Introduzione alla programmazione e a C++
Questa tutorial online continua con i concetti più avanzati; leggi la Parte III. In questo modulo ci concentreremo sull'uso dei cursori e sulla guida introduttiva degli oggetti.
Impara con l'esempio n. 2
In questo modulo ci concentreremo su come esercitarti con la decomposizione, comprendere i puntatori e iniziare a utilizzare oggetti e classi. Esamina i seguenti esempi. Scrivi i programmi autonomamente quando ti viene richiesto oppure esegui gli esperimenti. Non possiamo enfatizzare abbastanza che la chiave per diventare un buon programmatore sono la pratica, la pratica, la pratica.
Esempio 1: ulteriori pratiche di decomposizione
Considera il seguente output da un gioco semplice:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
La prima osservazione è il testo introduttivo che viene visualizzato una volta per programma dell'esecuzione. Abbiamo bisogno di un generatore di numeri casuali per definire la distanza nemica per ogni rotondo. Ci serve un meccanismo per ottenere l'angolo di input dal player e questo è ovviamente in una struttura ad anello, poiché si ripete fino a quando non colpiamo il nemico. Abbiamo anche serve una funzione per calcolare la distanza e l'angolo. Infine, dobbiamo tenere traccia di quanti colpi sono stati necessari per colpire il nemico e quanti nemici abbiamo durante l'esecuzione del programma. Di seguito è riportato un possibile schema del programma principale.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
La procedura Fire gestisce il gioco. In questa funzione, chiamiamo un generatore di numeri casuali per ottenere la distanza nemica, e poi impostare l'anello per ottenere l'input del giocatore e calcolare se ha colpito o meno il nemico. La la condizione di guardia in loop è quanto siamo arrivati a colpire il nemico.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
A causa delle chiamate a cos() e sin(), dovrai includere math.h. Prova scrivere questo programma, è un'ottima pratica per la decomposizione di problemi ed è una revisione del C++ di base. Ricorda di eseguire una sola attività per ogni funzione. Questo è il più sofisticato che abbiamo scritto finora, quindi potrebbe richiedere è ora di farlo.Ecco la nostra soluzione.
Esempio 2: esercitati con i puntatori
Ci sono quattro cose da ricordare quando si utilizzano i cursori:- I puntatori sono variabili che contengono gli indirizzi di memoria. Mentre un programma è in esecuzione,
tutte le variabili sono memorizzate in memoria, ciascuna nel proprio indirizzo o posizione univoco.
Un puntatore è un tipo speciale di variabile che contiene un indirizzo di memoria anziché
che un valore di dati. Così come i dati vengono modificati
quando si usa una variabile normale,
Il valore dell'indirizzo memorizzato in un puntatore viene modificato come variabile di puntatore
viene manipolato. Ecco un esempio:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - Di solito diciamo che un puntatore "indica" alla posizione in cui sta archiviando
(il "punto di accesso"). Nell'esempio precedente, intptr punta alla pointee
5.
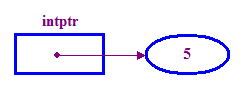
Nota l'utilizzo della funzione "nuovo" operatore per allocare la memoria per il nostro numero intero puntato. È una cosa che dobbiamo fare prima di provare ad accedere al punto.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.L'operatore * viene utilizzato per il deriferimento in C. Uno degli errori più comuni I programmatori C/C++ usano i puntatori per dimenticare di inizializzarli la punta. Questo a volte può causare un arresto anomalo di runtime, poiché stiamo accedendo una posizione in memoria che contiene dati sconosciuti. Se proviamo a modificare dati, possiamo causare una lieve corruzione della memoria, il che li rende un bug difficile da rintracciare.
- L'assegnazione di un puntatore tra due puntatori li fa puntare sullo stesso punto.
Quindi l'assegnazione y = x; indica che la y punta alla stessa punta di x. Assegnazione del puntatore
non tocca la punta. Cambia solo un puntatore in modo che abbia la stessa posizione
come un altro puntatore. Dopo l'assegnazione del puntatore, i due puntatori "condividono" il
puntato.

void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
Ecco una traccia di questo codice:
| 1. Alloca due puntatori x e y. L'assegnazione dei cursori non allocare alcun punto. | 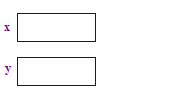 |
| 2. Posiziona una punta e imposta x per puntarla. | 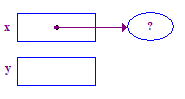 |
| 3. Dereferenzia x per memorizzare 42 nel punto in questione. Questo è un esempio di base dell'operazione di dereference. Inizia dalla x, segui la freccia per accedere il suo punto. | 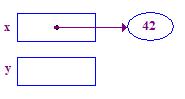 |
| 4. Prova a dereferenziare y per memorizzare 13 nel suo punto. Questo arresto anomalo si verifica perché non hanno una punta: non ne è mai stata assegnata una. | 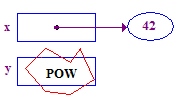 |
| 5. Assegna y = x; in modo che y punti al punto x. Ora x e y puntano a sono le stesse: sono "condivise". | 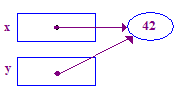 |
| 6. Prova a dereferenziare y per memorizzare 13 nel punto. Questa volta funziona, perché il compito precedente ti ha dato un punto. | 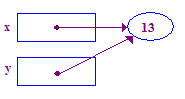 |
Come puoi vedere, le immagini sono molto utili per comprendere l'utilizzo del puntatore. Ecco in un altro esempio.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
Nota in questo esempio che non abbiamo mai allocato la memoria con il valore "new" operatore. Abbiamo dichiarato una variabile intero normale e l'abbiamo manipolata tramite puntatori.
In questo esempio, viene illustrato l'uso dell'operatore delete che rimuove l'allocazione heap e come allocarla per strutture più complesse. Tratteremo dell'organizzazione della memoria (heap e stack di runtime) in un'altra lezione. Per ora, pensa all'heap come a un archivio libero di memoria disponibile per i programmi in esecuzione.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
In questo ultimo esempio, viene mostrato come vengono utilizzati i puntatori per passare valori per riferimento. a una funzione. Questo è il modo in cui modifichiamo i valori delle variabili all'interno di una funzione.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
Se dovessimo lasciare fuori gli argomenti nella definizione di funzione duplicata, passiamo le variabili "per valore", cioè viene fatta una copia del valore la variabile. Qualsiasi modifica apportata alla variabile nella funzione modifica la copia. Non modificano la variabile originale.
Quando una variabile viene passata per riferimento non passiamo una copia del suo valore, passiamo l'indirizzo della variabile alla funzione. Qualsiasi modifica che apportiamo alla variabile locale, modifichi effettivamente la variabile originale trasmessa.
Se sei un programmatore C, questa è una nuova svolta. Potremmo fare lo stesso in Do dichiarando Duplica(). come Duplica(int *x), in questo caso x è un puntatore a un int, quindi chiama Duplica() con l'argomento &x (indirizzo-of x) e utilizza il de-riferimento di x all'interno di Duplica() (vedi di seguito). Ma C++ offre un modo più semplice per passare valori alle funzioni riferimento, anche se la vecchia "C" per farlo funziona ancora.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
Come puoi notare, con i riferimenti C++ non è necessario passare l'indirizzo di una variabile, dobbiamo rimuovere la variabile all'interno della funzione chiamata?
Che cosa restituisce il seguente programma? Disegna un'immagine del ricordo per capire meglio.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} Esegui il programma per vedere se hai ricevuto la risposta corretta.
Esempio 3: passaggio di valori per riferimento
Scrivi una funzione chiamata accelerate() che prenda come input la velocità di un veicolo e un importo. La funzione aggiunge la quantità alla velocità per accelerare il veicolo. Il parametro della velocità deve essere trasmesso per riferimento e l'importo in base al valore. Ecco la nostra soluzione.
Esempio 4: classi e oggetti
Prendi in considerazione la seguente classe:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
Nota che le variabili membro della classe hanno un trattino basso finale. Questo viene fatto per distinguere tra variabili locali e variabili di classe.
Aggiungi un metodo di decremento a questa classe. Ecco la nostra soluzione.
Le meraviglie della scienza: informatica
Esercitazioni
Come nel primo modulo di questo corso, non forniamo soluzioni per esercizi e progetti.
Ricorda che un buon programma...
... è scomposto logicamente in funzioni in cui una qualsiasi esegue una sola attività.
... ha un programma principale che sintetizza come una sintesi di ciò che farà il programma.
... ha nomi descrittivi di funzioni, costanti e variabili.
... usa delle costanti per evitare qualsiasi "magia" numeri del programma.
... ha un'interfaccia utente intuitiva.
Esercizi di riscaldamento
- Esercizio 1
Il numero intero 36 ha una proprietà peculiare: è un quadrato perfetto ed è anche la somma dei numeri interi da 1 a 8. Il successivo numero di questo tipo è 1225, che è 352 e la somma dei numeri interi da 1 a 49. Trovare il numero successivo che è un quadrato perfetto e anche la somma di una serie 1...n. Il prossimo numero potrebbe essere superiore a 32767. Puoi usare funzioni di libreria che conosci, (o formule matematiche) per velocizzare l'esecuzione del programma. È inoltre possibile scrivere questo programma usando for-loop per determinare se un numero è un un quadrato o la somma di una serie. Nota: a seconda della macchina e del programma, potrebbe volerci un po' per trovare questo numero.)
- Esercizio 2
La tua libreria universitaria ha bisogno del tuo aiuto per stimare la sua attività per il prossimo anno. L'esperienza ha dimostrato che le vendite dipendono molto dalla necessità o meno di un libro per un corso o solo facoltativo e se è stato utilizzato o meno nel corso in precedenza. Un nuovo libro di testo obbligatorio verrà venduto al 90% delle potenziali iscrizioni, ma se è stato usato in precedenza, solo il 65% lo comprerà. Analogamente, Il 40% dei potenziali iscritti acquisterà un nuovo libro di testo facoltativo, ma è stato utilizzato nel corso prima che solo il 20% effettui l'acquisto. (Tieni presente che "in uso" qui non si riferisce ai libri di seconda mano.)
Scrivi un programma che accetti come input una serie di libri (finché l'utente non inserisce una sentinella). Per ogni libro chiedi: un codice per il libro, il costo della singola copia il libro, il numero di libri a disposizione, la potenziale iscrizione a un corso, e i dati che indicano se il libro è obbligatorio/facoltativo, nuovo/usato in passato. Come l'output, mostra tutte le informazioni di input in una schermata ben formattata insieme quanti libri devono essere ordinati (se presenti, tieni presente che vengono ordinati solo i nuovi libri), il costo totale di ciascun ordine.
Una volta completata l'inserimento, mostra il costo totale di tutti gli ordini di libri e il profitto previsto se il negozio paga l'80% del prezzo di listino. Poiché non abbiamo ancora discusso di qualsiasi modo di gestire un grande set di dati in ingresso in un programma (rimanere ottimizzato!), elabora un libro alla volta e visualizza la relativa schermata di output. Quando l'utente ha terminato di inserire tutti i dati, il programma dovrebbe restituire il valore totale e quello del profitto.
Prima di iniziare a scrivere il codice, prenditi un po' di tempo per pensare alla progettazione di questo programma. Scomponi in un insieme di funzioni e crea una funzione main() che risulti come delineare la soluzione al problema. Assicurati che ogni funzione svolga una sola attività.
Ecco un output di esempio:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
Progetto di database
In questo progetto, creiamo un programma C++ completamente funzionale che implementa una semplice in un'applicazione di database.
Il nostro programma ci consentirà di gestire un database di compositori e informazioni pertinenti su questi argomenti. Le funzionalità del programma includono:
- Possibilità di aggiungere un nuovo compositore
- La capacità di classificare un compositore (ovvero di indicare quanto ci piace o non ci piace la musica del compositore)
- Possibilità di visualizzare tutti i compositori nel database
- Possibilità di visualizzare tutti i compositori per ranking
"Esistono due modi per creare una progettazione del software: un modo è renderlo così semplice che ci siano nessuna carenza, e l'altro modo è rendere la situazione così complicata da non ci sono carenze evidenti. Il primo metodo è molto più difficile". - C.A.R. Hoare
Molti di noi hanno imparato a progettare e programmare usando una procedura l'importanza di un approccio umile. La domanda principale con cui iniziamo è "Che cosa deve fare il programma?". Me scomporre la soluzione di un problema in attività, ognuna delle quali risolve una parte risolvere il problema. Queste attività mappano a funzioni del nostro programma, denominate in sequenza da main() o da altre funzioni. Questo approccio passo passo è ideale per alcuni i problemi da risolvere. Ma il più delle volte i nostri programmi non sono solo lineari sequenze di attività o eventi.
Con un approccio orientato agli oggetti, iniziamo con la domanda "Quale oggetti che sto modellando?" Anziché dividere un programma in attività come descritto in alto, lo dividiamo in modelli di oggetti fisici. Questi oggetti fisici hanno uno stato definito da un insieme di attributi e da un insieme di comportamenti o azioni che che possono eseguire. Queste azioni possono cambiare lo stato dell'oggetto e richiamare azioni su altri oggetti. La premessa di base è che un oggetto "sa" come fare le cose da solo.
Nella progettazione di oggetti OO, definiamo gli oggetti fisici in termini di classi e oggetti; attributi e comportamenti. Generalmente, un programma OO contiene un numero elevato di oggetti. Molti di questi oggetti, tuttavia, sono sostanzialmente gli stessi. Considera quanto segue.
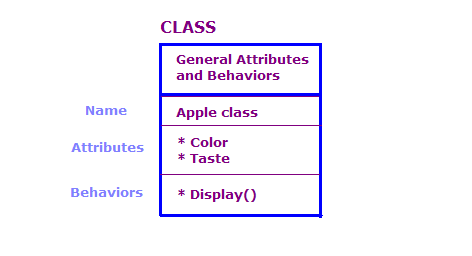
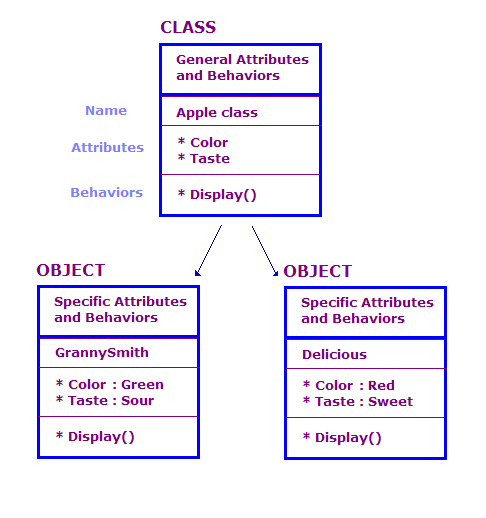
In questo diagramma, abbiamo definito due oggetti che sono della classe Apple. Ogni oggetto ha gli stessi attributi e azioni della classe, ma l'oggetto definisce gli attributi di un tipo specifico di mela. Inoltre, lo strumento azione mostra gli attributi per quell'oggetto specifico, ad esempio "Verde" e "Sour".
Una progettazione OO è composta da un insieme di classi, i dati associati a queste classi, e l'insieme di azioni che le classi possono eseguire. Dobbiamo anche identificare modi in cui interagiscono classi diverse. Questa interazione può essere eseguita da oggetti di una classe che richiama le azioni degli oggetti di altre classi. Ad esempio, potresti avere una classe AppleOutputer che restituisce il colore e il gusto di un array di oggetti Apple, chiamando il metodo Display() di ogni oggetto Apple.
Di seguito sono riportati i passaggi che svolgiamo per progettare l'ambiente esterno:
- Identificare le classi e definire in generale quale oggetto di ciascuna classe come dati e cosa può fare un oggetto.
- Definisci gli elementi dei dati di ogni classe
- Definisci le azioni di ogni classe e come possono essere alcune azioni di una classe
implementato utilizzando azioni di altre classi correlate.
In un sistema di grandi dimensioni, questi passaggi si verificano in modo iterativo a diversi livelli di dettaglio.
Per il sistema di database del compositore, abbiamo bisogno di una classe Composer che incapsula i dati che vogliamo memorizzare su un singolo compositore. Un oggetto di questa classe può promuovere o retrocedere se stesso (cambiarne il ranking) e visualizzare i relativi attributi.
Abbiamo anche bisogno di una raccolta di oggetti Composer. Per questo, definiamo una classe Database che gestisce i singoli record. Un oggetto di questa classe può aggiungere o recuperare Composer e visualizza quelli singoli richiamando l'azione di visualizzazione un oggetto Composer.
Infine, abbiamo bisogno di una sorta di interfaccia utente per fornire operazioni interattive. nel database. Si tratta di una classe segnaposto, cioè non sappiamo esattamente quale sarà ancora più simile, ma sappiamo che ne avremo bisogno. Forse il modello sarà grafico, ad esempio basato su testo. Per ora definiamo un segnaposto che potremo compilare in seguito.
Ora che abbiamo identificato le classi per l'applicazione del database Composer, il passaggio successivo consiste nel definire gli attributi e le azioni per le classi. In un contesto più un'applicazione complessa, ci sedevamo con carta e matita o UML o schede CRC o OOD per mappare la gerarchia delle classi e l'interazione degli oggetti.
Per il database del compositore, definiamo una classe Composer che contiene che vogliamo memorizzare su ciascun compositore. Contiene anche metodi per manipolare classifiche e visualizzare i dati.
La classe Database ha bisogno di una struttura per contenere gli oggetti Composer. Dobbiamo essere in grado di aggiungere un nuovo oggetto Composer alla struttura, nonché per recuperare un oggetto Composer specifico. Vorremmo visualizzare anche tutti gli oggetti in ordine di inserimento o per ranking.
La classe User Interface implementa un'interfaccia basata su menu, con gestori che nella classe Database.
Se i corsi sono facilmente comprensibili e le loro caratteristiche e azioni sono chiare, come nell'applicazione Composer, la progettazione delle classi è relativamente facile. Ma se hai domande su come le lezioni si relazionano e interagiscono, è meglio disegnarlo prima di iniziare e analizzarne i dettagli prima di iniziare alla programmazione.
Una volta che abbiamo un quadro chiaro del design e lo abbiamo valutato (ulteriori informazioni su questo definiamo l'interfaccia per ogni classe. L'implementazione non ci preoccupa dettagli a questo punto: solo gli attributi e le azioni e le parti di una classe" lo stato e le azioni sono disponibili per gli altri corsi.
In C++, lo facciamo solitamente definendo un file di intestazione per ogni classe. Il compositore ha membri di dati privati per tutti i dati che vogliamo archiviare in un compositore. Abbiamo bisogno delle funzioni di accesso (metodi "get") e dei mutatori (metodi "set"), nonché azioni principali per il corso.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
Anche la classe Database è semplice.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
Nota come abbiamo accuratamente incapsulato i dati specifici del compositore in un . Potremmo inserire uno struct o una classe nella classe Database per rappresentare Composer a cui è possibile accedere direttamente. ma questo sarebbe "sottooggettivazione", ovvero non stiamo modellando tanto con gli oggetti come potremmo fare.
Quando inizierai a lavorare all'implementazione di Composer e Database, che è molto più lineare avere una classe Composer separata. In particolare, le operazioni atomiche separate su un oggetto Composer semplificano notevolmente l'implementazione dei metodi Display() nella classe Database.
Naturalmente, c’è anche qualcosa come l’eccessiva oggettizzazione dove cerchiamo di rendere tutto un corso o ne abbiamo più del necessario. La creazione per trovare il giusto equilibrio e scoprirai che i singoli programmatori avranno opinioni divergenti.
Spesso, per capire se gli oggetti sono sovra o troppo poco creare un diagramma dei corsi. Come accennato in precedenza, è importante preparare un corso la progettazione prima di iniziare a programmare e questo può aiutarti ad analizzare il tuo approccio. Un comune la notazione usata a questo scopo UML (Unified Modeling Language) Ora che abbiamo le classi definite per gli oggetti Composer e Database, abbiamo bisogno un'interfaccia che consente all'utente di interagire con il database. Un semplice menu Procedi nel seguente modo:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Potremmo implementare l'interfaccia utente come classe o come programma procedurale. No tutto in un programma C++ deve essere una classe. Infatti, se l'elaborazione è sequenziale o orientato alle attività, come in questo programma di menu, consente di implementarlo in modo procedurale. È importante implementarlo in modo che rimanga un "segnaposto", Ad esempio, per creare una Graphic User Interface a un certo punto, non devi modificare nulla nel sistema, se non nell'interfaccia utente.
L'ultima cosa che ci serve per completare la domanda è un programma per testare i corsi. Per la classe Composer, vogliamo un programma main() che riceva input, compila un Composer e poi lo visualizza per verificare che la classe funzioni correttamente. Vogliamo anche chiamare tutti i metodi della classe Composer.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
Abbiamo bisogno di un programma di test simile per la classe Database.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
Questi semplici programmi di test sono un buon primo passo, ma richiedono la per controllare manualmente l'output e assicurarti che il programma funzioni correttamente. Come un sistema diventa più grande, l'ispezione manuale dell'output diventa rapidamente poco attuabile. In una lezione successiva presenteremo i programmi di test con autoverifica nel modulo dei test delle unità.
La progettazione della nostra applicazione è ora completa. Il passaggio successivo consiste nell'implementare i file .cpp per le classi e l'interfaccia utente.Per iniziare, procedi e copia/incolla il codice .h e il codice del driver di test riportato sopra nei file e compilali.Utilizza le funzionalità di i collaudatori per testare i corsi. Poi implementa la seguente interfaccia:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Utilizza i metodi definiti nella classe Database per implementare l'interfaccia utente. Rendi i tuoi metodi a prova di errori. Ad esempio, un ranking deve sempre rientrare nell'intervallo 1-10. Non consentire a nessuno di aggiungere "101 compositori", a meno che tu non abbia intenzione di modificare il struttura dei dati nella classe Database.
Ricorda che tutto il codice deve seguire le nostre convenzioni di codifica, che vengono ripetute qui per comodità:
- Ogni programma che scriviamo inizia con un commento nell'intestazione, in cui viene specificato il nome l'autore, i relativi dati di contatto, una breve descrizione e l'utilizzo (se pertinente). Ogni funzione/metodo inizia con un commento su operazione e utilizzo.
- Aggiungiamo commenti esplicativi utilizzando frasi complete, ogni volta che il codice non documentarsi, ad esempio se l'elaborazione è complicata, non ovvia interessante o importante.
- Utilizza sempre nomi descrittivi: le variabili sono parole minuscole separate da _, come in my_variable. I nomi di funzioni/metodi utilizzano lettere maiuscole per contrassegnare come in MyExcitingFunction(). Le costanti iniziano con una "k" e utilizza lettere maiuscole per contrassegnare le parole, ad esempio kDaysInWeek.
- Il rientro è in multipli di due. Il primo livello è di due spazi; se oltre il rientro è necessario, utilizziamo quattro spazi, sei spazi e così via.
Ti diamo il benvenuto nel Mondo reale!
In questo modulo introdurremo due strumenti molto importanti utilizzati nella maggior parte del software engineering le tue organizzazioni. Il primo è uno strumento di creazione, mentre il secondo è uno strumento di gestione delle configurazioni di un sistema operativo completo. Entrambi questi strumenti sono essenziali nell'ingegneria del software industriale, in cui molti ingegneri lavorano spesso su un unico grande sistema. Questi strumenti consentono di coordinare controllare le modifiche al codebase e fornire un mezzo efficiente per la compilazione e il collegamento di un sistema da molti file di programma e intestazione.
Crea file
Il processo di creazione di un programma è in genere gestito con uno strumento di creazione, che compila e collega i file richiesti, nell'ordine corretto. Molto spesso, i file C++ hanno come una funzione chiamata in un programma, che si trova in un'altra . È anche possibile che un file di intestazione sia necessario per diversi file .cpp. R che lo strumento di creazione determina l'ordine di compilazione corretto da queste dipendenze. Sarà compilano solo i file che sono stati modificati dall'ultima build. In questo modo è possibile molto tempo in sistemi composti da diverse centinaia o migliaia di file.
Viene comunemente utilizzato uno strumento di build open source chiamato make. Per saperne di più, leggi attraverso questo articolo. Vedi se riesci a creare un grafico delle dipendenze per l'applicazione Composer Database, per poi tradurlo in un makefile.Qui è la nostra soluzione.
Sistemi di gestione delle configurazioni
Il secondo strumento utilizzato nell’ingegneria del software industriale è la gestione della configurazione (CM). Viene utilizzato per gestire il cambiamento. Supponiamo che Bob e Susan siano entrambi scrittori di tecnologia. ed entrambi stanno lavorando all'aggiornamento di un manuale tecnico. Durante una riunione, assegna a ciascuno di loro una sezione dello stesso documento da aggiornare.
Il manuale tecnico viene memorizzato su un computer a cui possono accedere sia Bob che Susan. Senza alcuno strumento o processo CM, potrebbero sorgere diversi problemi. Uno. uno dei possibili scenari è che il computer su cui è archiviato il documento sia impostato in modo da Roberto e Susanna non possono lavorare sul manuale contemporaneamente. L'operazione rallenterà notevolmente.
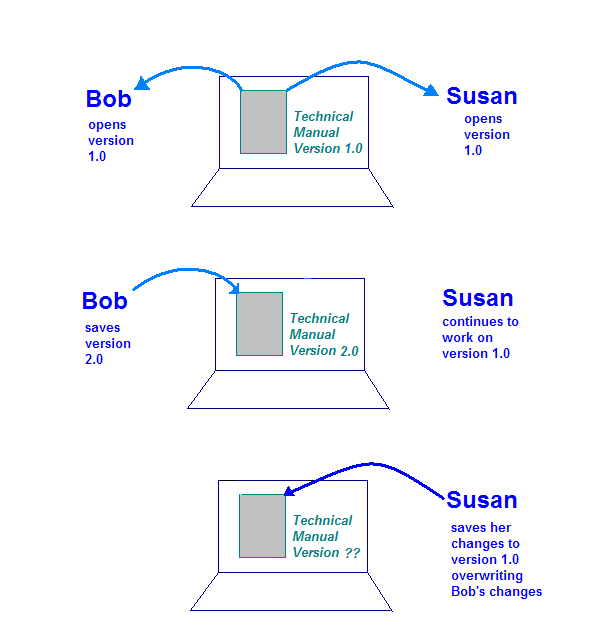
Si crea una situazione più pericolosa quando il computer di archiviazione consente il documento essere aperto da Bob e Susan contemporaneamente. Ecco cosa potrebbe succedere:
- Bob apre il documento sul computer e lavora alla sua sezione.
- Susan apre il documento sul computer e lavora nella sua sezione.
- Roberto completa le modifiche e salva il documento sul computer di archiviazione.
- Susan completa le modifiche e salva il documento sul computer di archiviazione.
Questa illustrazione mostra il problema che può verificarsi se non sono presenti controlli sulla copia unica del manuale tecnico. Quando Susan salva le modifiche, sovrascriverà quelle create da Roberto.
Questo è esattamente il tipo di situazione che un sistema CM può controllare. Con un CM sia Bob che Susan "pagheranno" la propria copia del documento manuali e lavorarci sopra. Quando Bob controlla di nuovo le modifiche, il sistema sa che Susan ha la propria copia. Quando Susan controlla la sua copia, il sistema analizza le modifiche apportate sia da Bob che da Susan e crea una nuova versione unisce i due insiemi di modifiche.
I sistemi CM presentano una serie di funzionalità, oltre a gestire le modifiche simultanee, come descritto in alto. Molti sistemi archiviano gli archivi di tutte le versioni di un documento, a partire dalla prima data di creazione. Nel caso di un manuale tecnico, può essere molto utile. quando un utente ha una versione precedente del manuale e pone domande a uno scrittore tecnico. Un sistema CM consente allo scrittore tecnico di accedere alla versione precedente e di poter per capire cosa vede l'utente.
I sistemi CM sono particolarmente utili per controllare le modifiche apportate al software. Tale sono chiamati sistemi di gestione della configurazione software (SCM, Software Configuration Management). Se consideri l'enorme numero di singoli file di codice sorgente in una grande dell'organizzazione e all'enorme numero di tecnici che devono apportare modifiche, è chiaro che un sistema SCM è fondamentale.
Gestione della configurazione software
I sistemi SCM si basano su un'idea semplice: le copie definitive dei tuoi file in un repository centrale. Le persone controllano copie dei file dal repository lavorare sulle copie per poi ricontrollarle una volta terminate. SCM sistemi di gestione e tracciamento delle revisioni di più persone rispetto a un unico master per iniziare.
Tutti i sistemi SCM offrono le seguenti funzionalità essenziali:
- Gestione della contemporaneità
- Controllo delle versioni
- Sincronizzazione
Esaminiamo ciascuna di queste funzionalità in maggiore dettaglio.
Gestione della contemporaneità
Per contemporaneità si intende la modifica simultanea di un file da parte di più persone. Con un repository di grandi dimensioni, vogliamo che le persone siano in grado di farlo, ma ad alcuni problemi.
Consideriamo un semplice esempio nel campo dell'ingegneria: supponiamo di consentire agli ingegneri di modificare lo stesso file contemporaneamente in un repository centrale di codice sorgente. Client1 e Client2 devono apportare modifiche a un file contemporaneamente:
- Client1 apre bar.cpp.
- Client2 apre bar.cpp.
- Client1 modifica il file e lo salva.
- Client2 modifica il file e lo salva sovrascrivendo le modifiche di Client1.
Ovviamente, non vogliamo che succeda. Anche se controllavamo la situazione in modo che i due ingegneri lavorino su copie separate invece che direttamente (come nell'illustrazione seguente), le copie devono essere in qualche modo riconciliate. Più alta I sistemi SCM affrontano questo problema consentendo a più ingegneri di controllare un file ("sincronizzare" o "aggiornare") e apportare le modifiche necessarie. SCM il sistema esegue quindi degli algoritmi per unire le modifiche al momento del check-in dei file. ("invio" o "commit") nel repository.
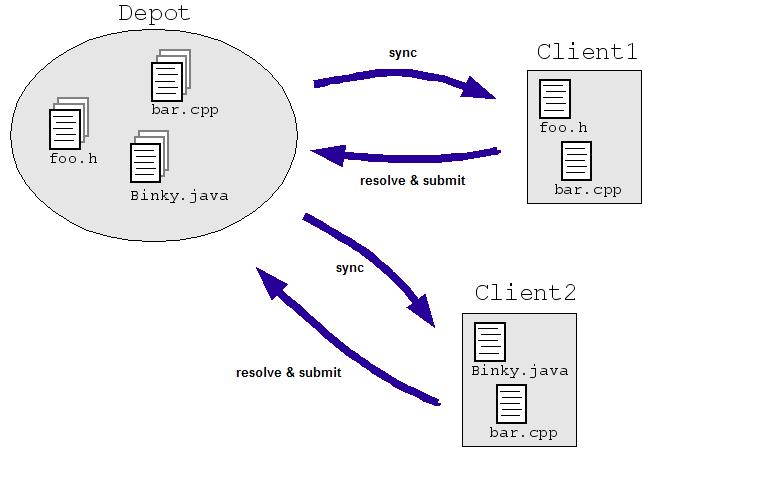
Questi algoritmi possono essere semplici (chiedi ai tecnici di risolvere le modifiche in conflitto) o meno semplici (determinare come unire le modifiche in conflitto in modo intelligente e chiedi solo a un ingegnere se il sistema si blocca davvero).
Controllo delle versioni
Con il controllo delle versioni si intende il monitoraggio delle revisioni dei file ricreare (o eseguire il rollback) a una versione precedente del file. Questa operazione può essere eseguita in creando una copia di archivio di ogni file quando questo viene archiviato nel repository, o salvando ogni modifica apportata a un file. Possiamo utilizzare in qualsiasi momento gli archivi o modificare le informazioni per creare una versione precedente. I sistemi di controllo delle versioni crea report di log relativi a chi ha fatto il check-in, quando e cosa le modifiche.
Sincronizzazione
Con alcuni sistemi SCM, i singoli file vengono archiviati ed esterni al repository. I sistemi più potenti ti consentono di esaminare più file alla volta. Ingegneri consultare la propria copia completa del repository (o parte di esso) e il lavoro dei file in base alle esigenze. Quindi esegue nuovamente il commit delle modifiche nel repository master periodicamente e aggiornano le proprie copie personali per restare al passo con le modifiche che altre persone hanno realizzato. Questo processo è chiamato sincronizzazione o aggiornamento.
Sovversione
Subversion (SVN) è un sistema open source per il controllo delle versioni. Ha tutte le descritte sopra.
SVN adotta una metodologia semplice in caso di conflitti. Un conflitto si verifica quando o più ingegneri apportano modifiche diverse alla stessa area del codebase entrambi inviano le loro modifiche. SVN avvisa solo i tecnici che c'è conflitto: spetta agli ingegneri risolverlo.
In questo corso utilizzeremo SVN per aiutarti ad acquisire familiarità con e la gestione delle configurazioni. Questi sistemi sono molto comuni nel settore.
Il primo passaggio consiste nell'installare SVN sul tuo sistema. Clic qui per istruzioni. Individua il tuo sistema operativo e scarica il file binario appropriato.
Terminologia di SVN
- Revisione: una modifica in un file o in un insieme di file. Una revisione è una "istantanea" in un progetto in continua evoluzione.
- Repository: la copia principale in cui SVN archivia la cronologia completa delle revisioni di un progetto. Ogni progetto ha un repository.
- Testo di lavoro: il testo in cui un tecnico apporta modifiche a un progetto. Là possono essere molte copie funzionanti di un dato progetto, ciascuna di proprietà di un singolo ingegnere.
- Check-out: per richiedere una copia funzionante dal repository. Una copia funzionante equivale allo stato del progetto al momento del pagamento.
- Esegui il commit: per inviare le modifiche dalla copia di lavoro al repository centrale. Si parla anche di check-in o invio.
- Aggiorna: per portare le altre persone modifiche dal repository alla copia di lavoro, o se la copia di lavoro presenta modifiche non ancora confermate. Questo è il come una sincronizzazione, come descritto sopra. Con l'aggiornamento/sincronizzazione si ottiene il testo di lavoro aggiornate con la copia del repository.
- Conflitto: la situazione in cui due ingegneri tentano di apportare modifiche alla stessa area di un file. SVN indica i conflitti, ma i tecnici devono risolverli.
- Messaggio di log: un commento che alleghi a una revisione quando ne esegui il commit, che che descrive le modifiche. Il log fornisce un riepilogo di ciò che sta accadendo in un progetto.
Ora che hai installato SVN, esamineremo alcuni comandi di base. La la prima cosa da fare è configurare un repository in una directory specificata. Ecco i tipi di :
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
Il comando import copia i contenuti della directory mytree nella cartella progetto di directory principale nel repository. Possiamo dare un'occhiata alla directory repository con il comando list
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
L'importazione non crea una copia funzionante. Per farlo, devi utilizzare svn checkout. Viene creata una copia funzionante della struttura di directory. Iniziamo fallo ora:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
Ora che hai una copia funzionante, puoi apportare modifiche ai file e alle directory là. La tua copia di lavoro è come qualsiasi altra raccolta di file e directory - puoi aggiungerne di nuovi, modificarli, spostarli, persino eliminare l'intero testo di lavoro. Tieni presente che se copi e sposti i file nella copia di lavoro, è importante utilizzare testo svn e spostamento svn anziché tramite i comandi del sistema operativo. Per aggiungere un nuovo file, utilizza svn add ed elimina utilizza svn delete. Se vuoi solo apportare modifiche, apri il file con l'editor e modificalo.
Esistono alcuni nomi di directory standard che vengono spesso utilizzati con Subversion. Il "tronco" directory rappresenta la principale linea di sviluppo del tuo progetto. A "rami" directory contiene qualsiasi versione del ramo su cui potresti stare lavorando.
$ svn list file:///usr/local/svn/repos /trunk /branches
Supponiamo che tu abbia apportato tutte le modifiche necessarie al tuo testo di lavoro vuoi sincronizzarlo con il repository. Se molti altri ingegneri lavorano in quest'area del repository, è importante mantenere aggiornata la copia di lavoro. Puoi utilizzare il comando svn status per visualizzare le modifiche in cui viene eseguito il deployment.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
Tieni presente che il comando status contiene molti flag per controllare questo output. Per visualizzare le modifiche specifiche in un file modificato, utilizza svn diff.
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...Infine, per aggiornare la copia di lavoro dal repository, utilizza il comando svn update.
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
È una posizione in cui potrebbe verificarsi un conflitto. Nell'output precedente, la "U" indica non sono state apportate modifiche alle versioni del repository di questi file e l'operazione. La "G" significa che è avvenuta un'unione. La versione del repository aveva è stata modificata, ma le modifiche non erano in conflitto con le tue. La "C" indica un conflitto. Ciò significa che le modifiche dal repository si sovrapponevano alle tue, e ora devi scegliere tra loro.
Per ogni file che presenta un conflitto, Subversion inserisce tre file nel tuo file di lavoro copia:
- file.mine: si tratta del file così com'era nella copia di lavoro prima di aggiornato la tua copia di lavoro.
- file.rOLDREV: si tratta del file che hai estratto dal repository prima di apportare le modifiche.
- file.rNEWREV: questo file è la versione attuale nel repository.
Per risolvere il conflitto, puoi procedere in uno dei tre seguenti modi:
- Scorri i file ed esegui l'unione manualmente.
- Copia uno dei file temporanei creati da SVN sulla tua versione di copia di lavoro.
- Esegui svn restore per eliminare tutte le modifiche.
Una volta risolto il conflitto, puoi informare SVN eseguendo svn managed. In questo modo i tre file temporanei vengono rimossi e SVN non visualizza più il file in un stato di conflitto.
L'ultima cosa da fare è eseguire il commit della versione finale nel repository. Questo viene eseguito con il comando svn commit. Quando esegui il commit di una modifica, per fornire un messaggio di log che descriva le modifiche. Questo messaggio di log è allegato alla revisione creata.
svn commit -m "Update files to include new headers."
C'è molto altro da scoprire su SVN e su come può supportare software di grandi dimensioni progetti di ingegneria Sul Web sono disponibili numerose risorse: cerca "Subversion" su Google.
Per fare pratica, crea un repository per il tuo sistema di database Composer e importa tutti i tuoi file. Quindi, controlla una copia funzionante e segui i comandi descritti in alto.
Riferimenti
Articolo di Wikipedia sul formato SVN
Applicazione: uno studio sull'anatomia
Dai un'occhiata agli eSkeletons di The University del Texas ad Austin