プログラミングと C++ の概要
このオンライン チュートリアルでは、より高度なコンセプトについて解説しています。パート 3 をご覧ください。このモジュールの焦点は、ポインタの使用とオブジェクトの作成の出発点です。
例 2 で学ぶ
このモジュールの焦点は、分解、ポインタの理解、オブジェクトとクラスの使用開始の練習を積み重ねることです。以下の例を参照してください。頼まれたら自分でプログラムを書くか、実験を行います。優れたプログラマーになるための鍵は、何度も練習することだということは、いくら強調してもしすぎることはありません。
例 1: その他の分解演習
単純なゲームからの出力について考えてみましょう。
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
最初の観察は、プログラムごとに 1 回表示される導入テキストです。 実行されます。それぞれの敵の距離を定義する乱数ジェネレータが必要です。 です。プレーヤーから角度の入力を取得するメカニズムが必要です。 敵にヒットするまで繰り返すので、明らかにループ構造になっています。また、 距離と角度を計算する関数が必要です。そして最後に、攻撃者の 敵をヒットするまでに要したショットの数、敵の数も確認できます。 ヒットします。メイン プログラムの概要は次のとおりです。
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
Fire プロシージャがゲームのプレイを処理します。この関数で 乱数ジェネレータを作成して敵の距離を取得し、 プレーヤーの入力を取得して、敵にヒットしたかどうかを計算します。「 ループの警備条件は、敵にどれだけ近づいているかを示します。
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
cos() と sin() の呼び出しのため、math.h を含める必要があります。試す このプログラムを書くことは、問題の分解や 基本的な C++ の復習です。各関数で 1 つのタスクのみを実行するようにしてください。これが 最も高度なプログラムであるため、 できます。解決策はこちらをご覧ください。
例 2: ポインタを使った練習
ポインタを操作するときは、次の 4 つの点に注意してください。 <ph type="x-smartling-placeholder">- </ph>
- ポインタは、メモリアドレスを保持する変数です。プログラムが実行されると
すべての変数は、それぞれ固有のアドレスまたは位置にメモリ内に保存されます。
ポインタは特殊な型の変数で、変数にはメモリアドレスが
決定できます通常の変数が使用されるときにデータが変更されるのと同様に、
ポインタに格納されているアドレスの値がポインタ変数として変更される。
操作されます。次に例を示します。
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - 通常、ポインタは「指し示す」保存先のロケーションに
(「参照先」)。上記の例では、intptr は参照先を指しています。
5.
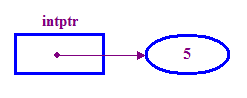
「new」という文字列が演算子を使用して、整数にメモリを割り当てます。 指先。これは、宛先にアクセスする前に行う必要があります。
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.C では逆参照に * 演算子を使用します。よくあるエラーは C/C++ プログラマーがポインタを操作するときに初期化を忘れてしまう 操作できます。これが原因でランタイムクラッシュが発生することがあります 不明なデータを含むメモリ内の場所です。これを修正して わずかなメモリ破損を引き起こす可能性があり、追跡が困難なバグです。
- 2 つのポインタ間のポインタ割り当てにより、2 つのポインタが同じポイント先を指すようになります。
代入 y = x です。は、y が x と同じ参照先を指すようにします。ポインタの割り当て
指先には触れません1 つのポインタを同じ位置に変えるだけです。
渡します。ポインタの割り当て後、2 つのポインタは「共有」します。
指先。
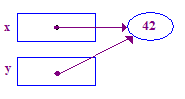
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
このコードのトレースは次のとおりです。
| 1. x と y の 2 つのポインタを割り当てます。ポインタの割り当てでは、 しないでください。 | 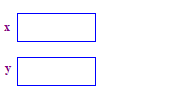 |
| 2. 指示先を割り当て、それを指すように x を設定します。 | 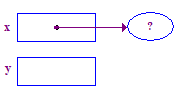 |
| 3. x を逆参照して、そのポインタに 42 を格納します。これは基本的な例です。 使用します。x から開始し、矢印に沿ってアクセス できます。 | 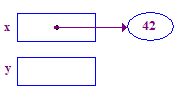 |
| 4. y を逆参照して、そのポインタに 13 を格納してみます。この操作はクラッシュします。 指先先がないため、指先は割り当てられていません。 | 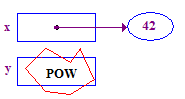 |
| 5. y = x; を割り当てます。y が x の指先を指すようにします。これで x と y が 「共有」です。 | 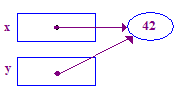 |
| 6. y を逆参照して、そのポインタに 13 を格納してみます。今回はうまくいきました 前の課題で指名先が与えられたからです | 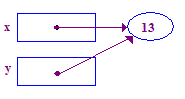 |
ご覧のとおり、画像はポインタの使用方法を理解するのに非常に役立ちます。こちらの 別の例で説明します。
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
この例では、「new」という文字列でメモリを割り当てたことは演算子を使用します。 通常の整数変数を宣言し、ポインタで操作していました。
この例では、リソースの割り当てを解除する delete 演算子の使用を より複雑な構造体の割り当て方法について説明しましたこのコースでは、 メモリ構成(ヒープとランタイム スタック)については別のレッスンで説明します。ここでは、 ヒープは、実行中のプログラムに利用できるメモリの空きストレージだと考えることができます。
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
この最後の例では、ポインタを使用して参照によって値を渡す方法を示します。 できます。これにより、関数内の変数の値を変更できます。
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
Duplicate 関数の定義の引数に & を含めない場合、 変数を「値で」渡します。つまり、 指定します。関数内で変数を変更すると、コピーが変更されます。 元の変数は変更されません。
変数が参照によって渡される場合、その値のコピーは渡されません。 変数のアドレスを関数に渡します。変更後すぐに 渡された元の変数を実際に変更します。
C プログラマーにとっては、これは新しいひねりです。C でも同じことができます。 Duplicate() の宣言 Duplicate(int *x)」と指定すると、 この場合は x int へのポインタの場合、引数 &x(x のアドレス)を指定して Duplicate() を呼び出し、逆参照 x 以内 Duplicate() (下記をご覧ください)。ただし C++ では、 古い「C」は確認しましょう。
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
C++ 参照では、変数のアドレスや値を渡す必要はありません。 呼び出された関数内で変数を逆参照する必要があるかどうかがわかります。
次のプログラムは何を出力しますか。思い出の絵を描いて考えてみましょう。
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} プログラムを実行して、正解を確認してください。
例 3: 参照によって値を渡す
車両の速度と数値を入力として受け取る accelerate() という関数を作成します。この関数は、速度にこの数値を加算して車両を加速させます。速度パラメータは参照によって渡す必要があり、値は値によって渡します。解決策はこちらをご覧ください。
例 4: クラスとオブジェクト
次のクラスについて考えてみましょう。
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
クラスメンバー変数の末尾にアンダースコアがあることに注意してください。これは、ローカル変数とクラス変数を区別するためです。
このクラスにデクリメント メソッドを追加します。解決策はこちらをご覧ください。
科学の素晴らしさ: コンピュータ サイエンス
エクササイズ
このコースの最初のモジュールと同様に、演習やプロジェクトに対するソリューションは提供していません。
良いプログラムであることを忘れないでください...
... 関数に論理的に分解される。この場合、任意の 1 つの関数が 1 つのタスクだけを実行します。
... メイン プログラムがあり、そのプログラムが何をするのかを概説するようなものになっています。
説明的な関数、定数、変数名があります。
... 「魔法」を避けるために定数を使用する数字だけではありません。
使いやすいユーザー インターフェースを備えています。
ウォームアップ
- 演習 1
整数 36 には、完全な正方形であることと、 1 から 8 までの整数の合計。その次の 1225 は 352 で、1 から 49 までの整数の合計になります。次の番号を探す 数列 1...n の和で計算します。この次の数字 32767 より大きい可能性があります。使い慣れているライブラリ関数や (または数式)を使用して、プログラムの実行を高速化できます。また、 for ループを使用してこのプログラムを作成し、数値が完全かどうかを判定します。 累乗されます(注: マシンやプログラムによっては、 この番号を見つけるまでにかなり時間がかかります)。
- 演習 2
大学の書店が次のビジネスを予測する際にサポートを必要としています 1 年ですこれまでの経験から、売上は書籍の必須性に大きく依存することがわかっています そのクラスで使用されているかどうか、 おすすめします新しい必須教科書が入学者の 90% に販売されます。 実際にクラスで使ったことがあれば、購入するのは 65% にすぎません。同様に 入学希望者の 40% はオプションの教科書を新たに購入しますが、 20% しか購入されないままです(ここでは「used」を 古本とは限りません)。
一連の書籍を入力として受け取る(ユーザーが入力するまで)プログラムを作成する 見かけなど)に注意を払います。書籍ごとにコードの提供を依頼します。書籍の 1 部あたりの料金 本、現在手元にある本の数、入学希望者 書籍が必須か任意か、新品か、過去に使用されていたかを示すデータが含まれます。として すべての入力情報を適切な形式で画面に表示し、 注文する必要がある書籍の数(該当する場合、新規の書籍のみが注文される) 各注文の合計費用を表します
すべての入力が完了したら、すべての書籍の注文の合計費用を表示します。 店舗が正規価格の 80% を支払った場合に期待される利益。まだ プログラムに取り込む大量のデータを扱う方法について、 一度に 1 冊の書籍を処理して、その書籍の出力画面を表示するだけで済みます。 ユーザーがすべてのデータの入力を完了すると、プログラムは 合計値と利益値。
コードの記述を開始する前に、このプログラムの設計について考えてください。 一連の関数に分解し、次のような main() 関数を作成します。 問題に対するソリューションの概要を示します。各関数が 1 つのタスクを実行するようにします。
出力例は次のとおりです。
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
データベース プロジェクト
このプロジェクトでは、シンプルなコードを実装する、完全に機能する C++ プログラムを作成します。 データベース アプリケーションです。
このプログラムでは、作曲家のデータベースと関連情報を管理できます 説明します。プログラムの特徴は次のとおりです。
- 新しい作曲者を追加する機能
- 作曲者をランク付けする機能 作曲者の音楽)
- データベース内のすべての作曲者を表示する機能
- すべての作曲者をランク別に表示できる。
「既存のキャンペーン構成を 一つの方法は、開発作業を簡素化するために、 もう 1 つの方法は、問題を非常に複雑にし、 明らかな欠陥ではありません1 つ目の方法の方がはるかに難しいです。」- C.A.R. Hoare
多くの人が「プロシージャル」を使用して設計とコーディングを行う方法をアプローチです まず最初に考えるべき問いは、「プログラムで何をすべきか」です。水 問題を解くタスクに分解します。タスクはそれぞれ、 解決できます。これらのタスクは、順番に呼び出されるプログラムの関数にマッピングされます。 他の関数から呼び出すことができます。段階的なアプローチは、 解決しなければならない問題です。しかし多くの場合、Google のプログラムは 一連のタスクやイベントが含まれます。
オブジェクト指向(OO)アプローチでは、最初に どうすればよいでしょうか?」説明したようにプログラムをタスクに分割する代わりに、 物体のモデルに分割しました。これらの物理オブジェクトは 一連の属性によって定義される状態、一連の動作またはアクションによって できます。これらのアクションにより、オブジェクトの状態が変更されることや、 他のオブジェクトのアクションを呼び出すことができます。基本的な前提は、オブジェクトが「認識している」方法 独りで何かをする時間はありません。
OO 設計では、クラスとオブジェクトの観点から物理オブジェクトを定義します。属性 制御します。通常、OO プログラムには多数のオブジェクトがあります。 ただし、これらのオブジェクトの多くは基本的に同じです。次の点を考慮してください。
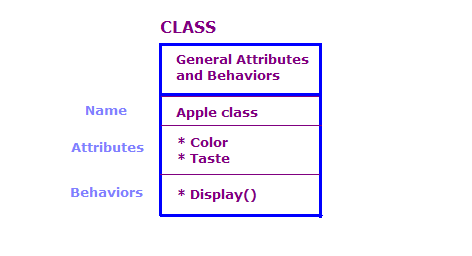
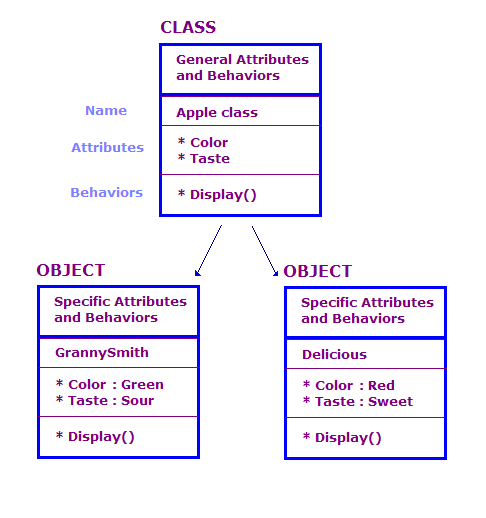
この図では、Apple クラスの 2 つのオブジェクトを定義しています。 各オブジェクトはクラスと同じ属性とアクションを持ちますが、 では、特定の種類のリンゴの属性を定義します。さらにディスプレイには アクションは、そのオブジェクトの属性を表示します(例: "緑"「Sour」です。
OO の設計は、一連のクラス、それらのクラスに関連付けられたデータ、 一連の処理を実行できますさらに、 やり取りする方法を紹介します。このインタラクションは、オブジェクトによって 他のクラスのオブジェクトのアクションを呼び出すクラスのものです。たとえば、 配列の色と色を出力する AppleOutputer クラスがある 各 Apple オブジェクトの Display() メソッドを呼び出します。
OO 設計の手順は以下のとおりです。
- クラスを特定し、各クラスのオブジェクトが一般的に何であるかを定義する オブジェクトでできることについて 学びます
- 各クラスのデータ要素を定義する
- 各クラスのアクションと、1 つのクラスのアクションをどのように実行できるかを定義する
他の関連クラスのアクションを使用して実装されます。
大規模なシステムの場合、これらのステップは異なる詳細レベルで繰り返し実行されます。
Composer データベース システムには、すべての依存関係をカプセル化する Composer クラスが必要です。 個々の作曲者に保存したいデータがありますこのクラスのオブジェクトは、 自身を昇格または降格(ランクを変更)したり、その属性を表示したりできます。
また、Composer オブジェクトのコレクションも必要です。このために、Database クラスを定義します。 個別のレコードを管理しますこのクラスのオブジェクトは、 Cloud Composer オブジェクトを作成し、個々のオブジェクトを表示するには、 Composer オブジェクトです
最後に、インタラクティブな操作を可能にするには、なんらかのユーザー インターフェースが必要です。 作成されます。これはプレースホルダ クラスです。つまり、 これから導入しますが、これから必要になることはわかっています。どちらともいえない グラフィカルな テキストベースになるからですここでは、プレースホルダを定義します。 後ほど入力できます。
Composer データベース アプリケーションのクラスを特定したので、 クラスの属性とアクションを定義します。もっと 紙と鉛筆で作業するか、 UML または CRC カード または OOD クラス階層とオブジェクトの相互作用をマッピングします
Composer データベースでは、関連するデータソースを含む Composer クラスを定義します。 各作曲者に保存したいデータがありますまた、コンテナを操作するためのメソッドも データの表示などを行います
Database クラスには、Composer オブジェクトを保持するためのなんらかの構造が必要です。 新しい Composer オブジェクトをその構造に追加するだけでなく、 取得しますすべてのオブジェクトを 検索結果に表示されます
User Interface クラスはメニュードリブン インターフェースを実装し、 Database クラスの呼び出しアクション。
クラスがわかりやすく、属性やアクションが明確であれば、 Composer アプリケーションと同様に、クラスの設計は比較的簡単です。しかし、 クラス間の関係性や関係性について 疑問がある場合は まず図を描いて詳細を確認してから コーディングに 専念できます
デザインを明確に把握し、評価したら、 各クラスのインターフェースを定義します。実装の心配は不要 属性やアクション、各要素の詳細を 取得して他のクラスでも利用できます。
C++ では通常、そのためにクラスごとにヘッダー ファイルを定義します。作曲家 クラスには、Composer に保存するすべてのデータのプライベート データ メンバーが含まれています。 アクセサ(「get」メソッド)とミューテータ(「set」メソッド)のほか、 メイン アクションを指定します。
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
Database クラスも単純です。
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
ここでは、作曲者固有のデータを別のデータセットに慎重にカプセル化し、 クラスです。Database クラスに構造体またはクラスを追加して、 そこから直接アクセスしましたですが、それは 「オブジェクト化不足」。つまり、オブジェクトでモデリングを行うのはそれほど多くしていません。 できることです。
Composer と Database の実装に着手すると、 Composer クラスを別に用意したほうがわかりやすくなります。特に Composer オブジェクトに対してアトミックな操作が個別に行われるため、実装が大幅に簡素化されます。 Database クラスの Display() メソッドのビューです。
もちろん、「過度に客観的」という言葉もあります。ここで すべてを 1 つのクラスにしようとするか、必要以上のクラスになるかのどちらかです。かかる時間 練習して適切なバランスを見つけると、個々のプログラマーが 意見が分かれます
自分が物事を過小評価しているかどうかを判断するには、 説明しました。先ほど述べたように アプローチを分析できます。共通 表記は、 UML(Unified Modeling Language) Composer オブジェクトと Database オブジェクトのクラスが定義されたので、次は ユーザーがデータベースを操作できるインターフェースです。シンプル メニューでは やってみましょう。
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
ユーザー インターフェースは、クラスとして、または手続き型プログラムとして実装できます。× C++ プログラムでは、すべてクラスである必要があります。実際、処理がシーケンシャルな場合は タスク指向では、このメニュー プログラムのように、プロシージャルに実装しても問題ありません。 「プレースホルダ」のままで実装することが重要です。 つまり、ある時点でグラフィカル ユーザー インターフェースを作成したい場合は、 ユーザーインターフェース以外は システム内で変更する必要はありません
最後にアプリケーションを完成させるために、クラスをテストするプログラムを用意します。 Composer クラスでは、入力を受け取り、 composer オブジェクトを取得し、それを表示してクラスが正しく動作していることを確認します。 また、Composer クラスのすべてのメソッドを呼び出します。
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
Database クラスにも、同様のテスト プログラムが必要です。
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
なお、このようなシンプルなテスト プログラムは、最初のステップとして最適ですが、 手動で出力を調べて、プログラムが正しく動作していることを確認します。として システムが大きくなると、出力を手作業で検査するのが急速に非現実的になります。 次のレッスンで、セルフチェック テスト プログラムをフォーム 単体テストです。
これで、アプリケーションのデザインが完成しました。次のステップでは クラスとユーザー インターフェースの .cpp ファイルです。まず 上記の .h とテストドライバのコードをコピーしてファイルに貼り付け、コンパイルします。使用 クラスをテストします。次に、次のインターフェースを実装します。
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Database クラスで定義したメソッドを使用して、ユーザー インターフェースを実装します。 メソッドをエラーのないものにする。たとえば、ランキングは常に 1〜10.変更する予定がなければ、誰にも 101 人の作曲者を追加できないようにします Database クラスのデータ構造。
注意 - すべてのコードは、Google のコーディング規則に従わなければなりません。 をご覧ください。
- 私たちが作成するすべてのプログラムは、ヘッダーコメントから始まります。 作成者、連絡先情報、簡単な説明、用途(該当する場合)。 すべての関数/メソッドは、オペレーションと使用法に関するコメントから始まります。
- コードが記述されるたびに、完全な文での説明コメントが追加されます。 たとえば、処理が複雑でわかりにくい場合や、 注目してください。
- 常にわかりやすい名前を使用してください。変数は、 _ で定義されます。関数/メソッド名では、大文字を使用してマークを MyExcitingFunction() などでも同様です。定数は「k」で始まるおよび 単語には大文字を使用します(例: kDaysInWeek)。
- インデントは 2 の倍数です。第 1 レベルは 2 つのスペースです。さらに インデントが必要な場合は、スペースを 4 つ、スペースを 6 つなど使用します。
現実の世界へようこそ!
このモジュールでは、ほとんどのソフトウェア エンジニアリングで使用される非常に重要な 2 つのツールを紹介します。 組織に提供します。1 つ目はビルドツールで、2 つ目は構成管理です。 ありませんどちらのツールも産業用ソフトウェアエンジニアリングに不可欠です。 1 つの大規模なシステムで多くのエンジニアが 作業していますこれらのツールは コードベースへの変更を制御し、コードをコンパイルするための 多くのプログラムやヘッダー・ファイルからシステムをリンクします。
Makefile
通常、プログラムのビルドプロセスは、ビルドツールを使用して 必要なファイルを正しい順序でリンクします。多くの場合、C++ ファイルは たとえば、あるプログラムで呼び出された関数が、別の依存関係にある 。または、複数の異なる .cpp ファイルでヘッダー ファイルが必要であることが考えられます。 ビルドツールがこれらの依存関係から正しいコンパイル順序を判断します。動作 前回のビルド以降に変更されたファイルのみをコンパイルすることもできます。これにより 多くの時間を費やすことになります
make と呼ばれるオープンソースのビルドツールが一般的に使用されています。詳しくは、 を 記事をご覧ください。 Composer Database アプリケーションに依存関係グラフを作成できるかどうかを確認し、 これを makefile に変換しますこちらは 説明します。
構成管理システム
産業用ソフトウェア エンジニアリングで使われる 2 つ目のツールは、Configuration Management です。 (CM)これは変更の管理に使用されます。ボブとスーザンが両方ともテクノロジー ライターで 技術マニュアルの更新に取り組んでいます会議中、 マネージャーは、更新する同じドキュメントの各セクションを割り当てます。
技術マニュアルは、ボブとスーザンの両方がアクセスできるコンピュータに保存されます。 CM のツールやプロセスがなければ、さまざまな問題が発生する可能性があります。1 本 考えられるシナリオとしては、ドキュメントを保存するコンピュータが Bob と Susan が同時に同じマニュアルに取り組むことはできません。こうすると遅くなります 大幅に下がります
ストレージ コンピュータでドキュメントが許可されると、より危険な状況が発生する Bob と Susan の双方が同時に 開くよう指示します次のような原因が考えられます。
- ボブはパソコンでドキュメントを開き、自分のセクションで作業しています。
- Susan はパソコンでドキュメントを開き、自分のセクションで作業しています。
- 変更を完了し、ドキュメントをストレージ コンピュータに保存します。
- Susan は変更を完了し、ドキュメントをストレージ パソコンに保存します。
この図は、コントロールがない場合に発生する可能性のある問題を示しています。 テクニカル マニュアル 1 部に記載してください。Susan が変更を保存すると、 Bob によって作成されたものは上書きされます。
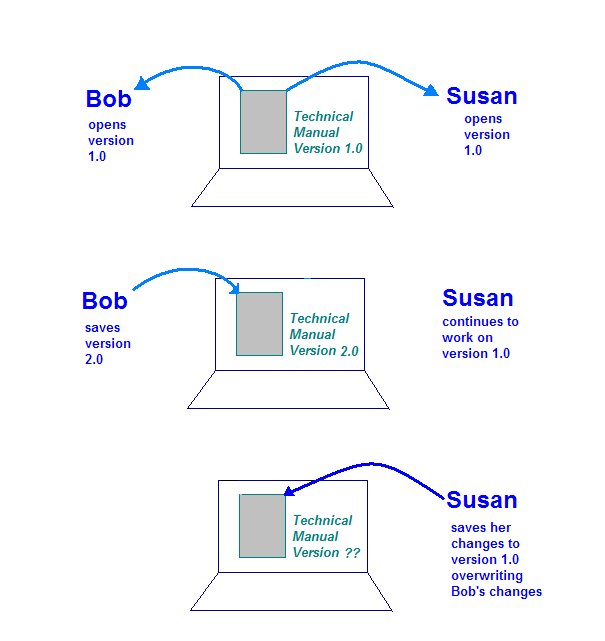
このような状況は、まさに CM システムで管理できるものです。CM の場合 Bob と Susan の両方が「check out」技術資料の独自のコピーを 手作業に頼って取り組まなければなりませんユーザー A が変更内容を確認すると、 コピーを作成されましたSusan が原稿をチェックすると Bob と Susan の両方が行った変更を分析して、 2 つの変更セットが結合されます
CM システムには、前述したような同時変更の管理にとどまらない多くの機能があります。 ご覧ください。多くのシステムでは、ドキュメントのすべてのバージョンをアーカイブして保存し、 作成されます。技術マニュアルの場合は ユーザーが古いバージョンのマニュアルを持っていて、テクニカル ライターに質問している場合。 CM システムでは テクニカルライターは古いバージョンにアクセスして ユーザーが何を見ているのかを確認します。
CM システムは、ソフトウェアに加えられた変更を制御するのに特に役立ちます。そのような ソフトウェア構成管理(SCM)システムと呼ばれます。もし 大規模なソフトウェアエンジニアリングで 膨大な数のソースコードファイルが 変更しなければならない膨大な数のエンジニアが SCM システムが重要であることは明らかです
ソフトウェア構成管理
SCM システムは、「ファイルの完全なコピー」という 中央リポジトリに保存されますリポジトリのファイルのコピーをチェックアウトして 完成したら再度チェックインしますSCM 1 つのマスターに対して複数のユーザーによるリビジョンを管理、追跡する あります。
すべての SCM システムには、次の基本機能が備わっています。
- 同時実行管理
- バージョニング
- 同期
それぞれの機能を詳しく見ていきましょう。
同時実行管理
同時実行とは、複数のユーザーが 1 つのファイルを同時に編集することです。 大規模なリポジトリではユーザーがこれを行えるようにする必要がありますが、 いくつかあります。
エンジニアリング分野の簡単な例を考えてみましょう。 ソースコードの中央リポジトリにある同じファイルを同時に変更できるからです。 Client1 と Client2 の両方が同時にファイルに変更を加える必要があります。
- Client1 が bar.cpp を開きます。
- Client2 が bar.cpp を開きます。
- Client1 がファイルを変更して保存します。
- Client2 がファイルを変更し、Client1 の変更を上書きして保存します。
このような事態は避けたいものです。たとえ 2 つの方法で状況を制御したとしても 2 人のエンジニアが、マスターを直接作成するのではなく、別々のコピーで作業できるようにする なんらかの方法でコピーを調整する必要があります。ほとんど SCM システムでは、複数のエンジニアがファイルをチェックできるようにすることで、この問題に対処しています。 (「sync」や「update」)を実行して、必要に応じて変更します。SCM ファイルがチェックインされると、システムがアルゴリズムを実行して変更をマージする (「submit」または「commit」)をリポジトリに送信します。
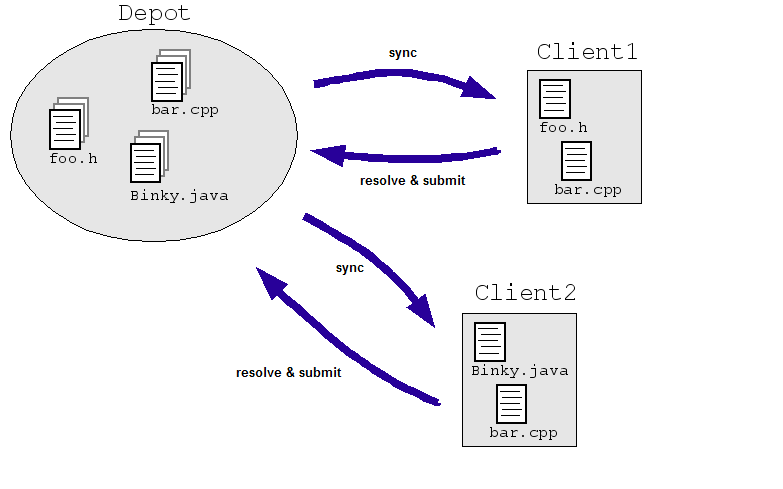
これらのアルゴリズムはシンプルにできます(競合する変更を解決するようエンジニアに依頼する)。 それほど単純ではない(競合する変更をインテリジェントにマージする方法を決定する) システムが実際に停止しているかどうかのみをエンジニアに尋ねる)。
バージョニング
バージョニングとは、ファイルの変更履歴を追跡することで、以下を可能にすることです。 以前の版を再作成する(または前の版にロールバックする)ことができます。この処理は、 すべてのファイルがリポジトリにチェックインされるときに、そのファイルのアーカイブ コピーが作成される。 ファイルへの変更をすべて保存することもできますアーカイブや 情報を変更して以前のバージョンを作成できますバージョニングシステムでは 変更のチェックイン ユーザー、チェックイン日時、変更内容を示すログ レポートを作成する 確認しました
同期
一部の SCM システムでは、個々のファイルがリポジトリに対してチェックインおよびチェックアウトされます。 比較的強力なシステムでは、一度に複数のファイルをチェックアウトできます。エンジニア リポジトリ(またはその一部)の独自の完全なリポジトリのコピーと、 必要に応じてファイルに追加します。その後、変更をマスター リポジトリに commit し直す 定期的に更新し、自分専用のコピーを更新して、最新の変更を反映させる あります。このプロセスは同期または更新と呼ばれます。
無効化
Subversion(SVN)はオープンソースのバージョン管理システムです。Kubernetes には、 説明しました。
SVN は、競合が発生した場合にシンプルな手法を採用します。2 つの Pod が 1 人以上のエンジニアがコードベースの同じ領域に異なる変更を加え、 双方が変更を送信しますSVN は エンジニアに委ねられます。
このコースでは、SVN を使用して 構成管理このようなシステムは、業界ではごく一般的です。
まず、システムに SVN をインストールします。[ こちら できます。ご使用のオペレーティング システムを確認し、適切なバイナリをダウンロードします。
一部の SVN 用語
- リビジョン: 1 つまたは複数のファイルに対する変更。リビジョンとは 「スナップショット」常に変わり続けるプロジェクトで
- リポジトリ: SVN がプロジェクトの完全な変更履歴を保存するマスターコピー。 各プロジェクトには 1 つのリポジトリがあります。
- 作業用コピー: エンジニアがプロジェクトに変更を加えるためのコピー。そこで、 1 人のエンジニアがそれぞれ所有している、特定のプロジェクトの作業用コピーを複数作成することもできます。
- チェックアウト: リポジトリの作業コピーをリクエストします。作業コピー チェックアウトされたプロジェクトの状態と同じになります。
- commit: 作業コピーから中央リポジトリに変更を送信します。 チェックインまたは送信とも呼ばれます。
- 更新:リポジトリから作業コピーに変更内容を コピーに commit されていない変更があるかどうかを確認できます。これが 同期と同じです。つまり、更新/同期で作業中のコピーが リポジトリのコピーで最新の状態に保たれます。
- 競合: 2 人のエンジニアが同じプロジェクトに変更を commit しようとした コピーされます。SVN は競合を示しますが、エンジニアはそれらを解決する必要があります。
- ログ メッセージ: commit 時にリビジョンに添付されたコメントで、 変更内容が表示されます。このログには、発生した問題の概要が表示されます。 権限。
SVN をインストールしたので、いくつかの基本的なコマンドを実行します。「 まず、指定したディレクトリにリポジトリを設定します。こちらの コマンド:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
import コマンドは、mytree ディレクトリの内容を ディレクトリ プロジェクトに作成されます。Google Cloud コンソールで list コマンドでリポジトリ
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
インポートでは作業コピーは作成されません。そのためには、svn checkout コマンドを使用できます。これにより、ディレクトリ ツリーの作業コピーが作成されます。では、 その手順は次のとおりです。
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
これで作業コピーが準備できたので、ファイルとディレクトリに変更を加えることができます。 できます。作業コピーは、他のファイルやディレクトリのコレクションと同様です 新しい画像の追加や編集、移動、 コピー全体を取得します。作業コピー内のファイルをコピーしたり移動したりすると、 代わりに svn copy と svn Move を使用することが重要です。 使用できます。新しいファイルを追加するには、svn add を使用して削除します。 svn delete を使用してファイルを削除する。編集だけが目的の場合は、 編集して編集することもできます。
Subversion では、いくつかの標準ディレクトリ名がよく使用されます。「トランク」ディレクトリ プロジェクトの主要開発ラインを定義します「枝」ディレクトリ には、作業中のすべてのブランチ バージョンが格納されています。
$ svn list file:///usr/local/svn/repos /trunk /branches
作業コピーに必要なすべての変更が加えられたとします リポジトリと同期するように指定します。他の多くのエンジニアが 作業コピーを最新の状態に保つことが重要です。 行った変更を表示するには、svn status コマンドを使用します。 できます。
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
この出力を制御するためのステータス コマンドには、多くのフラグがあることに注意してください。 変更されたファイルの特定の変更を表示するには、svn diff を使用します。
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...最後に、リポジトリの作業コピーを更新するには、svn update コマンドを使用します。
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
ここで競合が発生する可能性があります。上記の出力で、「U」は意味 これらのファイルのリポジトリ バージョンは変更されておらず、 行われました。「G」マージが発生したことを意味します。このリポジトリのバージョンが が変更されましたが、変更内容は自分のものと競合していません。「C」意味 あります。つまり、リポジトリからの変更が自分のものと重複しており、 どちらかを選ぶ必要があります
競合するファイルごとに、Subversion は作業ディレクトリ copy:
- file.mine: 以前の作業コピーに存在していたファイルです。 作業コピーを更新しました。
- file.rOLDREV: 前にリポジトリからチェックアウトしたファイルです。 変更します。
- file.rNEWREV: このファイルは、リポジトリの現在のバージョンです。
競合を解決するには、次の 3 つの方法があります。
- ファイルを確認し、手動でマージを行います。
- SVN によって作成された一時ファイルの 1 つを、作業コピーのバージョン上にコピーします。
- すべての変更を破棄するには、svn recover を実行します。
競合を解決したら、svnresolve を実行して SVN に通知します。 これにより 3 つの一時ファイルが削除され、SVN は あります。
最後に行う作業は、最終バージョンをリポジトリに commit することです。この svn commit コマンドを使用します。変更を commit するには、 変更を示すログメッセージが提供されます。このログメッセージが添付されています 自動的に適用されます。
svn commit -m "Update files to include new headers."
SVN について、そして SVN が大規模ソフトウェアをどのようにサポートできるかについて、学ぶべきことはまだたくさんある 支援します。ウェブ上にはさまざまなリソースがありますが、 Google で「Subversion」で検索してください。
演習として、Composer データベース システムのリポジトリを作成し、 確認できます。次に、作業コピーをチェックアウトし、指定されたコマンドを実行します。 ご覧ください。
参照
アプリケーション: A Study in Anatomy
大学の eSkeletons を確認する (テキサス対オースティン)