במילון המונחים הזה מוגדרים מונחים שקשורים לבינה מלאכותית.
A
אבלציה
טכניקה להערכת החשיבות של תכונה או רכיב על ידי הסרה זמנית של התכונה או הרכיב ממודל. לאחר מכן, מאמנים מחדש את המודל בלי התכונה או הרכיב האלה. אם הביצועים של המודל שאומן מחדש גרועים משמעותית, סביר להניח שהתכונה או הרכיב שהוסרו היו חשובים.
לדוגמה, נניח שאימנתם מודל סיווג על 10 תכונות והשגתם דיוק של 88% בקבוצת נתונים לבדיקה. כדי לבדוק את החשיבות של התכונה הראשונה, אפשר לאמן מחדש את המודל באמצעות תשע התכונות האחרות בלבד. אם הביצועים של המודל שאומן מחדש גרועים משמעותית (לדוגמה, דיוק של פחות מ-55%), כנראה שהתכונה שהוסרה הייתה חשובה. לעומת זאת, אם המודל שאומן מחדש משיג ביצועים טובים באותה מידה, כנראה שהתכונה הזו לא הייתה חשובה במיוחד.
הסרת תכונות יכולה לעזור גם לקבוע את החשיבות של:
- רכיבים גדולים יותר, כמו מערכת משנה שלמה של מערכת ML גדולה יותר
- תהליכים או טכניקות, כמו שלב של עיבוד מקדים של נתונים
בשני המקרים, תוכלו לראות איך הביצועים של המערכת משתנים (או לא משתנים) אחרי שתסירו את הרכיב.
A/B Testing
דרך סטטיסטית להשוואה בין שתי טכניקות (או יותר) – A ו-B. בדרך כלל, A היא טכניקה קיימת ו-B היא טכניקה חדשה. בדיקת A/B לא רק קובעת איזו טכניקה מניבה ביצועים טובים יותר, אלא גם אם ההבדל מובהק מבחינה סטטיסטית.
בדרך כלל, בבדיקות A/B משווים מדד יחיד בין שתי טכניקות. לדוגמה, מהי רמת הדיוק של מודל בהשוואה בין שתי טכניקות? עם זאת, בדיקות A/B יכולות גם להשוות בין מספר סופי של מדדים.
צ'יפ של פעולה מהירה
קטגוריה של רכיבי חומרה מיוחדים שנועדו לבצע חישובים של מפתחות שנדרשים לאלגוריתמים של למידה עמוקה.
שבבי האצה (או בקיצור מאיצים) יכולים להגדיל באופן משמעותי את המהירות והיעילות של משימות אימון והסקת מסקנות בהשוואה למעבד לשימוש כללי. הם אידיאליים לאימון רשתות עצביות ולמשימות דומות שדורשות הרבה כוח מחשוב.
דוגמאות לשבבי האצה:
- יחידות Tensor Processing Units (TPU) של Google עם חומרה ייעודית ללמידה עמוקה.
- מעבדי GPU של NVIDIA, שבתחילה נועדו לעיבוד גרפי, אבל הם מתוכננים לאפשר עיבוד מקבילי, שיכול להגדיל באופן משמעותי את מהירות העיבוד.
דיוק
מספר התחזיות הנכונות של הסיווג חלקי המספר הכולל של התחזיות. כלומר:
לדוגמה, למודל שביצע 40 חיזויים נכונים ו-10 חיזויים לא נכונים יהיה דיוק של:
סיווג בינארי מספק שמות ספציפיים לקטגוריות השונות של תחזיות נכונות ותחזיות שגויות. לכן, נוסחת הדיוק לסיווג בינארי היא:
where:
- TP הוא מספר החיוביים האמיתיים (תחזיות נכונות).
- TN הוא מספר השליליים האמיתיים (חיזויים נכונים).
- FP הוא מספר החיוביים הכוזבים (תחזיות שגויות).
- FN הוא מספר השליליים הכוזבים (תחזיות שגויות).
השוו בין דיוק לבין דיוק והחזרה.
מידע נוסף זמין במאמר סיווג: דיוק, היזכרות, פרסיזיה ומדדים קשורים בסדנה ללמידת מכונה.
לפעול
שלב בלולאה של סוכן שבו הסוכן מבצע את הפעולה שנבחרה במהלך שלב ההסבר. לדוגמה, שלב הפעולה יכול לשלוח בקשת API.
פעולה
בלמידת חיזוק, המנגנון שבאמצעותו הסוכן עובר בין מצבים של הסביבה. הסוכן בוחר את הפעולה באמצעות מדיניות.
מרחב פעולה
קבוצת המשאבים שסוכן יכול להשתמש בהם כדי לבצע משימה. מרחב הפעולה יכול לכלול את הכלים וממשקי ה-API שהסוכן יכול להפעיל, ואת ההרשאות שיש לסוכן. באופן כללי, מרחב הפעולה צריך להיות גדול מספיק כדי שהסוכן יוכל לבצע את המשימה. אם מרחב הפעולות קטן מדי, יכול להיות שלא יהיו לסוכן מספיק משאבים כדי לבצע את המשימה. אם מרחב הפעולה גדול מדי, הסוכן נוטה להיות מועד יותר לטעויות.
פונקציית הפעלה
פונקציה שמאפשרת לרשתות נוירונים ללמוד קשרים לא ליניאריים (מורכבים) בין התכונות לבין התווית.
פונקציות הפעלה פופולריות כוללות:
הגרפים של פונקציות ההפעלה אף פעם לא קווים ישרים. לדוגמה, הגרף של פונקציית ההפעלה ReLU מורכב משני קווים ישרים:

גרף של פונקציית ההפעלה הסיגמואידית נראה כך:

כדי לראות דוגמה, לוחצים על הסמל.
ברשת נוירונים, פונקציות ההפעלה משנות את הסכום המשוקלל של כל ערכי הקלט של נוירון. כדי לחשב סכום משוקלל, הנוירון מחבר את המכפלות של הערכים והמשקלים הרלוונטיים. לדוגמה, נניח שהקלט הרלוונטי לנוירון מורכב מהנתונים הבאים:
| ערך קלט | משקל הקלט |
| 2 | 1.3- |
| -1 | 0.6 |
| 3 | 0.4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
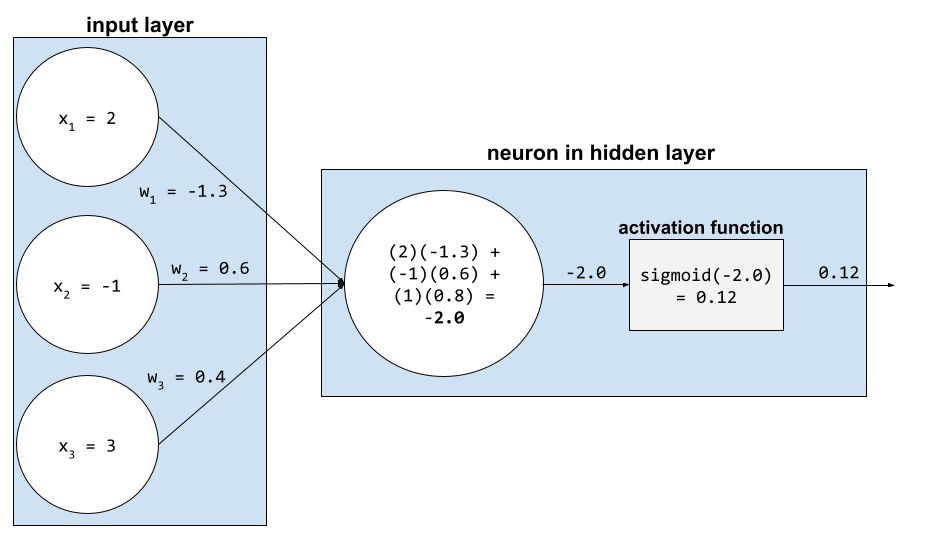
מידע נוסף מופיע במאמר רשתות עצביות: פונקציות הפעלה בסדנה ללימוד מכונת למידה.
למידה פעילה
גישת אימון שבה האלגוריתם בוחר חלק מהנתונים שהוא לומד מהם. למידה פעילה שימושית במיוחד כשקשה להשיג דוגמאות עם תוויות או שהן יקרות. במקום לחפש באופן אקראי מגוון רחב של דוגמאות מתויגות, אלגוריתם של למידה פעילה מחפש באופן סלקטיבי את טווח הדוגמאות הספציפי שהוא צריך כדי ללמוד.
AdaGrad
אלגוריתם מורכב של ירידת גרדיאנט שמשנה את קנה המידה של הגרדיאנטים של כל פרמטר, וכך למעשה נותן לכל פרמטר קצב למידה עצמאי. הסבר מלא זמין במאמר Adaptive Subgradient Methods for Online Learning and Stochastic Optimization.
התאמה
מילה נרדפת לשיפור או לכוונון עדין.
סוכן
תוכנה שיכולה להסיק מסקנות לגבי קלט של משתמשים כדי לתכנן ולבצע פעולות בשם המשתמש.
בלמידת חיזוק, סוכן הוא הישות שמשתמשת במדיניות כדי למקסם את התשואה הצפויה שמתקבלת ממעבר בין מצבים של הסביבה.
אג'נטי
צורת התואר של agent. המונח 'אקטיבי' מתייחס לתכונות של סוכנים (כמו אוטונומיה).
לולאה אג'נטית
מחזור שסוכן חוזר עליו עד שמתקיים תנאי סיום. המחזור בדרך כלל מורכב מארבעת השלבים הבאים:
תהליך עבודה אג'נטי
תהליך דינמי שבו סוכן מתכנן ומבצע פעולות באופן אוטונומי כדי להשיג מטרה. התהליך עשוי לכלול ניתוח, הפעלה של כלים חיצוניים ותיקון עצמי של התוכנית.
תזמור של סוכנים
ניהול וניתוב מרוכזים של משימות בין כמה סוכנים משנה או קריאות ל-LLM. תזמור סוכנים (Agent orchestration) מפרק משימות מורכבות לתתי-משימות קטנות יותר ומקצה אותן לסוכני המשנה המתאימים ביותר.
אשכול היררכי
מידע נוסף זמין במאמר בנושא אשכול היררכי.
סלופ
פלט ממערכת AI גנרטיבי שמעדיפה כמות על פני איכות. לדוגמה, דף אינטרנט עם רפש של בינה מלאכותית מלא בתוכן באיכות נמוכה שנוצר על ידי AI בעלות נמוכה.
זיהוי אנומליות
תהליך הזיהוי של ערכים חריגים. לדוגמה, אם הממוצע של תכונה מסוימת הוא 100 עם סטיית תקן של 10, אז זיהוי האנומליות צריך לסמן ערך של 200 כחשוד.
AR
קיצור של מציאות רבודה.
השטח מתחת לעקומת ה-PR
מידע נוסף על PR AUC (השטח מתחת לעקומת ה-PR)
שטח מתחת לעקומת ROC
מידע נוסף על AUC (השטח מתחת לעקומת ROC)
בינה מלאכותית כללית
מנגנון לא אנושי שמדגים מגוון רחב של יכולות לפתרון בעיות, יצירתיות ויכולת הסתגלות. לדוגמה, תוכנה שמדגימה בינה מלאכותית כללית יכולה לתרגם טקסט, להלחין סימפוניות ולהצטיין במשחקים שעדיין לא הומצאו.
לגבי בינה מלאכותית,
תוכנה או מודל לא אנושיים שיכולים לפתור משימות מורכבות. לדוגמה, תוכנית או מודל שמתרגמים טקסט, או תוכנית או מודל שמזהים מחלות מתמונות רדיולוגיות, שניהם מציגים בינה מלאכותית.
באופן רשמי, למידת מכונה היא תחום משנה של בינה מלאכותית. עם זאת, בשנים האחרונות, חלק מהארגונים התחילו להשתמש במונחים בינה מלאכותית ולמידת מכונה לסירוגין.
תשומת הלב,
מנגנון שמשמש ברשת נוירונים ומציין את החשיבות של מילה מסוימת או חלק ממילה. תשומת הלב דוחסת את כמות המידע שמודל צריך כדי לחזות את הטוקן או המילה הבאים. מנגנון תשומת לב טיפוסי עשוי לכלול סכום משוקלל של קבוצת קלטים, כאשר המשקל של כל קלט מחושב על ידי חלק אחר ברשת הנוירונים.
אפשר גם לעיין במאמרים בנושא קשב עצמי וקשב עצמי מרובה ראשים, שהם אבני הבניין של טרנספורמרים.
מידע נוסף על מנגנון תשומת הלב העצמית מופיע במאמר מודלים גדולים של שפה (LLM): מהו מודל שפה גדול? בסדרת המאמרים Machine Learning Crash Course.
מאפיין
מילה נרדפת לתכונה.
בנושא ההוגנות בלמידת מכונה, המונח 'מאפיינים' מתייחס בדרך כלל למאפיינים שקשורים לאנשים פרטיים.
דגימת מאפיינים
טקטיקה לאימון של יער החלטות שבה כל עץ החלטות מתבסס רק על קבוצת משנה אקראית של תכונות אפשריות כשהוא לומד את התנאי. באופן כללי, קבוצת משנה שונה של תכונות נדגמת עבור כל צומת. לעומת זאת, כשמאמנים עץ החלטה בלי דגימת מאפיינים, כל התכונות האפשריות נלקחות בחשבון לכל צומת.
AUC (השטח מתחת לעקומת ה-ROC)
מספר בין 0.0 ל-1.0 שמייצג את היכולת של מודל סיווג בינארי להפריד בין סיווגים חיוביים לבין סיווגים שליליים. ככל שערך ה-AUC קרוב יותר ל-1.0, כך יכולת המודל להפריד בין המחלקות טובה יותר.
לדוגמה, באיור הבא מוצג מודל סיווג שמפריד בצורה מושלמת בין מחלקות חיוביות (אליפסות ירוקות) לבין מחלקות שליליות (מלבנים סגולים). למודל המושלם הלא-מציאותי הזה יש AUC של 1.0:

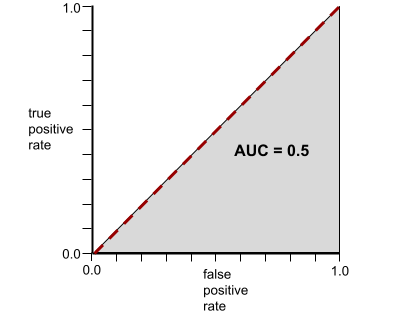
לעומת זאת, באיור הבא מוצגות התוצאות של מודל סיווג שיצר תוצאות אקראיות. המודל הזה כולל AUC של 0.5:

כן, למודל הקודם יש AUC של 0.5, ולא 0.0.
רוב הדגמים נמצאים איפשהו בין שני הקצוות. לדוגמה, המודל הבא מפריד בין ערכים חיוביים לשליליים במידה מסוימת, ולכן ערך ה-AUC שלו הוא בין 0.5 ל-1.0:

הפונקציה AUC מתעלמת מכל ערך שמגדירים עבור classification threshold. במקום זאת, המדד AUC מתחשב בכל ספי הסיווג האפשריים.
כדי לקבל מידע על הקשר בין AUC לבין עקומות ROC, לוחצים על הסמל.
הערך AUC מייצג את השטח מתחת לעקומת ROC. לדוגמה, עקומת ה-ROC של מודל שמפריד בצורה מושלמת בין ערכים חיוביים לערכים שליליים נראית כך:
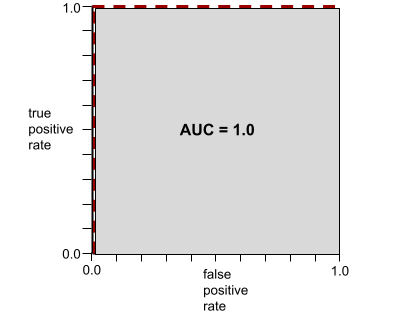
ה-AUC הוא השטח של האזור האפור באיור שלמעלה. במקרה החריג הזה, השטח הוא פשוט האורך של האזור האפור (1.0) כפול הרוחב של האזור האפור (1.0). לכן, המכפלה של 1.0 ו-1.0 היא 1.0 בדיוק, שהוא הציון הכי גבוה שאפשר לקבל ב-AUC.
לעומת זאת, עקומת ה-ROC של מודל סיווג שלא יכול להפריד בין מחלקות בכלל נראית כך. שטח האזור האפור הוא 0.5.
עקומת ROC אופיינית יותר נראית בערך כך:
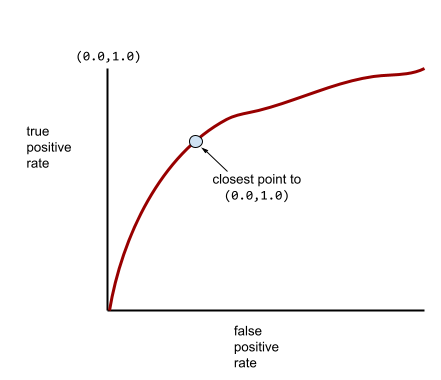
חישוב השטח מתחת לעקומה הזו באופן ידני הוא תהליך מייגע, ולכן בדרך כלל תוכנה מחשבת את רוב ערכי ה-AUC.
מידע נוסף זמין במאמר בנושא סיווג: ROC ו-AUC בקורס המקוצר בנושא למידת מכונה.
מציאות רבודה
טכנולוגיה שמציגה תמונה ממוחשבת על גבי תצוגת העולם האמיתי של המשתמש, וכך מספקת תצוגה מורכבת.
autoencoder
מערכת שלומדת לחלץ את המידע הכי חשוב מהקלט. אוטו-מקודדים הם שילוב של מקודד ומפענח. השימוש בקידוד אוטומטי מתבסס על התהליך הבא בן שני השלבים:
- הקודד ממפה את הקלט לפורמט (בדרך כלל) דחוס עם אובדן נתונים, שהוא פורמט ביניים.
- הפענוח יוצר גרסה עם אובדן נתונים של הקלט המקורי על ידי מיפוי של הפורמט עם פחות ממדים לפורמט הקלט המקורי עם יותר ממדים.
מכשירים אוטומטיים לאימון מקודדים מאומנים מקצה לקצה, כך שהמפענח מנסה לשחזר את הקלט המקורי מפורמט הביניים של המקודד בצורה הכי מדויקת שאפשר. מכיוון שהפורמט הביניים קטן יותר (ממדים נמוכים יותר) מהפורמט המקורי, האוטו-מקודד נאלץ ללמוד איזה מידע בקלט הוא חיוני, והפלט לא יהיה זהה לחלוטין לקלט.
לדוגמה:
- אם נתוני הקלט הם גרפיקה, העותק הלא מדויק יהיה דומה לגרפיקה המקורית, אבל עם שינויים מסוימים. יכול להיות שהעותק הלא מדויק מסיר רעשים מהגרפיקה המקורית או ממלא פיקסלים חסרים.
- אם נתוני הקלט הם טקסט, מקודד אוטומטי ייצור טקסט חדש שמחקה את הטקסט המקורי (אבל לא זהה לו).
אפשר לעיין גם במקודדים אוטומטיים וריאציוניים.
הערכה אוטומטית
שימוש בתוכנה כדי לשפוט את איכות הפלט של מודל.
כשהפלט של המודל פשוט יחסית, סקריפט או תוכנה יכולים להשוות את הפלט של המודל לתשובה מושלמת. הסוג הזה של הערכה אוטומטית נקרא לפעמים הערכה פרוגרמטית. מדדים כמו ROUGE או BLEU שימושיים לעיתים קרובות להערכה פרוגרמטית.
כשפלט המודל מורכב או אין תשובה נכונה אחת, לפעמים מתבצעת הערכה אוטומטית על ידי תוכנת ML נפרדת שנקראת בודק אוטומטי.
השוואה לבדיקה אנושית.
הטיית אוטומציה
כשמקבל החלטות אנושי מעדיף המלצות שנוצרו על ידי מערכת אוטומטית לקבלת החלטות על פני מידע שנוצר ללא אוטומציה, גם כשהמערכת האוטומטית לקבלת החלטות עושה טעויות.
מידע נוסף זמין במאמר הוגנות: סוגי הטיה בסדנת מבוא ללמידת מכונה.
AutoML
כל תהליך אוטומטי ליצירת מודלים של למידת מכונה. AutoML יכול לבצע באופן אוטומטי משימות כמו:
- מחפשים את המודל המתאים ביותר.
- כוונון היפר-פרמטרים.
- הכנת הנתונים (כולל ביצוע הנדסת תכונות).
- פורסים את המודל שנוצר.
AutoML שימושי למדעני נתונים כי הוא יכול לחסוך להם זמן ומאמץ בפיתוח צינורות של למידת מכונה ולשפר את דיוק התחזיות. הוא שימושי גם למי שאינם מומחים, כי הוא מאפשר להם לבצע משימות מורכבות של למידת מכונה.
מידע נוסף מופיע במאמר Automated Machine Learning (AutoML) בקורס המקוצר על למידת מכונה.
סוכן אוטונומי
סוכן שפועל להשגת יעד מורכב באמצעות תכנון, פעולה והתאמה ללא התערבות אנושית רציפה.
הערכה של כלי לדירוג אוטומטי
מנגנון היברידי להערכת האיכות של הפלט של מודל AI גנרטיבי, שמשלב הערכה אנושית עם הערכה אוטומטית. מודל דירוג אוטומטי הוא מודל ML שאומן על נתונים שנוצרו על ידי הערכה אנושית. באופן אידיאלי, מערכת דירוג אוטומטית לומדת לחקות בודק אנושי.יש מערכות מוכנות מראש למתן ציונים אוטומטיים, אבל המערכות הכי טובות הן אלה שעברו כוונון עדין במיוחד למשימה שאתם מעריכים.
מודל אוטו-רגרסיבי
מודל שמסיק חיזוי על סמך החיזויים הקודמים שלו. לדוגמה, מודלים אוטומטיים של שפה חוזים את הטוקן הבא על סמך הטוקנים שנחזו קודם. כל המודלים הגדולים של שפה שמבוססים על Transformer הם אוטורגרסיביים.
לעומת זאת, מודלים של תמונות שמבוססים על GAN בדרך כלל לא רגרסיביים אוטומטיים, כי הם יוצרים תמונה במעבר קדימה יחיד ולא באופן איטרטיבי בשלבים. עם זאת, מודלים מסוימים ליצירת תמונות הם אוטומטיים רגרסיביים כי הם יוצרים תמונה בשלבים.
הפסד עזר
פונקציית הפסד – פונקציה שמשמשת בשילוב עם פונקציית ההפסד הראשית של מודל רשת נוירונים, ומסייעת להאיץ את האימון במהלך האיטרציות הראשונות, כשמשקלים מאותחלים באופן אקראי.
פונקציות הפסד עזר דוחפות גרדיאנטים יעילים אל השכבות הקודמות. הפעולה הזו מקלה על התכנסות במהלך האימון, כי היא עוזרת להתמודד עם בעיית הגרדיאנט הנעלם.
דיוק ממוצע ב-k
מדד לסיכום הביצועים של מודל בהנחיה יחידה שמפיקה תוצאות מדורגות, כמו רשימה ממוספרת של המלצות לספרים. הדיוק הממוצע ב-k הוא, ובכן, הממוצע של ערכי הדיוק ב-k לכל תוצאה רלוונטית. לכן, הנוסחה לחישוב הדיוק הממוצע ב-k היא:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
where:
- \(n\) הוא מספר הפריטים הרלוונטיים ברשימה.
השוואה להיזכרות ב-k.
תנאי שמתייחס לציר
בעץ החלטה, תנאי שכולל רק תכונה אחת. לדוגמה, אם area הוא מאפיין, התנאי הבא הוא תנאי שמתיישר עם הציר:
area > 200
השוואה לתנאי אלכסוני.
B
backpropagation
האלגוריתם שמיישם ירידת גרדיאנט ברשתות נוירונים.
אימון של רשת נוירונים כולל הרבה איטרציות של המחזור הבא בן שני השלבים:
- במהלך המעבר קדימה, המערכת מעבדת אצווה של דוגמאות כדי להפיק חיזויים. המערכת משווה כל תחזית לכל ערך של תווית. ההפרש בין התחזית לבין ערך התווית הוא ההפסד של הדוגמה הזו. המערכת מסכמת את ההפסדים של כל הדוגמאות כדי לחשב את ההפסד הכולל של האצווה הנוכחית.
- במהלך המעבר לאחור (backpropagation), המערכת מצמצמת את אובדן המידע על ידי התאמת המשקלים של כל הנוירונים בכל השכבות הנסתרות.
נוירונים מלאכותיות מכילות בדרך כלל הרבה נוירונים בהרבה שכבות נסתרות. כל אחד מהנוירונים האלה תורם להפסד הכולל בדרכים שונות. האלגוריתם Backpropagation קובע אם להגדיל או להקטין את המשקלים שמוחלים על נוירונים מסוימים.
קצב הלמידה הוא מכפיל שקובע את מידת ההגדלה או ההקטנה של כל משקל בכל מעבר לאחור. קצב למידה גבוה יגדיל או יקטין כל משקל יותר מקצב למידה נמוך.
במונחים של חשבון אינפיניטסימלי, backpropagation מיישם את כלל השרשרת מתוך חשבון אינפיניטסימלי. כלומר, בשיטת backpropagation מחושב הנגזרת החלקית של השגיאה ביחס לכל פרמטר.
לפני שנים, מומחים ל-ML היו צריכים לכתוב קוד כדי להטמיע backpropagation. ממשקי API מודרניים של למידת מכונה, כמו Keras, מטמיעים עכשיו בשבילכם את האלגוריתם backpropagation. סוף סוף!
מידע נוסף זמין במאמר רשתות עצביות בקורס המקוצר על למידת מכונה.
bagging
שיטה לאימון אנסמבל שבו כל מודל מרכיב מתאמן על קבוצת משנה אקראית של דוגמאות לאימון שנדגמו עם החזרה. לדוגמה, יער אקראי הוא אוסף של עצי החלטה שאומנו באמצעות bagging.
המונח bagging הוא קיצור של bootstrap aggregating.
מידע נוסף זמין במאמר בנושא יערות אקראיים בקורס בנושא יערות החלטה.
bag of words
ייצוג של המילים בביטוי או בקטע, ללא קשר לסדר. לדוגמה, bag of words מייצג את שלושת הביטויים הבאים באופן זהה:
- הכלב קופץ
- קופץ מעל הכלב
- כלב קופץ
כל מילה ממופה לאינדקס בוקטור דליל, שבו לכל מילה באוצר המילים יש אינדקס. לדוגמה, הביטוי the dog jumps ממופה לווקטור מאפיינים עם ערכים שונים מאפס בשלושת האינדקסים שמתאימים למילים the, dog ו-jumps. הערך שאינו אפס יכול להיות כל אחת מהאפשרויות הבאות:
- 1 כדי לציין את נוכחות המילה.
- ספירה של מספר הפעמים שמילה מופיעה בתיק. לדוגמה, אם הביטוי הוא the maroon dog is a dog with maroon fur, אז גם maroon וגם dog ייוצגו כ-2, בעוד שהמילים האחרות ייוצגו כ-1.
- ערך אחר, כמו הלוגריתם של מספר הפעמים שמילה מופיעה בתיק.
baseline
מודל שמשמש כנקודת השוואה כדי לבדוק את הביצועים של מודל אחר (בדרך כלל מורכב יותר). לדוגמה, מודל רגרסיה לוגיסטית יכול לשמש כבסיס טוב למודל עמוק.
בבעיה מסוימת, ה-Baseline עוזר למפתחי מודלים לכמת את הביצועים המינימליים הצפויים שמודל חדש צריך להשיג כדי שהמודל החדש יהיה שימושי.
מודל בסיס
מודל שאומן מראש שיכול לשמש כנקודת התחלה לכוונון עדין כדי לטפל במשימות או באפליקציות ספציפיות.
כדאי לעיין גם במודל שעבר אימון מראש ובמודל בסיסי.
אצווה
קבוצת הדוגמאות שמשמשת באיטרציה אחת של אימון. גודל האצווה קובע את מספר הדוגמאות באצווה.
במאמר epoch מוסבר איך קבוצת נתונים קשורה ל-epoch.
מידע נוסף זמין במאמר רגרסיה ליניארית: היפר-פרמטרים בקורס המקוצר על למידת מכונה.
היקש באצווה
התהליך של הסקת תחזיות על כמה דוגמאות לא מסומנות שמחולקות לקבוצות משנה קטנות יותר ('אצוות').
הסקת מסקנות באצווה יכולה לנצל את תכונות ההקבלה של שבבי האצה. כלומר, כמה מאיצים יכולים להסיק תחזיות בו-זמנית על קבוצות שונות של דוגמאות לא מסומנות, וכך להגדיל באופן משמעותי את מספר ההסקות בשנייה.
מידע נוסף מופיע במאמר מערכות ML בייצור: הסקה סטטית לעומת הסקה דינמית בקורס המזורז ללמידת מכונה.
נורמליזציה של אצווה
נרמול של הקלט או הפלט של פונקציות ההפעלה בשכבה מוסתרת. לנורמליזציה של קבוצות יש כמה יתרונות:
- הגנה מפני משקלים של ערכים חריגים כדי להפוך את רשתות הנוירונים ליציבות יותר.
- הפעלת שיעורי למידה גבוהים יותר, שיכולים להאיץ את האימון.
- הפחתת התאמת יתר.
גודל אצווה
מספר הדוגמאות באצווה. לדוגמה, אם גודל האצווה הוא 100, המודל מעבד 100 דוגמאות לכל איטרציה.
אלה כמה אסטרטגיות פופולריות לגודל אצווה:
- Stochastic Gradient Descent (SGD), שבו גודל האצווה הוא 1.
- אצווה מלאה, שבה גודל האצווה הוא מספר הדוגמאות בקבוצת נתונים לאימון כולה. לדוגמה, אם קבוצת נתונים לאימון מכילה מיליון דוגמאות, גודל האצווה יהיה מיליון דוגמאות. שיטה של עדכון כל הנתונים בבת אחת היא בדרך כלל לא יעילה.
- מיני-batch שבו גודל האצווה הוא בדרך כלל בין 10 ל-1,000. בדרך כלל, אסטרטגיית המיני-batch היא היעילה ביותר.
מידע נוסף מפורט במאמרים הבאים:
- מערכות ML לייצור: הסקה סטטית לעומת הסקה דינמית בקורס המקוצר על למידת מכונה.
- Deep Learning Tuning Playbook.
רשת נוירונים בייסיאנית
רשת נוירונים הסתברותית שמתחשבת באי-ודאות במשקלים ובפלט. מודל רגרסיה של רשת נוירונים רגילה בדרך כלל מנבא ערך סקלרי. לדוגמה, מודל רגיל מנבא מחיר בית של 853,000. לעומת זאת, רשת נוירונים בייסיאנית חוזה התפלגות של ערכים. לדוגמה, מודל בייסיאני חוזה מחיר בית של 853,000 עם סטיית תקן של 67,200.
רשת נוירונים בייסיאנית מסתמכת על משפט בייס כדי לחשב את אי הוודאות במשקלים ובתחזיות. רשת עצבית בייסיאנית יכולה להיות שימושית כשחשוב לכמת את אי הוודאות, למשל במודלים שקשורים לתרופות. רשתות נוירונים בייסיאניות יכולות גם לעזור למנוע התאמת יתר.
אופטימיזציה בייסיאנית
מודל רגרסיה הסתברותי טכניקה לאופטימיזציה של פונקציות מטרה שדורשות הרבה משאבי מחשוב. במקום זאת, המודל מבצע אופטימיזציה של פונקציית סרוגייט שמבצעת כימות של אי-הוודאות באמצעות טכניקת למידה בייסיאנית. מכיוון שאופטימיזציה בייסיאנית היא תהליך יקר מאוד, בדרך כלל משתמשים בה כדי לבצע אופטימיזציה של משימות יקרות להערכה שיש להן מספר קטן של פרמטרים, כמו בחירה של היפרפרמטרים.
משוואת בלמן
בלמידת חיזוק, הזהות הבאה מסופקת על ידי פונקציית ה-Q האופטימלית:
\[Q(s, a) = r(s, a) + \gamma \mathbb{E}_{s'|s,a} \max_{a'} Q(s', a')\]
אלגוריתמים של למידת חיזוק משתמשים בזהות הזו כדי ליצור למידת Q באמצעות כלל העדכון הבא:
\[Q(s,a) \gets Q(s,a) + \alpha \left[r(s,a) + \gamma \displaystyle\max_{\substack{a_1}} Q(s',a') - Q(s,a) \right] \]
מעבר ללמידת חיזוק, למשוואת בלמן יש יישומים בתכנות דינמי. אפשר לעיין ב ערך בוויקיפדיה בנושא משוואת בלמן.
BERT (ייצוגים דו-כיווניים של מקודד מטרנספורמרים)
ארכיטקטורת מודל לייצוג של טקסט. מודל BERT מאומן יכול לשמש כחלק ממודל גדול יותר לסיווג טקסט או למשימות אחרות של למידת מכונה.
ל-BERT יש את המאפיינים הבאים:
- משתמש בארכיטקטורת Transformer, ולכן מסתמך על self-attention.
- משתמש בחלק המקודד של הטרנספורמר. תפקיד המקודד הוא ליצור ייצוגים טובים של טקסט, ולא לבצע משימה ספציפית כמו סיווג.
- היא דו-כיוונית.
- משתמש במיסוך לאימון לא מפוקח.
הווריאציות של BERT כוללות:
במאמר Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing מופיע סקירה כללית של BERT.
הטיה (אתיקה/הוגנות)
1. הצגת סטריאוטיפים, דעות קדומות או העדפה של דברים, אנשים או קבוצות מסוימים על פני אחרים. ההטיות האלה יכולות להשפיע על איסוף הנתונים ועל הפרשנות שלהם, על עיצוב המערכת ועל האופן שבו המשתמשים מבצעים אינטראקציה עם המערכת. דוגמאות להטיות מסוג זה:
- הטיית אוטומציה
- הטיית אישור
- הטיה של עורכי הניסוי
- הטיה בשיוך לקבוצה
- הטיה מרומזת
- הטיה לטובת קבוצת השייכות
- הטיית הומוגניות של קבוצת חוץ
2. שגיאה שיטתית שנובעת מהליך דגימה או דיווח. דוגמאות להטיות מסוג זה:
לא להתבלבל עם מונח ההטיה במודלים של למידת מכונה או עם הטיה בתחזית.
מידע נוסף זמין במאמר הוגנות: סוגי הטיה בקורס המזורז ללימוד מכונת למידה.
הטיה (מתמטיקה) או מונח הטיה
נקודת חיתוך או היסט מנקודת המוצא. הטיה היא פרמטר במודלים של למידת מכונה, שמסומל באחד מהערכים הבאים:
- b
- w0
לדוגמה, הטיה היא b בנוסחה הבאה:
בקו דו-ממדי פשוט, הטיה פשוט מייצגת את נקודת החיתוך עם ציר ה-y. לדוגמה, ההטיה של הקו באיור הבא היא 2.
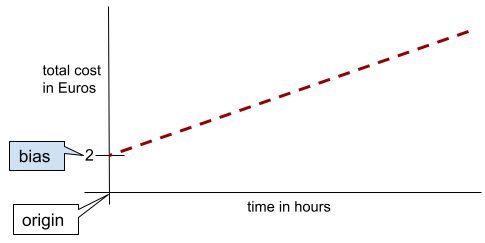
ההטיה קיימת כי לא כל המודלים מתחילים מהמקור (0,0). לדוגמה, נניח שעלות הכניסה לפארק שעשועים היא 2 אירו, ועל כל שעה שהלקוח נמצא בפארק הוא משלם עוד 0.5 אירו. לכן, למודל שממפה את העלות הכוללת יש הטיה של 2 כי העלות הכי נמוכה היא 2 אירו.
חשוב להבחין בין הטיה לבין הטיה באתיקה ובהוגנות או הטיה בתחזיות.
מידע נוסף זמין במאמר רגרסיה ליניארית בקורס המקוצר על למידת מכונה.
דו-כיווני
מונח שמשמש לתיאור מערכת שמעריכה את הטקסט שקודם לקטע טקסט יעד וגם את הטקסט שבא אחריו. לעומת זאת, מערכת חד-כיוונית מעריכה רק את הטקסט שקודם לקטע הטקסט הממוקד.
לדוגמה, נניח שיש מודל שפה עם מיסוך שצריך לקבוע את ההסתברויות של המילה או המילים שמיוצגות על ידי הקו התחתון בשאלה הבאה:
מה הבעיה שלך?
מודל שפה חד-כיווני יצטרך לבסס את ההסתברויות שלו רק על ההקשר שנוצר על ידי המילים What, is ו-the. לעומת זאת, מודל שפה דו-כיווני יכול גם להסיק הקשר מהמילים 'עם' ו'אתה', מה שיכול לעזור למודל ליצור תחזיות טובות יותר.
מודל שפה דו-כיווני
מודל שפה שקובע את ההסתברות שאסימון נתון יהיה נוכח במיקום נתון בקטע טקסט, על סמך הטקסט הקודם והטקסט הבא.
ביגרמה
N-gram שבו N=2.
סיווג בינארי
סוג של משימת סיווג שחוזה אחת משתי מחלקות שאינן חופפות:
לדוגמה, כל אחד משני המודלים הבאים של למידת מכונה מבצע סיווג בינארי:
- מודל שקובע אם הודעות אימייל הן ספאם (הסיווג החיובי) או לא ספאם (הסיווג השלילי).
- מודל שמעריך תסמינים רפואיים כדי לקבוע אם לאדם מסוים יש מחלה מסוימת (הסיווג החיובי) או שאין לו את המחלה הזו (הסיווג השלילי).
בניגוד לסיווג רב-מחלקתי.
אפשר לעיין גם במאמרים בנושא רגרסיה לוגיסטית וסף סיווג.
מידע נוסף זמין במאמר סיווג בקורס המקוצר על למידת מכונה.
תנאי בינארי
בעץ החלטה, תנאי שיש לו רק שתי תוצאות אפשריות, בדרך כלל כן או לא. לדוגמה, התנאי הבא הוא תנאי בינארי:
temperature >= 100
ההפך מתנאי לא בינארי.
מידע נוסף זמין במאמר סוגי תנאים בקורס בנושא יערות החלטה.
binning
מילה נרדפת לחלוקה לקטגוריות.
מודל קופסה שחורה
מודל שההסבר שלו לא הגיוני או שקשה לבני אדם להבין אותו. כלומר, למרות שאנשים יכולים לראות איך הנחיות משפיעות על התשובות, הם לא יכולים לקבוע בדיוק איך מודל של קופסה שחורה קובע את התשובה. במילים אחרות, למודל של קופסה שחורה חסרה יכולת פירוש.
רוב המודלים העמוקים והמודלים הגדולים של שפה הם קופסאות שחורות.
BLEU (Bilingual Evaluation Understudy)
מדד בין 0.0 ל-1.0 להערכת תרגומים אוטומטיים, למשל מספרדית ליפנית.
כדי לחשב ציון, בדרך כלל BLEU משווה בין התרגום של מודל ML (טקסט שנוצר) לבין התרגום של מומחה אנושי (טקסט ייחוס). מידת ההתאמה בין N-grams בטקסט שנוצר לבין טקסט ההשוואה קובעת את ציון ה-BLEU.
המאמר המקורי בנושא המדד הזה הוא BLEU: a Method for Automatic Evaluation of Machine Translation.
מידע נוסף זמין במאמר בנושא BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
מדד להערכת תרגומים אוטומטיים משפה אחת לשפה אחרת, במיוחד מאנגלית ואליה.
בתרגומים לאנגלית ומאנגלית, התוצאות של BLEURT קרובות יותר לדירוגים של בני אדם מאשר התוצאות של BLEU. בניגוד ל-BLEU, BLEURT מדגיש דמיון סמנטי (משמעות) ויכול להתאים לניסוח מחדש.
BLEURT מסתמך על מודל שפה גדול שעבר אימון מראש (BERT, ליתר דיוק) שעובר כוונון עדין על טקסט שנוצר על ידי מתרגמים אנושיים.
המאמר המקורי על המדד הזה הוא BLEURT: Learning Robust Metrics for Text Generation.
שאלות בוליאניות (BoolQ)
מערך נתונים להערכת רמת המיומנות של LLM במענה לשאלות שדורשות תשובה של כן או לא. כל אחת מהבעיות בקבוצת הנתונים כוללת שלושה רכיבים:
- שאילתה
- קטע שממנו אפשר להסיק את התשובה לשאילתה.
- התשובה הנכונה, שהיא כן או לא.
לדוגמה:
- שאילתה: האם יש תחנות כוח גרעיניות במישיגן?
- קטע: …three nuclear power plants supply Michigan with about 30% of its electricity.
- תשובה נכונה: כן
החוקרים אספו את השאלות מתוך שאילתות אנונימיות ומצטברות בחיפוש Google, ואז השתמשו בדפי ויקיפדיה כדי לבסס את המידע.
מידע נוסף זמין במאמר BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions.
BoolQ הוא רכיב של SuperGLUE ensemble.
BoolQ
קיצור לשאלות בוליאניות.
הגברה
טכניקה של למידת מכונה שמשלבת באופן איטרטיבי קבוצה של מודלים פשוטים לסיווג (שנקראים 'מסווגים חלשים') שלא תמיד מדויקים, למודל סיווג עם רמת דיוק גבוהה ('מסווג חזק'). השילוב מתבצע על ידי הגדלת המשקל של הדוגמאות שהמודל מסווג בצורה שגויה.
מידע נוסף זמין במאמר מהם עצי החלטה עם שיטת Gradient Boosting? בקורס בנושא יערות החלטה.
תיבה תוחמת (bounding box)
בתמונה, הקואורדינטות (x, y) של מלבן שמקיף אזור שמעניין אתכם, כמו הכלב בתמונה שלמטה.

שידור
הרחבת הצורה של אופרנד בפעולה מתמטית של מטריצה לממדים שתואמים לפעולה הזו. לדוגמה, באלגברה לינארית, שני האופרנדים בפעולת חיבור מטריצות צריכים להיות בעלי אותם ממדים. לכן, אי אפשר להוסיף מטריצה בצורה (m, n) לווקטור באורך n. השידור מאפשר את הפעולה הזו על ידי הרחבה וירטואלית של הווקטור באורך n למטריצה בצורה (m, n) על ידי שכפול אותם ערכים בכל עמודה.
פרטים נוספים מופיעים בתיאור הבא של שידור ב-NumPy.
bucketing
המרת תכונה אחת לכמה תכונות בינאריות שנקראות buckets או bins, בדרך כלל על סמך טווח ערכים. התכונה 'חיתוך' היא בדרך כלל תכונה רציפה.
לדוגמה, במקום לייצג את הטמפרטורה כמאפיין יחיד של נקודה צפה רציפה, אפשר לחלק טווחי טמפרטורות לקטגוריות נפרדות, כמו:
- <= 10 degrees Celsius would be the "cold" bucket.
- 11 עד 24 מעלות צלזיוס יהיו בקטגוריה 'ממוזג'.
- >= 25 degrees Celsius יהיה הדלי 'warm'.
המודל יתייחס לכל הערכים באותו דלי באופן זהה. לדוגמה, הערכים 13 ו-22 נמצאים שניהם בדלי של אזורים ממוזגים, ולכן המודל מתייחס לשני הערכים בצורה זהה.
מידע נוסף מופיע במאמר נתונים מספריים: חלוקה לקטגוריות בקורס המקוצר על למידת מכונה.
C
שכבת כיול
התאמה שמתבצעת אחרי החיזוי, בדרך כלל כדי לפצות על הטיה בחיזוי. התחזיות וההסתברויות המותאמות צריכות להתאים להתפלגות של קבוצת תוויות שנצפתה.
יצירת מועמדים
קבוצת ההמלצות הראשונית שנבחרה על ידי מערכת המלצות. לדוגמה, נניח שיש חנות ספרים שמציעה 100,000 כותרים. בשלב יצירת המועמדים נוצרת רשימה קטנה בהרבה של ספרים מתאימים למשתמש מסוים, למשל 500. אבל גם 500 ספרים זה יותר מדי ספרים להמלצה למשתמש. בשלבים הבאים והיקרים יותר של מערכת ההמלצות (כמו דירוג ודירוג מחדש), מספר ההמלצות מצטמצם לסט קטן יותר ושימושי יותר.
מידע נוסף זמין במאמר סקירה כללית על יצירת מועמדים בקורס בנושא מערכות המלצה.
דגימת מועמדים
אופטימיזציה בזמן האימון שמחשבת הסתברות לכל התוויות החיוביות, באמצעות, למשל, softmax, אבל רק עבור מדגם אקראי של תוויות שליליות. לדוגמה, אם יש לכם דוגמה עם התוויות beagle ו-dog, הדגימה של המועמדים מחשבת את ההסתברויות החזויות ואת מונחי ההפסד המתאימים עבור:
- beagle
- dog
- קבוצת משנה אקראית של שאר הסיווגים השליליים (לדוגמה, חתול, סוכרייה על מקל, גדר).
הרעיון הוא שהסיווגים השליליים יכולים ללמוד מחיזוק שלילי בתדירות נמוכה יותר, כל עוד הסיווגים החיוביים תמיד מקבלים חיזוק חיובי מתאים. זה מה שנצפה בפועל.
דגימת מועמדים יעילה יותר מבחינת חישובים מאלגוריתמים לאימון שמחשבים תחזיות עבור כל המחלקות השליליות, במיוחד כשמספר המחלקות השליליות גדול מאוד.
נתונים קטגוריים
מאפיינים עם קבוצה ספציפית של ערכים אפשריים. לדוגמה, נניח שיש מאפיין קטגוריאלי בשם traffic-light-state, שיכול לקבל רק אחד משלושת הערכים האפשריים הבאים:
redyellowgreen
אם מייצגים את traffic-light-state כמאפיין קטגוריאלי, מודל יכול ללמוד את ההשפעות השונות של red, green ו-yellow על התנהגות הנהג.
תכונות קטגוריות נקראות לפעמים תכונות בדידות.
ההפך מנתונים מספריים.
מידע נוסף זמין במאמר עבודה עם נתונים שמחולקים לקטגוריות בסדנה ללימוד מכונת למידה.
מודל שפה סיבתי
מילה נרדפת למודל שפה חד-כיווני.
כדי להבין את ההבדלים בין גישות שונות של מודלים לשפה, אפשר לעיין במאמר בנושא מודל שפה דו-כיווני.
CB
קיצור של CommitmentBank.
נקודת המרכז
המרכז של אשכול שנקבע על ידי אלגוריתם k-means או k-median. לדוגמה, אם k הוא 3, האלגוריתם k-means או k-median מוצא 3 מרכזים.
מידע נוסף זמין במאמר אלגוריתמים של אשכולות בקורס בנושא אשכולות.
centroid-based clustering
קטגוריה של אלגוריתמים של קיבוץ באשכולות שמארגנים נתונים באשכולות לא היררכיים. k-means הוא אלגוריתם הקיבוץ באשכולות שמבוסס על צנטרואיד והשימוש בו הוא הנפוץ ביותר.
ההבדל בין אלגוריתם זה לבין אלגוריתמים של קיבוץ היררכי.
מידע נוסף זמין במאמר אלגוריתמים של אשכולות בקורס בנושא אשכולות.
הנחיות בטכניקת שרשרת חשיבה
טכניקה של הנדסת הנחיות שמעודדת מודל שפה גדול (LLM) להסביר את החשיבה הרציונלית שלו, שלב אחר שלב. לדוגמה, נבחן את ההנחיה הבאה, תוך שימת לב מיוחדת למשפט השני:
כמה כוחות G יחווה נהג ברכב שמאיץ מ-0 ל-60 מייל לשעה ב-7 שניות? בתשובה, צריך להציג את כל החישובים הרלוונטיים.
התשובה של ה-LLM תהיה כנראה:
- תציג רצף של נוסחאות בפיזיקה, ותציב את הערכים 0, 60 ו-7 במקומות המתאימים.
- תסביר למה היא בחרה בנוסחאות האלה ומה המשמעות של המשתנים השונים.
הנחיות בטכניקת שרשרת חשיבה מאלצות את מודל ה-LLM לבצע את כל החישובים, מה שעשוי להוביל לתשובה נכונה יותר. בנוסף, הנחיה מסוג chain-of-thought מאפשרת למשתמש לבדוק את השלבים של מודל ה-LLM כדי לקבוע אם התשובה הגיונית.
ציון F של N-gram של תווים (ChrF)
מדד להערכת מודלים של תרגום אוטומטי. ציון F של N-גרמות של תווים קובע את מידת החפיפה בין N-גרמות בטקסט ההפניה לבין ה-N-גרמות בטקסט שנוצר על ידי מודל ML.
המדד 'ציון F של N-גרם של תווים' דומה למדדים במשפחות ROUGE ו-BLEU, אבל:
- המדד Character N-gram F-score פועל על N-grams של תווים.
- המדדים ROUGE ו-BLEU פועלים על N-gram של מילים או על אסימונים.
צ'אט, צ'ט, צאט, צט
התוכן של דיאלוג הלוך ושוב עם מערכת למידת מכונה, בדרך כלל מודל שפה גדול. האינטראקציה הקודמת בצ'אט (מה שכתבתם ואיך מודל השפה הגדול הגיב) הופכת להקשר לחלקים הבאים של הצ'אט.
צ'אטבוט הוא יישום של מודל שפה גדול.
נקודת ביקורת
נתונים שמתעדים את המצב של הפרמטרים של מודל, במהלך האימון או אחרי שהאימון מסתיים. לדוגמה, במהלך האימון, תוכלו:
- הפסקת האימון, אולי בכוונה או אולי כתוצאה משגיאות מסוימות.
- מצלמים את נקודת הביקורת.
- בשלב מאוחר יותר, טוענים מחדש את נקודת הבדיקה, אולי בחומרה אחרת.
- להתחיל מחדש את ההדרכה.
בחירת חלופות סבירות (COPA)
מערך נתונים להערכת היכולת של מודל LLM לזהות את התשובה הטובה יותר מבין שתי תשובות חלופיות להנחת יסוד. כל אחת מהבעיות במערך הנתונים מורכבת משלושה רכיבים:
- הנחת יסוד, שהיא בדרך כלל הצהרה שאחריה מופיעה שאלה
- שתי תשובות אפשריות לשאלה שמוצגת בפריט, שאחת מהן נכונה והשנייה לא נכונה
- התשובה הנכונה
לדוגמה:
- הנחת יסוד: האיש שבר את הבוהן. מה הייתה הסיבה לכך?
- תשובות אפשריות:
- יש לו חור בגרב.
- הוא הפיל פטיש על הרגל שלו.
- תשובה נכונה: 2
COPA הוא רכיב של SuperGLUE ensemble.
רמת הדיוק של הציטוט
מדד שעונה על השאלה הבאה:
מה אחוז הציטוטים בתשובה של מודל שפה גדול שהיו נכונים ותומכים?
כלומר, מהו אחוז הציטוטים שמכילים את העובדות המדויקות או את המידע הרלוונטי שנדרש לאימות הטענה שמופיעה בתשובה של מודל שפה גדול (LLM).
לדוגמה, אם תגובה של LLM ציטטה 10 מסמכים, אבל רק 7 מהציטוטים האלה היו נכונים ותומכים, אז דיוק הציטוט יהיה 0.7.
זכירת ציטוטים
מדד שעונה על השאלה הבאה:
כמה אחוזים ממסמכי המקור ששימשו את ה-LLM כדי ליצור את התשובה מצוטטים בפועל בתשובה?
לדוגמה, אם מודל LLM הסתמך על 20 מסמכים כדי ליצור את התשובה שלו, אבל התשובה ציטטה רק 11 מהם, אז ציון ההחזרה של הציטוט יהיה 0.55.
כיתה
קטגוריה שתווית יכולה להשתייך אליה. לדוגמה:
- במודל סיווג בינארי שמזהה ספאם, שתי המחלקות יכולות להיות ספאם ולא ספאם.
- במודל סיווג רב-מחלקתי שמזהה גזעי כלבים, המחלקות יכולות להיות פודל, ביגל, פאג וכן הלאה.
מודל סיווג חוזה סיווג. לעומת זאת, מודל רגרסיה חוזה מספר ולא מחלקה.
מידע נוסף זמין במאמר סיווג בקורס המקוצר על למידת מכונה.
קבוצת נתונים מאוזנת לפי כיתה
מערך נתונים שמכיל תוויות קטגוריות שבהן מספר המקרים של כל קטגוריה שווה בערך. לדוגמה, נניח שיש מערך נתונים בוטני עם תווית בינארית שיכולה להיות צמח מקומי או צמח לא מקומי:
- מערך נתונים עם 515 צמחים מקומיים ו-485 צמחים לא מקומיים הוא מערך נתונים מאוזן.
- מערך נתונים עם 875 צמחים מקומיים ו-125 צמחים לא מקומיים הוא מערך נתונים לא מאוזן לפי סיווג.
אין קו הפרדה רשמי בין מערכי נתונים מאוזנים לפי כיתה לבין מערכי נתונים לא מאוזנים לפי כיתה. ההבחנה הזו חשובה רק כשמודל שאומן על מערך נתונים עם חוסר איזון קיצוני בין המחלקות לא מצליח להתכנס. פרטים נוספים זמינים במאמר קבוצות נתונים: קבוצות נתונים לא מאוזנות בסדנה ללמידת מכונה.
מודל סיווג
מודל שהחיזוי שלו הוא סיווג. לדוגמה, כל אלה הם מודלים של סיווג:
- מודל שמנבא את השפה של משפט קלט (צרפתית? ספרדית? איטלקית?).
- מודל שמנבא את מיני העצים (אדר? אלון? באובב?).
- מודל שמנבא את הסיווג החיובי או השלילי של מצב רפואי מסוים.
לעומת זאת, מודלים של רגרסיה חוזים מספרים ולא סיווגים.
שני סוגים נפוצים של מודלים לסיווג הם:
סף סיווג (classification threshold)
בסיווג בינארי, מספר בין 0 ל-1 שממיר את הפלט הגולמי של מודל רגרסיה לוגיסטית לחיזוי של הסיווג החיובי או של הסיווג השלילי. חשוב לזכור שסף הסיווג הוא ערך שאדם בוחר, ולא ערך שנבחר על ידי אימון המודל.
מודל רגרסיה לוגיסטית מחזיר ערך גולמי בין 0 ל-1. לאחר מכן:
- אם הערך הגולמי הזה גדול יותר מסף הסיווג, אז המערכת חוזה את הסיווג החיובי.
- אם הערך הגולמי הזה נמוך מסף הסיווג, המערכת תנבא את הסיווג השלילי.
לדוגמה, נניח שסף הסיווג הוא 0.8. אם הערך הגולמי הוא 0.9, המודל חוזה את המחלקה החיובית. אם הערך הגולמי הוא 0.7, המודל חוזה את המחלקה השלילית.
הבחירה של סף הסיווג משפיעה מאוד על מספר התוצאות החיוביות הכוזבות והתוצאות השליליות הכוזבות.
מידע נוסף זמין במאמר ערכי סף ומטריצת בלבול בקורס המקוצר על למידת מכונה.
מסווג
מונח לא רשמי למודל סיווג.
קבוצת נתונים לא מאוזנת מבחינת כיתות
מערך נתונים של סיווג שבו המספר הכולל של תוויות של כל סיווג שונה באופן משמעותי. לדוגמה, נניח שיש קבוצת נתונים של סיווג בינארי עם שתי תוויות שמחולקות באופן הבא:
- 1,000,000 תוויות שליליות
- 10 תוויות חיוביות
היחס בין תוויות שליליות לחיוביות הוא 100,000 ל-1, ולכן זהו מערך נתונים עם חוסר איזון בין המחלקות.
לעומת זאת, מערך הנתונים הבא הוא מאוזן לפי מחלקות כי היחס בין התוויות השליליות לתוויות החיוביות קרוב יחסית ל-1:
- 517 תוויות שליליות
- 483 תוויות חיוביות
יכול להיות גם חוסר איזון בין הכיתות במערכי נתונים עם כמה כיתות. לדוגמה, מערך הנתונים הבא של סיווג רב-מחלקתי הוא גם לא מאוזן מבחינת מחלקות, כי לתווית אחת יש הרבה יותר דוגמאות מאשר לשתי התוויות האחרות:
- 1,000,000 תוויות עם הסיווג 'ירוק'
- 200 תוויות עם המחלקה purple
- 350 תוויות עם המחלקה orange
אימון של מערכי נתונים לא מאוזנים בכיתות יכול להציב אתגרים מיוחדים. פרטים נוספים זמינים במאמר Imbalanced datasets (מערכי נתונים לא מאוזנים) בסדנה בנושא למידת מכונה.
אפשר לעיין גם בערכים אנטרופיה, מחלקת הרוב ומחלקת המיעוט.
חיתוך
טכניקה לטיפול בערכים חריגים באמצעות אחת מהפעולות הבאות או שתיהן:
- הפחתת ערכים של תכונה שגדולים מסף מקסימלי עד לסף המקסימלי הזה.
- הגדלת ערכי התכונות שקטנים מסף מינימלי עד לסף המינימלי הזה.
לדוגמה, נניח שפחות מ-0.5% מהערכים של תכונה מסוימת נמצאים מחוץ לטווח 40-60. במקרה כזה, אפשר לבצע את הפעולות הבאות:
- כל הערכים מעל 60 (הסף המקסימלי) יקוצצו ל-60 בדיוק.
- כל הערכים שקטנים מ-40 (סף המינימום) יוגבלו ל-40 בדיוק.
ערכים חריגים עלולים לפגוע במודלים, ולפעמים לגרום למשקלים לגלוש במהלך האימון. חלק מהערכים החריגים יכולים גם לפגוע באופן משמעותי במדדים כמו דיוק. חיתוך הוא טכניקה נפוצה להגבלת הנזק.
חיתוך שיפועים מאלץ ערכים של שיפועים בטווח מוגדר במהלך האימון.
מידע נוסף זמין במאמר נתונים מספריים: נורמליזציה בסדנה ללימוד מכונת למידה.
Cloud TPU
מאיץ חומרה ייעודי שנועד להאיץ עומסי עבודה של למידת מכונה ב-Google Cloud.
סידור באשכולות
קיבוץ דוגמאות קשורות, במיוחד במהלך למידה לא מפוקחת. אחרי שכל הדוגמאות מקובצות, אפשר להוסיף משמעות לכל אשכול.
קיימים אלגוריתמים רבים של קיבוץ באשכולות. לדוגמה, האלגוריתם k-means מקבץ דוגמאות על סמך הקרבה שלהן למרכז מסה, כמו בתרשים הבא:

לאחר מכן, חוקר אנושי יכול לבדוק את האשכולות ולתת להם שמות. לדוגמה, הוא יכול לתת לאשכול 1 את השם 'עצים ננסיים' ולאשכול 2 את השם 'עצים בגודל מלא'.
דוגמה נוספת: אלגוריתם של אשכולות שמבוסס על המרחק של דוגמה מנקודת מרכז, כמו בדוגמה הבאה:

מידע נוסף זמין בקורס בנושא אשכולות.
עיבוד משותף
התנהגות לא רצויה שבה נוירונים חוזים דפוסים בנתוני האימון על ידי הסתמכות כמעט בלעדית על התפוקות של נוירונים ספציפיים אחרים, במקום להסתמך על ההתנהגות של הרשת כולה. אם הדפוסים שגורמים להתאמה משותפת לא מופיעים בנתוני האימות, ההתאמה המשותפת גורמת להתאמת יתר. רגולריזציה של נשירה מפחיתה את ההתאמה המשותפת כי הנשירה מבטיחה שהנוירונים לא יוכלו להסתמך רק על נוירונים ספציפיים אחרים.
סינון שיתופי
חיזוי של תחומי העניין של משתמש מסוים על סמך תחומי העניין של משתמשים רבים אחרים. סינון שיתופי משמש לעיתים קרובות במערכות המלצות.
מידע נוסף זמין במאמר בנושא סינון שיתופי בקורס בנושא מערכות המלצה.
CommitmentBank (CB)
מערך נתונים להערכת רמת המיומנות של מודל LLM בקביעה אם מחבר הקטע מאמין לסעיף יעד בתוך הקטע. כל רשומה במערך הנתונים מכילה:
- פסקה
- סעיף יעד בקטע הזה
- ערך בוליאני שמציין אם מחבר הקטע מאמין שהסעיף
לדוגמה:
- פסקה: What fun to hear Artemis laugh. היא ילדה כל כך רצינית. לא ידעתי שיש לה חוש הומור.
- סעיף היעד: she had a sense of humor
- Boolean: True, כלומר המחבר מאמין שהסעיף הממוקד
CommitmentBank הוא רכיב של SuperGLUE ensemble.
מודל קומפקטי
כל מודל קטן שמיועד להפעלה במכשירים קטנים עם משאבי מחשוב מוגבלים. לדוגמה, מודלים קומפקטיים יכולים לפעול בטלפונים ניידים, בטאבלטים או במערכות מוטמעות.
מחשוב
(שם עצם) משאבי המחשוב שמשמשים מודל או מערכת, כמו כוח עיבוד, זיכרון ואחסון.
סחף קונספט
שינוי בקשר בין התכונות לבין התווית. עם הזמן, סחף המושגים פוגע באיכות המודל.
במהלך האימון, המודל לומד את הקשר בין התכונות לבין התוויות שלהן בקבוצת הנתונים לאימון. אם התוויות ב קבוצת נתונים לאימון הן תחליפים טובים לעולם האמיתי, המודל צריך לספק תחזיות טובות לגבי העולם האמיתי. עם זאת, בגלל סחף מושגים, התחזיות של המודל נוטות להידרדר עם הזמן.
לדוגמה, מודל של סיווג בינארי שמנבא אם מודל מסוים של מכונית הוא "חסכוני בדלק". כלומר, התכונות יכולות להיות:
- משקל הרכב
- דחיסת מנוע
- סוג תיבת ההילוכים
כשהתווית היא אחת מהאפשרויות הבאות:
- חסכוני בדלק
- לא חסכוני בדלק
עם זאת, ההגדרה של "מכונית חסכונית בדלק" משתנה כל הזמן. דגם מכונית שסומן כחסכוני בדלק בשנת 1994, כמעט בוודאות יסומן כלא חסכוני בדלק בשנת 2024. מודל שסובל מסחף מושגים נוטה להפיק חיזויים פחות ופחות שימושיים לאורך זמן.
השוו והבדילו עם nonstationarity.
תנאי
בעץ החלטות, כל צומת שמבצע בדיקה. לדוגמה, עץ ההחלטות הבא מכיל שני תנאים:
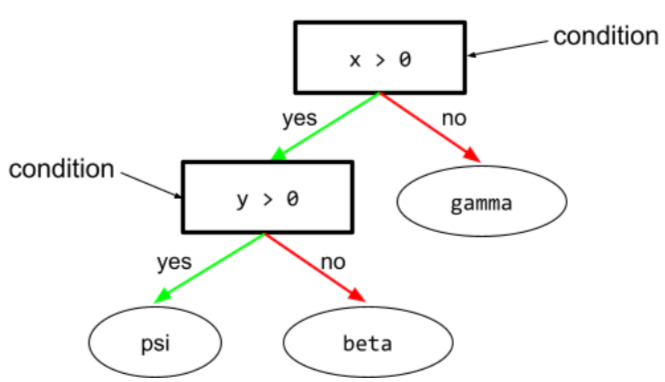
תנאי נקרא גם פיצול או בדיקה.
תנאי ניגודיות עם leaf.
ראה גם:
מידע נוסף זמין במאמר סוגי תנאים בקורס בנושא יערות החלטה.
המצאת סיפורים
מילה נרדפת למונח הזיה.
המונח 'המצאת סיפורים' כנראה מדויק יותר מבחינה טכנית מהמונח 'הזיה'. עם זאת, ההזיה הפכה לפופולרית קודם.
הגדרות אישיות
התהליך של הקצאת ערכי המאפיינים הראשוניים שמשמשים לאימון מודל, כולל:
- השכבות שמרכיבות את המודל
- מיקום הנתונים
- היפר-פרמטרים כמו:
בפרויקטים של למידת מכונה, אפשר לבצע את ההגדרה באמצעות קובץ הגדרה מיוחד או באמצעות ספריות הגדרה כמו אלה:
הטיית אישור
הנטייה לחפש מידע, לפרש אותו, להעדיף אותו ולזכור אותו באופן שמחזק את האמונות או ההשערות הקיימות של האדם. יכול להיות שמפתחים של למידת מכונה יאספו או יתייגו נתונים בדרכים שישפיעו על התוצאה ויאשרו את האמונות הקיימות שלהם. הטיית אישור היא סוג של הטיה מרומזת.
הטיית הנסיין היא סוג של הטיית אישור שבה הנסיין ממשיך לאמן מודלים עד שמאושרת השערה קיימת.
מטריצת בלבול
טבלה בגודל NxN שמסכמת את מספר התחזיות הנכונות והלא נכונות שבוצעו על ידי מודל סיווג. לדוגמה, הנה מטריצת בלבול עבור מודל של סיווג בינארי:
| גידול (צפוי) | Non-Tumor (predicted) | |
|---|---|---|
| גידול (ערך סף) | 18 (TP) | 1 (FN) |
| Non-Tumor (ground truth) | 6 (FP) | 452 (TN) |
מטריצת הבלבול שלמעלה מציגה את הנתונים הבאים:
- מתוך 19 התחזיות שבהן האמת הבסיסית הייתה Tumor, המודל סיווג 18 מהן בצורה נכונה ו-1 בצורה שגויה.
- מתוך 458 התחזיות שבהן האמת הבסיסית הייתה Non-Tumor, המודל סיווג 452 בצורה נכונה ו-6 בצורה שגויה.
מטריצת הבלבול של בעיית סיווג רב-מחלקתי יכולה לעזור לכם לזהות דפוסים של טעויות. לדוגמה, נניח שיש מטריצת בלבול למודל סיווג רב-סוגי עם 3 סוגים, שמסווג 3 סוגים שונים של אירוסים (Virginica, Versicolor ו-Setosa). כשנתוני האמת היו Virginica, מטריצת השגיאות מראה שהמודל היה הרבה יותר סביר לטעות ולחזות Versicolor מאשר Setosa:
| Setosa (predicted) | Versicolor (חזוי) | Virginica (חזוי) | |
|---|---|---|---|
| סטוסה (ערך סף) | 88 | 12 | 0 |
| Versicolor (ערך סף) | 6 | 141 | 7 |
| Virginica (ערכי סף) | 2 | 27 | 109 |
דוגמה נוספת: מטריצת בלבול יכולה לחשוף שמודל שאומן לזיהוי ספרות בכתב יד נוטה לחזות בטעות 9 במקום 4, או לחזות בטעות 1 במקום 7.
מטריצות השגיאה מכילות מספיק מידע כדי לחשב מגוון מדדי ביצועים, כולל דיוק ורגישות.
ניתוח של מחוז בחירה
פיצול משפט למבנים דקדוקיים קטנים יותר (רכיבים). חלק מאוחר יותר במערכת למידת המכונה, כמו מודל של הבנת שפה טבעית, יכול לנתח את המרכיבים בקלות רבה יותר מאשר המשפט המקורי. לדוגמה, המשפט הבא:
החבר שלי אימץ שני חתולים.
מנתח של מרכיבי משפט יכול לחלק את המשפט הזה לשני מרכיבים:
- My friend הוא צירוף שם עצם.
- adopted two cats הוא צירוף פועל.
אפשר לחלק את המרכיבים האלה למרכיבים קטנים יותר. לדוגמה, צירוף הפועל
אימצתי שני חתולים
אפשר לחלק אותם עוד יותר לקטגוריות הבאות:
- adopted הוא פועל.
- two cats (שני חתולים) הוא עוד צירוף שם עצם.
הטמעת שפה בהתאם להקשר
הטמעה שמתקרבת ל'הבנה' של מילים וביטויים בדומה למה שדוברים שוטפים יכולים לעשות. הטמעות של שפה בהקשר יכולות להבין תחביר, סמנטיקה והקשר מורכבים.
לדוגמה, נבחן הטמעות של המילה cow באנגלית. הטמעות ישנות יותר, כמו word2vec, יכולות לייצג מילים באנגלית כך שהמרחק במרחב ההטמעה מcow (פרה) לbull (שור) דומה למרחק מewe (כבשה) לram (איל) או מfemale (נקבה) לmale (זכר). הטמעות שפה בהקשר יכולות ללכת צעד אחד קדימה ולזהות שדוברי אנגלית משתמשים לפעמים במילה cow כדי להתייחס גם לפרה וגם לשור.
חלון ההקשר
מספר הטוקנים שמודל יכול לעבד בהנחיה נתונה. ככל שחלון ההקשר גדול יותר, המודל יכול להשתמש ביותר מידע כדי לספק תשובות עקביות וקוהרנטיות להנחיה.
תכונה רציפה
תכונה של נקודה צפה עם טווח אינסופי של ערכים אפשריים, כמו טמפרטורה או משקל.
ההבדל בין התכונה הזו לבין תכונה נפרדת.
דגימת נוחות [ברבים: דגימות נוחוּת]
שימוש במערך נתונים שלא נאסף באופן מדעי כדי להריץ ניסויים מהירים. בהמשך, חשוב לעבור למערך נתונים שנאסף באופן מדעי.
התכנסות
מצב שמתקבל כשערכי ההפסד משתנים מעט מאוד או לא משתנים בכלל בכל איטרציה. לדוגמה, מעקומת ההפסד הבאה אפשר לראות שההתכנסות מתרחשת בערך אחרי 700 איטרציות:
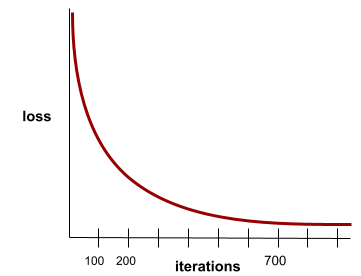
מודל מתכנס כשאימון נוסף לא ישפר אותו.
בלמידה עמוקה, ערכי ההפסד נשארים לפעמים קבועים או כמעט קבועים במשך הרבה איטרציות לפני שהם יורדים. במהלך תקופה ארוכה של ערכי הפסד קבועים, יכול להיות שתקבלו באופן זמני תחושה מוטעית של התכנסות.
אפשר לעיין גם במאמר בנושא עצירה מוקדמת.
מידע נוסף זמין במאמר Model convergence and loss curves (התכנסות מודל ועקומות הפסד) בסדנה ללימוד מכונת למידה.
תכנות בממשק שיחה
שיחה איטרטיבית ביניכם לבין מודל AI גנרטיבי, במטרה ליצור תוכנה. אתם מזינים הנחיה שמתארת תוכנה מסוימת. לאחר מכן, המודל משתמש בתיאור הזה כדי ליצור קוד. אחר כך, מזינים הנחיה חדשה כדי לטפל בפגמים בהנחיה הקודמת או בקוד שנוצר, והמודל יוצר קוד מעודכן. אתם ממשיכים להחליף תשובות עד שהתוכנה שנוצרה מספיק טובה.
קידוד שיחות הוא למעשה המשמעות המקורית של תכנות בשיטת Vibe coding.
ההפך מקידוד לפי מפרט.
פונקציה קמורה
פונקציה שבה האזור שמעל הגרף הוא קבוצה קמורה. הצורה של פונקציה קמורה טיפוסית דומה לצורה של האות U. לדוגמה, הפונקציות הבאות הן פונקציות קמורות:
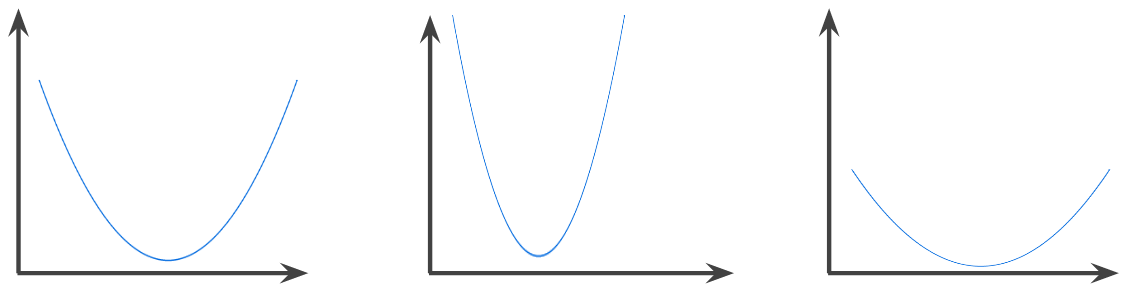
לעומת זאת, הפונקציה הבאה היא לא קמורה. שימו לב שהאזור שמעל התרשים הוא לא קבוצה קמורה:

לפונקציה קמורה לחלוטין יש בדיוק נקודת מינימום מקומית אחת, שהיא גם נקודת המינימום הגלובלית. הפונקציות הקלאסיות בצורת U הן פונקציות קמורות לחלוטין. עם זאת, חלק מהפונקציות הקמורות (לדוגמה, קווים ישרים) לא יוצרות צורה של U.
מידע נוסף זמין במאמר התכנסות ופונקציות קמורות בסדנה ללימוד מכונתית.
אופטימיזציה קמורה
התהליך של שימוש בטכניקות מתמטיות כמו ירידת גרדיאנט כדי למצוא את המינימום של פונקציה קמורה. חלק גדול מהמחקר בתחום למידת המכונה מתמקד בניסוח של בעיות שונות כבעיות אופטימיזציה קמורות, ובפתרון הבעיות האלה בצורה יעילה יותר.
פרטים נוספים זמינים בספר Convex Optimization של Boyd ו-Vandenberghe.
קבוצה קמורה
קבוצת משנה של מרחב אוקלידי, כך שקו שמצויר בין שתי נקודות כלשהן בקבוצת המשנה נשאר כולו בתוך קבוצת המשנה. לדוגמה, שתי הצורות הבאות הן קבוצות קמורות:

לעומת זאת, שתי הצורות הבאות הן לא קבוצות קמורות:

קונבולוציה
במתמטיקה, באופן לא פורמלי, תערובת של שתי פונקציות. בלימוד מכונה, קונבולוציה היא ערבוב של מסנן קונבולוציוני ומטריצת הקלט כדי לאמן משקלים.
המונח 'קונבולוציה' בלמידת מכונה הוא לרוב קיצור לפעולת קונבולוציה או לשכבת קונבולוציה.
בלי קונבולוציות, אלגוריתם של למידת מכונה יצטרך ללמוד משקל נפרד לכל תא בטנסור גדול. לדוגמה, אלגוריתם של למידת מכונה שאומן על תמונות בגודל 2K x 2K ייאלץ למצוא 4 מיליון משקלים נפרדים. בזכות קונבולוציות, אלגוריתם של למידת מכונה צריך למצוא משקלים רק לכל תא במסנן הקונבולוציה, וכך מצטמצם באופן משמעותי הזיכרון שנדרש לאימון המודל. כשמחילים את המסנן הקונבולוציוני, הוא פשוט משוכפל בתאים כך שכל תא מוכפל במסנן.
מסנן קונבולוציה
אחד משני השחקנים בפעולת קונבולוציה. (השחקן השני הוא פרוסה של מטריצת קלט). מסנן קונבולוציה הוא מטריצה עם דרגה זהה לזו של מטריצת הקלט, אבל עם צורה קטנה יותר. לדוגמה, אם מטריצת הקלט היא בגודל 28x28, המסנן יכול להיות כל מטריצה דו-ממדית קטנה יותר מ-28x28.
במניפולציה של תמונות, כל התאים במסנן קונבולוציה מוגדרים בדרך כלל לתבנית קבועה של אחדות ואפסים. בלמידת מכונה, מסנני קונבולוציה בדרך כלל מאותחלים עם מספרים אקראיים, ואז הרשת מתאמנת על הערכים האידיאליים.
שכבת קונבולוציה
שכבה של רשת נוירונים עמוקה שבה מסנן קונבולוציה מעביר מטריצת קלט. לדוגמה, נבחן את מסנן הקונבולוציה הבא בגודל 3x3:
![מטריצה בגודל 3x3 עם הערכים הבאים: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=0&hl=he)
באנימציה הבאה מוצגת שכבת קונבולוציה שמורכבת מ-9 פעולות קונבולוציה שכוללות את מטריצת הקלט בגודל 5x5. שימו לב שכל פעולת קונבולוציה פועלת על פרוסת 3x3 שונה של מטריצת הקלט. מטריצת 3x3 שמתקבלת (משמאל) מורכבת מתוצאות של 9 פעולות קונבולוציה:
![אנימציה שמציגה שתי מטריצות. המטריצה הראשונה היא מטריצת 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
המטריצה השנייה היא מטריצת 3x3:
[[181,303,618], [115,338,605], [169,351,560]].
המטריצה השנייה מחושבת על ידי החלת המסנן הקונבולוציוני [[0, 1, 0], [1, 0, 1], [0, 1, 0]] על קבוצות משנה שונות בגודל 3x3 של המטריצה בגודל 5x5.](https://developers.google.com/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=0&hl=he)
רשת נוירונים קונבולוציונית
רשת נוירונים שבה לפחות שכבה אחת היא שכבת קונבולוציה. רשת נוירונים קונבולוציונית טיפוסית מורכבת משילוב כלשהו של השכבות הבאות:
רשתות נוירונים מלאכותיות (CNN) השיגו הצלחה רבה בפתרון בעיות מסוימות, כמו זיהוי תמונות.
פעולה של קונבולוציה
הפעולה המתמטית הבאה בת שני השלבים:
- כפל של כל רכיב במסנן הקונבולוציה עם פרוסת מטריצת הקלט. (לפרוסת מטריצת הקלט יש דרגה וגודל זהים לאלה של מסנן הקונבולוציה).
- סכום כל הערכים במטריצת המוצרים שמתקבלת.
לדוגמה, מטריצת הקלט הבאה בגודל 5x5:
![מטריצה 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=0&hl=he)
עכשיו נדמיין מסנן קונבולוציה בגודל 2x2:
![המטריצה 2x2: [[1, 0], [0, 1]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=0&hl=he)
כל פעולת קונבולוציה כוללת פרוסה אחת בגודל 2x2 של מטריצת הקלט. לדוגמה, נניח שאנחנו משתמשים בפלח בגודל 2x2 בפינה הימנית העליונה של מטריצת הקלט. לכן, פעולת הקונבולוציה על הפרוסה הזו נראית כך:
![החלת מסנן הקונבולוציה [[1, 0], [0, 1]] על החלק בגודל 2x2 בפינה הימנית העליונה של מטריצת הקלט, שהוא [[128,97], [35,22]].
המסנן הקונבולוציוני משאיר את הערכים 128 ו-22 ללא שינוי, אבל מאפס את הערכים 97 ו-35. לכן, פעולת הקונבולוציה מחזירה את הערך 150 (128+22).](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=0&hl=he)
שכבת קונבולוציה מורכבת מסדרה של פעולות קונבולוציה, שכל אחת מהן פועלת על פרוסה אחרת של מטריצת הקלט.
COPA
קיצור של בחירת חלופות סבירות.
עלות
מילה נרדפת ל-loss.
אימון משותף
גישה של למידה מונחית למחצה, שימושית במיוחד כשמתקיימים כל התנאים הבאים:
- היחס בין דוגמאות לא מסומנות לבין דוגמאות מסומנות במערך הנתונים גבוה.
- זו בעיית סיווג (בינארית או מרובת מחלקות).
- מערך הנתונים מכיל שני סטים שונים של תכונות חיזוי, שהם בלתי תלויים ומשלימים זה את זה.
במהלך אימון משותף, אותות עצמאיים מוגברים והופכים לאות חזק יותר. לדוגמה, נניח שיש מודל סיווג שמסווג מכוניות משומשות בודדות כטובות או כגרועות. קבוצה אחת של תכונות חיזויות עשויה להתמקד במאפיינים מצטברים כמו השנה, היצרן והדגם של המכונית. קבוצה אחרת של תכונות חיזויות עשויה להתמקד ברשומת הנהיגה של הבעלים הקודמים ובהיסטוריית התחזוקה של המכונית.
המאמר המרכזי בנושא אימון משותף הוא Combining Labeled and Unlabeled Data with Co-Training מאת Blum ו-Mitchell.
הוגנות קונטרה-פקטואלית
מדד הוגנות שבודק אם מודל סיווג מפיק את אותה תוצאה עבור אדם מסוים כמו עבור אדם אחר שזהה לו, למעט מאפיינים רגישים מסוימים. הערכה של מודל סיווג מבחינת הוגנות קונטרה-פקטואלית היא שיטה אחת לחשיפת מקורות פוטנציאליים של הטיה במודל.
מידע נוסף זמין במאמרים הבאים:
- הוגנות: הוגנות מנוגדת לעובדות בקורס המקוצר על למידת מכונה.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
הטיית כיסוי
ראו הטיית בחירה.
crash blossom
משפט או ביטוי עם משמעות לא ברורה. פריחות של קריסות הן בעיה משמעותית בהבנה של שפה טבעית. לדוגמה, הכותרת Red Tape Holds Up Skyscraper היא כותרת עם משמעות כפולה כי מודל NLU יכול לפרש את הכותרת באופן מילולי או באופן פיגורטיבי.
מבקר/ת
מילה נרדפת ל-Deep Q-Network.
אנטרופיה צולבת
הכללה של Log Loss לבעיות סיווג מרובות מחלקות. האנטרופיה הצולבת מכמתת את ההבדל בין שני התפלגויות הסתברות. מידע נוסף זמין במאמר בנושא perplexity.
אימות צולב
מנגנון להערכת מידת ההכללה של מודל לנתונים חדשים. ההערכה מתבצעת על ידי בדיקת המודל מול קבוצות משנה של נתונים שלא חופפות זו לזו, שלא נכללו בקבוצת נתונים לאימון.
פונקציית התפלגות מצטברת (CDF)
פונקציה שמגדירה את התדירות של דגימות שקטנות מערך יעד או שוות לו. לדוגמה, נניח שיש התפלגות נורמלית של ערכים רציפים. פונקציית CDF מראה שכ-50% מהדגימות צריכות להיות קטנות מהממוצע או שוות לו, וכ-84% מהדגימות צריכות להיות קטנות מהממוצע או שוות לו בתוספת סטיית תקן אחת.
D
ניתוח נתונים
הבנת הנתונים על ידי בחינת דוגמאות, מדידות והמחשה. ניתוח נתונים יכול להיות שימושי במיוחד כשמקבלים מערך נתונים בפעם הראשונה, לפני שיוצרים את המודל הראשון. הוא גם חשוב להבנת ניסויים ולניפוי באגים במערכת.
הגדלת מערך הנתונים
הגדלה מלאכותית של טווח הדוגמאות ושל מספר הדוגמאות לאימון על ידי שינוי דוגמאות קיימות כדי ליצור דוגמאות נוספות. לדוגמה, נניח שתמונות הן אחת מהתכונות שלכם, אבל מערך הנתונים לא מכיל מספיק דוגמאות של תמונות כדי שהמודל יוכל ללמוד שיוכים שימושיים. מומלץ להוסיף למערך הנתונים מספיק תמונות מתויגות כדי לאפשר אימון תקין של המודל. אם זה לא אפשרי, אפשר להשתמש בהגדלת מערך הנתונים כדי לסובב, למתוח ולשקף כל תמונה כדי ליצור וריאציות רבות של התמונה המקורית. יכול להיות שזה יניב מספיק נתונים מתויגים כדי לאפשר אימון מצוין.
DataFrame
סוג נתונים פופולרי של pandas לייצוג מערכי נתונים בזיכרון.
אובייקט DataFrame דומה לטבלה או לגיליון אלקטרוני. לכל עמודה ב-DataFrame יש שם (כותרת), ולכל שורה יש מספר ייחודי שמזהה אותה.
כל עמודה ב-DataFrame בנויה כמו מערך דו-ממדי, אבל לכל עמודה אפשר להקצות סוג נתונים משלה.
אפשר לעיין גם בדף הרשמי של pandas.DataFrame reference.
מקביליות נתונים
שיטה להרחבת אימון או הסקת מסקנות, שבה משכפלים מודל שלם למספר מכשירים ואז מעבירים לכל מכשיר קבוצת משנה של נתוני הקלט. מקביליות נתונים יכולה לאפשר אימון והסקת מסקנות בגדלים גדולים מאוד של אצווה. עם זאת, מקביליות נתונים מחייבת שהמודל יהיה קטן מספיק כדי להתאים לכל המכשירים.
בדרך כלל, מקביליות נתונים מזרזת את האימון וההסקה.
אפשר לעיין גם במאמר בנושא מקביליות של מודלים.
Dataset API (tf.data)
API ברמה גבוהה של TensorFlow לקריאת נתונים ולהמרה שלהם לפורמט שנדרש לאלגוריתם של למידת מכונה.
אובייקט tf.data.Dataset מייצג רצף של רכיבים, שכל אחד מהם מכיל טנסור אחד או יותר. אובייקט tf.data.Iterator
מספק גישה לרכיבים של Dataset.
קבוצת נתונים
אוסף של נתונים גולמיים, בדרך כלל (אבל לא רק) בפורמט הבא:
- גיליון אלקטרוני
- קובץ בפורמט CSV (ערכים מופרדים בפסיקים)
גבול ההחלטה
הקו המפריד בין classes שנלמדו על ידי model בbinary class או בmulti-class classification problems. לדוגמה, בתמונה הבאה שמייצגת בעיית סיווג בינארית, גבול ההחלטה הוא הגבול בין המחלקה הכתומה למחלקה הכחולה:

יער החלטות
מודל שנוצר מכמה עצי החלטות. כדי לבצע חיזוי, יער ההחלטות צובר את החיזויים של עצי ההחלטות שלו. סוגים פופולריים של יערות החלטה כוללים יערות אקראיים ועצים עם שיפור גרדיאנט.
מידע נוסף זמין בקטע יערות של החלטות בקורס בנושא יערות של החלטות.
סף ההחלטה
מילה נרדפת לסף סיווג.
עץ החלטה
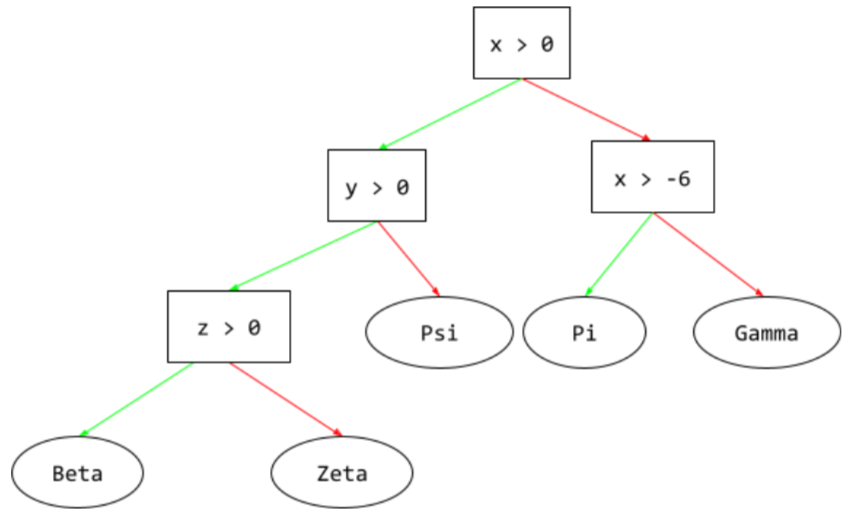
מודל של למידה מונחית שמורכב מקבוצה של תנאים וענפים שמאורגנים בהיררכיה. לדוגמה, זהו עץ החלטות:
מפענח
באופן כללי, כל מערכת ML שמבצעת המרה מייצוג מעובד, צפוף או פנימי לייצוג גולמי, דליל או חיצוני יותר.
מפענחים הם לרוב רכיב של מודל גדול יותר, והם משולבים לעיתים קרובות עם מקודד.
במשימות של רצף לרצף, מפענח מתחיל עם המצב הפנימי שנוצר על ידי המקודד כדי לחזות את הרצף הבא.
במאמר Transformer מופיעה הגדרה של מפענח בארכיטקטורת Transformer.
מידע נוסף זמין במאמר מודלים גדולים של שפה בקורס Machine Learning Crash Course.
מודל עמוק
רשת נוירונים שמכילה יותר משכבה נסתרת.
מודל עמוק נקרא גם רשת נוירונים עמוקה.
ההבדל בינו לבין מודל רחב.
של רשת עצבית עמוקה
מילה נרדפת למודל עמוק.
רשת Q עמוקה (DQN)
ב-Q-learning, נעשה שימוש ברשת עצבית עמוקה כדי לחזות פונקציות Q.
Critic הוא מילה נרדפת ל-Deep Q-Network.
שוויון דמוגרפי
מדד הוגנות שמתקיים אם תוצאות הסיווג של מודל לא תלויות במאפיין רגיש נתון.
לדוגמה, אם גם אנשי ליליפוט וגם אנשי ברובדינגנאג מגישים בקשה להתקבל לאוניברסיטת גלובדובדריב, שוויון דמוגרפי מושג אם אחוז אנשי ליליפוט שהתקבלו זהה לאחוז אנשי ברובדינגנאג שהתקבלו, ללא קשר לשאלה אם קבוצה אחת מוסמכת יותר בממוצע מהקבוצה השנייה.
ההגדרה הזו שונה מסיכויים שווים ומשוויון הזדמנויות, שמאפשרות לתוצאות הסיווג הכוללות להיות תלויות במאפיינים רגישים, אבל לא מאפשרות לתוצאות הסיווג של תוויות אמת בסיסית מסוימות להיות תלויות במאפיינים רגישים. במאמר "Attacking discrimination with smarter machine learning" (התמודדות עם אפליה באמצעות למידת מכונה חכמה יותר) מוצג תרשים שממחיש את היתרונות והחסרונות של אופטימיזציה להשגת שוויון דמוגרפי.
מידע נוסף זמין במאמר בנושא הוגנות: שוויון דמוגרפי בקורס המקוצר על למידת מכונה.
ניקוי רעשים
גישה נפוצה ללמידה מונחית עצמית שבה:
הסרת רעשים מאפשרת למידה מדוגמאות לא מסומנות. מערך הנתונים המקורי משמש כיעד או כתווית, והנתונים הרועשים משמשים כקלט.
חלק ממודלים של שפה עם מיסוך משתמשים בהסרת רעשים באופן הבא:
- רעש מתווסף באופן מלאכותי למשפט ללא תווית על ידי מיסוך של חלק מהטוקנים.
- המודל מנסה לחזות את הטוקנים המקוריים.
תכונה צפופה
תכונה שרוב הערכים שלה או כולם הם לא אפס, בדרך כלל טנזור של ערכים מסוג נקודה צפה. לדוגמה, טנסור 10-אלמנטים הבא הוא צפוף כי 9 מהערכים שלו הם לא אפס:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
ההבדל בין התכונה הזו לבין sparse feature.
שכבה צפופה
מילה נרדפת לשכבה מקושרת באופן מלא.
depth
הסכום של הרכיבים הבאים ברשת נוירונים:
- מספר השכבות הנסתרות
- מספר שכבות הפלט, שבדרך כלל הוא 1
- מספר שכבות ההטמעה
לדוגמה, רשת נוירונים עם חמש שכבות נסתרות ושכבת פלט אחת היא בעומק 6.
שימו לב ששכבת הקלט לא משפיעה על העומק.
רשת נוירונים מלאכותית (CNN) עם קונבולוציה נפרדת לפי עומק (sepCNN)
ארכיטקטורה של רשת נוירונים מורכבת שמבוססת על Inception, אבל מודולי Inception מוחלפים בה ב-convolutions נפרדים לפי עומק. נקרא גם Xception.
קונבולוציה ניתנת להפרדה לפי עומק (שנקראת גם קונבולוציה ניתנת להפרדה) מפרקת קונבולוציה תלת-ממדית רגילה לשתי פעולות קונבולוציה נפרדות שהן יעילות יותר מבחינת חישוב: קודם, קונבולוציה לפי עומק, עם עומק של 1 (n ✕ n ✕ 1), ואז, קונבולוציה לפי נקודה, עם אורך ורוחב של 1 (1 ✕ 1 ✕ n).
מידע נוסף זמין במאמר Xception: Deep Learning with Depthwise Separable Convolutions.
תווית נגזרת
מילה נרדפת ל-proxy label.
דטרמיניסטי
מערכת שתמיד מחזירה את אותה התוצאה עבור קלט נתון. לדוגמה, הפונקציה ReLU היא דטרמיניסטית כי:
- אם הקלט שלילי, הפלט תמיד יהיה 0.
- אם הקלט הוא לא שלילי, הפלט תמיד שווה לקלט.
לעומת זאת, פונקציה שמחזירה מספר אקראי בכל פעם שמפעילים אותה היא לא דטרמיניסטית.
בדרך כלל קל יותר לבדוק מערכות דטרמיניסטיות מאשר מערכות לא דטרמיניסטיות.
מודלים גדולים של שפה הם בדרך כלל לא דטרמיניסטיים. כלומר, התשובה של LLM לאותה הנחיה לרוב שונה.
מכשיר
מונח עמוס עם שתי הגדרות אפשריות:
- קטגוריה של חומרה שיכולה להריץ סשן של TensorFlow, כולל מעבדי CPU, מעבדי GPU ומעבדי TPU.
- כשמבצעים אימון של מודל ML על שבבי האצה (GPU או TPU), החלק במערכת שמבצע בפועל מניפולציה של טנסורים ושל הטבעות. המכשיר פועל על שבבי האצה. לעומת זאת, המארח פועל בדרך כלל על מעבד מרכזי.
פרטיות דיפרנציאלית
במידת מכונה, גישה לאנונימיזציה שמטרתה להגן על מידע אישי רגיש (לדוגמה, מידע אישי של אדם מסוים) שכלולים בקבוצת נתונים לאימון של מודל מפני חשיפה. הגישה הזו מבטיחה שהמודל לא ילמד או יזכור הרבה על אדם ספציפי. כדי להשיג את זה, אנחנו מבצעים דגימה ומוסיפים רעש במהלך אימון המודל כדי להסתיר נקודות נתונים ספציפיות, וכך מצמצמים את הסיכון לחשיפת נתוני אימון רגישים.
פרטיות דיפרנציאלית משמשת גם מחוץ ללמידת מכונה. לדוגמה, מדעני נתונים משתמשים לפעמים בפרטיות דיפרנציאלית כדי להגן על הפרטיות של אנשים פרטיים כשהם מחשבים נתונים סטטיסטיים על השימוש במוצר עבור מאפיינים דמוגרפיים שונים.
הפחתת ממדים
הקטנת מספר המאפיינים שמשמשים לייצוג תכונה מסוימת בווקטור תכונות, בדרך כלל על ידי המרה לווקטור הטמעה.
מימדים
מונח בעל עומס יתר עם אחת מההגדרות הבאות:
מספר הרמות של הקואורדינטות בTensor. לדוגמה:
- לסקלר יש אפס ממדים, לדוגמה:
["Hello"]. - לווקטור יש מימד אחד, לדוגמה,
[3, 5, 7, 11]. - למטריצה יש שני מאפיינים, לדוגמה,
[[2, 4, 18], [5, 7, 14]]. אפשר לציין באופן ייחודי תא מסוים בווקטור חד-ממדי באמצעות קואורדינטה אחת, אבל צריך שתי קואורדינטות כדי לציין באופן ייחודי תא מסוים במטריצה דו-ממדית.
- לסקלר יש אפס ממדים, לדוגמה:
מספר הרשומות בוקטור מאפיינים.
מספר האלמנטים בשכבת הטמעה.
הנחיות ישירות
מילה נרדפת להנחיות בלי דוגמאות (zero-shot prompting).
תכונה נפרדת
תכונה עם קבוצה סופית של ערכים אפשריים. לדוגמה, מאפיין שהערכים שלו יכולים להיות רק animal (בעל חיים), vegetable (ירק) או mineral (מינרל) הוא מאפיין נפרד (או קטגורי).
ההפך מתכונה מתמשכת.
מודל דיסקרימינטיבי
מודל שמנבא תוויות מתוך קבוצה של תכונות אחת או יותר. באופן פורמלי יותר, מודלים דיסקרימינטיביים מגדירים את ההסתברות המותנית של פלט בהינתן התכונות והמשקלים, כלומר:
p(output | features, weights)
לדוגמה, מודל שמנבא אם אימייל הוא ספאם על סמך תכונות ומשקלים הוא מודל דיסקרימינטיבי.
רוב המודלים של למידה מונחית, כולל מודלים של סיווג ורגרסיה, הם מודלים דיסקרימינטיביים.
בניגוד למודל גנרטיבי.
דיסקרימינטור
מערכת שקובעת אם הדוגמאות אמיתיות או מזויפות.
לחלופין, המערכת המשנית בתוך רשת גנרטיבית יריבה שקובעת אם הדוגמאות שנוצרו על ידי הגנרטור הן אמיתיות או מזויפות.
מידע נוסף זמין במאמר המסווג בקורס GAN.
השפעה לא פרופורציונלית
קבלת החלטות לגבי אנשים שמשפיעות באופן לא פרופורציונלי על קבוצות משנה שונות באוכלוסייה. בדרך כלל הכוונה היא למצבים שבהם תהליך אלגוריתמי של קבלת החלטות פוגע בקבוצות משנה מסוימות יותר מאחרות, או מועיל להן יותר מאשר לאחרות.
לדוגמה, נניח שיש אלגוריתם שקובע אם תושב ליליפוט זכאי להלוואה לרכישת בית זעיר, ושהאלגוריתם הזה נוטה יותר לסווג את התושב כ'לא זכאי' אם כתובת למשלוח דואר שלו מכילה מיקוד מסוים. אם לליליפוטים מסוג Big-Endian יש סיכוי גבוה יותר לכתובות למשלוח עם המיקוד הזה מאשר לליליפוטים מסוג Little-Endian, יכול להיות שהאלגוריתם הזה יגרום להשפעה לא פרופורציונלית.
ההגדרה הזו שונה מיחס מפלה, שמתמקדת בפערים שנוצרים כשמאפיינים של קבוצת משנה הם קלט מפורש לתהליך קבלת החלטות אלגוריתמי.
יחס שונה
הכללת מאפיינים רגישים של נושאים בתהליך קבלת החלטות אלגוריתמי, כך שקבוצות משנה שונות של אנשים מקבלות יחס שונה.
לדוגמה, נניח שיש אלגוריתם שקובע אם אנשים מליליפוט זכאים להלוואה לרכישת בית מיניאטורי על סמך הנתונים שהם מספקים בבקשת ההלוואה. אם האלגוריתם משתמש בהשתייכות של תושב ליליפוט כ-Big-Endian או כ-Little-Endian כקלט, הוא מבצע אפליה לאורך הממד הזה.
המושג הזה שונה מהשפעה לא פרופורציונלית, שמתמקד בפערים בהשפעות החברתיות של החלטות אלגוריתמיות על קבוצות משנה, בלי קשר לשאלה אם קבוצות המשנה האלה הן נתוני קלט למודל.
זיקוק
תהליך של הקטנת הגודל של מודל אחד (שנקרא מורה) למודל קטן יותר (שנקרא תלמיד) שמדמה את התחזיות של המודל המקורי בצורה נאמנה ככל האפשר. זיקוק מועיל כי למודל הקטן יש שני יתרונות מרכזיים על פני המודל הגדול יותר (המודל המלמד):
- זמן הסקת מסקנות מהיר יותר
- צריכת זיכרון ואנרגיה מופחתת
עם זאת, בדרך כלל התחזיות של התלמידים לא טובות כמו התחזיות של המורים.
בזיקוק, המודל התלמיד עובר אימון כדי למזער פונקציית הפסד על סמך ההבדל בין התוצאות של התחזיות של מודל התלמיד ומודל המורה.
השוו והבדילו בין זיקוק לבין המונחים הבאים:
מידע נוסף מופיע במאמר מודלים גדולים של שפה (LLM): כוונון עדין, זיקוק והנדסת הנחיות בקורס המקוצר על למידת מכונה.
distribution
התדירות והטווח של ערכים שונים עבור תכונה או תווית נתונים. התפלגות מתעדת את הסבירות של ערך מסוים.
בתמונה הבאה מוצגים היסטוגרמות של שתי התפלגויות שונות:
- בצד ימין, התפלגות חוק החזקה של העושר לעומת מספר האנשים שמחזיקים בעושר הזה.
- משמאל, התפלגות נורמלית של הגובה לעומת מספר האנשים בגובה הזה.
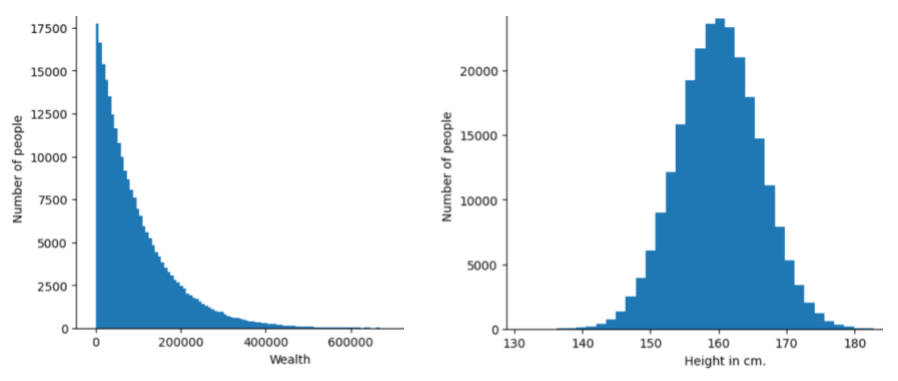
הבנת הפילוג של כל תכונה ותווית יכולה לעזור לכם לקבוע איך לנרמל ערכים ולזהות ערכים חריגים.
הביטוי out of distribution מתייחס לערך שלא מופיע במערך הנתונים או שהוא נדיר מאוד. לדוגמה, תמונה של כוכב שבתאי תיחשב כחריגה מהתפלגות הנתונים במערך נתונים שמורכב מתמונות של חתולים.
חלוקה לאשכולות
מידע נוסף זמין במאמר בנושא אשכול היררכי.
דגימה ברזולוציה נמוכה
מונח עמוס שיכול להתייחס לאחת מהאפשרויות הבאות:
- צמצום כמות המידע בתכונה כדי לאמן מודל בצורה יעילה יותר. לדוגמה, לפני אימון מודל לזיהוי תמונות, דגימת תמונות ברזולוציה גבוהה לפורמט ברזולוציה נמוכה יותר.
- אימון על אחוז נמוך באופן לא פרופורציונלי של דוגמאות של סיווג שיוצג יתר על המידה, כדי לשפר את אימון המודל על סיווגים שיוצגו פחות. לדוגמה, בקבוצת נתונים עם חוסר איזון בין מחלקות, המודלים נוטים ללמוד הרבה על מחלקת הרוב ולא מספיק על מחלקת המיעוט. הפחתת דגימה עוזרת לאזן את כמות האימון של רוב המחלקות ומיעוט המחלקות.
מידע נוסף זמין במאמר מערכי נתונים: מערכי נתונים לא מאוזנים בקורס המקוצר על למידת מכונה.
DQN
קיצור של Deep Q-Network (רשת Q עמוקה).
רגולריזציה של נשירה
סוג של רגולריזציה ששימושי באימון של רשתות נוירונים. הרגולריזציה של Dropout מסירה בחירה אקראית של מספר קבוע של יחידות בשכבת רשת לשלב אחד של גרדיאנט. ככל שיותר יחידות נושרות, כך הרגולריזציה חזקה יותר. זה דומה לאימון הרשת כדי לחקות אנסמבל גדול באופן אקספוננציאלי של רשתות קטנות יותר. פרטים מלאים זמינים במאמר Dropout: A Simple Way to Prevent Neural Networks from Overfitting.
דינמי
משהו שנעשה לעיתים קרובות או באופן רציף. המונחים דינמי ואונליין הם מילים נרדפות בתחום למידת המכונה. אלה שימושים נפוצים במונחים דינמי ואונליין בלמידת מכונה:
- מודל דינמי (או מודל אונליין) הוא מודל שעובר אימון מחדש לעיתים קרובות או באופן רציף.
- הדרכה דינמית (או הדרכה אונליין) היא תהליך של הדרכה בתדירות גבוהה או באופן רציף.
- הסקת מסקנות דינמית (או הסקת מסקנות אונליין) היא תהליך של יצירת תחזיות לפי דרישה.
מודל דינמי
מודל שעובר אימון מחדש לעיתים קרובות (אולי אפילו באופן רציף). מודל דינמי הוא 'לומד לכל החיים' שמתאים את עצמו כל הזמן לנתונים משתנים. מודל דינמי נקרא גם מודל אונליין.
השוואה למודל סטטי.
E
הרצה מיידית
סביבת תכנות של TensorFlow שבה פעולות מופעלות באופן מיידי. לעומת זאת, פעולות שמופעלות בביצוע גרף לא מופעלות עד שהן מוערכות באופן מפורש. ההרצה המיידית היא ממשק אימפרטיבי, בדומה לקוד ברוב שפות התכנות. בדרך כלל קל הרבה יותר לבצע ניפוי באגים בתוכניות של ביצוע מיידי מאשר בתוכניות של ביצוע גרף.
עצירה מוקדמת
שיטה לרגולריזציה שכוללת סיום של אימון לפני שההפסד של האימון מפסיק לרדת. בשיטת העצירה המוקדמת, עוצרים בכוונה את אימון המודל כשההפסד במערך נתוני האימות מתחיל לעלות, כלומר כשביצועי ההכללה מתדרדרים.
ההפך מיציאה מוקדמת.
מרחק בין תנועות של כלי עפר (EMD)
מדד לדמיון היחסי בין שתי התפלגויות. ככל שהמרחק בין המכונות קטן יותר, כך ההתפלגויות דומות יותר.
מרחק עריכה
מדד של מידת הדמיון בין שתי מחרוזות טקסט. בלמידת מכונה, מרחק העריכה שימושי מהסיבות הבאות:
- קל לחשב את מרחק העריכה.
- מרחק העריכה יכול להשוות בין שתי מחרוזות שידוע שהן דומות זו לזו.
- מרחק עריכה יכול לקבוע את מידת הדמיון בין מחרוזות שונות למחרוזת נתונה.
יש כמה הגדרות של מרחק עריכה, וכל אחת מהן משתמשת בפעולות שונות על מחרוזות. דוגמה מופיעה במאמר בנושא מרחק לבנשטיין.
סימון איינסום
סימון יעיל לתיאור האופן שבו צריך לשלב בין שני טנסורים. הטנסורים משולבים על ידי הכפלת הרכיבים של טנסור אחד ברכיבים של הטנסור השני, ואז חישוב סכום המכפלות. בסימון איינשטיין משתמשים בסמלים כדי לזהות את הצירים של כל טנזור, ואותם סמלים מסודרים מחדש כדי לציין את הצורה של הטנזור החדש שמתקבל.
NumPy מספקת הטמעה נפוצה של Einsum.
שכבת הטמעה
שכבה נסתרת מיוחדת שעוברת אימון על מאפיין קטגורי עם הרבה ממדים, כדי ללמוד בהדרגה וקטור הטמעה עם פחות ממדים. שכבת הטמעה מאפשרת לרשת נוירונים להתאמן בצורה יעילה הרבה יותר מאשר אימון רק על תכונת קטגוריה רב-ממדית.
לדוגמה, נכון לעכשיו, Earth תומך בכ-73,000 מיני עצים. נניח שהתכונה במודל היא מיני עצים, ולכן שכבת הקלט של המודל כוללת וקטור one-hot באורך 73,000 אלמנטים.
לדוגמה, יכול להיות שהתו baobab ייוצג כך:

מערך עם 73,000 רכיבים הוא ארוך מאוד. אם לא מוסיפים למודל שכבת הטמעה, האימון יימשך זמן רב מאוד כי צריך להכפיל 72,999 אפסים. יכול להיות שתבחרו ששכבת ההטמעה תכלול 12 ממדים. כתוצאה מכך, שכבת ההטמעה תלמד בהדרגה וקטור הטמעה חדש לכל מין של עץ.
במצבים מסוימים, גיבוב הוא חלופה סבירה לשכבת הטמעה.
מידע נוסף זמין במאמר Embeddings בקורס המקוצר על למידת מכונה.
מרחב הטמעה
מרחב וקטורי d-ממדי שאליו ממופים מאפיינים ממרחב וקטורי רב-ממדי. מרחב ההטמעה מאומן לזיהוי מבנה שרלוונטי לאפליקציה המיועדת.
המכפלה הסקלרית של שני וקטורי הטמעה היא מדד לדמיון ביניהם.
וקטור הטמעה
באופן כללי, מערך של מספרים בנקודה צפה שמופיעים בכל שכבה נסתרת ומתארים את נתוני הקלט של אותה שכבה נסתרת. לרוב, וקטור הטמעה הוא מערך של מספרים בנקודה צפה (floating-point) שאומנו בשכבת הטמעה. לדוגמה, נניח ששכבת הטמעה צריכה ללמוד וקטור הטמעה לכל אחד מ-73,000 מיני העצים בכדור הארץ. יכול להיות שהמערך הבא הוא וקטור ההטמעה של עץ באובב:

וקטור הטמעה הוא לא אוסף של מספרים אקראיים. שכבת הטמעה קובעת את הערכים האלה באמצעות אימון, בדומה לאופן שבו רשת נוירונים לומדת משקלים אחרים במהלך האימון. כל רכיב במערך הוא דירוג לפי מאפיין מסוים של מין העץ. איזה רכיב מייצג את המאפיין של איזה מין עץ? קשה מאוד לבני אדם לקבוע את זה.
החלק המדהים מבחינה מתמטית בווקטור הטמעה הוא שפריטים דומים כוללים קבוצות דומות של מספרים בנקודה צפה (floating-point). לדוגמה, מינים דומים של עצים יניבו קבוצה דומה יותר של מספרים עם נקודה צפה מאשר מינים שונים של עצים. עצי סקוויה ועצי רדווד הם מינים קרובים, ולכן קבוצת המספרים הצפים שלהם תהיה דומה יותר מאשר קבוצת המספרים הצפים של עצי רדווד ודקלים. המספרים בווקטור ההטמעה ישתנו בכל פעם שתאמנו מחדש את המודל, גם אם תאמנו אותו מחדש עם קלט זהה.
התנהגות בלתי צפויה
היכולת של מודל שפה גדול ליצור תשובות להנחיות שהוא לא אומן עליהן באופן מפורש.
פונקציית התפלגות מצטברת אמפירית (eCDF או EDF)
פונקציית התפלגות מצטברת שמבוססת על מדידות אמפיריות ממערך נתונים אמיתי. הערך של הפונקציה בכל נקודה לאורך ציר ה-x הוא החלק של התצפיות במערך הנתונים שקטן מהערך שצוין או שווה לו.
מזעור סיכון אמפירי (ERM)
בחירת הפונקציה שממזערת את ההפסד במערך האימון. השוואה לצמצום סיכונים מבניים.
מקודד
באופן כללי, כל מערכת ML שמבצעת המרה מייצוג גולמי, דליל או חיצוני לייצוג מעובד יותר, צפוף יותר או פנימי יותר.
מקודדים הם לרוב רכיב של מודל גדול יותר, ולעתים קרובות הם משולבים עם מפענח. חלק מהטרנספורמרים משלבים מקודדים עם מפענחים, אבל טרנספורמרים אחרים משתמשים רק במקודד או רק במפענח.
במערכות מסוימות, הפלט של המקודד משמש כקלט לרשת סיווג או רגרסיה.
במשימות של רצף לרצף, מקודד מקבל רצף קלט ומחזיר מצב פנימי (וקטור). לאחר מכן, המפענח משתמש במצב הפנימי הזה כדי לחזות את הרצף הבא.
הגדרה של מקודד בארכיטקטורת טרנספורמר מופיעה במאמר Transformer.
מידע נוסף מופיע במאמר LLMs: What's a large language model (מודלים גדולים של שפה: מהו מודל שפה גדול) בקורס Machine Learning Crash Course (קורס מקוצר על למידת מכונה).
נקודות קצה
מיקום שאפשר להקצות לו כתובת ברשת (בדרך כלל כתובת URL) שאפשר לגשת אליו כדי להשתמש בשירות.
ensemble
אוסף של מודלים שאומנו באופן עצמאי והתחזיות שלהם מחושבות כממוצע או מצטברות. במקרים רבים, מודל משולב מניב תחזיות טובות יותר ממודל יחיד. לדוגמה, יער אקראי הוא אנסמבל שנבנה מכמה עצי החלטה. חשוב לזכור שלא כל יערות ההחלטות הם אנסמבלים.
מידע נוסף זמין במאמר Random Forest בקורס המקוצר על למידת מכונה.
אנטרופיה
ב תורת המידע, אנטרופיה היא מדד למידת חוסר הצפיות של התפלגות הסתברויות. לחלופין, אנטרופיה מוגדרת גם ככמות המידע שכל דוגמה מכילה. הפיזור הוא בעל האנטרופיה הגבוהה ביותר האפשרית כשכל הערכים של משתנה אקראי הם בעלי סבירות שווה.
הנוסחה לחישוב האנטרופיה של קבוצה עם שני ערכים אפשריים, 0 ו-1 (לדוגמה, התוויות בבעיית סיווג בינארי), היא:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
where:
- H היא האנטרופיה.
- p הוא החלק היחסי של הדוגמאות מסוג '1'.
- q הוא החלק של הדוגמאות עם הערך '0'. הערה: q = (1 - p)
- הערך של log הוא בדרך כלל log2. במקרה הזה, יחידת האנטרופיה היא ביט.
לדוגמה, נניח את הדברים הבאים:
- 100 דוגמאות מכילות את הערך '1'
- 300 דוגמאות מכילות את הערך '0'
לכן, ערך האנטרופיה הוא:
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81 bits per example
קבוצה מאוזנת לחלוטין (לדוגמה, 200 ערכים של '0' ו-200 ערכים של '1') תהיה בעלת אנטרופיה של 1.0 ביט לכל דוגמה. ככל שקבוצה הופכת ללא מאוזנת יותר, האנטרופיה שלה מתקרבת ל-0.0.
בעצי החלטה, האנטרופיה עוזרת לגבש רווח מידע כדי לעזור למפצל לבחור את התנאים במהלך הצמיחה של עץ החלטה לסיווג.
השוואה של האנטרופיה עם:
- מדד גיני לאי-טוהר
- פונקציית האובדן cross-entropy
אנטרופיה נקראת לעיתים קרובות האנטרופיה של שאנון.
מידע נוסף זמין במאמר Exact splitter for binary classification with numerical features בקורס Decision Forests.
environment
בלמידת חיזוק, העולם שמכיל את הסוכן ומאפשר לסוכן לצפות במצב של העולם הזה. לדוגמה, העולם המיוצג יכול להיות משחק כמו שחמט, או עולם פיזי כמו מבוך. כשהסוכן מיישם פעולה בסביבה, הסביבה עוברת בין מצבים.
עיגון בנתונים בסביבה
הנתונים הגולמיים שמועברים חזרה לסוכן במהלך שלב המשוב של הלולאה האגנטית. לדוגמה, ביסוס סביבתי של סוכן יכול לכלול יומני שגיאות או את קוד ה-HTML של דף אינטרנט שנוצר לאחרונה.
פרק
בשיטת הלמידה באמצעות חיזוקים, כל אחד מהניסיונות החוזרים של הסוכן ללמוד סביבה.
זיכרון אפיזודי
במודלים מסוג LLM, המידע נלמד אחרי האימון. לעומת זאת, זיכרון סמנטי הוא מידע שנלמד במהלך האימון. זיכרון אפיזודי יכול להיות זמני (למשל, הוא נשמר רק במהלך הסשן הנוכחי עם הצ'אטבוט) או קבוע יותר (למשל, הוא נשמר בכל סשן שהמשתמש מפעיל).
אפשר לעיין גם במאמר בנושא זיכרון פרוצדורלי.
תקופה של זמן מערכת
מעבר אימון מלא על כל קבוצת נתונים לאימון, כך שכל דוגמה עברה עיבוד פעם אחת.
אפוקה מייצגת N/גודל אצווה אימונים של איטרציות, כאשר N הוא המספר הכולל של הדוגמאות.
לדוגמה, נניח את הדברים הבאים:
- מערך הנתונים מורכב מ-1,000 דוגמאות.
- גודל הקבוצה הוא 50 דוגמאות.
לכן, כל אפוקה דורשת 20 איטרציות:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
מידע נוסף זמין במאמר רגרסיה ליניארית: היפר-פרמטרים בקורס המקוצר על למידת מכונה.
מדיניות חמדנית של אפסילון
בלמידת חיזוק, מדיניות שפועלת לפי מדיניות אקראית בהסתברות אפסילון, או לפי מדיניות חמדנית בכל מקרה אחר. לדוגמה, אם אפסילון הוא 0.9, המדיניות היא מדיניות אקראית ב-90% מהמקרים ומדיניות חמדנית ב-10% מהמקרים.
במהלך פרקים עוקבים, האלגוריתם מקטין את הערך של אפסילון כדי לעבור ממדיניות אקראית למדיניות חמדנית. בשיטת המדיניות הזו, הנציג קודם בוחן את הסביבה באופן אקראי ואז מנצל את התוצאות של הבחינה האקראית.
שוויון הזדמנויות
מדד הוגנות להערכת היכולת של המודל לחזות את התוצאה הרצויה באופן שווה לכל הערכים של מאפיין רגיש. במילים אחרות, אם התוצאה הרצויה של מודל היא הסיווג החיובי, המטרה היא ששיעור החיוביים האמיתיים יהיה זהה לכל הקבוצות.
שוויון הזדמנויות קשור לסיכויים שווים, שמשמעותו שגם שיעורי החיוביים האמיתיים וגם שיעורי החיוביים הכוזבים זהים בכל הקבוצות.
נניח שאוניברסיטת גלאבדאבדריב מקבלת לתוכנית לימודים קפדנית במתמטיקה גם ליליפוטים וגם ברובדינגנאגים. בתי הספר התיכוניים של ליליפוט מציעים תוכנית לימודים מקיפה של שיעורי מתמטיקה, ורוב התלמידים עומדים בדרישות של התוכנית האוניברסיטאית. בבתי הספר התיכוניים של ברובדינגנאג לא מוצעים שיעורי מתמטיקה בכלל, וכתוצאה מכך, הרבה פחות תלמידים עומדים בדרישות. התנאי לשוויון הזדמנויות מתקיים לגבי התווית המועדפת 'התקבל' בהתייחס ללאום (ליליפוטי או ברובדינגנאגי) אם לתלמידים שעומדים בדרישות יש סיכוי שווה להתקבל, בלי קשר להיותם ליליפוטים או ברובדינגנאגים.
לדוגמה, נניח ש-100 אנשים מליליפוט ו-100 אנשים מברובדינגנאג הגישו בקשה להתקבל לאוניברסיטת גלובדאבדריב, וההחלטות לגבי הקבלה מתקבלות באופן הבא:
טבלה 1. מועמדים קטנים (90% מהם כשירים)
| כשירים | לא מתאים | |
|---|---|---|
| התקבל | 45 | 3 |
| נדחה | 45 | 7 |
| סה"כ | 90 | 10 |
|
אחוז הסטודנטים שעומדים בדרישות שהתקבלו: 45/90 = 50% אחוז הסטודנטים שלא עומדים בדרישות שנדחו: 7/10 = 70% האחוז הכולל של סטודנטים מליליפוט שהתקבלו: (45+3)/100 = 48% |
||
טבלה 2. מועמדים גדולים מאוד (10% כשירים):
| כשירים | לא מתאים | |
|---|---|---|
| התקבל | 5 | 9 |
| נדחה | 5 | 81 |
| סה"כ | 10 | 90 |
|
אחוז הסטודנטים שעומדים בדרישות שהתקבלו: 5/10 = 50% אחוז הסטודנטים שלא עומדים בדרישות שנדחו: 81/90 = 90% אחוז הסטודנטים הכולל מברובדינגנאג שהתקבלו: (5+9)/100 = 14% |
||
הדוגמאות הקודמות עומדות בדרישה לשוויון הזדמנויות לקבלה של תלמידים שעומדים בדרישות, כי גם לליליפוטים וגם לברובדינגנאגים שעומדים בדרישות יש סיכוי של 50% להתקבל.
למרות שהשוויון בהזדמנויות מתקיים, שני מדדי ההוגנות הבאים לא מתקיימים:
- שוויון דמוגרפי: שיעורי הקבלה של ליליפוטים ושל ברובדינגנאגים לאוניברסיטה שונים; 48% מהסטודנטים הליליפוטים מתקבלים, אבל רק 14% מהסטודנטים הברובדינגנאגים מתקבלים.
- סיכויים שווים: למרות שלתלמידים זכאים מליליפוט ולתלמידים זכאים מברובדינגנאג יש סיכוי שווה להתקבל, המגבלה הנוספת שלפיה לתלמידים לא זכאים מליליפוט ולתלמידים לא זכאים מברובדינגנאג יש סיכוי שווה להידחות לא מתקיימת. שיעור הדחייה של תושבי ליליפוט לא כשירים הוא 70%, לעומת 90% של תושבי ברובדינגנאג לא כשירים.
מידע נוסף זמין במאמר הוגנות: שוויון הזדמנויות בקורס Machine Learning Crash Course.
הסתברות שווה
מדד הוגנות שנועד להעריך אם מודל חוזה תוצאות באותה רמת דיוק לכל הערכים של מאפיין רגיש ביחס לסיווג חיובי ולסיווג שלילי – ולא רק ביחס לסיווג אחד. במילים אחרות, גם שיעור החיוביים האמיתיים וגם שיעור השליליים הכוזבים צריכים להיות זהים בכל הקבוצות.
הסיכויים שווים קשורים לשוויון הזדמנויות, שמתמקד רק בשיעורי השגיאות עבור סיווג יחיד (חיובי או שלילי).
לדוגמה, נניח שאוניברסיטת גלובדובדריב מקבלת לתוכנית לימודים קפדנית במתמטיקה גם ליליפוטים וגם ברובדינגנאגים. בתי הספר התיכוניים של ליליפוט מציעים תוכנית לימודים מקיפה של שיעורי מתמטיקה, ורוב התלמידים עומדים בדרישות של התוכנית האוניברסיטאית. בבתי הספר התיכוניים בברובדינגנאג לא מוצעים שיעורי מתמטיקה בכלל, וכתוצאה מכך, הרבה פחות תלמידים עומדים בדרישות. התנאי של סיכויים שווים מתקיים אם למועמדים יש סיכוי שווה להתקבל לתוכנית אם הם עומדים בדרישות, וסיכוי שווה להידחות אם הם לא עומדים בדרישות, בלי קשר לגודל שלהם.
נניח ש-100 אנשים מליליפוט ו-100 אנשים מברובדינגנאג הגישו בקשה להתקבל לאוניברסיטת גלובדאבדריב, וההחלטות לגבי הקבלה מתקבלות באופן הבא:
טבלה 3. מועמדים קטנים (90% מהם כשירים)
| כשירים | לא מתאים | |
|---|---|---|
| התקבל | 45 | 2 |
| נדחה | 45 | 8 |
| סה"כ | 90 | 10 |
|
אחוז התלמידים שעומדים בדרישות והתקבלו: 45/90 = 50% אחוז התלמידים שלא עומדים בדרישות ונדחו: 8/10 = 80% האחוז הכולל של תלמידי ליליפוט שהתקבלו: (45+2)/100 = 47% |
||
טבלה 4. מועמדים גדולים מאוד (10% כשירים):
| כשירים | לא מתאים | |
|---|---|---|
| התקבל | 5 | 18 |
| נדחה | 5 | 72 |
| סה"כ | 10 | 90 |
|
אחוז הסטודנטים שעומדים בדרישות שהתקבלו: 5/10 = 50% אחוז הסטודנטים שלא עומדים בדרישות שנדחו: 72/90 = 80% אחוז הסטודנטים הכולל מברובדינגנאג שהתקבלו: (5+18)/100 = 23% |
||
התנאי של סיכויים שווים מתקיים כי לסטודנטים מליליפוט ומברובדינגנאג שעומדים בדרישות יש סיכוי של 50% להתקבל, ולסטודנטים מליליפוט ומברובדינגנאג שלא עומדים בדרישות יש סיכוי של 80% להידחות.
ההגדרה הפורמלית של סיכויי הצלחה שווים מופיעה במאמר "Equality of Opportunity in Supervised Learning" (שוויון הזדמנויות בלמידה מפוקחת) באופן הבא: "המאפיין המנבא Ŷ עומד בדרישות של סיכויי הצלחה שווים ביחס למאפיין המוגן A ולתוצאה Y אם Ŷ ו-A הם בלתי תלויים, בהינתן Y".
Estimator
TensorFlow API שהוצא משימוש. כדאי להשתמש ב-tf.keras במקום ב-Estimators.
evals
משמש בעיקר כקיצור להערכות של מודלים גדולים של שפה. באופן כללי, evals הוא קיצור לכל סוג של הערכה.
הערכה
התהליך של מדידת האיכות של מודל או השוואה בין מודלים שונים.
כדי להעריך מודל של למידת מכונה מבוקרת, בדרך כלל משווים אותו לקבוצת נתונים לתיקוף ולקבוצת נתונים לבדיקה. הערכה של מודל שפה גדול כוללת בדרך כלל הערכות רחבות יותר של איכות ובטיחות.
סוכן להערכה
סוכן שמעריך את התוצאות של סוכן אחר לפני שהתוצאות האלה סופיות. אפשר לדמיין נציג אחד שמייצר מוצר ונציג נפרד – נציג ההערכה – שבודק את המוצר לפני שהוא יוצא לשוק.
מבקר הוא מילה נרדפת לסוכן מעריך.
התאמה מדויקת
מדד של הכול או כלום, שבו הפלט של המודל תואם לערך האמת או לטקסט ההפניה בדיוק או שלא תואם בכלל. לדוגמה, אם ערך האמת הוא orange, הפלט היחיד של המודל שעומד בדרישות של התאמה מדויקת הוא orange.
התאמה מדויקת יכולה גם להעריך מודלים שהפלט שלהם הוא רצף (רשימה מדורגת של פריטים). באופן כללי, התאמה מדויקת מחייבת שהרשימה המדורגת שנוצרה תהיה זהה לרשימת האמת; כלומר, כל פריט בשתי הרשימות צריך להיות באותו סדר. עם זאת, אם נתוני האמת הבסיסיים כוללים כמה רצפים נכונים, התאמה מדויקת מחייבת רק שהפלט של המודל יתאים לאחד מהרצפים הנכונים.
דוגמה
הערכים של שורה אחת ב-features ואולי label. דוגמאות בלמידה מונחית מתחלקות לשתי קטגוריות כלליות:
- דוגמה עם תווית מורכבת מתכונה אחת או יותר ומתווית. דוגמאות עם תוויות משמשות במהלך האימון.
- דוגמה לא מסומנת מורכבת מתכונה אחת או יותר, אבל לא כוללת תווית. דוגמאות לא מסומנות משמשות במהלך ההסקה.
לדוגמה, נניח שאתם מאמנים מודל כדי לקבוע את ההשפעה של תנאי מזג האוויר על ציוני התלמידים במבחנים. הנה שלוש דוגמאות עם תוויות:
| תכונות | תווית | ||
|---|---|---|---|
| טמפרטורה | לחות | לחץ | ציון הבדיקה |
| 15 | 47 | 998 | טוב |
| 19 | 34 | 1020 | מצוינת |
| 18 | 92 | 1012 | גרועה |
הנה שלוש דוגמאות ללא תווית:
| טמפרטורה | לחות | לחץ | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
השורה במערך נתונים היא בדרך כלל המקור הגולמי לדוגמה. כלומר, דוגמה בדרך כלל מורכבת מקבוצת משנה של העמודות במערך הנתונים. בנוסף, התכונות בדוגמה יכולות לכלול גם תכונות סינתטיות, כמו תכונות מצטלבות.
מידע נוסף זמין במאמר למידה מפוקחת בקורס מבוא ללמידת מכונה.
חזרה על חוויה
בלמידת חיזוק, טכניקת DQN משמשת לצמצום קורלציות זמניות בנתוני האימון. הסוכן שומר מעברים בין מצבים במאגר חוויות, ואז דוגם מעברים ממאגר החוויות כדי ליצור נתוני אימון.
הטיה של עורכי הניסוי
מידע נוסף על הטיית אישור
בעיית הגרדיאנט המתפוצץ
הנטייה של גרדיאנטים ברשתות נוירונים עמוקות (במיוחד רשתות נוירונים חוזרות) להיות תלולים (גבוהים) באופן מפתיע. שיפועים תלולים גורמים לעדכונים גדולים מאוד של המשקלים של כל צומת ברשת נוירונים עמוקה.
קשה או בלתי אפשרי לאמן מודלים שסובלים מבעיית הגרדיאנט המתפוצץ. חיתוך הדרגתי יכול לצמצם את הבעיה.
השוואה לבעיית שיפוע נעלם.
סיכום קיצוני (xsum)
מערך נתונים להערכת היכולת של LLM לסכם מסמך יחיד. כל רשומה במערך הנתונים כוללת:
- מסמך שנכתב על ידי British Broadcasting Corporation (BBC).
- סיכום של המסמך במשפט אחד.
פרטים נוספים זמינים במאמר Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization.
F
F1
מדד סיווג בינארי מסכם שמסתמך על דיוק וגם על היזכרות. זו הנוסחה:
עובדתיות
בעולם של למידת מכונה, מאפיין שמתאר מודל שהפלט שלו מבוסס על המציאות. המושג 'עובדתיות' הוא מושג ולא מדד. לדוגמה, נניח שאתם שולחים את הפרומפט הבא אל מודל שפה גדול:
מהו הכתיב הכימי של מלח שולחן?
מודל שמבצע אופטימיזציה של נכונות העובדות ישיב:
NaCl
קל להניח שכל המודלים צריכים להתבסס על עובדות. עם זאת, יש הנחיות מסוימות, כמו ההנחיות הבאות, שגורמות למודל AI גנרטיבי לבצע אופטימיזציה של יצירתיות ולא של דיוק עובדתי.
תספר לי חמשיר על אסטרונאוט וזחל.
לא סביר שהלימריק שיתקבל יתבסס על המציאות.
ההבדל בין המושג הזה לבין התבססות על עובדות.
מגבלת הוגנות
החלת אילוץ על אלגוריתם כדי להבטיח שמתקיימת הגדרה אחת או יותר של הוגנות. דוגמאות למגבלות הוגנות:- עיבוד שלאחר יצירת הפלט של המודל.
- שינוי פונקציית ההפסד כדי לשלב קנס על הפרה של מדד הוגנות.
- הוספה ישירה של אילוץ מתמטי לבעיית אופטימיזציה.
מדד הוגנות
הגדרה מתמטית של 'הוגנות' שאפשר למדוד. דוגמאות למדדי הוגנות נפוצים:
הרבה מדדים של הוגנות הם בלעדיים הדדית. אפשר לקרוא על כך במאמר בנושא אי-תאימות של מדדים של הוגנות.
תוצאה שלילית שגויה (FN)
דוגמה שבה המודל מנבא בטעות את הסיווג השלילי. לדוגמה, המודל מנבא שהודעת אימייל מסוימת אינה ספאם (הסיווג השלילי), אבל הודעת האימייל הזו היא למעשה ספאם.
שיעור השגיאות השליליות
החלק היחסי של דוגמאות חיוביות אמיתיות שהמודל טעה לגביהן וחיזה את הסיווג השלילי. הנוסחה הבאה משמשת לחישוב שיעור התוצאות השליליות השגויות:
מידע נוסף זמין במאמר ערכי סף ומטריצת בלבול בקורס המקוצר על למידת מכונה.
תוצאה חיובית שגויה (FP)
דוגמה שבה המודל חוזה בטעות את הסיווג החיובי. לדוגמה, המודל חוזה שהודעת אימייל מסוימת היא ספאם (הסיווג החיובי), אבל הודעת האימייל הזו לא ספאם בפועל.
מידע נוסף זמין במאמר ערכי סף ומטריצת בלבול בקורס המקוצר על למידת מכונה.
שיעור התוצאות החיוביות השגויות (FPR)
השיעור של הדוגמאות השליליות בפועל שהמודל טעה בהן וחיזה את הסיווג החיובי. הנוסחה הבאה משמשת לחישוב שיעור התוצאות החיוביות השגויות:
שיעור התוצאות החיוביות השגויות הוא ציר ה-x בעקומת ROC.
מידע נוסף זמין במאמר בנושא סיווג: ROC ו-AUC בקורס המקוצר בנושא למידת מכונה.
fast decay
טכניקת אימון לשיפור הביצועים של מודלים גדולים של שפה (LLM). התפוגה המהירה כוללת הפחתה מהירה של קצב הלמידה במהלך האימון. השיטה הזו עוזרת למנוע התאמת יתר של המודל לנתוני האימון, ומשפרת את ההכללה.
מאפיין
משתנה קלט במודל למידת מכונה. דוגמה מורכבת מתכונה אחת או יותר. לדוגמה, נניח שאתם מאמנים מודל כדי לקבוע את ההשפעה של תנאי מזג האוויר על ציוני התלמידים במבחנים. בטבלה הבאה מוצגות שלוש דוגמאות, שכל אחת מהן מכילה שלוש תכונות ותווית אחת:
| תכונות | תווית | ||
|---|---|---|---|
| טמפרטורה | לחות | לחץ | ציון הבדיקה |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
ניגודיות עם תווית.
מידע נוסף זמין במאמר Supervised Learning (למידה מפוקחת) בקורס Introduction to Machine Learning (מבוא ללמידת מכונה).
שילוב מאפיינים
תכונה סינתטית שנוצרת על ידי 'הצלבה' של תכונות קטגוריות או תכונות שמוגדרות כקבוצות.
לדוגמה, נניח שיש מודל של 'חיזוי מצב רוח' שמייצג טמפרטורה באחת מארבע הקטגוריות הבאות:
freezingchillytemperatewarm
המשתנה הזה מייצג את מהירות הרוח באחד משלושת הטווחים הבאים:
stilllightwindy
בלי שילובים של תכונות, המודל הלינארי מתאמן באופן עצמאי על כל אחד משבעת הדליים הקודמים. לכן, המודל מתאמן על, למשל,
freezing בנפרד מהאימון על, למשל,
windy.
אפשרות אחרת היא ליצור שילוב של טמפרטורה ומהירות רוח. לתכונה הסינתטית הזו יהיו 12 ערכים אפשריים:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
הודות לשילובים של תכונות, המודל יכול ללמוד את ההבדלים במצב הרוח בין יום freezing-windy ליום freezing-still.
אם תיצרו תכונה סינתטית משתי תכונות שלכל אחת מהן יש הרבה דליים שונים, לתכונה המשולבת שתתקבל יהיה מספר עצום של שילובים אפשריים. לדוגמה, אם לתכונה אחת יש 1,000 קטגוריות ולתכונה השנייה יש 2,000 קטגוריות, הצלבת התכונות תניב 2,000,000 קטגוריות.
באופן רשמי, צלב הוא מכפלה קרטזית.
השימוש בצירופי תכונות נעשה בעיקר עם מודלים לינאריים, ובדרך כלל לא עם רשתות עצביות.
מידע נוסף זמין במאמר נתונים קטגוריים: שילובים של תכונות בקורס המקוצר על למידת מכונה.
הנדסת פיצ'רים (feature engineering)
תהליך שכולל את השלבים הבאים:
- קביעה של תכונות שעשויות להיות שימושיות באימון מודל.
- המרת נתונים גולמיים ממערך הנתונים לגרסאות יעילות של התכונות האלה.
לדוגמה, יכול להיות שתקבעו ש-temperature הוא תכונה שימושית. אחר כך אפשר להתנסות בסיווג ל-buckets כדי לבצע אופטימיזציה של מה שהמודל יכול ללמוד מטווחים שונים של temperature.
הנדסת תכונות נקראת לפעמים חילוץ תכונות או הפיכה לתכונות.
מידע נוסף זמין במאמר נתונים מספריים: איך מודל מעכל נתונים באמצעות וקטורים של תכונות בסדנה המקוונת בנושא למידת מכונה.
חילוץ מאפיינים
מונח בעל עומס יתר עם אחת מההגדרות הבאות:
- שליפת ייצוגים של תכונות ביניים שחושבו על ידי מודל לא מפוקח או מודל שאומן מראש (לדוגמה, ערכים של שכבה נסתרת ברשת נוירונים) לשימוש כקלט במודל אחר.
- מילה נרדפת להנדסת פיצ'רים.
חשיבות התכונות
מילה נרדפת לחשיבות משתנה.
מערך תכונות
קבוצת התכונות שהמודל של למידת המכונה מתאמן עליהן. לדוגמה, קבוצת תכונות פשוטה למודל שמנבא מחירי דיור יכולה לכלול מיקוד, גודל הנכס ומצב הנכס.
מפרט תכונות
המאמר מתאר את המידע שנדרש כדי לחלץ נתוני תכונות ממאגר אחסון לפרוטוקולים tf.Example. מכיוון ש-tf.Example protocol buffer הוא רק מאגר אחסון לפרוטוקולים לנתונים, צריך לציין את הפרטים הבאים:
- הנתונים לחילוץ (כלומר, המפתחות של התכונות)
- סוג הנתונים (לדוגמה, float או int)
- האורך (קבוע או משתנה)
וקטור מאפיינים
מערך של ערכי feature שמרכיבים example. הווקטור המאפיין משמש כקלט במהלך האימון ובמהלך ההסקה. לדוגמה, וקטור התכונות של מודל עם שתי תכונות נפרדות יכול להיות:
[0.92, 0.56]
בכל דוגמה מופיעים ערכים שונים של וקטור התכונות, ולכן וקטור התכונות של הדוגמה הבאה יכול להיות משהו כזה:
[0.73, 0.49]
הנדסת תכונות קובעת איך לייצג תכונות בווקטור התכונות. לדוגמה, מאפיין קטגורי בינארי עם חמישה ערכים אפשריים יכול להיות מיוצג באמצעות קידוד one-hot. במקרה כזה, החלק של וקטור התכונות בדוגמה מסוימת יכלול ארבעה אפסים ו-1.0 אחד במיקום השלישי, באופן הבא:
[0.0, 0.0, 1.0, 0.0, 0.0]
דוגמה נוספת: נניח שהמודל שלכם מורכב משלושה מאפיינים:
- תכונה קטגורית בינארית עם חמישה ערכים אפשריים שמיוצגים באמצעות קידוד one-hot. לדוגמה:
[0.0, 1.0, 0.0, 0.0, 0.0] - תכונה קטגורית בינארית נוספת עם שלושה ערכים אפשריים שמיוצגים באמצעות קידוד one-hot. לדוגמה:
[0.0, 0.0, 1.0] - תכונה של נקודה צפה, לדוגמה:
8.3.
במקרה כזה, וקטור התכונות של כל דוגמה ייוצג על ידי תשעה ערכים. בהינתן הערכים לדוגמה ברשימה הקודמת, וקטור התכונות יהיה:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
מידע נוסף זמין במאמר נתונים מספריים: איך מודל מעכל נתונים באמצעות וקטורים של תכונות בסדנה המקוונת בנושא למידת מכונה.
הפיכת נתונים לתכונות
התהליך של חילוץ מאפיינים ממקור קלט, כמו מסמך או סרטון, ומיפוי המאפיינים האלה לווקטור מאפיינים.
חלק מהמומחים ל-ML משתמשים במונח featurization כמילה נרדפת לfeature engineering או לfeature extraction.
למידה משותפת (Federated)
גישה מבוזרת ללמידת מכונה שמאמנת מודלים של למידת מכונה באמצעות דוגמאות מבוזרות שנמצאות במכשירים כמו סמארטפונים. בלמידה משותפת (Federated), קבוצת משנה של מכשירים מורידה את המודל הנוכחי משרת מרכזי לתיאום. המכשירים משתמשים בדוגמאות שמאוחסנות במכשירים כדי לשפר את המודל. לאחר מכן המכשירים מעלים את השיפורים במודל (אבל לא את דוגמאות האימון) לשרת המתאם, שם הם מצטברים עם עדכונים אחרים כדי ליצור מודל גלובלי משופר. אחרי הצבירה, המודל שחושב על ידי המכשירים כבר לא נחוץ ואפשר לבטל אותו.
מכיוון שדוגמאות האימון אף פעם לא מועלות, למידה משותפת (Federated) פועלת לפי עקרונות הפרטיות של איסוף נתונים ממוקד והגבלה על איסוף המידע.
פרטים נוספים זמינים בקומיקס בנושא למידה משותפת (כן, קומיקס).
משוב
שלב בלולאה של סוכן שבו הסוכן מעריך את הפעולה שבוצעה במהלך שלב הפעולה. לדוגמה, אם הסוכן שלח בקשת API במהלך שלב הפעולה, בשלב המשוב אפשר לקבוע אם תגובת ה-API הייתה מוצלחת.
לולאת משוב
בלמידת מכונה, מצב שבו התחזיות של מודל משפיעות על נתוני האימון של אותו מודל או של מודל אחר. לדוגמה, מודל שממליץ על סרטים ישפיע על הסרטים שאנשים רואים, מה שישפיע על מודלים עתידיים להמלצות על סרטים.
מידע נוסף זמין במאמר מערכות ML לייצור: שאלות שכדאי לשאול בסדנה ללימוד למידת מכונה.
רשת נוירונים עם זרימה קדימה (FFN)
רשת נוירונים ללא חיבורים מחזוריים או רקורסיביים. לדוגמה, רשתות נוירונים עמוקות מסורתיות הן רשתות נוירונים עם זרימה קדימה. בניגוד לרשתות נוירונים חוזרות, שהן מחזוריות.
למידה עם כמה דוגמאות
גישה של למידת מכונה, שמשמשת לעיתים קרובות לסיווג אובייקטים, ומיועדת לאימון של מודלים יעילים לסיווג על סמך מספר קטן של דוגמאות לאימון.
כדאי לעיין גם במאמרים בנושא למידה חד-פעמית ולמידה ללא דוגמאות.
הנחיות עם כמה דוגמאות (few-shot prompting)
פרומפט שמכיל יותר מדוגמה אחת (מספר דוגמאות) שמדגימות איך מודל השפה הגדול צריך להשיב. לדוגמה, ההנחיה הארוכה הבאה מכילה שתי דוגמאות שמראות למודל שפה גדול איך לענות על שאילתה.
| החלקים של הנחיה | הערות |
|---|---|
| מהו המטבע הרשמי של המדינה שצוינה? | השאלה שרוצים שה-LLM יענה עליה. |
| צרפת: EUR | דוגמה אחת. |
| בריטניה: GBP | דוגמה נוספת. |
| הודו: | השאילתה בפועל. |
בדרך כלל, הנחיות עם כמה דוגמאות מניבות תוצאות טובות יותר מאשר הנחיות בלי דוגמאות והנחיות עם דוגמה אחת. עם זאת, כדי לעצב הנחיות עם כמה דוגמאות צריך להשתמש בהנחיה ארוכה יותר.
הנחיה עם כמה דוגמאות היא סוג של למידה עם כמה דוגמאות שמוחלת על למידה מבוססת-הנחיות.
מידע נוסף מופיע במאמר הנדסת הנחיות בקורס המקוצר על למידת מכונה.
כינור
ספריית הגדרות שמתמקדת ב-Python, ומגדירה את הערכים של פונקציות ומחלקות בלי קוד או תשתית פולשניים. במקרה של Pax – ובסיסי קוד אחרים של למידת מכונה – הפונקציות והמחלקות האלה מייצגות מודלים והיפרפרמטרים של אימון.
Fiddle מניח שבסיסי קוד של למידת מכונה מחולקים בדרך כלל ל:
- קוד הספרייה, שמגדיר את השכבות ואת האופטימיזציה.
- קוד 'דבק' של מערך הנתונים, שמפעיל את הספריות ומקשר בין כל הרכיבים.
Fiddle מתעד את מבנה הקריאה של קוד הדבק בצורה לא מוערכת וניתנת לשינוי.
כוונון עדין
שלב שני של אימון ספציפי למשימה שמתבצע במודל שעבר אימון מראש כדי לשפר את הפרמטרים שלו לתרחיש שימוש ספציפי. לדוגמה, רצף האימון המלא של חלק ממודלים גדולים של שפה הוא כזה:
- אימון מראש: אימון מודל שפה גדול (LLM) על מערך נתונים כללי עצום, כמו כל הדפים בוויקיפדיה באנגלית.
- כוונון עדין: אימון המודל שעבר אימון מראש לביצוע משימה ספציפית, כמו מענה לשאלות רפואיות. בדרך כלל, כוונון עדין כולל מאות או אלפי דוגמאות שמתמקדות במשימה הספציפית.
דוגמה נוספת: רצף האימון המלא של מודל גדול של תמונות הוא כדלקמן:
- אימון מראש: אימון של מודל תמונות גדול על מערך נתונים גדול של תמונות כלליות, כמו כל התמונות ב-Wikimedia Commons.
- כוונון עדין: אימון של מודל שעבר אימון מראש לביצוע משימה ספציפית, כמו יצירת תמונות של לווייתנים קטלניים.
תהליך הכוונון העדין יכול לכלול כל שילוב של האסטרטגיות הבאות:
- שינוי של כל הפרמטרים הקיימים של המודל שעבר אימון מראש. התהליך הזה נקרא לפעמים כוונון עדין מלא.
- שינוי רק של חלק מהפרמטרים הקיימים של המודל שאומן מראש (בדרך כלל, השכבות הכי קרובות לשכבת הפלט), בלי לשנות את שאר הפרמטרים הקיימים (בדרך כלל, השכבות הכי קרובות לשכבת הקלט). כוונון יעיל בפרמטרים
- הוספת עוד שכבות, בדרך כלל מעל השכבות הקיימות הכי קרובות לשכבת הפלט.
כוונון עדין הוא סוג של למידת העברה. לכן, יכול להיות שבמהלך הכוונון העדין נעשה שימוש בפונקציית הפסד שונה או בסוג מודל שונה מאלה ששימשו לאימון המודל שאומן מראש. לדוגמה, אפשר לבצע כוונון עדין של מודל גדול של תמונות שעבר אימון מראש כדי ליצור מודל רגרסיה שמחזיר את מספר הציפורים בתמונת קלט.
השוואה וניגוד בין כוונון עדין לבין המונחים הבאים:
מידע נוסף זמין במאמר Fine-tuning (כוונון עדין) בקורס המקוצר על למידת מכונה.
דגם הפלאש
משפחה של מודלים קטנים יחסית של Gemini שעברו אופטימיזציה למהירות ולזמן טעינה נמוך. מודלים של Flash מיועדים למגוון רחב של אפליקציות שבהן חשובות תשובות מהירות וקצב העברה גבוה.
פשתן
ספרייה בקוד פתוח עם ביצועים גבוהים ללמידה עמוקה, שמבוססת על JAX. Flax מספקת פונקציות לאימון רשתות עצביות, וגם שיטות להערכת הביצועים שלהן.
Flaxformer
ספריית Transformer בקוד פתוח, שמבוססת על Flax ומיועדת בעיקר לעיבוד שפה טבעית ולמחקר רב-אופני.
שער שכחה
החלק בתא Long Short-Term Memory שמווסת את זרימת המידע דרך התא. שערי שכחה שומרים על ההקשר על ידי החלטה איזה מידע להשליך ממצב התא.
מודל בסיס
מודל שעבר אימון מראש גדול מאוד שאומן על קבוצת נתונים לאימון עצומה ומגוונת. מודל בסיס יכול לבצע את שתי הפעולות הבאות:
- להגיב בצורה טובה למגוון רחב של בקשות.
- לשמש כמודל בסיסי לכוונון עדין נוסף או להתאמה אישית אחרת.
במילים אחרות, מודל בסיסי כבר מסוגל לבצע משימות רבות באופן כללי, אבל אפשר להתאים אותו עוד יותר כדי שיהיה שימושי יותר למשימה ספציפית.
fraction of successes
מדד להערכת הטקסט שנוצר על ידי מודל ML. המדד 'חלק ההצלחות' הוא מספר הפלט של הטקסט שנוצר בהצלחה חלקי המספר הכולל של פלט הטקסט שנוצר. לדוגמה, אם מודל שפה גדול יצר 10 בלוקים של קוד, וחמישה מהם היו מוצלחים, אז שיעור ההצלחה יהיה 50%.
למרות שהמדד 'שיעור ההצלחות' שימושי ברוב התחומים בסטטיסטיקה, בלמידת מכונה הוא שימושי בעיקר למדידת משימות שניתן לאמת, כמו יצירת קוד או בעיות מתמטיות.
full softmax
מילה נרדפת ל-softmax.
ההבדל בין שיטת הדגימה הזו לבין דגימת מועמדים.
מידע נוסף זמין במאמר רשתות עצביות: סיווג רב-מחלקתי בסדנה ללמידת מכונה.
שכבה מקושרת באופן מלא
שכבה נסתרת שבה כל צומת מחובר לכל צומת בשכבה הנסתרת הבאה.
שכבה שמחוברת באופן מלא נקראת גם שכבה צפופה.
שינוי פונקציה
פונקציה שמקבלת פונקציה כקלט ומחזירה פונקציה שעברה שינוי כפלט. JAX משתמשת בטרנספורמציות של פונקציות.
G
GAN
קיצור של רשת למידה חישובית גנרטיבית.
Gemini
הסביבה העסקית שכוללת את ה-AI הכי מתקדם של Google. המרכיבים של המערכת האקולוגית הזו כוללים:
- מודלים שונים של Gemini.
- ממשק שיחה אינטראקטיבי עם מודל Gemini. המשתמשים מקלידים הנחיות ו-Gemini משיב להנחיות האלה.
- ממשקי Gemini API שונים.
- מוצרים עסקיים שונים שמבוססים על מודלים של Gemini, לדוגמה, Gemini for Google Cloud.
המודלים של Gemini
מודלים מולטימודאליים מבוססי Transformer חדשניים של Google. מודלים של Gemini מיועדים במיוחד לשילוב עם סוכנים.
המשתמשים יכולים לקיים אינטראקציה עם מודלים של Gemini במגוון דרכים, כולל באמצעות ממשק דיאלוג אינטראקטיבי וערכות SDK.
Gemma
משפחה של מודלים קלים ופתוחים שמבוססים על אותם מחקרים וטכנולוגיות ששימשו ליצירת מודלים של Gemini. יש כמה מודלים שונים של Gemma, וכל אחד מהם מספק תכונות שונות, כמו ראייה, קוד וביצוע הוראות. פרטים נוספים מופיעים במאמר בנושא Gemma.
AI גנרטיבי או AI גנרטיבי
קיצור של בינה מלאכותית גנרטיבית.
הכללה
היכולת של מודל לבצע חיזויים נכונים לגבי נתונים חדשים שלא נראו קודם. מודל שיכול להכליל הוא ההפך ממודל שמותאם יתר על המידה.
מידע נוסף מופיע במאמר הכללה בקורס המקוצר על למידת מכונה.
עקומת הכללה
תרשים של הפסד האימון ושל הפסד האימות כפונקציה של מספר האיטרציות.
עקומת הכללה יכולה לעזור לכם לזהות התאמת יתר אפשרית. לדוגמה, עקומת ההכללה הבאה מצביעה על התאמת יתר, כי הפסד האימות בסופו של דבר גבוה משמעותית מהפסד האימון.
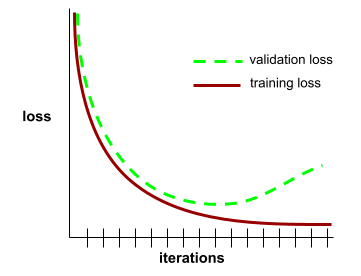
מידע נוסף מופיע במאמר הכללה בקורס המקוצר על למידת מכונה.
מודל לינארי מוכלל
הכללה של מודלים של רגרסיה של ריבועים פחותים, שמבוססים על רעש גאוסיאני, לסוגים אחרים של מודלים שמבוססים על סוגים אחרים של רעש, כמו רעש פואסוני או רעש קטגורי. דוגמאות למודלים לינאריים מוכללים:
- רגרסיה לוגיסטית
- רגרסיה רב-סיווגית
- רגרסיה של הריבועים הפחותים
אפשר למצוא את הפרמטרים של מודל ליניארי מוכלל באמצעות אופטימיזציה קמורה.
למודלים לינאריים מוכללים יש את המאפיינים הבאים:
- החיזוי הממוצע של מודל הרגרסיה האופטימלי של הריבועים הקטנים ביותר שווה לתווית הממוצעת בנתוני האימון.
- ההסתברות הממוצעת שחוזה מודל הרגרסיה הלוגיסטית האופטימלי שווה לתווית הממוצעת בנתוני האימון.
היכולת של מודל ליניארי מוכלל מוגבלת על ידי התכונות שלו. בניגוד למודל עמוק, מודל ליניארי מוכלל לא יכול "ללמוד תכונות חדשות".
טקסט שנוצר
באופן כללי, הטקסט שמופק על ידי מודל ML. כשמעריכים מודלים גדולים של שפה, חלק מהמדדים משווים בין הטקסט שנוצר לבין טקסט ייחוס. לדוגמה, נניח שאתם מנסים לקבוע עד כמה מודל למידת מכונה מתרגם ביעילות מצרפתית להולנדית. במקרה זה:
- הטקסט שנוצר הוא התרגום להולנדית שהמודל של למידת המכונה מוציא.
- טקסט העזר הוא התרגום להולנדית שמתרגם אנושי (או תוכנה) יוצר.
חשוב לדעת: חלק מאסטרטגיות ההערכה לא כוללות טקסט להשוואה.
רשת למידה חישובית גנרטיבית (GAN)
מערכת ליצירת נתונים חדשים שבה גנרטור יוצר נתונים ומפלה קובע אם הנתונים שנוצרו תקפים או לא תקפים.
מידע נוסף זמין בקורס בנושא רשתות למידה חישובית גנרטיבית (GAN).
סוכנים גנרטיביים (סימולקרה)
סוכנים עם אישיות, זיכרונות ושגרות ייחודיים שמדמים התנהגות אנושית מציאותית.
פרטים נוספים זמינים במאמר Generative Agents: Interactive Simulacra of Human Behavior.
בינה מלאכותית גנרטיבית
תחום מתפתח ומשנה את פני הדברים, ללא הגדרה רשמית. עם זאת, רוב המומחים מסכימים שמודלים של AI גנרטיבי יכולים ליצור ("לגנרר") תוכן שהוא כל אחד מהדברים הבאים:
- מורכב
- קוהרנטי
- מקורית
דוגמאות ל-AI גנרטיבי:
- מודלים גדולים של שפה, שיכולים ליצור טקסט מקורי מתוחכם ולענות על שאלות.
- מודל ליצירת תמונות, שיכול ליצור תמונות ייחודיות.
- מודלים ליצירת אודיו ומוזיקה, שיכולים ליצור מוזיקה מקורית או ליצור דיבור ריאליסטי.
- מודלים ליצירת סרטונים, שיכולים ליצור סרטונים מקוריים.
טכנולוגיות מוקדמות יותר, כולל LSTM ו-RNN, יכולות גם ליצור תוכן מקורי ועקבי. יש מומחים שרואים בטכנולוגיות המוקדמות האלה AI גנרטיבי, ויש מומחים שחושבים ש-AI גנרטיבי אמיתי צריך להיות מסוגל להפיק פלט מורכב יותר ממה שהטכנולוגיות המוקדמות האלה יכולות להפיק.
ההבדל בין למידת מכונה חיזויית לבין למידת מכונה תיאורית.
מודל גנרטיבי
מבחינה מעשית, מודל שמבצע אחת מהפעולות הבאות:
- יוצר (מפיק) דוגמאות חדשות ממערך הנתונים לאימון. לדוגמה, מודל גנרטיבי יכול ליצור שירה אחרי אימון על מערך נתונים של שירים. החלק היוצר של רשת למידה חישובית גנרטיבית (GAN) נכלל בקטגוריה הזו.
- הפונקציה קובעת את ההסתברות שדוגמה חדשה מגיעה ממערך האימון, או נוצרה מאותו מנגנון שיצר את מערך האימון. לדוגמה, אחרי אימון על מערך נתונים שמורכב ממשפטים באנגלית, מודל גנרטיבי יכול לקבוע את ההסתברות שקלט חדש הוא משפט תקף באנגלית.
מודל גנרטיבי יכול באופן תיאורטי להבחין בין ההתפלגות של דוגמאות או תכונות מסוימות במערך נתונים. כלומר:
p(examples)
מודלים של למידה לא מפוקחת הם גנרטיביים.
ההבדל ביניהם לבין מודלים דיסקרימינטיביים.
מחולל
מערכת המשנה בתוך רשת גנרטיבית יריבה שיוצרת דוגמאות חדשות.
ההפך ממודל דיסקרימינטיבי.
gini impurity
מדד שדומה לאנטרופיה. מפצלים משתמשים בערכים שנגזרים מאי-טוהר גיני או מאנטרופיה כדי ליצור תנאים לסיווג עצי החלטה. הרווח במידע נגזר מאנטרופיה. אין מונח מקביל שמקובל באופן אוניברסלי למדד שנגזר מאי-טוהר של גיני. עם זאת, המדד הזה, שאין לו שם, חשוב בדיוק כמו מדד הרווח במידע.
טומאת ג'יני נקראת גם מדד ג'יני או פשוט ג'יני.
קבוצת נתונים מושלמת
קבוצה של נתונים שנאספו באופן ידני ומייצגים בסיס מידע משותף. צוותים יכולים להשתמש במערך נתונים מוזהב אחד או יותר כדי להעריך את איכות המודל.
חלק ממערכי הזהב מתעדים תת-דומיינים שונים של נתוני האמת. לדוגמה, קבוצת נתונים מוזהבת לסיווג תמונות עשויה לכלול את תנאי התאורה ואת הרזולוציה של התמונה.
תשובה לדוגמה
תשובה שידוע שהיא טובה. לדוגמה, אם נותנים את ההנחיה הבאה:
2 + 2
התשובה המושלמת היא:
4
Google AI Studio
כלי של Google שמספק ממשק ידידותי למשתמש לניסוי ובנייה של אפליקציות באמצעות מודלים גדולים של שפה מבית Google. פרטים נוספים זמינים בדף הבית של Google AI Studio.
GPT (Generative Pre-trained Transformer)
משפחה של מודלים גדולים של שפה שמבוססים על Transformer ופותחו על ידי OpenAI.
גרסאות של GPT יכולות להתאים לכמה אופנים, כולל:
- יצירת תמונות (לדוגמה, ImageGPT)
- יצירת תמונות לפי טקסט (לדוגמה, DALL-E).
הדרגתי
הווקטור של הנגזרות החלקיות ביחס לכל המשתנים הבלתי תלויים. בלמידת מכונה, הגרדיאנט הוא וקטור של נגזרות חלקיות של פונקציית המודל. השיפוע מצביע על הכיוון של העלייה התלולה ביותר.
צבירת גרדיאנטים
טכניקת backpropagation שמעדכנת את הפרמטרים רק פעם אחת בכל תקופה ולא פעם אחת בכל איטרציה. אחרי העיבוד של כל מיני-batch, הצטברות הגרדיאנטים פשוט מעדכנת את הסכום הכולל של הגרדיאנטים. לאחר מכן, אחרי עיבוד של המיני-אצווה האחרונה בתקופה, המערכת מעדכנת סופית את הפרמטרים על סמך סכום כל שינויי הגרדיאנט.
הצטברות של גרדיאנטים שימושית כשגודל האצווה גדול מאוד בהשוואה לכמות הזיכרון שזמינה לאימון. כשזיכרון הוא בעיה, הנטייה הטבעית היא להקטין את גודל האצווה. עם זאת, הקטנת גודל האצווה בשיטת backpropagation רגילה מגדילה את מספר עדכוני הפרמטרים. הצטברות של גרדיאנטים מאפשרת למודל להימנע מבעיות בזיכרון, ועדיין להתאמן ביעילות.
עצי החלטה עם חיזוק גרדיאנט (GBT)
סוג של יער החלטות שבו:
- הדרכה מתבססת על חיזוק גרדיאנט.
- המודל החלש הוא עץ החלטה.
מידע נוסף זמין במאמר Gradient Boosted Decision Trees (עצים להחלטות עם שיפור גרדיאנט) בקורס Decision Forests (יערות החלטה).
חיזוק גרדיאנט
אלגוריתם אימון שבו מודלים חלשים מאומנים באופן איטרטיבי כדי לשפר את האיכות (להפחית את ההפסד) של מודל חזק. לדוגמה, מודל חלש יכול להיות מודל לינארי או מודל קטן של עץ החלטות. המודל החזק הופך לסכום של כל המודלים החלשים שאומנו קודם לכן.
בצורה הפשוטה ביותר של חיזוק גרדיאנט, בכל איטרציה מתבצע אימון של מודל חלש כדי לחזות את שיפוע אובדן המידע של המודל החזק. לאחר מכן, הפלט של המודל החזק מתעדכן על ידי חיסור הגרדיאנט החזוי, בדומה לירידת גרדיאנט.
where:
- $F_{0}$ הוא המודל של התחלה חזקה.
- $F_{i+1}$ הוא המודל החזק הבא.
- $F_{i}$ הוא המודל החזק הנוכחי.
- $\xi$ הוא ערך בין 0.0 ל-1.0 שנקרא התכווצות, שדומה לשיעור הלמידה בשיטת הגרדיאנט.
- $f_{i}$ הוא מודל חלש שאומן לחזות את שיפוע ההפסד של $F_{i}$.
וריאציות מודרניות של חיזוק גרדיאנט כוללות גם את הנגזרת השנייה (Hessian) של הפסד בחישוב שלהן.
עצי החלטה משמשים בדרך כלל כמודלים חלשים בשיטת חיזוק גרדיאנט. מידע נוסף מופיע במאמר בנושא gradient boosted (decision) trees.
חיתוך גרדיאנט
מנגנון נפוץ לצמצום הבעיה של גרדיאנטים מתפוצצים הוא הגבלה מלאכותית (חיתוך) של הערך המקסימלי של גרדיאנטים כשמשתמשים בירידת גרדיאנטים כדי לאמן מודל.
ירידה בשיפוע
טכניקה מתמטית שמטרתה למזער את ההפסד. בשיטת הגרדיאנט, המערכת משנה את המשקלים ואת ההטיות באופן איטרטיבי, עד שהיא מוצאת את השילוב הטוב ביותר לצמצום ההפסד.
השיטה של ירידת גרדיאנט קיימת כבר הרבה מאוד זמן, הרבה יותר זמן מלמידת מכונה.
מידע נוסף זמין במאמר רגרסיה לינארית: ירידה הדרגתית בסדנה ללימוד מכונת למידה.
תרשים
ב-TensorFlow, מפרט חישוב. הצמתים בתרשים מייצגים פעולות. הקצוות הם מכוונים ומייצגים העברה של תוצאת פעולה (Tensor) כאופרנד לפעולה אחרת. אפשר להשתמש ב-TensorBoard כדי להמחיש תרשים.
הרצת גרף
סביבת תכנות של TensorFlow שבה התוכנית יוצרת קודם גרף ואז מפעילה את הגרף הזה, כולו או חלקו. הביצוע של הגרף הוא מצב הביצוע שמוגדר כברירת מחדל ב-TensorFlow 1.x.
ההפך מ-eager execution.
מדיניות חמדנית
בלמידת חיזוק, מדיניות שתמיד בוחרת את הפעולה עם ההחזר הצפוי הכי גבוה.
עיגון בנתונים
מאפיין של מודל שהפלט שלו מבוסס על חומר מקור ספציפי (או "מעוגן" בו). לדוגמה, נניח שאתם מספקים ספר לימוד שלם בפיזיקה כקלט ("הקשר") למודל שפה גדול. לאחר מכן, מזינים למודל השפה הגדול פרומפט עם שאלה בפיזיקה. אם התשובה של המודל משקפת מידע שמופיע בספר הלימוד הזה, אז המודל מעוגן בספר הלימוד הזה.
חשוב לזכור שמודל מעוגן הוא לא תמיד מודל עובדתי. לדוגמה, יכול להיות שיש טעויות בספר הלימוד לפיזיקה שמוזן כקלט.
עיגון בנתונים
תהליך שבו תשובה של LLM מבוססת באופן מלא או חלקי על מידע שאוחזר ממקור מהימן אחד או יותר. לדוגמה, נניח שמשתמש מזין הנחיה למודל שפה גדול (LLM) לקבלת תחזית מזג האוויר בברלין להיום. יכול להיות שהתשובה תתבסס על מידע שנאסף מ-European Centre for Medium-Range Weather Forecasts (המרכז האירופי לתחזיות מזג אוויר לטווח בינוני).
Retrieval-augmented generation (יצירה משולבת-אחזור, RAG) היא טכניקה נפוצה להצמדת המודל לקרקע.
ערכי סף (ground truth)
ריאליטי.
מה שקרה בפועל.
לדוגמה, נניח שיש מודל של סיווג בינארי שמנבא אם סטודנט בשנה הראשונה באוניברסיטה יסיים את התואר תוך שש שנים. האמת הבסיסית של המודל הזה היא אם התלמיד או התלמידה סיימו את הלימודים תוך שש שנים.
הטיית ייחוס לקבוצה
הנחה שמה שנכון לגבי אדם מסוים נכון גם לגבי כל האנשים בקבוצה. ההשפעות של הטיית שיוך קבוצתית עלולות להיות חמורות יותר אם משתמשים בדגימה נוחה לאיסוף נתונים. במדגם לא מייצג, יכול להיות שיינתנו שיוכים שלא משקפים את המציאות.
כדאי לעיין גם בהטיה של הומוגניות מחוץ לקבוצה ובהטיה של העדפת קבוצת השייכות. מידע נוסף זמין גם במאמר הוגנות: סוגי הטיה בסדנה המקוונת בנושא למידת מכונה.
שכבות הגנה
כל תוכנה או תהליך שמונעים פגיעה בבני אדם או במערכות. הנזק יכול להיות מגוון, כולל מניעת דליפות נתונים או גישה לא מורשית, או לוודא שהתשובות של מודל שפה גדול לא מכילות חומר פוגע.
H
הזיה
הפקת פלט שנראה סביר אבל העובדות שבו שגויות על ידי מודל AI גנרטיבי שמצהיר שהוא מציג טענה לגבי העולם האמיתי. לדוגמה, מודל AI גנרטיבי שטוען שברק אובמה מת בשנת 1865 מייצר הזיות.
גיבוב (hashing)
בלמידת מכונה, מנגנון לקיבוץ נתונים קטגוריים, במיוחד כשמספר הקטגוריות גדול, אבל מספר הקטגוריות שמופיעות בפועל במערך הנתונים קטן יחסית.
לדוגמה, בכדור הארץ יש כ-73,000 מיני עצים. אפשר לייצג כל אחד מ-73,000 מיני העצים ב-73,000 קטגוריות נפרדות. לחלופין, אם רק 200 מתוך מיני העצים האלה מופיעים בפועל במערך נתונים, אפשר להשתמש בגיבוב כדי לחלק את מיני העצים ל-500 דליים.
מאגר אחד יכול להכיל כמה מיני עצים. לדוגמה, גיבוב יכול למקם את baobab ו-red maple – שני מינים שונים מבחינה גנטית – באותו דלי. בכל מקרה, גיבוב הוא עדיין דרך טובה למפות קבוצות גדולות של קטגוריות למספר הדליים שנבחר. גיבוב הופך מאפיין קטגורי עם מספר גדול של ערכים אפשריים למספר קטן בהרבה של ערכים על ידי קיבוץ ערכים בצורה דטרמיניסטית.
מידע נוסף זמין במאמר נתונים קטגוריים: אוצר מילים וקידוד one-hot בסדנה ללימוד למידת מכונה.
היוריסטיקה
פתרון פשוט לבעיה שאפשר ליישם במהירות. לדוגמה, 'בעזרת היוריסטיקה, הגענו לרמת דיוק של 86%. כשעברנו לרשת עצבית עמוקה, רמת הדיוק עלתה ל-98%".
שכבה נסתרת
שכבה ברשת נוירונים בין שכבת הקלט (התכונות) לבין שכבת הפלט (החיזוי). כל שכבה מוסתרת מורכבת מנוירון אחד או יותר. לדוגמה, רשת הנוירונים הבאה מכילה שתי שכבות נסתרות, הראשונה עם שלושה נוירונים והשנייה עם שני נוירונים:
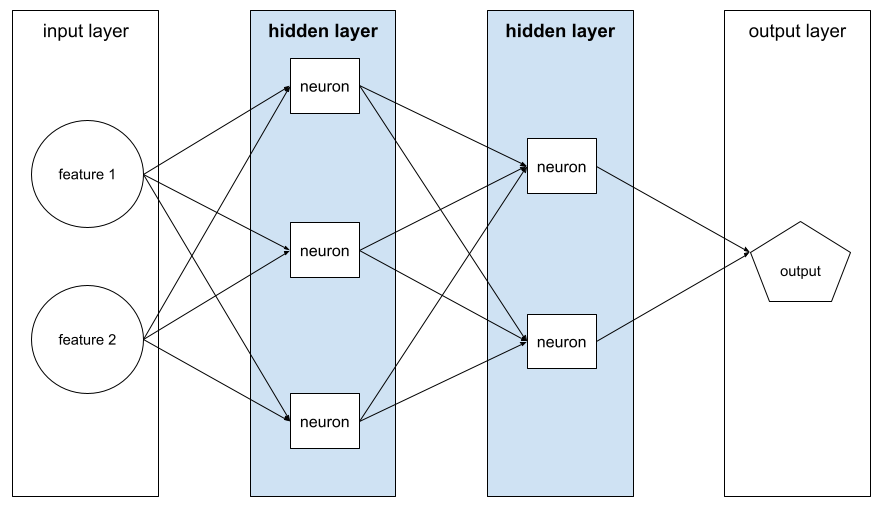
רשת עצבית עמוקה מכילה יותר משכבה נסתרת אחת. לדוגמה, האיור הקודם הוא רשת עצבית עמוקה כי המודל מכיל שתי שכבות מוסתרות.
מידע נוסף זמין במאמר רשתות עצביות: צמתים ושכבות מוסתרות בסדנה ללימוד מכונתית.
סידור היררכי באשכולות
קטגוריה של אלגוריתמים של אשכולות שיוצרים עץ של אשכולות. השיטה מתאימה במיוחד לנתונים היררכיים, כמו טקסונומיות בוטניות. יש שני סוגים של אלגוריתמים להיררכיה של אשכולות:
- בשיטת האשכול הצטברותי, כל דוגמה משויכת לאשכול משלה, ואז האשכולות הקרובים ביותר ממוזגים באופן איטרטיבי כדי ליצור עץ היררכי.
- חלוקה לקלאסטרים: קודם מקבצים את כל הדוגמאות לקלאסטר אחד, ואז מחלקים את הקלאסטר באופן איטרטיבי לעץ היררכי.
השיטה הזו שונה מאשכולות מבוססי-מרכז.
מידע נוסף זמין במאמר בנושא אלגוריתמים של אשכולות בקורס בנושא אשכולות.
טיפוס על גבעה
אלגוריתם לשיפור איטרטיבי ('הליכה בעלייה') של מודל למידת מכונה עד שהמודל מפסיק להשתפר ('מגיע לראש הגבעה'). הצורה הכללית של האלגוריתם היא:
- ליצור מודל התחלתי.
- יוצרים מודלים חדשים של מועמדים על ידי ביצוע שינויים קלים בדרך שבה מאמנים או מכווננים את המודל. יכול להיות שתצטרכו לעבוד עם מערך אימון שונה מעט או עם היפרפרמטרים שונים.
- מעריכים את המודלים החדשים המועמדים ובוחרים אחת מהפעולות הבאות:
- אם מודל מועמד מספק ביצועים טובים יותר ממודל ההתחלה, הוא הופך למודל ההתחלה החדש. במקרה כזה, חוזרים על שלבים 1, 2 ו-3.
- אם אף מודל לא עולה על המודל ההתחלתי, סימן שהגעתם לשיא וצריך להפסיק את האיטרציות.
הנחיות לגבי כוונון היפר-פרמטרים זמינות במדריך לשימוש בכלי כוונון ללמידה עמוקה. הנחיות בנושא הנדסת תכונות זמינות במודולים בנושא נתונים בקורס המקוצר על למידת מכונה.
ציר שבור
משפחה של פונקציות loss לסיווג שנועדו למצוא את גבול ההחלטה במרחק הכי גדול שאפשר מכל דוגמה לאימון, וכך למקסם את השוליים בין הדוגמאות לבין הגבול. KSVMs משתמשים ב-hinge loss (או בפונקציה קשורה, כמו squared hinge loss). בסיווג בינארי, פונקציית ההפסד של הציר מוגדרת כך:
כאשר y הוא התיוג האמיתי, -1 או +1, ו-y' הוא הפלט הגולמי של מודל הסיווג:
לכן, תרשים של הפסד ציר לעומת (y * y') נראה כך:

הטיה היסטורית
סוג של הטיה שכבר קיימת בעולם והגיעה למערך נתונים. ההטיות האלה נוטות לשקף סטריאוטיפים תרבותיים קיימים, אי-שוויון דמוגרפי ודעות קדומות כלפי קבוצות חברתיות מסוימות.
לדוגמה, נניח שיש מודל סיווג שמנבא אם מבקש הלוואה יפגר בתשלומים או לא. המודל הזה אומן על נתונים היסטוריים של פיגורים בתשלומים על הלוואות משנות ה-80 מבנקים מקומיים בשתי קהילות שונות. אם בעבר, הסיכוי של מועמדים מקהילה א' שלא לעמוד בתנאי ההלוואה היה גבוה פי שישה מהסיכוי של מועמדים מקהילה ב', יכול להיות שהמודל ילמד הטיה היסטורית שתגרום לו להיות פחות סביר לאשר הלוואות בקהילה א', גם אם התנאים ההיסטוריים שהובילו לשיעורי ברירת המחדל הגבוהים יותר בקהילה הזו כבר לא רלוונטיים.
מידע נוסף זמין במאמר הוגנות: סוגי הטיה בסדנת מבוא ללמידת מכונה.
נתונים במצב holdout
דוגמאות שלא נעשה בהן שימוש מכוון ("הוצאו") במהלך האימון. מערך הנתונים validation ומערך הנתונים test הם דוגמאות לנתוני holdout. נתוני החזקה (Holdout) עוזרים להעריך את היכולת של המודל לבצע הכללה לנתונים אחרים, מלבד הנתונים שעליהם הוא אומן. ההפסד בקבוצת ההחזקה מספק הערכה טובה יותר של ההפסד בקבוצת נתונים שלא נראתה מאשר ההפסד בקבוצת נתונים לאימון.
מארח
כשמאמנים מודל ML על שבבי האצה (GPU או TPU), החלק במערכת ששולט בשני הדברים הבאים:
- הזרימה הכוללת של הקוד.
- החילוץ והשינוי של צינור הקלט.
המארח פועל בדרך כלל במעבד, ולא בצ'יפ האצה. המכשיר מבצע מניפולציות על טנסורים בצ'יפים של המאיץ.
בדיקה אנושית
תהליך שבו אנשים שופטים את איכות הפלט של מודל ML. לדוגמה, אנשים דו-לשוניים שופטים את האיכות של מודל ML לתרגום. הערכה אנושית שימושית במיוחד לבדיקת מודלים שאין להם תשובה נכונה אחת.
ההבדל בין זה לבין הערכה אוטומטית והערכה על ידי מערכת אוטומטית למתן ציונים.
האדם שבתהליך (HITL)
ביטוי לא מוגדר היטב שיכול להיות שהוא מתייחס לאחת מהאפשרויות הבאות:
- מדיניות של צפייה בתוצרים של AI גנרטיבי באופן ביקורתי או סקפטי.
- אסטרטגיה או מערכת שמבטיחות שאנשים יעזרו לעצב, להעריך ולשפר את ההתנהגות של מודל. השארת אדם בתהליך מאפשרת ל-AI ליהנות מאינטליגנציה של מכונה וגם מאינטליגנציה אנושית. לדוגמה, מערכת שבה AI יוצר קוד שמהנדסי תוכנה בודקים אותו היא מערכת האדם שבתהליך.
היפר-פרמטר
המשתנים שאתם או שירות לכוונון היפר-פרמטרים משנים במהלך הפעלות עוקבות של אימון מודל. לדוגמה, קצב הלמידה הוא פרמטר-על. אפשר להגדיר את קצב הלמידה ל-0.01 לפני סשן אימון. אם תגיעו למסקנה ש-0.01 הוא ערך גבוה מדי, תוכלו להגדיר את קצב הלמידה ל-0.003 בסשן האימון הבא.
לעומת זאת, פרמטרים הם משקלים והטיות שונים שהמודל לומד במהלך האימון.
מידע נוסף זמין במאמר רגרסיה ליניארית: היפר-פרמטרים בקורס המקוצר על למידת מכונה.
מישור על
גבול שמפריד בין מרחב לשני תת-מרחבים. לדוגמה, קו הוא היפר-מישור בשני ממדים ומישור הוא היפר-מישור בשלושה ממדים. בדרך כלל, בלמידת מכונה, היפר-מישור הוא הגבול שמפריד בין מרחב רב-ממדי. Kernel Support Vector Machines משתמשות בהיפר-מישורים כדי להפריד בין מחלקות חיוביות למחלקות שליליות, לרוב במרחב רב-ממדי.
I
i.i.d.
קיצור של independently and identically distributed (מפוזר באופן עצמאי וזהה).
זיהוי תמונות, זיהוי תמונה
תהליך שמסווג אובייקטים, דפוסים או מושגים בתמונה. זיהוי תמונות נקרא גם סיווג תמונות.
קבוצת נתונים לא מאוזנת
מילה נרדפת ל-class-imbalanced dataset.
הטיה מרומזת
יצירת קשר או הנחה באופן אוטומטי על סמך מודלים של תודעה וזיכרונות. הטיות מובלעות יכולות להשפיע על:
- איך הנתונים נאספים ומסווגים.
- איך מערכות למידת מכונה מתוכננות ומפותחות.
לדוגמה, כשבונה מודל סיווג כדי לזהות תמונות חתונה, מהנדס יכול להשתמש בנוכחות של שמלה לבנה בתמונה כמאפיין. עם זאת, שמלות לבנות היו מקובלות רק בתקופות מסוימות ובתרבויות מסוימות.
אפשר לעיין גם במאמר בנושא הטיית אישור.
השלמת נתונים חסרים
קיצור של השלמת ערכים.
אי התאמה של מדדי הוגנות
הרעיון שלפיו חלק מהמושגים של הוגנות לא תואמים זה לזה ואי אפשר לספק אותם בו-זמנית. לכן, אין מדד אוניברסלי יחיד לכמותיות של הוגנות שאפשר להחיל על כל בעיות ה-ML.
יכול להיות שזה נשמע מייאש, אבל חוסר התאמה של מדדי הוגנות לא אומר שהמאמצים להשגת הוגנות הם חסרי תועלת. במקום זאת, הוא מציע להגדיר הוגנות בהקשר של בעיה נתונה של למידת מכונה, במטרה למנוע נזקים ספציפיים לתרחישי השימוש שלה.
במאמר "On the (im)possibility of fairness" יש דיון מפורט יותר על חוסר התאימות של מדדי הוגנות.
למידה בהקשר
מילה נרדפת ל-few-shot prompting.
בלתי תלויים ומחולקים באופן זהה (i.i.d)
נתונים שנלקחים מהתפלגות שלא משתנה, וכל ערך שנלקח לא תלוי בערכים שנלקחו קודם. משתנים בלתי תלויים ומחולקים זהה הם הגז האידיאלי של למידת מכונה – מבנה מתמטי שימושי אבל כמעט אף פעם לא נמצא בדיוק בעולם האמיתי. לדוגמה, התפלגות המבקרים בדף אינטרנט עשויה להיות i.i.d. במהלך חלון זמן קצר. כלומר, ההתפלגות לא משתנה במהלך חלון הזמן הקצר הזה, והביקור של אדם אחד בדרך כלל לא תלוי בביקור של אדם אחר. עם זאת, אם תרחיבו את חלון הזמן הזה, יכול להיות שתראו הבדלים עונתיים במבקרים בדף האינטרנט.
מידע נוסף זמין במאמר בנושא nonstationarity.
הוגנות אישית
מדד הוגנות שבודק אם סיווג של אנשים דומים הוא דומה. לדוגמה, יכול להיות שבאקדמיה בברובדינגנאג ירצו להבטיח הוגנות כלפי כל אחד מהתלמידים, ולכן יקפידו על כך שלשני תלמידים עם ציונים זהים וציונים זהים במבחנים סטנדרטיים יהיה סיכוי שווה להתקבל ללימודים.
חשוב לזכור שההוגנות האישית תלויה לחלוטין בהגדרה של 'דמיון' (במקרה הזה, ציונים במבחנים וציונים בלימודים), ויש סיכון ליצירת בעיות חדשות שקשורות להוגנות אם מדד הדמיון לא כולל מידע חשוב (כמו רמת הקושי של תוכנית הלימודים של התלמיד).
במאמר "הוגנות באמצעות מודעות" מופיע דיון מפורט יותר בנושא ההוגנות האישית.
היקש
בלמידת מכונה מסורתית, התהליך של ביצוע חיזויים על ידי החלת מודל שעבר אימון על דוגמאות לא מסומנות. מידע נוסף זמין במאמר בנושא למידה מפוקחת בקורס 'מבוא ל-ML'.
במודלים גדולים של שפה, היקש הוא התהליך של שימוש במודל מאומן כדי ליצור תשובה לקלט הנחיה.
למונח 'היסק' יש משמעות שונה בסטטיסטיקה. פרטים נוספים זמינים במאמר בוויקיפדיה בנושא הסקה סטטיסטית.
נתיב הסקה
בעץ החלטה, במהלך הסקת מסקנות, המסלול שדוגמה מסוימת עוברת מהשורש לתנאים אחרים, ומסתיים בעלה. לדוגמה, בעץ ההחלטה הבא, החצים העבים יותר מראים את נתיב ההסקה לדוגמה עם ערכי התכונות הבאים:
- x = 7
- y = 12
- z = -3
נתיב ההסקה באיור הבא עובר דרך שלושה תנאים לפני שהוא מגיע לעלה (Zeta).
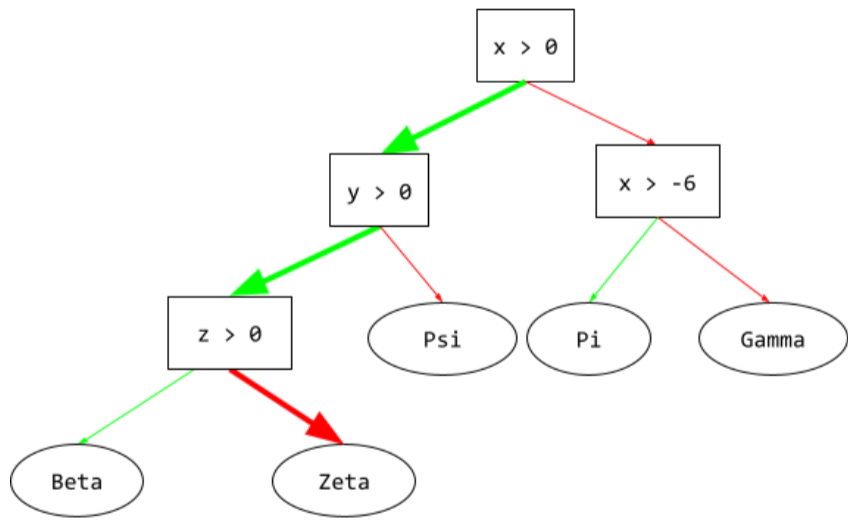
שלושת החיצים העבים מראים את נתיב ההסקה.
מידע נוסף זמין במאמר בנושא עצי החלטה בקורס בנושא יערות החלטה.
הרווח ממידע
ביערות החלטה, ההפרש בין האנטרופיה של צומת לבין הסכום המשוקלל (לפי מספר הדוגמאות) של האנטרופיה של צמתי הצאצאים שלה. האנטרופיה של צומת היא האנטרופיה של הדוגמאות בצומת הזה.
לדוגמה, נבחן את ערכי האנטרופיה הבאים:
- האנטרופיה של צומת ההורה = 0.6
- האנטרופיה של צומת משני אחד עם 16 דוגמאות רלוונטיות = 0.2
- אנטרופיה של צומת משני אחר עם 24 דוגמאות רלוונטיות = 0.1
לכן, 40% מהדוגמאות נמצאות בצומת צאצא אחד ו-60% נמצאות בצומת הצאצא השני. לכן:
- סכום האנטרופיה המשוקללת של צומתי הצאצא = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
לכן, הרווח מהמידע הוא:
- הרווח במידע = האנטרופיה של צומת האב – סכום האנטרופיה המשוקלל של הצמתים המשניים
- הרווח במידע = 0.6 – 0.14 = 0.46
רוב המסַפְּקִים מנסים ליצור תנאים שממקסמים את הרווח במידע.
הטיה לטובת קבוצת השייכות
העדפה של הקבוצה שאליה משתייכים או של מאפיינים אישיים. אם הבודקים או המדרגים הם חברים, בני משפחה או עמיתים של מפתח הלמידה החישובית, יכול להיות שהטיה בתוך הקבוצה תפסול את בדיקת המוצר או את מערך הנתונים.
הטיה לטובת הקבוצה היא סוג של הטיית ייחוס לקבוצה. אפשר לעיין גם במאמר בנושא הטיה של הומוגניות מחוץ לקבוצה.
מידע נוסף זמין במאמר הוגנות: סוגי הטיה בקורס המזורז ללימוד מכונת למידה.
מחולל קלט
מנגנון שבאמצעותו נתונים נטענים לתוך רשת נוירונים.
אפשר לחשוב על מחולל קלט כרכיב שאחראי לעיבוד נתונים גולמיים לטנסורים, שחוזרים עליהם כדי ליצור אצוות לאימון, להערכה ולהסקת מסקנות.
שכבת הקלט
השכבה של רשת הנוירונים שמכילה את וקטור התכונות. כלומר, שכבת הקלט מספקת דוגמאות לאימון או להסקת מסקנות. לדוגמה, שכבת הקלט ברשת נוירונים הבאה מורכבת משני מאפיינים:
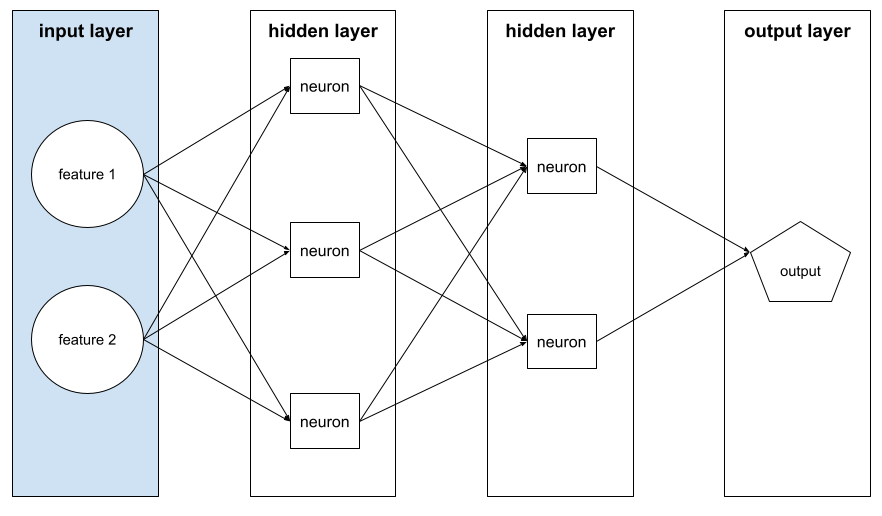
תנאי בתוך קבוצה
בעץ החלטות, תנאי שבודק אם פריט מסוים קיים בקבוצת פריטים. לדוגמה, התנאי הבא הוא תנאי בתוך קבוצה:
house-style in [tudor, colonial, cape]
במהלך ההסקה, אם הערך של feature בסגנון הבית הוא tudor או colonial או cape, התנאי הזה מקבל את הערך Yes. אם הערך של התכונה של סגנון הבית הוא משהו אחר (לדוגמה, ranch), התנאי הזה מקבל את הערך 'לא'.
תנאים בתוך קבוצה בדרך כלל מובילים לעצי החלטה יעילים יותר מאשר תנאים שבודקים תכונות בקידוד one-hot.
מכונה
מילה נרדפת לדוגמה.
התאמת מודל להנחיות
סוג של כוונון עדין שמשפר את היכולת של מודל AI גנרטיבי לפעול לפי הוראות. כוונון לפי הוראות כולל אימון של מודל על סדרה של הנחיות, שלרוב מכסות מגוון רחב של משימות. המודל שמתקבל אחרי כוונון לפי הוראות נוטה ליצור תשובות שימושיות להנחיות ללא דוגמאות במגוון משימות.
השוואה וניגוד עם:
יכולת פירוש
היכולת להסביר או להציג את הנימוקים של מודל למידת מכונה במונחים מובנים לאדם.
לדוגמה, רוב המודלים של רגרסיה לינארית ניתנים לפירוש בקלות. (צריך רק לבדוק את המשקלים שאומנו לכל תכונה). בנוסף, קל מאוד לפרש את התוצאות של יערות החלטה. עם זאת, כדי להבין חלק מהמודלים צריך להשתמש בהדמיה מתוחכמת.
אפשר להשתמש בכלי לפרשנות של למידה (LIT) כדי לפרש מודלים של ML.
הסכמה בין מעריכים
מדד לתדירות שבה מעריכים אנושיים מסכימים ביניהם כשהם מבצעים משימה. אם יש חוסר הסכמה בין הבודקים, יכול להיות שצריך לשפר את ההוראות לביצוע המשימה. נקרא גם הסכמה בין מבארים או מהימנות בין מעריכים. ראו גם את קאפה של כהן, שהוא אחד ממדדי ההסכמה הפופולריים ביותר בין מעריכים.
מידע נוסף זמין במאמר נתונים קטגוריים: בעיות נפוצות בסדנה ללימוד מכונת למידה.
חיתוך על איחוד (IoU)
החיתוך של שתי קבוצות חלקי האיחוד שלהן. במשימות של זיהוי תמונות באמצעות למידת מכונה, משתמשים ב-IoU כדי למדוד את הדיוק של תיבת התוחמת החזויה של המודל ביחס לתיבת התוחמת של האמת הבסיסית. במקרה הזה, ערך ה-IoU של שתי התיבות הוא היחס בין האזור החופף לבין האזור הכולל, והוא נע בין 0 (אין חפיפה בין תיבת התוחמת החזויה לבין תיבת התוחמת של נתוני האמת) לבין 1 (תיבת התוחמת החזויה ותיבת התוחמת של נתוני האמת הן בעלות אותן קואורדינטות בדיוק).
לדוגמה, בתמונה שלמטה:
- התיבה התוחמת החזויה (הקואורדינטות שמגדירות את המיקום של שולחן הלילה בציור לפי החיזוי של המודל) מודגשת בסגול.
- תיבה תוחמת של אמת קרקע (הקואורדינטות שמגדירות את המיקום של שידת הלילה בציור) מודגשת בירוק.
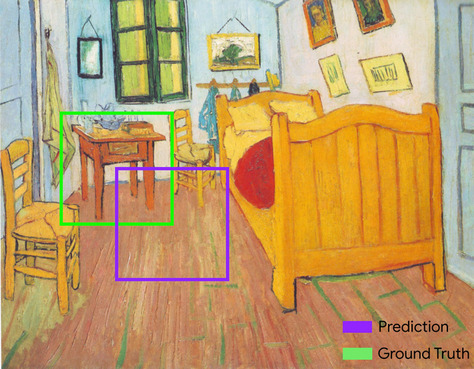
בדוגמה הזו, שטח החיתוך של תיבות התוחמות של החיזוי ושל נתוני האמת (בצד ימין למטה) הוא 1, ושטח האיחוד של תיבות התוחמות של החיזוי ושל נתוני האמת (בצד שמאל למטה) הוא 7, ולכן ערך ה-IoU הוא \(\frac{1}{7}\).
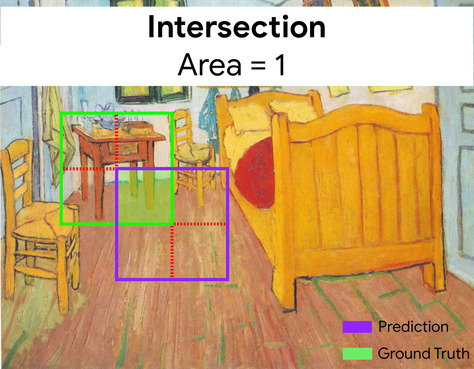
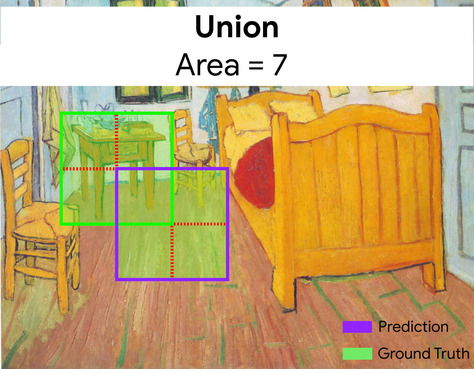
IoU
קיצור של intersection over union (חיתוך חלקי איחוד).
מטריצת פריטים
במערכות המלצות, מטריצה של ווקטורים של הטמעה שנוצרו על ידי פירוק מטריצות שמכילה אותות סמויים לגבי כל פריט. כל שורה במטריצת הפריטים מכילה את הערך של תכונה סמויה אחת לכל הפריטים. לדוגמה, ניקח מערכת להמלצות על סרטים. כל עמודה במטריצת הפריטים מייצגת סרט אחד. האותות הסמויים יכולים לייצג ז'אנרים, או להיות אותות שקשה יותר לפרש אותם, שכוללים אינטראקציות מורכבות בין ז'אנר, כוכבים, גיל הסרט או גורמים אחרים.
למטריצת הפריטים יש אותו מספר עמודות כמו למטריצת היעד שעוברת פירוק לגורמים. לדוגמה, אם יש מערכת המלצות לסרטים שמעריכה 10,000 שמות של סרטים, מטריצת הפריטים תכלול 10,000 עמודות.
פריטים
במערכת המלצות, הישויות שהמערכת ממליצה עליהן. לדוגמה, סרטונים הם הפריטים שחנות וידאו ממליצה עליהם, וספרים הם הפריטים שחנות ספרים ממליצה עליהם.
איטרציה
עדכון יחיד של הפרמטרים של מודל – המשקולות וההטיות של המודל – במהלך האימון. גודל האצווה קובע כמה דוגמאות המודל מעבד באיטרציה אחת. לדוגמה, אם גודל האצווה הוא 20, המודל מעבד 20 דוגמאות לפני התאמת הפרמטרים.
כשמאמנים רשת נוירונים, איטרציה אחת כוללת את שני המעברים הבאים:
- מעבר קדימה להערכת ההפסד באצווה אחת.
- מעבר אחורה (backpropagation) כדי לשנות את הפרמטרים של המודל על סמך הפסד וקצב הלמידה.
מידע נוסף זמין במאמר בנושא ירידת גרדיאנט בקורס המקוצר על למידת מכונה.
J
JAX
ספרייה של מחשוב מערכים, שמשלבת בין XLA (אלגברה לינארית מואצת) לבין דיפרנציאציה אוטומטית, למחשוב נומרי עתיר ביצועים. JAX מספקת API פשוט ועוצמתי לכתיבת קוד נומרי מואץ עם טרנספורמציות שניתנות להרכבה. JAX כולל תכונות כמו:
grad(הבחנה אוטומטית)jit(קומפילציה בזמן אמת)vmap(וקטוריזציה אוטומטית או עיבוד באצווה)pmap(הפעלה מקבילית)
JAX היא שפה להבעה וליצירה של טרנספורמציות של קוד נומרי, בדומה לספריית NumPy של Python, אבל בהיקף גדול בהרבה. (למעשה, ספריית .numpy ב-JAX היא גרסה שוות-ערך מבחינת פונקציונלית, אבל שנכתבה מחדש לחלוטין של ספריית Python NumPy).
JAX מתאים במיוחד להאצת משימות רבות של למידת מכונה, על ידי המרת המודלים והנתונים לפורמט שמתאים להרצה מקבילית ב-GPU וב-TPU accelerator chips.
Flax, Optax, Pax וספריות רבות אחרות מבוססות על תשתית JAX.
K
Keras
ממשק API פופולרי ללמידת מכונה ב-Python. Keras פועל על כמה מסגרות ללמידה עמוקה, כולל TensorFlow, שבו הוא זמין בתור tf.keras.
מכונות וקטוריות לתמיכה בגרעין (KSVM)
אלגוריתם סיווג שמנסה למקסם את השוליים בין מחלקות חיוביות לבין מחלקות שליליות על ידי מיפוי של וקטורים של נתוני קלט למרחב רב-ממדי. לדוגמה, נניח שיש בעיית סיווג שבה מערך הנתונים של הקלט כולל מאה מאפיינים. כדי למקסם את השוליים בין מחלקות חיוביות ושליליות, יכול להיות ש-KSVM ימפה את התכונות האלה באופן פנימי למרחב של מיליון ממדים. ב-KSVM נעשה שימוש בפונקציית הפסד שנקראת hinge loss.
נקודות מרכזיות
הקואורדינטות של תכונות מסוימות בתמונה. לדוגמה, במודל של זיהוי תמונות שמבחין בין מיני פרחים, נקודות מרכזיות יכולות להיות מרכז כל עלה כותרת, הגבעול, האבקן וכן הלאה.
אימות צולב k-fold
אלגוריתם לחיזוי היכולת של מודל להכליל נתונים חדשים. האות k ב-k-fold מתייחסת למספר הקבוצות השוות שאליהן מחלקים את הדוגמאות בסט נתונים. כלומר, מאמנים את המודל ובודקים אותו k פעמים. בכל סבב של אימון ובדיקה, קבוצה אחרת משמשת כקבוצת נתונים לבדיקה, וכל הקבוצות הנותרות משמשות כקבוצת האימון. אחרי k סבבים של אימון ובדיקה, מחשבים את הממוצע ואת סטיית התקן של המדדים שנבחרו לבדיקה.
לדוגמה, נניח שקבוצת הנתונים שלכם כוללת 120 דוגמאות. נניח שאתם מחליטים להגדיר את k ל-4. לכן, אחרי ערבוב הדוגמאות, מחלקים את מערך הנתונים לארבע קבוצות שוות של 30 דוגמאות ומבצעים ארבעה סבבים של אימון ובדיקה:
לדוגמה, יכול להיות שהמדד הכי משמעותי למודל רגרסיה לינארית הוא Mean Squared Error (MSE). לכן, צריך לחשב את הממוצע ואת סטיית התקן של ה-MSE בכל ארבעת הסיבובים.
k-means
אלגוריתם פופולרי של אשכולות שמקבץ דוגמאות בלמידה לא מפוקחת. האלגוריתם k-means מבצע את הפעולות הבאות:
- האלגוריתם קובע באופן איטרטיבי את k הנקודות המרכזיות הטובות ביותר (שנקראות צנטרואידים).
- משייך כל דוגמה למרכז המסה הקרוב ביותר. הדוגמאות הכי קרובות לאותו מרכז מסה שייכות לאותה קבוצה.
אלגוריתם k-means בוחר מיקומי מרכזים כדי למזער את הריבוע המצטבר של המרחקים מכל דוגמה למרכז הקרוב ביותר שלה.
לדוגמה, נבחן את התרשים הבא של גובה הכלב ביחס לרוחב הכלב:

אם k=3, אלגוריתם k-means יקבע שלושה מרכזים. כל דוגמה מוקצית למרכז המסה הקרוב ביותר שלה, וכך נוצרות שלוש קבוצות:

נניח שיצרן רוצה לקבוע את המידות האידיאליות לסוודרים לכלבים במידות Small, Medium ו-Large. שלושת המרכזים מזהים את הגובה הממוצע והרוחב הממוצע של כל כלב באותו אשכול. לכן, כדאי ליצרן לבסס את מידות הסוודרים על שלושת מרכזי המסה האלה. שימו לב: בדרך כלל, מרכז הכובד של אשכול לא מייצג דוגמה באשכול.
האיורים הקודמים מציגים את k-means לדוגמאות עם שני מאפיינים בלבד (גובה ורוחב). הערה: אלגוריתם k-means יכול לקבץ דוגמאות לפי הרבה תכונות.
מידע נוסף זמין במאמר מהו אשכול k-means? בקורס בנושא אשכולות.
k-median
אלגוריתם קיבוץ באשכולות שקשור קשר הדוק ל-k-means. ההבדל המעשי בין שני סוגי ההמרות הוא:
- בשיטת k-means, הצנטרואידים נקבעים על ידי מזעור סכום הריבועים של המרחק בין צנטרואיד פוטנציאלי לבין כל אחת מהדוגמאות שלו.
- בשיטת k-median, מרכזי המסה נקבעים על ידי מזעור סכום המרחק בין מרכז מסה פוטנציאלי לבין כל אחת מהדוגמאות שלו.
שימו לב גם להבדלים בהגדרות של המרחק:
- אלגוריתם k-means מסתמך על המרחק האוקלידי מהמרכז אל דוגמה. (במרחב דו-ממדי, המרחק האוקלידי הוא היתר במשולש ישר זווית, שמחושב באמצעות משפט פיתגורס). לדוגמה, המרחק בין (2,2) לבין (5,-2) בשיטת k-means יהיה:
- אלגוריתם k-median מסתמך על מרחק מנהטן מהצנטרואיד לדוגמה. המרחק הזה הוא סכום הדלתאות המוחלטות בכל מאפיין. לדוגמה, המרחק בין (2,2) לבין (5,-2) בשיטת k-median יהיה:
L
רגולריזציה של L0
סוג של רגולריזציה שמעניש את המספר הכולל של משקלים שאינם אפס במודל. לדוגמה, מודל עם 11 משקלים שונים מאפס ייענש יותר ממודל דומה עם 10 משקלים שונים מאפס.
רגולריזציה מסוג L0 נקראת לפעמים רגולריזציה מסוג L0-norm.
הפסד של L1
פונקציית הפסד שמחשבת את הערך המוחלט של ההפרש בין ערכי התוויות בפועל לבין הערכים שהמודל חוזה. לדוגמה, החישוב של הפסד L1 עבור קבוצה של חמש דוגמאות:
| ערך בפועל לדוגמה | הערך שהמודל חזה | הערך המוחלט של הדלתא |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = הפסד L1 | ||
ההפסד של L1 פחות רגיש לערכים חריגים מאשר ההפסד של L2.
השגיאה הממוצעת המוחלטת היא ממוצע הפסדי L1 לכל דוגמה.
מידע נוסף זמין במאמר Linear regression: Loss (רגרסיה לינארית: הפסד) בסדרת המאמרים Machine Learning Crash Course (מבוא ללמידת מכונה).
רגולריזציה של L1
סוג של רגולריזציה שמענישה משקלים באופן יחסי לסכום הערך המוחלט של המשקלים. רגולריזציה מסוג L1 עוזרת להקטין את המשקלים של תכונות לא רלוונטיות או רלוונטיות במידה מועטה לערך 0 בדיוק. תכונה עם משקל 0 למעשה מוסרת מהמודל.
השוואה לרגולריזציה מסוג L2.
הפסד L2
פונקציית הפסד שמחשבת את ריבוע ההפרש בין ערכי התוויות בפועל לבין הערכים שהמודל חוזה. לדוגמה, כך מחשבים את הפסד L2 עבור קבוצה של חמש דוגמאות:
| ערך בפועל לדוגמה | הערך שהמודל חזה | ריבוע של דלתא |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 loss | ||
בגלל ההעלאה בריבוע, פונקציית ההפסד L2 מגדילה את ההשפעה של ערכים חריגים. כלומר, פונקציית ההפסד L2 מגיבה בעוצמה רבה יותר לחיזויים לא טובים מאשר פונקציית ההפסד L1. לדוגמה, הפסד L1 עבור האצווה הקודמת יהיה 8 ולא 16. שימו לב שערך חריג אחד מייצג 9 מתוך 16.
מודלים של רגרסיה משתמשים בדרך כלל בהפסד L2 כפונקציית ההפסד.
השגיאה הריבועית הממוצעת היא הפסד L2 הממוצע לכל דוגמה. שגיאה בריבוע הוא שם נוסף לשגיאת L2.
מידע נוסף זמין במאמר Logistic regression: Loss and regularization (רגרסיה לוגיסטית: הפסד ורגולריזציה) בסדנה בנושא למידת מכונה.
רגולריזציה של L2
סוג של רגולריזציה שמעניש משקלים באופן יחסי לסכום הריבועים של המשקלים. רגולריזציה מסוג L2 עוזרת להסיט משקלים של ערכים חריגים (ערכים חיוביים גבוהים או ערכים שליליים נמוכים) קרוב יותר ל-0, אבל לא בדיוק ל-0. תכונות עם ערכים שקרובים מאוד ל-0 נשארות במודל, אבל לא משפיעות על התחזית של המודל.
רגולריזציה מסוג L2 תמיד משפרת את ההכללה במודלים לינאריים.
השוואה לרגולריזציה מסוג L1.
מידע נוסף זמין במאמר התאמת יתר: רגולריזציה מסוג L2 בקורס המקוצר על למידת מכונה.
תווית
בלמידת מכונה מפוקחת, החלק של ה"תשובה" או ה "תוצאה" בדוגמה.
כל דוגמה מתויגת מורכבת ממאפיין אחד או יותר ומתווית. לדוגמה, במערך נתונים לזיהוי ספאם, התווית תהיה כנראה 'ספאם' או 'לא ספאם'. במערך נתונים של גשמים, התווית יכולה להיות כמות הגשם שירדה במהלך תקופה מסוימת.
מידע נוסף זמין במאמר Supervised Learning (למידה מפוקחת) בסדרה Introduction to Machine Learning (מבוא ללמידת מכונה).
דוגמה מסומנת בתווית
דוגמה שמכילה תכונה אחת או יותר ותווית. לדוגמה, בטבלה הבאה מוצגות שלוש דוגמאות מתויגות ממודל להערכת שווי של בית, שלכל אחת מהן יש שלוש תכונות ותווית אחת:
| מספר חדרי שינה | מספר חדרי אמבטיה | גיל הבית | מחיר הבית (תווית) |
|---|---|---|---|
| 3 | 2 | 15 | $345,000 |
| 2 | 1 | 72 | $179,000 |
| 4 | 2 | 34 | $392,000 |
בלמידת מכונה מבוקרת, מודלים מתאמנים על דוגמאות מתויגות ומבצעים חיזויים על דוגמאות לא מתויגות.
השוואה בין דוגמה עם תוויות לבין דוגמאות ללא תוויות.
מידע נוסף זמין במאמר Supervised Learning (למידה מפוקחת) בסדרה Introduction to Machine Learning (מבוא ללמידת מכונה).
הדלפת תוויות
פגם בתכנון המודל שבו תכונה משמשת כפרוקסי לתווית. לדוגמה, נניח שיש לכם מודל של סיווג בינארי שמנבא אם לקוח פוטנציאלי ירכוש מוצר מסוים.
נניח שאחת התכונות של המודל היא בוליאנית בשם
SpokeToCustomerAgent. נניח גם שסוכן שירות לקוחות מוקצה אחרי שהלקוח הפוטנציאלי רכש את המוצר בפועל. במהלך האימון, המודל ילמד במהירות את הקשר בין SpokeToCustomerAgent לתווית.
מידע נוסף מופיע במאמר בנושא מעקב אחרי צינורות נתונים בקורס המקוצר על למידת מכונה.
lambda
מילה נרדפת ל-regularization rate.
המונח Lambda הוא מונח עמוס. במאמר הזה אנחנו מתמקדים בהגדרה של המונח רגולריזציה.
LaMDA (Language Model for Dialogue Applications)
מודל שפה גדול מבוסס Transformer שפותח על ידי Google ואומן על מערך נתונים גדול של דיאלוגים, שיכול ליצור תשובות ריאליסטיות לשיחות.
LaMDA: our breakthrough conversation technology (LaMDA: הטכנולוגיה פורצת הדרך שלנו לשיחות) מספק סקירה כללית.
ציוני דרך
מילה נרדפת ל-keypoints.
מודל שפה
מודל שמעריך את ההסתברות של טוקן או רצף של טוקנים שמופיעים ברצף ארוך יותר של טוקנים.
מידע נוסף זמין במאמר מהו מודל שפה? בקורס המקוצר על למידת מכונה.
מודל שפה גדול
לפחות, מודל שפה עם מספר גבוה מאוד של פרמטרים. באופן לא רשמי, כל מודל שפה שמבוסס על Transformer, כמו Gemini או GPT.
מידע נוסף זמין במאמר מודלים גדולים של שפה (LLM) בקורס המקוצר בנושא למידת מכונה.
זמן אחזור
משך הזמן שלוקח למודל לעבד קלט וליצור תשובה. תשובה עם זמן אחזור גבוה לוקחת יותר זמן ליצירה מאשר תשובה עם זמן אחזור נמוך.
הגורמים שמשפיעים על זמן הטעינה של מודלים גדולים של שפה כוללים:
- אורכי הטוקנים של הקלט והפלט
- מורכבות המודל
- התשתית שבה המודל פועל
אופטימיזציה של זמן האחזור היא חיונית ליצירת אפליקציות רספונסיביות וידידותיות למשתמש.
מרחב לטנטי
מילה נרדפת למרחב הטמעה.
שכבה
קבוצה של נוירונים ברשת נוירונים. אלה שלושה סוגים נפוצים של שכבות:
- שכבת הקלט, שמספקת ערכים לכל התכונות.
- שכבות מוסתרות אחת או יותר, שמזהות קשרים לא לינאריים בין התכונות לבין התווית.
- שכבת הפלט, שמספקת את החיזוי.
לדוגמה, באיור הבא מוצגת רשת נוירונים עם שכבת קלט אחת, שתי שכבות נסתרות ושכבת פלט אחת:
ב-TensorFlow, שכבות הן גם פונקציות Python שמקבלות טנסורים ואפשרויות הגדרה כקלט, ומפיקות טנסורים אחרים כפלט.
Layers API (tf.layers)
ממשק API של TensorFlow ליצירת רשת עצבית עמוקה כהרכב של שכבות. Layers API מאפשר לכם ליצור סוגים שונים של שכבות, למשל:
-
tf.layers.Denseעבור שכבה שמקושרת באופן מלא. -
tf.layers.Conv2Dלשכבת קונבולוציה.
ממשק ה-API של Layers פועל לפי מוסכמות ממשק ה-API של שכבות Keras. כלומר, מלבד קידומת שונה, לכל הפונקציות ב-Layers API יש את אותם שמות וחתימות כמו לפונקציות המקבילות ב-Keras layers API.
עלה
כל נקודת קצה בעץ החלטות. בניגוד לתנאי, צומת עלה לא מבצע בדיקה. במקום זאת, עלה הוא חיזוי אפשרי. עלה הוא גם צומת סופית של נתיב הסקה.
לדוגמה, עץ ההחלטות הבא מכיל שלושה עלים:
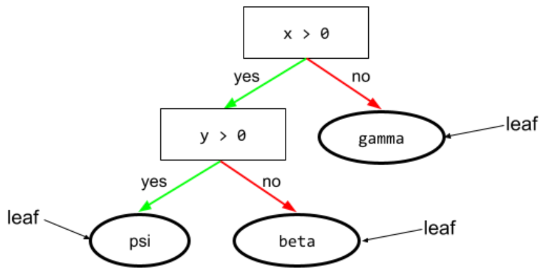
מידע נוסף זמין במאמר בנושא עצי החלטה בקורס בנושא יערות החלטה.
הכלי לפרשנות של למידה (LIT)
כלי ויזואלי ואינטראקטיבי להבנת מודלים ולהצגת נתונים בצורה ויזואלית.
אתם יכולים להשתמש ב-LIT בקוד פתוח כדי לפרש מודלים או כדי להציג נתונים טקסטואליים, נתונים של תמונות ונתונים טבלאיים.
קצב למידה
מספר נקודה צפה שמציין לאלגוריתם gradient descent עד כמה לשנות את המשקלים וההטיות בכל iteration. לדוגמה, קצב למידה של 0.3 יתאים את המשקלים וההטיות בעוצמה גדולה פי 3 בהשוואה לקצב למידה של 0.1.
קצב הלמידה הוא היפר-פרמטר מרכזי. אם מגדירים את קצב הלמידה נמוך מדי, האימון יימשך זמן רב מדי. אם מגדירים את קצב הלמידה גבוה מדי, לעיתים קרובות קשה להגיע להתכנסות בשיטת הגרדיאנט.
מידע נוסף זמין במאמר רגרסיה ליניארית: היפר-פרמטרים בקורס המקוצר על למידת מכונה.
רגרסיה של הריבועים הפחותים
מודל רגרסיה ליניארית שאומן על ידי מזעור הפסד L2.
מתן הנחיות בשיטת least-to-most
סוג של שרשור הנחיות שמחלק בעיות מורכבות לסדרה מסודרת של בעיות פשוטות יותר. לדוגמה, הנה אסטרטגיית הנחיות לפתרון בעיה מסוימת, מהקל אל הקשה:
- תחלק בעיה מורכבת לרשימה מסודרת של בעיות משנה פשוטות יותר. בדוגמה הזו, נניח שיש שלוש בעיות משנה.
- הנחיה 1: מבקשים מ-LLM לפתור את בעיית המשנה הראשונה. מודל ה-LLM מחזיר את תשובה 1.
- הנחיה 2: משלבים את כל התשובה 1 או חלק ממנה בהנחיה כדי לפתור את בעיית המשנה השנייה. ה-LLM מחזיר את תשובה 2.
- הנחיה 3: שילוב של חלק או כל התשובה 2 בהנחיה כדי לפתור את בעיית המשנה השלישית. התשובה של ה-LLM להנחיה 3 היא התשובה הסופית לבעיה המורכבת הראשונית.
חשוב לזכור שכל שלב תלוי בפתרון של השלב הקודם.
ההבדל בין השיטה הזו לבין הנחיה מסוג 'עץ מחשבה'.
מרחק לבנשטיין
מדד מרחק העריכה שמחשב את מספר הפעולות המינימלי של מחיקה, הוספה והחלפה שנדרשות כדי לשנות מילה אחת למילה אחרת. לדוגמה, מרחק לוינשטיין בין המילים "heart" ו-"darts" הוא שלוש, כי אלה שלושת השינויים המינימליים שצריך לבצע כדי להפוך מילה אחת לשנייה:
- לב ← דלב (החלפת האות 'ל' באות 'ד')
- deart → dart (מחיקת האות e)
- dart → darts (insert "s")
חשוב לזכור שהרצף הקודם הוא לא הדרך היחידה לבצע שלושה שינויים.
ליניארי
קשר בין שני משתנים או יותר שאפשר לייצג רק באמצעות חיבור וכפל.
הגרף של קשר לינארי הוא קו.
השוואה ללא לינארי.
מודל לינארי
מודל שמקצה משקל אחד לכל תכונה כדי ליצור תחזיות. (מודלים לינאריים משלבים גם הטיה). לעומת זאת, הקשר בין התכונות לבין התחזיות במודלים עמוקים הוא בדרך כלל לא לינארי.
בדרך כלל קל יותר לאמן מודלים לינאריים והם ניתנים יותר לפירוש ממודלים עמוקים. עם זאת, מודלים עמוקים יכולים ללמוד קשרים מורכבים בין תכונות.
רגרסיה לינארית ורגרסיה לוגיסטית הם שני סוגים של מודלים לינאריים.
רגרסיה לינארית
סוג של מודל למידת מכונה שבו מתקיימים שני התנאים הבאים:
- המודל הוא מודל לינארי.
- התחזית היא ערך נקודה צפה (floating-point). (זהו החלק של הרגרסיה ברגרסיה לינארית).
השוואה בין רגרסיה לינארית לבין רגרסיה לוגיסטית. כדאי גם להשוות בין רגרסיה לבין סיווג.
מידע נוסף זמין במאמר בנושא רגרסיה לינארית בקורס המקוצר על למידת מכונה.
LIT
קיצור של Learning Interpretability Tool (LIT), שנקרא בעבר Language Interpretability Tool.
LLM
קיצור של מודל שפה גדול.
הערכות של מודלים גדולים של שפה (LLM)
קבוצה של מדדים ונקודות השוואה להערכת הביצועים של מודלים גדולים של שפה (LLM). ברמת העל, הערכות של מודלים גדולים של שפה (LLM):
- לעזור לחוקרים לזהות תחומים שבהם צריך לשפר את מודלי ה-LLM.
- הם שימושיים להשוואה בין מודלי LLM שונים ולזיהוי מודל ה-LLM הכי טוב למשימה מסוימת.
- עוזרים להבטיח שהשימוש במודלים גדולים של שפה (LLM) יהיה בטוח ואתי.
מידע נוסף זמין במאמר מודלים גדולים של שפה (LLM) בקורס המקוצר על למידת מכונה.
רגרסיה לוגיסטית
סוג של מודל רגרסיה שמנבא הסתברות. למודלים של רגרסיה לוגיסטית יש את המאפיינים הבאים:
- התווית היא קטגורית. המונח רגרסיה לוגיסטית מתייחס בדרך כלל לרגרסיה לוגיסטית בינארית, כלומר למודל שמחשב הסתברויות לתוויות עם שני ערכים אפשריים. וריאנט פחות נפוץ, רגרסיה לוגיסטית מולטינומיאלית, מחשב הסתברויות לתוויות עם יותר משני ערכים אפשריים.
- פונקציית ההפסד במהלך האימון היא Log Loss. (אפשר להציב כמה יחידות של Log Loss במקביל לתוויות עם יותר משני ערכים אפשריים).
- למודל יש ארכיטקטורה לינארית, ולא רשת עצבית עמוקה. עם זאת, שאר ההגדרה הזו חלה גם על מודלים עמוקים שמנבאים הסתברויות של תוויות קטגוריות.
לדוגמה, נניח שיש מודל רגרסיה לוגיסטית שמחשב את ההסתברות שאימייל מסוים הוא ספאם או לא ספאם. במהלך ההסקה, נניח שהמודל חוזה 0.72. לכן, המודל מעריך:
- יש סיכוי של 72% שהאימייל הוא ספאם.
- יש סיכוי של 28% שהאימייל לא ספאם.
מודל רגרסיה לוגיסטית משתמש בארכיטקטורה הבאה בת שני השלבים:
- המודל יוצר חיזוי גולמי (y') על ידי החלת פונקציה לינארית של תכונות קלט.
- המודל משתמש בתחזית הגולמית הזו כקלט לפונקציית סיגמואיד, שממירה את התחזית הגולמית לערך בין 0 ל-1, לא כולל.
בדומה לכל מודל רגרסיה, מודל רגרסיה לוגיסטית חוזה מספר. עם זאת, המספר הזה בדרך כלל הופך לחלק ממודל סיווג בינארי באופן הבא:
- אם המספר החזוי גדול מסף הסיווג, מודל הסיווג הבינארי חוזה את המחלקה החיובית.
- אם המספר החזוי נמוך מסף הסיווג, מודל הסיווג הבינארי חוזה את המחלקה השלילית.
מידע נוסף זמין במאמר רגרסיה לוגיסטית בקורס המקוצר על למידת מכונה.
ערכי לוגיט
הווקטור של התחזיות הגולמיות (לא מנורמלות) שנוצרות על ידי מודל סיווג, שמועבר בדרך כלל לפונקציית נרמול. אם המודל פותר בעיה של סיווג רב-מחלקתי, בדרך כלל הלוגיטים הופכים לקלט של פונקציית softmax. לאחר מכן, פונקציית softmax יוצרת וקטור של הסתברויות (מנורמלות) עם ערך אחד לכל מחלקה אפשרית.
פונקציית הפסד לוגיסטי
פונקציית ההפסד שמשמשת ברגרסיה לוגיסטית בינארית.
מידע נוסף זמין במאמר Logistic regression: Loss and regularization (רגרסיה לוגיסטית: הפסד ורגולריזציה) בסדנה ללימוד מכונת למידה.
יחס הלוגים
הלוגריתם של הסיכויים לאירוע מסוים.
זיכרון ארוך לטווח קצר (LSTM)
סוג של תא ברשת נוירונים חוזרת שמשמש לעיבוד רצפים של נתונים באפליקציות כמו זיהוי כתב יד, תרגום אוטומטי וכתיבת כתוביות לתמונות. רשתות LSTM נותנות מענה לבעיית הגרדיאנט הנעלם שמתרחשת במהלך אימון של רשתות RNN בגלל רצפים ארוכים של נתונים. הן עושות זאת על ידי שמירה של היסטוריה במצב זיכרון פנימי שמבוסס על קלט חדש והקשר מתאים קודמים ברשת ה-RNN.
LoRA
קיצור של Low-Rank Adaptability (התאמה לדרגה נמוכה).
הפסד
במהלך האימון של מודל בפיקוח, נמדד המרחק בין התחזית של המודל לבין התווית שלו.
פונקציית הפסד מחשבת את ההפסד.
מידע נוסף זמין במאמר רגרסיה ליניארית: הפסד בסדנה בנושא למידת מכונה.
אתר אגרגטור של הפסדים
סוג של אלגוריתם למידת מכונה שמשפר את הביצועים של מודל על ידי שילוב התחזיות של כמה מודלים ושימוש בתחזיות האלה כדי ליצור תחזית אחת. כתוצאה מכך, מצטבר הפסדים יכול להפחית את השונות של התחזיות ולשפר את הדיוק שלהן.
עקומת הפסד
תרשים של הפסד כפונקציה של מספר האיטרציות של האימון. התרשים הבא מציג עקומת הפסד אופיינית:
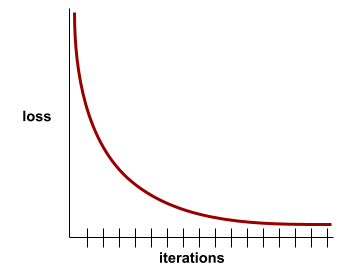
עקומות הפסד יכולות לעזור לכם לקבוע מתי המודל מתכנס או מתאים יתר על המידה.
עקומות הפסד יכולות להציג את כל סוגי ההפסד הבאים:
אפשר לעיין גם בעקומת הכללה.
מידע נוסף זמין במאמר התאמת יתר: פירוש עקומות הפסד בסדנה ללימוד מכונת למידה.
פונקציית אובדן
במהלך אימון או בדיקה, פונקציה מתמטית שמחשבת את ההפסד באצווה של דוגמאות. פונקציית הפסד מחזירה ערך הפסד נמוך יותר למודלים שמבצעים חיזויים טובים מאשר למודלים שמבצעים חיזויים לא טובים.
המטרה של האימון היא בדרך כלל למזער את ההפסד שמוחזר על ידי פונקציית הפסד.
קיימים סוגים רבים ושונים של פונקציות אובדן. בוחרים את פונקציית ההפסד המתאימה לסוג המודל שאתם בונים. לדוגמה:
- הפונקציה אובדן L2 (או השגיאה הריבועית הממוצעת) היא הפונקציה אובדן של רגרסיה ליניארית.
- Log Loss היא פונקציית האובדן של רגרסיה לוגיסטית.
משטח הפסד
תרשים של משקל לעומת הפסד. Gradient descent aims to find the weight(s) for which the loss surface is at a local minimum.
אפקט האמצע
הנטייה של מודל שפה גדול היא להשתמש במידע מתחילת חלון ההקשר ארוך ובסופו בצורה יעילה יותר מאשר במידע מהאמצע. כלומר, בהינתן הקשר ארוך, אפקט האובדן באמצע גורם לדיוק להיות:
- גבוה יחסית כשהמידע הרלוונטי ליצירת תשובה נמצא בתחילת או בסוף ההקשר.
- נמוכה יחסית כשהמידע הרלוונטי ליצירת תשובה נמצא באמצע ההקשר.
המונח מגיע מהמאמר Lost in the Middle: How Language Models Use Long Contexts.
Low-Rank Adaptability (LoRA)
טכניקה יעילה מבחינת פרמטרים לכוונון עדין שבה המערכת 'מקפיאה' את המשקולות של המודל שעבר אימון מראש (כך שאי אפשר לשנות אותן יותר), ואז מוסיפה למודל קבוצה קטנה של משקולות שאפשר לאמן. קבוצת המשקלים שאפשר לאמן (שנקראת גם 'מטריצות עדכון') קטנה משמעותית ממודל הבסיס, ולכן האימון שלה מהיר הרבה יותר.
היתרונות של LoRA:
- משפר את איכות התחזיות של מודל עבור הדומיין שבו מוחל הכוונון העדין.
- הוא מאפשר לבצע התאמה עדינה מהר יותר מטכניקות שדורשות התאמה עדינה של כל הפרמטרים של המודל.
- התכונה הזו מצמצמת את עלות החישוב של הסקת מסקנות על ידי הפעלה של הצגה בו-זמנית של כמה מודלים מיוחדים שמשתפים את אותו מודל בסיסי.
LSTM
קיצור של Long Short-Term Memory (זיכרון לטווח קצר וארוך).
M
למידה חישובית
תוכנה או מערכת שמאמנת מודל מנתוני קלט. המודל שעבר אימון יכול לבצע חיזויים שימושיים מנתונים חדשים (שלא נראו אף פעם) שנלקחו מאותו פיזור ששימש לאימון המודל.
למידת מכונה מתייחסת גם לתחום המחקר שעוסק בתוכנות או במערכות האלה.
מידע נוסף זמין בקורס מבוא ללמידת מכונה.
תרגום אוטומטי
שימוש בתוכנה (בדרך כלל, מודל למידת מכונה) כדי להמיר טקסט משפה אנושית אחת לשפה אנושית אחרת, למשל מאנגלית ליפנית.
מחלקה עם רוב
התווית הנפוצה יותר במערך נתונים עם חוסר איזון בין מחלקות. לדוגמה, אם יש מערך נתונים שמכיל 99% תוויות שליליות ו-1% תוויות חיוביות, התוויות השליליות הן מחלקת הרוב.
ההפך מminority class.
מידע נוסף זמין במאמר קבוצות נתונים: קבוצות נתונים לא מאוזנות בסדנה ללימוד מכונת למידה.
סוכן מנהל
נציג ששולט בנציג משנה אחד או יותר.
תהליך קבלת החלטות של מרקוב (MDP)
תרשים שמייצג את מודל קבלת ההחלטות שבו מתקבלות החלטות (או פעולות) כדי לנווט ברצף של מצבים, בהנחה שמתקיימת תכונת מרקוב. בלמידת חיזוק, המעברים האלה בין מצבים מחזירים תגמול מספרי.
מאפיין מרקוב
מאפיין של סביבות מסוימות, שבהן מעברי מצב נקבעים באופן מלא על ידי מידע שמשתמע מהמצב הנוכחי והפעולה של הסוכן.
מודל שפה עם מיסוך
מודל שפה שחוזה את ההסתברות של טוקנים מועמדים למילוי מקומות ריקים ברצף. לדוגמה, מודל שפה עם מיסוך יכול לחשב את ההסתברויות של מילים מועמדות להחלפת הקו התחתון במשפט הבא:
ה____ בכובע חזר.
בספרות המקצועית, בדרך כלל משתמשים במחרוזת MASK במקום בקו תחתון. לדוגמה:
המסכה בכובע חזרה.
רוב המודלים המודרניים של התממת שפה (MLM) הם דו-כיווניים.
math-pass@k
מדד לקביעת רמת הדיוק של מודל שפה גדול בפתרון בעיה מתמטית בתוך K ניסיונות. לדוגמה, math-pass@2 בודק את היכולת של מודל שפה גדול לפתור בעיות מתמטיות בשני ניסיונות. דיוק של 0.85 ב-math-pass@2 מציין שמודל LLM הצליח לפתור בעיות מתמטיות ב-85% מהמקרים, תוך שני ניסיונות.
המדד math-pass@k זהה למדד pass@k, אלא שהמונח math-pass@k משמש באופן ספציפי להערכה של מתמטיקה.
matplotlib
ספריית Python דו-ממדית לשרטוט גרפים בקוד פתוח. matplotlib עוזרת להמחיש היבטים שונים של למידת מכונה.
פירוק מטריצות
במתמטיקה, מנגנון למציאת המטריצות שמכפלתן הנקודתית קרובה למטריצת יעד.
במערכות המלצה, מטריצת היעד מכילה בדרך כלל את דירוגי המשתמשים של פריטים. לדוגמה, מטריצת היעד של מערכת להמלצות על סרטים יכולה להיראות כך, כאשר המספרים השלמים החיוביים הם דירוגי משתמשים ו-0 מציין שהמשתמש לא דירג את הסרט:
| קזבלנקה | סיפור פילדלפיה | הפנתר השחור | וונדר וומן | ספרות זולה | |
|---|---|---|---|---|---|
| משתמש 1 | 5.0 | 3.0 | 0.0 | 2.0 | 0.0 |
| משתמש 2 | 4.0 | 0.0 | 0.0 | 1.0 | 5.0 |
| משתמש 3 | 3.0 | 1.0 | 4.0 | 5.0 | 0.0 |
מערכת ההמלצות לסרטים מנסה לחזות את דירוגי המשתמשים לסרטים שלא סווגו. לדוגמה, האם משתמש 1 יאהב את הסרט הפנתר השחור?
אחת הגישות למערכות המלצות היא שימוש בפירוק מטריצות כדי ליצור את שתי המטריצות הבאות:
- מטריצת משתמשים, בצורה של מספר המשתמשים כפול מספר המאפיינים של ההטמעה.
- מטריצת פריטים, בצורה של מספר הממדים של ההטמעה כפול מספר הפריטים.
לדוגמה, אם נשתמש בפירוק מטריצות על שלושת המשתמשים וחמשת הפריטים שלנו, נקבל את מטריצת המשתמשים ומטריצת הפריטים הבאות:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
מכפלה סקלרית של מטריצת המשתמשים ומטריצת הפריטים יוצרת מטריצת המלצות שמכילה לא רק את דירוגי המשתמשים המקוריים, אלא גם תחזיות לגבי הסרטים שכל משתמש לא צפה בהם. לדוגמה, נניח שהדירוג של משתמש 1 לסרט קזבלנקה הוא 5.0. הנקודה שמתאימה לתא הזה במטריצת ההמלצות צריכה להיות בסביבות 5.0, ואכן:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9והכי חשוב, האם משתמש 1 יאהב את הסרט Black Panther? מכפלה סקלרית של השורה הראשונה והעמודה השלישית תניב דירוג צפוי של 4.3:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3בדרך כלל, פירוק מטריצה יוצר מטריצת משתמשים ומטריצת פריטים, שביחד הן קומפקטיות משמעותית ממטריצת היעד.
MBPP
קיצור של בעיות בסיסיות בעיקר ב-Python.
שגיאה ממוצעת מוחלטת (MAE)
ההפסד הממוצע לכל דוגמה כשמשתמשים ב-L1 loss. כדי לחשב את שגיאת הממוצע המוחלט, פועלים לפי השלבים הבאים:
- חישוב הפסד L1 עבור אצווה.
- מחלקים את ההפסד L1 במספר הדוגמאות באצווה.
לדוגמה, נניח שרוצים לחשב את הפסד L1 בקבוצה הבאה של חמש דוגמאות:
| ערך בפועל לדוגמה | הערך שהמודל חזה | הפסד (ההפרש בין הערך בפועל לבין הערך החזוי) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = הפסד L1 | ||
לכן, ערך הפונקציה L1 הוא 8 ומספר הדוגמאות הוא 5. לכן, השגיאה הממוצעת המוחלטת היא:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
השוואה בין שגיאת ממוצע מוחלט לבין שגיאת ממוצע ריבועי ושורש טעות ריבועית ממוצעת.
דיוק ממוצע ממוצע ב-k (mAP@k)
הממוצע הסטטיסטי של כל הציונים של דיוק ממוצע ב-k במערך נתוני אימות. אחד השימושים של מדד הדיוק הממוצע ב-k הוא להעריך את איכות ההמלצות שנוצרות על ידי מערכת המלצות.
למרות שהביטוי 'ממוצע ממוצע' נשמע מיותר, השם של המדד מתאים. בסופו של דבר, המדד הזה מחשב את הממוצע של כמה ערכים של דיוק ממוצע ב-k.
שגיאה ריבועית ממוצעת (MSE)
ההפסד הממוצע לכל דוגמה כשמשתמשים בהפסד L. כך מחשבים את השגיאה הריבועית הממוצעת:
- חישוב הפסד L2 עבור אצווה.
- מחלקים את הפסד L2 במספר הדוגמאות באצווה.
לדוגמה, נניח שאתם רוצים לחשב את הפסד על קבוצה של חמש דוגמאות:
| ערך בפועל | החיזוי של המודל | הפסד | פונקציית הפסד ריבועי |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 loss | |||
לכן, השגיאה הריבועית הממוצעת היא:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
השגיאה הריבועית הממוצעת היא אופטימיזציה פופולרית לאימון, במיוחד עבור רגרסיה לינארית.
השוואה בין שורש טעות ריבועית ממוצעת לבין טעות מוחלטת ממוצעת ושורש טעות ריבועית ממוצעת.
TensorFlow Playground משתמש בטעות ריבועית ממוצעת כדי לחשב את ערכי ההפסד.
רשת
במקביל למידת מכונה, מונח שקשור להקצאת הנתונים והמודל לשבבי TPU, ולהגדרת האופן שבו הערכים האלה יחולקו או ישוכפלו.
המונח Mesh (רשת) הוא מונח עמוס שיכול להתייחס לאחד מהדברים הבאים:
- פריסה פיזית של שבבי TPU.
- מבנה לוגי מופשט למיפוי הנתונים והמודל לשבבי TPU.
בכל מקרה, רשת מוגדרת כצורה.
מטא-למידה
תת-קבוצה של למידת מכונה שמגלה או משפרת אלגוריתם למידה. מערכת מטא-למידה יכולה גם לאמן מודל ללמוד במהירות משימה חדשה מכמות קטנה של נתונים או מניסיון שנצבר במשימות קודמות. אלגוריתמים של למידת-על בדרך כלל מנסים להשיג את המטרות הבאות:
- לשפר או ללמוד תכונות שנוצרו באופן ידני (כמו פונקציית אתחול או פונקציית אופטימיזציה).
- להיות יעילים יותר מבחינת נתונים וחישובים.
- שיפור ההכללה.
למידת מטא קשורה ללמידה מכמה דוגמאות.
ערך
נתון סטטיסטי שחשוב לכם.
יעד הוא מדד שמערכת למידת מכונה מנסה לבצע לו אופטימיזציה.
Metrics API (tf.metrics)
TensorFlow API להערכת מודלים. לדוגמה, tf.metrics.accuracy
קובע את התדירות שבה התחזיות של מודל תואמות לתוויות.
מיני-batch
קבוצת משנה קטנה שנבחרה באופן אקראי מתוך batch שעובר עיבוד באיטרציה אחת. גודל האצווה של אצווה קטנה הוא בדרך כלל בין 10 ל-1,000 דוגמאות.
לדוגמה, נניח שקבוצת נתונים לאימון כולה (הקבוצה המלאה) מורכבת מ-1,000 דוגמאות. נניח שאתם מגדירים את גודל הקבוצה של כל קבוצת נתונים קטנה ל-20. לכן, בכל איטרציה נקבע ההפסד על סמך 20 דוגמאות אקראיות מתוך 1,000 הדוגמאות, ואז מתבצעת התאמה של המשקלים ושל ההטיות בהתאם.
יעיל הרבה יותר לחשב את ההפסד במיני-אצווה מאשר לחשב את ההפסד בכל הדוגמאות באצווה המלאה.
מידע נוסף זמין במאמר רגרסיה ליניארית: היפר-פרמטרים בקורס המקוצר על למידת מכונה.
ירידה סטוכסטית בגרדיאנט של קבוצת נתונים קטנה
אלגוריתם gradient descent שמשתמש בmini-batches. במילים אחרות, שיטת הגרדיאנט הסתוקסטי של קבוצות קטנות מעריכה את הגרדיאנט על סמך קבוצת משנה קטנה של נתוני האימון. בשיטת הירידה התלולה הסטוכסטית הרגילה נעשה שימוש במיני-batch בגודל 1.
הפסד מינימקס
פונקציית הפסד עבור רשתות יריבות גנרטיביות, שמבוססת על אנטרופיה צולבת בין ההתפלגות של הנתונים שנוצרו לבין הנתונים האמיתיים.
הפסד מינימקס משמש במאמר הראשון לתיאור רשתות גנרטיביות יריבות.
מידע נוסף זמין במאמר בנושא פונקציות הפסד בקורס בנושא רשתות יריבות גנרטיביות.
כיתת מיעוט
התווית הפחות נפוצה במערך נתונים לא מאוזן של מחלקות. לדוגמה, אם יש מערך נתונים שמכיל 99% תוויות שליליות ו-1% תוויות חיוביות, התוויות החיוביות הן המחלקה הקטנה.
ההפך ממחלקת הרוב.
מידע נוסף זמין במאמר קבוצות נתונים: קבוצות נתונים לא מאוזנות בסדנה ללימוד מכונת למידה.
תערובת של מומחים
שיטה להגדלת היעילות של רשת נוירונים באמצעות שימוש רק בקבוצת משנה של הפרמטרים שלה (שנקראת מומחה) כדי לעבד טוקן או דוגמה נתונים. רשת שערים מעבירה כל טוקן קלט או דוגמה למומחה המתאים.
פרטים נוספים זמינים במאמרים הבאים:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mixture-of-Experts עם ניתוב Expert Choice
ML
קיצור של למידת מכונה.
MMIT
קיצור של multimodal instruction-tuned.
MNIST
קבוצת נתונים בנחלת הכלל שאוסף LeCun, Cortes ו-Burges, שמכילה 60,000 תמונות. בכל תמונה מוצג אופן הכתיבה הידנית של ספרה מסוימת מ-0 עד 9. כל תמונה מאוחסנת כמערך של מספרים שלמים בגודל 28x28, כאשר כל מספר שלם הוא ערך של גוון אפור בין 0 ל-255, כולל.
MNIST הוא מערך נתונים קנוני ללמידת מכונה, שמשמש לעיתים קרובות לבדיקת גישות חדשות ללמידת מכונה. פרטים נוספים מופיעים במאמר בנושא מסד הנתונים MNIST של ספרות בכתב יד.
אופן הפעולה
קטגוריית נתונים ברמה גבוהה. לדוגמה, מספרים, טקסט, תמונות, סרטונים ואודיו הם חמש קטגוריות שונות.
מודל
באופן כללי, כל מבנה מתמטי שמעבד נתוני קלט ומחזיר פלט. במילים אחרות, מודל הוא קבוצת הפרמטרים והמבנה שדרושים למערכת כדי לבצע חיזויים. בלמידת מכונה מבוקרת, מודל מקבל דוגמה כקלט ומסיק חיזוי כפלט. בלמידת מכונה בפיקוח, יש הבדלים בין המודלים. לדוגמה:
- מודל רגרסיה לינארית מורכב מקבוצה של משקלים ומהטיה.
- מודל של רשת נוירונים מורכב מ:
- קבוצה של שכבות מוסתרות, שכל אחת מהן מכילה נוירון אחד או יותר.
- המשקלים וההטיות שמשויכים לכל נוירון.
- מודל עץ החלטות מורכב מ:
- הצורה של העץ, כלומר התבנית שבה התנאים והעלים מחוברים.
- התנאים והעזיבות.
אפשר לשמור מודל, לשחזר אותו או ליצור ממנו עותקים.
למידת מכונה לא מפוקחת גם יוצרת מודלים, בדרך כלל פונקציה שיכולה למפות דוגמה של קלט לאשכול המתאים ביותר.
קיבולת המודל
מורכבות הבעיות שהמודל יכול ללמוד. ככל שהבעיות שמודל יכול ללמוד מורכבות יותר, כך היכולת של המודל גבוהה יותר. הקיבולת של מודל גדלה בדרך כלל עם מספר הפרמטרים של המודל. הגדרה רשמית של הקיבולת של מודל סיווג מופיעה במאמר בנושא ממד VC.
מודלים מדורגים
מערכת שבוחרת את המודל האידיאלי לשאילתת הסקה ספציפית.
תארו לעצמכם קבוצה של מודלים, החל ממודלים גדולים מאוד (עם הרבה פרמטרים) ועד למודלים קטנים בהרבה (עם הרבה פחות פרמטרים). מודלים גדולים מאוד צורכים יותר משאבי מחשוב בזמן הסקת מסקנות מאשר מודלים קטנים יותר. עם זאת, מודלים גדולים מאוד יכולים בדרך כלל להסיק בקשות מורכבות יותר ממודלים קטנים יותר. המודל קובע את מורכבות שאילתת ההיקש, ואז בוחר את המודל המתאים לביצוע ההיקש. הסיבה העיקרית לשימוש במודלים מדורגים היא לצמצם את עלויות ההסקה. בדרך כלל המערכת בוחרת מודלים קטנים יותר, ורק לשאילתות מורכבות יותר היא בוחרת מודל גדול יותר.
נניח שמודל קטן פועל בטלפון וגרסה גדולה יותר של אותו מודל פועלת בשרת מרוחק. העברת בקשות בין מודלים בצורה טובה מפחיתה את העלות ואת זמן האחזור, כי המודל הקטן יותר יכול לטפל בבקשות פשוטות, והמודל המרוחק מופעל רק כדי לטפל בבקשות מורכבות.
מידע נוסף מופיע במאמר בנושא ניתוב מודלים.
מקביליות של מודלים
שיטה להרחבת האימון או ההסקת מסקנות, שבה חלקים שונים של מודל אחד ממוקמים במכשירים שונים. מקביליות של מודלים מאפשרת להשתמש במודלים גדולים מדי שלא נכנסים למכשיר אחד.
כדי ליישם מקביליות של מודלים, מערכת בדרך כלל מבצעת את הפעולות הבאות:
- מפצלים את המודל לחלקים קטנים יותר.
- מפיץ את האימון של החלקים הקטנים האלה בין כמה מעבדים. כל מעבד מאמן חלק משלו במודל.
- התוצאות משולבות ליצירת מודל יחיד.
מקביליות של מודלים מאטה את האימון.
אפשר לעיין גם במקביליות נתונים.
נתב לדוגמה
האלגוריתם שקובע את המודל האידיאלי להסקת מסקנות במודל מדורג. נתב מודלים הוא בדרך כלל מודל למידת מכונה שלומד בהדרגה איך לבחור את המודל הכי טוב לקלט נתון. עם זאת, נתב מודלים יכול להיות לפעמים אלגוריתם פשוט יותר שאינו מבוסס על למידת מכונה.
אימון מודל
התהליך של קביעת המודל הטוב ביותר.
MOE
קיצור של תערובת של מומחים.
מומנטום
אלגוריתם מורכב של ירידת גרדיאנט שבו שלב הלמידה תלוי לא רק בנגזרת בשלב הנוכחי, אלא גם בנגזרות של השלבים שקדמו לו. בשיטת המומנטום, המערכת מחשבת ממוצע נע משוקלל אקספוננציאלית של הגרדיאנטים לאורך זמן, בדומה למומנטום בפיזיקה. המומנטום מונע לפעמים את התקיעה של תהליך הלמידה במינימום מקומי.
בעיות בסיסיות ב-Python (MBPP)
מערך נתונים להערכת רמת המיומנות של מודל שפה גדולה (LLM) ביצירת קוד Python. Mostly Basic Python Problems כולל כ-1,000 בעיות תכנות שמקורן במיקור המונים. כל בעיה בקבוצת הנתונים מכילה את הפרטים הבאים:
- תיאור המשימה
- קוד הפתרון
- שלושה תרחישי בדיקה אוטומטיים
MT
קיצור של תרגום אוטומטי.
שיתוף פעולה בין כמה סוכנים
מסגרת שבה סוכני AI מומחים רבים מקיימים אינטראקציה, מתווכחים או מעבירים משימות אחד לשני כדי לפתור בעיה מורכבת.
סיווג רב-מחלקתי
בלמידה מפוקחת, בעיית סיווג שבה מערך הנתונים מכיל יותר משני סוגים של תוויות. לדוגמה, התוויות במערך הנתונים של איריס חייבות להיות אחת משלוש המחלקות הבאות:
- Iris setosa
- Iris virginica
- Iris versicolor
מודל שאומן על מערך הנתונים של איריס ומנבא את סוג האיריס בדוגמאות חדשות, מבצע סיווג רב-מחלקתי.
לעומת זאת, בעיות סיווג שמבחינות בין שתי קטגוריות בדיוק הן מודלים של סיווג בינארי. לדוגמה, מודל אימייל שמנבא אם אימייל הוא ספאם או לא ספאם הוא מודל סיווג בינארי.
בבעיות של קיבוץ לאשכולות, סיווג רב-מחלקתי מתייחס ליותר משני אשכולות.
מידע נוסף זמין במאמר רשתות עצביות: סיווג רב-מחלקתי בקורס המקוצר בנושא למידת מכונה.
רגרסיה לוגיסטית רב-סיווגית
שימוש ברגרסיה לוגיסטית בבעיות של סיווג רב-מחלקתי.
מנגנון תשומת לב עצמית עם מספר ראשים
הרחבה של קשב עצמי שבה מנגנון הקשב העצמי מופעל כמה פעמים לכל מיקום ברצף הקלט.
טרנספורמרים הציגו קשב עצמי מרובה ראשים.
מכוונן להנחיות מולטי-מודאליות
מודל שעבר כוונון לפי הוראות שיכול לעבד קלט שהוא לא רק טקסט, כמו תמונות, סרטונים ואודיו.
מודל מולטי-מודאלי
מודל שהקלט, הפלט או שניהם כוללים יותר מאופן פעולה אחד. לדוגמה, נניח שיש מודל שמקבל כמאפיינים גם תמונה וגם כיתוב (שני סוגים של נתונים), ומוציא ציון שמציין עד כמה הכיתוב מתאים לתמונה. לכן, הקלט של המודל הזה הוא מרובה מצבים והפלט הוא חד-מצבי.
סיווג רב-נומינלי
מילה נרדפת לסיווג רב-מחלקתי.
רגרסיה מולטינומיאלית
מילה נרדפת לרגרסיה לוגיסטית רב-סיווגית.
הבנת הנקרא של כמה משפטים (MultiRC)
מערך נתונים להערכת היכולת של מודל LLM לענות על תרגילי בחירה מרובה. כל דוגמה בקבוצת הנתונים מכילה:
- פסקה עם הקשר
- שאלה לגבי הפסקה הזו
- כמה תשובות לשאלה. כל תשובה מסומנת בתווית True או False. יכול להיות שכמה תשובות יהיו נכונות.
לדוגמה:
פסקה עם הקשר:
סוזן רצתה לערוך מסיבת יום הולדת. היא התקשרה לכל החברים שלה. יש לה חמישה חברים. אמא שלה אמרה שסוזן יכולה להזמין את כולם למסיבה. החברה הכי טובה שלה לא יכלה להגיע למסיבה כי היא הייתה חולה. החברה השנייה שלה נסעה מחוץ לעיר. החברה השלישית שלה לא הייתה בטוחה שההורים שלה יאפשרו לה. החבר הרביעי השיב 'אולי'. החבר החמישי יכול להגיע למסיבה בוודאות. סוזן הייתה קצת עצובה. ביום המסיבה, כל חמשת החברים הגיעו. לכל חבר הייתה מתנה בשביל סוזן. סוזן שמחה ושלחה לכל חברה כרטיס תודה בשבוע שלאחר מכן.
שאלה: Did Susan's sick friend recover?
שאלות אמריקאיות:
- כן, היא החלימה. (True)
- לא (False)
- כן. (True)
- לא, היא לא החלימה. (False)
- כן, היא הייתה במסיבה של סוזן. (True)
MultiRC הוא רכיב של SuperGLUE ensemble.
פרטים נוספים זמינים במאמר Looking Beyond the Surface: A Challenge Set for Reading Comprehension over Multiple Sentences.
ריבוי משימות
טכניקה של למידת מכונה שבה מודל אחד מאומן לבצע כמה משימות.
מודלים לביצוע כמה משימות נוצרים על ידי אימון על נתונים שמתאימים לכל אחת מהמשימות השונות. כך המודל לומד לשתף מידע בין המשימות, מה שעוזר לו ללמוד בצורה יעילה יותר.
למודל שאומן למספר משימות יש לרוב יכולות הכללה משופרות, והוא יכול להיות חזק יותר בטיפול בסוגים שונים של נתונים.
לא
Nano
מודל Gemini קטן יחסית שמיועד לשימוש במכשיר. פרטים נוספים זמינים במאמר בנושא Gemini Nano.
כדאי לעיין גם במאמרים בנושא Pro ו-Ultra.
מלכודת NaN
כשמספר אחד במודל הופך ל-NaN במהלך האימון, מה שגורם להרבה מספרים אחרים במודל או לכולם להפוך בסופו של דבר ל-NaN.
NaN הוא קיצור של Not a Number (לא מספר).
עיבוד שפה טבעית (NLP)
תחום שמלמד מחשבים לעבד את מה שהמשתמש אמר או הקליד באמצעות כללים לשוניים. כמעט כל עיבוד השפה הטבעית המודרני מסתמך על למידת מכונה.הבנת שפה טבעית (NLU)
קבוצת משנה של עיבוד שפה טבעית שקובעת את הכוונות של משהו שנאמר או הוקלד. הבנת שפה טבעית (NLU) יכולה להתבסס על עיבוד שפה טבעית (NLP) כדי להתייחס להיבטים מורכבים של השפה כמו הקשר, סרקזם ורגשות.
סיווג שלילי
בסיווג בינארי, מחלקה אחת נקראת חיובית והשנייה נקראת שלילית. הסיווג החיובי הוא הדבר או האירוע שהמודל בודק, והסיווג השלילי הוא האפשרות השנייה. לדוגמה:
- הסיווג השלילי בבדיקה רפואית יכול להיות 'לא גידול'.
- הסיווג השלילי במודל סיווג של אימייל יכול להיות 'לא ספאם'.
ההגדרה הזו שונה מהכיתה החיובית.
דגימה שלילית
מילה נרדפת לדגימת מועמדים.
Neural Architecture Search (NAS)
טכניקה לעיצוב אוטומטי של הארכיטקטורה של רשת נוירונים. אלגוריתמים של NAS יכולים לצמצם את כמות הזמן והמשאבים שנדרשים לאימון רשת נוירונים.
בדרך כלל נעשה שימוש ב-NAS ב:
- מרחב חיפוש, שהוא קבוצה של ארכיטקטורות אפשריות.
- פונקציית כושר, שהיא מדד לביצועים של ארכיטקטורה מסוימת במשימה נתונה.
אלגוריתמים של NAS מתחילים בדרך כלל עם קבוצה קטנה של ארכיטקטורות אפשריות, ומרחיבים בהדרגה את מרחב החיפוש ככל שהאלגוריתם לומד יותר על הארכיטקטורות האפקטיביות. פונקציית הכושר מבוססת בדרך כלל על הביצועים של הארכיטקטורה על קבוצת נתונים לאימון, והאלגוריתם מאומן בדרך כלל באמצעות טכניקה של למידת חיזוק.
אלגוריתמים של NAS הוכיחו את עצמם כיעילים במציאת ארכיטקטורות עם ביצועים גבוהים למגוון משימות, כולל סיווג תמונות, סיווג טקסט ותרגום אוטומטי.
רשת הזרימה קדימה
מודל שמכיל לפחות שכבה מוסתרת אחת. רשת נוירונים עמוקה היא סוג של רשת נוירונים שמכילה יותר משכבה נסתרת אחת. לדוגמה, בתרשים הבא מוצגת רשת עצבית עמוקה שמכילה שתי שכבות נסתרות.
כל נוירון ברשת נוירונים מתחבר לכל הצמתים בשכבה הבאה. לדוגמה, בתרשים הקודם אפשר לראות שכל אחד משלושת הנוירונים בשכבה הנסתרת הראשונה מקושר בנפרד לשני הנוירונים בשכבה הנסתרת השנייה.
רשתות נוירונים שמיושמות במחשבים נקראות לפעמים רשתות נוירונים מלאכותיות כדי להבדיל ביניהן לבין רשתות נוירונים שנמצאות במוח ובמערכות עצבים אחרות.
חלק מהרשתות העצביות יכולות לחקות קשרים לא לינאריים מורכבים במיוחד בין תכונות שונות לבין התווית.
ראו גם רשת נוירונים מתקפלת ורשת נוירונים חוזרת.
מידע נוסף זמין במאמר רשתות עצביות בקורס המקוצר על למידת מכונה.
נוירון
בלמידת מכונה, יחידה נפרדת בשכבה נסתרת של רשת נוירונים. כל נוירון מבצע את הפעולה הבאה בשני שלבים:
- הפונקציה מחשבת את הסכום המשוקלל של ערכי הקלט כפול המשקלים התואמים שלהם.
- הפונקציה מעבירה את הסכום המשוקלל כקלט לפונקציית הפעלה.
נוירון בשכבה הנסתרת הראשונה מקבל קלט מערכי התכונות בשכבת הקלט. נוירון בכל שכבה מוסתרת מעבר לשכבה הראשונה מקבל קלט מהנוירונים בשכבה המוסתרת הקודמת. לדוגמה, נוירון בשכבה הנסתרת השנייה מקבל קלט מהנוירונים בשכבה הנסתרת הראשונה.
באיור הבא אפשר לראות שני נוירונים והקלט שלהם.
נוירון ברשת נוירונים מחקה את ההתנהגות של נוירונים במוח ובחלקים אחרים של מערכת העצבים.
N-gram
רצף מסודר של N מילים. לדוגמה, truly madly הוא ביגרם. הסדר חשוב, ולכן madly truly הוא ביגרם שונה מ-truly madly.
| לא | השמות של סוג ה-N-gram הזה | דוגמאות |
|---|---|---|
| 2 | ביגרם או 2-גרם | to go, go to, eat lunch, eat dinner |
| 3 | טריגרם או 3-גרם | ate too much, happily ever after, the bell tolls |
| 4 | 4 גרם | walk in the park, dust in the wind, the boy ate lentils |
הרבה מודלים של הבנת שפה טבעית מסתמכים על N-grams כדי לחזות את המילה הבאה שהמשתמש יקליד או יגיד. לדוגמה, נניח שמשתמש הקליד happily ever. מודל NLU שמבוסס על טריגרמות צפוי לחזות שהמשתמש יקליד את המילה after.
השוואה בין N-grams לבין bag of words, שהם קבוצות לא מסודרות של מילים.
מידע נוסף זמין במאמר מודלים גדולים של שפה בקורס Machine Learning Crash Course.
NLP
קיצור של עיבוד שפה טבעית.
NLU
קיצור של הבנת שפה טבעית.
צומת (עץ החלטה)
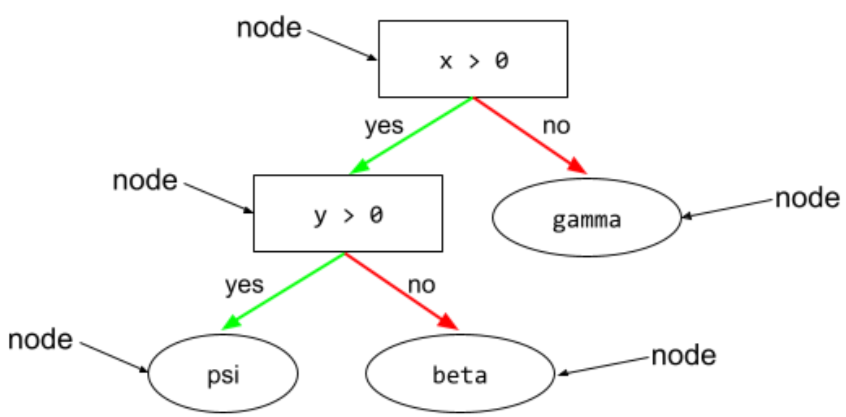
מידע נוסף זמין במאמר בנושא עצי החלטה בקורס בנושא יערות החלטה.
צומת (רשת נוירונים)
מידע נוסף מופיע במאמר רשתות עצביות בקורס המקוצר על למידת מכונה.
צומת (תרשים TensorFlow)
פעולה בגרף של TensorFlow.
רעש
באופן כללי, כל דבר שמסתיר את האות במערך נתונים. רעשים יכולים להופיע בנתונים במגוון דרכים. לדוגמה:
- המעריכים האנושיים טועים לפעמים בתיוג.
- במקרים של הקלטה על ידי בני אדם או מכשירים, יכול להיות שערכי התכונות לא יוקלטו או שיושמטו.
מצב לא בינארי
תנאי שמכיל יותר משני תוצאות אפשריות. לדוגמה, התנאי הלא בינארי הבא מכיל שלושה תוצאות אפשריות:
מידע נוסף זמין במאמר סוגי תנאים בקורס בנושא יערות החלטה.
לא דטרמיניסטי
מערכת שלא מובטח שתחזיר את אותו פלט עבור קלט נתון. מודלים גדולים של שפה (LLM) הם בדרך כלל לא דטרמיניסטיים. כלומר, מודלים גדולים של שפה יוצרים בדרך כלל תשובות שונות לאותה הנחיה.
בדרך כלל קשה הרבה יותר לבדוק מערכות לא דטרמיניסטיות מאשר מערכות דטרמיניסטיות.
מידע נוסף זמין במאמר בנושא הסתברותי.
לא לינארי
קשר בין שני משתנים או יותר שלא ניתן לייצג רק באמצעות חיבור וכפל. אפשר לייצג קשר לינארי כקו, אבל אי אפשר לייצג קשר לא לינארי כקו. לדוגמה, נניח שיש שני מודלים שכל אחד מהם מקשר בין תכונה אחת לתווית אחת. המודל בצד ימין הוא ליניארי והמודל בצד שמאל הוא לא ליניארי:

בקורס המקוצר על למידת מכונה, אפשר לעיין בקטע רשתות עצביות: צמתים ושכבות מוסתרות כדי להתנסות בסוגים שונים של פונקציות לא לינאריות.
הטיית סקר שלא מולא
ראו הטיית בחירה.
אי-סטציונריות
תכונה שהערכים שלה משתנים לאורך מאפיין אחד או יותר, בדרך כלל זמן. לדוגמה, הנה כמה דוגמאות לנתונים לא סטציונריים:
- מספר בגדי הים שנמכרים בחנות מסוימת משתנה בהתאם לעונה.
- הכמות של פרי מסוים שנקטף באזור מסוים היא אפס במשך רוב השנה, אבל גדולה לתקופה קצרה.
- בגלל שינויי האקלים, הטמפרטורות הממוצעות השנתיות משתנות.
ההפך מסטציונריות.
אין תשובה נכונה אחת (NORA)
הנחיה עם כמה תשובות נכונות. לדוגמה, להנחיה הבאה אין תשובה נכונה אחת:
תספר לי בדיחה מצחיקה על פילים.
הערכת התשובות להנחיות שאין להן תשובה נכונה אחת היא בדרך כלל סובייקטיבית הרבה יותר מהערכת הנחיות עם תשובה נכונה אחת. לדוגמה, כדי להעריך בדיחה על פיל צריך שיטה שיטתית לקביעת רמת ההומור של הבדיחה.
NORA
קיצור של אין תשובה נכונה אחת.
נירמול
באופן כללי, התהליך של המרת טווח הערכים בפועל של משתנה לטווח ערכים סטנדרטי, כמו:
- -1 עד +1
- 0 עד 1
- ציוני תקן (בערך, -3 עד +3)
לדוגמה, נניח שהטווח בפועל של ערכי תכונה מסוימת הוא 800 עד 2,400. במסגרת הנדסת תכונות, אפשר לנרמל את הערכים בפועל לטווח סטנדרטי, למשל מ-1 עד 1.
נרמול הוא משימה נפוצה בהנדסת תכונות. בדרך כלל, אימון המודלים מהיר יותר (והחיזויים מדויקים יותר) כשכל תכונה מספרית בווקטור התכונות נמצאת בטווח דומה.
אפשר לעיין גם במאמר נירמול לפי ציון Z.
מידע נוסף זמין במאמר נתונים מספריים: נורמליזציה בסדנה ללימוד למידת מכונה.
Notebook LM
כלי מבוסס-Gemini שמאפשר למשתמשים להעלות מסמכים ואז להשתמש בהנחיות כדי לשאול שאלות לגבי המסמכים, לסכם אותם או לארגן אותם. לדוגמה, סופר יכול להעלות כמה סיפורים קצרים ולבקש מ-NotebookLM למצוא את הנושאים המשותפים שלהם או לזהות איזה מהם יהיה הכי מתאים לעיבוד לסרט.
זיהוי של תכונות חדשות
התהליך של קביעה אם דוגמה חדשה (חדשנית) מגיעה מאותו פיזור כמו קבוצת נתונים לאימון. במילים אחרות, אחרי אימון על קבוצת נתונים לאימון, זיהוי חריגות קובע אם דוגמה חדשה (במהלך היקש או במהלך אימון נוסף) היא חריגה.
ההבדל בין התכונה הזו לבין זיהוי חריגות.
נתונים מספריים
מאפיינים שמיוצגים כמספרים שלמים או כמספרים ממשיים. לדוגמה, במודל להערכת שווי של בית, גודל הבית (במטרים רבועים או ברגל רבוע) כנראה ייוצג כנתונים מספריים. ייצוג של תכונה כנתונים מספריים מציין שלערכים של התכונה יש קשר מתמטי לתווית. כלומר, למספר המטרים הרבועים בבית יש כנראה קשר מתמטי כלשהו לערך הבית.
לא כל נתוני המספרים השלמים צריכים להיות מיוצגים כנתונים מספריים. לדוגמה, מיקודים בחלקים מסוימים בעולם הם מספרים שלמים, אבל מיקודים כאלה לא צריכים להיות מיוצגים כנתונים מספריים במודלים. הסיבה לכך היא שמיקוד של 20000 לא חזק פי שניים (או חצי) ממיקוד של 10000. בנוסף, למרות שיש קשר בין מיקודים שונים לבין ערכי נדל"ן שונים, אי אפשר להניח שערכי הנדל"ן במיקוד 20000 הם כפולים מערכי הנדל"ן במיקוד 10000.
במקום זאת, צריך להציג את המיקודים כנתונים קטגוריים.
תכונות מספריות נקראות לפעמים תכונות רציפות.
מידע נוסף זמין במאמר עבודה עם נתונים מספריים בקורס המקוצר על למידת מכונה.
NumPy
ספריית מתמטיקה בקוד פתוח שמספקת פעולות יעילות על מערכים ב-Python. pandas מבוססת על NumPy.
O
יעד
מדד שהאלגוריתם מנסה לבצע לו אופטימיזציה.
פונקציית מטרה
הנוסחה המתמטית או המדד שהמודל שואף לבצע אופטימיזציה לגביהם. לדוגמה, פונקציית היעד של רגרסיה לינארית היא בדרך כלל Mean Squared Loss (אובדן ממוצע בריבוע). לכן, כשמאמנים מודל של רגרסיה לינארית, האימון נועד לצמצם את אובדן המידע הממוצע בריבוע.
במקרים מסוימים, המטרה היא למקסם את פונקציית המטרה. לדוגמה, אם פונקציית היעד היא דיוק, המטרה היא למקסם את הדיוק.
מידע נוסף זמין במאמר בנושא הפסד.
תנאי עקיף
בעץ החלטה, תנאי שכולל יותר ממאפיין אחד. לדוגמה, אם הגובה והרוחב הם מאפיינים, אז התנאי הבא הוא תנאי אלכסוני:
height > width
ההגדרה הזו שונה מתנאי שמתיישר עם הציר.
מידע נוסף זמין במאמר סוגי תנאים בקורס בנושא יערות החלטה.
תצפית
שלב בלולאה של סוכן שבו הסוכן בודק או מעריך היבט מסוים של ההתקדמות שלו. לדוגמה, נניח שבשלב הפעולה נוצר קוד מסוים. לכן, בשלב observe יכול להיות שיופעלו בדיקות על הקוד שנוצר.
לא מקוון
מילה נרדפת ל-static.
הסקת מסקנות אופליין
התהליך שבו מודל יוצר קבוצה של חיזויים ואז שומר אותם במטמון. לאחר מכן, האפליקציות יכולות לגשת לתחזית המשוערת מהמטמון במקום להפעיל מחדש את המודל.
לדוגמה, נניח שיש מודל שמפיק תחזיות מזג אוויר מקומיות (חיזויים) אחת לארבע שעות. אחרי כל הרצת מודל, המערכת שומרת במטמון את כל התחזיות המקומיות. אפליקציות מזג האוויר מאחזרות את התחזיות מהמטמון.
הסקת מסקנות אופליין נקראת גם הסקת מסקנות סטטית.
ההבדל בין זה לבין הסקת מסקנות אונליין. מידע נוסף זמין במאמר מערכות ML לייצור: הסקה סטטית לעומת הסקה דינמית בתוכנית Machine Learning Crash Course.
קידוד one-hot
ייצוג נתונים קטגוריים כווקטור שבו:
- רכיב אחד מוגדר ל-1.
- כל שאר הרכיבים מוגדרים כ-0.
קידוד one-hot משמש בדרך כלל לייצוג מחרוזות או מזהים שיש להם קבוצה סופית של ערכים אפשריים.
לדוגמה, נניח שלתכונה קטגורית מסוימת בשם Scandinavia יש חמישה ערכים אפשריים:
- "Denmark"
- "Sweden"
- "Norway"
- "פינלנד"
- "איסלנד"
קידוד one-hot יכול לייצג כל אחד מחמשת הערכים באופן הבא:
| מדינה | וקטור | ||||
|---|---|---|---|---|---|
| "Denmark" | 1 | 0 | 0 | 0 | 0 |
| "Sweden" | 0 | 1 | 0 | 0 | 0 |
| "Norway" | 0 | 0 | 1 | 0 | 0 |
| "פינלנד" | 0 | 0 | 0 | 1 | 0 |
| "איסלנד" | 0 | 0 | 0 | 0 | 1 |
הודות לקידוד one-hot, מודל יכול ללמוד קשרים שונים על סמך כל אחת מחמש המדינות.
ייצוג מאפיין כנתונים מספריים הוא חלופה לקידוד "חם-יחיד". לצערנו, לא מומלץ לייצג את המדינות הסקנדינביות באמצעות מספרים. לדוגמה, הנה ייצוג מספרי:
- "Denmark" הוא 0
- "Sweden" הוא 1
- "Norway" הוא 2
- "Finland" הוא 3
- "Iceland" הוא 4
בקידוד מספרי, המודל יפרש את המספרים הגולמיים באופן מתמטי וינסה להתאמן על המספרים האלה. עם זאת, איסלנד לא גדולה פי שניים מנורווגיה (או קטנה פי שניים ממנה), ולכן המודל יגיע למסקנות מוזרות.
מידע נוסף זמין במאמר נתונים קטגוריים: אוצר מילים וקידוד one-hot בסדנה ללימוד למידת מכונה.
תשובה נכונה אחת (ORA)
הנחיה עם תשובה נכונה אחת. לדוגמה, נניח את ההנחיה הבאה:
נכון או לא נכון: שבתאי גדול יותר ממאדים.
התשובה הנכונה היחידה היא true.
ההפך מאין תשובה נכונה אחת.
one-shot learning
גישה של למידת מכונה, שמשמשת לעיתים קרובות לסיווג אובייקטים, ומיועדת ללמוד מודל סיווג יעיל מדוגמה אחת לאימון.
כדאי לעיין גם בלמידה מכמה דוגמאות ובלמידה מאפס דוגמאות.
הנחיות עם דוגמה אחת (one-shot prompting)
הנחיה שמכילה דוגמה אחת שמראה איך מודל שפה גדול צריך להגיב. לדוגמה, ההנחיה הבאה מכילה דוגמה אחת שמראה למודל שפה גדול איך עליו לענות על שאילתה.
| החלקים של הנחיה | הערות |
|---|---|
| מהו המטבע הרשמי של המדינה שצוינה? | השאלה שרוצים שה-LLM יענה עליה. |
| צרפת: EUR | דוגמה אחת. |
| הודו: | השאילתה בפועל. |
השוואה וניגוד בין הנחיות עם דוגמה אחת (one-shot prompting) לבין המונחים הבאים:
אחד מול כולם
בהינתן בעיית סיווג עם N מחלקות, פתרון שמורכב ממודל סיווג בינארי נפרד של N – מודל סיווג בינארי אחד לכל תוצאה אפשרית. לדוגמה, אם יש מודל שמסווג דוגמאות כבעלי חיים, צמחים או מינרלים, פתרון של אחד מול כולם יספק את שלושת המודלים הנפרדים הבאים של סיווג בינארי:
- בעל חיים לעומת לא בעל חיים
- ירק לעומת לא ירק
- מינרל לעומת לא מינרל
online
מילה נרדפת לדינמי.
היקש אונליין
יצירת תחזיות לפי דרישה. לדוגמה, נניח שאפליקציה מעבירה קלט למודל ושולחת בקשה לתחזית. מערכת שמשתמשת בהסקת מסקנות אונליין מגיבה לבקשה על ידי הפעלת המודל (ומחזירה את החיזוי לאפליקציה).
ההבדל בין זה לבין הסקת מסקנות אופליין.
מידע נוסף זמין במאמר מערכות ML לייצור: הסקה סטטית לעומת הסקה דינמית בתוכנית Machine Learning Crash Course.
פעולה (op)
ב-TensorFlow, כל הליך שיוצר, משנה או משמיד Tensor. לדוגמה, כפל מטריצות הוא פעולה שמקבלת שני טנסורים כקלט ומפיקה טנסור אחד כפלט.
Optax
ספרייה לעיבוד ולאופטימיזציה של גרדיאנטים ל-JAX. Optax מספקת אבני בניין שאפשר לשלב מחדש בדרכים מותאמות אישית כדי לבצע אופטימיזציה של מודלים פרמטריים כמו רשתות עצביות עמוקות, וכך מקלה על המחקר. יעדים נוספים:
- לספק הטמעות קריאות, שנבדקו היטב ויעילות של רכיבי ליבה.
- שיפור הפרודוקטיביות על ידי אפשרות לשלב רכיבים ברמה נמוכה באופטימיזטורים בהתאמה אישית (או ברכיבים אחרים לעיבוד גרדיאנטים).
- האצת האימוץ של רעיונות חדשים על ידי מתן אפשרות לכל אחד לתרום.
optimizer
הטמעה ספציפית של האלגוריתם gradient descent . בין האופטימיזטורים הפופולריים:
- AdaGrad, קיצור של ADAptive GRADient descent (שיפוע אדפטיבי).
- Adam, קיצור של ADAptive with Momentum (מותאם עם מומנטום).
ORA
קיצור של תשובה נכונה אחת.
הטיית הומוגניות של קבוצת חוץ
הנטייה לראות חברים בקבוצה החיצונית כדומים יותר מאשר חברים בקבוצה הפנימית, כשמשווים בין עמדות, ערכים, תכונות אישיות ומאפיינים אחרים. בתוך הקבוצה מתייחס לאנשים שיש לכם אינטראקציה איתם באופן קבוע; מחוץ לקבוצה מתייחס לאנשים שאין לכם אינטראקציה איתם באופן קבוע. אם יוצרים מערך נתונים על ידי בקשה מאנשים לספק מאפיינים לגבי קבוצות חיצוניות, יכול להיות שהמאפיינים האלה יהיו פחות מורכבים ויותר סטריאוטיפיים מאשר מאפיינים שהמשתתפים מפרטים לגבי אנשים בקבוצה הפנימית שלהם.
לדוגמה, תושבי ליליפוט יכולים לתאר את הבתים של תושבי ליליפוט אחרים בפירוט רב, ולציין הבדלים קטנים בסגנונות האדריכליים, בחלונות, בדלתות ובגדלים. אבל יכול להיות שאותם ליליפוטים פשוט יצהירו שכל תושבי ברובדינגנאג גרים בבתים זהים.
הטיית הומוגניות של קבוצה חיצונית היא סוג של הטיית ייחוס לקבוצה.
אפשר לעיין גם במאמר בנושא הטיה לטובת קבוצת השייכות.
זיהוי חריגות
תהליך הזיהוי של חריגים בקבוצת נתונים לאימון.
ההבדל בין זה לבין זיהוי של תכונות חדשות.
חריגים
ערכים שרחוקים מרוב הערכים האחרים. בלמידת מכונה, כל אחד מהערכים הבאים נחשב לחריג:
- נתוני קלט שהערכים שלהם חורגים ביותר מ-3 סטיות תקן מהממוצע.
- משקלים עם ערכים מוחלטים גבוהים.
- הערכים החזויים רחוקים יחסית מהערכים בפועל.
לדוגמה, נניח ש-widget-price היא תכונה של מודל מסוים.
נניח שהממוצע widget-price הוא 7 אירו וסטיית התקן היא אירו אחד. לכן, דוגמאות שמכילות widget-price של 12 אירו או 2 אירו ייחשבו לערכים חריגים, כי כל אחד מהמחירים האלה הוא חמש סטיות תקן מהממוצע.
בדרך כלל, חריגים נובעים משגיאות הקלדה או משגיאות אחרות בהזנה. במקרים אחרים, חריגים הם לא טעויות. אחרי הכול, ערכים שחמש סטיות תקן שלהם רחוקות מהממוצע הם נדירים אבל לא בלתי אפשריים.
ערכים חריגים גורמים לרוב לבעיות באימון המודל. חיתוך הוא אחת הדרכים לנהל חריגים.
מידע נוסף זמין במאמר עבודה עם נתונים מספריים בקורס המקוצר על למידת מכונה.
הערכה מחוץ לתיק (OOB)
מנגנון להערכת האיכות של יער החלטות על ידי בדיקה של כל עץ החלטות מול הדוגמאות שלא נעשה בהן שימוש במהלך האימון של עץ ההחלטות הזה. לדוגמה, בתרשים הבא אפשר לראות שהמערכת מאמנת כל עץ החלטה על כשני שלישים מהדוגמאות, ואז מבצעת הערכה על השליש הנותר של הדוגמאות.
הערכה מחוץ לחבילה היא קירוב שמרני ויעיל מבחינת חישובים של מנגנון האימות הצולב. באימות צולב, מאמנים מודל אחד לכל סבב של אימות צולב (לדוגמה, 10 מודלים מאומנים באימות צולב של 10 חלקים). בשיטת ההערכה OOB, מאמנים מודל יחיד. בגלל שbagging מעכב חלק מהנתונים מכל עץ במהלך האימון, הערכת OOB יכולה להשתמש בנתונים האלה כדי לבצע קירוב של אימות צולב.
מידע נוסף זמין במאמר Out-of-bag evaluation בקורס Decision Forests.
שכבת הפלט
השכבה ה'הסופית' של רשת נוירונים. שכבת הפלט מכילה את החיזוי.
האיור הבא מציג רשת עצבית עמוקה קטנה עם שכבת קלט, שתי שכבות נסתרות ושכבת פלט:
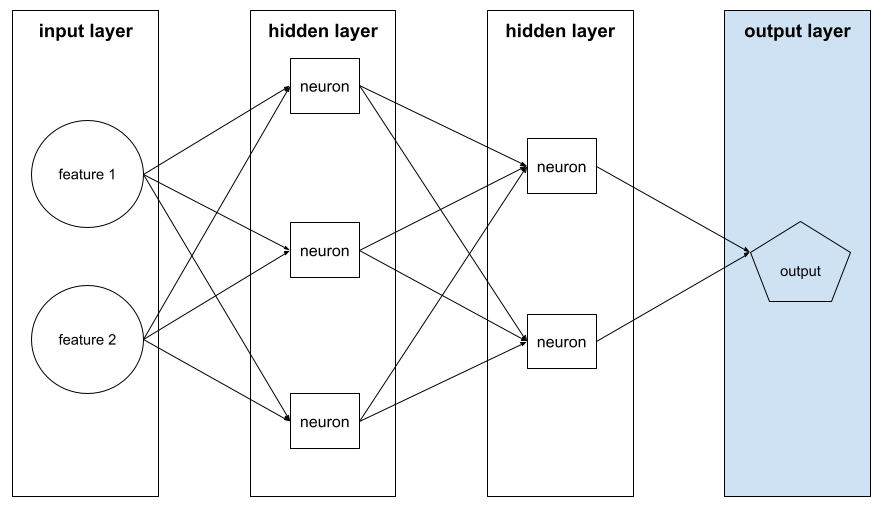
התאמת יתר (overfitting)
יצירת מודל שתואם לנתוני האימון בצורה כל כך מדויקת שהמודל לא מצליח לבצע חיזויים נכונים לגבי נתונים חדשים.
רגולריזציה יכולה לצמצם את התאמת היתר. אימון על קבוצת נתונים לאימון גדולה ומגוונת יכול גם להפחית את התאמת היתר.
מידע נוסף מופיע במאמר בנושא התאמת יתר בקורס המקוצר על למידת מכונה.
דגימת יתר
שימוש חוזר בדוגמאות של מחלקת מיעוט בקבוצת נתונים עם חוסר איזון בין המחלקות כדי ליצור קבוצת נתונים לאימון מאוזנת יותר.
לדוגמה, נניח שיש בעיית סיווג בינארית שבה היחס בין מחלקת הרוב למחלקת המיעוט הוא 5,000:1. אם מערך הנתונים מכיל מיליון דוגמאות, אז הוא מכיל רק כ-200 דוגמאות של המחלקה המיעוטית, וזה יכול להיות מעט מדי דוגמאות לאימון יעיל. כדי להתגבר על החוסר הזה, אפשר לבצע דגימת יתר (שימוש חוזר) ב-200 הדוגמאות האלה מספר פעמים, וכך אולי להגיע למספר מספיק של דוגמאות לאימון יעיל.
כשמבצעים דגימת יתר, צריך להיזהר מהתאמת יתר.
ההבדל בין זה לבין דילול יתר.
P
נתונים ארוזים
גישה לאחסון נתונים בצורה יעילה יותר.
מאגרי נתונים דחוסים שומרים נתונים בפורמט דחוס או בדרך אחרת שמאפשרת גישה יעילה יותר לנתונים. נתונים ארוזים מצמצמים את כמות הזיכרון והחישובים שנדרשים כדי לגשת אליהם, וכך האימון מהיר יותר וההסקה של המודל יעילה יותר.
לרוב משתמשים בנתונים דחוסים בשילוב עם טכניקות אחרות, כמו הגדלת מערך הנתונים ורגולריזציה, כדי לשפר עוד יותר את הביצועים של מודלים.
PaLM
קיצור של Pathways Language Model (מודל שפה של Pathways).
פנדות
API לניתוח נתונים מבוסס-עמודות, שמבוסס על numpy. הרבה מסגרות של למידת מכונה, כולל TensorFlow, תומכות במבני נתונים של pandas כקלט. פרטים נוספים זמינים בתיעוד של pandas.
פרמטר
המשקולות וההטיות שהמודל לומד במהלך האימון. לדוגמה, במודל של רגרסיה ליניארית, הפרמטרים מורכבים מההטיה (b) ומכל המשקלים (w1, w2 וכן הלאה) בנוסחה הבאה:
לעומת זאת, היפר-פרמטרים הם הערכים שאתם (או שירות לכוונון היפר-פרמטרים) מספקים למודל. לדוגמה, קצב הלמידה הוא פרמטר-על.
כוונון יעיל בפרמטרים
קבוצה של טכניקות לכוונון עדין של מודל שפה גדול שאומן מראש (PLM) בצורה יעילה יותר מאשר כוונון עדין מלא. בדרך כלל, כוונון יעיל בפרמטרים מכוונן הרבה פחות פרמטרים מאשר כוונון מלא, אבל בדרך כלל הוא יוצר מודל שפה גדול עם ביצועים טובים (או כמעט טובים) כמו מודל שפה גדול שנבנה מכוונון מלא.
השוואה בין כוונון יעיל בפרמטרים לבין:
כוונון יעיל בפרמטרים נקרא גם כוונון עדין ויעיל בפרמטרים.
שרת פרמטרים (PS)
משימה שעוקבת אחרי הפרמטרים של מודל בהגדרה מבוזרת.
עדכון הפרמטרים
הפעולה של התאמת הפרמטרים של מודל במהלך האימון, בדרך כלל במסגרת איטרציה אחת של ירידת גרדיאנט.
נגזרת חלקית
נגזרת שבה כל המשתנים, למעט אחד, נחשבים לקבועים. לדוגמה, הנגזרת החלקית של f(x, y) ביחס ל-x היא הנגזרת של f שנחשבת כפונקציה של x בלבד (כלומר, תוך שמירה על y כקבוע). הנגזרת החלקית של f ביחס ל-x מתמקדת רק בשינוי של x ומתעלמת מכל שאר המשתנים במשוואה.
הטיית השתתפות
מילה נרדפת להטיית סקר שלא מולא. ראו הטיית בחירה.
אסטרטגיית חלוקה למחיצות
האלגוריתם שבאמצעותו משתנים מחולקים בין שרתי פרמטרים.
pass at k (pass@k)
מדד לקביעת איכות הקוד (לדוגמה, Python) שנוצר על ידי מודל שפה גדול. באופן ספציפי יותר, הערך של k מציין את הסבירות שלפחות אחד מתוך k בלוקים של קוד שנוצרו יעבור את כל בדיקות היחידה שלו.
למודלים גדולים של שפה (LLM) יש לעיתים קרובות קושי ליצור קוד טוב לבעיות תכנות מורכבות. מהנדסי תוכנה מתמודדים עם הבעיה הזו על ידי הנחיית מודל שפה גדול (LLM) ליצור כמה (k) פתרונות לאותה בעיה. לאחר מכן, מהנדסי תוכנה בודקים כל אחד מהפתרונות באמצעות בדיקות יחידה. החישוב של pass@k תלוי בתוצאה של בדיקות היחידה:
- אם אחד או יותר מהפתרונות האלה עוברים את בדיקת היחידה, אז ה-LLM עובר את האתגר של יצירת הקוד.
- אם אף אחד מהפתרונות לא עובר את בדיקת היחידה, מודל ה-LLM נכשל באתגר הזה של יצירת קוד.
הנוסחה לחישוב ציון המעבר ב-k היא:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
באופן כללי, ערכים גבוהים יותר של k מניבים ציונים גבוהים יותר של מעבר ב-k, אבל ערכים גבוהים יותר של k דורשים יותר משאבים של מודל שפה גדול (LLM) ובדיקות יחידה (unit testing).
מודל השפה Pathways (PaLM)
מודל ישן יותר, שקדם למודלים של Gemini.
Pax
Framework לתכנות שנועד לאימון של מודלים של רשתות נוירונים בקנה מידה גדול, כלומר מודלים כל כך גדולים שהם מתפרסים על פני כמה יחידות TPU, פרוסות או אשכולות של שבבי האצה.
Pax מבוסס על Flax, שמבוסס על JAX.
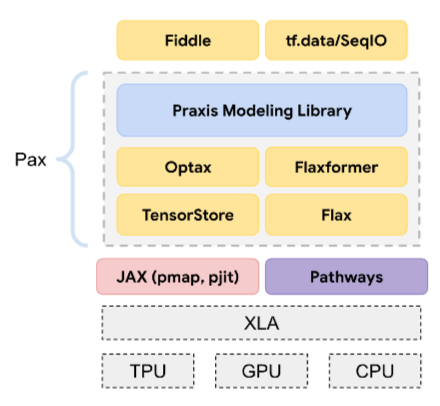
פרספטרון
מערכת (חומרה או תוכנה) שמקבלת ערך קלט אחד או יותר, מפעילה פונקציה על הסכום המשוקלל של הקלטים ומחשבת ערך פלט יחיד. בלמידת מכונה, הפונקציה היא בדרך כלל לא לינארית, כמו ReLU, sigmoid או tanh. לדוגמה, הפרספטרון הבא מסתמך על פונקציית הסיגמואיד כדי לעבד שלושה ערכי קלט:
באיור הבא, הפרספטרון מקבל שלושה קלטים, שכל אחד מהם עובר שינוי באמצעות משקל לפני שהוא נכנס לפרספטרון:

פרספטרונים הם הנוירונים ברשתות נוירונים.
ביצועים
מונח עם כמה משמעויות:
- המשמעות הסטנדרטית בהנדסת תוכנה. כלומר: כמה מהר (או ביעילות) פועל קטע התוכנה הזה?
- המשמעות בהקשר של למידת מכונה. התשובה לשאלה הבאה: עד כמה המודל הזה מדויק? כלומר, עד כמה התחזיות של המודל טובות?
חשיבות משתנים בתמורה
סוג של חשיבות משתנה שמעריך את העלייה בשגיאת החיזוי של מודל אחרי שינוי הערכים של התכונה. חשיבות המשתנה של פרמוטציה היא מדד שלא תלוי במודל.
בלבול
מדד אחד שמשקף את מידת ההצלחה של מודל בהשגת המטרה שלו. לדוגמה, נניח שהמשימה שלכם היא לקרוא את כמה האותיות הראשונות של מילה שמשתמש מקליד במקלדת של טלפון, ולהציע רשימה של מילים אפשריות להשלמה. הערך של מידת ההסתבכות, P, למשימה הזו הוא בערך מספר הניחושים שצריך להציע כדי שהרשימה תכיל את המילה האמיתית שהמשתמש מנסה להקליד.
המדד Perplexity קשור לcross-entropy באופן הבא:
פייפליין
התשתית שמקיפה אלגוריתם של למידת מכונה. פייפליין כולל את איסוף הנתונים, הכנסת הנתונים לקובצי נתוני אימון, אימון של מודל אחד או יותר וייצוא המודלים לסביבת הייצור.
מידע נוסף זמין במאמר צינורות ML בקורס בנושא ניהול פרויקטים של ML.
פייפליינינג
סוג של מקביליות מודל שבו העיבוד של מודל מחולק לשלבים עוקבים, וכל שלב מבוצע במכשיר אחר. בזמן ששלב מסוים מעבד אצווה אחת, השלב הקודם יכול לעבוד על האצווה הבאה.
אפשר לעיין גם במאמר בנושא הדרכה בשלבים.
pjit
פונקציית JAX שמפצלת קוד להרצה בכמה שבבי האצה. המשתמש מעביר פונקציה ל-pjit, שמחזירה פונקציה עם סמנטיקה שוות ערך, אבל היא עוברת קומפילציה לחישוב XLA שפועל בכמה מכשירים (כמו ליבות של GPU או TPU).
PJIT מאפשר למשתמשים לפצל חישובים בלי לשכתב אותם באמצעות מחלקת המחיצות SPMD.
נכון למרץ 2023, pjit מוזג עם jit. מידע נוסף זמין במאמר בנושא מערכים מבוזרים והקבלה אוטומטית.
plan-and-solve
אסטרטגיה אג'נטית שבה המודל מנסח קודם תוכנית מפורטת בת כמה שלבים, לפני שהוא מנסה לבצע פעולות כלשהן.
PLM
קיצור של מודל שפה שעבר אימון מראש.
פלאגין
כלי מודולרי סטנדרטי שאפשר לחבר בקלות לסוכן כדי להרחיב את היכולות שלו. לדוגמה, פלאגין של GitHub מאפשר לסוכנים לבצע פעולות כמו קריאת בעיות ב-GitHub ויצירת בקשות משיכה.
pmap
פונקציית JAX שמבצעת עותקים של פונקציית קלט במכשירי חומרה בסיסיים מרובים (מעבדים, מעבדים גרפיים או TPU), עם ערכי קלט שונים. פונקציית pmap מסתמכת על SPMD.
בלמידת חיזוק, מיפוי הסתברותי של סוכן ממצבים לפעולות.
איגום
הקטנת מטריצה (או מטריצות) שנוצרה על ידי שכבת קונבולוציה קודמת למטריצה קטנה יותר. בדרך כלל, כשמבצעים שילוב של נתונים, לוקחים את הערך המקסימלי או הממוצע של האזור שמשולב. לדוגמה, נניח שיש לנו את מטריצת 3x3 הבאה:
![המטריצה 3x3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingStart.svg?authuser=0&hl=he)
פעולת איגום, כמו פעולת קונבולוציה, מחלקת את המטריצה לפרוסות ואז מחליקה את פעולת הקונבולוציה בצעדים. לדוגמה, נניח שפעולת האיגום מחלקת את מטריצת הקונבולוציה לפרוסות בגודל 2x2 עם צעד של 1x1. כפי שאפשר לראות בתרשים הבא, מתבצעות ארבע פעולות של שיתוף משאבים. נניח שכל פעולת איגום בוחרת את הערך המקסימלי מתוך ארבעת הערכים בפרוסה הזו:
![מטריצת הקלט היא 3x3 עם הערכים: [[5,3,1], [8,2,5], [9,4,3]].
המטריצת המשנה בגודל 2x2 בפינה הימנית העליונה של מטריצת הקלט היא [[5,3], [8,2]], ולכן
פעולת האיגום בפינה הימנית העליונה מחזירה את הערך 8 (שהוא המקסימום מבין 5, 3, 8 ו-2). התת-מטריצה בגודל 2x2 בפינה השמאלית העליונה של מטריצת הקלט היא [[3,1], [2,5]], ולכן פעולת ה-pooling בפינה השמאלית העליונה מחזירה את הערך 5. המטריצה המשנית בגודל 2x2 בפינה הימנית התחתונה של מטריצת הקלט היא [[8,2], [9,4]], ולכן פעולת ה-pooling בפינה הימנית התחתונה מחזירה את הערך 9. המטריצה המשנית בגודל 2x2 בפינה השמאלית התחתונה של מטריצת הקלט היא
[[2,5], [4,3]], ולכן פעולת ה-pooling בפינה השמאלית התחתונה מחזירה את הערך
5. לסיכום, פעולת ה-pooling מניבה את המטריצה 2x2
[[8,5], [9,5]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=0&hl=he)
האיגום עוזר לאכוף אי-תלות בתרגום במטריצת הקלט.
האיגום ליישומי ראייה נקרא באופן רשמי יותר איגום מרחבי. בדרך כלל, ביישומים של סדרות עיתיות, איגום נקרא איגום זמני. בשימוש פחות רשמי, פעולת ה-Pooling נקראת לעיתים קרובות דגימת משנה או דגימת יתר.
קידוד לפי מיקום
שיטה להוספת מידע על המיקום של טוקן ברצף להטמעה של הטוקן. מודלים מסוג טרנספורמר משתמשים בקידוד מיקום כדי להבין טוב יותר את הקשר בין חלקים שונים ברצף.
בדרך כלל, קידוד לפי מיקום מבוסס על פונקציה סינוסואידית. (באופן ספציפי, התדירות והמשרעת של הפונקציה הסינוסואידית נקבעות לפי המיקום של הטוקן ברצף). הטכניקה הזו מאפשרת למודל Transformer ללמוד להתמקד בחלקים שונים של הרצף על סמך המיקום שלהם.
positive class
הכיתה שאתם בודקים.
לדוגמה, המחלקה החיובית במודל לסרטן יכולה להיות 'גידול'. הסיווג החיובי במודל לסיווג אימיילים יכול להיות 'ספאם'.
ההפך מכיתה שלילית.
עיבוד תמונה (Post Processing)
שינוי הפלט של מודל אחרי שהמודל הופעל. אפשר להשתמש בעיבוד שלאחר מכן כדי לאכוף אילוצי הוגנות בלי לשנות את המודלים עצמם.
לדוגמה, אפשר להחיל עיבוד אחרי על מודל סיווג בינארי על ידי הגדרת סף סיווג כך ששוויון הזדמנויות יישמר עבור מאפיין מסוים. כדי לעשות זאת, צריך לוודא ששיעור החיוביים האמיתיים זהה לכל הערכים של אותו מאפיין.
מודל שעבר אימון נוסף
מונח לא מוגדר היטב שמתייחס בדרך כלל למודל שעבר אימון מקדים ועבר עיבוד כלשהו, כמו אחד או יותר מהשלבים הבאים:
PR AUC (השטח מתחת לעקומת הדיוק וההחזרה)
השטח מתחת לעקומת הדיוק וההחזרה שחושבה על ידי אינטרפולציה, שהתקבלה משרטוט נקודות (החזרה, דיוק) עבור ערכים שונים של סף הסיווג.
Praxis
ספריית ליבת ML עם ביצועים גבוהים של Pax. ל-Praxis קוראים לעיתים קרובות 'ספריית השכבות'.
Praxis מכיל לא רק את ההגדרות של מחלקת Layer, אלא גם את רוב הרכיבים התומכים שלה, כולל:
- קלט של נתונים
- ספריות הגדרות (HParam ו-Fiddle)
- optimizers
Praxis מספק את ההגדרות של המחלקה Model.
דיוק
מדד למודלים של סיווג שעונה על השאלה הבאה:
כשהמודל חזה את הסיווג החיובי, מה אחוז החיזויים הנכונים?
זו הנוסחה:
where:
- חיובי אמיתי פירושו שהמודל חזה נכון את המחלקה החיובית.
- תוצאה חיובית שגויה פירושה שהמודל טעה וחיזוי את המחלקה החיובית.
לדוגמה, נניח שמודל יצר 200 תחזיות חיוביות. מתוך 200 התחזיות החיוביות האלה:
- 150 היו חיוביים אמיתיים.
- 50 מהן היו תוצאות חיוביות כוזבות.
במקרה זה:
ההגדרה הזו שונה מדיוק ומהחזרה.
מידע נוסף זמין במאמר סיווג: דיוק, היזכרות, פרסיזיה ומדדים קשורים בסדנה ללמידת מכונה.
דיוק ב-k (precision@k)
מדד להערכת רשימה מדורגת (מסודרת) של פריטים. המדד 'דיוק ב-k' מציין את החלק של k הפריטים הראשונים ברשימה שהם 'רלוונטיים'. כלומר:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
הערך של k צריך להיות קטן מאורך הרשימה שמוחזרת או שווה לו. שימו לב שאורך הרשימה שמוחזרת לא נכלל בחישוב.
רלוונטיות היא לרוב סובייקטיבית. אפילו מעריכים אנושיים מומחים חלוקים בדעתם לגבי הפריטים הרלוונטיים.
השווה ל:
עקומת דיוק-החזרה
עקומת הדיוק לעומת ההחזרה בספי סיווג שונים.
חיזוי (prediction)
הפלט של המודל. לדוגמה:
- החיזוי של מודל סיווג בינארי הוא או המחלקה החיובית או המחלקה השלילית.
- החיזוי של מודל סיווג רב-מחלקתי הוא מחלקה אחת.
- החיזוי של מודל רגרסיה לינארית הוא מספר.
הטיה בתחזית
ערך שמציין את המרחק בין הממוצע של התחזיות לבין הממוצע של התוויות במערך הנתונים.
לא להתבלבל עם מונח ההטיה במודלים של למידת מכונה או עם הטיה באתיקה ובהוגנות.
למידת מכונה חזויה
כל מערכת למידת מכונה רגילה (קלאסית).
למונח predictive ML אין הגדרה רשמית. המונח הזה מבחין בין קטגוריה של מערכות ML שלא מבוססות על AI גנרטיבי.
שוויון חזוי
מדד הוגנות שבודק אם שיעורי הדיוק שווים עבור קבוצות משנה שנבדקות במודל סיווג נתון.
לדוגמה, מודל שמנבא קבלה למכללה יעמוד בדרישות של שוויון חיזוי לפי לאום אם שיעור הדיוק שלו זהה עבור אנשים מליליפוט ואנשים מברובדינגנאג.
לפעמים קוראים לשיטה הזו גם שוויון חזוי בשיעורי ההמרה.
דיון מפורט יותר בנושא שוויון חיזוי זמין במאמר הסבר על הגדרות של הוגנות (סעיף 3.2.1).
השוואת מחירים חזויה
שם נוסף לשוויון חיזוי.
עיבוד מקדים
עיבוד נתונים לפני שהם משמשים לאימון מודל. העיבוד המקדים יכול להיות פשוט כמו הסרת מילים מקורפוס טקסט באנגלית שלא מופיעות במילון האנגלי, או מורכב כמו שינוי של נקודות נתונים באופן שמבטל כמה שיותר מאפיינים שקשורים למאפיינים רגישים. עיבוד מקדים יכול לעזור לעמוד באילוצי הוגנות.מודל שעבר אימון מראש
למרות שהמונח הזה יכול להתייחס לכל מודל מאומן או לווקטור הטמעה מאומן, כיום המונח 'מודל שעבר אימון מראש' מתייחס בדרך כלל למודל שפה גדול (LLM) מאומן או לצורה אחרת של מודל מאומן של AI גנרטיבי.
כדאי לעיין גם בערכים מודל בסיס ומודל בסיסי.
אימון מראש
אימון ראשוני של מודל על מערך נתונים גדול. חלק מהמודלים שעברו אימון מראש הם מודלים גדולים ומסורבלים, ובדרך כלל צריך לשפר אותם באמצעות אימון נוסף. לדוגמה, מומחים ללמידת מכונה יכולים לאמן מראש מודל שפה גדול על מערך נתונים עצום של טקסט, כמו כל הדפים באנגלית בוויקיפדיה. אחרי האימון המקדים, אפשר לשפר את המודל שנוצר באמצעות אחת מהטכניקות הבאות:
אמונה קודמת
מה אתם חושבים על הנתונים לפני שמתחילים לאמן את המודל על סמך הנתונים האלה. לדוגמה, רגולריזציה מסוג L2 מסתמכת על הנחה מוקדמת שמשקלים צריכים להיות קטנים ולהתפלג באופן נורמלי סביב אפס.
Pro
מודל Gemini עם פחות פרמטרים מ-Ultra אבל יותר פרמטרים מ-Nano. פרטים נוספים זמינים במאמר בנושא Gemini Pro.
probabilistic
באופן כללי, כל מצב שבו מתקבלות החלטות על סמך סבירות או סיכויים. מודלים מסוג LLM הם מערכות הסתברותיות, שמייצרות את המילה או המשפט הבאים בתשובה על סמך הסתברויות.
אם רמת האקראיות נמוכה יחסית, מודל LLM יבחר מילים או משפטים עם הסתברות גבוהה. אם רמת האקראיות גבוהה יחסית, מודל LLM יהיה יותר "יצירתי", ולפעמים יבחר מילים או משפטים עם הסתברויות נמוכות יותר.
מודל רגרסיה הסתברותי
מודל רגרסיה שמשתמש לא רק במשקלים של כל תכונה, אלא גם במידת אי הוודאות של המשקלים האלה. מודל רגרסיה הסתברותי יוצר חיזוי ואת אי הוודאות של החיזוי הזה. לדוגמה, מודל רגרסיה הסתברותי עשוי להניב תחזית של 325 עם סטיית תקן של 12. מידע נוסף על מודלים של רגרסיה הסתברותית זמין במאמר הזה ב-Colab בכתובת tensorflow.org.
פונקציית צפיפות הסתברות
פונקציה שמזהה את התדירות של דגימות נתונים עם ערך מסוים בדיוק. כשערכים של קבוצת נתונים הם מספרים רציפים עם נקודה צפה (floating-point), התאמות מדויקות הן נדירות. עם זאת, שילוב של פונקציית צפיפות הסתברות מהערך x לערך y מניב את התדירות הצפויה של דגימות נתונים בין x ל-y.
לדוגמה, נניח שיש התפלגות נורמלית עם ממוצע של 200 וסטיית תקן של 30. כדי לקבוע את התדירות הצפויה של דגימות נתונים שנמצאות בטווח 211.4 עד 218.7, אפשר לבצע אינטגרציה של פונקציית צפיפות ההסתברות להתפלגות נורמלית מ-211.4 עד 218.7.
זיכרון פרוצדורלי
בסוכנים, הידע על אופן ביצוע פעולה כלשהי. לדוגמה, יכול להיות שסוכן יפתח זיכרון פרוצדורלי של איך לחפש באינטרנט ואז יציג את שלושת האתרים המובילים.
הנחיה
כל טקסט שמוזן כקלט למודל שפה גדול כדי להתנות את המודל להתנהג בצורה מסוימת. ההנחיות יכולות להיות קצרות כמו ביטוי, או ארוכות ככל שרוצים (לדוגמה, הטקסט המלא של רומן). ההנחיות מחולקות לכמה קטגוריות, כולל אלה שמוצגות בטבלה הבאה:
| קטגוריית ההנחיה | דוגמה | הערות |
|---|---|---|
| שאלה | מהי מהירות התעופה של יונה? | |
| הוראות | תכתוב שיר מצחיק על ארביטראז'. | פרומפט שמבקש ממודל שפה גדול לעשות משהו. |
| דוגמה | תרגום קוד Markdown ל-HTML. לדוגמה:
Markdown: * list item HTML: <ul> <li>list item</li> </ul> |
המשפט הראשון בהנחיה לדוגמה הזו הוא הוראה. שאר ההנחיה היא הדוגמה. |
| תפקיד | תסביר למה משתמשים בשיטת גרדיאנט ירידה באימון של למידת מכונה, ברמה של דוקטורט בפיזיקה. | החלק הראשון של המשפט הוא הוראה, והביטוי to a PhD in Physics הוא החלק שמתייחס לתפקיד. |
| קלט חלקי שהמודל צריך להשלים | ראש ממשלת בריטניה מתגורר בכתובת | הנחיה חלקית לקלט יכולה להסתיים בפתאומיות (כמו בדוגמה הזו) או להסתיים בקו תחתון. |
מודל AI גנרטיבי יכול להגיב להנחיה באמצעות טקסט, קוד, תמונות, הטמעות, סרטונים… כמעט כל דבר.
למידה מבוססת-הנחיות
יכולת של מודלים מסוימים שמאפשרת להם להתאים את ההתנהגות שלהם בתגובה לקלט טקסט שרירותי (הנחיות). בפרדיגמה טיפוסית של למידה מבוססת-הנחיה, מודל שפה גדול מגיב להנחיה על ידי יצירת טקסט. לדוגמה, נניח שמשתמש מזין את ההנחיה הבאה:
סכמו את חוק התנועה השלישי של ניוטון.
מודל שיכול ללמוד על סמך הנחיות לא עובר אימון ספציפי כדי לענות על ההנחיה הקודמת. במקום זאת, המודל 'יודע' הרבה עובדות על פיזיקה, הרבה על כללי שפה כלליים והרבה על מה נחשב לתשובות שימושיות באופן כללי. הידע הזה מספיק כדי לספק תשובה (בתקווה) מועילה. משוב אנושי נוסף ("התשובה הזו הייתה מסובכת מדי" או "מה זה תגובה?") מאפשר למערכות מסוימות של למידה מבוססת-הנחיות לשפר בהדרגה את התועלת של התשובות שלהן.
שרשור הנחיות
שימוש בפלט של הנחיה אחת כקלט להנחיה אחרת. הנחיה מפורטת ממעט לרוב היא סוג פופולרי של שרשור הנחיות.
עיצוב הנחיות
מילה נרדפת להנדסת הנחיות.
הנדסת הנחיות
האומנות של יצירת הנחיות שמניבות את התשובות הרצויות ממודל שפה גדול. בני אדם מבצעים הנדסת הנחיות. כתיבת הנחיות מובנות היטב היא חלק חיוני בהבטחת תשובות מועילות ממודל שפה גדול. הנדסת הנחיות תלויה בגורמים רבים, כולל:
- קבוצת הנתונים שמשמשת לאימון מוקדם ואולי לכוונון עדין של מודל שפה גדול (LLM).
- רמת האקראיות ופרמטרים אחרים של פענוח שהמודל משתמש בהם כדי ליצור תשובות.
עיצוב פרומפטים הוא מונח נרדף להנדסת פרומפטים.
פרטים נוספים על כתיבת הנחיות מועילות מופיעים במאמר מבוא לעיצוב הנחיות.
קבוצת הנחיות
קבוצה של הנחיות להערכה של מודל שפה גדול. לדוגמה, באיור הבא מוצג סט של הנחיות שכולל שלוש הנחיות:

קבוצות טובות של פרומפטים כוללות אוסף מספיק "רחב" של פרומפטים כדי להעריך באופן יסודי את הבטיחות והתועלת של מודל שפה גדול.
אפשר לעיין גם במאמר בנושא קבוצת תשובות.
כוונון הנחיות
מנגנון כוונון יעיל בפרמטרים שלומד 'קידומת' שהמערכת מוסיפה לפני ההנחיה בפועל.
אחת מהווריאציות של שיפור הנחיות – שנקראת לפעמים שיפור באמצעות קידומת – היא הוספת הקידומת לכל שכבה. לעומת זאת, ברוב המקרים, כוונון הנחיות מוסיף רק קידומת לשכבת הקלט.
provenance
נתונים שמפרטים איך נוצר או שונה תוכן של מדיה דיגיטלית.
proxy (מאפיינים רגישים)
מאפיין שמשמש כתחליף למאפיין רגיש. לדוגמה, יכול להיות שמיקוד של אדם מסוים ישמש כפרוקסי לנתונים כמו הכנסה, גזע או מוצא אתני.תוויות של שרתי proxy
הנתונים שמשמשים לחישוב משוער של התוויות לא זמינים ישירות במערך נתונים.
לדוגמה, נניח שאתם צריכים לאמן מודל כדי לחזות את רמת הלחץ של העובדים. מערך הנתונים מכיל הרבה תכונות חיזוי, אבל לא מכיל תווית בשם stress level. אתם לא מתייאשים ובוחרים בתווית 'תאונות במקום העבודה' כתווית חלופית לרמת הלחץ. בסופו של דבר, עובדים שנמצאים במתח גבוה מעורבים ביותר תאונות מעובדים רגועים. או שכן? יכול להיות ששיעור התאונות במקומות העבודה עולה ויורד מכמה סיבות.
דוגמה נוספת: נניח שרוצים להגדיר את התווית is it raining? כתווית בוליאנית למערך הנתונים, אבל מערך הנתונים לא מכיל נתוני גשם. אם יש תמונות זמינות, יכול להיות שתגדירו תמונות של אנשים עם מטריות כתווית פרוקסי לשאלה is it raining? (האם יורד גשם?). האם זו תווית טובה לשימוש כפרוקסי? יכול להיות, אבל אנשים בתרבויות מסוימות נוטים יותר לשאת מטרייה כדי להגן על עצמם מפני השמש ולא מפני הגשם.
תוויות של שרתי proxy הן לרוב לא מושלמות. במידת האפשר, עדיף לבחור תוויות בפועל ולא תוויות פרוקסי. עם זאת, אם אין תווית בפועל, צריך לבחור את תווית ה-proxy בזהירות רבה, ולבחור את תווית ה-proxy שהכי פחות נוראית.
מידע נוסף זמין במאמר Datasets: Labels (קבוצות נתונים: תוויות) בקורס המקוצר על למידת מכונה.
פונקציה טהורה
פונקציה שהפלט שלה מבוסס רק על הקלט שלה, ואין לה תופעות לוואי. במילים אחרות, פונקציה טהורה לא משתמשת במצב גלובלי ולא משנה אותו, כמו התוכן של קובץ או הערך של משתנה מחוץ לפונקציה.
אפשר להשתמש בפונקציות טהורות כדי ליצור קוד בטוח לשימוש בריבוי תהליכים, וזה שימושי כשמבצעים שרדינג של קוד מודל בכמה שבבי האצה.
שיטות ההמרה של פונקציות ב-JAX מחייבות שהפונקציות שמוזנות יהיו פונקציות טהורות.
Q
פונקציית Q
בלמידת חיזוק, הפונקציה שמנבאת את התשואה הצפויה מביצוע פעולה במצב מסוים, ולאחר מכן פועלת לפי מדיניות נתונה.
פונקציית Q נקראת גם פונקציית ערך של מצב-פעולה.
Q-learning
בלמידת חיזוק, אלגוריתם שמאפשר לסוכן ללמוד את פונקציית ה-Q האופטימלית של תהליך קבלת החלטות של מרקוב על ידי יישום משוואת בלמן. מודלים של תהליך קבלת החלטות של מרקוב מייצגים סביבה.
quantile
כל קטגוריה בקטגוריות של קוונטילים.
חלוקה לקבוצות לפי אחוזון
חלוקת הערכים של מאפיין לקבוצות כך שכל קבוצה מכילה את אותו מספר דוגמאות (או מספר כמעט זהה). לדוגמה, באיור הבא, 44 נקודות מחולקות ל-4 קטגוריות, שבכל אחת מהן יש 11 נקודות. כדי שכל קטגוריה באיור תכיל את אותו מספר נקודות, חלק מהקטגוריות משתרעות על רוחב שונה של ערכי x.

מידע נוסף מופיע במאמר נתונים מספריים: חלוקה לקטגוריות בקורס המקוצר על למידת מכונה.
קוונטיזציה
מונח עמוס שיכול לשמש בכל אחת מהדרכים הבאות:
- הטמעה של חלוקה לקבוצות לפי כמות בתכונה מסוימת.
- הפיכת הנתונים לאפסים ולאחדות כדי לאחסן, לאמן ולהסיק מסקנות מהר יותר. נתונים בוליאניים עמידים יותר לרעשי רקע ולשגיאות בהשוואה לפורמטים אחרים, ולכן כימות יכול לשפר את נכונות המודל. טכניקות הכמותיות כוללות עיגול, חיתוך וחלוקה לקטגוריות.
הפחתת מספר הביטים שמשמשים לאחסון הפרמטרים של מודל. לדוגמה, נניח שהפרמטרים של מודל מאוחסנים כמספרים נקודה צפה (floating-point) של 32 ביט. הקוונטיזציה ממירה את הפרמטרים האלה מ-32 ביט ל-4, 8 או 16 ביט. הכימות מצמצם את:
- שימוש במחשוב, בזיכרון, בדיסק וברשת
- הזמן להסקת תחזית
- צריכת חשמל
עם זאת, לפעמים הכמתה מפחיתה את מידת הנכונות של התחזיות של המודל.
רשימת סרטונים
Operation של TensorFlow שמטמיע מבנה נתונים של תור. בדרך כלל נמצא בשימוש בקלט/פלט.
R
RAG
קיצור של retrieval-augmented generation (יצירה משולבת-אחזור, RAG).
יער אקראי
אנסמבל של עצי החלטה שבהם כל עץ החלטה מאומן עם רעש אקראי ספציפי, כמו bagging.
יערות אקראיים הם סוג של יער החלטות.
מידע נוסף זמין במאמר בנושא יער אקראי בקורס בנושא יערות החלטה.
מדיניות אקראית
בלמידת חיזוק, מדיניות שבוחרת פעולה באופן אקראי.
rank (ordinality)
המיקום הסידורי של מחלקה בבעיה של למידה חישובית שמסווגת מחלקות מהגבוה לנמוך. לדוגמה, מערכת לדירוג התנהגויות יכולה לדרג את התגמולים לכלב מהגבוה ביותר (סטייק) לנמוך ביותר (כרוב עלים נבול).
rank (Tensor)
מספר המאפיינים ב-Tensor. לדוגמה, לערך סקלרי יש דרגה 0, לווקטור יש דרגה 1 ולמטריצה יש דרגה 2.
לא להתבלבל עם דירוג (סדר).
דירוג
סוג של למידה מונחית שמטרתה לסדר רשימה של פריטים.
מעריך
אדם שמספק תוויות לדוגמאות. 'מבצע ההערכה' הוא שם נוסף ל'מדרג'.
מידע נוסף זמין במאמר נתונים קטגוריים: בעיות נפוצות בסדנה ללמידת מכונה.
הבנת הנקרא עם מערך נתונים של חשיבה הגיונית (ReCoRD)
מערך נתונים להערכת היכולת של מודל LLM לבצע היסק על סמך שכל ישר. כל דוגמה במערך הנתונים מכילה שלושה רכיבים:
- פסקות מתוך כתבה
- שאילתה שבה אחת מהישויות שזוהו במפורש או במרומז בקטע מוסתרת.
- התשובה (שם הישות שצריך להופיע במסכה)
רשימה מקיפה של דוגמאות מופיעה במאמר בנושא ReCoRD.
ReCoRD הוא רכיב של SuperGLUE.
RealToxicityPrompts
מערך נתונים שמכיל קבוצה של התחלות משפטים שעשויות להכיל תוכן רעיל. משתמשים במערך הנתונים הזה כדי להעריך את היכולת של מודל שפה גדול (LLM) ליצור טקסט לא רעיל כדי להשלים את המשפט. בדרך כלל, משתמשים ב-Perspective API כדי לקבוע את רמת הביצוע של ה-LLM במשימה הזו.
פרטים נוספים מופיעים במאמר RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models.
reason
שלב בלולאה של סוכן שבו הסוכן קובע מה לעשות. לדוגמה, הסוכן יכול לקבוע שצריך לשלוח בקשת API מסוימת.
recall
מדד למודלים של סיווג שעונה על השאלה הבאה:
אם האמת הבסיסית הייתה הסיווג החיובי, מהו אחוז התחזיות שהמודל זיהה בצורה נכונה כסיווג החיובי?
זו הנוסחה:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
where:
- חיובי אמיתי פירושו שהמודל חזה נכון את המחלקה החיובית.
- תוצאה שלילית שגויה פירושה שהמודל טעה בחיזוי הסיווג השלילי.
לדוגמה, נניח שהמודל שלכם ביצע 200 חיזויים על דוגמאות שבהן האמת הבסיסית הייתה הסיווג החיובי. מתוך 200 התחזיות האלה:
- 180 היו תוצאות חיוביות אמיתיות.
- 20 מהן היו תוצאות שליליות מטעות.
במקרה זה:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
מידע נוסף זמין במאמר בנושא סיווג: דיוק, היזכרות, פרסיזיה ומדדים קשורים.
ריקול ב-k (recall@k)
מדד להערכת מערכות שמפיקות רשימה מדורגת (מסודרת) של פריטים. המדד Recall at k מזהה את החלק של הפריטים הרלוונטיים מתוך k הפריטים הראשונים ברשימה, מתוך המספר הכולל של הפריטים הרלוונטיים שהוחזרו.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
הניגודיות עם דיוק ב-k.
זיהוי של הסקה לוגית מטקסט (RTE)
מערך נתונים להערכת היכולת של מודל LLM לקבוע אם אפשר להסיק השערה (לוגית) מקטע טקסט. כל דוגמה בהערכה של RTE מורכבת משלושה חלקים:
- קטע, בדרך כלל מכתבות חדשותיות או ממאמרים בוויקיפדיה
- השערה
- התשובה הנכונה, שהיא אחת מהאפשרויות הבאות:
- True, meaning the hypothesis can be entailed from the passage
- False, כלומר ההשערה לא יכולה להיות מוסקת מהקטע
לדוגמה:
- קטע: האירו הוא המטבע של האיחוד האירופי.
- היפותזה: בצרפת משתמשים באירו כמטבע.
- היסק: True, כי צרפת היא חלק מהאיחוד האירופי.
RTE הוא רכיב של SuperGLUE ensemble.
מערכת ההמלצות
מערכת שבוחרת לכל משתמש קבוצה קטנה יחסית של פריטים רצויים מתוך מאגר גדול. לדוגמה, מערכת להמלצה על סרטונים עשויה להמליץ על שני סרטונים מתוך מאגר של 100,000 סרטונים. למשתמש אחד היא תבחר את הסרטונים Casablanca ו-The Philadelphia Story, ולמשתמש אחר היא תבחר את הסרטונים Wonder Woman ו-Black Panther. מערכת המלצות לסרטונים עשויה לבסס את ההמלצות שלה על גורמים כמו:
- סרטים שמשתמשים דומים דירגו או צפו בהם.
- ז'אנר, במאים, שחקנים, קבוצה דמוגרפית לטירגוט...
מידע נוסף זמין בקורס בנושא מערכות המלצות.
ReCoRD
קיצור של Reading Comprehension with Commonsense Reasoning Dataset (הבנת הנקרא עם מערך נתונים של חשיבה הגיונית).
יחידה לינארית מתוקנת (ReLU)
פונקציית הפעלה עם ההתנהגות הבאה:
- אם הקלט שלילי או אפס, הפלט הוא 0.
- אם הקלט חיובי, הפלט שווה לקלט.
לדוגמה:
- אם הקלט הוא -3, הפלט הוא 0.
- אם הקלט הוא +3, הפלט הוא 3.0.
הנה גרף של ReLU:
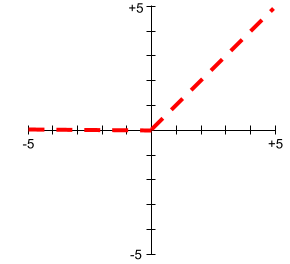
ReLU היא פונקציית הפעלה פופולרית מאוד. למרות ההתנהגות הפשוטה שלה, פונקציית ReLU עדיין מאפשרת לרשת נוירונים ללמוד על קשרים לא לינאריים בין תכונות לבין התווית.
רשת נוירונים חוזרת
רשת נוירונים שמופעלת בכוונה כמה פעמים, כשחלקים מכל הפעלה מוזנים להפעלה הבאה. באופן ספציפי, שכבות מוסתרות מההרצה הקודמת מספקות חלק מהקלט לאותה שכבה מוסתרת בהרצה הבאה. רשתות נוירונים חוזרות שימושיות במיוחד להערכת רצפים, כך שהשכבות הנסתרות יכולות ללמוד מהרצות קודמות של רשת הנוירונים בחלקים קודמים של הרצף.
לדוגמה, באיור הבא מוצגת רשת נוירונים חוזרת שפועלת ארבע פעמים. שימו לב שהערכים שנלמדו בשכבות הנסתרות מההרצה הראשונה הופכים לחלק מהקלט לאותן שכבות נסתרות בהרצה השנייה. באופן דומה, הערכים שנלמדו בשכבה הנסתרת בהרצה השנייה הופכים לחלק מהקלט לאותה שכבה נסתרת בהרצה השלישית. כך, רשת הנוירונים החוזרת מתאמנת בהדרגה ומנבאת את המשמעות של הרצף כולו, ולא רק את המשמעות של מילים בודדות.

טקסט לדוגמה
תשובה של מומחה להנחיה. לדוגמה, אם נותנים את ההנחיה הבאה:
תרגם את השאלה "What is your name?" מאנגלית לצרפתית.
תשובה של מומחה יכולה להיות:
Quel est votre nom?
מדדים שונים (כמו ROUGE) מודדים את מידת ההתאמה בין טקסט ההפניה לבין הטקסט שנוצר על ידי מודל ML.
הרהורים
אסטרטגיה לשיפור האיכות של תהליך עבודה מבוסס-סוכן על ידי בדיקה (רפלקציה) של פלט של שלב מסוים לפני העברת הפלט הזה לשלב הבא.
הבודק הוא לרוב אותו LLM שיצר את התשובה (אבל יכול להיות שזה יהיה LLM אחר). איך יכול להיות שאותו LLM שיצר תשובה ישפוט בצורה הוגנת את התשובה שהוא יצר? הטריק הוא להכניס את ה-LLM למצב חשיבה ביקורתי (רפלקטיבי). התהליך הזה דומה לתהליך שבו סופר משתמש בחשיבה יצירתית כדי לכתוב טיוטה ראשונה, ואז עובר לחשיבה ביקורתית כדי לערוך אותה.
לדוגמה, נניח שיש תהליך עבודה מבוסס-סוכן שהשלב הראשון שלו הוא ליצור טקסט לספלי קפה. ההנחיה לשלב הזה יכולה להיות:
אתם אנשים יצירתיים. תייצר טקסט הומוריסטי ומקורי באורך של פחות מ-50 תווים שמתאים לספל קפה.
עכשיו דמיינו את ההנחיה הרפלקטיבית הבאה:
אתה שותה קפה. האם התגובה הקודמת מצחיקה?
לאחר מכן, יכול להיות שרק טקסט שמקבל ציון גבוה של השתקפות יעבור לשלב הבא בתהליך העבודה.
מודל רגרסיה
באופן לא רשמי, מודל שמפיק חיזוי מספרי. (לעומת זאת, מודל סיווג יוצר חיזוי של מחלקה). לדוגמה, כל המודלים הבאים הם מודלים של רגרסיה:
- מודל שמנבא את הערך של בית מסוים באירו, למשל 423,000.
- מודל שמנבא את תוחלת החיים של עץ מסוים בשנים, כמו 23.2.
- מודל שמנבא את כמות הגשם באינצ'ים שתירד בעיר מסוימת במהלך שש השעות הבאות, למשל 0.18.
שני סוגים נפוצים של מודלים של רגרסיה:
- רגרסיה לינארית, שמוצאת את הקו שהכי מתאים לערכי התוויות ולמאפיינים.
- רגרסיה לוגיסטית, שיוצרת הסתברות בין 0.0 ל-1.0, שבדרך כלל ממופה על ידי המערכת לחיזוי של סיווג.
לא כל מודל שמפיק תחזיות מספריות הוא מודל רגרסיה. במקרים מסוימים, תחזית מספרית היא למעשה מודל סיווג עם שמות של מחלקות מספריות. לדוגמה, מודל שמנבא מיקוד מספרי הוא מודל סיווג ולא מודל רגרסיה.
רגולריזציה (regularization)
כל מנגנון שמפחית התאמת יתר. סוגים פופולריים של רגולריזציה כוללים:
- רגולריזציה מסוג L1
- רגולריזציה מסוג L2
- dropout regularization
- עצירה מוקדמת (זו לא שיטה רשמית של רגולריזציה, אבל היא יכולה להגביל ביעילות את התאמת היתר)
אפשר גם להגדיר רגולריזציה כעונש על מורכבות של מודל.
מידע נוסף זמין במאמר Overfitting: Model complexity (התאמת יתר: מורכבות המודל) בקורס המקוצר על למידת מכונה.
שיעור הרגולריזציה
מספר שמציין את החשיבות היחסית של רגולריזציה במהלך האימון. העלאת שיעור הרגולריזציה מפחיתה את ההתאמה העודפת, אבל עשויה להפחית את יכולת החיזוי של המודל. לעומת זאת, הקטנה של שיעור הרגולריזציה או השמטה שלו מגדילה את התאמת היתר.
מידע נוסף זמין במאמר התאמת יתר: רגולריזציה מסוג L2 בקורס המקוצר על למידת מכונה.
למידת חיזוקים (RL)
משפחה של אלגוריתמים שמלמדים מדיניות אופטימלית, שמטרתה למקסם את ההחזר באינטראקציה עם סביבה. לדוגמה, התגמול האולטימטיבי ברוב המשחקים הוא ניצחון. מערכות של למידת חיזוק יכולות להפוך למומחיות במשחקים מורכבים על ידי הערכה של רצפים של מהלכים קודמים במשחק שהובילו בסופו של דבר לניצחונות, ורצפים שהובילו בסופו של דבר להפסדים.
למידה חיזוקית ממשוב אנושי (RLHF)
שימוש במשוב ממדרגים אנושיים כדי לשפר את האיכות של התשובות של המודל. לדוגמה, מנגנון RLHF יכול לבקש מהמשתמשים לדרג את איכות התשובה של המודל באמצעות אמוג'י של לייק (👍) או דיסלייק (👎). המערכת יכולה לשנות את התשובות העתידיות שלה על סמך המשוב הזה.
ReLU
קיצור של Rectified Linear Unit (יחידה לינארית מתוקנת).
מאגר נתונים זמני להפעלה מחדש
באלגוריתמים דמויי DQN, הזיכרון שבו הסוכן משתמש כדי לאחסן מעברים בין מצבים לשימוש בחזרה על חוויה.
רפליקה
עותק (או חלק ממנו) של קבוצת נתונים לאימון או של מודל, שבדרך כלל מאוחסן במחשב אחר. לדוגמה, מערכת יכולה להשתמש באסטרטגיה הבאה כדי ליישם מקביליות נתונים:
- מציבים רפליקות של מודל קיים בכמה מכונות.
- שליחת קבוצות משנה שונות של קבוצת נתונים לאימון לכל עותק.
- מצטברים העדכונים של הפרמטר.
המונח 'עותק' יכול להתייחס גם לעותק אחר של שרת הסקת מסקנות. הגדלת מספר הרפליקות מגדילה את מספר הבקשות שהמערכת יכולה לטפל בהן בו-זמנית, אבל גם מגדילה את עלויות ההצגה.
הטיית דיווח
העובדה שהתדירות שבה אנשים כותבים על פעולות, תוצאות או מאפיינים לא משקפת את התדירות שלהם בעולם האמיתי או את המידה שבה מאפיין מסוים מאפיין קבוצה של אנשים. הטיה בדיווח יכולה להשפיע על הרכב הנתונים שמערכות למידת מכונה לומדות מהם.
לדוגמה, בספרים, המילה צחק נפוצה יותר מהמילה נשם. מודל למידת מכונה שמעריך את התדירות היחסית של צחוק ונשימה מתוך קורפוס של ספרים, כנראה יקבע שצחוק נפוץ יותר מנשימה.
מידע נוסף זמין במאמר הוגנות: סוגי הטיה בסדנת מבוא ללמידת מכונה.
בווקטור יהיה זהה,
תהליך מיפוי הנתונים לתכונות שימושיות.
דירוג מחדש
השלב האחרון של מערכת המלצות, שבמהלכו יכול להיות שהמערכת תדרג מחדש פריטים שקיבלו ציון לפי אלגוריתם אחר (בדרך כלל, לא אלגוריתם של למידת מכונה). בשלב של דירוג מחדש, המערכת מעריכה את רשימת הפריטים שנוצרה בשלב הניקוד, ומבצעת פעולות כמו:
- הסרת פריטים שהמשתמש כבר רכש.
- העלאת הניקוד של פריטים עדכניים יותר.
מידע נוסף זמין במאמר בנושא דירוג מחדש בקורס בנושא מערכות המלצה.
תשובה
הטקסט, התמונות, האודיו או הסרטון שמודל AI גנרטיבי מסיק. במילים אחרות, הנחיה היא הקלט למודל AI גנרטיבי, והתשובה היא הפלט.
קבוצת תשובות
אוסף התשובות שמודל שפה גדול מחזיר לקלט של הנחיות.
יצירה משולבת-אחזור (RAG)
טכניקה לשיפור האיכות של הפלט של מודל שפה גדול (LLM) על ידי עיגון הפלט למקורות ידע שאוחזרו אחרי שהמודל אומן. טכנולוגיית RAG משפרת את הדיוק של התשובות של מודלי LLM, כי היא מספקת למודל LLM שאומן גישה למידע שאוחזר ממאגרי ידע או ממסמכים מהימנים.
הנה כמה מהסיבות הנפוצות לשימוש ב-RAG:
- שיפור הדיוק העובדתי של תשובות שנוצרו על ידי מודל.
- מתן גישה למודל לידע שהוא לא אומן עליו.
- שינוי הידע שבו המודל משתמש.
- הפעלת האפשרות לציטוט מקורות על ידי המודל.
לדוגמה, נניח שאפליקציה ללימוד כימיה משתמשת ב-PaLM API כדי ליצור סיכומים שקשורים לשאילתות של משתמשים. כשחלק הקצה העורפי של האפליקציה מקבל שאילתה, הוא:
- מחפש (או מאחזר) נתונים שרלוונטיים לשאילתה של המשתמש.
- מצרף ("מרחיב") את נתוני הכימיה הרלוונטיים לשאילתה של המשתמש.
- ההנחיה הזו גורמת ל-LLM ליצור סיכום על סמך הנתונים שנוספו.
שורה חדשה
בלמידה מחיזוקים, בהינתן מדיניות מסוימת ומצב מסוים, הערך המוחזר הוא סכום כל התגמולים שהסוכן צפוי לקבל כשהוא פועל לפי המדיניות מהמצב ועד לסיום הפרק. הסוכן מתחשב באופי המעוכב של התגמולים הצפויים על ידי הנחה של התגמולים בהתאם למעברי המצב הנדרשים כדי לקבל את התגמול.
לכן, אם מקדם ההנחה הוא \(\gamma\), ו \(r_0, \ldots, r_{N}\)מציין את התגמולים עד סוף הפרק, חישוב התשואה הוא כדלקמן:
פרס
בשיטת הלמידה המחוזקת, התוצאה המספרית של ביצוע פעולה במצב, כפי שמוגדר על ידי הסביבה.
רגולריזציה של רכסים
מילה נרדפת לרגולריזציה של L2. המונח ridge regularization (רגולריזציה של רכס) נפוץ יותר בהקשרים של סטטיסטיקה טהורה, ואילו המונח L2 regularization (רגולריזציה של L2) נפוץ יותר בלמידת מכונה.
RNN
קיצור של רשתות נוירונים חוזרות.
עקומת ROC (מאפיין הפעולה של המקלט)
תרשים של שיעור החיוביים האמיתיים לעומת שיעור השליליים הכוזבים עבור סף סיווג שונים בסיווג בינארי.
הצורה של עקומת ROC מצביעה על היכולת של מודל סיווג בינארי להפריד בין סיווגים חיוביים לסיווגים שליליים. נניח, לדוגמה, שמודל סיווג בינארי מפריד בצורה מושלמת בין כל המחלקות השליליות לבין כל המחלקות החיוביות:
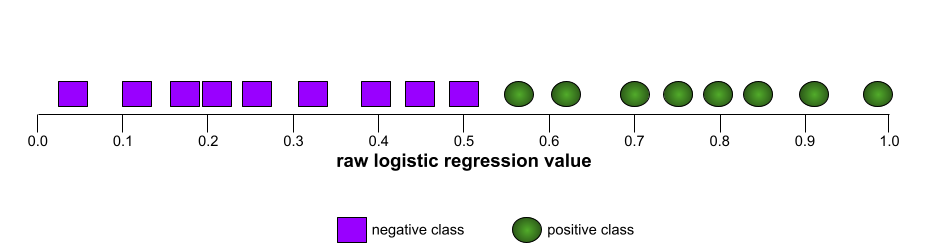
עקומת ה-ROC של המודל הקודם נראית כך:
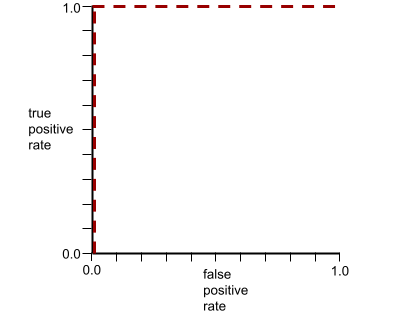
לעומת זאת, באיור הבא מוצגים ערכי הרגרסיה הלוגיסטית הגולמיים של מודל גרוע שלא מצליח להפריד בין מחלקות שליליות למחלקות חיוביות:
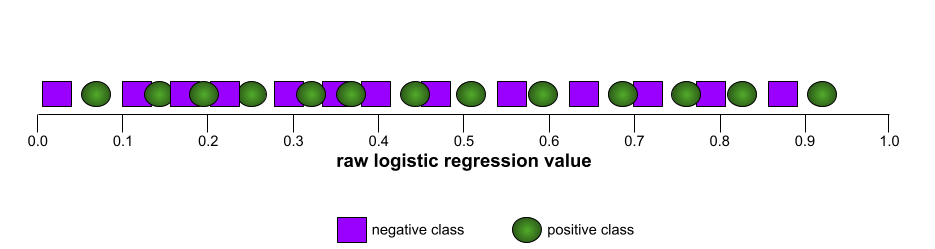
עקומת ה-ROC של המודל הזה נראית כך:
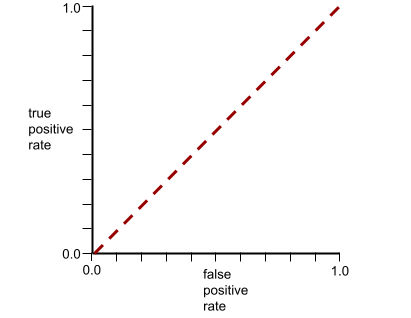
בינתיים, בעולם האמיתי, רוב מודלי הסיווג הבינארי מפרידים בין מחלקות חיוביות ושליליות במידה מסוימת, אבל בדרך כלל לא בצורה מושלמת. לכן, עקומת ROC טיפוסית נמצאת איפשהו בין שני הקצוות:
הנקודה בעקומת ROC שהכי קרובה ל-(0.0,1.0) מזהה באופן תיאורטי את סף הסיווג האידיאלי. עם זאת, יש כמה בעיות אחרות בעולם האמיתי שמשפיעות על הבחירה של סף הסיווג האידיאלי. לדוגמה, יכול להיות שתוצאות שליליות כוזבות גורמות להרבה יותר בעיות מאשר תוצאות חיוביות כוזבות.
מדד מספרי שנקרא AUC מסכם את עקומת ה-ROC לערך יחיד של נקודה צפה.
הנחיות לגילום תפקידים
הנחיה, בדרך כלל מתחילה בכינוי את/אתה/אתם, שמורה למודל AI גנרטיבי להתנהג כמו אדם מסוים או למלא תפקיד מסוים כשהוא יוצר את התשובה. הנחיות שקשורות לתפקיד יכולות לעזור למודל AI גנרטיבי להיכנס ל "מצב המחשבה" הנכון כדי ליצור תשובה שימושית יותר. לדוגמה, כל אחת מההנחיות הבאות להגדרת תפקיד יכולה להתאים בהתאם לסוג התשובה שאתם מחפשים:
יש לך דוקטורט במדעי המחשב.
אתה מהנדס תוכנה שאוהב לתת הסברים סבלניים על Python לתלמידים חדשים בתחום התכנות.
אתה גיבור פעולה עם כישורי תכנות מאוד ספציפיים. תמצא פריט מסוים ברשימת Python.
הרמה הבסיסית (root)
הצומת ההתחלתי (התנאי הראשון) בעץ החלטה. לפי המוסכמה, שורש העץ מוצג בחלק העליון של תרשימי עץ ההחלטות. לדוגמה:
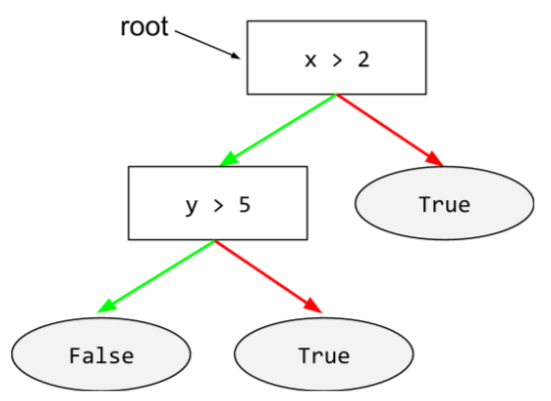
ספריית השורש
הספרייה שאתם מציינים לאירוח ספריות משנה של קובצי TensorFlow checkpoint וקובצי אירועים של כמה מודלים.
שורש טעות ריבועית ממוצעת (RMSE)
השורש הריבועי של הטעות הריבועית הממוצעת.
אינווריאנטיות סיבובית
בבעיה של סיווג תמונות, היכולת של אלגוריתם לסווג תמונות בהצלחה גם כשמשנים את הכיוון של התמונה. לדוגמה, האלגוריתם יכול לזהות מחבט טניס גם אם הוא מוצג כלפי מעלה, לצדדים או כלפי מטה. חשוב לזכור שלא תמיד כדאי להשתמש בתכונה הזו. לדוגמה, אם הספרה 9 מוצגת הפוכה, היא לא צריכה להיות מסווגת כ-9.
אפשר גם לקרוא על אינווריאנטיות להזזה ועל אינווריאנטיות לגודל.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
משפחה של מדדים להערכת מודלים של סיכום אוטומטי ותרגום מכונה. מדדי ROUGE קובעים את מידת החפיפה בין טקסט ייחוס לבין טקסט שנוצר על ידי מודל ML. כל אחד מהמדדים במשפחת ROUGE מודד חפיפה בצורה שונה. ציוני ROUGE גבוהים יותר מצביעים על דמיון רב יותר בין טקסט ההפניה לבין הטקסט שנוצר, בהשוואה לציוני ROUGE נמוכים יותר.
בדרך כלל, כל חבר במשפחת ROUGE יוצר את המדדים הבאים:
- דיוק
- זכירות
- F1
פרטים ודוגמאות מופיעים במאמרים הבאים:
ROUGE-L
חבר במשפחת ROUGE שמתמקד באורך של הרצף המשותף הארוך ביותר בטקסט ההפניה ובטקסט שנוצר. הנוסחאות הבאות משמשות לחישוב ההחזרה והדיוק של ROUGE-L:
אחר כך אפשר להשתמש ב-F1 כדי לסכם את הנתונים של ROUGE-L recall ו-ROUGE-L precision למדד אחד:
המדד ROUGE-L מתעלם ממעברי שורה בטקסט ההשוואה ובטקסט שנוצר, ולכן הרצף המשותף הארוך ביותר יכול לחצות כמה משפטים. אם טקסט ההפניה והטקסט שנוצר כוללים כמה משפטים, מדד טוב יותר בדרך כלל הוא וריאציה של ROUGE-L שנקראת ROUGE-Lsum. המדד ROUGE-Lsum קובע את הרצף המשותף הארוך ביותר לכל משפט בקטע, ואז מחשב את הממוצע של הרצפים המשותפים הארוכים ביותר האלה.
ROUGE-N
קבוצה של מדדים במשפחת ROUGE שמשווה בין ה-N-grams המשותפים בגודל מסוים בטקסט ההפניה לבין הטקסט שנוצר. לדוגמה:
- המדד ROUGE-1 מודד את מספר הטוקנים המשותפים בטקסט ההפניה ובטקסט שנוצר.
- ROUGE-2 מודד את מספר הביגרמות (2-גרמות) המשותפות בטקסט ההפניה ובטקסט שנוצר.
- המדד ROUGE-3 מודד את מספר הטריגרמים (3-גרמים) המשותפים בטקסט ההפניה ובטקסט שנוצר.
אפשר להשתמש בנוסחאות הבאות כדי לחשב את מדד ההחזרה (recall) של ROUGE-N ואת מדד הדיוק (precision) של ROUGE-N לכל חבר במשפחת ROUGE-N:
אחר כך אפשר להשתמש ב-F1 כדי לצמצם את הנתונים של ROUGE-N recall ו-ROUGE-N precision למדד אחד:
ROUGE-S
גרסה סלחנית של ROUGE-N שמאפשרת התאמה של skip-gram. כלומר, ROUGE-N סופר רק N-grams שתואמים בדיוק, אבל ROUGE-S סופר גם N-grams שמפרידה ביניהם מילה אחת או יותר. לדוגמה, שקול את הדברים הבאים:
- טקסט להפניה: עננים לבנים
- טקסט שנוצר: White billowing clouds
כשמחשבים את ROUGE-N, ה-2-gram, White clouds לא תואם ל-White billowing clouds. עם זאת, כשמחשבים את ROUGE-S, White clouds תואם ל-White billowing clouds.
סוכן נתב
סוכן שמסווג שאילתת משתמש ואז מפעיל את הסוכן המתאים ביותר לטיפול בה.
R בריבוע
מדד רגרסיה שמציין כמה מהשונות בתווית נובעת מתכונה יחידה או מקבוצת תכונות. מקדם המתאם R² הוא ערך בין 0 ל-1, שאפשר לפרש אותו באופן הבא:
- ערך של 0 ב-R-squared פירושו שאף אחד מהשינויים בתווית לא נובע מקבוצת התכונות.
- ערך של 1 ב-R בריבוע מציין שכל השונות של תווית מסוימת נובעת מקבוצת התכונות.
- ערך R בריבוע בין 0 ל-1 מציין את המידה שבה אפשר לחזות את השונות של התווית ממאפיין מסוים או מקבוצת המאפיינים. לדוגמה, אם ערך ה-R בריבוע הוא 0.10, המשמעות היא ש-10 אחוזים מהשונות בתווית נובעים מקבוצת התכונות. אם ערך ה-R בריבוע הוא 0.20, המשמעות היא ש-20 אחוזים נובעים מקבוצת התכונות, וכן הלאה.
מקדם המתאם R בריבוע הוא הריבוע של מקדם המתאם של פירסון בין הערכים שהמודל חזה לבין הערכים האמיתיים.
RTE
קיצור של Recognizing Textual Entailment.
S
הטיית דגימה
ראו הטיית בחירה.
דגימה עם החזרה
שיטה לבחירת פריטים מתוך קבוצת פריטים אפשריים, שבה אפשר לבחור את אותו פריט כמה פעמים. הביטוי 'עם החזרה' פירושו שאחרי כל בחירה, הפריט שנבחר מוחזר למאגר הפריטים שאפשר לבחור מהם. בשיטה ההפוכה, דגימה ללא החזרה, אפשר לבחור פריט מועמד רק פעם אחת.
לדוגמה, נניח שיש לכם את קבוצת הפירות הבאה:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}נניח שהמערכת בוחרת באופן אקראי את fig כפריט הראשון.
אם משתמשים בדגימה עם החזרה, המערכת בוחרת את הפריט השני מתוך הקבוצה הבאה:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}כן, זה אותו סט כמו קודם, כך שהמערכת יכולה לבחור שוב את fig.
אם משתמשים בדגימה ללא החזרה, אחרי שבוחרים דגימה אי אפשר לבחור אותה שוב. לדוגמה, אם המערכת בוחרת באופן אקראי את fig כמדגם הראשון, היא לא יכולה לבחור בו שוב.fig לכן, המערכת בוחרת את הדגימה השנייה מתוך הקבוצה הבאה (המצומצמת):
fruit = {kiwi, apple, pear, cherry, lime, mango}SavedModel
הפורמט המומלץ לשמירה ולשחזור של מודלים של TensorFlow. SavedModel הוא פורמט סריאליזציה שאינו תלוי בשפה וניתן לשחזור, שמאפשר למערכות ולכלים ברמה גבוהה יותר ליצור, לצרוך ולשנות מודלים של TensorFlow.
פרטים מלאים מופיעים בקטע שמירה ושחזור במדריך לתכנתים של TensorFlow.
חסכוני
אובייקט TensorFlow שאחראי לשמירת נקודות ביקורת (checkpoint) של המודל.
סקלרי
מספר בודד או מחרוזת בודדת שאפשר לייצג כטנזור מדרגה 0. לדוגמה, כל אחת משורות הקוד הבאות יוצרת סקלר אחד ב-TensorFlow:
breed = tf.Variable("poodle", tf.string)
temperature = tf.Variable(27, tf.int16)
precision = tf.Variable(0.982375101275, tf.float64)התאמה לעומס (scaling)
כל טרנספורמציה או טכניקה מתמטית שמשנה את הטווח של תווית, של ערך מאפיין או של שניהם. חלק מהשיטות לשינוי קנה מידה שימושיות מאוד לנורמליזציה.
דוגמאות נפוצות לשיטות שימושיות של שינוי קנה מידה בלמידת מכונה:
- קנה מידה לינארי, שבדרך כלל משתמש בשילוב של חיסור וחילוק כדי להחליף את הערך המקורי במספר בין -1 ל-+1 או בין 0 ל-1.
- סולם לוגריתמי, שמחליף את הערך המקורי בלוגריתם שלו.
- נורמליזציה של ציון Z, שמחליפה את הערך המקורי בערך נקודה צפה שמייצג את מספר סטיות התקן מהממוצע של התכונה.
scikit-learn
פלטפורמה פופולרית ללמידת מכונה בקוד פתוח. מידע נוסף זמין באתר scikit-learn.org.
דירוג
החלק במערכת ההמלצות שמספק ערך או דירוג לכל פריט שנוצר בשלב יצירת המועמדים.
הטיית בחירה
שגיאות במסקנות שמוסקים מנתונים שנלקחו לדוגמה בגלל תהליך בחירה שמייצר הבדלים שיטתיים בין הדוגמאות שנצפו בנתונים לבין אלה שלא נצפו. אלה סוגי הטיית הבחירה שקיימים:
- הטיה בכיסוי: האוכלוסייה שמיוצגת במערך הנתונים לא תואמת לאוכלוסייה שלגביה מודל למידת המכונה מפיק תחזיות.
- הטיית דגימה: הנתונים לא נאספים באופן אקראי מקבוצת היעד.
- הטיית סקר שלא מולא (נקראת גם הטיית השתתפות): משתמשים מקבוצות מסוימות בוחרים שלא להשתתף בסקרים בשיעורים שונים ממשתמשים מקבוצות אחרות.
לדוגמה, נניח שאתם יוצרים מודל למידת מכונה שמנבא את מידת ההנאה של אנשים מסרט. כדי לאסוף נתוני אימון, אתם מחלקים שאלון לכל מי שיושב בשורה הראשונה באולם קולנוע שבו מוקרן הסרט. מבלי לחשוב יותר מדי, יכול להיות שזו נראית דרך סבירה לאיסוף מערך נתונים. עם זאת, שיטת איסוף הנתונים הזו עלולה להוביל להטיות הבחירה הבאות:
- הטיה בכיסוי: אם המודל מתבסס על מדגם של אנשים שבחרו לצפות בסרט, יכול להיות שהתחזיות שלו לא יהיו רלוונטיות לאנשים שלא הביעו עניין ברמה הזו בסרט.
- הטיה בדגימה: במקום לדגום באופן אקראי מתוך האוכלוסייה המיועדת (כל האנשים בסרט), דגמתם רק את האנשים בשורה הראשונה. יכול להיות שהאנשים שישבו בשורה הראשונה התעניינו בסרט יותר מאלה שישבו בשורות אחרות.
- הטיה בגלל אי-היענות: באופן כללי, אנשים עם דעות מוצקות נוטים להשיב לסקרים אופציונליים בתדירות גבוהה יותר מאנשים עם דעות מתונות. מכיוון שהשתתפות בסקר על הסרט היא אופציונלית, סביר יותר שהתשובות יצרו התפלגות דו-אופנית ולא התפלגות נורמלית (בצורת פעמון).
קשב עצמי (נקרא גם שכבת קשב עצמי)
שכבה של רשת נוירונים שמבצעת טרנספורמציה של רצף הטמעות (לדוגמה, הטמעות של טוקנים) לרצף אחר של הטמעות. כל הטמעה ברצף הפלט נוצרת על ידי שילוב מידע מהאלמנטים של רצף הקלט באמצעות מנגנון הפניית תשומת לב.
החלק self במונח self-attention מתייחס לרצף שמתייחס לעצמו ולא להקשר אחר. קשב עצמי הוא אחד מאבני הבניין העיקריות של טרנספורמרים, והוא משתמש בטרמינולוגיה של חיפוש במילון, כמו 'שאילתה', 'מפתח' ו'ערך'.
שכבת קשב עצמי מתחילה ברצף של ייצוגי קלט, אחד לכל מילה. ייצוג הקלט של מילה יכול להיות הטמעה פשוטה. לכל מילה ברצף קלט, הרשת מחשבת את מידת הרלוונטיות של המילה לכל רכיב ברצף המילים כולו. הציונים לרלוונטיות קובעים עד כמה הייצוג הסופי של המילה משלב את הייצוגים של מילים אחרות.
לדוגמה, נבחן את המשפט הבא:
החיה לא חצתה את הכביש כי היא הייתה עייפה מדי.
באיור הבא (מתוך Transformer: A Novel Neural Network Architecture for Language Understanding) מוצג דפוס הקשב של שכבת קשב עצמי עבור כינוי הגוף it. עובי הקו מציין את מידת התרומה של כל מילה לייצוג:
שכבת הקשב העצמי מדגישה מילים שרלוונטיות למילה it. במקרה הזה, שכבת תשומת הלב למדה להדגיש מילים שהיא עשויה להתייחס אליהן, והיא מקצה את המשקל הגבוה ביותר למילה animal (חיה).
ברצף של n טוקנים, מנגנון הקשב העצמי מבצע טרנספורמציה של רצף של הטמעות n פעמים נפרדות, פעם אחת בכל מיקום ברצף.
כדאי לעיין גם במאמרים בנושא תשומת לב ותשומת לב עצמית עם מספר ראשים.
תיקון עצמי
היכולת של סוכן לזהות שגיאה בפלט שלו ואז לנסות גישה אחרת.
למידה בפיקוח עצמי
משפחה של טכניקות להמרת בעיה של למידת מכונה לא מבוקרת לבעיה של למידת מכונה מבוקרת על ידי יצירת תוויות חלופיות מדוגמאות לא מתויגות.
חלק מהמודלים שמבוססים על טרנספורמר, כמו BERT, משתמשים בלמידה בפיקוח עצמי.
אימון בפיקוח עצמי הוא גישה של למידה מונחית למחצה.
אימון עצמי
וריאציה של למידה בפיקוח עצמי, שימושית במיוחד כשמתקיימים כל התנאים הבאים:
- היחס בין דוגמאות לא מסומנות לבין דוגמאות מסומנות במערך הנתונים גבוה.
- זו בעיה של סיווג.
באימון עצמי, המערכת חוזרת על שני השלבים הבאים עד שהמודל מפסיק להשתפר:
- משתמשים בלמידת מכונה מבוקרת כדי לאמן מודל על הדוגמאות המתויגות.
- משתמשים במודל שנוצר בשלב 1 כדי ליצור תחזיות (תוויות) בדוגמאות שלא סומנו בתוויות, ומעבירים את הדוגמאות שבהן רמת הביטחון גבוהה לדוגמאות שסומנו בתוויות עם התווית החזויה.
שימו לב שבכל איטרציה של שלב 2 מתווספות דוגמאות מתויגות נוספות לשלב 1, לצורך אימון.
זיכרון סמנטי
המידע שזמין ל-LLM בסיום האימון. לדוגמה, זיכרון סמנטי כולל ידע מצוין בדקדוק, באוצר מילים ובעובדות שהמודל אומן עליהן באופן מפורש.
הזיכרון הסמנטי לא כולל מידע שנאסף מיצירה משופרת באמצעות אחזור.
הסבר על זיכרון סמנטי בהשוואה לזיכרון אפיזודי.
למידה מונחית למחצה
אימון מודל על נתונים שחלק מדוגמאות האימון שלהם מתויגות וחלק לא. טכניקה אחת ללמידה מונחית למחצה היא להסיק תוויות לדוגמאות לא מסומנות, ואז לאמן את התוויות שהוסקו כדי ליצור מודל חדש. למידה חצי-מפוקחת יכולה להיות שימושית אם קשה להשיג תוויות, אבל יש הרבה דוגמאות לא מסומנות.
אימון עצמי הוא אחת הטכניקות ללמידה מונחית למחצה.
מאפיין רגיש
מאפיין אנושי שעשוי לקבל התייחסות מיוחדת מסיבות משפטיות, אתיות, חברתיות או אישיות.ניתוח סנטימנט
שימוש באלגוריתמים סטטיסטיים או של למידת מכונה כדי לקבוע את הגישה הכללית של קבוצה – חיובית או שלילית – כלפי שירות, מוצר, ארגון או נושא. לדוגמה, באמצעות הבנת שפה טבעית, אלגוריתם יכול לבצע ניתוח סנטימנטים על המשוב הטקסטואלי מקורס באוניברסיטה כדי לקבוע עד כמה התלמידים אהבו או לא אהבו את הקורס באופן כללי.
מידע נוסף זמין במדריך בנושא סיווג טקסט.
מודל רצף
מודל שהקלט שלו תלוי ברצף. לדוגמה, חיזוי הסרטון הבא שייצפה מתוך רצף של סרטונים שנצפו בעבר.
משימה של רצף לרצף
משימה שממירה רצף קלט של טוקנים לרצף פלט של טוקנים. לדוגמה, שני סוגים פופולריים של משימות sequence-to-sequence הם:
- מתרגמים:
- רצף קלט לדוגמה: "I love you" (אני אוהב/ת אותך).
- רצף פלט לדוגמה: "Je t'aime."
- מענה לשאלות:
- רצף קלט לדוגמה: "Do I need my car in New York City?"
- רצף פלט לדוגמה: "לא. עדיף להשאיר את הרכב בבית".
מנה
התהליך של הפיכת מודל מאומן לזמין כדי לספק תחזיות באמצעות הסקת מסקנות אונליין או הסקת מסקנות אופליין.
shape (Tensor)
מספר הרכיבים בכל ממד של טנזור. הצורה מיוצגת כרשימה של מספרים שלמים. לדוגמה, לטנזור הדו-ממדי הבא יש צורה של [3,4]:
[[5, 7, 6, 4], [2, 9, 4, 8], [3, 6, 5, 1]]
TensorFlow משתמש בפורמט row-major (בסגנון C) כדי לייצג את סדר המימדים, ולכן הצורה ב-TensorFlow היא [3,4] ולא [4,3]. במילים אחרות, בטנזור דו-ממדי של TensorFlow, הצורה היא [[מספר השורות, מספר העמודות]].
צורה סטטית היא צורה של טנסור שידועה בזמן הקומפילציה.
צורה דינמית היא לא ידועה משך הזמן לקימפול ולכן היא תלויה בנתוני זמן הריצה. טנסור כזה יכול להיות מיוצג באמצעות ממד placeholder ב-TensorFlow, כמו בדוגמה [3, ?].
פצל
חלוקה לוגית של קבוצת נתונים לאימון או של המודל. בדרך כלל, תהליך מסוים יוצר רסיסים על ידי חלוקה של הדוגמאות או הפרמטרים לחלקים בגודל שווה (בדרך כלל). כל רסיס מוקצה למכונה אחרת.
החלוקה של מודל נקראת מקבילות של מודל, והחלוקה של נתונים נקראת מקבילות של נתונים.
כיווץ
היפר-פרמטר בחיזוק גרדיאנט ששולט בהתאמת יתר. ההתכווצות בחיזוק גרדיאנט דומה לקצב הלמידה בירידת גרדיאנט. הערך של ההתכווצות הוא מספר עשרוני בין 0.0 ל-1.0. ערך כיווץ נמוך יותר מפחית את התאמת היתר יותר מערך כיווץ גבוה יותר.
הערכה מקבילה
השוואה בין האיכות של שני מודלים על סמך התשובות שלהם לאותה הנחיה. לדוגמה, נניח שנותנים את ההנחיה הבאה לשני מודלים שונים:
צור תמונה של כלב חמוד שמלהטט עם שלושה כדורים.
בבדיקה של תמונות זו לצד זו, בודק יבחר את התמונה ה "טובה יותר" (יותר מדויקת? יותר יפה? יותר חמודים?).
פונקציית סיגמואיד
פונקציה מתמטית ש'דוחסת' ערך קלט לטווח מוגבל, בדרך כלל 0 עד 1 או -1 עד +1. כלומר, אפשר להעביר כל מספר (שניים, מיליון, מינוס מיליארד, מה שרוצים) לפונקציית הסיגמואיד, והפלט עדיין יהיה בטווח המוגבל. גרף של פונקציית ההפעלה הסיגמואידית נראה כך:
לפונקציית הסיגמואיד יש כמה שימושים בלמידת מכונה, כולל:
- המרת הפלט הגולמי של מודל רגרסיה לוגיסטית או רגרסיה מולטינומיאלית להסתברות.
- משמשת כפונקציית הפעלה בחלק מהרשתות העצביות.
מדד הדמיון
באלגוריתמים של אשכולות, המדד שמשמש לקביעת מידת הדמיון בין שני מקרים.
תוכנית יחידה / נתונים מרובים (SPMD)
טכניקה של מקביליות שבה אותו חישוב מורץ על נתוני קלט שונים במקביל במכשירים שונים. המטרה של SPMD היא להשיג תוצאות מהר יותר. זהו הסגנון הנפוץ ביותר של תכנות מקבילי.
אי-תלות בגודל
בבעיה של סיווג תמונות, היכולת של אלגוריתם לסווג תמונות בהצלחה גם כשגודל התמונה משתנה. לדוגמה, האלגוריתם עדיין יכול לזהות חתול גם אם הוא צורך 2 מיליון פיקסלים וגם אם הוא צורך 200,000 פיקסלים. חשוב לציין שגם לאלגוריתמים הטובים ביותר לסיווג תמונות יש מגבלות מעשיות לגבי אי-תלות בגודל. לדוגמה, סביר להניח שאלגוריתם (או אדם) לא יסווג נכון תמונה של חתול אם היא תהיה בגודל של 20 פיקסלים בלבד.
אפשר גם לקרוא על אינווריאנטיות להזזה ועל אינווריאנטיות לסיבוב.
מידע נוסף זמין בקורס בנושא אשכולות.
רישום
בלמידת מכונה לא מפוקחת, קטגוריה של אלגוריתמים שמבצעים ניתוח דמיון מקדים על דוגמאות. אלגוריתמים של סקיצות משתמשים ב פונקציית גיבוב (hash) שרגישה למיקום כדי לזהות נקודות שסביר להניח שהן דומות, ואז מקבצים אותן לדליים.
השימוש בשיטת הסקיצה מצמצם את כמות החישובים שנדרשת לחישובי דמיון במערכי נתונים גדולים. במקום לחשב את הדמיון לכל זוג דוגמאות בקבוצת הנתונים, אנחנו מחשבים את הדמיון רק לכל זוג נקודות בכל קטגוריה.
skip-gram
n-gram שיכול להיות שחסרות בו מילים מההקשר המקורי (או שהוא 'מדלג' על מילים), כלומר יכול להיות שהמילים לא היו סמוכות במקור. באופן מדויק יותר, k-skip-n-gram הוא n-gram שבו יכול להיות שדילגו על עד k מילים.
לדוגמה, המשפט "the quick brown fox" מכיל את ה-2-גרמים האפשריים הבאים:
- "the quick"
- "quick brown"
- "brown fox"
'1-skip-2-gram' הוא צמד מילים שיש ביניהן מילה אחת לכל היותר. לכן, הביטוי "the quick brown fox" כולל את ה-2-grams הבאים עם דילוג של 1:
- "the brown"
- "quick fox"
בנוסף, כל ה-2-grams הם גם 1-skip-2-grams, כי אפשר לדלג על פחות ממילה אחת.
דיאגרמות דילוג שימושיות להבנת ההקשר הרחב יותר של מילה. בדוגמה, המילה fox הייתה משויכת ישירות למילה quick בקבוצה של 1-skip-2-grams, אבל לא בקבוצה של 2-grams.
דיאגרמות Skip-gram עוזרות לאמן מודלים של הטמעת מילה.
softmax
פונקציה שקובעת הסתברויות לכל מחלקה אפשרית במודל סיווג רב-מחלקה. סכום ההסתברויות הוא בדיוק 1.0. לדוגמה, בטבלה הבאה אפשר לראות איך פונקציית softmax מחלקת הסתברויות שונות:
| התמונה היא… | Probability |
|---|---|
| כלב | 0.85 |
| cat | .13 |
| סוס | .02 |
Softmax נקרא גם full softmax.
ההבדל בין שיטת הדגימה הזו לבין דגימת מועמדים.
מידע נוסף זמין במאמר רשתות עצביות: סיווג רב-מחלקתי בקורס המקוצר בנושא למידת מכונה.
כוונון הנחיות רך
טכניקה לכוונון מודל שפה גדול למשימה מסוימת, בלי כוונון עדין שדורש הרבה משאבים. במקום לאמן מחדש את כל המשקלים במודל, שינוי עדין של הנחיה משנה באופן אוטומטי הנחיה כדי להשיג את אותה מטרה.
בהינתן הנחיה טקסטואלית, כוונון הנחיה רך בדרך כלל מוסיף להנחיה הטמעות של טוקנים נוספים ומבצע אופטימיזציה של הקלט באמצעות הפצת שגיאה לאחור.
הנחיה 'קשה' מכילה טוקנים בפועל במקום הטבעות של טוקנים.
תכונה דלילה
תכונה שהערכים שלה הם בעיקר אפס או ריקים. לדוגמה, תכונה שמכילה ערך 1 יחיד ומיליון ערכים של 0 היא דלילה. לעומת זאת, לתכונה צפופה יש ערכים שהם בעיקר לא אפס או לא ריקים.
בלמידת מכונה, מספר מפתיע של מאפיינים הם מאפיינים דלילים. תכונות קטגוריות הן בדרך כלל תכונות דלילות. לדוגמה, מתוך 300 מיני עצים אפשריים ביער, דוגמה אחת יכולה לזהות רק עץ אדר. או מתוך מיליוני הסרטונים האפשריים בספריית סרטונים, דוגמה אחת יכולה לזהות רק את הסרט 'קזבלנקה'.
במודל, בדרך כלל מייצגים מאפיינים דלילים באמצעות קידוד חם-יחיד. אם הקידוד מסוג "חם-יחיד" גדול, אפשר להוסיף שכבת הטמעה מעל הקידוד מסוג "חם-יחיד" כדי לשפר את היעילות.
ייצוג דליל
אחסון רק של המיקומים של רכיבים שאינם אפס בתכונה דלילה.
לדוגמה, נניח שיש תכונה קטגורית בשם species שמזהה את 36 מיני העצים ביער מסוים. בנוסף, נניח שכל דוגמה מזהה רק מין אחד.
אפשר להשתמש בווקטור בקידוד one-hot כדי לייצג את מיני העצים בכל דוגמה.
וקטור one-hot יכיל ערך 1 אחד (לייצוג של מין העץ הספציפי בדוגמה) ו-35 ערכים של 0 (לייצוג של 35 מיני העצים שלא בדוגמה). לכן, ייצוג one-hot של maple יכול להיראות כך:

לחלופין, ייצוג דליל יזהה פשוט את המיקום של המין המסוים. אם maple נמצא במיקום 24, הייצוג הדליל של maple יהיה פשוט:
24
שימו לב שהייצוג הדליל הרבה יותר קומפקטי מהייצוג one-hot.
כדי לראות דוגמה קצת יותר מורכבת, לוחצים על הסמל.
נניח שכל דוגמה במודל צריכה לייצג את המילים במשפט באנגלית, אבל לא את הסדר שלהן. השפה האנגלית כוללת כ-170,000 מילים, ולכן היא מאפיין קטגורי עם כ-170,000 רכיבים. רוב המשפטים באנגלית משתמשים בחלק קטן מאוד מ-170,000 המילים האלה, ולכן קבוצת המילים בדוגמה אחת כמעט תמיד תהיה נתונים דלילים.
נניח שיש לכם את המשפט הבא:
My dog is a great dog
אפשר להשתמש בווקטור one-hot כדי לייצג את המילים במשפט הזה. בגרסה הזו, כמה תאים בווקטור יכולים להכיל ערך שונה מאפס. בנוסף, בגרסה הזו, תא יכול להכיל מספר שלם שאינו 1. המילים my, is, a ו-great מופיעות רק פעם אחת במשפט, אבל המילה dog מופיעה פעמיים. שימוש בווריאציה הזו של וקטורים עם קידוד one-hot לייצוג המילים במשפט הזה יוצר את הווקטור הבא עם 170,000 רכיבים:

ייצוג דליל של אותו משפט יהיה פשוט:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
מידע נוסף זמין במאמר עבודה עם נתונים שמחולקים לקטגוריות בסדנת מבוא ללמידת מכונה.
וקטור דליל
וקטור שהערכים שלו הם בעיקר אפסים. כדאי לעיין גם במאמרים בנושא תכונת הדלילות ודלילות.
sparsity
מספר הרכיבים שמוגדרים לאפס (או לערך null) בווקטור או במטריצה, חלקי המספר הכולל של הערכים בווקטור או במטריצה. לדוגמה, נניח שיש מטריצה עם 100 רכיבים, שבה 98 תאים מכילים אפס. החישוב של הדלילות מתבצע כך:
דלילות המאפיינים מתייחסת לדלילות של וקטור מאפיינים, ודלילות המודל מתייחסת לדלילות של משקלי המודל.
איגום מרחבי
קידוד לפי מפרט
התהליך של כתיבה ותחזוקה של קובץ בשפה טבעית (לדוגמה, אנגלית) שמתאר תוכנה. אחר כך אפשר להנחות מודל AI גנרטיבי או מהנדס תוכנה אחר ליצור את התוכנה שתואמת לתיאור הזה.
בדרך כלל צריך לבצע איטרציה על קוד שנוצר באופן אוטומטי. בקידוד ספציפי, חוזרים על הפעולה בקובץ התיאור. לעומת זאת, בתכנות שיחתי, חוזרים על הפעולה בתיבת ההנחיה. בפועל, יצירת קוד אוטומטית כוללת לפעמים שילוב של גם קידוד ספציפי וגם קידוד שיחתי.
פיצול
מפצל
במהלך אימון של עץ החלטה, השגרה (והאלגוריתם) שאחראית למציאת התנאי הטוב ביותר בכל צומת.
SPMD
קיצור של single program / multiple data (תוכנית אחת / נתונים מרובים).
SQuAD
ראשי תיבות של Stanford Question Answering Dataset (מערך נתונים של סטנפורד למענה על שאלות), שהוצג במאמר SQuAD: 100,000+ Questions for Machine Comprehension of Text (מערך SQuAD: יותר מ-100,000 שאלות להבנת טקסט על ידי מכונה). השאלות במערך הנתונים הזה מגיעות מאנשים ששואלים שאלות לגבי מאמרים בוויקיפדיה. לחלק מהשאלות ב-SQuAD יש תשובות, אבל לחלק אחר אין תשובות בכוונה. לכן, אפשר להשתמש ב-SQuAD כדי להעריך את היכולת של LLM לבצע את שתי הפעולות הבאות:
- לענות על שאלות שאפשר לענות עליהן.
- לזהות שאלות שאי אפשר לענות עליהן.
התאמה מדויקת בשילוב עם F1 הם המדדים הנפוצים ביותר להערכת מודלים גדולים של שפה (LLM) בהשוואה ל-SQuAD.
squared hinge loss
הריבוע של הפסד הציר. הפסד ציר בריבוע מעניש חריגים בצורה חמורה יותר מאשר הפסד ציר רגיל.
squared loss
מילה נרדפת להפסד L2.
אימון מדורג
טקטיקה לאימון מודל ברצף של שלבים נפרדים. המטרה יכולה להיות האצת תהליך האימון או שיפור איכות המודל.
האיור הבא ממחיש את הגישה של הוספה הדרגתית של שכבות:
- שלב 1 מכיל 3 שכבות מוסתרות, שלב 2 מכיל 6 שכבות מוסתרות ושלב 3 מכיל 12 שכבות מוסתרות.
- בשלב 2 מתחילים באימון עם המשקלים שנלמדו ב-3 השכבות המוסתרות של שלב 1. בשלב 3 מתחיל האימון עם המשקלים שנלמדו ב-6 השכבות המוסתרות של שלב 2.
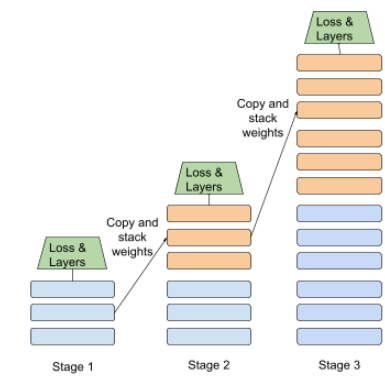
מידע נוסף זמין במאמר בנושא צינורות (pipelining).
הסמוי הסופי
בלמידת חיזוק, ערכי הפרמטרים שמתארים את ההגדרה הנוכחית של הסביבה, שהסוכן משתמש בה כדי לבחור פעולה.
פונקציית ערך של מצב-פעולה
מילה נרדפת ל-Q-function.
סוכן מכונת מצבים
סוכן שתהליכי העבודה שלו מוגבלים על ידי כללים נוקשים. בדרך כלל, סוכני מכונת מצבים עושים פחות טעויות מסוכנים אוטונומיים, אבל אין להם את החופש להתאים את עצמם למצבים שלא נכללים במגבלות שלהם.
סטטי
משהו שעושים פעם אחת ולא באופן רציף. המונחים סטטי ואופליין הם מילים נרדפות. אלה שימושים נפוצים במונחים סטטי ואופליין בלמידת מכונה:
- מודל סטטי (או מודל אופליין) הוא מודל שעובר אימון פעם אחת ואז משתמשים בו למשך תקופה.
- אימון סטטי (או אימון אופליין) הוא תהליך האימון של מודל סטטי.
- היקש סטטי (או היקש אופליין) הוא תהליך שבו מודל יוצר קבוצה של תחזיות בכל פעם.
ניגודיות לדינמי.
היקש סטטי
מילה נרדפת להסקת מסקנות במצב אופליין.
סטציונריות
תכונה שהערכים שלה לא משתנים לאורך מאפיין אחד או יותר, בדרך כלל זמן. לדוגמה, תכונה שהערכים שלה דומים ב-2021 וב-2023 מציגה סטציונריות.
בעולם האמיתי, מעט מאוד תכונות מציגות סטציונריות. גם תכונות שמזוהות עם יציבות (כמו גובה פני הים) משתנות עם הזמן.
ההפך מאי-סטציונריות.
שלב
העברה קדימה והעברה אחורה של batch אחד.
מידע נוסף על המעבר קדימה והמעבר אחורה זמין במאמר בנושא backpropagation.
גודל השלב
מילה נרדפת לקצב למידה.
ירידת גרדיאנט סטוכסטית (SGD)
אלגוריתם gradient descent שבו גודל האצווה הוא אחד. במילים אחרות, SGD מתאמן על דוגמה אחת שנבחרה באופן אחיד ואקראי מתוך קבוצת נתונים לאימון.
מידע נוסף זמין במאמר רגרסיה ליניארית: היפר-פרמטרים בקורס המקוצר על למידת מכונה.
פסיעה
בפעולת קונבולוציה או איגום, הדלתא בכל מימד של הסדרה הבאה של פרוסות הקלט. לדוגמה, באנימציה הבאה מוצג פסיעה (1,1) במהלך פעולת קונבולוציה. לכן, פרוסת הקלט הבאה מתחילה מיקום אחד מימין לפרוסת הקלט הקודמת. כשהפעולה מגיעה לקצה הימני, הפלח הבא נמצא בצד שמאל, אבל מיקום אחד למטה.
בדוגמה שלמעלה מוצג קפיצה דו-ממדית. אם מטריצת הקלט היא תלת-ממדית, גם הצעד יהיה תלת-ממדי.
צמצום סיכונים מבניים (SRM)
אלגוריתם שמאזן בין שני יעדים:
- הצורך לבנות את המודל הכי מדויק (לדוגמה, עם האובדן הכי נמוך).
- הצורך לשמור על מודל פשוט ככל האפשר (לדוגמה, רגולריזציה חזקה).
לדוגמה, פונקציה שממזערת את אובדן הנתונים + הרגולריזציה במערך האימון היא אלגוריתם של מזעור סיכונים מבניים.
ההפך מצמצום סיכונים אמפירי.
סוכן משנה
מודל מיוחד וממוקד שמופעל על ידי סוכן ניהול כדי לטפל בקבוצת משנה ספציפית של בעיה גדולה יותר. בדרך כלל, ל-sub-agents יש מרחב פעולה מצומצם יותר מאשר לאגנטים.
דגימת משנה
טוקן של תת-מילה
במודלים של שפה, טוקן הוא מחרוזת משנה של מילה, שיכולה להיות המילה כולה.
לדוגמה, המילה itemize (לפרט) יכולה להתפצל לחלקים item (פריט, מילת בסיס) ו-ize (סיומת), וכל אחד מהם מיוצג על ידי טוקן משלו. פיצול מילים לא נפוצות לחלקים כאלה, שנקראים תת-מילים, מאפשר למודלים של שפה לפעול על החלקים הנפוצים יותר של המילה, כמו תחיליות וסיומות.
לעומת זאת, מילים נפוצות כמו going לא יפוצלו ועשויות להיות מיוצגות על ידי טוקן יחיד.
סיכום
ב-TensorFlow, ערך או קבוצת ערכים שמחושבים בשלב מסוים, בדרך כלל משמשים למעקב אחרי מדדי מודל במהלך האימון.
SuperGLUE
קבוצה של מערכי נתונים לדירוג היכולת הכוללת של מודל שפה גדול (LLM) להבין וליצור טקסט. האנסמבל מורכב ממערכי הנתונים הבאים:
- Boolean Questions (BoolQ)
- CommitmentBank (CB)
- בחירת חלופות סבירות (COPA)
- הבנת הנקרא של כמה משפטים (MultiRC)
- מערך נתונים של הבנת הנקרא עם הסקה מבוססת-שכל ישר (ReCoRD)
- Recognizing Textual Entailment (RTE)
- מילים בהקשר (WiC)
- Winograd Schema Challenge (WSC)
פרטים נוספים זמינים במאמר SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.
למידת מכונה מפוקחת
אימון מודל מתכונות והתוויות התואמות שלהן. למידת מכונה מפוקחת דומה ללימוד נושא מסוים על ידי עיון בסדרת שאלות ובתשובות המתאימות להן. אחרי שהתלמידים יבינו את הקשר בין השאלות לתשובות, הם יוכלו לענות על שאלות חדשות (שלא נראו קודם) באותו נושא.
השוואה ללמידת מכונה לא מפוקחת.
מידע נוסף זמין במאמר Supervised Learning (למידה מפוקחת) בקורס Introduction to ML (מבוא ל-ML).
תכונה סינתטית
תכונה שלא מופיעה בין תכונות הקלט, אבל מורכבת מאחת או יותר מהן. שיטות ליצירת תכונות סינתטיות:
- חלוקה לקטגוריות של תכונה רציפה לקטגוריות של טווחים.
- יצירת תכונה חוצה.
- הכפלה (או חלוקה) של ערך תכונה אחד בערך של תכונה אחרת(או תכונות אחרות) או בעצמו. לדוגמה, אם
aו-bהם מאפייני קלט, אלה דוגמאות למאפיינים סינתטיים:- ab
- a2
- החלת פונקציה טרנסצנדנטית על ערך של תכונה. לדוגמה, אם
cהוא מאפיין קלט, אלה דוגמאות למאפיינים סינתטיים:- sin(c)
- ln(c)
תכונות שנוצרו על ידי נרמול או שינוי קנה מידה בלבד לא נחשבות לתכונות סינתטיות.
T
T5
מודל ללמידת העברה מטקסט לטקסט, שהוצג על ידי Google AI בשנת 2020. T5 הוא מודל מקודד-מפענח שמבוסס על ארכיטקטורת Transformer, שאומן על מערך נתונים גדול במיוחד. הוא יעיל במגוון משימות של עיבוד שפה טבעית (NLP), כמו יצירת טקסט, תרגום שפות ומענה על שאלות בסגנון שיחה.
השם T5 מגיע מחמש האותיות T בביטוי Text-to-Text Transfer Transformer (יצירת טקסט על סמך טקסט).
T5X
מסגרת ללמידת מכונה מבוססת קוד פתוח שנועדה ליצור ולאמן מודלים של עיבוד שפה טבעית (NLP) בקנה מידה גדול. T5 מיושם בבסיס הקוד של T5X (שמבוסס על JAX ועל Flax).
tabular Q-learning
בלמידת חיזוק, מיישמים Q-learning באמצעות טבלה לאחסון פונקציות Q לכל שילוב של מצב ופעולה.
יעד
מילה נרדפת לתווית.
רשת היעד
ב-Deep Q-learning, רשת נוירונים שהיא קירוב יציב של רשת הנוירונים הראשית, כאשר רשת הנוירונים הראשית מיישמת פונקציית Q או מדיניות. לאחר מכן, אפשר לאמן את הרשת הראשית על ערכי ה-Q שחזתה רשת היעד. כך נמנעים ממצב של משוב שמתרחש כשהרשת הראשית מתאמנת על ערכי Q שהיא עצמה חוזה. כך אפשר לשפר את יציבות האימון.
משימה
בעיה שאפשר לפתור באמצעות טכניקות של למידת מכונה, כמו:
פירוק משימות
פירוק של יעד גדול לשלבים קטנים וניתנים לביצוע. סוכנים מטפלים בבעיות מסוימות באמצעות פירוק משימות.
טמפרטורה
היפרפרמטר ששולט במידת הרנדומיזציה של הפלט של מודל. טמפרטורות גבוהות יותר יובילו לתוצאות אקראיות יותר, ואילו טמפרטורות נמוכות יותר יובילו לתוצאות פחות אקראיות.
הטמפרטורה הטובה ביותר תלויה באפליקציה הספציפית ובערכי המחרוזת.
נתונים זמניים
נתונים שנרשמו בנקודות זמן שונות. לדוגמה, נתוני מכירות של מעילי חורף שנרשמו לכל יום בשנה הם נתונים זמניים.
Tensor
מבנה הנתונים העיקרי בתוכניות TensorFlow. טנסורים הם מבני נתונים בעלי N ממדים (כאשר N יכול להיות מספר גדול מאוד), בדרך כלל סקלרים, וקטורים או מטריצות. הרכיבים של Tensor יכולים להכיל ערכים של מספרים שלמים, נקודה צפה או מחרוזות.
TensorBoard
לוח הבקרה שבו מוצגים הסיכומים שנשמרו במהלך ההרצה של תוכנית TensorFlow אחת או יותר.
TensorFlow
פלטפורמה מבוזרת ללמידת מכונה בקנה מידה גדול. המונח מתייחס גם לשכבת ה-API הבסיסית במערך TensorFlow, שתומכת בחישוב כללי בתרשימי זרימת נתונים.
למרות ש-TensorFlow משמש בעיקר ללמידת מכונה, אפשר להשתמש בו גם למשימות שאינן קשורות ללמידת מכונה, שדורשות חישובים מספריים באמצעות תרשימי זרימת נתונים.
TensorFlow Playground
תוכנית שממחישה איך היפרפרמטרים שונים משפיעים על אימון המודל (בעיקר רשת נוירונים). כדי להתנסות ב-TensorFlow Playground, עוברים אל http://playground.tensorflow.org.
TensorFlow Serving
פלטפורמה לפריסת מודלים מאומנים בסביבת ייצור.
Tensor Processing Unit (TPU)
מעגל משולב לאפליקציות ספציפיות (ASIC) שמבצע אופטימיזציה של הביצועים של עומסי עבודה של למידת מכונה. ה-ASIC האלה נפרסים כשבבי TPU מרובים במכשיר TPU.
דירוג טנסור
מידע נוסף זמין במאמר בנושא rank (Tensor).
צורת טנסור
מספר הרכיבים שTensor מכיל במאפיינים שונים.
לדוגמה, לטנזור [5, 10] יש צורה של 5 בממד אחד ו-10 בממד אחר.
גודל הטנסור
המספר הכולל של ערכים סקלריים שמוכלים ב-Tensor. לדוגמה, לטנזור [5, 10] יש גודל של 50.
TensorStore
ספרייה לקריאה ולכתיבה יעילות של מערכים גדולים רב-ממדיים.
תנאי סיום
ב-AI סוכן, הקריטריונים המוגדרים מראש שמנחים את הסוכן להפסיק את האיטרציה. לדוגמה, הנה כמה תנאי סיום אפשריים:
- הסוכן השלים את המטרה.
- הסוכן לא יכול להשתמש במשאבים נוספים.
- human-in-the-loop זיהה בעיה.
בלמידת חיזוק, התנאים שמגדירים מתי מסתיים פרק, למשל כשהסוכן מגיע למצב מסוים או חורג ממספר סף של מעברים בין מצבים. לדוגמה, באיקס עיגול, פרק מסתיים כששחקן מסמן שלושה ריבועים רצופים או כשכל הריבועים מסומנים.
בדיקה
הפסד בבדיקה
מדד שמייצג את ההפסד של מודל בהשוואה לקבוצת נתונים לבדיקה. כשבונים מודל, בדרך כלל מנסים למזער את אובדן הבדיקה. הסיבה לכך היא שערך נמוך של הפסד בבדיקה הוא אות איכות חזק יותר מערך נמוך של הפסד באימון או של הפסד באימות.
פער גדול בין הפסד הבדיקה לבין הפסד האימון או הפסד האימות מצביע לפעמים על הצורך להגדיל את שיעור הרגולריזציה.
קבוצת נתונים לבדיקה
קבוצת משנה של מערך הנתונים ששמורה לבדיקה של מודל שאומן.
באופן מסורתי, מחלקים את הדוגמאות במערך הנתונים לשלוש קבוצות משנה נפרדות:
- קבוצת נתונים לאימון
- קבוצת נתונים לתיקוף
- קבוצת נתונים לבדיקה
כל דוגמה בקבוצת נתונים צריכה להיות שייכת רק לאחת מקבוצות המשנה הקודמות. לדוגמה, דוגמה אחת לא יכולה להיות גם בקבוצת נתונים לאימון וגם בקבוצת נתונים לבדיקה.
קבוצת הנתונים לאימון וקבוצת הנתונים לתיקוף קשורות קשר הדוק לאימון של מודל. מכיוון שקבוצת נתונים לבדיקה משויכת לאימון באופן עקיף בלבד, הפסד הבדיקה הוא מדד פחות מוטה ואיכותי יותר מאשר הפסד האימון או הפסד האימות.
מידע נוסף זמין במאמר מערכי נתונים: חלוקת מערך הנתונים המקורי בקורס המקוצר על למידת מכונה.
טווח טקסט
טווח האינדקס של המערך שמשויך לחלק משני של מחרוזת טקסט.
לדוגמה, המילה good במחרוזת Python s="Be good now" תופסת את טווח הטקסט מ-3 עד 6.
tf.Example
מאגר אחסון לפרוטוקולים סטנדרטי לתיאור נתוני קלט לאימון או היקש של מודל למידת מכונה.
tf.keras
הטמעה של Keras שמשולבת ב-TensorFlow.
סף (עבור עצי החלטה)
בתנאי שמוגדר לאורך ציר, הערך שמאפיין מושווה אליו. לדוגמה, 75 הוא ערך הסף בתנאי הבא:
grade >= 75
מידע נוסף זמין במאמר Exact splitter for binary classification with numerical features בקורס Decision Forests.
ניתוח של סדרות זמנים
תחום משנה של למידת מכונה וסטטיסטיקה שבו מנתחים נתונים זמניים. סוגים רבים של בעיות בלמידת מכונה דורשים ניתוח של סדרות זמן, כולל סיווג, אשכולות, חיזוי וזיהוי אנומליות. לדוגמה, אפשר להשתמש בניתוח של סדרות זמן כדי לחזות את המכירות העתידיות של מעילי חורף לפי חודש, על סמך נתוני מכירות היסטוריים.
timestep
תא אחד 'לא מגולגל' בתוך רשת נוירונים חוזרת. לדוגמה, באיור הבא מוצגים שלושה שלבים בזמן (מסומנים במדדי המשנה t-1, t ו-t+1):

token
במודל שפה, היחידה האטומית שהמודל מתאמן עליה ומבצע חיזויים לגביה. אסימון הוא בדרך כלל אחד מהבאים:
- מילה – לדוגמה, הביטוי "dogs like cats" (כלבים אוהבים חתולים) מורכב משלושה טוקנים של מילים: "dogs", "like" ו-"cats".
- תו – לדוגמה, הביטוי bike fish מורכב מתשעה טוקנים של תווים. (שימו לב שהרווח נחשב כאחד מהטוקנים).
- מילים חלקיות – מילה אחת יכולה להיות טוקן אחד או כמה טוקנים. מילת משנה מורכבת ממילת בסיס, מקידומת או מסיומת. לדוגמה, מודל שפה שמשתמש במילים חלקיות כאסימונים עשוי לראות את המילה dogs כשני אסימונים (מילת הבסיס dog והסיומת s של צורת הרבים). אותו מודל שפה עשוי לראות במילה 'גבוה יותר' שתי מילים משנה (מילת הבסיס 'גבוה' והסיומת 'יותר').
בדומיינים מחוץ למודלי שפה, טוקנים יכולים לייצג סוגים אחרים של יחידות אטומיות. לדוגמה, בראייה ממוחשבת, טוקן יכול להיות קבוצת משנה של תמונה.
מידע נוסף זמין במאמר מודלים גדולים של שפה בקורס Machine Learning Crash Course.
tokenizer
מערכת או אלגוריתם שמתרגמים רצף של נתוני קלט לטוקנים.
רוב המודלים הבסיסיים המודרניים הם רב-אופניים. טוקנייזר למערכת מולטימודלית צריך לתרגם כל סוג קלט לפורמט המתאים. לדוגמה, אם נתוני הקלט כוללים גם טקסט וגם גרפיקה, יכול להיות שהטוקנייזר יתרגם את טקסט הקלט למילים חלקיות ואת תמונות הקלט לטלאים קטנים. לאחר מכן, הטוקנייזר צריך להמיר את כל הטוקנים למרחב הטמעה מאוחד יחיד, כדי שהמודל יוכל 'להבין' זרם של קלט רב-אופני.
דיוק top-k
אחוז הפעמים שבהן 'תווית היעד' מופיעה בתוך k המיקומים הראשונים של רשימות שנוצרו. הרשימות יכולות להיות המלצות מותאמות אישית או רשימה של פריטים שמסודרים לפי softmax.
דיוק k המובילים נקרא גם דיוק ב-k.
מגדל
רכיב של רשת עצבית עמוקה שהוא בעצמו רשת עצבית עמוקה. במקרים מסוימים, כל מגדל קורא ממקור נתונים עצמאי, והמגדלים האלה נשארים עצמאיים עד שהפלט שלהם משולב בשכבה סופית. במקרים אחרים (לדוגמה, ב-מקודד וב-מפענח של טרנספורמרים), יש קשרים צולבים בין המגדלים.
תוכן רעיל
המידה שבה התוכן פוגעני, מאיים או מעליב. הרבה מודלים של למידת מכונה יכולים לזהות, למדוד ולסווג רעילות. רוב המודלים האלה מזהים רעילות לפי כמה פרמטרים, כמו רמת השפה הפוגעת ורמת השפה המאיימת.
TPU
קיצור של Tensor Processing Unit (יחידת עיבוד טנסור).
שבב TPU
מאיץ אלגברה לינארית שניתן לתכנות עם זיכרון בעל רוחב פס גבוה על השבב, שעבר אופטימיזציה לעומסי עבודה של למידת מכונה. כמה שבבי TPU נפרסים במכשיר TPU.
מכשיר TPU
לוח מעגלים מודפס (PCB) עם כמה שבבי TPU, ממשקי רשת עם רוחב פס גבוה ורכיבי חומרה לקירור המערכת.
צומת TPU
משאב TPU ב-Google Cloud עם סוג TPU ספציפי. צומת ה-TPU מתחבר לרשת ה-VPC מרשת VPC שכנה. צומתי TPU הם משאב שמוגדר ב-Cloud TPU API.
TPU Pod
תצורה ספציפית של מכשירי TPU במרכז נתונים של Google. כל המכשירים ב-TPU Pod מחוברים זה לזה דרך רשת ייעודית מהירה. TPU Pod הוא ההגדרה הגדולה ביותר של מכשירי TPU שזמינה לגרסה ספציפית של TPU.
משאב TPU
ישות TPU ב-Google Cloud שאתם יוצרים, מנהלים או משתמשים בה. לדוגמה, צומתי TPU וסוגי TPU הם משאבי TPU.
TPU slice
TPU slice הוא חלק קטן ממכשירי TPU ב-TPU Pod. כל המכשירים בפרוסת TPU מחוברים זה לזה ברשת ייעודית במהירות גבוהה.
סוג ה-TPU
הגדרה של מכשירי TPU אחד או יותר עם גרסת חומרה ספציפית של TPU. כשיוצרים צומת TPU ב-Google Cloud, בוחרים את סוג ה-TPU. לדוגמה, סוג TPU v2-8 הוא מכשיר TPU v2 יחיד עם 8 ליבות. סוג TPU v3-2048 כולל 256 מכשירי TPU v3 שמחוברים לרשת ו-2,048 ליבות בסך הכול. סוגי TPU הם משאב שמוגדר ב-Cloud TPU API.
TPU worker
תהליך שפועל במחשב מארח ומבצע תוכניות של למידת מכונה במכשירי TPU.
הדרכה
התהליך של קביעת הפרמטרים האידיאליים (משקלים והטיות) שמרכיבים מודל. במהלך האימון, מערכת קוראת דוגמאות ומתאימה בהדרגה את הפרמטרים. במהלך האימון, כל דוגמה משמשת בין כמה פעמים למיליארדי פעמים.
מידע נוסף זמין במאמר Supervised Learning (למידה מפוקחת) בקורס Introduction to ML (מבוא ל-ML).
הפסד האימון
מדד שמייצג את ההפסד של מודל במהלך איטרציה מסוימת של אימון. לדוגמה, נניח שפונקציית ההפסד היא Mean Squared Error. יכול להיות שההפסד של האימון (השגיאה הממוצעת בריבוע) באיטרציה העשירית הוא 2.2, וההפסד של האימון באיטרציה ה-100 הוא 1.9.
עקומת הפסד מציגה את הפסד האימון לעומת מספר האיטרציות. עקומת הפסד מספקת את הרמזים הבאים לגבי האימון:
- שיפוע כלפי מטה מעיד על שיפור במודל.
- שיפוע כלפי מעלה מרמז שהמודל הולך ונעשה גרוע יותר.
- שיפוע שטוח מרמז שהמודל הגיע להתכנסות.
לדוגמה, עקומת ההפסד הבאה היא אידיאלית במידה מסוימת, והיא מציגה:
- שיפוע חד כלפי מטה במהלך האיטרציות הראשוניות, שמצביע על שיפור מהיר של המודל.
- שיפוע שמשתטח בהדרגה (אבל עדיין יורד) עד לסיום האימון, מה שמצביע על שיפור מתמשך במודל בקצב איטי יותר מאשר במהלך האיטרציות הראשוניות.
- שיפוע שטוח לקראת סוף האימון, שמצביע על התכנסות.
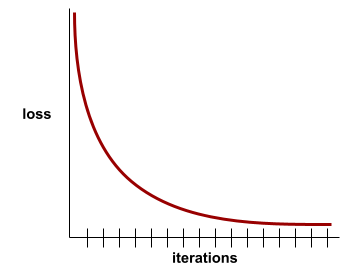
למרות שחשוב להבין את הפסדי האימון, כדאי גם לעיין במושג הכללה.
training-serving skew
ההבדל בין הביצועים של מודל מסוים במהלך האימון לבין הביצועים של אותו מודל במהלך הצגת המודעות.
קבוצת נתונים לאימון
קבוצת המשנה של מערך הנתונים שמשמשת לאימון מודל.
באופן מסורתי, הדוגמאות במערך הנתונים מחולקות לשלוש קבוצות משנה נפרדות:
- קבוצת נתונים לאימון
- קבוצת נתונים לתיקוף
- קבוצת נתונים לבדיקה
באופן אידיאלי, כל דוגמה בקבוצת הנתונים צריכה להיות שייכת רק לאחת מקבוצות המשנה הקודמות. לדוגמה, דוגמה אחת לא יכולה להיות גם בקבוצת נתונים לאימון וגם בקבוצת נתונים לתיקוף.
מידע נוסף זמין במאמר מערכי נתונים: חלוקת מערך הנתונים המקורי בקורס המקוצר על למידת מכונה.
מסלול
בלמידת חיזוק, רצף של טופלים שמייצגים רצף של מעברי מצב של הסוכן, כאשר כל טופל מתאים למצב, לפעולה, למשוב ולמצב הבא של מעבר מצב נתון.
למידה בהעברה
העברת מידע ממשימת למידת מכונה אחת לאחרת. לדוגמה, בלמידה רב-משימתית, מודל יחיד פותר כמה משימות, כמו מודל עמוק שיש לו צמתי פלט שונים למשימות שונות. העברת ידע יכולה לכלול העברת ידע מפתרון של משימה פשוטה יותר למשימה מורכבת יותר, או העברת ידע ממשימה שבה יש יותר נתונים למשימה שבה יש פחות נתונים.
רוב מערכות הלמידה החישובית פותרות משימה אחת. למידה בהעברה היא שלב ראשוני לקראת בינה מלאכותית, שבו תוכנית אחת יכולה לפתור כמה משימות.
רובוטריק
ארכיטקטורה של רשת נוירונים שפותחה ב-Google ומסתמכת על מנגנוני self-attention כדי להמיר רצף של הטמעות קלט לרצף של הטמעות פלט, בלי להסתמך על convolutions או על רשתות נוירונים חוזרות. אפשר לראות טרנספורמר כסטאק של שכבות קשב עצמי.
טרנספורמציה יכולה לכלול כל אחד מהרכיבים הבאים:
מקודד הופך רצף של הטמעות לרצף חדש באורך זהה. מקודד כולל N שכבות זהות, שכל אחת מהן מכילה שתי שכבות משנה. שתי שכבות המשנה האלה מוחלות בכל מיקום של רצף הטמעת הקלט, ומשנות כל אלמנט ברצף להטמעה חדשה. שכבת המשנה הראשונה של המקודד צוברת מידע מרצף הקלט. שכבת המשנה השנייה של המקודד הופכת את המידע המצטבר להטמעה של פלט.
מפענח הופך רצף של הטמעות קלט לרצף של הטמעות פלט, שאולי יהיה באורך שונה. מפענח כולל גם N שכבות זהות עם שלוש שכבות משנה, שתיים מהן דומות לשכבות המשנה של המקודד. שכבת המשנה השלישית של המפענח מקבלת את הפלט של המקודד ומפעילה את מנגנון הקשב העצמי כדי לאסוף ממנו מידע.
בפוסט בבלוג Transformer: A Novel Neural Network Architecture for Language Understanding מוצג מבוא טוב לטרנספורמרים.
מידע נוסף זמין במאמר LLMs: What's a large language model? (מודלים גדולים של שפה: מהו מודל שפה גדול?) בקורס Machine Learning Crash Course (קורס מקוצר על למידת מכונה).
אינווריאנטיות תרגומית
בבעיה של סיווג תמונות, היכולת של אלגוריתם לסווג תמונות בהצלחה גם כשמיקום האובייקטים בתוך התמונה משתנה. לדוגמה, האלגוריתם עדיין יכול לזהות כלב, בין אם הוא נמצא במרכז הפריים או בקצה השמאלי של הפריים.
אפשר גם לקרוא על אי-תלות בגודל ועל אי-תלות בסיבוב.
הנחיות בטכניקת עץ החשיבה (ToT)
אסטרטגיית הנחיות מתוחכמת שמעודדת מודל LLM לחפש ולשפר את הפתרונות הביניים המבטיחים ביותר, ולזנוח את השאר. הנחיה מסוג 'עץ מחשבה' משתמשת באלגוריתם כמו זה שמופיע בהמשך:
- לחלק בעיה מורכבת לענפים שונים (אסטרטגיות פוטנציאליות), כל אחד מורכב מכמה שלבים.
- מנחים את מודל השפה הגדול לעבוד על כל הסתעפות בנפרד.
- אחרי כל שלב, מבקשים מ-LLM להעריך את איכות הפתרון בכל ענף.
- ממשיכים לשפר את הענפים המבטיחים ביותר ומבטלים את השאר.
- אם ענף מבטיח נכשל בסופו של דבר, חוזרים אחורה ומנסים שלבים מבטיחים אחרים.
טריגרמה
N-gram שבו N=3.
מענה על שאלות טריוויה
מערכי נתונים להערכת היכולת של מודל שפה גדול לענות על שאלות טריוויה. כל מערך נתונים מכיל זוגות של שאלות ותשובות שנכתבו על ידי חובבי טריוויה. מערכי נתונים שונים מבוססים על מקורות שונים, כולל:
- חיפוש באינטרנט (TriviaQA)
- ויקיפדיה (TriviaQA_wiki)
מידע נוסף זמין במאמר TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension.
שלילי אמיתי (TN)
דוגמה שבה המודל מנבא בצורה נכונה את הסיווג השלילי. לדוגמה, המודל מסיק שהודעת אימייל מסוימת היא לא ספאם, והודעת האימייל הזו באמת לא ספאם.
חיובי אמיתי (TP)
דוגמה שבה המודל מנבא בצורה נכונה את הסיווג החיובי. לדוגמה, המודל מסיק שהודעת אימייל מסוימת היא ספאם, והודעת האימייל הזו באמת ספאם.
שיעור חיובי אמיתי (TPR)
מילה נרדפת לrecall. כלומר:
שיעור החיוביים האמיתיים הוא ציר ה-y בעקומת ROC.
TTL
קיצור של time to live (אורך חיים).
מענה לשאלות בשפות מגוונות מבחינה טיפולוגית (TyDi QA)
מערך נתונים גדול להערכת היכולת של מודל LLM לענות על שאלות. מערך הנתונים מכיל זוגות של שאלות ותשובות בשפות רבות.
פרטים נוספים זמינים במאמר TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages.
U
UCR
קיצור של שיעור הטענות הלא נתמכות.
Ultra
מודל Gemini עם הכי הרבה פרמטרים. פרטים נוספים זמינים במאמר בנושא Gemini Ultra.
כדאי לעיין גם במאמרים בנושא Pro ו-Nano.
חוסר מודעות (למאפיין רגיש)
מצב שבו קיימים מאפיינים רגישים, אבל הם לא נכללים בנתוני האימון. מכיוון שלעתים קרובות יש קורלציה בין מאפיינים רגישים לבין מאפיינים אחרים בנתונים של מישהו, יכול להיות שלמודל שאומן בלי להביא בחשבון מאפיין רגיש עדיין תהיה השפעה לא שוויונית ביחס למאפיין הזה, או שהוא יפר אילוצים אחרים של הוגנות.
התאמה חסרה (underfitting)
יצירת מודל עם יכולת חיזוי נמוכה, כי המודל לא הצליח לתפוס באופן מלא את המורכבות של נתוני האימון. יש הרבה בעיות שיכולות לגרום להתאמה חסרה, כולל:
- אימון על קבוצה שגויה של תכונות.
- אימון של פחות מדי תקופות אימון או עם קצב למידה נמוך מדי.
- אימון עם שיעור רגולריזציה גבוה מדי.
- מספר קטן מדי של שכבות נסתרות ברשת נוירונים עמוקה.
מידע נוסף מופיע במאמר בנושא התאמת יתר בקורס המקוצר על למידת מכונה.
תת-דגימה
הסרת דוגמאות מהסיווג הרוב במערך נתונים לא מאוזן של סיווגים כדי ליצור קבוצת נתונים לאימון מאוזנת יותר.
לדוגמה, נניח שיש מערך נתונים שבו היחס בין הסיווג הנפוץ ביותר לבין הסיווג הנפוץ הכי פחות הוא 20:1. כדי להתגבר על חוסר האיזון הזה בין המחלקות, אפשר ליצור קבוצת נתונים לאימון שמורכבת מכל הדוגמאות של המחלקה המיעוטית, אבל רק מעשירית מהדוגמאות של המחלקה הרובנית. כך נוצר יחס של 2:1 בין המחלקות בקבוצת הנתונים לאימון. בזכות דילול הדגימה, יכול להיות שקבוצת הנתונים לאימון המאוזנת יותר הזו תניב מודל טוב יותר. לחלופין, יכול להיות שקבוצת נתונים לאימון המאוזנת יותר הזו לא תכיל מספיק דוגמאות לאימון מודל יעיל.
ההבדל בין השיטה הזו לבין דגימת יתר.
חד-כיווני
מערכת שמעריכה רק את הטקסט שקודם לקטע טקסט היעד. לעומת זאת, במערכת דו-כיוונית מתבצעת הערכה של הטקסט שקודם לקטע הטקסט המיועד ושל הטקסט שאחריו. פרטים נוספים זמינים במאמר בנושא דו-כיווניות.
מודל שפה חד-כיווני
מודל שפה שמבוסס על הסתברויות רק של טוקנים שמופיעים לפני הטוקנים המטורגטים, ולא אחריהם. ההפך ממודל שפה דו-כיווני.
דוגמה ללא תווית
דוגמה שמכילה features אבל לא label. לדוגמה, בטבלה הבאה מוצגות שלוש דוגמאות לא מסומנות ממודל להערכת שווי של בית. לכל דוגמה יש שלושה מאפיינים, אבל לא מצוין ערך הבית:
| מספר חדרי שינה | מספר חדרי אמבטיה | גיל הבית |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
בלמידת מכונה מבוקרת, מודלים מתאמנים על דוגמאות מתויגות ומבצעים חיזויים על דוגמאות לא מתויגות.
בלמידה מונחית למחצה ובלמידה לא מונחית, נעשה שימוש בדוגמאות לא מסומנות במהלך האימון.
השוואה בין דוגמה ללא תווית לבין דוגמה עם תווית.
למידת מכונה לא מפוקחת
אימון מודל כדי למצוא דפוסים במערך נתונים, בדרך כלל מערך נתונים לא מסומן.
השימוש הנפוץ ביותר בלמידת מכונה לא מפוקחת הוא אשכול נתונים לקבוצות של דוגמאות דומות. לדוגמה, אלגוריתם ללמידת מכונה לא מפוקחת יכול לקבץ שירים לאשכולות על סמך מאפיינים שונים של המוזיקה. האשכולות שמתקבלים יכולים לשמש כקלט לאלגוריתמים אחרים של למידת מכונה (למשל, לשירות המלצות למוזיקה). האשכולות יכולים לעזור אם יש מעט תוויות שימושיות או אם אין כאלה בכלל. לדוגמה, בתחומים כמו מניעת ניצול לרעה והונאה, אשכולות יכולים לעזור לבני אדם להבין טוב יותר את הנתונים.
ההבדל בין למידת מכונה לא מפוקחת לבין למידת מכונה מפוקחת.
מידע נוסף זמין במאמר מהי למידת מכונה? בקורס 'מבוא ל-ML'.
שיעור התלונות שלא נתמכות (UCR)
אחוז הטענות בתגובה שלא מבוססות על מידע. לדוגמה, אם תגובה של LLM כוללת 10 טענות אבל רק אחת מהן מבוססת על מקורות, מדד ה-UCR הוא 90%.
שיעור גבוה של תשובות לא נכונות מצביע על כך שמודל שפה גדול מייצר הזיות בתדירות גבוהה מדי.
כדאי לעיין גם בדיוק הציטוט ובהיקף הציטוט.
מידול של שיפור הביצועים באמצעות הוספת נכסים
טכניקת מידול, שנפוצה בשימוש בשיווק, שמדמה את ה"השפעה הסיבתית" (שנקראת גם "ההשפעה המצטברת") של "טיפול" על "פרט". להלן שתי דוגמאות:
- רופאים יכולים להשתמש במודלים לחיזוי עלייה כדי לחזות את הירידה בשיעור התמותה (השפעה סיבתית) של הליך רפואי (טיפול) בהתאם לגיל ולהיסטוריה הרפואית של מטופל (אדם).
- משווקים יכולים להשתמש במודלים של עלייה כדי לחזות את העלייה בהסתברות לרכישה (השפעה סיבתית) כתוצאה מפרסומת (טיפול) שמוצגת לאדם (משתמש).
ההבדל בין מודלים לחיזוי עלייה לבין סיווג או רגרסיה הוא שבמודלים לחיזוי עלייה תמיד חסרות חלק מהתוויות (לדוגמה, מחצית מהתוויות בטיפולים בינאריים). לדוגמה, מטופל יכול לקבל טיפול או לא לקבל טיפול. לכן, אנחנו יכולים לראות אם המטופל יחלים או לא יחלים רק באחד משני המצבים האלה (אבל אף פעם לא בשניהם). היתרון העיקרי של מודל עלייה הוא שהוא יכול ליצור תחזיות לגבי מצב שלא נצפה (ההפוך לעובדה) ולהשתמש בהן כדי לחשב את ההשפעה הסיבתית.
הגדלת המשקל
החלת משקל על המחלקה downsampled ששווה לפקטור שבו נעשה downsampling.
מטריצת משתמשים
במערכות המלצות, וקטור הטמעה שנוצר על ידי פירוק מטריצות ומכיל אותות סמויים לגבי העדפות המשתמש. כל שורה במטריצת המשתמשים מכילה מידע על העוצמה היחסית של אותות סמויים שונים עבור משתמש יחיד. לדוגמה, ניקח מערכת להמלצות על סרטים. במערכת הזו, האותות הסמויים במטריצת המשתמשים יכולים לייצג את ההתעניינות של כל משתמש בז'אנרים מסוימים, או אותות שקשה יותר לפרש שכוללים אינטראקציות מורכבות בין כמה גורמים.
מטריצת המשתמשים כוללת עמודה לכל תכונה סמויה ושורה לכל משתמש. כלומר, למטריצת המשתמשים יש אותו מספר שורות כמו למטריצת היעד שעוברת פירוק לגורמים. לדוגמה, אם יש מערכת להמלצות על סרטים למיליון משתמשים, מטריצת המשתמשים תכלול מיליון שורות.
V
אימות
הערכה ראשונית של איכות המודל. במסגרת האימות, אנחנו בודקים את איכות התחזיות של המודל בהשוואה לקבוצת נתונים לתיקוף.
מכיוון שקבוצת נתונים לתיקוף שונה מקבוצת נתונים לאימון, האימות עוזר למנוע התאמת יתר.
אפשר לחשוב על הערכת המודל ביחס ל קבוצת נתונים לתיקוף כסיבוב הראשון של הבדיקה, ועל הערכת המודל ביחס לקבוצת נתונים לבדיקה כסיבוב השני של הבדיקה.
הפסד אימות
מדד שמייצג את הפסד של מודל בקבוצת נתונים לתיקוף במהלך איטרציה מסוימת של אימון.
אפשר לעיין גם בעקומת הכללה.
קבוצת נתונים לתיקוף
קבוצת המשנה של מערך הנתונים שמשמשת לביצוע הערכה ראשונית של מודל מאומן. בדרך כלל, מעריכים את המודל שאומן ביחס לקבוצת נתונים לתיקוף כמה פעמים לפני שמעריכים את המודל ביחס לקבוצת נתונים לבדיקה.
באופן מסורתי, מחלקים את הדוגמאות במערך הנתונים לשלוש קבוצות משנה נפרדות:
- קבוצת נתונים לאימון
- קבוצת נתונים לתיקוף
- קבוצת נתונים לבדיקה
באופן אידיאלי, כל דוגמה בקבוצת הנתונים צריכה להיות שייכת רק לאחת מקבוצות המשנה הקודמות. לדוגמה, דוגמה אחת לא יכולה להיות גם בקבוצת נתונים לאימון וגם בקבוצת נתונים לתיקוף.
מידע נוסף זמין במאמר מערכי נתונים: חלוקת מערך הנתונים המקורי בקורס המקוצר על למידת מכונה.
השלמת ערכים חסרים
התהליך של החלפת ערך חסר בתחליף קביל. אם חסר ערך, אפשר להתעלם מהדוגמה כולה או להשתמש בהשלמת ערכים כדי להציל את הדוגמה.
לדוגמה, נניח שיש קבוצת נתונים שמכילה מאפיין temperature שאמור להירשם כל שעה. עם זאת, קריאת הטמפרטורה לא הייתה זמינה בשעה מסוימת. קטע מקבוצת הנתונים:
| חותמת זמן | טמפרטורה |
|---|---|
| 1680561000 | 10 |
| 1680564600 | 12 |
| 1680568200 | חסר |
| 1680571800 | 20 |
| 1680575400 | 21 |
| 1680579000 | 21 |
המערכת יכולה למחוק את הדוגמה החסרה או להזין את רמת האקראיות החסרה כ-12, 16, 18 או 20, בהתאם לאלגוריתם ההשלמה.
בעיית הגרדיאנט הנעלם
הנטייה של הגרדיאנטים של שכבות מוסתרות מוקדמות של חלק מרשתות עצביות עמוקות להפוך לפתע לשטוחות (נמוכות). שיפועים נמוכים יותר ויותר מובילים לשינויים קטנים יותר ויותר במשקלים בצמתים ברשת נוירונים עמוקה, וכתוצאה מכך למידה מועטה או ללא למידה בכלל. קשה או בלתי אפשרי לאמן מודלים שסובלים מבעיית הגרדיאנט הנעלם. תאי זיכרון לטווח קצר לזמן ארוך (LSTM) פותרים את הבעיה הזו.
השוואה לבעיית הגרדיאנט המתפוצץ.
חשיבות המשתנים
קבוצת ציונים שמציינת את החשיבות היחסית של כל תכונה למודל.
לדוגמה, נניח שיש עץ החלטה שמבצע הערכה של מחירי בתים. נניח שעץ ההחלטה הזה משתמש בשלושה מאפיינים: גודל, גיל וסגנון. אם קבוצת חשיבויות משתנים לשלושת המאפיינים מחושבת כ- {size=5.8, age=2.5, style=4.7}, אז המאפיין size חשוב יותר לעץ ההחלטה מהמאפיינים age או style.
קיימים מדדים שונים לחשיבות משתנים, שיכולים לספק למומחי ML מידע על היבטים שונים של מודלים.
מקודד אוטומטי וריאציוני (VAE)
סוג של autoencoder שמנצל את הפער בין הקלט לפלט כדי ליצור גרסאות שונות של הקלט. מקודדים אוטומטיים משתנים שימושיים ל-AI גנרטיבי.
מודלים של VAE מבוססים על הסקה וריאציונית: טכניקה להערכת הפרמטרים של מודל הסתברותי.
וקטור
מונח עמוס מאוד שהמשמעות שלו משתנה בין תחומים מתמטיים ומדעיים שונים. במסגרת למידת מכונה, לווקטור יש שתי תכונות:
- סוג הנתונים: וקטורים בלמידת מכונה מכילים בדרך כלל מספרים עם נקודה צפה (floating-point).
- מספר האלמנטים: זהו האורך של הווקטור או הממד שלו.
לדוגמה, נניח שיש וקטור תכונות שמכיל שמונה מספרים בנקודה צפה. וקטור המאפיינים הזה הוא באורך או בממד של שמונה. הערה: לווקטורים של למידת מכונה יש בדרך כלל מספר עצום של ממדים.
אפשר לייצג סוגים רבים ושונים של מידע כווקטור. לדוגמה:
- כל מיקום על פני כדור הארץ יכול להיות מיוצג כווקטור דו-ממדי, כאשר מימד אחד הוא קו הרוחב והשני הוא קו האורך.
- המחירים הנוכחיים של כל אחת מ-500 מניות יכולים להיות מיוצגים כווקטור של 500 ממדים.
- אפשר לייצג התפלגות הסתברויות על מספר סופי של מחלקות כווקטור. לדוגמה, מערכת סיווג רב-מחלקתי שמנבאת אחד משלושה צבעי פלט (אדום, ירוק או צהוב) יכולה להפיק את הווקטור
(0.3, 0.2, 0.5)כדי לצייןP[red]=0.3, P[green]=0.2, P[yellow]=0.5.
אפשר לשרשר וקטורים, ולכן אפשר לייצג מגוון מדיות שונות כווקטור יחיד. חלק מהמודלים פועלים ישירות על שרשור של הרבה קידודים חמים.
מעבדים ייעודיים כמו TPU מותאמים לביצוע פעולות מתמטיות על וקטורים.
שיא
הפלטפורמה של Google Cloud ל-AI ולמידת מכונה. Vertex מספקת כלים ותשתית לפיתוח, לפריסה ולניהול של אפליקציות AI, כולל גישה למודלים של Gemini.תכנות בשיטת Vibe coding
הזנת הנחיה למודל AI גנרטיבי כדי ליצור תוכנה. כלומר, ההנחיות מתארות את המטרה והתכונות של התוכנה, ומודל AI גנרטיבי מתרגם אותן לקוד מקור. הקוד שנוצר לא תמיד תואם לכוונות שלכם, ולכן בדרך כלל נדרשת איטרציה בתכנות בשיטת Vibe coding.
אנדריי קרפטי טבע את המונח תכנות בשיטת Vibe coding בפוסט הזה ב-X. בפוסט ב-X, קרפתי מתאר את זה כ "סוג חדש של קידוד...שבו נכנעים לגמרי לאווירה..." לכן, המונח במקור התייחס לגישה מכוונת וגמישה ליצירת תוכנה, שבה יכול להיות שאפילו לא בודקים את הקוד שנוצר. עם זאת, המונח התפתח במהירות בתחומים רבים, ועכשיו הוא מתייחס לכל סוג של קוד שנוצר על ידי AI.
לתיאור מפורט יותר של תכנות בשיטת Vibe coding, אפשר לעיין במאמר מה זה תכנות בשיטת Vibe coding?
בנוסף, השוו והבדילו בין תכנות בשיטת Vibe coding לבין:
W
פונקציית הפסד Wasserstein
אחת מפונקציות ההפסד שבהן נעשה שימוש בדרך כלל ברשתות יריבות גנרטיביות, על סמך מרחק העברת האדמה בין התפלגות הנתונים שנוצרו לבין הנתונים האמיתיים.
משקל
ערך שהמודל מכפיל בערך אחר. אימון הוא התהליך של קביעת המשקלים האידיאליים של מודל מסוים. הסקת מסקנות היא התהליך של שימוש במשקלים שנלמדו כדי ליצור תחזיות.
מידע נוסף זמין במאמר בנושא רגרסיה לינארית בקורס המקוצר על למידת מכונה.
שיטת הריבועים הפחותים לסירוגין עם משקל (WALS)
אלגוריתם למזעור פונקציית המטרה במהלך פירוק מטריצות במערכות המלצות, שמאפשר להפחית את המשקל של הדוגמאות החסרות. אלגוריתם WALS ממזער את השגיאה הריבועית המשוקללת בין המטריצה המקורית לבין השחזור, על ידי מעבר לסירוגין בין תיקון הפירוק לשורות לבין תיקון הפירוק לעמודות. כל אחת מהאופטימיזציות האלה ניתנת לפתרון באמצעות אופטימיזציה קמורה של ריבועים פחותים. פרטים נוספים מופיעים בקורס בנושא מערכות המלצה.
סכום משוקלל
הסכום של כל ערכי הקלט הרלוונטיים כפול המשקלים המתאימים שלהם. לדוגמה, נניח שהקלט הרלוונטי מורכב מהרכיבים הבאים:
| ערך קלט | משקל הקלט |
| 2 | 1.3- |
| -1 | 0.6 |
| 3 | 0.4 |
לכן הסכום המשוקלל הוא:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
סכום משוקלל הוא ארגומנט הקלט של פונקציית הפעלה.
WiC
קיצור של מילים בהקשר.
מודל רחב
מודל ליניארי שבדרך כלל כולל הרבה תכונות קלט דלילות. אנחנו קוראים לו 'רחב' כי מודל כזה הוא סוג מיוחד של רשת נוירונים עם מספר גדול של נתוני קלט שמתחברים ישירות לצומת הפלט. לעתים קרובות קל יותר לנפות באגים במודלים רחבים ולבדוק אותם מאשר במודלים עמוקים. אמנם מודלים רחבים לא יכולים לבטא אי-ליניאריות באמצעות שכבות מוסתרות, אבל הם יכולים להשתמש בטרנספורמציות כמו שילוב תכונות וחלוקה לקטגוריות כדי ליצור מודלים של אי-ליניאריות בדרכים שונות.
השוואה למודל עמוק.
רוחב
מספר הנוירונים בשכבה מסוימת של רשת נוירונים.
WikiLingua (wiki_lingua)
מערך נתונים להערכת היכולת של מודל LLM לסכם מאמרים קצרים. WikiHow, אנציקלופדיה של מאמרים שמסבירים איך לבצע משימות שונות, הוא המקור שנכתב על ידי בני אדם גם למאמרים וגם לסיכומים. כל רשומה במערך הנתונים כוללת:
- מאמר שנוצר על ידי הוספה של כל שלב בגרסת הפרוזה (הפסקה) של הרשימה הממוספרת, ללא משפט הפתיחה של כל שלב.
- סיכום של המאמר, שמורכב ממשפט הפתיחה של כל שלב ברשימה הממוספרת.
פרטים נוספים זמינים במאמר WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization.
אתגר סכימת וינוגרד (WSC)
פורמט (או מערך נתונים שתואם לפורמט הזה) להערכת היכולת של מודל שפה גדול (LLM) לקבוע את הצירוף הנומינלי שאליו מתייחסת מילת גוף.
כל רשומה באתגר סכימת וינוגרד כוללת:
- קטע קצר שמכיל כינוי גוף של יעד
- כינוי גוף ליעד
- צירופי שמות עצם אפשריים, ואחריהם התשובה הנכונה (ערך בוליאני). אם כינוי הגוף שאליו מתייחסים מתייחס למועמד הזה, התשובה היא True. אם כינוי הגוף לא מתייחס למועמד הזה, התשובה היא False.
לדוגמה:
- קטע: Mark told Pete many lies about himself, which Pete included in his book. הוא היה צריך להיות יותר כנה.
- כינוי הגוף הממוקד: הוא
- צירופי שם עצם מוצעים:
- סימון: True, כי כינוי המטרה מתייחס למארק
- פיט: False, כי כינוי הגוף לא מתייחס לפיט
אתגר סכמת וינוגרד הוא רכיב של SuperGLUE.
חכמת ההמון
הרעיון שלפיו חישוב ממוצע של הדעות או ההערכות של קבוצה גדולה של אנשים ("הקהל") מוביל לרוב לתוצאות טובות באופן מפתיע. לדוגמה, נניח שמשחקים משחק שבו אנשים מנחשים כמה סוכריות ג'לי יש בצנצנת גדולה. למרות שרוב הניחושים האישיים לא יהיו מדויקים, הוכח אמפירית שהממוצע של כל הניחושים קרוב באופן מפתיע למספר האמיתי של סוכריות הג'לי בצנצנת.
מודלים משולבים הם מקבילה תוכנתית לחוכמת ההמונים. גם אם מודלים בודדים מפיקים תחזיות לא מדויקות באופן קיצוני, ממוצע התחזיות של הרבה מודלים יוצר לעיתים קרובות תחזיות טובות באופן מפתיע. לדוגמה, למרות שעץ החלטות בודד עשוי לספק תחזיות לא טובות, יער החלטות לרוב מספק תחזיות טובות מאוד.
WMT
באופן מוזר, קיצור של Conference on Machine Translation (כנס בנושא תרגום מכונה). (הקיצור הוא WMT כי השם המקורי היה Workshop on Machine Translation). הכנס מתמקד בפיתוחים במערכות של תרגום אוטומטי.
הטמעת מילה
ייצוג כל מילה בקבוצת מילים בווקטור הטמעה, כלומר ייצוג כל מילה כווקטור של ערכים עשרוניים בין 0.0 ל-1.0. למילים עם משמעויות דומות יש ייצוגים דומים יותר מאשר למילים עם משמעויות שונות. לדוגמה, המילים גזר, סלרי ומלפפון יקבלו ייצוגים דומים יחסית, שיהיו שונים מאוד מהייצוגים של המילים מטוס, משקפי שמש ומשחת שיניים.
מילים בהקשר (WiC)
מערך נתונים להערכת היכולת של LLM להשתמש בהקשר כדי להבין מילים שיש להן כמה משמעויות. כל רשומה במערך הנתונים מכילה:
- שני משפטים, שכל אחד מהם מכיל את מילת היעד
- מילת היעד
- התשובה הנכונה (ערך בוליאני), כאשר:
- הערך True מציין שלמילת היעד יש את אותה משמעות בשני המשפטים
- הערך False מציין שלמילה המטרה יש משמעות שונה בשני המשפטים
לדוגמה:
- שני משפטים:
- יש הרבה אשפה בקרקעית הנהר.
- אני תמיד מניח מים ליד המיטה כשאני הולך לישון.
- מילת היעד: bed
- תשובה נכונה: False, because the target word has a different meaning in the two sentences.
פרטים נוספים זמינים במאמר WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations.
Words in Context הוא רכיב של SuperGLUE ensemble.
WSC
קיצור של Winograd Schema Challenge (אתגר סכימת וינוגרד).
X
XLA (אלגברה לינארית מואצת)
קומפיילר ללמידת מכונה בקוד פתוח למעבדי GPU, מעבדי CPU ומאיצי ML.
הקומפיילר XLA לוקח מודלים ממסגרות פופולריות של למידת מכונה כמו PyTorch, TensorFlow ו-JAX, ומבצע אופטימיזציה שלהם לביצועים גבוהים בפלטפורמות חומרה שונות, כולל מעבדים גרפיים, מעבדים מרכזיים ומאיצי למידת מכונה.
XL-Sum (xlsum)
מערך נתונים להערכת רמת המיומנות של מודל שפה גדול (LLM) בסיכום טקסט. XL-Sum מספק רשומות בשפות רבות. כל רשומה במערך הנתונים מכילה:
- מאמר שנלקח מ-British Broadcasting Company (BBC).
- סיכום של המאמר, שנכתב על ידי מחבר המאמר. שימו לב שהסיכום יכול להכיל מילים או ביטויים שלא מופיעים במאמר.
פרטים נוספים זמינים במאמר XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages.
xsum
קיצור של סיכום קיצוני.
Z
למידה ללא דוגמאות
סוג של אימון למידת מכונה שבו המודל מסיק תחזית למשימה שהוא לא אומן לבצע באופן ספציפי. במילים אחרות, המודל לא מקבל דוגמאות לאימון ספציפי למשימה, אבל מתבקש לבצע הסקת מסקנות לגבי אותה משימה.
הנחיות בלי דוגמאות (zero-shot prompting)
הנחיה שלא כוללת דוגמה לאופן שבו מודל שפה גדול צריך להגיב. לדוגמה:
| החלקים של הנחיה | הערות |
|---|---|
| מהו המטבע הרשמי של המדינה שצוינה? | השאלה שרוצים שה-LLM יענה עליה. |
| הודו: | השאילתה בפועל. |
מודל השפה הגדול עשוי להגיב באחת מהדרכים הבאות:
- רופיות
- INR
- ₹
- רופי הודי
- רופי
- רופי הודי
כל התשובות נכונות, אבל יכול להיות שתעדיפו פורמט מסוים.
השוואה וניגוד בין הנחיות בלי דוגמאות (zero-shot prompting) לבין המונחים הבאים:
נורמליזציה של ציון תקן
טכניקת שינוי קנה מידה שמחליפה ערך גולמי של מאפיין בערך נקודה צפה שמייצג את מספר סטיות התקן מהממוצע של המאפיין הזה. לדוגמה, נניח שיש תכונה שהממוצע שלה הוא 800 וסטיית התקן שלה היא 100. בטבלה הבאה אפשר לראות איך נורמליזציה של ציון Z ממפה את הערך הגולמי לציון ה-Z שלו:
| ערך גולמי | ציון תקן |
|---|---|
| 800 | 0 |
| 950 | +1.5 |
| 575 | -2.25 |
לאחר מכן, מודל למידת המכונה מתאמן על ציוני ה-Z של התכונה במקום על הערכים הגולמיים.
מידע נוסף זמין במאמר נתונים מספריים: נורמליזציה בסדנה ללימוד מכונת למידה.