程式設計和 C++ 簡介
此線上教學課程僅含更進階的概念,請詳閱第三部分。本單元的重點在於使用指標,以及如何開始使用物件。
按照範例 #2 學習
本單元的重點在於透過分解方法、瞭解指標,以及開始使用物件和類別來練習更多做法。逐步完成下列範例。在詢問時自行撰寫程式,或是自行進行實驗。我們不強調要成為優秀的程式設計師,關鍵就在於熟練吧!
範例 1:更多分解練習
請看以下簡易遊戲的輸出內容:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
第一個觀察是簡介文字,每個程式顯示一次 我們需要隨機號碼產生器,才能定義每個項目的敵方距離 第 2 輪。我們需要一種機制,以便從播放器取得角度輸入, 循環式結構顯然會重複出現,直到擊敗敵人為止我們也會 需要一個函式來計算距離和角度。最後,我們必須追蹤 玩家需要多少鏡頭才能擊敗敵人?還有在機器上有多少敵人 在程式執行期間發生命中。以下是主要計畫的大綱。
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
消防程序會處理遊戲的進行過程。在此函式中,我們呼叫 隨機數字產生器以取得敵方距離,然後將這個迴圈設定為 取得玩家的輸入,並計算他們是否達成目標。 迴圈條件是我們能打擊敵人的距離。
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
由於對 cos() 和 sin() 的呼叫,您必須加入 math.h。嘗試 撰寫這個程式時,最好的方式是分解問題 以及基本 C++ 的評論請記得每個函式僅執行一項工作。這是 截至目前為止,我們已編寫出最複雜的程式,因此 。請參閱這裡提供的解決方案。
範例 2:使用指標練習
使用指標時,有四件事需要記住:- 指標是保留記憶體位址的變數。隨著程式的執行
所有變數都會儲存在記憶體中,每個變數都有各自的專屬位址或位置。
指標是包含記憶體位址的特殊變數類型
而非資料值就像使用常變數時資料會被修改一樣
系統會將儲存在指標中的地址值修改為指標變數
都已經過操弄。範例如下:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - 我們通常說有一個指標儲存位置
(簡稱「pointee」)。因此,在上述範例中,入侵點指向指標
5. AI 必須採行
隱私保護設計原則
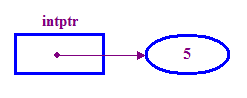
請注意,「new」為整數分配記憶體的運算子 而且會詳細說明嘗試存取指標前,我們必須完成這個動作。
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.* 運算子的用途是在 C 中取消參照。最常見的錯誤之一 C/C++ 程式設計師需要使用指標時忘記初始化 然後是第一位這有時可能會導致執行階段當機,因為我們在存取 表示記憶體中的一個位置,包含未知的資料。如果我們嘗試修改這個描述 資料,便可造成細微的記憶體毀損,造成難以追蹤的錯誤。
- 兩點間的指標指派可讓指標指向同一個指標。
因此指派 y = x;讓 y 指向與 X 相同的指標。指標指派
不要碰到手指。只需要變更一個指標,使其包含相同位置
做為另一個指標指標指派完成後,兩點會「分享」這個
而且會詳細說明
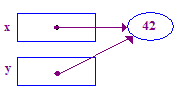
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
程式碼的追蹤記錄如下:
| 1. 分配兩個指標 x 和 y。分配指標後 不分配任何分數。 | 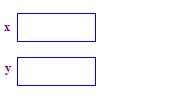 |
| 2. 分配 Point 並將 x 設定為指向它。 |  |
| 3. 解除參照 x 可將 42 置於其指標中。這只是基本範例 處理問題從 x 開始,點選箭頭即可開啟 更是如此 | 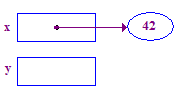 |
| 4. 嘗試解除參照以將 13 分在其尖端。這項當機問題的原因在於 沒有推手 -- 從未被指派過 |  |
| 5. 指派 y = x;讓 y 指向 x 的指標。現在將 x 和 y 點指向 大家可以「分享」 | 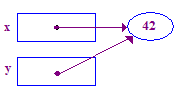 |
| 6. 嘗試解除參照以將 13 分在其尖端。這次成功了 因為前一次作業給了我一個分數 | 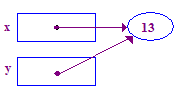 |
如您所見,圖片對於瞭解指標的用法非常實用。這裡是 另一個例子
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
請注意,在本例中,我們從未透過「new」分配記憶體運算子。 我們宣告了正常的整數變數,並透過指標加以操控。
在這個範例中,我們說明如何使用刪除運算子,以便取消分配 以及我們如何為更複雜的結構分配記憶體本單元稍後會介紹 記憶體整理 (堆積和執行階段堆疊)目前,您只需要 請將堆積視為執行程式可用的記憶體存放區
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
在最後一個範例中,我們會說明如何使用指標透過參照傳遞值 至函式這就是我們修改函式中變數值的方式。
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
如果我們要將重複函式定義中的 & 退出, 我們會「透過值」傳遞變數,也就是副本由 變數。對函式中的變數所做的變更,都會修改副本。 而不會修改原始變數。
透過參照傳遞變數時,系統不會傳送其值的副本, 我們要將變數的地址傳遞至函式任何 就必須修改傳入的原始變數
如果您是 C 程式設計師,也可以在 C 語言中 宣告 Duplicate() 與 Duplicate(int *x) 相同, 這樣的話 x 為 int,然後透過引數 &x (x 的地址) 呼叫 Duplicate() 呼叫 x 內 Duplicate() (請見下文)。但是 C++ 可讓您更簡單地透過 。這個方法仍然有效
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
請注意,使用 C++ 參照時,我們不需要傳遞變數的地址,也不需要傳遞 我們需要將呼叫函式中的變數解除參照嗎?
以下的程式會輸出什麼?繪製回憶集錦的相片來找出答案。
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} 執行程式,看看是否獲得正確答案。
範例 3:透過參照傳送值
請編寫名為 Lift() 的函式,這個函式會將這個函式視為車輛的速度和金額。這個函式會將金額加入速度,以加快車輛速度。速度參數應透過參照方式,並依值傳遞金額。如需解決方案,請按這裡。
範例 4:類別與物件
請考慮使用下列類別:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
請注意,類別成員變數結尾有底線。這是為了區分本機變數和類別變數。
在這個類別中新增遞減方法。如需解決方案,請按這裡。
科學的奧秘:電腦科學
演習
如同本課程的第一個單元,我們並未提供運動和專案解決方案。
記住一項好計畫...
... 會按照邏輯分解為只有一個函式的函式 只會執行一項工作
... 有一個主要程式,大致說明程式的作用。
...具有描述性函式、常數和變數名稱。
... 使用常數避免任何「魔幻」中的數字。
...有容易使用的使用者介面。
暖身運動
- 運動 1
整數 36 具有 Peculiar 屬性:這是完全正方形,也 從 1 到 8 的整數總和下一個數字為 1225, 是 352,而 1 到 49 之間的整數總和。尋找下一個號碼 也是完全的正方形,也是序列 1...n 的總和。下一個號碼 可能會大於 32767您可以運用程式庫函式 (或數學公式),可加快程式的執行速度。您也可以 使用 BERT 編寫這個程式 判斷數字是否為 平方或序列的總和。(注意:視您的電腦和程式而定, 要過段時間才會找到這個數字)。
- 運動 2
你的大學書店需要你的協助,以估計接下來的店面業務 。經驗指出,銷售是否需仰賴書籍 在課程中使用 。全新的必要教科書會賣出 90% 的潛在入學率 但如果先前已在課堂上用過,只有 65% 的使用者會購買。同樣地 有 40% 的潛在註冊對象會購買新的教科書 (選用), 在課堂中學習,只有 20% 的人會購買。(請注意,「二手」 並不代表二手書籍)。
撰寫接受一連串的程式 (使用者尚未進入) Sentinel)。為每本書要求輸入以下代碼:書籍的代碼、單一副本的費用 書籍、目前持有的書籍數量、潛在班級註冊人數、 以及說明書籍是否為必要/選用、新舊/過去使用過的資料。阿斯 輸出時,所有輸入資訊都會以完整格式化的畫面顯示 需要訂購的書籍數量 (如果有,請注意,只有新書需要訂購), 每筆訂單的總費用。
然後,在所有輸入完成後,顯示所有書籍訂單的總費用。 如果商店支付定價 80% 的預期利潤由於我們尚未執行 討論了任何如何處理傳送到程式的大量資料 (保持 調整完畢!),請一次處理一本書,並顯示該書的輸出畫面。 當使用者將完所有資料輸入完畢後,程式應輸出 「總計」和「利潤」
開始編寫程式碼之前,請花點時間思考這個程式的設計。 分解為一組函式,並建立可讀取類似 概述您的解決方案確保每個函式都能執行一項工作。
以下是輸出範例:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
資料庫專案
在本專案中,我們會建立功能完整的 C++ 程式,以 資料庫應用程式
我們的計畫可讓我們管理作曲家資料庫及相關資訊 對他們提出質疑這項計畫的功能包括:
- 可新增作曲家
- 對作曲家進行排名的能力 (亦即指出我們喜愛或不喜歡的程度) 作曲家的音樂)
- 能查看資料庫中的所有作曲家
- 可依等級查看所有作曲家
「建構機器學習模型的方法有兩種 軟體設計:其中一個方法是簡單設定 另一個方式是使作業變得很複雜 沒有任何明顯的缺陷第一種方法實在困難許多。」- C.A.R. Hoare
許多人學到如何以「程序」來設計及編寫程式碼。 我們首先的核心問題是「這個程式的運作方式為何?」。三 分解問題的解決方案,各自解決 問題。這些工作會對應到程式中以依序呼叫的函式 來自 main() 或其他函式這個逐步指南非常適合 我們需要解決的問題比起以往,我們的程式 工作或事件的序列。
透過物件導向 (OO) 方法時,我們先從 我是否會建立物件模型?」與其將程式分割為多項任務 就能分割為實體物體的模型這些實體物件 由一組屬性定義的狀態,以及一組行為或動作 才能發揮效用操作可能會改變物件狀態 叫用其他物件的動作。基本上,當物件「知道」做法 以及建構自己的生成式 AI 模型
在 OO 設計中,我們依照類別和物件定義實體物件屬性 和行為OO 程式中通常會有大量物件。 不過,這些物件大多都相同。請考量下列幾項重點。

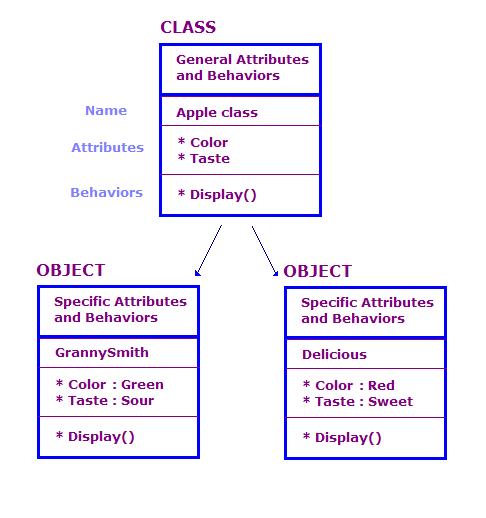
此圖定義了兩個 Apple 類別的物件。 每個物件的屬性和動作都與類別相同,但物件 定義特定類型的蘋果。此外,多媒體廣告聯播網 動作會顯示該特定物件的屬性,例如 「綠色」和「Sour」。
OO 設計包含一組類別、與這些類別相關聯的資料 以及類別可執行的動作我們也要找出 以及不同的課程互動方式物件可執行這項互動 叫用其他類別物件的動作。舉例來說,我們 可能會有 AppleOutputer 類別,用來輸出陣列的顏色和味道 呼叫每個 Apple 物件的 Display() 方法。
以下是我們執行 OO 設計的步驟:
- 識別類別,並一般定義每個類別的物件 可用於儲存資料,以及物件可執行的操作
- 定義每個類別的資料元素
- 定義每個類別的動作,以及單一類別的一些動作
以使用其他相關類別的動作實作
對大型系統而言,這些步驟會在不同層級反覆執行。
如果是 Composer 資料庫系統,我們需要使用 Composer 類別來封裝所有 我們要儲存在個別作曲家的資料。這個類別的物件可以 宣傳或降低排名 (變更排名),並顯示其屬性。
我們也需要一組 Composer 物件。為此,我們要定義 Database 類別 管理個別記錄這個類別的物件可新增或擷取 Composer 物件,並叫用顯示動作以顯示個別物件 Composer 物件
最後,我們需要某種使用者介面來提供互動操作 。這是預留位置類別,也就是說,我們真的不知道 但我們知道現在需要用到使用者介面不確定 例如以圖形形式呈現現在,我們定義了預留位置 之後再填入各個欄位
現在我們已識別 Composer 資料庫應用程式的類別 下一步是定義類別的屬性和動作在 或用紙筆或寫作 UML 或 CRC 卡 或 OOD。 列出類別階層和物件的互動方式
以 Composer 資料庫來說,我們會定義包含相關 我們要儲存在各個作曲家的資料此外也包含 排名及顯示資料
資料庫類別需要某種結構來保存 Composer 物件。 我們必須能夠在結構中新增 Composer 物件 擷取特定 Composer 物件我們也想要顯示所有 物件 按項目順序或排名
使用者介面類別會實作選單導向的介面,其中處理常式會 呼叫動作。
如果課程內容簡單易懂 也清楚當中的屬性和動作 與 Composer 應用程式一樣,設計類別相對簡單。但 若您覺得類別彼此關聯和互動方式有任何問題, 建議您先繪製 編寫程式碼
一旦我們清楚瞭解設計,並評估過設計後, ),我們會定義每個類別的介面。不必擔心導入作業 就此進入狀況 - 包括屬性和動作以及 類別狀態和動作可由其他類別使用
在 C++ 中,我們通常會為每個類別定義標頭檔案。Composer (作曲家) 類別具備私人資料成員,能存放要儲存在 Composer 中的所有資料。 我們需要存取子 (「get」方法) 和變動器 (「set」方法),以及 為類別的主要動作。
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
此外,資料庫類別也較為簡單。
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
請注意,我們如何將作曲家專屬資料妥善封裝在 類別我們可以在 Database 類別中加入結構體或類別,以代表 Composer 記錄,並直接從該記錄存取。但這會 「物件等級不足」 也就是在建立物件模型時 我們會盡力而為
開始建構 Composer 和資料庫時 類別,只要使用獨立的 Composer 類別,就能得到許多好處。我們要用 在 Composer 物件上分別建立獨立的不可分割作業,可大幅簡化實作過程 Display() 方法的一系列內容。
當然,還有一種說法是「過度物件化」在哪? 也就是把所有東西都想成一個全班,或者是不必要的課程。虛擬機器 然後練習找到平衡 就會知道個別的程式設計師 抱持不同看法的使用者
判斷問題是否過度或目標不足經常可以藉由謹慎的判斷來解決 為類別繪製圖表如先前所述,設計課程很重要 因為這有助於分析您的做法常見的 這種用途的標記法 UML (整合模型語言) 現在,您已為 Composer 和 Database 物件定義了類別,接著需要 可讓使用者與資料庫互動的介面。簡單的選單 模仿動作:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
我們可以將使用者介面以類別或程序程式的形式實作。非 C++ 程式中的所有項目都必須是類別。事實上,如果後續處理作業 或任務導向的選單計畫,可以按程序實作。 請務必在實作時保持「預留位置」 例如,如果想建立圖形使用者介面 不必在系統中進行任何變更,只要更改使用者介面即可。
最後,我們需要完成應用程式的程式,也就是測試類別的程式。 如果是 Composer 類別,我們希望 main() 程式接收輸入內容,並填入 kubectl 物件,然後顯示,確保類別可以正常運作。 此外,我們也會呼叫 Composer 類別的所有方法。
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
我們需要為 Database 類別提供類似的測試計畫。
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
別忘了,這些簡單的測試計畫雖然是不錯的第一步,但需要 以手動檢查輸出內容,確保程式能正常運作。阿斯 如果系統變大,迅速對輸出內容進行人工檢查會變得不切實際。 在後續課程中,我們會在表單中 單元測試
應用程式的設計現已完成。下一步是導入 類別和使用者介面的 .cpp 檔案首先, 複製上述 .h 和測試驅動程式程式碼,然後編譯這些檔案。使用 來測試課程接著,請實作以下介面:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
使用您在資料庫類別中定義的方法實作使用者介面。 提供方法防範錯誤。舉例來說,排名一律應落在範圍之內 1-10。請勿允許任何人新增 101 位作曲,除非您打算變更 儲存於資料庫類別中的資料結構
請記住,所有程式碼都必須遵守我們的編碼慣例, 為了方便起見,以下將說明:
- 我們編寫的每項程式都以標頭註解開始,提供 作者、聯絡資訊、簡短說明和使用方式 (如適用)。 每個函式/方法一開始都會有有關作業和使用情況的註解。
- 我們會在程式碼出現時,以完整的句子加入說明註解 而非記錄本身。舉例來說,如果處理過程很複雜、沒有明顯影響 有趣或值得關注的議題
- 請一律使用描述性名稱:變數是指小寫字詞,並以 _,如 my_variable 所示。函式/方法名稱會使用大寫字母標示 如下所示:常數開頭為「k」和 請使用大寫字母來標記字詞,例如:kDaysInWeek。
- 縮排是兩個倍數的倍數。第一層是兩個空格如果進一步 需要縮排,而使用四個空格、六個空格等。
歡迎來到真實世界!
在這個單元中,我們將介紹大多數軟體工程用到的兩項重要工具 員工只能在您的 Google Cloud 機構中存取資源 無法在其他機構存取資源其一是建構工具 第二項是設定管理 有些人會將 Cloud Storage 視為檔案系統 但實際上不是這兩項工具都是工業軟體工程中不可或缺的一環, 許多工程師通常只依賴單一大型系統。這些工具有助於統整 並有效地進行編譯 並從多個程式和標頭檔案中連結系統。
Makefiles
建構程式的程序通常是透過建構工具管理 並以正確順序連結必要檔案在多數情況下 依附元件,例如,在某個程式中呼叫的函式位於另一個程式內 計畫。或者幾個不同的 .cpp 檔案都需要標頭檔案。A 罩杯 建構工具會從這些依附元件找出正確的編譯順序。這會導致 只會編譯自上次版本後變更的檔案。這可節省 包含數百或數千個檔案的系統。
常用的開放原始碼建構工具稱為 make。若要瞭解功能,請閱讀 透過這個 文章。 請確認您是否可以為 Composer 資料庫應用程式建立依附元件圖表。 並轉譯成 makefile這裡是 我們的解決方案
設定管理系統
工業軟體工程使用的第二種工具是 Configuration Management (CM)。用於管理變更。假設 Bob 和 Susan 都是科技記者 兩者皆正著手更新技術手冊使用者在會議期間 管理員會指派同一文件中的每個區段來更新程式碼。
系統會將技術手冊儲存在 Bob 和 Susan 都能存取的電腦上。 如果沒有任何 CM 工具或程序,可能會導致許多問題發生。一 可能是儲存文件的電腦進行設定 小明和阿蘇無法同時處理手冊作業。這會導致 大幅降低
因為儲存電腦允許文件,而發生更危險的情況 由 Bob 和 Susan 同時開啟以下是可能的情況:
- 志明在電腦上開啟文件,接著完成他的部分工作。
- 珊珊打開電腦,準備文件。
- 白先生完成變更,並將文件儲存在儲存裝置中。
- 珊珊已完成變更,並將文件儲存在儲存電腦上。
這張插圖顯示沒有控制選項時可能發生的問題 技術支援手冊珊珊儲存變更後 覆寫由 Bob 製作的說明文字
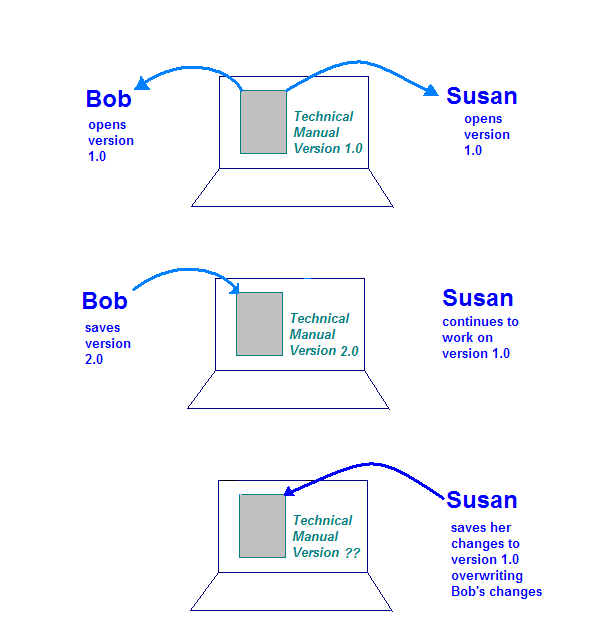
這就是 CM 系統可以控制的這種情況類型。與社群管理員分享 Bob 和 Susan 會執行「結帳」自己的技術 不必動手操作當小明再次檢查變更時,系統會得知 感謝了珊珊拍了她當系統檢查小珊的文案時,系統會 分析小包和阿蘇所做的變更並建立新版本 將兩組變更合併在一起
CM 系統除了管理並行變更之外,還有多項功能 (如上所述) 。許多系統會儲存文件所有版本的封存檔 建立時間。就技術手冊而言,這是很有幫助的做法 使用者以舊版手冊提出問題時,就會觸發這個事件。 CM 系統將允許技術撰寫者存取舊版本, 瞭解使用者看到的內容
CM 系統特別適合用於控管軟體變更。這些 系統稱為軟體設定管理 (SCM) 系統如果您考慮 大型軟體工程中大量的個別原始碼檔案 以及需要進行變更的大量工程師 SCM 系統顯然至關重要
軟體設定管理
SCM 系統的基礎概念如下:您的檔案最終副本 都會保存在中央存放區中使用者會查看存放區中的檔案副本 編輯這些副本,完成後再返回查看。SCM 系統管理並追蹤多位使用者對單一主節點的修訂版本 設定。
所有 SCM 系統都提供下列基本功能:
- 並行管理
- 版本管理
- 同步處理
現在來逐一詳細介紹這些功能。
並行管理
「並行」是指多位使用者同時編輯檔案。 我們希望使用者能透過大型存放區完成這項作業,但這可以 可解決一些問題
以工程領域的一個簡單的例子為例:假設我們允許工程師 ,在原始碼的中央存放區裡同時修改相同的檔案。 Client1 和 Client2 兩者都需要同時變更檔案:
- Client1 會開啟 bar.cpp。
- 用戶端 2 會開啟 bar.cpp。
- Client1 會變更並儲存檔案。
- Client2 會修改檔案並儲存變更,覆寫 Client1 的變更。
當然,我們不希望發生這種情形。即使我們控制了 讓兩名工程師在個別副本上工作,而非直接在主要執行個體上 設定 (如下圖所示) 時,副本必須依循某種方式核對。大多數 SCM 系統允許多位工程師查看檔案,以便處理這個問題 (「同步處理」或「更新」) 並視需要進行變更。社群管理員 系統會在檔案重新上架時,執行演算法來合併變更 (「提交」或「修訂」) 至存放區。
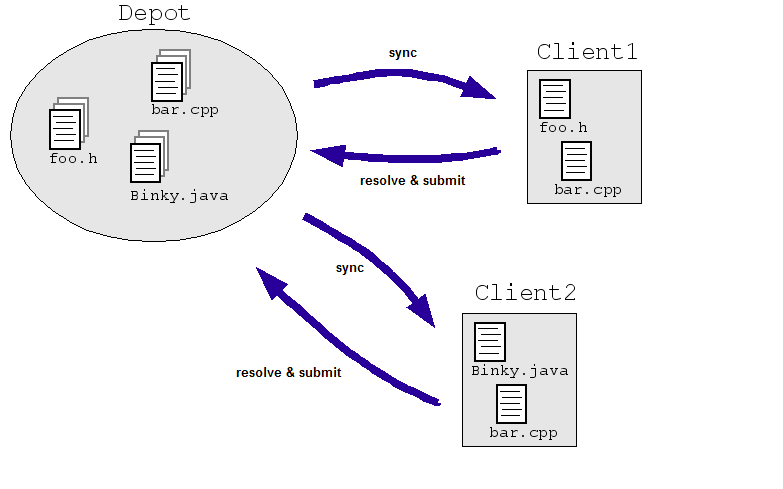
這些演算法可能相當簡單 (要求工程師解決不一致的變更) (判斷如何巧妙地合併衝突的變更) 並只在系統真的卡住時詢問工程師。
版本管理
版本管理是用來追蹤檔案修訂版本, 重新建立 (或復原) 先前的檔案版本。系統會在 在存放區中登錄檔案時,為每個檔案建立封存副本 或儲存所有檔案變更我們隨時都可以使用封存內容 或變更資訊即可建立先前的版本此外,版本管理系統 建立記錄報表,以瞭解已檢查變更的使用者、登入時間以及 變更的內容
同步處理
在部分 SCM 系統中,個別檔案會簽入或移出存放區。 更強大的系統可讓您一次查看多個檔案。工程師 查看專屬、完整的存放區副本 (或其中一部分) 檔案。然後,他們將變更提交回主要存放區 定期更新,並自行更新個人副本,隨時掌握最新變更 也是別人做的事這個過程稱為同步處理或更新。
子版本
子版本 (SVN) 是開放原始碼版本管控系統。它具備 功能。
當衝突發生時,SVN 會採用簡單的方法。衝突是指 有一或多個工程師對程式碼集的相同區域做出不同變更 然後都提交變更SVN 只會警告工程師 衝突 - 工程師可以自行解決。
在本課程中,我們會透過 SVN 協助您熟悉 以及設定管理這類系統在業界非常常見,
首先在系統中安裝 SVN。按一下 這篇文章 操作說明。找到您的作業系統並下載適當的二進位檔。
一些 SVN 術語
- 修訂版本:單一檔案或一組檔案的變更。修訂版本是一次 「快照」也面臨瞬息萬變的專案中
- 存放區:SVN 用來儲存專案完整修訂版本記錄的主要副本。 每項專案都有一個存放區。
- 工作複本:工程師對專案做出變更的內容副本。有 可以為特定專案多個工作副本,而每個專案皆由個別工程師擁有。
- 結帳:從存放區要求有效副本。工作副本 等於專案簽出時的狀態。
- 修訂:將工作副本中的變更傳送至中央存放區。 又稱為簽到或提交。
- 更新:將他人帶往把變更複製到工作副本 或指出您的工作副本是否有未提交的變更。這是 與同步處理相同,如上所述。因此,透過更新/同步處理功能,您可以複製工作副本 保持在最新狀態。
- 衝突:兩位工程師嘗試提交相同變更 檔案區域SVN 表示衝突,但工程師必須解決。
- 記錄訊息:您修訂時附加至修訂版本的註解, 說明變更紀錄可提供問題的摘要 資源數量
現在您已安裝 SVN,我們將執行一些基本指令。 首先,請在指定目錄中設定存放區接著來介紹 指令:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
import 指令會將 Directory mytree 的內容複製到 複製到存放區中的所有目錄專案我們可以查看 將 list 指令加到存放區
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
匯入作業不會建立有效的副本。如要執行上述操作,您必須使用 svn Checkout 指令。這項操作會建立目錄樹狀結構的有效副本。我們 請進行下列步驟:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
備妥工作副本後,您現在可以變更檔案和目錄 好在那裡。工作副本就像任何其他檔案和目錄集合一樣 - 您可以新增社群、進行編輯、移動位置,甚至刪除 整份工作副本請注意,如果在工作副本中複製及移動檔案 請務必使用 svn copy 和 svn move,而不是 例如作業系統指令如要新增檔案,請使用 svn add 和刪除 檔案使用 svn delete。如果您只想編輯文件,只要開啟 檔案就能直接編輯!
一些標準目錄名稱經常與 Subversion 搭配使用。「後車廂」目錄 是專案的主要開發線。一個「支線」目錄 包含您正在使用的任何分支版本版本
$ svn list file:///usr/local/svn/repos /trunk /branches
假設您已經對線上副本做所有必要變更 選擇要與存放區同步處理的結果如果有許多其他工程師 請務必隨時更新作業副本, 您可以利用 svn status 指令來查看您正在進行的變更 執行。
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
請注意,狀態指令上有許多旗標可控制這項輸出內容。 如要查看修改後檔案中的特定變更,請使用 svn diff。
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...最後,如要從存放區更新工作副本,請使用 svn update 指令。
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
這部分可能會發生衝突。上方輸出內容中的「U」代表 這些檔案的存放區版本沒有任何變更,而且更新 執行完畢。「G」表示發生合併。存放區版本有 但這些變更並未與您的變更發生衝突。「C」代表 衝突問題。也就是說,您在存放區中的變更 現在您需要選擇其中一種方案
子版本會在您的工作中放入三個檔案,並解決每個發生衝突的檔案 副本:
- file.mine:這是您之前在工作副本中存有的檔案 已更新你的工作副本
- file.rOLDREV:這是您之前從存放區簽出的檔案 進行變更
- file.rNEWREV:這個檔案是存放區中的目前版本。
你可以透過下列三種方式之一來解決衝突:
- 逐一瀏覽檔案,手動合併。
- 將 SVN 建立的其中一個暫存檔案複製到工作副本版本。
- 執行 svn restore 來捨棄所有變更。
問題解決後,請執行 svn 解決 通知 SVN。 這麼做會移除這三個暫存檔案,且 SVN 不會再透過 衝突狀態。
最後,請將最終版本提交至存放區。這個 svnCommit 指令。提交變更時,您需要 提供描述變更的記錄訊息。這份記錄訊息附加了 會是你建立的修訂版本
svn commit -m "Update files to include new headers."
關於 SVN,還有許多值得探討的主題,包括 SVN 如何支援大型軟體 和工程專案網路上有許多資源 用「Subversion」透過 Google 搜尋
在實務上,為 Composer 資料庫系統建立存放區,然後匯入 所有檔案都沒問題接著瀏覽一份有效版本,並依照 。
參考資料
申請:剖析研究
試試大學的 eSkeletons 奧斯汀的德克薩斯州