
1. לפני שמתחילים
מטרת קוד ה-codelab הזה היא להתבסס על תוצאה הסופית של ה-codelab הקודם בסדרה לצורך זיהוי של תגובות ספאם באמצעות TensorFlow.js.
במעבדת הקוד האחרונה יצרתם דף אינטרנט עם פונקציונליות מלאה בבלוג וידאו בדיוני. הצלחת לסנן תגובות ספאם לפני שהן נשלחו לשרת לאחסון, או ללקוחות מחוברים אחרים. אפשר לעשות זאת באמצעות מודל לזיהוי ספאם של תגובות מותאמות מראש שמופעל על ידי TensorFlow.js בדפדפן.
התוצאה הסופית של שיעור Lab זה מופיעה בהמשך:
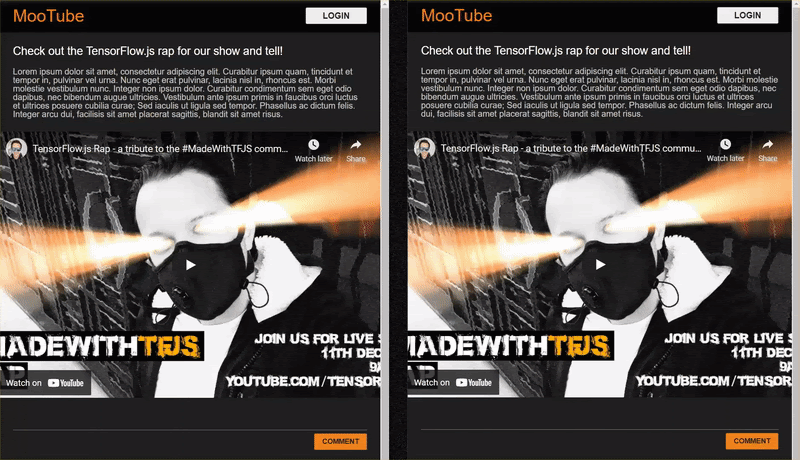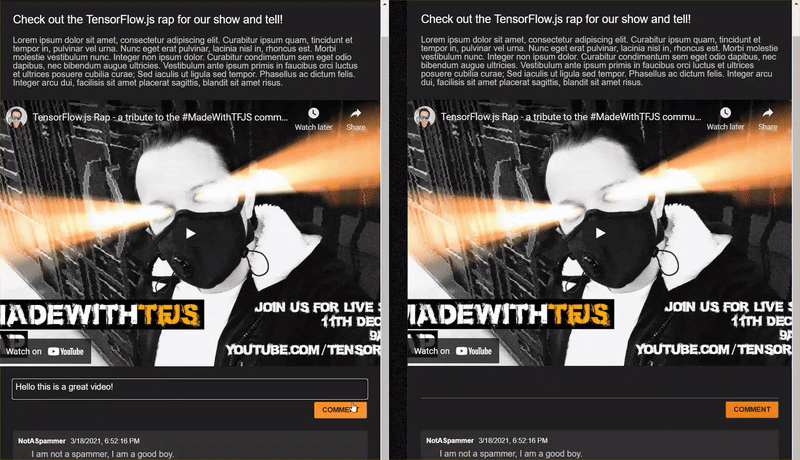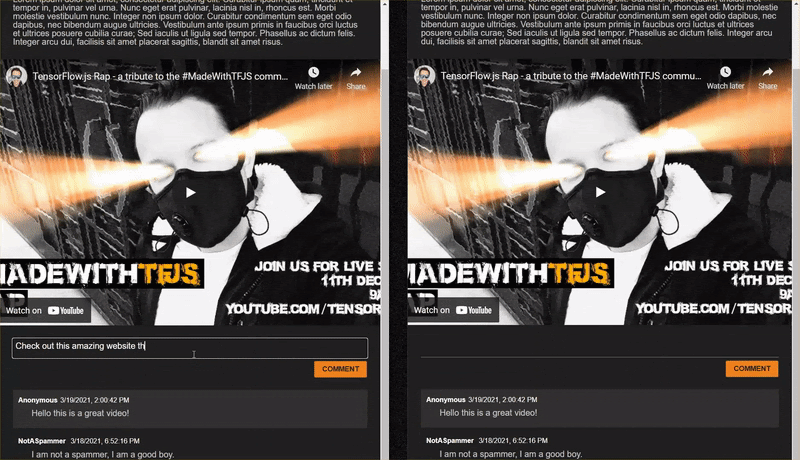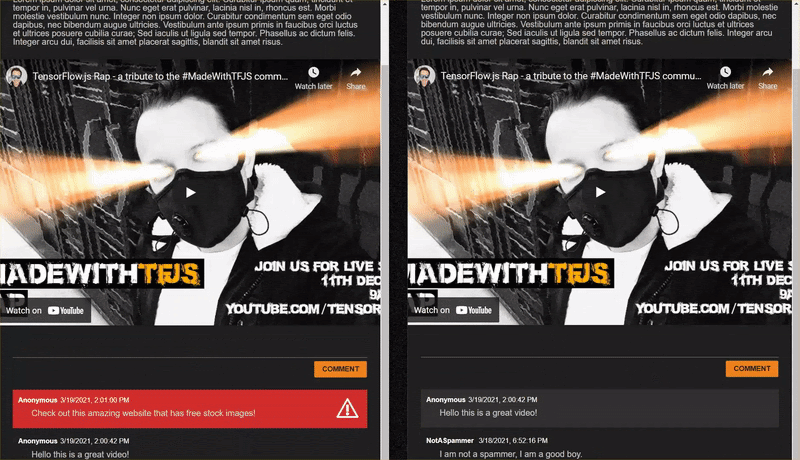
אומנם זה עבד טוב, אבל יש מקרי קצה שלא הצלחנו לזהות. אפשר לאמן מחדש את המודל כדי להביא בחשבון את המצבים שהוא לא הצליח לטפל בהם.
שיעור Lab זה מתמקד בשימוש בעיבוד שפה טבעית (אומנות בהבנת שפה אנושית באמצעות מחשב) ומדגים איך לשנות אפליקציית אינטרנט קיימת שיצרתם (מומלץ מאוד לבצע את סדר ה-Codelabs בסדר), כדי להתמודד עם הבעיה האמיתית של ספאם בתגובות, שמפתחי אינטרנט רבים ייתקלו בו כשהם עובדים על אחד מהאפליקציות ההולכת וגדלות של אפליקציות אינטרנט שקיימות היום.
ב-codelab זה תוכלו להתקדם עוד צעד על ידי אימון מחדש של המודל ל-ML כדי להביא בחשבון שינויים בתוכן של הודעות ספאם שעשויים להתפתח עם הזמן, על סמך מגמות עכשוויות או נושאים פופולריים בדיון שמאפשרים לכם לעדכן את המודל ולטפל בשינויים האלה.
דרישות מוקדמות
- השלמת את מעבדת הקוד הראשונה בסדרה הזו.
- ידע בסיסי בטכנולוגיות אינטרנט, כולל HTML , CSS ו-JavaScript.
מה תיצור
תשתמשו שוב באתר שנוצר בעבר עבור בלוג וידאו פיקטיבי עם קטע תגובות בזמן אמת ושדרגו אותו כדי לטעון גרסה מותאמת אישית של מודל זיהוי הספאם באמצעות TensorFlow.js, כדי שהביצועים שלו יהיו טובים יותר ממקרים אחרים של תקלה שהוא לא היה פועל בעבר. כמובן שמפתחי אתרים ומהנדסי תוכנה יכולים לשנות את חוויית המשתמש ההשערית הזו לשימוש חוזר בכל אתר שבו אתם עובדים מדי יום, ולהתאים את הפתרון לכל מקרה שימוש של הלקוח. למשל, בלוג, פורום או כל סוג אחר של מערכת ניהול תוכן, כמו Drupal.
הגיע הזמן לפרוץ...
מה תלמדו
מה עליך לעשות?
- זיהוי מקרי קצה שהמודל הנלמד מראש נכשל
- אימון מחדש של מודל הסיווג לספאם שנוצר באמצעות Maker Maker.
- מייצאים את המודל המבוסס על Python לפורמט TensorFlow.js לשימוש בדפדפנים.
- עדכן את המודל המתארח ואת המילון שלו למודל החדש שהוזמן ובדוק את התוצאות
ההנחה היא שהיכרות עם HTML5, CSS ו-JavaScript נחשבת עבור שיעור ה-Lab הזה. כמו כן, תריצו קוד Python כלשהו באמצעות notebook ו- "co lab; כדי לאמן מחדש את המודל שנוצר באמצעות Maker Maker, אך לא נדרשת ידע ב-Python כדי לעשות זאת.
2. תהליך ההגדרה
שוב, תשתמש ב-Glitch.com כדי לארח ולשנות את אפליקציית האינטרנט. אם לא השלמתם את מעבד הקוד המקדים, תוכלו לשכפל את התוצאה הסופית כאן כנקודת ההתחלה. אם יש לכם שאלות לגבי אופן הפעולה של הקוד, מומלץ מאוד להשלים את שיעור ה-Lab הקודם שהסביר איך ליצור את אפליקציית האינטרנט הפעילה לפני שממשיכים.
ב-Glitch, פשוט לוחצים על הלחצן רמיקס זה כדי לפצל אותו וליצור קבוצה חדשה של קבצים שניתן לערוך.
3. עיון במקרי קצה בפתרון הקודם
אם תפתחו את האתר המלא ששכפול ותנסו להקליד חלק מהתגובות, תשימו לב שחלק גדול מהזמן פועל כראוי, חוסמים תגובות שנשמעות כמו ספאם ומאפשרות לקבל תגובות לגיטימיות.
עם זאת, אם תתנהגו בצורה מקצועית ותנסו לבטא את דפוסי הפעולה שלכם, סביר להניח שתוכלו להצליח בשלב כלשהו. בעזרת תקופת ניסיון ושגיאה תוכלו ליצור באופן ידני דוגמאות כמו אלו שמפורטות בהמשך. מדביקים את האפליקציות האלה באפליקציית האינטרנט הקיימת, בודקים את המסוף ובודקים אם הסבירות לכך תחזור אם התגובה היא ספאם:
תגובות לגיטימיות שפורסמו ללא בעיה (שליליים אמיתיים):
- "וואו, אני אוהב את הסרטון הזה, כל הכבוד!" סבירות ספאם: 47.91854%
- "אוהב מאוד את ההדגמות האלה! יש עוד פרטים:** ציטוט; סבירות ספאם: 47.15898%
- "באיזה אתר אפשר לבקר כדי לקבל מידע נוסף?" סבירות ספאם: 15.32495%
זו סבירות גבוהה, ההסתברות לכל האפשרויות שמצוינות למעלה היא נמוכה למדי, ועברה בהצלחה את SPAM_THRESHOLD כברירת המחדל של סבירות 75% לפני שננקטה פעולה (מוגדר בקוד script.js מקוד הקוד הקודם).
עכשיו ננסה לכתוב עוד תגובות חדשניות שמסומנות כספאם, גם אם הן לא...
תגובות לגיטימיות שסומנו כספאם (תוצאות חיוביות שקריות):
- &PLURAL;האם מישהו יכול לקשר את האתר של המסכה שהוא לובש אותה? סבירות לספאם: 98.46466%
- "האם אפשר לקנות את השיר הזה ב-Spotify? יש להודיע לי על כך!" סבירות לספאם: 94.40953%
- "האם מישהו יכול לפנות אליי עם פרטים על אופן ההורדה של TensorFlow.js?" סבירות ספאם: 83.20084%
אויש… נראה שהתגובות הלגיטימיות האלה מסומנות כספאם כאשר הן מותרות. מה הפתרון?
אפשרות אחת פשוטה היא להגדיל את ה-SPAM_THRESHOLD כדי להיות בטוחים ב-98.5%. במקרה כזה, התגובות עם הסיווג הלא נכון יפורסמו. זכרו גם את התוצאות הנוספות הבאות:
תגובות ספאם שסומנו כספאם (חיובי חיובי):
- " זה מגניב, אבל כדאי לבדוק את קישורי ההורדה באתר שלי שהם טובים יותר!" הסתברות לספאם: 99.77873%
- "אני יודע/ת שחלק מהאנשים שיכולים לקבל חלק מהתרופות שלך יכולים רק לראות את קובץ ה-pr0 שלי לקבלת פרטים" ספאם הסתברות: 98.46955%
- "הצג את הפרופיל שלי כדי להוריד עוד יותר סרטונים מדהימים עוד יותר! http://example.com" ספאם הסתברות: 96.26383%
אוקיי, אז זה עובד כמצופה עם הסף המקורי שלנו בשיעור של 75%, אבל בהתחשב בשלב הקודם שינית את SPAM_THRESHOLD כך שיהיה גבוה מ-98.5%, המשמעות היא שתי דוגמאות משלימות, כך שייתכן שהסף גבוה מדי. אולי 96% יותר טוב? אבל אם תעשו זאת, אחת מהתגובות בסעיף הקודם (תוצאות חיוביות שקריות) תסומן כספאם כשהיא הייתה לגיטימית, כי היא דורגה ב-98.46466%.
במקרה כזה, מומלץ לתעד את כל תגובות הספאם האמיתיות האלה ופשוט לבצע מחדש את הפעולות שנכשלו. כשמגדירים סף לחיוב של 96%, המערכת עדיין מתעדת את כל התוצאות החיוביות האמיתיות ומבטלת 2 החיוביות השגויות שלמעלה. לא נורא אם משנים רק מספר אחד.
בואו נמשיך...
תגובות ספאם שמותר לפרסם (שליליים שגויים):
- "היכנסו לפרופיל שלי כדי להוריד עוד יותר סרטונים נהדרים עוד יותר!" סבירות ספאם: 7.54926%
- "קבלו הנחה על שיעורי ההדרכה שלנו במכון הכושר, pr0file!" סבירות ספאם: 17.49849%
- "omg GOOG מלאי של צילומים חדשים! מקבלים לפני מאוחר מדי!" סבירות ספאם: 20.42894%
בתגובות האלה, לא ניתן לבצע פעולות נוספות, על ידי שינוי ערך הפרמטר SPAM_THRESHOLD. ירידה בסף מספאם מ-96% ל-9% ומעלה תוביל לסימון תגובות אמיתיות כספאם – אחת מהן קיבלה דירוג של 58% למרות שהיא לגיטימית. הדרך היחידה להתמודדות עם תגובות כאלה היא לאמן מחדש את המודל בעזרת מקרי קצה כאלה בנתוני האימון, כך שהוא לומד להתאים את הראייה שלו לעולם לגבי ספאם או לא.
האפשרות היחידה שנותרה כרגע היא לאמן מחדש את המודל, אבל למדת גם איך לחדד את הסף לקבלת החלטות בנוגע לספאם כדי לשפר גם את הביצועים. אנושיים, 75% נראה בטוחים למדי, אך במודל זה היה עליכם להגדיל ל-81.5% כדי להיות יותר יעילים עם קלט לדוגמה.
אין ערך קסם אחד שפועל היטב במודלים שונים. יש להגדיר את ערך הסף הזה לכל מודל, אחרי הניסיון עם נתונים בפועל מה עובד טוב.
במצבים מסוימים, תוצאות חיוביות שקריות (או שליליות) עלולות להוביל להשלכות חמורות (למשל, בתחום הרפואי) כך שתוכלו לשנות את הסף כך שיהיה גבוה מאוד ולבקש בדיקות ידניות יותר עבור אלה שלא עומדים בסף. זוהי הבחירה שלך כמפתח ודורש מספר ניסויים.
4. אימון חוזר של מודל הזיהוי של תגובות ספאם
בקטע הקודם זיהית כמה מקרים של כשלים במודל, שבהם האפשרות היחידה הייתה לאמן את המודל מחדש כדי להביא בחשבון את המצבים האלה. במערכת ייצור, תוכלו למצוא את התגובות האלה לאורך זמן כשאנשים מסמנים תגובה כספאם באופן ידני, ושהמנהלים שלהם בודקים את התגובות שסומנו. הם מגלים שהם לא באמת ספאם, והם עשויים לסמן תגובות כאלה כדי לאמן מחדש. בהנחה שאספת כמות גדולה של נתונים חדשים למקרהי הקצה האלה (כדי לקבל את התוצאות הטובות ביותר, כדאי שיהיו כמה גרסאות למשפטים החדשים האלה), אם נמשיך, נראה לך איך לאמן מחדש את המודל תוך התחשבות במקרים האלה.
סיכום דגם מוגדר מראש
המודל המוכן מראש היה מודל שנוצר על ידי צד שלישי באמצעות בונה המודלים, תוך שימוש במודל "ממוצע של מילים ומירכאות; לתפקוד.
בזמן שהמודל נבנה עם יוצר המודלים, עליך לעבור לזמן קצר ל-Python כדי לאמן מחדש את המודל, ולאחר מכן לייצא את המודל שנוצר לפורמט TensorFlow.js כדי להשתמש בו בדפדפן. למרבה המזל, ליוצר המודלים יהיה קל מאוד להשתמש במודלים שלהם, כך שיהיה לכם קל לעקוב אחרי התהליך. אנחנו נדריך אתכם בתהליך, אז אל דאגה, אם מעולם לא השתמשתם ב-Python!
שיתופי פעולה
מכיוון שאין לכם הרבה חששות לגבי מעבדת הקוד הזו כשאתם רוצים להגדיר שרת Linux עם כל תוכנות ה-Python השונות, אתם יכולים פשוט להריץ קוד דרך דפדפן האינטרנט באמצעות "Colab Notebook" מחברות אלה יכולות להתחבר אל "backend" – זה פשוט שרת שיש בו כמה דברים מותקנים מראש, שמהם ניתן להפעיל קוד שרירותי בדפדפן האינטרנט ולראות את התוצאות. אפשרות זו שימושית מאוד לאבות טיפוס מהיר או לשימוש במדריכים כאלה.
פשוט עברו אל colab.research.google.com ותוצג לכם מסך פתיחה כפי שמוצג כאן:
עכשיו לוחצים על הלחצן פנקס חדש בפינה השמאלית התחתונה של החלון הקופץ. לאחר מכן אמורים להופיע קווסט ריק:
נהדר! השלב הבא הוא חיבור של ממשק הקצה לממשק קצה עורפי כך שתוכלו להריץ את קוד ה-Python שאתם כותבים. כדי לעשות זאת, לוחצים על התחברות בפינה השמאלית העליונה ובוחרים באפשרות התחברות לזמן ריצה מתארח.
לאחר החיבור אתה אמור לראות את סמלי RAM ודיסק במקומם, כך:
יפה מאוד! עכשיו אפשר להתחיל לתכנת ב-Python כדי לאמן מחדש את מודל Maker Maker. לשם כך, בצע את הצעדים שבהמשך.
שלב 1
בתא הראשון שריק כרגע, מעתיקים את הקוד הבא. הוא יתקין עבורך את TensorFlow Lite Maker Maker באמצעות מנהל החבילות של Python&" (שנקרא "pip" (הוא דומה ל-npm שרוב הקוראים במעבדה הזו עשויים להכיר את הסביבה העסקית של JS):
!pip install -q tflite-model-maker
הדבקת הקוד בתא באמצעות ההפעלה לא תצליח. אחר כך, מציבים את הסמן מעל התא האפור שבו הדבקתם את הקוד שלמעלה וסמל קטן של "play" יופיע משמאל לתא כפי שמוצג למטה:
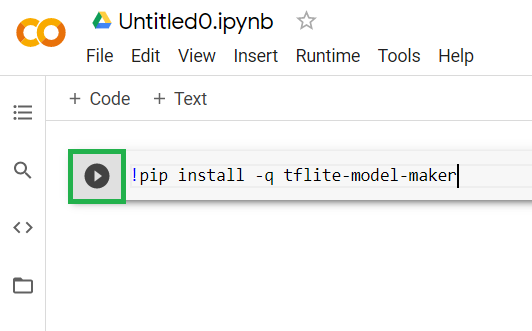 יש ללחוץ על לחצן ההפעלה כדי להפעיל את הקוד שהוקלד בתא.
יש ללחוץ על לחצן ההפעלה כדי להפעיל את הקוד שהוקלד בתא.
עכשיו יוצג מודל היצרן:
לאחר השלמת ביצוע התא הזה, יש לעבור לשלב הבא למטה.
שלב 2
לאחר מכן, מוסיפים תא קוד חדש כפי שמוצג בו, כדי שאפשר יהיה להדביק קוד נוסף אחרי התא הראשון ולהפעיל אותו בנפרד:
התא הבא שיבוצע יכלול מספר ייבואים שהקוד בשאר הפנקס יצטרך להשתמש. מעתיקים ומדביקים את הפרטים הבאים בתא החדש שנוצר:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
דברים רגילים למדי, גם אם אתם לא מכירים את Python. בתהליך הייבוא של כל חלק מהפונקציות והפונקציות של יוצר המודלים הנדרשות לסיווג הספאם. בנוסף, נבדק אם אתם מפעילים את TensorFlow 2.x, שהוא דרישה לשימוש ביוצר המודלים.
לבסוף, בדיוק כמו לפני כן, מבצעים את התא על ידי הקשה על הסמל "play" כשמעבירים את העכבר מעל התא, ולאחר מכן מוסיפים תא קוד חדש לשלב הבא.
שלב 3
בשלב הבא, מורידים את הנתונים משרת מרוחק למכשיר ומגדירים את המשתנה training_data כנתיב של הקובץ המקומי שיווצר:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/laurencemoroney-blog.appspot.com/jm_blog_comments_extras.csv', extract=False)
יוצר המודלים יכול לאמן מודלים מקובצי CSV פשוטים כמו זה שהורדת. פשוט צריך לציין אילו עמודות מכילות את הטקסט ואת העמודות שמחזיקות בתוויות. איך לעשות זאת בשלב 5. אם תרצו, תוכלו להוריד את קובץ ה-CSV ישירות כדי לראות מה הוא מכיל.
השם הרצוי יהיה שם הקובץ jm_blog_comments_extras.csv – הקובץ הזה הוא פשוט נתוני הגרסה המקוריים שבהם השתמשנו כדי ליצור את מודל הספאם של התגובה הראשונה משולב עם הנתונים החדשים של מקרה הקצה שגילית, כך שכולם יהיו בקובץ אחד. תצטרכו גם את נתוני האימון המקוריים המשמשים לאימון המודל בנוסף למשפטים החדשים שמהם אתם רוצים ללמוד.
אופציונלי: אם מורידים את קובץ ה-CSV הזה ובודקים את השורות האחרונות, אפשר לראות דוגמאות למקרים של פעילות קצה שלא פעלו כראוי בעבר. הם התווספו לסוף נתוני האימון הקיימים, המודל שנוצר מראש לאימון עצמו.
יש לבצע את התא הזה, ובסיום הביצוע, להוסיף תא חדש ולעבור לשלב 4.
שלב 4
כשמשתמשים ב'יוצר המודלים', אין צורך לבנות מודלים מאפס. בדרך כלל אתם משתמשים במודלים קיימים שתוכלו להתאים אישית לצרכים שלכם.
מודל המודלים מספק כמה הטמעות של מודלים שנלמדו מראש. אפשר להשתמש בהן, אבל הדרך הפשוטה והמהירה ביותר להתחיל היא average_word_vec, וזה מה שבו השתמשת ב-codelab הקודם כדי לבנות את האתר. זהו הקוד:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
לאחר מכן אפשר להדביק את הפריט הזה לאחר להדביק אותו בתא החדש.
הסבר על
num_words
פרמטר
זהו מספר המילים שבהן רוצים להשתמש במודל. אתם עשויים לחשוב שככל שעדיף יותר מילים, אבל יש בדרך כלל נקודה מתוקה על סמך התדירות שבה כל מילה נמצאת בשימוש. אם תשתמשו בכל המילה שבגוף הטקסט, בסופו של דבר המודל עלול ללמוד ולאזן את המשקלים של מילים שנעשה בהן שימוש רק פעם אחת – זה לא מועיל במיוחד. אתם יכולים למצוא בכל גוף טקסט טקסט של מילים רבות שנעשה בהן שימוש פעם אחת או פעמיים, ובדרך כלל לא כדאי להשתמש בהן במודל, כי יש להן השפעה מזערית על סנטימנט הטקסט הכולל. באמצעות הפרמטר num_words אפשר להתאים את המודל למספר המילים הרצוי. מספר קטן יותר כאן יהיה עם מודל קטן ומהיר יותר, אך הוא עשוי להיות פחות מדויק, מאחר שהוא מזהה פחות מילים. מספר גדול יותר כאן יהיה עם דגם גדול יותר ועשוי להיות איטי יותר. כדי למצוא את נקודת המבט הזו, צריך לבחור מהנדס למידה. כך תוכלו להבין מה הכי מתאים לצרכים שלכם.
הסבר על
wordvec_dim
פרמטר
הפרמטר wordvec_dim הוא מספר המאפיינים שבהם רוצים להשתמש כשהוקטור של כל מילה. מאפיינים אלה הם למעשה המאפיינים השונים (שנוצרים על ידי אלגוריתם הלמידה החישובית במהלך האימון) שאותם ניתן למדוד כל מילה נתונה, שהתוכנית תשתמש בה כדי לנסות ולשייך בצורה הטובה ביותר מילים דומות בצורה משמעותית.
לדוגמה, אם היה לכם מאפיין שמציין איך "med" מילה הייתה מילה, כמו "pills" , ייתכן שהציון שלה יהיה גבוה כאן במאפיין הזה, והיא תשויך למילים אחרות עם ניקוד גבוה כמו "xray" , אבל "cat" יקבל ציון נמוך במאפיין הזה. ייתכן שיתברר שמאפיין &מירכאות רפואיות; שימושי לקביעת ספאם כאשר משלבים אותו עם מאפיינים פוטנציאליים אחרים.
במקרה של מילים שמדורגות גבוה ב &מאפיין רפואי;&, יכול להיות שמאפיין שני שמקשר מילים לגוף האדם יכול להיות מועיל. מילים כמו "leg", "arm", "neck" יכולות לקבל כאן ציון גבוה, וגם די גבוהות במאפיין הרפואי.
המודל הזה יכול להשתמש במאפיינים האלה כדי להפעיל אותו כדי לזהות מילים שיש סיכוי גבוה יותר שהן משויכות לספאם. יכול להיות שהאימיילים שמכילים ספאם צפויים יותר לכלול מילים שהן גם חלקיות רפואיות וגם איברי גוף.
כלל אצבע שנקבע מהמחקר הוא שהשורש הרביעי של מספר המילים פועל היטב עבור הפרמטר הזה. לכן, אם אני משתמש ב-2,000 מילים, נקודת התחלה טובה תהיה 7 מימדים. אם משנים את מספר המילים שמופיעות, אפשר גם לשנות זאת.
הסבר על
seq_len
פרמטר
בדרך כלל, המודלים מחושבים מאוד בכל הנוגע לערכי קלט. עבור מודל שפה, פירוש הדבר שמודל השפה יכול לסווג משפטים של אורך, סטטיים ואורך מסוים. הפרמטר הזה נקבע באמצעות הפרמטר seq_len, כאשר הוא מייצג את 'אורך הרצף'. כשממירים מילים למספרים (או אסימונים), כל משפט הופך לרצף של האסימונים האלה. כדי לאמן את המודל שלך (במקרה הזה), לסווג את הביטויים שמכילים 20 אסימונים ולזהות אותם. אם המשפט ארוך יותר, הוא ייחתך. אם היא תהיה קצרה יותר, היא תרוץ – בדיוק כמו במעבדת הקוד הראשונה בסדרה הזו.
שלב 5 – טוענים את נתוני האימון
מוקדם יותר הורדת את קובץ ה-CSV. עכשיו הגיע הזמן להשתמש בכלי לטעינת נתונים כדי להפוך את הנתונים לנתונים לאימון שהמודל יכול לזהות.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
אם פותחים את קובץ ה-CSV בעורך, אפשר לראות שכל שורה כוללת שני ערכים, והם מתוארים בטקסט בשורה הראשונה של הקובץ. בדרך כלל, כל רשומה נחשבת כ'עמודה&33'. ניתן לראות שהתיאור בעמודה הראשונה הוא commenttext, ושהרשומה הראשונה בכל שורה היא טקסט של התגובה.
באופן דומה, התיאור בעמודה השנייה הוא spam, וניתן לראות שהערך השני בכל שורה הוא TRUE או FALSE כדי לציין אם הטקסט הזה נחשב כספאם או לא. המאפיינים האחרים מגדירים את מפרט המודל שיצרתם בשלב 4, יחד עם תו מפריד, שבמקרה הזה הוא פסיק, כי הקובץ מופרד בפסיקים. כמו כן, אפשר להגדיר פרמטר להשמעה אקראית כדי לסדר מחדש את נתוני האימון. כך, הנתונים שנראים דומים או נאספים יחד מפוזרים באופן אקראי בקבוצת הנתונים.
לאחר מכן תשתמשו ב-data.split() כדי לפצל את הנתונים לנתוני הדרכה ובדיקה. .9
שלב 6 – בניית המודל
יש להוסיף עוד תא שבו נוסיף את הקוד כדי לבנות את המודל:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
פעולה זו יוצרת מודל של סיווג טקסט עם יוצר המודלים, ואתם מציינים את נתוני האימון שבהם אתם רוצים להשתמש (כפי שהוגדר בשלב 4), את מפרט המודלים (שהוגדר גם בשלב 4) ואת מספר התקופות במקרה הזה, 50.
העיקרון הבסיסי של למידה חישובית הוא סוג של התאמת דפוסים. בתחילה, הוא יטען את המשקלים המאמנים מראש עבור מילים, וינסה לקבץ אותן יחד עם 'חיזוי''. כאשר הן יקובצו יחדיו כספאם, ואילו לא. בפעם הראשונה, סביר להניח שהוא יהיה קרוב ל-50:50, מכיוון שהמודל מתחיל רק כפי שמוצג כאן:

לאחר מכן, הוא ימדוד את התוצאות של השינוי וישנה את המשקלים של המודל כדי להתאים את החיזוי שלו, וינסה שוב. זוהי תקופה. אם מציינים את ה-epochs=50, הוא יעבור את הערך 'loop''; 50 פעמים כפי שמוצג כאן:

לכן, עד להגעה אל התקופה ה-50, המודל ישלח דיווח ברמת דיוק גבוהה יותר. במקרה כזה, מוצג 99.1%!
שלב 7 – ייצוא המודל
אחרי שהאימון יסתיים תוכלו לייצא את המודל. TensorFlow מאמן מודל בפורמט משלו, וצריך להמיר אותו לפורמט TensorFlow.js לשימוש בדף אינטרנט. פשוט מדביקים את הטקסט הבא בתא חדש ומפעילים אותו:
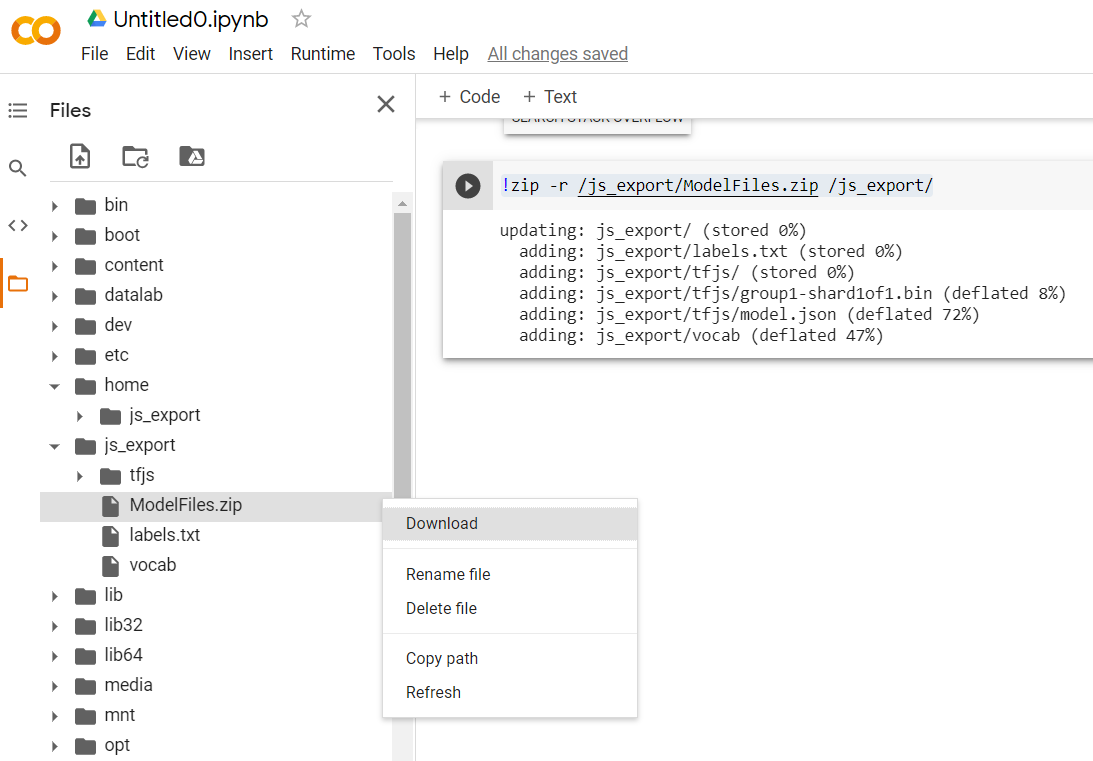
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
לאחר הפעלת הקוד, אם לוחצים על סמל התיקייה הקטנה בצד ימין של ה-Colab, אפשר לנווט לתיקייה שייצאתם אליה למעלה (בספריית הבסיס – ייתכן שתצטרכו לעלות רמה) ולמצוא את חבילת ה-ZIP של הקבצים שיוצאו הכלולים ב-ModelFiles.zip.
עכשיו מורידים את קובץ ה-ZIP למחשב, כי משתמשים בו כמו במעבדת הקוד הראשונה:
נהדר! החלק ב-Python הסתיים, ועכשיו אפשר לחזור ל-JavaScript הידוע והאהוב. סוף סוף!
5. הצגת מודל הלמידה החישובית החדש
כמעט סיימת לטעון את המודל. לפני שתעשו זאת, עליכם להעלות את קובצי הדגם החדשים שהורדתם מוקדם יותר ב-Codelab, כך שיהיו מתארחים וניתן לשימוש בקוד שלכם.
ראשית, אם עדיין לא עשית זאת, פתח את הקבצים של הדגם שהורדת עכשיו מהפנקס של Colab של 'יוצר המודלים'. הקבצים הבאים אמורים להופיע בתיקיות השונות שלו:
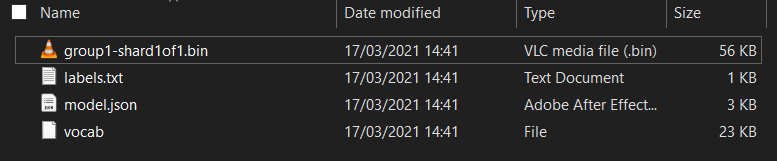
מה יש לכם כאן?
model.json- זהו אחד מהקבצים שמהם מורכב מודל TensorFlow.js. ניתן להפנות לקובץ ספציפי זה בקוד JS.group1-shard1of1.bin- זהו קובץ בינארי שמכיל הרבה מהנתונים השמורים של מודל TensorFlow.js ושצריך לארח מקום כלשהו בשרת לצורך הורדה באותה ספרייה כמוmodel.jsonשלמעלה.vocab- הקובץ המוזר הזה ללא תוסף הוא משהו מ-Model Maker שמראה לנו איך לקודד מילים במשפטים כדי שהמודל יבין איך להשתמש בהם. נפרט את הנושא הזה בקטע הבא.labels.txt- השם הזה מכיל רק את שמות הכיתות ש המודל יחזה. עבור מודל זה אם פותחים קובץ זה בעורך הטקסט שלכם, פשוט יש להוסיף " "false" ו-"true" המציין "לא ספאם" או "spam" בתור פלט החיזוי.
אירוח קובצי הדגם של TensorFlow.js
תחילה מציבים את הקבצים model.json ו-*.bin שנוצרו על שרת אינטרנט כדי שתוכלו לגשת אליהם דרך דף האינטרנט שלכם.
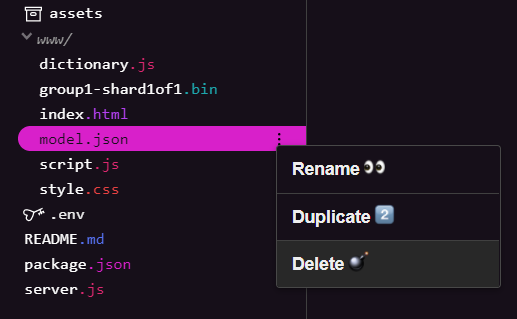
מחיקה של קובצי דגמים קיימים
תוך כדי בניית התוצאה הסופית של מעבדת הקוד הראשונה בסדרה זו, עליכם למחוק תחילה את קובצי הדגמים הקיימים שהועלו. אם אתם משתמשים ב-Glitch.com, עליכם לבדוק את חלונית הקבצים שמימין ל-model.json ול-group1-shard1of1.bin. לשם כך, לוחצים על התפריט הנפתח של 3 נקודות לכל קובץ ובוחרים באפשרות מחיקה כפי שמוצג כאן:
העלאת קבצים חדשים ל-Glitch
נהדר! עכשיו מעלים את החדשים:
- פותחים את התיקייה נכסים בחלונית הימנית של פרויקט Glitch ומוחקים נכסים ישנים שהועלו אם יש להם שמות זהים.
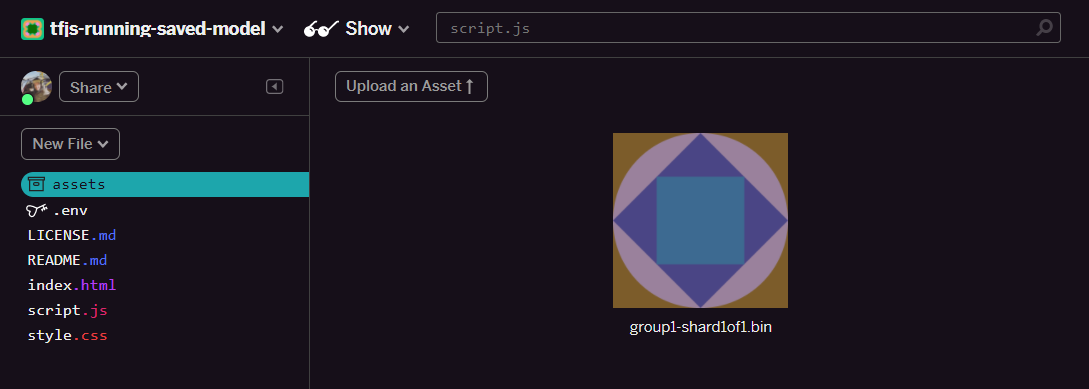
- לוחצים על העלאת נכס ובוחרים באפשרות
group1-shard1of1.binלהעלאה לתיקייה הזו. לאחר ההעלאה, הוא אמור להיראות כך:
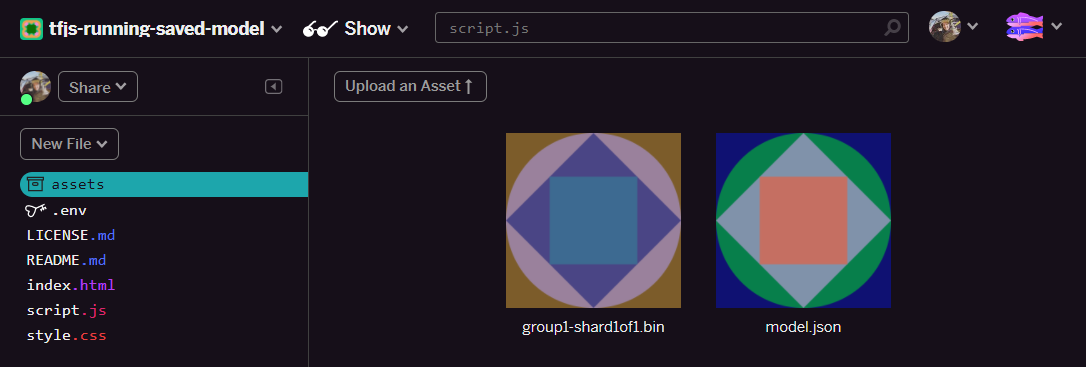
- נהדר! עכשיו צריך לבצע שוב את הפעולה הזו עבור הקובץ example.json, כך ששני קבצים אמורים להיות בתיקיית הנכסים שלכם:
- אם לוחצים על הקובץ
group1-shard1of1.binשהעלית כרגע, אפשר להעתיק את כתובת ה-URL אל המיקום שלה. העתקת הנתיב הזה כפי שהוא מוצג כאן:
- עכשיו בפינה הימנית התחתונה של המסך, לוחצים על כלים > מסוף. יש להמתין לטעינה של חלון המסוף.
- לאחר הטעינה, צריך להקליד את הטקסט הבא ולאחר מכן להקיש על Enter כדי לשנות את הספרייה לתיקייה
www:
טרמינל:
cd www
- בשלב הבא, יש להשתמש ב-
wgetכדי להוריד את שני הקבצים שהועלו עכשיו על ידי החלפת כתובות ה-URL שלמטה בכתובות ה-URL שיצרת עבור הקבצים בתיקיית הנכסים ב-Glitch (יש לבדוק בתיקיית הנכסים של כל כתובת URL מותאמת אישית של כל קובץ).
שימו לב שהרווח בין שתי כתובות ה-URL יהיה זהה לכך שכתובות ה-URL שבהן תצטרכו להשתמש יהיו שונות מאלה שיוצגו, אבל ייראו דומות:
טרמינל
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
סופר! כעת יצרת עותק של הקבצים שהועלו לתיקייה www.
עם זאת, כרגע הן יורדו עם שמות מוזרים. אם מקלידים ls במסוף ומקישים על Enter, מופיעה משהו כזה:

- באמצעות הפקודה
mvאפשר לשנות את שמות הקבצים. מזינים את הטקסט הבא במסוף ומקישים על Enter אחרי כל שורה:
טרמינל:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- לבסוף, מרעננים את פרויקט Glitch על ידי הקלדת
refreshבמסוף ומקישים על Enter:
טרמינל:
refresh
לאחר הרענון אמורה להופיע עכשיו התיקייה model.json וגם התיקייה group1-shard1of1.bin בתיקייה www בממשק המשתמש:
נהדר! השלב האחרון הוא לעדכן את הקובץ dictionary.js.
- יש להמיר את קובץ ה-VOcab החדש לפורמט הנכון של JS באופן ידני באמצעות עורך הטקסט או באמצעות הכלי הזה ולשמור את הפלט המתקבל כ-
dictionary.jsבתיקייתwww. אם כבר יש לך קובץdictionary.js, אפשר פשוט להעתיק את התוכן החדש ולהדביק אותו מעליו ולשמור את הקובץ.
כל הכבוד! עדכנתם בהצלחה את כל הקבצים שהשתנו. עכשיו, אם תנסו להשתמש באתר, תוכלו לראות איך המודל המאומן צריך להביא בחשבון את המקרים המקריים שהתגלו ולמדו מהם:
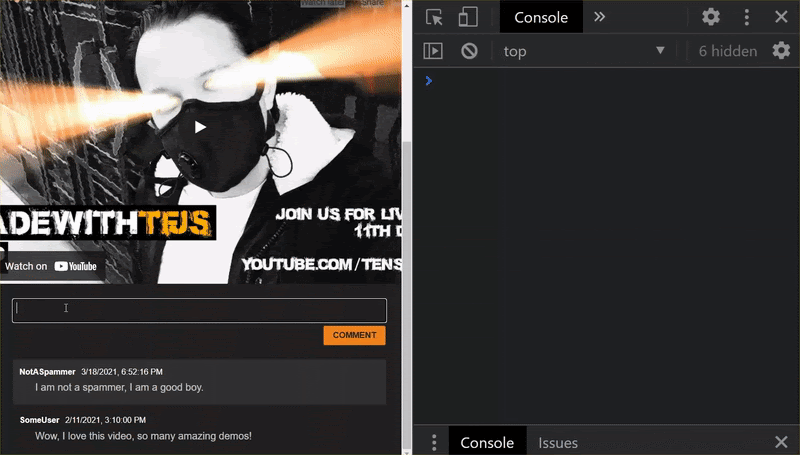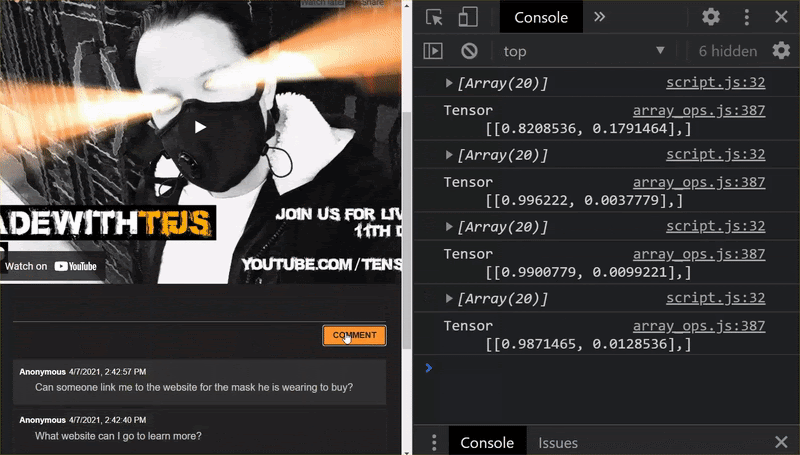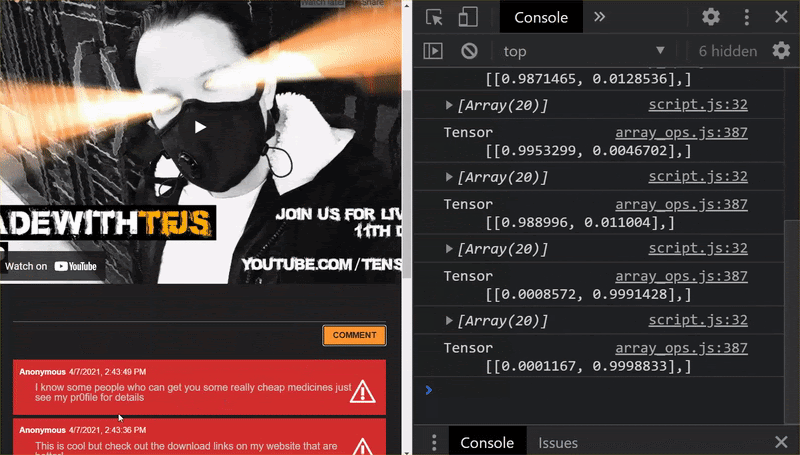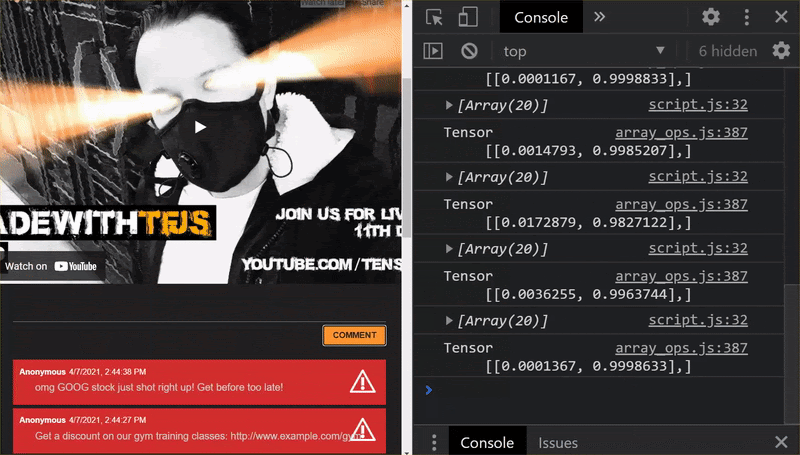
כפי שאפשר לראות, 6 הראשונים מסווגים כראוי כ'לא ספאם', והקבוצה השנייה מתוך 6 מזוהים כספאם. יופי!
ננסה גם כמה וריאציות כדי לראות אם היא כללית. במקור היה משפט כושל, כמו:
"omg GOOG Shot Right up! מקבלים לפני מאוחר מדי!"
הסיווג הזה נכון עכשיו לספאם, אבל מה יקרה אם תשנו אותו ל:
"הערך של XYZ עלה כעת! צריך לקנות קצת לפני שיהיה מאוחר מדי!"
כאן מוצג חיזוי בשיעור של 98% שהספאם נכון, גם אם שיניתם מעט את סמל המניה ואת הניסוח.
כמובן, אם תתנסו בפועל לבטל את המודל החדש, תוכלו לעשות זאת. בנוסף, תוכלו לאסוף עוד נתוני אימונים כדי להגדיל את הסיכוי לזכות בווריאציות ייחודיות יותר של מצבים נפוצים שבהם אתם עשויים להיתקל באינטרנט. במעבדה עתידית אנחנו נראה לכם איך לשפר את המודל באופן שוטף בעזרת נתונים בזמן אמת כשהם מסומנים.
6. מעולה!
מזל טוב, הצלחת לאמן מחדש מודל קיים של למידה חישובית כדי לעדכן את עצמו כך שיתאים למקרים בקצה שמצאת, ופרסת את השינויים האלה בדפדפן עם TensorFlow.js בשביל אפליקציה בעולם האמיתי.
סיכום
ב-codelab הזה:
- מקרים של קצה קצה שלא פעלו בעת השימוש במודל הספאם שהוגדר מראש
- אימון מחדש של מודל יוצר המודלים כדי להביא בחשבון את מקרי הקצה שגילית
- הייצוא של המודל המיומן החדש לפורמט TensorFlow.js
- עדכנתם את אפליקציית האינטרנט כדי להשתמש בקבצים החדשים
מה השלב הבא?
לכן העדכון הזה יפעל נהדר, אבל כמו כל אפליקציית אינטרנט, השינויים יתבצעו עם הזמן. הרבה יותר כדאי אם האפליקציה משפרת את עצמה באופן קבוע לאורך זמן, במקום שאנחנו צריכים לעשות זאת באופן ידני בכל פעם. האם לדעתך תוכלו לבצע באופן אוטומטי את השלבים הבאים כדי לאמן מחדש מודל באופן אוטומטי לאחר שיש לכם 100 תגובות חדשות שסומנו כסיווג שגוי? החליטו על הכובע הרגיל שלכם בתחום הנדסת האתרים, ואתם מבינים איך ליצור צינור כדי לעשות זאת באופן אוטומטי. אם לא, אל דאגה, חפשו את מעבדת הקוד הבאה בסדרה שתראו כיצד לעשות זאת.
משתפים איתנו את המתכונים
אתם יכולים להרחיב בקלות את הפעילות שלכם עוד היום לתרחישים אחרים לדוגמה, ואנחנו ממליצים לכם לחשוב מחוץ לתיבה ולהמשיך להשתמש בפריצה.
אל תשכחו לתייג אותנו ברשתות החברתיות באמצעות ה-hashtag #MadeWithTFJS כדי שהפרויקט שלכם יוצג בבלוג TensorFlow או אפילו באירועים עתידיים. נשמח לראות מה מכינים.
ניתוח מעמיק יותר של TensorFlow.js
- שימוש באירוח Firebase כדי לפרוס מארח של TensorFlow.js ולאסוף אותו בקנה מידה גדול.
- יצירת מצלמת אינטרנט חכמה באמצעות מודל לזיהוי אובייקטים שנוצר מראש, עם TensorFlow.js
אתרים שכדאי לבדוק
- האתר הרשמי של TensorFlow.js
- מודלים מוכנים מראש של TensorFlow.js
- API של TensorFlow.js
- TensorFlow.js Show &Tell – מקבלים השראה ולראות מה אנשים אחרים יצרו.