หน้านี้มีคำศัพท์ในพจนานุกรม Generative AI ดูคำศัพท์ทั้งหมดได้โดยคลิกที่นี่
A
การดัดแปลง
คำพ้องความหมายของการปรับแต่งหรือการปรับแต่ง
ตัวแทน
ซอฟต์แวร์ที่สามารถให้เหตุผลเกี่ยวกับอินพุตของผู้ใช้เพื่อวางแผนและดำเนินการในนามของผู้ใช้
ในการเรียนรู้แบบเสริมกำลัง เอเจนต์คือเอนทิตีที่ใช้นโยบายเพื่อเพิ่มผลตอบแทนที่คาดไว้ให้ได้มากที่สุด ซึ่งได้จากการ เปลี่ยนสถานะของสภาพแวดล้อม
เป็น Agent
รูปแบบคำคุณศัพท์ของagent Agentic หมายถึงคุณสมบัติ ที่เอเจนต์มี (เช่น ความเป็นอิสระ)
เวิร์กโฟลว์ของ Agentic AI
กระบวนการแบบไดนามิกที่เอเจนต์วางแผนและ ดำเนินการโดยอัตโนมัติเพื่อบรรลุเป้าหมาย กระบวนการนี้อาจเกี่ยวข้องกับการให้เหตุผล การเรียกใช้เครื่องมือภายนอก และการแก้ไขแผนด้วยตนเอง
ขยะ AI
เอาต์พุตจากระบบ Generative AI ที่เน้นปริมาณมากกว่าคุณภาพ ตัวอย่างเช่น หน้าเว็บที่มีขยะ AI จะเต็มไปด้วยเนื้อหาคุณภาพต่ำที่ AI สร้างขึ้นอย่างถูกๆ
การประเมินอัตโนมัติ
การใช้ซอฟต์แวร์เพื่อตัดสินคุณภาพของเอาต์พุตของโมเดล
เมื่อเอาต์พุตโมเดลค่อนข้างตรงไปตรงมา สคริปต์หรือโปรแกรมจะเปรียบเทียบเอาต์พุตโมเดลกับคำตอบที่ถูกต้องได้ บางครั้งเราเรียกการประเมินอัตโนมัติประเภทนี้ว่าการประเมินแบบเป็นโปรแกรม เมตริก เช่น ROUGE หรือ BLEU มักมีประโยชน์สำหรับการประเมินแบบเป็นโปรแกรม
เมื่อเอาต์พุตโมเดลมีความซับซ้อนหรือไม่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว บางครั้งโปรแกรม ML แยกต่างหากที่เรียกว่าเครื่องมือให้คะแนนอัตโนมัติจะทำการประเมินอัตโนมัติ
เปรียบเทียบกับการประเมินโดยเจ้าหน้าที่
การประเมิน Autorater
กลไกแบบผสมสำหรับการตัดสินคุณภาพของเอาต์พุตของโมเดลGenerative AI ซึ่งรวมการประเมินโดยเจ้าหน้าที่เข้ากับการประเมินอัตโนมัติ เครื่องมือให้คะแนนอัตโนมัติคือโมเดล ML ที่ฝึกโดยใช้ข้อมูลที่สร้างขึ้นจากการประเมินโดยเจ้าหน้าที่ ในอุดมคติแล้ว โปรแกรมให้คะแนนอัตโนมัติ จะเรียนรู้ที่จะเลียนแบบผู้ประเมินที่เป็นมนุษย์มีเครื่องมือให้คะแนนอัตโนมัติที่สร้างไว้ล่วงหน้า แต่เครื่องมือให้คะแนนอัตโนมัติที่ดีที่สุดคือเครื่องมือที่ ได้รับการปรับแต่งมาโดยเฉพาะสำหรับงานที่คุณกำลังประเมิน
โมเดลอัตถดถอย
โมเดลที่อนุมานการคาดการณ์ตามการคาดการณ์ก่อนหน้าของตัวเอง เช่น โมเดลภาษาแบบถดถอยอัตโนมัติจะคาดการณ์โทเค็นถัดไปโดยอิงตามโทเค็นที่คาดการณ์ไว้ก่อนหน้านี้ โมเดลภาษาขนาดใหญ่ที่อิงตาม Transformer ทั้งหมดเป็นแบบ Auto-Regressive
ในทางตรงกันข้าม โมเดลรูปภาพที่อิงตาม GAN มักจะไม่ใช่แบบถดถอยอัตโนมัติ เนื่องจากโมเดลจะสร้างรูปภาพในการส่งต่อครั้งเดียวและไม่ใช่แบบวนซ้ำใน ขั้นตอนต่างๆ อย่างไรก็ตาม โมเดลการสร้างรูปภาพบางโมเดลเป็นแบบถดถอยอัตโนมัติเนื่องจาก โมเดลจะสร้างรูปภาพเป็นขั้นตอน
B
โมเดลพื้นฐาน
โมเดลที่ผ่านการฝึกมาก่อนซึ่งใช้เป็นจุดเริ่มต้นสำหรับการปรับแต่งเพื่อจัดการกับงานหรือแอปพลิเคชันที่เฉพาะเจาะจง
ดูโมเดลก่อนการฝึก และโมเดลพื้นฐานด้วย
C
การเขียนพรอมต์แบบเชนออฟทอท
เทคนิควิศวกรรมพรอมต์ (Prompt Engineering)ที่กระตุ้นให้โมเดลภาษาขนาดใหญ่ (LLM) อธิบายการให้เหตุผลทีละขั้นตอน ตัวอย่างเช่น ลองพิจารณาพรอมต์ต่อไปนี้ โดยให้ความสนใจเป็นพิเศษกับประโยคที่ 2
ผู้ขับขี่จะได้รับแรงโน้มถ่วงกี่ G ในรถยนต์ที่วิ่งจาก 0 ถึง 60 ไมล์ต่อชั่วโมงใน 7 วินาที แสดงการคำนวณที่เกี่ยวข้องทั้งหมดในคำตอบ
คำตอบของ LLM น่าจะมีลักษณะดังนี้
- แสดงลำดับสูตรฟิสิกส์ โดยเสียบค่า 0, 60 และ 7 ในตำแหน่งที่เหมาะสม
- อธิบายเหตุผลที่เลือกใช้สูตรเหล่านั้นและความหมายของตัวแปรต่างๆ
การแจ้งแบบลูกโซ่จะบังคับให้ LLM ทำการคำนวณทั้งหมด ซึ่งอาจนำไปสู่คำตอบที่ถูกต้องมากขึ้น นอกจากนี้ การแจ้งแบบลูกโซ่ความคิด ยังช่วยให้ผู้ใช้ตรวจสอบขั้นตอนของ LLM เพื่อพิจารณาว่าคำตอบสมเหตุสมผลหรือไม่
แชท
เนื้อหาของบทสนทนาไปมากับระบบ ML ซึ่งโดยทั่วไปคือโมเดลภาษาขนาดใหญ่ การโต้ตอบก่อนหน้าในแชท (สิ่งที่คุณพิมพ์และวิธีที่โมเดลภาษาขนาดใหญ่ตอบกลับ) จะกลายเป็น บริบทสำหรับส่วนต่อๆ ไปของแชท
แชทบ็อตคือแอปพลิเคชันของโมเดลภาษาขนาดใหญ่
การฝังภาษาตามบริบท
การฝังที่เข้าใกล้ "ความเข้าใจ" คำ และวลีในแบบที่ผู้พูดที่เป็นมนุษย์สามารถทำได้ การฝังภาษาตามบริบท สามารถเข้าใจไวยากรณ์ ความหมาย และบริบทที่ซับซ้อน
ตัวอย่างเช่น ลองพิจารณาการฝังคำว่า cow ในภาษาอังกฤษ การฝังรุ่นเก่า เช่น word2vec สามารถแสดงคำภาษาอังกฤษ ในลักษณะที่ระยะทางในพื้นที่การฝัง จาก cow ถึง bull จะคล้ายกับระยะทางจาก ewe (แกะตัวเมีย) ถึง ram (แกะตัวผู้) หรือจาก female ถึง male การฝังภาษาตามบริบทสามารถก้าวไปอีกขั้นด้วยการจดจำว่าบางครั้งผู้พูดภาษาอังกฤษใช้คำว่าcow ในความหมายของวัวตัวเมียหรือวัวตัวผู้
หน้าต่างบริบท
จำนวนโทเค็นที่โมเดลประมวลผลได้ในพรอมต์ที่กำหนด ยิ่งหน้าต่างบริบทมีขนาดใหญ่เท่าใด โมเดลก็จะใช้ข้อมูลได้มากขึ้นเท่านั้น เพื่อสร้างคำตอบที่สอดคล้องและสมเหตุสมผล กับพรอมต์
การเขียนโค้ดแบบสนทนา
การโต้ตอบแบบวนซ้ำระหว่างคุณกับโมเดล Generative AI เพื่อวัตถุประสงค์ ในการสร้างซอฟต์แวร์ คุณป้อนพรอมต์ที่อธิบายซอฟต์แวร์บางอย่าง จากนั้น โมเดลจะใช้คำอธิบายดังกล่าวเพื่อสร้างโค้ด จากนั้นคุณจะออกพรอมต์ใหม่ เพื่อแก้ไขข้อบกพร่องในพรอมต์ก่อนหน้าหรือในโค้ดที่สร้างขึ้น และโมเดลจะสร้างโค้ดที่อัปเดตแล้ว คุณทั้ง 2 คนจะสลับกันไปมาจนกว่าซอฟต์แวร์ที่สร้างขึ้นจะดีพอ
การเขียนโค้ดการสนทนาเป็นความหมายดั้งเดิมของVibe Coding
เปรียบเทียบกับการเขียนโค้ดตามข้อกำหนด
D
การเขียนพรอมต์โดยตรง
คำพ้องความหมายของการแจ้งแบบศูนย์ช็อต
การกลั่น
กระบวนการลดขนาดโมเดลหนึ่ง (เรียกว่าครู) ให้เป็นโมเดลที่เล็กลง (เรียกว่านักเรียน) ซึ่งเลียนแบบการคาดการณ์ของโมเดลเดิมอย่างแม่นยำที่สุด การกลั่น มีประโยชน์เนื่องจากโมเดลขนาดเล็กมีข้อดี 2 ประการที่สำคัญกว่าโมเดลขนาดใหญ่ (ครู) ดังนี้
- เวลาอนุมานที่เร็วขึ้น
- ลดการใช้หน่วยความจำและพลังงาน
อย่างไรก็ตาม โดยทั่วไปแล้วการคาดการณ์ของนักเรียนมักจะไม่ดีเท่าการคาดการณ์ของครู
การกลั่นจะฝึกโมเดลนักเรียนเพื่อลดฟังก์ชันการสูญเสียตามความแตกต่างระหว่างเอาต์พุตของการคาดการณ์ของโมเดลนักเรียนและโมเดลครู
เปรียบเทียบการกลั่นกับคำต่อไปนี้
ดูข้อมูลเพิ่มเติมได้ที่ LLM: การปรับแต่ง การกลั่น และการออกแบบพรอมต์ ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
E
evals
ใช้เป็นคำย่อสำหรับการประเมิน LLM เป็นหลัก ในวงกว้าง evals เป็นคำย่อของการประเมินในรูปแบบใดก็ได้
การประเมิน
กระบวนการวัดคุณภาพของโมเดลหรือการเปรียบเทียบโมเดลต่างๆ กับโมเดลอื่นๆ
โดยปกติแล้ว คุณจะประเมินโมเดลแมชชีนเลิร์นนิงที่มีการควบคุมดูแลโดยเปรียบเทียบกับชุดข้อมูลสำหรับตรวจสอบความถูกต้องและชุดทดสอบ การประเมิน LLM โดยทั่วไปจะเกี่ยวข้องกับการประเมินคุณภาพและความปลอดภัยในวงกว้าง
F
ข้อเท็จจริง
ในโลกของ ML พร็อพเพอร์ตี้ที่อธิบายโมเดลซึ่งเอาต์พุตอิงตามความเป็นจริง ความถูกต้องตามข้อเท็จจริงเป็นแนวคิด ไม่ใช่เมตริก เช่น สมมติว่าคุณส่งพรอมต์ต่อไปนี้ ไปยังโมเดลภาษาขนาดใหญ่
สูตรเคมีของเกลือแกงคืออะไร
โมเดลที่เพิ่มประสิทธิภาพด้านข้อเท็จจริงจะตอบว่า
NaCl
การคิดว่าโมเดลทั้งหมดควรอิงตามข้อเท็จจริงเป็นสิ่งที่น่าดึงดูดใจ อย่างไรก็ตาม พรอมต์บางอย่าง เช่น พรอมต์ต่อไปนี้ ควรทำให้โมเดล Generative AI เพิ่มประสิทธิภาพความคิดสร้างสรรค์มากกว่าความถูกต้องตามข้อเท็จจริง
เขียนร้อยกรองลิเมอริกเกี่ยวกับนักบินอวกาศและหนอนผีเสื้อ
ไม่น่าเป็นไปได้ที่กลอนลิเมอริกที่ได้จะอิงตามความเป็นจริง
แตกต่างจากความสมเหตุสมผล
ลดลงอย่างรวดเร็ว
เทคนิคการฝึกเพื่อปรับปรุงประสิทธิภาพของ LLM Fast decay involves rapidly decreasing the learning rate during training. กลยุทธ์นี้ช่วยป้องกันไม่ให้โมเดลโอเวอร์ฟิตกับข้อมูลฝึกฝน และปรับปรุงการทั่วไป
Few-Shot Prompting
พรอมต์ที่มีตัวอย่างมากกว่า 1 รายการ ("ไม่กี่") ซึ่งแสดงให้เห็นว่าโมเดลภาษาขนาดใหญ่ ควรตอบสนองอย่างไร ตัวอย่างเช่น พรอมต์ยาวต่อไปนี้มีตัวอย่าง 2 รายการที่แสดงให้โมเดลภาษาขนาดใหญ่เห็นวิธีตอบคำค้นหา
| ส่วนต่างๆ ของพรอมต์ | หมายเหตุ |
|---|---|
| สกุลเงินอย่างเป็นทางการของประเทศที่ระบุคืออะไร | คำถามที่คุณต้องการให้ LLM ตอบ |
| ฝรั่งเศส: EUR | ตัวอย่าง |
| สหราชอาณาจักร: GBP | อีกตัวอย่างหนึ่ง |
| อินเดีย: | คำค้นหาจริง |
โดยทั่วไปแล้ว การแจ้งแบบ Few-Shot จะให้ผลลัพธ์ที่ต้องการมากกว่าการแจ้งแบบ Zero-Shot และการแจ้งแบบ One-Shot อย่างไรก็ตาม Few-Shot Prompting ต้องใช้พรอมต์ที่ยาวกว่า
Few-Shot Prompting เป็นรูปแบบหนึ่งของการเรียนรู้แบบ Few-Shot ที่ใช้กับการเรียนรู้ตามพรอมต์
ดูข้อมูลเพิ่มเติมได้ที่พรอมต์ เอนจิเนียริง ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
การปรับแต่ง
การฝึกครั้งที่ 2 ที่เจาะจงงานซึ่งดำเนินการกับโมเดลที่ฝึกล่วงหน้าเพื่อปรับแต่งพารามิเตอร์สำหรับกรณีการใช้งานที่เฉพาะเจาะจง ตัวอย่างเช่น ลำดับการฝึกแบบเต็มสำหรับโมเดลภาษาขนาดใหญ่บางรุ่นมีดังนี้
- การฝึกล่วงหน้า: ฝึกโมเดลภาษาขนาดใหญ่ในชุดข้อมูลทั่วไปขนาดใหญ่ เช่น หน้า Wikipedia ทั้งหมดในภาษาอังกฤษ
- การปรับแต่ง: ฝึกโมเดลที่ผ่านการฝึกมาก่อนให้ทำงานเฉพาะเจาะจง เช่น ตอบคำค้นหาทางการแพทย์ โดยปกติแล้ว การปรับแต่งอย่างละเอียดต้องใช้ตัวอย่างหลายร้อยหรือหลายพันรายการที่มุ่งเน้นงานที่เฉพาะเจาะจง
อีกตัวอย่างหนึ่งคือลำดับการฝึกแบบเต็มสำหรับโมเดลรูปภาพขนาดใหญ่มีดังนี้
- การฝึกเบื้องต้น: ฝึกโมเดลรูปภาพขนาดใหญ่ในชุดข้อมูลรูปภาพทั่วไปจำนวนมาก เช่น รูปภาพทั้งหมดใน Wikimedia Commons
- การปรับแต่ง: ฝึกโมเดลที่ฝึกไว้ล่วงหน้าให้ทำงานเฉพาะเจาะจง เช่น สร้างรูปภาพของวาฬเพชฌฆาต
การปรับแต่งอาจเกี่ยวข้องกับกลยุทธ์ต่อไปนี้ร่วมกัน
- การแก้ไขทั้งหมดของพารามิเตอร์ที่มีอยู่ของโมเดลที่ฝึกไว้ล่วงหน้า ซึ่งบางครั้งเรียกว่าการปรับแต่งแบบละเอียด
- การแก้ไขเฉพาะพารามิเตอร์บางส่วนที่มีอยู่ของโมเดลที่ผ่านการฝึกมาก่อน (โดยปกติคือเลเยอร์ที่อยู่ใกล้เลเยอร์เอาต์พุตมากที่สุด) ในขณะที่คงพารามิเตอร์อื่นๆ ที่มีอยู่ไว้ไม่เปลี่ยนแปลง (โดยปกติคือเลเยอร์ที่อยู่ใกล้เลเยอร์อินพุตมากที่สุด) ดูการปรับแต่งที่มีประสิทธิภาพด้านพารามิเตอร์
- การเพิ่มเลเยอร์อื่นๆ โดยปกติจะอยู่เหนือเลเยอร์ที่มีอยู่ซึ่งอยู่ใกล้กับ เลเยอร์เอาต์พุตมากที่สุด
การปรับแต่งโมเดลเป็นรูปแบบหนึ่งของการเรียนรู้แบบโอน ดังนั้น การปรับแต่งอาจใช้ Loss Function หรือโมเดล ประเภทอื่นที่แตกต่างจากที่ใช้ฝึกโมเดลที่ผ่านการฝึกมาก่อน เช่น คุณอาจปรับแต่งโมเดลรูปภาพขนาดใหญ่ที่ฝึกไว้ล่วงหน้าเพื่อสร้างโมเดลการถดถอยที่แสดงจำนวนนกในรูปภาพอินพุต
เปรียบเทียบการปรับแต่งกับคำศัพท์ต่อไปนี้
ดูข้อมูลเพิ่มเติมได้ที่การปรับแต่ง ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
โมเดล Flash
กลุ่มโมเดล Gemini ขนาดค่อนข้างเล็กที่เพิ่มประสิทธิภาพเพื่อความเร็ว และเวลาในการตอบสนองที่ต่ำ โมเดล Flash ออกแบบมาสําหรับแอปพลิเคชันที่หลากหลาย ซึ่งการตอบกลับที่รวดเร็วและการส่งข้อความปริมาณมากเป็นสิ่งสําคัญ
โมเดลพื้นฐาน
โมเดลที่ได้รับการฝึกเบื้องต้นขนาดใหญ่มาก ซึ่งได้รับการฝึกจากชุดฝึกที่หลากหลายและมีขนาดใหญ่ โมเดลพื้นฐานสามารถทำทั้ง 2 อย่างต่อไปนี้ได้
- ตอบสนองต่อคำขอที่หลากหลายได้ดี
- ใช้เป็นโมเดลพื้นฐานสำหรับการปรับแต่งเพิ่มเติมหรือการปรับแต่งอื่นๆ
กล่าวคือ โมเดลพื้นฐานมีความสามารถสูงอยู่แล้วในแง่ทั่วไป แต่สามารถปรับแต่งเพิ่มเติมให้มีประโยชน์มากยิ่งขึ้นสำหรับงานที่เฉพาะเจาะจงได้
เศษส่วนของความสำเร็จ
เมตริกสําหรับประเมินข้อความที่โมเดล ML สร้างขึ้น เศษส่วนของความสำเร็จคือจำนวนเอาต์พุตข้อความที่สร้างขึ้นซึ่ง "สำเร็จ" หารด้วยจำนวนเอาต์พุตข้อความที่สร้างขึ้นทั้งหมด ตัวอย่างเช่น หากโมเดลภาษาขนาดใหญ่สร้างโค้ด 10 บล็อก และมี 5 บล็อกที่สำเร็จ เศษส่วนของความสำเร็จ จะเป็น 50%
แม้ว่าเศษส่วนของความสำเร็จจะมีประโยชน์อย่างกว้างขวางในสถิติ แต่ใน ML เมตริกนี้มีประโยชน์หลักๆ ในการวัดงานที่ตรวจสอบได้ เช่น การสร้างโค้ดหรือปัญหาทางคณิตศาสตร์
G
Gemini
ระบบนิเวศที่ประกอบด้วย AI ที่ทันสมัยที่สุดของ Google องค์ประกอบของระบบนิเวศนี้ ประกอบด้วย
- โมเดลต่างๆ ของ Gemini
- อินเทอร์เฟซการสนทนาแบบอินเทอร์แอกทีฟกับโมเดล Gemini ผู้ใช้พิมพ์พรอมต์และ Gemini จะตอบกลับพรอมต์เหล่านั้น
- Gemini API ต่างๆ
- ผลิตภัณฑ์ทางธุรกิจต่างๆ ที่อิงตามโมเดล Gemini เช่น Gemini สำหรับ Google Cloud
โมเดลต่างๆ ของ Gemini
Transformer ที่ทันสมัยของ Google โมเดลหลายรูปแบบ โมเดล Gemini ออกแบบมาโดยเฉพาะ เพื่อผสานรวมกับเอเจนต์
ผู้ใช้โต้ตอบกับโมเดล Gemini ได้หลายวิธี รวมถึงผ่าน อินเทอร์เฟซกล่องโต้ตอบแบบอินเทอร์แอกทีฟและผ่าน SDK
Gemma
โมเดลโอเพนซอร์สแบบน้ำหนักเบาตระกูลหนึ่งที่สร้างขึ้นจากงานวิจัยและเทคโนโลยีเดียวกันกับที่ใช้สร้างโมเดล Gemini มีโมเดล Gemma หลายรุ่นให้เลือกใช้ ซึ่งแต่ละรุ่นจะมีฟีเจอร์ที่แตกต่างกัน เช่น วิชัน, โค้ด และการปฏิบัติตามคำสั่ง ดูรายละเอียดได้ที่ Gemma
GenAI หรือ genAI
คำย่อของ Generative AI
ข้อความที่สร้างขึ้น
โดยทั่วไปคือข้อความที่โมเดล ML แสดง เมื่อประเมินโมเดลภาษาขนาดใหญ่ เมตริกบางอย่างจะเปรียบเทียบข้อความที่สร้างขึ้นกับข้อความอ้างอิง ตัวอย่างเช่น สมมติว่าคุณ พยายามพิจารณาว่าโมเดล ML แปลจากภาษาฝรั่งเศส เป็นภาษาดัตช์ได้มีประสิทธิภาพเพียงใด ในกรณีนี้
- ข้อความที่สร้างขึ้นคือคำแปลภาษาดัตช์ที่โมเดล ML แสดง
- ข้อความอ้างอิงคือคำแปลภาษาดัตช์ที่นักแปล (หรือซอฟต์แวร์) สร้างขึ้น
โปรดทราบว่ากลยุทธ์การประเมินบางอย่างไม่มีข้อความอ้างอิง
Generative AI
สาขาที่กำลังเกิดใหม่ซึ่งมีการเปลี่ยนแปลงและไม่มีคำจำกัดความอย่างเป็นทางการ อย่างไรก็ตาม ผู้เชี่ยวชาญส่วนใหญ่เห็นพ้องต้องกันว่าโมเดล Generative AI สามารถ สร้าง ("สร้าง") เนื้อหาที่มีลักษณะดังต่อไปนี้
- ซับซ้อน
- สอดคล้องกัน
- เดิม
ตัวอย่างของ Generative AI ได้แก่
- โมเดลภาษาขนาดใหญ่ที่สามารถสร้าง ข้อความต้นฉบับที่ซับซ้อนและตอบคำถามได้
- โมเดลการสร้างรูปภาพที่สร้างรูปภาพที่ไม่ซ้ำกันได้
- โมเดลการสร้างเสียงและเพลง ซึ่งสามารถแต่งเพลงต้นฉบับหรือ สร้างคำพูดที่สมจริง
- โมเดลการสร้างวิดีโอที่สร้างวิดีโอต้นฉบับได้
เทคโนโลยีรุ่นก่อนๆ บางอย่าง รวมถึง LSTM และ RNN ก็สามารถสร้างเนื้อหาต้นฉบับและ สอดคล้องกันได้เช่นกัน ผู้เชี่ยวชาญบางคนมองว่าเทคโนโลยีรุ่นก่อนๆ เหล่านี้เป็น Generative AI ขณะที่บางคนรู้สึกว่า Generative AI ที่แท้จริงต้องมีเอาต์พุตที่ซับซ้อนกว่าที่เทคโนโลยีรุ่นก่อนๆ เหล่านั้นสร้างขึ้นได้
แตกต่างจาก ML เชิงคาดการณ์
คำตอบดี
คำตอบที่ทราบว่าดี ตัวอย่างเช่น หากมีพรอมต์ต่อไปนี้
2 + 2
คำตอบที่ดีที่สุดคือ
4
GPT (Generative Pre-trained Transformer)
ตระกูลโมเดลภาษาขนาดใหญ่ที่อิงตาม Transformer ซึ่งพัฒนาโดย OpenAI
รูปแบบ GPT สามารถใช้กับรูปแบบต่างๆ ได้ ซึ่งรวมถึง
- การสร้างรูปภาพ (เช่น ImageGPT)
- การสร้างรูปภาพจากข้อความ (เช่น DALL-E)
H
อาการหลอนของ AI
การสร้างเอาต์พุตที่ดูสมเหตุสมผลแต่ไม่ถูกต้องตามข้อเท็จจริงโดยโมเดลGenerative AI ที่อ้างว่าเป็นการยืนยันเกี่ยวกับโลกแห่งความเป็นจริง ตัวอย่างเช่น โมเดล Generative AI ที่อ้างว่าบารัก โอบามา เสียชีวิตในปี 1865 หลอน
การประเมินโดยมนุษย์
กระบวนการที่ผู้ใช้ประเมินคุณภาพของเอาต์พุตโมเดล ML เช่น การให้ผู้ใช้ที่พูดได้ 2 ภาษาประเมินคุณภาพของโมเดลการแปลด้วย ML การประเมินโดยเจ้าหน้าที่จะมีประโยชน์อย่างยิ่งในการประเมินโมเดลที่ไม่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว
เปรียบเทียบกับการประเมินอัตโนมัติและ การประเมินโดยผู้ให้คะแนนอัตโนมัติ
ต้องมีคนคอยตรวจสอบ (HITL)
สำนวนที่ไม่ได้กำหนดไว้อย่างชัดเจนซึ่งอาจหมายถึงสิ่งใดสิ่งหนึ่งต่อไปนี้
- นโยบายในการดูผลลัพธ์ของ Generative AI อย่างมีวิจารณญาณหรือ อย่างระมัดระวัง
- กลยุทธ์หรือระบบที่ใช้เพื่อให้มั่นใจว่าผู้คนจะช่วยกำหนด ประเมิน และปรับแต่งลักษณะการทำงานของโมเดล การให้มนุษย์เข้ามามีส่วนร่วมจะช่วยให้ AI ได้รับประโยชน์จาก ทั้งปัญญาประดิษฐ์และความฉลาดของมนุษย์ ตัวอย่างเช่น ระบบที่ AI สร้างโค้ดซึ่งวิศวกรซอฟต์แวร์จะตรวจสอบในภายหลังคือระบบที่มีมนุษย์เป็นผู้ควบคุม
I
การเรียนรู้ในบริบท
คำพ้องความหมายของ Few-Shot Prompting
การอนุมาน
ในแมชชีนเลิร์นนิงแบบเดิม กระบวนการคาดการณ์จะทำโดย การใช้โมเดลที่ฝึกแล้วกับตัวอย่างที่ไม่ได้ติดป้ายกำกับ ดูข้อมูลเพิ่มเติมได้ที่การเรียนรู้แบบมีผู้ดูแลในหลักสูตร Intro to ML
ในโมเดลภาษาขนาดใหญ่ การอนุมานคือ กระบวนการใช้โมเดลที่ฝึกแล้วเพื่อสร้างคำตอบ สำหรับพรอมต์อินพุต
การอนุมานมีความหมายที่แตกต่างออกไปเล็กน้อยในสถิติ ดูรายละเอียดได้ที่ บทความวิกิพีเดียเกี่ยวกับการอนุมานทางสถิติ
การปรับแต่งคำสั่ง
รูปแบบหนึ่งของการปรับแต่งที่ช่วยเพิ่มความสามารถของโมเดล Generative AI ในการทำตามคำสั่ง การปรับแต่งตามคำสั่งเกี่ยวข้องกับการฝึกโมเดลในชุดพรอมต์คำสั่ง ซึ่งมักจะครอบคลุมงานที่หลากหลาย จากนั้นโมเดลที่ปรับแต่งตามคำสั่งมักจะ สร้างคำตอบที่มีประโยชน์สำหรับ พรอมต์แบบ Zero-Shot ในงานต่างๆ
เปรียบเทียบกับ
L
โมเดลภาษาขนาดใหญ่
อย่างน้อยที่สุด โมเดลภาษาที่มีพารามิเตอร์จำนวนมาก หรือจะพูดอย่างไม่เป็นทางการก็ได้ว่าโมเดลภาษาที่อิงตามTransformer เช่น Gemini หรือ GPT
ดูข้อมูลเพิ่มเติมได้ที่โมเดลภาษาขนาดใหญ่ (LLM) ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
เวลาในการตอบสนอง
เวลาที่โมเดลใช้ในการประมวลผลอินพุตและสร้างคำตอบ การตอบสนองที่มีเวลาในการตอบสนองสูงจะใช้เวลาในการสร้างนานกว่าการตอบสนองที่มีเวลาในการตอบสนองต่ำ
ปัจจัยที่มีผลต่อเวลาในการตอบสนองของโมเดลภาษาขนาดใหญ่ ได้แก่
- ความยาวของโทเค็นอินพุตและเอาต์พุต
- ความซับซ้อนของโมเดล
- โครงสร้างพื้นฐานที่โมเดลทำงานอยู่
การเพิ่มประสิทธิภาพเพื่อลดเวลาในการตอบสนองเป็นสิ่งสำคัญในการสร้างแอปพลิเคชันที่ตอบสนองได้ดีและเป็นมิตรต่อผู้ใช้
LLM
ตัวย่อของโมเดลภาษาขนาดใหญ่
การประเมิน LLM (Evals)
ชุดเมตริกและการเปรียบเทียบสำหรับประเมินประสิทธิภาพของ โมเดลภาษาขนาดใหญ่ (LLM) การประเมิน LLM ในระดับสูงมีดังนี้
- ช่วยนักวิจัยระบุจุดที่ LLM จำเป็นต้องได้รับการปรับปรุง
- มีประโยชน์ในการเปรียบเทียบ LLM ต่างๆ และระบุ LLM ที่ดีที่สุดสำหรับงานหนึ่งๆ
- ช่วยให้มั่นใจว่า LLM จะปลอดภัยและมีจริยธรรมในการใช้งาน
ดูข้อมูลเพิ่มเติมได้ที่โมเดลภาษาขนาดใหญ่ (LLM) ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
LoRA
คำย่อของ Low-Rank Adaptability
ความสามารถในการปรับตัวแบบ Low-Rank (LoRA)
เทคนิคประหยัดพารามิเตอร์สำหรับ การปรับแต่งที่ "ตรึง" น้ำหนักที่ผ่านการฝึกมาก่อนของโมเดล (เพื่อให้แก้ไขไม่ได้อีกต่อไป) แล้วแทรกชุดน้ำหนักที่ฝึกได้ขนาดเล็ก ลงในโมเดล ชุดน้ำหนักที่ฝึกได้นี้ (หรือที่เรียกว่า "เมทริกซ์การอัปเดต") มีขนาดเล็กกว่าโมเดลพื้นฐานอย่างมาก จึงฝึกได้เร็วกว่ามาก
LoRA มีสิทธิประโยชน์ดังนี้
- ปรับปรุงคุณภาพการคาดการณ์ของโมเดลสำหรับโดเมนที่มีการปรับแต่ง
- ปรับแต่งได้เร็วกว่าเทคนิคที่ต้องปรับแต่งพารามิเตอร์ทั้งหมดของโมเดล
- ลดต้นทุนการคำนวณของการอนุมานโดยการเปิดใช้ การแสดงพร้อมกันของโมเดลเฉพาะทางหลายรายการที่ใช้โมเดลพื้นฐานเดียวกัน
M
การแปลด้วยคอมพิวเตอร์
การใช้ซอฟต์แวร์ (โดยปกติคือโมเดลแมชชีนเลิร์นนิง) เพื่อแปลงข้อความจาก ภาษาหนึ่งของมนุษย์เป็นอีกภาษาหนึ่งของมนุษย์ เช่น จากอังกฤษเป็น ญี่ปุ่น
ความแม่นยำของค่าเฉลี่ยที่ k (mAP@k)
ค่าเฉลี่ยทางสถิติของคะแนนความแม่นยำเฉลี่ยที่ k ทั้งหมดในชุดข้อมูลการตรวจสอบ การใช้ความแม่นยำเฉลี่ยที่ตำแหน่ง k อย่างหนึ่งคือการประเมิน คุณภาพของคำแนะนำที่สร้างโดยระบบแนะนำ
แม้ว่าวลี "ค่าเฉลี่ย" จะฟังดูซ้ำซ้อน แต่ชื่อของเมตริกก็เหมาะสม เนื่องจากเมตริกนี้จะหาค่าเฉลี่ยของค่าความแม่นยำเฉลี่ยที่ k หลายค่า
Mixture of Experts
รูปแบบการเพิ่มประสิทธิภาพโครงข่ายระบบประสาทเทียมโดยใช้เพียงชุดย่อยของพารามิเตอร์ (เรียกว่าผู้เชี่ยวชาญ) เพื่อประมวลผลโทเค็นหรือตัวอย่างอินพุตที่กำหนด เครือข่ายการควบคุมการเข้าถึงจะกำหนดเส้นทางโทเค็นอินพุตหรือตัวอย่างแต่ละรายการไปยังผู้เชี่ยวชาญที่เหมาะสม
ดูรายละเอียดได้ที่เอกสารต่อไปนี้
- โครงข่ายระบบประสาทเทียมขนาดใหญ่มาก: เลเยอร์ Sparsely-Gated Mixture-of-Experts
- Mixture-of-Experts พร้อมการกำหนดเส้นทางตามตัวเลือกของผู้เชี่ยวชาญ
MMIT
คำย่อของ multimodal instruction-tuned
การเรียงซ้อนโมเดล
ระบบที่เลือกโมเดลที่เหมาะสมที่สุดสําหรับการอนุมาน คําค้นหาที่เฉพาะเจาะจง
ลองนึกถึงกลุ่มโมเดลที่มีตั้งแต่ขนาดใหญ่มาก (มีพารามิเตอร์จำนวนมาก) ไปจนถึงขนาดเล็กกว่ามาก (มีพารามิเตอร์น้อยกว่ามาก) โมเดลขนาดใหญ่มากใช้ทรัพยากรการคำนวณมากกว่าในเวลาการอนุมานมากกว่าโมเดลขนาดเล็ก อย่างไรก็ตาม โดยทั่วไปแล้วโมเดลขนาดใหญ่มากจะอนุมานคำขอที่ซับซ้อนกว่าโมเดลขนาดเล็กได้ การเรียงซ้อนโมเดลจะกำหนดความซับซ้อนของคำค้นหาการอนุมาน จากนั้นจะเลือกโมเดลที่เหมาะสมเพื่อทำการอนุมาน แรงจูงใจหลักในการเรียงซ้อนโมเดลคือการลดต้นทุนการอนุมานโดย โดยทั่วไปแล้วจะเลือกโมเดลขนาดเล็กกว่า และเลือกโมเดลขนาดใหญ่กว่าเฉพาะสำหรับคำค้นหาที่ซับซ้อนกว่า
ลองนึกภาพว่าโมเดลขนาดเล็กทำงานบนโทรศัพท์และโมเดลเวอร์ชันที่ใหญ่กว่า ทำงานบนเซิร์ฟเวอร์ระยะไกล การเรียงต่อโมเดลที่ดีจะช่วยลดต้นทุนและเวลาในการตอบสนองโดยการเปิดให้โมเดลขนาดเล็กจัดการคำขอที่เรียบง่าย และเรียกใช้โมเดลระยะไกลเพื่อจัดการคำขอที่ซับซ้อนเท่านั้น
ดูเราเตอร์รุ่นเพิ่มเติม
เราเตอร์โมเด็ม
อัลกอริทึมที่กำหนดโมเดลที่เหมาะสมที่สุดสำหรับการอนุมานในการเรียงซ้อนโมเดล โดยปกติแล้วเราเตอร์โมเดลจะเป็นโมเดลแมชชีนเลิร์นนิงที่ค่อยๆ เรียนรู้วิธีเลือกโมเดลที่ดีที่สุดสำหรับอินพุตที่กำหนด อย่างไรก็ตาม บางครั้งเราเตอร์โมเดลอาจเป็นอัลกอริทึมที่ไม่ใช่แมชชีนเลิร์นนิงที่เรียบง่ายกว่า
MOE
คำย่อของMixture of Experts
MT
ตัวย่อของการแปลด้วยคอมพิวเตอร์
N
Nano
โมเดล Gemini ขนาดค่อนข้างเล็กซึ่งออกแบบมาเพื่อใช้ในอุปกรณ์ ดูรายละเอียดได้ที่ Gemini Nano
ไม่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว (NORA)
พรอมต์ที่มีคำตอบที่ถูกต้องหลายรายการ ตัวอย่างเช่น พรอมต์ต่อไปนี้ไม่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว
เล่าเรื่องตลกเกี่ยวกับช้างให้ฟังหน่อย
การประเมินคำตอบของพรอมต์ที่ไม่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว มักจะมีความเป็นอัตนัยมากกว่าการประเมินพรอมต์ที่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว เช่น การประเมินมุกตลกเกี่ยวกับช้างต้องมีวิธีที่เป็นระบบเพื่อพิจารณาว่ามุกตลกนั้นตลกแค่ไหน
NORA
คำย่อของไม่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว
Notebook LM
เครื่องมือที่ทำงานด้วย Gemini ซึ่งช่วยให้ผู้ใช้อัปโหลดเอกสาร แล้วใช้พรอมต์เพื่อถามคำถาม สรุป หรือจัดระเบียบเอกสารเหล่านั้นได้ ตัวอย่างเช่น นักเขียนอาจอัปโหลดเรื่องสั้นหลายเรื่อง และขอให้ NotebookLM ค้นหาธีมร่วมหรือระบุว่าเรื่องใด เหมาะที่จะนำไปสร้างเป็นภาพยนตร์มากที่สุด
O
คำตอบที่ถูกต้อง 1 ข้อ (ORA)
พรอมต์ที่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว ตัวอย่างเช่น ลองพิจารณาพรอมต์ต่อไปนี้
จริงหรือเท็จ: ดาวเสาร์มีขนาดใหญ่กว่าดาวอังคาร
คำตอบที่ถูกต้องเพียงอย่างเดียวคือ true
เปรียบเทียบกับไม่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว
การเขียนพรอมต์แบบ One-Shot Prompting
พรอมต์ที่มีตัวอย่างหนึ่งตัวอย่างที่แสดงให้เห็นว่าโมเดลภาษาขนาดใหญ่ควรตอบสนองอย่างไร ตัวอย่างเช่น พรอมต์ต่อไปนี้มีตัวอย่างหนึ่งที่แสดงให้โมเดลภาษาขนาดใหญ่เห็นว่า ควรตอบคำค้นหาอย่างไร
| ส่วนต่างๆ ของพรอมต์ | หมายเหตุ |
|---|---|
| สกุลเงินอย่างเป็นทางการของประเทศที่ระบุคืออะไร | คำถามที่คุณต้องการให้ LLM ตอบ |
| ฝรั่งเศส: EUR | ตัวอย่าง |
| อินเดีย: | คำค้นหาจริง |
เปรียบเทียบการแจ้งแบบนัดเดียวกับคำศัพท์ต่อไปนี้
ORA
ตัวย่อของคำตอบที่ถูกต้องเพียงข้อเดียว
P
การปรับแต่งที่มีประสิทธิภาพด้านพารามิเตอร์
ชุดเทคนิคในการปรับแต่งโมเดลภาษาที่ฝึกไว้ล่วงหน้า (PLM) ขนาดใหญ่ ให้มีประสิทธิภาพมากกว่าการปรับแต่งทั้งหมด การปรับแต่งที่มีประสิทธิภาพด้านพารามิเตอร์ มักจะปรับแต่งพารามิเตอร์จำนวนน้อยกว่าการปรับแต่งแบบเต็ม แต่โดยทั่วไปแล้วจะสร้างโมเดลภาษาขนาดใหญ่ที่มีประสิทธิภาพ ดี (หรือเกือบดี) เท่ากับโมเดลภาษาขนาดใหญ่ที่สร้างจากการปรับแต่งแบบเต็ม
เปรียบเทียบการปรับแต่งที่มีประสิทธิภาพด้านพารามิเตอร์กับ
การปรับแต่งที่มีประสิทธิภาพด้านพารามิเตอร์เรียกอีกอย่างว่าการปรับแต่งแบบละเอียดที่มีประสิทธิภาพด้านพารามิเตอร์
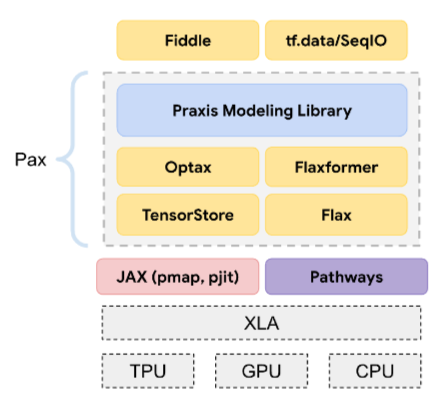
Pax
เฟรมเวิร์กการเขียนโปรแกรมที่ออกแบบมาเพื่อฝึกโมเดล โครงข่ายระบบประสาทเทียมขนาดใหญ่ ซึ่งมีขนาดใหญ่มากจนครอบคลุมชิป TPU ตัวเร่ง หลายส่วนแบ่ง หรือพ็อด
Pax สร้างขึ้นบน Flax ซึ่งสร้างขึ้นบน JAX
PLM
คำย่อของโมเดลภาษาที่ฝึกล่วงหน้า
โมเดลที่ฝึกภายหลัง
คำที่กำหนดอย่างกว้างๆ ซึ่งโดยทั่วไปหมายถึงโมเดลที่ผ่านการฝึกมาก่อนซึ่งผ่านการประมวลผลภายหลังมาแล้ว เช่น อย่างน้อย 1 รายการต่อไปนี้
โมเดลที่ฝึกไว้ล่วงหน้า
แม้ว่าคำนี้จะหมายถึงโมเดลหรือเวกเตอร์การฝังที่ผ่านการฝึกใดๆ แต่ปัจจุบันโมเดลที่ผ่านการฝึกเบื้องต้นมักหมายถึงโมเดลภาษาขนาดใหญ่ที่ผ่านการฝึก หรือโมเดล Generative AI รูปแบบอื่นๆ ที่ผ่านการฝึก
ดูโมเดลพื้นฐานและ โมเดลพื้นฐานด้วย
การฝึกล่วงหน้า
การฝึกโมเดลเบื้องต้นในชุดข้อมูลขนาดใหญ่ โมเดลที่ผ่านการฝึกมาก่อนบางโมเดล เป็นโมเดลขนาดใหญ่ที่ทำงานได้ไม่ดีนักและมักจะต้องปรับแต่งผ่านการฝึกเพิ่มเติม เช่น ผู้เชี่ยวชาญด้าน ML อาจฝึกล่วงหน้าโมเดลภาษาขนาดใหญ่ในชุดข้อมูลข้อความขนาดใหญ่ เช่น หน้าภาษาอังกฤษทั้งหมดใน Wikipedia หลังจากการฝึกเบื้องต้น โมเดลที่ได้อาจได้รับการปรับแต่งเพิ่มเติมผ่านเทคนิคต่อไปนี้
Pro
โมเดล Gemini ที่มีพารามิเตอร์น้อยกว่า Ultra แต่มีพารามิเตอร์มากกว่า Nano ดูรายละเอียดได้ที่ Gemini Pro
prompt
ข้อความใดก็ตามที่ป้อนเป็นอินพุตไปยังโมเดลภาษาขนาดใหญ่ เพื่อกำหนดให้โมเดลทำงานในลักษณะใดลักษณะหนึ่ง พรอมต์อาจสั้นเพียง วลีเดียวหรือยาวเท่าใดก็ได้ (เช่น ข้อความทั้งหมดของนวนิยาย) พรอมต์ จะอยู่ในหลายหมวดหมู่ รวมถึงหมวดหมู่ที่แสดงในตารางต่อไปนี้
| หมวดหมู่พรอมต์ | ตัวอย่าง | หมายเหตุ |
|---|---|---|
| คำถาม | นกพิราบบินได้เร็วแค่ไหน | |
| โรงเรียนฝึกอบรม | แต่งกลอนตลกๆ เกี่ยวกับการเก็งกำไร | พรอมต์ที่ขอให้โมเดลภาษาขนาดใหญ่ทำบางอย่าง |
| ตัวอย่าง | แปลโค้ด Markdown เป็น HTML เช่น
มาร์กดาวน์: * รายการ HTML: <ul> <li>รายการ</li> </ul> |
ประโยคแรกในพรอมต์ตัวอย่างนี้คือคำสั่ง ส่วนที่เหลือของพรอมต์คือตัวอย่าง |
| บทบาท | อธิบายเหตุผลที่ใช้การไล่ระดับความชันในการฝึกแมชชีนเลิร์นนิงให้ ผู้ที่จบปริญญาเอกสาขาฟิสิกส์ | ส่วนแรกของประโยคคือคำสั่ง ส่วนวลี "to a PhD in Physics" คือส่วนบทบาท |
| อินพุตบางส่วนเพื่อให้โมเดลทำให้เสร็จสมบูรณ์ | นายกรัฐมนตรีแห่งสหราชอาณาจักรอาศัยอยู่ที่ | พรอมต์อินพุตบางส่วนอาจสิ้นสุดอย่างกะทันหัน (ดังตัวอย่างนี้) หรือลงท้ายด้วยขีดล่าง |
โมเดล Generative AI สามารถตอบสนองต่อพรอมต์ด้วยข้อความ โค้ด รูปภาพ การฝัง วิดีโอ และอื่นๆ อีกมากมาย
การเรียนรู้ตามพรอมต์
ความสามารถของโมเดลบางอย่างที่ช่วยให้โมเดลปรับเปลี่ยนลักษณะการทำงานเพื่อตอบสนองต่อข้อความที่ป้อนโดยพลการ (พรอมต์) ได้ ในกระบวนทัศน์การเรียนรู้ตามพรอมต์ทั่วไป โมเดลภาษาขนาดใหญ่จะตอบกลับพรอมต์โดยการสร้างข้อความ ตัวอย่างเช่น สมมติว่าผู้ใช้ป้อนพรอมต์ต่อไปนี้
สรุปกฎการเคลื่อนที่ข้อที่ 3 ของนิวตัน
โมเดลที่รองรับการเรียนรู้ตามพรอมต์ไม่ได้ผ่านการฝึกมาเพื่อตอบพรอมต์ก่อนหน้าโดยเฉพาะ แต่โมเดลจะ "รู้" ข้อเท็จจริงมากมายเกี่ยวกับฟิสิกส์ กฎเกณฑ์ทั่วไปของภาษา และสิ่งที่ประกอบกันเป็นคำตอบที่มีประโยชน์โดยทั่วไป ความรู้นั้นเพียงพอที่จะให้คำตอบที่ (หวังว่า) จะเป็นประโยชน์ ความคิดเห็นเพิ่มเติมจากเจ้าหน้าที่ ("คำตอบนั้นซับซ้อนเกินไป" หรือ "รีแอ็กชันคืออะไร") ช่วยให้ระบบการเรียนรู้บางระบบที่อิงตามพรอมต์ค่อยๆ ปรับปรุงประโยชน์ของคำตอบ
การออกแบบพรอมต์
คำพ้องความหมายของวิศวกรรมพรอมต์
วิศวกรรมพรอมต์
ศิลปะในการสร้างพรอมต์ที่กระตุ้นให้โมเดลภาษาขนาดใหญ่สร้างคำตอบที่ต้องการ มนุษย์จะทำพรอมต์ วิศวกรรม การเขียนพรอมต์ที่มีโครงสร้างดีเป็นส่วนสำคัญในการรับประกัน คำตอบที่เป็นประโยชน์จากโมเดลภาษาขนาดใหญ่ วิศวกรรมพรอมต์ (Prompt Engineering) ขึ้นอยู่กับหลายปัจจัย ได้แก่
- ชุดข้อมูลที่ใช้ในการฝึกเบื้องต้นและอาจใช้ปรับแต่งโมเดลภาษาขนาดใหญ่
- อุณหภูมิและพารามิเตอร์การถอดรหัสอื่นๆ ที่โมเดลใช้เพื่อสร้างคำตอบ
การออกแบบพรอมต์เป็นคำพ้องความหมายของวิศวกรรมพรอมต์
ดูรายละเอียดเพิ่มเติมเกี่ยวกับการเขียนพรอมต์ที่เป็นประโยชน์ได้ที่ ข้อมูลเบื้องต้นเกี่ยวกับการออกแบบพรอมต์
ชุดพรอมต์
กลุ่มพรอมต์สำหรับการประเมิน โมเดลภาษาขนาดใหญ่ ตัวอย่างเช่น ภาพต่อไปนี้ แสดงชุดพรอมต์ที่ประกอบด้วยพรอมต์ 3 รายการ
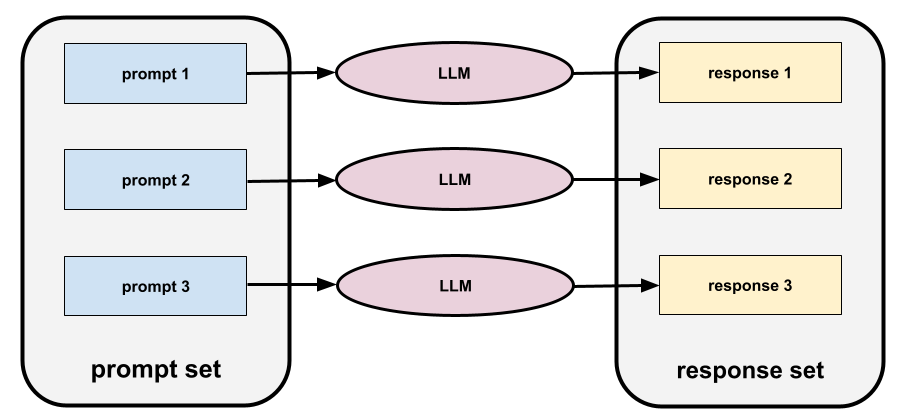
ชุดพรอมต์ที่ดีประกอบด้วยคอลเล็กชันพรอมต์ที่ "หลากหลาย" เพียงพอที่จะ ประเมินความปลอดภัยและประโยชน์ของโมเดลภาษาขนาดใหญ่อย่างละเอียด
ดูชุดคำตอบด้วย
การปรับแต่งพรอมต์
กลไกการปรับแต่งที่มีประสิทธิภาพของพารามิเตอร์ ซึ่งจะเรียนรู้ "คำนำหน้า" ที่ระบบจะเพิ่มไว้หน้าพรอมต์จริง
การปรับพรอมต์รูปแบบหนึ่งซึ่งบางครั้งเรียกว่าการปรับคำนำหน้าคือการเพิ่มคำนำหน้าที่ทุกเลเยอร์ ในทางตรงกันข้าม การปรับพรอมต์ส่วนใหญ่จะเพิ่มเลเยอร์อินพุตเป็นคำนำหน้าเท่านั้น
R
ข้อความอ้างอิง
คำตอบของผู้เชี่ยวชาญต่อพรอมต์ เช่น หากได้รับพรอมต์ต่อไปนี้
แปลคำถาม "คุณชื่ออะไร" จากภาษาอังกฤษเป็นภาษาฝรั่งเศส
คำตอบของผู้เชี่ยวชาญอาจเป็นดังนี้
Comment vous appelez-vous?
เมตริกต่างๆ (เช่น ROUGE) จะวัดระดับที่ข้อความอ้างอิง ตรงกับข้อความที่สร้างขึ้นของโมเดล ML
ทบทวนความคิด
กลยุทธ์ในการปรับปรุงคุณภาพของเวิร์กโฟลว์แบบเอเจนต์โดยการตรวจสอบ (พิจารณา) เอาต์พุตของขั้นตอนก่อนที่จะส่งเอาต์พุตนั้นไปยังขั้นตอนถัดไป
โดยปกติแล้ว ผู้ตรวจสอบจะเป็น LLM ตัวเดียวกับที่สร้างคำตอบ (แม้ว่าอาจเป็น LLM อื่นก็ได้) LLM เดียวกันที่สร้างคำตอบจะเป็นผู้ตัดสินที่ยุติธรรมสำหรับคำตอบของตัวเองได้อย่างไร "เคล็ดลับ" คือการทำให้ LLM มีความคิดเชิงวิพากษ์ (ไตร่ตรอง) กระบวนการนี้คล้ายกับนักเขียนที่ใช้ความคิดสร้างสรรค์ ในการเขียนฉบับร่างแรก แล้วเปลี่ยนไปใช้ความคิดเชิงวิพากษ์ เพื่อแก้ไข
ตัวอย่างเช่น ลองนึกถึงเวิร์กโฟลว์แบบเอเจนต์ซึ่งมีขั้นตอนแรกเป็นการสร้าง ข้อความสำหรับแก้วกาแฟ ข้อความแจ้งสำหรับขั้นตอนนี้อาจเป็น
คุณเป็นครีเอเตอร์ สร้างข้อความตลกๆ ที่ไม่ซ้ำใครซึ่งมีความยาวไม่เกิน 50 อักขระ เหมาะสำหรับแก้วกาแฟ
ตอนนี้ลองนึกถึงพรอมต์การไตร่ตรองต่อไปนี้
คุณเป็นคนดื่มกาแฟ คุณคิดว่าคำตอบก่อนหน้านี้ตลกไหม
จากนั้นเวิร์กโฟลว์อาจส่งต่อเฉพาะข้อความที่ได้รับคะแนนการสะท้อนสูง ไปยังขั้นตอนถัดไป
การเรียนรู้แบบเสริมกำลังจากฟีดแบ็กของมนุษย์ (Reinforcement Learning from Human Feedback หรือ RLHF)
การใช้ความคิดเห็นจากผู้ให้คะแนนที่เป็นมนุษย์เพื่อปรับปรุงคุณภาพคำตอบของโมเดล ตัวอย่างเช่น กลไก RLHF สามารถขอให้ผู้ใช้ ให้คะแนนคุณภาพของคำตอบของโมเดลด้วยอีโมจิ 👍 หรือ 👎 จากนั้นระบบ จะปรับคำตอบในอนาคตตามความคิดเห็นนั้น
การตอบกลับ
ข้อความ รูปภาพ เสียง หรือวิดีโอที่โมเดล Generative AI อนุมาน กล่าวอีกนัยหนึ่งคือ พรอมต์คืออินพุตของโมเดล Generative AI และคำตอบคือเอาต์พุต
ชุดคำตอบ
ชุดคำตอบที่โมเดลภาษาขนาดใหญ่ส่งกลับไปยังอินพุต ชุดพรอมต์
การเขียนพรอมต์ตามบทบาท
พรอมต์ที่มักเริ่มต้นด้วยคำสรรพนามคุณ ซึ่ง บอกโมเดล Generative AI ให้แสร้งเป็นบุคคลหรือบทบาทหนึ่งๆ เมื่อสร้างคำตอบ การใช้พรอมต์ตามบทบาทจะช่วยให้โมเดล Generative AI มี "กรอบความคิด" ที่เหมาะสม เพื่อสร้างคำตอบที่เป็นประโยชน์มากขึ้น ตัวอย่างเช่น พรอมต์บทบาทต่อไปนี้อาจเหมาะสม ทั้งนี้ขึ้นอยู่กับประเภทของคำตอบที่คุณต้องการ
คุณมีปริญญาเอกสาขาวิทยาการคอมพิวเตอร์
คุณเป็นวิศวกรซอฟต์แวร์ที่ชอบอธิบายเรื่อง Python ให้แก่นักเรียนนักศึกษาที่เพิ่งเริ่มเรียนการเขียนโปรแกรมอย่างอดทน
คุณเป็นฮีโร่ที่เก่งกาจด้านการเขียนโปรแกรม โปรดยืนยันว่าคุณจะค้นหารายการที่เฉพาะเจาะจงในรายการ Python
S
การปรับแต่งพรอมต์แบบซอฟต์
เทคนิคในการปรับโมเดลภาษาขนาดใหญ่ สำหรับงานหนึ่งๆ โดยไม่ต้องใช้การปรับแต่งที่ต้องใช้ทรัพยากรจำนวนมาก การปรับพรอมต์แบบ Soft จะปรับพรอมต์โดยอัตโนมัติเพื่อให้บรรลุเป้าหมายเดียวกันแทนที่จะฝึกน้ำหนักทั้งหมดในโมเดลใหม่
เมื่อได้รับพรอมต์ที่เป็นข้อความ การปรับพรอมต์แบบซอฟต์ โดยทั่วไปจะผนวกการฝังโทเค็นเพิ่มเติมลงในพรอมต์และใช้ การแพร่ย้อนกลับเพื่อเพิ่มประสิทธิภาพอินพุต
พรอมต์ "ฮาร์ด" มีโทเค็นจริงแทนที่จะเป็นโทเค็นแบบฝัง
การเขียนโค้ดตามข้อกำหนด
กระบวนการเขียนและดูแลรักษาไฟล์ในภาษาที่มนุษย์ใช้ (เช่น ภาษาอังกฤษ) ซึ่งอธิบายซอฟต์แวร์ จากนั้นคุณสามารถบอกโมเดล Generative AI หรือ วิศวกรซอฟต์แวร์คนอื่นให้สร้างซอฟต์แวร์ที่ตรงกับคำอธิบายนั้น
โดยทั่วไปแล้ว โค้ดที่สร้างขึ้นโดยอัตโนมัติต้องมีการทำซ้ำ ในการเขียนโค้ดตามข้อกำหนด คุณจะวนซ้ำในไฟล์คำอธิบาย ในทางตรงกันข้าม การเขียนโค้ดแบบสนทนาจะวนซ้ำภายใน ช่องพรอมต์ ในทางปฏิบัติ การสร้างโค้ดอัตโนมัติบางครั้งเกี่ยวข้องกับทั้งการเขียนโค้ดตามข้อกำหนดและการเขียนโค้ดแบบสนทนา
T
อุณหภูมิ
ไฮเปอร์พารามิเตอร์ที่ควบคุมระดับความสุ่ม ของเอาต์พุตของโมเดล อุณหภูมิที่สูงขึ้นจะทำให้เอาต์พุตมีความสุ่มมากขึ้น ขณะที่อุณหภูมิที่ต่ำลงจะทำให้เอาต์พุตมีความสุ่มน้อยลง
การเลือกอุณหภูมิที่ดีที่สุดขึ้นอยู่กับการใช้งานและ/หรือค่าสตริงที่เฉพาะเจาะจง
U
Ultra
โมเดล Gemini ที่มีพารามิเตอร์มากที่สุด ดูรายละเอียดได้ที่ Gemini Ultra
V
Vertex
แพลตฟอร์มของ Google Cloud สำหรับ AI และแมชชีนเลิร์นนิง Vertex มีเครื่องมือ และโครงสร้างพื้นฐานสำหรับการสร้าง การติดตั้งใช้งาน และการจัดการแอปพลิเคชัน AI รวมถึงสิทธิ์เข้าถึงโมเดล GeminiVibe Coding
การป้อนพรอมต์ให้โมเดล Generative AI สร้างซอฟต์แวร์ กล่าวคือ พรอมต์ของคุณ อธิบายวัตถุประสงค์และฟีเจอร์ของซอฟต์แวร์ ซึ่งโมเดล Generative AI จะแปลเป็นซอร์สโค้ด โค้ดที่สร้างขึ้นอาจไม่ตรงกับความตั้งใจของคุณเสมอไป ดังนั้น Vibe Coding จึงมักต้องมีการทำซ้ำ
Andrej Karpathy เป็นผู้บัญญัติคำว่า vibe coding ในโพสต์บน X นี้ ในโพสต์บน X คาร์พาธีอธิบายว่า "การเขียนโค้ดรูปแบบใหม่...ที่คุณปล่อยใจไปกับฟีลลิ่งอย่างเต็มที่..." ดังนั้น เดิมทีคำนี้จึงหมายถึงแนวทางที่ตั้งใจให้หลวมๆ ในการสร้างซอฟต์แวร์ ซึ่งคุณอาจไม่ได้ตรวจสอบโค้ดที่สร้างขึ้นด้วยซ้ำ อย่างไรก็ตาม คำนี้ได้พัฒนาอย่างรวดเร็วในหลายวงการจนปัจจุบันหมายถึงการเขียนโค้ดที่ AI สร้างขึ้นทุกรูปแบบ
ดูคำอธิบาย Vibe Coding เพิ่มเติมได้ที่ Vibe Coding คืออะไร
นอกจากนี้ ให้เปรียบเทียบ Vibe Coding กับสิ่งต่อไปนี้
Z
Zero-Shot Prompting
พรอมต์ที่ไม่ได้ระบุตัวอย่างวิธีที่คุณต้องการให้โมเดลภาษาขนาดใหญ่ตอบ เช่น
| ส่วนต่างๆ ของพรอมต์ | หมายเหตุ |
|---|---|
| สกุลเงินอย่างเป็นทางการของประเทศที่ระบุคืออะไร | คำถามที่คุณต้องการให้ LLM ตอบ |
| อินเดีย: | คำค้นหาจริง |
โมเดลภาษาขนาดใหญ่อาจตอบกลับด้วยข้อความต่อไปนี้
- รูปี
- INR
- ₹
- รูปีอินเดีย
- รูปี
- รูปีอินเดีย
คำตอบทั้งหมดถูกต้อง แต่คุณอาจชอบรูปแบบใดรูปแบบหนึ่งมากกว่า
เปรียบเทียบการแจ้งแบบศูนย์ช็อตกับคำศัพท์ต่อไปนี้