آموزش زبان C++
بخش های اولیه این آموزش، مطالب پایه ای را که قبلاً در دو ماژول آخر ارائه شده است، پوشش می دهد و اطلاعات بیشتری در مورد مفاهیم پیشرفته ارائه می دهد. تمرکز ما در این ماژول بر روی حافظه پویا و جزئیات بیشتر در مورد اشیاء و کلاس ها است. برخی از موضوعات پیشرفته نیز معرفی شده اند، مانند وراثت، چند شکلی، الگوها، استثناها و فضاهای نام. ما بعداً در دوره پیشرفته C ++ اینها را مطالعه خواهیم کرد.
طراحی شی گرا
این یک آموزش عالی در مورد طراحی شی گرا است. ما روش ارائه شده در اینجا را در پروژه این ماژول اعمال خواهیم کرد.
با مثال شماره 3 یاد بگیرید
تمرکز ما در این ماژول بر روی تمرین بیشتر با اشاره گرها، طراحی شی گرا، آرایه های چند بعدی و کلاس ها/اشیاء است. با مثال های زیر کار کنید. ما نمی توانیم به اندازه کافی تاکید کنیم که کلید تبدیل شدن به یک برنامه نویس خوب تمرین، تمرین، تمرین است!تمرین شماره 1: بیشتر با اشاره گرها تمرین کنید
اگر به تمرین اضافی با اشاره گر نیاز دارید، این منبع را بخوانید که تمام جنبه های اشاره گرها را پوشش می دهد و نمونه های برنامه زیادی را ارائه می دهد.
خروجی برنامه زیر چیست؟ لطفا برنامه را اجرا نکنید، بلکه تصویر حافظه را بکشید تا خروجی مشخص شود.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}پس از اینکه خروجی را با دست مشخص کردید، برنامه را اجرا کنید تا ببینید درست است یا خیر.
تمرین شماره 2: بیشتر با کلاس ها و اشیا تمرین کنید
اگر به تمرین اضافی با کلاس ها و اشیاء نیاز دارید، در اینجا منبعی وجود دارد که از طریق اجرای دو کلاس کوچک انجام می شود. برای انجام تمرینات کمی زمان بگذارید.
تمرین شماره 3: آرایه های چند بعدی
برنامه زیر را در نظر بگیرید:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}یک خط در این برنامه با علامت "این خط چگونه کار می کند؟" وجود دارد. - می تونی بفهمی؟ اینجا توضیح ماست.
برنامه ای بنویسید که یک آرایه 3 کم نور را مقداردهی اولیه کند و مقدار بعد سوم را با مجموع هر سه شاخص پر کند. راه حل ما اینجاست .
تمرین شماره 4: یک نمونه طراحی گسترده OO
در اینجا یک مثال طراحی شی گرا با جزئیات وجود دارد که کل فرآیند را از ابتدا تا انتها طی می کند. کد نهایی به زبان برنامه نویسی جاوا نوشته شده است، اما با توجه به اینکه چقدر پیش رفته اید، می توانید آن را بخوانید.
لطفاً برای کار کردن با کل این مثال وقت بگذارید. این یک تصویر عالی از فرآیند و ابزار طراحی است که از آن پشتیبانی می کند.
تست واحد
مقدمه
تست بخش مهمی از فرآیند مهندسی نرم افزار است. تست واحد نوع خاصی از تست است که عملکرد یک ماژول کوچک و واحد از کد منبع را بررسی می کند. تست واحد همیشه توسط مهندس انجام می شود و معمولاً همزمان با کدگذاری ماژول انجام می شود. درایورهای تستی که برای تست کلاس های Composer و Database استفاده کردید نمونه هایی از تست های واحد هستند.
آزمون های واحد دارای ویژگی های زیر هستند. آنها...
- یک جزء را به صورت مجزا آزمایش کنید
- قطعی هستند
- معمولاً روی یک کلاس نگاشت می شوند
- از وابستگی به منابع خارجی مانند پایگاه داده ها، فایل ها، شبکه اجتناب کنید
- سریع اجرا کنید
- می تواند به هر ترتیبی اجرا شود
چارچوب ها و متدولوژی های خودکاری وجود دارد که پشتیبانی و سازگاری را برای تست واحد در سازمان های بزرگ مهندسی نرم افزار فراهم می کند. چارچوبهای آزمایشی واحد منبع باز پیچیدهای وجود دارد که بعداً در این درس با آنها آشنا خواهیم شد.
تست هایی که به عنوان بخشی از تست واحد رخ می دهد در زیر نشان داده شده است.

در دنیای ایده آل، موارد زیر را آزمایش می کنیم:
- رابط ماژول برای اطمینان از اینکه اطلاعات به درستی وارد و خارج می شود آزمایش می شود.
- ساختارهای داده محلی مورد بررسی قرار می گیرند تا اطمینان حاصل شود که داده ها را به درستی ذخیره می کنند.
- شرایط مرزی برای اطمینان از عملکرد صحیح ماژول در مرزهایی که پردازش را محدود یا محدود می کند، آزمایش می شود.
- ما مسیرهای مستقل را از طریق ماژول آزمایش می کنیم تا مطمئن شویم که هر مسیر و بنابراین هر دستور در ماژول حداقل یک بار اجرا شده است.
- در نهایت، باید بررسی کنیم که خطاها به درستی مدیریت می شوند.
پوشش کد
در واقع، ما نمی توانیم با آزمایش خود به "پوشش کد" کامل برسیم. پوشش کد یک روش تحلیلی است که تعیین می کند کدام بخش از یک سیستم نرم افزاری توسط مجموعه تست اجرا شده (پوشش داده شده) و کدام بخش اجرا نشده است. اگر تلاش کنیم و به پوشش 100% برسیم، زمان بیشتری را صرف نوشتن تست های واحد خواهیم کرد تا نوشتن کد واقعی! برای تمام مسیرهای مستقل موارد زیر، تست های واحد را در نظر بگیرید. این می تواند به سرعت به یک مشکل نمایی تبدیل شود.
در این نمودار، خطوط قرمز تست نمی شوند، در حالی که خطوط بدون رنگ تست می شوند.
به جای تلاش برای پوشش 100٪، ما روی تست هایی تمرکز می کنیم که اطمینان ما را از عملکرد صحیح ماژول افزایش می دهد. ما برای مواردی مانند:
- موارد پوچ
- تست های محدوده، به عنوان مثال، تست های ارزش مثبت/منفی
- موارد لبه
- موارد شکست
- آزمایش مسیرهایی که به احتمال زیاد در بیشتر مواقع اجرا می شوند
چارچوب های تست واحد
اکثر چارچوبهای تست واحد از ادعاها برای آزمایش مقادیر در طول اجرای یک مسیر استفاده میکنند. ادعاها عباراتی هستند که صحت یک شرط را بررسی می کنند. نتیجه یک ادعا می تواند موفقیت، شکست غیرکشنده یا شکست کشنده باشد. پس از انجام یک ادعا، اگر نتیجه موفقیت یا شکست غیرکشنده باشد، برنامه به طور معمول ادامه می یابد. اگر یک شکست مرگبار رخ دهد، عملکرد فعلی متوقف می شود.
تست ها شامل کدهایی هستند که حالت را تنظیم می کند یا ماژول شما را دستکاری می کند، همراه با تعدادی ادعا که نتایج مورد انتظار را تأیید می کند. اگر همه اظهارات در یک آزمون موفقیت آمیز باشند، یعنی درست برگردند، آنگاه آزمون موفق می شود. در غیر این صورت شکست می خورد.
یک مورد آزمایشی شامل یک یا چند آزمایش است. ما آزمایشها را در موارد آزمایشی گروهبندی میکنیم که ساختار کد آزمایششده را منعکس میکند. در این دوره، ما از CPPUnit به عنوان چارچوب تست واحد خود استفاده می کنیم. با این فریم ورک می توانیم تست های واحد را در C++ بنویسیم و به صورت خودکار اجرا کنیم و گزارشی از موفقیت یا شکست تست ها ارائه کنیم.
نصب CPPUnit
کد CPPUnit را از SourceForge دانلود کنید. یک دایرکتوری مناسب پیدا کنید و فایل tar.gz را در آنجا قرار دهید. سپس دستورات زیر (در لینوکس، یونیکس) را با نام فایل cppunit مناسب وارد کنید:
gunzip filename.tar.gz tar -xvf filename.tar
اگر در ویندوز کار می کنید، ممکن است لازم باشد یک ابزار برای استخراج فایل های tar.gz پیدا کنید. مرحله بعدی کامپایل کتابخانه ها است. به دایرکتوری cppunit تغییر دهید. یک فایل INSTALL در آنجا وجود دارد که دستورالعمل های خاصی را ارائه می دهد. معمولاً باید اجرا کنید:
./configure make install
اگر با مشکل مواجه شدید به فایل INSTALL مراجعه کنید. کتابخانه ها معمولاً در دایرکتوری cppunit/src/cppunit یافت می شوند. برای بررسی کارکرد کامپایل، به دایرکتوری cppunit/examples/simple بروید و «make» را تایپ کنید. اگر همه چیز درست کامپایل شد، پس شما آماده هستید.
یک آموزش عالی در اینجا موجود است. لطفاً این آموزش را دنبال کنید و کلاس اعداد مختلط و تستهای واحد مربوط به آن را ایجاد کنید. چندین مثال اضافی در دایرکتوری cppunit/examples وجود دارد.
چرا باید این کار را انجام دهم؟؟؟
تست واحد به چند دلیل در صنعت بسیار مهم است. شما قبلاً با یک دلیل آشنا هستید: ما به روشی برای بررسی کار خود در هنگام توسعه کد نیاز داریم. حتی زمانی که در حال توسعه یک برنامه بسیار کوچک هستیم، به طور غریزی نوعی جستجوگر یا درایور می نویسیم تا مطمئن شویم که برنامه ما آنچه را که انتظار می رود انجام می دهد.
از تجربه طولانی، مهندسان میدانند که احتمال اینکه یک برنامه در اولین تلاش کار کند بسیار کم است. تستهای واحد بر اساس این ایده، برنامههای آزمایشی را به صورت خودکار و قابل تکرار میسازند. ادعاها جای بازرسی دستی خروجی را می گیرند. و از آنجایی که تفسیر نتایج آسان است (آزمون یا موفق می شود یا با شکست مواجه می شود)، آزمایش ها می توانند بارها و بارها اجرا شوند و یک شبکه ایمنی ایجاد کنند که کد شما را در برابر تغییر انعطاف پذیرتر می کند.
بیایید این را به صورت دقیق بیان کنیم: وقتی برای اولین بار کد نهایی خود را در CVS ارسال می کنید، کاملاً کار می کند. و برای مدتی کاملاً به کار خود ادامه می دهد. سپس یک روز، شخص دیگری کد شما را تغییر می دهد. دیر یا زود کسی کد شما را می شکند. آیا فکر می کنید آنها خود به خود متوجه می شوند؟ محتمل نیست اما وقتی تست های واحد را می نویسید، سیستم هایی وجود دارند که می توانند آنها را هر روز به صورت خودکار اجرا کنند. به این سیستم های یکپارچه سازی پیوسته می گویند. بنابراین هنگامی که مهندس X کد شما را می شکند، سیستم ایمیل های بدی را برای آنها ارسال می کند تا زمانی که آن را برطرف کنند. حتی اگر مهندس X شما هستید!
علاوه بر کمک به شما در توسعه نرم افزار و سپس ایمن نگه داشتن آن نرم افزار در مواجهه با تغییرات، تست واحد:
- یک مشخصات اجرایی و مستنداتی ایجاد می کند که با کد هماهنگ می ماند. به عبارت دیگر، میتوانید یک آزمون واحد را بخوانید تا بدانید که ماژول از چه رفتاری پشتیبانی میکند.
- به شما کمک می کند الزامات را از پیاده سازی جدا کنید. از آنجایی که شما رفتار قابل مشاهده بیرونی را ابراز می کنید، این فرصت را خواهید داشت که به جای اختلاط در ایده ها در مورد نحوه اجرای رفتار، صریحاً در مورد آن فکر کنید.
- از آزمایش پشتیبانی می کند. اگر یک شبکه ایمنی دارید که به شما هشدار می دهد وقتی رفتار یک ماژول را خراب کردید، به احتمال زیاد چیزهایی را امتحان کنید و طرح های خود را دوباره پیکربندی کنید.
- طرح های شما را بهبود می بخشد. نوشتن تست های واحد کامل اغلب از شما نیاز دارد که کد خود را قابل آزمایش تر کنید. کد قابل آزمایش اغلب ماژولارتر از کد غیر قابل آزمایش است.
- کیفیت را بالا نگه می دارد. یک اشکال کوچک در یک سیستم حیاتی می تواند باعث از دست دادن میلیون ها دلار یک شرکت یا حتی بدتر از آن، خوشحالی یا اعتماد کاربر شود. شبکه ایمنی که واحد تست می کند این امکان را کاهش می دهد. با تشخیص زودهنگام باگها، آنها همچنین به تیمهای QA این امکان را میدهند که به جای گزارش شکستهای آشکار، بر روی سناریوهای شکست پیچیدهتر و دشوارتر وقت بگذارند.
برای نوشتن تست های واحد با استفاده از CPPUnit برای برنامه پایگاه داده Composer کمی زمان بگذارید. برای راهنمایی به دایرکتوری cppunit/examples/ مراجعه کنید.
گوگل چگونه کار می کند
مقدمهتصور کنید راهبی در قرون وسطی به هزاران نسخه خطی موجود در آرشیو صومعه خود نگاه می کند. «اون یکی از ارسطو کجاست…»

خوشبختانه برای او، دستنوشتهها بر اساس محتوا سازماندهی شدهاند و با نمادهای خاصی برای تسهیل بازیابی اطلاعات موجود در هر یک نوشته شدهاند. بدون چنین سازمانی، یافتن نسخه خطی مربوطه بسیار دشوار خواهد بود.
فعالیت ذخیره سازی و بازیابی اطلاعات مکتوب از مجموعه های بزرگ، بازیابی اطلاعات (IR) نامیده می شود. این فعالیت در طول قرن ها به ویژه با اختراعاتی مانند کاغذ و ماشین چاپ اهمیت فزاینده ای پیدا کرده است. قبلاً چیزی بود که فقط چند نفر در آن مشغول بودند. با این حال، اکنون صدها میلیون نفر هر روز هنگام استفاده از موتور جستجو یا جستجوی دسکتاپ خود به بازیابی اطلاعات می پردازند.
شروع کار با بازیابی اطلاعات

دکتر سوس در طول 30 سال 46 کتاب برای کودکان نوشت. کتابهای او از گربهها، گاوها و فیلها، از کیستها، گرینچها و لوراکس میگفتند. یادتان هست کدام موجودات در کدام داستان بودند؟ مگر اینکه شما والدین باشید، فقط فرزندان می توانند به شما بگویند که کدام مجموعه از داستان های دکتر سوس دارای این موجودات است:
(گاو و زنبور عسل) یا کلاغ
ما برخی از مدل های کلاسیک بازیابی اطلاعات را برای کمک به حل این مشکل اعمال خواهیم کرد.
یک رویکرد آشکار، زور بی رحمانه است: تمام 46 داستان دکتر سوس را به دست آورید و شروع به خواندن کنید. برای هر کتاب، توجه داشته باشید که کدام کتاب حاوی کلمات COW و BEE است و در عین حال به دنبال کتاب هایی باشید که حاوی کلمه CROWS هستند. کامپیوترها در این امر بسیار سریعتر از ما هستند. اگر تمام متن های کتاب های دکتر سوس را به صورت دیجیتال داشته باشیم، مثلاً به صورت فایل های متنی، فقط می توانیم از طریق فایل ها grep کنیم. برای مجموعه کوچکی مانند کتاب های دکتر سوس، این تکنیک به خوبی جواب می دهد.
با این حال، موقعیتهای زیادی وجود دارد که ما به موارد بیشتری نیاز داریم. برای مثال، مجموعه تمام دادههایی که در حال حاضر آنلاین هستند، برای grep بسیار بزرگ است. همچنین ما فقط مدارکی را نمی خواهیم که با شرایط ما مطابقت داشته باشد، بلکه عادت کرده ایم که آنها را بر اساس ارتباط آنها رتبه بندی کنیم.
روش دیگر علاوه بر grep، ایجاد فهرستی از اسناد در یک مجموعه قبل از انجام جستجو است. نمایه در IR شبیه به نمایه پشت کتاب درسی است. ما فهرستی از تمام کلمات (یا اصطلاحات ) در هر داستان دکتر سوس تهیه میکنیم، و از کلماتی مانند «the»، «and» و دیگر ربطها، حروف اضافه و غیره حذف میکنیم (به اینها کلمات توقف میگویند). سپس این اطلاعات را به گونهای نمایش میدهیم که یافتن اصطلاحات و شناسایی داستانهایی که در آن هستند را تسهیل میکند.
یکی از نمایش های ممکن، یک ماتریس با داستان ها در بالای صفحه، و اصطلاحات ذکر شده در هر ردیف است. "1" در یک ستون نشان می دهد که عبارت در داستان برای آن ستون ظاهر می شود.
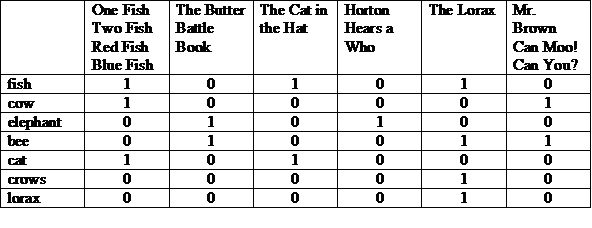
میتوانیم هر سطر یا ستون را بهعنوان یک بردار بیت ببینیم. بردار بیت یک ردیف نشان می دهد که این عبارت در کدام داستان ها ظاهر می شود. بردار بیت ستون نشان می دهد که چه عباراتی در داستان ظاهر می شوند.
بازگشت به مشکل اصلی:
(گاو و زنبور عسل) یا کلاغ
بردارهای بیت را برای این عبارت ها در نظر می گیریم و ابتدا کمی AND را انجام می دهیم، سپس روی نتیجه یک OR بیتی انجام می دهیم.
(100001 و 010011) یا 000010 = 000011
پاسخ: «آقای براون کان مو! میتونی؟" و "لوراکس". این نمونه ای از مدل بازیابی بولی است که یک مدل "تطابق دقیق" است.
فرض کنید قرار بود ماتریس را گسترش دهیم تا همه داستان های دکتر سوس و همه اصطلاحات مرتبط را در داستان ها لحاظ کنیم. ماتریس به طور قابل توجهی رشد می کند، و یک مشاهدات مهم این است که بیشتر ورودی ها 0 خواهند بود. یک ماتریس احتمالا بهترین نمایش برای شاخص نیست. ما باید راهی پیدا کنیم تا فقط 1ها را ذخیره کنیم.
برخی از پیشرفت ها
ساختاری که در IR برای حل این مشکل استفاده می شود، شاخص معکوس نامیده می شود. ما یک فرهنگ لغت از اصطلاحات را نگه میداریم، و سپس برای هر اصطلاح، فهرستی داریم که اسنادی را که اصطلاح در آنها آمده است، ثبت میکند. به این لیست، لیست ارسال ها می گویند. یک لیست پیوندی به تنهایی برای نشان دادن این ساختار به خوبی کار می کند که در زیر نشان داده شده است.

اگر با لیستهای پیوندی آشنا نیستید، کافی است در گوگل در «لیست پیوندی در سی پلاس پلاس» جستجو کنید، و منابع زیادی پیدا خواهید کرد که نحوه ایجاد یک و نحوه استفاده از آن را توضیح میدهند. در ماژول بعدی این موضوع را با جزئیات بیشتری پوشش خواهیم داد.
توجه داشته باشید که به جای نام داستان از شناسه های سند ( DocIDs ) استفاده می کنیم. ما همچنین این DocID ها را مرتب می کنیم زیرا پردازش پرس و جوها را تسهیل می کند.
چگونه یک پرس و جو را پردازش می کنیم؟ برای مشکل اصلی، ابتدا لیست پست های COW و سپس لیست پست های BEE را پیدا می کنیم. سپس آنها را با هم "ادغام" می کنیم:
- نشانگرها را در هر دو لیست حفظ کنید و به طور همزمان در بین دو لیست پست ها قدم بزنید.
- در هر مرحله، DocID اشاره شده توسط هر دو نشانگر را مقایسه کنید.
- اگر آنها یکسان هستند، آن DocID را در یک لیست نتیجه قرار دهید، در غیر این صورت نشانگر را که به سمت شناسه کوچکتر نشان می دهد پیش ببرید.
در اینجا نحوه ایجاد یک شاخص معکوس آمده است:
- به هر سند مورد علاقه یک DocID اختصاص دهید.
- برای هر سند، اصطلاحات مربوط به آن را مشخص کنید (tokenize).
- برای هر عبارت، یک رکورد متشکل از عبارت، DocID که در آن یافت میشود و یک فرکانس در آن سند ایجاد کنید. توجه داشته باشید که اگر یک عبارت خاص در بیش از یک سند ظاهر شود، چندین رکورد وجود دارد.
- رکوردها را بر اساس مدت مرتب کنید.
- فرهنگ لغت و فهرست پستها را با پردازش رکوردهای منفرد برای یک ترم، و همچنین ترکیب چندین رکورد برای عباراتی که در بیش از یک سند ظاهر میشوند، ایجاد کنید. یک لیست پیوندی از DocIDها (به ترتیب مرتب شده) ایجاد کنید. هر جمله همچنین دارای یک فرکانس است که مجموع فرکانس های موجود در تمام رکوردهای یک ترم است.
پروژه
چندین سند متن ساده طولانی پیدا کنید که بتوانید با آنها آزمایش کنید. پروژه ایجاد یک شاخص معکوس از اسناد، با استفاده از الگوریتمهایی است که در بالا توضیح داده شد. همچنین باید یک رابط برای ورودی پرس و جوها و یک موتور برای پردازش آنها ایجاد کنید. شما می توانید یک شریک پروژه در انجمن پیدا کنید.
در اینجا یک فرآیند ممکن برای تکمیل این پروژه وجود دارد:
- اولین کاری که باید انجام دهید، تعریف استراتژی برای شناسایی اصطلاحات در اسناد است. فهرستی از تمام کلمات توقف که می توانید به آنها فکر کنید تهیه کنید و تابعی بنویسید که کلمات موجود در فایل ها را بخواند، اصطلاحات را ذخیره کند و کلمات توقف را حذف کند. ممکن است مجبور شوید با مرور لیست اصطلاحات از یک تکرار، کلمات توقف بیشتری را به لیست خود اضافه کنید.
- موارد تست CPPUnit را بنویسید تا عملکرد خود را آزمایش کنید و یک makefile برای جمع آوری همه چیز برای ساخت شما. فایل های خود را در CVS بررسی کنید، به خصوص اگر با شرکای خود کار می کنید. ممکن است بخواهید درباره نحوه باز کردن نمونه CVS خود برای مهندسین راه دور تحقیق کنید.
- پردازش را برای گنجاندن داده های مکان اضافه کنید، یعنی کدام فایل و در کجای فایل یک اصطلاح قرار دارد؟ ممکن است بخواهید یک محاسبه برای تعریف شماره صفحه یا شماره پاراگراف پیدا کنید.
- موارد تست CPPUnit را برای آزمایش این عملکرد اضافی بنویسید.
- یک نمایه معکوس ایجاد کنید و داده های مکان را در رکورد هر عبارت ذخیره کنید.
- موارد تست بیشتری بنویسید
- یک رابط طراحی کنید تا به کاربر اجازه دهد یک پرس و جو را وارد کند.
- با استفاده از الگوریتم جستجو که در بالا توضیح داده شد، شاخص معکوس را پردازش کرده و داده های مکان را به کاربر برگردانید.
- حتماً موارد تست را برای این قسمت پایانی نیز قرار دهید.
همانطور که در همه پروژه ها انجام داده ایم، از انجمن و چت برای یافتن شرکای پروژه و به اشتراک گذاشتن ایده ها استفاده کنید.
یک ویژگی اضافی
یک مرحله پردازش متداول در بسیاری از سیستم های IR، stemming نامیده می شود. ایده اصلی در پشت stemming این است که کاربرانی که برای اطلاعات در مورد "بازیابی" جستجو می کنند به اسنادی نیز علاقه مند می شوند که دارای اطلاعاتی شامل "بازیابی"، "بازیابی شده"، "بازیابی" و غیره باشند. سیستمها میتوانند به دلیل ریشهبندی ضعیف مستعد خطا باشند، بنابراین این کار کمی مشکل است. به عنوان مثال، یک کاربر علاقه مند به "بازیابی اطلاعات" ممکن است سندی با عنوان "اطلاعات در مورد گلدن رتریور" به دلیل ریشه گرفتن دریافت کند. یک الگوریتم مفید برای استقرار الگوریتم پورتر است.