Bu sayfada Dil Değerlendirmesi sözlük terimleri yer almaktadır. Tüm terimler için burayı tıklayın.
A
dikkat
Nöral ağda kullanılan ve belirli bir kelimenin veya kelimenin bir kısmının önemini belirten bir mekanizma. Dikkat, bir modelin sonraki jetonu/kelimeyi tahmin etmek için ihtiyaç duyduğu bilgi miktarını sıkıştırır. Tipik bir dikkat mekanizması, bir giriş grubu üzerinde ağırlıklı toplam içerebilir. Bu toplamda her girişin ağırlığı, nöral ağın başka bir bölümü tarafından hesaplanır.
Dönüştürücüler'in yapı taşları olan öz dikkat ve çok başlı öz dikkat hakkında da bilgi edinin.
Kendine dikkat hakkında daha fazla bilgi için Makine Öğrenimi Acele Kursu'ndaki LLM'ler: Büyük dil modeli nedir? başlıklı makaleyi inceleyin.
otomatik kodlayıcı
Girişten en önemli bilgileri çıkarmayı öğrenen bir sistem. Otomatik kodlayıcılar, kodlayıcı ve kod çözücü kombinasyonudur. Otomatik kodlayıcılar aşağıdaki iki adımlı süreci kullanır:
- Kodlayıcı, girişi (genellikle) kayıplı, daha düşük boyutlu (ara) bir biçimle eşler.
- Kod çözücü, düşük boyutlu biçimi orijinal yüksek boyutlu giriş biçimiyle eşleyerek orijinal girişin kayıplı bir sürümünü oluşturur.
Otomatik kodlayıcılar, kod çözücünün kodlayıcının ara biçimindeki orijinal girişi mümkün olduğunca yakın bir şekilde yeniden oluşturmaya çalışmasıyla uçtan uca eğitilir. Ara biçimi orijinal biçime kıyasla daha küçük (düşük boyutlu) olduğundan, otomatik kodlayıcı, girişteki hangi bilgilerin önemli olduğunu öğrenmek zorunda kalır ve çıkış, girişle tamamen aynı olmaz.
Örneğin:
- Giriş verileri bir grafikse tam olmayan kopya, orijinal grafiğe benzer ancak biraz değiştirilmiş olur. Tam olarak aynı olmayan kopya, orijinal grafikteki gürültüyü kaldırıyor veya eksik pikselleri dolduruyor olabilir.
- Giriş verileri metinse otomatik kodlayıcı, orijinal metni taklit eden (ancak aynı olmayan) yeni bir metin oluşturur.
Varyasyonel otomatik kodlayıcılar hakkında da bilgi edinin.
otomatik değerlendirme
Bir modelin çıktısının kalitesini değerlendirmek için yazılım kullanma
Model çıkışı nispeten basit olduğunda bir komut dosyası veya program, modelin çıkışını ideal yanıt ile karşılaştırabilir. Bu tür otomatik değerlendirmelere bazen programlı değerlendirme denir. ROUGE veya BLEU gibi metrikler genellikle programatik değerlendirme için yararlıdır.
Model çıktısı karmaşıksa veya tek bir doğru yanıt yoksa otomatik değerlendirmeyi bazen otomatik değerlendirici adlı ayrı bir yapay zeka programı gerçekleştirir.
Gerçek kişi tarafından yapılan değerlendirme ile karşılaştırın.
otomatik yorum değerlendirmesi
Üretken yapay zeka modelinin çıktısının kalitesini değerlendirmek için insan değerlendirmesini otomatik değerlendirmeyle birleştiren karma bir mekanizma. Otomatik metin yazarı, gerçek kişiler tarafından yapılan değerlendirme ile oluşturulan verilerle eğitilmiş bir makine öğrenimi modelidir. İdeal olarak, otomatik derecelendirme sistemi gerçek bir değerlendiriciyi taklit etmeyi öğrenir.Hazır otomatik yazıcılar mevcuttur ancak en iyi otomatik yazıcılar, özellikle değerlendirdiğiniz göreve göre hassas ayarlanmıştır.
otoregresif model
Kendi önceki tahminlerine dayanarak tahminde bulunan bir model. Örneğin, otomatik geriye dönük dil modelleri, daha önce tahmin edilen jetonlara göre bir sonraki jetonu tahmin eder. Transformer tabanlı tüm büyük dil modelleri otomatik geriye dönüktür.
Buna karşılık, GAN tabanlı görüntü modelleri genellikle otomatik regresif değildir. Bunun nedeni, bu modellerin bir resmi adım adım iteratif olarak değil, tek bir ileri geçişte oluşturmasıdır. Ancak belirli resim oluşturma modelleri, resimleri adım adım oluşturdukları için otomatik regresif olurlar.
k değerinde ortalama hassasiyet
Bir modelin, sıralanmış sonuçlar (ör. kitap önerilerinin numaralandırılmış listesi) oluşturan tek bir istemdeki performansını özetleyen metrik. k değerinde ortalama hassasiyet, her ilgili sonuç için k değerinde hassasiyet değerlerinin ortalamasıdır. Bu nedenle, k için ortalama hassasiyet formülü şu şekildedir:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
Bu örnekte:
- \(n\) , listedeki alakalı öğelerin sayısıdır.
k ile geri çağırma ile karşılaştırın.
B
kelime çantası
Sıradan bağımsız olarak bir kelime öbeğindeki veya pasajdaki kelimelerin temsili. Örneğin, kelime öbeği aşağıdaki üç ifadeyi aynı şekilde temsil eder:
- köpek zıplıyor
- köpeği atlar
- köpek atlar
Her kelime, seyrek bir vektör içindeki bir dizinle eşlenir. Bu vektörde, kelime hazinesindeki her kelime için bir dizin bulunur. Örneğin, köpek zıplıyor ifadesi, köpek, zıplıyor ve köpek kelimelerine karşılık gelen üç dizinin sıfır olmayan değerlerine sahip bir özellik vektörüne eşlenir. Sıfır olmayan değer aşağıdakilerden herhangi biri olabilir:
- Bir kelimenin varlığını belirtmek için 1.
- Bir kelimenin torbada kaç kez göründüğünün sayısı. Örneğin, ifade Kahverengi köpek, kahverengi tüyleri olan bir köpektir şeklindeyse hem kahverengi hem de köpek 2 olarak, diğer kelimeler ise 1 olarak temsil edilir.
- Bir kelimenin torbada kaç kez göründüğünün sayısına ait logaritma gibi başka bir değer.
BERT (Dönüştürücülerden Çift Yönlü Kodlayıcı Temsilleri)
Metin temsilciliği için bir model mimarisi. Eğitilmiş bir BERT modeli, metin sınıflandırma veya diğer makine öğrenimi görevleri için daha büyük bir modelin parçası olarak kullanılabilir.
BERT'in özellikleri şunlardır:
- Transformer mimarisini kullanır ve bu nedenle öz dikkate dayanır.
- Dönüştürücünün kodlayıcı bölümünü kullanır. Kodlayıcının görevi, sınıflandırma gibi belirli bir görevi yerine getirmek yerine iyi metin temsilleri üretmektir.
- İki yönlü olmalıdır.
- Gözetimsiz eğitim için maskelemeyi kullanır.
BERT'in varyantları şunlardır:
BERT'e genel bakış için Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing başlıklı makaleyi inceleyin.
iki yönlü
Hedef metin bölümünün hem öncesinde hem de ardından gelen metni değerlendiren bir sistemi tanımlamak için kullanılan terim. Buna karşılık, tek yönlü bir sistem yalnızca hedef metin bölümünün öncesinde gelen metni değerlendirir.
Örneğin, aşağıdaki soruda altı çizili kelimeyi veya kelimeleri temsil eden kelimelerin olasılıklarını belirlemesi gereken bir maskeli dil modelini ele alalım:
What is the _____ with you?
Tek yönlü bir dil modelinin olasılıklarını yalnızca "Ne", "nedir" ve "o" kelimelerinin sağladığı bağlama göre belirlemesi gerekir. Buna karşılık, iki yönlü bir dil modeli "ile" ve "siz" kelimelerinden de bağlam bilgisi edinebilir. Bu da modelin daha iyi tahminler yapmasına yardımcı olabilir.
çift yönlü dil modeli
Belirli bir jetonun, metin alıntısındaki belirli bir konumda bulunma olasılığını önceki ve sonraki metne göre belirleyen bir dil modeli.
büyük harf
N=2 olan bir N-gram.
BLEU (İki Dilli Değerlendirme Asistanı)
İspanyolca'dan Japonca'ya yapılan makine çevirilerini değerlendirmek için kullanılan 0, 0 ile 1, 0 arasında bir metriktir.
BLEU, puan hesaplamak için genellikle bir makine öğrenimi modelinin çevirisini (oluşturulan metin) bir uzmanın çevirisiyle (referans metin) karşılaştırır. Oluşturulan metindeki ve referans metindeki N-gram eşleşmesinin derecesi BLEU puanını belirler.
Bu metrik hakkındaki orijinal makale BLEU: a Method for Automatic Evaluation of Machine Translation (BLEU: Makine Çevirisinin Otomatik Değerlendirilmesi İçin Bir Yöntem) başlıklı makaledir.
BLEURT işlevine de göz atın.
BLEURT (Bilingual Evaluation Understudy from Transformers)
Bir dilden diğerine, özellikle de İngilizceden ve İngilizceye yapılan makine çevirilerini değerlendirmek için kullanılan bir metriktir.
İngilizceden ve İngilizceye yapılan çevirilerde BLEURT, BLEU'ya kıyasla gerçek kişiler tarafından verilen puanlara daha yakındır. BLEU'den farklı olarak BLEURT, anlamsal benzerlikleri vurgular ve başka bir dilde yorumlamayı kabul edebilir.
BLEURT, önceden eğitilmiş büyük bir dil modelini (tam olarak BERT) kullanır. Bu model daha sonra gerçek çevirmenler tarafından yazılmış metinlerle ince ayarlanır.
Bu metrik hakkındaki orijinal makale BLEURT: Learning Robust Metrics for Text Generation (BLEURT: Metin Oluşturma İçin Güçlü Metrikler Öğrenme) başlıklı makaledir.
C
nedensel dil modeli
Tek yönlü dil modeli ile eş anlamlıdır.
Dil modellemede farklı yönsel yaklaşımları karşılaştırmak için iki yönlü dil modeli konusuna bakın.
düşünce zinciri istemi
Büyük dil modelini (LLM) mantığını adım adım açıklamaya teşvik eden bir istem mühendisliği tekniği. Örneğin, ikinci cümleye özellikle dikkat ederek aşağıdaki istemi inceleyin:
7 saniyede 0'dan 100 kilometre hıza çıkan bir araçta sürücü kaç g kuvveti yaşar? Yanıtta, ilgili tüm hesaplamaları gösterin.
LLM'nin yanıtı büyük olasılıkla:
- Uygun yerlere 0, 60 ve 7 değerlerini ekleyerek bir dizi fizik formülü gösterin.
- Bu formülleri neden seçtiğini ve çeşitli değişkenlerin ne anlama geldiğini açıklayın.
Düşünce zinciri istemi, LLM'yi tüm hesaplamaları yapmaya zorlar. Bu da daha doğru bir yanıta yol açabilir. Ayrıca düşünce zinciri istemi, kullanıcının cevabın mantıklı olup olmadığını belirlemek için LLM'nin adımlarını incelemesini sağlar.
sohbet
Genellikle büyük dil modeli olan bir yapay zeka sistemiyle yapılan karşılıklı konuşmanın içeriği. Sohbetteki önceki etkileşim (ne yazdığınız ve büyük dil modelinin nasıl yanıt verdiği), sohbetin sonraki bölümlerinin bağlamı olur.
Chat bot, büyük dil modelinin bir uygulamasıdır.
yalan söyleme
Halüsinasyon ile eş anlamlıdır.
Konfabulasyon, halüsinasyondan daha teknik açıdan doğru bir terimdir. Ancak halüsinasyon ilk olarak popüler oldu.
seçim bölgesi ayrıştırma
Cümleyi daha küçük dil bilgisi yapılarına ("bileşenler") bölmek. ML sisteminin sonraki bir kısmı (ör. doğal dil anlama modeli) bileşenleri orijinal cümleden daha kolay ayrıştırabilir. Örneğin, aşağıdaki cümleyi ele alalım:
Arkadaşım iki kedi sahiplendi.
Seçim bölgesi ayrıştırıcısı bu cümleyi aşağıdaki iki bileşene ayırabilir:
- Arkadaşım bir isim tamlamasıdır.
- İki kedi sahiplendi bir fiil öbeğidir.
Bu bileşenler daha küçük bileşenlere ayrılabilir. Örneğin,
iki kedi sahiplendi
aşağıdaki alt kategorilere ayrılabilir:
- adopted bir fiildir.
- İki kedi de bir isim öbeğidir.
bağlama dayalı dil yerleştirme
Kelimeleri ve ifadeleri, akıcı bir şekilde konuşan insanların anlayabileceği şekilde "anlamaya" yakın bir yerleşim. Bağlamsallaştırılmış dil embeddings'leri karmaşık söz dizimi, anlambilim ve bağlamı anlayabilir.
Örneğin, İngilizce cow kelimesinin yerleştirilmelerini ele alalım. word2vec gibi eski yerleştirmeler, İngilizce kelimeleri yerleşim alanında inek ile boğa arasındaki mesafenin koyun (dişi koyun) ile koç (erkek koyun) arasındaki mesafeye veya dişi ile erkek arasındaki mesafeye benzer olacak şekilde temsil edebilir. Bağlamsallaştırılmış dil yerleştirmeleri, İngilizce konuşan kişilerin bazen inek veya boğa anlamına gelen cow kelimesini gelişigüzel kullandığını fark ederek bir adım daha ileri gidebilir.
bağlam penceresi
Bir modelin belirli bir istemde işleyebileceği jeton sayısı. Bağlam penceresi ne kadar büyük olursa model, istem için tutarlı ve tutarlı yanıtlar sağlamak üzere o kadar fazla bilgi kullanabilir.
kilitlenme çiçeği
Anlamı belirsiz bir cümle veya kelime öbeği. Kilitlenme çiçekleri, doğal dil anlama konusunda önemli bir sorun teşkil eder. Örneğin, Kırmızı Kurdele Gökdeleni Engelliyor başlığı, bir NLU modelinin başlığı kelimenin tam anlamıyla veya mecazi olarak yorumlayabileceği için kilitlenme çiçeğidir.
D
kod çözücü
Genel olarak, işlenmiş, yoğun veya dahili bir temsilden daha ham, seyrek veya harici bir temsile dönüştüren tüm ML sistemleri.
Kod çözücüler genellikle daha büyük bir modelin bileşenidir ve sıklıkla bir kodlayıcı ile birlikte kullanılır.
Diziden diziye görevlerde kod çözücü, sonraki diziyi tahmin etmek için kodlayıcı tarafından oluşturulan dahili durumla başlar.
Dönüştürücü mimarisindeki kod çözücünün tanımı için Dönüştürücü başlıklı makaleyi inceleyin.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Büyük dil modelleri bölümüne bakın.
gürültü giderme
Aşağıdakileri içeren kendi kendini denetleyen öğrenme için yaygın bir yaklaşım:
Gürültü giderme, etiketlenmemiş örneklerden öğrenmeyi sağlar. Orijinal veri kümesi hedef veya etiket, gürültülü veriler ise giriş olarak kullanılır.
Bazı maskeli dil modelleri gürültü giderme özelliğini aşağıdaki gibi kullanır:
- İşaretlenmemiş bir cümleye, jetonların bazıları maskelenerek yapay olarak gürültü eklenir.
- Model, orijinal jetonları tahmin etmeye çalışır.
doğrudan istem
Sıfır görevli istem ile eş anlamlıdır.
E
mesafeyi düzenleme
İki metin dizesinin birbirine ne kadar benzediğinin ölçümü. Makine öğrenimindeki düzenleme mesafesi şu nedenlerle yararlıdır:
- Düzenleme mesafesinin hesaplanması kolaydır.
- Düzenleme mesafesi, birbirine benzer olduğu bilinen iki dizeyi karşılaştırabilir.
- Düzenleme mesafesi, farklı dizelerin belirli bir dizeye ne kadar benzediğini belirleyebilir.
Düzenleme mesafesinin her biri farklı dize işlemleri kullanan birkaç tanımı vardır. Örnek için Levenshtein mesafesi başlıklı makaleyi inceleyin.
yerleştirme katmanı
Kademeli olarak daha düşük boyutlu bir yerleştirme vektörü öğrenmek için yüksek boyutlu bir kategorik özellikte eğitilen özel bir gizli katman. Yerleştirme katmanı, bir nöral ağın yalnızca yüksek boyutlu kategorik özellikte eğitilmesine kıyasla çok daha verimli bir şekilde eğitilmesini sağlar.
Örneğin, Earth şu anda yaklaşık 73.000 ağaç türünü desteklemektedir. Ağaç türünün modelinizde bir özellik olduğunu varsayalım. Bu durumda, modelinizin giriş katmanı 73.000 öğe uzunluğunda bir tek sıcaklık vektörü içerir.
Örneğin, baobab şu şekilde gösterilebilir:

73.000 öğe içeren bir dizi çok uzundur. Modele bir yerleştirme katmanı eklemezseniz 72.999 sıfırın çarpılması nedeniyle eğitim çok zaman alır. Belki de yerleştirme katmanını 12 boyuttan oluşacak şekilde seçersiniz. Sonuç olarak, yerleştirme katmanı her ağaç türü için kademeli olarak yeni bir yerleştirme vektörü öğrenir.
Belirli durumlarda, karma oluşturma, yerleştirme katmanına makul bir alternatiftir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Embedding'ler bölümüne bakın.
yerleştirme alanı
Daha yüksek boyutlu bir vektör alanından gelen özelliklerin eşlendiği d boyutlu vektör alanı. Yerleştirme alanı, amaçlanan uygulama için anlamlı olan yapıyı yakalayacak şekilde eğitilir.
İki yerleştirmenin nokta çarpımı, benzerliklerinin bir ölçüsüdür.
yerleştirme vektörü
Genel olarak, herhangi bir gizli katmandan alınan ve bu gizli katmanın girişlerini tanımlayan kayan noktalı sayı dizisidir. Yerleştirme vektörü genellikle bir yerleştirme katmanında eğitilen kayan noktalı sayı dizisidir. Örneğin, bir yerleştirme katmanının Dünya'daki 73.000 ağaç türünün her biri için bir yerleştirme vektörü öğrenmesi gerektiğini varsayalım. Aşağıdaki dizi, bir baobab ağacının yerleştirme vektörü olabilir:

Yerleştirme vektörü, rastgele sayılardan oluşan bir grup değildir. Bir yerleştirme katmanı, eğitim sırasında sinir ağının diğer ağırlıkları öğrenme şekline benzer şekilde bu değerleri eğitim yoluyla belirler. Dizinin her öğesi, bir ağaç türünün bazı özelliklerine göre bir derecelendirmedir. Hangi öğe hangi ağaç türünün özelliğini temsil eder? Bu, insanların belirlemesi çok zordur.
Bir yerleştirme vektörünün matematiksel açıdan dikkate değer kısmı, benzer öğelerin benzer kayan noktalı sayı kümelerine sahip olmasıdır. Örneğin, benzer ağaç türleri, benzer olmayan ağaç türlerine kıyasla daha benzer bir kayan noktalı sayı grubuna sahiptir. Sekoya ve sekoya ağacı, birbirine yakın ağaç türleridir. Bu nedenle, sekoya ve hindistancevizi ağacına kıyasla daha benzer bir kayan noktalı sayı grubuna sahiptirler. Modeli aynı girişle yeniden eğitseniz bile, yerleştirme vektöründeki sayılar modeli her yeniden eğittiğinizde değişir.
kodlayıcı
Genel olarak, ham, seyrek veya harici bir temsili daha işlenmiş, daha yoğun veya daha dahili bir temsile dönüştüren herhangi bir yapay zeka sistemidir.
Kodlayıcılar genellikle daha büyük bir modelin bileşenidir ve sıklıkla bir kod çözücü ile birlikte kullanılır. Bazı Transformer'lar kodlayıcıları kod çözücülerle eşlerken diğerleri yalnızca kodlayıcıyı veya yalnızca kod çözücüyü kullanır.
Bazı sistemler, kodlayıcının çıkışını sınıflandırma veya regresyon ağının girişi olarak kullanır.
Diziden diziye görevlerde kodlayıcı, giriş dizisini alır ve dahili bir durum (vektör) döndürür. Ardından kod çözücü, sonraki sırayı tahmin etmek için bu dahili durumu kullanır.
Dönüştürücü mimarisinde kodlayıcının tanımı için Dönüştürücü başlıklı makaleyi inceleyin.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki LLM'ler: Büyük dil modeli nedir? başlıklı makaleyi inceleyin.
evals
Öncelikle LLM değerlendirmeleri için kısaltma olarak kullanılır. Daha geniş bir açıdan bakıldığında evals, değerlendirme biçimlerinin kısaltmasıdır.
değerlendirme
Bir modelin kalitesini ölçme veya farklı modelleri birbiriyle karşılaştırma işlemi.
Bir gözetimli makine öğrenimi modelini değerlendirmek için genellikle doğrulama kümesi ve test kümesi ile karşılaştırırsınız. LLM'yi değerlendirme genellikle daha kapsamlı kalite ve güvenlik değerlendirmelerini içerir.
C
çok görevli istem
Büyük dil modelinin nasıl yanıt vermesi gerektiğini gösteren birden fazla ("birkaç") örnek içeren bir istem. Örneğin, aşağıdaki uzun istemde büyük bir dil modelinin bir sorguyu nasıl yanıtlayacağını gösteren iki örnek yer almaktadır.
| Bir istemin bölümleri | Notlar |
|---|---|
| Belirtilen ülkenin resmi para birimi nedir? | LLM'nin yanıtlamasını istediğiniz soru. |
| Fransa: avro | Bir örnek vereyim. |
| Birleşik Krallık: GBP | Başka bir örnek. |
| Hindistan: | Gerçek sorgu. |
Çok görevli istem, genellikle sıfır görevli istem ve tek görevli istem'den daha iyi sonuçlar verir. Ancak çok görevli istem, daha uzun bir istem gerektirir.
Çok görevli istem, istem tabanlı öğrenmeye uygulanan bir az sayıda örnekle öğrenme biçimidir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki İstem mühendisliği bölümüne bakın.
Keman
İşlevlerin ve sınıfların değerlerini müdahaleci kod veya altyapı olmadan ayarlayan, Python'a öncelik veren bir yapılandırma kitaplığı. Pax ve diğer makine öğrenimi kod tabanlarında bu işlevler ve sınıflar modelleri ve eğitim hiper parametrelerini temsil eder.
Fiddle, makine öğrenimi kod tabanlarının genellikle aşağıdakilere ayrıldığını varsayar:
- Katmanları ve optimizatörleri tanımlayan kitaplık kodu.
- Kitaplıkları çağıran ve her şeyi birbirine bağlayan veri kümesi "yapıştırıcı" kodu.
Fiddle, yapıştırma kodunun çağrı yapısını değerlendirilmemiş ve değiştirilebilir bir biçimde yakalar.
ince ayar
Önceden eğitilmiş bir modelde, belirli bir kullanım alanı için parametrelerini hassaslaştırmak amacıyla göreve özel ikinci bir eğitim geçişi. Örneğin, bazı büyük dil modelleri için tam eğitim sırası aşağıdaki gibidir:
- Ön eğitim: Büyük bir dil modelini, tüm İngilizce Wikipedia sayfaları gibi geniş bir genel veri kümesiyle eğitin.
- İnce ayarlama: Önceden eğitilmiş modeli, tıbbi sorgulara yanıt vermek gibi belirli bir görevi gerçekleştirecek şekilde eğitin. İnce ayar genellikle belirli göreve odaklanan yüzlerce veya binlerce örnek içerir.
Başka bir örnek olarak, büyük bir resim modeli için tam eğitim sırası aşağıda verilmiştir:
- Ön eğitim: Wikimedia Commons'taki tüm resimler gibi geniş bir genel resim veri kümesinde büyük bir resim modeli eğitin.
- İnce ayarlama: Önceden eğitilmiş modeli, orka resimleri oluşturma gibi belirli bir görevi gerçekleştirecek şekilde eğitin.
İnce ayar, aşağıdaki stratejilerin herhangi bir kombinasyonunu içerebilir:
- Önceden eğitilmiş modelin mevcut parametrelerinin tümünü değiştirme Buna bazen tam hassas ayar da denir.
- Önceden eğitilmiş modelin mevcut parametrelerinin yalnızca bir kısmını (genellikle çıktı katmanına en yakın katmanlar) değiştirirken diğer mevcut parametreleri (genellikle giriş katmanına en yakın katmanlar) değiştirmeden bırakma Parametreleri verimli şekilde kullanma başlıklı makaleyi inceleyin.
- Genellikle çıkış katmanına en yakın mevcut katmanların üzerine daha fazla katman ekleme.
İnce ayar, transfer öğrenimi biçimlerinden biridir. Bu nedenle, hassas ayarlama işleminde, önceden eğitilmiş modeli eğitmek için kullanılanlardan farklı bir kayıp işlevi veya farklı bir model türü kullanılabilir. Örneğin, önceden eğitilmiş büyük bir resim modelinde ince ayar yaparak giriş resmindeki kuş sayısını döndüren bir regresyon modeli oluşturabilirsiniz.
İnce ayarlama ile aşağıdaki terimleri karşılaştırın:
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki İnce ayarlama bölümüne bakın.
Keten
JAX'in üzerine inşa edilmiş, derin öğrenme için yüksek performanslı açık kaynak kitaplık. Flax, sinir ağlarını eğitmek için işlevler ve performanslarını değerlendirme yöntemleri sağlar.
Flaxformer
Flax üzerine inşa edilmiş, açık kaynak bir Transformer kitaplığı. Öncelikle doğal dil işleme ve çoklu modaliteli araştırmalar için tasarlanmıştır.
G
Gemini
Google'ın en gelişmiş yapay zekasını içeren ekosistem. Bu ekosistemin öğeleri şunlardır:
- Çeşitli Gemini modelleri.
- Gemini modelinin etkileşimli sohbet arayüzü. Kullanıcılar istemler yazar ve Gemini bu istemlere yanıt verir.
- Çeşitli Gemini API'leri.
- Gemini modellerine dayalı çeşitli işletme ürünleri (ör. Google Cloud için Gemini).
Gemini modelleri
Google'ın son teknoloji Transformer tabanlı çoklu modal modelleri. Gemini modelleri, özellikle müşteri temsilcileriyle entegre edilecek şekilde tasarlanmıştır.
Kullanıcılar, etkileşimli bir iletişim arayüzü ve SDK'lar dahil olmak üzere çeşitli şekillerde Gemini modelleriyle etkileşim kurabilir.
oluşturulan metin
Genel olarak, bir makine öğrenimi modelinin oluşturduğu metindir. Büyük dil modelleri değerlendirilirken bazı metrikler, oluşturulan metni referans metinle karşılaştırır. Örneğin, bir ML modelinin Fransızcadan Hollandacaya ne kadar etkili bir şekilde çeviri yaptığını belirlemeye çalıştığınızı varsayalım. Bu durumda:
- Oluşturulan metin, makine öğrenimi modelinin çıkardığı Hollandaca çeviridir.
- Referans metin, gerçek bir çevirmen (veya yazılım) tarafından oluşturulan Hollandaca çeviridir.
Bazı değerlendirme stratejilerinin referans metni içermediğini unutmayın.
üretken yapay zeka
Resmi bir tanımı olmayan, yeni ve dönüştürücü bir alan. Bununla birlikte, çoğu uzman üretken yapay zeka modellerinin aşağıdakilerin tümünü içeren içerikler oluşturabileceği ("üretebildiği") konusunda hemfikirdir:
- karmaşık
- tutarlı
- orijinal
Örneğin, üretken yapay zeka modelleri karmaşık makaleler veya resimler oluşturabilir.
LSTM'ler ve RNN'ler de dahil olmak üzere bazı eski teknolojiler özgün ve tutarlı içerikler oluşturabilir. Bazı uzmanlar bu eski teknolojileri üretken yapay zeka olarak görürken diğerleri, gerçek üretken yapay zekanın bu eski teknolojilerin üretebileceğinden daha karmaşık bir çıktı gerektirdiğini düşünüyor.
Tahmine dayalı makine öğrenimi ile karşılaştırın.
altın yanıt
İyi olduğu bilinen bir yanıt. Örneğin, aşağıdaki istem için:
2 + 2
En iyi yanıt şudur:
4
GPT (Üretken Önceden Eğitilmiş Dönüştürücü)
OpenAI tarafından geliştirilen Transformer tabanlı büyük dil modelleri ailesi.
GPT varyantları aşağıdakiler gibi birden fazla mod için geçerli olabilir:
- görüntü üretme (ör. ImageGPT)
- metinden görüntü oluşturma (ör. DALL-E).
H
halüsinasyon
Gerçek dünya hakkında bir iddiada bulunduğunu iddia eden bir üretken yapay zeka modeli tarafından makul görünen ancak gerçekte yanlış olan çıkışların üretilmesi. Örneğin, Barack Obama'nın 1865'te öldüğünü iddia eden bir üretken yapay zeka modeli halüsinasyon görüyordur.
gerçek kişi tarafından yapılan değerlendirme
Kullanıcıların bir makine öğrenimi modelinin çıktısının kalitesini değerlendirdiği bir süreçtir. Örneğin, iki dili bilen kullanıcıların bir makine öğrenimi çeviri modelinin kalitesini değerlendirmesi. Gerçek kişiler tarafından yapılan değerlendirmeler, özellikle tek bir doğru yanıtı olmayan modelleri değerlendirmek için kullanışlıdır.
Otomatik değerlendirme ve otomatik değerlendirme ile karşılaştırın.
I
bağlam içinde öğrenme
Çok görevli istem ile eş anlamlıdır.
L
LaMDA (İletişim Uygulamaları İçin Dil Modeli)
Google tarafından geliştirilen, gerçekçi konuşma yanıtları oluşturabilen büyük bir diyalog veri kümesinde eğitilmiş Transformer tabanlı büyük dil modeli.
LaMDA: çığır açan konuşma teknolojimiz başlıklı makalede bu konuya genel bir bakış sunulmaktadır.
dil modeli
Daha uzun bir jeton dizisinde jeton veya jeton dizisinin gerçekleşme olasılığını tahmin eden bir model.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Dil modeli nedir? başlıklı makaleyi inceleyin.
büyük dil modeli
En azından çok sayıda parametre içeren bir dil modeli. Daha basit bir ifadeyle, Gemini veya GPT gibi Transformer tabanlı dil modelleri.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Büyük dil modelleri (LLM'ler) bölümüne bakın.
gizli alan
Yerleştirme alanı ile eş anlamlıdır.
Levenshtein Uzaklığı
Bir kelimeyi başka bir kelimeyle değiştirmek için gereken en az silme, ekleme ve değiştirme işlemlerini hesaplayan bir düzenleme mesafesi metriği. Örneğin, "kalp" ve "ok" kelimeleri arasındaki Levenshtein mesafesi üçtür. Bunun nedeni, bir kelimeyi diğerine dönüştürmek için gereken en az değişikliğin aşağıdaki üç düzenleme olmasıdır:
- kalp → deap ("h" yerine "d" yazın)
- deart → dart ("e" silinir)
- dart → darts ("s" ekleyin)
Üç düzenlemenin tek yolunun yukarıdaki sıra olmadığını unutmayın.
LLM
Büyük dil modeli kısaltması.
LLM değerlendirmeleri (evals)
Büyük dil modellerinin (LLM'ler) performansını değerlendirmek için kullanılan bir dizi metrik ve karşılaştırma. Genel olarak LLM değerlendirmeleri:
- Araştırmacıların, LLM'lerin iyileştirilmesi gereken alanlarını belirlemesine yardımcı olun.
- Farklı LLM'leri karşılaştırmak ve belirli bir görev için en iyi LLM'yi belirlemek için yararlıdır.
- LLM'lerin güvenli ve etik bir şekilde kullanılmasına yardımcı olma
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Büyük dil modelleri (LLM'ler) bölümüne bakın.
LoRA
Düşük Sıralı Uyumluluk kısaltması.
Düşük Sıralı Uyumluluk (LoRA)
Modelin önceden eğitilmiş ağırlıklarını "dondurup" (artık değiştirilemeyecek şekilde) ve ardından modele küçük bir eğitilebilir ağırlık grubu ekleyen ince ayar için parametre açısından verimli bir teknik. Bu eğitilebilir ağırlıklar grubu ("güncelleme matrisleri" olarak da bilinir), temel modelden çok daha küçüktür ve bu nedenle eğitilmesi çok daha hızlıdır.
LoRA aşağıdaki avantajları sağlar:
- İnce ayarların uygulandığı alan için modelin tahminlerinin kalitesini artırır.
- Bir modelin tüm parametrelerinin ince ayarlanmasını gerektiren tekniklere kıyasla daha hızlı ince ayar yapar.
- Aynı temel modeli paylaşan birden fazla özel modelin eşzamanlı olarak sunulmasını sağlayarak tahminin hesaplama maliyetini düşürür.
M
maskelenmiş dil modeli
Bir sıradaki boşlukları doldurmak için aday jetonların olasılığını tahmin eden dil modeli. Örneğin, maskelenmiş bir dil modeli, aşağıdaki cümledeki altı çizili kelimenin yerine geçebilecek kelimelerin olasılıklarını hesaplayabilir:
Şapkadaki ____ geri geldi.
Literatürde genellikle alt çizgi yerine "MASK" dizesi kullanılır. Örneğin:
Şapkadaki "MASK" geri geldi.
Modern maskelenmiş dil modellerinin çoğu iki yönlüdür.
k değerinde ortalama ortalama hassasiyet (mAP@k)
Bir doğrulama veri kümesindeki tüm k için ortalama hassasiyet puanlarının istatistiksel ortalaması. k değerinde ortalama hassasiyetin bir kullanım alanı, öneri sistemi tarafından oluşturulan önerilerin kalitesini değerlendirmektir.
"Ortalama ortalama" ifadesi gereksiz görünse de metriğin adı uygundur. Sonuçta bu metrik, birden fazla k değerinde ortalama kesinlik değerinin ortalamasını bulur.
meta öğrenme
Bir öğrenme algoritmasını keşfeden veya iyileştiren makine öğreniminin alt kümesi. Meta öğrenme sistemi, bir modeli küçük miktarda veri veya önceki görevlerde edinilen deneyimlerden yeni bir görevi hızlı bir şekilde öğrenecek şekilde eğitmeyi de amaçlayabilir. Meta öğrenme algoritmaları genellikle aşağıdakileri gerçekleştirmeye çalışır:
- El ile tasarlanmış özellikleri (ör. başlatıcı veya optimizatör) iyileştirme veya öğrenme
- Daha fazla veri ve hesaplama verimliliği elde edin.
- Genelleştirmeyi iyileştirin.
Meta öğrenme, az sayıda örnekle öğrenme ile ilgilidir.
uzmanların karışımı
Belirli bir giriş jetonunu veya öreğini işlemek için yalnızca parametrelerinin bir alt kümesini (uzman olarak bilinir) kullanarak sinir ağının verimliliğini artırmaya yönelik bir şema. Giriş ağı, her giriş jetonunu veya örneği uygun uzmanlara yönlendirir.
Ayrıntılı bilgi için aşağıdaki makalelerden birini inceleyin:
- Çok Büyük Nöral Ağlar: Seyrek Kapılı Uzman Karışım Katmanı
- Uzman Seçimi Yönlendirmesi ile Uzman Karması
MMIT
Çok modlu talimat ayarlı kısaltması.
yöntem
Üst düzey bir veri kategorisi. Örneğin, sayılar, metin, resimler, video ve ses beş farklı modalitedir.
model paralelliği
Bir modelin farklı bölümlerini farklı cihazlara yerleştiren bir eğitim veya çıkarım ölçeklendirme yöntemi. Model paralelliği, tek bir cihaza sığmayacak kadar büyük modelleri etkinleştirir.
Bir sistem, model paralelliğini uygulamak için genellikle aşağıdakileri yapar:
- Modeli daha küçük parçalara böler.
- Bu küçük parçaların eğitimini birden fazla işlemciye dağıtır. Her işlemci, modelin kendi bölümünü eğitir.
- Sonuçları birleştirerek tek bir model oluşturur.
Model paralelliği eğitimi yavaşlatır.
Ayrıca veri paralelliği konusuna da bakın.
MOE
Uzmanlardan oluşan bir grup kısaltması.
çok başlı kendi kendine dikkat
Giriş dizisindeki her konum için kendi kendine dikkat mekanizmasını birden çok kez uygulayan kendi kendine dikkat özelliğinin bir uzantısıdır.
Dönüştürücüler, çok başlı öz dikkat özelliğini kullanıma sundu.
çok modlu talimat ayarlı
Metnin yanı sıra görüntü, video ve ses gibi girişleri işleyebilecek talimatlara göre ayarlanmış bir modeldir.
çok modlu model
Girişleri, çıkışları veya her ikisi birden birden fazla modalite içeren bir model. Örneğin, hem resim hem de metin başlığını (iki mod) özellik olarak alan ve metin başlığının resme ne kadar uygun olduğunu belirten bir puan veren bir model düşünün. Bu modelin girişleri çok modlu, çıkışı ise tek modludur.
H
doğal dil işleme
Bilgisayarlara, kullanıcının söylediği veya yazdığı ifadeleri dil kurallarını kullanarak işlemeyi öğreten alan. Modern doğal dil işleme yöntemlerinin neredeyse tamamı makine öğreniminden yararlanır.doğal dil anlama
Söylenen veya yazılan bir şeyin niyetlerini belirleyen doğal dil işleme alt kümesi. Doğal dil anlama, doğal dil işlemenin ötesine geçerek bağlam, alay ve yaklaşım gibi dilin karmaşık yönlerini dikkate alabilir.
N-gram
N kelimelik sıralı bir dizi. Örneğin, truly madly 2 gramdır. Sıranın önemli olması nedeniyle madly truly, truly madly ile aynı 2 gram değildir.
| H | Bu tür bir N-gram için adlar | Örnekler |
|---|---|---|
| 2 | iki heceli veya 2 heceli | gitmek, gitmek için, öğle yemeği yemek, akşam yemeği yemek |
| 3 | üçlü veya 3'lü | ate too much, happily ever after, the bell tolls |
| 4 | 4 gram | walk in the park, dust in the wind, the boy ate lentils |
Birçok doğal dil anlama modeli, kullanıcının yazacağı veya söyleyeceği bir sonraki kelimeyi tahmin etmek için N-gramlara dayanır. Örneğin, bir kullanıcının sonsuza kadar mutlu yazdığını varsayalım. Üçlülere dayalı bir NLU modeli, kullanıcının bir sonraki kelimeyi sonra yazacağını tahmin eder.
N-gramları, sırasız kelime grupları olan kelime torbasıyla karşılaştırın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Büyük dil modelleri bölümüne bakın.
NLP
Doğal dil işleme kısaltması.
NLU
Doğal dil anlama kısaltması.
Tek doğru yanıt yok (NORA)
Birden fazla uygun yanıtı olan bir istem. Örneğin, aşağıdaki istemde tek bir doğru yanıt yoktur:
Bana fillerle ilgili bir fıkra anlat.
Doğru yanıtı olmayan istemleri değerlendirmek zor olabilir.
NORA
Tek doğru cevap yok ifadesinin kısaltması.
O
tek görevli istem
Büyük dil modelinin nasıl yanıt vermesi gerektiğini gösteren bir örnek içeren istem. Örneğin, aşağıdaki istemde büyük bir dil modelinin bir sorguyu nasıl yanıtlaması gerektiğini gösteren bir örnek yer almaktadır.
| Bir istemin bölümleri | Notlar |
|---|---|
| Belirtilen ülkenin resmi para birimi nedir? | LLM'nin yanıtlamasını istediğiniz soru. |
| Fransa: avro | Bir örnek vereyim. |
| Hindistan: | Gerçek sorgu. |
Tek seferlik istem ile aşağıdaki terimleri karşılaştırın:
P
parametreleri verimli şekilde kullanma
Büyük bir önceden eğitilmiş dil modelini (PLM) tam ince ayarlama işleminden daha verimli bir şekilde ince ayarlama yapmak için kullanılan bir teknik grubu. Parametre verimliliği odaklı ayarlama, genellikle tam ince ayarlamaya kıyasla çok daha az sayıda parametrede ince ayar yapar. Yine de genellikle tam ince ayarlamayla oluşturulan büyük bir dil modeliyle aynı performansı (veya neredeyse aynı performansı) gösteren bir büyük dil modeli oluşturur.
Parametre verimliliği ayarlamayı aşağıdakilerle karşılaştırın:
Parametrelerin verimli şekilde kullanıldığı ayarlama, parametreleri verimli şekilde kullanma olarak da bilinir.
ardışık düzen
Bir modelin işlemeninin art arda aşamalara bölündüğü ve her aşamanın farklı bir cihazda yürütüldüğü bir model paralelliği biçimi. Bir aşama bir grubu işlerken önceki aşama bir sonraki grup üzerinde çalışabilir.
Ayrıca aşamalı eğitim konusuna da bakın.
PLM
Önceden eğitilmiş dil modeli kısaltması.
konumsal kodlama
Bir jetonun bir dizilimdeki konumu hakkındaki bilgileri jetonun yerleştirilmesine ekleme tekniği. Transformer modelleri, dizinin farklı parçaları arasındaki ilişkiyi daha iyi anlamak için konumsal kodlama kullanır.
Pozisyonsal kodlamanın yaygın bir uygulamasında sinüs fonksiyonu kullanılır. (Özellikle, sinüsoidal işlevin frekansı ve genliği, jetonun dizindeki konumuna göre belirlenir.) Bu teknik, bir Transformer modelinin, konumlarına göre sıranın farklı bölümlerine dikkat etmeyi öğrenmesini sağlar.
eğitilmiş model
Genellikle aşağıdakilerden biri veya daha fazlası gibi bazı son işlemlerden geçmiş önceden eğitilmiş bir modeli ifade eden, gevşek tanımlanmış bir terimdir:
k değerinde hassasiyet (precision@k)
Sıralı (sıralı) bir öğe listesini değerlendirmek için kullanılan bir metrik. k değerinde hassasiyet, söz konusu listedeki ilk k öğenin "alakalı" olan kısmını tanımlar. Yani:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
k değerinin, döndürülen listenin uzunluğundan az veya ona eşit olması gerekir. Döndürülen listenin uzunluğunun hesaplamaya dahil edilmediğini unutmayın.
Alaka düzeyi genellikle özneldir. Uzman değerlendiriciler bile hangi öğelerin alakalı olduğu konusunda genellikle aynı fikirde değildir.
Şununla karşılaştır:
önceden eğitilmiş model
Genellikle, eğitilmiş bir modeldir. Bu terim, daha önce eğitilmiş bir gömülü vektör anlamına da gelebilir.
Önceden eğitilmiş dil modeli terimi genellikle önceden eğitilmiş bir büyük dil modelini ifade eder.
ön eğitim
Bir modelin büyük bir veri kümesinde ilk eğitimi. Bazı önceden eğitilmiş modeller hantal devler gibidir ve genellikle ek eğitimle hassaslaştırılması gerekir. Örneğin, makine öğrenimi uzmanları, Wikipedia'daki tüm İngilizce sayfalar gibi geniş bir metin veri kümesinde büyük dil modelini önceden eğitebilir. Ön eğitimden sonra, elde edilen model aşağıdaki tekniklerden herhangi biri kullanılarak daha da hassaslaştırılabilir:
istem
Modeli belirli bir şekilde davranmaya koşullandırmak için büyük dil modeline giriş olarak girilen tüm metinler. İstemler bir kelime öbeği kadar kısa veya istediğiniz kadar uzun olabilir (örneğin, bir romanın tamamı). İstemler, aşağıdaki tabloda gösterilenler de dahil olmak üzere birden fazla kategoriye ayrılır:
| İstem kategorisi | Örnek | Notlar |
|---|---|---|
| Soru | Güvercin ne kadar hızlı uçabilir? | |
| Talimat | Fırsatçılık hakkında komik bir şiir yazın. | Büyük dil modelinden bir şey yapmasını isteyen istem. |
| Örnek | Markdown kodunu HTML'ye çevirin. Örneğin:
Markdown: * liste öğesi HTML: <ul> <li>liste öğesi</li> </ul> |
Bu örnek istemdeki ilk cümle bir talimattır. İstemin geri kalanı örnektir. |
| Rol | Fizik alanında doktora yapmak için makine öğrenimi eğitiminde gradyan azalma yönteminin neden kullanıldığını açıklayın. | Cümlenin ilk kısmı bir talimattır; "Fizik alanında doktora" ifadesi ise rol bölümüdür. |
| Modelin tamamlaması için kısmi giriş | Birleşik Krallık Başbakanı şu adreste yaşıyor: | Tamamlama girişi istemi, aniden (bu örnekte olduğu gibi) veya alt çizgiyle bitebilir. |
Üretken yapay zeka modelleri, istemlere metin, kod, resim, yerleşim, video gibi neredeyse her şeyle yanıt verebilir.
istem tabanlı öğrenme
Belirli modellerin, davranışlarını rastgele metin girişlerine (istemler) göre uyarlamalarına olanak tanıyan bir özelliktir. İstem tabanlı öğrenme paradigmasında büyük dil modelleri, istemlere metin üreterek yanıt verir. Örneğin, bir kullanıcının aşağıdaki istemi girdiğini varsayalım:
Newton'un üçüncü hareket yasasını özetleyin.
İstem tabanlı öğrenme yapabilen bir model, önceki istemi yanıtlamak için özel olarak eğitilmez. Model, fizik, genel dil kuralları ve genel olarak yararlı yanıtları oluşturan konular hakkında çok sayıda bilgi "biliyor". Bu bilgiler, faydalı bir yanıt (umarım) sağlamak için yeterlidir. Ek insan geri bildirimleri ("Bu yanıt çok karmaşıktı." veya "Yanıtınız ne anlama geliyor?") bazı istem tabanlı öğrenme sistemlerinin yanıtlarının yararlılığını kademeli olarak artırmasını sağlar.
istem tasarımı
İstem mühendisliği ile eş anlamlıdır.
istem mühendisliği
Büyük dil modelinden istenen yanıtları alan istemler oluşturma sanatı. İstem mühendisliği, insanlar tarafından gerçekleştirilir. Büyük dil modelinden yararlı yanıtlar almanın önemli bir parçası, iyi yapılandırılmış istemler yazmaktır. İstem mühendisliği aşağıdakiler gibi birçok faktöre bağlıdır:
- Büyük dil modelini ön eğitmek ve muhtemelen ince ayarlamak için kullanılan veri kümesi.
- Modelin yanıt oluşturmak için kullandığı sıcaklık ve diğer kod çözme parametreleri.
İstem tasarımı, istem mühendisliğinin eş anlamlısıdır.
Faydalı istemler yazma hakkında daha fazla bilgi için İstem tasarımına giriş başlıklı makaleyi inceleyin.
istem ayarı
Sistemin gerçek istemin başına eklediği bir "ön ek" öğrenen parametrelerin verimli kullanıldığı ayarlama mekanizması.
İstem ayarının bir varyantı (bazen önek ayarı olarak adlandırılır) ön eki her katmana eklemektir. Buna karşılık, çoğu istem ayarı yalnızca giriş katmanına bir ön ek ekler.
K
k değerinde geri çağırma (recall@k)
Sıralı (sıralı) bir öğe listesi yayınlayan sistemleri değerlendirmek için kullanılan bir metrik. k'ta geri çağırma, listelenen ilk k öğedeki alakalı öğelerin, döndürülen toplam alakalı öğe sayısına oranını tanımlar.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
k değerinde hassasiyet ile kontrast.
referans metni
Uzmanın bir isteme verdiği yanıt. Örneğin, aşağıdaki istemde:
"Adınız ne?" sorusunu İngilizceden Fransızcaya çevirin.
Bir uzmanın yanıtı şöyle olabilir:
Comment vous appelez-vous?
Çeşitli metrikler (ör. ROUGE), referans metninin bir yapay zeka modelinin oluşturduğu metinle eşleşme derecesini ölçer.
rol istemi
Üretken yapay zeka modelinin yanıtı için hedef kitleyi tanımlayan istemin isteğe bağlı bir parçasıdır. Büyük dil modelleri, rol istemi olmadan soruları soran kullanıcı için yararlı olabilecek veya olamayacak bir yanıt sağlar. Büyük dil modelleri, rol istemi ile belirli bir hedef kitle için daha uygun ve daha faydalı bir şekilde yanıt verebilir. Örneğin, aşağıdaki istemlerin rol istemi kısmı kalın olarak gösterilir:
- Bu dokümanı ekonomi alanında doktora öğrencisi için özetleyin.
- On yaşındaki bir çocuğa gelgitlerin nasıl çalıştığını açıklayın.
- 2008 mali krizini açıklayın. Küçük bir çocukla veya golden retriever ile konuşuyormuş gibi konuşun.
ROUGE (Tahmin Değerlendirmesi İçin Hatırlama Odaklı Yardımcı Oyuncu)
Otomatik özetleme ve makine çevirisi modellerini değerlendiren bir metrik ailesi. ROUGE metrikleri, bir referans metninin bir yapay zeka modelinin oluşturulan metniyle örtüşme derecesini belirler. ROUGE ailesinin her üyesi, çakışma ölçümlerini farklı bir şekilde yapar. Daha yüksek ROUGE puanları, referans metin ile oluşturulan metin arasında daha fazla benzerlik olduğunu gösterir.
Her ROUGE aile üyesi genellikle aşağıdaki metrikleri oluşturur:
- Hassasiyet
- Geri çağırma
- F1
Ayrıntılar ve örnekler için:
ROUGE-L
Referans metin ve oluşturulan metin içindeki en uzun ortak alt dizinin uzunluğuna odaklanan ROUGE ailesinin bir üyesidir. Aşağıdaki formüller, ROUGE-L için geri çağırma ve kesinliği hesaplar:
Ardından, ROUGE-L geri çağırma ve ROUGE-L doğruluğunu tek bir metriğe toplamak için F1 kullanabilirsiniz:
ROUGE-L, referans metin ve oluşturulan metindeki tüm yeni satırları yoksayar. Bu nedenle, en uzun ortak alt dize birden fazla cümleyi kapsayabilir. Referans metin ve oluşturulan metin birden fazla cümle içeriyorsa genellikle ROUGE-L'nin ROUGE-Lsum adlı bir varyantı daha iyi bir metriktir. ROUGE-Lsum, bir pasajdaki her cümle için en uzun ortak alt dizeyi belirler ve ardından bu en uzun ortak alt dizilerin ortalamasını hesaplar.
ROUGE-N
ROUGE ailesindeki bir metrik grubu. Referans metin ile oluşturulan metin arasındaki belirli boyuttaki ortak N-gramları karşılaştırır. Örneğin:
- ROUGE-1, referans metin ile oluşturulan metinde paylaşılan jetonların sayısını ölçer.
- ROUGE-2, referans metin ile oluşturulan metinde paylaşılan bigramların (2 gram) sayısını ölçer.
- ROUGE-3, referans metin ile oluşturulan metinde ortak üçlü grupların (üçlü gruplar) sayısını ölçer.
ROUGE-N ailesinin herhangi bir üyesi için ROUGE-N geri çağırma ve ROUGE-N hassasiyetini hesaplamak üzere aşağıdaki formülleri kullanabilirsiniz:
Ardından, ROUGE-N geri çağırma ve ROUGE-N doğruluğunu tek bir metriğe toplamak için F1 kullanabilirsiniz:
ROGUE-S
Skip-gram eşlemesini etkinleştiren, ROUGE-N'in hoşgörülü bir biçimidir. Yani ROUGE-N yalnızca tam olarak eşleşen N-gramları sayarken ROUGE-S bir veya daha fazla kelimeyle ayrılmış N-gramları da sayar. Örneğin aşağıdakileri göz önünde bulundurabilirsiniz:
- reference text: Beyaz bulutlar
- Oluşturulan metin: Beyaz bulutlar
ROUGE-N hesaplanırken 2 gramlık Beyaz bulutlar, Beyaz bulutlar ile eşleşmez. Ancak ROUGE-S hesaplanırken Beyaz bulutlar, Beyaz kabarık bulutlar ile eşleşir.
S
öz dikkat (öz dikkat katmanı olarak da bilinir)
Bir dizi yerleştirmeyi (ör. jeton yerleştirmeleri) başka bir yerleştirme dizisine dönüştüren nöral ağ katmanı. Çıkış dizisindeki her yerleştirme, bir dikkat mekanizması aracılığıyla giriş dizisinin öğelerinden alınan bilgiler birleştirilerek oluşturulur.
Öz dikkat ifadesindeki öz, başka bir bağlam yerine kendi kendisine dikkat eden sırayı ifade eder. Öz dikkat, dönüştürücüler için temel yapı taşlarından biridir ve "sorgu", "anahtar" ve "değer" gibi sözlük arama terminolojisini kullanır.
Öz dikkat katmanı, her kelime için bir tane olmak üzere bir giriş temsili dizisiyle başlar. Bir kelimenin giriş temsili basit bir yerleştirme olabilir. Ağ, giriş dizisindeki her kelime için kelimenin kelime dizisinin tamamındaki her öğeyle alaka düzeyini puanlar. Alaka düzeyi puanları, kelimenin nihai temsilinin diğer kelimelerin temsillerini ne kadar içerdiğini belirler.
Örneğin, aşağıdaki cümleyi ele alalım:
Hayvan çok yorgun olduğu için caddeyi geçmedi.
Aşağıdaki görselde (Transformer: A Novel Neural Network Architecture for Language Understanding'dan alınmıştır), bir kendi kendine dikkat katmanının it (o) şahıs zamiri için dikkat kalıbı gösterilmektedir. Her satırın koyuluğu, her bir kelimenin temsile ne kadar katkıda bulunduğunu gösterir:
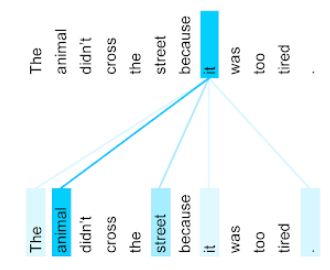
Öz dikkat katmanı, "o" ile alakalı kelimeleri vurgular. Bu örnekte dikkat katmanı, kendisinin atıfta bulunabileceği kelimeleri vurgulamayı öğrenmiştir ve en yüksek ağırlığı hayvan'a atamıştır.
n işaret dizisi için kendi kendine dikkat, dizideki her konumda bir kez olmak üzere n ayrı kez bir dizi yerleştirmeyi dönüştürür.
Dikkat ve çoklu başlık kendi kendine dikkat hakkında da bilgi edinin.
yaklaşım analizi
Bir grubun bir hizmete, ürüne, kuruluşa veya konuya karşı genel tutumunu (pozitif veya negatif) belirlemek için istatistiksel veya makine öğrenimi algoritmalarının kullanılması. Örneğin, doğal dil anlama özelliğini kullanan bir algoritma, öğrencilerin bir üniversite kursundan ne kadar memnun kaldığını belirlemek için kursla ilgili metin geri bildirimlerinde duygu analizi yapabilir.
Daha fazla bilgi için Metin sınıflandırma kılavuzuna bakın.
sırayla sıraya görev
Bir giriş jeton dizisini çıkış jeton dizisine dönüştüren bir görev. Örneğin, sırayla sıraya göre görevler için iki popüler tür vardır:
- Çevirmenler:
- Örnek giriş dizisi: "Seni seviyorum."
- Örnek çıkış sırası: "Je t'aime."
- Soru yanıtlama:
- Örnek giriş sırası: "New York'ta arabama ihtiyacım var mı?"
- Örnek çıkış sırası: "Hayır. Arabanızı evde bırakın."
atlama gramı
Orijinal bağlamdaki kelimeleri atlayabilen (veya "atlayabilen") bir n-gram. Yani N kelimenin başlangıçta bitişik olmayabilir. Daha açık belirtmek gerekirse, "k atlama n-gramı", k'ya kadar kelimenin atlanmış olabileceği bir n-gramdır.
Örneğin, "the quick brown fox" (cesur kahverengi tilki) ifadesi aşağıdaki olası 2 gramları içerir:
- "the quick"
- "quick brown"
- "kahverengi tilki"
"1 atlama 2 gram", aralarında en fazla 1 kelime bulunan bir kelime çiftidir. Bu nedenle, "the quick brown fox" ifadesi aşağıdaki 1 sıçrama 2 gramı içerir:
- "the brown"
- "quick fox"
Ayrıca, birden fazla kelime atlanabilir olduğundan tüm 2 gramlar aynı zamanda 1 atlamalı 2 gramdır.
Atlama gramları, bir kelimenin etrafındaki bağlamı daha iyi anlamak için yararlıdır. Örnekte, "fox" 1-skip-2-gram kümesinde doğrudan "quick" ile ilişkilendirilmiştir ancak 2-gram kümesinde ilişkilendirilmemiştir.
Atlama gramları, kelime yerleştirme modellerini eğitmeye yardımcı olur.
yumuşak istem ayarı
Kaynak yoğun ince ayar yapmadan belirli bir görev için büyük dil modelini ayarlama tekniği. Yumuşak istem ayarı, modeldeki tüm ağırlıkları yeniden eğitmek yerine, aynı hedefe ulaşmak için istemi otomatik olarak ayarlar.
Metin istemi verildiğinde yumuşak istem ayarlama genellikle isme ek jeton ekleme işlemi yapar ve girişi optimize etmek için geri yayılımı kullanır.
"Sabit" istem, jeton yerleştirmeleri yerine gerçek jetonlar içerir.
seyrek özellik
Değerleri çoğunlukla sıfır veya boş olan bir özellik. Örneğin, tek bir 1 değeri ve bir milyon 0 değeri içeren bir özellik seyrektir. Buna karşılık, yoğun bir özellik, çoğunlukla sıfır veya boş olmayan değerlere sahiptir.
Makine öğrenimindeki şaşırtıcı sayıda özellik seyrek özelliktir. Kategorik özellikler genellikle seyrek özelliklerdir. Örneğin, bir ormandaki 300 olası ağaç türünden tek bir örnekte yalnızca bir akçaağaç tanımlanabilir. Video kitaplığındaki milyonlarca videodan tek bir örnekte yalnızca "Casablanca" bulunabilir.
Bir modelde, seyrek özellikleri genellikle tek sıcak kodlama ile temsil edersiniz. Tek sıcak kodlama büyükse daha fazla verimlilik için tek sıcak kodlamanın üzerine bir gömülü katman yerleştirebilirsiniz.
seyrek gösterim
Seyrek bir özellikte yalnızca sıfır olmayan öğelerin konumlarını depolama.
Örneğin, species adlı kategorik bir özelliğin belirli bir ormandaki 36 ağaç türünü tanımladığını varsayalım. Ayrıca, her örnek'in yalnızca tek bir türü tanımladığını varsayalım.
Her örnekteki ağaç türlerini temsil etmek için tek sıcaklık değerine sahip bir vektör kullanabilirsiniz.
Tek sıcak vektör, tek bir 1 (bu örnekteki belirli ağaç türünü temsil etmek için) ve 35 0 (bu örnekte bulunmayan 35 ağaç türünü temsil etmek için) içerir. Bu nedenle, maple için tek sıcak temsil aşağıdaki gibi görünebilir:

Alternatif olarak, seyrek temsil yalnızca belirli türün konumunu tanımlar. maple 24. sıradaysa maple için seyrek gösterim şu şekilde olur:
24
Seyrek temsilin, tek sıcak temsile kıyasla çok daha kompakt olduğuna dikkat edin.
Biraz daha karmaşık bir örnek için simgeyi tıklayın.
Modelinizdeki her bir örneğin, İngilizce bir cümledeki kelimeleri (ancak kelimelerin sırasını değil) temsil etmesi gerektiğini varsayalım. İngilizce yaklaşık 170.000 kelimeden oluştuğu için yaklaşık 170.000 öğe içeren kategorik bir özelliktir. İngilizce cümlelerin çoğu bu 170.000 kelimenin çok küçük bir kısmını kullandığından, tek bir örnekteki kelime grubu neredeyse kesin olarak seyrek veri olacaktır.
Aşağıdaki cümleyi ele alalım:
My dog is a great dog
Bu cümledeki kelimeleri temsil etmek için tek sıcak vektörün bir varyantını kullanabilirsiniz. Bu varyantta, vektördeki birden fazla hücre sıfır olmayan bir değer içerebilir. Ayrıca bu varyantta bir hücre, bir dışında bir tam sayı içerebilir. "Köpeğim", "harika", "bir" ve "köpek" kelimeleri cümlede yalnızca bir kez görünse de "köpek" kelimesi iki kez görünür. Bu cümledeki kelimeleri temsil etmek için tek sıcak vektörlerin bu varyantını kullandığımızda aşağıdaki 170.000 öğeli vektörü elde ederiz:

Aynı cümlenin seyrek temsili şu şekilde olur:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Daha fazla bilgi için Makine Öğrenimi Acele Kursu'ndaki Kategorik verilerle çalışma bölümüne bakın.
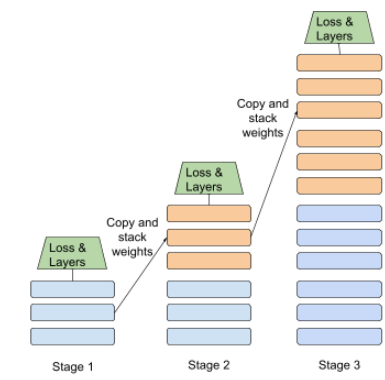
aşamalı eğitim
Bir modeli ayrı aşamalar halinde eğitme taktiği. Amaç, eğitim sürecini hızlandırmak veya daha iyi model kalitesi elde etmek olabilir.
Aşağıda, kademeli yığın yaklaşımını gösteren bir görsel verilmiştir:
- 1. aşama 3 gizli katman, 2. aşama 6 gizli katman ve 3. aşama 12 gizli katman içerir.
- 2. Aşama, 1. Aşama'nın 3 gizli katmanında öğrenilen ağırlıklarla eğitime başlar. 3. Aşama, 2. Aşama'nın 6 gizli katmanında öğrenilen ağırlıklarla eğitime başlar.
İş akışı konusuna da göz atın.
alt kelime belirteci
Dil modellerinde, bir kelimenin alt dizesi olan ve kelimenin tamamı da olabilecek işaret.
Örneğin, "itemize" gibi bir kelime "item" (kök kelime) ve "ize" (son ek) parçalarına ayrılabilir. Bu parçaların her biri kendi jetonuyla temsil edilir. Sık kullanılmayan kelimelerin alt kelimeler adı verilen parçalara bölünmesi, dil modellerinin kelimenin önek ve son ek gibi daha yaygın bileşenleri üzerinde çalışmasını sağlar.
Buna karşılık, "going" gibi yaygın kelimeler bölünmeyebilir ve tek bir jetonla temsil edilebilir.
T
T5
Google Yapay Zeka tarafından 2020'de kullanıma sunulan metinden metne transfer öğrenme modeli. T5, Transformer mimarisine dayalı, son derece büyük bir veri kümesinde eğitilmiş bir kodlayıcı-kod çözücü modelidir. Metin oluşturma, dil çevirme ve soruları konuşma dilinde yanıtlama gibi çeşitli doğal dil işleme görevlerinde etkilidir.
T5, adını "Text-to-Text Transfer Transformer " (Metinden Metne Aktarım Dönüştürücü) ifadesindeki beş T'den alır.
T5X
Büyük ölçekli doğal dil işleme (NLP) modelleri oluşturmak ve eğitmek için tasarlanmış açık kaynak bir makine öğrenimi çerçevesi. T5, T5X kod tabanında (JAX ve Flax üzerine kuruludur) uygulanır.
sıcaklık
Bir modelin çıkışının rastgelelik derecesini kontrol eden hiper parametre. Yüksek sıcaklıklar daha rastgele sonuçlara, düşük sıcaklıklar ise daha az rastgele sonuçlara yol açar.
En iyi sıcaklığı seçmek, uygulamaya ve modelin çıktısının tercih edilen özelliklerine bağlıdır. Örneğin, reklam öğesi çıkışı oluşturan bir uygulama oluştururken sıcaklığı artırmanız muhtemeldir. Buna karşılık, modelin doğruluğunu ve tutarlılığını artırmak için resimleri veya metni sınıflandıran bir model oluştururken sıcaklığı düşürmeniz muhtemeldir.
Sıcaklık genellikle softmax ile birlikte kullanılır.
metin aralığı
Bir metin dizesinin belirli bir alt bölümüyle ilişkili dizi dizini aralığı.
Örneğin, s="Be good now" Python dizesi içindeki good kelimesi 3 ile 6 arasındaki metin aralığını kaplar.
token
Dil modelinde, modelin eğitildiği ve tahminlerde bulunduğu atomik birimdir. Jetonlar genellikle aşağıdakilerden biridir:
- bir kelimedir. Örneğin, "köpekler kedileri sever" ifadesi üç kelime jetonundan oluşur: "köpekler", "sever" ve "kedileri".
- karakterden oluşur. Örneğin, "bisiklet balık" ifadesi dokuz karakter jetonundan oluşur. (Boşluğun jetonlardan biri olarak sayıldığını unutmayın.)
- alt kelimeler (tek bir kelime tek bir jeton veya birden fazla jeton olabilir). Alt kelime, bir kök kelime, ön ek veya son ekten oluşur. Örneğin, alt kelimeleri jeton olarak kullanan bir dil modeli, "köpekler" kelimesini iki jeton olarak görebilir ("köpek" kök kelimesi ve çoğul soneki "ler"). Aynı dil modeli, tek bir kelime olan "uzun"u iki alt kelime olarak (kök kelime "uzun" ve son ek "er") görebilir.
Dil modellerinin dışındaki alanlarda jetonlar, diğer türde atomik birimleri temsil edebilir. Örneğin, bilgisayar görüşünde jeton bir resmin alt kümesi olabilir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Büyük dil modelleri bölümüne bakın.
en iyi k doğruluğu
Oluşturulan listelerin ilk k konumunda bir "hedef etiketinin" görünme yüzdesi. Listeler, kişiselleştirilmiş öneriler veya softmax'e göre sıralanmış öğelerin listesi olabilir.
En yüksek k doğruluğu, k doğruluğu olarak da bilinir.
toksik
İçeriğin kötüye kullanım amaçlı, tehdit edici veya rahatsız edici olma derecesi. Birçok makine öğrenimi modeli, toksisiteyi tespit edip ölçebilir. Bu modellerin çoğu, toksikliği kötüye kullanım amaçlı dil düzeyi ve tehdit edici dil düzeyi gibi birden fazla parametreyle tanımlar.
Transformatör
Google'da geliştirilen ve dönüşüm veya yinelenen sinir ağlarına ihtiyaç duymadan bir giriş dizilimini çıkış dizilimine dönüştürmek için kendi kendine dikkat mekanizmalarına dayanan bir nöral ağ mimarisi. Bir dönüştürücü, öz dikkat katmanlarının yığını olarak görülebilir.
Dönüştürücüler aşağıdakilerden herhangi birini içerebilir:
- Kodlayıcı
- Kod çözücü
- hem kodlayıcı hem de kod çözücü
Kodlayıcı, bir dizi yerleştirmeyi aynı uzunlukta yeni bir diziye dönüştürür. Bir kodlayıcı, her biri iki alt katman içeren N adet aynı katman içerir. Bu iki alt katman, giriş yerleştirme dizisinin her konumuna uygulanarak dizinin her öğesini yeni bir yerleştirmeye dönüştürür. İlk kodlayıcı alt katmanı, giriş dizisindeki bilgileri toplar. İkinci kodlayıcı alt katmanı, birleştirilen bilgileri çıkış yerleştirmesine dönüştürür.
Kod çözücü, bir giriş yerleştirilmiş öğesi dizisini muhtemelen farklı uzunlukta bir çıkış yerleştirilmiş öğesi dizisine dönüştürür. Kod çözücü, üç alt katmana sahip N tane aynı katman da içerir. Bu katmanlardan ikisi, kodlayıcı alt katmanlarına benzer. Üçüncü kod çözücü alt katmanı, kodlayıcının çıkışını alır ve buradan bilgi toplamak için öz dikkat mekanizmasını uygular.
Transformer: A Novel Neural Network Architecture for Language Understanding (Dönüştürücü: Dil Anlama İçin Yeni Bir Nöral Ağ Mimarisi) adlı blog yayını, dönüştürücülere dair iyi bir giriş niteliğindedir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki LLM'ler: Büyük dil modeli nedir? başlıklı makaleyi inceleyin.
üçlü
N=3 olan bir N-gram.
U
tek yönlü
Yalnızca hedef metin bölümünün öncesinde gelen metni değerlendiren bir sistemdir. Buna karşılık, iki yönlü sistem hem hedef metin bölümünün öncesinde hem de ardından gelen metni değerlendirir. Daha fazla bilgi için iki yönlü bağlantıya bakın.
tek yönlü dil modeli
Olasılıklarını yalnızca hedef jetonlardan sonra değil, önce gelen jetonlara dayandıran bir dil modeli. İki yönlü dil modeliyle karşılaştırın.
V
varyasyonel otomatik kodlayıcı (VAE)
Girişlerin değiştirilmiş sürümlerini oluşturmak için girişler ile çıkışlar arasındaki tutarsızlıktan yararlanan bir tür otomatik kodlayıcı. Varyasyonal otomatik kodlayıcılar, üretken yapay zeka için yararlıdır.
VAE'ler, varyasyonal çıkarıma dayanır. Varyasyonal çıkarım, olasılık modelinin parametrelerini tahmin etmeye yönelik bir tekniktir.
W
kelime yerleştirme
Bir kelime grubundaki her kelimeyi yerleştirme vektörü içinde temsil etme; yani her kelimeyi 0,0 ile 1,0 arasında kayan nokta değerlerinin bir vektörü olarak temsil etme. Benzer anlamlara sahip kelimeler, farklı anlamlara sahip kelimelere kıyasla daha benzer temsillere sahiptir. Örneğin, havuç, kereviz ve salatalık gibi ürünlerin temsilleri birbirine oldukça benzerken uçak, güneş gözlüğü ve diş macunu gibi ürünlerin temsilleri birbirinden çok farklıdır.
Z
sıfır görevli istem
Büyük dil modelinin nasıl yanıt vermesini istediğinize dair bir örnek vermeyen istem. Örneğin:
| Bir istemin bölümleri | Notlar |
|---|---|
| Belirtilen ülkenin resmi para birimi nedir? | LLM'nin yanıtlamasını istediğiniz soru. |
| Hindistan: | Gerçek sorgu. |
Büyük dil modeli aşağıdakilerden herhangi biriyle yanıt verebilir:
- Rupi
- INR
- ₹
- Hint rupisi
- Rupi
- Hindistan rupisi
Tüm yanıtlar doğrudur ancak belirli bir biçimi tercih edebilirsiniz.
Sıfır atışlı istem ile aşağıdaki terimleri karşılaştırın: