
1. قبل از شروع
TensorFlow یک چارچوب یادگیری ماشین چند منظوره است. میتوان از آن برای آموزش مدلهای بزرگ در میان خوشهها در فضای ابری یا اجرای مدلها به صورت محلی در یک سیستم جاسازی شده مانند تلفن شما استفاده کرد.
این کد لبه از TensorFlow Lite برای اجرای یک مدل طبقهبندی صوتی در دستگاه اندرویدی استفاده میکند.
چیزی که یاد خواهید گرفت
- چگونه می توان یک مدل یادگیری ماشینی از پیش آموزش دیده را برای استفاده پیدا کرد.
- نحوه انجام طبقه بندی صدا بر روی صدای ضبط شده در زمان واقعی.
- نحوه استفاده از کتابخانه پشتیبانی TensorFlow Lite برای پیش پردازش ورودی مدل و خروجی مدل پس از پردازش.
- نحوه استفاده از Audio Task Library برای انجام تمام کارهای مرتبط با صدا.
چیزی که خواهی ساخت
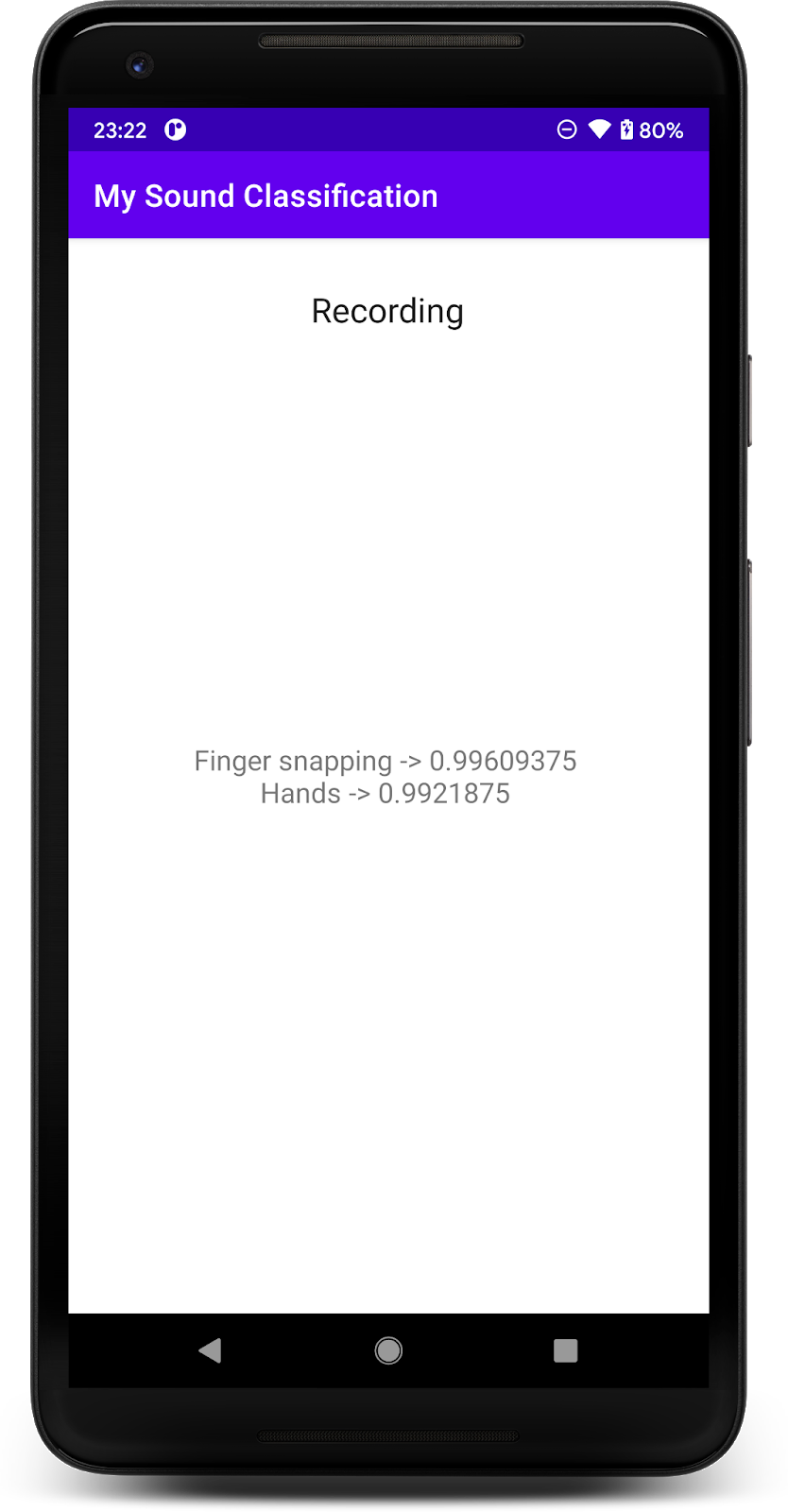
یک برنامه ساده تشخیص صدا که یک مدل تشخیص صدا TensorFlow Lite را برای شناسایی صداها از میکروفون در زمان واقعی اجرا می کند.
آنچه شما نیاز دارید
- نسخه اخیر اندروید استودیو (نسخه 4.1.2 و بالاتر)
- دستگاه اندروید فیزیکی با نسخه اندروید در API 23 (Android 6.0)
- کد نمونه
- دانش اولیه توسعه اندروید در Kotlin
2. کد نمونه را دریافت کنید
کد را دانلود کنید
برای دانلود تمامی کدهای این کد لبه روی لینک زیر کلیک کنید:
فایل فشرده دانلود شده را باز کنید. با این کار یک پوشه ریشه ( odml-pathways ) با تمام منابعی که نیاز دارید باز می شود. برای این کد لبه، شما فقط به منابع موجود در زیر شاخه audio_classification/codelab1/android نیاز دارید.
توجه: اگر ترجیح می دهید می توانید مخزن را شبیه سازی کنید:
git clone https://github.com/googlecodelabs/odml-pathways.git
زیر شاخه android در audio_classification/codelab1/android شامل دو فهرست است:
 starter — کد شروعی که برای این Codelab بر اساس آن می سازید.
starter — کد شروعی که برای این Codelab بر اساس آن می سازید. - نهایی - کد تکمیل شده برای برنامه نمونه تمام شده.
برنامه شروع را وارد کنید
بیایید با وارد کردن برنامه شروع به Android Studio شروع کنیم.
- Android Studio را باز کرده و Import Project (Gradle، Eclipse ADT، و غیره) را انتخاب کنید.
- پوشه
starter(audio_classification/codelab1/android/starter) را از کد منبعی که قبلا دانلود کرده اید باز کنید.

برای اطمینان از اینکه همه وابستگیها برای برنامه شما در دسترس هستند، باید پروژه خود را با فایلهای gradle همگامسازی کنید، پس از اتمام فرآیند واردات.
- انتخاب پروژه همگام سازی با فایل های Gradle (
 ) از نوار ابزار Android Studio.
) از نوار ابزار Android Studio.
برنامه استارتر را اجرا کنید
اکنون که پروژه را به Android Studio وارد کرده اید، برای اولین بار آماده اجرای برنامه هستید.
دستگاه اندروید خود را از طریق USB به رایانه خود وصل کنید و روی Run کلیک کنید (  ) در نوار ابزار Android Studio.
) در نوار ابزار Android Studio.
3. یک مدل از پیش آموزش دیده پیدا کنید
برای انجام طبقه بندی صدا، به یک مدل نیاز دارید. با یک مدل از قبل آموزش دیده شروع کنید تا مجبور نباشید خودتان آن را آموزش دهید.
برای یافتن مدل های از پیش آموزش دیده از TensorFlow Hub ( www.tfhub.dev ) استفاده خواهید کرد.
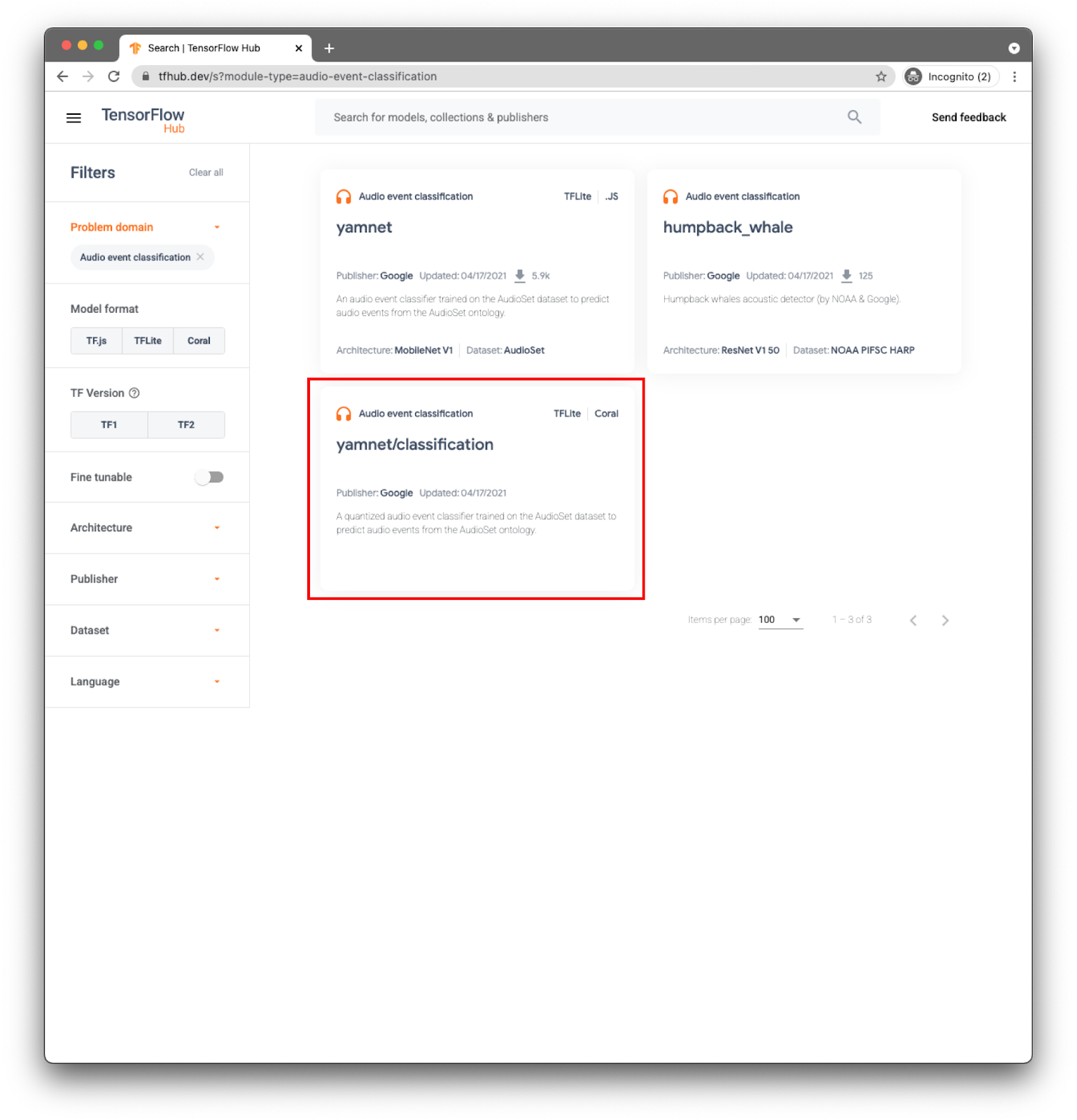
مدل ها بر اساس دامنه دسته بندی می شوند. موردی که در حال حاضر به آن نیاز دارید از دامنه های مشکل صوتی است.
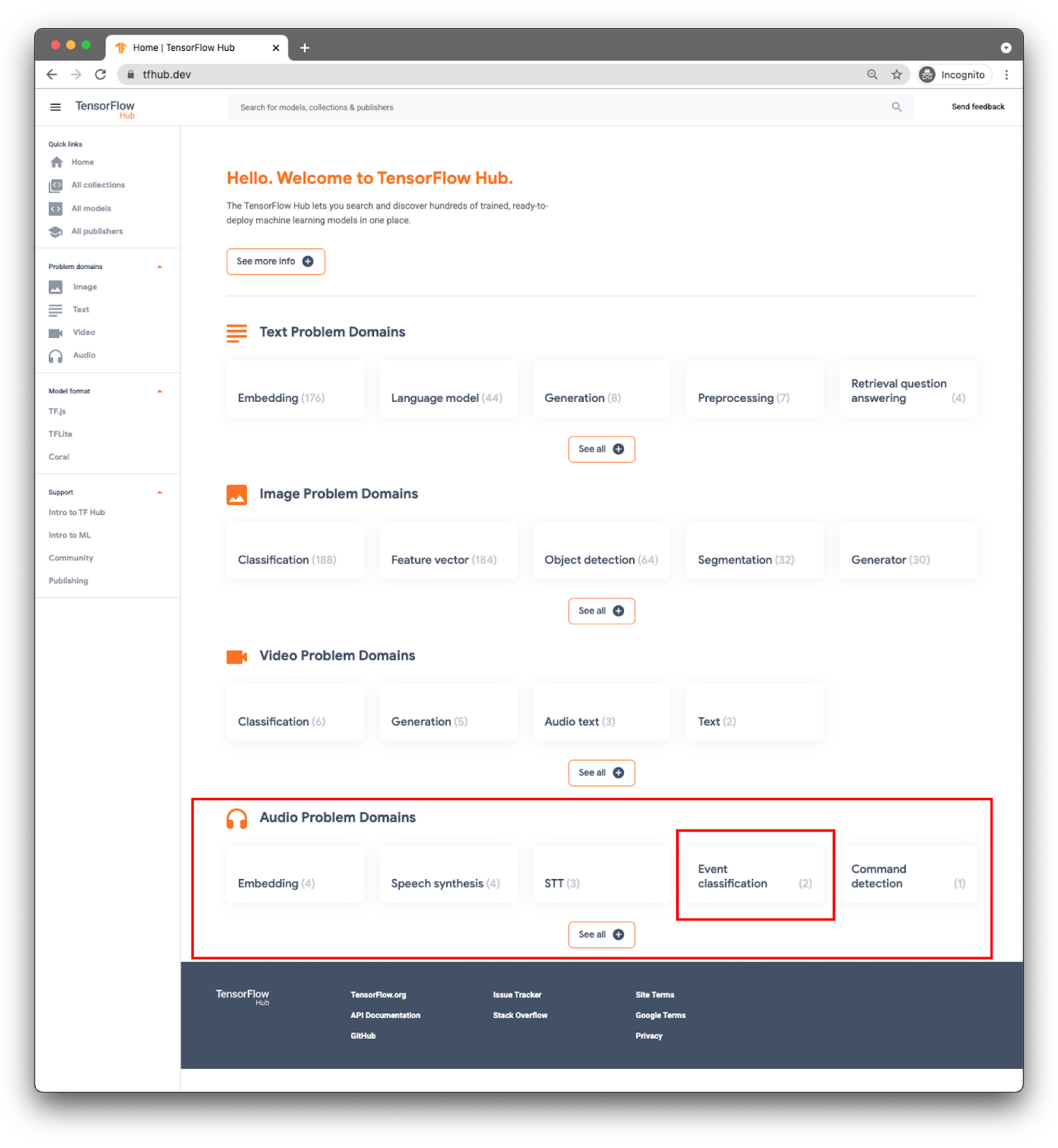
برای برنامه خود، طبقه بندی رویدادها را با مدل YAMNet انجام خواهید داد.
YAMNet یک طبقهبندی کننده رویداد صوتی است که شکل موج صوتی را به عنوان ورودی دریافت میکند و برای هر یک از 521 رویداد صوتی پیشبینیهای مستقلی انجام میدهد.
مدل yamnet/طبقهبندی قبلاً به TensorFlow Lite تبدیل شده است و دارای ابردادههای خاصی است که TFLite Task Library برای صوتی را قادر میسازد تا استفاده از مدل را در دستگاههای تلفن همراه آسانتر کند.
برگه سمت راست را انتخاب کنید: TFLite (yamnet/classification/tflite) و روی دانلود کلیک کنید. همچنین می توانید متادیتای مدل را در پایین مشاهده کنید.
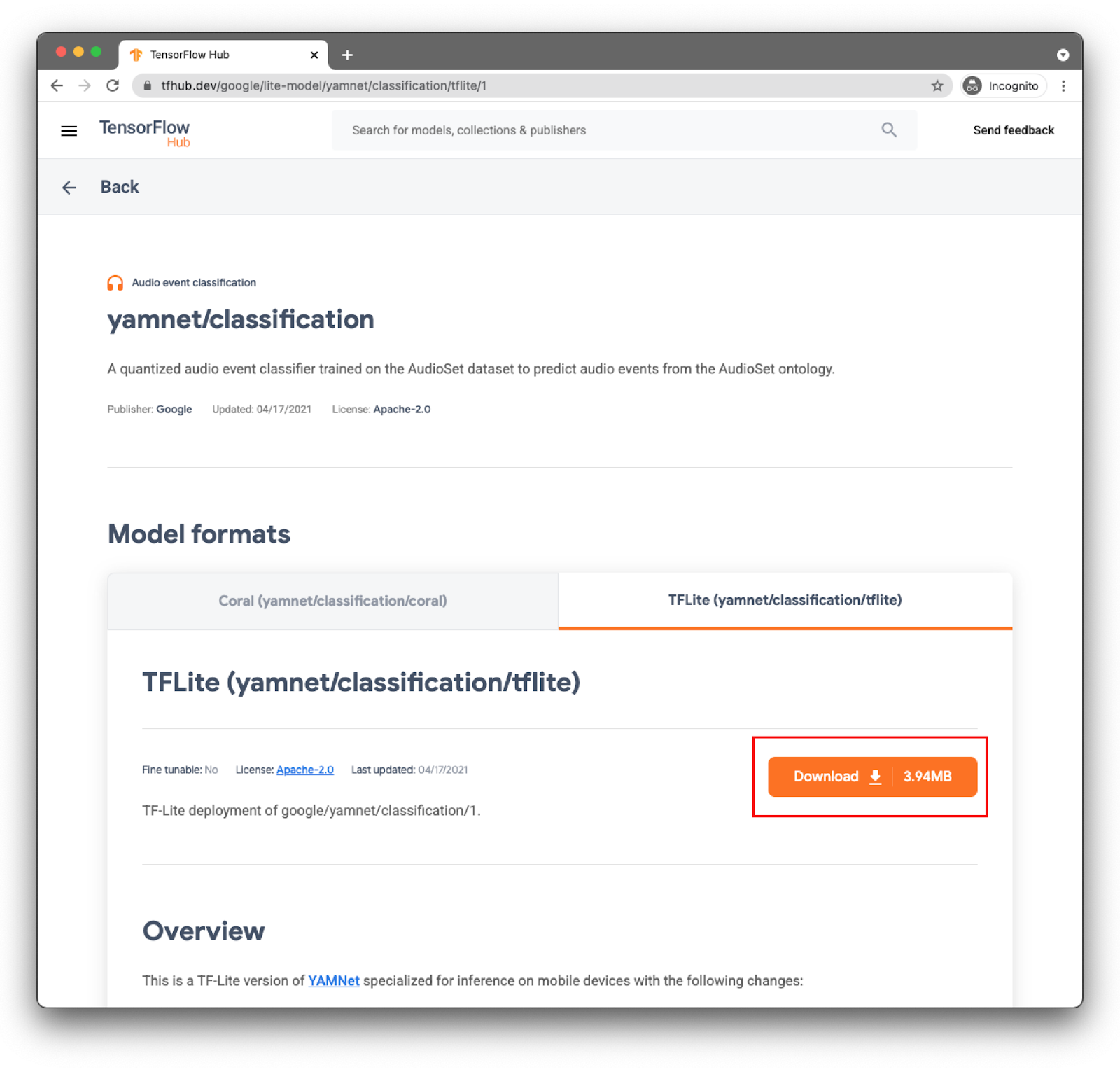
این فایل مدل ( lite-model_yamnet_classification_tflite_1.tflite ) در مرحله بعد استفاده خواهد شد.
4. مدل جدید را به برنامه پایه وارد کنید
اولین قدم این است که مدل دانلود شده را از مرحله قبل به پوشه دارایی ها در برنامه خود منتقل کنید.
در Android Studio، در کاوشگر پروژه، روی پوشه assets کلیک راست کنید.
یک پنجره بازشو با لیستی از گزینه ها مشاهده خواهید کرد. یکی از این موارد باز کردن پوشه در سیستم فایل شما خواهد بود. در مک این گزینه در Finder Reveal ، در ویندوز Open در Explorer و در اوبونتو Show in Files خواهد بود. مناسب برای سیستم عامل خود را پیدا کنید و آن را انتخاب کنید.
سپس مدل دانلود شده را در آن کپی کنید.
پس از انجام این کار، به اندروید استودیو برگردید و باید فایل خود را در پوشه دارایی ها مشاهده کنید.
5. مدل جدید را در برنامه پایه بارگذاری کنید
اکنون برخی از TODO ها را دنبال می کنید و طبقه بندی صدا را با مدلی که در مرحله قبل به پروژه اضافه کرده اید فعال می کنید.
برای سهولت یافتن TODO ها، در Android Studio، به منو بروید: View > Tool Windows > TODO . پنجرهای با لیست باز میشود و میتوانید روی آن کلیک کنید تا مستقیماً به کد بروید.
در فایل build.gradle (نسخه ماژول) اولین وظیفه را خواهید یافت.
TODO 1 برای اضافه کردن وابستگی های اندروید است:
implementation 'org.tensorflow:tensorflow-lite-task-audio:0.2.0'
بقیه تغییرات کد روی MainActivity خواهد بود
TODO 2.1 متغیری را با نام مدل ایجاد می کند تا در مراحل بعدی بارگذاری شود.
var modelPath = "lite-model_yamnet_classification_tflite_1.tflite"
TODO 2.2 شما یک آستانه حداقل برای پذیرش یک پیش بینی از مدل تعریف خواهید کرد. این متغیر بعدا استفاده خواهد شد.
var probabilityThreshold: Float = 0.3f
TODO 2.3 جایی است که مدل را از پوشه دارایی ها بارگیری می کنید. کلاس AudioClassifier تعریف شده در Audio Task Library برای بارگذاری مدل آماده شده است و تمام روش های لازم برای اجرای استنتاج و همچنین کمک به ایجاد یک ضبط کننده صوتی را در اختیار شما قرار می دهد.
val classifier = AudioClassifier.createFromFile(this, modelPath)
6. ضبط صدا
Audio Tasks API چند روش کمکی دارد که به شما کمک می کند یک ضبط کننده صوتی با پیکربندی مناسبی که مدل شما انتظار دارد بسازید (مثلاً: Sample Rate، Bitrate، تعداد کانال ها). با این کار نیازی نیست آن را با دست پیدا کنید و همچنین اشیاء پیکربندی را ایجاد کنید.
TODO 3.1: متغیر تانسور را ایجاد کنید که ضبط را برای استنتاج ذخیره می کند و مشخصات قالب را برای ضبط کننده ایجاد می کند.
val tensor = classifier.createInputTensorAudio()
TODO 3.2: مشخصات ضبط کننده صدا را که توسط ابرداده مدل در مرحله قبل تعریف شده بود نشان دهید.
val format = classifier.requiredTensorAudioFormat
val recorderSpecs = "Number Of Channels: ${format.channels}\n" +
"Sample Rate: ${format.sampleRate}"
recorderSpecsTextView.text = recorderSpecs
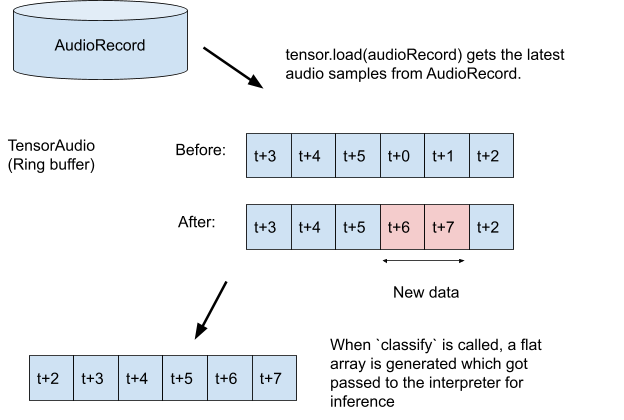
TODO 3.3 : ضبط کننده صدا را ایجاد کرده و شروع به ضبط کنید.
val record = classifier.createAudioRecord()
record.startRecording()
در حال حاضر، برنامه شما در حال گوش دادن به میکروفون تلفن شما است، اما هنوز هیچ نتیجه گیری انجام نمی دهد. در مرحله بعد به این موضوع می پردازید.
7. استنتاج را به مدل خود اضافه کنید
در این مرحله کد استنتاج را به برنامه خود اضافه کرده و روی صفحه نمایش می دهید. کد از قبل دارای یک رشته تایمر است که هر نیم ثانیه یکبار اجرا میشود و در آنجا استنتاج اجرا میشود.
پارامترهای متد scheduleAtFixedRate عبارتند از مدت زمان انتظار برای شروع اجرا و زمان بین اجرای متوالی کار، در کد زیر هر 500 میلی ثانیه.
Timer().scheduleAtFixedRate(1, 500) {
...
}
TODO 4.1 کد را برای استفاده از مدل اضافه کنید. ابتدا ضبط را در یک تانسور صوتی بارگذاری کنید و سپس آن را به طبقهبندی کننده ارسال کنید:
tensor.load(record)
val output = classifier.classify(tensor)
TODO 4.2 برای اینکه نتایج استنتاج بهتری داشته باشید، هر طبقهبندی که احتمال بسیار کمی دارد را فیلتر میکنید. در اینجا از متغیر ایجاد شده در مرحله قبل ( probabilityThreshold ) استفاده خواهید کرد:
val filteredModelOutput = output[0].categories.filter {
it.score > probabilityThreshold
}
TODO 4.3: برای سهولت خواندن نتیجه، اجازه دهید یک رشته با نتایج فیلتر شده ایجاد کنیم:
val outputStr = filteredModelOutput.sortedBy { -it.score }
.joinToString(separator = "\n") { "${it.label} -> ${it.score} " }
TODO 4.4 رابط کاربری را به روز کنید. در این برنامه بسیار ساده، نتیجه فقط در یک TextView نشان داده می شود. از آنجایی که طبقه بندی در موضوع اصلی نیست، برای ایجاد این به روز رسانی باید از یک کنترلر استفاده کنید.
runOnUiThread {
textView.text = outputStr
}
شما تمام کدهای لازم را اضافه کرده اید:
- مدل را از پوشه assets بارگیری کنید
- یک ضبط کننده صدا با پیکربندی صحیح ایجاد کنید
- استنتاج در حال اجرا
- بهترین نتایج را روی صفحه نمایش دهید
تنها چیزی که در حال حاضر نیاز است آزمایش برنامه است.
8. برنامه نهایی را اجرا کنید
شما مدل طبقه بندی صدا را در برنامه ادغام کرده اید، پس بیایید آن را آزمایش کنیم.
دستگاه اندروید خود را وصل کنید و روی Run کلیک کنید (  ) در نوار ابزار Android Studio.
) در نوار ابزار Android Studio.
در اولین اجرا، باید مجوز ضبط صدا را به برنامه بدهید.
پس از دادن مجوز، برنامه در شروع کار از میکروفون تلفن استفاده می کند. برای آزمایش، شروع به صحبت در نزدیکی تلفن کنید زیرا یکی از کلاس هایی که YAMNet تشخیص می دهد گفتار است. یکی دیگر از کلاس های آسان برای تست زدن انگشت یا کف زدن است.
شما همچنین می توانید سعی کنید پارس سگ و بسیاری از رویدادهای احتمالی دیگر را تشخیص دهید (521). برای فهرست کامل، میتوانید کد منبع آنها را بررسی کنید یا میتوانید متادیتا را با فایل برچسبها مستقیماً بخوانید.
9. تبریک!
در این کد لبه، شما یاد گرفتید که چگونه یک مدل از پیش آموزش دیده برای طبقه بندی صدا پیدا کنید و آن را با استفاده از TensorFlow Lite در برنامه تلفن همراه خود مستقر کنید. برای کسب اطلاعات بیشتر در مورد TFLite، نگاهی به نمونه های دیگر TFLite بیندازید.
آنچه را پوشش داده ایم
- نحوه استقرار یک مدل TensorFlow Lite در یک برنامه اندروید.
- نحوه پیدا کردن و استفاده از مدل ها از TensorFlow Hub.
مراحل بعدی
- مدل را با داده های خود سفارشی کنید.
بیشتر بدانید
- مستندات TensorFlow Lite
- کتابخانه پشتیبانی TensorFlow Lite
- کتابخانه وظیفه TensorFlow Lite
- اسناد TensorFlow Hub
- یادگیری ماشین روی دستگاه با فناوریهای Google