এই বিভাগটি নিম্নলিখিত তিনটি প্রশ্ন অন্বেষণ করে:
- শ্রেণী-ভারসাম্যযুক্ত ডেটাসেট এবং শ্রেণী-ভারসাম্যহীন ডেটাসেটের মধ্যে পার্থক্য কী?
- কেন একটি ভারসাম্যহীন ডেটাসেট প্রশিক্ষণ কঠিন?
- ভারসাম্যহীন ডেটাসেট প্রশিক্ষণের সমস্যাগুলি কীভাবে আপনি কাটিয়ে উঠতে পারেন?
শ্রেণী-ভারসাম্যহীন ডেটাসেট বনাম শ্রেণী-ভারসাম্যহীন ডেটাসেট
একটি শ্রেণীবদ্ধ লেবেল ধারণকারী একটি ডেটাসেট বিবেচনা করুন যার মান হয় ধনাত্মক শ্রেণী বা ঋণাত্মক শ্রেণী। একটি শ্রেণি-ভারসাম্যযুক্ত ডেটাসেটে , ইতিবাচক শ্রেণি এবং নেতিবাচক শ্রেণির সংখ্যা প্রায় সমান। উদাহরণস্বরূপ, 235টি ইতিবাচক ক্লাস এবং 247টি নেতিবাচক ক্লাস ধারণকারী একটি ডেটাসেট একটি সুষম ডেটাসেট।
একটি শ্রেণী-ভারসাম্যহীন ডেটাসেটে , একটি লেবেল অন্যটির তুলনায় যথেষ্ট বেশি সাধারণ। বাস্তব জগতে, শ্রেণী-ভারসাম্যহীন ডেটাসেটগুলি শ্রেণী-ভারসাম্যযুক্ত ডেটাসেটের তুলনায় অনেক বেশি সাধারণ। উদাহরণস্বরূপ, ক্রেডিট কার্ড লেনদেনের ডেটাসেটে, প্রতারণামূলক কেনাকাটা উদাহরণগুলির 0.1%-এরও কম হতে পারে। একইভাবে, একটি মেডিকেল ডায়াগনসিস ডেটাসেটে, একটি বিরল ভাইরাসে আক্রান্ত রোগীর সংখ্যা মোট উদাহরণের 0.01% এর কম হতে পারে। একটি শ্রেণী-ভারসাম্যহীন ডেটাসেটে:
- আরও সাধারণ লেবেলকে মেজরিটি ক্লাস বলা হয়।
- কম সাধারণ লেবেলটিকে সংখ্যালঘু শ্রেণী বলা হয়।
মারাত্মকভাবে ক্লাস-ভারসাম্যহীন ডেটাসেট প্রশিক্ষণের অসুবিধা
প্রশিক্ষণের লক্ষ্য এমন একটি মডেল তৈরি করা যা সফলভাবে ইতিবাচক শ্রেণিকে নেতিবাচক শ্রেণি থেকে আলাদা করে। এটি করার জন্য, ব্যাচগুলিতে পজিটিভ ক্লাস এবং নেগেটিভ ক্লাস উভয়েরই যথেষ্ট সংখ্যক প্রয়োজন। একটি হালকা শ্রেণী-ভারসাম্যহীন ডেটাসেটের প্রশিক্ষণের সময় এটি কোনও সমস্যা নয় কারণ এমনকি ছোট ব্যাচগুলিতে সাধারণত ইতিবাচক শ্রেণি এবং নেতিবাচক শ্রেণি উভয়েরই যথেষ্ট উদাহরণ থাকে। যাইহোক, একটি গুরুতর শ্রেণী-ভারসাম্যহীন ডেটাসেটে যথাযথ প্রশিক্ষণের জন্য যথেষ্ট সংখ্যালঘু শ্রেণীর উদাহরণ নাও থাকতে পারে।
উদাহরণস্বরূপ, চিত্র 6-এ চিত্রিত শ্রেণি-ভারসাম্যহীন ডেটাসেট বিবেচনা করুন যেখানে:
- 200টি লেবেল সংখ্যাগরিষ্ঠ শ্রেণিতে রয়েছে।
- 2 labels are in the minority class.
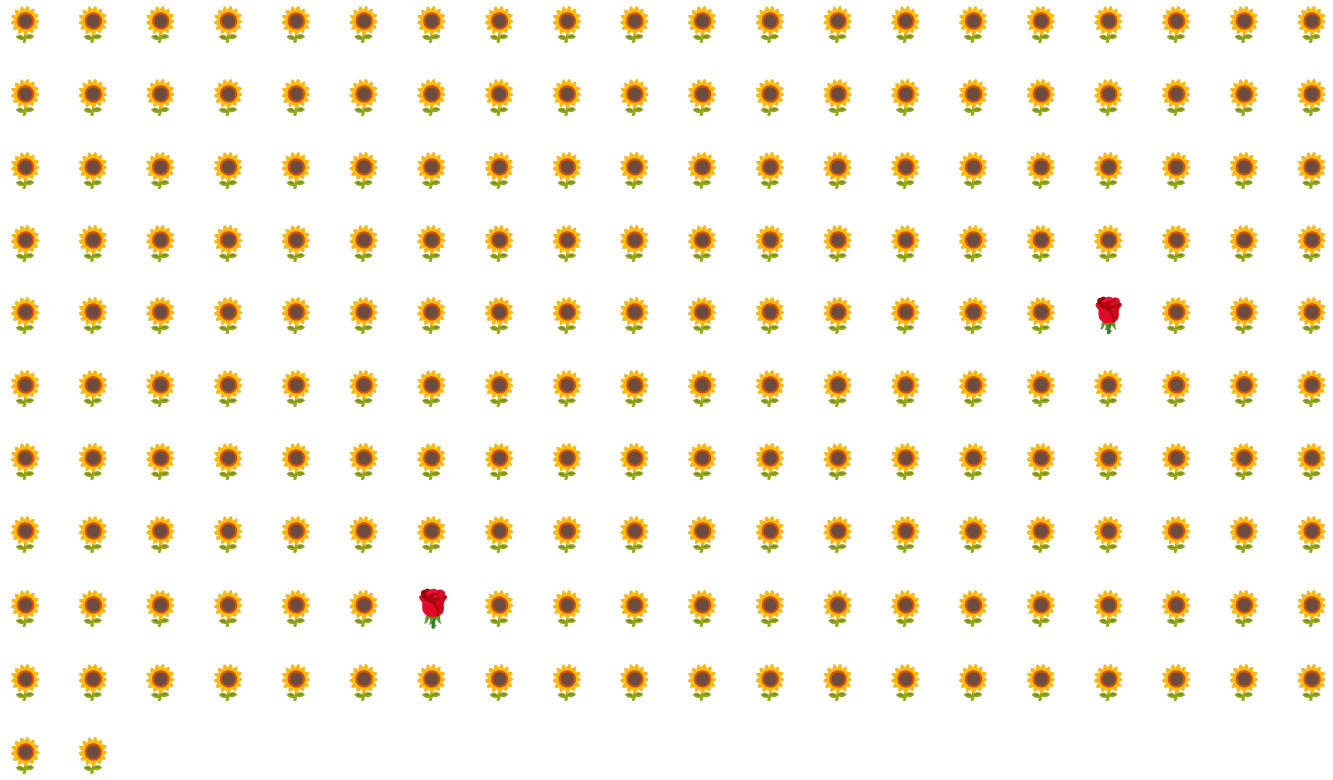
ব্যাচের আকার 20 হলে, অধিকাংশ ব্যাচে সংখ্যালঘু শ্রেণীর কোনো উদাহরণ থাকবে না। If the batch size is 100, each batch will contain an average of only one minority class example, which is insufficient for proper training. এমনকি একটি অনেক বড় ব্যাচের আকার এখনও এমন একটি ভারসাম্যহীন অনুপাত দেবে যে মডেলটি সঠিকভাবে প্রশিক্ষণ নাও দিতে পারে।
একটি শ্রেণী-ভারসাম্যহীন ডেটাসেট প্রশিক্ষণ
প্রশিক্ষণের সময়, একটি মডেল দুটি জিনিস শিখতে হবে:
- What each class looks like; অর্থাৎ, কোন বৈশিষ্ট্যের মান কোন শ্রেণীর সাথে সঙ্গতিপূর্ণ?
- প্রতিটি ক্লাস কতটা সাধারণ; অর্থাৎ, ক্লাসের আপেক্ষিক বন্টন কি?
Standard training conflates these two goals. বিপরীতে, নিম্নোক্ত দ্বি-পদক্ষেপের কৌশল নামক ডাউনস্যাম্পলিং এবং সংখ্যাগরিষ্ঠ শ্রেণীর ওজন বৃদ্ধি এই দুটি লক্ষ্যকে আলাদা করে, মডেলটিকে উভয় লক্ষ্য অর্জনে সক্ষম করে।
ধাপ 1: সংখ্যাগরিষ্ঠ শ্রেণির নমুনা নিন
Downsampling means training on a disproportionately low percentage of majority class examples. অর্থাৎ, আপনি কৃত্রিমভাবে একটি শ্রেণী-ভারসাম্যহীন ডেটাসেটকে প্রশিক্ষণ থেকে সংখ্যাগরিষ্ঠ শ্রেণীর উদাহরণ বাদ দিয়ে কিছুটা ভারসাম্যপূর্ণ হতে বাধ্য করেন। ডাউনস্যাম্পলিং মডেলটিকে সঠিকভাবে এবং দক্ষতার সাথে প্রশিক্ষণ দেওয়ার জন্য প্রতিটি ব্যাচে সংখ্যালঘু শ্রেণীর যথেষ্ট উদাহরণ রয়েছে এমন সম্ভাবনাকে ব্যাপকভাবে বৃদ্ধি করে।
উদাহরণস্বরূপ, চিত্র 6-এ দেখানো শ্রেণী-ভারসাম্যহীন ডেটাসেটটিতে 99% সংখ্যাগরিষ্ঠ শ্রেণী এবং 1% সংখ্যালঘু শ্রেণীর উদাহরণ রয়েছে। সংখ্যাগরিষ্ঠ শ্রেণীকে 25 এর ফ্যাক্টর দ্বারা ডাউনস্যাম্প করা কৃত্রিমভাবে আরও সুষম প্রশিক্ষণ সেট তৈরি করে (80% সংখ্যাগরিষ্ঠ শ্রেণী থেকে 20% সংখ্যালঘু শ্রেণী) চিত্র 7 এ প্রস্তাবিত:

ধাপ 2: ডাউনস্যাম্পল ক্লাসের ওজন বাড়ান
ডাউনস্যাম্পলিং মডেলটিকে একটি কৃত্রিম বিশ্ব দেখানোর মাধ্যমে একটি ভবিষ্যদ্বাণীর পক্ষপাতের পরিচয় দেয় যেখানে ক্লাসগুলি বাস্তব বিশ্বের তুলনায় আরও ভারসাম্যপূর্ণ। এই পক্ষপাত সংশোধন করার জন্য, আপনাকে অবশ্যই সংখ্যাগরিষ্ঠ শ্রেণীগুলির "উচ্চ ওজন" করতে হবে যে ফ্যাক্টরটিতে আপনি স্যাম্পল করেছেন। ওজন কমানোর অর্থ হল সংখ্যালঘু শ্রেণীর উদাহরণের ক্ষতির চেয়ে সংখ্যাগরিষ্ঠ শ্রেণীর উদাহরণের ক্ষতিকে আরও কঠোরভাবে বিবেচনা করা।
উদাহরণ স্বরূপ, আমরা সংখ্যাগরিষ্ঠ শ্রেণীকে 25 এর একটি গুণনীয়ক দ্বারা কমিয়েছি, তাই আমাদের অবশ্যই সংখ্যাগরিষ্ঠ শ্রেণীটিকে 25 এর একটি গুণনীয়ক দ্বারা আপওয়েট করতে হবে। অর্থাৎ, যখন মডেলটি ভুলবশত সংখ্যাগরিষ্ঠ শ্রেণীর পূর্বাভাস দেয়, তখন ক্ষতিটিকে 25টি ত্রুটি হিসাবে বিবেচনা করুন (নিয়মিত ক্ষতিকে 25 দ্বারা গুণ করুন)।

আপনার ডেটাসেটের ভারসাম্য বজায় রাখতে আপনার কতটা কম এবং ওজন কমানো উচিত? উত্তর নির্ধারণ করার জন্য, আপনি অন্যান্য হাইপারপ্যারামিটারের সাথে যেমন পরীক্ষা করবেন ঠিক তেমনই বিভিন্ন ডাউনস্যাম্পলিং এবং আপওয়েটিং ফ্যাক্টর নিয়ে পরীক্ষা করা উচিত।
এই প্রযুক্তির সুবিধা
সংখ্যাগরিষ্ঠ শ্রেণীর নমুনা কমানো এবং ওজন বৃদ্ধি নিম্নলিখিত সুবিধা নিয়ে আসে:
- আরও ভাল মডেল: ফলস্বরূপ মডেল নিম্নলিখিত দুটিই "জানে":
- বৈশিষ্ট্য এবং লেবেল মধ্যে সংযোগ
- ক্লাসের প্রকৃত বন্টন
- দ্রুত একত্রিত হওয়া: প্রশিক্ষণের সময়, মডেলটি সংখ্যালঘু শ্রেণীকে আরও প্রায়ই দেখে, যা মডেলটিকে দ্রুত একত্রিত হতে সাহায্য করে।