C++ 言語のチュートリアル
このセクションの チュートリアル このコースですでに説明した 高度なコンセプトについて詳しく学ぶことができます。Google このモジュールでは、動的メモリに焦点を当て、オブジェクトとクラスについて詳しく説明します。 継承、ポリモーフィズム、テンプレート、 例外と名前空間があります。これらについては、Advanced C++ コースで後ほど学習します。
オブジェクト指向の設計
これは非常に良い オブジェクト指向設計に関するチュートリアル新しいルールを 方法論について学習しました。
例 3 で学ぶ
このモジュールでは、ポインタ、オブジェクト指向、 多次元配列、クラス/オブジェクトなどがあります。以下の手順を実施します 説明します。優れたプログラマーになるための鍵は、 何度も練習することです!演習 1: ポインタを使って練習する
ポインタに関するその他の演習が必要な場合は、 この リソースです。このリソースには、ポインタのあらゆる側面が網羅されており、多くのプログラム例が含まれています。
次のプログラムの出力はどうなるでしょうか。プログラムを実行せずに、 出力が決定します。
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}手動で出力を確認したら、プログラムを実行して、 正解。
演習 2: クラスとオブジェクトを使った演習
クラスとオブジェクトについてさらに演習が必要な場合は、 こちら 2 つの小さなクラスの実装を通じて提供されるリソースです。一部を食べる エクササイズをする時間を確保できます。
演習 3: 多次元配列
次のプログラムについて考えてみましょう。
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}このプログラムに「How does this line work?」という行があります。 - わかる? こちらで説明をご覧ください。
3 次元配列を初期化して 3 次元を塗りつぶすプログラムを作成する 3 つのインデックスの合計で計算します 解決策はこちらをご覧ください。
演習 4: 広範な OO 設計例
こちらの オブジェクト指向設計サンプルでは、 プロセスです。最終的なコードは Java SDK で記述します。 詳しく見ていきますが、このコースでは、これまでに学んだ内容を あります。
時間をかけてこの例全体を説明してください。とても プロセスとそれをサポートする設計ツールが示されています。
単体テスト
はじめに
テストは、ソフトウェア エンジニアリング プロセスの重要な部分です。単体テスト は、1 つの小規模なアプリの機能をチェックする ソースコードのモジュールです。単体テストは常にエンジニアが行い、 通常はモジュールをコーディングするときに同時に行います。使用するテストドライバ 単体テストの例としては、Composer クラスと Database クラスをテストする場合が挙げられます。
単体テストには次の特性があります。広告主は...
- コンポーネントを個別にテストする
- 決定的
- 1 つのクラスに 1 つの
- 外部リソースへの依存関係を回避します。たとえば、データベース、ファイル、ネットワーク
- 迅速に実行して
- 任意の順序で実行可能
サポートとガバナンスを提供する自動化されたフレームワークと手法が 大規模なソフトウェア エンジニアリング組織の単体テストにおいて、一貫性を維持しています。 オープンソースの高度な単体テスト フレームワークがいくつか用意されています。 後ほど詳しく説明します。
単体テストの一環として行われるテストを以下に示します。
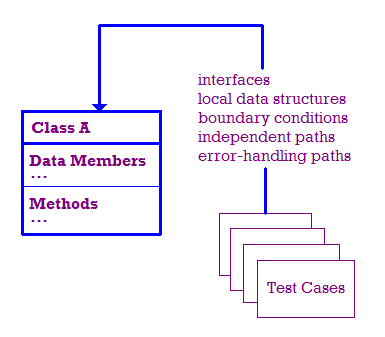
理想的には、以下についてテストします。
- モジュール インターフェースのテストにより、情報のやり取りが確認 確認します。
- データが適切に格納されているかどうかは、ローカルデータ構造が検証されます。
- 境界条件をテストして、モジュールが正しく動作していることを確認する 境界内のトラフィックを保護します。
- モジュール内の独立したパスをテストして、各パスを検証し、
モジュール内の各ステートメントが少なくとも 1 回実行されます。
- 最後に、エラーが適切に処理されていることを確認する必要があります。
コード カバレッジ
実際には、完全な「コード カバレッジ」は達成できません検証しています。 コード カバレッジとは、ソフトウェアのどの部分を テストケース スイートによって実行された(カバーされている)かどうか、また、 未履行となりますカバレッジを 100% にしようとすれば 実際のコードを記述するよりも、単体テストを作成する方がよいでしょう。ユニットの考案を検討する 次の独立したパスをすべてテストします。これはすぐに 困難です。
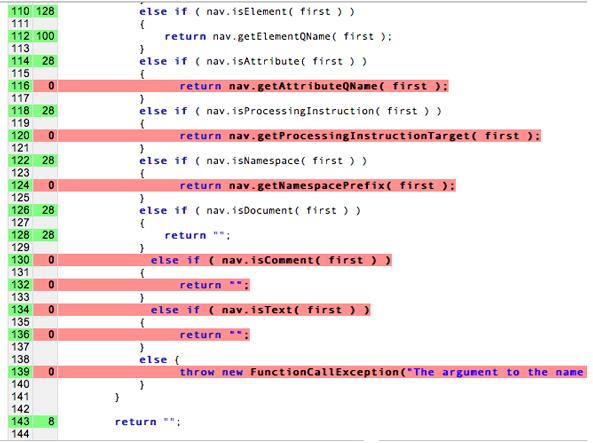
この図では、赤い線はテストされておらず、色付けされていない線はテストされています。 検証できます。
100% のカバレッジを目指すのではなく、テストの信頼性を高めることに重点を置いている 確認する必要があります。以下のような項目についてテストします。
- null ケース
- 範囲テスト(例: 正負の値のテスト)
- エッジケース
- 失敗のケース
- ほとんどの時間で実行される可能性が最も高いパスをテストする
単体テスト フレームワーク
ほとんどの単体テスト フレームワークでは、アサーションを使用して、 あります。アサーションは、条件が true かどうかを確認するステートメントです。「 結果は、成功、非致命的な失敗、致命的な失敗のいずれかになります。変更後 アサーションが実行され、結果が次のいずれかの状態になると、プログラムは通常どおり続行します。 致命的でない失敗を表します。致命的な障害が発生した場合、現在の関数は 中止されます。
テストは、状態の設定やモジュールの操作を行うコードを、 期待される結果を検証する複数のアサーションが記述されています。すべてのアサーションが テストが成功する(true を返す)場合、テストは成功します。 失敗します。
テストケースには 1 つ以上のテストが含まれます。テストは、さまざまなテストケースに テストしたコードの構造が反映されます。このコースでは 単体テスト フレームワークとして CPPUnit を導入しました。このフレームワークでは、単体テストと 自動的に実行し、成功または失敗に関するレポートを生成します 含まれています。
CPPUnit のインストール
CPPUnit コードを SourceForge。 適切なディレクトリを探し、そこに tar.gz ファイルを配置します。次に、 必要な cppunit ファイルを置き換えて(Linux、Unix の場合) name:
gunzip filename.tar.gz tar -xvf filename.tar
Windows で作業している場合、tar.gz を解凍するユーティリティを見つける必要があるかもしれません。 できます。次のステップは、ライブラリをコンパイルすることです。cppunit ディレクトリに移動します。 具体的な手順が記載された INSTALL ファイルがあります。通常、 次のコマンドを実行します。
./configure make install
問題が発生した場合は、インストール ファイルを参照してください。ライブラリは通常、 cppunit/src/cppunit ディレクトリですコンパイルが成功したことを確認するために、 cppunit/examples/simple ディレクトリに移動して 「make」と入力します条件 すべて正常にコンパイルされれば 準備は完了です
わかりやすいチュートリアルが こちらをご覧ください。 このチュートリアルでは、複素数のクラスとそれに関連付けられたクラスを作成してください。 単体テストです。cppunit/examples ディレクトリには、他にもいくつかの例があります。
なぜこれをする必要があるのですか?
単体テストは、いくつかの理由から、業界において極めて重要です。あなたは チェックする手段が必要になり、 コードの開発に集中できます小さなプログラムを開発しているときも なんらかのチェッカーやドライバを記述して、プログラムが想定どおりに動作することを確認します。
エンジニアは長い経験から、プログラムがうまく機能し、 とても小さくなります単体テストは、この考え方に基づいて、テストを 自己チェックでき、再現可能です。アサーションは、 出力を検査します。また、結果(テスト、 合格か不合格かを問いません。テストを何度でも実施でき、 変更に対するコードの復元性を高めるセーフティ ネットを構築できます。
具体的には、完成したコードを最初に Cloud Storage に CVS は完璧に動作します。しばらくの間は問題なく機能します。その後 誰かがコードを変更したからです遅かれ早かれ誰かが壊してしまう できます。子どもたちが自然に気づくと思うか?可能性は低いです。しかし、 単体テストを毎日自動的に実行できるシステムがあります このようなシステムは継続的インテグレーション システムと呼ばれます。エンジニアが X によりコードが機能しなくなると、修正されるまでシステムから悪質なメールが送信される できます。エンジニア X がお前だったとしても!
ソフトウェアの開発を支援すること 変更に伴い、単体テストが次のように行われます。
- 同期された実行可能な仕様とドキュメントを作成 説明します。つまり 単体テストをお読みいただくと 動作を制御します。
- 要件を実装から分離するのに役立ちます。アサートしているので、 行動について明確に考える機会が与えられます。 実装方法に関するアイデアを 混同せずに済みます
- テストに対応。安全を確保するための モジュールの動作が分割されている場合、 設計を再構成します。
- デザインが改善されます。多くの場合、徹底した単体テストを作成するには コードをテストしやすくなります多くの場合、テスト可能なコードはテスト不可能なコードよりもモジュール性が高い できます。
- 高い品質を維持。重要なシステムの小さなバグが 何百万ドルもの損失を被り、さらに悪いことにユーザーの幸福や信頼を失うことになります。「 セーフティ ネットとして利用できます。虫をつかむ それにより、QA チームがより高度で難しい作業に時間を費やせるようになります。 使用することに集中できます。
Composer データベース アプリケーションの CPPUnit を使用して単体テストを作成します。 詳しくは、cppunit/examples/ ディレクトリをご覧ください。
Google の取り組み
はじめに中世の修道士が 世界中の何千もの原稿を 保管していました。「アリストテレスのあれはどこ?」

彼にとって幸いなことに、原稿は内容別に整理されており、 特殊な記号を付けて、 あります。このような組織がなければ、関連する組織を見つけることは あります
大規模なコレクションから書き込まれた情報を保存および取得するアクティビティ 情報検索(IR)と呼ばれます。この活動はますます 何世紀にもわたって重要視され、特に紙や印刷などの発明で重要でした。 押します。かつては、ごく少数の人しか占有されていないものでした。さて、 その一方で何億人もの人々があらゆる場所で情報検索に 検索エンジンを使ったりパソコンで検索をしたり
情報取得のスタートガイド

スース博士は 30 年の間に 46 冊の児童書を執筆しました。彼の著書は、 猫、牛、象などが認識できます覚えてる? 物語に登場する生き物は?保護者でない限り、変更できるのはお子様のみです ドクター・スースの物語のうち、
(COW と BEE)または CROWS
この問題を解決するために、いくつかの従来の情報検索モデルを適用します。 困難です。
明白なアプローチは総当たり攻撃です。ドクター・スースの物語 46 話をすべて手に入れて、 あります。各書籍について、「COW」と「BEE」という単語が含まれる書籍をメモし、 同時に、「CROWS」という単語を含む書籍を探します。コンピュータは 迅速に進めることができますドクター・スースの本からのテキストがすべて テキスト ファイルのようにデジタル形式でファイルを 調べるだけで済みます1 つの ドクター・スースの本など小さなコレクションに 適している場合
しかし、状況もより多く必要となります。たとえば、このコレクションは 全データの 70%が大きすぎて grep では処理できませんまた、 条件に一致するドキュメントのみを取得したいので、 関連性に応じてランク付けされます
grep 以外に、コレクション内のドキュメントのインデックスを作成する方法もあります。 確認できます。IR のインデックスは、 教科書の裏側です各単語に含まれるすべての単語(または単語)のリストを、 ドクター・スースの物語です 前置詞など(これらはストップワードと呼ばれます)。次に、 用語を簡単に見つけて問題を特定できるようにします。 理解できます
考えられる表現の一つとして、上部にストーリーがある行列があります。 各行にリストされている用語を比較します列内の「1」は、そのキーワードが含まれることを示します その列のストーリーに表示されます
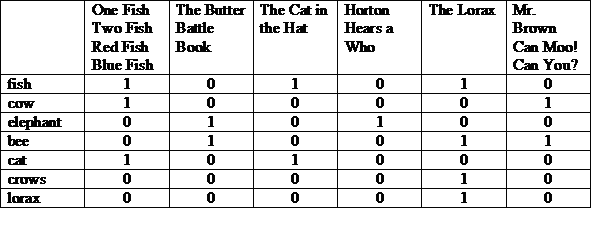
各行または各列をビットベクトルとして表すことができます。行のビットベクトルは、 そのキーワードが含まれるストーリー列のビットベクトルは、どの単語が ストーリーに登場します。
元の問題に立ち返ってみましょう。
(COW と BEE)または CROWS
これらの項のビットベクトルを取得し、ビット演算 AND 演算です。 演算を行います
(100001 および 010011) または 000010 = 000011
その答えは「Mr.ブラウン カン ムー!お願いできますか?」“The Lorax”などですこれはイラストです 「完全一致」モデルである Boolean Retrieval モデルを比較しました。
この表にドクター・スースのストーリーをすべて含めて 適切な用語を見つけ出しますマトリックスはかなり大きくなるため エントリのほとんどが 0 になります。マトリックスはおそらく最適ではない 必要があります。1 だけを保存する方法を見つける必要があります。
一部の機能強化
この問題を解決するために IR で使用される構造は、転置インデックスと呼ばれます。 用語の辞書を用意して、用語ごとにリストを キーワードが含まれる文書を記録します。このリストは投稿と呼ばれます。 list を使用します。次に示すように、単体でリンクされたリストを使用すると、この構造を表現できます。 ご覧ください
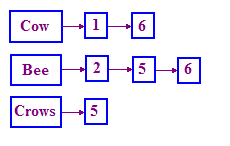
リンクリストについてよく知らない場合は、「リンクされたリスト」で Google 検索してください。
list in C++」には、リストの作成方法を説明する多くのリソースがあります。
説明します。これについては、別のモジュールで詳しく説明します。
ここでは、ドキュメントの名前の代わりにドキュメント ID(DocIDs)を 説明します。また、クエリを処理しやすくするため、これらの DocID の並べ替えも行っています。
クエリの処理方法元の問題では、最初に COW の投稿を見つける BEE の投稿リストの順に選択します。次に、それらを「結合」します。
- 両方のリストにマーカーを配置し、2 つの投稿リストについて確認する できます。
- 各ステップで、両方のポインタが指す DocID を比較します。
- 同じである場合は、その DocID を結果リストに配置し、それ以外の場合はポインタを進めます。 小さな docID を指しています
反転インデックスの作成方法は次のとおりです。
- 対象となる各ドキュメントに DocID を割り当てます。
- ドキュメントごとに関連用語を特定します(トークン化)。
- キーワードごとに、キーワードとその DocID で構成されるレコードを 頻度が表示されます。ラベルは 同じ用語が複数のドキュメントに出現している場合に、レコードとして重複しない。
- レコードを用語で並べ替えます。
- 次の単語のレコードを 1 つ処理して、辞書と投稿のリストを作成する 出現する単語の複数のレコードを結合する 確認しました。DocID のリンクリストを(並べ替え順で)作成する。各 キーワードにも頻度があります。頻度は、すべてのレコードの 定義します。
プロジェクト
テストに使える長い平文のドキュメントをいくつか見つけます。「 アルゴリズムを使用して、ドキュメントから反転インデックスを作成します。 使用できます。クエリを入力するためのインターフェースも作成する必要があります。 それらを処理するエンジンですプロジェクト パートナーはフォーラムで探すことができます。
このプロジェクトを完了するためのプロセスは次のとおりです。
- 最初に行うべきことは、ドキュメント内の用語を識別するための戦略を定義することです。 考えられるすべてのストップワードのリストを作成し、 ファイル内の単語を読み取り、用語を保存し、ストップワードを削除します。 リストを確認する際に、リストにストップワードを追加する必要が生じる場合があります。 反復できます。
- 関数をテストする CPPUnit テストケースと、すべての機能を組み込む makefile を作成する 使用できます。ファイルを CVS にチェックインする(特に 協力してきましたCVS インスタンスを開く方法について調べて、 リモートエンジニアに提供します
- 位置情報(どのファイルとその場所)を含める処理を追加します ファイル名は?計算を考え出して、次の単語を ページ番号や段落番号を指定します
- この追加機能をテストする CPPUnit テストケースを作成します。
- 反転インデックスを作成し、各用語のレコードに位置データを格納する。
- さらにテストケースを作成する。
- ユーザーがクエリを入力できるインターフェースを設計します。
- 上記の検索アルゴリズムを使用して、反転インデックスを処理し、 ユーザーに位置情報を返します。
- この最後の部分のテストケースも必ず含めてください。
すべてのプロジェクトで実施しているように、フォーラムとチャットを使用してプロジェクト パートナーを探します。 アイデアを共有してください。
追加機能
多くの IR システムで一般的な処理ステップは「ステミング」と呼ばれています。「 ステミングの背後にある主な考え方は、ユーザーが「取得」 情報に「retrieve」、 「retrieved」や「retrieving」などがあります。システムはエラーの影響を受けやすいため、 難しい場合があるからですたとえばあるユーザーが 「情報検索」では、「Information on Golden」というタイトルのドキュメントが取得されます。 取得しています。ステミングに有用なアルゴリズムは、 ポーター アルゴリズム。