
1. 准备工作
TensorFlow 是一种多用途机器学习框架。它可用于在云端跨集群训练大型模型,或在手机等嵌入式系统上本地运行模型。
此 Codelab 使用 TensorFlow Lite 在 Android 设备上运行音频分类模型。
学习内容
- 如何查找可供使用的预训练机器学习模型。
- 如何对实时捕获的音频进行音频分类。
- 如何使用 TensorFlow Lite 支持库对模型输入和后处理模型输出进行预处理。
- 如何使用音频任务库执行所有音频相关工作。
构建内容
一个简单的音频识别器应用,可运行 TensorFlow Lite 音频识别模型来实时识别来自麦克风的音频
所需物品
- 最新版本的 Android Studio (v4.1.2+)
- API 为 23 的 Android 实体设备 (Android 6.0)
- 示例代码
- 使用 Kotlin 进行 Android 开发的基础知识
2. 获取示例代码
下载代码
点击下面的链接可下载本 Codelab 的所有代码:
解压下载的 ZIP 文件。此操作会解压缩一个根文件夹 (odml-pathways),其中包含您需要的所有资源。在本 Codelab 中,您只需要 audio_classification/codelab1/android 子目录中的源代码。
注意:如果您愿意,也可以克隆代码库:
git clone https://github.com/googlecodelabs/odml-pathways.git
audio_classification/codelab1/android 代码库中的 android 子目录包含两个目录:
 starter - 本 Codelab 的起始代码。
starter - 本 Codelab 的起始代码。- final - 完成后的示例应用的完整代码。
导入起始应用
首先,将入门应用导入 Android Studio。
- 打开 Android Studio,然后选择 Import Project(Gradle、Eclipse ADT 等)。
- 打开您之前下载的源代码中的
starter文件夹 (audio_classification/codelab1/android/starter)。

为确保所有依赖项都可供您的应用使用,您应该在导入过程完成后将项目与 gradle 文件同步。
- 从 Android Studio 工具栏中选择 Sync Project with Gradle Files (
 )。
)。
运行起始应用
现在,您已将项目导入 Android Studio,可以首次运行应用了。
通过 USB 将 Android 设备连接到计算机,然后点击 Android Studio 工具栏中的 Run (  )。
)。
3.查找预训练模型
为进行音频分类,您需要一个模型。从预训练模型开始,这样您就不必自行训练一个模型了。
要查找预训练模型,您将使用 TensorFlow Hub ( www.tfhub.dev)。
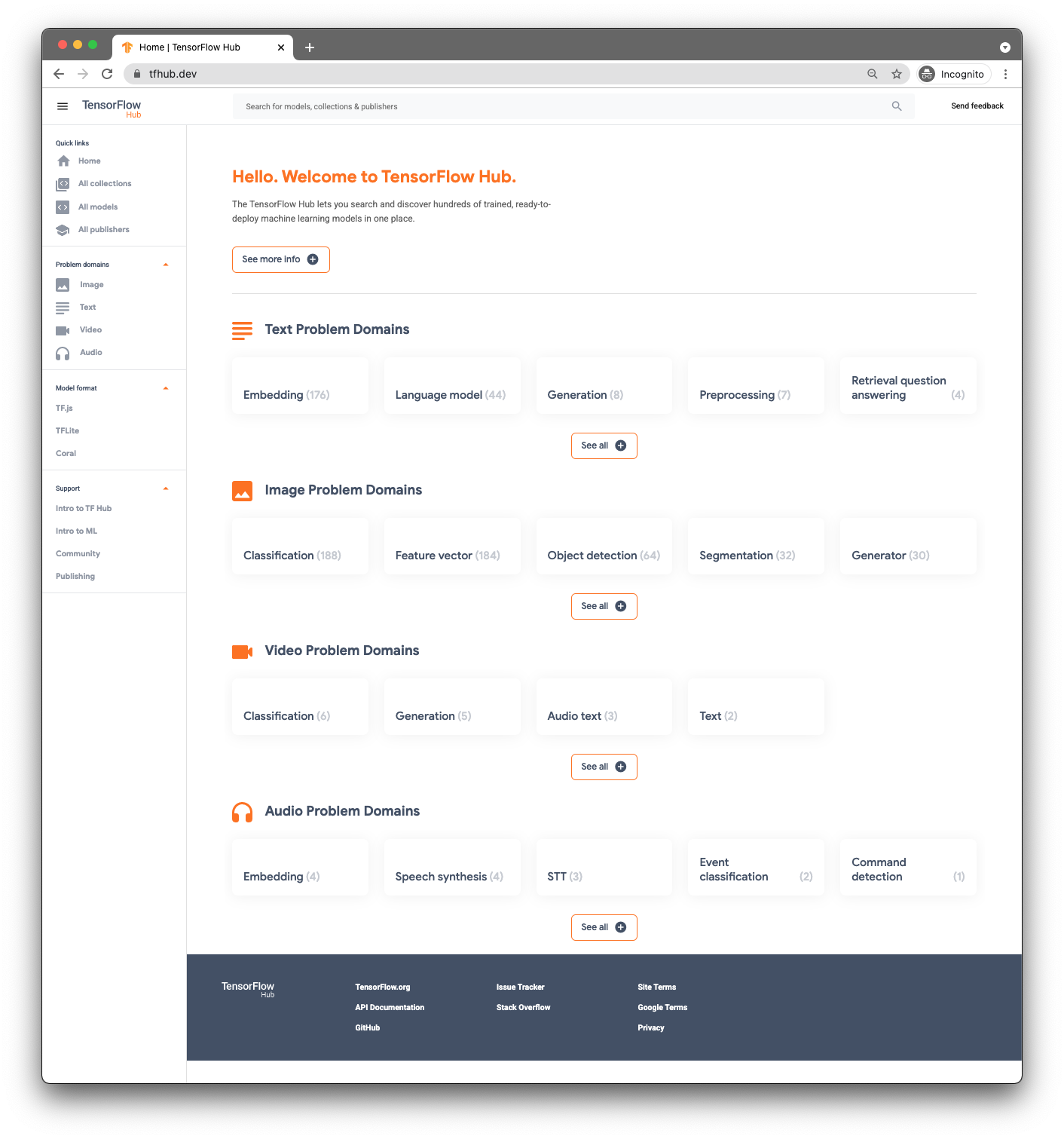
模型按网域分类。您现在需要用到的是音频问题网域中提供的域名。
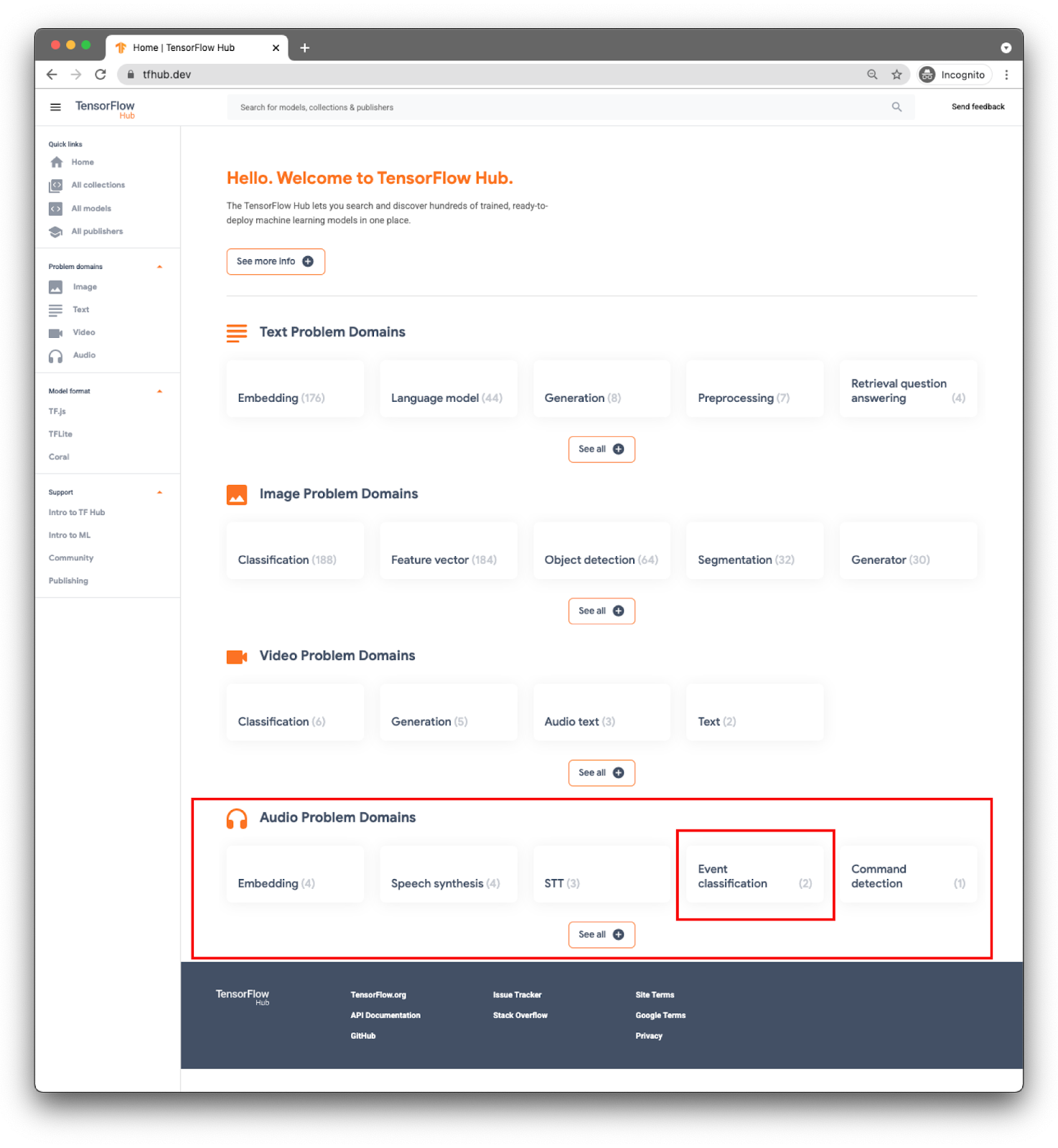
对于您的应用,您将使用 YAMNet 模型进行事件分类。
YAMNet 是一种音频事件分类器,它采用音频波形作为输入,并对 521 个音频事件中的每个音频事件进行独立预测。
模型 yamnet/classification 已转换为 TensorFlow Lite 并具有特定的元数据,该配置可让 TFLite 音频库任务库使模型在移动设备上更易于使用。
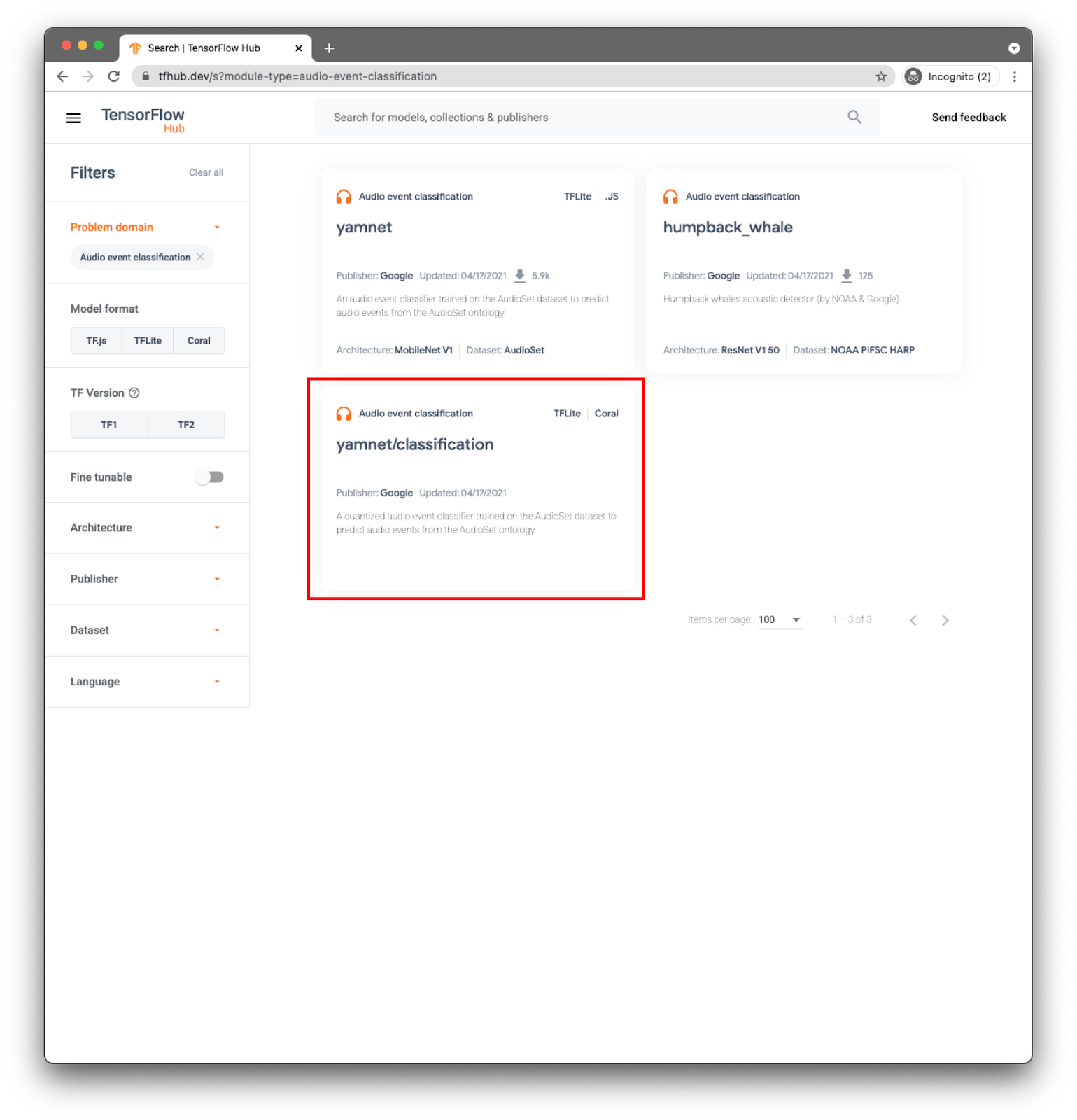
选择正确的标签页:TFLite (yamnet/classification/tflite),然后点击下载。您还可以在底部查看模型的元数据。
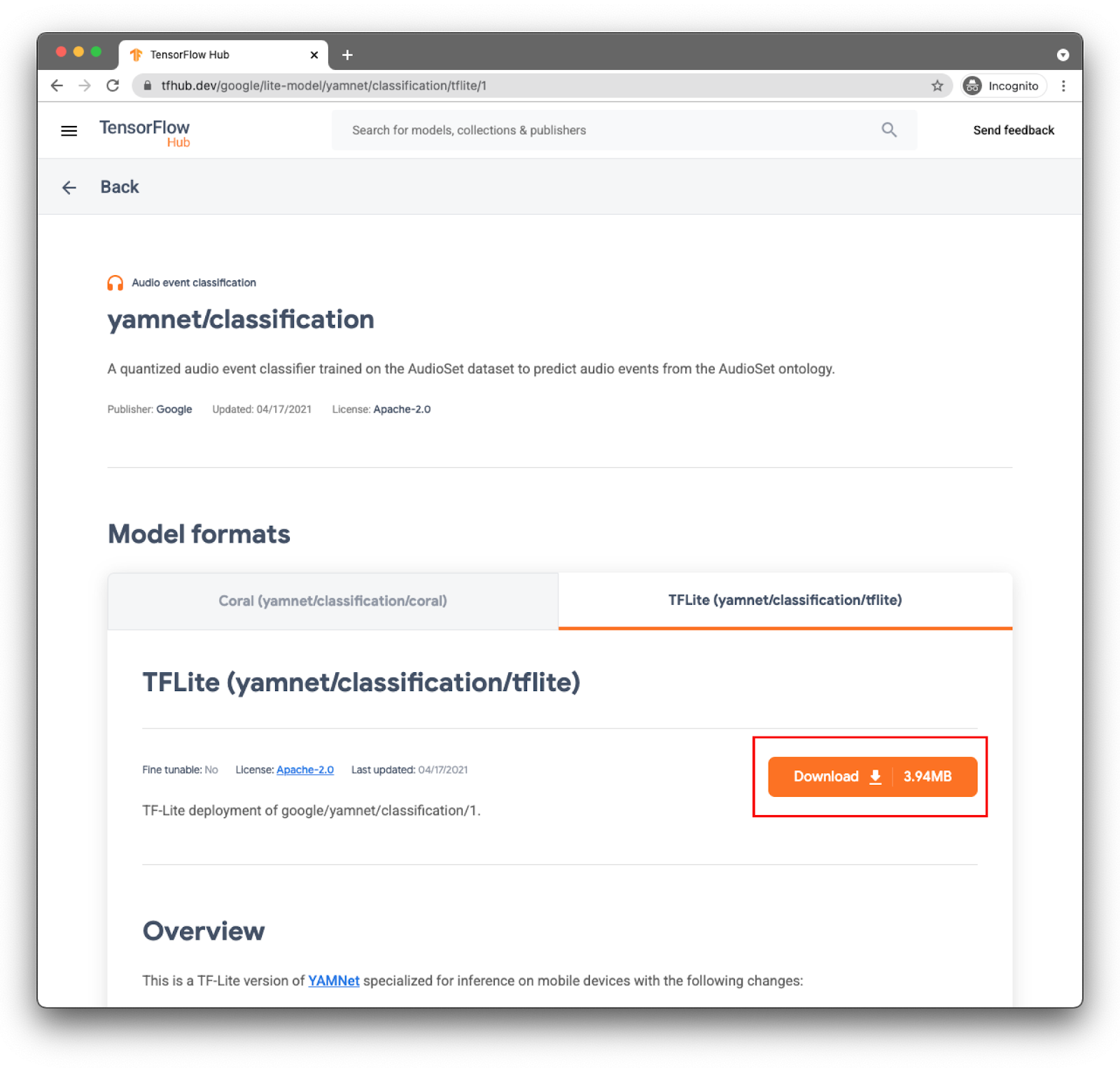
下一步中将使用此模型文件 (lite-model_yamnet_classification_tflite_1.tflite)。
4.将新模型导入基本应用
第一步是将已下载的模型从上一步移至应用中的“素材资源”文件夹。
在 Android Studio 中的 Project Explorer 中,右键点击 assets 文件夹。
您将看到一个弹出式窗口,其中包含选项列表。其中一种方法是在文件系统中打开该文件夹。如果是在 Mac 上,则显示为在 Finder 中显示;在 Windows 中,则会显示为在资源管理器中打开;而在 Ubuntu 中则会显示为在“文件”中显示。找到适合您的操作系统的操作系统,然后选择该操作系统。
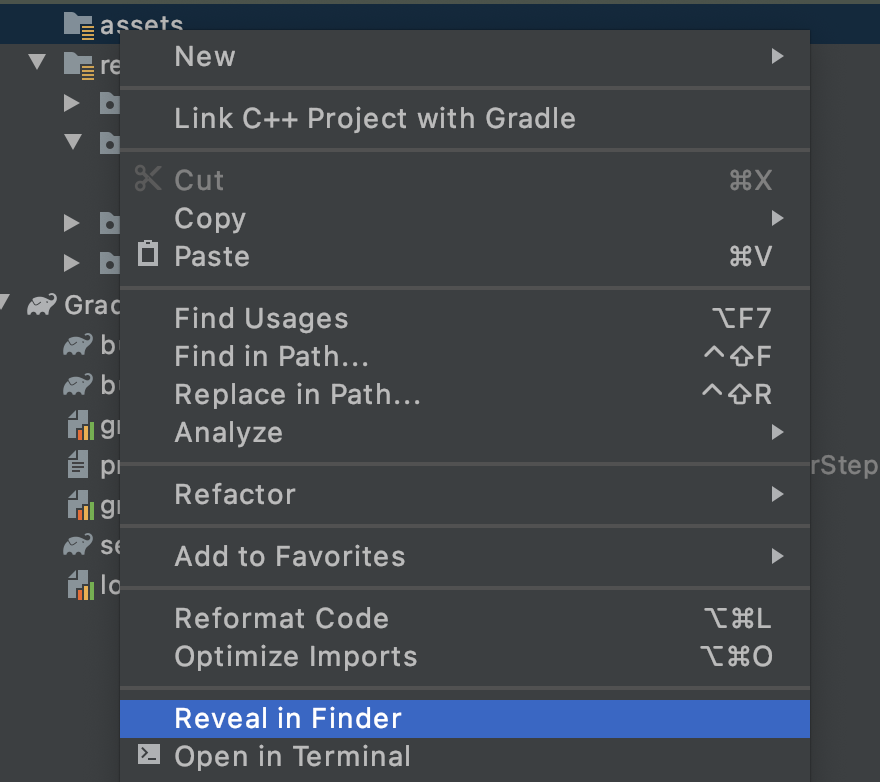
然后将下载的模型复制到其中。
完成此操作后,请返回到 Android Studio,您应该会在 assets 文件夹中看到您的文件。
5. 在基础应用中加载新模型
现在,您需要关注一些 TODO,然后使用您在上一步中刚刚添加到项目中的模型进行音频分类。
为了轻松找到 TODO,请在 Android Studio 中依次转到菜单:View > Tool Windows > TODO。系统会打开一个包含该列表的窗口,您只需点击该窗口即可直接查看代码。
在文件 build.gradle(模块版本)中,您可以找到第一个任务。
TODO 1 是添加 Android 依赖项:
implementation 'org.tensorflow:tensorflow-lite-task-audio:0.2.0'
其余的代码更改都将在 MainActivity 上进行
TODO 2.1 会创建包含模型名称的变量,以供后续步骤加载。
var modelPath = "lite-model_yamnet_classification_tflite_1.tflite"
在 TODO 2.2 中,您将定义接受模型预测所需的最低阈值。此变量将在稍后使用。
var probabilityThreshold: Float = 0.3f
TODO 2.3 用于从资源文件夹中加载模型。Audio Task 库中定义的 AudioClassifier 类已准备好加载模型,并为您提供运行推断和帮助创建录音器的所有必要方法。
val classifier = AudioClassifier.createFromFile(this, modelPath)
6.捕获音频
Audio Tasks API 提供了一些辅助方法,可帮助您创建具有模型所期望的适当配置(例如采样率、比特率、声道数量)的录音器。这样一来,您就无需手动查找配置,也无需创建配置对象。
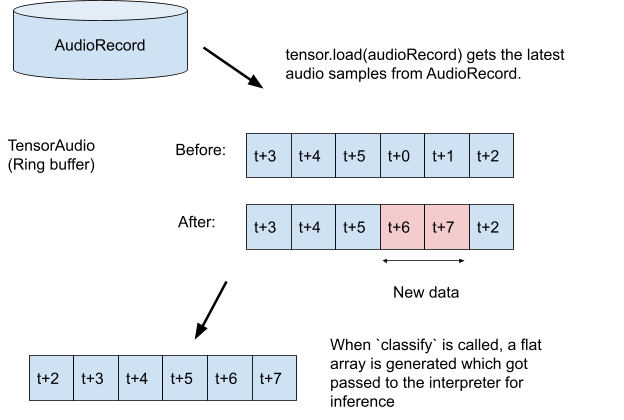
TODO 3.1:创建一个张量变量,用于存储推理的录制内容,并构建录制器的格式规范。
val tensor = classifier.createInputTensorAudio()
TODO 3.2:显示上一步中通过模型的元数据定义的音频录制器规范。
val format = classifier.requiredTensorAudioFormat
val recorderSpecs = "Number Of Channels: ${format.channels}\n" +
"Sample Rate: ${format.sampleRate}"
recorderSpecsTextView.text = recorderSpecs
TODO 3.3:创建录音机并开始录制。
val record = classifier.createAudioRecord()
record.startRecording()
截至目前,应用会监听手机的麦克风,但仍然不做任何推断。您将在接下来的步骤中解决此问题。
7. 将推断添加到模型中
在此步骤中,您将向应用添加推断代码并将其显示在屏幕上。代码已有一个每 0.5 秒执行一次的计时器线程,这是将运行推断的位置。
方法 scheduleAtFixedRate 的参数是每 500 毫秒在代码中开始等待和连续执行任务之间间隔的时间。
Timer().scheduleAtFixedRate(1, 500) {
...
}
TODO 4.1 添加代码以使用该模型。首先将录制内容加载到音频张量中,然后将其传递给分类器:
tensor.load(record)
val output = classifier.classify(tensor)
TODO 4.2,以便获得更好的推断结果,您可以过滤掉所有概率非常低的分类。在这里,您将使用在上一步中创建的变量 (probabilityThreshold):
val filteredModelOutput = output[0].categories.filter {
it.score > probabilityThreshold
}
TODO 4.3:为了更轻松地读取结果,让我们创建一个包含过滤结果的字符串:
val outputStr = filteredModelOutput.sortedBy { -it.score }
.joinToString(separator = "\n") { "${it.label} -> ${it.score} " }
TODO 4.4 更新界面。在这个非常简单的应用中,结果仅在 TextView 中显示。由于分类不在主线程中,因此您需要使用处理程序进行此项更新。
runOnUiThread {
textView.text = outputStr
}
您添加了执行以下操作所需的所有代码:
- 从资源文件夹中加载模型
- 使用正确配置创建录音器
- 运行推断
- 在屏幕上显示最佳结果
现在,您只要测试应用即可。
8. 运行最终应用
您已经将音频分类模型集成到应用中,下面我们来对其进行测试。
连接您的 Android 设备,然后点击 Android Studio 工具栏中的 Run (  )。
)。
首次执行时,您需要向应用授予录音权限。
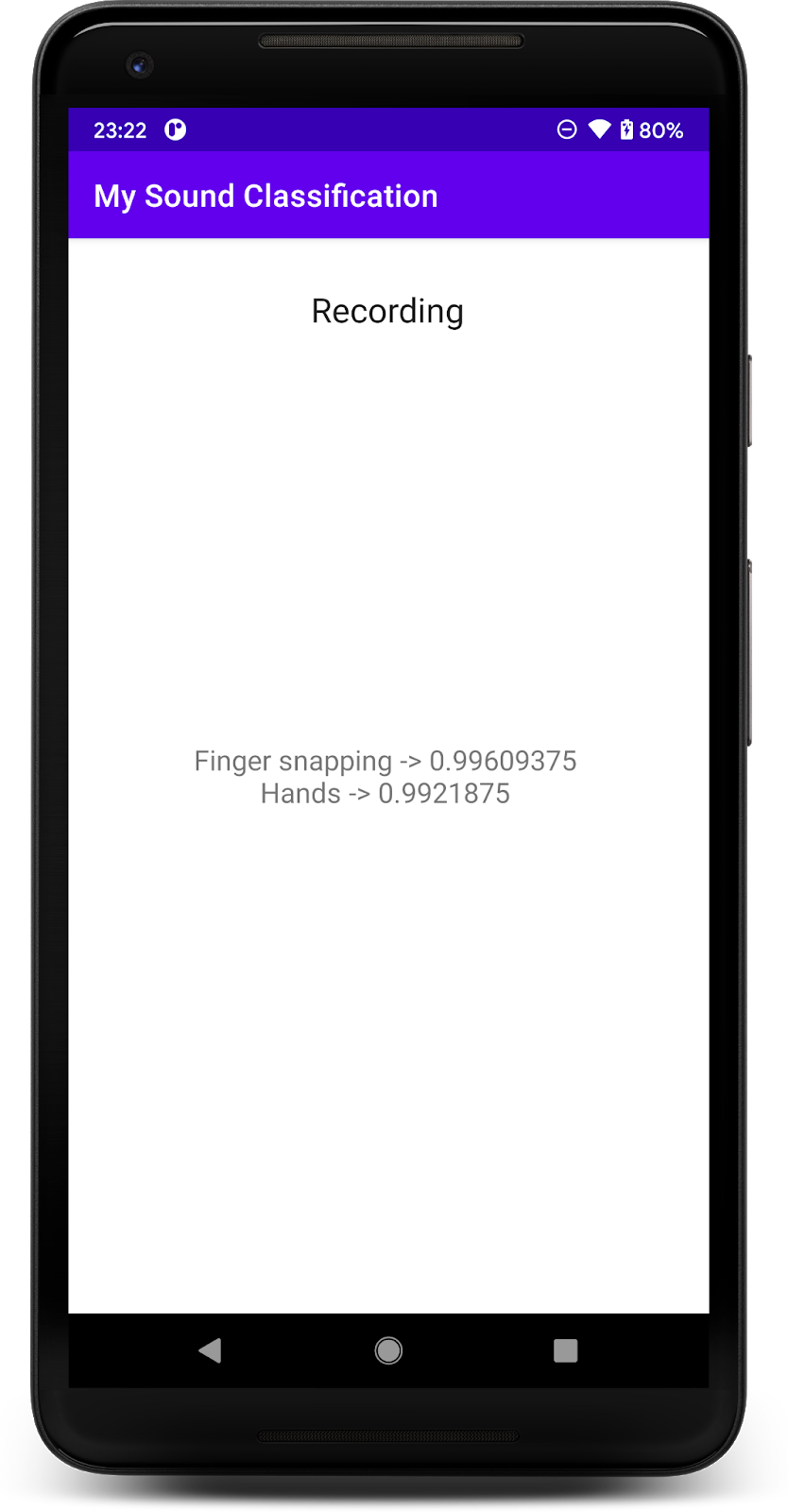
授予权限后,应用会在启动时使用手机的麦克风。要进行测试,请开始在手机附近讲话,因为 YAMNet 检测到的课程之一就是语音。另一个易于测试的类是手指贴靠或拍手。
您还可以尝试检测狗的叫声以及许多其他可能的事件 (521)。如需查看完整列表,您可以查看其源代码,也可以直接使用标签文件读取元数据
9. 恭喜!
在此 Codelab 中,您学习了如何使用 TensorFlow Lite 为音频分类查找预训练模型并将其部署到移动应用。如需详细了解 TFLite,请参阅其他 TFLite 示例。
所学内容
- 如何在 Android 应用中部署 TensorFlow Lite 模型。
- 如何从 TensorFlow 查找和使用模型。
后续步骤
- 使用您自己的数据自定义模型。
了解详情
- TensorFlow Lite 文档
- TensorFlow Lite 支持库
- TensorFlow Lite Task 库
- TensorFlow Hub 文档
- 基于 Google 技术的设备端机器学习