
1. قبل البدء
تم تصميم هذا الدرس التطبيقي حول الترميز استنادًا إلى النتيجة النهائية من الدرس التطبيقي السابق في هذه السلسلة بشأن رصد التعليقات غير المرغوب فيها باستخدام TensorFlow.js.
في الدرس التطبيقي الأخير حول الترميز، أنشأت صفحة ويب تعمل بشكل كامل لمدونة فيديو خيالية. تمكّنت من فلترة التعليقات بحثًا عن المحتوى غير المرغوب فيه قبل إرسالها إلى الخادم بغرض تخزينها، أو إلى برامج أخرى مرتبطة، وذلك باستخدام نموذج مدرّب مسبقًا للتعليقات غير المرغوب فيها وتكون مدعومة من TensorFlow.js في المتصفّح.
في ما يلي النتيجة النهائية لهذا الدرس التطبيقي حول الترميز:
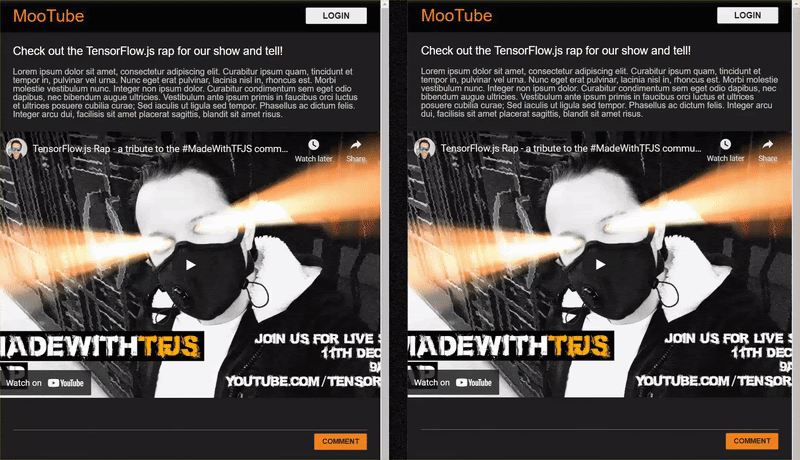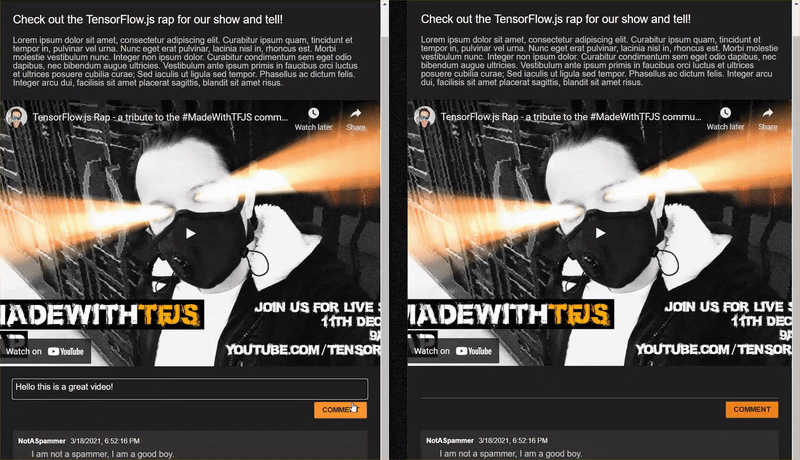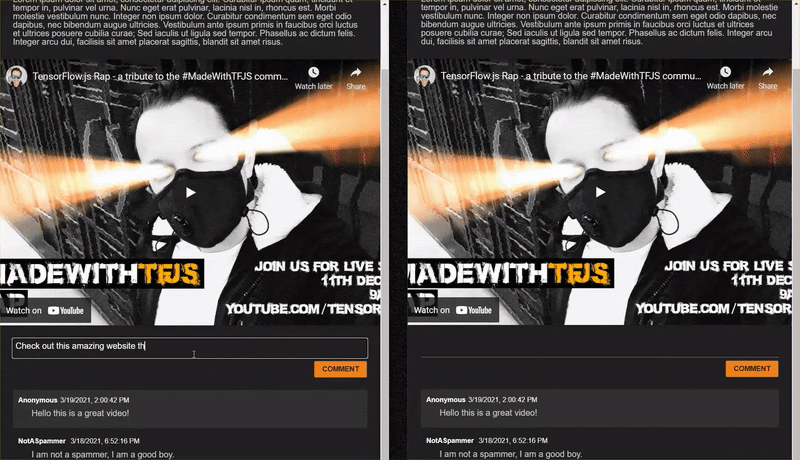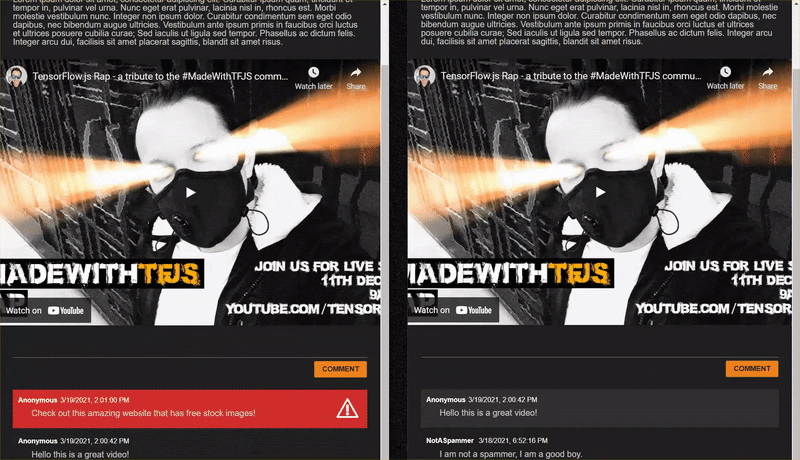
بالرغم من أن هذا كان جيدًا جدًا، هناك بعض حالات الحافة التي تعذّر اكتشافها من قبل. ويمكنك إعادة ضبط النموذج لمراعاة المواقف التي تعذّر عليها التعامل معها.
يركّز هذا الدرس التطبيقي على استخدام تقنية معالجة اللغات الطبيعية (فن فهم اللغة البشرية باستخدام الكمبيوتر) ويوضح لك كيفية تعديل تطبيق الويب الحالي الذي أنشأته (يُنصح بشدة بإجراء الدروس التطبيقية حول الترميز) لمعالجة المشكلة الحقيقية للغاية التي تمثل وجود تعليقات غير مرغوب فيها والتي يواجهها العديد من مطوّري الويب بالتأكيد أثناء عملها على واحد من العدد المتزايد باستمرار من تطبيقات الويب الرائجة اليوم.
في هذا الدرس التطبيقي حول الترميز، ستحصل على خطوة أبعد من خلال إعادة تدريب نموذج تعلُّم الآلة ليشمل التغييرات في محتوى الرسائل غير المرغوب فيها التي قد تتطور بمرور الوقت، استنادًا إلى المؤشرات الحالية أو المواضيع الشائعة للمناقشة، ما يسمح لك بالحفاظ على النموذج محدّثًا وحلّ هذه التغييرات.
المتطلّبات الأساسية
- لقد أكملت الدرس التطبيقي الأول حول الترميز في هذه السلسلة.
- معرفة أساسية بتقنيات الويب بما في ذلك HTML وCSS وJavaScript.
العناصر التي سيتم إنشاؤها
يمكنك إعادة استخدام الموقع الإلكتروني الذي تم إنشاؤه سابقًا لمدونة فيديو وهمية مع قسم للتعليق في الوقت الفعلي وترقيته لتحميل إصدار مخصص ومُدرّب من نموذج اكتشاف المحتوى غير المرغوب فيه باستخدام TensorFlow.js، حتى يتمكن من تحقيق أداء أفضل في الحالات التي كان من الممكن أن يتعذّر عليه إكماله في السابق. وبالطبع، بصفتك مطوّري برامج ومهندسين على الويب، يمكنك تغيير تجربة المستخدم الافتراضية هذه لإعادة استخدامها على أي موقع إلكتروني قد تعمل عليه في مهامك اليومية وتكيف الحل ليلائم أي حالة من حالات استخدام العملاء، سواء كانت مدونة أو منتدى أو أي شكل من أنظمة إدارة المحتوى، مثل Drupal.
لنبدأ عمليات الاختراق...
ما ستتعرّف عليه
عليك تنفيذ ما يلي:
- تحديد الحالات التي تعذّر فيها النموذج المدرّب مسبقًا
- أعِد التدريب على نموذج تصنيف الرسائل غير المرغوب فيها الذي تم إنشاؤه باستخدام مصمم النماذج.
- عليك تصدير هذا النموذج المستند إلى Python إلى تنسيق TensorFlow.js لاستخدامه في المتصفّحات.
- حدِّث النموذج المستضاف وقاموسه باستخدام النموذج الذي تم تدريبه حديثًا وتحقّق من النتائج.
ومن المفترض أن تكون على دراية بكل من HTML5 وCSS وJavaScript في هذا الدرس التطبيقي. ستعمل أيضًا على تشغيل بعض رموز Python عبر دفتر ملاحظات &&co;co" لإعادة تدريب النموذج الذي تم إنشاؤه باستخدام أداة إنشاء النماذج، ولكن ليس عليك معرفة بايثون بذلك.
2. بدء عملية الإعداد
ستستخدم مرة أخرى Glitch.com لاستضافة تطبيق الويب وتعديله. إذا لم تكن قد أكملت الدرس التطبيقي حول الترميز المطلوب مسبقًا، يمكنك نسخ النتيجة النهائية هنا كنقطة بداية. إذا كانت لديك أي أسئلة حول آلية عمل الرمز، ننصحك بشدة بإكمال الدرس التطبيقي السابق حول الترميز الذي شرح كيفية إنشاء تطبيق الويب المُفعَّل قبل المتابعة.
على Glitch، ما عليك سوى النقر على زر إعادة مزج هذا لعمل برنامج المتصفح وإنشاء مجموعة جديدة من الملفات التي يمكنك تعديلها.
3- اكتشاف حالات الحافة في الحل السابق
إذا فتحت الموقع الإلكتروني المكتمل الذي استنسخته للتو وحاولت كتابة بعض التعليقات، ستلاحظ أن معظم الوقت يعمل على النحو المنشود، ما يؤدي إلى حظر التعليقات التي تبدو غير مرغوب فيها على النحو المتوقّع، المسموح بها من خلال ردود شرعية.
ولكن إذا نجح حرفك وحاولت صياغة النموذج لاختراق النموذج، ستنجح على الأرجح في أي وقت. بعد قليل من التجربة والخطأ، يمكنك إنشاء أمثلة يدويًا مثل الأمثلة المعروضة أدناه. حاوِل لصق هذه العناصر في تطبيق الويب الحالي وتحقّق من وحدة التحكّم وتعرّف على الاحتمالات التي يمكنك الرجوع إليها إذا كان التعليق غير مرغوب فيه:
تعليقات مشروعة يتم نشرها بدون مشكلة (سلبيات حقيقية):
- "رائع، أحب هذا الفيديو، عمل رائع. احتمال غير مرغوب فيه: 47.91854%
- "أعجبني جدًا هذه العروض التوضيحية. لقد اطّلعنا على المزيد من التفاصيل・quot; احتمال الرسائل غير المرغوب فيها: 47.15898%
- "ما هو الموقع الإلكتروني الذي يمكنني الانتقال إليه لمعرفة المزيد من المعلومات・quot; احتمال غير مرغوب فيه: 15.32495%
هذا أمر رائع، حيث تكون الاحتمالات لكل ما سبق منخفضة جدًا وتتيح الوصول إلى SPAM_THRESHOLD تلقائي من الحد الأدنى للاحتمال بنسبة 75% قبل اتخاذ إجراء (كما هو محدّد في رمز script.js من الدرس التطبيقي السابق).
لنحاول الآن كتابة المزيد من التعليقات الجريئة التي يتم وضع علامة عليها كمحتوى غير مرغوب فيه على الرغم من أنها ليست...
التعليقات المشروعة التي تم وضع علامة عليها كرسائل غير مرغوب فيها (الإيجابيات):
- "هل يمكن لمستخدم ربط الموقع الإلكتروني بالقناع الذي يرتديه・quot; احتمال نشر الرسائل غير المرغوب فيها: 98.46466%
- "هل يمكنني شراء هذه الأغنية على Spotify؟ يُرجى إعلامنا بالأمر. احتمال نشر الرسائل غير المرغوب فيها: 94.40953%
- "هل يمكن لأحد الاتصال بي وتزويدي بتفاصيل حول كيفية تنزيل TensorFlow.js}{quot; احتمال نشر الرسائل غير المرغوب فيها: 83.20084%
عذرًا! يبدو أنّ هذه التعليقات المشروعة قد تمّ وضع علامة عليها كغير مرغوب فيها عندما يجب السماح بها. كيفية حلّ المشكلة:
ويتمثل أحد الخيارات البسيطة في زيادة SPAM_THRESHOLD لتكون واثقة بنسبة تزيد على 98.5%. وفي هذه الحالة، سيتم نشر هذه التعليقات التي تم تصنيفها بشكل خاطئ. مع أخذ ذلك في الاعتبار، دعنا نتابع النتائج الأخرى المحتملة أدناه...
التعليقات غير المرغوب فيها التي تم وضع علامة عليها كغير مرغوب فيها (الإيجابيات)):
- "هذا رائع، ولكن اطّلِع على روابط التنزيل الأفضل على موقعي الإلكتروني. احتمال الرسائل غير المرغوب فيها: 99.77873%
- "أعرف أن بعض الأشخاص الذين يمكنهم إعطائك بعض الأدوية لا يرون سوى ملف pr0file للحصول على التفاصيل"؛ رسائل الاحتمالية غير المرغوب فيها: 98.46955%
- "الاطّلاع على ملفي الشخصي لتنزيل فيديو أكثر تطورًا وأفضل من ذلك هنا. http://example.com" احتمال نشر محتوى غير مرغوب فيه: 96.26383%
حسنًا، يعمل ذلك على النحو المتوقّع مع الحد الأدنى الأصلي الذي يبلغ 75%، ولكن نظرًا لأنّه في الخطوة السابقة، غيّرت SPAM_THRESHOLD إلى نسبة تزيد على 98.5%، فهذا يعني أنّه سيتم السماح بمثالين هنا، وبالتالي قد يكون الحد الأقصى مرتفعًا جدًا. ربما تكون النسبة 96% أفضل. ولكن إذا فعلت ذلك، سيتم وضع علامة على أحد التعليقات في القسم السابق (الإيجابيات الخاطئة) باعتبارها محتوى غير مرغوب فيه عندما تكون مشروعة كما تم تقييمها بنسبة 98.46466%.
في هذه الحالة، قد يكون من الأفضل التقاط جميع هذه التعليقات غير المرغوب فيها الحقيقية وإعادة التدريب على عمليات الإخفاق المذكورة أعلاه. عند ضبط الحدّ على 96%، ستظل جميع الحالات الموجبة الصحيحة صحيحة، وبالتالي يمكنك إزالة 2 من النتائج الموجبة الخاطئة أعلاه. لا بأس كثيرًا بتغيير رقم واحد فقط.
لنبدأ...
التعليقات غير المرغوب فيها التي تم السماح بنشرها (التعليقات السلبية السلبية):
- &الاطّلاع على ملفي الشخصي لتنزيل المزيد من الفيديوهات الرائعة والأفضل من ذلك احتمال نشر الرسائل غير المرغوب فيها: 7.54926%
- "احصل على خصم في صفوف التدريب على صالة الألعاب الرياضية. شاهد pr0file!" احتمال غير مرغوب فيه: 17.49849%
- &"omg GOOG سهم صاعد إلى الأعلى! بادر بنشرها قبل فوات الأوان. احتمال نشر الرسائل غير المرغوب فيها: 20.42894%
بالنسبة إلى هذه التعليقات، لا يمكنك اتخاذ أي إجراء ببساطة عن طريق تغيير قيمة SPAM_THRESHOLD. ويؤدي خفض الحد الأدنى للمحتوى غير المرغوب فيه من 96% إلى 9% تقريبًا إلى وضع علامة على التعليقات الحقيقية باعتبارها محتوى غير مرغوب فيه، حيث يحصل أحد هذه التقييمات على تقييم 58% على الرغم من أنها مشروعة. والطريقة الوحيدة للتعامل مع مثل هذه التعليقات هي إعادة تدريب النموذج مع حالات الحافة المضمنة في بيانات التدريب بحيث يتعلم كيفية تعديلها للعالم من خلال المحتوى غير المرغوب فيه أو لا.
وفي حين أن الخيار الوحيد المتبقي الآن هو إعادة ضبط النموذج، ولاحظت أيضًا كيف يمكنك تحسين الحد الأدنى للوقت الذي تقرر فيه استدعاء شيء غير مرغوب فيه لتحسين الأداء أيضًا. بصفتك شخصًا، تبدو 75% واثقة إلى حد ما، ولكن بالنسبة إلى هذا النموذج، كنت بحاجة إلى زيادة بنسبة 81.5% لتكون أكثر فاعلية مع أمثلة المدخلات.
ما من قيمة سحرية واحدة تعمل بشكلٍ جيد في مختلف النماذج، ويجب ضبط قيمة الحد الأدنى هذه على أساس كل نموذج بعد إجراء التجارب باستخدام بيانات فعلية للسلعة التي تحقّق أداءً جيدًا.
وقد تكون هناك بعض الحالات التي يكون فيها النتائج الموجبة الخاطئة (أو السلبية) لها عواقب خطيرة (على سبيل المثال، في مجال الطب) لذا قد تحتاج إلى ضبط الحد الأقصى ليكون مرتفعًا جدًا وطلب المزيد من المراجعات اليدوية لأولئك الذين لا يستوفون الحد الأدنى. هذا اختيارك بصفتك مطوّر برامج ويتطلب بعض التجارب.
4. إعادة ضبط نموذج رصد التعليقات غير المرغوب فيها
في القسم السابق، حدّدت عددًا من حالات الحواف التي تعذّر تنفيذها في النموذج الذي كان الخيار الوحيد فيه هو إعادة تدريب النموذج على مراعاة هذه الحالات. وفي نظام إنتاج، يمكنك أن تجد هذه التعليقات بمرور الوقت عندما يبلِّغ الأشخاص عن تعليق على أنّه غير مرغوب فيه يدويًا، أو أن المشرفين الذين يراجعون التعليقات التي تم الإبلاغ عنها يدركون أن بعضها ليس محتوى غير مرغوب فيه، ويمكنهم وضع علامة على هذه التعليقات لإعادة تدريبها. بافتراض أنّك قد جمعت مجموعة جديدة من البيانات الجديدة لهذه الحالات من الحالات (للحصول على أفضل النتائج، يجب أن يكون لديك بعض الاختلافات من هذه الجُمل الجديدة، إن أمكن)، سنتابع الآن تعليمك كيفية إعادة تدريب النموذج مع مراعاة حالات الحافة هذه.
ملخّص النموذج المعدّ مسبقًا
إنّ النموذج الذي تم إنشاؤه مسبقًا والذي استخدمته عبارة عن نموذج تم إنشاؤه من قِبل جهة خارجية عبر أداة إنشاء النماذج التي تستخدم &"؛متوسّط كلمة تضمين{/1}"؛
عند إنشاء النموذج باستخدام مصمم النماذج، ستحتاج إلى التبديل إلى Python لفترة قصيرة لإعادة تدريب النموذج، ثم تصدير النموذج الذي تم إنشاؤه إلى تنسيق TensorFlow.js بحيث يمكنك استخدامه في المتصفح. ولحسن الحظ، يعمل مصمم النماذج على تسهيل عملية استخدام النماذج للغاية، لذلك سيكون من السهل المتابعة معها وسنرشدك خلال العملية؛ لذا لا تقلق إذا لم تكن قد استخدمت Python من قبل.
أعمال التعاون
لا داعي للقلق بشأن هذا الدرس التطبيقي حول الترميز الذي تريده عند إعداد خادم Linux يتضمّن جميع الأدوات المساعدة Python المختلفة، يمكنك تنفيذ الرمز باستخدام متصفّح الويب باستخدام "Colab Notebook". ويمكن ربط هذه المفكرات بـ "&رمز خلفية" - وهو ببساطة خادم يحتوي على بعض العناصر المثبتة مسبقًا والتي يمكنك من خلالها تنفيذ رمز عشوائي داخل متصفح الويب ومعرفة النتائج. وتُعدّ هذه الطريقة مفيدة جدًا للنماذج الأولية السريعة أو للاستخدام في برامج تعليمية مثل هذه.
ما عليك سوى الانتقال إلى colab.research.google.com وستظهر لك شاشة ترحيب كما هو موضّح:
الآن انقر على الزر مفكرة جديدة في الجزء السفلي الأيسر من النافذة المنبثقة وسيظهر لك تعاون فني فارغ على النحو التالي:
رائع! وتتمثل الخطوة التالية في ربط الملف الشخصي للواجهة الأمامية بخادم خلفي حتى تتمكن من تنفيذ رمز Python الذي تكتبه. ويمكنك إجراء ذلك من خلال النقر على ربط في أعلى يسار الصفحة واختيار ربط وقت التشغيل المستضاف.
بعد الاتصال، من المفترض أن تظهر رموز RAM والقرص في مكانها، على النحو التالي:
أحسنت. يمكنك الآن بدء الترميز في Python لإعادة ضبط نموذج مصمم النماذج. ما عليك سوى اتباع الخطوات التالية.
الخطوة الأولى
في الخلية الأولى الفارغة حاليًا، انسخ الرمز التالي. وسيؤدي هذا التطبيق إلى تثبيت أداة إنشاء النماذج TensorFlow Lite نيابةً عنك باستخدام مدير الحزم Python's الذي يُسمى "pip" (يشبه npm الذي قد يكون معظم قرّاء مختبَر الرمز هذا مألوفًا أكثر من منظومة JavaScript المتكاملة):
!pip install -q tflite-model-maker
بينما لن يؤدي لصق الرمز إلى الخلية إلى تنفيذه. بعد ذلك، مرّر مؤشر الماوس فوق الخلية الرمادية التي لصقت فيها الرمز أعلاه، وسيظهر رمز صغير على &رمز التشغيل:
 انقر على زر التشغيل لتنفيذ الرمز الذي تم كتابته للتو في الخلية.
انقر على زر التشغيل لتنفيذ الرمز الذي تم كتابته للتو في الخلية.
ستظهر لك الآن الشركة المصنّعة للنموذج مُثبّت:
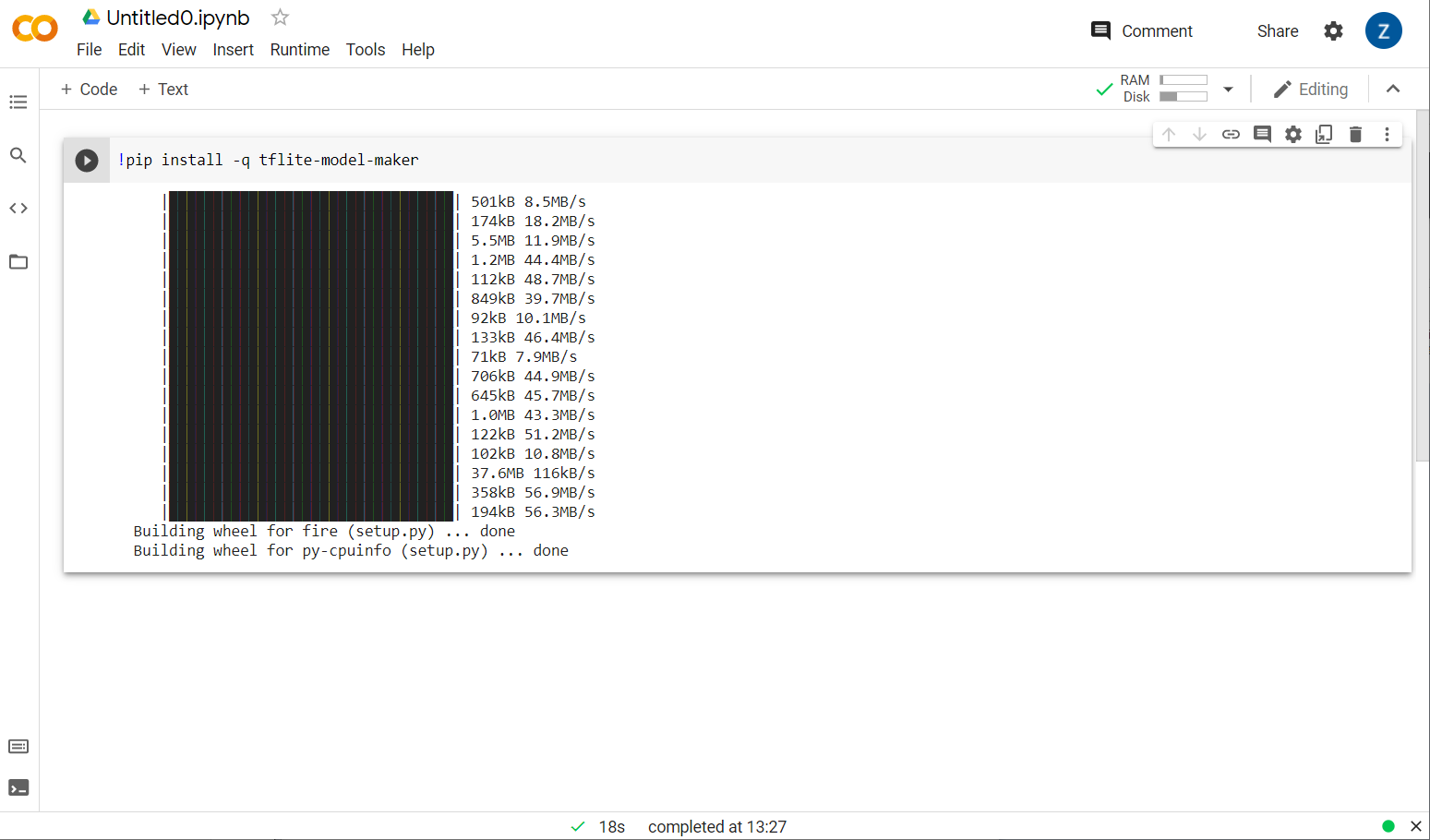
بعد اكتمال هذه الخلية كما هو موضح، يمكنك الانتقال إلى الخطوة التالية أدناه.
الخطوة 2
بعد ذلك، أضِف خلية رموز جديدة كما هو موضّح حتى تتمكن من لصق رمز أكثر بعد الخلية الأولى وتنفيذها بشكلٍ منفصل:
ستحتوي الخلية التالية التي تم تنفيذها على عدد من عمليات الاستيراد التي سيحتاج إليها الرمز في باقي أجهزة الكمبيوتر الدفترية. انسخ ما يلي والصقه في الخلية الجديدة التي تم إنشاؤها:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
هي مواد عادية جدًا، حتى إذا لم تكن معتادًا على Python. ما عليك سوى استيراد بعض الأدوات المساعدة ووظائف "أداة إنشاء النماذج" المطلوبة لأداة تصنيف الرسائل غير المرغوب فيها. سيؤدي ذلك أيضًا إلى التحقُّق مما إذا كنت تشغِّل TensorFlow 2.x وهو مطلوب لاستخدام أداة إنشاء النماذج.
أخيرًا، تمامًا كما في السابق، يمكنك تنفيذ الخلية عن طريق الضغط على الرمز "play" عند تمرير الماوس فوق الخلية، ثم إضافة خلية رمز جديدة إلى الخطوة التالية.
الخطوة الثالثة
الخطوة التالية هي تنزيل البيانات من خادم بعيد على جهازك، وضبط المتغيّر training_data ليكون مسار الملف المحلي الناتج الذي تم تنزيله:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/laurencemoroney-blog.appspot.com/jm_blog_comments_extras.csv', extract=False)
يمكن لـ "أداة إنشاء النماذج" تدريب النماذج من ملفات CSV بسيطة، مثل الملف الذي تم تنزيله. ما عليك سوى تحديد الأعمدة التي تحتفظ بالنص والأعمدة التي تحتفظ بها. وستتعرّف على كيفية إجراء ذلك في الخطوة 5. يمكنك تنزيل ملف CSV بنفسك مباشرةً لمعرفة ما يحتوي عليه إن أردت.
أنت حريص على ملاحظة اسم هذا الملف هو jm_blog_comments_extras.csv - وهذا الملف هو ببساطة بيانات التدريب الأصلية التي استخدمناها لإنشاء أول نموذج للتعليقات غير المرغوب فيها مجمّع مع البيانات الجديدة لحالة الأحرف التي اكتشفتها فكل ذلك في ملف واحد. يجب الحصول على بيانات التدريب الأصلية المستخدَمة لتدريب النموذج، بالإضافة إلى الجمل الجديدة التي تريد التعلّم منها.
اختياري: في حال تنزيل ملف CSV هذا والاطّلاع على الأسطر القليلة الأخيرة، سترى أمثلة لحالات الأحرف التي لم تكن تعمل بشكل صحيح من قبل. وتمت إضافتها للتو إلى نهاية بيانات التدريب الحالية التي طوّرها النموذج المعدّ مسبقًا لتدريب نفسه.
نفِّذ هذه الخلية، ثم بعد الانتهاء من تنفيذها، أضِف خلية جديدة، ثم انتقِل إلى الخطوة 4.
الخطوة الرابعة
عند استخدام مصمم النماذج، لا تصمم نماذج من البداية. بشكل عام، تستخدم النماذج الحالية التي سيتم تخصيصها وفقًا لاحتياجاتك.
يوفّر"أداة إنشاء النماذج"العديد من عمليات تضمين النماذج التي تم تعلّمها مسبقًا، والتي يمكنك استخدامها، ولكن أبسطها وأسرعها هي average_word_vec، وهو ما استخدمته في الدرس التطبيقي السابق لإنشاء موقعك الإلكتروني. وإليك الرمز:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
هيّا نفّذ ذلك بعد لصقه في الخلية الجديدة.
فهم
num_words
المعلّمة
هذه هي عدد الكلمات التي تريد أن يستخدمها النموذج. قد تعتقد أنه كلما كان ذلك أفضل، كان ذلك أفضل، وبصفة عامة، يعتمد ذلك على معدل تكرار استخدام كل كلمة. إذا كنت تستخدم كل كلمة في المجموعة الكاملة، قد ينتهي بك الأمر إلى نموذج يحاول تعلُّم وتوازن بين ترجيحات الكلمات التي تُستخدم مرة واحدة فقط، ولن يكون ذلك مفيدًا جدًا. وستعثر في أي مجموعة نصية على أن العديد من الكلمات لا تُستخدم سوى مرة أو مرتين، ولا تستحق استخدامها بشكل عام في نموذجك لأنها لها تأثير ضئيل على الشعور العام. وبالتالي، يمكنك ضبط النموذج على عدد الكلمات التي تريدها باستخدام المَعلمة num_words. سيحمل الرقم الأصغر هنا نموذجًا أصغر وأسرع، ولكنه قد يكون أقل دقة، لأنه يتعرّف على كلمات أقل. كلما كان العدد الأكبر هنا يحتوي على نموذج أكبر وقد يكون أبطأ. العثور على أفضل مكان هو أمر أساسي، ويعود إليك الأمر كمهندس تعلُّم الآلة لتحديد ما يناسب حالة استخدامك.
فهم
wordvec_dim
المعلّمة
المعلمة wordvec_dim هي عدد الأبعاد التي تريد استخدامها لمتجه كل كلمة. الأبعاد هي في الأساس السمات المختلفة (التي يتم إنشاؤها من خلال خوارزمية تعلُّم الآلة عند التدريب) والتي يمكن قياس أي كلمة معيّنة من خلالها والتي سيستخدمها البرنامج لمحاولة ربط الكلمات المماثلة بطريقة مفيدة.
على سبيل المثال، إذا كان لديك بُعد لمستوى الكلمة "&"،؛ حيث إن كلمة مثل ""؛ قد يتّضح أنّ البُعد&الاكتفاء الطبي يساعد في تحديد المحتوى غير المرغوب فيه عند دمجها مع أبعاد أخرى محتملة، وبالتالي قد يكون استخدامها مفيدًا.
وفي حالة الكلمات التي تحقّق درجة عالية في &&;البُعد الطبي&;يمكن أن تفيد أن البُعد الثاني الذي يربط الكلمات بجسم الإنسان قد يكون مفيدًا. وقد تكون هناك كلمات مرتفعة مثل "leg;quot;, "arm", "neck";
ويمكن أن يستخدم النموذج هذه المكوّنات بعد ذلك لكي يتمكّن من رصد الكلمات التي يُحتمل أن تكون مرتبطة بالمحتوى غير المرغوب فيه. ثمة احتمال أكبر أن تحتوي الرسائل الإلكترونية غير المرغوب فيها على كلمات تحتوي على أعضاء طبية وأعضاء من جسم الإنسان.
القاعدة العامة التي تم تحديدها من خلال البحث هي أن الجذر الرابع لعدد الكلمات يعمل بشكل جيد لهذه المعلمة. لذلك، إذا كنت أستخدم 2000 كلمة، ستكون نقطة البداية الجيدة لهذا العنصر هي 7 أبعاد. إذا غيّرت عدد الكلمات المستخدمة، يمكنك أيضًا تغيير ذلك.
فهم
seq_len
المعلّمة
تكون النماذج صارمة جدًا بشكل عام عندما يتعلق الأمر بقيم الإدخال. وبالنسبة إلى نموذج اللغة، يعني هذا أن نموذج اللغة يمكنه تصنيف الجمل من طول معيّن أو ثابت. يتم تحديد ذلك من خلال مَعلمة seq_len، حيث يرمز هذا إلى "طول التسلسل'". عند تحويل الكلمات إلى أرقام (أو رموز مميزة)، تصبح الجملة تسلسلاً من هذه الرموز المميزة. وبالتالي سيتم تدريب النموذج (في هذه الحالة) لتصنيف الجمل التي تحتوي على 20 رمزًا مميزًا والتعرّف عليها. وإذا كانت الجملة أطول من ذلك، سيتم اقتطاعها. وإذا كانت أقصر من ذلك، ستتم إضافتها، كما هو الحال في الدرس التطبيقي الأول حول الترميز في هذه السلسلة.
الخطوة 5: تحميل بيانات التدريب
تنزيل ملف CSV سابقًا. وقد حان الوقت الآن لاستخدام برنامج تحميل البيانات لتحويل هذا الملف إلى بيانات التدريب التي يمكن للنموذج التعرّف عليها.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
إذا فتحت ملف CSV في محرّر، ستلاحظ أنّ كل سطر يحتوي على قيمتَين، وتم وصف ذلك مع النص في السطر الأول من الملف. عادةً ما يُعتبر كل إدخال "عمودًا'؛ سترى أنّ الواصف للعمود الأول هو commenttext، وأنّ الإدخال الأول في كل سطر هو نص التعليق.
وبالمثل، وصف الوصف للعمود الثاني هو spam، وستلاحظ أن الإدخال الثاني في كل سطر هو TRUE أو FALSE للإشارة إلى ما إذا كان النص يعتبر تعليقًا غير مرغوب فيه أم لا. تحدد الخصائص الأخرى مواصفات النموذج التي أنشأتها في الخطوة رقم 4، بالإضافة إلى حرف المُحدِّد، الذي يكون في هذه الحالة فاصلة نظرًا لفصل الملف بفواصل. ويمكنك أيضًا ضبط معلمة ترتيب عشوائي لإعادة ترتيب بيانات التدريب بشكل عشوائي، بحيث يتم توزيع العناصر التي قد تكون مشابهة أو تم جمعها معًا بشكل عشوائي على مستوى مجموعة البيانات.
وبعد ذلك، ستستخدم data.split() لتقسيم البيانات إلى بيانات التدريب والاختبار. يشير .9 إلى أنه سيتم استخدام 90% من مجموعة البيانات في التدريب والباقي للاختبار.
الخطوة 6: إنشاء النموذج
أضف خلية أخرى حيث سنضيف رمزًا لإنشاء النموذج:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
يؤدي ذلك إلى إنشاء نموذج مصنّف نصي باستخدام أداة إنشاء النماذج، وتحديد بيانات التدريب التي تريد استخدامها (تم تحديد ذلك في الخطوة 4)، ومواصفات النموذج (التي تم إعدادها أيضًا في الخطوة 4)، وعدد الفترات، في هذه الحالة 50.
المبدأ الأساسي لتعلم الآلة هو شكل من أشكال مطابقة الأنماط. في البداية، ستحمّل قيم الترجيح المُدرَّبة مسبقًا للكلمات، وستحاول تجميعها مع "توقعات'؛ من بينها عند تجميعها معًا، الإشارة إلى الرسائل غير المرغوب فيها، وتلك التي لا تريد ذلك. في المرة الأولى تقريبًا، من المحتمل أن يكون قريبًا من 50:50، لأن النموذج يبدأ فقط كما هو موضح أدناه:

وستقيّم بعد ذلك نتائج ذلك، وستغيّر قيم ترجيح النموذج لتعديل توقّعه، وسيحاول مرة أخرى. هذه فترة. لذلك، من خلال تحديد epochs=50، فإنها ستحتوي على ذلك "loop' 50 مرة كما هو موضح:

وبذلك، عند الوصول إلى الحقبة الخمسين، سيبلّغ النموذج عن مستوى أعلى من الدقة. في هذه الحالة، يتم عرض 99.1%
الخطوة 7: تصدير النموذج
وبعد انتهاء التدريب، يمكنك عندئذٍ تصدير النموذج. ويدرِّب TensorFlow نموذجًا بتنسيقه الخاص، ويجب تحويله إلى تنسيق TensorFlow.js لاستخدامه في صفحة ويب. ما عليك سوى لصق ما يلي في خلية جديدة وتنفيذها:
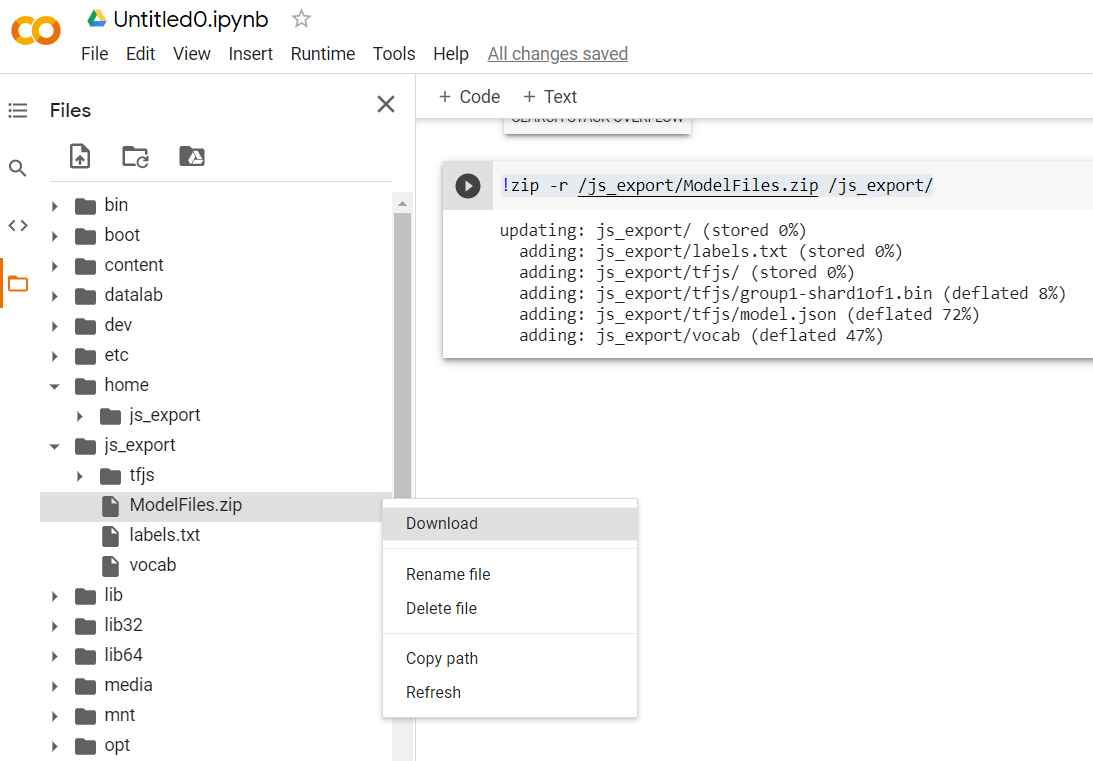
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
بعد تنفيذ هذا الرمز، إذا نقرت على رمز المجلد الصغير على يمين Colab، يمكنك الانتقال إلى المجلد الذي تم تصديره إلى أعلاه (في الدليل الجذري - قد تحتاج إلى الانتقال إلى مستوى أعلى) والعثور على حزمة ZIP للملفات التي تم تصديرها في ModelFiles.zip.
نزِّل ملف zip هذا على جهاز الكمبيوتر الآن لأنك ستستخدم هذه الملفات تمامًا كما في الدرس التطبيقي الأول حول الترميز:
رائع! لقد انتهى الجزء Python، ويمكنك الآن الرجوع إلى أرض JavaScript التي تعرفها وتفضّلها. أخيرًا!
5. عرض النموذج الجديد لتعلم الآلة
أنت الآن مستعد تقريبًا لتحميل النموذج. قبل أن تتمكن من إجراء ذلك، يجب تحميل ملفات النماذج الجديدة التي تم تنزيلها سابقًا في الدرس التطبيقي حول الترميز حتى تتم استضافتها ويمكن استخدامها داخل الرمز.
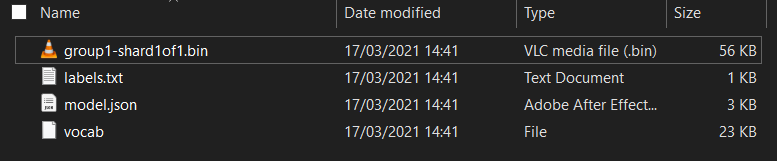
أولاً، إذا لم تكن قد فعلت ذلك من قبل، فك ضغط ملفات النموذج الذي تم تنزيله للتو من المفكرة Colab lab التي شغّلتها للتو. من المفترض أن تظهر الملفات التالية في مجلداتها المختلفة:
ما هي الأدوات المتوفّرة لديك؟
model.json: هذا هو أحد الملفات التي تشكّل نموذج TensorFlow.js المُدرَّب. ستشير إلى هذا الملف المحدّد في رمز JavaScript.group1-shard1of1.bin: هذا ملف ثنائي يحتوي على قدر كبير من البيانات المحفوظة الخاصة بنموذج TensorFlow.js الذي تم تصديره، ويجب استضافته في مكان ما على الخادم لتنزيله في الدليل نفسه الوارد فيmodel.json.vocab- هذا الملف الغريب الذي ليس له إضافة هو شيء من مصمم النماذج يوضح لنا كيفية ترميز الكلمات في الجمل حتى يتمكن النموذج من فهم كيفية استخدامها. ستستعرض المزيد من التفاصيل في القسم التالي.labels.txt: يحتوي هذا ببساطة على أسماء الفئات الناتجة التي سيتوقّعها النموذج. بالنسبة إلى هذا النموذج، إذا فتحت هذا الملف في محرر النصوص، يتم ببساطة تضمين "؛false"&&;;quot;true" مُشار إليها تشير إلى "ليس رسائل غير مرغوب فيها&&;; أو "spam" كمخرجات لتوقّعاتك.
استضافة ملفات نموذج TensorFlow.js
ضع أولاً الملفين model.json و*.bin اللذين تم إنشاؤهما على خادم ويب حتى تتمكن من الوصول إليهما من خلال صفحة ويب.
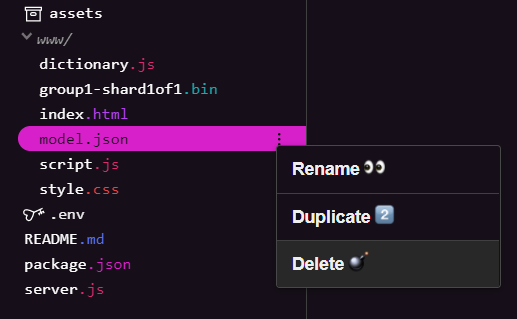
حذف ملفات النماذج الحالية
بالاستناد إلى النتيجة النهائية للدرس التطبيقي الأول للترميز في هذه السلسلة، عليك أولاً حذف ملفات النماذج الحالية التي تم تحميلها. في حال استخدام Glitch.com، ما عليك سوى التحقّق من لوحة الملفات على يمين الصفحة في model.json وgroup1-shard1of1.bin، ثم النقر على القائمة المنسدلة المكوّنة من 3 نقاط لكل ملف واختيار حذف كما هو موضّح:
تحميل ملفات جديدة إلى Glitch
رائع! والآن حمّل الصور الجديدة:
- افتح مجلد مواد العرض في اللوحة اليمنى لمشروع Glitch واحذف أي مواد عرض قديمة تمّ تحميلها إذا كانت لها الأسماء نفسها.
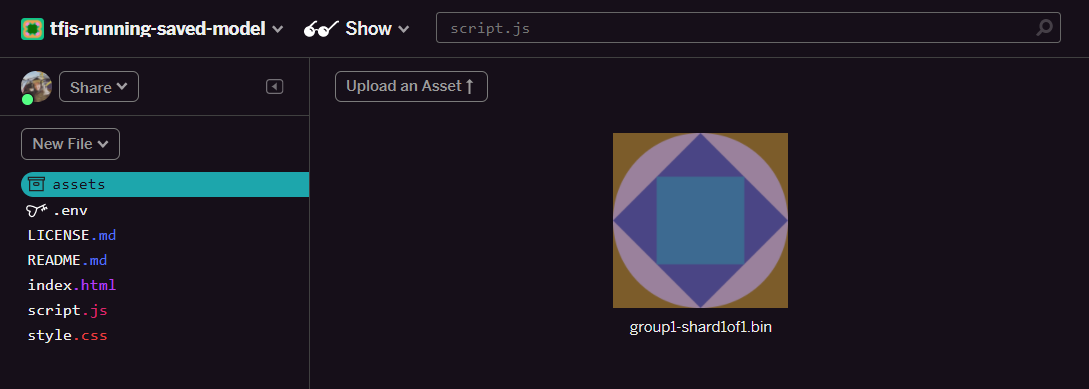
- انقر على تحميل مادة عرض واختَر
group1-shard1of1.binلتحميلها إلى هذا المجلد. من المفترض أن يظهر الآن على النحو التالي بعد التحميل:
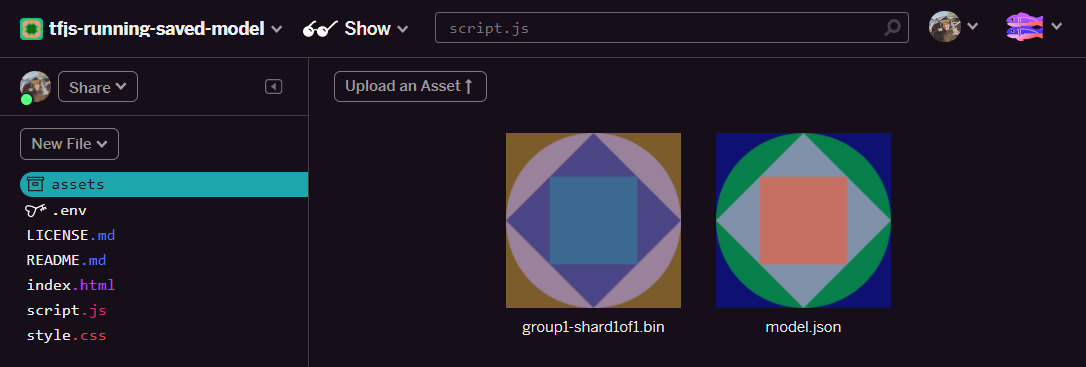
- رائع! نفِّذ الإجراء نفسه مع ملف form.json أيضًا، في حين من المفترض أن يظهر ملفان في مجلد مواد العرض كما يلي:
- إذا نقرت على ملف
group1-shard1of1.binالذي حمّلته للتو، ستتمكن من نسخ عنوان URL إلى موقعه. انسخ هذا المسار الآن كما هو موضح:
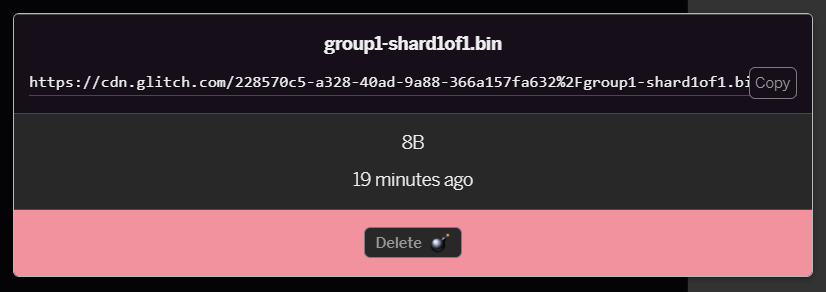
- الآن في أسفل يمين الشاشة، انقر على الأدوات >؛ الوحدة الطرفية. انتظر حتى يتم تحميل نافذة الوحدة الطرفية.
- بعد التحميل، اكتب ما يلي، ثم اضغط على Enter لتغيير الدليل إلى مجلد
www:
المحطة الطرفية:
cd www
- بعد ذلك، استخدِم
wgetلتنزيل الملفَين اللذين تم تحميلهما للتو من خلال استبدال عناوين URL أدناه بعناوين URL التي أنشأتها للملفات في مجلد مواد العرض في Glitch (تحقَّق من مجلد مواد العرض لكل عنوان URL مخصّص لكل ملف).
تجدر الإشارة إلى أن المساحة بين عنواني URL وأن عناوين URL التي تحتاج إلى استخدامها ستختلف عن تلك المعروضة، لكن ستبدو متشابهة:
المحطة
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
ممتاز! لقد أنشأت الآن نسخة من الملفات التي تم تحميلها إلى مجلد www.
ومع ذلك، سيتم تنزيلها الآن بأسماء غريبة. إذا كتبت ls في الوحدة الطرفية واضغط على Enter، سيظهر لك ما يلي:

- سيؤدي استخدام الأمر
mvإلى إعادة تسمية الملفات. اكتب ما يلي في وحدة التحكم واضغط على Enter بعد كل سطر:
المحطة الطرفية:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- أخيرًا، عليك إعادة تحميل مشروع Glitch من خلال كتابة
refreshفي الوحدة الطرفية والضغط على Enter:
المحطة الطرفية:
refresh
بعد إعادة التحميل، من المفترض أن ترى model.json وgroup1-shard1of1.bin في المجلد www في واجهة المستخدم:
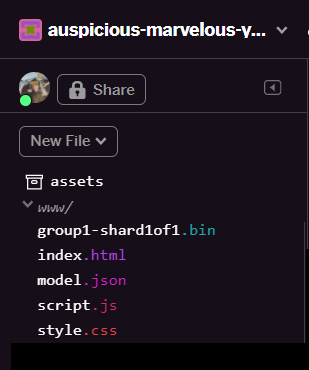
رائع! الخطوة الأخيرة هي تعديل ملف dictionary.js.
- حوِّل ملف vocab الجديد الذي تم تنزيله إلى تنسيق JS الصحيح يدويًا بنفسك من خلال محرِّر النصوص أو باستخدام هذه الأداة واحفظ المخرجات الناتجة بتنسيق
dictionary.jsفي مجلدwww. إذا كان لديك ملفdictionary.js، يمكنك ببساطة نسخ المحتوى الجديد ولصقه فوقه وحفظ الملف.
رائع! لقد نجحت في تحديث جميع الملفات التي تم تغييرها، وإذا حاولت الآن استخدام الموقع الإلكتروني، ستلاحظ كيف يجب أن يتمكن النموذج الذي تمت إعادة تدريبه من مراعاة حالات الحافة التي تم اكتشافها وتعلمها من النحو الموضح:
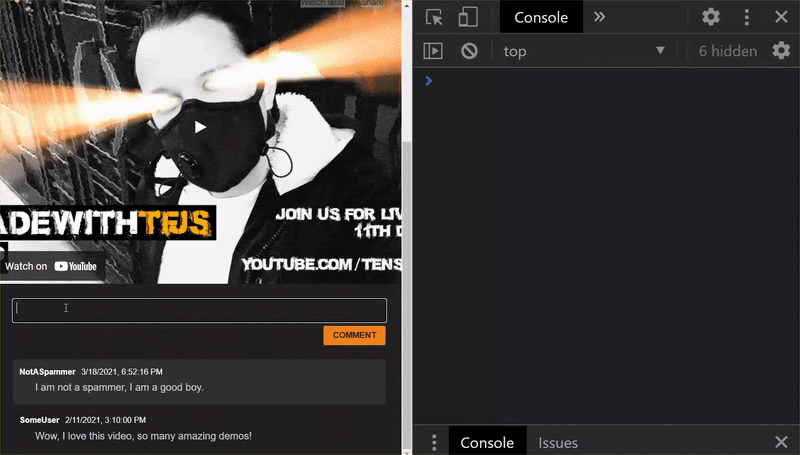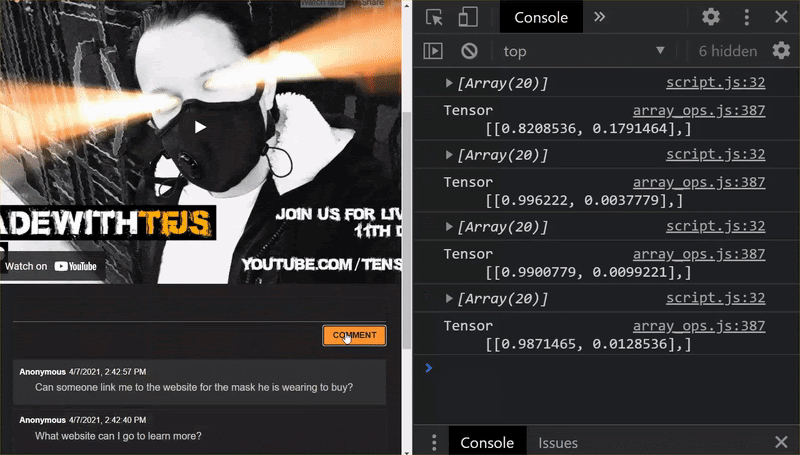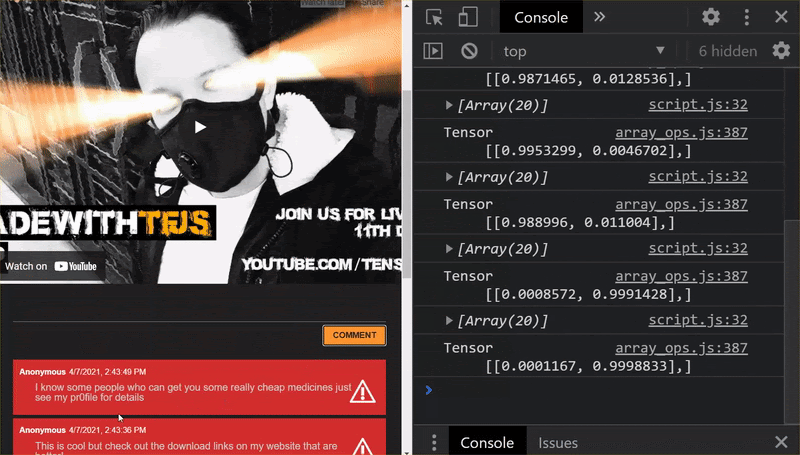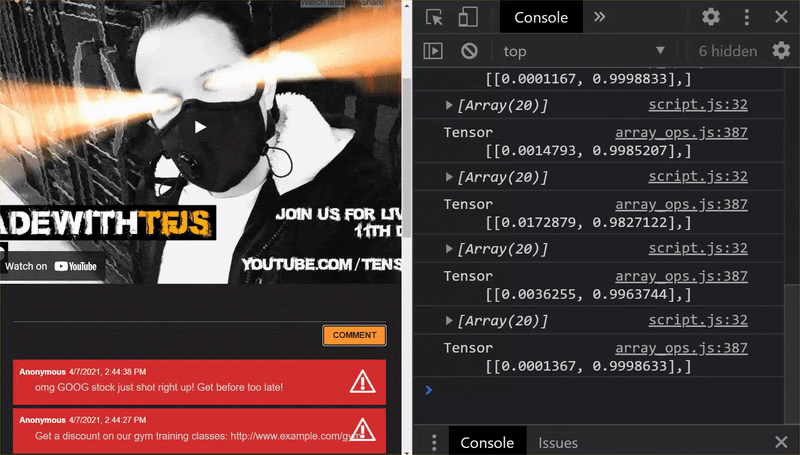
كما ترى، يتم تصنيف أول 6 مجموعات بشكل صحيح على أنها غير مرغوب فيها، ويتم تحديد المجموعة الثانية من 6 على أنها غير مرغوب فيها. ممتاز.
لنجرّب بعض الصيغ أيضًا لمعرفة ما إذا كانت قد تمت عموميتها بشكل جيد. في الأصل، تعذّرت تنفيذ جملة مثل:
"يا إلهي، ارتجت أسهمك مباشرةً. بادر بنشره قبل الأوان.
يتم الآن تصنيف هذا المحتوى بشكل صحيح على أنه محتوى غير مرغوب فيه، ولكن ماذا يحدث في حال تغييره إلى:
"لذا زاد سعر سهم XYZ! اشترِ بعض المنتجات مباشرةً قبل أن نتأخر،
في هذه الحالة، ستحصل على توقّع بنسبة% 98 من أن يكون محتوى غير مرغوب فيه صحيحًا على الرغم من تغيير رمز السهم والصياغة قليلاً.
بالطبع، إذا حاولت كسر هذا النموذج الجديد، ستتمكن من ذلك، وسيتم جمع مزيد من بيانات التدريب للحصول على أفضل فرصة لجذب المزيد من الأشكال الفريدة في المواقف الشائعة التي من المحتمل أن تواجهها على الإنترنت. في درس تطبيقي مقبل للترميز، سنعرض لك كيفية تحسين النموذج باستمرار باستخدام البيانات المباشرة بعد الإبلاغ عنه.
6- تهانينا.
تهانينا، لقد تمكّنت من إعادة تدريب نموذج تعلُّم الآلة الحالي بحيث يتم تعديله للتوافق مع الحالات التي عثرت عليها ونشرت هذه التغييرات في المتصفّح باستخدام TensorFlow.js لتطبيق حقيقي.
الملخّص
في هذا الدرس التطبيقي حول الترميز:
- تم اكتشاف حالات حواف لم تكن تعمل عند استخدام نموذج التعليقات غير المرغوب فيها سابق الإعداد
- تمت إعادة تدريب نموذج صانع النماذج لمراعاة حالات الحواف التي اكتشفتها
- تم تصدير النموذج المدرّب الجديد إلى التنسيق TensorFlow.js
- تم تحديث تطبيق الويب لاستخدام الملفات الجديدة.
الخطوات التالية
يعمل هذا التحديث بشكل رائع، ولكن كما هو الحال مع أي تطبيق ويب، سيتم إجراء التغييرات بمرور الوقت. وسيكون من الأفضل كثيرًا أن يحسّن التطبيق نفسه بمرور الوقت بدلاً من اتخاذ هذا الإجراء يدويًا في كل مرة. هل تعتقد أنّك ربما قد اتّبعت هذه الخطوات تلقائيًا لإعادة ضبط نموذج تلقائيًا بعد أن حصلت على 100 تعليق جديد تمّ تصنيفه بشكل خاطئ على سبيل المثال؟ ضَع القبعة العادية لهندسة الويب ويمكنك على الأرجح معرفة كيفية إنشاء مسار التعلّم تلقائيًا. وإذا لم تكن تشعر بالقلق، ابحث عن الدرس التطبيقي التالي حول الترميز في السلسلة التي ستوضح لك كيفية تنفيذ ذلك.
مشاركة ما تنشئه معنا
يمكنك تمديد فترة اشتراكك بسهولة في حالات استخدام تصميمات الإعلانات الأخرى أيضًا، ونشجّعك على التفكير خارج الصندوق ومواصلة الاختراق.
لا تنسَ الإشارة إلينا على وسائل التواصل الاجتماعي باستخدام الهاشتاغ #MadeWithTFJS حتى تتمكّن من عرض مشروعك على مدونة TensorFlow أو حتى الأحداث المستقبلية. نتطلّع إلى معرفة ما تقدّمه.
المزيد من الدروس التطبيقية حول الترميز TensorFlow.js لمعرفة المزيد من المعلومات
- استخدِم استضافة Firebase لنشر واستضافة نموذج TensorFlow.js على نطاق واسع.
- إنشاء كاميرا ويب ذكية باستخدام نموذج رصد عناصر معدّ مسبقًا باستخدام TensorFlow.js
المواقع الإلكترونية لإتمام الدفع
- الموقع الإلكتروني الرسمي TensorFlow.js
- نماذج TensorFlow.js المعدّة مسبقًا
- واجهة برمجة تطبيقات TensorFlow.js
- TensorFlow.js Show & Say - احصل على أفكار ملهمة وتعرّف على إنجازات الآخرين.