- L2 रेगुलराइज़ेशन
- ड्रॉपआउट रेगुलराइज़ेशन
- अर्ली स्टॉपिंग (यह सामान्य तौर पर इस्तेमाल होने वाला तरीका नहीं है, लेकिन इससे ओवरफ़िटिंग को कम किया जा सकता है)
रेगुलराइज़ेशन को मॉडल की जटिलता पर लगने वाले जुर्माने के तौर पर भी तय किया जा सकता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग: मॉडल की जटिलता देखें.
रेगुलराइज़ेशन रेट
यह एक ऐसा नंबर होता है जो ट्रेनिंग के दौरान, रेगुलराइज़ेशन के महत्व को दिखाता है. रेगुलराइज़ेशन रेट बढ़ाने से ओवरफ़िटिंग कम हो जाती है. हालांकि, इससे मॉडल की अनुमान लगाने की क्षमता कम हो सकती है. इसके उलट, रेगुलराइज़ेशन रेट को कम करने या हटाने से ओवरफ़िटिंग बढ़ जाती है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग: L2 रेगुलराइज़ेशन देखें.
रीइन्फ़ोर्समेंट लर्निंग (आरएल)
यह एल्गोरिदम का एक ग्रुप है. यह सबसे सही नीति के बारे में जानकारी इकट्ठा करता है. इसका मकसद, एनवायरमेंट के साथ इंटरैक्ट करते समय, रिटर्न को ज़्यादा से ज़्यादा बढ़ाना है. उदाहरण के लिए, ज़्यादातर गेम में सबसे बड़ा इनाम जीत होती है. रीइन्फ़ोर्समेंट लर्निंग सिस्टम, मुश्किल गेम खेलने में माहिर हो सकते हैं. इसके लिए, वे गेम में पहले की गई चालों के क्रम का आकलन करते हैं. इससे उन्हें यह पता चलता है कि किन चालों से जीत मिली और किन चालों से हार.
लोगों के सुझाव पर आधारित रीइन्फ़ोर्समेंट लर्निंग (आरएलएचएफ़)
मॉडल के जवाबों की क्वालिटी को बेहतर बनाने के लिए, लोगों से मिले सुझाव/राय या शिकायत का इस्तेमाल करना. उदाहरण के लिए, RLHF की मदद से, लोगों से यह पूछा जा सकता है कि वे किसी मॉडल के जवाब की क्वालिटी को 👍 या 👎 इमोजी से रेट करें. इसके बाद, सिस्टम उस सुझाव/राय/शिकायत के आधार पर, आने वाले समय में अपने जवाबों में बदलाव कर सकता है.
ReLU
Rectified Linear Unit के लिए इस्तेमाल किया जाने वाला छोटा नाम.
रिप्ले बफ़र
DQN जैसे एल्गोरिदम में, एजेंट की ओर से इस्तेमाल की गई मेमोरी. इसका इस्तेमाल, एक्सपीरियंस रीप्ले में इस्तेमाल करने के लिए, स्टेट ट्रांज़िशन को सेव करने के लिए किया जाता है.
प्रतिरूप
यह ट्रेनिंग सेट या मॉडल की कॉपी (या उसका हिस्सा) होती है. आम तौर पर, इसे किसी दूसरी मशीन पर सेव किया जाता है. उदाहरण के लिए, कोई सिस्टम डेटा पैरललिज़्म को लागू करने के लिए, यहां दी गई रणनीति का इस्तेमाल कर सकता है:
- किसी मौजूदा मॉडल की रेप्लिका को एक से ज़्यादा मशीनों पर रखें.
- हर रेप्लिका को ट्रेनिंग सेट के अलग-अलग सबसेट भेजें.
- पैरामीटर के अपडेट को एग्रीगेट करें.
रेप्लिका, इनफ़्रेंस सर्वर की किसी दूसरी कॉपी को भी कहा जा सकता है. रेप्लिका की संख्या बढ़ाने से, सिस्टम एक साथ ज़्यादा अनुरोधों को पूरा कर सकता है. हालांकि, इससे अनुरोधों को पूरा करने की लागत भी बढ़ जाती है.
रिपोर्टिंग बायस
इस बात से कोई फ़र्क़ नहीं पड़ता कि लोग कितनी बार किसी कार्रवाई, नतीजे या प्रॉपर्टी के बारे में लिखते हैं. इससे यह पता नहीं चलता कि असल दुनिया में वे कितनी बार ऐसा करते हैं या किसी प्रॉपर्टी की कितनी विशेषताएं लोगों के किसी ग्रुप से जुड़ी हैं. रिपोर्टिंग बायस से, मशीन लर्निंग सिस्टम को मिलने वाले डेटा की बनावट पर असर पड़ सकता है.
उदाहरण के लिए, किताबों में हंसा शब्द का इस्तेमाल, सांस ली शब्द के मुकाबले ज़्यादा किया जाता है. मशीन लर्निंग मॉडल, किसी किताब के कॉर्पस से हंसने और सांस लेने की फ़्रीक्वेंसी का अनुमान लगाता है. इससे शायद यह पता चलेगा कि हंसना, सांस लेने से ज़्यादा सामान्य है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: पूर्वाग्रह के टाइप देखें.
प्रतिनिधित्व
डेटा को काम की सुविधाओं से मैप करने की प्रोसेस.
फिर से रैंक करना
यह सुझाव देने वाले सिस्टम का आखिरी चरण होता है. इसमें स्कोर किए गए आइटम को किसी अन्य (आम तौर पर, एमएल से अलग) एल्गोरिदम के हिसाब से फिर से ग्रेड किया जा सकता है. री-रैंकिंग, स्कोरिंग फ़ेज़ में जनरेट की गई आइटम की सूची का आकलन करती है. इसके तहत, ये कार्रवाइयां की जाती हैं:
- ऐसे आइटम हटाना जिन्हें उपयोगकर्ता पहले ही खरीद चुका है.
- नए आइटम के स्कोर को बढ़ाना.
ज़्यादा जानकारी के लिए, Recommendation Systems कोर्स में फिर से रैंक करना देखें.
जवाब
टेक्स्ट, इमेज, ऑडियो या वीडियो, जिसे जनरेटिव एआई मॉडल अनुमानित करता है. दूसरे शब्दों में, प्रॉम्प्ट, जनरेटिव एआई मॉडल के लिए इनपुट होता है और जवाब, आउटपुट होता है.
जवाबों का सेट
लार्ज लैंग्वेज मॉडल, प्रॉम्प्ट सेट के इनपुट के आधार पर जवाबों का कलेक्शन जनरेट करता है.
जानकारी खोजकर जवाब देने की सुविधा (आरएजी)
यह लार्ज लैंग्वेज मॉडल (एलएलएम) के आउटपुट की क्वालिटी को बेहतर बनाने की एक तकनीक है. इसके लिए, मॉडल को ट्रेनिंग देने के बाद, जानकारी के स्रोतों से मिली जानकारी का इस्तेमाल किया जाता है. आरएजी, एलएलएम के जवाबों को ज़्यादा सटीक बनाता है. इसके लिए, यह ट्रेनिंग वाले एलएलएम को भरोसेमंद नॉलेज बेस या दस्तावेज़ों से मिली जानकारी का ऐक्सेस देता है.
जानकारी खोजकर जवाब जनरेट करने की तकनीक का इस्तेमाल करने की सामान्य वजहें ये हैं:
- मॉडल के जनरेट किए गए जवाबों में तथ्यों की सटीकता को बढ़ाना.
- मॉडल को ऐसी जानकारी का ऐक्सेस देना जिसके बारे में उसे ट्रेनिंग नहीं दी गई है.
- मॉडल के इस्तेमाल किए गए ज्ञान को बदलना.
- मॉडल को सोर्स के उद्धरण देने की सुविधा चालू करना.
उदाहरण के लिए, मान लें कि कोई केमिस्ट्री ऐप्लिकेशन, उपयोगकर्ता की क्वेरी से जुड़ी खास जानकारी जनरेट करने के लिए PaLM API का इस्तेमाल करता है. जब ऐप्लिकेशन के बैकएंड को कोई क्वेरी मिलती है, तो बैकएंड:
- यह कुकी, उपयोगकर्ता की क्वेरी से जुड़ा डेटा खोजती है ("फिर से पाती है").
- यह उपयोगकर्ता की क्वेरी में, केमिस्ट्री से जुड़ा काम का डेटा जोड़ता है ("बढ़ाता है").
- यह एलएलएम को, जोड़े गए डेटा के आधार पर खास जानकारी बनाने का निर्देश देता है.
रिटर्न
रीइन्फ़ोर्समेंट लर्निंग में, किसी नीति और किसी स्थिति को देखते हुए, रिटर्न का मतलब उन सभी इनामों के योग से होता है जो एजेंट को स्टेट से एपिसोड के आखिर तक नीति का पालन करने पर मिलने की उम्मीद होती है. एजेंट, इनाम मिलने में होने वाली देरी को ध्यान में रखता है. इसके लिए, वह इनाम पाने के लिए ज़रूरी स्टेट ट्रांज़िशन के हिसाब से इनाम में छूट देता है.
इसलिए, अगर छूट का फ़ैक्टर \(\gamma\)है और \(r_0, \ldots, r_{N}\)एपिसोड के आखिर तक मिलने वाले इनाम को दिखाता है, तो रिटर्न की गिनती इस तरह की जाती है:
इनाम
रीइन्फ़ोर्समेंट लर्निंग में, एनवायरमेंट के हिसाब से, स्टेट में ऐक्शन लेने पर मिलने वाला संख्यात्मक नतीजा.
रिज़ रेगुलराइज़ेशन
L2 रेगुलराइज़ेशन के लिए समानार्थी शब्द. रिज रेगुलराइज़ेशन शब्द का इस्तेमाल, प्योर स्टैटिस्टिक्स के कॉन्टेक्स्ट में ज़्यादा किया जाता है. वहीं, L2 रेगुलराइज़ेशन का इस्तेमाल, मशीन लर्निंग में ज़्यादा किया जाता है.
RNN
रीकरंट न्यूरल नेटवर्क का संक्षिप्त नाम.
आरओसी (रिसीवर ऑपरेटिंग कैरेक्टरिस्टिक) कर्व
यह बाइनरी क्लासिफ़िकेशन में, अलग-अलग क्लासिफ़िकेशन थ्रेशोल्ड के लिए, ट्रू पॉज़िटिव रेट बनाम फ़ॉल्स पॉज़िटिव रेट का ग्राफ़ है.
आरओसी कर्व का आकार, बाइनरी क्लासिफ़िकेशन मॉडल की पॉज़िटिव क्लास को नेगेटिव क्लास से अलग करने की क्षमता के बारे में बताता है. उदाहरण के लिए, मान लें कि बाइनरी क्लासिफ़िकेशन मॉडल, सभी नेगेटिव क्लास को सभी पॉज़िटिव क्लास से पूरी तरह अलग करता है:
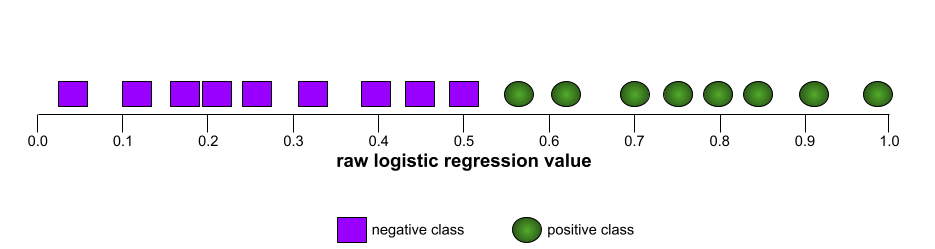
ऊपर दिए गए मॉडल के लिए आरओसी कर्व ऐसा दिखता है:
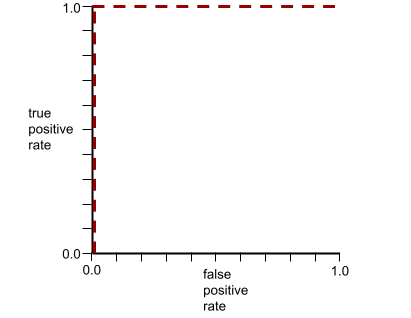
इसके उलट, इस इमेज में एक खराब मॉडल के लिए लॉजिस्टिक रिग्रेशन की रॉ वैल्यू दिखाई गई हैं. यह मॉडल, नेगेटिव क्लास को पॉज़िटिव क्लास से अलग नहीं कर सकता:
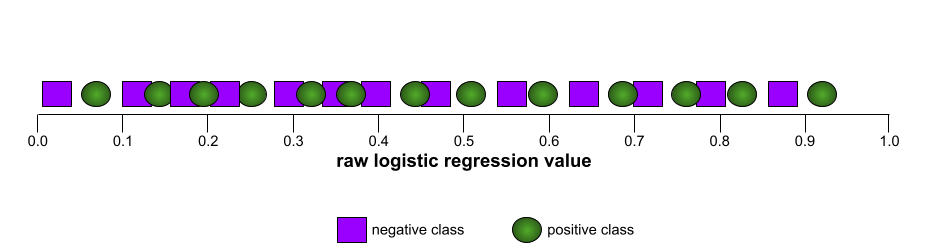
इस मॉडल के लिए आरओसी कर्व ऐसा दिखता है:
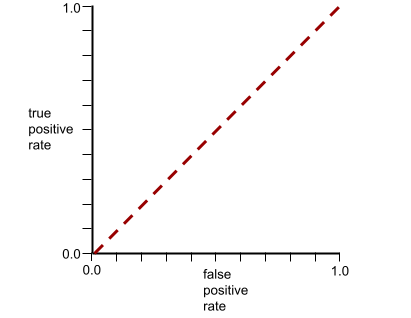
वहीं, असल दुनिया में ज़्यादातर बाइनरी क्लासिफ़िकेशन मॉडल, पॉज़िटिव और नेगेटिव क्लास को कुछ हद तक अलग करते हैं. हालांकि, वे आम तौर पर ऐसा पूरी तरह से नहीं कर पाते. इसलिए, एक सामान्य आरओसी कर्व, इन दोनों एक्सट्रीम के बीच कहीं होता है:
आरओसी कर्व पर (0.0,1.0) के सबसे करीब वाला पॉइंट, सैद्धांतिक तौर पर सबसे सही क्लासिफ़िकेशन थ्रेशोल्ड की पहचान करता है. हालांकि, असल दुनिया की कई अन्य समस्याएं, क्लासिफ़िकेशन के सही थ्रेशोल्ड को चुनने पर असर डालती हैं. उदाहरण के लिए, ऐसा हो सकता है कि गलत पहचान किए जाने से ज़्यादा नुकसान, पहचान न किए जाने से होता हो.
AUC नाम की संख्यात्मक मेट्रिक, आरओसी कर्व को एक फ़्लोटिंग-पॉइंट वैल्यू में बदल देती है.
भूमिका के हिसाब से प्रॉम्प्ट देना
यह एक प्रॉम्प्ट होता है. आम तौर पर, इसकी शुरुआत तुम सर्वनाम से होती है. इसमें जनरेटिव एआई मॉडल को यह निर्देश दिया जाता है कि जवाब जनरेट करते समय, वह किसी व्यक्ति या भूमिका के तौर पर काम करे. रोल प्रॉम्प्टिंग से, जनरेटिव एआई मॉडल को सही "माइंडसेट" में लाने में मदद मिल सकती है, ताकि वह ज़्यादा काम का जवाब जनरेट कर सके. उदाहरण के लिए, आपको जिस तरह का जवाब चाहिए उसके हिसाब से, भूमिका के बारे में बताने वाले इनमें से कोई भी प्रॉम्प्ट सही हो सकता है:
आपने कंप्यूटर साइंस में पीएचडी की हो.
तुम एक सॉफ़्टवेयर इंजीनियर हो. तुम्हें प्रोग्रामिंग सीखने वाले नए छात्र-छात्राओं को Python के बारे में विस्तार से जानकारी देना पसंद है.
तुम एक ऐक्शन हीरो हो और तुम्हारे पास प्रोग्रामिंग की खास तरह की स्किल हैं. मुझे भरोसा दिलाओ कि तुम Python की किसी लिस्ट में कोई आइटम ढूंढ सकते हो.
रूट
डिसिज़न ट्री में, शुरुआती नोड (पहली शर्त). आम तौर पर, डायग्राम में रूट को डिसिज़न ट्री में सबसे ऊपर रखा जाता है. उदाहरण के लिए:
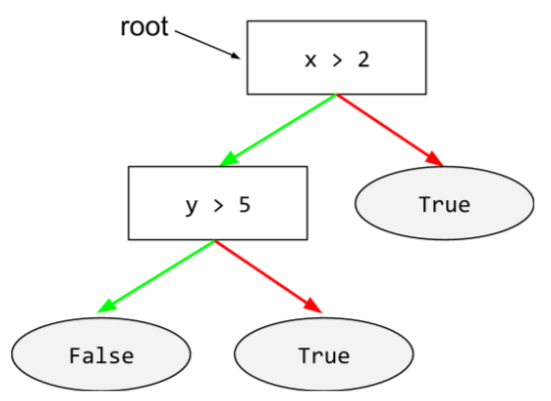
रूट डायरेक्ट्री
यह वह डायरेक्ट्री होती है जिसे आपने TensorFlow चेकपॉइंट और कई मॉडल की इवेंट फ़ाइलों की सबडायरेक्ट्री होस्ट करने के लिए तय किया है.
रूट मीन स्क्वेयर्ड एरर (आरएमएसई)
यह मीन स्क्वेयर्ड एरर का वर्गमूल होता है.
रोटेशनल इनवेरियंस
इमेज क्लासिफ़िकेशन की समस्या में, किसी एल्गोरिदम की यह क्षमता कि वह इमेज के ओरिएंटेशन में बदलाव होने पर भी, इमेज को सही तरीके से क्लासिफ़ाई कर सके. उदाहरण के लिए, एल्गोरिदम अब भी टेनिस रैकेट की पहचान कर सकता है. भले ही, वह ऊपर की ओर, बगल में या नीचे की ओर दिख रहा हो. ध्यान दें कि रोटेशनल इनवेरियंस हमेशा सही नहीं होता. उदाहरण के लिए, उल्टे 9 को 9 के तौर पर क्लासिफ़ाई नहीं किया जाना चाहिए.
ट्रांसलेशनल इनवेरियंस और साइज़ इनवेरियंस के बारे में भी जानें.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
यह मेट्रिक का एक ग्रुप है. इससे, जवाब की खास जानकारी अपने-आप जनरेट होने और मशीन ट्रांसलेशन मॉडल का आकलन किया जाता है. ROUGE मेट्रिक से यह पता चलता है कि रेफ़रंस टेक्स्ट, एमएल मॉडल के जनरेट किए गए टेक्स्ट से कितना मिलता-जुलता है. ROUGE फ़ैमिली का हर सदस्य, ओवरलैप को अलग-अलग तरीके से मेज़र करता है. ROUGE स्कोर ज़्यादा होने का मतलब है कि रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में कम ROUGE स्कोर की तुलना में ज़्यादा समानता है.
ROUGE फ़ैमिली का हर सदस्य आम तौर पर ये मेट्रिक जनरेट करता है:
- स्पष्टता
- रीकॉल
- F1
ज़्यादा जानकारी और उदाहरणों के लिए, यहां जाएं:
ROUGE-L
यह ROUGE फ़ैमिली का सदस्य है. यह रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में सबसे लंबे कॉमन सबसीक्वेंस की लंबाई पर फ़ोकस करता है. यहां दिए गए फ़ॉर्मूले, ROUGE-L के लिए रीकॉल और सटीक होने का हिसाब लगाते हैं:
इसके बाद, ROUGE-L रीकॉल और ROUGE-L प्रेसिज़न को एक ही मेट्रिक में रोल अप करने के लिए, F1 का इस्तेमाल किया जा सकता है:
ROUGE-L, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में मौजूद नई लाइनों को अनदेखा करता है. इसलिए, सबसे लंबा कॉमन सबसीक्वेंस एक से ज़्यादा वाक्यों में हो सकता है. जब रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में कई वाक्य शामिल होते हैं, तो आम तौर पर ROUGE-Lsum मेट्रिक बेहतर होती है. यह ROUGE-L का एक वैरिएंट है. ROUGE-Lsum, किसी पैसेज के हर वाक्य के लिए सबसे लंबे कॉमन सबसीक्वेंस का पता लगाता है. इसके बाद, उन सबसे लंबे कॉमन सबसीक्वेंस का औसत कैलकुलेट करता है.
ROUGE-N
यह ROUGE फ़ैमिली की मेट्रिक का एक सेट है. यह रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में, एक तय साइज़ के शेयर किए गए N-ग्राम की तुलना करता है. उदाहरण के लिए:
- ROUGE-1, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में शेयर किए गए टोकन की संख्या को मेज़र करता है.
- ROUGE-2, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में, शेयर किए गए बिगराम (2-ग्राम) की संख्या को मेज़र करता है.
- ROUGE-3, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में मौजूद, एक जैसे ट्रायग्राम (3-ग्राम) की संख्या को मेज़र करता है.
ROUGE-N फ़ैमिली के किसी भी सदस्य के लिए, ROUGE-N रीकॉल और ROUGE-N प्रेसिज़न का हिसाब लगाने के लिए, यहां दिए गए फ़ॉर्मूले इस्तेमाल किए जा सकते हैं:
इसके बाद, ROUGE-N रीकॉल और ROUGE-N प्रेसिज़न को एक ही मेट्रिक में रोल अप करने के लिए, F1 का इस्तेमाल किया जा सकता है:
ROUGE-S
यह ROUGE-N का एक ऐसा फ़ॉर्मूला है जो skip-gram मैचिंग को चालू करता है. इसका मतलब है कि ROUGE-N सिर्फ़ उन N-ग्राम की गिनती करता है जो पूरी तरह मैच करते हैं. हालांकि, ROUGE-S एक या उससे ज़्यादा शब्दों से अलग किए गए N-ग्राम की भी गिनती करता है. उदाहरण के लिए, आप नीचे दिया गया तरीका अपना सकते हैं:
- रेफ़रंस टेक्स्ट: सफ़ेद बादल
- जनरेट किया गया टेक्स्ट: सफ़ेद रंग के बादल
ROUGE-N का हिसाब लगाते समय, 2-ग्राम, सफ़ेद बादल, सफ़ेद बादल से मेल नहीं खाता. हालांकि, ROUGE-S का हिसाब लगाते समय, सफ़ेद बादल, सफ़ेद बादल से मेल खाते हैं.
R-squared
यह रिग्रेशन मेट्रिक है. इससे पता चलता है कि किसी लेबल में कितना बदलाव, किसी एक सुविधा या सुविधाओं के सेट की वजह से हुआ है. R-स्क्वेयर्ड की वैल्यू 0 से 1 के बीच होती है. इसे इस तरह समझा जा सकता है:
- R-स्क्वेयर्ड की वैल्यू 0 होने का मतलब है कि लेबल में मौजूद किसी भी बदलाव की वजह, फ़ीचर सेट नहीं है.
- R-स्क्वेयर्ड का मान 1 होने का मतलब है कि किसी लेबल के सभी वैरिएशन, फ़ीचर सेट की वजह से हैं.
- R-स्क्वेयर्ड की वैल्यू 0 से 1 के बीच होती है. इससे पता चलता है कि किसी खास सुविधा या सुविधाओं के सेट से, लेबल के वैरिएशन का कितना अनुमान लगाया जा सकता है. उदाहरण के लिए, R-स्क्वेयर्ड की वैल्यू 0.10 का मतलब है कि लेबल में 10% वैरिएंस, फ़ीचर सेट की वजह से है. R-स्क्वेयर्ड की वैल्यू 0.20 का मतलब है कि 20% वैरिएंस, फ़ीचर सेट की वजह से है. इसी तरह, अन्य वैल्यू का मतलब भी निकाला जा सकता है.
आर-स्क्वेयर्ड, मॉडल की अनुमानित वैल्यू और ग्राउंड ट्रुथ के बीच पियर्सन कोरिलेशन कोएफ़िशिएंट का स्क्वेयर होता है.
RTE
टेक्स्ट से जुड़ी जानकारी को समझने की क्षमता के लिए संक्षिप्त नाम.
S
सैंपलिंग बायस
चुने जाने का पूर्वाग्रह देखें.
रिप्लेसमेंट के साथ सैंपलिंग
यह, उम्मीदवार के तौर पर शामिल आइटम के सेट से आइटम चुनने का एक तरीका है. इसमें एक ही आइटम को कई बार चुना जा सकता है. "बदलाव के साथ" वाक्यांश का मतलब है कि हर बार चुनने के बाद, चुने गए आइटम को संभावित आइटम के पूल में वापस कर दिया जाता है. इसके उलट, बिना रिप्लेसमेंट के सैंपलिंग का मतलब है कि किसी आइटम को सिर्फ़ एक बार चुना जा सकता है.
उदाहरण के लिए, यहां दिए गए फलों के सेट पर ध्यान दें:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}मान लें कि सिस्टम, fig को पहले आइटम के तौर पर रैंडम तरीके से चुनता है.
अगर सैंपलिंग की सुविधा का इस्तेमाल किया जा रहा है, तो सिस्टम इस सेट से दूसरा आइटम चुनता है:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}हां, यह पहले जैसा ही सेट है. इसलिए, सिस्टम fig को फिर से चुन सकता है.
रिप्लेसमेंट के बिना सैंपलिंग का इस्तेमाल करने पर, चुने गए सैंपल को दोबारा नहीं चुना जा सकता. उदाहरण के लिए, अगर सिस्टम ने पहले सैंपल के तौर पर fig को चुना है, तो fig को फिर से नहीं चुना जा सकता. इसलिए, सिस्टम नीचे दिए गए (कम किए गए) सेट से दूसरा सैंपल चुनता है:
fruit = {kiwi, apple, pear, cherry, lime, mango}सेव मॉडल
TensorFlow मॉडल को सेव करने और वापस पाने के लिए सुझाया गया फ़ॉर्मैट. SavedModel, भाषा से अलग, रिकवर किया जा सकने वाला सीरियलाइज़ेशन फ़ॉर्मैट है. इससे, हाई-लेवल सिस्टम और टूल, TensorFlow मॉडल बना सकते हैं, उनका इस्तेमाल कर सकते हैं, और उन्हें बदल सकते हैं.
पूरी जानकारी के लिए, TensorFlow प्रोग्रामर गाइड का सेव करना और वापस लाना सेक्शन देखें.
सेवर
यह TensorFlow ऑब्जेक्ट, मॉडल के चेकपॉइंट सेव करने के लिए ज़िम्मेदार होता है.
स्केलर
एक संख्या या एक स्ट्रिंग, जिसे रैंक 0 के टेंसर के तौर पर दिखाया जा सकता है. उदाहरण के लिए, कोड की ये लाइनें TensorFlow में एक-एक स्केलर बनाती हैं:
breed = tf.Variable("poodle", tf.string)
temperature = tf.Variable(27, tf.int16)
precision = tf.Variable(0.982375101275, tf.float64)स्केलिंग
कोई भी गणितीय ट्रांसफ़ॉर्म या तकनीक, जो किसी लेबल, सुविधा की वैल्यू या दोनों की रेंज को बदलती है. स्केलिंग के कुछ तरीके, नॉर्मलाइज़ेशन जैसे ट्रांसफ़ॉर्मेशन के लिए बहुत काम के होते हैं.
मशीन लर्निंग में, स्केलिंग के इन तरीकों का इस्तेमाल किया जाता है:
- लीनियर स्केलिंग. आम तौर पर, इसमें घटाने और भाग देने के कॉम्बिनेशन का इस्तेमाल किया जाता है. इससे ओरिजनल वैल्यू को -1 और +1 के बीच की संख्या या 0 और 1 के बीच की संख्या से बदला जाता है.
- लॉगरिद्मिक स्केलिंग, जो ओरिजनल वैल्यू को उसके लॉगरिद्म से बदल देती है.
- ज़ेड-स्कोर नॉर्मलाइज़ेशन, जो ओरिजनल वैल्यू को फ़्लोटिंग-पॉइंट वैल्यू से बदलता है. यह वैल्यू, उस सुविधा के औसत से स्टैंडर्ड डेविएशन की संख्या को दिखाती है.
scikit-learn
यह एक लोकप्रिय ओपन-सोर्स मशीन लर्निंग प्लैटफ़ॉर्म है. scikit-learn.org पर जाएं.
स्कोरिंग
सुझाव देने वाले सिस्टम का वह हिस्सा जो कैंडिडेट जनरेशन फ़ेज़ में तैयार किए गए हर आइटम के लिए वैल्यू या रैंकिंग देता है.
चुने जाने से जुड़ा पूर्वाग्रह
सैंपल किए गए डेटा से निकाले गए नतीजों में गड़बड़ियां. ऐसा इसलिए होता है, क्योंकि डेटा को चुनने की प्रोसेस में, डेटा में मौजूद सैंपल और मौजूद न होने वाले सैंपल के बीच व्यवस्थित तरीके से अंतर किया जाता है. चुने जाने के पक्ष में होने वाले ये पूर्वाग्रह मौजूद हैं:
- कवरेज से जुड़ा पूर्वाग्रह: डेटासेट में मौजूद आबादी, उस आबादी से मेल नहीं खाती जिसके बारे में मशीन लर्निंग मॉडल अनुमान लगा रहा है.
- सैंपलिंग बायस: टारगेट ग्रुप से डेटा को रैंडम तरीके से इकट्ठा नहीं किया जाता है.
- जवाब न देने की वजह से होने वाला पूर्वाग्रह (इसे सर्वे में हिस्सा लेने की वजह से होने वाला पूर्वाग्रह भी कहा जाता है): कुछ ग्रुप के उपयोगकर्ता, अन्य ग्रुप के उपयोगकर्ताओं की तुलना में अलग-अलग दरों पर सर्वे से ऑप्ट-आउट करते हैं.
उदाहरण के लिए, मान लें कि आपको एक ऐसा मशीन लर्निंग मॉडल बनाना है जो यह अनुमान लगाता है कि लोगों को कोई फ़िल्म कितनी पसंद आएगी. ट्रेनिंग डेटा इकट्ठा करने के लिए, आपने थिएटर की पहली लाइन में बैठे सभी लोगों को एक सर्वे दिया. पहली नज़र में, यह डेटासेट इकट्ठा करने का सही तरीका लग सकता है. हालांकि, इस तरह से डेटा इकट्ठा करने पर, चुनने से जुड़ी ये समस्याएं हो सकती हैं:
- कवरेज बायस: जिन लोगों ने फ़िल्म देखने का विकल्प चुना है उनसे सैंपल लेने पर, हो सकता है कि आपका मॉडल उन लोगों के लिए सामान्य तौर पर अनुमान न लगा पाए जिन्होंने फ़िल्म में पहले से ही दिलचस्पी नहीं दिखाई है.
- सैंपलिंग बायस: आपने फ़िल्म देखने आए सभी लोगों में से रैंडम तरीके से सैंपल लेने के बजाय, सिर्फ़ पहली लाइन में बैठे लोगों से सैंपल लिया. ऐसा हो सकता है कि पहली लाइन में बैठे लोगों की दिलचस्पी फ़िल्म में, अन्य लाइनों में बैठे लोगों की तुलना में ज़्यादा हो.
- जवाब न देने से जुड़ा पूर्वाग्रह: आम तौर पर, जिन लोगों की राय काफ़ी मज़बूत होती है वे उन लोगों की तुलना में, वैकल्पिक सर्वे में ज़्यादा बार जवाब देते हैं जिनकी राय सामान्य होती है. फ़िल्म के बारे में सर्वे करना ज़रूरी नहीं है. इसलिए, जवाबों के सामान्य (घंटी के आकार वाले) डिस्ट्रिब्यूशन के बजाय, बाइमॉडेल डिस्ट्रिब्यूशन बनने की संभावना ज़्यादा होती है.
सेल्फ़-अटेंशन (इसे सेल्फ़-अटेंशन लेयर भी कहा जाता है)
यह एक न्यूरल नेटवर्क लेयर होती है. यह एंबेडिंग के क्रम (उदाहरण के लिए, टोकन एंबेडिंग) को एंबेडिंग के दूसरे क्रम में बदलती है. आउटपुट सीक्वेंस में मौजूद हर एंबेडिंग को, अटेंशन मैकेनिज़्म के ज़रिए, इनपुट सीक्वेंस के एलिमेंट से मिली जानकारी को इंटिग्रेट करके बनाया जाता है.
सेल्फ़-अटेंशन में सेल्फ़ का मतलब है कि सीक्वेंस, किसी दूसरे कॉन्टेक्स्ट के बजाय खुद पर ध्यान दे रहा है. सेल्फ़-अटेंशन, ट्रांसफ़ॉर्मर के मुख्य बिल्डिंग ब्लॉक में से एक है. यह डिक्शनरी लुकअप की शब्दावली का इस्तेमाल करता है. जैसे, "क्वेरी", "की", और "वैल्यू".
सेल्फ़-अटेंशन लेयर, इनपुट के तौर पर मिले शब्दों के क्रम से शुरू होती है. इसमें हर शब्द के लिए एक इनपुट होता है. किसी शब्द के लिए इनपुट रिप्रेजेंटेशन, एक सामान्य एम्बेडिंग हो सकती है. इनपुट सीक्वेंस में मौजूद हर शब्द के लिए, नेटवर्क यह स्कोर करता है कि वह शब्द, शब्दों के पूरे सीक्वेंस में मौजूद हर एलिमेंट से कितना मिलता-जुलता है. रिलेवंस स्कोर से यह पता चलता है कि किसी शब्द के फ़ाइनल रिप्रेजेंटेशन में, अन्य शब्दों के रिप्रेजेंटेशन को कितना शामिल किया गया है.
उदाहरण के लिए, इस वाक्य पर ध्यान दें:
जानवर सड़क पार नहीं कर सका, क्योंकि वह बहुत थका हुआ था.
नीचे दी गई इमेज (ट्रांसफ़ॉर्मर: भाषा समझने के लिए एक नई न्यूरल नेटवर्क आर्किटेक्चर से ली गई) में, सर्वनाम यह के लिए सेल्फ़-अटेंशन लेयर का अटेंशन पैटर्न दिखाया गया है. इसमें हर लाइन की डार्कनेस से पता चलता है कि हर शब्द, प्रज़ेंटेशन में कितना योगदान देता है:
सेल्फ़-अटेंशन लेयर, "यह" से जुड़े शब्दों को हाइलाइट करती है. इस मामले में, अटेंशन लेयर ने उन शब्दों को हाइलाइट करना सीख लिया है जिनके बारे में वह बात कर रहा है. साथ ही, जानवर शब्द को सबसे ज़्यादा वेट असाइन किया है.
n टोकन के सीक्वेंस के लिए, सेल्फ़-अटेंशन, एंबेडिंग के सीक्वेंस को n बार बदलता है. ऐसा सीक्वेंस में हर पोज़िशन पर एक बार होता है.
ध्यान और मल्टी-हेड सेल्फ़-अटेंशन के बारे में भी जानें.
सेल्फ़-सुपरवाइज़्ड लर्निंग
यह एक ऐसी तकनीक है जिसकी मदद से, अनसुपरवाइज़्ड मशीन लर्निंग की समस्या को सुपरवाइज़्ड मशीन लर्निंग की समस्या में बदला जाता है. इसके लिए, बिना लेबल वाले उदाहरणों से सरोगेट लेबल बनाए जाते हैं.
Transformer पर आधारित कुछ मॉडल, जैसे कि BERT, सेल्फ-सुपरवाइज़्ड लर्निंग का इस्तेमाल करते हैं.
सेल्फ़-सुपरवाइज़्ड ट्रेनिंग, सेमी-सुपरवाइज़्ड लर्निंग का एक तरीका है.
सेल्फ़-ट्रेनिंग
यह सेल्फ़-सुपरवाइज़्ड लर्निंग का एक वैरिएंट है. यह खास तौर पर तब काम आता है, जब ये सभी शर्तें पूरी होती हैं:
- डेटासेट में, बिना लेबल वाले उदाहरणों का अनुपात, लेबल वाले उदाहरणों के मुकाबले ज़्यादा है.
- यह वर्गीकरण की समस्या है.
सेल्फ़-ट्रेनिंग की सुविधा, इन दो चरणों को तब तक दोहराती है, जब तक मॉडल की परफ़ॉर्मेंस बेहतर होना बंद नहीं हो जाती:
- लेबल किए गए उदाहरणों के आधार पर मॉडल को ट्रेन करने के लिए, सुपरवाइज़्ड मशीन लर्निंग का इस्तेमाल करें.
- पहले चरण में बनाए गए मॉडल का इस्तेमाल करके, बिना लेबल वाले उदाहरणों के लिए अनुमान (लेबल) जनरेट करें. साथ ही, जिन उदाहरणों के लिए अनुमान सही होने की संभावना ज़्यादा है उन्हें अनुमानित लेबल के साथ लेबल किए गए उदाहरणों में ले जाएं.
ध्यान दें कि दूसरे चरण के हर वर्शन में, पहले चरण के लिए लेबल किए गए ज़्यादा उदाहरण जोड़े जाते हैं, ताकि मॉडल को बेहतर तरीके से ट्रेन किया जा सके.
सेमी-सुपरवाइज़्ड लर्निंग
ऐसे डेटा पर मॉडल को ट्रेन करना जिसमें ट्रेनिंग के कुछ उदाहरणों में लेबल मौजूद हैं, लेकिन अन्य उदाहरणों में लेबल मौजूद नहीं हैं. सेमी-सुपरवाइज़्ड लर्निंग की एक तकनीक यह है कि बिना लेबल वाले उदाहरणों के लिए लेबल का अनुमान लगाया जाए. इसके बाद, अनुमानित लेबल पर ट्रेनिंग दी जाए, ताकि एक नया मॉडल बनाया जा सके. अगर लेबल हासिल करना महंगा है, लेकिन बिना लेबल वाले उदाहरण बहुत ज़्यादा हैं, तो सेमी-सुपरवाइज़्ड लर्निंग फ़ायदेमंद हो सकती है.
सेल्फ़-ट्रेनिंग, सेमी-सुपरवाइज़्ड लर्निंग की एक तकनीक है.
संवेदनशील एट्रिब्यूट
यह एक मानवीय एट्रिब्यूट है. कानूनी, नैतिक, सामाजिक या निजी वजहों से इस पर खास ध्यान दिया जा सकता है.भावनाओं का विश्लेषण
किसी सेवा, प्रॉडक्ट, संगठन या विषय के बारे में किसी ग्रुप के रवैये का पता लगाने के लिए, आंकड़ों या मशीन लर्निंग के एल्गोरिदम का इस्तेमाल करना. यह रवैया सकारात्मक या नकारात्मक हो सकता है. उदाहरण के लिए, आम बोलचाल की भाषा को समझने की सुविधा का इस्तेमाल करके, कोई एल्गोरिदम किसी यूनिवर्सिटी के कोर्स के बारे में मिले टेक्स्ट वाले सुझाव, शिकायत या राय का विश्लेषण कर सकता है. इससे यह पता लगाया जा सकता है कि आम तौर पर छात्रों को कोर्स पसंद आया या नहीं.
ज़्यादा जानकारी के लिए, टेक्स्ट क्लासिफ़िकेशन गाइड देखें.
सीक्वेंस मॉडल
ऐसा मॉडल जिसके इनपुट, क्रम से एक-दूसरे पर निर्भर करते हैं. उदाहरण के लिए, पहले देखे गए वीडियो के क्रम के आधार पर, यह अनुमान लगाना कि अगला वीडियो कौन-सा देखा जाएगा.
सीक्वेंस-टू-सीक्वेंस टास्क
यह एक ऐसा टास्क है जो टोकन के इनपुट सीक्वेंस को टोकन के आउटपुट सीक्वेंस में बदलता है. उदाहरण के लिए, सीक्वेंस-टू-सीक्वेंस के दो लोकप्रिय टास्क ये हैं:
- अनुवादक:
- इनपुट के तौर पर इस्तेमाल किया गया सैंपल सीक्वेंस: "मुझे तुमसे प्यार है."
- आउटपुट का सैंपल क्रम: "Je t'aime."
- सवाल का जवाब देना:
- इनपुट सीक्वेंस का उदाहरण: "क्या मुझे मुंबई में अपनी कार की ज़रूरत है?"
- जवाब के तौर पर मिले आउटपुट का क्रम: "नहीं. अपनी कार घर पर ही रखो."
व्यक्ति खा सकता है
ट्रेन किए गए मॉडल को उपलब्ध कराने की प्रोसेस, ताकि ऑनलाइन इन्फ़रेंस या ऑफ़लाइन इन्फ़रेंस के ज़रिए अनुमान लगाए जा सकें.
शेप (टेंसर)
टेंसर के हर डाइमेंशन में मौजूद एलिमेंट की संख्या. शेप को पूर्णांकों की सूची के तौर पर दिखाया जाता है. उदाहरण के लिए, यहां दिए गए दो डाइमेंशन वाले टेंसर का आकार [3,4] है:
[[5, 7, 6, 4], [2, 9, 4, 8], [3, 6, 5, 1]]
TensorFlow, डाइमेंशन के क्रम को दिखाने के लिए, पंक्ति-मुख्य (C-स्टाइल) फ़ॉर्मैट का इस्तेमाल करता है. इसलिए, TensorFlow में शेप [3,4] के बजाय [4,3] होता है. दूसरे शब्दों में, दो डाइमेंशन वाले TensorFlow Tensor में, शेप [पंक्तियों की संख्या, कॉलम की संख्या] होती है.
स्टैटिक शेप, एक ऐसा टेंसर शेप होता है जिसके बारे में कंपाइल टाइम पर जानकारी होती है.
कंपाइल टाइम पर, डाइनैमिक शेप अनजान होता है. इसलिए, यह रनटाइम डेटा पर निर्भर करता है. इस टेंसर को TensorFlow में प्लेसहोल्डर डाइमेंशन के साथ दिखाया जा सकता है. जैसे, [3, ?] में दिखाया गया है.
शार्ड
ट्रेनिंग सेट या मॉडल का लॉजिकल डिविज़न. आम तौर पर, कुछ प्रोसेस उदाहरणों या पैरामीटर को बराबर साइज़ वाले हिस्सों में बांटकर, शार्ड बनाती हैं. इसके बाद, हर शार्ड को अलग-अलग मशीन पर असाइन किया जाता है.
मॉडल को शार्ड करने को मॉडल पैरललिज़्म कहा जाता है; डेटा को शार्ड करने को डेटा पैरललिज़्म कहा जाता है.
श्रिंकेज
यह ग्रैडिएंट बूस्टिंग में मौजूद एक हाइपरपैरामीटर है. यह ओवरफ़िटिंग को कंट्रोल करता है. ग्रेडिएंट बूस्टिंग में श्रिंकेज, ग्रेडिएंट डिसेंट में लर्निंग रेट के जैसा होता है. सिकुड़ने की दर, 0.0 और 1.0 के बीच की दशमलव वैल्यू होती है. श्रिंकेज वैल्यू कम होने पर, ओवरफ़िटिंग की समस्या कम होती है. वहीं, श्रिंकेज वैल्यू ज़्यादा होने पर, ओवरफ़िटिंग की समस्या ज़्यादा होती है.
साथ-साथ होने वाला आकलन
एक ही प्रॉम्प्ट के लिए, दो मॉडल के जवाबों की तुलना करके, उनकी क्वालिटी का आकलन किया जा रहा है. उदाहरण के लिए, मान लें कि यहां दिया गया प्रॉम्प्ट, दो अलग-अलग मॉडल को दिया गया है:
एक प्यारे कुत्ते की इमेज बनाओ, जो तीन गेंदों से करतब दिखा रहा हो.
साथ-साथ तुलना करने के दौरान, रेटिंग देने वाला व्यक्ति यह चुनता है कि कौनसी इमेज "बेहतर" है (क्या वह ज़्यादा सटीक है? ज़्यादा सुंदर? Cuter?).
सिगमॉइड फ़ंक्शन
यह एक गणितीय फ़ंक्शन है, जो इनपुट वैल्यू को सीमित रेंज में "स्क्वीज़" करता है. आम तौर पर, यह रेंज 0 से 1 या -1 से +1 होती है. इसका मतलब है कि सिग्मॉइड फ़ंक्शन में कोई भी संख्या (दो, दस लाख, नेगेटिव अरब वगैरह) डाली जा सकती है. हालांकि, आउटपुट हमेशा तय सीमा के अंदर ही होगा. सिगमॉइड ऐक्टिवेशन फ़ंक्शन का प्लॉट ऐसा दिखता है:
मशीन लर्निंग में सिगमॉइड फ़ंक्शन का इस्तेमाल कई कामों के लिए किया जाता है. जैसे:
- लॉजिस्टिक रिग्रेशन या मल्टीनोमियल रिग्रेशन मॉडल के रॉ आउटपुट को संभावना में बदलना.
- कुछ न्यूरल नेटवर्क में ऐक्टिवेशन फ़ंक्शन के तौर पर काम करता है.
मिलते-जुलते डिज़ाइन
क्लस्टरिंग एल्गोरिदम में, इस मेट्रिक का इस्तेमाल यह तय करने के लिए किया जाता है कि कोई दो उदाहरण कितने मिलते-जुलते हैं.
सिंगल प्रोग्राम / मल्टीपल डेटा (एसपीएमडी)
यह एक पैरललिज़्म तकनीक है. इसमें एक ही कंप्यूटेशन को अलग-अलग डिवाइसों पर, अलग-अलग इनपुट डेटा के साथ पैरलल तरीके से चलाया जाता है. एसपीएमडी का मकसद, नतीजों को ज़्यादा तेज़ी से पाना है. यह पैरलल प्रोग्रामिंग की सबसे सामान्य स्टाइल है.
साइज़ इनवेरियंस
इमेज क्लासिफ़िकेशन की समस्या में, किसी एल्गोरिदम की इमेज को सही तरीके से क्लासिफ़ाई करने की क्षमता. भले ही, इमेज का साइज़ बदल गया हो. उदाहरण के लिए, एल्गोरिदम अब भी किसी बिल्ली की पहचान कर सकता है, भले ही वह 20 लाख पिक्सल का इस्तेमाल करे या 2 लाख पिक्सल का. ध्यान दें कि इमेज क्लासिफ़िकेशन के सबसे अच्छे एल्गोरिदम में भी, साइज़ इनवेरियंस की सीमाएं होती हैं. उदाहरण के लिए, सिर्फ़ 20 पिक्सल वाली बिल्ली की इमेज को कोई एल्गोरिदम (या इंसान) सही तरीके से कैटगरी में नहीं रख पाएगा.
ट्रांसलेशनल इनवेरियंस और रोटेशनल इनवेरियंस के बारे में भी जानें.
ज़्यादा जानकारी के लिए, क्लस्टरिंग कोर्स देखें.
स्केचिंग
अनसुपरवाइज़्ड मशीन लर्निंग में, एल्गोरिदम की एक कैटगरी होती है. यह उदाहरणों पर समानता का शुरुआती विश्लेषण करती है. स्केचिंग एल्गोरिदम, लोकलिटि-सेंसिटिव हैश फ़ंक्शन का इस्तेमाल करके, एक जैसे पॉइंट की पहचान करते हैं. इसके बाद, उन्हें बकेट में ग्रुप करते हैं.
स्केचिंग से, बड़े डेटासेट पर समानता की कैलकुलेशन के लिए ज़रूरी कंप्यूटेशन कम हो जाता है. डेटासेट में मौजूद हर उदाहरण के हर जोड़े के लिए समानता का हिसाब लगाने के बजाय, हम सिर्फ़ हर बकेट में मौजूद पॉइंट के हर जोड़े के लिए समानता का हिसाब लगाते हैं.
स्किप-ग्राम
यह एक n-ग्राम है, जिसमें ओरिजनल कॉन्टेक्स्ट के शब्दों को हटाया जा सकता है या "स्किप" किया जा सकता है. इसका मतलब है कि N शब्द, मूल रूप से आस-पास नहीं थे. ज़्यादा सटीक तरीके से कहें, तो "k-स्किप-n-ग्राम" एक n-ग्राम होता है, जिसमें ज़्यादा से ज़्यादा k शब्दों को स्किप किया जा सकता है.
उदाहरण के लिए, "the quick brown fox" में ये 2-ग्राम हो सकते हैं:
- "the quick"
- "quick brown"
- "brown fox"
"1-स्किप-2-ग्राम" शब्दों का ऐसा जोड़ा होता है जिसमें ज़्यादा से ज़्यादा एक शब्द होता है. इसलिए, "the quick brown fox" में 1-स्किप 2-ग्राम इस तरह से हैं:
- "भूरे रंग का"
- "क्विक फ़ॉक्स"
इसके अलावा, सभी 2-ग्राम, 1-स्किप-2-ग्राम भी हैं, क्योंकि एक से कम शब्द स्किप किए जा सकते हैं.
स्किप-ग्राम, किसी शब्द के आस-पास के कॉन्टेक्स्ट को बेहतर तरीके से समझने में मददगार होते हैं. उदाहरण में, 1-स्किप-2-ग्राम के सेट में "fox" को सीधे तौर पर "quick" से जोड़ा गया था, लेकिन 2-ग्राम के सेट में ऐसा नहीं किया गया था.
स्किप-ग्राम, वर्ड एम्बेडिंग मॉडल को ट्रेनिंग देने में मदद करते हैं.
सॉफ़्टमैक्स
यह फ़ंक्शन, मल्टी-क्लास क्लासिफ़िकेशन मॉडल में हर संभावित क्लास के लिए संभावनाएं तय करता है. सभी संभावनाओं का जोड़ 1.0 होता है. उदाहरण के लिए, यहां दी गई टेबल से पता चलता है कि सॉफ़्टमैक्स, अलग-अलग संभावनाओं को कैसे डिस्ट्रिब्यूट करता है:
| इमेज एक... | प्रॉबेबिलिटी |
|---|---|
| कुत्ता | .85 |
| cat | .13 |
| घोड़ा | .02 |
सॉफ़्टमैक्स को फ़ुल सॉफ़्टमैक्स भी कहा जाता है.
उम्मीदवार के सैंपल से तुलना करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में न्यूरल नेटवर्क: मल्टी-क्लास क्लासिफ़िकेशन देखें.
सॉफ़्ट प्रॉम्प्ट ट्यूनिंग
यह किसी खास टास्क के लिए, लार्ज लैंग्वेज मॉडल को ट्यून करने की एक तकनीक है. इसमें, फ़ाइन-ट्यूनिंग की तरह ज़्यादा संसाधनों की ज़रूरत नहीं होती. मॉडल में मौजूद सभी वज़न को फिर से ट्रेनिंग देने के बजाय, सॉफ्ट प्रॉम्प्ट ट्यूनिंग एक ही लक्ष्य को हासिल करने के लिए, प्रॉम्प्ट को अपने-आप अडजस्ट कर देती है.
टेक्स्ट वाले प्रॉम्प्ट के लिए, सॉफ़्ट प्रॉम्प्ट ट्यूनिंग आम तौर पर प्रॉम्प्ट में अतिरिक्त टोकन एम्बेडिंग जोड़ती है. साथ ही, इनपुट को ऑप्टिमाइज़ करने के लिए बैकप्रोपैगेशन का इस्तेमाल करती है.
"हार्ड" प्रॉम्प्ट में टोकन एम्बेडिंग के बजाय, असल टोकन होते हैं.
स्पार्स फ़ीचर
ऐसी सुविधा जिसकी वैल्यू ज़्यादातर शून्य या खाली होती हैं. उदाहरण के लिए, अगर किसी सुविधा में एक वैल्यू 1 है और 10 लाख वैल्यू 0 हैं, तो उसे स्पार्स कहा जाता है. इसके उलट, डेंस फ़ीचर में ऐसी वैल्यू होती हैं जो ज़्यादातर शून्य या खाली नहीं होती हैं.
मशीन लर्निंग में, ज़्यादातर फ़ीचर स्पार्स फ़ीचर होते हैं. कैटगोरिकल फ़ीचर आम तौर पर स्पार्स फ़ीचर होती हैं. उदाहरण के लिए, किसी जंगल में पेड़ की 300 संभावित प्रजातियों में से, एक उदाहरण सिर्फ़ मेपल के पेड़ की पहचान कर सकता है. इसके अलावा, वीडियो लाइब्रेरी में मौजूद लाखों वीडियो में से किसी एक उदाहरण में सिर्फ़ "कैसाब्लांका" की पहचान की जा सकती है.
किसी मॉडल में, आम तौर पर स्पार्स फ़ीचर को वन-हॉट एन्कोडिंग की मदद से दिखाया जाता है. अगर वन-हॉट एन्कोडिंग बड़ी है, तो बेहतर परफ़ॉर्मेंस के लिए, वन-हॉट एन्कोडिंग के ऊपर एम्बेडिंग लेयर लगाई जा सकती है.
स्पार्स वेक्टर के तौर पर डेटा को दिखाना
स्पार्स फ़ीचर में, सिर्फ़ गैर-शून्य एलिमेंट की जगह(जगहों) को सेव करना.
उदाहरण के लिए, मान लें कि कैटगरी वाली कोई सुविधा है, जिसका नाम species है. यह किसी जंगल में मौजूद 36 तरह के पेड़ों की पहचान करती है. यह भी मान लें कि हर उदाहरण में सिर्फ़ एक प्रजाति की पहचान की गई है.
हर उदाहरण में पेड़ की प्रजातियों को दिखाने के लिए, वन-हॉट वेक्टर का इस्तेमाल किया जा सकता है.
वन-हॉट वेक्टर में एक 1 (उदाहरण में पेड़ की किसी खास प्रजाति को दिखाने के लिए) और 35 0 (उदाहरण में पेड़ की 35 प्रजातियों को नहीं दिखाने के लिए) शामिल होंगे. इसलिए, maple का वन-हॉट रिप्रेजेंटेशन कुछ ऐसा दिख सकता है:

इसके अलावा, स्पार्स रिप्रेजेंटेशन से सिर्फ़ किसी खास प्रजाति की जगह की पहचान की जा सकती है. अगर maple 24वें स्थान पर है, तो maple का स्पार्स प्रज़ेंटेशन यह होगा:
24
ध्यान दें कि स्पार्स प्रज़ेंटेशन, वन-हॉट प्रज़ेंटेशन की तुलना में ज़्यादा कॉम्पैक्ट होता है.
थोड़े ज़्यादा जटिल उदाहरण के लिए, आइकॉन पर क्लिक करें.
मान लें कि आपके मॉडल में मौजूद हर उदाहरण में, अंग्रेज़ी के वाक्य में मौजूद शब्दों को शामिल करना ज़रूरी है. हालांकि, उन शब्दों का क्रम अलग-अलग हो सकता है. अंग्रेज़ी में करीब 1,70,000 शब्द होते हैं. इसलिए, अंग्रेज़ी एक कैटगरिकल फ़ीचर है, जिसमें करीब 1,70,000 एलिमेंट होते हैं. अंग्रेज़ी के ज़्यादातर वाक्यों में, उन 1,70,000 शब्दों का बहुत छोटा हिस्सा इस्तेमाल किया जाता है. इसलिए, किसी एक उदाहरण में शब्दों का सेट, लगभग निश्चित रूप से स्पार्स डेटा होगा.
इस वाक्य पर ध्यान दें:
My dog is a great dog
इस वाक्य में मौजूद शब्दों को दिखाने के लिए, वन-हॉट वेक्टर के किसी वैरिएंट का इस्तेमाल किया जा सकता है. इस वैरिएंट में, वेक्टर की एक से ज़्यादा सेल में शून्य से अलग वैल्यू हो सकती है. इसके अलावा, इस वैरिएंट में किसी सेल में एक के अलावा कोई और पूर्णांक हो सकता है. हालांकि, वाक्य में "my", "is", "a", और "great" शब्द सिर्फ़ एक बार आए हैं, लेकिन "dog" शब्द दो बार आया है. इस वाक्य में मौजूद शब्दों को दिखाने के लिए, वन-हॉट वेक्टर के इस वैरिएंट का इस्तेमाल करने पर, 1,70,000 एलिमेंट वाला यह वेक्टर मिलता है:

इसी वाक्य को कम शब्दों में इस तरह लिखा जा सकता है:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटगरी में बांटे गए डेटा का इस्तेमाल करना लेख पढ़ें.
स्पार्स वेक्टर
ऐसा वेक्टर जिसकी वैल्यू ज़्यादातर शून्य होती हैं. विरल फ़ीचर और विरलता के बारे में भी जानें.
कम जानकारी होना
किसी वेक्टर या मैट्रिक्स में शून्य (या शून्य) पर सेट किए गए एलिमेंट की संख्या को उस वेक्टर या मैट्रिक्स में मौजूद कुल एंट्री की संख्या से भाग दिया जाता है. उदाहरण के लिए, 100 एलिमेंट वाली एक ऐसी मैट्रिक्स पर विचार करें जिसमें 98 सेल में शून्य है. विरलता का हिसाब इस तरह लगाया जाता है:
फ़ीचर स्पार्सिटी का मतलब, फ़ीचर वेक्टर की स्पार्सिटी से है; मॉडल स्पार्सिटी का मतलब, मॉडल के वेट की स्पार्सिटी से है.
स्पेशल पूलिंग
पूलिंग देखें.
स्पेसिफ़िकेशनल कोडिंग
सॉफ़्टवेयर के बारे में जानकारी देने वाली फ़ाइल को किसी आम भाषा (उदाहरण के लिए, अंग्रेज़ी) में लिखने और उसे अपडेट रखने की प्रोसेस. इसके बाद, जनरेटिव एआई मॉडल या किसी अन्य सॉफ़्टवेयर इंजीनियर को, उस जानकारी के हिसाब से सॉफ़्टवेयर बनाने के लिए कहा जा सकता है.
अपने-आप जनरेट होने वाले कोड में आम तौर पर बदलाव करने की ज़रूरत होती है. स्पेसिफ़िकेशनल कोडिंग में, ब्यौरे वाली फ़ाइल को दोहराया जाता है. इसके उलट, बातचीत वाली कोडिंग में, आपको प्रॉम्प्ट बॉक्स में ही बदलाव करने का विकल्प मिलता है. असल में, कोड अपने-आप जनरेट होने की प्रोसेस में कभी-कभी, स्पेसिफ़िकेशनल कोडिंग और बातचीत वाली कोडिंग, दोनों का इस्तेमाल किया जाता है.
बांटें
डिसिज़न ट्री में, शर्त का दूसरा नाम.
स्प्लिटर
डिसिज़न ट्री को ट्रेन करते समय, हर नोड पर सबसे अच्छी कंडीशन ढूंढने के लिए, रूटीन (और एल्गोरिदम) ज़िम्मेदार होता है.
SPMD
यह सिंगल प्रोग्राम / मल्टीपल डेटा का संक्षिप्त रूप है.
SQuAD
यह Stanford Question Answering Dataset का संक्षिप्त नाम है. इसे SQuAD: 100,000+ Questions for Machine Comprehension of Text पेपर में पेश किया गया था. इस डेटासेट में मौजूद सवाल, Wikipedia लेखों के बारे में सवाल पूछने वाले लोगों से मिले हैं. SQuAD में कुछ सवालों के जवाब दिए गए हैं, लेकिन अन्य सवालों के जवाब जान-बूझकर नहीं दिए गए हैं. इसलिए, SQuAD का इस्तेमाल करके, यह आकलन किया जा सकता है कि एलएलएम इन दोनों कामों को कर सकता है या नहीं:
- ऐसे सवालों के जवाब दें जिनके जवाब दिए जा सकते हैं.
- ऐसे सवालों की पहचान करना जिनके जवाब नहीं दिए जा सकते.
SQuAD के हिसाब से एलएलएम का आकलन करने के लिए, पूरी तरह मेल खाने वाले जवाब और F1 सबसे आम मेट्रिक हैं.
स्क्वेयर्ड हिंज लॉस
हिंज लॉस का स्क्वेयर. स्क्वेयर्ड हिंज लॉस, आउटलायर को सामान्य हिंज लॉस की तुलना में ज़्यादा नुकसान पहुंचाता है.
स्क्वेयर्ड लॉस
L2 नुकसान के लिए समानार्थी शब्द.
स्टेज के हिसाब से ट्रेनिंग
यह मॉडल को अलग-अलग चरणों में ट्रेनिंग देने की एक रणनीति है. इसका मकसद, ट्रेनिंग प्रोसेस को तेज़ करना या मॉडल की क्वालिटी को बेहतर बनाना हो सकता है.
प्रोग्रेसिव स्टैकिंग के तरीके का इलस्ट्रेशन यहां दिखाया गया है:
- पहले चरण में तीन हिडन लेयर, दूसरे चरण में छह हिडन लेयर, और तीसरे चरण में 12 हिडन लेयर होती हैं.
- दूसरे चरण में, पहले चरण की तीन हिडन लेयर से मिले वेट का इस्तेमाल करके ट्रेनिंग शुरू की जाती है. तीसरे चरण में, ट्रेनिंग की शुरुआत दूसरे चरण की छह हिडन लेयर में सीखी गई वैल्यू से होती है.
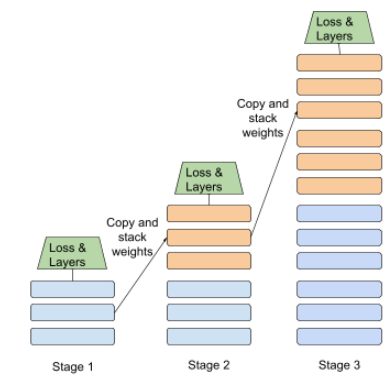
पाइपलाइनिंग के बारे में भी जानें.
राज्य
रीइन्फ़ोर्समेंट लर्निंग में, पैरामीटर की वे वैल्यू जो एनवायरमेंट के मौजूदा कॉन्फ़िगरेशन के बारे में बताती हैं. एजेंट इनका इस्तेमाल करके, कार्रवाई चुनता है.
स्टेट-ऐक्शन वैल्यू फ़ंक्शन
Q-फ़ंक्शन के लिए समानार्थी शब्द.
स्टैटिक
कोई काम जो लगातार न किया जाए, बल्कि एक बार किया जाए. स्टैटिक और ऑफ़लाइन शब्द एक-दूसरे के समानार्थी हैं. मशीन लर्निंग में static और offline का इस्तेमाल आम तौर पर इन कामों के लिए किया जाता है:
- स्टैटिक मॉडल (या ऑफ़लाइन मॉडल) एक ऐसा मॉडल होता है जिसे एक बार ट्रेन किया जाता है. इसके बाद, इसका इस्तेमाल कुछ समय तक किया जाता है.
- स्टैटिक ट्रेनिंग (या ऑफ़लाइन ट्रेनिंग) का मतलब, स्टैटिक मॉडल को ट्रेनिंग देने की प्रोसेस से है.
- स्टैटिक इन्फ़रेंस (या ऑफ़लाइन इन्फ़रेंस) एक ऐसी प्रोसेस है जिसमें मॉडल, एक बार में अनुमानों का एक बैच जनरेट करता है.
डाइनैमिक के साथ कंट्रास्ट करें.
स्टैटिक इन्फ़रेंस
ऑफ़लाइन इन्फ़रेंस के लिए समानार्थी शब्द.
स्टेशनैरिटी
ऐसी सुविधा जिसकी वैल्यू एक या उससे ज़्यादा डाइमेंशन (आम तौर पर, समय) के हिसाब से नहीं बदलती. उदाहरण के लिए, अगर किसी सुविधा की वैल्यू 2021 और 2023 में लगभग एक जैसी दिखती हैं, तो इसका मतलब है कि वह सुविधा स्टेशनरी है.
असल दुनिया में, बहुत कम सुविधाओं में स्टेशनरी की सुविधा होती है. स्थिरता से जुड़ी सुविधाओं (जैसे, समुद्र का स्तर) में भी समय के साथ बदलाव होता है.
इसकी तुलना नॉनस्टेशनैरिटी से करें.
चरण
एक बैच का फ़ॉरवर्ड पास और बैकवर्ड पास.
फ़ॉरवर्ड पास और बैकवर्ड पास के बारे में ज़्यादा जानने के लिए, बैकप्रॉपैगेशन देखें.
स्टेप साइज़
लर्निंग रेट का समानार्थी शब्द.
स्टोकेस्टिक ग्रेडिएंट डिसेंट (एसजीडी)
यह ग्रैडिएंट डिसेंट एल्गोरिदम है, जिसमें बैच साइज़ एक होता है. दूसरे शब्दों में कहें, तो SGD, ट्रेनिंग सेट से एक उदाहरण को रैंडम तरीके से चुनकर ट्रेनिंग देता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: हाइपरपैरामीटर देखें.
स्ट्राइड
कनवोल्यूशनल ऑपरेशन या पूलिंग में, इनपुट स्लाइस की अगली सीरीज़ के हर डाइमेंशन में डेल्टा. उदाहरण के लिए, यहां दिए गए ऐनिमेशन में, कनवोल्यूशनल ऑपरेशन के दौरान (1,1) स्ट्राइड को दिखाया गया है. इसलिए, अगला इनपुट स्लाइस, पिछले इनपुट स्लाइस की तुलना में एक पोज़िशन दाईं ओर से शुरू होता है. जब ऑपरेशन दाईं ओर के किनारे पर पहुंच जाता है, तो अगला स्लाइस बाईं ओर के किनारे पर होता है, लेकिन एक पोज़िशन नीचे होता है.
ऊपर दिए गए उदाहरण में, दो डाइमेंशन वाले स्ट्राइड के बारे में बताया गया है. अगर इनपुट मैट्रिक्स तीन डाइमेंशन वाली है, तो स्ट्राइड भी तीन डाइमेंशन वाली होगी.
स्ट्रक्चरल रिस्क मिनिमाइज़ेशन (एसआरएम)
ऐसा एल्गोरिदम जो दो लक्ष्यों को ध्यान में रखता है:
- सबसे सटीक अनुमान लगाने वाला मॉडल बनाना (उदाहरण के लिए, सबसे कम नुकसान).
- मॉडल को जितना हो सके उतना आसान रखना चाहिए. उदाहरण के लिए, स्ट्रॉन्ग रेगुलराइज़ेशन.
उदाहरण के लिए, ट्रेनिंग सेट पर नुकसान+रेगुलराइज़ेशन को कम करने वाला फ़ंक्शन, स्ट्रक्चरल रिस्क मिनिमाइज़ेशन एल्गोरिदम होता है.
इसकी तुलना अनुभवजन्य जोखिम को कम करने से करें.
सबसैंपलिंग
पूलिंग देखें.
सबवर्ड टोकन
लैंग्वेज मॉडल में, टोकन किसी शब्द का सबस्ट्रिंग होता है. यह पूरा शब्द भी हो सकता है.
उदाहरण के लिए, "itemize" जैसे किसी शब्द को "item" (मूल शब्द) और "ize" (सफ़िक्स) जैसे हिस्सों में बांटा जा सकता है. इनमें से हर हिस्से को उसके टोकन से दिखाया जाता है. कम इस्तेमाल होने वाले शब्दों को इस तरह के हिस्सों में बांटने से, भाषा मॉडल को शब्द के ज़्यादा इस्तेमाल होने वाले हिस्सों पर काम करने की अनुमति मिलती है. इन हिस्सों को सबवर्ड कहा जाता है. जैसे, प्रीफ़िक्स और सफ़िक्स.
इसके उलट, "going" जैसे सामान्य शब्दों को अलग-अलग नहीं किया जाता और इन्हें एक ही टोकन से दिखाया जा सकता है.
खास जानकारी
TensorFlow में, किसी खास स्टेप पर कैलकुलेट की गई वैल्यू या वैल्यू का सेट. इसका इस्तेमाल आम तौर पर, ट्रेनिंग के दौरान मॉडल मेट्रिक को ट्रैक करने के लिए किया जाता है.
SuperGLUE
एलएलएम की टेक्स्ट को समझने और जनरेट करने की क्षमता को रेट करने के लिए, डेटासेट का एक ग्रुप. इस मॉडल में ये डेटासेट शामिल हैं:
- बूलियन सवाल (BoolQ)
- CommitmentBank (CB)
- भरोसेमंद विकल्पों का चुनाव (सीओपीए)
- एक से ज़्यादा वाक्यों को पढ़कर जवाब देना (मल्टीआरसी)
- रीडिंग कॉम्प्रिहेंशन विद कॉमनसेंस रीज़निंग डेटासेट (ReCoRD)
- टेक्स्ट से जुड़ी जानकारी को समझना (आरटीई)
- कॉन्टेक्स्ट के हिसाब से शब्दों का इस्तेमाल (डब्ल्यूआईसी)
- विनोग्राड स्कीमा चैलेंज (डब्ल्यूएससी)
ज़्यादा जानकारी के लिए, SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems देखें.
सुपरवाइज़्ड मशीन लर्निंग
सुविधाओं और उनके लेबल से मॉडल को ट्रेनिंग देना. सुपरवाइज़्ड मशीन लर्निंग, किसी विषय को सीखने के लिए सवालों के सेट और उनके जवाबों का अध्ययन करने जैसा है. जब छात्र-छात्रा को सवालों और जवाबों के बीच मैपिंग करने में महारत हासिल हो जाती है, तब वह उसी विषय पर नए (पहले कभी नहीं देखे गए) सवालों के जवाब दे सकता है.
इसकी तुलना अनसुपरवाइज़्ड मशीन लर्निंग से करें.
ज़्यादा जानकारी के लिए, एमएल कोर्स की बुनियादी जानकारी में पर्यवेक्षित लर्निंग देखें.
सिंथेटिक फ़ीचर
ऐसी सुविधा जो इनपुट सुविधाओं में मौजूद नहीं है, लेकिन उनमें से एक या उससे ज़्यादा सुविधाओं से मिलकर बनी है. अप्राकृतिक सुविधाओं को बनाने के तरीकों में ये शामिल हैं:
- किसी कंटीन्यूअस फ़ीचर को रेंज बिन में बकेटिंग करना.
- क्रॉस-फ़िचर बनाना.
- किसी सुविधा की वैल्यू को दूसरी सुविधा की वैल्यू या खुद से गुणा (या भाग) करना. उदाहरण के लिए, अगर
aऔरbइनपुट फ़ीचर हैं, तो यहां सिंथेटिक फ़ीचर के उदाहरण दिए गए हैं:- ab
- a2
- किसी फ़ीचर वैल्यू पर ट्रांसेंडेंटल फ़ंक्शन लागू करना. उदाहरण के लिए, अगर
cएक इनपुट सुविधा है, तो यहां सिंथेटिक सुविधाओं के उदाहरण दिए गए हैं:- sin(c)
- ln(c)
सिर्फ़ नॉर्मलाइज़ेशन या स्केलिंग करके बनाई गई सुविधाओं को सिंथेटिक सुविधाएं नहीं माना जाता.
T
T5
यह टेक्स्ट-टू-टेक्स्ट ट्रांसफ़र लर्निंग मॉडल है. इसे Google AI ने 2020 में लॉन्च किया था. T5, एन्कोडर-डिकोडर मॉडल है. यह ट्रांसफ़ॉर्मर आर्किटेक्चर पर आधारित है. इसे बहुत बड़े डेटासेट पर ट्रेन किया गया है. यह Natural Language Processing (एनएलपी) से जुड़े कई टास्क को आसानी से पूरा कर सकता है. जैसे, टेक्स्ट जनरेट करना, भाषाओं का अनुवाद करना, और बातचीत के तरीके से सवालों के जवाब देना.
T5 का नाम, "टेक्स्ट-टू-टेक्स्ट ट्रांसफ़र ट्रांसफ़ॉर्मर" में मौजूद पांच T से लिया गया है.
T5X
यह एक ओपन-सोर्स, मशीन लर्निंग फ़्रेमवर्क है. इसे बड़े पैमाने पर नैचुरल लैंग्वेज प्रोसेसिंग (एनएलपी) मॉडल बनाने और ट्रेन करने के लिए डिज़ाइन किया गया है. T5 को T5X कोडबेस पर लागू किया गया है. यह JAX और Flax पर बनाया गया है.
टेबल में तैयार डेटा के लिए Q-लर्निंग
रीइन्फ़ोर्समेंट लर्निंग में, Q-लर्निंग को लागू करना. इसके लिए, एक टेबल का इस्तेमाल करके स्टेट और ऐक्शन के हर कॉम्बिनेशन के लिए, Q-फ़ंक्शन सेव किए जाते हैं.
टारगेट
लेबल के लिए समानार्थी शब्द.
टारगेट नेटवर्क
डीप क्यू-लर्निंग में, एक न्यूरल नेटवर्क होता है. यह मुख्य न्यूरल नेटवर्क का एक स्थिर अनुमान होता है. मुख्य न्यूरल नेटवर्क, क्यू-फ़ंक्शन या नीति को लागू करता है. इसके बाद, टारगेट नेटवर्क से अनुमानित Q-वैल्यू के आधार पर, मुख्य नेटवर्क को ट्रेन किया जा सकता है. इसलिए, आपको ऐसे फ़ीडबैक लूप को रोकने में मदद मिलती है जो मुख्य नेटवर्क के खुद से अनुमानित Q-वैल्यू पर ट्रेनिंग देने के दौरान होता है. इस फ़ीडबैक को अनदेखा करने से, ट्रेनिंग की स्थिरता बढ़ती है.
टास्क
ऐसी समस्या जिसे मशीन लर्निंग की तकनीकों का इस्तेमाल करके हल किया जा सकता है. जैसे:
तापमान
यह एक हाइपरपैरामीटर है. यह मॉडल के आउटपुट में रैंडमनेस की डिग्री को कंट्रोल करता है. तापमान जितना ज़्यादा होगा, आउटपुट उतना ही ज़्यादा रैंडम होगा. वहीं, तापमान जितना कम होगा, आउटपुट उतना ही कम रैंडम होगा.
सबसे सही तापमान चुनना, ऐप्लिकेशन और/या स्ट्रिंग वैल्यू पर निर्भर करता है.
समय के हिसाब से डेटा
अलग-अलग समय पर रिकॉर्ड किया गया डेटा. उदाहरण के लिए, साल के हर दिन के लिए रिकॉर्ड की गई सर्दियों के कोट की बिक्री, समय के हिसाब से डेटा होगा.
Tensor
TensorFlow प्रोग्राम में इस्तेमाल होने वाला मुख्य डेटा स्ट्रक्चर. टेंसर, N-डाइमेंशनल (जहां N बहुत बड़ा हो सकता है) डेटा स्ट्रक्चर होते हैं. ये आम तौर पर स्केलर, वेक्टर या मैट्रिक्स होते हैं. टेंसर के एलिमेंट में पूर्णांक, फ़्लोटिंग-पॉइंट या स्ट्रिंग वैल्यू हो सकती हैं.
TensorBoard
यह डैशबोर्ड, एक या उससे ज़्यादा TensorFlow प्रोग्राम के एक्ज़ीक्यूशन के दौरान सेव की गई खास जानकारी दिखाता है.
TensorFlow
यह बड़े पैमाने पर डिस्ट्रिब्यूट किया गया मशीन लर्निंग प्लैटफ़ॉर्म है. इस शब्द का मतलब, TensorFlow स्टैक में मौजूद एपीआई की बुनियादी लेयर भी है. यह डेटाफ़्लो ग्राफ़ पर सामान्य कंप्यूटेशन के साथ काम करती है.
TensorFlow का इस्तेमाल मुख्य रूप से मशीन लर्निंग के लिए किया जाता है. हालांकि, इसका इस्तेमाल ऐसे नॉन-एमएल टास्क के लिए भी किया जा सकता है जिनमें डेटाफ़्लो ग्राफ़ का इस्तेमाल करके संख्यात्मक कंप्यूटेशन की ज़रूरत होती है.
TensorFlow Playground
यह एक ऐसा प्रोग्राम है जो यह दिखाता है कि अलग-अलग हाइपरपैरामीटर, मॉडल (मुख्य रूप से न्यूरल नेटवर्क) की ट्रेनिंग को किस तरह से प्रभावित करते हैं. TensorFlow Playground को आज़माने के लिए, http://playground.tensorflow.org पर जाएं.
TensorFlow Serving
ट्रेन किए गए मॉडल को प्रोडक्शन में डिप्लॉय करने के लिए एक प्लैटफ़ॉर्म.
टेंसर प्रोसेसिंग यूनिट (टीपीयू)
यह ऐप्लिकेशन के लिए खास तौर पर बनाया गया इंटिग्रेटेड सर्किट (एएसआईसी) है. यह मशीन लर्निंग के वर्कलोड की परफ़ॉर्मेंस को ऑप्टिमाइज़ करता है. इन एएसआईसी को TPU डिवाइस पर कई TPU चिप के तौर पर डिप्लॉय किया जाता है.
टेंसर रैंक
rank (Tensor) देखें.
टेंसर का आकार
किसी Tensor में अलग-अलग डाइमेंशन में मौजूद एलिमेंट की संख्या.
उदाहरण के लिए, [5, 10]टेंसर का आकार एक डाइमेंशन में 5 और दूसरे में 10 है.
टेंसर का साइज़
किसी Tensor में मौजूद स्केलर की कुल संख्या. उदाहरण के लिए, a
[5, 10] टेंसर का साइज़ 50 है.
TensorStore
यह एक लाइब्रेरी है. इसका इस्तेमाल करके, कई डाइमेंशन वाले बड़े ऐरे को आसानी से पढ़ा और लिखा जा सकता है.
खाते के बंद होने की शर्त
रीइन्फ़ोर्समेंट लर्निंग में, वे शर्तें जो यह तय करती हैं कि एपिसोड कब खत्म होगा. जैसे, जब एजेंट किसी खास स्थिति में पहुंच जाता है या स्थिति में बदलाव की थ्रेशोल्ड संख्या से ज़्यादा हो जाता है. उदाहरण के लिए, टिक-टैक-टो (इसे नट्स ऐंड क्रॉस भी कहा जाता है) में, कोई एपिसोड तब खत्म होता है, जब कोई खिलाड़ी लगातार तीन स्पेस मार्क कर देता है या जब सभी स्पेस मार्क हो जाते हैं.
जांच
डिसिज़न ट्री में, शर्त का दूसरा नाम.
टेस्ट लॉस
यह मेट्रिक, टेस्ट सेट के हिसाब से मॉडल के लॉस को दिखाती है. मॉडल बनाते समय, आम तौर पर टेस्ट लॉस को कम करने की कोशिश की जाती है. ऐसा इसलिए है, क्योंकि कम टेस्ट लॉस, कम ट्रेनिंग लॉस या कम पुष्टि करने वाले लॉस की तुलना में ज़्यादा भरोसेमंद क्वालिटी सिग्नल होता है.
कभी-कभी, टेस्ट लॉस और ट्रेनिंग लॉस या पुष्टि करने के लॉस के बीच का बड़ा अंतर यह बताता है कि आपको रेगुलराइज़ेशन रेट को बढ़ाना होगा.
टेस्ट सेट
यह डेटासेट का सबसेट होता है. इसका इस्तेमाल, ट्रेन किए गए मॉडल की जांच करने के लिए किया जाता है.
आम तौर पर, डेटासेट में मौजूद उदाहरणों को इन तीन अलग-अलग सबसेट में बांटा जाता है:
- ट्रेनिंग सेट
- वैलिडेशन सेट
- टेस्ट सेट
डेटासेट में मौजूद हर उदाहरण, ऊपर दिए गए सबसेट में से सिर्फ़ एक से जुड़ा होना चाहिए. उदाहरण के लिए, एक ही उदाहरण ट्रेनिंग सेट और टेस्ट सेट, दोनों का हिस्सा नहीं होना चाहिए.
ट्रेनिंग सेट और वैलिडेशन सेट, दोनों ही मॉडल को ट्रेनिंग देने के लिए ज़रूरी होते हैं. टेस्ट सेट, ट्रेनिंग से सिर्फ़ परोक्ष रूप से जुड़ा होता है. इसलिए, टेस्ट लॉस, ट्रेनिंग लॉस या पुष्टि करने वाले डेटा का लॉस की तुलना में कम पक्षपाती और बेहतर क्वालिटी वाली मेट्रिक है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: ओरिजनल डेटासेट को बांटना लेख पढ़ें.
टेक्स्ट स्पैन
यह टेक्स्ट स्ट्रिंग के किसी खास सब-सेक्शन से जुड़ा ऐरे इंडेक्स स्पैन होता है.
उदाहरण के लिए, Python स्ट्रिंग s="Be good now" में मौजूद शब्द good, टेक्स्ट स्पैन 3 से 6 तक होता है.
tf.Example
यह मशीन लर्निंग मॉडल को ट्रेनिंग देने या अनुमान लगाने के लिए, इनपुट डेटा के बारे में बताने वाला एक स्टैंडर्ड प्रोटोकॉल बफ़र है.
tf.keras
Keras को TensorFlow में इंटिग्रेट किया गया है.
थ्रेशोल्ड (डिसीज़न ट्री के लिए)
ऐक्सिस के साथ अलाइन की गई शर्त में, वह वैल्यू जिससे सुविधा की तुलना की जा रही है. उदाहरण के लिए, यहां दी गई शर्त में 75 थ्रेशोल्ड वैल्यू है:
grade >= 75
ज़्यादा जानकारी के लिए, फ़ैसले लेने वाले फ़ॉरेस्ट कोर्स में संख्यात्मक सुविधाओं के साथ बाइनरी क्लासिफ़िकेशन के लिए सटीक स्प्लिटर देखें.
टाइम सीरीज़ का विश्लेषण
यह मशीन लर्निंग और आंकड़ों का एक उपक्षेत्र है. इसमें समय के साथ बदले डेटा का विश्लेषण किया जाता है. मशीन लर्निंग की कई समस्याओं के लिए, टाइम सीरीज़ का विश्लेषण करना ज़रूरी होता है. इनमें क्लासिफ़िकेशन, क्लस्टरिंग, पूर्वानुमान, और गड़बड़ी का पता लगाना शामिल है. उदाहरण के लिए, टाइम सीरीज़ विश्लेषण का इस्तेमाल करके, सर्दियों के कोट की आने वाले महीनों की बिक्री का अनुमान लगाया जा सकता है. इसके लिए, बिक्री के पुराने डेटा का इस्तेमाल किया जाता है.
टाइमस्टेप
रीकरंट न्यूरल नेटवर्क में मौजूद एक "अनरोल्ड" सेल. उदाहरण के लिए, यहां दिए गए डायग्राम में तीन टाइमस्टेप दिखाए गए हैं. इन्हें सबस्क्रिप्ट t-1, t, और t+1 के तौर पर लेबल किया गया है:

टोकन
भाषा मॉडल में, यह सबसे छोटी इकाई होती है जिस पर मॉडल को ट्रेनिंग दी जाती है और जिसके आधार पर अनुमान लगाए जाते हैं. आम तौर पर, टोकन इनमें से कोई एक होता है:
- एक शब्द—उदाहरण के लिए, "dogs like cats" वाक्यांश में तीन शब्द टोकन होते हैं: "dogs", "like", और "cats".
- एक वर्ण—उदाहरण के लिए, "बाइक मछली" वाक्यांश में नौ वर्ण टोकन होते हैं. (ध्यान दें कि खाली जगह को एक टोकन के तौर पर गिना जाता है.)
- सबवर्ड—इसमें एक शब्द, एक या एक से ज़्यादा टोकन हो सकता है. सबवर्ड में मूल शब्द, प्रीफ़िक्स या सफ़िक्स होता है. उदाहरण के लिए, सबवर्ड को टोकन के तौर पर इस्तेमाल करने वाला कोई भाषा मॉडल, "dogs" शब्द को दो टोकन के तौर पर देख सकता है. जैसे, मूल शब्द "dog" और बहुवचन प्रत्यय "s". वही भाषा मॉडल, "taller" शब्द को दो उपशब्दों के तौर पर देख सकता है. जैसे, मूल शब्द "tall" और प्रत्यय "er".
भाषा मॉडल के अलावा अन्य डोमेन में, टोकन अन्य तरह की ऐटम यूनिट को दिखा सकते हैं. उदाहरण के लिए, कंप्यूटर विज़न में, टोकन किसी इमेज का सबसेट हो सकता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लार्ज लैंग्वेज मॉडल देखें.
टोकनाइज़र
यह एक सिस्टम या एल्गोरिदम है, जो इनपुट डेटा के क्रम को टोकन में बदलता है.
ज़्यादातर मॉडर्न फ़ाउंडेशन मॉडल मल्टीमॉडल होते हैं. मल्टीमॉडल सिस्टम के लिए टोकनाइज़र को, हर तरह के इनपुट को सही फ़ॉर्मैट में बदलना होगा. उदाहरण के लिए, अगर इनपुट डेटा में टेक्स्ट और ग्राफ़िक, दोनों शामिल हैं, तो टोकनाइज़र इनपुट टेक्स्ट को सबवर्ड में और इनपुट इमेज को छोटे-छोटे पैच में बदल सकता है. इसके बाद, टोकनाइज़र को सभी टोकन को एक ही यूनिफ़ाइड एम्बेडिंग स्पेस में बदलना होगा. इससे मॉडल को मल्टीमॉडल इनपुट की स्ट्रीम को "समझने" में मदद मिलती है.
टॉप-के ऐक्यूरेसी
जनरेट की गई सूचियों की पहली k पोज़िशन में "टारगेट लेबल" के दिखने का प्रतिशत. ये सूचियां, आपकी दिलचस्पी के हिसाब से दिए गए सुझाव हो सकते हैं. इसके अलावा, ये softmax के हिसाब से क्रम में लगाए गए आइटम की सूची भी हो सकती हैं.
टॉप-k ऐक््यूरेसी को k पर ऐक््यूरेसी के तौर पर भी जाना जाता है.
टॉवर
यह डीप न्यूरल नेटवर्क का एक कॉम्पोनेंट है. यह खुद भी एक डीप न्यूरल नेटवर्क है. कुछ मामलों में, हर टावर अलग-अलग डेटा सोर्स से डेटा लेता है. ये टावर तब तक अलग-अलग रहते हैं, जब तक इनके आउटपुट को फ़ाइनल लेयर में नहीं मिला दिया जाता. अन्य मामलों में, (उदाहरण के लिए, कई Transformers के encoder और decoder टावर में), टावरों के बीच क्रॉस-कनेक्शन होते हैं.
बुरा बर्ताव
कॉन्टेंट कितना आपत्तिजनक, डराने-धमकाने वाला या गाली-गलौज वाला है. मशीन लर्निंग के कई मॉडल, आपत्तिजनक कॉन्टेंट की पहचान कर सकते हैं, उसका आकलन कर सकते हैं, और उसे अलग-अलग कैटगरी में बांट सकते हैं. इनमें से ज़्यादातर मॉडल, कई पैरामीटर के आधार पर बुरे बर्ताव की पहचान करते हैं. जैसे, गाली-गलौज वाली भाषा का लेवल और धमकी देने वाली भाषा का लेवल.
टीपीयू (TPU)
टेंसर प्रोसेसिंग यूनिट के लिए इस्तेमाल किया जाने वाला संक्षिप्त नाम.
TPU चिप
यह एक प्रोग्रामेबल लीनियर अलजेब्रा ऐक्सलरेटर है. इसमें ऑन-चिप हाई बैंडविथ मेमोरी होती है. इसे मशीन लर्निंग के वर्कलोड के लिए ऑप्टिमाइज़ किया गया है. एक TPU डिवाइस पर कई TPU चिप डिप्लॉय किए जाते हैं.
TPU डिवाइस
यह एक प्रिंटेड सर्किट बोर्ड (पीसीबी) होता है. इसमें कई टीपीयू चिप, ज़्यादा बैंडविड्थ वाले नेटवर्क इंटरफ़ेस, और सिस्टम को ठंडा रखने वाला हार्डवेयर होता है.
TPU नोड
Google Cloud पर मौजूद एक टीपीयू संसाधन, जिसमें टीपीयू टाइप की जानकारी दी गई हो. टीपीयू नोड, पीयर वीपीसी नेटवर्क से आपके वीपीसी नेटवर्क से कनेक्ट होता है. टीपीयू नोड, Cloud TPU API में तय किया गया एक संसाधन है.
टीपीयू (TPU) पॉड
Google के डेटा सेंटर में TPU डिवाइसों का कोई खास कॉन्फ़िगरेशन. टीपीयू पॉड में मौजूद सभी डिवाइस, एक-दूसरे से कनेक्ट होते हैं. इसके लिए, तेज़ स्पीड वाला एक खास नेटवर्क इस्तेमाल किया जाता है. टीपीयू पॉड, किसी टीपीयू वर्शन के लिए उपलब्ध टीपीयू डिवाइसों का सबसे बड़ा कॉन्फ़िगरेशन होता है.
TPU रिसॉर्स
Google Cloud पर मौजूद ऐसी टीपीयू इकाई जिसे बनाया, मैनेज किया या इस्तेमाल किया जाता है. उदाहरण के लिए, TPU नोड और TPU टाइप, TPU संसाधन हैं.
TPU स्लाइस
टीपीयू स्लाइस, टीपीयू पॉड में मौजूद टीपीयू डिवाइसों का एक छोटा हिस्सा होता है. टीपीयू स्लाइस में मौजूद सभी डिवाइस, एक-दूसरे से हाई-स्पीड नेटवर्क के ज़रिए कनेक्ट होते हैं.
TPU का टाइप
किसी खास टीपीयू हार्डवेयर वर्शन के साथ एक या उससे ज़्यादा टीपीयू डिवाइस का कॉन्फ़िगरेशन. Google Cloud पर TPU नोड बनाते समय, टीपीयू का टाइप चुना जाता है. उदाहरण के लिए, v2-8
TPU टाइप, आठ कोर वाला एक TPU v2 डिवाइस है. v3-2048 टीपीयू टाइप में, नेटवर्क से जुड़े 256 टीपीयू v3 डिवाइस और कुल 2048 कोर होते हैं. टीपीयू टाइप एक संसाधन है, जिसे Cloud TPU API में तय किया गया है.
TPU वर्कर
यह एक ऐसी प्रोसेस है जो होस्ट मशीन पर चलती है और TPU डिवाइसों पर मशीन लर्निंग प्रोग्राम को एक्ज़ीक्यूट करती है.
ट्रेनिंग
मॉडल में शामिल पैरामीटर (वज़न और बायस) तय करने की प्रोसेस. ट्रेनिंग के दौरान, सिस्टम उदाहरण पढ़ता है और धीरे-धीरे पैरामीटर में बदलाव करता है. ट्रेनिंग के दौरान, हर उदाहरण का इस्तेमाल कुछ बार से लेकर अरबों बार तक किया जाता है.
ज़्यादा जानकारी के लिए, एमएल कोर्स की बुनियादी जानकारी में पर्यवेक्षित लर्निंग देखें.
ट्रेनिंग लॉस
यह मेट्रिक, ट्रेनिंग के किसी खास इटरेशन के दौरान मॉडल के लॉस को दिखाती है. उदाहरण के लिए, मान लें कि लॉस फ़ंक्शन Mean Squared Error है. ऐसा हो सकता है कि 10वें इटरेशन के लिए ट्रेनिंग लॉस (मीन स्क्वेयर्ड एरर) 2.2 हो और 100वें इटरेशन के लिए ट्रेनिंग लॉस 1.9 हो.
लॉस कर्व, ट्रेनिंग लॉस की तुलना में इटरेशन की संख्या को प्लॉट करता है. लॉस कर्व से, ट्रेनिंग के बारे में ये संकेत मिलते हैं:
- नीचे की ओर झुकी हुई लाइन का मतलब है कि मॉडल बेहतर हो रहा है.
- ऊपर की ओर बढ़ती हुई ढलान का मतलब है कि मॉडल की परफ़ॉर्मेंस खराब हो रही है.
- स्लोप के फ़्लैट होने का मतलब है कि मॉडल कन्वर्जेंस पर पहुंच गया है.
उदाहरण के लिए, यहां दिए गए लॉस कर्व से पता चलता है कि:
- शुरुआती इटरेशन के दौरान, नीचे की ओर तेज़ी से गिरता हुआ स्लोप. इससे पता चलता है कि मॉडल में तेज़ी से सुधार हो रहा है.
- ट्रेनिंग के आखिर तक, धीरे-धीरे कम होने वाला (लेकिन अब भी नीचे की ओर) स्लोप. इसका मतलब है कि मॉडल में सुधार जारी है, लेकिन शुरुआती इटरेशन की तुलना में कुछ हद तक धीमी गति से.
- ट्रेनिंग के आखिर में, लॉस में धीरे-धीरे कमी होना. इससे पता चलता है कि मॉडल कन्वर्ज हो रहा है.
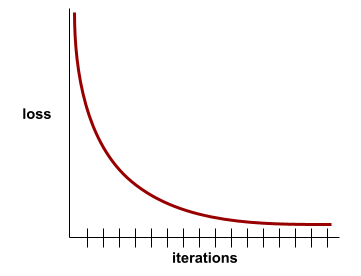
ट्रेनिंग लॉस अहम होता है. हालांकि, सामान्यीकरण के बारे में भी जानें.
ट्रेनिंग और ब्राउज़र में वेब पेज खोलने के दौरान परफ़ॉर्मेंस में अंतर
ट्रेनिंग के दौरान मॉडल की परफ़ॉर्मेंस और सर्विस देने के दौरान उसी मॉडल की परफ़ॉर्मेंस के बीच का अंतर.
ट्रेनिंग सेट
डेटासेट का वह सबसेट जिसका इस्तेमाल मॉडल को ट्रेन करने के लिए किया जाता है.
आम तौर पर, डेटासेट में मौजूद उदाहरणों को तीन अलग-अलग सबसेट में बांटा जाता है:
- ट्रेनिंग सेट
- वैलिडेशन सेट
- टेस्ट सेट
आदर्श रूप से, डेटासेट में मौजूद हर उदाहरण, ऊपर दिए गए सबसेट में से सिर्फ़ एक से जुड़ा होना चाहिए. उदाहरण के लिए, एक ही उदाहरण को ट्रेनिंग सेट और पुष्टि करने वाले सेट, दोनों में शामिल नहीं किया जाना चाहिए.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: ओरिजनल डेटासेट को बांटना लेख पढ़ें.
ट्रैजेक्ट्री
रीइन्फ़ोर्समेंट लर्निंग में, टपल का एक क्रम होता है. यह एजेंट के स्टेट ट्रांज़िशन के क्रम को दिखाता है. इसमें हर टपल, किसी दिए गए स्टेट ट्रांज़िशन के लिए स्टेट, ऐक्शन, इनाम, और अगली स्टेट से मेल खाता है.
ट्रांसफ़र लर्निंग
एक मशीन लर्निंग टास्क से दूसरे टास्क में जानकारी ट्रांसफ़र करना. उदाहरण के लिए, मल्टी-टास्क लर्निंग में एक मॉडल कई टास्क हल करता है. जैसे, डीप मॉडल में अलग-अलग टास्क के लिए अलग-अलग आउटपुट नोड होते हैं. ट्रांसफ़र लर्निंग में, किसी आसान टास्क के समाधान से जुड़ी जानकारी को ज़्यादा मुश्किल टास्क में ट्रांसफ़र किया जा सकता है. इसके अलावा, इसमें ऐसे टास्क से जुड़ी जानकारी को ट्रांसफ़र किया जा सकता है जिसमें ज़्यादा डेटा उपलब्ध है. इस जानकारी को ऐसे टास्क में ट्रांसफ़र किया जाता है जिसमें कम डेटा उपलब्ध है.
ज़्यादातर मशीन लर्निंग सिस्टम, एक काम करते हैं. ट्रांसफ़र लर्निंग, आर्टिफ़िशियल इंटेलिजेंस की ओर पहला कदम है. इसमें एक प्रोग्राम, कई टास्क पूरे कर सकता है.
ट्रांसफ़र्मर
यह Google में डेवलप किया गया एक न्यूरल नेटवर्क आर्किटेक्चर है. यह सेल्फ़-अटेंशन मेकेनिज़्म पर काम करता है. इसकी मदद से, इनपुट एम्बेडिंग के क्रम को आउटपुट एम्बेडिंग के क्रम में बदला जाता है. इसके लिए, कन्वलूशन या रीकरंट न्यूरल नेटवर्क का इस्तेमाल नहीं किया जाता. ट्रांसफ़ॉर्मर को सेल्फ़-अटेंशन लेयर के स्टैक के तौर पर देखा जा सकता है.
ट्रांसफ़ॉर्मर में इनमें से कोई भी शामिल हो सकता है:
एन्कोडर, एम्बेडिंग के किसी क्रम को उसी लंबाई के नए क्रम में बदलता है. एन्कोडर में एक जैसी N लेयर होती हैं. इनमें से हर लेयर में दो सब-लेयर होती हैं. इन दो सब-लेयर को इनपुट एंबेडिंग सीक्वेंस की हर पोज़िशन पर लागू किया जाता है. इससे सीक्वेंस का हर एलिमेंट, एक नई एंबेडिंग में बदल जाता है. पहला एनकोडर सब-लेयर, इनपुट सीक्वेंस से मिली जानकारी को इकट्ठा करता है. दूसरी एन्कोडर सब-लेयर, एग्रीगेट की गई जानकारी को आउटपुट एम्बेडिंग में बदल देती है.
डिकोडर, इनपुट एम्बेडिंग के क्रम को आउटपुट एम्बेडिंग के क्रम में बदलता है. इसकी लंबाई अलग-अलग हो सकती है. डीकोडर में भी तीन सब-लेयर वाली N एक जैसी लेयर शामिल होती हैं. इनमें से दो लेयर, एनकोडर की सब-लेयर जैसी होती हैं. तीसरी डिकोडर सब-लेयर, एनकोडर के आउटपुट को लेती है और उससे जानकारी इकट्ठा करने के लिए, सेल्फ़-अटेंशन मेकेनिज़्म लागू करती है.
ब्लॉग पोस्ट Transformer: A Novel Neural Network Architecture for Language Understanding में, ट्रांसफ़ॉर्मर के बारे में अच्छी जानकारी दी गई है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में एलएलएम: लार्ज लैंग्वेज मॉडल क्या होता है? लेख पढ़ें.
ट्रांसलेशनल इनवेरियंस
इमेज क्लासिफ़िकेशन की समस्या में, किसी एल्गोरिदम की यह क्षमता होती है कि वह इमेज में मौजूद ऑब्जेक्ट की पोज़िशन बदलने पर भी इमेज को सही तरीके से क्लासिफ़ाई कर सके. उदाहरण के लिए, एल्गोरिदम अब भी कुत्ते की पहचान कर सकता है. भले ही, वह फ़्रेम के बीच में हो या फ़्रेम के बाईं ओर हो.
साइज़ इनवेरियंस और रोटेशनल इनवेरियंस के बारे में भी जानें.
ट्रायग्राम
एक N-ग्राम, जिसमें N=3 है.
मज़ेदार सवालों के जवाब देना
एलएलएम की सामान्य ज्ञान के सवालों के जवाब देने की क्षमता का आकलन करने के लिए डेटासेट. हर डेटासेट में, सामान्य ज्ञान के सवालों और उनके जवाबों के जोड़े होते हैं. इन्हें सामान्य ज्ञान में दिलचस्पी रखने वाले लोग तैयार करते हैं. अलग-अलग डेटासेट, अलग-अलग सोर्स से लिए जाते हैं. जैसे:
- वेब पर खोज (TriviaQA)
- Wikipedia (TriviaQA_wiki)
ज़्यादा जानकारी के लिए, TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension देखें.
ट्रू नेगेटिव (टीएन)
इस उदाहरण में, मॉडल ने नेगेटिव क्लास का सही अनुमान लगाया है. उदाहरण के लिए, मॉडल यह अनुमान लगाता है कि कोई ईमेल मैसेज स्पैम नहीं है और वह ईमेल मैसेज वाकई स्पैम नहीं है.
ट्रू पॉज़िटिव (टीपी)
ऐसा उदाहरण जिसमें मॉडल, पॉज़िटिव क्लास का सही अनुमान लगाता है. उदाहरण के लिए, मॉडल यह अनुमान लगाता है कि कोई ईमेल मैसेज स्पैम है और वह ईमेल मैसेज वाकई स्पैम है.
ट्रू पॉज़िटिव रेट (टीपीआर)
recall का समानार्थी शब्द. यानी:
ट्रू पॉज़िटिव रेट, आरओसी कर्व में y-ऐक्सिस होता है.
TTL (टीटीएल)
यह लाइव करने का समय का संक्षिप्त नाम है.
टाइपोलॉजिकल डाइवर्स क्वेश्चन आंसरिंग (TyDi QA)
एलएलएम की, सवालों के जवाब देने की क्षमता का आकलन करने के लिए एक बड़ा डेटासेट. इस डेटासेट में, कई भाषाओं में सवाल और जवाब के जोड़े शामिल हैं.
ज़्यादा जानकारी के लिए, TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages देखें.
U
Ultra
सबसे ज़्यादा पैरामीटर वाला Gemini मॉडल. ज़्यादा जानकारी के लिए, Gemini Ultra लेख पढ़ें.
Pro और Nano के बारे में भी जानें.
संवेदनशील एट्रिब्यूट के बारे में जानकारी न होना
ऐसी स्थिति जिसमें संवेदनशील एट्रिब्यूट मौजूद हैं, लेकिन उन्हें ट्रेनिंग डेटा में शामिल नहीं किया गया है. संवेदनशील एट्रिब्यूट अक्सर किसी व्यक्ति के डेटा के अन्य एट्रिब्यूट से जुड़े होते हैं. इसलिए, किसी संवेदनशील एट्रिब्यूट के बारे में जानकारी न होने पर भी, उस एट्रिब्यूट के हिसाब से मॉडल पर अलग-अलग असर पड़ सकता है. इसके अलावा, मॉडल निष्पक्षता से जुड़ी अन्य शर्तों का उल्लंघन भी कर सकता है.
अंडरफ़िटिंग
मॉडल का अनुमान लगाने की क्षमता कम होना, क्योंकि मॉडल ने ट्रेनिंग डेटा की जटिलता को पूरी तरह से कैप्चर नहीं किया है. कई समस्याओं की वजह से अंडरफ़िटिंग हो सकती है. इनमें ये समस्याएं शामिल हैं:
- सुविधाओं के गलत सेट पर ट्रेनिंग दी गई हो.
- बहुत कम इपॉक के लिए ट्रेनिंग दी गई है या लर्निंग रेट बहुत कम है.
- रेगुलराइज़ेशन रेट बहुत ज़्यादा होने पर ट्रेनिंग.
- डीप न्यूरल नेटवर्क में बहुत कम हिडन लेयर उपलब्ध कराना.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में ओवरफ़िटिंग देखें.
अंडरसैंपलिंग
ट्रेनिंग सेट को ज़्यादा संतुलित बनाने के लिए, क्लास के असंतुलित डेटासेट में मौजूद ज़्यादातर क्लास से उदाहरण हटाना.
उदाहरण के लिए, ऐसे डेटासेट पर विचार करें जिसमें माइनॉरिटी क्लास के मुकाबले मेजॉरिटी क्लास का अनुपात 20:1 है. क्लास के इस असंतुलन को दूर करने के लिए, एक ट्रेनिंग सेट बनाया जा सकता है. इसमें माइनॉरिटी क्लास के सभी उदाहरण शामिल किए जा सकते हैं. हालांकि, मेजॉरिटी क्लास के सिर्फ़ दसवें हिस्से के उदाहरण शामिल किए जा सकते हैं. इससे ट्रेनिंग-सेट क्लास का अनुपात 2:1 हो जाएगा. अंडरसैंपलिंग की वजह से, इस ज़्यादा संतुलित ट्रेनिंग सेट से बेहतर मॉडल तैयार किया जा सकता है. इसके अलावा, इस बेहतर ट्रेनिंग सेट में, असरदार मॉडल को ट्रेन करने के लिए ज़रूरी उदाहरण मौजूद नहीं हो सकते.
इसकी तुलना ओवरसैंपलिंग से करें.
एकतरफ़ा
ऐसा सिस्टम जो सिर्फ़ उस टेक्स्ट का आकलन करता है जो टेक्स्ट के टारगेट सेक्शन से पहले आता है. इसके उलट, दोनों दिशाओं में काम करने वाला सिस्टम, टेक्स्ट के टारगेट सेक्शन से पहले और बाद के टेक्स्ट, दोनों का आकलन करता है. ज़्यादा जानकारी के लिए, दोनों दिशाओं में देखें.
एकतरफ़ा लैंग्वेज मॉडल
यह एक लैंग्वेज मॉडल है. यह टारगेट टोकन से पहले दिखने वाले टोकन के आधार पर ही संभावनाओं का अनुमान लगाता है, बाद में दिखने वाले टोकन के आधार पर नहीं. इसकी तुलना दोनों भाषाओं में काम करने वाले लैंग्वेज मॉडल से करें.
बिना लेबल वाला उदाहरण
ऐसा उदाहरण जिसमें सुविधाएं शामिल हैं, लेकिन लेबल नहीं है. उदाहरण के लिए, यहां दी गई टेबल में, घर की वैल्यू का अनुमान लगाने वाले मॉडल के तीन ऐसे उदाहरण दिखाए गए हैं जिन्हें लेबल नहीं किया गया है. इनमें से हर उदाहरण में तीन सुविधाएं हैं, लेकिन घर की वैल्यू नहीं है:
| कमरों की संख्या | बाथरूम की संख्या | घर की उम्र |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
सुपरवाइज़्ड मशीन लर्निंग में, मॉडल को लेबल किए गए उदाहरणों के आधार पर ट्रेन किया जाता है. साथ ही, वे बिना लेबल वाले उदाहरणों के आधार पर अनुमान लगाते हैं.
सेमी-सुपरवाइज़्ड और अनसुपरवाइज़्ड लर्निंग में, ट्रेनिंग के दौरान बिना लेबल वाले उदाहरणों का इस्तेमाल किया जाता है.
लेबल किए गए उदाहरण के साथ, बिना लेबल वाले उदाहरण की तुलना करें.
अनसुपरवाइज़्ड मशीन लर्निंग
किसी डेटासेट में पैटर्न ढूंढने के लिए, मॉडल को ट्रेन करना. आम तौर पर, यह लेबल नहीं किया गया डेटासेट होता है.
बिना निगरानी वाली मशीन लर्निंग का सबसे ज़्यादा इस्तेमाल, डेटा को मिलते-जुलते उदाहरणों के ग्रुप में क्लस्टर करने के लिए किया जाता है. उदाहरण के लिए, बिना निगरानी वाले मशीन लर्निंग एल्गोरिदम, संगीत की अलग-अलग प्रॉपर्टी के आधार पर गानों को क्लस्टर कर सकता है. इन क्लस्टर का इस्तेमाल, मशीन लर्निंग के अन्य एल्गोरिदम के लिए इनपुट के तौर पर किया जा सकता है. उदाहरण के लिए, संगीत के सुझाव देने वाली सेवा के लिए. अगर काम के लेबल कम हैं या मौजूद नहीं हैं, तो क्लस्टरिंग से मदद मिल सकती है. उदाहरण के लिए, धोखाधड़ी और गलत इस्तेमाल रोकने जैसे डोमेन में क्लस्टर, लोगों को डेटा को बेहतर तरीके से समझने में मदद कर सकते हैं.
इसकी तुलना सुपरवाइज़्ड मशीन लर्निंग से करें.
ज़्यादा जानकारी के लिए, एमएल के बारे में जानकारी देने वाले कोर्स में मशीन लर्निंग क्या है? देखें.
अपलिफ़्ट मॉडलिंग
यह मॉडलिंग की एक ऐसी तकनीक है जिसका इस्तेमाल आम तौर पर मार्केटिंग में किया जाता है. यह किसी "इलाज" का किसी "व्यक्ति" पर पड़ने वाले "कारण और असर" (इसे "इंक्रीमेंटल इम्पैक्ट" भी कहा जाता है) को मॉडल करती है. यहां दो उदाहरण दिए गए हैं:
- डॉक्टर, अपलिफ़्ट मॉडलिंग का इस्तेमाल करके यह अनुमान लगा सकते हैं कि किसी मरीज़ (व्यक्ति) की उम्र और मेडिकल इतिहास के आधार पर, किसी मेडिकल प्रक्रिया (इलाज) से उसकी मौत के जोखिम (कारण-कार्य संबंध) में कितनी कमी आएगी.
- मार्केटर, अपलिफ़्ट मॉडलिंग का इस्तेमाल करके यह अनुमान लगा सकते हैं कि किसी व्यक्ति (इकाई) को विज्ञापन (ट्रीटमेंट) दिखाने की वजह से, खरीदारी की संभावना (वजह से होने वाला असर) में कितनी बढ़ोतरी हुई.
अपलिफ़्ट मॉडलिंग, क्लासिफ़िकेशन या रिग्रेशन से इस मामले में अलग है कि अपलिफ़्ट मॉडलिंग में कुछ लेबल हमेशा मौजूद नहीं होते. उदाहरण के लिए, बाइनरी ट्रीटमेंट में आधे लेबल. उदाहरण के लिए, किसी मरीज़ को इलाज मिल सकता है या नहीं भी मिल सकता है; इसलिए, हम सिर्फ़ यह देख सकते हैं कि इन दो स्थितियों में से किसी एक में मरीज़ ठीक होगा या नहीं. हालांकि, दोनों स्थितियों में ऐसा कभी नहीं होता. अपलिफ़्ट मॉडल का मुख्य फ़ायदा यह है कि यह ऐसी स्थिति के लिए अनुमान जनरेट कर सकता है जिसे देखा नहीं गया है (काउंटरफ़ैक्चुअल). साथ ही, इसका इस्तेमाल वजह और असर का हिसाब लगाने के लिए किया जा सकता है.
अपवेटिंग
डाउनसैंपल किए गए क्लास को उतना ही वेट असाइन करें जितना डाउनसैंपल किया गया है.
उपयोगकर्ता मैट्रिक्स
सुझाव देने वाले सिस्टम में, मैट्रिक्स फ़ैक्टराइज़ेशन से जनरेट किया गया एम्बेडिंग वेक्टर होता है. इसमें उपयोगकर्ता की प्राथमिकताओं के बारे में छिपे हुए सिग्नल होते हैं. उपयोगकर्ता मैट्रिक्स की हर लाइन में, किसी एक उपयोगकर्ता के लिए अलग-अलग लेटेंट सिग्नल की तुलनात्मक ताकत के बारे में जानकारी होती है. उदाहरण के लिए, फ़िल्म का सुझाव देने वाले सिस्टम पर विचार करें. इस सिस्टम में, उपयोगकर्ता मैट्रिक्स में मौजूद लेटेंट सिग्नल, किसी खास शैली में हर उपयोगकर्ता की दिलचस्पी को दिखा सकते हैं. इसके अलावा, ये ऐसे सिग्नल भी हो सकते हैं जिन्हें समझना मुश्किल होता है. इनमें कई फ़ैक्टर के आधार पर जटिल इंटरैक्शन शामिल होते हैं.
उपयोगकर्ता मैट्रिक्स में, हर लेटेंट फ़ीचर के लिए एक कॉलम और हर उपयोगकर्ता के लिए एक लाइन होती है. इसका मतलब है कि उपयोगकर्ता मैट्रिक्स में उतनी ही लाइनें होती हैं जितनी टारगेट मैट्रिक्स में होती हैं. उदाहरण के लिए, अगर 10 लाख उपयोगकर्ताओं के लिए किसी मूवी का सुझाव देने वाला सिस्टम दिया गया है, तो उपयोगकर्ता मैट्रिक्स में 10 लाख लाइनें होंगी.
V
वैलिडेशन
किसी मॉडल की क्वालिटी का शुरुआती आकलन. पुष्टि करने की प्रोसेस में, मॉडल के अनुमानों की क्वालिटी की जांच की जाती है. इसके लिए, पुष्टि करने के लिए इस्तेमाल किए जाने वाले डेटा सेट का इस्तेमाल किया जाता है.
पुष्टि करने के लिए इस्तेमाल किया गया डेटा, ट्रेनिंग के लिए इस्तेमाल किए गए डेटा से अलग होता है. इसलिए, पुष्टि करने से ओवरफ़िटिंग से बचने में मदद मिलती है.
मॉडल का आकलन करने के लिए, पुष्टि करने वाले सेट का इस्तेमाल करना, टेस्टिंग का पहला राउंड माना जा सकता है. वहीं, मॉडल का आकलन करने के लिए, टेस्ट सेट का इस्तेमाल करना, टेस्टिंग का दूसरा राउंड माना जा सकता है.
पुष्टि करने के दौरान होने वाला नुकसान
यह एक मेट्रिक है. यह ट्रेनिंग के किसी इटरेशन के दौरान, पुष्टि करने वाले सेट पर मॉडल के लॉस को दिखाती है.
जनरलाइज़ेशन कर्व भी देखें.
वैलिडेशन सेट
डेटासेट का वह सबसेट जो ट्रेन किए गए मॉडल के ख़िलाफ़ शुरुआती आकलन करता है. आम तौर पर, ट्रेन किए गए मॉडल का आकलन टेस्ट सेट के आधार पर करने से पहले, कई बार मान्य किए गए सेट के आधार पर किया जाता है.
आम तौर पर, डेटासेट में मौजूद उदाहरणों को इन तीन अलग-अलग सबसेट में बांटा जाता है:
- ट्रेनिंग सेट
- वैलिडेशन सेट
- टेस्ट सेट
आदर्श रूप से, डेटासेट में मौजूद हर उदाहरण, ऊपर दिए गए सबसेट में से सिर्फ़ एक से जुड़ा होना चाहिए. उदाहरण के लिए, एक ही उदाहरण को ट्रेनिंग सेट और पुष्टि करने वाले सेट, दोनों में शामिल नहीं किया जाना चाहिए.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में डेटासेट: ओरिजनल डेटासेट को बांटना लेख पढ़ें.
वैल्यू का अनुमान लगाना
किसी वैल्यू के मौजूद न होने पर, उसकी जगह स्वीकार की जाने वाली वैल्यू का इस्तेमाल करने की प्रोसेस. वैल्यू मौजूद न होने पर, पूरे उदाहरण को खारिज किया जा सकता है. इसके अलावा, उदाहरण को ठीक करने के लिए वैल्यू का अनुमान लगाया जा सकता है.
उदाहरण के लिए, मान लें कि किसी डेटासेट में temperature एक ऐसी सुविधा है जिसे हर घंटे रिकॉर्ड किया जाना चाहिए. हालांकि, किसी खास घंटे के लिए तापमान की रीडिंग उपलब्ध नहीं थी. यहां डेटासेट का एक सेक्शन दिया गया है:
| टाइमस्टैम्प | तापमान |
|---|---|
| 1680561000 | 10 |
| 1680564600 | 12 |
| 1680568200 | मौजूद नहीं |
| 1680571800 | 20 |
| 1680575400 | 21 |
| 1680579000 | 21 |
सिस्टम, उदाहरण में मौजूद तापमान की वैल्यू को मिटा सकता है या अनुमानित तापमान को 12, 16, 18 या 20 के तौर पर सेट कर सकता है. यह अनुमान लगाने के लिए इस्तेमाल किए गए एल्गोरिदम पर निर्भर करता है.
वैनिशिंग ग्रेडिएंट की समस्या
कुछ डीप न्यूरल नेटवर्क की शुरुआती हिडन लेयर के ग्रेडिएंट काफ़ी कम हो जाते हैं. ग्रेडिएंट जितना कम होगा, डीप न्यूरल नेटवर्क में नोड के वेट में उतना ही कम बदलाव होगा. इससे मॉडल को सीखने में कम या कोई मदद नहीं मिलेगी. वैनिशिंग ग्रेडिएंट की समस्या वाले मॉडल को ट्रेन करना मुश्किल या नामुमकिन हो जाता है. लॉन्ग शॉर्ट-टर्म मेमोरी सेल इस समस्या को हल करती हैं.
इसकी तुलना एक्सप्लोडिंग ग्रेडिएंट की समस्या से करें.
वैरिएबल के महत्व
स्कोर का एक ऐसा सेट जो मॉडल के लिए हर फ़ीचर की अहमियत दिखाता है.
उदाहरण के लिए, डिसिज़न ट्री पर आधारित एक मॉडल लें, जो घर की कीमतों का अनुमान लगाता है. मान लें कि इस फ़ैसले के ट्री में तीन सुविधाओं का इस्तेमाल किया गया है: साइज़, उम्र, और स्टाइल. अगर तीन सुविधाओं के लिए, वैरिएबल के महत्व का सेट {size=5.8, age=2.5, style=4.7} के तौर पर कैलकुलेट किया जाता है, तो साइज़, उम्र या स्टाइल की तुलना में फ़ैसले के ट्री के लिए ज़्यादा अहम होता है.
वैरिएबल की अहमियत को मेज़र करने वाली अलग-अलग मेट्रिक मौजूद हैं. इनसे एमएल विशेषज्ञों को मॉडल के अलग-अलग पहलुओं के बारे में जानकारी मिल सकती है.
वैरिएशनल ऑटोएन्कोडर (वीएई)
यह एक तरह का ऑटोएन्कोडर होता है. यह इनपुट और आउटपुट के बीच के अंतर का इस्तेमाल करके, इनपुट के बदले हुए वर्शन जनरेट करता है. वेरिएशनल ऑटोएन्कोडर, जनरेटिव एआई के लिए फ़ायदेमंद होते हैं.
वीएई, वैरिएशनल इन्फ़रेंस पर आधारित होते हैं. यह एक ऐसी तकनीक है जिसका इस्तेमाल, किसी संभावना मॉडल के पैरामीटर का अनुमान लगाने के लिए किया जाता है.
वेक्टर
यह एक ऐसा शब्द है जिसका इस्तेमाल बहुत ज़्यादा किया जाता है. इसका मतलब गणित और विज्ञान के अलग-अलग फ़ील्ड में अलग-अलग होता है. मशीन लर्निंग में, किसी वेक्टर की दो प्रॉपर्टी होती हैं:
- डेटा टाइप: मशीन लर्निंग में वेक्टर, आम तौर पर फ़्लोटिंग-पॉइंट नंबर सेव करते हैं.
- एलिमेंट की संख्या: यह वेक्टर की लंबाई या इसका डाइमेंशन होता है.
उदाहरण के लिए, एक फ़ीचर वेक्टर पर विचार करें, जिसमें आठ फ़्लोटिंग-पॉइंट नंबर होते हैं. इस फ़ीचर वेक्टर की लंबाई या डाइमेंशन आठ है. ध्यान दें कि मशीन लर्निंग वेक्टर में अक्सर डाइमेंशन की संख्या बहुत ज़्यादा होती है.
कई तरह की जानकारी को वेक्टर के तौर पर दिखाया जा सकता है. उदाहरण के लिए:
- धरती की सतह पर मौजूद किसी भी जगह को दो डाइमेंशन वाले वेक्टर के तौर पर दिखाया जा सकता है. इसमें एक डाइमेंशन अक्षांश और दूसरा देशांतर होता है.
- 500 स्टॉक की मौजूदा कीमतों को 500 डाइमेंशन वाले वेक्टर के तौर पर दिखाया जा सकता है.
- क्लास की सीमित संख्या के लिए प्रॉबबिलिटी डिस्ट्रिब्यूशन को वेक्टर के तौर पर दिखाया जा सकता है. उदाहरण के लिए, मल्टीक्लास क्लासिफ़िकेशन सिस्टम, तीन आउटपुट रंगों (लाल, हरा या पीला) में से किसी एक का अनुमान लगाता है. यह
P[red]=0.3, P[green]=0.2, P[yellow]=0.5का मतलब बताने के लिए,(0.3, 0.2, 0.5)वेक्टर को आउटपुट कर सकता है.
वेक्टर को एक साथ जोड़ा जा सकता है. इसलिए, अलग-अलग तरह के मीडिया को एक वेक्टर के तौर पर दिखाया जा सकता है. कुछ मॉडल, कई वन-हॉट एन्कोडिंग के कॉनकैटेनेशन पर सीधे तौर पर काम करते हैं.
टीपीयू जैसे खास प्रोसेसर, वेक्टर पर गणितीय कार्रवाइयां करने के लिए ऑप्टिमाइज़ किए जाते हैं.
वेक्टर, रैंक 1 का टेंसर होता है.
शीर्ष बिंदु
Google Cloud का एआई और मशीन लर्निंग प्लैटफ़ॉर्म. Vertex, एआई ऐप्लिकेशन बनाने, डिप्लॉय करने, और मैनेज करने के लिए टूल और इन्फ़्रास्ट्रक्चर उपलब्ध कराता है. इसमें Gemini के मॉडल का ऐक्सेस भी शामिल है.वाइब कोडिंग
सॉफ़्टवेयर बनाने के लिए, जनरेटिव एआई मॉडल को प्रॉम्प्ट देना. इसका मतलब है कि आपके प्रॉम्प्ट में सॉफ़्टवेयर के मकसद और सुविधाओं के बारे में बताया जाता है. जनरेटिव एआई मॉडल, इसे सोर्स कोड में बदलता है. जनरेट किया गया कोड हमेशा आपकी उम्मीदों के मुताबिक नहीं होता. इसलिए, वाइब कोडिंग के लिए आम तौर पर दोहराव की ज़रूरत होती है.
आंद्रे करपाथी ने इस X पोस्ट में वाइब कोडिंग शब्द का इस्तेमाल किया था. X पर की गई पोस्ट में, कार्पेथी ने इसे "एक नई तरह की कोडिंग...जहां आप पूरी तरह से वाइब्स के हिसाब से काम करते हैं..." बताया है. इसलिए, इस शब्द का मतलब मूल रूप से सॉफ़्टवेयर बनाने के लिए जान-बूझकर ढीला-ढाला तरीका अपनाना है. इसमें जनरेट किए गए कोड की जांच भी नहीं की जाती है. हालांकि, कई लोगों के लिए इस शब्द का मतलब अब तेज़ी से बदल गया है. अब इसका मतलब, एआई से जनरेट की गई कोडिंग के किसी भी रूप से है.
वाइब कोडिंग के बारे में ज़्यादा जानकारी के लिए, वाइब कोडिंग क्या है?.
इसके अलावा, वाइब कोडिंग की तुलना इन चीज़ों से करें और इनके बीच अंतर बताएं:
W
Wasserstein loss
यह लॉस फ़ंक्शन, जनरेटिव ऐडवर्सैरियल नेटवर्क में आम तौर पर इस्तेमाल किया जाता है. यह जनरेट किए गए डेटा और असली डेटा के डिस्ट्रिब्यूशन के बीच अर्थ मूवर डिस्टेंस पर आधारित होता है.
वज़न का डेटा
यह एक ऐसी वैल्यू होती है जिसे मॉडल, दूसरी वैल्यू से गुणा करता है. ट्रेनिंग, मॉडल के सबसे सही वेट तय करने की प्रोसेस है; अनुमान, अनुमान लगाने के लिए सीखे गए वेट का इस्तेमाल करने की प्रोसेस है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन देखें.
वेटेड ऑल्टरनेटिंग लीस्ट स्क्वेयर (डब्ल्यूएएलएस)
सुझाव देने वाले सिस्टम में मैट्रिक्स फ़ैक्टराइज़ेशन के दौरान ऑब्जेक्टिव फ़ंक्शन को कम करने के लिए एल्गोरिदम. इससे, मौजूद न होने वाले उदाहरणों को कम किया जा सकता है. WALS, ओरिजनल मैट्रिक्स और रीकंस्ट्रक्शन के बीच वेटेड स्क्वेयर्ड एरर को कम करता है. इसके लिए, वह बारी-बारी से पंक्ति के फ़ैक्टराइज़ेशन और कॉलम के फ़ैक्टराइज़ेशन को ठीक करता है. इनमें से हर ऑप्टिमाइज़ेशन को, लीस्ट स्क्वेयर कॉन्वेक्स ऑप्टिमाइज़ेशन की मदद से हल किया जा सकता है. ज़्यादा जानकारी के लिए, सुझाव देने वाले सिस्टम का कोर्स देखें.
वेटेड सम
सभी काम की इनपुट वैल्यू का योग, जिसे उनके संबंधित वेट से गुणा किया जाता है. उदाहरण के लिए, मान लें कि काम के इनपुट में यह जानकारी शामिल है:
| इनपुट वैल्यू | इनपुट वज़न |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
इसलिए, वज़न के हिसाब से कुल स्कोर यह होगा:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
वेटेड सम, ऐक्टिवेशन फ़ंक्शन का इनपुट आर्ग्युमेंट होता है.
WiC
कॉन्टेक्स्ट के हिसाब से शब्दों के इस्तेमाल के लिए अब्रिविएशन.
वाइड मॉडल
यह एक लीनियर मॉडल है, जिसमें आम तौर पर कई स्पार्स इनपुट फ़ीचर होते हैं. हम इसे "वाइड" मॉडल कहते हैं, क्योंकि यह एक खास तरह का न्यूरल नेटवर्क होता है. इसमें कई इनपुट होते हैं, जो सीधे तौर पर आउटपुट नोड से कनेक्ट होते हैं. डीप मॉडल की तुलना में, वाइड मॉडल को डीबग करना और उनकी जांच करना ज़्यादा आसान होता है. वाइड मॉडल, हिडन लेयर के ज़रिए नॉनलीनियरिटी को एक्सप्रेस नहीं कर सकते. हालांकि, वाइड मॉडल अलग-अलग तरीकों से नॉनलीनियरिटी को मॉडल करने के लिए, फ़ीचर क्रॉसिंग और बकेटाइज़ेशन जैसे ट्रांसफ़ॉर्मेशन का इस्तेमाल कर सकते हैं.
डीप मॉडल से तुलना करें.
चौड़ाई
किसी न्यूरल नेटवर्क की किसी लेयर में मौजूद न्यूरॉन की संख्या.
WikiLingua (wiki_lingua)
यह डेटासेट, छोटे लेखों की खास जानकारी देने की एलएलएम की क्षमता का आकलन करने के लिए बनाया गया है. WikiHow, एक ऐसा एनसाइक्लोपीडिया है जिसमें अलग-अलग कामों को करने का तरीका बताया गया है. यह दोनों लेखों और खास जानकारी के लिए, इंसानों के लिखे हुए सोर्स का इस्तेमाल करता है. डेटासेट की हर एंट्री में ये शामिल होते हैं:
- एक लेख, जिसे नंबर वाली सूची के गद्य (पैराग्राफ़) वर्शन के हर चरण को जोड़कर बनाया जाता है. इसमें हर चरण का शुरुआती वाक्य शामिल नहीं होता.
- उस लेख की खास जानकारी. इसमें नंबर वाली सूची में दिए गए हर चरण का शुरुआती वाक्य शामिल होता है.
ज़्यादा जानकारी के लिए, WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization लेख पढ़ें.
विनोग्राड स्कीमा चैलेंज (डब्ल्यूएससी)
यह एक फ़ॉर्मैट है. इसका इस्तेमाल, एलएलएम की इस क्षमता का आकलन करने के लिए किया जाता है कि वह किसी सर्वनाम से जुड़े संज्ञा वाक्यांश का पता लगा सकता है या नहीं. इस फ़ॉर्मैट के मुताबिक, डेटासेट भी तैयार किया जा सकता है.
विनोग्राड स्कीमा चैलेंज में हर एंट्री में ये शामिल होते हैं:
- एक छोटा पैसेज, जिसमें टारगेट किया गया सर्वनाम शामिल हो
- टारगेट किया गया सर्वनाम
- संभावित संज्ञा वाक्यांश, जिनके बाद सही जवाब (बूलियन) दिया गया है. अगर टारगेट किया गया सर्वनाम इस उम्मीदवार के बारे में बताता है, तो जवाब True होता है. अगर टारगेट किया गया सर्वनाम, इस उम्मीदवार के बारे में नहीं बताता है, तो जवाब False होता है.
उदाहरण के लिए:
- पैसेज: मार्क ने पीट से अपने बारे में कई झूठ बोले, जिन्हें पीट ने अपनी किताब में शामिल किया. उसे ज़्यादा ईमानदारी दिखानी चाहिए थी.
- टारगेट किया गया सर्वनाम: वह
- कैंडिडेट के संज्ञा वाक्यांश:
- मार्क: सही है, क्योंकि टारगेट किया गया सर्वनाम मार्क के लिए इस्तेमाल किया गया है
- पीट: गलत, क्योंकि टारगेट सर्वनाम, पीटर के लिए इस्तेमाल नहीं किया गया है
विनोग्राड स्कीमा चैलेंज, SuperGLUE का हिस्सा है.
विज़डम ऑफ़ द क्राउड
यह सिद्धांत बताता है कि लोगों के बड़े ग्रुप ("क्राउड") की राय या अनुमानों का औसत निकालने पर, अक्सर अच्छे नतीजे मिलते हैं. उदाहरण के लिए, एक ऐसे गेम के बारे में सोचें जिसमें लोग यह अनुमान लगाते हैं कि एक बड़े जार में कितनी जेली बीन्स भरी गई हैं. हालांकि, ज़्यादातर लोगों के अनुमान सही नहीं होंगे, लेकिन सभी अनुमानों का औसत, जार में मौजूद जेली बीन्स की असल संख्या के काफ़ी करीब होता है. यह बात अनुभव के आधार पर साबित हुई है.
Ensembles, 'विज़डम ऑफ़ द क्राउड' के सिद्धांत पर काम करने वाला सॉफ़्टवेयर है. भले ही, अलग-अलग मॉडल बहुत ज़्यादा गलत अनुमान लगाएं, लेकिन कई मॉडल के अनुमानों का औसत निकालने पर, अक्सर हैरान करने वाले सटीक अनुमान मिलते हैं. उदाहरण के लिए, ऐसा हो सकता है कि कोई डिसिज़न ट्री सही अनुमान न लगा पाए. हालांकि, डिसिज़न फ़ॉरेस्ट अक्सर बहुत अच्छे अनुमान लगाता है.
WMT
यह मशीनी अनुवाद पर कॉन्फ़्रेंस का संक्षिप्त नाम है. (इसका संक्षिप्त नाम WMT है, क्योंकि इसका मूल नाम Workshop on Machine Translation था.) इस कॉन्फ़्रेंस में, मशीन ट्रांसलेशन सिस्टम के डेवलपमेंट पर फ़ोकस किया जाता है.
वर्ड एम्बेडिंग
एंबेडिंग वेक्टर में, शब्दों के सेट में मौजूद हर शब्द को वेक्टर के तौर पर दिखाना. इसका मतलब है कि हर शब्द को 0.0 और 1.0 के बीच की फ़्लोटिंग-पॉइंट वैल्यू के वेक्टर के तौर पर दिखाना. एक जैसे मतलब वाले शब्दों के वेक्टर, अलग-अलग मतलब वाले शब्दों के वेक्टर की तुलना में ज़्यादा मिलते-जुलते होते हैं. उदाहरण के लिए, गाजर, अजवाइन, और खीरे के सभी डाइमेंशन के लिए, एक जैसे वेक्टर मिलेंगे. ये वेक्टर, हवाई जहाज़, धूप का चश्मा, और टूथपेस्ट के वेक्टर से काफ़ी अलग होंगे.
कॉन्टेक्स्ट के हिसाब से शब्द (डब्ल्यूआईसी)
यह डेटासेट, इस बात का आकलन करने के लिए है कि एलएलएम, कॉन्टेक्स्ट का इस्तेमाल करके उन शब्दों को कितनी अच्छी तरह समझता है जिनके कई मतलब होते हैं. डेटासेट की हर एंट्री में यह जानकारी शामिल होती है:
- दो वाक्य, जिनमें से हर वाक्य में टारगेट किया गया शब्द मौजूद हो
- टारगेट किया गया शब्द
- सही जवाब (बूलियन), जहां:
- True का मतलब है कि टारगेट किए गए शब्द का मतलब दोनों वाक्यों में एक जैसा है
- झूठा का मतलब है कि टारगेट किए गए शब्द का मतलब दोनों वाक्यों में अलग-अलग है
उदाहरण के लिए:
- दो वाक्य:
- नदी के किनारे बहुत सारा कचरा पड़ा है.
- सोते समय, मैं अपने बिस्तर के बगल में एक गिलास पानी रखता/रखती हूँ.
- टारगेट किया गया शब्द: बिस्तर
- सही जवाब: गलत, क्योंकि टारगेट किए गए शब्द का मतलब दोनों वाक्यों में अलग-अलग है.
ज़्यादा जानकारी के लिए, WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations देखें.
Words in Context, SuperGLUE ensemble का एक कॉम्पोनेंट है.
WSC
विनोग्राड स्कीमा चैलेंज का संक्षिप्त नाम.
X
XLA (ऐक्सलरेटेड लीनियर ऐलजेब्रा)
यह जीपीयू, सीपीयू, और एमएल ऐक्सलरेटर के लिए, ओपन-सोर्स मशीन लर्निंग कंपाइलर है.
XLA कंपाइलर, PyTorch, TensorFlow, और JAX जैसे लोकप्रिय एमएल फ़्रेमवर्क से मॉडल लेता है. इसके बाद, उन्हें अलग-अलग हार्डवेयर प्लैटफ़ॉर्म पर बेहतर तरीके से एक्ज़ीक्यूट करने के लिए ऑप्टिमाइज़ करता है. इनमें जीपीयू, सीपीयू, और एमएल ऐक्सलरेटर शामिल हैं.
XL-Sum (xlsum)
यह एक ऐसा डेटासेट है जिसका इस्तेमाल, टेक्स्ट को खास जानकारी में बदलने के लिए एलएलएम की परफ़ॉर्मेंस का आकलन करने के लिए किया जाता है. XL-Sum, कई भाषाओं में जवाब देता है. डेटासेट की हर एंट्री में यह जानकारी शामिल होती है:
- ब्रिटिश ब्रॉडकास्टिंग कंपनी (बीबीसी) से लिया गया एक लेख.
- लेखक ने लेख के बारे में कम शब्दों में जानकारी दी है. ध्यान दें कि जवाब में ऐसे शब्द या वाक्यांश शामिल हो सकते हैं जो लेख में मौजूद नहीं हैं.
ज़्यादा जानकारी के लिए, XL-Sum: 44 भाषाओं के लिए बड़े पैमाने पर मल्टीलिंग्वल ऐब्स्ट्रैक्टिव समराइज़ेशन देखें.
xsum
ज़्यादा जानकारी को कम शब्दों में बताने के लिए इस्तेमाल किया जाने वाला संक्षिप्त नाम.
Z
बिना उदाहरण वाली लर्निंग
यह एक तरह की मशीन लर्निंग ट्रेनिंग है. इसमें मॉडल, किसी ऐसे टास्क के लिए अनुमान लगाता है जिसके लिए उसे पहले से ट्रेन नहीं किया गया है. दूसरे शब्दों में कहें, तो मॉडल को टास्क के हिसाब से ट्रेनिंग के उदाहरण नहीं दिए जाते. हालांकि, उसे उस टास्क के लिए अनुमान लगाने के लिए कहा जाता है.
बिना उदाहरण वाला प्रॉम्प्ट
ऐसा प्रॉम्प्ट जिसमें यह नहीं बताया गया है कि आपको लार्ज लैंग्वेज मॉडल से किस तरह का जवाब चाहिए. उदाहरण के लिए:
| एक प्रॉम्ट के हिस्से | नोट |
|---|---|
| चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब आपको एलएलएम से चाहिए. |
| भारत: | असल क्वेरी. |
लार्ज लैंग्वेज मॉडल, इनमें से कोई भी जवाब दे सकता है:
- रुपया
- INR
- ₹
- भारतीय रुपया
- रुपया
- भारतीय रुपया
सभी जवाब सही हैं, हालांकि आपको कोई खास फ़ॉर्मैट पसंद आ सकता है.
ज़ीरो-शॉट प्रॉम्प्टिंग की तुलना इन शब्दों से करें और इनमें अंतर बताएं:
ज़ेड-स्कोर नॉर्मलाइज़ेशन
यह स्केलिंग की एक ऐसी तकनीक है जो रॉ फ़ीचर वैल्यू को फ़्लोटिंग-पॉइंट वैल्यू से बदल देती है. यह वैल्यू, उस फ़ीचर के औसत से मानक विचलनों की संख्या को दिखाती है. उदाहरण के लिए, मान लें कि किसी सुविधा का औसत 800 है और उसका स्टैंडर्ड डेविएशन 100 है. यहां दी गई टेबल में दिखाया गया है कि Z-स्कोर नॉर्मलाइज़ेशन, रॉ वैल्यू को उसके Z-स्कोर पर कैसे मैप करेगा:
| असल वैल्यू | ज़ेड-स्कोर |
|---|---|
| 800 | 0 |
| 950 | +1.5 |
| 575 | -2.25 |
इसके बाद, मशीन लर्निंग मॉडल, रॉ वैल्यू के बजाय उस सुविधा के लिए Z-स्कोर पर ट्रेन करता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में संख्यात्मक डेटा: सामान्यीकरण देखें.