
1. قبل از شروع
در کد لبه قبلی، یک برنامه پایه برای طبقه بندی صدا ساخته اید.
اگر میخواهید مدل طبقهبندی صدا را برای تشخیص صداهای کلاسهای مختلف که در یک مدل از پیش آموزش دیده وجود ندارد، سفارشی کنید، چه؟ یا اگر بخواهید مدل را با استفاده از داده های خود شخصی سازی کنید چه؟
در این Codelab، شما یک مدل طبقه بندی صوتی از پیش آموزش دیده را برای تشخیص صدای پرندگان سفارشی می کنید. همین تکنیک را می توان با استفاده از داده های خود تکرار کرد.
پیش نیازها
این کد لبه برای توسعه دهندگان باتجربه تلفن همراه که می خواهند با یادگیری ماشین تجربه کسب کنند، طراحی شده است. باید با:
- توسعه اندروید با استفاده از Kotlin و Android Studio
- سینتکس پایه پایتون
چیزی که یاد خواهید گرفت
- نحوه انجام آموزش انتقال برای دامنه صوتی
- چگونه داده های خود را ایجاد کنید
- نحوه استقرار مدل خود در برنامه اندروید
آنچه شما نیاز دارید
- نسخه اخیر اندروید استودیو (نسخه 4.1.2 و بالاتر)
- دستگاه اندروید فیزیکی با نسخه اندروید در API 23 (Android 6.0)
- کد نمونه
- دانش اولیه توسعه اندروید در Kotlin
2. مجموعه داده پرندگان
شما از مجموعه داده Birdsong استفاده خواهید کرد که از قبل برای سهولت استفاده از آن آماده شده است. تمام فایل های صوتی از وب سایت Xeno-canto می آیند.
این مجموعه داده شامل آهنگ هایی از:
نام : گنجشک خانه | کد : houspa |
| |
نام : قبض صلیب سرخ | کد : redcro |
| |
نام : سینه سفید چوبی | کد : wbwwre1 |
| |
نام : Antpitta با تاج شاه بلوط | کد : chcant2 |
| |
نام : Azara's Spinetail | کد : azaspi1 |
|










این مجموعه داده در یک فایل فشرده است و محتویات آن عبارتند از:
- یک
metadata.csvکه تمام اطلاعات مربوط به هر فایل صوتی را دارد، مانند اینکه چه کسی صدا را ضبط کرده است، کجا ضبط شده است، مجوز استفاده و نام پرنده. - یک پوشه قطار و تست.
- در داخل پوشه های قطار/آزمون، یک پوشه برای هر کد پرنده وجود دارد. در داخل هر یک از آنها همه فایل های wav. برای آن پرنده در آن تقسیم وجود دارد.
فایل های صوتی همگی با فرمت wav هستند و از این مشخصات پیروی می کنند:
- نرخ نمونه برداری 16000 هرتز
- 1 کانال صوتی (مونو)
- نرخ 16 بیت
این مشخصات مهم است زیرا شما از یک مدل پایه استفاده خواهید کرد که انتظار داده در این فرمت را دارد. برای کسب اطلاعات بیشتر در مورد آن، می توانید اطلاعات تکمیلی را در این پست وبلاگ بخوانید.
برای آسانتر کردن کل فرآیند، نیازی به دانلود مجموعه داده روی دستگاه خود نخواهید داشت، بلکه از آن در Google Colab (در ادامه این راهنما) استفاده خواهید کرد.
اگر می خواهید از داده های خود استفاده کنید، تمام فایل های صوتی شما نیز باید در این فرمت خاص باشند.
3. کد نمونه را دریافت کنید
کد را دانلود کنید
برای دانلود تمامی کدهای این کد لبه روی لینک زیر کلیک کنید:
یا اگر ترجیح می دهید، مخزن را شبیه سازی کنید:
git clone https://github.com/googlecodelabs/odml-pathways.git
فایل فشرده دانلود شده را باز کنید. با این کار یک پوشه ریشه ( odml-pathways ) با تمام منابعی که نیاز دارید باز می شود. برای این کد لبه، شما فقط به منابع موجود در زیر شاخه audio_classification/codelab2/android نیاز دارید.
زیرشاخه android در audio_classification/codelab2/android شامل دو فهرست است:
 starter — کد شروعی که برای این Codelab بر اساس آن می سازید.
starter — کد شروعی که برای این Codelab بر اساس آن می سازید. - نهایی - کد تکمیل شده برای برنامه نمونه تمام شده.
برنامه شروع را وارد کنید
با وارد کردن برنامه شروع به Android Studio شروع کنید:
- Android Studio را باز کرده و Import Project (Gradle، Eclipse ADT، و غیره) را انتخاب کنید.
- پوشه
starter(audio_classification/codelab2/android/starter) را از کد منبعی که قبلا دانلود کرده اید باز کنید.

برای اطمینان از اینکه همه وابستگیها برای برنامه شما در دسترس هستند، باید پروژه خود را با فایلهای gradle همگامسازی کنید، پس از اتمام فرآیند واردات.
- انتخاب پروژه همگام سازی با فایل های Gradle (
 ) از نوار ابزار Android Studio.
) از نوار ابزار Android Studio.
4. برنامه شروع را درک کنید
این برنامه همان برنامه ای است که در اولین کد لبه برای طبقه بندی صدا ساخته شده بود: یک برنامه پایه برای طبقه بندی صدا ایجاد کنید.
برای به دست آوردن درک بهتر از کد در جزئیات، توصیه می شود که قبل از ادامه، آن Codelab را انجام دهید.
تمام کدها در MainActivity هستند (تا حد امکان ساده باشند).
به طور خلاصه، کد به وظایف زیر می پردازد:
- در حال بارگذاری مدل
val classifier = AudioClassifier.createFromFile(this, modelPath)
- ایجاد ضبط صوت و شروع ضبط
val tensor = classifier.createInputTensorAudio()
val format = classifier.requiredTensorAudioFormat
val recorderSpecs = "Number Of Channels: ${format.channels}\n" +
"Sample Rate: ${format.sampleRate}"
recorderSpecsTextView.text = recorderSpecs
val record = classifier.createAudioRecord()
record.startRecording()
- ایجاد یک رشته تایمر برای اجرای استنتاج. پارامترهای متد
scheduleAtFixedRateمدت زمان انتظار برای شروع اجرا و زمان بین اجرای کار متوالی است. در کد زیر، در 1 میلی ثانیه شروع می شود و هر 500 میلی ثانیه دوباره اجرا می شود.
Timer().scheduleAtFixedRate(1, 500) {
...
}
- اجرای استنتاج روی صدای ضبط شده
val numberOfSamples = tensor.load(record)
val output = classifier.classify(tensor)
- طبقه بندی فیلتر برای امتیازات پایین
val filteredModelOutput = output[0].categories.filter {
it.score > probabilityThreshold
}
- نتایج را روی صفحه نمایش دهید
val outputStr = filteredModelOutput.map { "${it.label} -> ${it.score} " }
.joinToString(separator = "\n")
runOnUiThread {
textView.text = outputStr
}
اکنون می توانید برنامه را اجرا کرده و همانطور که هست با آن بازی کنید، اما به یاد داشته باشید که از یک مدل از قبل آموزش دیده عمومی تر استفاده می کند.
5. یک مدل طبقه بندی صوتی سفارشی را با Model Maker آموزش دهید
در مرحله قبل، برنامه ای را دانلود کردید که از یک مدل از پیش آموزش دیده برای طبقه بندی رویدادهای صوتی استفاده می کند. اما گاهی اوقات لازم است این مدل را برای رویدادهای صوتی مورد علاقه خود سفارشی کنید یا آن را به یک نسخه تخصصی تر تبدیل کنید.
همانطور که قبلا ذکر شد، شما این مدل را برای صداهای پرنده تخصصی خواهید کرد. در اینجا مجموعه داده ای با فایل های صوتی پرندگان است که از وب سایت Xeno-canto تهیه شده است.
مشارکتی
بعد، بیایید برای آموزش مدل سفارشی به Google Colab برویم.
آموزش مدل سفارشی حدود 30 دقیقه طول می کشد.
اگر میخواهید از این مرحله رد شوید، میتوانید مدلی را که روی colab آموزش دادهاید با مجموعه داده ارائه شده دانلود کنید و به مرحله بعد بروید.
6. مدل سفارشی TFLite را به برنامه اندروید اضافه کنید
اکنون که مدل طبقه بندی صوتی خود را آموزش داده اید و آن را به صورت محلی ذخیره کرده اید، باید آن را در پوشه دارایی های برنامه اندروید قرار دهید.
اولین قدم این است که مدل دانلود شده را از مرحله قبل به پوشه دارایی ها در برنامه خود منتقل کنید.
- در Android Studio، با نمای Android Project، روی پوشه assets راست کلیک کنید.
- یک پنجره بازشو با لیستی از گزینه ها مشاهده خواهید کرد. یکی از این موارد باز کردن پوشه در سیستم فایل شما خواهد بود. مناسب برای سیستم عامل خود را پیدا کنید و آن را انتخاب کنید. در مک این گزینه در Finder Reveal، در ویندوز Open در Explorer و در اوبونتو Show in Files خواهد بود.

- مدل دانلود شده را در پوشه کپی کنید.
پس از انجام این کار، به اندروید استودیو برگردید و باید فایل خود را در پوشه دارایی ها مشاهده کنید.

7. مدل جدید را در برنامه پایه بارگذاری کنید
برنامه پایه قبلاً از یک مدل از پیش آموزش دیده استفاده می کند. شما آن را با چیزی که به تازگی آموزش داده اید جایگزین خواهید کرد.
- TODO 1: برای بارگذاری مدل جدید پس از افزودن آن به پوشه دارایی ها ، مقدار متغیر
modelPathرا تغییر دهید:
var modelPath = "my_birds_model.tflite"
مدل جدید دارای دو خروجی (هد) است:
- خروجی اصلی و عمومی تر از مدل پایه ای که استفاده کردید، در این مورد YAMNet.
- خروجی ثانویه که مخصوص پرندگانی است که در تمرین استفاده کرده اید.
این امر ضروری است زیرا YAMNet با تشخیص چندین کلاس رایج، مانند Silence، کار بسیار خوبی انجام می دهد. با این کار، لازم نیست نگران کلاس های دیگری باشید که به مجموعه داده خود اضافه نکرده اید.
کاری که اکنون انجام میدهید این است که اگر طبقهبندی YAMNet امتیاز بالایی را برای کلاس پرنده نشان دهد، در خروجی دیگر بررسی میکنید که کدام پرنده است.
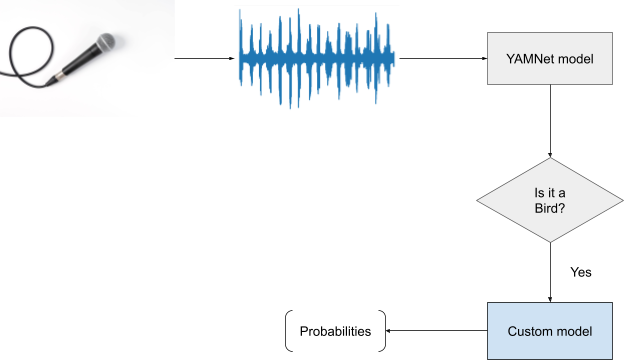
- TODO 2: اگر اولین رئیس طبقه بندی اعتماد به نفس بالایی داشته باشد، بخوانید، صدای پرنده است. در اینجا شما فیلتر را تغییر میدهید تا هر چیزی که Bird نیست را نیز فیلتر کنید:
val filteredModelOuput = output[0].categories.filter {
it.label.contains("Bird") && it.score > .3
}
- TODO 3: اگر سر پایه مدل تشخیص دهد که یک پرنده در صدا با احتمال خوب وجود دارد، متوجه خواهید شد که کدام یک در سر دوم است:
if (filteredModelOutput.isNotEmpty()) {
Log.i("Yamnet", "bird sound detected!")
filteredModelOutput = output[1].categories.filter {
it.score > probabilityThreshold
}
}
و بس. تغییر مدل برای استفاده از مدلی که به تازگی آموزش داده اید ساده است.
مرحله بعدی آزمایش آن است.
8. برنامه را با مدل جدید خود تست کنید
شما مدل طبقه بندی صوتی خود را در برنامه ادغام کرده اید، پس بیایید آن را آزمایش کنیم.
- دستگاه اندروید خود را وصل کنید و روی Run کلیک کنید (
 ) در نوار ابزار Android Studio.
) در نوار ابزار Android Studio.
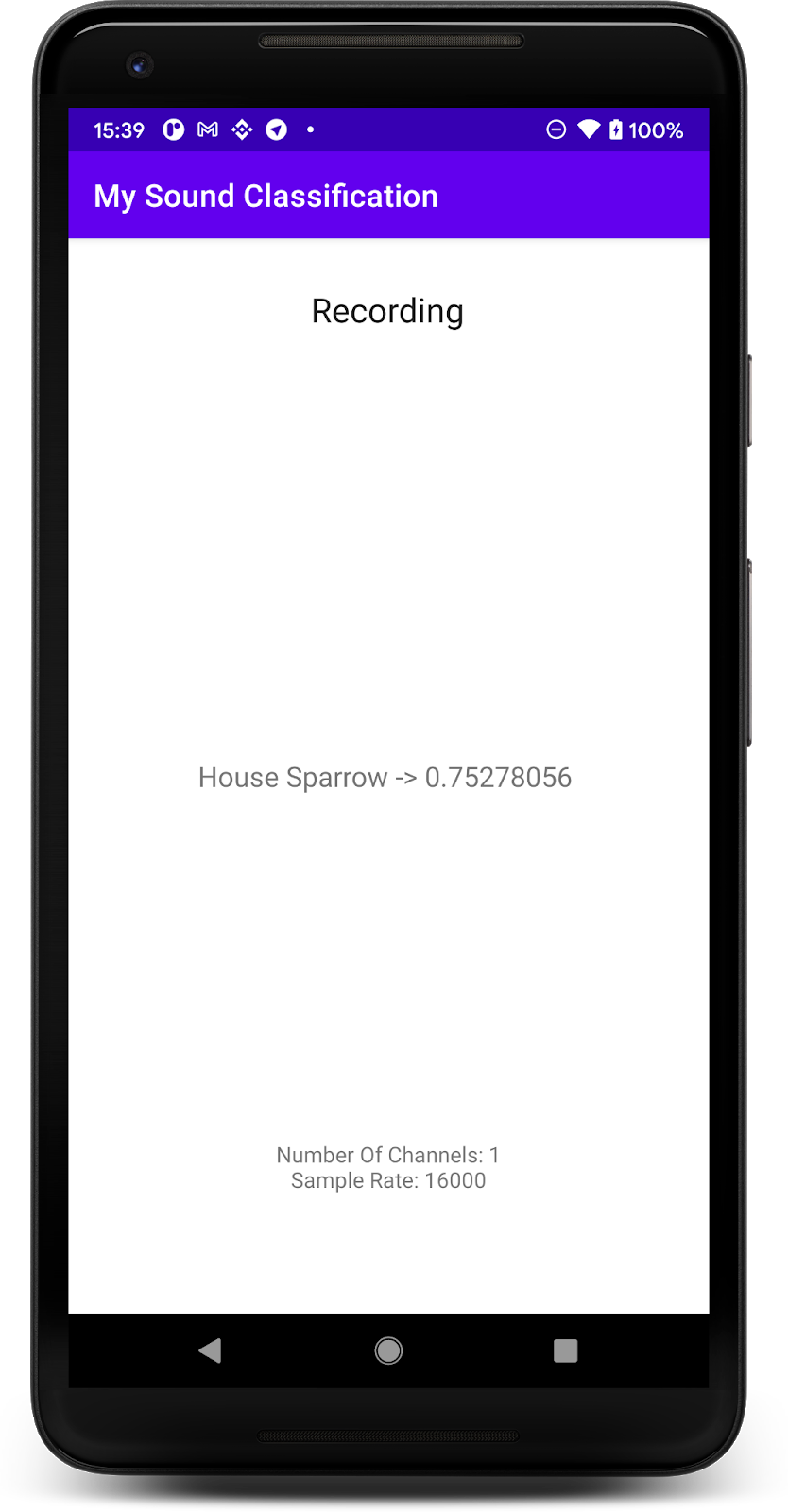
برنامه باید بتواند صدای پرندگان را به درستی پیش بینی کند. برای آسانتر کردن آزمایش، کافی است یکی از فایلهای صوتی را از رایانه خود (از مراحل قبلی) پخش کنید و تلفن شما باید بتواند آن را تشخیص دهد. وقتی این کار را کرد، نام پرندگان و احتمال درست بودن آن را روی صفحه نمایش می دهد.
9. تبریک می گویم
در این کد لبه، یاد گرفتید که چگونه مدل طبقهبندی صوتی خود را با Model Maker ایجاد کنید و آن را با استفاده از TensorFlow Lite در برنامه تلفن همراه خود مستقر کنید. برای کسب اطلاعات بیشتر در مورد TFLite، نگاهی به نمونه های دیگر TFLite بیندازید.
آنچه را پوشش داده ایم
- چگونه مجموعه داده خود را آماده کنید
- نحوه انجام آموزش انتقال برای طبقه بندی صدا با Model Maker
- نحوه استفاده از مدل خود در برنامه اندروید
مراحل بعدی
- با داده های خودت امتحان کن
- آنچه را که می سازید با ما به اشتراک بگذارید
بیشتر بدانید
- پیوند به مسیر یادگیری
- مستندات TensorFlow Lite
- مستندات مدل ساز
- اسناد TensorFlow Hub
- یادگیری ماشین روی دستگاه با فناوریهای Google