In diesem Abschnitt werden die folgenden drei Fragen behandelt:
- Was ist der Unterschied zwischen klassenbalancierten und klassenunbalancierten Datasets?
- Warum ist das Training mit einem unausgewogenen Dataset schwierig?
- Wie können Sie die Probleme beim Trainieren unausgewogener Datasets überwinden?
Klassenausgeglichene und klassenunausgeglichene Datasets
Angenommen, Sie haben ein Dataset mit einem kategorialen Label, dessen Wert entweder die positive oder die negative Klasse ist. In einem klassenbalancierten Dataset> ist die Anzahl der positiven Klassen und negativen Klassen ungefähr gleich. Ein Dataset mit 235 positiven und 247 negativen Klassen ist beispielsweise ein ausgeglichenes Dataset.
In einem Dataset mit unausgewogenen Klassen ist ein Label deutlich häufiger als das andere. In der Praxis sind Datasets mit unausgeglichenen Klassen viel häufiger als Datasets mit ausgeglichenen Klassen. In einem Dataset mit Kreditkartentransaktionen machen betrügerische Käufe beispielsweise weniger als 0,1% der Beispiele aus. In einem Datensatz für medizinische Diagnosen kann die Anzahl der Patienten mit einem seltenen Virus weniger als 0,01% der Gesamtbeispiele betragen. Bei einem Dataset mit unausgewogenen Klassen:
- Das häufigere Label wird als Mehrheitsklasse bezeichnet.
- Das weniger häufige Label wird als Minderheitsklasse bezeichnet.
Schwierigkeiten beim Trainieren von Datasets mit stark unausgeglichenen Klassen
Beim Training soll ein Modell erstellt werden, das die positive Klasse erfolgreich von der negativen Klasse unterscheidet. Dazu benötigen Batches eine ausreichende Anzahl von sowohl positiven als auch negativen Klassen. Das ist kein Problem, wenn Sie ein Dataset mit leicht unausgeglichenen Klassen verwenden, da auch kleine Batches in der Regel genügend Beispiele für die positive und die negative Klasse enthalten. Ein stark unausgeglichenes Dataset enthält jedoch möglicherweise nicht genügend Beispiele für die Minderheitenklasse für ein angemessenes Training.
Betrachten Sie beispielsweise den in Abbildung 6 dargestellten Datensatz mit ungleichmäßiger Klassenverteilung, in dem gilt:
- 200 Labels gehören zur Mehrheitsklasse.
- Zwei Labels gehören zur Minderheitsklasse.
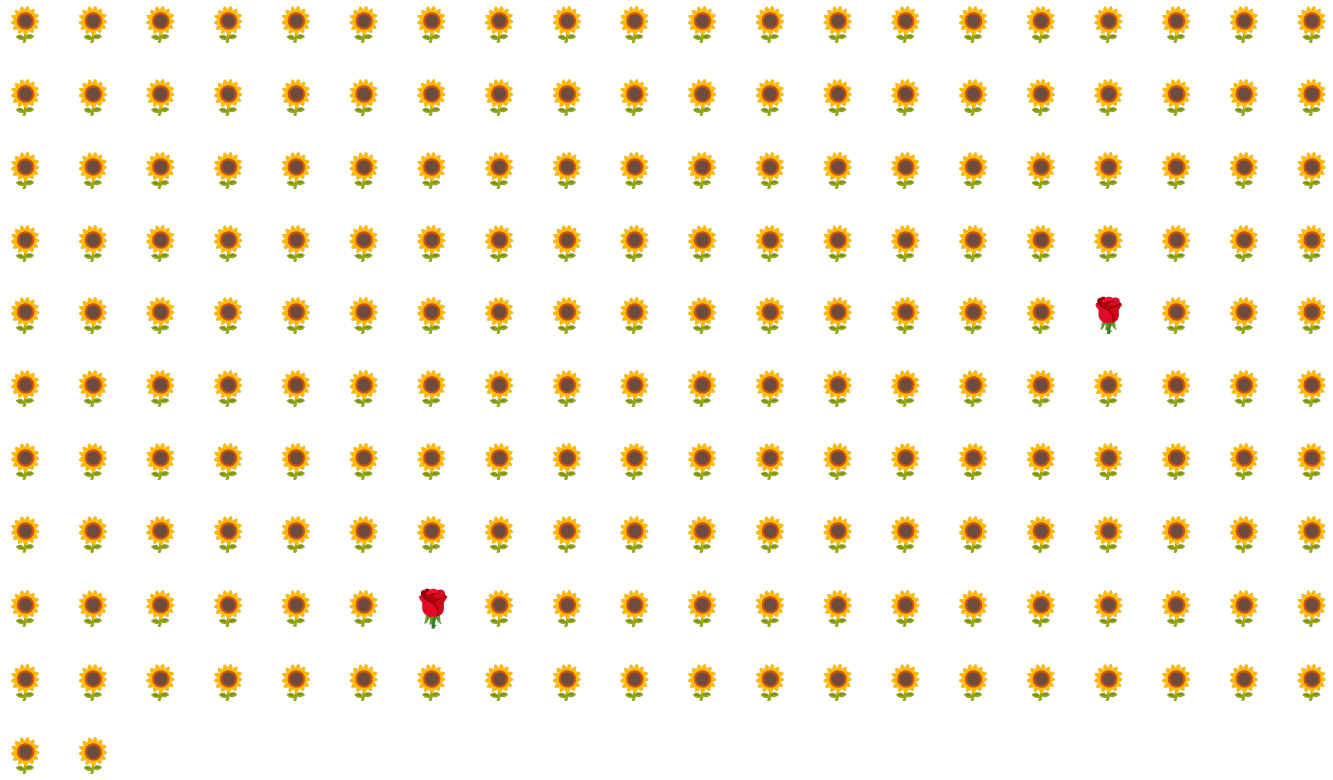
Wenn die Batchgröße 20 ist, enthalten die meisten Batches keine Beispiele für die Minderheitsklasse. Wenn die Batchgröße 100 beträgt, enthält jeder Batch im Durchschnitt nur ein Beispiel für die Minderheitsklasse. Das reicht für ein angemessenes Training nicht aus. Auch bei einer viel größeren Batchgröße ist das Verhältnis so unausgewogen, dass das Modell möglicherweise nicht richtig trainiert wird.
Training eines klassenungleichgewichteten Datasets
Während des Trainings sollte ein Modell zwei Dinge lernen:
- Wie die einzelnen Klassen aussehen, d. h., welche Featurewerte welcher Klasse entsprechen.
- Wie häufig die einzelnen Klassen sind, d. h. wie die relative Verteilung der Klassen aussieht.
Beim Standardtraining werden diese beiden Ziele vermischt. Im Gegensatz dazu werden sie bei der folgenden zweistufigen Technik namens Downsampling und Upweighting der Mehrheitsklasse getrennt, sodass das Modell beide Ziele erreichen kann.
Schritt 1: Die Mehrheitsklasse unterabstampten
Downsampling bedeutet, dass das Training mit einem unverhältnismäßig niedrigen Prozentsatz von Beispielen der Mehrheitsklasse erfolgt. Das heißt, Sie zwingen ein Dataset mit Klassenungleichgewicht künstlich dazu, etwas ausgeglichener zu werden, indem Sie viele Beispiele der Mehrheitsklasse aus dem Training weglassen. Durch Downsampling wird die Wahrscheinlichkeit, dass jeder Batch genügend Beispiele der Minderheitsklasse enthält, um das Modell richtig und effizient zu trainieren, erheblich erhöht.
Das in Abbildung 6 dargestellte Dataset mit unausgeglichenen Klassen besteht beispielsweise aus 99% Beispielen der Mehrheitsklasse und 1% Beispielen der Minderheitsklasse. Durch das Downsampling der Mehrheitsklasse um den Faktor 25 wird künstlich ein ausgeglicheneres Trainingsset erstellt (80% Mehrheitsklasse zu 20% Minderheitsklasse), wie in Abbildung 7 dargestellt:

Schritt 2: Unterabgetastete Klasse gewichten
Durch Downsampling wird ein Vorhersage-Bias eingeführt, da dem Modell eine künstliche Welt präsentiert wird, in der die Klassen ausgeglichener sind als in der realen Welt. Um diesen Bias zu korrigieren, müssen Sie die Mehrheitsklassen um den Faktor gewichten, um den Sie das Downsampling durchgeführt haben. Beim Hochstufen wird der Verlust bei einem Beispiel der Mehrheitsklasse stärker gewichtet als der Verlust bei einem Beispiel der Minderheitsklasse.
Wenn wir die Mehrheitsklasse beispielsweise um den Faktor 25 unterabgetastet haben, müssen wir sie um den Faktor 25 gewichten. Wenn das Modell also fälschlicherweise die Mehrheitsklasse vorhersagt, behandeln Sie den Verlust so, als wären es 25 Fehler (multiplizieren Sie den regulären Verlust mit 25).

Wie stark sollten Sie das Downsampling und die Gewichtung vornehmen, um Ihr Dataset neu auszugleichen? Um die Antwort zu ermitteln, sollten Sie mit verschiedenen Faktoren für Downsampling und Gewichtung experimentieren, genau wie mit anderen Hyperparametern.
Vorteile dieser Methode
Das Downsampling und die Gewichtung der Mehrheitsklasse bieten folgende Vorteile:
- Besseres Modell:Das resultierende Modell „kennt“ beides:
- Die Verbindung zwischen Funktionen und Labels
- Die tatsächliche Verteilung der Klassen
- Schnellere Konvergenz:Während des Trainings wird die Minderheitsklasse häufiger berücksichtigt, was zu einer schnelleren Konvergenz des Modells führt.