In diesem Glossar werden allgemeine Begriffe des maschinellen Lernens sowie Begriffe speziell für TensorFlow definiert.
A
Ablation
Ein Verfahren, mit dem die Wichtigkeit eines Features oder einer Komponente bewertet wird, indem es vorübergehend aus einem Modell entfernt wird. Anschließend trainieren Sie das Modell ohne dieses Feature oder diese Komponente neu. Wenn das neu trainierte Modell eine erheblich schlechtere Leistung erzielt, war das entfernte Feature oder die entfernte Komponente wahrscheinlich wichtig.
Angenommen, Sie trainieren ein Klassifizierungsmodell für 10 Features und erreichen eine Genauigkeit von 88% im Test-Dataset. Wenn Sie die Wichtigkeit des ersten Features prüfen möchten, können Sie das Modell nur mit den neun anderen Features neu trainieren. Wenn das neu trainierte Modell erheblich schlechter abschneidet (z. B. eine Genauigkeit von 55 %), war das entfernte Feature wahrscheinlich wichtig. Wenn dagegen das neu trainierte Modell die gleiche Leistung erzielt, war dieses Feature wahrscheinlich nicht so wichtig.
Ablation kann auch helfen, die Bedeutung von Folgendem zu bestimmen:
- Größere Komponenten, z. B. ein ganzes Subsystem eines größeren ML-Systems
- Prozesse oder Techniken, z. B. ein Schritt zur Datenvorverarbeitung
In beiden Fällen würden Sie beobachten, wie sich die Leistung des Systems nach dem Entfernen der Komponente ändert.
A/B-Tests
Ein statistischer Vergleich von zwei (oder mehr) Verfahren – dem A und dem B. Normalerweise ist A eine vorhandene und B eine neue Technik. A/B-Tests ermitteln nicht nur, welches Verfahren besser funktioniert, sondern auch, ob der Unterschied statistisch signifikant ist.
Bei A/B-Tests wird in der Regel ein einzelner Messwert für zwei Verfahren verglichen, z. B. wie ein Vergleich der Modellgenauigkeit für zwei Techniken funktioniert? A/B-Tests können jedoch auch eine beliebige endliche Anzahl von Messwerten vergleichen.
Beschleunigerchip
Eine Kategorie spezialisierter Hardwarekomponenten, die für die Durchführung von Schlüsselberechnungen für Deep-Learning-Algorithmen entwickelt wurden.
Beschleunigerchips (oder kurz Beschleuniger) können die Geschwindigkeit und Effizienz von Trainings- und Inferenzaufgaben im Vergleich zu einer CPU für allgemeine Zwecke erheblich erhöhen. Sie sind ideal für das Trainieren neuronaler Netzwerke und ähnliche rechenintensive Aufgaben.
Beispiele für Beschleuniger-Chips:
- Tensor Processing Units (TPUs) von Google mit dedizierter Hardware für Deep Learning.
- Die GPUs von NVIDIA wurden zwar ursprünglich für die Grafikverarbeitung entwickelt, sind aber für die parallele Verarbeitung konzipiert, wodurch die Verarbeitungsgeschwindigkeit erheblich erhöht werden kann.
Genauigkeit
Die Anzahl der korrekten Vorhersagen für die Klassifizierung geteilt durch die Gesamtzahl der Vorhersagen. Das bedeutet:
Ein Modell, das 40 richtige und 10 falsche Vorhersagen getroffen hat, hätte beispielsweise eine Genauigkeit von:
Die binäre Klassifizierung gibt den verschiedenen Kategorien von richtigen Vorhersagen und falschen Vorhersagen spezifische Namen. Die Genauigkeitsformel für die binäre Klassifizierung lautet also:
Dabei gilt:
- TP ist die Anzahl der richtig positiven (richtigen Vorhersagen).
- TN ist die Anzahl der richtig negativen Ergebnisse (richtige Vorhersagen).
- FP ist die Anzahl der falsch positiven Ergebnisse (falsche Vorhersagen).
- FN ist die Anzahl der falsch negativen (falschen Vorhersagen).
Die Genauigkeit mit Precision und Recall vergleichen und gegenüberstellen
Aktion
Beim Reinforcement Learning der Mechanismus, mit dem der Agent zwischen Zuständen der Umgebung wechselt. Der Agent wählt die Aktion mithilfe einer Richtlinie aus.
Aktivierungsfunktion
Eine Funktion, mit der neuronale Netzwerke nicht lineare (komplexe) Beziehungen zwischen Features und dem Label lernen können.
Beliebte Aktivierungsfunktionen sind unter anderem:
Die Diagramme von Aktivierungsfunktionen bestehen nie aus einzelnen geraden Linien. Das Diagramm der ReLU-Aktivierungsfunktion besteht beispielsweise aus zwei geraden Linien:

Das Diagramm der Sigmoidaktivierungsfunktion sieht so aus:

Klicken Sie auf das Symbol, um ein Beispiel aufzurufen.
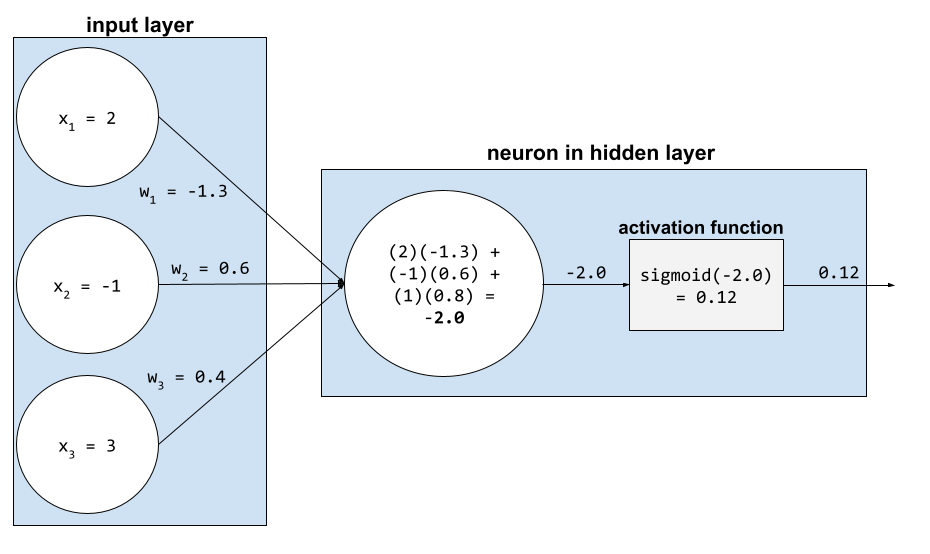
In einem neuronalen Netzwerk ändern Aktivierungsfunktionen die gewichtete Summe aller Eingaben in ein Neuron. Zur Berechnung einer gewichteten Summe addiert das Neuron die Produkte der relevanten Werte und Gewichtungen. Angenommen, die relevante Eingabe für ein Neuron besteht aus Folgendem:
| Eingabewert | Eingabegewichtung |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0Angenommen, der Designer dieses neuronalen Netzes wählt die Sigmoidfunktion als Aktivierungsfunktion aus. In diesem Fall berechnet das Neuron den Sigmoid von -2,0, was ungefähr 0,12 entspricht. Daher übergibt das Neuron 0,12 (statt -2,0) an die nächste Ebene im neuronalen Netzwerk. Die folgende Abbildung veranschaulicht den relevanten Teil des Prozesses:
aktives Lernen
Ein Trainingsansatz, bei dem der Algorithmus einige der Daten wählt, aus denen er lernt. Aktives Lernen ist besonders nützlich, wenn die Beschaffung von Beispielen mit Label knapp oder teuer ist. Anstatt blind nach einer Vielzahl von Beispielen mit Labels zu suchen, sucht ein aktiver Lernalgorithmus selektiv nach genau den Beispielen, die er zum Lernen benötigt.
AdaGrad
Ein ausgefeilter Algorithmus für den Gradientenabstieg, der die Gradienten jedes Parameters neu skaliert und jedem Parameter eine unabhängige Lernrate zuweist. Eine ausführliche Erläuterung finden Sie in diesem AdaGrad-Artikel.
Agent
Beim Bestärkendes Lernen die Entität, die eine Richtlinie verwendet, um die erwartete Rendite des Wechsels zwischen den Zuständen der Umgebung zu maximieren.
Im Allgemeinen ist ein Agent eine Software, die autonom eine Reihe von Aktionen zur Erreichung eines Ziels plant und ausführt und sich in der Lage ist, sich an Änderungen in der Umgebung anzupassen. Beispielsweise könnten LLM-basierte Agents das LMM verwenden, um einen Plan zu erstellen, anstatt eine Richtlinie für Reinforcement Learning anzuwenden.
agglomeratives Clustering
Siehe Hierarchisches Clustering.
Anomalieerkennung
Der Prozess zum Identifizieren von Ausreißern. Wenn der Mittelwert für ein bestimmtes Feature beispielsweise 100 mit einer Standardabweichung von 10 ist, sollte die Anomalieerkennung den Wert 200 als verdächtig kennzeichnen.
AR
Abkürzung für Augmented Reality
Bereich unter der PR-Kurve
Weitere Informationen finden Sie unter PR AUC (Area Under the PR Curve).
Bereich unter der ROC-Kurve
Siehe AUC (Fläche unter der ROC-Kurve).
künstliche allgemeine Intelligenz
Ein nicht menschlicher Mechanismus, der ein breites Spektrum an Problemlösung, Kreativität und Anpassungsfähigkeit zeigt. Beispielsweise könnte ein Programm, das künstliche allgemeine Intelligenz zeigt, Text übersetzen, Symphonien komponieren und sich vor allem bei Spielen glänzen, die noch nicht erfunden wurden.
künstliche Intelligenz
Ein nicht menschliches Programm oder model, das anspruchsvolle Aufgaben lösen kann Ein Programm oder Modell, das Text übersetzt, oder ein Programm oder Modell, das Krankheiten auf radiologischen Bildern identifiziert, weisen beide Arten von künstlicher Intelligenz auf.
Formell ist maschinelles Lernen ein Teilgebiet der künstlichen Intelligenz. In den letzten Jahren haben einige Unternehmen jedoch damit begonnen, die Begriffe künstliche Intelligenz und maschinelles Lernen austauschbar zu verwenden.
aufmerksamkeit
Ein Mechanismus, der in einem neuronalen Netzwerk verwendet wird und die Bedeutung eines bestimmten Wortes oder Teils eines Wortes angibt. Aufmerksamkeit komprimiert die Menge an Informationen, die ein Modell benötigt, um das nächste Token bzw. Wort vorherzusagen. Ein typischer Aufmerksamkeitsmechanismus kann aus einer gewichteten Summe einer Reihe von Eingaben bestehen, wobei die Gewichtung für jede Eingabe von einem anderen Teil des neuronalen Netzwerks berechnet wird.
Weitere Informationen finden Sie unter Selbstaufmerksamkeit und Selbstaufmerksamkeit in mehreren Bereichen – die Bausteine von Transformers.
Attribut
Synonym für feature.
Im Bereich der Fairness beim maschinellen Lernen beziehen sich Attribute oft auf Merkmale, die sich auf Einzelpersonen beziehen.
Attribut-Sampling
Taktik zum Trainieren einer Entscheidungsstruktur, bei der jeder Entscheidungsbaum beim Lernen der Bedingung nur eine zufällige Teilmenge möglicher Features berücksichtigt. Im Allgemeinen wird für jeden Knoten eine unterschiedliche Teilmenge von Features erfasst. Im Gegensatz dazu werden beim Trainieren eines Entscheidungsbaums ohne Attributabtastung alle möglichen Merkmale für jeden Knoten berücksichtigt.
AUC (Fläche unter der ROC-Kurve)
Eine Zahl zwischen 0,0 und 1,0, die die Fähigkeit eines binären Klassifizierungsmodells darstellt, positive Klassen von negativen Klassen zu trennen. Je näher die AUC bei 1,0 liegt, desto besser ist das Modell in der Lage, Klassen voneinander zu trennen.
Die folgende Abbildung zeigt beispielsweise ein Klassifikatormodell, das positive Klassen (grüne Ovale) von negativen Klassen (violette Rechtecke) perfekt trennt. Dieses unrealistisch perfekte Modell hat eine AUC von 1,0:

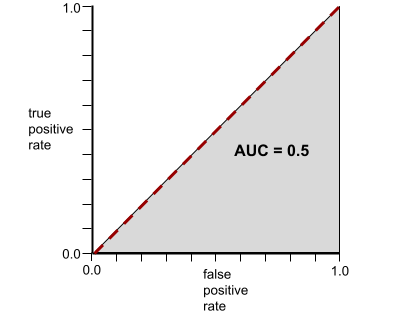
Umgekehrt zeigt die folgende Abbildung die Ergebnisse für ein Klassifikatormodell, das zufällige Ergebnisse generiert hat. Dieses Modell hat einen AUC von 0,5:

Ja, das vorherige Modell hat einen AUC von 0,5, nicht 0,0.
Die meisten Modelle befinden sich irgendwo zwischen den beiden Extremen. Das folgende Modell trennt beispielsweise Positive von negativen Werten etwas und hat daher einen AUC zwischen 0, 5 und 1, 0:

AUC ignoriert alle Werte, die Sie für den Klassifizierungsschwellenwert festgelegt haben. Stattdessen berücksichtigt AUC alle möglichen Klassifizierungsschwellenwerte.
Klicken Sie auf das Symbol, um mehr über die Beziehung zwischen AUC- und ROC-Kurven zu erfahren.
AUC steht für die Fläche unter einer ROC-Kurve. Die ROC-Kurve für ein Modell, das Positive von Negativen genau trennt, sieht beispielsweise so aus:
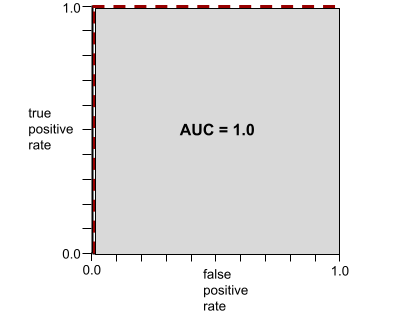
AUC ist die Fläche der grauen Region in der vorherigen Abbildung. In diesem ungewöhnlichen Fall ist der Bereich einfach die Länge des grauen Bereichs (1,0) multipliziert mit der Breite der grauen Region (1,0). Das Produkt von 1,0 und 1,0 ergibt also einen AUC-Wert von genau 1,0, was den höchstmöglichen AUC-Wert ist.
Umgekehrt sieht die ROC-Kurve für einen Klassifikator, der Klassen nicht trennen kann, so aus. Die Fläche dieser grauen Region beträgt 0,5.
Eine typischere ROC-Kurve sieht ungefähr so aus:
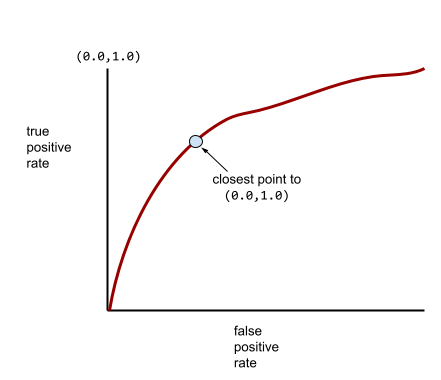
Es wäre mühsam, die Fläche unter dieser Kurve manuell zu berechnen. Deshalb berechnet ein Programm normalerweise die meisten AUC-Werte.
augmented reality
Eine Technologie, die ein computergeneriertes Bild der Sicht eines Nutzers der realen Welt überlagert und so eine zusammengesetzte Ansicht bietet.
Autoencoder
Ein System, das lernt, die wichtigsten Informationen aus der Eingabe zu extrahieren. Autoencoder sind eine Kombination aus einem Encoder und Decoder. Autoencoder nutzen den folgenden zweistufigen Prozess:
- Der Encoder ordnet die Eingabe einem (üblicherweise) verlustbehafteten Format mit niedrigeren Dimensionen zu.
- Der Decoder erstellt eine verlustbehaftete Version der ursprünglichen Eingabe, indem er das niedrigerdimensionale Format dem ursprünglichen höherdimensionalen Eingabeformat zuordnet.
Autoencoder werden durchgängig trainiert. Dabei versucht der Decoder, die ursprüngliche Eingabe möglichst genau aus dem Zwischenformat des Encoders zu rekonstruieren. Da das Zwischenformat kleiner (niedrigerdimensional) als das Originalformat ist, muss der Autoencoder lernen, welche Informationen in der Eingabe wichtig sind, und die Ausgabe ist nicht perfekt mit der Eingabe identisch.
Beispiel:
- Wenn es sich bei den Eingabedaten um eine Grafik handelt, würde die nicht exakte Kopie der Originalgrafik ähnlich, aber etwas abgeändert sein. Vielleicht entfernt die nicht exakte Kopie das Rauschen aus der Originalgrafik oder füllt einige fehlende Pixel auf.
- Wenn die Eingabedaten Text sind, generiert ein Autoencoder neuen Text, der den Originaltext imitiert (aber nicht damit identisch ist).
Siehe auch Verschiedene Autoencoder.
Automation Bias
Wenn ein menschlicher Entscheidungsträger Empfehlungen von einem automatisierten Entscheidungssystem gegenüber Informationen ohne Automatisierung bevorzugt, selbst wenn das automatisierte Entscheidungssystem Fehler macht.
AutoML
Jeder automatisierte Prozess zum Erstellen von Modellen für maschinelles Lernen. So kann AutoML automatisch Aufgaben ausführen:
- Suchen Sie nach dem am besten geeigneten Modell.
- Hyperparameter abstimmen.
- Bereiten Sie Daten vor (einschließlich der Durchführung von Feature Engineering).
- Stellen Sie das resultierende Modell bereit.
AutoML ist für Data Scientists nützlich, da sie damit Zeit und Mühe bei der Entwicklung von ML-Pipelines sparen und die Vorhersagegenauigkeit verbessern können. Es ist auch für Nicht-Experten nützlich, da komplizierte ML-Aufgaben für sie besser zugänglich sind.
automatisch-regressives Modell
Ein model, das eine Vorhersage anhand seiner eigenen vorherigen Vorhersagen ableitet. Autoregressive Sprachmodelle sagen beispielsweise das nächste Token anhand der zuvor vorhergesagten Tokens voraus. Alle Large Language Models, die auf Transformer basieren, sind automatisch regressiv.
Im Gegensatz dazu sind GAN-basierte Bildmodelle normalerweise nicht automatisch regressiv, da sie ein Bild in einem einzigen Vorwärtsdurchlauf und nicht iterativ in Schritten generieren. Bestimmte Bildgenerierungsmodelle sind jedoch automatisch regressiv, da sie ein Bild schrittweise generieren.
Hilfsverlust
Eine Verlustfunktion, die in Verbindung mit der Hauptverlustfunktion eines neuronalen Netzwerks verwendet wird und dazu beiträgt, das Training während der ersten Iterationen zu beschleunigen, wenn Gewichtungen zufällig initialisiert werden.
Durch Hilfsverlustfunktionen werden effektive Gradienten an die früheren Layers übertragen. Dies erleichtert die Konvergenz während des Trainings, da das Problem mit dem verschwindenden Farbverlauf bekämpft wird.
Durchschnittliche Precision
Messwert zur Zusammenfassung der Leistung einer Rangfolge von Ergebnissen. Zur Berechnung der durchschnittlichen Precision wird der Durchschnitt der Precision-Werte für jedes relevante Ergebnis (jedes Ergebnis in der Rangliste, bei dem der Recall im Vergleich zum vorherigen Ergebnis zunimmt) berechnet.
Siehe auch Fläche unter der PR-Kurve.
Bedingung an Achsen ausgerichtet
In einem Entscheidungsbaum eine Bedingung, die nur ein einzelnes Feature enthält. Wenn beispielsweise die Fläche ein Element ist, dann ist die folgende Bedingung auf Achse ausgerichtet:
area > 200
Stellen Sie einen Kontrast mit der Schräglage her.
B
Backpropagation (Backpropagierung)
Der Algorithmus, der den Gradientenabstieg in neuronalen Netzwerken implementiert.
Das Training eines neuronalen Netzwerks umfasst viele Iterationen des folgenden Zyklus mit zwei Durchgängen:
- Während des Vorwärtsdurchlaufs verarbeitet das System einen Batch von Beispielen, um Vorhersagen zu liefern. Das System vergleicht jede Vorhersage mit jedem label-Wert. Die Differenz zwischen der Vorhersage und dem Labelwert ist der loss für dieses Beispiel. Das System aggregiert die Verluste für alle Beispiele, um den Gesamtverlust für den aktuellen Batch zu berechnen.
- Während der Rückpropagierung (Rückpropagierung) reduziert das System den Verlust, indem es die Gewichtung aller Neuronen in allen verborgenen Ebenen anpasst.
Neuronale Netzwerke enthalten oft viele Neuronen auf vielen verborgenen Schichten. Jedes dieser Neuronen trägt auf unterschiedliche Weise zum Gesamtverlust bei. Rückpropagierung bestimmt, ob die auf bestimmte Neuronen angewendeten Gewichtungen erhöht oder verringert werden.
Die Lernrate ist ein Multiplikator, der das Ausmaß festlegt, in dem jeder Rückwärtsdurchlauf jede Gewichtung erhöht oder verringert. Eine große Lernrate erhöht oder verringert jede Gewichtung um mehr als eine kleine Lernrate.
In der Kalkulation wird durch die Rückpropagierung die Kettenregel aus der Kalkulation implementiert. Das heißt, die Rückpropagierung berechnet die partielle Ableitung des Fehlers in Bezug auf jeden Parameter.
Vor Jahren mussten ML-Anwender Code schreiben, um die Backpropagation zu implementieren. Moderne ML-APIs wie TensorFlow implementieren jetzt die Backpropagation für Sie. Geschafft!
Bagging
Eine Methode zum Trainieren eines Ensembles, bei der jedes einzelne Modell anhand einer zufälligen Teilmenge von Trainingsbeispielen trainiert, die mit Ersatz errechnet wurden. Eine Random Forest ist beispielsweise eine Sammlung von Entscheidungsbäumen, die mit Bagging trainiert werden.
Der Begriff Bagging steht für bootstrap aggregat (Bagging).
Worttasche
Darstellung der Wörter in einem Satz oder einer Passage, unabhängig von der Reihenfolge Beispielsweise steht "Bag of Words" für die folgenden drei Wortgruppen identisch:
- Der Hund springt
- springt der Hund
- Hund springt
Jedes Wort wird einem Index in einem dünnbesetzten Vektor zugeordnet, in dem für jedes Wort im Vokabular ein Index vorhanden ist. Beispielsweise wird die Wortgruppe der Hund springt einem Featurevektor mit Werten ungleich null in den drei Indexen zugeordnet, die den Wörtern the, dog und jumps entsprechen. Folgende Werte ungleich null sind möglich:
- Eine 1, die auf das Vorhandensein eines Wortes verweist.
- Gibt an, wie oft ein Wort in der Tasche erscheint. Wenn die Wortgruppe beispielsweise der kastanienbraune Hund ist ein Hund mit kastanienbraunem Fell lautet, werden sowohl kastanienbraun als auch Hund als 2 und die anderen Wörter als 1 dargestellt.
- Ein anderer Wert, z. B. der Logarithmus zur Anzahl der Male, die ein Wort in der Tasche auftaucht.
baseline
model, das als Referenzpunkt für den Vergleich der Leistung eines anderen Modells (normalerweise ein komplexeres Modell) verwendet wird. Ein logistisches Regressionsmodell kann beispielsweise als gute Basis für ein tiefes Modell dienen.
Die Referenz hilft Modellentwicklern bei einem bestimmten Problem, die erwartete Mindestleistung zu quantifizieren, die ein neues Modell erreichen muss, damit es nützlich ist.
Batch
Die Beispiele, die in einer Trainingsiteration verwendet werden. Die Batchgröße bestimmt die Anzahl der Beispiele in einem Batch.
Informationen dazu, wie sich ein Batch auf eine Epoche bezieht, finden Sie unter Epoche.
Batch-Inferenz
Das Ableiten von Vorhersagen aus mehreren Beispielen ohne Label, die in kleinere Teilmengen („Batches“) unterteilt sind.
Batchinferenzen können die Parallelisierungsfeatures von Beschleunigerchips nutzen. Das heißt, mehrere Beschleuniger können gleichzeitig Vorhersagen für verschiedene Batches von Beispielen ohne Label ableiten, was die Anzahl der Inferenzen pro Sekunde drastisch erhöht.
Batchnormalisierung
Normalisierung der Eingabe oder Ausgabe der Aktivierungsfunktionen in einer verborgenen Schicht. Die Batchnormalisierung kann folgende Vorteile bieten:
- Erhöhen Sie die Stabilität von neuronalen Netzwerken, indem Sie sie vor Ausreißergewichten schützen.
- Aktivieren Sie höhere Lernraten, um das Training zu beschleunigen.
- Reduzieren Sie die Überanpassung.
Batchgröße
Die Anzahl der Beispiele in einem Batch. Wenn die Batchgröße beispielsweise 100 beträgt, verarbeitet das Modell 100 Beispiele pro Iteration.
Im Folgenden sind beliebte Strategien für die Batchgröße aufgeführt:
- Stochastic Gradient Descent (SGD) mit einer Batchgröße von 1.
- Vollständiger Batch, bei dem die Batchgröße die Anzahl der Beispiele im gesamten Trainingssatz ist. Wenn das Trainings-Dataset beispielsweise eine Million Beispiele enthält, beträgt die Batchgröße eine Million Beispiele. Ein vollständiger Batch ist normalerweise eine ineffiziente Strategie.
- Minibatch, bei denen die Batchgröße normalerweise zwischen 10 und 1.000 liegt. Mini-Batch ist in der Regel die effizienteste Strategie.
Bayessches neuronales Netzwerk
Ein probabilistisches neuronales Netzwerk, das Unsicherheiten bei Gewichtungen und Ausgaben berücksichtigt. Ein Regressionsmodell für ein neuronales Standardnetzwerk prognostiziert in der Regel einen Skalarwert. Ein Standardmodell sagt beispielsweise einen Hauspreis von 853.000 voraus. Im Gegensatz dazu sagt ein bayessches neuronales Netzwerk eine Werteverteilung voraus. Ein Bayessches Modell sagt beispielsweise einen Hauspreis von 853.000 mit einer Standardabweichung von 67.200 voraus.
Ein Bayes's neuronales Netzwerk basiert auf dem Bayes-Satz, um Unsicherheiten in Gewichtungen und Vorhersagen zu berechnen. Ein Bayes'sches neuronales Netzwerk kann nützlich sein, wenn es wichtig ist, Unsicherheiten zu quantifizieren, z. B. in Modellen für Arzneimittel. Bayessche neuronale Netzwerke können auch dazu beitragen, Überanpassung zu vermeiden.
Bayes'sche Optimierung
Ein probabilistisches Regressionsmodell zur Optimierung rechenintensiver Zielfunktionen, indem stattdessen ein Ersatzwert optimiert wird, der die Unsicherheit mit einer Bayesschen Lernmethode quantifiziert. Da die Bayes'sche Optimierung selbst sehr teuer ist, wird sie in der Regel verwendet, um kostspielige Auswertungsaufgaben zu optimieren, die nur wenige Parameter enthalten, z. B. die Auswahl von Hyperparametern.
Bellman-Gleichung
Beim Reinforcement Learning wird die folgende Identität durch die optimale Q-Funktion erfüllt:
\[Q(s, a) = r(s, a) + \gamma \mathbb{E}_{s'|s,a} \max_{a'} Q(s', a')\]
Die Algorithmen des Reinforcement Learning wenden diese Identität über die folgende Aktualisierungsregel an, um Q-learning zu erstellen:
\[Q(s,a) \gets Q(s,a) + \alpha \left[r(s,a) + \gamma \displaystyle\max_{\substack{a_1}} Q(s',a') - Q(s,a) \right] \]
Neben Reinforcement Learning ist die Bellman-Gleichung auch auf die dynamische Programmierung anwendbar. Weitere Informationen finden Sie im Wikipedia-Eintrag zur Bellman-Gleichung.
BERT (Bidirektionale Encoder-Darstellungen von Transformers)
Eine Modellarchitektur für die Textdarstellung. Ein trainiertes BERT-Modell kann als Teil eines größeren Modells für die Textklassifizierung oder andere ML-Aufgaben verwendet werden.
BERT hat die folgenden Eigenschaften:
- Verwendet die Transformer-Architektur und setzt daher auf Selbstaufmerksamkeit.
- Verwendet den encoder-Teil des Transformers. Die Aufgabe des Encoders besteht darin, gute Textdarstellungen zu erstellen, anstatt eine bestimmte Aufgabe wie Klassifizierung auszuführen.
- bidirektional.
- Verwendet Maskierung für unüberwachtes Training.
Zu den Varianten von BERT gehören:
Einen Überblick über BERT finden Sie unter Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing.
Voreingenommenheit (Ethik/Fairness)
1. Vorurteile, Vorurteile oder Bevorzugung bestimmter Dinge, Personen oder Gruppen gegenüber anderen. Diese Verzerrungen können sich auf die Erfassung und Interpretation von Daten, das Design eines Systems und die Interaktion von Nutzern mit einem System auswirken. Zu den Formen dieser Art von Verzerrung gehören:
- Automatisierungsverzerrung
- Bestätigungsfehler
- Voreingenommenheit der Testperson
- Gruppenattributionsverzerrung
- implizite Voreingenommenheit
- In-Group-Verzerrung
- Out-Group-Homogenitätsverzerrung
2. Systematischer Fehler, der durch eine Stichproben- oder Berichterstattung verursacht wird. Zu den Formen dieser Art von Verzerrung gehören:
- Abdeckungsverzerrung
- Non-Response Bias
- Beteiligungsverzerrung
- Verzerrung der Berichterstattung
- Stichprobenverzerrung
- Auswahlverzerrung
Nicht zu verwechseln mit dem Begriff Verzerrung in ML-Modellen oder Vorhersageverzerrung.
Voreingenommenheit (Mathematik) oder Voreingenommenheitsbegriff
Achsenabschnitt oder Versatz von einem Ursprung. Verzerrungen sind ein Parameter in Modellen für maschinelles Lernen, der durch eine der folgenden Aktionen symbolisiert wird:
- b
- W0
Beispielsweise ist Verzerrung das b in der folgenden Formel:
Bei einer einfachen zweidimensionalen Linie bedeutet Verzerrung lediglich einen „y-Achsenabschnitt“. Beispielsweise beträgt die Verzerrung der Linie in der folgenden Abbildung 2.
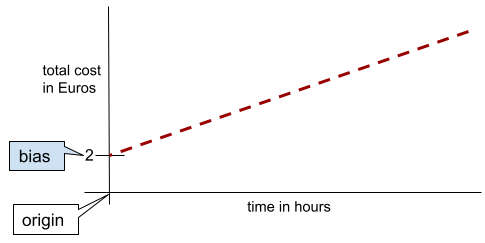
Es liegt eine Verzerrung vor, da nicht alle Modelle am Ursprung (0,0) beginnen. Beispiel: Ein Freizeitpark kostet 2 € und zusätzlich 0,5 € pro Stunde, die ein Kunde aufhält. Daher hat ein Modell, das die Gesamtkosten abbildet, eine Verzerrung von 2, da die niedrigsten Kosten 2 € sind.
Verzerrungen sind nicht mit Voreingenommenheit in Ethik und Fairness oder Vorhersageverzerrung zu verwechseln.
bidirektional
Begriff, der ein System beschreibt, das den Text auswertet, der einem Zieltext sowohl vorhergeht als auch folgen. Im Gegensatz dazu wertet ein unidirektionales System nur den Text aus, der einem Zieltextabschnitt vor geht.
Angenommen, Sie haben ein maskiertes Sprachmodell, das Wahrscheinlichkeiten für die Wörter ermitteln muss, die die Unterstreichung in der folgenden Frage darstellen:
Was ist _____ mit dir?
Ein unidirektionales Sprachmodell müsste seine Wahrscheinlichkeiten nur auf dem Kontext basieren, der von den Wörtern „Was“, „ist“ und „der“ bereitgestellt wird. Im Gegensatz dazu könnte ein bidirektionales Sprachmodell auch Kontext von „mit“ und „Sie“ erhalten, was dem Modell helfen kann, bessere Vorhersagen zu generieren.
bidirektionales Sprachmodell
Ein Sprachmodell, das anhand des vorherigen und folgenden Textes die Wahrscheinlichkeit bestimmt, mit der ein bestimmtes Token an einer bestimmten Stelle in einem Textauszug vorhanden ist.
Bigram
Ein N-Gramm, in dem N=2 ist.
Binäre Klassifizierung
Ein Typ der Klassifizierungsaufgabe, die eine von zwei sich gegenseitig ausschließenden Klassen vorhersagt:
- der positiven Klasse
- die negative Klasse
Die folgenden beiden Modelle für maschinelles Lernen führen jeweils eine binäre Klassifizierung durch:
- Ein Modell, das bestimmt, ob E-Mails Spam (positive Klasse) oder kein Spam (negative Klasse) sind.
- Ein Modell, das medizinische Symptome bewertet, um festzustellen, ob eine Person eine bestimmte Krankheit (positive Klasse) oder nicht diese Krankheit (die negative Klasse) hat.
Kontrast mit der Klassifizierung mit mehreren Klassen
Weitere Informationen finden Sie unter Logistische Regression und Klassifizierungsschwellenwert.
Binärbedingung
In einem Entscheidungsbaum eine Bedingung, die nur zwei mögliche Ergebnisse hat, normalerweise ja oder nein. Das folgende Beispiel ist eine binäre Bedingung:
temperature >= 100
Stellen Sie einen Kontrast mit einer nicht binären Bedingung her.
Gruppieren
Synonym für Bucketing.
BLEU (Bilingual Evaluation Understudy)
Ein Wert zwischen 0,0 und 1,0 (einschließlich), der die Qualität einer Übersetzung zwischen zwei menschlichen Sprachen angibt, z.B.zwischen Englisch und Russisch. Ein BLEU-Wert von 1,0 weist auf eine perfekte Übersetzung hin, ein BLEU-Wert von 0,0 auf eine schlechte Übersetzung.
Boosting
Ein Verfahren für maschinelles Lernen, bei dem eine Reihe einfacher und nicht sehr genauer Klassifikatoren (auch als „schwache“ Klassifikatoren bezeichnet) iterativ zu einem Klassifikator mit hoher Genauigkeit (ein „starker“ Klassifikator) kombiniert werden. Dazu werden die Beispiele, die das Modell derzeit falsch klassifiziert, gewichtet.
Begrenzungsrahmen
In einem Bild die Koordinaten (x, y) eines Rechtecks um einen Interessenbereich, z. B. den Hund im Bild unten.

Broadcasting
Erweiterung der Form eines Operanden in einer mathematischen Matrixoperation auf Dimensionen, die für diese Operation kompatibel sind Beispielsweise erfordert die lineare Algebra, dass die beiden Operanden in einer Matrixaddierungsoperation dieselben Dimensionen haben müssen. Folglich können Sie keine Matrix der Form (m, n) zu einem Vektor der Länge n hinzufügen. Broadcasting ermöglicht diesen Vorgang, indem der Vektor der Länge n virtuell zu einer Formmatrix (m, n) erweitert wird, indem in jeder Spalte dieselben Werte nach unten repliziert werden.
Bei den folgenden Definitionen untersagt die lineare Algebra A+B beispielsweise, weil A und B unterschiedliche Dimensionen haben:
A = [[7, 10, 4],
[13, 5, 9]]
B = [2]
Beim Broadcasting wird jedoch die Operation A+B durch virtuelle Erweiterung von B ermöglicht:
[[2, 2, 2],
[2, 2, 2]]
Somit ist A+B jetzt ein gültiger Vorgang:
[[7, 10, 4], + [[2, 2, 2], = [[ 9, 12, 6],
[13, 5, 9]] [2, 2, 2]] [15, 7, 11]]
Weitere Informationen finden Sie in der folgenden Beschreibung der Übertragung in NumPy.
Bucketing
Konvertieren eines einzelnen Features in mehrere binäre Features, die als Buckets oder Bins bezeichnet werden und in der Regel auf einem Wertebereich basieren. Das Chopped-Feature ist in der Regel ein kontinuierliches Feature.
Anstatt die Temperatur beispielsweise als einzelnes konstantes Gleitkommafeature darzustellen, können Sie Temperaturbereiche beispielsweise in separate Buckets aufteilen:
- <= 10 Grad Celsius wäre der „kalte“ Eimer.
- 11 bis 24 Grad Celsius wäre die Kategorie „Temperär“.
- >= 25 Grad Celsius wäre der „warme“ Eimer.
Das Modell behandelt jeden Wert im selben Bucket identisch. Beispielsweise befinden sich die Werte 13 und 22 beide im gemäßigten Bucket, sodass das Modell die beiden Werte identisch behandelt.
C
Kalibrierungsschicht
Eine Anpassung nach der Vorhersage, in der Regel zur Berücksichtigung von Vorhersageverzerrungen. Die angepassten Vorhersagen und Wahrscheinlichkeiten sollten der Verteilung eines beobachteten Satzes von Labels entsprechen.
Kandidatengenerierung
Der erste Satz von Empfehlungen, die von einem Empfehlungssystem ausgewählt wurden. Angenommen, eine Buchhandlung bietet 100.000 Titel. In der Phase der Kandidatengenerierung wird eine viel kleinere Liste geeigneter Bücher für einen bestimmten Nutzer erstellt, z. B. 500. Aber selbst 500 Bücher sind viel zu viele, um sie einem Nutzer zu empfehlen. Nachfolgende, teurere Phasen eines Empfehlungssystems (z. B. Bewertung und Neueinstufung) reduzieren diese 500 auf einen viel kleineren, nützlicheren Satz von Empfehlungen.
Kandidatenstichproben
Eine Optimierung während der Trainingszeit, die eine Wahrscheinlichkeit für alle positiven Labels berechnet, z. B. mit Softmax, aber nur für eine zufällige Stichprobe von negativen Labels. Bei einem Beispiel mit den Bezeichnungen Beagle und dog werden bei der Kandidatenstichprobe beispielsweise die vorhergesagten Wahrscheinlichkeiten und die entsprechenden Verlustbedingungen für Folgendes berechnet:
- Beagle
- Hund
- Eine zufällige Teilmenge der verbleibenden negativen Klassen (z. B. cat, lollipop, fence).
Die Idee ist, dass negative Klassen von weniger häufig negativer Verstärkung lernen können, solange positive Klassen immer eine ordnungsgemäße positive Verstärkung erhalten, was in der Tat empirisch beobachtet wird.
Die Stichprobennahme ist recheneffizienter als Trainingsalgorithmen, die Vorhersagen für alle negativen Klassen berechnen, insbesondere wenn die Anzahl negativer Klassen sehr groß ist.
kategoriale Daten
Funktionen mit einem bestimmten Satz möglicher Werte Betrachten Sie beispielsweise ein kategoriales Feature namens traffic-light-state, das nur einen der folgenden drei möglichen Werte haben kann:
redyellowgreen
Durch Darstellung von traffic-light-state als kategoriales Feature kann ein Modell die unterschiedlichen Auswirkungen von red, green und yellow auf das Fahrerverhalten lernen.
Kategorische Merkmale werden manchmal als diskrete Merkmale bezeichnet.
Stellen Sie einen Kontrast zu numerischen Daten her.
Kausales Sprachmodell
Synonym für unidirektionales Sprachmodell.
Unter Bidirektionales Sprachmodell erfahren Sie, wie Sie verschiedenen richtungsweisenden Ansätzen bei der Sprachmodellierung gegenüberstellen.
Schwerpunkt
Mittelpunkt eines Clusters, bestimmt durch einen k-Means- oder k-Median-Algorithmus. Wenn für k beispielsweise 3 steht, findet der k-Means- bzw. k-Median-Algorithmus 3 Schwerpunkte.
Schwerpunkt-basiertes Clustering
Eine Kategorie von Clustering-Algorithmen, die Daten in nicht hierarchischen Clustern organisiert. k-Means ist der am häufigsten verwendete Schwerpunkt-basierte Clustering-Algorithmus.
Dies steht im Gegensatz zu Algorithmen des hierarchischen Clustering.
Chain-of-Thought Prompting
Ein Prompt Engineering, das ein Large Language Model (LLM) dazu anregt, seine Gründe Schritt für Schritt zu erklären. Betrachten Sie zum Beispiel die folgende Aufforderung und achten Sie dabei besonders auf den zweiten Satz:
Wie viele Kräfte würde ein Fahrer in einem Auto erleben, das in 7 Sekunden von 0 auf 60 Meilen pro Stunde fährt? Zeigen Sie in der Antwort alle relevanten Berechnungen an.
Die Antwort des LLM würde wahrscheinlich:
- Zeigen Sie eine Folge physikalischer Formeln, wobei Sie die Werte 0, 60 und 7 an geeigneten Stellen einsetzen.
- Erklären Sie, warum diese Formeln ausgewählt wurden und was die verschiedenen Variablen bedeuten.
Eine Chain-of-Thought Prompting zwingt das LLM, alle Berechnungen durchzuführen, was zu einer genaueren Antwort führen könnte. Darüber hinaus können Nutzer mithilfe von Chain-of-Thought Prompts die Schritte des LLM prüfen, um festzustellen, ob die Antwort sinnvoll ist.
Chat
Der Inhalt eines Hin- und Her-Dialogs mit einem ML-System, in der Regel ein Large Language Model. Die vorherige Interaktion in einem Chat (Ihre Eingabe und die Antwort des Large Language Model) wird zum Kontext für die nachfolgenden Teile des Chats.
Ein Chatbot ist eine Anwendung eines Large Language Model.
checkpoint
Daten, die den Status der Parameter eines Modells bei einem bestimmten Trainingsdurchlauf erfassen. Mit Prüfpunkten können Modell-Gewichtungen exportiert oder das Training über mehrere Sitzungen hinweg durchgeführt werden. Prüfpunkte ermöglichen auch das Training, damit vergangene Fehler fortgesetzt werden, z. B. das vorzeitige Beenden von Jobs.
Bei der Feinabstimmung ist der Ausgangspunkt für das Training des neuen Modells ein bestimmter Checkpoint des vortrainierten Modells.
Klasse
Eine Kategorie, zu der ein Label gehören kann. Beispiel:
- In einem binären Klassifizierungsmodell, das Spam erkennt, können die beiden Klassen Spam und Kein Spam sein.
- In einem Klassifizierungsmodell mit mehreren Klassen, das Hunderassen identifiziert, können die Klassen Pudel, Beagle, Mops usw. sein.
Ein Klassifizierungsmodell sagt eine Klasse vorher. Im Gegensatz dazu sagt ein Regressionsmodell eine Zahl statt einer Klasse vorher.
Klassifizierungsmodell
Ein model, dessen Vorhersage eine model ist. Im Folgenden finden Sie beispielsweise Klassifizierungsmodelle:
- Ein Modell, das die Sprache eines Eingabesatzes vorhersagt (Französisch? Spanisch? Italienisch?).
- Ein Modell, das Baumarten (Maple? Oak? Affenbrot?).
- Ein Modell, das die positive oder negative Klasse für eine bestimmte Krankheit vorhersagt.
Im Gegensatz dazu sagen Regressionsmodelle Zahlen statt Klassen voraus.
Zwei gängige Arten von Klassifizierungsmodellen sind:
Klassifizierungsschwellenwert
In einer binären Klassifizierung eine Zahl zwischen 0 und 1, die die Rohausgabe eines logistischen Regressionsmodells in eine Vorhersage der positiven Klasse oder der negativen Klasse umwandelt. Beachten Sie, dass der Klassifizierungsschwellenwert ein Wert ist, den ein Mensch auswählt, kein Wert, der durch das Modelltraining ausgewählt wird.
Ein logistisches Regressionsmodell gibt einen Rohwert zwischen 0 und 1 aus. Dann:
- Wenn dieser Rohwert größer als der Klassifizierungsschwellenwert ist, wird die positive Klasse vorhergesagt.
- Wenn dieser Rohwert kleiner als der Klassifizierungsschwellenwert ist, wird die negative Klasse vorhergesagt.
Angenommen, der Klassifizierungsschwellenwert beträgt 0,8. Ist der Rohwert 0,9, sagt das Modell die positive Klasse vorher. Wenn der Rohwert 0,7 ist, sagt das Modell die negative Klasse vorher.
Die Auswahl des Klassifizierungsschwellenwerts wirkt sich stark auf die Anzahl der falsch positiven und falsch negativen aus.
Dataset mit unausgeglichener Klasse
Ein Dataset für ein Klassifizierungsproblem, bei dem die Gesamtzahl der Labels jeder Klasse signifikant unterschiedlich ist. Betrachten Sie beispielsweise ein binäres Klassifizierungs-Dataset, dessen zwei Labels so unterteilt sind:
- 1.000.000 auszuschließende Labels
- 10 positive Labels
Das Verhältnis von negativen zu positiven Labels beträgt 100.000:1, also ist dies ein Dataset mit unausgeglichener Klasse.
Im Gegensatz dazu hat das folgende Dataset keine Klassenunausgeglichenheit, da das Verhältnis von negativen zu positiven Labels relativ nahe bei 1 liegt:
- 517 auszuschließende Labels
- 483 positive Labels
Datasets mit mehreren Klassen können auch ohne Klassenausgleichung vorliegen. Das folgende Klassifizierungs-Dataset mit mehreren Klassen ist beispielsweise ebenfalls klassenungleichmäßig, da ein Label weit mehr Beispiele hat als die anderen beiden:
- 1.000.000 Labels der Klasse „green“
- 200 Labels mit der Klasse „Lila“
- 350 Labels der Klasse „orange“
Weitere Informationen finden Sie unter Entropie, Mehrheitsklasse und Minderheitenklasse.
Clipping
Ein Verfahren zum Umgang mit Ausreißern, indem Sie einen oder beide der folgenden Schritte ausführen:
- Reduzieren der feature-Werte, die über einem maximalen Schwellenwert liegen, bis zu diesem maximalen Schwellenwert.
- Erhöhen der Featurewerte, die unter einem Mindestschwellenwert liegen, bis zu diesem Mindestschwellenwert.
Angenommen, < 0,5% der Werte für ein bestimmtes Feature liegen außerhalb des Bereichs von 40–60. In diesem Fall können Sie so vorgehen:
- Begrenzen Sie alle Werte über 60 (den maximalen Schwellenwert) auf genau 60.
- Begrenzen Sie alle Werte unter 40 (dem Mindestgrenzwert) so, dass sie genau 40 sind.
Ausreißer können Modelle beschädigen, was manchmal zu einem Überlauf von Gewichten während des Trainings führen kann. Einige Ausreißer können Messwerte wie die Genauigkeit erheblich beeinträchtigen. Clipping ist eine gängige Technik zur Begrenzung des Schadens.
Das Beschneiden von Farbverlauf erzwingt während des Trainings Gradientenwerte innerhalb eines bestimmten Bereichs.
Cloud TPU
Spezialisierter Hardwarebeschleuniger zur Beschleunigung von ML-Arbeitslasten in Google Cloud
Clustering
Gruppieren verwandter Beispiele, insbesondere beim unüberwachten Lernen Sobald alle Beispiele gruppiert sind, kann ein Mensch jedem Cluster optional eine Bedeutung verleihen.
Es gibt viele Clustering-Algorithmen. Die Beispiele für k-means-Algorithmuscluster basieren auf ihrer Nähe zu einem Schwerpunkt, wie im folgenden Diagramm dargestellt:

Ein menschlicher Forscher könnte die Cluster dann überprüfen und Cluster 1 beispielsweise als „Zwergbäume“ und Cluster 2 als „Bäume in Originalgröße“ kennzeichnen.
Als weiteres Beispiel könnten Sie einen Clustering-Algorithmus betrachten, der auf der Entfernung eines Beispiels von einem Mittelpunkt basiert. Der Algorithmus ist wie folgt dargestellt:

gemeinsame Anpassung
Wenn Neuronen Muster in Trainingsdaten vorhersagen, indem sie sich fast ausschließlich auf die Ausgaben bestimmter anderer Neuronen und nicht auf das Verhalten des Netzwerks als Ganzes stützen. Wenn die Muster, die die Co-Anpassung verursachen, in den Validierungsdaten nicht vorhanden sind, führt dies zu einer Überanpassung. Die Dropout-Regularisierung reduziert die Co-Anpassung, da Dropout sicherstellt, dass Neuronen sich nicht ausschließlich auf bestimmte andere Neuronen verlassen können.
gemeinsames Filtern
Sie treffen Vorhersagen zu den Interessen eines Nutzers basierend auf den Interessen vieler anderer Nutzer. Das kollaborative Filtern wird häufig in Empfehlungssystemen verwendet.
Konzept-Drift
Eine Änderung der Beziehung zwischen Funktionen und Label. Im Laufe der Zeit verringert Konzeptabweichungen die Qualität eines Modells.
Während des Trainings lernt das Modell die Beziehung zwischen den Features und ihren Labels im Trainings-Dataset. Wenn die Labels im Trainings-Dataset gute Proxys für die reale Welt sind, sollte das Modell gute Vorhersagen in der realen Welt treffen. Aufgrund der Konzeptabweichung verschlechtern die Vorhersagen des Modells jedoch tendenziell mit der Zeit.
Betrachten Sie beispielsweise ein binäres Klassifizierungsmodell, das vorhersagt, ob ein bestimmtes Automodell „spritsparend“ ist. Das sind die Funktionen:
- Fahrzeuggewicht
- Motorkompression
- Getriebetyp
Das Label ist jedoch entweder:
- spritsparend
- nicht spritsparend
Das Konzept des „spritsparenden Autos“ ändert sich jedoch ständig. Ein Automodell mit dem Label Kraftstoffeffizient von 1994 würde 2024 mit ziemlicher Sicherheit als nicht spritsparend gekennzeichnet werden. Ein Modell, das einer Konzeptabweichung unterliegt, macht im Laufe der Zeit immer weniger nützliche Vorhersagen.
Vergleiche die Unterschiede zu Nichtstationarität.
Bedingung
In einem Entscheidungsbaum jeder Knoten, der einen Ausdruck auswertet. Der folgende Teil eines Entscheidungsbaums enthält beispielsweise zwei Bedingungen:
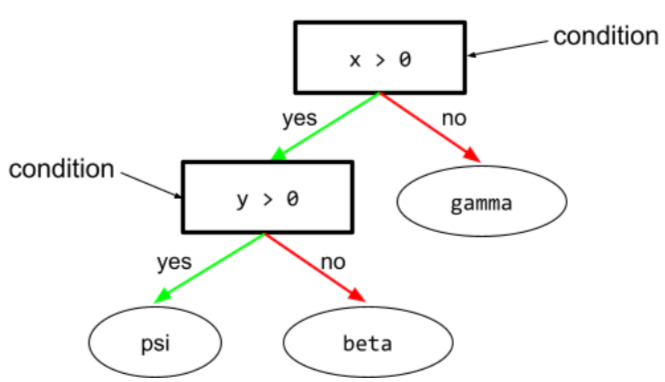
Eine Bedingung wird auch als Split oder Test bezeichnet.
Kontrast der Bedingung mit Blatt.
Weitere Informationen
Konfabulation
Synonym für Halluzination.
Konfabulation ist wahrscheinlich ein technisch genauerer Begriff als Halluzination. Die Halluzination wurde jedoch zuerst populär.
Konfiguration
Prozess der Zuweisung der anfänglichen Attributwerte zum Trainieren eines Modells, darunter:
- von den Zusammensetzungsebenen des Modells
- den Speicherort der Daten
- Hyperparameter wie:
In Projekten für maschinelles Lernen kann die Konfiguration über eine spezielle Konfigurationsdatei oder mithilfe von Konfigurationsbibliotheken wie den folgenden erfolgen:
Bestätigungsverzerrung
Die Tendenz, Informationen so zu suchen, zu interpretieren, zu bevorzugen und sich daran zu erinnern, dass die bestehenden Überzeugungen oder Hypothesen bestätigt werden. Entwickler für maschinelles Lernen können versehentlich Daten so erfassen oder kennzeichnen, dass ein Ergebnis beeinflusst wird, das ihre bestehenden Überzeugungen unterstützt. Der Bestätigungsfehler ist eine Form der impliziten Voreingenommenheit.
Experimentatorverzerrung ist eine Form der Bestätigungsverzerrung, bei der ein Experimentator so lange Modelle trainiert, bis eine bereits bestehende Hypothese bestätigt ist.
Wahrheitsmatrix
Eine NxN-Tabelle, in der die Anzahl der richtigen und falschen Vorhersagen eines Klassifizierungsmodells zusammengefasst ist. Betrachten Sie beispielsweise die folgende Wahrheitsmatrix für ein binäres Klassifizierungsmodell:
| Tumor (prognostiziert) | Ohne Tumor (prognostiziert) | |
|---|---|---|
| Tumor (Ground Truth) | 18 (TP) | 1 (FN) |
| Kein Tumor (Ground Truth) | 6 (FP) | 452 (TN) |
Die obige Wahrheitsmatrix zeigt Folgendes:
- Von den 19 Vorhersagen, bei denen Ground Truth Tumor war, hat das Modell 18 richtig klassifiziert und 1 falsch klassifiziert.
- Von den 458 Vorhersagen, bei denen Ground Truth Nicht-Tumor war, hat das Modell 452 richtig klassifiziert und 6 falsch klassifiziert.
Die Wahrheitsmatrix für ein Klassifizierungsproblem mit mehreren Klassen kann Ihnen helfen, Fehlermuster zu identifizieren. Betrachten Sie beispielsweise die folgende Wahrheitsmatrix für ein 3-Klassen-Klassifizierungsmodell mit mehreren Klassen, das drei verschiedene Iris-Typen kategorisiert (Virginica, Versicolor und Setosa). Als Ground Truth Virginica war, zeigt die Wahrheitsmatrix, dass das Modell Versicolor mit größerer Wahrscheinlichkeit fälschlicherweise vorhergesagt hat als Setosa:
| Setosa (vorhergesagt) | Versicolor (vorhergesagt) | Virginica (vorhergesagt) | |
|---|---|---|---|
| Setosa (Ground Truth) | 88 | 12 | 0 |
| Versicolor (Ground Truth) | 6 | 141 | 7 |
| Virginica (Ground Truth) | 2 | 27 | 109 |
Als weiteres Beispiel könnte eine Wahrheitsmatrix zeigen, dass ein Modell, das für die Erkennung handschriftlicher Ziffern trainiert wurde, tendenziell fälschlicherweise 9 statt 4 oder fälschlicherweise 1 statt 7 vorhersagen.
Wahrheitsmatrixen enthalten genügend Informationen, um eine Vielzahl von Leistungsmesswerten wie Precision und Recall zu berechnen.
Wahlkreis-Parsing
Das Einteilen eines Satzes in kleinere grammatische Strukturen („Bestandteile“). In einem späteren Teil des ML-Systems, z. B. bei einem Natural Language Understanding-Modell, lassen sich die Bürger leichter parsen als der ursprüngliche Satz. Betrachten Sie zum Beispiel den folgenden Satz:
Meine Freundin hat zwei Katzen adoptiert.
Ein Wähler-Parser kann diesen Satz in die folgenden beiden Bestandteile unterteilen:
- Mein Freund ist eine Nominalphrase.
- adopted zwei cats ist eine Verbphrase.
Diese Personengruppen lassen sich weiter in kleinere Gruppen unterteilen. Zum Beispiel könnte die Verb-Phrase
adoptierte zwei Katzen
könnte weiter unterteilt werden in:
- adopted ist ein Verb.
- two cats ist eine weitere Nominalphrase.
kontextbezogene Spracheinbettung
Eine Einbettung, die dem „Verstehen“ von Wörtern und Wortgruppen so nahe kommt, wie es von Muttersprachlern möglich ist. Kontextisierte Spracheinbettungen können komplexe Syntax, Semantik und Kontext verstehen.
Betrachten Sie beispielsweise Einbettungen des englischen Wortes cow. Ältere Einbettungen wie word2vec können englische Wörter darstellen, sodass die Entfernung im Einbettungsbereich von kuh zu bull der Entfernung von ewe (weibliches Schaf) zu ram (männliches Schaf) oder von weiblich zu männlich entspricht. Kontextisierte Spracheinbettungen können noch einen Schritt weiter gehen, da englischsprachige Nutzer manchmal das Wort kuh für Kuh oder Stier verwenden.
Kontextfenster
Die Anzahl der Tokens, die ein Modell in einer bestimmten Eingabeaufforderung verarbeiten kann. Je größer das Kontextfenster, desto mehr Informationen kann das Modell verwenden, um kohärente und konsistente Antworten auf den Prompt zu liefern.
stetiges Feature
Ein Gleitkommawert mit einem unendlichen Bereich möglicher Werte, z. B. Temperatur oder Gewicht.
Kontrast mit der diskreten Funktion
willkürliche Stichproben
Ein nicht wissenschaftlich erfasstes Dataset für schnelle Experimente verwenden. Später ist es wichtig, zu einem wissenschaftlich erfassten Dataset zu wechseln.
Konvergenz
Ein Zustand, der erreicht wird, wenn sich die loss-Werte bei jeder Iteration nur sehr gering oder gar nicht ändern. Die folgende Verlustkurve deutet beispielsweise auf eine Konvergenz bei etwa 700 Iterationen hin:
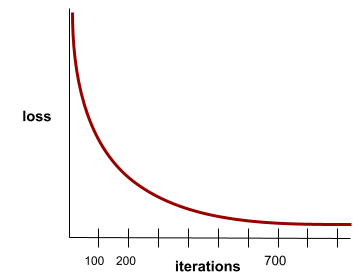
Ein Modell konvergiert, wenn es durch zusätzliches Training nicht verbessert wird.
Beim Deep Learning bleiben Verlustwerte manchmal während vieler Iterationen konstant oder annähernd so stark, bevor sie schließlich absteigen. Während eines langen Zeitraums konstanter Verlustwerte können Sie vorübergehend ein falsches Konvergenzgefühl bekommen.
Weitere Informationen finden Sie unter Frühzeitiges Beenden.
konvexe Funktion
Eine Funktion, in der der Bereich über dem Graphen der Funktion eine konvexe Menge ist. Die prototypische konvexe Funktion ist in etwa so geformt wie der Buchstabe U. Im Folgenden finden Sie beispielsweise alle konvexen Funktionen:
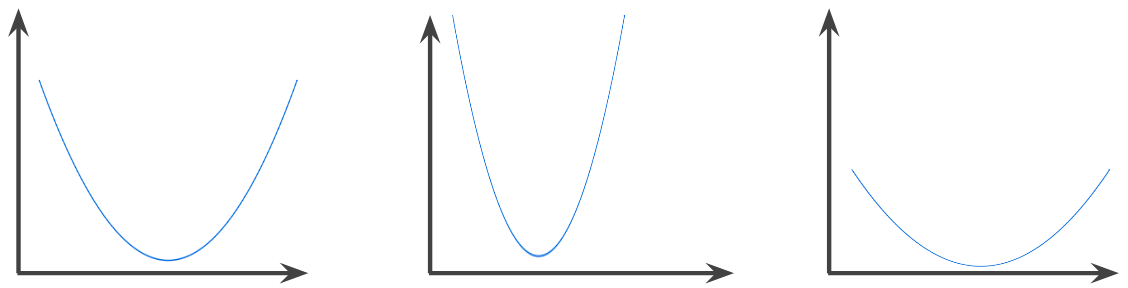
Im Gegensatz dazu ist die folgende Funktion nicht konvex. Beachten Sie, dass die Region über dem Diagramm keine konvexe Menge ist:

Eine streng konvexe Funktion hat genau einen lokalen Mindestpunkt, der auch der globale Mindestpunkt ist. Die klassischen U-förmigen Funktionen sind strikt konvexe Funktionen. Einige konvexe Funktionen (z. B. gerade Linien) sind jedoch nicht U-förmig.
Conversion-Optimierung
Der Einsatz mathematischer Techniken wie dem Gradientenverfahren, um das Minimum einer konvexen Funktion zu ermitteln. In intensiver Forschung im Bereich des maschinellen Lernens wurden verschiedene Probleme als konvexe Optimierungsprobleme formuliert und effizienter gelöst.
Ausführliche Informationen finden Sie unter Boyd und Vandenberghe: Convex-Optimierung.
Convex-Set
Eine Teilmenge des euklidischen Raums, sodass eine zwischen zwei beliebigen Punkten der Teilmenge gezeichnete Linie vollständig innerhalb der Teilmenge bleibt. Die folgenden beiden Formen sind z. B. konvexe Mengen:

Im Gegensatz dazu sind die folgenden beiden Formen keine konvexen Mengen:

Faltung
In der Mathematik, beiläufig gesagt, eine Mischung aus zwei Funktionen. Beim maschinellen Lernen werden bei einer Faltung der Convolutional-Filter und die Eingabematrix vermischt, um Gewichtungen zu trainieren.
Der Begriff „Faltung“ im maschinellen Lernen ist oft eine Abkürzung für Faltungsvorgang oder Faltungsschicht.
Ohne Faltungen müsste ein Algorithmus für maschinelles Lernen eine separate Gewichtung für jede Zelle in einem großen Tensor lernen. Beispielsweise müsste bei einem Training eines Algorithmus für maschinelles Lernen mit Bildern mit 2.000 × 2.000 Bildern 4 Millionen separate Gewichtungen ermittelt werden. Dank Faltungen muss ein Algorithmus für maschinelles Lernen nur die Gewichtung für jede Zelle im Faltungsfilter ermitteln. Dadurch wird der zum Trainieren des Modells erforderliche Arbeitsspeicher drastisch reduziert. Wenn der Faltungsfilter angewendet wird, wird er einfach über die Zellen hinweg repliziert, sodass jede Zelle mit dem Filter multipliziert wird.
Faltungsfilter
Einer der beiden Akteure bei einem Faltungsvorgang. (Der andere Akteur ist ein Slice einer Eingabematrix.) Ein Faltungsfilter ist eine Matrix, die denselben Rang wie die Eingabematrix, aber eine kleinere Form hat. Bei einer 28 x 28-Eingabematrix kann der Filter beispielsweise eine beliebige 2D-Matrix sein, die kleiner als 28 x 28 ist.
Bei der fotografischen Bearbeitung sind alle Zellen in einem Faltungsfilter in der Regel auf ein konstantes Muster von Einsen und Nullen eingestellt. Beim maschinellen Lernen werden Faltungsfilter in der Regel mit Zufallszahlen gesetzt. Anschließend trainiert das Netzwerk die idealen Werte.
Convolutional Layer
Eine Ebene eines neuronalen Deep-Learning-Netzwerks, in der ein Convolutionalfilter eine Eingabematrix durchläuft. Betrachten Sie beispielsweise den folgenden Convolutional-Filter (3 x 3):
![Eine 3x3-Matrix mit den folgenden Werten: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?hl=de)
Die folgende Animation zeigt eine Faltungsschicht, die aus neun Faltungsvorgängen besteht, die die 5x5-Eingabematrix einbeziehen. Beachten Sie, dass jeder Faltungsvorgang mit einem anderen 3x3-Slice der Eingabematrix funktioniert. Die resultierende 3x3-Matrix (rechts) besteht aus den Ergebnissen der 9 Faltungsoperationen:
![Eine Animation mit zwei Matrizen. Die erste Matrix ist die 5x5-Matrix: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179],101740
Die zweite Matrix ist die 3x3-Matrix: [[181,303,618], [115,338,605], [169,351,560]].
Die zweite Matrix wird berechnet, indem der Faltungsfilter [[0, 1, 0], [1, 0, 1], [0, 1, 0]] auf verschiedene 3x3-Teilmengen der 5x5-Matrix angewendet wird.](https://developers.google.com/static/machine-learning/glossary/images/AnimatedConvolution.gif?hl=de)
Convolutional Neural Network
Ein neuronales Netzwerk, in dem mindestens eine Schicht eine Faltungsschicht ist. Ein typisches neuronales Faltungsnetzwerk besteht aus einer Kombination der folgenden Schichten:
Convolutional Neural Networks waren bei bestimmten Problemen wie der Bilderkennung sehr erfolgreich.
Faltungsvorgang
Die folgende zweistufige mathematische Operation:
- Elementweise Multiplikation des Faltungsfilters und eines Slice einer Eingabematrix. (Das Slice der Eingabematrix hat denselben Rang und dieselbe Größe wie der Faltungsfilter.)
- Summe aller Werte in der resultierenden Produktmatrix.
Betrachten Sie zum Beispiel die folgende 5x5-Eingabematrix:
![Die 5x5-Matrix: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40]2,17,1](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?hl=de)
Stellen Sie sich nun den folgenden 2x2-Faltungsfilter vor:
![Die 2x2-Matrix: [[1, 0], [0, 1]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?hl=de)
Jeder Faltungsvorgang umfasst ein einzelnes 2x2-Slice der Eingabematrix. Angenommen, wir verwenden das 2x2-Slice oben links in der Eingabematrix. Der Faltungsvorgang für dieses Slice sieht also so aus:
![Anwenden des Faltungsfilters [[1, 0], [0, 1]] auf den oberen linken 2x2-Abschnitt der Eingabematrix, also [[128,97], [35,22]],
Der Faltungsfilter lässt die Werte 128 und 22 intakt, aber 97 und 35 werden auf Null gesetzt. Folglich ergibt der Faltungsvorgang den Wert 150 (128 + 22).](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?hl=de)
Eine Faltungsschicht besteht aus einer Reihe von Faltungsvorgängen, die jeweils auf einen anderen Abschnitt der Eingabematrix wirken.
Kosten
Synonym für loss.
gemeinsames Training
Ein Ansatz für halbüberwachtes Lernen ist besonders nützlich, wenn alle der folgenden Bedingungen erfüllt sind:
- Das Verhältnis von Beispielen ohne Label zu Beispielen mit Label im Dataset ist hoch.
- Dies ist ein Klassifizierungsproblem (binär oder mehrere Klassen).
- Das Dataset enthält zwei verschiedene Gruppen von Vorhersagefeatures, die unabhängig voneinander und komplementär sind.
Co-Training verstärkt im Wesentlichen unabhängige Signale zu einem stärkeren Signal. Nehmen wir zum Beispiel ein Klassifizierungsmodell, das einzelne Gebrauchtwagen als Gut oder Schlecht einstuft. Ein Satz von Vorhersagemerkmalen könnte sich auf aggregierte Eigenschaften wie das Baujahr, die Marke und das Modell des Autos konzentrieren. Ein anderer Satz von Vorhersagemerkmalen könnte sich auf den Fahrtverlauf des Vorbesitzers und den Wartungsverlauf des Autos konzentrieren.
Der grundlegende Artikel zum gemeinsamen Training ist Combining Labeled and Unlabeled Data with Co-Training von Blu und Mitchell.
kontrafaktische Fairness
Ein Fairness-Messwert, der prüft, ob ein Klassifikator für eine Person dasselbe Ergebnis liefert wie für eine andere Person, die mit der ersten identisch ist. Ausgenommen hiervon sind ein oder mehrere sensible Attribute. Die Bewertung eines Klassifikators auf kontrafaktische Fairness ist eine Methode, um potenzielle Quellen von Verzerrungen in einem Modell aufzudecken.
Eine ausführlichere Besprechung von kontrafaktischer Fairness findest du im Artikel When Worlds Collide: Integrate Different Counterfactual Assures in Fairness (in englischer Sprache).
Abdeckungsverzerrung
Siehe Auswahlverzerrung.
Crash Blossom
Ein Satz oder eine Wortgruppe mit mehrdeutiger Bedeutung. Crashblüten stellen ein erhebliches Problem beim natürlichen Sprachverständnis dar. Die Überschrift Red Tape Holds Up Skyscraper ist beispielsweise eine Crashblüte, weil ein NLU-Modell die Überschrift buchstäblich oder bildlich interpretieren könnte.
Kritiker
Synonym für Deep Q-Network.
Kreuzentropie
Eine Generalisierung von Logverlust auf Klassifizierungsprobleme mit mehreren Klassen. Kreuzentropie quantifiziert die Differenz zwischen zwei Wahrscheinlichkeitsverteilungen. Weitere Informationen finden Sie unter Perplexity.
Kreuzvalidierung
Ein Mechanismus zum Schätzen, wie gut sich ein model auf neue Daten verallgemeinern würde. Dazu wird das Modell anhand einer oder mehreren nicht überlappenden Datenteilmengen getestet, die aus dem model ausgeschlossen wurden.
Kumulative Verteilungsfunktion (CDF)
Eine Funktion, die die Häufigkeit der Stichproben definiert, die kleiner oder gleich einem Zielwert ist. Betrachten Sie beispielsweise eine Normalverteilung kontinuierlicher Werte. Ein CDF gibt an, dass etwa 50% der Stichproben kleiner oder gleich dem Mittelwert sein sollten und dass etwa 84% der Stichproben kleiner oder gleich einer Standardabweichung über dem Mittelwert sein sollten.
D
Datenanalyse
Verständnis von Daten durch Berücksichtigung von Stichproben, Messungen und Visualisierungen Die Datenanalyse kann besonders nützlich sein, wenn zuerst ein Dataset empfangen und dann das erste model erstellt wird. Sie ist auch für das Verständnis von Tests und das Beheben von Problemen mit dem System von entscheidender Bedeutung.
Datenerweiterung
Die Reichweite und Anzahl der Trainingsbeispiele werden durch Umwandlung vorhandener Beispiele in zusätzliche Beispiele künstlich erhöht. Angenommen, Bilder gehören zu Ihren Features, aber Ihr Dataset enthält nicht genügend Bildbeispiele für das Modell, um nützliche Verknüpfungen zu lernen. Idealerweise fügen Sie dem Dataset genügend Bilder mit Labels hinzu, damit das Modell ordnungsgemäß trainieren kann. Wenn dies nicht möglich ist, kann die Datenerweiterung jedes Bild rotieren, strecken und reflektieren, um viele Varianten des Originalbilds zu generieren. Möglicherweise werden genügend Daten mit Labels geliefert, um ein hervorragendes Training zu ermöglichen.
DataFrame
Ein beliebter Datentyp pandas zur Darstellung von Datasets im Arbeitsspeicher.
Ein DataFrame ist vergleichbar mit einer Tabelle oder einer Tabellenkalkulation. Jede Spalte eines DataFrames hat einen Namen (einen Header) und jede Zeile ist durch eine eindeutige Zahl gekennzeichnet.
Jede Spalte in einem DataFrame ist wie ein 2D-Array strukturiert, mit der Ausnahme, dass jeder Spalte ein eigener Datentyp zugewiesen werden kann.
Weitere Informationen finden Sie auf der offiziellen Referenzseite zu pandas.DataFrame.
Datenparallelität
Eine Methode zum Skalieren des Trainings oder der Inferenz, bei der ein ganzes Modell auf mehrere Geräte repliziert und dann eine Teilmenge der Eingabedaten an jedes Gerät übergeben wird. Die Datenparallelität kann das Training und die Inferenz für sehr große Batchgrößen ermöglichen. Die Datenparallelität setzt jedoch voraus, dass das Modell klein genug ist, um auf alle Geräte zu passen.
Datenparallelität beschleunigt in der Regel Training und Inferenz.
Siehe auch Modellparallelität.
Dataset oder Dataset
Eine Sammlung von Rohdaten, die üblicherweise (aber nicht ausschließlich) in einem der folgenden Formate organisiert werden:
- Tabelle
- Eine Datei im CSV-Format (comma-separated values, kommagetrennte Werte)
Dataset API (tf.data)
Eine allgemeine TensorFlow API zum Lesen und Transformieren von Daten in eine von einem Algorithmus für maschinelles Lernen benötigte Form.
Ein tf.data.Dataset-Objekt steht für eine Abfolge von Elementen, in der jedes Element einen oder mehrere Tensors enthält. Ein tf.data.Iterator-Objekt bietet Zugriff auf die Elemente einer Dataset.
Weitere Informationen zur Dataset API finden Sie unter tf.data: TensorFlow-Eingabepipelines erstellen im TensorFlow-Programmierhandbuch.
Entscheidungsgrenze
Das Trennzeichen zwischen Klassen, die von einem Modell in einer binären Klasse oder Klassifizierungsproblemen mit mehreren Klassen erlernt wurden. In der folgenden Abbildung, die ein binäres Klassifizierungsproblem darstellt, ist die Entscheidungsgrenze beispielsweise die Grenze zwischen der orangefarbenen und der blauen Klasse:

Entscheidungswald
Ein Modell, das aus mehreren Entscheidungsbäumen erstellt wurde. Eine Entscheidungsstruktur trifft die Vorhersagen ihrer Entscheidungsbäume, um eine Vorhersage zu treffen. Zu den beliebtesten Arten von Entscheidungsstrukturen gehören Random Forests und Gradient Boosted Trees.
Schwellenwert für die Entscheidung
Synonym für Klassifizierungsschwellenwert.
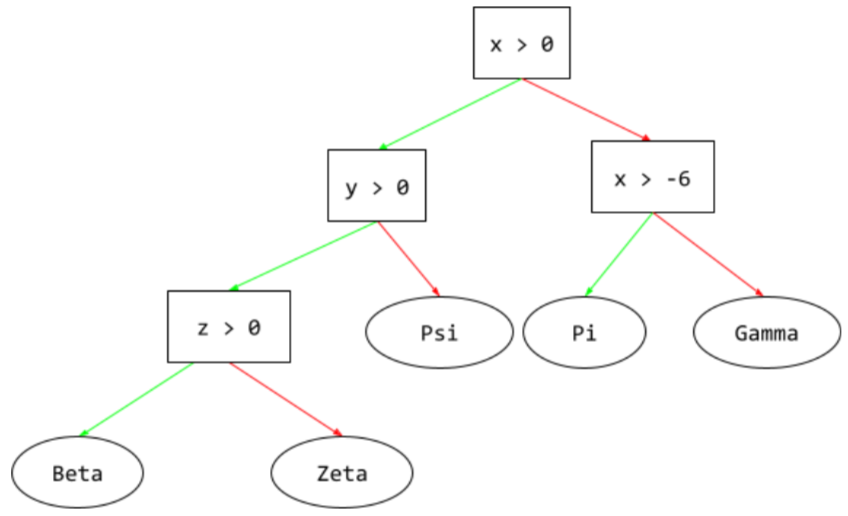
Entscheidungsbaum
Ein Modell für überwachtes Lernen, das aus einer Reihe von hierarchisch organisierten conditions und conditions besteht. Das folgende Beispiel zeigt einen Entscheidungsbaum:
Decoder
Im Allgemeinen gilt für jedes ML-System, das von einer verarbeiteten, dichten oder internen Darstellung in eine grobe, dünnbesetzte oder externe Darstellung konvertiert wird.
Decoder sind oft eine Komponente eines größeren Modells, in der sie häufig mit einem Encoder gekoppelt werden.
Bei Sequenz-zu-Sequenz-Aufgaben beginnt ein Decoder mit dem vom Encoder generierten internen Status, um die nächste Sequenz vorherzusagen.
Die Definition eines Decoders in der Transformer-Architektur finden Sie unter Transformer.
Deep Model
Ein neuronales Netzwerk mit mehr als einer verborgenen Ebene.
Ein tiefes Modell wird auch als neuronales Deep-Learning-Netzwerk bezeichnet.
Kontrast mit dem breiten Modell
neuronales Deep-Learning-Netzwerk
Synonym für tiefes Modell.
Deep Q-Network (DQN)
In Q-learning ein tiefes neuronales Netzwerk, das Q-Funktionen vorhersagt.
Kritik ist ein Synonym für Deep Q-Network.
demografische Gleichheit
Ein Fairness-Messwert, der erfüllt wird, wenn die Ergebnisse der Klassifizierung eines Modells nicht von einem bestimmten sensiblen Attribut abhängen.
Wenn beispielsweise sowohl die Lilliputianer als auch die Brobdingnagier sich für die Glubbdubdrib University bewerben, wird die demografische Parität erreicht, wenn der Prozentsatz der aufgenommenen Lilliputer dem Prozentsatz der zugelassenen Brobdingnagier entspricht, unabhängig davon, ob eine Gruppe im Durchschnitt besser qualifiziert ist als die andere.
Im Kontrast zu den ausgeglichenen Chancen und der Chancengleichheit können Klassifizierungsergebnisse in zusammengefasster Form von sensiblen Attributen abhängen. Klassifizierungsergebnisse für bestimmte Ground-Truth-Labels dürfen jedoch nicht von sensiblen Attributen abhängen. Eine Visualisierung zu den Vor- und Nachteilen der demografischen Parität finden Sie unter Diskriminierung durch intelligentes maschinelles Lernen angreifen.
Entrauschen
Ein gängiger Ansatz für selbstüberwachtes Lernen, bei dem:
Rauschunterdrückung ermöglicht Lernen aus Beispielen ohne Label. Das ursprüngliche Dataset dient als Ziel oder Label und die verrauschten Daten als Eingabe.
Einige maskierte Sprachmodelle verwenden die Entrauschung so:
- Rauschen wird einem Satz ohne Label künstlich hinzugefügt, indem einige der Tokens maskiert werden.
- Das Modell versucht, die ursprünglichen Tokens vorherzusagen.
vollbesetztes Feature
Ein Feature, bei dem die meisten oder alle Werte ungleich null sind, in der Regel ein Tensor von Gleitkommawerten. Der folgende Tensor mit 10 Elementen ist beispielsweise dicht, weil 9 seiner Werte ungleich null sind:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Kontrast mit dünnbesetztem Feature
dichte Ebene
Synonym für vollständig verbundene Ebene.
Tiefe
Die Summe der folgenden Werte in einem neuronalen Netzwerk:
- die Anzahl der ausgeblendeten Ebenen
- die Anzahl der Ausgabeebenen (in der Regel 1)
- Anzahl der Einbettungsebenen
Ein neuronales Netzwerk mit fünf verborgenen Schichten und einer Ausgabeschicht hat beispielsweise eine Tiefe von 6.
Die Eingabeschicht hat keinen Einfluss auf die Tiefe.
Deeplink-separable Convolutional Neural Network (sepCNN)
Eine Architektur des Convolutional Neural Network, die auf Inception basiert, in der Inception-Module jedoch durch tief trennbare Faltungen ersetzt werden. Auch als Xception bezeichnet.
Eine tief trennbare Faltung (auch als trennbare Faltung abgekürzt) umfasst eine Standardfaltung in 3D in zwei separate Faltungsvorgänge, die recheneffizienter sind: zuerst eine tiefenweise Faltung mit einer Tiefe von 1 (n × n × 1) und dann eine punktweise Faltung mit einer Länge und Breite von 1 (1 × n).
Weitere Informationen finden Sie unter Xception: Deep Learning with Depthwise Separable Convolutions.
abgeleitetes Label
Synonym für Proxylabel.
Gerät
Ein überladener Begriff mit den folgenden zwei möglichen Definitionen:
- Hardwarekategorie für die Ausführung einer TensorFlow-Sitzung, einschließlich CPUs, GPUs und TPUs.
- Beim Trainieren eines ML-Modells auf Beschleunigerchips (GPUs oder TPUs) ist der Teil des Systems, der Tensoren und Einbettungen tatsächlich manipuliert. Das Gerät wird auf Beschleunigerchips ausgeführt. Im Gegensatz dazu wird der Host normalerweise auf einer CPU ausgeführt.
Differential Privacy
Beim maschinellen Lernen ein Anonymisierungsansatz zum Schutz sensibler Daten (z. B. personenbezogene Daten einer Person), die im Trainings-Dataset eines Modells enthalten sind, vor Offenlegung. Dadurch wird sichergestellt, dass das model nicht viel über eine bestimmte Person lernt oder sich daran erinnert. Dazu werden während des Modelltrainings Stichproben erhoben und Rauschen hinzugefügt, um einzelne Datenpunkte zu verbergen und das Risiko der Offenlegung vertraulicher Trainingsdaten zu verringern.
Differential Privacy wird auch außerhalb des maschinellen Lernens verwendet. Data Scientists verwenden beispielsweise manchmal Differential Privacy, um die Privatsphäre der einzelnen Personen zu schützen, wenn sie Produktnutzungsstatistiken für unterschiedliche demografische Merkmale berechnen.
Dimensionsreduzierung
Verringern der Anzahl der Dimensionen, die zur Darstellung eines bestimmten Elements in einem Featurevektor verwendet werden, in der Regel durch Konvertieren in einen Einbettungsvektor.
Dimensionen
Überladener Begriff mit einer der folgenden Definitionen:
Die Anzahl der Koordinatenebenen in Tensor. Beispiel:
- Ein Skalar hat keine Dimensionen, z. B.
["Hello"]. - Ein Vektor hat eine Dimension, z. B.
[3, 5, 7, 11]. - Eine Matrix hat zwei Dimensionen, z. B.
[[2, 4, 18], [5, 7, 14]].
Sie können eine bestimmte Zelle in einem eindimensionalen Vektor mit einer Koordinate eindeutig angeben. Sie benötigen zwei Koordinaten, um eine bestimmte Zelle in einer zweidimensionalen Matrix eindeutig zu definieren.
- Ein Skalar hat keine Dimensionen, z. B.
Die Anzahl der Einträge in einem Featurevektor.
Die Anzahl der Elemente in einer Einbettungsebene.
direkte Aufforderung
Synonym für Zero-Shot-Prompts.
diskretes Feature
Ein Feature mit einem endlichen Satz möglicher Werte. Beispielsweise ist ein Merkmal, dessen Werte nur Tier, Gemüse oder Mineral sein können, ein diskretes (oder kategoriales) Merkmal.
Kontrast mit der kontinuierlichen Funktion
diskriminierendes Modell
Ein model, das model aus einem oder mehreren model vorhersagt. Formalere definieren diskriminierende Modelle die bedingte Wahrscheinlichkeit einer Ausgabe angesichts der Features und Gewichtungen, d. h.:
p(output | features, weights)
Ein Modell, das anhand von Features und Gewichtungen vorhersagt, ob eine E-Mail Spam ist, ist beispielsweise ein diskriminierendes Modell.
Die überwiegende Mehrheit der Modelle für überwachtes Lernen, einschließlich Klassifizierungs- und Regressionsmodelle, sind diskriminierende Modelle.
Kontrast mit generativem Modell.
Diskriminator
Ein System, das bestimmt, ob Beispiele echt oder gefälscht sind.
Alternativ ein Subsystem in einem generativen kontradiktorischen Netzwerk, das bestimmt, ob die vom Generator erstellten Beispiele echt oder gefälscht sind.
unterschiedliche Auswirkungen
Entscheidungen über Menschen treffen, die unterschiedliche Untergruppen überproportional beeinflussen. Dies bezieht sich in der Regel auf Situationen, in denen ein algorithmischer Entscheidungsprozess einigen Untergruppen mehr schadet oder vorteilhafter als andere ist.
Nehmen wir zum Beispiel an, ein Algorithmus, der die Berechtigung eines Lilliputers für einen Mini-Hypotheken bestimmt, würde diese eher als „unzulässig“ einstufen, wenn die Postanschrift eine bestimmte Postleitzahl enthält. Wenn Big-Endian Lilliputian eher Postadressen mit dieser Postleitzahl haben als Little-Endian Lilliputian, kann dieser Algorithmus verschiedene Auswirkungen haben.
Im Gegensatz dazu steht eine unterschiedliche Behandlung, bei der Unterschiede im Mittelpunkt stehen, die entstehen, wenn die Merkmale von Untergruppen explizit in einen algorithmischen Entscheidungsprozess einbezogen werden.
unterschiedliche Behandlung
Dabei werden die sensiblen Attribute von Personen in einen algorithmischen Entscheidungsprozess einbezogen, um verschiedene Untergruppen von Menschen unterschiedlich zu behandeln.
Stellen Sie sich beispielsweise einen Algorithmus vor, der die Berechtigung von Lilliputians für einen Mini-Hypotheken anhand der Daten bestimmt, die er bei seinem Kreditantrag zur Verfügung stellt. Wenn der Algorithmus die Zugehörigkeit einer Lilliputianen als Big-Endian oder Little-Endian als Eingabe verwendet, erfolgt eine unterschiedliche Behandlung entlang dieser Dimension.
Im Gegensatz dazu stehen disparate impact (unterschiedliche Auswirkungen) auf Unterschiede bei den gesellschaftlichen Auswirkungen algorithmischer Entscheidungen auf Untergruppen im Mittelpunkt, unabhängig davon, ob diese Untergruppen Eingaben in das Modell sind.
Destillation
Prozess der Verkleinerung der Größe eines model (als model bezeichnet) in ein kleineres Modell (das sogenannte model), das die Vorhersagen des ursprünglichen Modells so realistisch wie möglich emuliert. Die Destillation ist nützlich, da das kleinere Modell gegenüber dem größeren Modell (der Lehrkraft) zwei wesentliche Vorteile hat:
- Schnellere Inferenzzeit
- Geringerer Speicher- und Energieverbrauch
Allerdings sind die Vorhersagen der Schüler oder Studenten in der Regel nicht so gut wie die der Lehrkraft.
Die Destillation trainiert das Schülermodell, um eine Verlustfunktion zu minimieren, die auf der Differenz zwischen den Ausgaben der Vorhersagen des Schüler- und des Lehrermodells basiert.
Die Destillation mit den folgenden Begriffen vergleichen und gegenüberstellen:
Verteilung
Die Häufigkeit und der Bereich verschiedener Werte für ein bestimmtes Feature oder ein Label. Eine Verteilung gibt die Wahrscheinlichkeit eines bestimmten Werts an.
Die folgende Abbildung zeigt Histogramme zweier unterschiedlicher Verteilungen:
- Links das Potenzgesetz des Wohlstands im Vergleich zur Anzahl der Menschen, die diesen Vermögen besitzen.
- Rechts eine normale Verteilung der Größe im Vergleich zur Anzahl der Personen mit dieser Größe.
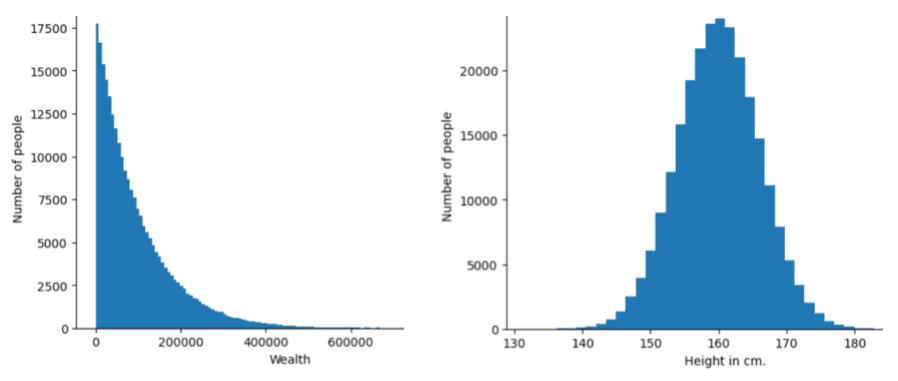
Wenn Sie die einzelnen Features und die Verteilung der Labels kennen, können Sie ermitteln, wie Sie Werte normalisieren und Ausreißer erkennen.
Der Ausdruck out of distribution bezieht sich auf einen Wert, der im Dataset nicht vorhanden oder sehr selten ist. Beispielsweise würde ein Bild des Planeten Saturn bei einem Datensatz, der aus Katzenbildern besteht, als nicht verteilt betrachtet.
Diversitäts-Clustering
Siehe Hierarchisches Clustering.
Downsampling
Überlastete Begriffe, die Folgendes bedeuten können:
- Die Informationsmenge in einem Feature reduzieren, um ein Modell effizienter zu trainieren. Bevor Sie beispielsweise ein Bilderkennungsmodell trainieren, reduzieren Sie Bilder mit hoher Auflösung auf ein Format mit geringerer Auflösung.
- Training mit einem unverhältnismäßig niedrigen Prozentsatz der überrepräsentierten Klassenbeispiele, um das Modelltraining für unterrepräsentierte Klassen zu verbessern. In einem Dataset ohne Klassenausgleich lernen Modelle beispielsweise viel über die Mehrheitsklasse und nicht genug über die Minderheitenklasse. Downsampling hilft dabei, ein ausgewogenes Verhältnis des Trainingsumfangs auf die Mehrheits- und Minderheitenklassen zu finden.
DQN
Abkürzung für Deep Q-Network
Dropout-Regularisierung
Eine Form der Regularisierung, die für das Training von neuronalen Netzwerken nützlich ist. Bei der Dropout-Regularisierung wird für einen einzelnen Gradientenschritt eine zufällige Auswahl einer festen Anzahl von Einheiten in einer Netzwerkebene entfernt. Je mehr Einheiten ausgelassen werden, desto stärker ist die Regularisierung. Dies entspricht dem Training des Netzwerks, um eine exponentiell große Ensemble kleiner Netzwerke zu emulieren. Weitere Informationen finden Sie unter Dropout: Eine einfache Möglichkeit, neuronale Netzwerke vor Überanpassung zu vermeiden.
dynamic
Etwas, das häufig oder fortlaufend ausgeführt wird. Die Begriffe dynamisch und online sind im maschinellen Lernen Synonyme. Im Folgenden werden gängige Anwendungsfälle von Dynamik und Online im maschinellen Lernen beschrieben:
- Ein dynamisches Modell (oder Online-Modell) ist ein Modell, das häufig oder kontinuierlich neu trainiert wird.
- Dynamisches Training (oder Onlinetraining) ist ein Prozess, bei dem häufig oder kontinuierlich trainiert wird.
- Dynamische Inferenz (oder Online-Inferenz) ist der Prozess, bei dem Vorhersagen bei Bedarf generiert werden.
dynamisches Modell
Ein model, das häufig (möglicherweise sogar kontinuierlich) neu trainiert wird. Ein dynamisches Modell ist ein „lebenslanger Lerner“, der sich kontinuierlich an sich ändernde Daten anpasst. Ein dynamisches Modell wird auch als Online-Modell bezeichnet.
Kontrast mit statischem Modell
E
ambitionierte Ausführung
Eine TensorFlow-Programmierumgebung, in der operations sofort ausgeführt werden. Im Gegensatz dazu werden Vorgänge, die in der Ausführung von Diagrammen aufgerufen werden, erst dann ausgeführt, wenn sie explizit ausgewertet wurden. Die schnelle Ausführung ist eine imperative Schnittstelle, ähnlich wie der Code in den meisten Programmiersprachen. Eifrige Ausführungsprogramme sind im Allgemeinen viel einfacher zu debuggen als Programme zur Ausführung von Grafiken.
vorzeitiges Beenden
Eine Methode für die Regularisierung, bei der das Training beendet wird, bevor der Trainingsverlust sinkt. Beim vorzeitigen Beenden beenden Sie absichtlich das Training des Modells, wenn der Verlust bei einem Validierungs-Dataset zunimmt, d. h. wenn sich die Leistung der Generalisierung verschlechtert.
Entfernung der Erdbewegung (EMD)
Ein Maß für die relative Ähnlichkeit von zwei Verteilungen. Je geringer die Entfernung der Erdbewegung ist, desto ähnlicher sind die Verteilungen.
Entfernung bearbeiten
Ein Maß dafür, wie ähnlich zwei Textzeichenfolgen einander sind. Beim maschinellen Lernen ist die Entfernungsbearbeitung nützlich, da sie einfach zu berechnen ist und eine effektive Möglichkeit ist, zwei Strings zu vergleichen, die bekanntermaßen ähnlich sind, oder um Strings zu finden, die einem bestimmten String ähnlich sind.
Es gibt mehrere Definitionen für Entfernungen, die jeweils unterschiedliche Zeichenfolgenvorgänge verwenden. Für die Levenshtein-Entfernung werden beispielsweise die wenigsten Lösch-, Einfüge- und Ersetzungsvorgänge berücksichtigt.
Der Levenshtein-Abstand zwischen den Wörtern „heart“ und „darts“ beträgt beispielsweise 3, da die folgenden drei Bearbeitungen die geringsten Änderungen sind, um ein Wort in ein anderes umzuwandeln:
- Herz → Deart („h“ durch „d“ ersetzen)
- deart → dart („e“ löschen)
- dart → Darts („s“ einfügen)
Einsummierung
Eine effiziente Notation zum Beschreiben, wie zwei Tensoren kombiniert werden sollen. Die Tensoren werden kombiniert, indem die Elemente eines Tensors mit den Elementen des anderen Tensors multipliziert und dann die Produkte summiert werden. Die Einsummenschreibweise verwendet Symbole, um die Achsen der einzelnen Tensoren zu identifizieren. Diese Symbole werden neu angeordnet, um die Form des neuen resultierenden Tensors anzugeben.
NumPy bietet eine gängige Einsum-Implementierung.
Einbettungsebene
Eine spezielle verborgene Ebene, die mit einem hochdimensionalen kategorialen Feature trainiert, um schrittweise einen Einbettungsvektor mit niedrigerer Dimension zu lernen. Mit einer Einbettungsebene kann ein neuronales Netzwerk weitaus effizienter trainieren als nur das hochdimensionale kategoriale Merkmal zu trainieren.
Zum Beispiel unterstützt die Erde derzeit etwa 73.000 Baumarten. Angenommen, Baumarten sind ein Merkmal in Ihrem Modell. Daher umfasst die Eingabeebene Ihres Modells einen One-Hot-Vektor mit 73.000 Elementen.
So würde baobab unter Umständen in etwa so dargestellt werden:

Ein Array mit 73.000 Elementen ist sehr lang. Wenn Sie dem Modell keine Einbettungsebene hinzufügen, wird das Training aufgrund der Multiplikation von 72.999 Nullen sehr zeitaufwendig. Vielleicht wählen Sie die Einbettungsebene für 12 Dimensionen aus. Daher lernt die Einbettungsebene nach und nach einen neuen Einbettungsvektor für jede Baumart.
In bestimmten Situationen ist Hashing eine sinnvolle Alternative zu einer Einbettungsebene.
Einbettungsbereich
Der d-dimensionale Vektorraum, dem Merkmale aus einem höherdimensionalen Vektorraum zugeordnet werden. Idealerweise enthält der Einbettungsbereich eine Struktur, die aussagekräftige mathematische Ergebnisse liefert. In einem idealen Einbettungsbereich können beispielsweise durch Addieren und Subtrahieren von Einbettungen Wort Analogieaufgaben gelöst werden.
Das Punktprodukt zweier Einbettungen ist ein Maß für ihre Ähnlichkeit.
Einbettungsvektor
Im Grunde genommen ein Array von Gleitkommazahlen aus jeder ausgeblendeten Ebene, die die Eingaben für diese verborgene Ebene beschreiben. Häufig ist ein Einbettungsvektor ein Array von Gleitkommazahlen, das in einer Einbettungsebene trainiert wird. Angenommen, eine Einbettungsebene muss für jede der 73.000 Baumarten auf der Erde einen Einbettungsvektor lernen. Vielleicht ist das folgende Array der Einbettungsvektor für einen Affenbrotbaum:

Ein Einbettungsvektor ist keine Gruppe von Zufallszahlen. Eine Einbettungsebene bestimmt diese Werte durch Training, ähnlich wie ein neuronales Netzwerk während des Trainings andere Gewichtungen lernt. Jedes Element des Arrays ist eine Bewertung sowie ein Merkmal einer Baumart. Welches Element stellt das Merkmal welcher Baumart dar? Das ist für Menschen sehr schwer festzustellen.
Der mathematische Aspekt eines Einbettungsvektors ist, dass ähnliche Elemente ähnliche Gleitkommazahlensätze haben. Ähnliche Baumarten haben beispielsweise ähnlichere Gleitkommazahlen als unterschiedliche Baumarten. Mammutbäume und Mammutbäume sind verwandte Baumarten, daher weisen sie ähnliche Gleitkommazahlen auf als Mammutbäume und Kokospalmen. Die Zahlen im Einbettungsvektor ändern sich jedes Mal, wenn Sie das Modell neu trainieren, auch wenn Sie es mit identischer Eingabe neu trainieren.
Empirische kumulierte Verteilungsfunktion (eCDF oder EDF)
Eine kumulierte Verteilungsfunktion, die auf empirischen Messwerten aus einem realen Dataset basiert. Der Wert der Funktion an einem beliebigen Punkt auf der x-Achse ist der Anteil der Beobachtungen im Dataset, die kleiner oder gleich dem angegebenen Wert sind.
Empirische Risikominimierung (ERM)
Die Funktion auswählen, die den Verlust im Trainings-Dataset minimiert. Im Gegensatz zur strukturellen Risikominimierung.
Encoder
Im Allgemeinen gilt für jedes ML-System, das von einer Roh-, dünnbesetzten oder externen Darstellung in eine verarbeitetere, dichtere oder internere Darstellung konvertiert wird.
Encoder sind oft eine Komponente eines größeren Modells, in der sie häufig mit einem Decoder gekoppelt sind. Einige Transformer koppeln Encoder und Decodierer, während andere nur den Encoder oder nur den Decoder verwenden.
Einige Systeme verwenden die Ausgabe des Encoders als Eingabe für ein Klassifizierungs- oder Regressionsnetzwerk.
Bei Sequenz-zu-Sequenz-Aufgaben übernimmt ein Encoder eine Eingabesequenz und gibt einen internen Zustand (einen Vektor) zurück. Anschließend verwendet der Decoder diesen internen Zustand, um die nächste Sequenz vorherzusagen.
Die Definition eines Encoders in der Transformer-Architektur finden Sie unter Transformer.
Ensemble
Eine Sammlung von unabhängig trainierten Modellen, deren Vorhersagen gemittelt oder aggregiert werden. In vielen Fällen liefert ein Ensemble bessere Vorhersagen als ein einzelnes Modell. Eine Random Forest ist beispielsweise ein Ensemble aus mehreren Entscheidungsbäumen. Beachten Sie, dass nicht alle Entscheidungsstrukturen Gruppen sind.
Entropie
In der Informationstheorie wird beschrieben, wie unvorhersehbar eine Wahrscheinlichkeitsverteilung ist. Alternativ wird die Entropie auch definiert, wie viele Informationen in jedem Beispiel enthalten sind. Eine Verteilung hat die höchstmögliche Entropie, wenn alle Werte einer zufälligen Variablen gleich wahrscheinlich sind.
Die Entropie einer Menge mit den beiden möglichen Werten „0“ und „1“ (z. B. die Labels in einem binären Klassifizierungsproblem) wird anhand der folgenden Formel berechnet:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
Dabei gilt:
- H ist die Entropie.
- p ist der Anteil an „1“-Beispielen.
- q ist der Anteil an „0“-Beispielen. Beachten Sie, dass q = (1 - p)
- log ist in der Regel log2. In diesem Fall ist die Entropie ein Bit.
Nehmen wir beispielsweise Folgendes an:
- 100 Beispiele enthalten den Wert „1“
- 300 Beispiele enthalten den Wert „0“
Daher ist der Entropiewert:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) - (0,75)log2(0,75) = 0,81 Bit pro Beispiel
Ein perfekt ausbalancierter Satz (z. B. 200 „0“ und 200 „1“) hätte eine Entropie von 1, 0 Bit pro Beispiel. Wenn eine Menge unausgewogen ist, bewegt sich seine Entropie in Richtung 0,0.
In Entscheidungsbäumen hilft die Entropie beim Formulieren eines Informationsgewinns, damit der Splitter die Bedingungen während des Wachstums eines Klassifizierungsentscheidungsbaums auswählen kann.
Entropie vergleichen mit:
- Gini-Unreinheit
- Kreuzentropie-Verlustfunktion
Die Entropie wird oft als Shannon-Entropie bezeichnet.
Umgebung
Beim Reinforcement Learning die Welt, die den Agent enthält und dem Agent die Beobachtung des Status dieser Welt ermöglicht. Die repräsentierte Welt kann beispielsweise ein Spiel wie Schach oder eine physische Welt wie ein Labyrinth sein. Wenn der Agent eine Aktion auf die Umgebung anwendet, wechselt die Umgebung zwischen den Status.
Folge
Beim Reinforcement Learning jeder der wiederholten Versuche des Agents, eine Umgebung zu lernen.
Epoche
Ein vollständiges Training umfasst den gesamten Trainingssatz, sodass jedes Beispiel einmal verarbeitet wurde.
Eine Epoche stellt die Trainings-Iterationen N/Batchgröße dar, wobei N die Gesamtzahl der Beispiele ist.
Nehmen wir beispielsweise Folgendes an:
- Das Dataset besteht aus 1.000 Beispielen.
- Die Batchgröße beträgt 50 Beispiele.
Daher sind für eine Epoche 20 Iterationen erforderlich:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Epsilon-Greedy-Richtlinie
Beim Reinforcement Learning eine Richtlinie, die entweder einer Zufallsrichtlinie mit Epsilon-Wahrscheinlichkeit oder einer Greedy-Richtlinie folgt. Wenn der Wert für Epsilon beispielsweise 0, 9 beträgt, dann folgt die Richtlinie in 90% der Fälle einer Zufallsrichtlinie und in 10% der Fälle einer Greedy-Richtlinie.
Über aufeinanderfolgende Folgen reduziert der Algorithmus den Wert von Epsilon, um von einer zufälligen Richtlinie hin eine gierige Richtlinie zu befolgen. Durch die Verschiebung der Richtlinie untersucht der Agent zuerst die Umgebung nach dem Zufallsprinzip und nutzt dann gierig die Ergebnisse der zufälligen explorativen Datenanalyse aus.
Chancengleichheit
Ein Fairness-Messwert, mit dem beurteilt werden soll, ob ein Modell das gewünschte Ergebnis für alle Werte eines sensiblen Attributs gleichermaßen gut vorhersagt. Mit anderen Worten: Wenn das gewünschte Ergebnis für ein Modell die positive Klasse ist, wäre das Ziel, die tatsächliche positive Rate für alle Gruppen gleich zu haben.
Chancengleichheit hängt mit der gleichmäßigen Wahrscheinlichkeit zusammen. Dies erfordert, dass sowohl die Richtig-Positiv-Raten als auch die Falsch-Positiv-Raten für alle Gruppen gleich sind.
Angenommen, die Glubbdubdrib University gestattet sowohl den Lilliputianen als auch den Brobdingnagians ein strenges Mathematikprogramm. Die Sekundarschulen der Lilliputians bieten einen robusten Lehrplan für Mathematikunterricht und die überwiegende Mehrheit der Schüler ist für das Universitätsprogramm qualifiziert. An den Sekundarschulen von Brobdingnagians gibt es überhaupt keinen Mathematikunterricht, wodurch deutlich weniger Schüler qualifiziert sind. Die Chancengleichheit ist für das bevorzugte Label "zugelassen" in Bezug auf die Nationalität (Lilliputian oder Brobdingnagian) erfüllt, wenn qualifizierte Studierende mit gleicher Wahrscheinlichkeit zugelassen werden, unabhängig davon, ob sie Lilliputer oder Brobdingnagian sind.
Angenommen, 100 Lilliputianer und 100 Brobdingnagian bewerben sich für die Glubbdubdrib University und die Zulassungsentscheidungen werden wie folgt getroffen:
Tabelle 1. Lilliputische Bewerber (90% sind qualifiziert)
| Qualifiziert | Unqualifiziert | |
|---|---|---|
| Zugelassen | 45 | 3 |
| Abgelehnt | 45 | 7 |
| Gesamt | 90 | 10 |
|
Prozentsatz der zugelassenen Studenten: 45 ÷ 90 = 50% Prozentsatz der abgelehnten Studenten: 7 ÷ 10 = 70% Gesamtzahl der aufgenommenen liliputischen Schüler: (45 + 3) ÷ 100 = 48% |
||
Tabelle 2 Bewerber nach Brobdingnagian (10% sind qualifiziert):
| Qualifiziert | Unqualifiziert | |
|---|---|---|
| Zugelassen | 5 | 9 |
| Abgelehnt | 5 | 81 |
| Gesamt | 10 | 90 |
|
Prozentsatz der zugelassenen Studenten: 5 ÷ 10 = 50% Prozentsatz der abgelehnten Studenten: 81 ÷ 90 = 90% Gesamtzahl der zugelassenen Studenten: (5 + 9) ÷ 100 = 14% |
||
Die vorherigen Beispiele erfüllen die Chancengleichheit für die Akzeptanz qualifizierter Studenten, da sowohl qualifizierte Lilliputiane als auch Brobdingnagians eine Chance von 50% haben, zugelassen zu werden.
Auch wenn die Chancengleichheit erfüllt ist, werden die folgenden beiden Fairness-Messwerte nicht erfüllt:
- demografische Parität: Lilliputianer und Brobdingnagier werden zu unterschiedlichen Preisen an der Universität zugelassen; 48% der Lilliputianer werden zugelassen, aber nur 14% der Brobdingnagian Studierenden werden zugelassen.
- Ausgleichschancen: Obwohl qualifizierte Lilliputian und Brobdingnagian Studierende die gleiche Chance haben, zugelassen zu werden, wird die zusätzliche Einschränkung, dass sowohl nicht qualifizierte Lilliputians als auch Brobdingnagian die gleiche Chance haben, abgelehnt zu werden, nicht erfüllt. Unqualifizierte Lilliputisten haben eine Ablehnungsrate von 70 %, während unqualifizierte Brobdingnagians eine Ablehnungsrate von 90% haben.
Eine ausführlichere Beschreibung der Chancengleichheit finden Sie unter "Chancengleichheit im überwachten Lernen". Eine Visualisierung zu den Vor- und Nachteilen bei der Optimierung der Chancengleichheit finden Sie unter Diskriminierung durch intelligentes maschinelles Lernen angreifen.
Entspricht
Ein Fairness-Messwert, mit dem beurteilt werden soll, ob ein Modell Ergebnisse für alle Werte eines sensiblen Attributs in Bezug auf die positive Klasse und die negative Klasse gleichermaßen gut vorhersagt – und nicht nur die eine oder die andere Klasse. Mit anderen Worten: Sowohl die Rate für richtig positive Ergebnisse als auch die Rate falsch negativer Ergebnisse sollten für alle Gruppen gleich sein.
Eine ausgeglichene Wahrscheinlichkeit bezieht sich auf die Chancengleichheit, die sich nur auf Fehlerraten für eine einzelne Klasse (positiv oder negativ) konzentriert.
Nehmen wir zum Beispiel an, die Glubbdubdrib University gestattet sowohl den Lilliputianen als auch den Brobdingnagiern ein anspruchsvolles Mathematikprogramm. Die Sekundarschulen der Lilliputians bieten einen soliden Lehrplan für Mathematikkurse und die überwiegende Mehrheit der Schüler ist für das Universitätsprogramm qualifiziert. An den Sekundarschulen der Brobdingnagians wird gar kein Mathematikunterricht angeboten, wodurch deutlich weniger Schüler qualifiziert sind. Die ausgleichende Wahrscheinlichkeit ist dabei gegeben, dass ein Bewerber unabhängig davon, ob er ein Lilliputer oder ein Brobdingnagian ist, mit gleich hoher Wahrscheinlichkeit für das Programm zugelassen wird, und wenn er nicht qualifiziert ist, ist die Wahrscheinlichkeit, dass er abgelehnt wird, gleich hoch.
Angenommen, 100 Lilliputianer und 100 Brobdingnagier bewerben sich für die Glubbdubdrib University und die Zulassungsentscheidungen werden wie folgt getroffen:
Tabelle 3 Lilliputische Bewerber (90% sind qualifiziert)
| Qualifiziert | Unqualifiziert | |
|---|---|---|
| Zugelassen | 45 | 2 |
| Abgelehnt | 45 | 8 |
| Gesamt | 90 | 10 |
|
Prozentsatz der zugelassenen Studierenden: 45/90 = 50% Prozentsatz der abgelehnten Studenten: 8 ÷ 10 = 80% Gesamtzahl der zugelassenen Studenten: (45 + 2) ÷ 100 = 47% |
||
Tabelle 4 Bewerber nach Brobdingnagian (10% sind qualifiziert):
| Qualifiziert | Unqualifiziert | |
|---|---|---|
| Zugelassen | 5 | 18 |
| Abgelehnt | 5 | 72 |
| Gesamt | 10 | 90 |
|
Prozentsatz der zugelassenen Studenten: 5 ÷ 10 = 50% Prozentsatz der abgelehnten Studenten: 72 ÷ 90 = 80% Gesamtzahl der zugelassenen Studenten: (5 + 18) ÷ 100 = 23% |
||
Die ausgleichenden Chancen sind erfüllt, da qualifizierte Lilliputian- und Brobdingnagian-Studenten eine Chance von 50% haben, und nicht qualifizierte Lilliputian und Brobdingnagian eine Chance von 80 %, abgelehnt zu werden.
Die gleichmäßige Wahrscheinlichkeit wird in "Equality of Opportunity in Supervised Learning" wie folgt definiert: "Prädiktor Ŷ erfüllt die ausgegleichten Chancen in Bezug auf das geschützte Attribut A und das Ergebnis Y, wenn Ŷ und A unabhängig sind und an die Bedingungen Y gebunden sind."
Estimator
Eine verworfene TensorFlow API. Verwenden Sie tf.keras anstelle von Schätzern.
Kennenlernen
Prozess der Messung der Qualität der Vorhersagen eines Modells für maschinelles Lernen. Bei der Entwicklung eines Modells wenden Sie Bewertungsmesswerte in der Regel nicht nur auf das Trainings-Dataset an, sondern auch auf ein Validierungs-Dataset und ein Test-Dataset. Mithilfe von Bewertungsmesswerten können Sie auch verschiedene Modelle miteinander vergleichen.
Beispiel
Die Werte einer Zeile mit features und möglicherweise eines Labels. Beispiele beim überwachten Lernen lassen sich in zwei allgemeine Kategorien unterteilen:
- Ein Beispiel mit Label besteht aus einem oder mehreren Elementen und einem Label. Beispiele mit Labels werden während des Trainings verwendet.
- Ein Beispiel ohne Label besteht aus einem oder mehreren Elementen, aber ohne Label. Beispiele ohne Label werden während der Inferenz verwendet.
Angenommen, Sie trainieren ein Modell, um den Einfluss von Wetterbedingungen auf die Prüfungsergebnisse von Studenten zu ermitteln. Hier sind drei Beispiele mit Labels:
| Funktionen | Label | ||
|---|---|---|---|
| Temperatur | Luftfeuchtigkeit | Luftdruck | Prüfungspunktzahl |
| 15 | 47 | 998 | Gut |
| 19 | 34 | 1.020 | Großartig |
| 18 | 92 | 1012 | Schlecht |
Hier sind drei Beispiele ohne Labels:
| Temperatur | Luftfeuchtigkeit | Luftdruck | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
Die Zeile eines Datasets ist in der Regel die Rohquelle für ein Beispiel. Das heißt, ein Beispiel besteht in der Regel aus einer Teilmenge der Spalten im Dataset. Darüber hinaus können die Features in einem Beispiel auch synthetische Features wie Feature Crosses enthalten.
Erneute Wiedergabe
Beim Reinforcement Learning wird ein DQN-Verfahren verwendet, um zeitliche Korrelationen in Trainingsdaten zu reduzieren. Der Agent speichert Zustandsübergänge in einem Wiederholungspuffer und probiert dann Übergänge aus dem Wiederholungspuffer aus, um Trainingsdaten zu erstellen.
Verzerrung durch Experimentator
Siehe Bestätigungsverzerrung.
Problem mit explodierendem Farbverlauf
Die Tendenz von Verläufen in neuronalen Deep-Learning-Netzwerken (insbesondere in recurrent neuronalen Netzen) zu erstaunlich steil (hoch). Steile Gradienten führen häufig zu sehr großen Aktualisierungen der Gewichtungen jedes Knotens in einem neuronalen Deep-Learning-Netzwerk.
Modelle, die unter dem Problem mit dem explodierenden Gradienten leiden, lassen sich nur schwer oder gar nicht trainieren. Das Clipping mit Farbverlauf kann dieses Problem beheben.
Vergleichen Sie das mit dem Problem mit einem verschwindenden Farbverlauf.
F
F1
Ein Sammelmesswert für die binäre Klassifizierung, der sowohl auf Precision und Recall basiert. Die Formel lautet:
Beispiel:
- Precision = 0,6
- Recall = 0,4
Wenn Precision und Recall ziemlich ähnlich sind (wie im vorherigen Beispiel), liegt F1 nah an ihrem Mittelwert. Wenn sich Precision und Recall deutlich unterscheiden, liegt F1 näher am niedrigeren Wert. Beispiel:
- Precision = 0,9
- Recall = 0,1
Fairness-Einschränkung
Anwenden einer Einschränkung auf einen Algorithmus, um sicherzustellen, dass eine oder mehrere Definitionen von Fairness erfüllt sind Beispiele für Fairness-Einschränkungen:- Nachverarbeitung der Ausgabe des Modells
- Änderung der Verlustfunktion, um eine Strafe für einen Verstoß gegen einen Fairness-Messwert einzubinden.
- Direktes Hinzufügen einer mathematischen Einschränkung zu einem Optimierungsproblem.
Fairness-Messwert
Eine mathematische Definition von „Fairness“, die messbar ist. Zu den am häufigsten verwendeten Messwerten für Fairness gehören:
- Wahrscheinlichkeiten ausgeglichen
- prädiktive Gleichheit
- kontrafaktische Fairness
- demografische Gleichheit
Viele Fairness-Messwerte schließen sich gegenseitig aus (siehe Inkompatibilität von Fairness-Messwerten).
Falsch-negativ (FN)
Ein Beispiel, in dem das Modell fälschlicherweise die negative Klasse vorhersagt. Das Modell sagt beispielsweise voraus, dass eine bestimmte E-Mail-Nachricht kein Spam (die negative Klasse), aber tatsächlich Spam ist.
Rate falsch negativer Ergebnisse
Der Anteil tatsächlicher positiver Beispiele, für die das Modell die negative Klasse versehentlich vorhergesagt hat. Die folgende Formel berechnet die falsch negative Rate:
falsch positives Ergebnis (FP)
Ein Beispiel, in dem das Modell fälschlicherweise die positive Klasse vorhersagt. Das Modell sagt beispielsweise voraus, dass eine bestimmte E-Mail-Nachricht Spam (die positive Klasse) ist, aber diese E-Mail-Nachricht tatsächlich kein Spam ist.
Rate falsch positiver Ergebnisse (FPR)
Der Anteil der tatsächlichen negativen Beispiele, für die das Modell versehentlich die positive Klasse vorhergesagt hat. Die folgende Formel berechnet die Falsch-Positiv-Rate:
Die Falsch-Positiv-Rate ist die x-Achse einer ROC-Kurve.
Feature
Eine Eingabevariable für ein Modell für maschinelles Lernen. Ein Beispiel besteht aus einem oder mehreren Features. Angenommen, Sie trainieren ein Modell, um den Einfluss von Wetterbedingungen auf die Prüfungsergebnisse von Studenten zu ermitteln. Die folgende Tabelle zeigt drei Beispiele, von denen jedes drei Elemente und ein Label enthält:
| Funktionen | Label | ||
|---|---|---|---|
| Temperatur | Luftfeuchtigkeit | Luftdruck | Prüfungspunktzahl |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1.020 | 84 |
| 18 | 92 | 1012 | 87 |
Stellen Sie einen Kontrast mit Label her.
Featureverknüpfung
Ein synthetisches Feature, das durch „Crossing“ von kategorialen oder Bucket-Features gebildet wird.
Nehmen wir als Beispiel ein Modell für Stimmungsprognosen, das die Temperatur in einem der folgenden vier Gruppen darstellt:
freezingchillytemperatewarm
Die Windgeschwindigkeit wird in einem der folgenden drei Gruppen dargestellt:
stilllightwindy
Ohne Feature-Crosses wird das lineare Modell unabhängig auf jedem der vorherigen sieben Buckets trainiert. Das Modell wird also beispielsweise unabhängig vom Training auf windy mit freezing trainiert.
Alternativ können Sie eine Feature-Kreuzung von Temperatur und Windgeschwindigkeit erstellen. Dieses synthetische Feature hätte die folgenden 12 möglichen Werte:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Dank Featureverknüpfungen kann das Modell Stimmungsunterschiede zwischen einem freezing-windy- und einem freezing-still-Tag lernen.
Wenn Sie ein synthetisches Merkmal aus zwei Merkmalen erstellen, die jeweils viele verschiedene Buckets haben, ergibt die resultierende Featureverknüpfung eine große Anzahl möglicher Kombinationen. Wenn ein Feature beispielsweise 1.000 Buckets und das andere 2.000 Buckets hat, umfasst die resultierende Featureverknüpfung 2.000.000 Buckets.
Formell ist ein Kreuz ein kartesisches Produkt.
Featureverknüpfungen werden meist mit linearen Modellen und selten mit neuronalen Netzwerken verwendet.
Feature Engineering
Ein Prozess, der die folgenden Schritte umfasst:
- Bestimmen, welche Features zum Trainieren eines Modells nützlich sein könnten.
- Konvertierung von Rohdaten aus dem Dataset in effiziente Versionen dieser Features.
So lässt sich beispielsweise festlegen, dass temperature ein nützliches Feature ist. Anschließend können Sie mit dem Bucketing experimentieren, um zu optimieren, was das Modell aus verschiedenen temperature-Bereichen lernen kann.
Feature Engineering wird manchmal als Feature-Extraktion oder Designisierung bezeichnet.
Featureextraktion
Überladener Begriff mit einer der folgenden Definitionen:
- Abrufen von Darstellungen von Zwischenmerkmalen, die von einem unüberwachten oder vortrainierten Modell berechnet wurden (z. B. Werte von verborgenen Schichten in einem neuronalen Netzwerk), zur Verwendung in einem anderen Modell als Eingabe.
- Synonym für Feature Engineering.
Merkmalwichtigkeiten
Synonym für variable Bedeutungen.
Feature-Set
Die Gruppe der Features, mit der Ihr Modell für maschinelles Lernen trainiert wird. Beispielsweise können Postleitzahl, Größe der Unterkunft und Zustand der Unterkunft einen einfachen Featuresatz für ein Modell umfassen, das Immobilienpreise vorhersagt.
Featurespezifikation
Beschreibt die erforderlichen Informationen zum Extrahieren von features-Daten aus dem tf.Example-Protokollpuffer. Da der Protokollpuffer von tf.Example nur ein Container für Daten ist, müssen Sie Folgendes angeben:
- Die zu extrahierenden Daten (Schlüssel für die Features)
- Der Datentyp (z. B. Gleitkommazahl oder Ganzzahl)
- Die Länge (fest oder variabel)
Featurevektor
Das Array der feature-Werte, das ein Beispiel umfasst. Der Featurevektor wird während des Trainings und während der Inferenz eingegeben. Der Featurevektor für ein Modell mit zwei diskreten Features könnte beispielsweise so aussehen:
[0.92, 0.56]
Jedes Beispiel stellt unterschiedliche Werte für den Featurevektor bereit, sodass der Featurevektor für das nächste Beispiel in etwa so aussehen könnte:
[0.73, 0.49]
Feature Engineering bestimmt, wie Features im Featurevektor dargestellt werden. Beispielsweise kann ein binäres kategoriales Feature mit fünf möglichen Werten mit One-Hot-Codierung dargestellt werden. In diesem Fall würde der Teil des Featurevektors für ein bestimmtes Beispiel aus vier Nullen und einer einzelnen 1,0 an der dritten Position bestehen:
[0.0, 0.0, 1.0, 0.0, 0.0]
Nehmen wir als weiteres Beispiel an, Ihr Modell besteht aus drei Merkmalen:
- ein binäres kategoriales Feature mit fünf möglichen Werten, die mit One-Hot-Codierung dargestellt werden. Beispiel:
[0.0, 1.0, 0.0, 0.0, 0.0] - ein weiteres binäres kategoriales Feature mit drei möglichen Werten, die mit One-Hot-Codierung dargestellt werden. Beispiel:
[0.0, 0.0, 1.0] - Ein Gleitkommazahl-Feature, z. B.
8.3.
In diesem Fall würde der Featurevektor für jedes Beispiel durch neun Werte dargestellt werden. Anhand der Beispielwerte in der vorherigen Liste würde der Featurevektor so aussehen:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Typisierung
Das Extrahieren von Features aus einer Eingabequelle, z. B. einem Dokument oder Video, und Zuordnen dieser Merkmale zu einem Featurevektor.
Einige ML-Experten verwenden die Funktionsfähigkeit als Synonym für Feature Engineering oder Feature-Extraktion.
föderiertes Lernen
Ein Ansatz für verteiltes maschinelles Lernen, bei dem Modelle für maschinelles Lernen mit dezentralisierten Beispielen auf Geräten wie Smartphones trainiert werden. Beim föderierten Lernen lädt eine Untergruppe von Geräten das aktuelle Modell von einem zentralen koordinierenden Server herunter. Die Geräte verwenden die auf den Geräten gespeicherten Beispiele, um das Modell zu verbessern. Die Geräte laden dann die Modellverbesserungen (aber nicht die Trainingsbeispiele) auf den koordinierenden Server hoch, wo sie mit anderen Aktualisierungen aggregiert werden, um ein verbessertes globales Modell zu erzielen. Nach der Aggregation sind die von Geräten berechneten Modellaktualisierungen nicht mehr erforderlich und können verworfen werden.
Da die Trainingsbeispiele nie hochgeladen werden, folgt das föderierte Lernen den Datenschutzprinzipien einer fokussierten Datenerfassung und Datenminimierung.
Weitere Informationen zum föderierten Lernen finden Sie in dieser Anleitung.
Feedback-Schleife
Beim maschinellen Lernen eine Situation, in der die Vorhersagen eines Modells die Trainingsdaten für dasselbe oder ein anderes Modell beeinflussen. Ein Modell, das Filme empfiehlt, wirkt sich beispielsweise auf die Filme aus, die die Nutzer sehen. Dies wirkt sich dann auf nachfolgende Filmempfehlungsmodelle aus.
Neurales Feed-Forward-Netzwerk (FFN)
Ein neuronales Netzwerk ohne zyklische oder rekursive Verbindungen. Herkömmliche neuronale Deep-Learning-Netzwerke sind beispielsweise neuronale Feed-Forward-Netzwerke. Im Gegensatz dazu sind rekursive neuronale Netzwerke zyklisch.
wenige Schritte zum Lernen
Ein Ansatz des maschinellen Lernens, der häufig zur Objektklassifizierung verwendet wird und zum Trainieren effektiver Klassifikatoren anhand einer kleinen Anzahl von Trainingsbeispielen dient.
Weitere Informationen finden Sie unter One-Shot Learning und Zero-Shot Learning.
Prompts mit wenigen Aufnahmen
Eine Aufforderung, die mehr als ein (ein paar) Beispiel enthält, das zeigt, wie das Large Language Model reagieren sollte. Die folgende ausführliche Eingabeaufforderung enthält beispielsweise zwei Beispiele, die für ein Large Language Model zeigen, wie eine Abfrage beantwortet wird.
| Bestandteile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Frankreich: EUR | Ein Beispiel: |
| Vereinigtes Königreich: GBP | Ein weiteres Beispiel. |
| Indien: | Die eigentliche Abfrage. |
Wenige Prompts liefern in der Regel bessere Ergebnisse als Null-Shot-Prompts und One-Shot-Prompts. Solche Prompts erfordern jedoch länger.
Die Option „Wenige Prompts“ ist eine Form von wenigen Prompts für Prompt-basiertes Lernen.
Geige
Eine Konfigurationsbibliothek, die Python zuerst bietet und die Werte von Funktionen und Klassen ohne invasiven Code oder invasive Infrastruktur festlegt. Im Fall von Pax – und anderen ML-Codebasen – stellen diese Funktionen und Klassen Modelle und Training-Hyperparameter dar.
Fiddle geht davon aus, dass die Codebasis für maschinelles Lernen normalerweise wie folgt unterteilt ist:
- Bibliothekscode, der die Ebenen und Optimierer definiert.
- Dataset-„Glue“-Code, der die Bibliotheken aufruft und alles miteinander verbindet.
Fiddle erfasst die Aufrufstruktur des Glue-Codes in einer nicht ausgewerteten und änderbaren Form.
Abstimmung
Ein zweiter, aufgabenspezifischer Trainingspass, der mit einem vortrainierten Modell ausgeführt wird, um seine Parameter für einen bestimmten Anwendungsfall zu optimieren. Für einige Large Language Models sieht der vollständige Trainingsablauf beispielsweise so aus:
- Vortraining: Trainieren Sie ein Large Language Model mit einem riesigen allgemeinen Dataset, z. B. allen englischsprachigen Wikipedia-Seiten.
- Feinabstimmung:Trainieren Sie das vortrainierte Modell für die Ausführung einer bestimmten Aufgabe, z. B. zum Antworten auf medizinische Anfragen. Die Feinabstimmung umfasst in der Regel Hunderte oder Tausende von Beispielen, die auf die jeweilige Aufgabe ausgerichtet sind.
Als weiteres Beispiel sieht die vollständige Trainingssequenz für ein Modell mit großen Bildern so aus:
- Vortraining:Trainieren Sie ein Modell mit großen Bildern anhand eines umfangreichen allgemeinen Bild-Datasets, z. B. mit allen Bildern in Wikimedia Commons.
- Feinabstimmung:Trainieren Sie das vortrainierte Modell für die Ausführung einer bestimmten Aufgabe, z. B. zum Generieren von Bildern von Orcas.
Die Optimierung kann eine beliebige Kombination der folgenden Strategien umfassen:
- Alle vorhandenen Parameter des vortrainierten Modells ändern. Dies wird auch als vollständige Feinabstimmung bezeichnet.
- Nur einige der vorhandenen Parameter des vortrainierten Modells ändern (in der Regel die Ebenen, die der Ausgabeschicht am nächsten sind) und andere vorhandene Parameter unverändert lassen (in der Regel die Ebenen, die der Eingabeebene am nächsten sind). Siehe parametersparende Abstimmung.
- Weitere Ebenen hinzufügen, in der Regel auf den vorhandenen Ebenen, die der Ausgabeschicht am nächsten sind
Abstimmung ist eine Form des Lerntransfers. Daher kann bei der Feinabstimmung eine andere Verlustfunktion oder ein anderer Modelltyp als der zum Trainieren des vortrainierten Modells verwendet werden. Sie könnten beispielsweise ein vortrainiertes großes Bildmodell optimieren, um ein Regressionsmodell zu erstellen, das die Anzahl der Vögel in einem Eingabebild zurückgibt.
Die Feinabstimmung mit den folgenden Begriffen vergleichen und gegenüberstellen:
Kristallgrau
Eine leistungsstarke Open-Source- Bibliothek für Deep Learning, die auf JAX basiert. Flax bietet Funktionen für das Training von neuronalen Netzwerken sowie Methoden zur Leistungsbewertung.
Flachsformer
Eine auf Flax basierende Open-Source-Transformer-Bibliothek, die hauptsächlich für Natural Language Processing und multimodale Forschung entwickelt wurde.
Vergiss Gate
Der Teil einer Zelle eines Langzeitspeichers, der den Informationsfluss durch die Zelle reguliert. Vergessen-Gatter bewahren den Kontext auf, indem entschieden wird, welche Informationen aus dem Zellenstatus verworfen werden sollen.
vollständiges Softmax
Synonym für softmax.
Im Vergleich zur Stichprobenerhebung für Kandidaten
vollständig verbundene Ebene
Eine verborgene Ebene, in der jeder Knoten mit allen Knoten der nachfolgenden verborgenen Ebene verbunden ist
Eine vollständig verbundene Ebene wird auch als dichte Ebene bezeichnet.
Funktionstransformation
Eine Funktion, die eine Funktion als Eingabe verwendet und eine transformierte Funktion als Ausgabe zurückgibt. JAX verwendet Funktionstransformationen.
G
GAN
Abkürzung für Generative Adversarial Network.
Generalisierung
Fähigkeit eines Modells, korrekte Vorhersagen für neue, zuvor unbekannte Daten zu treffen. Ein Modell, das generalisieren kann, ist das Gegenteil eines Modells mit Überanpassung.
Generalisierungskurve
Diagramm des Trainingsverlusts und des Validierungsverlusts als Funktion der Anzahl der Iterationen
Mit einer Generalisierungskurve können Sie eine mögliche Überanpassung erkennen. Die folgende Generalisierungskurve deutet beispielsweise auf eine Überanpassung hin, da der Validierungsverlust letztendlich deutlich höher wird als der Trainingsverlust.
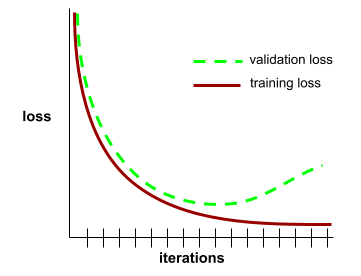
Generalisiertes lineares Modell
Eine Verallgemeinerung von Modellen der Regression der kleinsten Quadrate, die auf dem Gaußschen Rauschen basiert, auf andere Modelltypen, die auf anderen Arten von Rauschen basieren, z. B. Poisson-Rauschen oder kategoriales Rauschen. Beispiele für generalisierte lineare Modelle:
- logistische Regression
- Regression mit mehreren Klassen
- Regression der kleinsten Quadrate
Die Parameter eines generalisierten linearen Modells können durch die konvexe Optimierung ermittelt werden.
Generalisierte lineare Modelle haben die folgenden Eigenschaften:
- Die durchschnittliche Vorhersage des optimalen Regressionsmodells mit den kleinsten Quadraten ist gleich dem Durchschnittslabel der Trainingsdaten.
- Die durchschnittliche Wahrscheinlichkeit, die vom optimalen logistischen Regressionsmodell vorhergesagt wird, entspricht dem Durchschnittslabel der Trainingsdaten.
Die Leistungsfähigkeit eines generalisierten linearen Modells ist durch seine Features begrenzt. Im Gegensatz zu einem tiefen Modell kann ein generalisiertes lineares Modell nicht "neue Features lernen".
Generative Adversarial Network (GAN)
Ein System zum Erstellen neuer Daten, in dem ein Generator Daten erstellt und ein Diskriminator bestimmt, ob die erstellten Daten gültig oder ungültig sind.
Generative AI
Ein aufstrebendes transformatives Feld ohne formale Definition. Dennoch sind sich die meisten Experten einig, dass Generative-AI-Modelle folgende Inhalte erstellen („generieren“) können:
- Komplex
- kohärent
- ursprünglich
Ein generatives KI-Modell kann beispielsweise anspruchsvolle Aufsätze oder Bilder erstellen.
Einige ältere Technologien, einschließlich LSTMs und RNNs, können auch eigene und kohärente Inhalte generieren. Einige Experten betrachten diese früheren Technologien als Generative AI, während andere der Meinung sind, dass echte Generative AI komplexere Ausgaben erfordert, als diese früheren Technologien liefern können.
Kontrast mit Prognose-ML
Generatives Modell
Praktisch gesehen ein Modell, das eines der folgenden Ziele erfüllt:
- Erstellt (erzeugt) neue Beispiele aus dem Trainings-Dataset. Ein generatives Modell könnte beispielsweise nach dem Training mit einem Dataset von Gedichten Gedichte erstellen. Der Generator eines generativen Angriffsnetzwerks fällt in diese Kategorie.
- Bestimmt die Wahrscheinlichkeit, dass ein neues Beispiel aus dem Trainings-Dataset stammt oder mit demselben Mechanismus erstellt wurde, mit dem das Trainings-Dataset erstellt wurde. Nach dem Training mit einem Dataset, das aus englischen Sätzen besteht, könnte ein generatives Modell beispielsweise die Wahrscheinlichkeit bestimmen, dass die neue Eingabe ein gültiger englischer Satz ist.
Ein generatives Modell kann theoretisch die Verteilung von Beispielen oder bestimmten Merkmalen in einem Dataset erkennen. Das bedeutet:
p(examples)
Unüberwachtes Lernen ist generativ.
Im Vergleich zu diskriminierenden Modellen
Generator
Das Subsystem innerhalb eines generativen kontradiktorischen Netzwerks, das neue Beispiele erstellt.
Im Vergleich zum diskriminierenden Modell
Gini-Unreinheit
Ein Messwert, der der Entropie ähnelt. Splitter verwenden Werte, die entweder von der gini-Unreinheit oder von Entropie abgeleitet sind, um Bedingungen für Entscheidungsbäume zu erstellen. Informationsgewinn wird aus der Entropie abgeleitet. Es gibt keinen allgemein akzeptierten äquivalenten Begriff für den von der gini-Unreinheit abgeleiteten Messwert. Dieser unbenannte Messwert ist jedoch genauso wichtig wie der Informationsgewinn.
Die Gini-Unreinheit wird auch als Gini-Index oder einfach gini bezeichnet.
Goldenes Dataset
Eine Reihe manuell ausgewählter Daten, die Ground Truth erfassen. Teams können ein oder mehrere goldene Datasets verwenden, um die Qualität eines Modells zu bewerten.
Einige goldene Datasets erfassen verschiedene Subdomains von Ground Truth. Mit einem goldenen Dataset für die Bildklassifizierung können beispielsweise Lichtverhältnisse und die Bildauflösung erfasst werden.
GPT (generativer vortrainierter Transformer)
Eine Familie von Large Language Models, die auf Transformer basieren und von OpenAI entwickelt wurden.
GPT-Varianten können auf mehrere Modalitäten angewendet werden, darunter:
- Bildgenerierung (z. B. ImageGPT)
- Text-zu-Bild-Generierung (z. B. DALL-E).
Farbverlauf
Vektor von partiellen Ableitungen in Bezug auf alle unabhängigen Variablen. Beim maschinellen Lernen ist der Gradient der Vektor der partiellen Ableitungen der Modellfunktion. Der Farbverlauf zeigt in Richtung des steilsten Anstiegs.
Akkumulation von Gradienten
Ein Verfahren der Rückpropagierung, bei dem die Parameter nur einmal pro Epoche und nicht einmal pro Iteration aktualisiert werden. Nach der Verarbeitung jedes Mini-Batch wird durch die Gradientenakkumulation einfach die laufende Summe der Gradienten aktualisiert. Nach der Verarbeitung des letzten Mini-Batch in der Epoche aktualisiert das System schließlich die Parameter basierend auf der Summe aller Gradientenänderungen.
Die Gradientakkumulation ist nützlich, wenn die Batchgröße im Vergleich zum verfügbaren Arbeitsspeicher für das Training sehr groß ist. Bei Speicherproblemen besteht die natürliche Tendenz, die Batchgröße zu reduzieren. Durch die Reduzierung der Batchgröße bei der normalen Backpropagation erhöht sich jedoch die Anzahl der Parameteraktualisierungen. Durch die Akkumulation des Gradienten kann das Modell Speicherprobleme vermeiden und trotzdem effizient trainieren.
Gradienten-Boosting-Bäume (GBT)
Eine Art von Entscheidungsgesamtheit, in der:
- Das Training basiert auf dem Gradienten-Boosting.
- Das schwache Modell ist ein Entscheidungsbaum.
Gradient-Boosting
Trainingsalgorithmus, mit dem schwache Modelle trainiert werden, um die Qualität eines starken Modells iterativ zu verbessern (den Verlust zu reduzieren). Ein schwaches Modell kann beispielsweise ein lineares oder ein kleines Entscheidungsbaummodell sein. Das starke Modell wird dann die Summe aller zuvor trainierten schwachen Modelle.
In der einfachsten Form des Gradienten-Boosting wird bei jeder Iteration ein schwaches Modell trainiert, um den Verlustgrad des starken Modells vorherzusagen. Anschließend wird die Ausgabe des starken Modells durch Subtrahieren des vorhergesagten Gradienten aktualisiert, ähnlich wie beim Gradientenabstieg.
Dabei gilt:
- $F_{0}$ ist das starke Startmodell.
- $F_{i+1}$ ist das nächste starke Modell.
- $F_{i}$ ist das derzeit starke Modell.
- $\xi$ ist ein Wert zwischen 0,0 und 1,0, der als Schrumpfung bezeichnet wird und der Lernrate beim Gradientenabstieg entspricht.
- $f_{i}$ ist das schwache Modell, das darauf trainiert wurde, den Verlustgrad von $F_{i}$ vorherzusagen.
Bei modernen Varianten des Gradienten-Boosting wird auch die zweite Ableitung des Verlusts (Hessisches) zur Berechnung verwendet.
Entscheidungsbäume werden häufig als schwache Modelle beim Gradienten-Boosting verwendet. Weitere Informationen finden Sie unter Entscheidungsbäume mit Farbverlauf.
Farbverlaufs-Clipping
Ein häufig verwendeter Mechanismus zur Minderung des explodierenden Gradientenproblems durch die künstliche Begrenzung (Einschränkung) des Maximalwerts von Gradienten, wenn das Gradientenabstieg zum Trainieren eines Modells verwendet wird.
Gradientenabstieg
Eine mathematische Technik zur Minimierung von Verlust. Beim Gradientenabstieg werden Gewichtungen und Voreingenommenheiten schrittweise angepasst, um schrittweise die beste Kombination zu finden, um den Verlust zu minimieren.
Das Gradientenverfahren ist älter – also viel, viel älter – als maschinelles Lernen.
Grafik
In TensorFlow eine Berechnungsspezifikation. Knoten im Diagramm stellen Vorgänge dar. Edges sind gerichtet und stellen die Übergabe des Ergebnisses eines Vorgangs (eines Tensors) als Operand an einen anderen Vorgang dar. Mit TensorBoard können Sie eine Grafik visualisieren.
Graph Execution
Eine TensorFlow-Programmierumgebung, in der das Programm zuerst einen Graphen erstellt und dann diesen Graph ganz oder teilweise ausführt. Die Ausführung des Graphen ist der Standardausführungsmodus in TensorFlow 1.x.
Stellen Sie es sich gegenüber einer ehrgeizigen Ausführung gegenüber.
Greedy-Richtlinie
Beim Reinforcement Learning eine Richtlinie, die immer die Aktion mit der höchsten erwarteten Rendite auswählt.
Ground Truth
Realität.
Was tatsächlich passiert ist.
Stellen Sie sich beispielsweise ein binäres Klassifizierungsmodell vor, das vorhersagt, ob ein Studierende im ersten Universitätsjahr den Abschluss innerhalb von sechs Jahren abschließen wird. Die Ground-Truth-Frage für dieses Modell ist, ob der Student den Abschluss tatsächlich innerhalb von sechs Jahren gemacht hat.
Gruppenattributionsverzerrung
Unter der Annahme, dass das, was für eine Person trifft, auch für alle in dieser Gruppe gilt. Die Auswirkungen einer Gruppenattributionsverzerrung können sich noch verstärken, wenn für die Datenerhebung eine willkürliche Stichprobe verwendet wird. In einer nicht repräsentativen Stichprobe können Zuordnungen vorgenommen werden, die die Realität nicht widerspiegeln.
Siehe auch Out-Group-Homogenitätsverzerrung und In-Group-Verzerrung.
H
KI-Halluzination
Erstellung einer plausibel erscheinenden, aber sachlich falschen Ausgabe durch ein Generative-AI-Modell, das vorgibt, eine Behauptung über die reale Welt zu treffen. Ein Generative-AI-Modell, in dem behauptet wird, Barack Obama sei 1865 gestorben, ist beispielsweise eine Halluzination.
Hash-Technologie
Beim maschinellen Lernen gibt es einen Mechanismus zum Bucketing kategorischer Daten, insbesondere wenn die Anzahl der Kategorien groß ist, aber die Anzahl der tatsächlich im Datensatz vorhandenen Kategorien vergleichsweise klein ist.
Auf der Erde beispielsweise leben etwa 73.000 Baumarten. Sie könnten jede der 73.000 Baumarten in 73.000 separaten kategorialen Gruppen darstellen. Wenn in einem Dataset nur 200 dieser Baumarten tatsächlich vorhanden sind, könnten Sie alternativ Hashing verwenden, um die Baumarten in etwa 500 Buckets aufzuteilen.
Ein Bucket könnte mehrere Baumarten enthalten. Bei der Hash-Technologie werden beispielsweise Baobab und roter Ahorn – zwei genetisch unähnliche Arten – in denselben Bucket aufgenommen. Unabhängig davon ist die Hash-Technologie immer noch eine gute Möglichkeit, um der ausgewählten Anzahl von Buckets große kategoriale Datasets zuzuordnen. Beim Hashing wird ein kategoriales Merkmal mit einer großen Anzahl möglicher Werte in eine viel kleinere Anzahl von Werten umgewandelt, indem Werte auf deterministische Weise gruppiert werden.
Heuristik
Eine einfache und schnell implementierte Lösung für ein Problem. Beispiel: „Mit einer Heuristik haben wir eine Genauigkeit von 86% erreicht. Als wir zu einem neuronalen Deep-Learning-Netzwerk wechselten, stieg die Genauigkeit auf 98%.“
versteckte Schicht
Eine Schicht in einem neuronalen Netzwerk zwischen der Eingabeebene (den Features) und der Ausgabeebene (die Vorhersage). Jede verborgene Schicht besteht aus einem oder mehreren Neuronen. Das folgende neuronale Netzwerk enthält beispielsweise zwei versteckte Schichten, die erste mit drei Neuronen und die zweite mit zwei Neuronen:
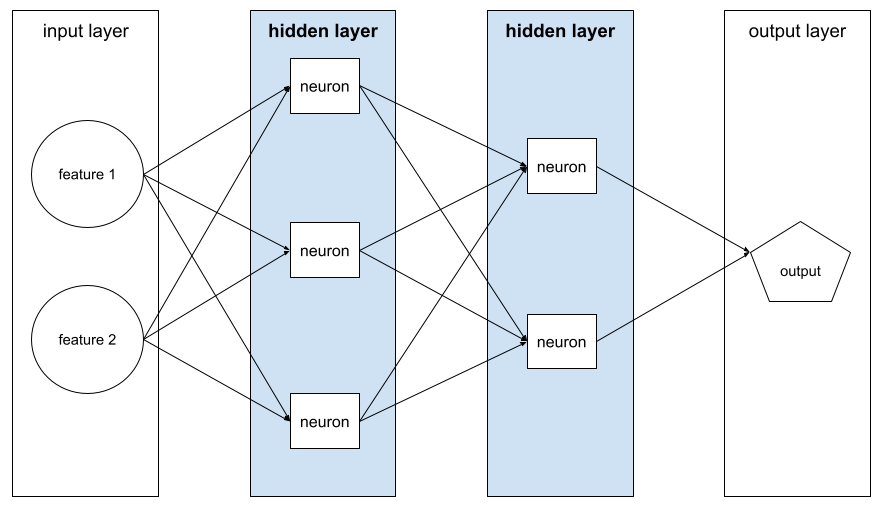
Ein neuronales Deep-Learning-Netzwerk enthält mehr als eine verborgene Ebene. Die vorherige Abbildung ist beispielsweise ein neuronales Deep-Learning-Netzwerk, da das Modell zwei versteckte Ebenen enthält.
hierarchisches Clustering
Eine Kategorie von Clustering-Algorithmen, die eine Clusterstruktur erstellen. Das hierarchische Clustering eignet sich gut für hierarchische Daten, z. B. für botanische Taxonomien. Es gibt zwei Arten von hierarchischen Clustering-Algorithmen:
- Beim Agglomerative Clustering wird jedes Beispiel zuerst einem eigenen Cluster zugewiesen. Anschließend werden die nächstgelegenen Cluster iterativ zusammengeführt, um eine hierarchische Struktur zu erstellen.
- Beim Divisive Clustering werden zuerst alle Beispiele in einem Cluster gruppiert und dieser wird dann iterativ in eine hierarchische Struktur unterteilt.
Kontrast mit schwerpunktbasiertem Clustering
Scharnierverlust
Eine Familie von Verlustfunktionen für die Klassifizierung, die entwickelt wurde, um die Entscheidungsgrenze so weit wie möglich von jedem Trainingsbeispiel entfernt zu halten, wodurch der Abstand zwischen Beispielen und der Grenze maximiert wird. KSVMs verwenden den Verlust von Scharniern (oder eine ähnliche Funktion wie den quadratischen Scharnierverlust). Für die binäre Klassifizierung ist die Scharnierverlustfunktion so definiert:
Dabei ist y das tatsächliche Label, entweder -1 oder +1, und y' die Rohausgabe des Klassifikatormodells:
Daher sieht die Darstellung des Verlusts der Scharnier im Vergleich zu (y * y) so aus:

historische Voreingenommenheit
Ein Typ der Voreingenommenheit, der bereits auf der Welt existiert und in ein Dataset aufgenommen wurde. Diese Voreingenommenheiten neigen dazu, bestehende kulturelle Stereotype, demografische Ungleichheiten und Vorurteile gegenüber bestimmten sozialen Gruppen widerzuspiegeln.
Stellen Sie sich beispielsweise ein Klassifizierungsmodell in Betracht, das vorhersagt, ob ein Kreditbewerber seinen Kredit nicht mehr akzeptiert. Das Modell wurde anhand von Standarddaten für frühere Kredite aus den 1980er-Jahren von lokalen Banken in zwei verschiedenen Gemeinschaften trainiert. Wenn frühere Bewerber aus Community A mit sechsmal höherer Wahrscheinlichkeit keinen Kredit für ihre Kredite aufnehmen würden als Bewerber aus Community B, lernt das Modell möglicherweise eine historische Verzerrung, wodurch das Modell die Wahrscheinlichkeit, dass Kredite in Community A genehmigt werden, geringer war, auch wenn die historischen Bedingungen, die zu den höheren Standardzinsen in dieser Community geführt haben, nicht mehr relevant waren.
Holdout-Daten
Beispiele, die während des Trainings absichtlich nicht verwendet („herausgehalten“) werden. Das Validierungs-Dataset und das Test-Dataset sind Beispiele für Holdout-Daten. Mit Holdout-Daten können Sie die Fähigkeit Ihres Modells bewerten, auf andere Daten als die Daten zu generalisieren, mit denen es trainiert wurde. Der Verlust im Holdout-Dataset bietet eine bessere Schätzung des Verlusts eines nicht gesehenen Datasets als der Verlust im Trainings-Dataset.
Gastgeber
Beim Trainieren eines ML-Modells auf Beschleunigerchips (GPUs oder TPUs) wird der Teil des Systems verwendet, der die beiden folgenden Vorgänge steuert:
- Der gesamte Ablauf des Codes.
- Extraktion und Transformation der Eingabepipeline.
Der Host wird normalerweise auf einer CPU und nicht auf einem Beschleunigerchip ausgeführt. Das Gerät manipuliert Tensoren auf den Beschleunigerchips.
Hyperparameter
Die Variablen, die von Ihnen oder einem Hyperparameter-Abstimmungsdienstwährend aufeinanderfolgender Trainingsläufe eines Modells angepasst werden. Beispielsweise ist die Lernrate ein Hyperparameter. Sie können die Lernrate vor einer Trainingseinheit auf 0,01 setzen. Wenn Sie feststellen, dass 0,01 zu hoch ist, können Sie die Lernrate für die nächste Trainingssitzung auf 0,003 setzen.
Im Gegensatz dazu sind Parameter die verschiedenen Gewichtungen und Verzerrungen, die das Modell während des Trainings lernt.
Hyperplane
Begrenzung, die einen Raum in zwei Unterräume trennt. Eine Linie ist beispielsweise eine Hyperebene in zwei Dimensionen und eine Ebene eine Hyperebene in drei Dimensionen. Im maschinellen Lernen ist eine Hyperebene typischerweise die Grenze, die einen hochdimensionalen Raum voneinander trennt. Kernel Support Vector Machines verwenden Hyperebenen, um positive von negativen Klassen zu trennen, oft in einem sehr hochdimensionalen Bereich.
I
i.i.d.
Abkürzung für unabhängig und identisch verteilt.
bilderkennung
Ein Prozess zum Klassifizieren von Objekten, Mustern oder Konzepten in einem Bild. Die Bilderkennung wird auch als Bildklassifizierung bezeichnet.
Weitere Informationen finden Sie unter ML-Praxis: Bildklassifizierung.
unausgeglichenes Dataset
Synonym für class-imbalanced Dataset.
impliziter Bias
Es wird automatisch eine Verbindung oder Annahme basierend auf den eigenen Gedankenmodellen und Erinnerungen hergestellt. Implizite Voreingenommenheit kann Folgendes beeinflussen:
- Wie Daten erhoben und klassifiziert werden
- Wie Systeme für maschinelles Lernen konzipiert und entwickelt werden
Bei der Erstellung eines Klassifikators zur Identifizierung von Hochzeitsfotos könnte ein Entwickler z. B. das Vorhandensein eines weißen Kleides in einem Foto als Merkmal verwenden. Weiße Kleider waren jedoch nur in bestimmten Epochen und in bestimmten Kulturen üblich.
Weitere Informationen finden Sie unter Bestätigungsverzerrung.
Imputation
Kurzform der Wertschätzung.
Inkompatibilität von Fairness-Messwerten
Die Idee, dass einige Vorstellungen der Fairness nicht miteinander kompatibel sind und nicht gleichzeitig erfüllt werden können. Daher gibt es keinen universellen Messwert zur Quantifizierung der Fairness, der auf alle ML-Probleme angewendet werden kann.
Dies mag abschreckend erscheinen, bedeutet jedoch nicht, dass die Inkompatibilität von Fairness-Messwerten erfolglos sind. Stattdessen wird darauf hingewiesen, dass Fairness für ein bestimmtes ML-Problem kontextuell definiert werden muss, um Schäden in Bezug auf die jeweiligen Anwendungsfälle zu verhindern.
Eine ausführlichere Diskussion dieses Themas finden Sie unter Über die (un)Möglichkeit der Fairness.
kontextbezogenes Lernen
Synonym für wenige Shot-Prompts.
unabhängig und identisch verteilt (i.i.d)
Daten, die aus einer Verteilung stammen, die sich nicht ändert, und bei der jeder gezeichnete Wert nicht von zuvor gezeichneten Werten abhängt. Ein I. D. ist das ideale Gas des maschinellen Lernens – ein nützliches mathematisches Konstrukt, das in der realen Welt jedoch fast nie genau zu finden ist. Die Verteilung der Besucher einer Webseite kann beispielsweise über ein kurzes Zeitfenster hinweg erfolgen, d. h., die Verteilung ändert sich während dieses kurzen Zeitraums nicht und der Besuch einer Person ist im Allgemeinen unabhängig vom Besuch einer anderen Person. Verlängern Sie dieses Zeitfenster jedoch, können saisonale Unterschiede bei den Besuchern der Webseite auftreten.
Weitere Informationen finden Sie unter Nichtstationarität.
individuelle Fairness
Ein Fairness-Messwert, der prüft, ob ähnliche Personen ähnlich klassifiziert werden. Die Brobdingnagian Academy möchte beispielsweise die Fairness des Einzelnen erfüllen, indem sichergestellt wird, dass zwei Studenten mit identischen Noten und standardisierten Prüfungsergebnissen mit gleicher Wahrscheinlichkeit zugelassen werden.
Beachten Sie, dass die individuelle Fairness vollständig davon abhängt, wie Sie „Ähnlichkeit“ definieren (in diesem Fall Noten und Testergebnisse). Es besteht das Risiko, dass neue Fairness-Probleme entstehen, wenn Ihrem Ähnlichkeitsmesswert wichtige Informationen (z. B. die Genauigkeit des Lehrplans eines Schülers) fehlen.
Im Artikel Fairness durch Bekanntheit findest du eine ausführlichere Beschreibung der individuellen Fairness.
Inferenz
Beim maschinellen Lernen der Prozess des Treffens von Vorhersagen, indem ein trainiertes Modell auf Beispiele ohne Label angewendet wird.
Die Inferenz hat in der Statistik eine andere Bedeutung. Weitere Informationen finden Sie im Wikipedia-Artikel zur statistischen Inferenz.
Inferenzpfad
In einem Entscheidungsbaum wird während der Inferenz die Route eines bestimmten Beispiels vom Stamm zu anderen Bedingungen geführt, die mit einem Blatt endet. Im folgenden Entscheidungsbaum zeigen die dickeren Pfeile beispielsweise den Inferenzpfad für ein Beispiel mit den folgenden Featurewerten an:
- x = 7
- y = 12
- z = -3
Der Inferenzpfad in der folgenden Abbildung durchläuft drei Bedingungen, bevor er das Blatt (Zeta) erreicht.
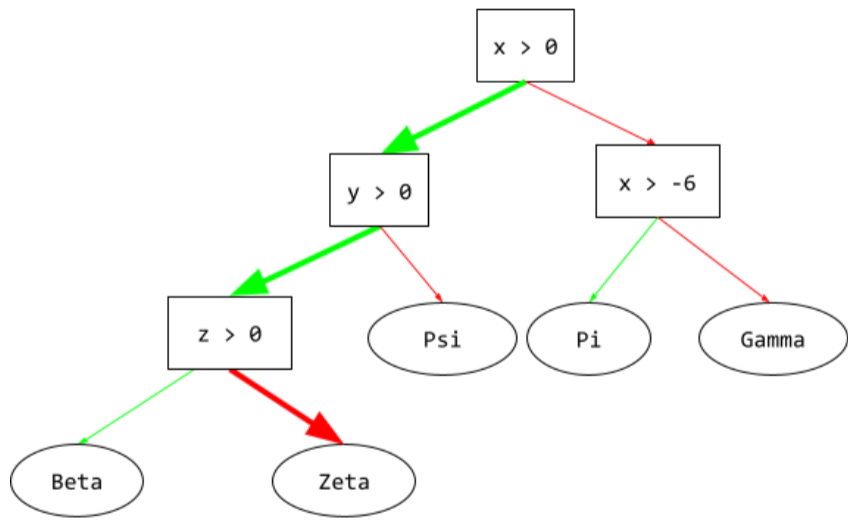
Die drei dicken Pfeile zeigen den Ableitungspfad an.
Informationsgewinn
In Entscheidungsstrukturen die Differenz zwischen der Entropie eines Knotens und der gewichteten Summe (nach Anzahl der Beispiele) der Entropie seiner untergeordneten Knoten. Die Entropie eines Knotens ist die Entropie der Beispiele in diesem Knoten.
Betrachten Sie beispielsweise die folgenden Entropiewerte:
- Entropie des übergeordneten Knotens = 0,6
- Entropie eines untergeordneten Knotens mit 16 relevanten Beispielen = 0,2
- Entropie eines anderen untergeordneten Knotens mit 24 relevanten Beispielen = 0,1
40% der Beispiele befinden sich also in einem untergeordneten Knoten und 60% im anderen untergeordneten Knoten. Beispiele:
- Summe der gewichteten Entropie der untergeordneten Knoten = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Der Informationsgewinn ist also:
- Informationsgewinn = Entropie des übergeordneten Knotens - gewichtete Entropiesumme der untergeordneten Knoten
- Informationsgewinn = 0,6 - 0,14 = 0,46
Die meisten Splitter versuchen, Bedingungen zu schaffen, die den Informationsgewinn maximieren.
In-Group-Verzerrung
Sie zeigen eine Vorurteile auf die eigene Gruppe oder die eigenen Eigenschaften. Wenn es sich bei den Testern um Freunde, Familienmitglieder oder Kollegen des Entwicklers für maschinelles Lernen handelt, können durch Verzerrungen innerhalb einer Gruppe Produkttests oder das Dataset entwertet werden.
In-Group-Verzerrungen sind eine Form der Gruppenattributionsverzerrung. Siehe auch Out-Group-Homogenitätsverzerrung.
Eingabegenerator
Ein Mechanismus, mit dem Daten in ein neuronales Netzwerk geladen werden.
Ein Eingabegenerator kann als eine Komponente betrachtet werden, die für die Verarbeitung von Rohdaten in Tensoren verantwortlich ist, die iteriert werden, um Batches für Training, Auswertung und Inferenz zu generieren.
Eingabeschicht
Die Ebene eines neuronalen Netzwerks, das den Featurevektor enthält. Das heißt, die Eingabeschicht enthält Beispiele für Training oder Inferenz. Beispielsweise besteht die Eingabeschicht im folgenden neuronalen Netzwerk aus zwei Merkmalen:
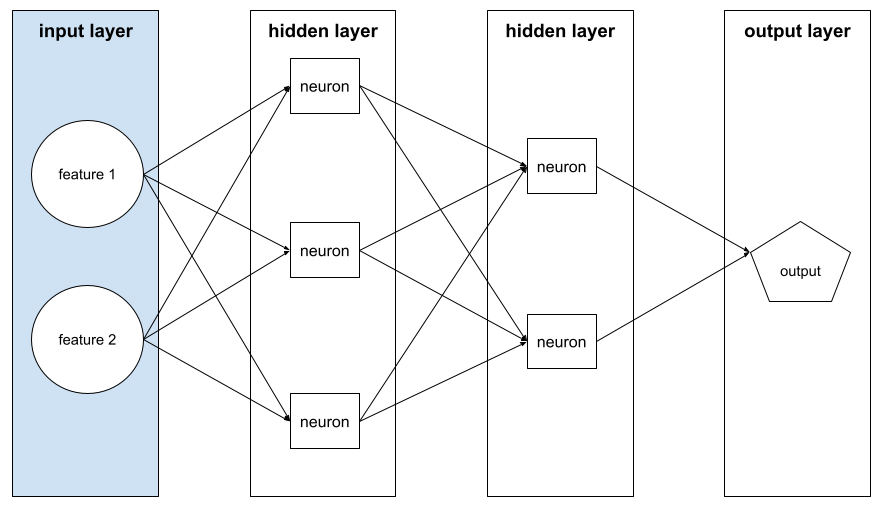
Eingestellte Bedingung
Eine Bedingung in einem Entscheidungsbaum, mit der geprüft wird, ob ein Element in einer Gruppe von Elementen vorhanden ist. Das folgende Beispiel zeigt eine bereits festgelegte Bedingung:
house-style in [tudor, colonial, cape]
Wenn bei der Inferenz der Wert des Features des Hausstils tudor, colonial oder cape ist, wird diese Bedingung mit „Ja“ ausgewertet. Wenn der Wert des hausinternen Elements etwas anderes ist (z. B. ranch), wird diese Bedingung mit „Nein“ ausgewertet.
Setzte Bedingungen führen in der Regel zu effizienteren Entscheidungsbäumen als Bedingungen, bei denen One-Hot-codierte Features getestet werden.
Instanz
Synonym für Beispiel.
Anweisungsabstimmung
Eine Form der Feinabstimmung, mit der ein Generative AI-Modell besser den Anweisungen folgen kann. Bei der Befehlsabstimmung wird ein Modell anhand einer Reihe von Anweisungsaufforderungen trainiert, die in der Regel eine Vielzahl von Aufgaben abdecken. Das resultierende, auf Anweisungen abgestimmte Modell generiert dann tendenziell nützliche Antworten auf Zero-Shot-Prompts für eine Vielzahl von Aufgaben.
Vergleich mit:
Interpretierbarkeit
Die Fähigkeit, die Begründung eines ML-Modells einem Menschen verständlich zu erklären oder zu präsentieren.
Die meisten linearen Regressionsmodelle beispielsweise sind hochgradig interpretierbar. Sie müssen sich nur die trainierten Gewichtungen für jedes Feature ansehen. Außerdem lassen sich Entscheidungsbereiche sehr gut interpretieren. Einige Modelle erfordern jedoch eine ausgefeilte Visualisierung, um interpretierbar zu werden.
Zum Interpretieren von ML-Modellen können Sie das Learning Interpretability Tool (LIT) verwenden.
Vereinbarung zwischen Prüfern
Ein Maß dafür, wie oft sich Prüfer bei der Erledigung einer Aufgabe einig sind. Wenn die Prüfer anderer Meinung sind, muss die Anleitung für die Aufgabe möglicherweise verbessert werden. Wird auch als Vereinbarung zwischen Kommentatoren oder Zwischennotatoren-Zuverlässigkeit bezeichnet. Siehe auch Cohens Kappa, eine der beliebtesten Messungen für Vereinbarungen zwischen Prüfern.
Schnittmenge über Union (IoU)
Die Schnittmenge zweier Mengen geteilt durch ihre Vereinigung. Bei der Bilderkennung durch maschinelles Lernen wird IoU verwendet, um die Genauigkeit des vorhergesagten Begrenzungsrahmens des Modells in Bezug auf den Ground-Truth-Begrenzungsrahmen zu messen. In diesem Fall ist die IoU für die beiden Rahmen das Verhältnis zwischen dem überlappenden Bereich und der Gesamtfläche. Ihr Wert reicht von 0 (keine Überschneidung des vorhergesagten Begrenzungsrahmens und Ground-Truth-Begrenzungsrahmens) bis 1 (der vorhergesagte Begrenzungsrahmen und der Ground-Truth-Begrenzungsrahmen haben exakt dieselben Koordinaten).
Hier ein Beispiel:
- Der vorhergesagte Begrenzungsrahmen (die Koordinaten, durch die sich der Ort der Nachttabelle im Gemälde vom Modell begrenzt) wird lila dargestellt.
- Der Ground-Truth-Begrenzungsrahmen (die Koordinaten, die den tatsächlichen Standort der Nachttabelle im Gemälde begrenzen) ist grün umrandet.
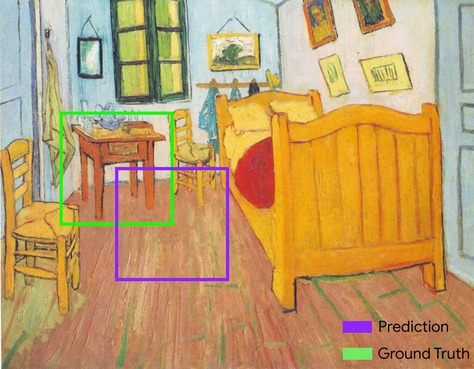
Hier beträgt die Schnittmenge der Begrenzungsrahmen für Vorhersage und Ground Truth (unten links) 1 und die Union der Begrenzungsrahmen für Vorhersage und Ground Truth (unten rechts) ist 7, sodass der IoU \(\frac{1}{7}\)ist.
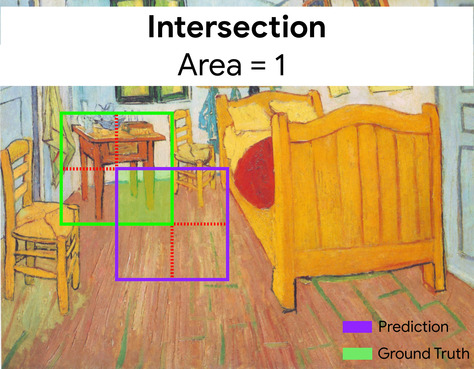
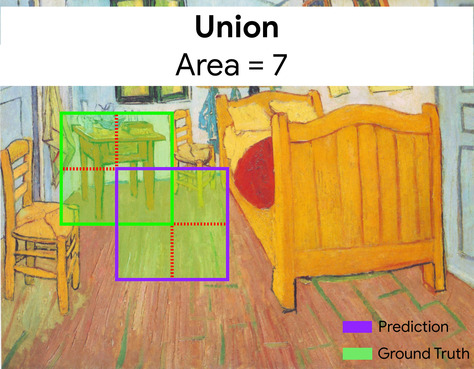
IoU
Abkürzung für Intersection over Union.
Artikelmatrix
In Empfehlungssystemen eine Matrix aus Einbettungsvektoren, die durch die Matrixfaktorisierung generiert wurde und latente Signale zu jedem Element enthält. Jede Zeile der Elementmatrix enthält den Wert eines einzelnen latenten Merkmals für alle Elemente. Stellen Sie sich zum Beispiel ein Empfehlungssystem für Filme vor. Jede Spalte in der Elementmatrix stellt einen einzelnen Film dar. Die latenten Signale können Genres repräsentieren oder schwer zu interpretierende Signale sein, die komplexe Interaktionen zwischen Genre, Stars, Filmalter oder anderen Faktoren beinhalten.
Die Artikelmatrix hat die gleiche Anzahl von Spalten wie die Zielmatrix, die faktorisiert wird. Beispiel: Bei einem Filmempfehlungssystem, das 10.000 Filmtitel bewertet, hat die Artikelmatrix 10.000 Spalten.
items
In einem Empfehlungssystem die Entitäten, die ein System empfiehlt. Beispielsweise sind Videos die Artikel, die in einem Videoladen empfohlen werden, während Bücher die Artikel sind, die eine Buchhandlung empfiehlt.
Iteration
Eine einzelne Aktualisierung der Modellparameter – der Gewichtungen und Verzerrungen des Modells während des Trainings. Die Batchgröße bestimmt, wie viele Beispiele das Modell in einer einzelnen Iteration verarbeitet. Wenn die Batchgröße beispielsweise 20 beträgt, verarbeitet das Modell 20 Beispiele, bevor die Parameter angepasst werden.
Beim Trainieren eines neuronalen Netzes umfasst ein einzelner Durchlauf die folgenden zwei Durchgänge:
- Ein Vorwärtsdurchlauf zur Bewertung des Verlusts bei einem einzelnen Batch.
- Einen Rückwärtstermin (Rückpropagierung), um die Parameter des Modells auf der Grundlage des Verlusts und der Lernrate anzupassen.
J
JAX
Eine Array-Computing-Bibliothek, die XLA (Accelerated Linear Algebra) und automatische Differenzierung für numerisches Hochleistungs-Computing kombiniert. JAX bietet eine einfache und leistungsstarke API zum Schreiben von beschleunigtem numerischem Code mit zusammensetzbaren Transformationen. JAX bietet unter anderem folgende Funktionen:
grad(automatische Differenzierung)jit(Just-in-Time-Kompilierung)vmap(automatische Vektorisierung oder Batchverarbeitung)pmap(Parallelisierung)
JAX ist eine Sprache zum Ausdrucken und Zusammenstellen von Transformationen von numerischem Code, die der NumPy-Bibliothek von Python ähnlich, aber viel größer ist. Die .numpy-Bibliothek unter JAX ist funktional äquivalent, aber vollständig umgeschriebene Version der Python NumPy-Bibliothek.
JAX eignet sich besonders zur Beschleunigung vieler ML-Aufgaben, indem die Modelle und Daten in eine Form umgewandelt werden, die für Parallelität zwischen GPU- und TPU TPU geeignet ist.
Flax, Optax, Pax und viele weitere Bibliotheken basieren auf der JAX-Infrastruktur.
K
Keras
Eine beliebte Python API für maschinelles Lernen. Keras wird in mehreren Deep-Learning-Frameworks ausgeführt, einschließlich TensorFlow, wo es als tf.keras zur Verfügung gestellt wird.
Kernel Support Vector Machines (KSVMs)
Ein Klassifizierungsalgorithmus, der versucht, den Abstand zwischen positiven und negativen Klassen zu maximieren, indem Eingabedatenvektoren einem höherdimensionalen Raum zugeordnet werden. Betrachten Sie beispielsweise ein Klassifizierungsproblem, bei dem das Eingabe-Dataset 100 Features hat. Um die Marge zwischen positiven und negativen Klassen zu maximieren, könnte eine KSVM diese Merkmale intern einem Bereich mit einer Million Dimensionen zuordnen. KSVMs verwenden eine Verlustfunktion namens Scharnierverlust.
Keypoints
Die Koordinaten bestimmter Elemente in einem Bild. Bei einem Bilderkennungsmodell, das Blumenarten unterscheidet, können beispielsweise Schlüsselpunkte der Mittelpunkt der einzelnen Blütenblätter, der Stamm, der Stapel usw. sein.
k-Fold-Kreuzvalidierung
Algorithmus zur Vorhersage der Fähigkeit eines Modells, neue Daten zu verallgemeinern. Das k im k-Falz bezieht sich auf die Anzahl der gleichen Gruppen, in die Sie die Beispiele eines Datasets unterteilen, d. h., Sie trainieren und testen Ihr Modell k-mal. Für jede Trainings- und Testrunde wird eine andere Gruppe als Test-Dataset verwendet und alle verbleibenden Gruppen werden zum Trainings-Dataset. Nach k Trainings- und Testrunden berechnen Sie den Mittelwert und die Standardabweichung der ausgewählten Testmesswerte.
Angenommen, Ihr Dataset besteht aus 120 Beispielen. Nehmen wir weiter an, Sie möchten k auf 4 setzen. Daher teilen Sie das Dataset nach dem Zufallsmix der Beispiele in vier gleiche Gruppen mit je 30 Beispielen auf und führen vier Trainings-/Testrunden durch:
Zum Beispiel ist der Messwert Mittlere quadratische Abweichung (MSE) möglicherweise der aussagekräftigste Messwert für ein lineares Regressionsmodell. Daher würden Sie den Mittelwert und die Standardabweichung der MSE über alle vier Runden ermitteln.
K-Means
Ein beliebter Clustering-Algorithmus, der Beispiele für unüberwachtes Lernen gruppiert. Der k-Means-Algorithmus funktioniert im Grunde:
- Bestimmt iterativ die besten k Mittelpunkte (sogenannte Schwerpunkte).
- Weist jedes Beispiel dem nächstgelegenen Schwerpunkt zu. Die Beispiele, die dem gleichen Schwerpunkt am nächsten liegen, gehören zur selben Gruppe.
Der k-Means-Algorithmus wählt Schwerpunktpositionen aus, um die kumulative Quadratzahl der Entfernungen zwischen den Beispielen und dem nächstgelegenen Schwerpunkt zu minimieren.
Betrachten Sie zum Beispiel das folgende Diagramm, das die Größe von Hunden zu der Hundebreite zeigt:

Wenn k=3 ist, bestimmt der k-Means-Algorithmus drei Schwerpunkte. Jedes Beispiel wird dem nächstgelegenen Schwerpunkt zugewiesen, sodass drei Gruppen entstehen:

Stellen Sie sich vor, ein Hersteller möchte die idealen Größen für kleine, mittlere und große Pullover für Hunde ermitteln. Die drei Schwerpunkte identifizieren die mittlere Höhe und Breite der einzelnen Hunde im Cluster. Der Hersteller sollte also die Sweatergrößen auf diesen drei Schwerpunkten basieren. Beachten Sie, dass der Schwerpunkt eines Clusters normalerweise kein Beispiel im Cluster ist.
Die vorherigen Abbildungen zeigen k-Means für Beispiele mit nur zwei Merkmalen (Höhe und Breite). Mit k-Means können Sie Beispiele für viele Funktionen gruppieren.
k-Medianwert
Clustering-Algorithmus, der eng mit k-Means verwandt ist. Der praktische Unterschied zwischen den beiden ist folgende:
- Bei k-Means werden Schwerpunkte durch Minimierung der Summe der Quadrate der Entfernung zwischen einem Schwerpunktkandidat und jedem seiner Beispiele bestimmt.
- Im k-Median werden Schwerpunkte bestimmt, indem die Summe der Entfernung zwischen einem Schwerpunktkandidat und jedem seiner Beispiele minimiert wird.
Beachten Sie, dass die Definitionen für Entfernungen ebenfalls unterschiedlich sind:
- k-means basiert auf der euklidischen Entfernung vom Schwerpunkt zu einem Beispiel. (In zwei Dimensionen bedeutet der euklidische Abstand, die Hypotenuse mit dem Satz des Pythagoras zu berechnen.) Die k-means-Entfernung zwischen (2,2) und (5,-2) würde beispielsweise so aussehen:
- Der k-Medianwert basiert auf der Manhattan-Distanz vom Schwerpunkt zu einem Beispiel. Die Entfernung ist die Summe der absoluten Deltas in jeder Dimension. Der k-Medianwert zwischen (2,2) und (5,-2) würde beispielsweise so aussehen:
L
L0-Regularisierung
Eine Art der Regularisierung, die die Gesamtzahl der Gewichtungen ungleich null in einem Modell bestraft. Beispiel: Ein Modell mit 11 Gewichtungen ungleich null wird stärker bestraft als ein ähnliches Modell mit zehn Gewichtungen ungleich null.
Die L0-Regularisierung wird manchmal als L0-Norm-Regularisierung bezeichnet.
L1-Verlust
Eine Verlustfunktion, die den absoluten Wert der Differenz zwischen tatsächlichen label-Werten und den von einem Modell vorhergesagten Werten berechnet. Hier sehen Sie beispielsweise die Berechnung des L1-Verlusts für einen Batch mit fünf Beispielen:
| Tatsächlicher Wert des Beispiels | Vorhersagewert des Modells | Absoluter Wert der Differenz |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = Verlust von L1 | ||
Der L1-Verlust ist weniger empfindlich auf Ausreißer als L2-Verlust.
Der mittlere absolute Fehler ist der durchschnittliche L1-Verlust pro Beispiel.
L1-Regularisierung
Art der Regularisierung, bei der Gewichtungen proportional zur Summe des absoluten Werts der Gewichtungen bestraft werden. Mit der L1-Regularisierung kann die Gewichtung irrelevanter oder kaum relevanter Features auf genau 0 gesenkt werden. Ein Feature mit der Gewichtung 0 wird effektiv aus dem Modell entfernt.
Stellen Sie einen Kontrast mit der L2-Regularisierung her.
L2-Verlust
Eine Verlustfunktion, die das Quadrat der Differenz zwischen tatsächlichen label-Werten und den von einem Modell vorhergesagten Werten berechnet. Hier sehen Sie beispielsweise die Berechnung des L2-Verlusts für einen Batch aus fünf Beispielen:
| Tatsächlicher Wert des Beispiels | Vorhersagewert des Modells | Quadrat des Deltas |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2-Verlust | ||
Durch die Quadratformatierung verstärkt der L2-Verlust den Einfluss von Ausreißern. Das heißt, der L2-Verlust reagiert stärker auf schlechte Vorhersagen als der L1-Verlust. Der L1-Verlust für den vorherigen Batch wäre beispielsweise 8 statt 16. Beachten Sie, dass ein einzelner Ausreißer 9 von 16 Ausreißer darstellt.
Regressionsmodelle verwenden in der Regel den L2-Verlust als Verlustfunktion.
Der mittlere quadratische Fehler ist der durchschnittliche L2-Verlust pro Beispiel. Quadratischer Verlust ist eine andere Bezeichnung für L2-Verlust.
L2-Regularisierung
Art der Regularisierung, bei der Gewichtungen proportional zur Summe der Quadrate der Gewichtungen bestraft werden. Die L2-Regularisierung hilft dabei, Ausreißer-Gewichtungen (mit hohen positiven oder niedrigen negativen Werten) näher an 0, aber nicht ganz an 0 zu bewegen. Features mit Werten, die sehr nahe bei 0 liegen, verbleiben im Modell, haben aber keinen großen Einfluss auf die Vorhersage des Modells.
Die L2-Regularisierung verbessert immer die Generalisierung in linearen Modellen.
Stellen Sie einen Kontrast mit der L1-Regularisierung her.
Label
Beim überwachten maschinellen Lernen der „Antwort“- oder „Ergebnis“-Teil eines Beispiels.
Jedes Beispiel mit Label besteht aus einem oder mehreren Features und einem Label. In einem Dataset zur Spamerkennung würde das Label beispielsweise entweder „Spam“ oder „Kein Spam“ lauten. In einem Niederschlags-Dataset kann das Label die Regenmenge sein, die in einem bestimmten Zeitraum fiel.
Beispiel für ein Label
Ein Beispiel, das ein oder mehrere Features und ein Label enthält. Die folgende Tabelle enthält beispielsweise drei Beispiele mit Labels aus einem Hausbewertungsmodell mit jeweils drei Merkmalen und einem Label:
| Anzahl der Schlafzimmer | Anzahl der Badezimmer | Hausalter | Hauspreis (Label) |
|---|---|---|---|
| 3 | 2 | 15 | 345.000 $ |
| 2 | 1 | 72 | 179.000 $ |
| 4 | 2 | 34 | 392.000 $ |
Beim überwachten maschinellen Lernen werden Modelle anhand von Beispielen mit Labels trainiert und Vorhersagen für Beispiele ohne Label treffen.
Beispiel mit einem Label ohne Label und Beispiel ohne Label.
Labelleck
Modelldesignfehler, bei dem ein Feature ein Stellvertreter für das Label ist. Stellen Sie sich beispielsweise ein binäres Klassifizierungsmodell vor, das vorhersagt, ob ein potenzieller Kunde ein bestimmtes Produkt kaufen wird oder nicht.
Angenommen, eines der Merkmale für das Modell ist ein boolescher Wert mit dem Namen SpokeToCustomerAgent. Nehmen wir außerdem an, dass ein Kunden-Agent erst zugewiesen wird, nachdem der potenzielle Kunde das Produkt tatsächlich gekauft hat. Während des Trainings lernt das Modell schnell die Verknüpfung zwischen SpokeToCustomerAgent und dem Label.
Lambda
Synonym für Regularisierungsrate.
Lambda ist ein überladener Begriff. Hier liegt der Fokus auf der Definition des Begriffs innerhalb der Regularisierung.
LaMDA (Language Model for Dialogue Applications)
Ein von Google entwickeltes Large Language Model auf der Grundlage von Transformer, das mit einem großen Dialog-Dataset trainiert wurde, das realistische dialogorientierte Antworten generieren kann.
LaMDA: Unsere bahnbrechende Unterhaltungstechnologie bietet einen Überblick.
landmarks
Synonym für Schlüsselpunkte.
Language Model
Ein model, das die Wahrscheinlichkeit schätzt, mit der ein model oder eine Folge von Tokens in einer längeren Folge von Tokens auftritt.
Large Language Model
Ein informeller Begriff ohne strikte Definition, der in der Regel ein Sprachmodell mit einer hohen Anzahl von Parametern bezeichnet. Einige Large Language Models enthalten über 100 Milliarden Parameter.
latenter Bereich
Synonym für Raum einbetten.
Layer
Eine Reihe von Neuronen in einem neuronalen Netz. Es gibt drei gängige Ebenentypen:
- Die Eingabeebene, die Werte für alle Features bereitstellt.
- Eine oder mehrere ausgeblendete Ebenen, die nicht lineare Beziehungen zwischen den Elementen und dem Label finden.
- Die Ausgabeschicht, die die Vorhersage bereitstellt.
Die folgende Abbildung zeigt beispielsweise ein neuronales Netzwerk mit einer Eingabeschicht, zwei verborgenen Ebenen und einer Ausgabeschicht:
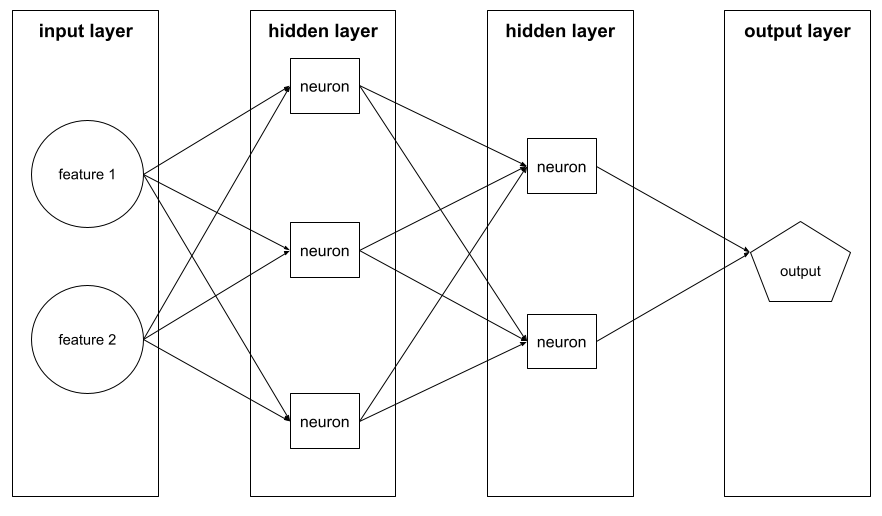
In TensorFlow sind Ebenen auch Python-Funktionen, die Tensoren und Konfigurationsoptionen als Eingabe nehmen und andere Tensoren als Ausgabe erzeugen.
Layers API (tf.layers)
Eine TensorFlow API zum Erstellen eines neuronalen tiefen neuronalen Netzwerks als Kombination von Ebenen. Mit der Layers API können Sie verschiedene Arten von Ebenen erstellen, z. B.:
tf.layers.Densefür eine vollständig verbundene Ebenetf.layers.Conv2Dfür eine Convolutional Layer.
Die Layers API folgt den Layers API-Konventionen von Keras. Abgesehen von einem anderen Präfix haben alle Funktionen in der Layers API dieselben Namen und Signaturen wie ihre Gegenstücke in der Keras Layers API.
Blatt
Beliebiger Endpunkt in einem Entscheidungsbaum Im Gegensatz zu einer Bedingung führt ein Blatt keinen Test durch. Vielmehr ist ein Blatt eine mögliche Vorhersage. Ein Blatt ist auch der Terminalknoten eines Inferenzpfads.
Der folgende Entscheidungsbaum enthält beispielsweise drei Blätter:
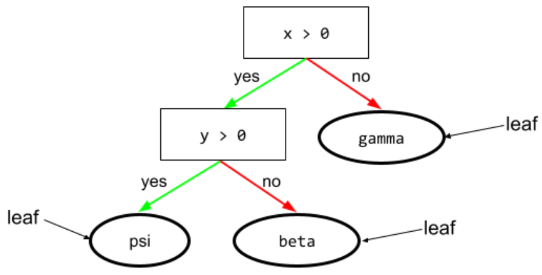
Lern-Interpretierbarkeits-Tool (LIT)
Ein visuelles, interaktives Tool zum Verstehen von Modellen und zur Datenvisualisierung.
Sie können Open-Source-LIT verwenden, um Modelle zu interpretieren oder um Text-, Bild- und Tabellendaten zu visualisieren.
Lernrate
Eine Gleitkommazahl, die dem Algorithmus für den Gradientenabstieg angibt, wie stark die Gewichtung und Verzerrungen bei jeder Iteration angepasst werden sollen. Bei einer Lernrate von 0,3 werden Gewichtungen und Verzerrungen beispielsweise dreimal stärker angepasst als bei einer Lernrate von 0,1.
Die Lernrate ist ein wichtiger Hyperparameter. Wenn Sie die Lernrate zu niedrig einstellen, dauert das Training zu lange. Wenn Sie die Lernrate zu hoch ansetzen, hat der Gradientenabstieg oft Schwierigkeiten, die Konvergenz zu erreichen.
Regression der kleinsten Quadrate
Ein lineares Regressionsmodell, das durch Minimieren von L2-Verlust trainiert wurde.
Linear
Beziehung zwischen zwei oder mehr Variablen, die ausschließlich durch Addition und Multiplikation dargestellt werden kann.
In der Darstellung einer linearen Beziehung wird eine Linie dargestellt.
Stellen Sie einen Kontrast mit nicht linear her.
lineares Modell
Ein model, das eine model pro model zuweist, um model zu treffen. Lineare Modelle beinhalten auch eine Verzerrung. Im Gegensatz dazu ist das Verhältnis von Merkmalen zu Vorhersagen in tiefen Modellen in der Regel nicht linear.
Lineare Modelle sind in der Regel einfacher zu trainieren und interpretierbar als tiefe Modelle. Tiefe Modelle können jedoch komplexe Beziehungen zwischen Merkmalen erlernen.
Die lineare Regression und die logistische Regression sind zwei Arten von linearen Modellen.
lineare Regression
Ein Modell für maschinelles Lernen, bei dem die beiden folgenden Bedingungen zutreffen:
- Das Modell ist ein lineares Modell.
- Die Vorhersage ist ein Gleitkommawert. (Dies ist der Regressionsteil der linearen Regression.)
Stellen Sie der linearen Regression einen Vergleich mit der logistischen Regression gegenüber. Stellen Sie der Regression außerdem einen Unterschied zur Klassifizierung.
LIT
Abkürzung für Learning Interpretability Tool (LIT), das zuvor als Language Interpretability Tool bekannt war.
LLM
Abkürzung für Large Language Model.
logistische Regression
Art von Regressionsmodell, das eine Wahrscheinlichkeit vorhersagt. Logistische Regressionsmodelle haben die folgenden Merkmale:
- Das Label ist kategorial. Der Begriff logistische Regression bezieht sich in der Regel auf binäre logistische Regression, d. h. auf ein Modell, das Wahrscheinlichkeiten für Labels mit zwei möglichen Werten berechnet. Mit einer weniger gängigen Variante, der multinomialen logistischen Regression, werden Wahrscheinlichkeiten für Labels mit mehr als zwei möglichen Werten berechnet.
- Die Verlustfunktion während des Trainings ist Logverlust. Mehrere Logverlusteinheiten können für Labels mit mehr als zwei möglichen Werten parallel platziert werden.
- Das Modell hat eine lineare Architektur, kein neuronales Deep-Learning-Netzwerk. Der Rest dieser Definition gilt jedoch auch für tiefe Modelle, die Wahrscheinlichkeiten für kategoriale Labels vorhersagen.
Nehmen wir als Beispiel ein logistisches Regressionsmodell, das die Wahrscheinlichkeit berechnet, dass eine eingegebene E-Mail Spam oder kein Spam ist. Angenommen, das Modell sagt während der Inferenz 0,72 voraus. Daher schätzt das Modell:
- Eine 72-prozentige Wahrscheinlichkeit, dass die E-Mail Spam ist.
- Eine 28-prozentige Wahrscheinlichkeit, dass die E-Mail kein Spam ist.
Ein logistisches Regressionsmodell verwendet die folgende zweistufige Architektur:
- Das Modell generiert eine Rohvorhersage (y') durch Anwenden einer linearen Funktion von Eingabemerkmalen.
- Das Modell verwendet diese Rohvorhersage als Eingabe in eine Sigmoidfunktion, die die Rohvorhersage in einen Wert zwischen 0 und 1 (ausschließlich) umwandelt.
Wie jedes Regressionsmodell sagt auch ein logistisches Regressionsmodell eine Zahl voraus. Diese Zahl wird jedoch in der Regel so Teil eines binären Klassifizierungsmodells:
- Wenn die vorhergesagte Zahl größer ist als der Klassifizierungsschwellenwert, sagt das binäre Klassifizierungsmodell die positive Klasse vorher.
- Wenn die vorhergesagte Zahl kleiner als der Klassifizierungsschwellenwert ist, sagt das binäre Klassifizierungsmodell die negative Klasse vorher.
Logits
Der Vektor von Rohvorhersagen (nicht normalisiert), die ein Klassifizierungsmodell generiert und die normalerweise an eine Normalisierungsfunktion übergeben wird. Wenn das Modell ein Klassifizierungsproblem mit mehreren Klassen löst, werden Logits in der Regel zu einer Eingabe für die Funktion Softmax. Die Softmax-Funktion generiert dann einen Vektor von (normalisierten) Wahrscheinlichkeiten mit einem Wert für jede mögliche Klasse.
Logarithmischer Verlust
Die Verlustfunktion, die in der binären logistischen Regression verwendet wird.
Log-Wahrscheinlichkeiten
Logarithmus der Chancen eines Ereignisses
Long-Term Memory (LSTM)
Ein Zellentyp in einem recurrent neuronalen Netzwerk, der zur Verarbeitung von Datensequenzen in Anwendungen wie Handschrifterkennung, maschinelle Übersetzung und Bilduntertitelung verwendet wird. LSTMs befassen sich mit dem Verschwinden des Gradientenproblems, das beim Trainieren von RNNs aufgrund langer Datensequenzen auftritt. Dazu wird der Verlauf in einem internen Speicherzustand basierend auf neuer Eingabe und Kontext von vorherigen Zellen im RNN beibehalten.
LoRA
Abkürzung für Anpassungsfähigkeit bei niedrigem Rang
Niederlage
Während des Trainings eines überwachten Modells wird gemessen, wie weit die Vorhersage eines Modells von seinem Label entfernt ist.
Eine Verlustfunktion berechnet den Verlust.
Verlustdienstleister
Art von Algorithmus für maschinelles Lernen, der die Leistung eines Modells verbessert, indem die Vorhersagen mehrerer Modelle kombiniert und anhand dieser Vorhersagen eine einzige Vorhersage getroffen werden. Dadurch kann ein Verlustaggregator die Varianz der Vorhersagen reduzieren und die Genauigkeit der Vorhersagen verbessern.
Verlustkurve
Ein Diagramm des Verlusts als Funktion der Anzahl der Trainingsdurchläufe. Das folgende Diagramm zeigt eine typische Verlustkurve:
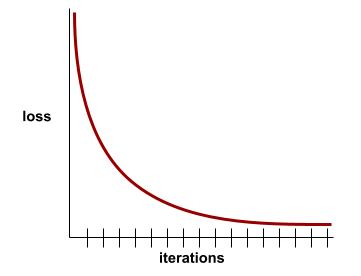
Verlustkurven können Ihnen dabei helfen zu bestimmen, wann Ihr Modell konvergent oder Überanpassung ist.
Verlustkurven können die folgenden Verlusttypen darstellen:
Siehe auch Generalisierungskurve.
Verlustfunktion
Während des Trainings oder des Tests eine mathematische Funktion, die den Verlust für einen Batch von Beispielen berechnet. Eine Verlustfunktion gibt einen geringeren Verlust für Modelle zurück, die gute Vorhersagen machen, als für Modelle, die schlechte Vorhersagen treffen.
Das Ziel des Trainings besteht in der Regel darin, den Verlust zu minimieren, den eine Verlustfunktion zurückgibt.
Es gibt viele verschiedene Arten von Verlustfunktionen. Wählen Sie die entsprechende Verlustfunktion für die Art des Modells aus, das Sie erstellen. Beispiel:
- L2-Verlust (oder mittlerer quadratischer Fehler) ist die Verlustfunktion bei der linearen Regression.
- Logverlust ist die Verlustfunktion für die logistische Regression.
Verlustoberfläche
Ein Diagramm von Gewicht(en) im Vergleich zu Verlust. Ziel des Gradientenabstiegs ist es, das Gewicht bzw. die Gewichte zu ermitteln, für die die Verlustoberfläche ein lokales Minimum ist.
Anpassungsfähigkeit bei niedrigem Rang (LoRA)
Ein Algorithmus zum effizienten Abstimmen von Parametern, mit dem nur eine Teilmenge der Parameter eines Large Language Model verfeinert wird. LoRA bietet folgende Vorteile:
- Sie erfolgt schneller als Verfahren, bei denen alle Parameter eines Modells abgestimmt werden müssen.
- Reduziert die Rechenkosten für die Inferenz im abgestimmten Modell.
Bei einem mit LoRA abgestimmten Modell wird die Qualität der Vorhersagen beibehalten oder verbessert.
LoRA ermöglicht mehrere spezialisierte Versionen eines Modells.
LSTM
Abkürzung für Long-Short-Term Memory
M
Machine Learning
Ein Programm oder System, das ein Modell anhand von Eingabedaten trainiert. Das trainierte Modell kann nützliche Vorhersagen aus neuen (noch nie gesehenen) Daten treffen, die aus der gleichen Verteilung stammen, die auch zum Trainieren des Modells verwendet wird.
Maschinelles Lernen bezieht sich auch auf die Studienbereiche dieser Programme oder Systeme.
Mehrheitsklasse
Gängigeres Label in einem Dataset mit unausgeglichener Klasse. Bei einem Dataset, das beispielsweise 99% negative Labels und 1% positive Labels enthält, sind die negativen Labels die Mehrheitsklasse.
Stellen Sie einen Kontrast zur Minderheitsklasse her.
Markov-Entscheidungsprozess (MDP)
Diagramm, das das Entscheidungsmodell darstellt, bei dem Entscheidungen (oder Aktionen) zum Navigieren durch eine Folge von Bundesstaaten unter der Annahme der Markov-Property getroffen werden. Beim Bestärkendes Lernen geben diese Übergänge zwischen Stadien eine numerische Prämie zurück.
Markov-Property
Eigenschaft bestimmter Umgebungen, bei denen Statusübergänge vollständig durch die Informationen im aktuellen Status und die Aktion des Agents bestimmt werden.
Masked Language Model
Ein Sprachmodell, das die Wahrscheinlichkeit vorhersagt, dass Kandidatentoken Lücken in einer Sequenz füllen. Ein maskiertes Language Model kann beispielsweise die Wahrscheinlichkeit berechnen, dass potenzielle Worte die Unterstreichung im folgenden Satz ersetzen:
Das ____ mit dem Hut ist zurück.
In der Literatur wird in der Regel die Zeichenfolge „MASK“ statt unterstrichen verwendet. Beispiel:
Die MASK im Hut ist wieder da.
Die meisten modernen maskierten Sprachmodelle sind bidirektional.
matplotlib
Eine Open-Source-Bibliothek für Python 2D-Darstellung. Mit matplotlib können Sie verschiedene Aspekte des maschinellen Lernens visualisieren.
Matrixfaktorisierung
In der Mathematik ein Mechanismus zum Auffinden der Matrix, deren Punktprodukt sich einer Zielmatrix annähert.
In Empfehlungssystemen enthält die Zielmatrix häufig die Bewertungen der Nutzer für Artikel. Die Zielmatrix für ein Filmempfehlungssystem könnte beispielsweise so aussehen, wobei die positiven Ganzzahlen Nutzerbewertungen sind und 0 bedeutet, dass der Nutzer den Film nicht bewertet hat:
| Casablanca | Philadelphia Story | Black Panther | Wonder Woman | Pulp Fiction | |
|---|---|---|---|---|---|
| Nutzer 1 | 5 | 3 | 0.0 | 2 | 0.0 |
| Nutzer 2 | 4.0 | 0.0 | 0.0 | 1 | 5 |
| Nutzer 3 | 3 | 1 | 4.0 | 5,0 | 0.0 |
Das Filmempfehlungssystem versucht, Nutzerbewertungen für Filme ohne Altersfreigabe vorherzusagen. Gefällt Nutzer 1 beispielsweise Black Panther?
Ein Ansatz für Empfehlungssysteme besteht darin, mit der Matrixfaktorisierung die folgenden beiden Matrizen zu generieren:
- Eine Nutzermatrix in Form der Anzahl der Nutzer × der Anzahl der Einbettungsdimensionen
- Eine Artikelmatrix in Form der Anzahl der Einbettungsdimensionen × der Anzahl der Elemente
Wenn Sie beispielsweise die Matrixfaktorisierung bei unseren drei Nutzern und fünf Elementen verwenden, könnten Sie die folgende Nutzer- und Artikelmatrix erhalten:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
Das Skalarprodukt der Nutzer- und Artikelmatrix ergibt eine Empfehlungsmatrix, die nicht nur die ursprünglichen Nutzerbewertungen enthält, sondern auch Vorhersagen für die Filme, die jeder Nutzer noch nicht gesehen hat. Nehmen wir zum Beispiel die Bewertung Casablanca von Nutzer 1 mit 5,0. Das Skalarprodukt, das dieser Zelle in der Empfehlungsmatrix entspricht, sollte hoffentlich bei etwa 5,0 liegen.Diese lautet:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9
Und was noch wichtiger ist: Gefällt Nutzer 1 Black Panther? Wenn das Skalarprodukt der ersten Zeile und der dritten Spalte entspricht, ergibt sich eine vorhergesagte Bewertung von 4,3:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3
Die Matrixfaktorisierung liefert in der Regel eine Nutzermatrix und eine Artikelmatrix, die zusammen deutlich kompakter als die Zielmatrix sind.
Mittlerer absoluter Fehler (MAE)
Der durchschnittliche Verlust pro Beispiel, wenn der L1-Verlust verwendet wird. Berechnen Sie den mittleren absoluten Fehler so:
- Berechnen Sie den L1-Verlust für einen Batch.
- Dividiere den Verlust L1 durch die Anzahl der Beispiele im Batch.
Betrachten wir zum Beispiel die Berechnung des L1-Verlusts in dem folgenden Batch mit fünf Beispielen:
| Tatsächlicher Wert des Beispiels | Vorhersagewert des Modells | Verlust (Differenz zwischen tatsächlich und vorhergesagtem Wert) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = Verlust von L1 | ||
Der Verlust von L1 beträgt also 8 und die Anzahl der Beispiele beträgt 5. Daher beträgt der mittlere absolute Fehler:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
„Kontrast Mean Absolute Error“ mit mittlerem quadratischem Fehler und Root Mean Squared Error.
Mittlere quadratische Abweichung (MSE)
Der durchschnittliche Verlust pro Beispiel, wenn L2-Verlust verwendet wird. Berechnen Sie den mittleren quadratischen Fehler so:
- Berechnen Sie den L2-Verlust für einen Batch.
- Dividiere den Verlust L2 durch die Anzahl der Beispiele im Batch.
Betrachten Sie zum Beispiel den Verlust in den folgenden fünf Beispielen:
| Tatsächlicher Wert | Vorhersage des Modells | Verlust | Quadratischer Verlust |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2-Verlust | |||
Der mittlere quadratische Fehler ist daher:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
Mittlere quadratische Abweichung ist eine beliebte Trainingsoptimierung, insbesondere für die lineare Regression.
„Kontrast Mean Squared Error“ mit mittlerem absolutem Fehler und Root Mean Squared Error aus.
TensorFlow Playground verwendet den mittleren quadratischen Fehler zur Berechnung von Verlustwerten.
Mesh-Netzwerk
In der parallelen ML-Programmierung ein Begriff, der mit der Zuweisung der Daten und des Modells zu TPU-Chips und der Definition dessen, wie diese Werte fragmentiert oder repliziert werden, in Verbindung steht.
„Mesh“ ist ein überlasteter Begriff, der Folgendes bedeuten kann:
- Ein physisches Layout von TPU-Chips.
- Ein abstraktes logisches Konstrukt zum Zuordnen der Daten und des Modells zu den TPU-Chips.
In beiden Fällen wird ein Mesh-Netzwerk als Form angegeben.
Meta-Learning
Ein Teilbereich des maschinellen Lernens, mit dem ein Lernalgorithmus erkannt oder verbessert wird. Ein Meta-Lernsystem kann auch darauf abzielen, ein Modell so zu trainieren, dass es schnell eine neue Aufgabe aus einer kleinen Datenmenge oder aus Erfahrungen aus früheren Aufgaben lernt. Meta-Learning-Algorithmen versuchen im Allgemeinen, Folgendes zu erreichen:
- Verbessern oder erlernen Sie manuell entwickelte Funktionen (z. B. einen Initialisierer oder einen Optimierer).
- Daten- und recheneffizienter sein
- Verbessern Sie die Generalisierung.
Meta-Learning ist mit wenigen Lerneinheiten verbunden.
Messwert
Eine Statistik, die dich interessiert.
Ein Ziel ist ein Messwert, den ein System für maschinelles Lernen zu optimieren versucht.
Metrics API (tf.metrics)
Eine TensorFlow API zum Bewerten von Modellen. Beispielsweise bestimmt tf.metrics.accuracy, wie oft die Vorhersagen eines Modells mit Labels übereinstimmen.
Minibatch
Eine kleine, zufällig ausgewählte Teilmenge eines Batches, das in einer Iteration verarbeitet wird. Die Batchgröße eines Mini-Batch liegt in der Regel zwischen 10 und 1.000 Beispielen.
Angenommen, der gesamte Trainingssatz (der vollständige Batch) besteht aus 1.000 Beispielen. Angenommen, Sie legen die Batchgröße jedes Minibatches auf 20 fest. Daher bestimmt jede Iteration den Verlust an zufälligen 20 der 1.000 Beispiele und passt dann die Gewichtungen und Verzerrungen entsprechend an.
Es ist viel effizienter, den Verlust eines Mini-Batch zu berechnen, als der Verlust bei allen Beispielen im vollständigen Batch.
stochastisches Gradientenabstieg im Mini-Batch
Ein Algorithmus für den Gradientenabstieg, der Minibatches verwendet. Mit anderen Worten, der stochastische Gradientenabstieg im Mini-Batches schätzt den Gradienten anhand einer kleinen Teilmenge der Trainingsdaten. Beim regulären stochastischen Gradientenabstieg wird ein Minibatch der Größe 1 verwendet.
Minimax-Verlust
Eine Verlustfunktion für generative kontradiktorische Netzwerke, basierend auf der Kreuzentropie zwischen der Verteilung generierter und echter Daten.
Der minimale Verlust wird im ersten Artikel zur Beschreibung von generativen kontradiktorischen Netzwerken verwendet.
Minderheitenklasse
Das weniger verbreitete Label in einem Dataset mit unausgeglichener Klasse. Wenn beispielsweise ein Dataset zu 99% negative Labels und zu 1% positive Labels enthält, sind die positiven Labels die Minderheitenklasse.
Im Kontrast zur Mehrheitsklasse
ML
Abkürzung für Machine Learning.
MNIST
Ein von LeCun, Cortes und Burges zusammengestelltes öffentliches Dataset mit 60.000 Bildern, auf denen jeweils zu sehen ist, wie ein Mensch eine bestimmte Ziffer von 0 bis 9 manuell geschrieben hat. Jedes Bild wird als 28 × 28-Array aus Ganzzahlen gespeichert, wobei jede Ganzzahl ein Graustufenwert zwischen 0 und 255 ist.
MNIST ist ein kanonisches Dataset für maschinelles Lernen, das häufig zum Testen neuer Ansätze für maschinelles Lernen verwendet wird. Weitere Informationen finden Sie in der MNIST-Datenbank für handschriftliche Ziffern.
Modalität
Eine allgemeine Datenkategorie. Zahlen, Text, Bilder, Video und Audio sind beispielsweise fünf verschiedene Modalitäten.
model
Im Allgemeinen jedes mathematische Konstrukt, das Eingabedaten verarbeitet und eine Ausgabe zurückgibt. Anders ausgedrückt: Ein Modell ist der Satz von Parametern und der Struktur, die ein System benötigt, um Vorhersagen zu treffen. Beim überwachten maschinellen Lernen nimmt ein Modell ein Beispiel als Eingabe und leitet eine Vorhersage als Ausgabe ab. Beim überwachten maschinellen Lernen unterscheiden sich die Modelle etwas. Beispiel:
- Ein lineares Regressionsmodell besteht aus einer Reihe von Gewichtungen und einer Verzerrung.
- Ein neuronales Netzwerkmodell besteht aus:
- Eine Reihe von ausgeblendeten Ebenen, die jeweils ein oder mehrere Neuronen enthalten.
- Gewichtungen und Verzerrungen, die mit jedem Neuron verbunden sind.
- Ein Entscheidungsbaum-Modell besteht aus:
- Die Form des Baums, d. h. das Muster, in dem die Bedingungen und Blätter miteinander verbunden sind.
- Die Bedingungen und Blätter.
Sie können ein Modell speichern, wiederherstellen oder kopieren.
Auch durch unüberwachtes maschinelles Lernen werden Modelle generiert. Dies ist in der Regel eine Funktion, mit der ein Eingabebeispiel dem am besten geeigneten Cluster zugeordnet werden kann.
Modellkapazität
Die Komplexität der Probleme, die ein Modell lernen kann. Je komplexer die Probleme, die ein Modell lernen kann, desto höher ist seine Kapazität. Die Kapazität eines Modells erhöht sich in der Regel mit der Anzahl der Modellparameter. Die formale Definition der Klassifikatorkapazität finden Sie unter VC-Dimension.
Modellkaskaden
Ein System, das das ideale model für eine bestimmte Inferenzabfrage auswählt.
Stellen Sie sich eine Gruppe von Modellen vor, die von sehr groß (viele Parameter) bis viel kleiner (viel weniger Parameter) reichen. Sehr große Modelle verbrauchen bei der Inferenz mehr Rechenressourcen als kleinere Modelle. Allerdings können aus sehr großen Modellen in der Regel komplexere Anfragen abgeleitet werden als aus kleineren Modellen. Die Modellkaskadierung bestimmt die Komplexität der Inferenzabfrage und wählt dann das geeignete Modell zum Ausführen der Inferenz aus. Die Hauptmotivation für die Modellkaskadierung besteht in der Reduzierung der Inferenzkosten. Dazu werden in der Regel kleinere Modelle und nur ein größeres Modell für komplexere Abfragen ausgewählt.
Stellen Sie sich vor, ein kleines Modell wird auf einem Smartphone und eine größere Version dieses Modells auf einem Remoteserver ausgeführt. Eine gute Modellkaskadierung reduziert Kosten und Latenz, indem das kleinere Modell für die Verarbeitung einfacher Anfragen aktiviert und das Remote-Modell nur zur Verarbeitung komplexer Anfragen aufgerufen wird.
Siehe auch Modellrouter.
Modellparallelität
Eine Methode zum Skalieren von Training oder Inferenz, bei der verschiedene Teile eines model auf verschiedenen model angewendet werden. Die Modellparallelität ermöglicht Modelle, die zu groß für ein einzelnes Gerät sind.
Zur Implementierung der Modellparallelität geht ein System in der Regel so vor:
- Das Modell wird in kleinere Teile zerlegt.
- Verteilt das Training dieser kleineren Teile auf mehrere Prozessoren. Jeder Prozessor trainiert seinen eigenen Teil des Modells.
- Die Ergebnisse werden kombiniert, um ein einzelnes Modell zu erstellen.
Modellparallelität verlangsamt das Training.
Siehe auch Datenparallelität.
Modellrouter
Der Algorithmus, der das ideale model für die model bei der model bestimmt. Ein Modellrouter ist in der Regel ein Modell für maschinelles Lernen, das nach und nach lernt, das beste Modell für eine bestimmte Eingabe auszuwählen. Ein Modellrouter kann jedoch manchmal ein einfacherer Algorithmus ohne maschinelles Lernen sein.
Modelltraining
Der Prozess zur Bestimmung des besten model.
Erfolge
Ein ausgefeilter Algorithmus für Gradientenverfahren, bei dem ein Lernschritt nicht nur von der Ableitung im aktuellen Schritt, sondern auch von den Ableitungen der unmittelbar vorhergehenden Schritte abhängt. Im Moment wird ein exponentiell gewichteter gleitender Durchschnitt der Gradienten im Zeitverlauf berechnet, ähnlich dem Schwung in der Physik. Im Moment kann verhindert werden, dass das Lernen im lokalen Minimalwert stecken bleibt.
Klassifizierung mit mehreren Klassen
Beim überwachten Lernen ein Klassifizierungsproblem, bei dem das Dataset mehr als zwei Klassen mit Labels enthält. Die Labels im Iris-Dataset müssen beispielsweise eine der folgenden drei Klassen sein:
- Iris Setosa
- Iris Virginica
- Iris Versicolor
Ein mit dem Iris-Dataset trainiertes Modell, das den Iris-Typ in neuen Beispielen vorhersagt, führt eine Klassifizierung mit mehreren Klassen durch.
Im Gegensatz dazu sind Klassifizierungsprobleme, die zwischen genau zwei Klassen unterscheiden, binäre Klassifizierungsmodelle. Beispielsweise ist ein E-Mail-Modell, das entweder Spam oder Kein Spam vorhersagt, ein binäres Klassifizierungsmodell.
Bei Clustering-Problemen bezieht sich die Klassifizierung mit mehreren Klassen auf mehr als zwei Cluster.
logistische Regression mit mehreren Klassen
Verwendung der logistischen Regression bei Klassifizierungsproblemen mit mehreren Klassen.
Selbstaufmerksamkeit mit mehreren Kopfen
Eine Erweiterung der Selbstaufmerksamkeit, bei der der Selbstaufmerkungsmechanismus für jede Position in der Eingabesequenz mehrmals angewendet wird.
Transformers hat Mehrkopf-Selbstaufmerksamkeit eingeführt.
multimodales Modell
Ein Modell, dessen Ein- und/oder Ausgaben mehr als eine Modalität enthalten. Angenommen, ein Modell nimmt sowohl ein Bild als auch eine Bildunterschrift (zwei Modalitäten) als Features an und gibt eine Punktzahl aus, die angibt, wie angemessen die Bildunterschrift für das Bild ist. Die Eingaben dieses Modells sind multimodal und die Ausgabe unimodal.
multinomische Klassifizierung
Synonym für die Klassifizierung mit mehreren Klassen.
multinomische Regression
Synonym für die logistische Regression mit mehreren Klassen.
Multitasking
Verfahren für maschinelles Lernen, bei dem ein einzelnes model für die Ausführung mehrerer model trainiert wird.
Multitask-Modelle werden durch Training mit Daten erstellt, die für jede der verschiedenen Aufgaben geeignet sind. Auf diese Weise kann das Modell lernen, Informationen zwischen den Aufgaben zu teilen, wodurch das Modell effektiver lernen kann.
Ein für mehrere Aufgaben trainiertes Modell bietet häufig verbesserte Generalisierungsfähigkeiten und ist bei der Verarbeitung verschiedener Datentypen robuster.
N
NaN-Falle
Wenn eine Zahl im Modell während des Trainings zu einer NaN wird, werden letztendlich viele oder alle anderen Zahlen in Ihrem Modell zu einem NaN.
NaN ist eine Abkürzung für Not a Number.
Natural Language Understanding
Feststellen von Absichten eines Nutzers auf der Grundlage dessen, was er eingegeben oder gesagt hat. Beispielsweise nutzt eine Suchmaschine Natural Language Understanding, um anhand der eingegebenen oder Äußerungen des Nutzers zu ermitteln, wonach der Nutzer sucht.
auszuschließende Klasse
Bei der binären Klassifizierung wird eine Klasse als positiv und die andere als negativ bezeichnet. Die positive Klasse ist das Objekt oder Ereignis, auf das bzw. das das Modell testet, und die negative Klasse ist die andere Möglichkeit. Beispiel:
- Die negative Klasse bei einem medizinischen Test könnte „kein Tumor“ sein.
- Die negative Klasse in einem E-Mail-Klassifikator ist möglicherweise „kein Spam“.
Im Kontrast zur positiven Klasse stehen.
negative Stichprobe
Synonym für Stichproben von Kandidaten.
Neural Architecture Search (NAS)
Ein Verfahren zum automatischen Entwerfen der Architektur eines neuronalen Netzwerks. NAS-Algorithmen können den Zeit- und Ressourcenaufwand zum Trainieren eines neuronalen Netzwerks reduzieren.
NAS verwendet in der Regel Folgendes:
- Ein Suchbereich, der eine Reihe möglicher Architekturen darstellt.
- Eine Fitnessfunktion, mit der gemessen wird, wie gut eine bestimmte Architektur bei einer bestimmten Aufgabe funktioniert.
NAS-Algorithmen beginnen oft mit einer kleinen Gruppe möglicher Architekturen und erweitern den Suchbereich allmählich, während der Algorithmus lernt, welche Architekturen effektiv sind. Die Fitnessfunktion basiert in der Regel auf der Leistung der Architektur auf einem Trainings-Dataset und der Algorithmus wird in der Regel mit einer Technik des bestärkenden Lernens trainiert.
NAS-Algorithmen haben sich bei der Suche nach leistungsstarken Architekturen für eine Vielzahl von Aufgaben erwiesen, einschließlich Bildklassifizierung, Textklassifizierung und maschineller Übersetzung.
neuronales Netzwerk
Ein model, das mindestens eine model enthält. Ein neuronales Deep-Learning-Netzwerk ist eine Art von neuronalem Netzwerk mit mehr als einer versteckten Schicht. Das folgende Diagramm zeigt beispielsweise ein neuronales Deep-Learning-Netzwerk mit zwei verborgenen Schichten.
Jedes Neuron in einem neuronalen Netzwerk ist mit allen Knoten der nächsten Schicht verbunden. Im obigen Diagramm sehen Sie beispielsweise, dass jedes der drei Neuronen der ersten versteckten Schicht separat mit beiden Neuronen der zweiten versteckten Schicht verbunden ist.
Neuronale Netzwerke, die auf Computern implementiert sind, werden manchmal als künstliche neuronale Netzwerke bezeichnet, um sie von neuronalen Netzwerken in Gehirnen und anderen Nervensystemen zu unterscheiden.
Einige neuronale Netzwerke können extrem komplexe nicht lineare Beziehungen zwischen verschiedenen Merkmalen und dem Label imitieren.
Weitere Informationen finden Sie unter Convolutional Neural Network und Recurrent Neural Network.
Neuron
Beim maschinellen Lernen eine einzelne Einheit innerhalb einer verborgenen Schicht eines neuronalen Netzwerks. Jedes Neuron führt die folgende zweistufige Aktion aus:
- Berechnet die gewichtete Summe von Eingabewerten multipliziert mit ihren entsprechenden Gewichtungen.
- Übergibt die gewichtete Summe als Eingabe an eine Aktivierungsfunktion.
Ein Neuron auf der ersten verborgenen Ebene akzeptiert Eingaben von den Featurewerten der Eingabeschicht. Ein Neuron, das sich auf einer versteckten Schicht jenseits der ersten Schicht befindet, akzeptiert Eingaben von den Neuronen in der vorherigen verborgenen Schicht. Beispielsweise akzeptiert ein Neuron der zweiten verborgenen Schicht Eingaben von den Neuronen der ersten verborgenen Schicht.
In der folgenden Abbildung werden zwei Neuronen und ihre Eingaben gezeigt.
Ein Neuron in einem neuronalen Netzwerk ahmt das Verhalten von Neuronen im Gehirn und anderen Teilen von Nervensystemen nach.
N-Gramm
Eine geordnete Folge von n Wörtern. Zum Beispiel ist truly madly ein 2-Gramm. Da Reihenfolge relevant ist, ist madly Real ein anderes 2-Gramm als wirklich verrückt.
| N | Name(n) für diese Art von N-Gramm | Beispiele |
|---|---|---|
| 2 | Bigram oder 2-Gramm | essen gehen, besuchen, zu Mittag essen, zu Abend essen |
| 3 | Trigram oder 3-Gramm | zu viel gegessen, drei blinde Mäuse, der Glockenton |
| 4 | 4 Gramm | im Park spazieren gehen, im Wind staunen, der Junge aß Linsen |
Viele Modelle für Natural Language Understanding beruhen auf N-Grammen, um das nächste Wort vorherzusagen, das der Nutzer eingeben oder sagen wird. Angenommen, ein Nutzer hat Three blind eingegeben. Ein NLU-Modell, das auf Trigrammen basiert, würde wahrscheinlich vorhersagen, dass der Nutzer als Nächstes Mäuse eintippen wird.
Stellen Sie N-Gramme mit Bag of Words (Bag of Words) gegenüber, bei denen es sich um ungeordnete Wortgruppen handelt.
NLU
Abkürzung für Natural Language Understanding (Natursprachverständnis).
Knoten (Entscheidungsbaum)
In einem Entscheidungsbaum jede Bedingung oder ein Blatt
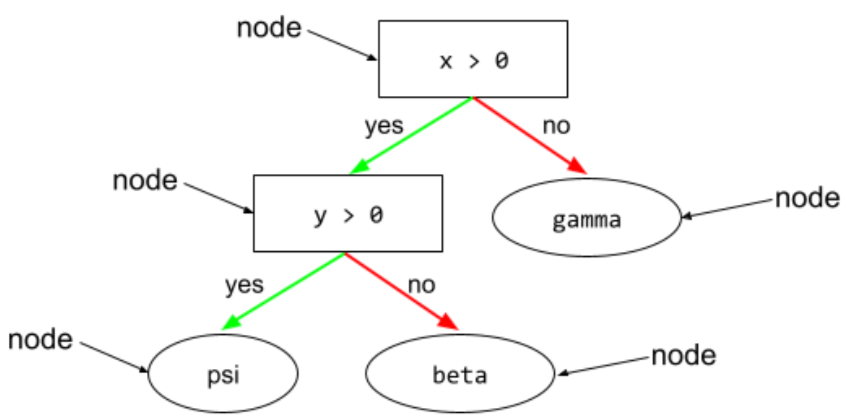
Knoten (neuronales Netzwerk)
Ein Neuron in einer verborgenen Ebene.
Knoten (TensorFlow-Grafik)
Ein Vorgang in einer TensorFlow-Grafik.
Rauschen
Im Grunde alles, was das Signal in einem Dataset verdeckt. Rauschen kann auf verschiedene Weise in Daten eingeführt werden. Beispiel:
- Menschliche Prüfer machen bei der Beschriftung Fehler.
- Menschen und Instrumente erfassen Featurewerte falsch oder lassen sie aus.
nichtbinäre Bedingung
Eine Bedingung mit mehr als zwei möglichen Ergebnissen. Die folgende nicht binäre Bedingung beispielsweise enthält drei mögliche Ergebnisse:
nicht linear
Beziehung zwischen zwei oder mehr Variablen, die nicht ausschließlich durch Addition und Multiplikation dargestellt werden können. Eine lineare Beziehung kann als Linie dargestellt werden, eine nicht lineare Beziehung nicht als Linie. Betrachten Sie zum Beispiel zwei Modelle, die jeweils ein einzelnes Feature mit einem einzelnen Label verknüpfen. Das Modell auf der linken Seite ist linear und das Modell auf der rechten Seite nicht linear:

Negativverzerrung
Siehe Auswahlverzerrung.
Nichtstationarität
Ein Element, dessen Werte sich in einer oder mehreren Dimensionen ändern, in der Regel zeitweise. Betrachten Sie zum Beispiel die folgenden Beispiele für Nichtstationarität:
- Die Anzahl der in einem bestimmten Geschäft verkauften Badebekleidung variiert je nach Saison.
- Die Menge einer bestimmten Frucht, die in einer bestimmten Region geerntet wird, ist für einen Großteil des Jahres bei null, für einen kurzen Zeitraum aber sehr groß.
- Aufgrund des Klimawandels ändern sich die Durchschnittstemperaturen im Jahr.
Stellen Sie einen Kontrast zu Stationarität her.
Normalisierung
Ganz allgemein gesagt, der Prozess der Umwandlung des tatsächlichen Wertebereichs einer Variablen in einen Standardbereich von Werten, z. B.:
- -1 bis +1
- 0 bis 1
- die Normalverteilung
Angenommen, der tatsächliche Wertebereich eines bestimmten Elements liegt zwischen 800 und 2.400. Im Rahmen von Feature Engineering können Sie die tatsächlichen Werte auf einen Standardbereich wie -1 bis +1 normalisieren.
Normalisierung ist eine gängige Aufgabe im Feature Engineering. Modelle werden normalerweise schneller trainiert (und liefern bessere Vorhersagen), wenn jedes numerische Feature im Featurevektor ungefähr den gleichen Bereich hat.
Neuheitserkennung
Prozess, bei dem festgestellt wird, ob ein neues (neues) Beispiel aus der gleichen Verteilung wie das Trainings-Dataset stammt. Mit anderen Worten: Nach dem Training mit dem Trainings-Dataset bestimmt die Neuheitserkennung, ob ein neues Beispiel (während der Inferenz oder während eines zusätzlichen Trainings) ein Ausreißer ist.
Kontrast mit der Ausreißererkennung
numerische Daten
Elemente, die als Ganzzahlen oder reellwertige Zahlen dargestellt werden. Beispielsweise würde ein Hausbewertungsmodell die Größe eines Hauses (in Quadratfuß oder Quadratmetern) wahrscheinlich als numerische Daten darstellen. Wenn ein Element als numerische Daten dargestellt wird, bedeutet dies, dass die Werte des Elements eine mathematische Beziehung zum Label haben. Das heißt, die Anzahl der Quadratmeter in einem Haus steht wahrscheinlich in einem mathematischen Verhältnis zum Wert des Hauses.
Nicht alle Ganzzahldaten sollten als numerische Daten dargestellt werden. Beispielsweise sind Postleitzahlen in einigen Teilen der Welt Ganzzahlen. Ganzzahlige Postleitzahlen sollten in Modellen nicht als numerische Daten dargestellt werden. Das liegt daran, dass die Postleitzahl 20000 nicht doppelt (oder halb) so stark wie die Postleitzahl 10000 ist. Obwohl verschiedene Postleitzahlen mit unterschiedlichen Immobilienwerten korrelieren, können wir nicht davon ausgehen, dass Immobilienwerte bei der Postleitzahl 20000 doppelt so wertvoll sind wie Immobilienwerte unter der Postleitzahl 10000.
Postleitzahlen sollten stattdessen als kategoriale Daten dargestellt werden.
Numerische Features werden manchmal als kontinuierliche Features bezeichnet.
NumPy
Eine Open-Source-Mathematikbibliothek, die effiziente Arrayvorgänge in Python bietet. pandas basiert auf NumPy.
O
Ziel
Ein Messwert, den Ihr Algorithmus zu optimieren versucht.
objektive Funktion
Die mathematische Formel oder der Messwert, die bzw. der mit einem Modell optimiert werden soll. Die objektive Funktion für die lineare Regression ist beispielsweise in der Regel der mittlere quadratische Verlust. Daher wird beim Training eines linearen Regressionsmodells versucht, den mittleren quadratischen Verlust zu minimieren.
In einigen Fällen besteht das Ziel darin, die Zielfunktion zu maximieren. Wenn die Zielfunktion beispielsweise die Genauigkeit ist, besteht das Ziel darin, die Genauigkeit zu maximieren.
Siehe auch loss.
schräge Zustand
In einem Entscheidungsbaum eine Bedingung, die mehr als ein Feature umfasst. Wenn beispielsweise Höhe und Breite beide Elemente sind, ist die folgende schräge Bedingung:
height > width
Im Kontrast zu einer auf Achse ausgerichteten Bedingung stehen.
Offlinegerät
Synonym für statisch.
Offline-Inferenz
Prozess eines Modells, bei dem ein Batch von Vorhersagen generiert und diese Vorhersagen dann im Cache gespeichert (gespeichert) werden. Anwendungen können dann auf die abgeleitete Vorhersage aus dem Cache zugreifen, anstatt das Modell noch einmal auszuführen.
Stellen Sie sich beispielsweise ein Modell vor, das alle vier Stunden lokale Wettervorhersagen (Vorhersagen) generiert. Nach jeder Modellausführung speichert das System alle lokalen Wettervorhersagen im Cache. Wetter-Apps rufen die Vorhersagen aus dem Cache ab.
Offlineinferenz wird auch als statische Inferenz bezeichnet.
Es steht ein Kontrast mit der Online-Inferenz zur Verfügung.
One-Hot-Codierung
Kategoriale Daten als Vektor darstellen, in dem:
- Ein Element ist auf „1“ festgelegt.
- Für alle anderen Elemente ist der Wert „0“ festgelegt.
Die One-Hot-Codierung wird im Allgemeinen zur Darstellung von Strings oder Kennungen verwendet, die einen begrenzten Satz möglicher Werte haben.
Angenommen, ein bestimmtes kategoriales Feature namens Scandinavia hat fünf mögliche Werte:
- "Dänemark"
- „Schweden“
- „Norwegen“
- „Finnland“
- „Island“
Die One-Hot-Codierung könnte jeden der fünf Werte so darstellen:
| country | Vektor | ||||
|---|---|---|---|---|---|
| "Dänemark" | 1 | 0 | 0 | 0 | 0 |
| „Schweden“ | 0 | 1 | 0 | 0 | 0 |
| „Norwegen“ | 0 | 0 | 1 | 0 | 0 |
| „Finnland“ | 0 | 0 | 0 | 1 | 0 |
| „Island“ | 0 | 0 | 0 | 0 | 1 |
Dank der One-Hot-Codierung kann ein Modell basierend auf jedem der fünf Länder unterschiedliche Verbindungen lernen.
Eine Alternative zur One-Hot-Codierung ist die Darstellung eines Elements als numerische Daten. Leider ist es keine gute Wahl, die skandinavischen Länder numerisch abzubilden. Betrachten Sie beispielsweise die folgende numerische Darstellung:
- „Dänemark“ ist 0
- „Schweden“ hat den Wert 1
- „Norwegen“ hat den Wert 2
- „Finnland“ hat den Wert 3
- „Island“ wird 4
Bei der numerischen Codierung würde ein Modell die Rohzahlen mathematisch interpretieren und versuchen, mit diesen Zahlen zu trainieren. Island ist jedoch nicht doppelt (oder halb so viel) wie Norwegen. Das Modell würde daher seltsame Schlussfolgerungen ziehen.
One-Shot-Learning
Ein Ansatz des maschinellen Lernens, der häufig zur Objektklassifizierung verwendet wird und dazu dient, anhand eines einzigen Trainingsbeispiels effektive Klassifikatoren zu erlernen.
Weitere Informationen finden Sie unter Erste Schritte und Zero-Shot-Learning.
One-Shot Prompting
Eine Aufforderung mit einem Beispiel, das zeigt, wie das Large Language Model reagieren sollte. Die folgende Eingabeaufforderung enthält beispielsweise ein Beispiel für ein Large Language Model, das zeigt, wie eine Abfrage beantwortet werden sollte.
| Bestandteile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Frankreich: EUR | Ein Beispiel: |
| Indien: | Die eigentliche Abfrage. |
Vergleichen Sie One-Shot Prompts mit den folgenden Begriffen und stellen Sie sie gegenüber:
Einzel gegen alle
Bei einem Klassifizierungsproblem mit N Klassen eine Lösung, die aus N separaten binären Klassifikatoren besteht – einem binären Klassifikator für jedes mögliche Ergebnis. Bei einem Modell, das Beispiele als Tier, Gemüse oder Mineral klassifiziert, würde eine 1-gegen-all-Lösung beispielsweise die folgenden drei separaten binären Klassifikatoren bereitstellen:
- Tier oder kein Tier
- Gemüse oder nicht pflanzlich
- Mineralien und nicht Mineralien
online
Synonym für dynamisch.
Online-Inferenz
Vorhersagen werden bei Bedarf generiert. Angenommen, eine Anwendung übergibt eine Eingabe an ein Modell und stellt eine Anfrage für eine Vorhersage aus. Ein System, das Onlineinferenz verwendet, antwortet auf die Anfrage, indem es das Modell ausführt (und die Vorhersage an die Anwendung zurückgibt).
Stellen Sie einen Kontrast zur Offline-Inferenz her.
Vorgang (Vorgang)
In TensorFlow jedes Verfahren, mit dem ein Tensor erstellt, bearbeitet oder zerstört wird. Eine Matrixmultiplikation ist beispielsweise eine Operation, bei der zwei Tensoren als Eingabe verwendet und ein Tensor als Ausgabe generiert wird.
Optax
Eine Bibliothek für Gradientenverarbeitung und Optimierung für JAX Optax erleichtert die Forschung durch die Bereitstellung von Bausteinen, die sich auf individuelle Weise neu kombinieren lassen, um parametrische Modelle wie neuronale Deep-Learning-Netzwerke zu optimieren. Weitere Ziele:
- Lesbare, gut getestete, effiziente Implementierungen von Kernkomponenten bereitstellen
- Steigerung der Produktivität, indem Elemente auf niedriger Ebene zu benutzerdefinierten Optimierungstools (oder anderen Komponenten zur Gradientenverarbeitung) kombiniert werden können
- die Einführung neuer Ideen zu beschleunigen, indem es jedem leicht gemacht wird, einen Beitrag zu leisten.
Optimierer
Eine spezifische Implementierung des Gradientenabstiegs-Algorithmus. Beliebte Optimierer:
- AdaGrad steht für ADAptive GRADient Abstammung.
- Adam steht für „ADAptive with Momentum“.
Out-Group-Homogenitätsverzerrung
Die Tendenz, Mitglieder aus der externen Gruppe als ähnlich zu betrachten, wenn man Einstellungen, Werte, Persönlichkeitsmerkmale und andere Eigenschaften vergleicht. In-Group bezieht sich auf Personen, mit denen Sie regelmäßig interagieren, und Out-Group bezieht sich auf Personen, mit denen Sie nicht regelmäßig interagieren. Wenn Sie ein Dataset erstellen, indem Sie Nutzer bitten, Attribute zu externen Gruppen anzugeben, sind diese Attribute möglicherweise weniger differenziert und stereotyper als Attribute, die die Teilnehmer für Personen in ihrer Gruppe angeben.
Sie könnten beispielsweise die Häuser anderer Lilliputer sehr detailliert beschreiben und kleine Unterschiede in Architekturstilen, Fenstern, Türen und Größen zitieren. Dieselben Lilliputianer könnten jedoch auch einfach behaupten, dass Brobdingnagier alle in identischen Häusern leben.
Die Out-Group-Homogenitätsverzerrung ist eine Form der Gruppenattributionsverzerrung.
Weitere Informationen finden Sie unter In-Group-Verzerrung.
Ausreißererkennung
Der Prozess zum Identifizieren von Ausreißern in einem Trainings-Dataset.
Kontrast mit der Neuheitserkennung
erkennen
Werte, die von den meisten anderen Werten entfernt sind. Beim maschinellen Lernen sind einige der folgenden Ausreißer:
- Eingabedaten, deren Werte mehr als etwa drei Standardabweichungen vom Mittelwert abweichen.
- Gewichtungen mit hohen absoluten Werten
- Die vorhergesagten Werte, die relativ weit von den tatsächlichen Werten entfernt sind.
Angenommen, widget-price ist ein Feature eines bestimmten Modells.
Angenommen, der Mittelwert widget-price beträgt 7 € mit einer Standardabweichung von 1 €. Beispiele mit einem widget-price von 12 € oder 2 € gelten daher als Ausreißer, da jeder dieser Preise fünf Standardabweichungen vom Mittelwert entfernt.
Ausreißer werden oft durch Tippfehler oder andere Eingabefehler verursacht. In anderen Fällen sind Ausreißer keine Fehler. Schließlich sind Werte, die fünf Standardabweichungen vom Mittelwert entfernt sind, selten, aber kaum unmöglich.
Ausreißer verursachen häufig Probleme beim Modelltraining. Clips ist eine Möglichkeit, Ausreißer zu umgehen.
Out-of-Bag-Bewertung (OOB-Bewertung)
Ein Mechanismus zur Bewertung der Qualität einer Entscheidungsstruktur, indem jeder Entscheidungsbaum mit den Beispielen verglichen wird, die nicht während des Trainings dieses Entscheidungsbaums verwendet werden. Im folgenden Diagramm sehen Sie beispielsweise, dass das System jeden Entscheidungsbaum für etwa zwei Drittel der Beispiele trainiert und dann anhand des verbleibenden Drittels der Beispiele auswertet.
Die Out-of-Bag-Bewertung ist eine recheneffiziente und konservative Näherung des Kreuzvalidierungsmechanismus. Bei der Kreuzvalidierung wird für jede Kreuzvalidierungsrunde ein Modell trainiert (z. B. werden 10 Modelle in einer zehnfachen Kreuzvalidierung trainiert). Bei der OOB-Bewertung wird ein einzelnes Modell trainiert. Da beim Bagging während des Trainings einige Daten von jedem Baum bei der OOB-Bewertung berücksichtigt werden, kann die Kreuzvalidierung näherungsweise anhand dieser Daten ermittelt werden.
Ausgabeschicht
Die „letzte“ Schicht eines neuronalen Netzwerks. Die Ausgabeebene enthält die Vorhersage.
Die folgende Abbildung zeigt ein kleines neuronales Deep-Learning-Netzwerk mit einer Eingabeschicht, zwei verborgenen Schichten und einer Ausgabeschicht:
Überanpassung
Erstellen eines model, das den model so ähnlich ist, dass das Modell keine korrekten Vorhersagen für neue Daten trifft.
Regularisierung kann eine Überanpassung reduzieren. Das Training mit einem großen und vielfältigen Trainings-Dataset kann auch Überanpassung reduzieren.
Oversampling
Wiederverwendung der Beispiele einer Minderheitsklasse in einem Dataset mit unausgeglichener Klasse, um einen ausgewogeneren Trainingssatz zu erstellen
Stellen Sie sich beispielsweise ein binäres Klassifizierungsproblem vor, bei dem das Verhältnis der Mehrheitsklasse zur Minderheitenklasse 5.000:1 beträgt. Wenn das Dataset eine Million Beispiele enthält, enthält es nur etwa 200 Beispiele der Minderheitenklasse, was möglicherweise zu wenige Beispiele für ein effektives Training sind. Um diesen Mangel zu umgehen, können Sie diese 200 Beispiele mehrmals abfragen (wiederverwenden). So erhalten Sie möglicherweise genügend Beispiele für ein nützliches Training.
Achten Sie bei einer Überstichprobe auf eine Überanpassung.
Hier kommt es zu einem Kontrast mit Untersampling.
P
gepackte Daten
Ein Ansatz zum effizienteren Speichern von Daten.
In gepackten Daten werden Daten entweder in einem komprimierten Format oder auf eine andere Art und Weise gespeichert, die einen effizienteren Zugriff ermöglicht. Gepackte Daten minimieren den Speicher- und Rechenaufwand für den Zugriff, was zu einem schnelleren Training und effizienteren Modellinferenzen führt.
Datenpakete werden häufig mit anderen Techniken wie Datenerweiterung und Regularisierung verwendet, um die Leistung von Modellen weiter zu verbessern.
pandas
Eine spaltenorientierte Datenanalyse-API, die auf numpy basiert. Viele Frameworks für maschinelles Lernen, einschließlich TensorFlow, unterstützen Pandas-Datenstrukturen als Eingaben. Weitere Informationen finden Sie in der pandas-Dokumentation.
Parameter
Die Gewichtungen und Verzerrungen, die ein Modell während des Trainings erlernt. In einem linearen Regressionsmodell bestehen die Parameter beispielsweise aus der Verzerrung (b) und allen Gewichtungen (w1, w2 usw.) in der folgenden Formel:
Im Gegensatz dazu sind Hyperparameter die Werte, die Sie (oder ein Hyperparameter-Drehdienst) für das Modell bereitstellen. Beispielsweise ist die Lernrate ein Hyperparameter.
Parameter-effiziente Abstimmung
Eine Reihe von Techniken zur Feinabstimmung eines großen vortrainierten Language Model (PLM) effizienter als eine vollständige Feinabstimmung. Bei der Parameteroptimierung werden in der Regel weitaus weniger Parameter als eine vollständige Feinabstimmung optimiert. Im Allgemeinen ist damit jedoch ein Large Language Model möglich, das genauso gut (oder fast genauso gut) wie ein Large Language Model funktioniert, das auf vollständiger Feinabstimmung basiert.
Parametersparende Abstimmung vergleichen und gegenüberstellen mit:
Die Parameter-optimierte Abstimmung wird auch als parametereffiziente Feinabstimmung bezeichnet.
Parameterserver (PS)
Ein Job, der die Parameter eines Modells in einer verteilten Einstellung verfolgt.
Parameterupdate
Vorgang des Anpassens der Parameter eines Modells während des Trainings, in der Regel innerhalb einer einzelnen Iteration des Gradientenabstiegs.
partielle Ableitung
Ableitung, bei der bis auf eine der Variablen alle Variablen als Konstante gelten. Die partielle Ableitung von f(x, y) in Bezug auf x ist beispielsweise die Ableitung von f, die als Funktion von x allein betrachtet wird (d. h. y konstant bleibt). Die partielle Ableitung von f in Bezug auf x konzentriert sich nur darauf, wie sich x ändert, und ignoriert alle anderen Variablen in der Gleichung.
Beteiligungsverzerrung
Synonym für „Non-Response Bias“. Siehe Auswahlverzerrung.
Partitionierungsstrategie
Der Algorithmus, nach dem Variablen auf Parameterserver aufgeteilt werden.
Pax
Ein Programmier-Framework zum Trainieren von großen neuronalen Netzwerkmodellen, die so groß sind, dass sie mehrere TPU-Beschleunigerchips Slices oder Pods umfassen.
Pax basiert auf Flax, das auf JAX basiert.
Perceptron
Ein System (entweder Hardware oder Software), das einen oder mehrere Eingabewerte annimmt, eine Funktion mit der gewichteten Summe der Eingaben ausführt und einen einzelnen Ausgabewert berechnet. Beim maschinellen Lernen ist die Funktion in der Regel nicht linear, z. B. ReLU, sigmoid oder tanh. Das folgende Perceptron stützt sich beispielsweise auf die Sigmoidfunktion, um drei Eingabewerte zu verarbeiten:
In der folgenden Abbildung nimmt das Perzeptron drei Eingaben an, von denen jede selbst durch eine Gewichtung modifiziert wird, bevor sie in das Perzeptron eintritt:

Perzeptronen sind die Neuronen in neuronalen Netzen.
Leistung
Überladener Begriff mit den folgenden Bedeutungen:
- Die Standardbedeutung in der Softwareentwicklung. Wie schnell (oder effizient) läuft diese Software?
- Die Bedeutung des maschinellen Lernens. Hier wird die folgende Frage beantwortet: Wie richtig ist dieses model? Das heißt, wie gut sind die Vorhersagen des Modells?
Bedeutungen von Permutationsvariablen
Typ der Variablenwichtigkeit, der die Zunahme des Vorhersagefehlers eines Modells nach der Änderung der Werte des Features bewertet. Die Bedeutung von Permutationvariablen ist ein modellunabhängiger Messwert.
Verwirrung
Ein Maß dafür, wie gut ein model seine Aufgabe erledigt. Angenommen, Ihre Aufgabe besteht darin, die ersten Buchstaben eines Wortes zu lesen, das ein Nutzer auf einer Smartphonetastatur eingibt, und Ihnen eine Liste möglicher Vervollständigungswörter anzubieten. Die Perplexität (P) entspricht für diese Aufgabe ungefähr der Anzahl der Vermutungen, die Sie anbieten müssen, damit Ihre Liste das tatsächliche Wort enthält, das der Nutzer eingeben möchte.
Die Perplexität hängt so mit der Kreuzentropie zusammen:
Pipeline
Die Infrastruktur eines Algorithmus für maschinelles Lernen. Eine Pipeline umfasst das Erfassen der Daten, das Einfügen der Daten in Trainingsdatendateien, das Trainieren eines oder mehrerer Modelle und das Exportieren der Modelle in die Produktion.
Rohrleitungen
Eine Form der Modellparallelität, bei der die Verarbeitung eines Modells in aufeinanderfolgende Phasen unterteilt ist und jede Phase auf einem anderen Gerät ausgeführt wird. Während in einer Phase ein Batch verarbeitet wird, kann die vorherige Phase mit dem nächsten Batch weiterarbeiten.
Weitere Informationen finden Sie unter Gestaffeltes Training.
Pjit
Eine JAX-Funktion, die Code zur Ausführung auf mehrere Beschleunigerchips teilt Der Nutzer übergibt eine Funktion an pjit, die eine Funktion mit der entsprechenden Semantik zurückgibt, die jedoch in eine XLA-Berechnung kompiliert wird, die auf mehreren Geräten wie GPUs oder TPU-Kernen ausgeführt wird.
Mit pjit können Nutzer Berechnungen mit dem SPMD-Partitioner fragmentieren, ohne sie neu zu schreiben.
Im März 2023 wurde pjit mit jit zusammengeführt. Weitere Informationen finden Sie unter Verteilte Arrays und automatische Parallelisierung.
PLM
Abkürzung für vortrainiertes Sprachmodell
PMap
Eine JAX-Funktion, die Kopien einer Eingabefunktion auf mehreren zugrunde liegenden Hardwaregeräten (CPUs, GPUs oder TPUs) mit unterschiedlichen Eingabewerten ausführt. Pmap basiert auf SPMD.
policy
Beim Reinforcement Learning die probabilistische Zuordnung eines Agents von Bundesstaaten zu Aktionen.
Pooling
Die Matrix (oder Matrix), die von einer früheren Faltungsschicht erstellt wurde, werden auf eine kleinere Matrix reduziert. Beim Pooling wird in der Regel entweder der Maximal- oder der Durchschnittswert über den Poolbereich hinweg ermittelt. Angenommen, wir haben die folgende 3x3-Matrix:
![Die 3x3-Matrix [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingStart.svg?hl=de)
Bei einem Pooling-Vorgang wird die Matrix genau wie bei einer Faltung in Segmente aufgeteilt und diese Faltungsfunktion wird dann in Schritte gleitet. Angenommen, die Pooling-Operation teilt die Faltungsmatrix in 2x2-Slices mit einem 1x1-Schritt auf. Wie das folgende Diagramm zeigt, finden vier Pooling-Vorgänge statt. Angenommen, jeder Pooling-Vorgang wählt den Maximalwert der vier in diesem Slice aus:
![Die Eingabematrix ist 3x3 mit den Werten: [[5,3,1], [8,2,5], [9,4,3]].
Die 2x2-Submatrix oben links der Eingabematrix ist [[5,3], [8,2]], sodass der Pooling-Vorgang oben links den Wert 8 ergibt (das Maximum von 5, 3, 8 und 2). Die 2x2-Submatrix oben rechts der Eingabematrix ist [[3,1], [2,5]], sodass der Pooling-Vorgang oben rechts den Wert 5 liefert. Die 2x2-Submatrix unten links der Eingabematrix ist [[8,2], [9,4]], sodass der Pooling-Vorgang unten links den Wert 9 liefert. Die 2x2-Submatrix unten rechts der Eingabematrix ist [[2,5], [4,3]], sodass der Pooling-Vorgang unten rechts den Wert 5 liefert. Zusammenfassend lässt sich sagen, dass der Pooling-Vorgang die 2x2-Matrix [[8,5], [9,5]] liefert.](https://developers.google.com/static/machine-learning/glossary/images/PoolingConvolution.svg?hl=de)
Pooling hilft bei der Durchsetzung einer Übersetzungsinvarianz in der Eingabematrix.
Pooling für Vision-Anwendungen wird formeller als räumliches Pooling bezeichnet. Bei Zeitreihenanwendungen wird Pooling in der Regel als temporales Pooling bezeichnet. Weniger formell wird das Pooling häufig als Subsampling oder Downsampling bezeichnet.
Positionscodierung
Ein Verfahren zum Hinzufügen von Informationen zur Position eines Tokens in einer Sequenz zur Einbettung des Tokens. Transformer-Modelle verwenden die Positionscodierung, um die Beziehung zwischen verschiedenen Teilen der Sequenz besser zu verstehen.
Eine gängige Implementierung der positionalen Codierung verwendet eine Sinusoidfunktion. Genauer gesagt werden Frequenz und Amplitude der Sinusoidalfunktion durch die Position des Tokens in der Sequenz bestimmt. Mit diesem Verfahren kann ein Transformer-Modell lernen, verschiedene Teile der Sequenz basierend auf ihrer Position zu berücksichtigen.
positive Klasse
Der Kurs, für den Sie den Test durchführen.
Die positive Klasse in einem Krebsmodell könnte beispielsweise „Tumor“ sein. Die positive Klasse in einem E-Mail-Klassifikator kann „Spam“ sein.
Stellen Sie einen Kontrast mit der negativen Klasse dar.
Nachbearbeitung
Ausgabe eines Modells anpassen, nachdem das Modell ausgeführt wurde. Die Nachverarbeitung kann verwendet werden, um Fairness-Einschränkungen durchzusetzen, ohne die Modelle selbst zu ändern.
Sie können beispielsweise die Nachbearbeitung auf einen binären Klassifikator anwenden, indem Sie einen Klassifizierungsschwellenwert so festlegen, dass die Chancengleichheit für ein bestimmtes Attribut aufrechterhalten wird. Dazu wird geprüft, ob die Rate echt positiver Ergebnisse für alle Werte dieses Attributs gleich ist.
PR AUC (Fläche unter der PR-Kurve)
Fläche unter der interpolierten Precision-/Recall-Kurve, die durch die Darstellung von Recall-, Precision-Punkten für verschiedene Werte des Klassifizierungsschwellenwerts ermittelt wird. Je nach Berechnung kann die PR AUC der durchschnittlichen Genauigkeit des Modells entsprechen.
Praxis
Eine leistungsstarke ML-Kernbibliothek von Pax. Praxis wird oft als „Layer Library“ bezeichnet.
Praxis enthält nicht nur die Definitionen für die Layer-Klasse, sondern auch die meisten ihrer unterstützenden Komponenten, darunter:
- Dateneingaben
- Konfigurationsbibliotheken (HParam und Fiddle)
- Optimierer
Praxis stellt die Definitionen für die Modellklasse bereit.
Precision
Ein Messwert für Klassifizierungsmodelle, der die folgende Frage beantwortet:
Welcher Prozentsatz der Vorhersagen war richtig, als das Modell die positive Klasse vorhergesagt hat?
Die Formel lautet:
Dabei gilt:
- Richtig positiv bedeutet, dass das Modell die positive Klasse richtig vorhergesagt hat.
- Falsch positiv bedeutet, dass das Modell die positive Klasse fälschlicherweise vorhergesagt hat.
Angenommen, ein Modell hat 200 positive Vorhersagen gemacht. Von diesen 200 positiven Vorhersagen:
- 150 waren richtig positive Ergebnisse.
- 50 waren falsch-positiv.
In diesem Fall gilt:
Stellen Sie sich einen Kontrast mit Genauigkeit und Trefferquote gegenüber.
Precision-/Recall-Kurve
Eine Kurve der Genauigkeit im Vergleich zur Trefferquote bei verschiedenen Klassifizierungsschwellenwerten.
prognostizierter Wert
Die Ausgabe eines Modells. Beispiel:
- Die Vorhersage eines binären Klassifizierungsmodells ist entweder die positive oder die negative Klasse.
- Die Vorhersage eines Klassifizierungsmodells mit mehreren Klassen ist eine Klasse.
- Die Vorhersage eines linearen Regressionsmodells ist eine Zahl.
Vorhersageverzerrung
Ein Wert, der angibt, wie weit der Durchschnitt der Vorhersagen vom Durchschnitt der Labels im Dataset abweicht.
Nicht zu verwechseln mit dem Begriff Voreingenommenheit in ML-Modellen oder mit Voreingenommenheit in Ethik und Fairness.
Vorhersage-ML
Jedes standardmäßige („klassisches“) Machine Learning-System.
Für den Begriff Prognose-ML gibt es keine formale Definition. Vielmehr unterscheidet der Begriff eine Kategorie von ML-Systemen, die nicht auf generativer KI basieren.
Vorhersageparität
Ein Fairness-Messwert, der prüft, ob die Precision-Raten für einen bestimmten Klassifikator für die untersuchten Untergruppen äquivalent sind.
Beispielsweise würde ein Modell, das die Akzeptanz von Colleges prognostiziert, die vorhergesagte Parität für die Nationalität erfüllen, wenn seine Precision-Rate für Lilliputians und Brobdingnagier gleich ist.
Die vorausschauende Parität wird manchmal auch als vorausschauende Ratenparität bezeichnet.
Unter Erläuterung der Fairness-Definitionen (Abschnitt 3.2.1) finden Sie eine detailliertere Beschreibung der Vorhersageparität.
Prognoserateparität
Ein anderer Name für Vorhersageparität.
Vorverarbeitung
Daten verarbeiten, bevor sie zum Trainieren eines Modells verwendet werden. Die Vorverarbeitung kann so einfach sein wie das Entfernen von Wörtern aus einem englischen Textkorpus, die nicht im englischen Wörterbuch vorkommen, oder sie kann so komplex sein wie das Umformulieren von Datenpunkten so, dass so viele Attribute ausgeschlossen werden, die mit sensiblen Attributen korrelieren. Die Vorverarbeitung kann helfen, Fairness-Einschränkungen zu erfüllen.vortrainiertes Modell
Modelle oder Modellkomponenten (z. B. ein Einbettungsvektor), die bereits trainiert wurden. Manchmal geben Sie vortrainierte Einbettungsvektoren in ein neuronales Netzwerk ein. In anderen Fällen trainiert Ihr Modell die Einbettungsvektoren selbst, anstatt sich auf die vortrainierten Einbettungen zu verlassen.
Der Begriff vortrainiertes Language Model bezieht sich auf ein Large Language Model, das Vortraining durchlaufen hat.
Vortraining
Erstes Training eines Modells mit einem großen Dataset. Einige vortrainierte Modelle sind ungeschickt und müssen in der Regel durch ein zusätzliches Training verfeinert werden. Beispielsweise können ML-Experten ein Large Language Model für ein umfangreiches Text-Dataset wie alle englischen Seiten in Wikipedia vorab trainieren. Nach dem Vorabtraining kann das resultierende Modell durch eine der folgenden Techniken weiter verfeinert werden:
- Destillation
- Feinabstimmung
- Anpassung von Anleitungen
- parametersparende Abstimmung
- Einstellung von Aufforderungen
vorherige Überzeugung
Was Sie über die Daten denken, bevor Sie mit dem Training beginnen. Die L2-Regularisierung beruht beispielsweise auf der vorherigen Überzeugung, dass Gewichtungen klein und normal um null verteilt sein sollten.
probabilistisches Regressionsmodell
Ein Regressionsmodell, das nicht nur die Gewichtungen für jedes Feature verwendet, sondern auch die Unsicherheit dieser Gewichtungen. Ein probabilistisches Regressionsmodell generiert eine Vorhersage und die Unsicherheit dieser Vorhersage. Ein probabilistisches Regressionsmodell könnte beispielsweise eine Vorhersage von 325 mit einer Standardabweichung von 12 liefern. Weitere Informationen zu probabilistischen Regressionsmodellen finden Sie unter Colab auf Tensorflow.org.
Wahrscheinlichkeitsdichtefunktion
Eine Funktion, die die Häufigkeit von Stichproben ermittelt, die genau einen bestimmten Wert haben. Wenn die Werte eines Datasets fortlaufende Gleitkommazahlen sind, treten selten genaue Übereinstimmungen auf. Durch das integrating einer Wahrscheinlichkeitsdichtefunktion vom Wert x bis zum Wert y wird jedoch die erwartete Häufigkeit von Stichproben zwischen x und y erzielt.
Angenommen, Sie haben eine Normalverteilung mit einem Mittelwert von 200 und einer Standardabweichung von 30. Um die erwartete Häufigkeit von Stichproben in den Bereich 211,4 bis 218,7 zu bestimmen, können Sie die Wahrscheinlichkeitsdichtefunktion für eine Normalverteilung von 211,4 bis 218,7 einbinden.
Prompt
Text, der als Eingabe in ein Large Language Model eingegeben wird, um das Modell so zu konditionieren, dass es sich auf ein bestimmtes Verhalten verhält. Aufforderungen können kurz oder beliebig lang sein (z. B. der gesamte Text eines Romans). Aufforderungen lassen sich in mehrere Kategorien einteilen, darunter die in der folgenden Tabelle gezeigten:
| Aufforderungskategorie | Beispiel | Hinweise |
|---|---|---|
| Frage | Wie schnell kann eine Taube fliegen? | |
| Anleitung | Schreib ein lustiges Gedicht über Arbitrage. | Eine Aufforderung, die das Large Language Model zu Maßnahmen auffordert. |
| Beispiel | Übersetzen Sie Markdown-Code in HTML. Beispiel:
Markdown: * Listeneintrag HTML: <ul> <li>Listeneintrag</li> </ul> |
Der erste Satz in diesem Beispiel-Prompt ist eine Anweisung. Der Rest des Prompts ist das Beispiel. |
| Rolle | Erläutern Sie, warum das Gradientenverfahren beim Training von maschinellem Lernen zum Thema Physik verwendet wird. | Der erste Teil des Satzes ist eine Anweisung. Der Satz „an einen Doktortitel in Physik“ ist die Rolle. |
| Teileingabe für den Abschluss des Modells | Der Premierminister des Vereinigten Königreichs lebt in | Eine teilweise Eingabe-Prompt kann entweder abrupt enden (wie in diesem Beispiel) oder mit einem Unterstrich enden. |
Ein Generative-AI-Modell kann auf einen Prompt mit Text, Code, Bildern, Einbettungen, Videos usw. reagieren.
Prompt-basiertes Lernen
Eine Funktion bestimmter Modelle, die es ihnen ermöglichen, ihr Verhalten als Reaktion auf beliebige Texteingaben (Aufforderungen) anzupassen. Bei einem typischen Prompt-basierten Lernmodell reagiert ein Large Language Model auf eine Aufforderung mit dem Generieren von Text. Angenommen, ein Nutzer gibt die folgende Eingabeaufforderung ein:
Das dritte Newtonsche Gesetz zusammenfassen.
Ein Modell, das Prompt-basiertes Lernen ermöglicht, wird nicht speziell für die Beantwortung der vorherigen Aufforderung trainiert. Das Modell „weiß“ viel über Physik, viel über allgemeine Sprachregeln und darüber, was allgemein nützliche Antworten sind. Dieses Wissen reicht aus, um eine (hoffentlich) nützliche Antwort zu geben. Zusätzliches menschliches Feedback ("Diese Antwort war zu kompliziert." oder "Was ist eine Reaktion?") ermöglicht einigen Prompt-basierten Lernsystemen, den Nutzen ihrer Antworten nach und nach zu verbessern.
Prompt-Design
Synonym für Prompt Engineering.
Prompt Engineering
Die Kunst, Aufforderungen zu erstellen, die von einem Large Language Model die gewünschten Antworten erhalten. Menschen führen Prompt- Engineering durch. Das Schreiben gut strukturierter Prompts ist ein wesentlicher Bestandteil der Gewährleistung nützlicher Antworten von einem Large Language Model. Prompt Engineering hängt von vielen Faktoren ab, darunter:
- Mit dem Dataset wird das Large Language Model vortrainiert und möglicherweise optimiert.
- Die temperature und andere Decodierungsparameter, die das Modell zum Generieren von Antworten verwendet.
Weitere Informationen zum Schreiben hilfreicher Prompts finden Sie unter Einführung in den Prompt-Entwurf.
Prompt-Entwurf ist ein Synonym für Prompt Engineering.
Aufforderungsabstimmung
Ein Mechanismus zur effizienten Abstimmung von Parametern, der ein „Präfix“ erlernt, das das System der eigentlichen Eingabeaufforderung vorangestellt hat.
Eine Variante der Feinabstimmung von Aufforderungen – auch Präfixabstimmung genannt – besteht darin, das Präfix jeder Schicht voranzustellen. Im Gegensatz dazu wird bei der Feinabstimmung von Aufforderungen bei der meisten Einstellung nur der Eingabeebene ein Präfix hinzugefügt.
Proxy-Labels
Daten zur Annäherung von Labels, die in einem Dataset nicht direkt verfügbar sind.
Angenommen, Sie müssen ein Modell trainieren, um den Stresslevel von Mitarbeitern vorherzusagen. Ihr Dataset enthält viele Vorhersagemerkmale, aber kein Label mit dem Namen Stresslevel. Sie lassen sich nicht erschrecken und wählen „Arbeitsunfälle“ als Proxy-Label für das Stresslevel aus. Schließlich geraten Mitarbeitende unter starkem Stress mehr Unfällen als ruhige Mitarbeiter. Oder doch? Vielleicht steigen und fallen Arbeitsunfälle aus verschiedenen Gründen.
Nehmen wir als zweites Beispiel an, Sie möchten Is it raining? ein boolesches Label für Ihr Dataset sein, das Dataset enthält jedoch keine Regendaten. Wenn Fotos vorhanden sind, können Bilder von Personen mit Regenschirmen als Proxy-Label für Regnet es? verwendet werden. Ist das ein gutes Proxy-Label? Möglicherweise ist die Wahrscheinlichkeit, dass Menschen in einigen Kulturen einen Regenschirm zum Schutz vor Sonnenlicht tragen, höher als vor Regen.
Proxy-Labels sind oft nicht perfekt. Wenn möglich, sollten Sie tatsächliche Labels anstelle von Proxy-Labels verwenden. Wenn jedoch ein tatsächliches Proxy-Label fehlt, wählen Sie das Proxy-Label sehr sorgfältig aus und wählen Sie den am wenigsten schrecklichen Kandidat für das Proxy-Label aus.
Proxy (sensible Attribute)
Ein Attribut, das als Ersatz für ein sensibles Attribut verwendet wird. Beispielsweise kann die Postleitzahl einer Person als Stellvertreter ihres Einkommens, ihrer ethnischen Herkunft oder ihrer ethnischen Zugehörigkeit verwendet werden.reine Funktion
Funktion, deren Ausgaben nur auf ihren Eingaben basieren und keine Nebeneffekte haben. Insbesondere verwendet oder ändert eine reine Funktion keinen globalen Status wie den Inhalt einer Datei oder den Wert einer Variablen außerhalb der Funktion.
Mit reinen Funktionen können Thread-sicherer Code erstellt werden. Dies ist vorteilhaft, wenn model über mehrere model fragmentiert wird.
Die Methoden zur Funktionstransformation von JAX setzen voraus, dass die Eingabefunktionen reine Funktionen sind.
F
Q-Funktion
Beim Bestärkendes Lernen ist dies die Funktion, die die erwartete Rückgabe einer Aktion in einem Status und anschließendes Befolgen einer bestimmten Richtlinie vorhersagt.
Die Q-Funktion wird auch als Status-Aktionswert-Funktion bezeichnet.
Q-Learning
Reinforcement Learning, ein Algorithmus, mit dem ein Agent die optimale Q-Funktion eines Markov-Entscheidungsprozesses anhand der Bellman-Gleichung erlernt. Der Markov-Entscheidungsprozess modelliert eine Umgebung.
Quantil
Jeder Bucket im Quantil-Bucketing
Quantil-Bucketing
Wenn Sie die Werte eines Features auf Buckets verteilen, damit jeder Bucket die gleiche (oder nahezu dieselbe) Anzahl von Beispielen enthält In der folgenden Abbildung werden beispielsweise 44 Punkte in 4 Buckets unterteilt, von denen jeder 11 Punkte enthält. Damit jeder Bucket in der Abbildung die gleiche Anzahl von Punkten enthält, erstrecken sich einige Buckets über eine andere Breite von x-Werten.

Quantisierung
Überladener Begriff, der auf folgende Weise verwendet werden könnte:
- Implementierung von Quantil-Bucketing für eine bestimmte Funktion
- Umwandlung von Daten in Nullen und Einsen für ein schnelleres Speichern, Trainieren und Ableiten Da Boolesche Daten robuster gegen Rauschen und Fehler sind als andere Formate, kann die Quantisierung die Korrektheit des Modells verbessern. Zu den Quantisierungstechniken gehören Rundung, Abschneiden und Gruppieren.
Reduzieren der Anzahl der Bits, die zum Speichern der Parameter eines Modells verwendet werden. Angenommen, die Parameter eines Modells werden als 32-Bit-Gleitkommazahlen gespeichert. Die Quantisierung wandelt diese Parameter von 32 Bit in 4, 8 oder 16 Bit um. Die Quantisierung reduziert Folgendes:
- Rechen-, Arbeitsspeicher-, Laufwerk- und Netzwerknutzung
- Es ist an der Zeit, eine Vorhersage abzuleiten
- Stromverbrauch
Durch Quantisierung wird jedoch manchmal die Richtigkeit der Vorhersagen eines Modells beeinträchtigt.
kuh
Einen TensorFlow-Vorgang, der eine Warteschlangendatenstruktur implementiert. Wird normalerweise bei E/A verwendet.
R
RAG
Abkürzung für retrieval-augmented generation.
Random Forest
Eine Gruppe von Entscheidungsbäumen, in denen jeder Entscheidungsbaum mit einem bestimmten Zufallsrauschen wie Bagging trainiert wird.
Random Forests sind eine Art von Entscheidungsstruktur.
Zufallsrichtlinie
Beim bestärkenden Lernen eine Richtlinie, die eine Aktion nach dem Zufallsprinzip auswählt.
Rangliste
Eine Art des überwachten Lernens, deren Ziel darin besteht, eine Liste von Elementen zu sortieren.
Rang (Ordinalität)
Die Ordinalposition einer Klasse in einem ML-Problem, das Klassen von der höchsten zur niedrigsten Kategorie kategorisiert. Zum Beispiel könnte ein Verhaltensrangfolgesystem die Belohnungen eines Hundes von der höchsten (ein Steak) bis nach der niedrigsten (verwelkten Grünkohl) sortieren.
Rang (Tensor)
Die Anzahl der Dimensionen in einem Tensor. Ein Skalar hat beispielsweise Rang 0, ein Vektor hat Rang 1 und eine Matrix hat Rang 2.
Nicht zu verwechseln mit dem Attribut Rang (Ordinalität).
Bewerter
Ein Mensch, der Labels für Beispiele bereitstellt. „Kommentator“ ist ein anderer Name für Bewerter.
Rückruf
Ein Messwert für Klassifizierungsmodelle, der die folgende Frage beantwortet:
Wenn Ground Truth die positive Klasse war, wie viel Prozent der Vorhersagen hat das Modell dann korrekt als positive Klasse identifiziert?
Die Formel lautet:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
Dabei gilt:
- Richtig positiv bedeutet, dass das Modell die positive Klasse richtig vorhergesagt hat.
- Falsch-negativ bedeutet, dass das Modell die negative Klasse fälschlicherweise vorhergesagt hat.
Angenommen, Ihr Modell hat 200 Vorhersagen für Beispiele getroffen, für die Ground Truth die positive Klasse war. Von diesen 200 Vorhersagen:
- 180 waren richtig positive Ergebnisse.
- 20 waren falsch-negative Ergebnisse.
In diesem Fall gilt:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Empfehlungssystem
Ein System, das für jeden Nutzer eine relativ kleine Gruppe von gewünschten Elementen aus einem großen Korpus auswählt. Ein Videoempfehlungssystem kann beispielsweise zwei Videos aus einem Korpus von 100.000 Videos empfehlen und für einen Nutzer Casablanca und The Philadelphia Story und für einen anderen Wonder Woman und Black Panther auswählen. Die Empfehlungen eines Videoempfehlungssystems können beispielsweise auf folgenden Faktoren basieren:
- Filme, die von ähnlichen Nutzern bewertet oder angesehen wurden.
- Genre, Regisseure, Schauspieler, Zielgruppe...
Rektifizierte lineare Einheit (ReLU)
Eine Aktivierungsfunktion mit folgendem Verhalten:
- Wenn die Eingabe negativ oder null ist, ist die Ausgabe 0.
- Wenn die Eingabe positiv ist, ist die Ausgabe gleich der Eingabe.
Beispiel:
- Wenn die Eingabe -3 ist, ist die Ausgabe 0.
- Wenn die Eingabe +3 ist, ist die Ausgabe 3,0.
Hier ist eine Darstellung von ReLU:
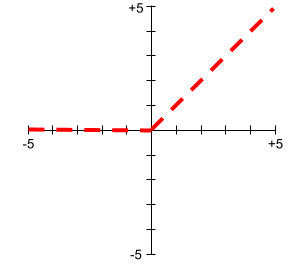
ReLU ist eine sehr beliebte Aktivierungsfunktion. Trotz seines einfachen Verhaltens ermöglicht ReLU ein neuronales Netzwerk, nicht lineare Beziehungen zwischen Features und dem Label zu erkennen.
neuronales Recurrent-Netzwerk
Ein neuronales Netzwerk, das absichtlich mehrmals ausgeführt wird und bei dem Teile jeder Ausführung in die nächste Ausführung einfließen. Insbesondere liefern ausgeblendete Ebenen aus der vorherigen Ausführung bei der nächsten Ausführung einen Teil der Eingabe für dieselbe verborgene Ebene. Recurrent neuronale Netzwerke sind besonders nützlich für die Auswertung von Sequenzen, damit die verborgenen Schichten aus früheren Durchläufen des neuronalen Netzwerks in früheren Teilen der Sequenz lernen können.
Die folgende Abbildung zeigt beispielsweise ein neuronales Recurrent-Netzwerk, das viermal ausgeführt wird. Beachten Sie, dass die Werte, die aus dem ersten Durchlauf in den ausgeblendeten Ebenen erkannt wurden, im zweiten Durchlauf Teil der Eingabe für dieselben versteckten Ebenen werden. In ähnlicher Weise werden die Werte, die beim zweiten Durchlauf in der ausgeblendeten Ebene erkannt wurden, im dritten Durchlauf Teil der Eingabe in diese versteckte Ebene. Auf diese Weise trainiert und prognostiziert das recurrent neuronale Netzwerk nach und nach die Bedeutung der gesamten Sequenz und nicht nur die Bedeutung einzelner Wörter.

Regressionsmodell
Inoffiziell ein Modell, das eine numerische Vorhersage generiert. Im Gegensatz dazu generiert ein Klassifizierungsmodell eine Klassenvorhersage. Im Folgenden finden Sie beispielsweise nur Regressionsmodelle:
- Ein Modell, das den Wert eines bestimmten Hauses vorhersagt,z. B. 423.000 €.
- Ein Modell, das die Lebenserwartung eines bestimmten Baums vorhersagt, z. B. 23,2 Jahre.
- Ein Modell, das die Regenmenge vorhersagt, die in einer bestimmten Stadt in den nächsten sechs Stunden fallen wird, z. B. 0,18 Zoll.
Zwei gängige Arten von Regressionsmodellen sind:
- Lineare Regression, die die Linie ermittelt, die am besten zu Labelwerten für Features passt.
- Logistische Regression, bei der eine Wahrscheinlichkeit zwischen 0,0 und 1,0 generiert wird, die ein System normalerweise dann einer Klassenvorhersage zuordnet.
Nicht jedes Modell, das numerische Vorhersagen ausgibt, ist ein Regressionsmodell. In manchen Fällen ist eine numerische Vorhersage eigentlich nur ein Klassifizierungsmodell, das zufällig numerische Klassennamen hat. Beispielsweise ist ein Modell, das eine numerische Postleitzahl vorhersagt, ein Klassifizierungsmodell und kein Regressionsmodell.
Regularisierung
Jeder Mechanismus, der eine Überanpassung reduziert. Zu den beliebtesten Arten der Regularisierung gehören:
- L1-Regularisierung
- L2-Regularisierung
- Dropout-Regularisierung
- frühes Anhalten: Dies ist keine formale Regularisierungsmethode, kann Überanpassung aber effektiv begrenzen.
Regularisierung kann auch als Nachteil für die Komplexität eines Modells definiert werden.
Regularisierungsrate
Eine Zahl, die die relative Bedeutung der Regularisierung während des Trainings angibt. Durch eine Erhöhung der Regularisierungsrate wird die Überanpassung reduziert, aber möglicherweise auch die Vorhersageleistung des Modells. Umgekehrt erhöht sich durch das Reduzieren oder Auslassen der Regularisierungsrate die Überanpassung.
Reinforcement Learning (RL)
Eine Familie von Algorithmen, die eine optimale Richtlinie erlernen, deren Ziel darin besteht, bei der Interaktion mit einer Umgebung den Return zu maximieren. Die ultimative Belohnung der meisten Spiele ist beispielsweise der Sieg. Bestärkende Lernsysteme können zu Experten für komplexe Spiele werden, indem sie Sequenzen früherer Spielzüge bewerten, die schließlich zu Siegen und Sequenzen, die letztendlich zu Niederlagen führen, ausgewertet werden.
Bestärkendes Lernen durch menschliches Feedback (RLHF)
Das Feedback von Prüfern nutzen, um die Qualität der Antworten eines Modells zu verbessern. Beispielsweise kann ein RLHF-Mechanismus Nutzer bitten, die Qualität der Antwort eines Modells mit einem 👍 oder 👎-Emoji zu bewerten. Anhand dieses Feedbacks kann das System dann seine zukünftigen Antworten anpassen.
ReLU
Abkürzung für Rektifizierte lineare Einheit.
Wiederholungspuffer
In DQN-ähnlichen Algorithmen der Arbeitsspeicher, der vom Agent zum Speichern von Statusübergängen zur Verwendung in der Erholung von Erfahrungen verwendet wird.
Replikat
Eine Kopie des Trainingssatzes oder des Modells, normalerweise auf einem anderen Computer. Beispielsweise könnte ein System die folgende Strategie zur Implementierung der Datenparallelität verwenden:
- Platzieren Sie Replikate eines vorhandenen Modells auf mehreren Maschinen.
- Verschiedene Teilmengen des Trainings-Datasets an jedes Replikat senden.
- Aggregieren Sie die Aktualisierungen des Parameters.
Berichtsverzerrung
Die Tatsache, dass die Häufigkeit, mit der Menschen über Aktionen, Ergebnisse oder Eigenschaften schreiben, spiegelt weder ihre tatsächliche Häufigkeit noch den Grad wider, in dem eine Eigenschaft für eine Gruppe von Individuen charakteristisch ist. Verzerrungen bei der Berichterstellung können die Zusammensetzung der Daten beeinflussen, von denen Systeme für maschinelles Lernen lernen.
In Büchern ist zum Beispiel das Wort lacht häufiger als atmen. Ein Modell für maschinelles Lernen, das die relative Häufigkeit von Lachen und Atmen aus einem Buchkorpus schätzt, würde wahrscheinlich bestimmen, dass Lachen häufiger als Atmen ist.
Darstellung
Der Prozess der Zuordnung von Daten zu nützlichen Funktionen.
Re-Ranking
Die letzte Phase eines Empfehlungssystems, in der bewertete Elemente gemäß einem anderen Algorithmus (in der Regel kein ML-Algorithmus) neu benotet werden können. Beim erneuten Ranking wird die Liste der Elemente ausgewertet, die in der Bewertungsphase generiert wurden. Dazu gehören:
- Artikel entfernen, die der Nutzer bereits gekauft hat
- Die Bewertung neuerer Artikel wird erhöht.
Retrieval-Augmented Generation (RAG)
Verfahren zur Verbesserung der Qualität der Ausgabe von Large Language Models (LLM), indem sie auf Wissensquellen gelegt wird, die nach dem Training des Modells abgerufen wurden RAG verbessert die Genauigkeit von LLM-Antworten, indem es dem trainierten LLM Zugriff auf Informationen aus vertrauenswürdigen Wissensdatenbanken oder Dokumenten gewährt.
Häufige Gründe für die Verwendung der Abruf-erweiterten Generierung sind:
- Die faktische Genauigkeit der generierten Antworten eines Modells erhöhen.
- Dem Modell Zugriff auf Wissen gewähren, mit dem es nicht trainiert wurde.
- Ändern des Wissens, das das Modell verwendet.
- Das Modell zum Zitieren von Quellen aktivieren.
Angenommen, eine Chemieanwendung verwendet die PaLM API, um Zusammenfassungen zu Nutzerabfragen zu generieren. Wenn das Back-End der Anwendung eine Anfrage empfängt, führt das Back-End folgende Schritte aus:
- Sucht nach Daten, die für die Suchanfrage des Nutzers relevant sind („abruft“).
- Die relevanten Chemiedaten werden an die Suchanfrage des Nutzers angehängt.
- Weist das LLM an, anhand der angehängten Daten eine Zusammenfassung zu erstellen.
return
Beim Reinforcement Learning ist die Summe bei einer bestimmten Richtlinie und einem bestimmten Bundesstaat die Summe aller Belohnungen, die der Agent erhält, wenn er die Richtlinie vom Bundesstaat bis zum Ende der Folge befolgt. Der Agent berücksichtigt die Verzögerung erwarteter Prämien, indem er Prämien entsprechend den für den Erhalt der Prämie erforderlichen Statusumstellungen reduziert.
Wenn also der Rabattfaktor \(\gamma\)beträgt und \(r_0, \ldots, r_{N}\)die Prämien bis zum Ende der Folge angibt, wird die Rendite so berechnet:
eine Belohnung
Beim Reinforcement Learning ist das numerische Ergebnis der Ausführung einer Aktion in einem Zustand, wie von der Umgebung definiert.
Rimmenregularisierung
Synonym für L2-Regularisierung. Der Begriff Randregulierung wird häufiger im Kontext reiner Statistiker verwendet, während L2-Regularisierung häufiger beim maschinellen Lernen verwendet wird.
Logo: RNN
Abkürzung für recurrent neural Networks.
ROC-Kurve (Receiver Operating Curve)
Ein Diagramm der Rate echt positiver Ergebnisse im Vergleich zur Rate falsch positiver Ergebnisse für verschiedene Klassifizierungsschwellenwerte bei der binären Klassifizierung.
Die Form einer ROC-Kurve deutet auf die Fähigkeit eines binären Klassifizierungsmodells hin, positive von negativen Klassen zu trennen. Angenommen, ein binäres Klassifizierungsmodell trennt zum Beispiel alle negativen Klassen perfekt von allen positiven Klassen:
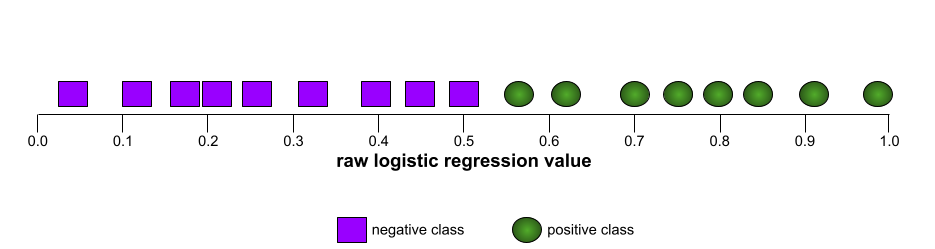
Die ROC-Kurve für das vorherige Modell sieht so aus:
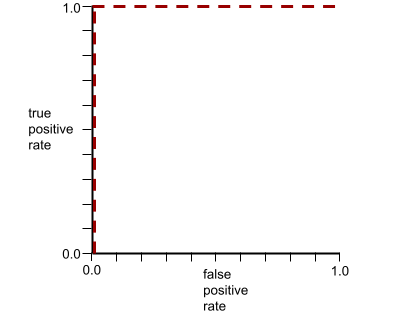
Im Gegensatz dazu werden in der folgenden Abbildung die unbearbeiteten logistischen Regressionswerte für ein schlechtes Modell grafisch dargestellt, das negative Klassen überhaupt nicht von positiven Klassen trennen kann:
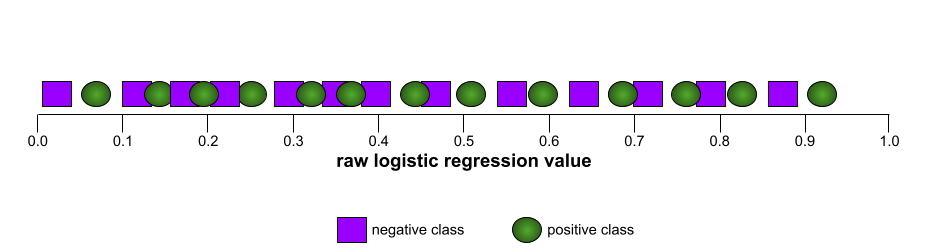
Die ROC-Kurve für dieses Modell sieht so aus:

In der realen Welt trennen die meisten binären Klassifizierungsmodelle positive und negative Klassen zu einem gewissen Grad, aber in der Regel nicht perfekt. Eine typische ROC-Kurve liegt also irgendwo zwischen zwei Extremen:
Der Punkt auf einer ROC-Kurve, der (0,0;1,0) am nächsten ist, gibt theoretisch den idealen Klassifizierungsschwellenwert an. Die Auswahl des idealen Klassifizierungsschwellenwerts wird jedoch von einigen anderen realen Problemen beeinflusst. Falsch negative Ergebnisse bereiten beispielsweise viel schmerzhaftere Ergebnisse an als falsch positive.
Ein numerischer Messwert namens AUC fasst die ROC-Kurve in einen einzelnen Gleitkommawert zusammen.
Rollenaufforderung
Ein optionaler Teil eines Prompts, der eine Zielgruppe für die Antwort eines Generative AI-Modells angibt. Ohne Rollenaufforderung liefert ein Large Language Model eine Antwort, die für die Person, die die Fragen stellt, nützlich oder nicht nützlich sein kann. Mit einer Rollenaufforderung kann ein Large Language Model die Antwort auf eine Weise beantworten, die für eine bestimmte Zielgruppe geeigneter und hilfreicher ist. Beispielsweise ist der Teil der folgenden Aufforderungen fett formatiert:
- Fasse diesen Artikel für einen Doktortitel in Wirtschaftswissenschaften zusammen.
- Beschreibe, wie die Gezeiten für ein zehnjähriges Kind funktionieren.
- Die Finanzkrise von 2008 erklären Sprechen Sie mit einem Kind oder einem Golden Retriever.
root
Startknoten (die erste Bedingung) in einem Entscheidungsbaum. Konventionsgemäß wird bei Diagrammen die Wurzel an der Spitze des Entscheidungsbaums platziert. Beispiel:
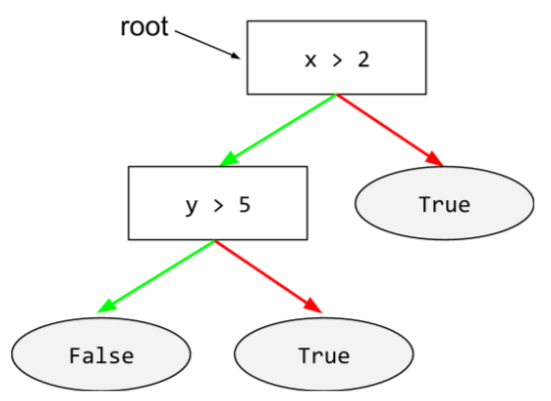
Stammverzeichnis
Das Verzeichnis, das Sie zum Hosten von Unterverzeichnissen des TensorFlow-Prüfpunkts und der Ereignisdateien mehrerer Modelle angeben.
Wurzel des mittleren quadratischen Fehlers (Root Mean Squared Error, RMSE)
Die Quadratwurzel des mittleren quadratischen Fehlers.
Rotationsinvarianz
Bei einem Problem zur Bildklassifizierung die Fähigkeit eines Algorithmus, Bilder auch dann erfolgreich zu klassifizieren, wenn sich die Ausrichtung des Bildes ändert. Der Algorithmus kann beispielsweise einen Tennisschläger erkennen, ob er nach oben, seitlich oder nach unten zeigt. Eine Rotationsinvarianz ist nicht immer erwünscht. So sollte beispielsweise eine verkehrte 9 nicht als 9 klassifiziert werden.
Siehe auch Translationale Invarianz und Größeninvarianz.
R-Quadrat
Ein Regressionsmesswert, der angibt, wie stark ein Label auf ein einzelnes Feature oder einen Featuresatz zurückzuführen ist. Das R-Quadrat ist ein Wert zwischen 0 und 1, den Sie so interpretieren können:
- Ein R-Quadrat von 0 bedeutet, dass keine Variante eines Labels auf den Featuresatz zurückzuführen ist.
- Ein R-Quadrat von 1 bedeutet, dass die gesamte Schwankung eines Labels auf den Elementsatz zurückzuführen ist.
- Ein R-Quadrat zwischen 0 und 1 gibt das Ausmaß an, in dem die Abweichungen des Labels von einem bestimmten Feature oder dem Feature-Set vorhergesagt werden können. Ein R-Quadrat von 0,10 bedeutet beispielsweise, dass 10 % der Varianz im Label auf den Featuresatz zurückzuführen sind, ein R-Quadrat von 0,20, dass 20 % auf den Feature-Set zurückzuführen sind usw.
R-Quadrat ist das Quadrat des Pearson-Korrelationskoeffizienten zwischen den von einem Modell vorhergesagten Werten und Ground Truth.
S
Stichprobenverzerrung
Siehe Auswahlverzerrung.
Stichprobennahme mit Ersatz
Methode zum Auswählen von Elementen aus einer Reihe von möglichen Elementen, bei der dasselbe Element mehrmals ausgewählt werden kann. Der Ausdruck "mit Ersatz" bedeutet, dass das ausgewählte Element nach jeder Auswahl an den Pool der möglichen Elemente zurückgegeben wird. Die umgekehrte Methode, Stichproben ohne Ersatz, bedeutet, dass ein mögliches Element nur einmal ausgewählt werden kann.
Betrachten Sie zum Beispiel die folgende Obstsorte:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
Angenommen, das System wählt fig nach dem Zufallsprinzip als erstes Element aus.
Wenn Sie die Stichprobenerhebung mit Ersatz verwenden, wählt das System das zweite Element aus der folgenden Gruppe aus:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
Ja, das ist derselbe Wert wie zuvor, sodass das System möglicherweise noch einmal fig auswählen könnte.
Wenn Sie eine Stichprobe ohne Ersatz verwenden, kann eine Stichprobe nach der Auswahl nicht noch einmal ausgewählt werden. Wenn das System beispielsweise fig nach dem Zufallsprinzip als erste Stichprobe auswählt, kann fig nicht noch einmal ausgewählt werden. Daher wählt das System die zweite Stichprobe aus der folgenden (reduzierten) Menge aus:
fruit = {kiwi, apple, pear, cherry, lime, mango}
SavedModel
Das empfohlene Format zum Speichern und Wiederherstellen von TensorFlow-Modellen. VoiceOver ist ein sprachneutrales, wiederherstellbares Serialisierungsformat, das es übergeordneten Systemen und Tools ermöglicht, TensorFlow-Modelle zu erstellen, zu verarbeiten und zu verarbeiten.
Ausführliche Informationen finden Sie im Kapitel Saving and Restore im TensorFlow Programmer's Guide.
Kostengünstig
Ein TensorFlow-Objekt, das für die Speicherung von Modellprüfpunkten verantwortlich ist.
Skalar
Eine einzelne Zahl oder ein einzelner String, der als Tensor vom Rang 0 dargestellt werden kann. Beispielsweise erstellen die folgenden Codezeilen jeweils einen Skalar in TensorFlow:
breed = tf.Variable("poodle", tf.string)
temperature = tf.Variable(27, tf.int16)
precision = tf.Variable(0.982375101275, tf.float64)
Skalierung
Jede mathematische Transformation oder Technik, die den Bereich eines Label- und/oder Featurewerts verschiebt. Einige Arten der Skalierung sind sehr nützlich für Transformationen wie die Normalisierung.
Gängige Formen der Skalierung, die beim maschinellen Lernen nützlich sind:
- Lineare Skalierung, bei der normalerweise eine Kombination aus Subtraktion und Division verwendet wird, um den ursprünglichen Wert durch eine Zahl zwischen -1 und +1 oder zwischen 0 und 1 zu ersetzen.
- logarithmische Skalierung, bei der der ursprüngliche Wert durch seinen Logarithmus ersetzt wird.
- Z-Score-Normalisierung, die den ursprünglichen Wert durch einen Gleitkommawert ersetzt, der die Anzahl der Standardabweichungen vom Mittelwert dieses Features darstellt.
scikit-learn
Eine beliebte Open-Source-Plattform für maschinelles Lernen. Siehe scikit-learn.org.
Bewertung
Der Teil eines Empfehlungssystems, der einen Wert oder eine Rangfolge für jeden Artikel angibt, der in der Phase der Kandidatgenerierung erstellt wurde.
Auswahlverzerrung
Fehler in Schlussfolgerungen aus Stichprobendaten aufgrund eines Auswahlprozesses, der systematische Unterschiede zwischen den in den Daten beobachteten Stichproben und den nicht beobachteten Stichproben erzeugt. Es gibt die folgenden Formen der Auswahlverzerrung:
- Abdeckungsverzerrung: Die im Dataset dargestellte Population stimmt nicht mit der Population überein, für die das Modell für maschinelles Lernen Vorhersagen trifft.
- Stichprobenverzerrung: Die Daten der Zielgruppe werden nicht nach dem Zufallsprinzip erfasst.
- Nicht-Antwortverzerrung (auch als Teilnahmeverzerrung bezeichnet): Nutzer aus bestimmten Gruppen nehmen zu unterschiedlichen Häufigkeiten an Umfragen teil als Nutzer aus anderen Gruppen.
Angenommen, Sie erstellen ein Modell für maschinelles Lernen, das vorhersagt, wie gut ein Film läuft. Zum Erfassen von Trainingsdaten geben Sie allen in der ersten Reihe eines Kinos, in dem der Film gezeigt wird, eine Umfrage aus. Dies mag nach einer vernünftigen Methode zum Erfassen eines Datasets klingen. Diese Form der Datenerhebung kann jedoch zu den folgenden Formen der Auswahlverzerrung führen:
- Abdeckungsverzerrung: Durch Stichproben aus einer Population, die sich den Film angesehen hat, werden die Vorhersagen Ihres Modells möglicherweise nicht auf Personen verallgemeinert, die dieses Interesse an dem Film noch nicht zum Ausdruck gebracht haben.
- Stichprobenverzerrung: Anstelle einer zufälligen Stichprobennahme von der gewünschten Bevölkerung (alle Personen im Film) haben Sie nur die Personen in der ersten Reihe genommen. Es ist möglich, dass die Personen in der ersten Reihe mehr an dem Film interessiert waren als die Personen in den anderen Zeilen.
- Non-Response-Verzerrung: Im Allgemeinen nehmen Personen mit einer ausgeprägten Meinung häufiger an optionalen Umfragen teil als Personen mit einer eher schwachen Meinung. Da die Filmumfrage optional ist, bilden die Antworten eher eine bimodale Verteilung als eine normale (glockenförmige) Verteilung.
Selbstaufmerksamkeit
Eine neuronale Netzwerkschicht, die eine Folge von Einbettungen (z. B. Tokeneinbettungen) in eine andere Folge von Einbettungen umwandelt. Jede Einbettung in der Ausgabesequenz wird erstellt, indem Informationen aus den Elementen der Eingabesequenz über einen attention-Mechanismus integriert werden.
Der self-Teil der Self-Aufmerksamkeit bezieht sich auf die Abfolge, die auf sich selbst achtet, nicht auf einen anderen Kontext. Selbstaufmerksamkeit ist einer der Hauptbausteine für Transformers. Sie verwendet Terminologie für die Wörterbuchsuche, z. B. "Abfrage", "Schlüssel" und "Wert".
Eine Selbstaufmerksamkeitsschicht beginnt mit einer Abfolge von Eingabedarstellungen, eine für jedes Wort. Die Eingabedarstellung für ein Wort kann eine einfache Einbettung sein. Für jedes Wort in einer Eingabesequenz bewertet das Netzwerk die Relevanz des Wortes für jedes Element in der gesamten Wortsequenz. Die Relevanzwerte bestimmen, wie stark die endgültige Darstellung des Wortes die Darstellungen anderer Wörter enthält.
Betrachten Sie zum Beispiel den folgenden Satz:
Das Tier ist die Straße nicht überquert, weil es zu müde war.
Die folgende Abbildung aus Transformer: A Novel Neural Network Architecture for Language Understanding zeigt das Aufmerksamkeitsmuster einer Selbstaufmerksamkeit für das Pronomen it, wobei die Dunkelheit jeder Zeile angibt, welchen Beitrag jedes Wort zur Darstellung beiträgt:
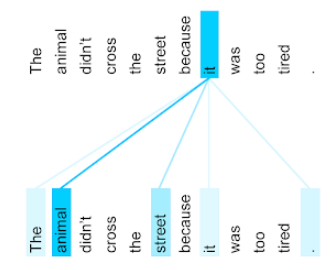
Die Ebene „Selbstaufmerksamkeit“ hebt Wörter hervor, die für „es“ relevant sind. In diesem Fall hat die Aufmerksamkeitsschicht gelernt, Wörter hervorzuheben, auf die sie sich beziehen könnte, und weist tier die höchste Gewichtung zu.
Bei einer Sequenz von n Tokens wandelt Self-attention eine Sequenz von Einbettungen n separate Male um, einmal an jeder Position in der Sequenz.
Weitere Informationen findest du unter Aufmerksamkeit und Selbstaufmerksamkeit mit mehreren Kopfen.
selbstüberwachtes Lernen
Eine Reihe von Techniken zur Umwandlung eines unüberwachten maschinellen Lernens in ein Problem für überwachtes maschinelles Lernen, indem Ersatzlabels aus Beispielen ohne Label erstellt werden.
Einige auf Transformer basierende Modelle wie BERT nutzen selbstüberwachtes Lernen.
Selbstüberwachtes Training ist ein halbüberwachter Lernansatz.
selbsttraining
Eine Variante des selbstüberwachten Lernens, die besonders nützlich ist, wenn alle der folgenden Bedingungen erfüllt sind:
- Das Verhältnis von Beispielen ohne Label zu Beispielen mit Label im Dataset ist hoch.
- Dies ist ein Klassifizierungsproblem.
Beim Selbsttraining werden die folgenden zwei Schritte durchlaufen, bis sich das Modell nicht mehr verbessert:
- Verwenden Sie überwachtes maschinelles Lernen, um ein Modell anhand der mit Labels versehenen Beispiele zu trainieren.
- Verwenden Sie das in Schritt 1 erstellte Modell, um Vorhersagen (Labels) für die Beispiele ohne Label zu generieren. Verschieben Sie dann diejenigen, bei denen eine hohe Konfidenz besteht, in die Beispiele mit Labels mit dem vorhergesagten Label.
Beachten Sie, dass mit jeder Iteration von Schritt 2 weitere Beispiele mit Labels für Schritt 1 hinzugefügt werden, mit denen das Training trainiert werden soll.
halbüberwachtes Lernen
Modell mit Daten trainieren, bei denen einige Trainingsbeispiele Labels haben, andere jedoch nicht. Eine Technik für semiüberwachtes Lernen besteht darin, Labels für die Beispiele ohne Labels abzuleiten und dann mit den abgeleiteten Labels zu trainieren, um ein neues Modell zu erstellen. Halbüberwachtes Lernen kann nützlich sein, wenn die Beschaffung von Labels teuer ist, aber zahlreiche Beispiele ohne Label vorhanden sind.
Selbsttraining ist eine Technik für das halbüberwachte Lernen.
sensibles Attribut
Eine menschliche Eigenschaft, die aus rechtlichen, ethischen, sozialen oder persönlichen Gründen besonders berücksichtigt werden kann.Histogramm: Sentimentanalyse
Die Verwendung statistischer oder maschineller Lernalgorithmen, um die allgemeine Einstellung einer Gruppe – positiv oder negativ – gegenüber einer Dienstleistung, einem Produkt, einer Organisation oder einem Thema zu bestimmen. Beispielsweise kann ein Algorithmus mithilfe von Natural Language Understanding eine Sentimentanalyse für das Textfeedback aus einem Universitätskurs durchführen, um festzustellen, inwieweit Studenten der Kurs im Allgemeinen gefallen bzw. nicht gefallen hat.
Sequenzmodell
Ein Modell, dessen Eingaben eine sequenzielle Abhängigkeit haben. Zum Beispiel die Vorhersage des nächsten angesehenen Videos aus einer Abfolge zuvor angesehener Videos.
Sequenz-zu-Sequenz-Aufgabe
Eine Aufgabe, die eine Eingabesequenz von Tokens in eine Ausgabesequenz von Tokens konvertiert. Zwei beliebte Arten von Sequenz-zu-Sequenz-Aufgaben sind beispielsweise:
- Übersetzer:
- Beispieleingabesequenz: „Ich liebe dich.“
- Beispielausgabesequenz: „Je t'aime.“
- Fragen beantworten:
- Beispiel für eine Eingabesequenz: „Brauche ich mein Auto in New York City?“
- Beispiel für eine Ausgabesequenz: „Nein. Bitte lassen Sie Ihr Auto zu Hause.“
Portion
Prozess, bei dem ein trainiertes Modell zur Bereitstellung von Vorhersagen über Online-Inferenz oder Offline-Inferenz verfügbar gemacht wird.
Form (Tensor)
Die Anzahl der Elemente in jeder Dimension eines Tensors. Die Form wird als Liste von Ganzzahlen dargestellt. Der folgende zweidimensionale Tensor hat beispielsweise die Form [3,4]:
[[5, 7, 6, 4], [2, 9, 4, 8], [3, 6, 5, 1]]
Da TensorFlow das Zeilenformat (C-Stil) verwendet, um die Reihenfolge der Dimensionen darzustellen, lautet die Form in TensorFlow [3,4] und nicht [4,3]. Mit anderen Worten, bei einem zweidimensionalen TensorFlow Tensor ist die Form [Anzahl der Zeilen, Anzahl der Spalten].
Shard
Eine logische Division des Trainings-Datasets oder des Modells. In der Regel werden bei einigen Prozessen Shards erstellt, indem die Beispiele oder Parameter in (normalerweise) gleich große Blöcke unterteilt werden. Jeder Shard wird dann einem anderen Computer zugewiesen.
Das Fragmentieren eines Modells wird als Modellparallelität bezeichnet, das Fragmentieren von Daten als Datenparallelität.
verkleinert
Ein Hyperparameter im Gradienten-Boosting, der die Überanpassung steuert. Die Verkleinerung beim Gradienten-Boosting ist analog zur Lernrate beim Gradientenabstieg. Die Verkleinerung ist ein Dezimalwert zwischen 0,0 und 1,0. Ein niedrigerer Verkleinerungswert verringert eine Überanpassung mehr als ein größerer Verkleinerungswert.
Sigmoidfunktion
Eine mathematische Funktion, mit der ein Eingabewert in einen eingeschränkten Bereich verschoben wird, in der Regel zwischen 0 und 1 oder -1 bis +1. Sie können also eine beliebige Zahl (zwei, eine Million, negative Milliarde usw.) an ein Sigmoid übergeben, und die Ausgabe bleibt im eingeschränkten Bereich. Das Diagramm der Sigmoidaktivierungsfunktion sieht so aus:
Die Sigmoidfunktion wird beim maschinellen Lernen mehrfach verwendet:
- Die Rohausgabe eines logistischen Regressionsmodells oder eines multinomialen Regressionsmodells in einen Wahrscheinlichkeitswert konvertieren
- In einigen neuronalen Netzwerken als Aktivierungsfunktion
Ähnlichkeitsmaß
In den Clustering-Algorithmen wird anhand des Messwerts bestimmt, wie ähnlich (wie ähnlich) die beiden Beispiele sind.
Single Program / Multiple Data (SPMD)
Parallelitätsverfahren, bei dem dieselbe Berechnung für verschiedene Eingabedaten parallel auf verschiedenen Geräten ausgeführt wird. Ziel von SPMD ist es, schneller Ergebnisse zu erhalten. Dies ist der gängigste Stil der parallelen Programmierung.
Größeninvarianz
Bei einem Problem zur Bildklassifizierung die Fähigkeit eines Algorithmus, Bilder auch dann erfolgreich zu klassifizieren, wenn sich die Größe des Bildes ändert. Beispielsweise kann der Algorithmus eine Katze trotzdem identifizieren, ob sie 2 Millionen oder 200.000 Pixel verbraucht. Beachten Sie, dass selbst die besten Algorithmen zur Bildklassifizierung dennoch praktische Grenzen in Bezug auf Größenabweichungen haben. Beispielsweise ist es unwahrscheinlich, dass ein Algorithmus (oder eine Person) ein Katzenbild, das nur 20 Pixel hat, korrekt klassifiziert.
Siehe auch Übersetzungsinvarianz und Rotationsinvarianz.
Skizzieren
Eine Kategorie von Algorithmen beim unüberwachten Machine Learning, die eine vorläufige Ähnlichkeitsanalyse an Beispielen durchführen. Zeichenalgorithmen verwenden eine ortsabhängige Hash-Funktion, um Punkte zu identifizieren, die wahrscheinlich ähnlich sind, und sie dann in Buckets zu gruppieren.
Das Skizzieren reduziert den Rechenaufwand für Ähnlichkeitsberechnungen bei großen Datasets. Anstatt die Ähnlichkeit für jedes einzelne Paar von Beispielen im Dataset zu berechnen, berechnen wir die Ähnlichkeit nur für jedes Punktpaar in jedem Bucket.
Skip-Gramm
Ein N-Gramm, bei dem Wörter aus dem ursprünglichen Kontext weggelassen (oder „überspringen“) werden, sodass die N-Wörter möglicherweise nicht ursprünglich nebeneinander standen. Genauer gesagt ist ein „k-skip-n-gram“ ein N-Gramm, für das bis zu k Wörter übersprungen wurden.
Der schnelle braune Fuchs hat beispielsweise die folgenden 2 Gramm:
- „die schnelle“
- "schnelles Braun"
- "brauner Fuchs"
„1-überspringen-2-gramm“ ist ein Wortpaar, in dem höchstens ein Wort zwischen ihnen steht. Daher hat „der schnell braune Fuchs“ die folgenden 2 Gramme, die man überspringen kann:
- „der Braun“
- „Quick Fox“
Außerdem sind alle 2-Gramme auch 1-überspringen-2-Gramme, da weniger als ein Wort übersprungen werden kann.
Mit Skip-Grammen können Sie den Kontext eines Wortes besser verstehen. Im Beispiel wurde „Fuchs“ in der Gruppe von 1-überspringen-2-Grammen direkt mit „schnell“ in Verbindung gebracht, aber nicht in der Menge der 2-Gramme.
Skip-Gramme helfen beim Trainieren von Worteinbettungsmodellen.
Softmax-Funktion
Eine Funktion, die Wahrscheinlichkeiten für jede mögliche Klasse in einem Klassifizierungsmodell mit mehreren Klassen bestimmt. Die Wahrscheinlichkeiten ergeben insgesamt genau 1,0. Die folgende Tabelle zeigt beispielsweise, wie Softmax verschiedene Wahrscheinlichkeiten verteilt:
| Das Bild ist... | Probability |
|---|---|
| Hund | 0,85 |
| Cat | 0,13 |
| Pferd | ,02 |
Softmax wird auch als vollständiges Softmax bezeichnet.
Im Vergleich zur Stichprobenerhebung für Kandidaten
Vorläufige Einstellung von Prompts
Verfahren zur Abstimmung eines Large Language Model für eine bestimmte Aufgabe ohne ressourcenintensive Feinabstimmung. Anstatt alle Gewichtungen im Modell neu zu trainieren, wird bei der Feinabstimmung von weichen Prompts automatisch eine Aufforderung so angepasst, dass dasselbe Ziel erreicht wird.
Bei einer Aufforderung in Textform werden bei der Feinabstimmung von Aufforderungen in der Regel zusätzliche Tokeneinbettungen an die Aufforderung angehängt und die Eingabe wird durch Backpropagierung optimiert.
Eine „harte“ Eingabeaufforderung enthält tatsächliche Tokens anstelle von Tokeneinbettungen.
dünnbesetztes Feature
Ein Feature, dessen Werte überwiegend null oder leer sind. Beispiel: Ein Feature mit einem einzelnen Wert 1 und einer Million 0-Werten ist dünnbesetzt. Im Gegensatz dazu hat ein dichtes Feature Werte, die überwiegend nicht null oder leer sind.
Beim maschinellen Lernen gibt es erstaunlich viele Funktionen, die nur dünnbesetzt sind. Kategorische Merkmale sind in der Regel dünnbesetzte Merkmale. Beispielsweise könnte von den 300 möglichen Baumarten in einem Wald in einem einzelnen Beispiel nur ein Ahornbaum identifiziert werden. Oder unter den Millionen möglicher Videos in einer Videobibliothek könnte ein einzelnes Beispiel nur „Casablanca“ heißen.
In einem Modell stellen Sie dünnbesetzte Features in der Regel mit One-Hot-Codierung dar. Wenn die One-Hot-Codierung groß ist, können Sie für eine höhere Effizienz eine Einbettungsschicht über die One-Hot-Codierung legen.
dünnbesetzte Darstellung
Nur die Position(en) von Elementen ungleich null in einem dünnbesetzten Feature speichern.
Angenommen, ein kategoriales Feature namens species identifiziert die 36 Baumarten in einem bestimmten Wald. Nehmen wir weiter an, dass jedes Beispiel nur eine einzelne Art identifiziert.
Sie könnten einen One-Hot-Vektor verwenden, um die Baumarten in jedem Beispiel darzustellen.
Ein One-Hot-Vektor enthält eine einzelne 1 (zur Darstellung der jeweiligen Baumart in diesem Beispiel) und 35 0s (um die 35 Baumarten darzustellen, die in diesem Beispiel nicht). Die One-Hot-Darstellung von maple könnte also in etwa so aussehen:

Alternativ würde bei einer dünnbesetzten Darstellung einfach die Position der jeweiligen Art identifiziert werden. Wenn sich maple auf Position 24 befindet, würde die dünnbesetzte Darstellung von maple einfach so aussehen:
24
Beachten Sie, dass die dünnbesetzte Darstellung viel kompakter ist als die One-Hot-Darstellung.
Klicken Sie auf das Symbol, um ein etwas komplexeres Beispiel anzuzeigen.
Angenommen, jedes Beispiel in Ihrem Modell muss die Wörter – aber nicht die Reihenfolge dieser Wörter – in einem englischen Satz darstellen. Englisch besteht aus etwa 170.000 Wörtern. Englisch ist also ein kategoriales Merkmal mit etwa 170.000 Elementen. Die meisten englischen Sätze enthalten einen sehr winzigen Bruchteil dieser 170.000 Wörter, sodass die Wörter in einem einzigen Beispiel mit hoher Wahrscheinlichkeit wenig Daten enthalten.
Betrachten Sie den folgenden Satz:
My dog is a great dog
Sie können eine Variante eines One-Hot-Vektors verwenden, um die Wörter in diesem Satz darzustellen. Bei dieser Variante können mehrere Zellen im Vektor einen Wert ungleich null enthalten. Außerdem kann in dieser Variante eine Zelle eine andere Ganzzahl enthalten. Obwohl die Wörter „my“, „is“, „a“ und „great“ nur einmal im Satz vorkommen, kommt das Wort „Hund“ zweimal vor. Wenn Sie diese Variante von One-Hot-Vektoren zur Darstellung der Wörter in diesem Satz verwenden,ergibt sich der folgende Vektor mit 170.000 Elementen:

Eine dünnbesetzte Darstellung desselben Satzes wäre einfach:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
dünnbesetzter Vektor
Ein Vektor, dessen Werte hauptsächlich Nullen sind. Weitere Informationen finden Sie unter Sparse-Feature und Datendichte.
dünne Besetzung
Die Anzahl der Elemente, die in einem Vektor oder einer Matrix auf null (oder null) gesetzt sind, geteilt durch die Gesamtzahl der Einträge in diesem Vektor oder dieser Matrix. Angenommen, eine Matrix mit 100 Elementen hat 98 Zellen, die Null enthalten. Die Datendichte wird so berechnet:
Feature-Datendichte bezieht sich auf die Datendichte eines Featurevektors, Datenknappheit auf die Datendichte der Modellgewichtungen.
räumliches Pooling
Siehe Pooling.
split
In einem Entscheidungsbaum ein anderer Name für eine Bedingung
Splitter
Beim Training eines Entscheidungsbaums sind die Routine (und der Algorithmus) für die Suche nach der besten Bedingung auf jedem Knoten verantwortlich.
SPMD
Abkürzung für einzelnes Programm / mehrere Daten.
Verlust der quadratischen Scharnier
Das Quadrat des Verlusts des Scharniers. Beim quadratischen Scharnierverlust werden Ausreißer stärker bestraft als beim normalen Scharnierverlust.
Quadratischer Verlust
Synonym für L2-Verlust.
Gestaffeltes Training
Taktik, bei der ein Modell in einer Abfolge von diskreten Phasen trainiert wird. Das Ziel kann entweder die Beschleunigung des Trainingsprozesses oder die Verbesserung der Modellqualität sein.
Hier sehen Sie eine Abbildung des Progressive-Stacking-Ansatzes:
- Phase 1 enthält drei versteckte Ebenen, Phase 2 sechs versteckte Ebenen und Phase 3 12 versteckte Ebenen.
- Phase 2 beginnt mit dem Training mit den Gewichtungen, die Sie in den drei verborgenen Schichten von Phase 1 gelernt haben. Phase 3 beginnt mit dem Training mit den erlernten Gewichten aus den 6 verborgenen Schichten von Phase 2.
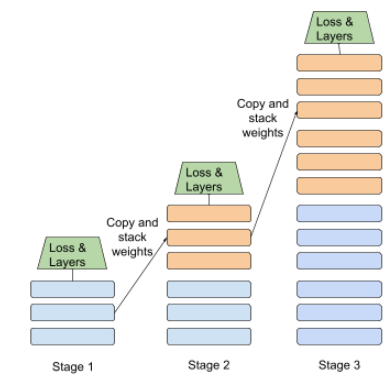
Weitere Informationen finden Sie unter Pipeline.
state
Beim Reinforcement Learning die Parameterwerte, die die aktuelle Konfiguration der Umgebung beschreiben, mit der der Agent eine Aktion auswählt.
State-Action-Wert-Funktion
Synonym für Q-Funktion.
Statisch
Einmal anstatt fortlaufend. Die Begriffe statisch und offline sind Synonyme. static und offline werden beim maschinellen Lernen häufig verwendet:
- Statisches Modell (oder Offline-Modell) ist ein Modell, das einmal trainiert und dann für eine gewisse Zeit verwendet wird.
- Statisches Training (oder Offlinetraining) ist der Prozess des Trainings eines statischen Modells.
- Eine statische Inferenz (oder Offlineinferenz) ist ein Prozess, bei dem ein Modell einen Batch von Vorhersagen auf einmal generiert.
Kontrast mit dynamisch
statische Inferenz
Synonym für Offlineinferenz.
stehen bleiben
Ein Element, dessen Werte sich in einer oder mehreren Dimensionen nicht ändern (in der Regel zeitbezogen). Beispiel: Ein Element, dessen Werte 2021 und 2023 ungefähr gleich aussehen, weist Schreibstabilität auf.
In der realen Welt weist nur sehr wenige Elemente Stationarität auf. Auch Funktionen, die für Stabilität bekannt sind (z. B. den Meeresspiegel), ändern sich im Laufe der Zeit.
Stellen Sie einen Kontrast zu Nichtstationarität her.
Schritt
Vorwärts- und Rückwärtsdurchlauf eines Batches.
Weitere Informationen zu Vorwärts- und Rückwärtsterminierung finden Sie unter Rückpropagierung.
Schrittgröße
Synonym für Lernrate.
Stochastisches Gradientenabstieg (SGD)
Ein Algorithmus für den Gradientenabstieg, bei dem die Batchgröße eins ist. Mit anderen Worten, SGD wird anhand eines einzelnen Beispiels trainiert, das gleichmäßig aus einem Trainingssatz zufällig ausgewählt wird.
Stride
Bei einem Faltungsvorgang oder Pooling das Delta in jeder Dimension der nächsten Reihe von Eingabesegmenten. Die folgende Animation zeigt beispielsweise einen Schritt (1,1) während eines Faltvorgangs. Daher beginnt das nächste Eingabesegment eine Position rechts vom vorherigen Eingabesegment. Wenn der Vorgang den rechten Rand erreicht, ist das nächste Kreissegment ganz links, nur eine Position weiter unten.
Das vorherige Beispiel zeigt einen zweidimensionalen Schritt. Wenn die Eingabematrix dreidimensional ist, wäre der Schritt ebenfalls dreidimensional.
Strukturelle Risikominimierung (SRM)
Ein Algorithmus, der zwei Ziele miteinander in Einklang bringt:
- Die Notwendigkeit, das beste Vorhersagemodell zu erstellen (z. B. den niedrigsten Verlust).
- Das Modell muss so einfach wie möglich gehalten werden (z. B. starke Regularisierung).
Eine Funktion zur Minimierung von Verlust und Regularisierung im Trainings-Dataset ist beispielsweise ein Algorithmus zur strukturellen Risikominimierung.
Im Gegensatz zur empirischen Risikominimierung.
Subsampling
Siehe Pooling.
Unterworttoken
In Sprachmodellen ein Token, das ein Teilstring eines Wortes ist, bei dem es sich um das gesamte Wort handeln kann.
Ein Wort wie „itemize“ kann beispielsweise in die Stücke „item“ (Stammwort) und „ize“ (ein Suffix) aufgeteilt werden, die jeweils durch ein eigenes Token dargestellt werden. Durch die Aufteilung ungewöhnlicher Wörter in solche, sogenannte Unterwörter, können Sprachmodelle mit den am häufigsten verwendeten Bestandteilen des Wortes arbeiten, z. B. Präfixe und Suffixe.
Umgekehrt lassen sich gängige Wörter wie „fortlaufend“ nicht aufsplitten, sondern können durch ein einzelnes Token dargestellt werden.
Zusammenfassung
In TensorFlow ein Wert oder eine Gruppe von Werten, der in einem bestimmten Schritt berechnet wurde und der normalerweise zum Nachverfolgen von Modellmesswerten während des Trainings verwendet wird.
überwachtes maschinelles Lernen
Beim Trainieren eines model aus model und den entsprechenden model. Das überwachte maschinelle Lernen ist analog zum Erlernen eines Fachs, indem eine Reihe von Fragen und die entsprechenden Antworten untersucht werden. Nachdem der Schüler die Zuordnung von Fragen und Antworten gemeistert hat, kann er Antworten auf neue (bisher unbekannte) Fragen zum selben Thema geben.
Dies ist mit unüberwachtem maschinellem Lernen vergleichbar.
synthetisches Feature
Ein Feature, das nicht zu den Eingabefeatures gehört, aber aus einem oder mehreren dieser Features zusammengestellt wurde. Folgende Methoden zum Erstellen synthetischer Features sind verfügbar:
- Bucketing eines fortlaufenden Features in Bereichsbereiche.
- Eine Feature-Cross-Funktion erstellen
- Multiplizieren (oder Dividieren) eines Merkmalswerts mit anderen Merkmalswerten oder durch sich selbst. Wenn
aundbbeispielsweise Eingabefeatures sind, sind die folgenden Beispiele für synthetische Features:- ab
- a2
- Eine transzendentale Funktion auf einen Merkmalswert anwenden Wenn
cbeispielsweise ein Eingabefeature ist, dann finden Sie hier Beispiele für synthetische Features:- sin(c)
- ln(c)
Durch die Normalisierung oder Skalierung allein erstellte Features werden nicht als synthetische Features betrachtet.
T
T5
Ein Text-zu-Text-Lernmodell, das 2020 von Google AI eingeführt wurde. T5 ist ein Encoder-Decoder-Modell, das auf der Transformer-Architektur basiert und mit einem extrem großen Dataset trainiert wurde. Er kann bei einer Vielzahl von Natural Language Processing-Aufgaben eingesetzt werden, z. B. beim Generieren von Text, Übersetzen von Sprachen und Beantworten von Fragen in natürlicher Sprache.
T5 wird nach den fünf Ts in „Text-to-Text Transfer Transformer“ benannt.
T5X
Ein Open-Source-Framework für maschinelles Lernen, das zum Erstellen und Trainieren von großen NLP-Modellen (Natural Language Processing) entwickelt wurde. T5 wird auf der T5X-Codebasis implementiert, die auf JAX und Flax basiert.
Tabellarisches Q-Learning
Implementieren Sie beim bestärkenden Lernen Q-learning mithilfe einer Tabelle, in der die Q-Funktionen für jede Kombination aus Zustand und Aktion gespeichert werden.
Ziel
Synonym für label.
Zielnetzwerk
In Deep Q-learning ein neuronales Netzwerk, das eine stabile Näherung des neuronalen Hauptnetzwerks ist, wobei das neuronale Hauptnetzwerk entweder eine Q-Funktion oder eine Richtlinie implementiert. Anschließend können Sie das Hauptnetzwerk mit den vom Zielnetzwerk vorhergesagten Q-Werten trainieren. Daher verhindern Sie die Feedbackschleife, die auftritt, wenn das Hauptnetzwerk anhand von selbst vorhergesagten Q-Werten trainiert. Durch das Vermeiden dieses Feedbacks erhöht sich die Stabilität des Trainings.
Task (in computational context, see definition)
Ein Problem, das mit Techniken des maschinellen Lernens gelöst werden kann, z. B.:
Temperatur
Ein Hyperparameter, der den Grad der Zufälligkeit einer Modellausgabe steuert. Bei höheren Temperaturen ist die Ausgabe zufälliger, bei niedrigeren Temperaturen ist die Ausgabe weniger zufällig.
Die Auswahl der besten Temperatur hängt von der spezifischen Anwendung und den bevorzugten Attributen der Modellausgabe ab. Beispielsweise würden Sie die Temperatur wahrscheinlich erhöhen, wenn Sie eine Anwendung erstellen, mit der Creatives generiert werden. Umgekehrt würden Sie wahrscheinlich die Temperatur senken, wenn Sie ein Modell erstellen, das Bilder oder Text klassifiziert, um die Genauigkeit und Konsistenz des Modells zu verbessern.
Die Temperatur wird häufig mit Softmax verwendet.
zeitliche Daten
Daten, die zu verschiedenen Zeitpunkten aufgezeichnet wurden. Die für jeden Tag des Jahres erfassten Wintermantelverkäufe sind z. B. zeitliche Daten.
Tensor
Die primäre Datenstruktur in TensorFlow-Programmen. Tensoren sind N-dimensionale Datenstrukturen, wobei N eine sehr große Datenstruktur sein kann. Meist sind Skalare, Vektoren oder Matrizen. Die Elemente eines Tensors können Ganzzahl-, Gleitkomma- oder String-Werte enthalten.
TensorBoard
Das Dashboard mit den Zusammenfassungen, die während der Ausführung eines oder mehrerer TensorFlow-Programme gespeichert wurden.
TensorFlow
Eine große, verteilte Plattform für maschinelles Lernen. Der Begriff bezieht sich auch auf die Basis-API-Ebene im TensorFlow-Stack, die allgemeine Berechnungen zu Dataflow-Diagrammen unterstützt.
Obwohl TensorFlow hauptsächlich für maschinelles Lernen verwendet wird, können Sie TensorFlow auch für Nicht-ML-Aufgaben verwenden, die numerische Berechnungen mithilfe von Dataflow-Diagrammen erfordern.
TensorFlow-Playground
Ein Programm, das visualisiert, wie verschiedene Hyperparameter das Training des Modells (hauptsächlich neuronale Netzwerke) beeinflussen. Rufen Sie http://playground.tensorflow.org auf, um TensorFlow Playground zu testen.
TensorFlow bereitstellen
Eine Plattform zum Bereitstellen trainierter Modelle in der Produktion.
Tensor Processing Unit (TPU)
Ein anwendungsspezifischer integrierter Schaltkreis (ASIC), der die Leistung von ML-Arbeitslasten optimiert. Diese ASICs werden als mehrere TPU-Chips auf einem TPU-Gerät bereitgestellt.
Tensor-Rang
Siehe Rang (Tensor).
Tensor-Form
Die Anzahl der Elemente, die ein Tensor in verschiedenen Dimensionen enthält.
Ein [5, 10]-Tensor hat beispielsweise die Form 5 in einer Dimension und 10 in einer anderen.
Tensorgröße
Die Gesamtzahl der Skalare, die ein Tensor enthält. Ein [5, 10]-Tensor hat beispielsweise eine Größe von 50.
TensorStore
Eine Bibliothek zum effizienten Lesen und Schreiben großer mehrdimensionaler Arrays.
Kündigungsbedingung
Beim Bestärkendes Lernen werden die Bedingungen definiert, die bestimmen, wann eine Folge endet, z. B. wenn der Agent einen bestimmten Status erreicht oder einen Schwellenwert für Statusübergänge überschreitet. Bei Tic-Tac-Toe (auch als „Noughts“ und „Crosses“ bezeichnet) endet eine Folge entweder, wenn ein Spieler drei aufeinanderfolgende Leerzeichen markiert oder wenn alle Leerzeichen markiert sind.
Test
In einem Entscheidungsbaum ein anderer Name für eine Bedingung
Testverlust
Ein Messwert, der den Verlust eines Modells gegenüber dem Test-Dataset darstellt. Beim Erstellen eines model versuchen Sie in der Regel, den Testverlust zu minimieren. Das liegt daran, dass ein geringer Testverlust ein besseres Signal als ein niedriger Trainingsverlust oder ein geringer Validierungsverlust darstellt.
Eine große Lücke zwischen dem Testverlust und dem Trainings- oder Validierungsverlust weist manchmal darauf hin, dass Sie die Regularisierungsrate erhöhen müssen.
Test-Dataset
Eine Teilmenge des Datasets, die zum Testen eines trainierten Modells reserviert ist.
Traditionell unterteilen Sie Beispiele im Dataset in die folgenden drei unterschiedlichen Teilmengen:
- ein Trainings-Set
- ein Validierungs-Dataset
- ein Test-Dataset
Jedes Beispiel in einem Dataset sollte nur zu einer der vorhergehenden Teilmengen gehören. Beispielsweise sollte ein einzelnes Beispiel nicht gleichzeitig zum Trainings-Dataset und zum Test-Dataset gehören.
Das Trainings- und das Validierungs-Dataset sind beide eng mit dem Training eines Modells verbunden. Da das Test-Dataset nur indirekt mit dem Training verknüpft ist, ist der Testverlust ein weniger verzerrter, hochwertigerer Messwert als der Trainingsverlust oder der Validierungsverlust.
Textbereich
Der Array-Index-Span, der einem bestimmten Unterabschnitt eines Textstrings zugeordnet ist.
Das Wort good im Python-String s="Be good now" belegt beispielsweise die Textspanne von 3 bis 6.
tf.Example
Einem standardmäßigen Protokollpuffer zum Beschreiben von Eingabedaten für das Training oder die Inferenz von ML-Modellen.
tf.keras
Eine in TensorFlow integrierte Keras-Implementierung.
Grenzwert (für Entscheidungsbäume)
In einer achsenbasierten Bedingung der Wert, mit dem ein Element verglichen wird Beispielsweise ist 75 der Schwellenwert in der folgenden Bedingung:
grade >= 75
Zeitreihenanalyse
Ein Teilbereich des maschinellen Lernens und der Statistik, der zeitliche Daten analysiert. Viele Arten von Problemen beim maschinellen Lernen erfordern eine Zeitreihenanalyse, einschließlich Klassifizierung, Clustering, Prognosen und Anomalieerkennung. Mit der Zeitachsenanalyse können Sie beispielsweise den zukünftigen Umsatz von Wintermänteln nach Monat basierend auf historischen Verkaufsdaten prognostizieren.
Timestep
Eine „nicht gerollte“ Zelle in einem recurrent neuronalen Netzwerk. Die folgende Abbildung zeigt beispielsweise drei Zeitschritte, die mit den Subskripten t-1, t und t+1 gekennzeichnet sind:

Token
In einem Sprachmodell die atomare Einheit, mit der das Modell trainiert und für die es Vorhersagen trifft. Ein Token hat in der Regel eines der folgenden Elemente:
- ein Wort. Die Wortgruppe "Hunde wie Katzen" besteht beispielsweise aus drei Worttokens: "Hunde", "wie" und "Katzen".
- ein Zeichen verwenden. Der Ausdruck "bike Fish" besteht beispielsweise aus neun Zeichentokens. Hinweis: Der leere Bereich zählt als eines der Tokens.
- Unterwörtern – in denen ein einzelnes Wort ein einzelnes Token oder mehrere Tokens sein kann. Ein Unterwort besteht aus einem Stammwort, einem Präfix oder einem Suffix. In einem Sprachmodell, das Unterwörter als Tokens verwendet, könnte beispielsweise das Wort "dogs" als zwei Tokens betrachtet werden (das Stammwort "dog" und das Pluralsuffix "s"). Im selben Sprachmodell könnte das einzelne Wort „größer“ als zwei Unterwörter (das Stammwort „tall“ und das Suffix „er“) angezeigt werden.
In Domains außerhalb von Sprachmodellen können Tokens andere Arten von atomaren Einheiten darstellen. Im Bereich des maschinellen Sehens kann ein Token beispielsweise eine Teilmenge eines Bildes sein.
Tower
Eine Komponente eines neuronalen Deep-Learning-Netzwerks, die selbst ein neuronales Deep-Learning-Netzwerk ist. In einigen Fällen liest jeder Turm aus einer unabhängigen Datenquelle und diese Masten bleiben unabhängig, bis ihre Ausgabe in einer endgültigen Ebene kombiniert wird. In anderen Fällen, z. B. im Encoder und im Decoder-Stapel/-Tower vieler Transformers, haben die Türme Querverbindungen zueinander.
TPU
Abkürzung für Tensor Processing Unit.
TPU-Chip
Ein programmierbarer linearer Algebrabeschleuniger mit einem On-Chip-Arbeitsspeicher mit hoher Bandbreite, der für ML-Arbeitslasten optimiert ist. Auf einem TPU-Gerät werden mehrere TPU-Chips bereitgestellt.
TPU-Gerät
Eine Leiterplatte mit mehreren TPU-Chips, Netzwerkschnittstellen mit hoher Bandbreite und Hardware für die Systemkühlung.
TPU-Master
Der zentrale Koordinationsprozess, der auf einem Hostcomputer ausgeführt wird und Daten, Ergebnisse, Programme, Leistungs- und Systemzustandsinformationen an die TPU-Worker sendet und empfängt. Der TPU-Master verwaltet auch das Einrichten und Herunterfahren von TPU-Geräten.
TPU-Knoten
Eine TPU-Ressource in Google Cloud mit einem bestimmten TPU-Typ. Der TPU-Knoten stellt über ein Peer-VPC-Netzwerk eine Verbindung zu Ihrem VPC-Netzwerk her. TPU-Knoten sind eine in der Cloud TPU API definierte Ressource.
TPU-Pod
Eine spezifische Konfiguration von TPU-Geräten in einem Google-Rechenzentrum. Alle Geräte in einem TPU Pod sind über ein dediziertes Hochgeschwindigkeitsnetzwerk miteinander verbunden. Ein TPU-Pod ist die größte Konfiguration von TPU-Geräten, die für eine bestimmte TPU-Version verfügbar sind.
TPU-Ressource
Eine TPU-Entität in Google Cloud, die Sie erstellen, verwalten oder nutzen. TPU-Knoten und TPU-Typen sind beispielsweise TPU-Ressourcen.
TPU-Slice
Ein TPU-Slice ist ein Bruchteil der TPU-Geräte in einem TPU-Pod. Alle Geräte in einem TPU-Slice sind über ein dediziertes Hochgeschwindigkeitsnetzwerk miteinander verbunden.
TPU-Typ
Konfiguration mit einem oder mehreren TPU-Geräten mit einer bestimmten TPU-Hardwareversion. Sie wählen einen TPU-Typ aus, wenn Sie einen TPU-Knoten in Google Cloud erstellen. Ein v2-8-TPU-Typ ist beispielsweise ein einzelnes TPU v2-Gerät mit 8 Kernen. Ein v3-2048-TPU-Typ hat 256 mit dem Netzwerk verbundene TPU v3-Geräte und insgesamt 2.048 Kerne. TPU-Typen sind eine in der Cloud TPU API definierte Ressource.
TPU-Worker
Ein Prozess, der auf einem Hostcomputer und Programmen für maschinelles Lernen auf TPU-Geräten ausgeführt wird.
Training
Prozess zur Bestimmung der idealen Parameter (Gewichtungen und Voreingenommenheiten) in einem Modell. Während des Trainings liest ein System Beispiele ein und passt Parameter schrittweise an. Die einzelnen Beispiele werden beim Training einige Male bis mehrere Male verwendet.
Trainingsverlust
Ein Messwert, der den Verlust eines Modells während eines bestimmten Trainingsdurchlaufs darstellt. Angenommen, die Verlustfunktion ist mittlerer quadratischer Fehler. Vielleicht beträgt der Trainingsverlust (der mittlere quadratische Fehler) für den 10.Durchlauf 2,2 und der Trainingsverlust für den 100.Durchlauf 1,9.
In einer Verlustkurve wird der Trainingsverlust im Vergleich zur Anzahl der Iterationen dargestellt. Eine Verlustkurve liefert die folgenden Hinweise zum Training:
- Eine Steigung deutet darauf hin, dass sich das Modell verbessert.
- Eine Steigung deutet darauf hin, dass das Modell verschlechtert wird.
- Eine flache Steigung impliziert, dass das Modell eine Konvergenz erreicht hat.
Die folgende etwas idealisierte Verlustkurve zeigt beispielsweise:
- Ein steiler Abfall während der ersten Iterationen, was eine schnelle Modellverbesserung impliziert.
- Eine allmähliche (aber immer weiter abfallende) Steigung bis zum Ende des Trainings, was eine kontinuierliche Modellverbesserung mit einem etwas langsameren Tempo als während der ersten Iterationen impliziert.
- Ein flacher Hang gegen Ende des Trainings, was eine Konvergenz suggeriert.
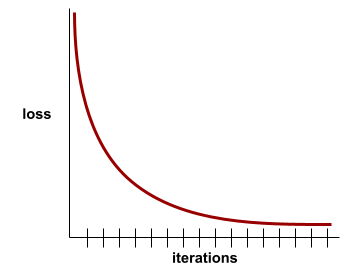
Obwohl der Trainingsverlust wichtig ist, siehe auch Generalisierung.
Abweichungen zwischen Training und Bereitstellung
Der Unterschied zwischen der Leistung eines Modells während des Trainings und der Leistung desselben Modells während der Bereitstellung.
Trainings-Dataset
Die Teilmenge des Datasets, die zum Trainieren eines Modells verwendet wird.
Traditionell werden Beispiele im Dataset in die folgenden drei Teilmengen unterteilt:
- ein Trainings-Dataset
- ein Validierungs-Dataset
- ein Test-Dataset
Idealerweise sollte jedes Beispiel im Dataset nur zu einer der vorhergehenden Teilmengen gehören. Beispielsweise sollte ein einzelnes Beispiel nicht sowohl zum Trainings- als auch zum Validierungs-Dataset gehören.
Flugbahn
Beim Reinforcement Learning ist eine Folge von Tupeln, die eine Folge von Statusübergängen des Agents darstellen, wobei jedes Tupel dem Zustand, Aktion, Belohnung und dem nächsten Zustand für einen bestimmten Zustandsübergang entspricht.
Lerntransfer
Übertragen von Informationen von einer Aufgabe für maschinelles Lernen in eine andere Beim Multi-Task-Lernen löst ein einzelnes Modell beispielsweise mehrere Aufgaben, z. B. ein tiefes Modell, das verschiedene Ausgabeknoten für verschiedene Aufgaben hat. Beim Lernen wird entweder Wissen von der Lösung einer einfacheren Aufgabe auf eine komplexere Aufgabe übertragen oder es wird Wissen von einer Aufgabe, in der mehr Daten vorhanden sind, auf eine Aufgabe übertragen, in der weniger Daten vorhanden sind.
Die meisten Systeme für maschinelles Lernen lösen eine einzelne Aufgabe. Lerntransfer ist ein kleiner Schritt in Richtung künstlicher Intelligenz, bei der ein einzelnes Programm mehrere Aufgaben lösen kann.
Transformer
Eine von Google entwickelte neuronale Netzwerkarchitektur, die auf Selbstaufmerksamkeitsmechanismen stützt, um eine Folge von Eingabeeinbettungen in eine Folge von Ausgabeeinbettungen umzuwandeln, ohne auf Faltungen oder recurrent neuronale Netze zurückzugreifen. Ein Transformer kann als ein Stapel von Selbstaufmerksamkeitsschichten betrachtet werden.
Ein Transformer kann Folgendes enthalten:
Ein Encoder wandelt eine Sequenz von Einbettungen in eine neue Sequenz derselben Länge um. Ein Encoder umfasst N identische Schichten, von denen jede zwei Unterschichten enthält. Diese beiden Unterebenen werden auf jede Position der Einbettungssequenz der Eingabe angewendet und wandeln jedes Element der Sequenz in eine neue Einbettung um. Die erste Encoder-Unterebene aggregiert Informationen aus der gesamten Eingabesequenz. Die zweite Codierer-Unterebene wandelt die aggregierten Informationen in eine Ausgabeeinbettung um.
Ein Decoder wandelt eine Sequenz von Eingabeeinbettungen in eine Sequenz von Ausgabeeinbettungen um, wobei diese auch eine andere Länge haben kann. Ein Decoder umfasst außerdem n identische Schichten mit drei Unterschichten, von denen zwei den Encoder-Unterschichten ähneln. Die dritte Decoder-Unterebene verwendet die Ausgabe des Encoders und wendet den Self-Aufmerksamkeitsmechanismus an, um Informationen daraus zu erfassen.
Der Blogpost Transformer: A Novel Neural Network Architecture for Language Understanding bietet eine gute Einführung in Transformers.
Translation Invarianz
Bei einem Problem zur Bildklassifizierung die Fähigkeit eines Algorithmus, Bilder auch dann erfolgreich zu klassifizieren, wenn sich die Position von Objekten innerhalb des Bildes ändert. Der Algorithmus kann beispielsweise weiterhin einen Hund identifizieren, unabhängig davon, ob er sich in der Mitte oder am linken Ende des Frames befindet.
Siehe auch Größeninvarianz und Rotationsinvarianz.
Trigram
Ein N-Gramm, in dem N=3 ist.
richtig negativ (TN)
Ein Beispiel, in dem das Modell die negative Klasse richtig vorhersagt. Das Modell leitet beispielsweise ab, dass eine bestimmte E-Mail-Nachricht kein Spam und diese E-Mail in Wirklichkeit kein Spam ist.
richtig positives Ergebnis (TP)
Ein Beispiel, in dem das Modell die positive Klasse richtig vorhersagt. Das Modell schlussfolgert beispielsweise, dass eine bestimmte E-Mail-Nachricht Spam und diese E-Mail-Nachricht in Wirklichkeit Spam ist.
Rate richtig positiver Ergebnisse (TPR)
Synonym für Recall. Das bedeutet:
Die Richtig-Positiv-Rate ist die Y-Achse in einer ROC-Kurve.
U
Unkenntnis (auf ein sensibles Attribut)
Eine Situation, in der sensible Attribute vorhanden sind, aber nicht in den Trainingsdaten enthalten sind. Da sensible Attribute oft mit anderen Attributen der eigenen Daten korreliert werden, kann ein Modell, das ohne Kenntnis eines sensiblen Attributs trainiert wurde, dennoch unterschiedliche Auswirkungen in Bezug auf dieses Attribut haben oder gegen andere Fairness-Einschränkungen verstoßen.
Unteranpassung
Erstellen eines model mit unzureichenden Vorhersagefähigkeiten, da das Modell die Komplexität der Trainingsdaten nicht vollständig erfasst hat. Viele Probleme können zu einer Unteranpassung führen, darunter:
- Es wird ein Training zu den falschen Funktionen durchgeführt.
- Das Training erfolgt über zu wenige Epochen oder mit einer zu niedrigen Lernrate.
- Training mit zu hoher Regularisierungsrate.
- Sie stellen zu wenige verborgene Ebenen in einem neuronalen Deep-Learning-Netzwerk bereit.
Untersampling
Beispiele aus der Mehrheitsklasse in einem Dataset mit unausgeglichener Klasse entfernen, um ein ausgewogeneres Trainings-Dataset zu erstellen
Betrachten Sie beispielsweise ein Dataset, bei dem das Verhältnis der Mehrheitsklasse zur Minderheitenklasse 20:1 beträgt. Um dieses Klassenungleichgewicht zu überwinden, können Sie ein Trainings-Dataset erstellen, das aus allen Beispielen der Minderheitenklasse, aber nur einem Zehntel der Mehrheitsklassenbeispiele besteht. Dadurch würde ein Trainings-Set-Klassenverhältnis von 2:1 erzeugt. Dank Untersampling kann dieses ausgewogenere Trainings-Dataset ein besseres Modell liefern. Alternativ enthält dieses ausgewogene Trainings-Dataset möglicherweise nicht genügend Beispiele, um ein effektives Modell zu trainieren.
Stellen Sie einen Kontrast mit Oversampling her.
unidirektional
Ein System, das nur den Text bewertet, der einem Zieltext vor ist. Im Gegensatz dazu wertet ein bidirektionales System sowohl den Text aus, der einem Zieltextabschnitt vorgeht als auch folgen. Weitere Informationen finden Sie unter bidirektionale Anwendungen.
Unidirektionales Sprachmodell
Ein Sprachmodell, das seine Wahrscheinlichkeiten nur auf den Tokens stützt, die vor und nicht nach den Zieltoken(s) erscheinen. Kontrast mit dem bidirektionalen Sprachmodell
Beispiel ohne Label
Ein Beispiel, das Features, aber kein Label enthält. Die folgende Tabelle zeigt beispielsweise drei Beispiele ohne Label aus einem Hausbewertungsmodell mit jeweils drei Merkmalen, aber ohne Hauswert:
| Anzahl der Schlafzimmer | Anzahl der Badezimmer | Hausalter |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
Beim überwachten maschinellen Lernen werden Modelle anhand von Beispielen mit Labels trainiert und Vorhersagen für Beispiele ohne Label treffen.
Beim halbüberwachten und unüberwachten Lernen werden während des Trainings Beispiele ohne Label verwendet.
Vergleichen Sie ein Beispiel ohne Label mit einem Beispiel mit Label.
unüberwachtes maschinelles Lernen
model trainieren, um Muster in einem Dataset zu erkennen – in der Regel in einem Dataset ohne Label
Unüberwachtes maschinelles Lernen wird am häufigsten verwendet, um Daten in Gruppen ähnlicher Beispiele zu gruppieren. Beispielsweise kann ein Algorithmus für unbeaufsichtigtes maschinelles Lernen Songs anhand verschiedener Eigenschaften der Musik gruppieren. Die resultierenden Cluster können als Eingabe für andere Algorithmen für maschinelles Lernen dienen (z. B. für einen Musikempfehlungsdienst). Clustering kann hilfreich sein, wenn nützliche Labels knapp sind oder fehlen. In Bereichen wie Missbrauch und Betrug können Cluster zum Beispiel Menschen helfen, die Daten besser zu verstehen.
Hier kommt überwachtes maschinelles Lernen zum Einsatz.
Leistungssteigerung
Modellierungstechnik, die häufig im Marketing verwendet wird und den "kausalen Effekt" (auch als "inkrementelle Auswirkung" bezeichnet) einer "Behandlung" auf eine "Person" modelliert. Hier sind zwei Beispiele:
- Ärzte können die Uplift-Modellierung verwenden, um den Rückgang der Sterblichkeit (kausaler Effekt) eines medizinischen Eingriffs (Behandlung) abhängig vom Alter und der Krankengeschichte eines Patienten (einer Person) vorherzusagen.
- Werbetreibende können die Steigerungsmodellierung verwenden, um die Steigerung der Kaufwahrscheinlichkeit (kausaler Effekt) aufgrund einer Werbung (Behandlung) für eine Person (Einzelperson) vorherzusagen.
Die Steigerungsmodellierung unterscheidet sich von der Klassifizierung oder Regression dadurch, dass einige Labels (z. B. die Hälfte der Labels bei binären Verarbeitungen) bei der Steigerungsmodellierung immer fehlen. Ein Patient kann beispielsweise entweder in Behandlung oder nicht behandelt werden. Daher können wir nur beobachten, ob der Patient heilen wird oder nicht, und zwar nur in einer dieser beiden Situationen (jedoch nie in beiden). Der Hauptvorteil eines Steigerungsmodells besteht darin, dass es Vorhersagen für die unbeobachtete Situation (die kontrafaktische Situation) generieren und zur Berechnung des kausalen Effekts verwenden kann.
Gewichtsreduktion
Sie wenden eine Gewichtung auf die Klasse downsampled an, die dem Faktor entspricht, um den Sie die Daten heruntergerechnet haben.
Nutzermatrix
In Empfehlungssystemen ein Einbettungsvektor, der durch die Matrixfaktorisierung generiert wird und latente Signale zu Nutzerpräferenzen enthält. Jede Zeile der Nutzermatrix enthält Informationen zur relativen Stärke verschiedener latenter Signale für einen einzelnen Nutzer. Stellen Sie sich zum Beispiel ein Empfehlungssystem für Filme vor. In diesem System können die latenten Signale in der Nutzermatrix das Interesse der einzelnen Nutzer in bestimmten Genres widerspiegeln oder schwer zu interpretierende Signale sein, die komplexe Interaktionen über mehrere Faktoren hinweg beinhalten.
Die User-Matrix hat eine Spalte für jedes latente Merkmal und eine Zeile für jeden Nutzenden. Das heißt, die Nutzermatrix hat die gleiche Anzahl von Zeilen wie die Zielmatrix, die faktorisiert wird. Beispiel: Bei einem Filmempfehlungssystem für 1.000.000 Nutzer enthält die Nutzermatrix 1.000.000 Zeilen.
V
validation
Die anfängliche Bewertung der Qualität eines Modells. Bei der Validierung wird die Qualität der Vorhersagen eines Modells mit dem Validierungs-Dataset verglichen.
Da sich das Validierungs-Dataset vom Trainings-Dataset unterscheidet, schützt die Validierung vor einer Überanpassung.
Sie können sich die Bewertung des Modells anhand des Validierungs-Datasets als erste Testrunde und die Bewertung des Modells anhand des Test-Datasets als zweite Testrunde vorstellen.
Validierungsverlust
Ein Messwert, der den Verlust eines Modells im Validierungs-Dataset während einer bestimmten Iteration des Trainings darstellt.
Siehe auch Generalisierungskurve.
Validierungs-Dataset
Die Teilmenge des Datasets, die eine Erstbewertung für ein trainiertes Modell durchführt. In der Regel bewerten Sie das trainierte Modell mehrmals anhand des Validierungs-Datasets, bevor Sie es anhand des Test-Datasets evaluieren.
Traditionell unterteilen Sie die Beispiele im Dataset in die folgenden drei unterschiedlichen Teilmengen:
- ein Trainings-Set
- ein Validierungs-Dataset
- ein Test-Dataset
Idealerweise sollte jedes Beispiel im Dataset nur zu einer der vorhergehenden Teilmengen gehören. Beispielsweise sollte ein einzelnes Beispiel nicht sowohl zum Trainings- als auch zum Validierungs-Dataset gehören.
Wertberechnung
Der Prozess, bei dem ein fehlender Wert durch einen akzeptablen Ersatz ersetzt wird. Wenn ein Wert fehlt, können Sie entweder das gesamte Beispiel verwerfen oder die Wert Imputation verwenden, um das Beispiel zu retten.
Nehmen wir als Beispiel ein Dataset mit einem temperature-Feature, das stündlich aufgezeichnet werden soll. Die Temperatur war jedoch für eine bestimmte Stunde nicht verfügbar. Hier ist ein Abschnitt des Datasets:
| Zeitstempel | Temperatur |
|---|---|
| 1680561000 | 10 |
| 1680564600 | 12 |
| 1680568200 | Fehlend |
| 1680571800 | 20 |
| 1680575400 | 21 |
| 1680579000 | 21 |
Ein System könnte das fehlende Beispiel entweder löschen oder die fehlende Temperatur abhängig vom Imputationsalgorithmus als 12, 16, 18 oder 20 setzen.
Problem mit verschwindendem Farbverlauf
Die Tendenz, dass die Gradienten früher verborgener Ebenen einiger neuronaler Deep-Learning-Netzwerke erstaunlich flach (niedrig) werden. Zunehmende niedrigere Gradienten führen zu zunehmend kleineren Änderungen an den Gewichtungen von Knoten in einem neuronalen Deep-Learning-Netzwerk, was zu wenig oder gar keinem Lernen führt. Modelle, die unter dem abnehmenden Gradientenproblem leiden, lassen sich nur schwer oder gar nicht trainieren. Dieses Problem wird durch Zellen vom Typ Long-Term Memory behoben.
Vergleichen Sie dazu das Problem mit einem explodierenden Farbverlauf.
unterschiedliche Bedeutungen
Eine Reihe von Bewertungen, die die relative Bedeutung der einzelnen Features für das Modell angeben.
Angenommen, Sie haben einen Entscheidungsbaum zur Schätzung von Hauspreisen. Angenommen, dieser Entscheidungsbaum verwendet drei Funktionen: Größe, Alter und Stil. Wenn eine Gruppe variabler Wichtigkeiten für die drei Elemente mit {size=5.8, age=2.5, style=4.7} berechnet wird, ist die Größe für den Entscheidungsbaum wichtiger als Alter oder Stil.
Es gibt unterschiedliche Messwerte für die veränderliche Wichtigkeit, die ML-Experten über verschiedene Aspekte von Modellen informieren können.
Variational Autoencoder (VAE)
Ein Typ von Autoencoder, der die Diskrepanz zwischen Ein- und Ausgaben nutzt, um modifizierte Versionen der Eingaben zu generieren. Variationale Autoencoder sind nützlich für Generative AI.
VAEs basieren auf der Variationsinferenz: einer Methode zur Schätzung der Parameter eines Wahrscheinlichkeitsmodells.
Vektor
Stark überladener Begriff, dessen Bedeutung sich in verschiedenen mathematischen und wissenschaftlichen Bereichen unterscheidet. Im Rahmen des maschinellen Lernens hat ein Vektor zwei Eigenschaften:
- Datentyp: Vektoren im maschinellen Lernen enthalten in der Regel Gleitkommazahlen.
- Anzahl der Elemente: Dies ist die Länge des Vektors oder seine Dimension.
Angenommen, Sie haben einen Featurevektor, der acht Gleitkommazahlen enthält. Dieser Featurevektor hat eine Länge oder Dimension von acht. Vektoren für maschinelles Lernen haben oft sehr viele Dimensionen.
Sie können viele verschiedene Arten von Informationen als Vektor darstellen. Beispiel:
- Jede Position auf der Erdoberfläche kann als zweidimensionaler Vektor dargestellt werden, wobei eine Dimension der Breitengrad und die andere der Längengrad ist.
- Die aktuellen Kurse von jeweils 500 Aktien können als 500-dimensionaler Vektor dargestellt werden.
- Eine Wahrscheinlichkeitsverteilung über eine endliche Anzahl von Klassen kann als Vektor dargestellt werden. Beispielsweise könnte ein Klassifizierungssystem mit mehreren Klassen, das eine von drei Ausgabefarben (Rot, Grün oder Gelb) vorhersagt, den Vektor
(0.3, 0.2, 0.5)als Mittelwert vonP[red]=0.3, P[green]=0.2, P[yellow]=0.5ausgeben.
Vektoren können verkettet werden. Daher kann eine Vielzahl verschiedener Medien als ein einzelner Vektor dargestellt werden. Einige Modelle arbeiten direkt in der Verkettung vieler One-Hot-Codierungen.
Spezialisierte Prozessoren wie TPUs sind für mathematische Operationen auf Vektoren optimiert.
Ein Vektor ist ein Tensor des Rangs 1.
W
Verlust von Wasserstein
Eine der Verlustfunktionen, die häufig in generativen Angriffsnetzwerken verwendet wird, basierend auf der Entfernung der Earth Mover zwischen der Verteilung der generierten Daten und echten Daten.
Gewicht
Wert, den ein Modell mit einem anderen Wert multipliziert. Beim Training werden die Idealgewichte eines Modells bestimmt. Bei der Inferenz werden diese gelernten Gewichtungen für Vorhersagen verwendet.
Gewichtete abwechselnde kleinste Quadrate (WALS)
Ein Algorithmus zum Minimieren der Zielfunktion während der Matrixfaktorisierung in Empfehlungssystemen, der eine Heruntergewichtung der fehlenden Beispiele ermöglicht. WALS minimiert den gewichteten quadratischen Fehler zwischen der ursprünglichen Matrix und der Rekonstruktion, indem zwischen der Anpassung der Zeilenfaktorisierung und der Spaltenfaktorisierung gewechselt wird. Jede dieser Optimierungen kann durch die konvexe Optimierung der kleinsten Quadrate gelöst werden. Weitere Informationen finden Sie im Kurs Recommendation Systems.
gewichtete Summe
Die Summe aller relevanten Eingabewerte multipliziert mit den entsprechenden Gewichtungen. Angenommen, die relevanten Eingaben bestehen aus Folgendem:
| Eingabewert | Eingabegewichtung |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
Die gewichtete Summe ist daher:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Eine gewichtete Summe ist das Eingabeargument für eine Aktivierungsfunktion.
Breites Modell
Ein lineares Modell, das in der Regel viele dünnbesetzte Eingabefeatures hat. Wir bezeichnen es als "breit", da ein solches Modell eine spezielle Art von neuronalem Netzwerk mit einer großen Anzahl von Eingaben ist, die direkt mit dem Ausgabeknoten verbunden sind. Breite Modelle lassen sich häufig einfacher debuggen und prüfen als tiefe Modelle. Obwohl breite Modelle Nichtlinearitäten nicht über verborgene Ebenen ausdrücken können, können breite Modelle Transformationen wie Feature Crossing und Bucketisierung verwenden, um Nichtlinearitäten auf verschiedene Weise zu modellieren.
Kontrast mit tiefem Modell.
Breite
Die Anzahl der Neuronen in einer bestimmten Schicht eines neuronalen Netzes.
Weisheit der Menge
Die Idee, dass die Durchschnittsermittlung der Meinungen oder Schätzungen einer großen Personengruppe („die Menge“) oft erstaunlich gute Ergebnisse liefert. Nehmen wir als Beispiel ein Spiel, bei dem Leute die Anzahl der in ein großes Glas verpackten Jelly Beans erraten. Obwohl die meisten einzelnen Vermutungen ungenau sein werden, ist der Durchschnitt aller Vermutungen empirisch erstaunlich nahe an der tatsächlichen Anzahl der Jelly Beans im Becher gelegen.
Ensembles sind Software-Analoge zur Weisheit der Massen. Selbst wenn einzelne Modelle extrem ungenaue Vorhersagen treffen, führt die Durchschnittsermittlung der Vorhersagen vieler Modelle oft zu erstaunlich guten Vorhersagen. Obwohl beispielsweise ein einzelner Entscheidungsbaum schlechte Vorhersagen macht, liefert eine Entscheidungsstruktur oft sehr gute Vorhersagen.
Worteinbettung
Darstellung jedes Wortes in einem Wortsatz innerhalb eines Einbettungsvektors, d. h. jedes Wort als Vektor von Gleitkommawerten zwischen 0,0 und 1,0 Wörter mit ähnlicher Bedeutung werden ähnlicher dargestellt als Wörter mit unterschiedlichen Bedeutungen. So würden beispielsweise Karotten, Verkäufer und Gurken relativ ähnlich dargestellt, was sich stark von den Darstellungen von Flugzeug, Sonnenbrille und Zahnpasta unterscheidet.
X
XLA (beschleunigte lineare Algebra)
Ein Open-Source-Compiler für maschinelles Lernen für GPUs, CPUs und ML-Beschleuniger.
Der XLA-Compiler übernimmt Modelle aus gängigen ML-Frameworks wie PyTorch, TensorFlow und JAX und optimiert sie für eine leistungsstarke Ausführung auf verschiedenen Hardwareplattformen wie GPUs, CPUs und ML-Beschleunigern.
Z
Zero-Shot-Learning
Art des Trainings für maschinelles Lernen, bei dem das Modell eine Vorhersage für eine Aufgabe ableitet, mit der es noch nicht speziell trainiert wurde. Das Modell erhält also keine aufgabenspezifischen Trainingsbeispiele, wird aber gebeten, für diese Aufgabe eine Inferenz auszuführen.
Zero-Shot-Prompts
Eine Aufforderung, die kein Beispiel dafür bietet, wie das Large Language Model reagieren soll. Beispiel:
| Bestandteile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Indien: | Die eigentliche Abfrage. |
Das Large Language Model kann mit Folgendem antworten:
- Rupie
- INR
- ₹
- Indische Rupie
- Die Rupie
- Indische Rupie
Alle Antworten sind richtig, auch wenn Sie vielleicht ein bestimmtes Format bevorzugen.
Vergleichen Sie Zero-Shot-Prompts mit den folgenden Begriffen und stellen Sie sie gegenüber:
Normalisierung des Z-Scores
Ein Skalierungsverfahren, bei dem ein Feature-Rohwert durch einen Gleitkommawert ersetzt wird, der die Anzahl der Standardabweichungen vom Mittelwert dieses Features darstellt. Betrachten Sie beispielsweise ein Feature mit einem Mittelwert von 800 und dessen Standardabweichung 100. Die folgende Tabelle zeigt, wie die Normalisierung bei der Z-Wertung den Rohwert seinem Z-Wert zuordnen würde:
| Unverarbeiteter Wert | Z-Score |
|---|---|
| 800 | 0 |
| 950 | +0,7 |
| 575 | -2,25 |
Das Modell für maschinelles Lernen wird dann anhand der Z-Werte für dieses Feature und nicht anhand der Rohwerte trainiert.