C++ 語言教學課程
本課程的初期章節 教學課程 涵蓋已展示的基本資料 ,並提供更多有關進階概念的資訊。我們的 本單元的重點在於動態記憶體,以及物件和類別的詳細資訊。 我們也導入了一些進階主題,像是繼承、多態性、範本 例外狀況和命名空間我們會在後續的 C++ 進階課程中研究這些內容。
物件導向設計
太棒了 物件導向設計相關教學課程。我們會將 方法。
按照範例 #3 學習
本單元的重點在於運用指標和物件導向的方式取得更多練習。 設計、多維度陣列以及類別/物件逐步完成下列工作: 範例。我們不能強調的關鍵在於您能成為優秀的程式設計師 熟能生巧!練習 #1:利用指標進行更多練習
如需使用指標進行額外練習,請閱讀 本 資源,涵蓋指標的所有面向,並提供多種程式範例。
請問以下程式的輸出內容為何?請勿執行該程式, 再繪製記憶圖片來判斷輸出內容
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}手動決定輸出內容後,請執行程式來確認是否 正確。
練習 #2:進一步練習運用類別和物件
如果您需要額外練習類別和物件 這裡 是逐步實作兩個小型類別的資源。休息一下 完成運動的時間。
練習 #3:多維度陣列
請考慮參加以下計畫:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}本程式中是否有一行標示為「此行如何運作?」 - 你能瞭解嗎? 如需相關說明,請參閱這裡。
撰寫用來初始化 3Dim 陣列並填入第 3 個維度的程式 值與這三個索引的總和。 請參閱這裡提供的解決方案。
練習 #4:廣泛的 OO 設計範例
請參閱 物件導向設計範例,其中包含整個 整個流程最終程式碼是以 Java 編寫 但只要唸出 越來越熱烈。
請花點時間完成整個範例。太棒了 程序插圖,以及輔助這個程序的設計工具。
Unit Testing (單元測試)
簡介
測試是軟體工程程序中相當重要的一環,單元測試 是一種特定測試,用來檢查單一、小規模的 原始碼的模組。工程師一律會進行單元測試, 通常是在編寫模組時一併完成可讓您的測試驅動程式 用於測試 Composer 和 Database 類別都是單元測試的例子。
單元測試具有下列特性。他們...
- 獨立測試某個元件
- 具有確定性
- 通常會對應至單一類別
- 避免依賴外部資源,例如資料庫, 檔案, 網路
- 快速執行
- 可以依任何順序執行
此外,自動化架構和方法都能支援 為大型軟體工程機構的單元測試保持一致。 有幾種複雜的開放原始碼單元測試架構, 我們稍後將在本課程中說明這點
以下說明單元測試過程中發生的測試。
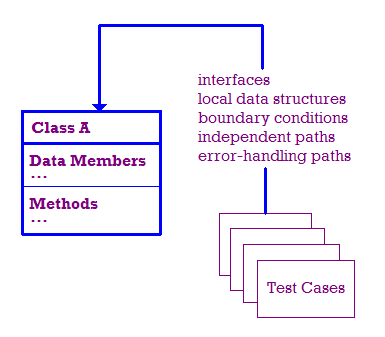
在理想情況下,我們會測試下列項目:
- 模組介面經過測試,確保資訊傳入和傳出 正確。
- 會檢查本機資料結構,確保其儲存資料正確無誤。
- 測試邊界條件,確保模組可正確運作 以限製或限制處理的範圍。
- 我們會透過模組測試個別路徑,確保每個路徑
因此模組中的每個陳述式至少會執行一次。
- 最後,我們要確認錯誤是否妥善處理。
程式碼涵蓋率
事實上,我們無法獲得完整的「程式碼涵蓋率」。 程式碼涵蓋率是一種分析方法,可決定軟體的哪些部分 測試案例套件的執行位置 (涵蓋) 尚未執行。如果我們嘗試達成 100% 的涵蓋率,會花費更多時間 撰寫單元測試,更不用編寫實際程式碼!考慮構思單元 測試下列所有獨立路徑這很快就會成為 指數性問題
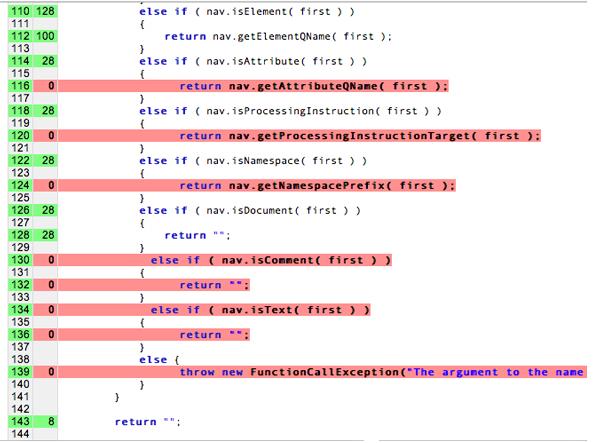
在本圖表中,紅線並未測試,而無顏色的線條卻 目標使用者、使用的資料 以及模型訓練與測試方式
我們的調查重點不在於 100% 的涵蓋範圍,而是著重提升我們有信心的測試。 確認模組是否正常運作我們測試的項目包括:
- 空值案件
- 範圍測試,例如正/負值測試
- 極端案例
- 故障案例
- 測試大部分時間最有可能執行的路徑
單元測試架構
大多數單元測試架構都會在執行容器時,使用斷言來測試值 可建立個別路徑斷言是用來檢查條件是否為 True 的陳述式。 斷言的結果可能為成功、不嚴重失敗或嚴重故障。更新後 執行斷言,如果結果為 成功或嚴重失敗如果發生嚴重錯誤,目前的函式 已取消。
測試是由用來設定狀態或操控模組的程式碼, 並搭配多個斷言來驗證預期結果。如果所有斷言 測試成功,亦即傳回 true,就表示測試成功;否則 失敗。
測試案例包含一或多個測試。我們將測試分組為測試案例 反映測試程式碼的結構。在本課程中,我們將使用 CPPUnit 做為單元測試架構。這個架構可讓我們編寫單元測試 並自動執行,並提供報表,說明測試成功與否 測試
CPPUnit 安裝
從以下網址下載 CPPUnit 程式碼: SourceForge。 找出適當的目錄,並將 tar.gz 檔案放在目錄中。接著,請輸入 指令 (在 Linux 或 Unix 中),換成適當的 cppunit 檔案 名稱:
gunzip filename.tar.gz tar -xvf filename.tar
如果您使用的是 Windows,可能需要尋找可以擷取 tar.gz 的公用程式 檔案。下一步是編譯程式庫。切換至 cppunit 目錄。 這個 INSTALL 檔案會提供具體指示。這些廣告活動 您必須執行
./configure make install
如果您遇到問題,請參考 INSTALL 檔案的說明。通常會有 可在 cppunit/src/cppunit 目錄中找到。如要檢查編譯是否正常運作 請前往 cppunit/examples/simple 目錄,然後輸入「make」。如果 一切都沒問題,這樣就大功告成了!
您可找到合適的教學課程 請按這裡。 請逐步執行這個教學課程,並建立複數類別及其相關聯的 單元測試cppunit/examples 目錄中還有幾個其他範例。
為什麼要這麼做?
單元測試在業界中相當重要,原因如下。您 都很熟悉一個原因:除了檢查工作外, 開發程式碼即使在開發人數極小的程式 撰寫某種檢查工具或驅動程式,確保程式正常運作。
從長遠的經驗來看,工程師都知道程式能發揮作用 因為第一次嘗試很小單元測試是根據這個概念為基礎 這些程式會自我檢查 以及可重複執行的計畫斷言會取代 也會檢查輸出內容此外,由於測試結果相當容易 檢查是否通過或失敗) 即可不斷執行測試 增強程式碼的彈性
讓我們具體說明一下:當您初次將完成的程式碼提交至 CVS 的效率無庸置疑而且會繼續完美運作一段時間接著 其他人會變更你的程式碼其他人會在不久後失去 程式碼。你認為他們會自行注意到嗎?不太可能。但當你 有些系統可以每天自動執行,方便您編寫單元測試 這些稱為持續整合系統。當工程師 X 打破你的程式碼,系統會傳送騷擾電子郵件給他們,直到問題修正為止 基礎架構即使 X 工程師是你也一樣!
這項解決方案除了可協助開發人員開發軟體, 如有變更,單元測試會:
- 建立可執行的規格,以及保持同步的說明文件 呼叫程式碼換句話說,您可以閱讀單元測試來瞭解 以及模組支援的行為。
- 可協助您將需求與實作項目區隔開來。因為你要斷言 從外顯現狀,您有機會仔細思考 而不是混合如何實作行為
- 支援實驗。如果有安全網提醒你 找出模組的行為後,就更有可能嘗試 然後重新設定設計
- 提升設計效果。編寫完整的單元測試通常需要您 讓程式碼更易於測試可測試的程式碼通常模組化,比起無法測試的程式碼更加完善 再也不是件繁重乏味的工作
- 維持高品質。重大系統中的小錯誤 以損失數百萬美元 甚至在使用者的滿意度或信任度上下降 就能降低這類可能性。擷取錯誤 還讓品質確保團隊能把時間投入在更複雜且困難上 而不是回報明顯故障
請花點時間在 Composer 資料庫應用程式中使用 CPPUnit 編寫單元測試。 如需相關說明,請參閱 cppunit/examples/ 目錄。
《Google 模式》
簡介想像一下中世紀的少女看著數以千計的手稿 封存與歷史「哪裡是阿里斯托爾的...」

幸好,手稿是依照內容和旁白進行排序 帶有特殊符號,方便擷取包含於 如果沒有這類機構,我們很難找出 手稿。
儲存和擷取大型集合中寫入資訊的活動 稱為「資訊擷取 (IR)」。這類活動越來越普遍 對這些新技術至關重要,特別是紙張和印刷品等發明 媒體。過去只有少數人會住。現在, 但每天都有數億人參與資訊檢索作業 使用者經常透過搜尋引擎或電腦搜尋資料
資訊檢索入門

蘇斯博士在過去 30 年內為 46 本童書撰寫了 46 本童書,他讀書時 貓、牛、大象、誰、小妖精和怪物。你還記得嗎? 哪個故事包含哪些生物?除非你是家長,否則只有孩子可以 告訴你哪一組蘇斯博士的故事擁有這些生物:
(COW 和 BEE) 或 CROWS
我們將應用一些傳統的資訊檢索模型來解決這個問題 問題。
顯而易見的方式就是開始暴力:取得 46 博士博士學位的故事,然後開始 讀取。記下每本書中哪些包含 COW 和 BEE 的字詞,以及 同時,尋找含有 CROWS 一詞的書籍。電腦 就比我們更快如果我們能拿到蘇斯博士的書本, 或是文字檔等數位格式換 像是蘇斯博士的書等小館,這種技巧就很好。
不過,在很多情況下,我們需要更多的理由。例如:集合 目前線上的所有資料中有 40% 的資料過大,無法 grep 處理。我們也 單純想尋找符合條件的文件 而我們已經習慣 根據關聯性排序廣告
除了 grep 以外,另一種方法是在集合中為文件建立索引 再開始搜尋IR 中的索引類似於 教科書的背面我們會一份清單,列出每個字詞中的所有字詞 (或條款) Seuss 博士的故事,留下「the」、「and」和其他相關字句 介系詞等等 (稱為停止字詞)。接著,我們會代表 也更容易找到這些字詞 但對於故事
其中一種可能的表示法 列出的字詞欄中如有「1」,代表字詞已出現在 顯示該欄位的故事
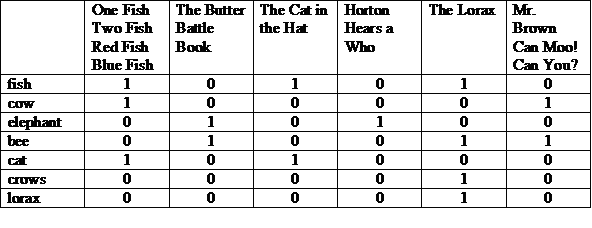
我們可以以位元向量的形式查看每個資料列或資料欄。資料列的位元向量表示 您要在報導中提及「搜尋字詞」一詞資料欄的位元向量可指出字詞 出現在故事中
返回原始問題:
(COW 和 BEE) 或 CROWS
我們以位元向量輸入這些字詞,然後依序執行位元 AND 和 在結果加上位元的 OR。
(100001 和 010011) 或 000010 = 000011
答案:「先生棕色 Can Moo!你能嗎?」以及《The Lorax》這是插圖 布林擷取模式 (即「完全比對」模式)。
假設我們擴大矩陣範圍,納入蘇蘇斯博士的所有故事, 在報導中列出相關字詞矩陣會大幅增加 觀察次數大多為 0矩陣在各方面可能不理想 表示法因此我們想辦法只保存這 1 人!
部分強化功能
而 IR 中用來解決這個問題的結構稱為「反向索引」。 我們會為字詞建立字典,每個字詞都有一份清單。 記錄字詞發生所在文件。這份清單稱為貼文 list。私有連結的清單非常適合用來反映這種結構,如圖所示 。
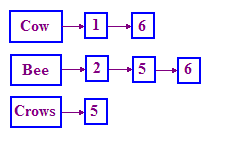
如果不熟悉連結清單,只要在「已連結」
您會看到許多資源
說明如何建立這個 YAML 檔案
以及如何運用相關細節將於後續單元中詳細說明。
請注意,我們使用文件 ID (DocIDs) 而不是 故事我們也會排序這些 DocID,以便處理查詢。
我們如何處理查詢?對於原始問題,我們會先找到 COW 的張貼內容 和 BEE 的貼文清單然後進行「合併」:
- 將標記維護在兩份清單中,並逐步說明兩份發布清單 。
- 在每個步驟中,比較兩個指標指向的 DocID。
- 如果兩者相同,請將該 DocID 加入結果清單;如果沒有,請將指標往前推 指向小型 docID。
以下說明如何建立反向索引:
- 為每份感興趣的文件指派 DocID。
- 為每個文件找出相關字詞 (權杖化)。
- 為每個字詞建立由字詞 (文件 ID) 組成的記錄。 找到,並在該文件中出現頻率。請注意 。
- 按字詞排序記錄。
- 處理單一記錄以建立字典和張貼清單 與類似搜尋字詞的 而非一份文件建立 DocID 的連結清單 (按照排序順序)。每項 字詞也具有頻率,也就是所有記錄的總和 。
專案內容
尋找多個可進行實驗的冗長純文字文件。 都是使用 相同。此外,您還必須建立用於輸入查詢的介面 並提供處理引擎的引擎您可以在論壇中尋找專案合作夥伴。
以下是完成這項專案的可能程序:
- 首先,請定義在文件中識別字詞的策略。 列出您可想到的所有停用字詞,並編寫函式 讀取檔案中的字詞、儲存字詞,並排除非檢索用字。 當您在檢閱清單中 從疊代擷取出來的字詞
- 編寫用於測試函式的 CPPUnit 測試案例,並編寫 makefile 來提供所有 共同建構檢查檔案為 CVS,尤其是在 與合作夥伴攜手合作建議您研究如何開啟 CVS 執行個體 遠端工程師
- 新增處理程序來納入位置資料,也就是檔案和位置 檔案名稱為何?建議你算出計算結果 頁碼或段落編號。
- 請編寫 CPPUnit 測試案例,以測試這項額外功能。
- 建立反向索引,並將位置資料儲存在每個字詞的記錄中。
- 編寫更多測試案例。
- 設計可讓使用者輸入查詢的介面。
- 使用上述搜尋演算法,處理反向索引和 然後將位置資料傳回給使用者。
- 請務必在最後部分中加入測試案例。
和所有專案一樣,請透過論壇和即時通訊尋找專案合作夥伴 並分享想法
額外功能
在許多 IR 系統中,常見的處理步驟稱為「字根」。 主要概念是:使用者會搜尋「擷取」相關資訊 對於包含「擷取」資訊 「擷取」、「擷取」等等系統可能容易出錯 不容易理解,所以這有點棘手舉例來說,使用者 可能會收到標題為「金購資訊」的文件 「重試」。詞幹的實用演算法是 Porter 演算法。