Samouczek języka C++
Początkowe sekcje tego samouczek obejmują podstawowy materiał już przedstawiony w dwóch ostatnich modułach i przedstawimy więcej informacji na temat zaawansowanych zagadnień. Nasze W tym module skupmy się na pamięci dynamicznej, a bardziej szczegółowo o obiektach i klasach. Zostały również wprowadzone niektóre zaawansowane tematy, takie jak dziedziczenie, polimorfizm, szablony, wyjątków i przestrzeni nazw. Zagadnienia omówimy w dalszej części szkolenia C++ dla zaawansowanych.
Projektowanie obiektowe
To doskonała tutorial (samouczek) na temat projektowania zorientowanego na obiekt. Zastosujemy omówioną w tym module.
Ucz się na przykładzie nr 3
W tym module skoncentrujemy się na nauce korzystania ze wskaźników, wielowymiarowych tablic i klas/obiektów. Wykonaj te czynności przykłady. Kluczem do bycia dobrym programistą jest to ćwiczenie, ćwiczenie, ćwiczenie!Ćwiczenie 1: Ćwicz, używając wskaźników
Jeśli potrzebujesz dodatkowych ćwiczeń ze wskazówkami, przeczytaj to , w którym omówione są wszystkie aspekty programu i zawiera wiele przykładów programu.
Jakie są efekty działania poniższego programu? Nie uruchamiaj programu, ale i narysuj obraz pamięci, aby określić dane wyjściowe.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}Po ręcznym określeniu wyników uruchom program, aby sprawdzić, Zgadza się.
Ćwiczenie 2: więcej ćwiczeń na klasach i przedmiotach
Jeśli potrzebujesz dodatkowych ćwiczeń z klasami i obiektami, tutaj to zasób, który wymaga wdrożenia 2 niewielkich klas. Weź kilka czas na ćwiczenia.
Ćwiczenie 3: Tablice wielowymiarowe
Rozważ ten program:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}W programie znajduje się wiersz zatytułowany „Jak działa ta linia?”. – Czy potrafisz to zrozumieć? Tutaj znajdziesz wyjaśnienie.
Napisz program, który inicjuje tablicę trójwymiarową i wypełnia trzeci wymiar sumą wszystkich 3 indeksów. Oto nasze rozwiązanie.
Ćwiczenie nr 4: Przykład rozbudowanego projektu OO
Oto szczegółowy opis przykład projektowania zorientowanego na obiekt, który opisuje od początku do końca. Końcowy kod jest napisany w Javie w języku programowania, ale możesz go przeczytać, biorąc pod uwagę przyszli.
Poświęć trochę czasu na zapoznanie się z tym przykładem. To świetnie ilustracja przedstawiająca proces i oferujące go narzędzia do projektowania.
Egzaminy jednostkowe
Wprowadzenie
Testowanie jest kluczowym elementem procesu inżynierii oprogramowania. Test jednostkowy to konkretny rodzaj testu, który sprawdza funkcjonalność z kodu źródłowego.Testy jednostkowe są zawsze wykonywane przez inżyniera i są zazwyczaj w tym samym czasie co kodowanie modułu. Motywy testowe używane do testowania klas Composer i Database to przykłady testów jednostkowych.
Testy jednostkowe mają następujące cechy. No i...
- testowanie komponentu w izolacji
- są deterministyczne
- zwykle mapuje się na jedne zajęcia
- unikanie zależności od zasobów zewnętrznych, bazy danych, pliki, sieć
- szybkie wykonywanie
- może być uruchamiana w dowolnej kolejności
Istnieją zautomatyzowane platformy i metodologie, które zapewniają pomoc w dużych organizacjach zajmujących się inżynierią oprogramowania. Istnieją zaawansowane programy typu open source do testowania jednostek, Więcej informacji na ten temat znajdziesz w dalszej części tej lekcji.
Poniżej przedstawiliśmy testy przeprowadzane w ramach testowania jednostkowego.
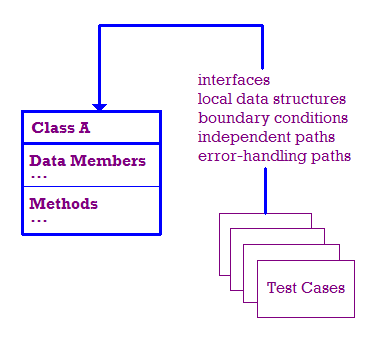
W idealnym świecie sprawdzamy, czy:
- Interfejs modułu jest testowany, aby zapewnić przepływ informacji .
- Lokalne struktury danych są sprawdzane pod kątem poprawnego przechowywania danych.
- Warunki granicy są sprawdzane w celu sprawdzenia, czy moduł działa prawidłowo nie przekracza granic, które ograniczają przetwarzanie.
- Testujemy niezależne ścieżki w module, aby upewnić się, że każda z nich
więc każda instrukcja w module zostanie wykonana co najmniej raz.
- Na koniec musimy sprawdzić, czy błędy są obsługiwane prawidłowo.
Pokrycie kodu
W rzeczywistości nie jesteśmy w stanie uzyskać pełnego „zasięgu kodu”, z testowaniem. Pokrycie kodu to metoda analizy, która określa, które części oprogramowania zostały wykonane (opisane) w ramach zestawu przypadków testowych i które części nie zostało wykonane. Jeśli spróbujemy uzyskać 100% pokrycia, będziemy spędzić więcej czasu pisanie testów jednostkowych niż pisanie prawdziwego kodu. Zastanów się nad wymyśleniem jednostki dla wszystkich niezależnych ścieżek poniżej. Może to szybko zmienić się w problem wykładniczy.
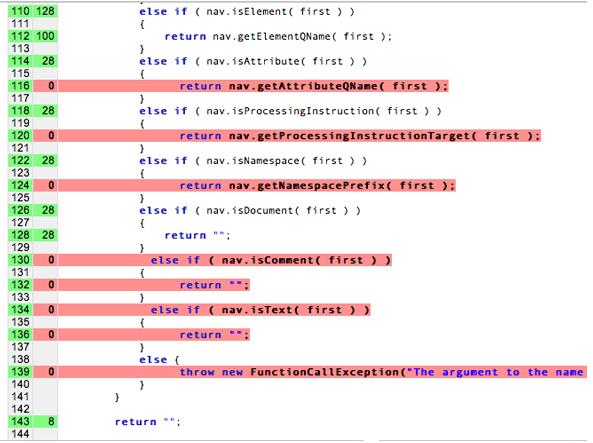
Na tym schemacie linie czerwone nie są testowane, a linie bezbarwne – i testowania modelu.
Zamiast próbować 100% zasięgu, koncentrujemy się na testach, które zwiększają pewność że moduł działa prawidłowo. Sprawdzamy m.in.:
- Przypadki null
- Testy zakresu, np. testy wartości dodatniej i ujemnej
- Skrajne przypadki
- Zgłoszenia awarii
- Testowanie ścieżek, które są najczęściej wykonywane
Platformy testów jednostkowych
Większość platform do testowania jednostkowego używa asercji do testowania wartości podczas wykonywania ścieżki. Asercje to stwierdzenia, które sprawdzają, czy określony warunek jest spełniony. może prowadzić do powodzenia, niepowodzenia niekrytycznego lub krytycznej. Po jeśli zostanie przeprowadzone asercja, program będzie kontynuowany w zwykły sposób, jeśli wynik będzie albo powodzenia lub niekrytycznego błędu. W przypadku błędu krytycznego bieżąca funkcja został przerwany.
Testy składają się z kodu, który konfiguruje stan lub modyfikuje moduł, z szeregiem asercji, które weryfikują oczekiwane wyniki. Jeśli wszystkie asercje jeśli test okaże się skuteczny, tj. zwrócono wartość prawda, wówczas test się powiedzie; w przeciwnym razie nie uda się.
Przypadek testowy zawiera jeden lub więcej testów. Grupujemy testy w przypadki testowe, które: odzwierciedlają strukturę testowanego kodu. Na tym szkoleniu wykorzystamy CPPUnit. Za jej pomocą możemy pisać testy jednostkowe w języku C++ i uruchamiać je automatycznie, przesyłając raport o udanej lub niepowodzeniu testów.
Instalacja CPPUnit
Pobierz kod CPPUnit ze strony SourceForge. Znajdź odpowiedni katalog i umieść w nim plik tar.gz. Następnie wpisz następujące polecenia (w systemach Linux i Unix), zastępując odpowiedni plik cppunit nazwa:
gunzip filename.tar.gz tar -xvf filename.tar
Jeśli pracujesz w systemie Windows, możesz potrzebować narzędzia do wyodrębniania pliku tar.gz. . Następnym krokiem jest skompilowanie bibliotek. Przejdź do katalogu cppunit. Znajduje się tam plik INSTALL zawierający konkretne instrukcje. Zwykle musisz uruchomić:
./configure make install
W razie problemów zajrzyj do pliku INSTALL. Biblioteki są zwykle znajduje się w katalogu cppunit/src/cppunit. Aby sprawdzić, czy kompilacja zadziałała, przejdź do katalogu cppunit/examples/simple i wpisz „make”. Jeśli wszystko się zgadza i wszystko jest gotowe.
Dostępny jest doskonały samouczek, tutaj. W tym samouczku utwórz klasę liczb zespolonych i powiązaną z nią klasę testów jednostkowych. W katalogu cppunit/examples znajduje się kilka dodatkowych przykładów.
Dlaczego muszę to zrobić???
Testowanie jednostkowe z kilku powodów jest niezwykle ważne w branży. To już zna już jeden powód: potrzebujemy sposobu na sprawdzenie naszej pracy, podczas gdy programowania. Nawet jeśli opracowujemy bardzo mały program, napisz coś w rodzaju elementu śledzącego lub sterownika, aby upewnić się, że nasz program działa zgodnie z oczekiwaniami.
Z doświadczenia inżynierowie wiedzą, że program może zadziałać. są bardzo małe. Opierając się na tej koncepcji, przeprowadzamy testy jednostkowe do automatycznego sprawdzania programów i ich powtarzania. Asercje zastępują ręczne sprawdzając dane wyjściowe. A ponieważ można łatwo zinterpretować wyniki (test z pozytywną lub niekorzystną skutecznością), testy można przeprowadzać wielokrotnie, co zapewnia czyli zabezpieczenia, które zwiększają odporność kodu na zmiany.
Ujmijmy to w konkretny sposób: gdy po raz pierwszy prześlesz gotowy kod CVS, działa idealnie. I jeszcze przez jakiś czas działa idealnie. Potem Pewnego dnia ktoś inny zmieni Twój kod. Prędzej czy później, że ktoś się zepsuje kod. Czy myślisz, że sami zauważą? Nieprawdopodobne. Ale gdy na potrzeby pisania testów jednostkowych, istnieją systemy, które mogą je uruchamiać automatycznie codziennie. Są to tzw. systemy ciągłej integracji. Kiedy ten inżynier X spowoduje złamanie kodu, system będzie wysyłać do nich nieprzyjemne e-maile, dopóki nie naprawi to problemu . Nawet jeśli inżynier X to TY!
Oprócz pomocy w tworzeniu oprogramowania, a następnie zabezpieczaniu go i testowanie jednostkowe w obliczu zmian:
- Tworzy specyfikację wykonywalną i synchronizowaną dokumentację z kodem. Innymi słowy, możesz przeczytać test jednostkowy, by dowiedzieć się, przez moduł.
- Pomaga oddzielić wymagania od implementacji. Ponieważ zgłaszasz prawa zachowanie jest widoczne z zewnątrz, możesz dokładnie się nad nim zastanowić zamiast mieszania różnych pomysłów na ich wdrożenie.
- Umożliwia eksperymentowanie. Jeśli masz sieć zabezpieczeń, która powiadomi Cię, jeśli w pewnym momencie nie działasz w ramach modułu, spróbuj i zmienianie ich konfiguracji.
- Pozwala ulepszyć projekty. Pisanie szczegółowych testów jednostkowych często wymaga aby lepiej przetestować kod. Testowy kod jest często bardziej modułowy niż nietestowalny w kodzie.
- Utrzymuje wysoką jakość. Niewielki błąd w krytycznym systemie może spowodować, że firma chcą stracić miliony dolarów, a co gorsza – szczęścia i zaufanie użytkownika. zabezpieczenia jednostkowe. Łapiąc owady na wczesnym etapie, pozwalają też zespołom ds. kontroli jakości poświęcić czas na bardziej zaawansowane i trudniejsze zadania i sytuacji niepowodzeń, a nie zgłaszać ewidentne błędy.
Poświęć trochę czasu na opisanie testów jednostkowych za pomocą CPPUnit aplikacji bazy danych Composer. Więcej informacji znajdziesz w katalogu cppunit/examples/.
Jak działa Google
WprowadzenieWyobraź sobie średniowiecza mnicha przeglądającego tysiące rękopisów do archiwów swojego klasztoru.„Gdzie jest ten Arystoteles...”

Na szczęście rękopisy są porządkowane według treści i inspirowane ze specjalnymi symbolami ułatwiającymi uzyskanie informacji zawartych w każdy. Bez takiej organizacji bardzo trudno byłoby znaleźć rękopis.
Zapisywanie i pobieranie zapisanych informacji z dużych zbiorów to pobieranie informacji (IR). Liczba takich działań jest coraz większa ważne na przestrzeni stuleci, zwłaszcza w kontekście wynalazków, takich jak papier i druk. naciśnij. Kiedyś była tam tylko kilka osób. Teraz, ale setki milionów osób co roku poszukują informacji gdy korzystają z wyszukiwarki lub korzystają z wyszukiwarki na komputerze.
Wprowadzenie do pobierania informacji

W ciągu 30 lat dr Seuss napisał 46 książek dla dzieci. Jego książki opowiedziały kotów, krów i słoni, z drzwiami i loraksy. Czy pamiętasz? które stworzenia były w której historii? Tylko dzieci mogą korzystać z tej funkcji i powiedzieć, w których opowieściach z dr. Seussem występują stworzenia:
(COW i BEE) lub CROWS
Zastosujemy kilka klasycznych modeli pobierania informacji, które pomogą nam rozwiązać ten problem .
Oczywistym podejściem jest brute-force. Aby zdobyć wszystkie 46 historii z serii Dr. Seuss, czytanie. Przy każdej książce zaznacz, które z nich zawierają słowa COW i BEE. jednocześnie wyszukaj książki zawierające wyraz CROWS. Komputery są bardzo ważne szybciej niż my. Jeśli mamy cały tekst z książek Dr. Seussa w postaci cyfrowej, np. plików tekstowych, możemy je po prostu przeglądać. Dla ta metoda sprawdza się w przypadku niewielkiej kolekcji, np. książek dr. Seussa.
Jest jednak wiele sytuacji, w których potrzebujemy więcej. Na przykład kolekcja danych dostępnych obecnie online jest za duży, aby grep mógł go obsłużyć. Nie zakładamy też, zależy nam tylko na dokumentów, które spełniają nasze warunki. Przyzwyczailiśmy się uszeregować je według trafności.
Innym sposobem oprócz grep jest utworzenie indeksu dokumentów w kolekcji przed rozpoczęciem wyszukiwania. Indeks IR jest podobny do indeksu w na odwrocie podręcznika. W każdym z nich tworzymy listę wszystkich słów (lub haseł) Doktor Seuss, pomijając słowa takie jak „the”, „i” i inne spójniki, przyimki itp. (są to tzw. słowa-klucze). Następnie reprezentujemy te informacje w sposób ułatwiający znalezienie tych terminów historii, w których się znajdują.
Jedną z możliwych postaci jest macierz z artykułami na górze, warunki wymienione w poszczególnych wierszach. „1” w kolumnie oznacza, że dane hasło się wyświetla. w artykułach w tej kolumnie.
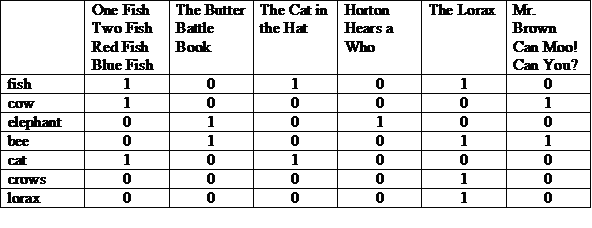
Każdy wiersz lub kolumnę możemy wyświetlić jako wektor bitowy. Wektor bitowy wiersza wskazuje i w których z nich pojawia się dane hasło. Wektor bitowy kolumny wskazuje, które wyrazy pojawi się w historii.
Wracając do pierwotnego problemu:
(COW i BEE) lub CROWS
Bierzemy wektory bitowe dla tych haseł i najpierw stosujemy operator bitowy I, a następnie lub w pozycji bitowej funkcji LUB na wyniku.
(100001 i 010011) lub 000010 = 000011
Odpowiedź: „Pan. Brązowy Puszka! Potrafisz?” i „Loraksa”. To jest ilustracja modelu pobierania wartości logicznej, który jest modelem „dopasowania ścisłego”.
Załóżmy, że rozwijamy macierz, aby obejmowała wszystkie historie z dr. Seussa powiązane z nimi hasła. Macierz znacznie się rozwinie, obserwacja to większość wpisów ma wartość 0. Macierz prawdopodobnie nie jest najlepsza dla indeksu. Musimy znaleźć sposób na przechowywanie tych danych.
Niektóre ulepszenia
Struktura wykorzystywana w podczerwieni do rozwiązania tego zadania jest nazywana odwróconym indeksem. Prowadzimy słownik haseł, a dla każdego z nich mamy listę który rejestruje dokumenty, w których występuje dane hasło. Ta lista jest nazywana ogłoszeniami. . Pojedynczo połączona lista dobrze prezentuje tę strukturę, jak widać poniżej. poniżej.

Jeśli nie korzystasz z połączonych list, wyszukaj w Google „połączone listy”
w C++”. Znajdziesz tam wiele materiałów opisujących jego tworzenie,
i sposobach ich wykorzystania. Omówimy to szczegółowo w dalszej części modułu.
Zwróć uwagę, że zamiast nazwy pliku danych używamy identyfikatorów dokumentów (DocIDs). historię. Identyfikatory DocID są również sortowane, ponieważ ułatwiają przetwarzanie zapytań.
Jak przetwarzamy zapytanie? W przypadku pierwotnego problemu najpierw znajdujemy posty COW. a następnie listę postów BEE. Następnie „scalamy” je ze sobą:
- Umieść znaczniki na obu listach i przeglądaj obie listy postów jednocześnie.
- W każdym kroku porównaj identyfikator DocID wskazywany przez oba wskaźniki.
- Jeśli są takie same, umieść ten identyfikator DocID na liście wyników, w przeciwnym razie przesuń wskaźnik do przodu wskazujący mniejszy identyfikator dokumentu.
Aby utworzyć odwrócony indeks:
- Przypisz identyfikator DocID do każdego interesującego Cię dokumentu.
- Dla każdego dokumentu określ odpowiednie warunki (tokenizacja).
- Dla każdego hasła utwórz rekord składający się z hasła, identyfikator DocID, w którym oraz częstotliwość w danym dokumencie. Pamiętaj, że może być ich wiele zapisy dotyczące określonego hasła, jeśli występuje on w więcej niż 1 dokumencie.
- Posortuj rekordy według hasła.
- Utwórz słownik i listę postów, przetwarzając pojedyncze rekordy dla jednego hasła, a także łączenie wielu rekordów dla haseł występujących na więcej niż jeden dokument. Utwórz linkowaną listę identyfikatorów DocID (w kolejności posortowanej). Każdy to hasło ma także częstotliwość, która jest sumą częstotliwości wszystkich rekordów danego terminu.
Projekt
Znajdź kilka długich dokumentów zawierających zwykły tekst, które możesz przetestować. projekt polega na utworzeniu odwróconego indeksu z dokumentów przy użyciu algorytmów opisane powyżej. Trzeba też utworzyć interfejs do wprowadzania zapytań i mechanizmu ich przetwarzania. Partnera projektu możesz znaleźć na forum.
Oto możliwy proces ukończenia projektu:
- Najpierw musisz zdefiniować strategię identyfikowania terminów w dokumentach. Sporządź listę wszystkich odrzucanych słów, które przychodzą Ci do głowy, i napisz funkcję, która odczytuje słowa w plikach, zapisuje hasła i eliminuje pomijane słowa. Być może podczas przeglądania listy haseł z iteracji.
- Napisz przypadki testowe CPPUnit, aby przetestować funkcję, oraz plik Makefile, aby przenieść wszystko podczas tworzenia. Sprawdź pliki w pliku CVS, szczególnie jeśli dla partnerów. Dowiedz się, jak otworzyć instancję CVS dla zdalnych inżynierów.
- Dodaj przetwarzanie, aby uwzględnić dane o lokalizacji, czyli wybrać plik i gdzie Czy plik zawiera wyszukiwane hasło? Możesz obliczyć obliczenia, które pozwolą zdefiniować numer strony lub akapitu.
- Zapisz przypadki testowe CPPUnit, aby przetestować tę dodatkową funkcję.
- Utwórz odwrócony indeks i zapisz dane o lokalizacji w rekordzie każdego hasła.
- napisać więcej przypadków testowych,
- Zaprojektować interfejs umożliwiający użytkownikowi wpisanie zapytania.
- Używając opisanego powyżej algorytmu wyszukiwania, przetwórz odwrócony indeks i zwróci użytkownikowi dane o lokalizacji.
- Pamiętaj, by w tej ostatniej części uwzględnić przypadki testowe.
Tak jak w przypadku wszystkich projektów, skorzystaj z forum i czatu, aby znaleźć partnerów i dziel się pomysłami.
Dodatkowa funkcja
Częstym etapem przetwarzania w wielu systemach IR jest nazywany stempingiem. że użytkownicy szukający informacji na temat „pobierania” będą też zainteresowani dokumentami zawierającymi hasło „retrieve”, „pobieram”, „pobieram” itd. Systemy mogą być narażone na błędy spowodowane albo kiepsko sznurowadła, więc to trochę trudne. Na przykład użytkownik zainteresowany w obszarze „pobieranie informacji” może wyświetlić się dokument o nazwie „Informacje w Złotych”. retrievery”. Przydatnym algorytmem wycinków jest Algorytm Portera.