مقدمه ای بر برنامه نویسی و C++
این آموزش آنلاین با مفاهیم پیشرفته تر ادامه می یابد - لطفا قسمت سوم را بخوانید. تمرکز ما در این ماژول بر روی استفاده از اشاره گرها و شروع کار با اشیا خواهد بود.
با مثال شماره 2 یاد بگیرید
تمرکز ما در این ماژول بر روی تمرین بیشتر با تجزیه، درک اشاره گرها و شروع کار با اشیا و کلاس ها است. با مثال های زیر کار کنید. وقتی از شما خواسته شد برنامه ها را خودتان بنویسید یا آزمایش ها را انجام دهید. ما نمی توانیم به اندازه کافی تاکید کنیم که کلید تبدیل شدن به یک برنامه نویس خوب تمرین، تمرین، تمرین است!
مثال شماره 1: تمرین بیشتر تجزیه
خروجی زیر را از یک بازی ساده در نظر بگیرید:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
اولین مشاهده متن مقدماتی است که در هر اجرای برنامه یک بار نمایش داده می شود. برای تعیین فاصله دشمن برای هر دور به یک مولد اعداد تصادفی نیاز داریم. ما به مکانیزمی برای دریافت ورودی زاویه از بازیکن نیاز داریم و این بدیهی است که در ساختار حلقه ای است زیرا تا زمانی که به دشمن ضربه بزنیم تکرار می شود. برای محاسبه فاصله و زاویه نیز به یک تابع نیاز داریم. در نهایت، ما باید تعداد شلیک هایی که برای اصابت به دشمن انجام شده و همچنین تعداد دشمنانی که در طول اجرای برنامه زده ایم را پیگیری کنیم. در اینجا یک طرح کلی برای برنامه اصلی وجود دارد.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
رویه Fire اجرای بازی را کنترل می کند. در آن تابع، یک مولد اعداد تصادفی را فراخوانی می کنیم تا فاصله دشمن را بدست آوریم، و سپس حلقه را برای دریافت ورودی بازیکن و محاسبه اینکه آیا آنها به دشمن ضربه زده اند یا نه، تنظیم می کنیم. شرط نگهبانی در حلقه این است که چقدر به ضربه زدن به دشمن نزدیک شده ایم.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
به دلیل فراخوانی های cos() و sin()، باید math.h را وارد کنید. سعی کنید این برنامه را بنویسید - این تمرین عالی در تجزیه مسئله و بررسی خوب C ++ پایه است. به یاد داشته باشید که در هر تابع فقط یک کار را انجام دهید. این پیچیدهترین برنامهای است که تاکنون نوشتهایم، بنابراین انجام آن ممکن است کمی طول بکشد. راه حل ما اینجاست .
مثال شماره 2: با اشاره گرها تمرین کنید
هنگام کار با اشاره گرها باید چهار چیز را به خاطر بسپارید:- اشاره گرها متغیرهایی هستند که آدرس های حافظه را نگه می دارند. همانطور که یک برنامه در حال اجرا است، همه متغیرها در حافظه ذخیره می شوند، هر کدام در آدرس یا مکان منحصر به فرد خود. اشاره گر نوع خاصی از متغیر است که به جای یک مقدار داده، یک آدرس حافظه دارد. همانطور که داده ها هنگام استفاده از یک متغیر معمولی تغییر می کنند، مقدار آدرس ذخیره شده در یک اشاره گر نیز با دستکاری متغیر اشاره گر تغییر می یابد. در اینجا یک مثال است:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - ما معمولاً می گوییم که یک اشاره گر به مکانی که در آن ذخیره می شود ("pointee") "اشاره" می کند. بنابراین در مثال بالا، intptr به pointee 5 اشاره می کند.
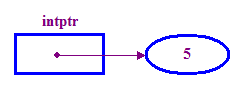
به استفاده از عملگر "new" برای تخصیص حافظه برای عدد صحیح اشاره گر ما توجه کنید. این کاری است که ما باید قبل از تلاش برای دسترسی به pointee انجام دهیم.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.عملگر * برای ارجاع مجدد در C استفاده می شود. یکی از رایج ترین خطاهایی که برنامه نویسان C/C++ در کار با اشاره گرها مرتکب می شوند، فراموش کردن مقداردهی اولیه pointee است. این گاهی اوقات می تواند باعث خرابی زمان اجرا شود زیرا ما به مکانی در حافظه دسترسی داریم که حاوی داده های ناشناخته است. اگر سعی کنیم این دادهها را اصلاح کنیم، میتوانیم باعث خرابی ظریف حافظه شویم و ردیابی آن را به یک اشکال سخت تبدیل کنیم.
- انتساب اشاره گر بین دو نشانگر باعث می شود که آنها به یک اشاره گر اشاره کنند. بنابراین انتساب y = x; باعث می شود که y به همان نقطه نقطه x اشاره کند. انتساب اشاره گر با اشاره گر لمس نمی شود. فقط یک اشاره گر را تغییر می دهد تا مکان یک اشاره گر دیگر را داشته باشد. پس از تخصیص نشانگر، دو اشاره گر "اشتراک" اشاره گر.
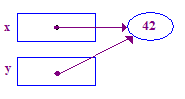
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
این هم ردی از این کد:
| 1. دو نشانگر x و y را اختصاص دهید. تخصیص نشانگرها هیچ نقطه ای را تخصیص نمی دهد . | 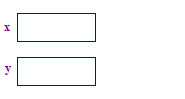 |
| 2. یک pointee اختصاص دهید و x را برای اشاره به آن تنظیم کنید. | 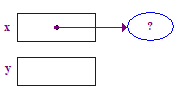 |
| 3. X را برای ذخیره 42 در pointee خود تعیین کنید. این یک مثال اساسی از عملیات reference است. از x شروع کنید، فلش را دنبال کنید تا به pointee آن دسترسی پیدا کنید. | 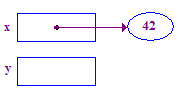 |
| 4. سعی کنید y را به 13 در pointee آن ذخیره کنید. این از کار می افتد زیرا y یک اشاره گر ندارد -- هرگز به آن اختصاص داده نشده است. |  |
| 5. اختصاص y = x; به طوری که y به نقطه ی x اشاره می کند. اکنون x و y به یک نقطه اشاره می کنند -- آنها در حال "اشتراک گذاری" هستند. | 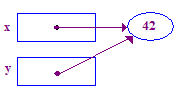 |
| 6. سعی کنید y را به ذخیره 13 در pointee آن تغییر دهید. این بار کار می کند، زیرا تکلیف قبلی به y یک نقطه اشاره می کند. | 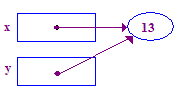 |
همانطور که می بینید، تصاویر برای درک استفاده از اشاره گر بسیار مفید هستند. در اینجا یک مثال دیگر است.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
در این مثال توجه کنید که ما هرگز حافظه را با عملگر "new" اختصاص ندادیم. ما یک متغیر عدد صحیح معمولی را اعلام کردیم و آن را از طریق نشانگرها دستکاری کردیم.
در این مثال، استفاده از عملگر حذف را نشان میدهیم که حافظه پشته را حذف میکند و چگونه میتوانیم برای ساختارهای پیچیدهتر تخصیص دهیم. در درس دیگری به سازماندهی حافظه (پشته پشته و زمان اجرا) خواهیم پرداخت. در حال حاضر، فقط به heap به عنوان یک ذخیره رایگان از حافظه در دسترس برای برنامه های در حال اجرا فکر کنید.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
در این مثال نهایی، نشان میدهیم که چگونه از نشانگرها برای ارسال مقادیر با ارجاع به یک تابع استفاده میشود. به این صورت است که مقادیر متغیرهای یک تابع را تغییر می دهیم.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
اگر بخواهیم &'ها را در تعریف تابع Duplicate از آرگومانها خارج کنیم، متغیرها را با مقدار پاس میکنیم، یعنی یک کپی از مقدار متغیر ساخته میشود. هر تغییری که روی متغیر در تابع ایجاد شود، کپی را تغییر می دهد. آنها متغیر اصلی را تغییر نمی دهند.
هنگامی که یک متغیر با مرجع ارسال می شود، ما یک کپی از مقدار آن را ارسال نمی کنیم، بلکه آدرس متغیر را به تابع ارسال می کنیم. هر تغییری که روی متغیر محلی انجام دهیم، در واقع متغیر اصلی ارسال شده را تغییر میدهد.
اگر یک برنامه نویس C هستید، این یک پیچ جدید است. ما میتوانیم همین کار را در C با اعلام Duplicate() به عنوان Duplicate(int *x) انجام دهیم، در این صورت x نشانگر یک int است، سپس Duplicate() را با آرگومان &x (آدرس x ) فراخوانی کنیم و از de- استفاده کنیم. ارجاع x در Duplicate() (به زیر مراجعه کنید). اما C++ راه سادهتری برای انتقال مقادیر به توابع با مرجع ارائه میکند، حتی اگر روش قدیمی C برای انجام آن هنوز کار کند.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
توجه داشته باشید که با ارجاعات C++، ما نیازی به انتقال آدرس یک متغیر نداریم، و همچنین نیازی به تغییر ارجاع متغیر در داخل تابع فراخوانی نداریم.
خروجی برنامه زیر چیست؟ تصویری از حافظه بکشید تا متوجه شوید.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} برنامه را اجرا کنید تا ببینید آیا پاسخ صحیح را دریافت کرده اید یا خیر.
مثال شماره 3: عبور مقادیر توسط مرجع
تابعی به نام accelerate() بنویسید که سرعت یک وسیله نقلیه و مقداری را به عنوان ورودی می گیرد. این عملکرد مقداری را به سرعت برای شتاب دادن به خودرو اضافه می کند. پارامتر سرعت باید با مرجع و مقدار بر ارزش ارسال شود. راه حل ما اینجاست .
مثال شماره 4: کلاس ها و اشیاء
کلاس زیر را در نظر بگیرید:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
توجه داشته باشید که متغیرهای عضو کلاس دارای زیرخط انتهایی هستند. این کار برای تمایز بین متغیرهای محلی و متغیرهای کلاس انجام می شود.
یک متد کاهشی به این کلاس اضافه کنید. راه حل ما اینجاست .
شگفتی های علم: علوم کامپیوتر
تمرینات
همانطور که در ماژول اول این دوره، ما راه حلی برای تمرین ها و پروژه ها ارائه نمی دهیم.
به یاد داشته باشید که یک برنامه خوب ...
... به طور منطقی به توابعی تجزیه می شود که در آن هر تابع یک و تنها یک کار را انجام می دهد.
... یک برنامه اصلی دارد که به عنوان یک طرح کلی از آنچه برنامه انجام خواهد داد خوانده می شود.
... دارای نام تابع توصیفی، ثابت و متغیر است.
... از ثابت ها برای جلوگیری از هر گونه اعداد "جادویی" در برنامه استفاده می کند.
... دارای رابط کاربری دوستانه است.
تمرینات گرم کردن
- تمرین 1
عدد صحیح 36 خاصیت عجیبی دارد: این یک مربع کامل است و همچنین مجموع اعداد صحیح از 1 تا 8 است. عدد بعدی 1225 است که 352 است و مجموع اعداد صحیح از 1 تا 49 است. عدد بعدی که مربع کامل و همچنین مجموع یک سری 1...n است. این عدد بعدی ممکن است بزرگتر از 32767 باشد. می توانید از توابع کتابخانه ای که می شناسید (یا فرمول های ریاضی) استفاده کنید تا برنامه خود را سریعتر اجرا کنید. همچنین می توان این برنامه را با استفاده از حلقه های for نوشت تا مشخص شود یک عدد مربع کامل است یا مجموع یک سری. (توجه: بسته به دستگاه و برنامه شما، یافتن این عدد ممکن است مدت زیادی طول بکشد.)
- تمرین 2
فروشگاه کتاب کالج شما برای تخمین کسب و کار خود برای سال آینده به کمک شما نیاز دارد. تجربه نشان داده است که فروش تا حد زیادی به این بستگی دارد که آیا کتاب برای یک دوره مورد نیاز است یا فقط اختیاری است و اینکه آیا قبلاً در کلاس از آن استفاده شده است یا خیر. یک کتاب درسی جدید و مورد نیاز به 90٪ از ثبت نام های احتمالی فروخته می شود، اما اگر قبلاً در کلاس استفاده شده باشد، فقط 65٪ خرید می کنند. به طور مشابه، 40٪ از ثبت نام های آینده نگر یک کتاب درسی جدید و اختیاری می خرند، اما اگر قبلاً در کلاس استفاده شده باشد، تنها 20٪ آن را خریداری می کنند. (توجه داشته باشید که «استفاده شده» در اینجا به معنای کتاب های دست دوم نیست.)
برنامه ای بنویسید که یک سری کتاب را به عنوان ورودی بپذیرد (تا زمانی که کاربر وارد یک نگهبان شود). برای هر کتاب درخواست کنید: یک کد برای کتاب، هزینه تک نسخه برای کتاب، تعداد فعلی کتاب های موجود، ثبت نام در کلاس آینده، و داده هایی که نشان می دهد کتاب مورد نیاز/اختیاری، جدید/استفاده شده در گذشته است. . به عنوان خروجی، تمام اطلاعات ورودی را در یک صفحه با قالب بندی زیبا به همراه تعداد کتاب هایی که باید سفارش دهید (در صورت وجود، توجه داشته باشید که فقط کتاب های جدید سفارش داده می شوند)، هزینه کل هر سفارش را نشان دهید.
سپس، پس از تکمیل تمام ورودیها، هزینه کل تمام سفارشهای کتاب و سود مورد انتظار را در صورتی که فروشگاه 80 درصد قیمت فهرست را پرداخت کند، نشان دهید. از آنجایی که ما هنوز درباره هیچ روشی برای مقابله با مجموعه بزرگی از دادههایی که وارد یک برنامه میشوند صحبت نکردهایم (با ما همراه باشید!)، فقط یک کتاب را در یک زمان پردازش کنید و صفحه خروجی آن کتاب را نشان دهید. سپس، هنگامی که کاربر وارد کردن تمام داده ها را به پایان رساند، برنامه شما باید مقدار کل و سود را خروجی دهد.
قبل از شروع کدنویسی، کمی وقت بگذارید و به طراحی این برنامه فکر کنید. به مجموعه ای از توابع تجزیه کنید و یک تابع main() ایجاد کنید که مانند طرح کلی برای حل مشکل شما خوانده می شود. مطمئن شوید که هر تابع یک کار را انجام می دهد.
در اینجا خروجی نمونه است:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
پروژه پایگاه داده
در این پروژه، ما یک برنامه C++ کاملا کاربردی ایجاد می کنیم که یک برنامه پایگاه داده ساده را پیاده سازی می کند.
برنامه ما به ما این امکان را می دهد که پایگاه داده آهنگسازان و اطلاعات مربوط به آنها را مدیریت کنیم. ویژگی های برنامه عبارتند از:
- امکان اضافه کردن آهنگساز جدید
- توانایی رتبه بندی یک آهنگساز (یعنی نشان می دهد که چقدر موسیقی آهنگساز را دوست داریم یا دوست نداریم)
- امکان مشاهده تمامی آهنگسازان در پایگاه داده
- امکان مشاهده تمامی آهنگسازان بر اساس رتبه
"دو راه برای ساختن یک طراحی نرم افزار وجود دارد: یک راه این است که آن را به قدری ساده کنیم که به وضوح هیچ نقصی وجود نداشته باشد، و راه دیگر این است که آن را آنقدر پیچیده کنیم که هیچ نقص آشکاری وجود نداشته باشد. روش اول بسیار دشوارتر است. " - ماشین هور
بسیاری از ما طراحی و کدنویسی را با استفاده از رویکرد "روشی" آموختیم. سوال اصلی که با آن شروع می کنیم این است که "برنامه باید چه کاری انجام دهد؟" ما راه حل یک مشکل را به وظایفی تجزیه می کنیم که هر کدام بخشی از مشکل را حل می کند. این وظایف به توابعی در برنامه ما نگاشت می شوند که به صورت متوالی از main() یا از توابع دیگر فراخوانی می شوند. این رویکرد گام به گام برای برخی از مشکلاتی که باید حل کنیم ایده آل است. اما اغلب اوقات، برنامه های ما فقط توالی خطی از وظایف یا رویدادها نیستند.
با رویکرد شی گرا (OO)، ما با این سوال شروع می کنیم که "چه اشیاء دنیای واقعی را مدل می کنم؟" به جای تقسیم یک برنامه به وظایف همانطور که در بالا توضیح داده شد، آن را به مدل هایی از اشیاء فیزیکی تقسیم می کنیم. این اشیاء فیزیکی دارای حالتی هستند که با مجموعه ای از ویژگی ها و مجموعه ای از رفتارها یا اعمالی که می توانند انجام دهند تعریف شده است. اعمال ممکن است وضعیت شی را تغییر دهند، یا ممکن است اعمال سایر اشیاء را فراخوانی کنند. فرض اصلی این است که یک شی "می داند" چگونه کارها را به تنهایی انجام دهد.
در طراحی OO، ما اشیاء فیزیکی را بر حسب کلاس ها و اشیاء تعریف می کنیم. صفات و رفتارها به طور کلی تعداد زیادی از اشیاء در یک برنامه OO وجود دارد. با این حال، بسیاری از این اشیاء اساساً یکسان هستند. موارد زیر را در نظر بگیرید.
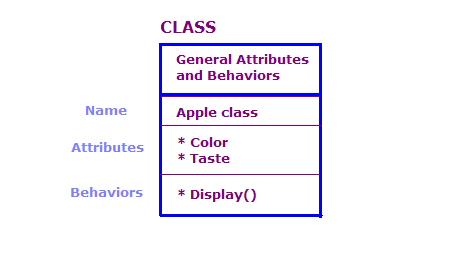
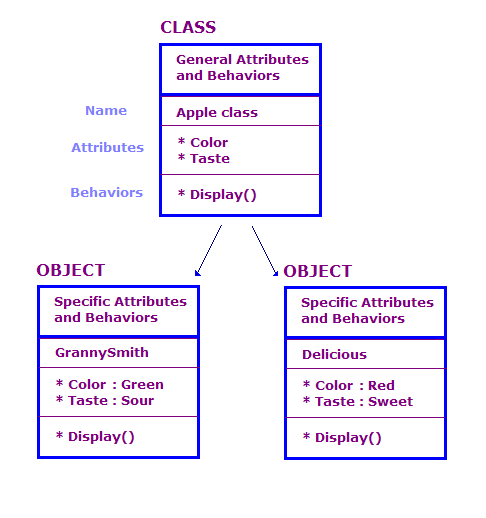
در این نمودار دو شی از کلاس اپل تعریف کرده ایم. هر شیء دارای ویژگی ها و اقدامات مشابه با کلاس است، اما شی ویژگی ها را برای نوع خاصی از سیب تعریف می کند. علاوه بر این، اکشن Display ویژگی های آن شی خاص را نشان می دهد، به عنوان مثال، "سبز" و "ترش".
یک طراحی OO شامل مجموعه ای از کلاس ها، داده های مرتبط با این کلاس ها و مجموعه ای از اقداماتی است که کلاس ها می توانند انجام دهند. ما همچنین باید روش های تعامل طبقات مختلف را شناسایی کنیم. این تعامل را می توان توسط اشیاء یک کلاس با فراخوانی اعمال اشیاء کلاس های دیگر انجام داد. به عنوان مثال، ما میتوانیم یک کلاس AppleOutputer داشته باشیم که رنگ و طعم آرایهای از اشیاء اپل را با فراخوانی متد Display() هر شیء اپل خروجی میدهد.
در اینجا مراحلی که ما در انجام طراحی OO انجام می دهیم آمده است:
- کلاس ها را شناسایی کنید و به طور کلی تعریف کنید که یک شی از هر کلاس چه چیزی را به عنوان داده ذخیره می کند و یک شی چه کاری می تواند انجام دهد.
- عناصر داده هر کلاس را تعریف کنید
- اقدامات هر کلاس را تعریف کنید و چگونه برخی از اقدامات یک کلاس را می توان با استفاده از اقدامات سایر کلاس های مرتبط پیاده سازی کرد.
برای یک سیستم بزرگ، این مراحل به طور مکرر در سطوح مختلف جزئیات انجام می شود.
برای سیستم پایگاه داده composer، ما به یک کلاس Composer نیاز داریم که تمام دادههایی را که میخواهیم روی یک آهنگساز ذخیره کنیم، کپسوله میکند. یک شی از این کلاس می تواند خود را ارتقا یا تنزل دهد (رتبه خود را تغییر دهد)، و ویژگی های خود را نمایش دهد.
ما همچنین به مجموعه ای از آبجکت های Composer نیاز داریم. برای این کار، یک کلاس Database تعریف می کنیم که رکوردهای فردی را مدیریت می کند. یک شی از این کلاس می تواند اشیاء Composer را اضافه یا بازیابی کند، و با فراخوانی عمل نمایش یک شی Composer، موارد جداگانه را نمایش دهد.
در نهایت، ما به نوعی رابط کاربری برای ارائه عملیات تعاملی در پایگاه داده نیاز داریم. این یک کلاس مکان نگهدار است، به عنوان مثال، ما واقعاً هنوز نمی دانیم که رابط کاربری قرار است چگونه باشد، اما می دانیم که به آن نیاز داریم. شاید گرافیکی باشد، شاید مبتنی بر متن باشد. در حال حاضر، ما یک مکان نگهدار تعریف می کنیم که می توانیم بعداً آن را پر کنیم.
اکنون که کلاسها را برای برنامه پایگاه داده composer شناسایی کردهایم، گام بعدی تعریف ویژگیها و اقدامات برای کلاسها است. در یک برنامه پیچیده تر، ما با مداد و کاغذ یا کارت های UML یا CRC یا OOD می نشینیم تا سلسله مراتب کلاس و نحوه تعامل اشیاء را ترسیم کنیم.
برای پایگاه داده آهنگساز خود، یک کلاس Composer تعریف می کنیم که حاوی داده های مربوطه ای است که می خواهیم روی هر آهنگساز ذخیره کنیم. همچنین شامل روش هایی برای دستکاری رتبه بندی ها و نمایش داده ها می باشد.
کلاس Database به نوعی ساختار برای نگهداری اشیاء Composer نیاز دارد. ما باید بتوانیم یک شی Composer جدید به ساختار اضافه کنیم و همچنین یک شی Composer خاص را بازیابی کنیم. همچنین میخواهیم تمام اشیاء را به ترتیب ورود یا رتبهبندی نمایش دهیم.
کلاس User Interface یک رابط منو محور را با کنترل کننده هایی که اقدامات را در کلاس Database فراخوانی می کنند، پیاده سازی می کند.
اگر کلاسها به راحتی قابل درک باشند و ویژگیها و عملکردهای آنها روشن باشد، مانند برنامه composer، طراحی کلاسها نسبتاً آسان است. اما اگر سوالی در مورد نحوه ارتباط و تعامل کلاس ها در ذهن شما وجود دارد، بهتر است ابتدا آن را ترسیم کنید و قبل از شروع به کدنویسی، جزئیات را بررسی کنید.
هنگامی که تصویر واضحی از طراحی داشته باشیم و آن را ارزیابی کنیم (به زودی در این مورد بیشتر توضیح خواهیم داد)، رابط کاربری را برای هر کلاس تعریف می کنیم. ما در این مرحله نگران جزئیات پیادهسازی نیستیم - فقط ویژگیها و اقدامات و بخشهایی از حالت و اقدامات یک کلاس برای کلاسهای دیگر در دسترس است.
در C++ معمولاً این کار را با تعریف یک فایل هدر برای هر کلاس انجام می دهیم. کلاس Composer دارای اعضای داده خصوصی برای تمام داده هایی است که می خواهیم در یک آهنگساز ذخیره کنیم. ما به دسترسیها (روشهای «get») و جهشدهندهها (روشهای «set»)، و همچنین اقدامات اولیه برای کلاس نیاز داریم.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
کلاس Database نیز ساده است.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
توجه کنید که چگونه داده های خاص آهنگساز را در یک کلاس جداگانه با دقت کپسوله کرده ایم. میتوانستیم یک ساختار یا کلاس در کلاس Database برای نمایش رکورد Composer قرار دهیم و مستقیماً در آنجا به آن دسترسی داشته باشیم. اما این میتواند «زیر عینیتسازی» باشد، یعنی تا آنجا که میتوانیم با اشیا مدلسازی نمیکنیم.
وقتی شروع به کار روی اجرای کلاس های Composer و Database می کنید، خواهید دید که داشتن یک کلاس Composer جداگانه بسیار تمیزتر است. به طور خاص، داشتن عملیات اتمی جداگانه روی یک شی Composer، اجرای متدهای Display() در کلاس Database را بسیار ساده می کند.
البته چیزی به نام «بیشینه سازی» نیز وجود دارد که در آن سعی می کنیم همه چیز را یک کلاس دربیاوریم یا کلاس های بیشتری از نیاز خود داریم. یافتن تعادل مناسب نیاز به تمرین دارد و متوجه خواهید شد که برنامه نویسان فردی نظرات متفاوتی خواهند داشت.
تعیین اینکه آیا شما بیش از حد یا کمتر از حد عینی سازی می کنید، اغلب می تواند با ترسیم دقیق کلاس های خود مشخص شود. همانطور که قبلا ذکر شد، مهم است که قبل از شروع به کدنویسی، یک طراحی کلاس را طراحی کنید و این می تواند به شما در تجزیه و تحلیل رویکردتان کمک کند. نماد رایجی که برای این منظور استفاده می شود UML (زبان مدلسازی یکپارچه) است. اکنون که کلاس های تعریف شده برای اشیاء Composer و Database را داریم، به رابطی نیاز داریم که به کاربر اجازه می دهد با پایگاه داده تعامل داشته باشد. یک منوی ساده این کار را انجام می دهد:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
ما می توانیم رابط کاربری را به عنوان یک کلاس یا به عنوان یک برنامه رویه ای پیاده سازی کنیم. همه چیز در یک برنامه C++ نباید یک کلاس باشد. در واقع، اگر پردازش متوالی یا وظیفه محور باشد، مانند این برنامه منو، اجرای آن به صورت رویه ای خوب است. مهم است که آن را به گونه ای پیاده سازی کنیم که به عنوان یک "placeholder" باقی بماند، یعنی اگر بخواهیم در مقطعی یک رابط کاربری گرافیکی ایجاد کنیم، نباید چیزی جز رابط کاربری در سیستم تغییر دهیم.
آخرین چیزی که برای تکمیل برنامه نیاز داریم یک برنامه برای آزمایش کلاس ها است. برای کلاس Composer، ما یک برنامه main() میخواهیم که ورودی بگیرد، یک شی composer را پر کند و سپس آن را نمایش دهد تا مطمئن شود کلاس به درستی کار میکند. همچنین می خواهیم تمام متدهای کلاس Composer را فراخوانی کنیم.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
ما به یک برنامه تست مشابه برای کلاس Database نیاز داریم.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
توجه داشته باشید که این برنامه های آزمایشی ساده قدم اول خوبی هستند، اما از ما می خواهند که خروجی را به صورت دستی بررسی کنیم تا مطمئن شویم برنامه به درستی کار می کند. با بزرگتر شدن سیستم، بازرسی دستی خروجی به سرعت غیرعملی می شود. در درس بعدی، برنامه های تست خودآزمایی را در قالب تست واحد معرفی خواهیم کرد.
طراحی برنامه ما اکنون کامل شده است. مرحله بعدی پیاده سازی فایل های cpp. برای کلاس ها و رابط کاربری است. برای شروع، ادامه دهید و .h و کد درایور تست بالا را در فایلها کپی/پیست کنید و آنها را کامپایل کنید. از درایورهای تست برای تست کلاس های خود استفاده کنید. سپس رابط زیر را پیاده سازی کنید:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
از متدهایی که در کلاس Database تعریف کرده اید برای پیاده سازی رابط کاربری استفاده کنید. روش های خود را ضد خطا کنید. به عنوان مثال، یک رتبه بندی همیشه باید در محدوده 1-10 باشد. اجازه ندهید کسی 101 آهنگساز اضافه کند، مگر اینکه قصد تغییر ساختار داده در کلاس پایگاه داده را داشته باشید.
به یاد داشته باشید - همه کدهای شما باید از قوانین کدگذاری ما پیروی کنند، که برای راحتی شما در اینجا تکرار می شود:
- هر برنامه ای که می نویسیم با یک نظر هدر شروع می شود که نام نویسنده، اطلاعات تماس آنها، توضیحات کوتاه و استفاده (در صورت لزوم) ارائه می شود. هر تابع/روش با یک نظر در مورد عملکرد و استفاده شروع می شود.
- ما نظرات توضیحی را با استفاده از جملات کامل اضافه می کنیم، زمانی که کد خود را مستند نمی کند، به عنوان مثال، اگر پردازش مشکل، غیر واضح، جالب یا مهم باشد.
- همیشه از نام های توصیفی استفاده کنید: متغیرها کلمات کوچکی هستند که با _ از هم جدا می شوند، مانند my_variable. نام تابع/روش از حروف بزرگ برای علامت گذاری کلمات استفاده می کند، مانند MyExcitingFunction(). ثابت ها با یک "k" شروع می شوند و مانند kDaysInWeek از حروف بزرگ برای علامت گذاری کلمات استفاده می کنند.
- تورفتگی در مضرب دو است. سطح اول دو فضا است. در صورت نیاز به تورفتگی بیشتر، از چهار فاصله، شش فاصله و غیره استفاده می کنیم.
به دنیای واقعی خوش آمدید!
در این ماژول به معرفی دو ابزار بسیار مهم مورد استفاده در اکثر سازمان های مهندسی نرم افزار می پردازیم. اولی یک ابزار ساخت و دومی یک سیستم مدیریت پیکربندی است. هر دوی این ابزارها در مهندسی نرم افزار صنعتی ضروری هستند، جایی که بسیاری از مهندسان اغلب بر روی یک سیستم بزرگ کار می کنند. این ابزارها به هماهنگ کردن و کنترل تغییرات در پایه کد کمک می کنند و ابزاری کارآمد برای کامپایل و پیوند دادن یک سیستم از بسیاری از فایل های برنامه و هدر فراهم می کنند.
فایل های ایجاد شده
فرآیند ساخت یک برنامه معمولاً با یک ابزار ساخت مدیریت می شود که فایل های مورد نیاز را به ترتیب صحیح کامپایل و پیوند می دهد. اغلب، فایلهای ++C وابستگی دارند، به عنوان مثال، تابعی که در یک برنامه نامیده میشود، در برنامه دیگری قرار دارد. یا شاید یک فایل هدر برای چندین فایل cpp. مختلف مورد نیاز باشد. یک ابزار ساخت، ترتیب صحیح کامپایل را از این وابستگی ها مشخص می کند. همچنین فقط فایل هایی را کامپایل می کند که از آخرین بیلد تغییر کرده اند. این می تواند زمان زیادی را در سیستم های متشکل از صدها یا هزاران فایل ذخیره کند.
معمولاً از یک ابزار ساخت متن باز به نام make استفاده می شود. برای آشنایی با آن، این مقاله را بخوانید. ببینید آیا میتوانید یک نمودار وابستگی برای برنامه Composer Database ایجاد کنید و سپس آن را به یک makefile ترجمه کنید. راه حل ما اینجاست .
سیستم های مدیریت پیکربندی
دومین ابزار مورد استفاده در مهندسی نرم افزار صنعتی Configuration Management (CM) است. این برای مدیریت تغییرات استفاده می شود. فرض کنید باب و سوزان هر دو نویسنده فناوری هستند و هر دو در حال کار بر روی به روز رسانی یک کتابچه راهنمای فنی هستند. در طول یک جلسه، مدیر آنها به هر یک از آنها بخشی از همان سند را برای به روز رسانی اختصاص می دهد.
کتابچه راهنمای فنی در رایانه ای ذخیره می شود که هم باب و هم سوزان می توانند به آن دسترسی داشته باشند. بدون وجود ابزار یا فرآیند CM، تعدادی از مشکلات ممکن است ایجاد شود. یکی از سناریوهای احتمالی این است که کامپیوتری که سند را ذخیره می کند ممکن است به گونه ای تنظیم شود که باب و سوزان نتوانند هر دو به طور همزمان روی دفترچه راهنما کار کنند. این کار آنها را به میزان قابل توجهی کند می کند.
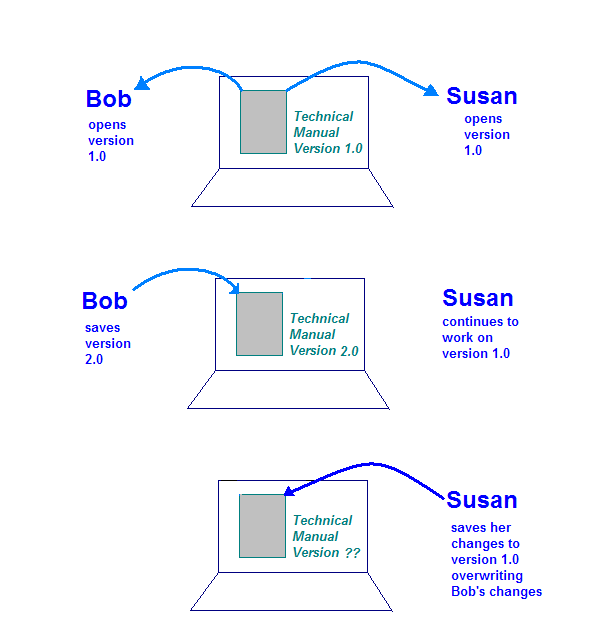
زمانی که رایانه ذخیرهسازی اجازه میدهد سند توسط باب و سوزان به طور همزمان باز شود، وضعیت خطرناکتری ایجاد میشود. در اینجا چیزی است که ممکن است اتفاق بیفتد:
- باب سند را در رایانه خود باز می کند و در بخش خود کار می کند.
- سوزان سند را در رایانه خود باز می کند و روی بخش خود کار می کند.
- باب تغییرات خود را تکمیل می کند و سند را در رایانه ذخیره سازی ذخیره می کند.
- سوزان تغییرات خود را تکمیل می کند و سند را در رایانه ذخیره سازی ذخیره می کند.
این تصویر مشکلی را نشان می دهد که در صورت عدم وجود کنترل بر روی تک نسخه راهنمای فنی ممکن است رخ دهد. هنگامی که سوزان تغییرات خود را ذخیره می کند، تغییرات ایجاد شده توسط باب را بازنویسی می کند.
این دقیقاً همان موقعیتی است که یک سیستم CM می تواند کنترل کند. با یک سیستم CM، باب و سوزان هر دو نسخه راهنمای فنی خود را بررسی کرده و روی آنها کار می کنند. هنگامی که باب تغییرات خود را دوباره بررسی می کند، سیستم می داند که سوزان نسخه خود را بررسی کرده است. هنگامی که سوزان نسخه خود را بررسی می کند، سیستم تغییراتی را که باب و سوزان انجام داده اند تجزیه و تحلیل می کند و نسخه جدیدی ایجاد می کند که دو مجموعه تغییرات را با هم ادغام می کند.
سیستم های CM دارای تعدادی ویژگی فراتر از مدیریت تغییرات همزمان هستند که در بالا توضیح داده شد. بسیاری از سیستمها آرشیو تمام نسخههای یک سند را از اولین باری که ایجاد شد ذخیره میکنند. در مورد یک کتابچه راهنمای فنی، زمانی که کاربر نسخه قدیمی کتابچه راهنمای کاربر را داشته باشد و از یک نویسنده فناوری سوال می پرسد، این می تواند بسیار مفید باشد. یک سیستم CM به نویسنده فناوری اجازه می دهد تا به نسخه قدیمی دسترسی داشته باشد و بتواند آنچه را که کاربر می بیند ببیند.
سیستم های CM به ویژه در کنترل تغییرات ایجاد شده در نرم افزار مفید هستند. چنین سیستم هایی سیستم های مدیریت پیکربندی نرم افزار (SCM) نامیده می شوند. اگر تعداد زیادی فایل کد منبع فردی را در یک سازمان بزرگ مهندسی نرم افزار و تعداد زیادی مهندسانی که باید در آنها تغییراتی ایجاد کنند را در نظر بگیرید، واضح است که یک سیستم SCM حیاتی است.
مدیریت پیکربندی نرم افزار
سیستم های SCM بر اساس یک ایده ساده هستند: کپی های قطعی فایل های شما در یک مخزن مرکزی نگهداری می شوند. افراد کپی فایلها را از مخزن بررسی میکنند، روی آن کپیها کار میکنند و پس از اتمام دوباره آنها را بررسی میکنند. سیستمهای SCM ویرایشهای چند نفر را در برابر یک مجموعه اصلی مدیریت و پیگیری میکنند.
تمام سیستم های SCM ویژگی های اساسی زیر را ارائه می دهند:
- مدیریت همزمانی
- نسخه سازی
- همگام سازی
بیایید هر یک از این ویژگی ها را با جزئیات بیشتری بررسی کنیم.
مدیریت همزمانی
Concurrency به ویرایش همزمان یک فایل توسط بیش از یک نفر اشاره دارد. با یک مخزن بزرگ، ما می خواهیم مردم بتوانند این کار را انجام دهند، اما می تواند منجر به برخی مشکلات شود.
یک مثال ساده را در حوزه مهندسی در نظر بگیرید: فرض کنید به مهندسان اجازه میدهیم فایل مشابهی را به طور همزمان در یک مخزن مرکزی کد منبع تغییر دهند. Client1 و Client2 هر دو نیاز به ایجاد تغییرات در یک فایل به طور همزمان دارند:
- Client1 bar.cpp را باز می کند.
- Client2 bar.cpp را باز می کند.
- Client1 فایل را تغییر می دهد و آن را ذخیره می کند.
- Client2 فایل را تغییر می دهد و آن را با بازنویسی تغییرات Client1 ذخیره می کند.
بدیهی است که ما نمی خواهیم این اتفاق بیفتد. حتی اگر وضعیت را با قرار دادن دو مهندس به جای کار مستقیم روی یک مجموعه اصلی (مانند تصویر زیر) روی نسخههای جداگانه کار کنیم، کپیها باید به نحوی با هم تطبیق داده شوند. اکثر سیستمهای SCM با این مشکل مقابله میکنند و به چندین مهندس اجازه میدهند تا یک فایل را بررسی کنند ("همگامسازی" یا "بهروزرسانی") و در صورت نیاز تغییراتی را ایجاد کنند. سپس سیستم SCM الگوریتمهایی را اجرا میکند تا تغییرات را با بررسی مجدد فایلها ("ارسال" یا "تعهد") در مخزن ادغام کند.
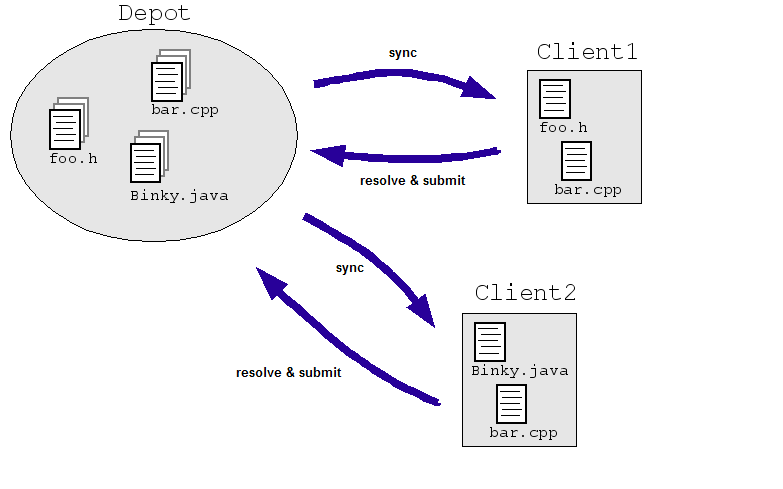
این الگوریتمها میتوانند ساده باشند (از مهندسان بخواهید تغییرات متناقض را حل کنند) یا نه چندان ساده (تعیین کنید که چگونه تغییرات متناقض را به طور هوشمند ادغام کنید و فقط از یک مهندس بپرسید که آیا سیستم واقعاً گیر میکند یا خیر).
نسخه سازی
نسخه سازی اشاره به پیگیری ویرایش های فایل دارد که امکان ایجاد مجدد (یا بازگشت به) نسخه قبلی فایل را فراهم می کند. این کار یا با ایجاد یک کپی بایگانی از هر فایل زمانی که در مخزن بررسی می شود، یا با ذخیره هر تغییر ایجاد شده در یک فایل انجام می شود. در هر زمان میتوانیم از آرشیو استفاده کنیم یا اطلاعات را برای ایجاد نسخه قبلی تغییر دهیم. سیستمهای نسخهسازی همچنین میتوانند گزارشهای گزارشی از افرادی که تغییرات را بررسی کردهاند، زمانی که بررسی شدهاند و چه تغییراتی داشتهاند ایجاد کنند.
همگام سازی
در برخی از سیستمهای SCM، فایلهای فردی داخل و خارج از مخزن بررسی میشوند. سیستم های قدرتمندتر به شما این امکان را می دهند که همزمان بیش از یک فایل را بررسی کنید. مهندسان نسخه کامل خود را از مخزن (یا بخشی از آن) بررسی می کنند و در صورت نیاز روی فایل ها کار می کنند. سپس تغییرات خود را به صورت دورهای به مخزن اصلی برمیگردانند و نسخههای شخصی خود را بهروزرسانی میکنند تا از تغییراتی که دیگران ایجاد کردهاند بهروز بمانند. به این فرآیند همگام سازی یا به روز رسانی می گویند.
براندازی
Subversion (SVN) یک سیستم کنترل نسخه منبع باز است. تمام ویژگی هایی که در بالا توضیح داده شد را دارد.
SVN یک روش ساده را در هنگام بروز تعارض اتخاذ می کند. تضاد زمانی است که دو یا چند مهندس تغییرات متفاوتی را در یک ناحیه از پایه کد ایجاد می کنند و سپس هر دو تغییرات خود را ارسال می کنند. SVN فقط به مهندسان هشدار می دهد که درگیری وجود دارد - حل آن به عهده مهندسان است.
ما قصد داریم در طول این دوره از SVN استفاده کنیم تا به شما کمک کنیم تا با مدیریت پیکربندی آشنا شوید. چنین سیستم هایی در صنعت بسیار رایج هستند.
اولین قدم این است که SVN را روی سیستم خود نصب کنید. برای دستورالعمل اینجا را کلیک کنید. سیستم عامل خود را پیدا کنید و باینری مناسب را دانلود کنید.
برخی از اصطلاحات SVN
- Revision: تغییر در یک فایل یا مجموعه ای از فایل ها. یک بازنگری یک "عکس فوری" در یک پروژه دائما در حال تغییر است.
- Repository: نسخه اصلی که در آن SVN تاریخچه ویرایش کامل پروژه را ذخیره می کند. هر پروژه یک مخزن دارد.
- کپی کاری: کپی که در آن یک مهندس تغییراتی را در پروژه ایجاد می کند. میتواند نسخههای کاری زیادی از یک پروژه خاص وجود داشته باشد که هر کدام متعلق به یک مهندس است.
- بررسی کنید: برای درخواست یک نسخه کارآمد از مخزن. یک کپی کاری برابر با وضعیت پروژه در هنگام بررسی است.
- تعهد: برای ارسال تغییرات از نسخه کاری خود به مخزن مرکزی. همچنین به عنوان ورود یا ارسال نیز شناخته می شود.
- به روز رسانی: برای آوردن تغییرات دیگران از مخزن به نسخه کاری شما، یا نشان دادن اینکه آیا نسخه کاری شما تغییرات غیرمتعهد دارد یا خیر. همانطور که در بالا توضیح داده شد، این همان همگام سازی است. بنابراین، به روز رسانی/همگام سازی کپی کاری شما را با نسخه مخزن به روز می کند.
- Conflict: وضعیتی که دو مهندس سعی می کنند تغییراتی را در یک ناحیه از یک پرونده ایجاد کنند. SVN تضادها را نشان می دهد، اما مهندسان باید آنها را حل کنند.
- پیام گزارش: نظری که هنگام انجام ویرایش به آن پیوست میکنید و تغییرات شما را توضیح میدهد. گزارش خلاصه ای از آنچه در یک پروژه در حال انجام است را ارائه می دهد.
اکنون که SVN را نصب کرده اید، چند دستور اساسی را اجرا می کنیم. اولین کاری که باید انجام دهید این است که یک مخزن در یک دایرکتوری مشخص راه اندازی کنید. در اینجا دستورات وجود دارد:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
دستور import محتویات دایرکتوری mytree را در پروژه دایرکتوری موجود در مخزن کپی می کند. می توانیم با دستور list نگاهی به دایرکتوری موجود در مخزن بیندازیم
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
واردات یک کپی کاری ایجاد نمی کند. برای این کار باید از دستور svn checkout استفاده کنید. این یک کپی کاری از درخت دایرکتوری ایجاد می کند. بیایید این کار را اکنون انجام دهیم:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
اکنون که یک کپی کار دارید، می توانید تغییراتی در فایل ها و دایرکتوری های آنجا ایجاد کنید. کپی کاری شما درست مانند هر مجموعه دیگری از فایل ها و فهرست ها است - می توانید فایل های جدید اضافه کنید یا آنها را ویرایش کنید، آنها را جابه جا کنید، حتی می توانید کل کپی کار را حذف کنید. توجه داشته باشید که اگر فایلها را در کپی کار خود کپی و انتقال میدهید، مهم است که به جای دستورات سیستم عامل خود از svn copy و svn move استفاده کنید. برای افزودن فایل جدید از svn add و برای حذف فایل از svn delete استفاده کنید. اگر تنها کاری که می خواهید انجام دهید ویرایش است، فقط فایل را با ویرایشگر خود باز کنید و آن را ویرایش کنید!
برخی از نامهای دایرکتوری استاندارد وجود دارند که اغلب با Subversion استفاده میشوند. دایرکتوری "Trunk" خط اصلی توسعه پروژه شما را در خود جای داده است. دایرکتوری "branches" هر نسخه شعبه ای را که ممکن است روی آن کار کنید را در خود نگه می دارد.
$ svn list file:///usr/local/svn/repos /trunk /branches
بنابراین، فرض کنید تمام تغییرات مورد نیاز را در نسخه کاری خود ایجاد کرده اید و می خواهید آن را با مخزن همگام سازی کنید. اگر بسیاری از مهندسان دیگر در این زمینه از مخزن کار می کنند، مهم است که نسخه کاری خود را به روز نگه دارید. می توانید از دستور svn status برای مشاهده تغییراتی که ایجاد کرده اید استفاده کنید.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
توجه داشته باشید که تعداد زیادی پرچم روی فرمان وضعیت برای کنترل این خروجی وجود دارد. اگر می خواهید تغییرات خاصی را در یک فایل اصلاح شده مشاهده کنید، از svn diff استفاده کنید.
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...در نهایت، برای به روز رسانی کپی کاری خود از مخزن، از دستور svn update استفاده کنید.
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
این جایی است که ممکن است درگیری رخ دهد. در خروجی بالا، "U" نشان می دهد که هیچ تغییری در نسخه های مخزن این فایل ها ایجاد نشده است و به روز رسانی انجام شده است. "G" به معنای ادغام رخ داده است. نسخه مخزن تغییر کرده بود، اما تغییرات با شما تضادی نداشت. "C" نشان دهنده یک درگیری است. این به این معنی است که تغییرات از مخزن با شما همپوشانی دارند و اکنون باید بین آنها یکی را انتخاب کنید.
برای هر فایلی که دارای تضاد است، Subversion سه فایل را در کپی کاری شما قرار می دهد:
- file.mine: این فایل شماست، همانطور که قبل از به روز رسانی نسخه کاری خود در نسخه کاری شما وجود داشت.
- file.rOLDREV: این فایلی است که قبل از ایجاد تغییرات از مخزن بررسی کرده اید.
- file.rNEWREV: این فایل نسخه فعلی موجود در مخزن است.
شما می توانید یکی از سه کار را برای حل تعارض انجام دهید:
- فایل ها را مرور کنید و ادغام را به صورت دستی انجام دهید.
- یکی از فایل های موقت ایجاد شده توسط SVN را روی نسخه کپی کاری خود کپی کنید.
- svn revert را اجرا کنید تا همه تغییرات شما حذف شود.
پس از حل و فصل درگیری ، به SVN اجازه می دهید با اجرای SVN حل شود . این سه پرونده موقت را حذف می کند و SVN دیگر پرونده را در حالت درگیری مشاهده نمی کند.
آخرین کاری که باید انجام دهید این است که نسخه نهایی خود را به مخزن متعهد کنید. این کار با دستور تعهد SVN انجام می شود. هنگامی که مرتکب تغییر می شوید ، باید یک پیام ورود به سیستم ارائه دهید ، که تغییرات شما را توصیف می کند. این پیام ورود به نسخه ای که ایجاد می کنید پیوست شده است.
svn commit -m "Update files to include new headers."
چیزهای بیشتری برای یادگیری در مورد SVN وجود دارد ، و اینکه چگونه می تواند از پروژه های بزرگ مهندسی نرم افزار پشتیبانی کند. منابع گسترده ای در وب وجود دارد - فقط یک جستجوی Google را در مورد "براندازی" انجام دهید.
برای تمرین ، یک مخزن برای سیستم پایگاه داده آهنگساز خود ایجاد کنید و تمام پرونده های خود را وارد کنید. سپس یک کپی کاری را پرداخت کنید و از دستورات توضیح داده شده در بالا بروید.
مراجع
کاربرد: یک مطالعه در آناتومی
اسکلت ها را از دانشگاه تگزاس در آستین بررسی کنید