Tutorial sul linguaggio C++
Nelle prime sezioni di questo tutorial tratta il materiale di base già presentato ultimi due moduli e fornire maggiori informazioni sui concetti avanzati. Le nostre in questo modulo parleremo della memoria dinamica e di ulteriori dettagli su oggetti e classi. Vengono introdotti anche alcuni argomenti avanzati, come ereditarietà, polimorfismo, modelli, le eccezioni e gli spazi dei nomi. Li analizzeremo più avanti, nel corso Advanced C++.
Design orientato agli oggetti
Questo è un ottimo tutorial sulla progettazione orientata agli oggetti. Applicheremo metodologia qui presentata nel progetto di questo modulo.
Impara con l'esempio n. 3
In questo modulo ci concentreremo su come fare più pratica con i puntatori, le progettazione, array multidimensionali e classi/oggetti. Segui questi passaggi esempi. Non possiamo enfatizzare abbastanza che la chiave per diventare un buon programmatore è pratica, esercitazione, pratica!Esercizio 1: fai più pratica con i puntatori
Se hai bisogno di esercitarti ulteriormente con i cursori, leggi tutto questo Risorsa dell'IA che tratta tutti gli aspetti dei cursori e fornisce molti esempi di programmi.
Qual è l'output del seguente programma? Non eseguire il programma, ma per tracciare l'immagine della memoria per determinare l'output.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}Dopo aver determinato manualmente l'output, esegui il programma per vedere se risposta esatta.
Esercizio 2: Fai più pratica con classi e oggetti
Per fare pratica con classi e oggetti, qui è una risorsa che passa per l'implementazione di due piccole classi. Prendi qualche tempo necessario per completare gli esercizi.
Esercizio 3: Array multidimensionali
Prendi in considerazione il seguente programma:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}Nel programma è presente una riga denominata "Come funziona questa linea?" - Riesci a capirlo? Qui puoi trovare la nostra spiegazione.
Scrivi un programma che inizializza un array a 3 dim e riempie la terza dimensione con la somma di tutti e tre gli indici. Ecco la nostra soluzione.
Esercizio 4: esempio di progettazione estesa di una UO
Ecco una descrizione dettagliata esempio di progettazione orientata agli oggetti, che comprende l'intero processo dall'inizio alla fine. Il codice finale è scritto in Java linguaggio di programmazione, ma che sarai in grado di leggerlo considerando quanto dista sono arrivate.
Dedica del tempo a esaminare l'intero esempio. È un ottimo illustrazione del processo e degli strumenti di progettazione che lo supportano.
Test delle unità
Introduzione
I test sono una parte fondamentale del processo di progettazione del software. Un test delle unità è un particolare tipo di test, che verifica la funzionalità di un singolo del codice sorgente.I test delle unità vengono sempre eseguiti dal tecnico e vengono di solito vengono eseguite nello stesso momento in cui programmano il modulo. I collaudatori che utilizzati per testare le classi Composer e Database sono esempi di test delle unità.
I test delle unità presentano le caratteristiche elencate di seguito. Ha…
- testare un componente in modo isolato
- sono deterministici
- di solito sono mappati a una singola classe
- evitare dipendenze da risorse esterne, ad esempio database, file, reti
- sono eseguite rapidamente
- possono essere eseguiti in qualsiasi ordine
Esistono metodologie e framework automatizzati che forniscono supporto e e coerenza per i test delle unità nelle grandi organizzazioni di software engineering. Esistono alcuni sofisticati framework per i test delle unità open source, che esamineremo più avanti in questa lezione.
I test che vengono eseguiti nell'ambito dei test delle unità sono illustrati di seguito.

In un mondo ideale, testiamo quanto segue:
- L'interfaccia del modulo è testata per garantire il flusso di informazioni in entrata e in uscita in modo corretto.
- Le strutture di dati locali vengono esaminate per verificare che i dati siano archiviati correttamente.
- Le condizioni al confine vengono testate per verificare che il modulo funzioni correttamente ai confini che limitano o limitano il trattamento.
- Testiamo percorsi indipendenti nel modulo per assicurarci che ogni percorso, e
quindi ogni istruzione nel modulo viene eseguita almeno una volta.
- Infine, dobbiamo verificare che gli errori siano gestiti correttamente.
Copertura del codice
In realtà, non è possibile ottenere una "copertura del codice" completa con i nostri test. La copertura del codice è un metodo di analisi che determina quali parti di un software eseguito (coperto) dalla suite dello scenario di test e quali parti sono state non sono state eseguite. Se cerchiamo di raggiungere una copertura del 100%, passeremo più tempo scrivere i test delle unità anziché scrivere il codice vero e proprio. Valuta la possibilità di elaborare un'unità per tutti i percorsi indipendenti degli elementi indicati di seguito. Questo può diventare rapidamente esponenziale.
In questo diagramma, le linee rosse non vengono testate, mentre le linee non colorate sono viene testato.
Invece di tentare di coprire il 100%, ci concentriamo su test che aumentano la nostra fiducia che il modulo funzioni correttamente. Testiamo elementi quali:
- Casi nulli
- Test degli intervalli, ad esempio test di valori positivi/negativi
- Casi limite
- Casi di errore
- Test dei percorsi con maggiore probabilità di essere eseguiti
Framework di test delle unità
La maggior parte dei framework di test delle unità utilizza le asserzioni per testare i valori durante l'esecuzione di un percorso. Le asserzioni sono istruzioni che verificano se una condizione è vera. La Il risultato di un'asserzione può essere successo, errore non irreversibile o errore irreversibile. Dopo il giorno viene eseguita un'asserzione, il programma continua normalmente se il risultato è non riuscito o non irreversibile. In caso di errore irreversibile, la funzione corrente viene interrotta.
I test consistono in un codice che imposta lo stato o manipola il modulo, accoppiato con varie asserzioni che verificano i risultati attesi. Se tutte le asserzioni se un test ha esito positivo, ovvero restituisce true, il test ha esito positivo; altrimenti non riesce.
Uno scenario di test contiene uno o più test. raggruppiamo i test in scenari di test che che riflettano la struttura del codice testato. In questo corso useremo CPPUnit come framework di test delle unità. Con questo framework, possiamo scrivere test delle unità in C++ ed eseguirli automaticamente, fornendo un report sull'esito positivo o negativo dei test.
Installazione CPPUnit
Scarica il codice CPPUnit da SourceForge. Individua una directory appropriata e inserisci al suo interno il file tar.gz. Quindi, inserisci i seguenti comandi (in Linux, Unix), sostituendo il file cppunit appropriato nome:
gunzip filename.tar.gz tar -xvf filename.tar
Se lavori in Windows, potresti dover trovare un'utilità per estrarre il file tar.gz . Il passaggio successivo è la compilazione delle librerie. Passa alla directory cppunit. È disponibile un file INSTALL che fornisce istruzioni specifiche. Di solito, devi eseguire:
./configure make install
In caso di problemi, consulta il file INSTALL. Le librerie sono di solito trovato nella directory cppunit/src/cppunit. Per verificare che la compilazione abbia funzionato, vai nella directory cppunit/examples/simple e digita "make". Se la compilazione è corretta, allora è tutto a posto.
È disponibile un ottimo tutorial qui Segui questo tutorial e crea la classe di numeri complessi e le relative delle unità di misura. La directory cppunit/examples contiene diversi esempi aggiuntivi.
Perché devo farlo??
Il test delle unità è di fondamentale importanza nel settore per diversi motivi. Stai già conoscete un motivo: dobbiamo controllare in qualche modo il nostro lavoro mentre lo sviluppo del codice. Anche quando stiamo sviluppando un programma molto piccolo, istintivamente scrivere controlli o driver per assicurarci che il nostro programma funzioni come previsto.
Per una lunga esperienza, gli ingegneri sanno che è probabile che un programma funzioni al primo tentativo sono molto piccole. I test delle unità si basano su questa idea eseguendo test programmi autoverificabili e ripetibili. Le asserzioni sostituiscono manualmente e l'ispezione dell'output. Inoltre, poiché è facile interpretare i risultati (il test supera o non supera i controlli), i test possono essere eseguiti più volte, fornendo una rete di sicurezza che rende il tuo codice più resistente al cambiamento.
Mettiamolo in termini concreti: quando invii per la prima volta il codice finito nella CVS, funziona perfettamente. E continua a funzionare perfettamente per un po' di tempo. Poi un giorno, qualcun altro cambia il tuo codice. Prima o poi qualcuno si romperà il tuo codice. Supponiamo che se ne accorgano da soli? Poco probabile. Ma quando dei test delle unità, esistono sistemi in grado di eseguirli, automaticamente, ogni giorno. Questi sistemi sono chiamati sistemi di integrazione continua. Quindi, quando quell'ingegnere X interrompe il codice e il sistema invia email indesiderate fino a quando non risolve il problema li annotino. Anche se l'ingegnere X sei TU!
Oltre ad aiutarti a sviluppare software e quindi a mantenerlo sicuro a fronte del cambiamento, il test delle unità:
- Crea una specifica eseguibile e la documentazione che rimane sincronizzata con il codice. In altre parole, puoi leggere un test delle unità per scoprire comportamento supportato dal modulo.
- Aiuta a separare i requisiti dall'implementazione. Poiché stai affermando un comportamento visibile esternamente, puoi pensarci in modo esplicito invece di combinare idee su come implementare questo comportamento.
- Supporta la sperimentazione. Se hai una rete di sicurezza per avvisarti quando se hai suddiviso il comportamento di un modulo, è più probabile che tu stia provando e riconfigurare i progetti.
- Migliora i tuoi progetti. Scrivere test approfonditi delle unità richiede spesso per rendere il tuo codice più testabile. Il codice verificabile è spesso più modulare che non testabile le API nel tuo codice.
- Mantiene alta la qualità. Un piccolo bug in un sistema critico può far sì che un'azienda perdere milioni di dollari o, peggio ancora, la fiducia o la felicità di un utente. La rete di sicurezza offerta dai test delle unità riduce questa possibilità. Rilevando insetti fin da subito, inoltre, consentono ai team di QA di dedicare del tempo anziché segnalare errori evidenti.
Prenditi il tempo necessario per scrivere i test delle unità utilizzando CPPUnit per l'applicazione di database Composer. Fai riferimento alla directory cppunit/examples/ per assistenza.
Come funziona Google
IntroduzioneImmagina un monaco nel Medioevo che guarda migliaia di manoscritti archivi del suo monastero."Dov'è quella di Aristotele?"

Fortunatamente per lui, i manoscritti sono organizzati per contenuto e sono con simboli speciali per facilitare il recupero delle informazioni contenute nei ciascuna. Senza un'organizzazione del genere, sarebbe molto difficile trovare manoscritto.
Attività di archiviazione e recupero di informazioni scritte da grandi raccolte è chiamato Recupero delle informazioni (IR). Questa attività è diventata sempre più importanti nel corso dei secoli, soprattutto con invenzioni come la carta e la stampa premi. Un tempo era un'abitazione in cui erano occupate solo poche persone. Tuttavia, centinaia di milioni di persone si occupano di recupero delle informazioni ogni giorno in cui utilizzano un motore di ricerca o eseguono ricerche sul desktop.
Guida introduttiva al recupero delle informazioni

Il dottor Seuss ha scritto 46 libri per bambini in 30 anni. I suoi libri raccontavano di gatti, mucche ed elefanti, di chi è, brindisi e il lorax. Ti ricordi quali creature erano presenti in quale storia? A meno che tu non sia un genitore, solo i bambini possono dirti quale serie di storie del Dr. Seuss contiene le creature:
(mucca e api) o COGLI
Applicheremo alcuni modelli classici di recupero delle informazioni per risolvere questo problema problema.
Un approccio ovvio è la forza bruta: recupera tutte le 46 storie di Dr. Seuss e inizia per la lettura. Per ogni libro, indica quale o quali contengono le parole COW e BEE, e cerca nello stesso momento libri che contengono la parola CROWS. I computer sono molto più velocemente di noi. Se abbiamo tutto il testo dei libri di Dr. Seuss in formato digitale, ad esempio come file di testo, possiamo eseguire il grep attraverso i file. Per un piccola collezione come i libri del dottor Seuss, questa tecnica funziona bene.
Tuttavia, ci sono molte situazioni in cui abbiamo bisogno di di più. Ad esempio, la raccolta di tutti i dati attualmente online è troppo grande per essere gestito da grep. Inoltre, non solo i documenti che corrispondono alla nostra condizione, siamo abituati a classificandoli in base alla pertinenza.
Un altro approccio, oltre a grep, consiste nel creare un indice dei documenti in una raccolta prima di effettuare la ricerca. Un indice in IR è simile a un indice a livello di retro di un libro di testo. Creiamo un elenco di tutte le parole (o termini) in ogni la storia del dottor Seuss, senza usare parole come "the", "and" e altri elementi di connessione, preposizioni ecc. (sono chiamate interruzioni). Quindi rappresentiamo queste informazioni in modo da facilitare l'individuazione dei termini e l'identificazione le storie in cui si trovano.
Una possibile rappresentazione è una matrice con le notizie nella parte superiore e i termini elencati in ciascuna riga. Il valore "1" in una colonna indica che il termine compare nella storia per quella colonna.
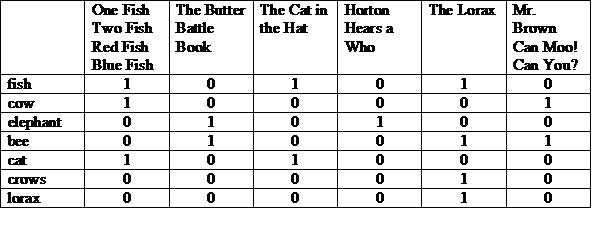
Possiamo visualizzare ogni riga o colonna come un vettore di bit. Il vettore di bit di una riga indica in cui compare il termine. Il vettore di bit di una colonna indica quali termini appaiono nella storia.
Torniamo al nostro problema originale:
(mucca e api) o COGLI
Prendiamo i vettori di bit per questi termini, prima facciamo un passo a bit E, poi OR a bit a livello di bit sul risultato.
(100001 e 010011) o 000010 = 000011
La risposta: "Sig. Brown can Muu! Tu?" e "The Lorax". Questa è un'illustrazione del modello Recupero booleano, che è un modello di "corrispondenza esatta".
Supponiamo di dover espandere la matrice per includere tutte le storie del dottor Seuss e tutte termini pertinenti nelle notizie. La matrice crescerebbe notevolmente e un aspetto osservazione è che la maggior parte delle voci è 0. Una matrice probabilmente non è la migliore rappresentazione per l'indice. Dobbiamo trovare un modo per archiviare solo i dati 1.
Alcuni miglioramenti
La struttura utilizzata in IR per risolvere questo problema è chiamata indice invertito. Conserviamo un dizionario di termini e, per ogni termine, abbiamo un elenco che registri i documenti in cui si trova il termine. Questo elenco è chiamato posting elenco predefinito. Un elenco collegato singolarmente è efficace per rappresentare questa struttura come mostrato di seguito.

Se non hai familiarità con gli elenchi collegati, esegui una ricerca su Google utilizzando
elenco in C++", troverai molte risorse che descrivono come crearne uno,
e come viene utilizzato. Approfondiremo questo aspetto in un modulo successivo.
Tieni presente che utilizziamo gli ID documento (DocIDs) anziché il nome del storia. Questi DocID vengono ordinati per facilitare l'elaborazione delle query.
Come elaboriamo una query? Per il problema originale, prima troviamo i post COW quindi l'elenco di annunci BEE. Quindi le "uniamo":
- Mantieni gli indicatori in entrambi gli elenchi e illustra i due elenchi di post contemporaneamente.
- In ogni passaggio, confronta il DocID a cui punta entrambi i puntatori.
- Se sono uguali, inserisci quel DocID in un elenco di risultati, altrimenti fai avanzare il puntatore che rimanda al docID più piccolo.
Ecco come possiamo creare un indice invertito:
- Assegnare un DocID a ciascun documento di interesse.
- Per ogni documento identifica i termini pertinenti (tokenizza).
- Per ogni termine, crea un record composto dal termine, il DocID in cui e la frequenza al suo interno. Tieni presente che possono esserci più per un determinato termine, se compare in più di un documento.
- Ordina i record per termine.
- Crea il dizionario e l'elenco dei post elaborando singoli record per un termine e anche la combinazione di più record per i termini che appaiono di un solo documento. Crea un elenco collegato dei DocID (in ordine ordinato). Ciascuna termine ha anche una frequenza che è la somma delle frequenze di tutti i record per un termine.
Il progetto
Trova diversi lunghi documenti in testo non crittografato con cui eseguire esperimenti. La progetto è creare un indice invertito dai documenti, utilizzando gli algoritmi descritti sopra. Dovrai inoltre creare un'interfaccia per l'input delle query e un motore per elaborarle. Puoi trovare un partner di progetto nel forum.
Ecco un possibile processo per completare questo progetto:
- La prima cosa da fare è definire una strategia per l'identificazione dei termini nei documenti. Crea un elenco di tutte le stopword che ti vengono in mente e scrivi una funzione che legge le parole nei file, li salva ed elimina le stop-word. È possibile che tu debba aggiungere altre stopword all'elenco man mano che esamini l'elenco i termini di un'iterazione.
- Scrivi scenari di test CPPUnit per testare la tua funzione e un makefile per portare tutto per la tua build. Archiviate i file in CSV, in particolare se collaborare con i partner. Ti consigliamo di scoprire come aprire l'istanza CVS agli ingegneri remoti.
- Aggiungi l'elaborazione per includere i dati sulla posizione, ovvero il file e la posizione il file è un termine? Potrebbe essere utile eseguire un calcolo per definire di pagina o di paragrafo.
- Scrivi scenari di test della CPPUnit per testare questa funzionalità aggiuntiva.
- Crea un indice invertito e memorizza i dati sulla posizione nel record di ciascun termine.
- Scrivi altri scenari di test.
- Progetta un'interfaccia per consentire a un utente di inserire una query.
- Utilizzando l'algoritmo di ricerca descritto sopra, elaboriamo l'indice invertito e restituire i dati sulla posizione all'utente.
- Includi anche scenari di test per questa parte finale.
Come abbiamo fatto per tutti i progetti, usa il forum e la chat per trovare i partner per il progetto. e condividere idee.
Un'ulteriore funzionalità
Una fase di elaborazione comune in molti sistemi IR è chiamata stemming. La L'idea principale alla base dello stemming è che gli utenti che cercano informazioni sul "recupero" saranno interessati anche ai documenti contenenti informazioni contenenti il termine "recupero", "recuperato", "recupero" e così via. I sistemi possono essere suscettibili di errori dovuti a una radice scadente, quindi è un po' complicato. Ad esempio, un utente interessato in "recupero di informazioni", potrebbe ricevere un documento intitolato "Informazioni su Retriever" a causa della radice stemming. Un algoritmo utile per lo stemming è Algoritmo di porter: