
1. 始める前に
この Codelab では、畳み込みと、コンピュータ ビジョン シナリオで畳み込みが非常に強力な理由について学習します。
前の Codelab では、ファッション アイテムのコンピュータ ビジョン用のシンプルなディープ ニューラル ネットワーク(DNN)を作成しました。このルールでは、写真に写っているのが衣料品のみで、それが中央に配置されていることが要件だったため、制限がありました。
もちろん、これは現実的なシナリオではありません。DNN では、他のオブジェクトと一緒に写っている写真や、正面の中央に配置されていない写真の衣料品を識別できるようにする必要があります。これを行うには、畳み込みを使用する必要があります。
前提条件
この Codelab は、機械学習の「Hello World」と コンピュータ ビジョン モデルを構築するの 2 つのパートで完了した作業を基にしています。続行する前に、これらの Codelab を完了してください。
学習内容
- 畳み込みとは
- 特徴マップを作成する方法
- プーリングとは
作成するアプリの概要
- 画像のフィーチャー マップ
必要なもの
Codelab の残りのコードは、Colab で実行できます。
TensorFlow と、前の Codelab でインストールしたライブラリも必要です。
2. 畳み込みとは
畳み込みとは、画像を渡して処理し、重要な特徴を抽出するためのフィルタです。
たとえば、スニーカーを履いている人物の画像があるとします。画像にスニーカーが含まれていることを検出するにはどうすればよいですか?プログラムが画像をスニーカーとして認識できるようにするには、重要な特徴を抽出し、重要でない特徴をぼかす必要があります。これは特徴マッピングと呼ばれます。
機能マッピング プロセスは理論的には単純です。画像のすべてのピクセルをスキャンし、隣接するピクセルを確認します。これらのピクセルの値をフィルタ内の同等の重みで乗算します。
次に例を示します。
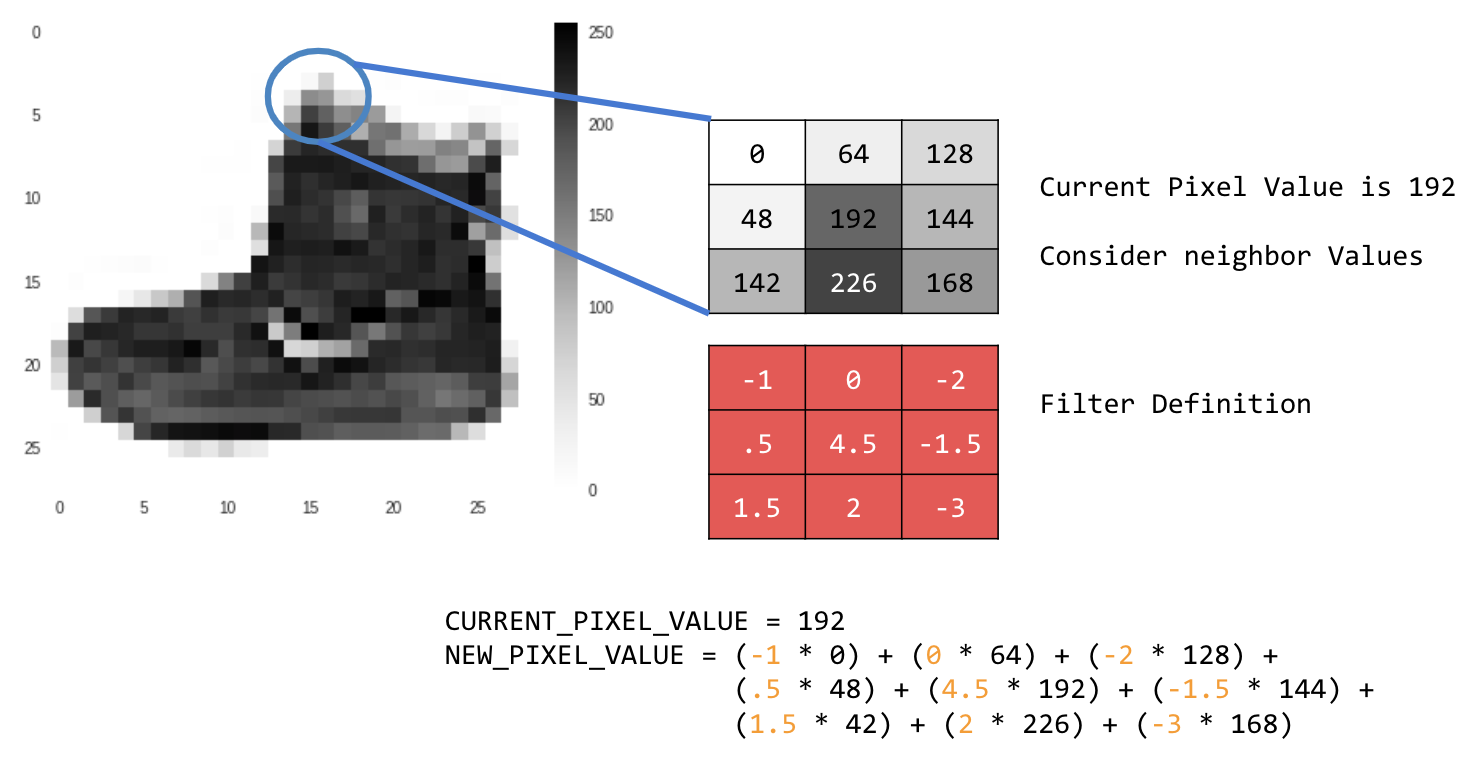
この場合、3x3 の畳み込み行列、つまり画像カーネルが指定されています。
現在のピクセル値は 192 です。新しいピクセルの値は、近隣の値を調べ、フィルタで指定された値を乗算し、新しいピクセルの値を最終的な値にすることで計算できます。
それでは、2D グレースケール画像で基本的な畳み込みを作成して、畳み込みの仕組みを見ていきましょう。
このことを SciPy の ascent 画像で示します。角度や線がたくさんある、素敵な内蔵画像です。
3. コーディングを開始する
まず、いくつかの Python ライブラリと登山の写真をインポートします。
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
次に、Pyplot ライブラリ matplotlib を使用して画像を描画し、画像がどのようなものかを確認します。
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

階段の画像であることがわかります。試して分離できる機能はたくさんあります。たとえば、強い縦線がある。
画像は NumPy 配列として保存されるため、その配列をコピーするだけで変換後の画像を作成できます。size_x 変数と size_y 変数には画像のサイズが格納されるため、後でループ処理できます。
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
4. 畳み込み行列を作成する
まず、畳み込み行列(またはカーネル)を 3x3 の配列として作成します。
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
出力ピクセルを計算します。画像を反復処理し、1 ピクセルのマージンを残して、現在のピクセルの各近傍にフィルタで定義された値を乗算します。
つまり、現在のピクセルの上と左にある隣接ピクセルに、フィルタの左上の項目が乗算されます。次に、結果に重みを掛け、結果が 0 ~ 255 の範囲内であることを確認します。
最後に、変換された画像に新しい値を読み込みます。
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
5. 結果を確認する
次に、画像をプロットして、フィルタを適用した効果を確認します。
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

次のフィルタ値と、それらが画像に与える影響について考えてみましょう。
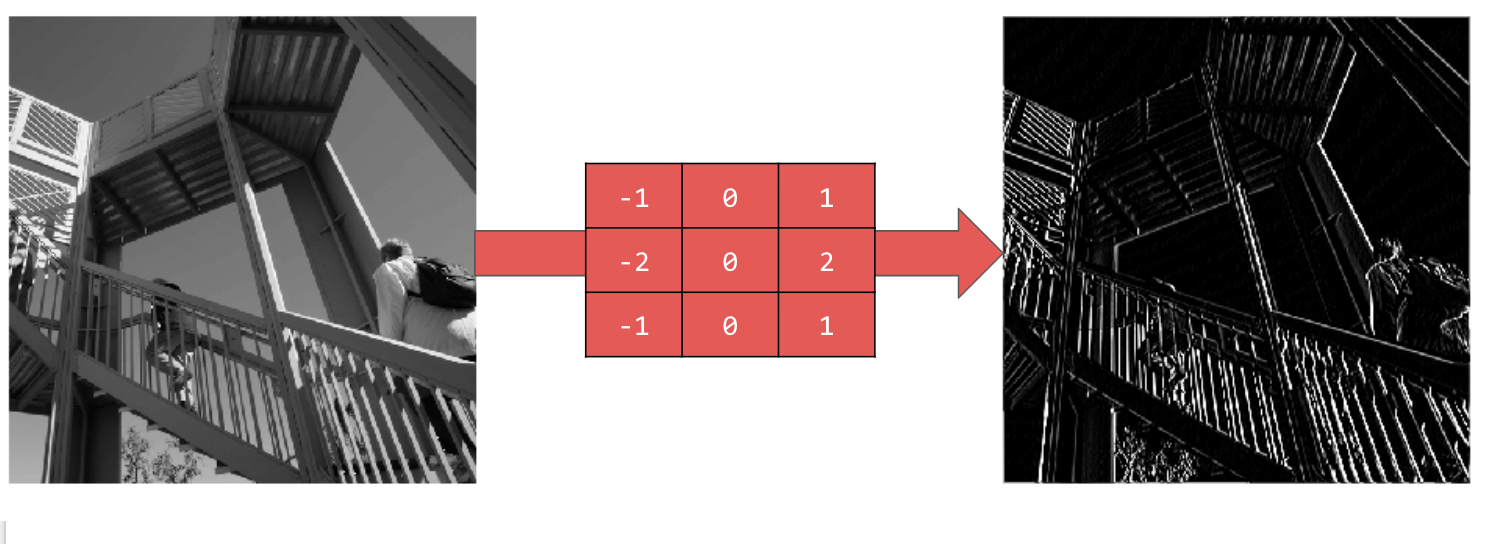
[-1,0,1,-2,0,2,-1,0,1] を使用すると、非常に強力な縦線が得られます。
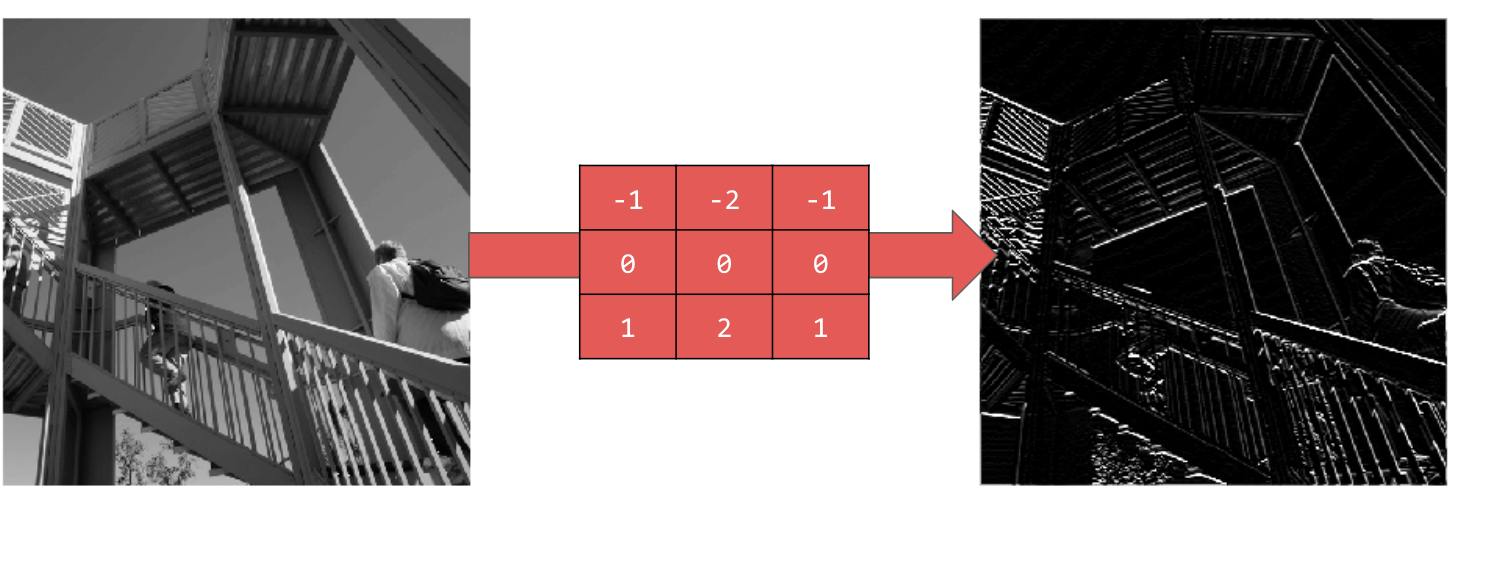
[-1,-2,-1,0,0,0,1,2,1] を使用すると、水平線が生成されます。
さまざまな値を試してみましょう。また、5x5 や 7x7 など、サイズの異なるフィルタも試してください。
6. プーリングについて
画像の重要な特徴を特定したら、どうすればよいでしょうか?生成された特徴マップを使用して画像を分類するにはどうすればよいですか?
畳み込みと同様に、プーリングは特徴の検出に非常に役立ちます。プーリング レイヤは、検出された特徴を維持しながら、画像内の情報の総量を減らします。
プーリングにはさまざまなタイプがありますが、ここでは最大プーリングを使用します。
画像を反復処理し、各ポイントで、ピクセルとその右、下、右下の近傍を検討します。それらの最大値(max プーリング)を取得し、新しい画像に読み込みます。したがって、新しい画像は古い画像の 4 分の 1 のサイズになります。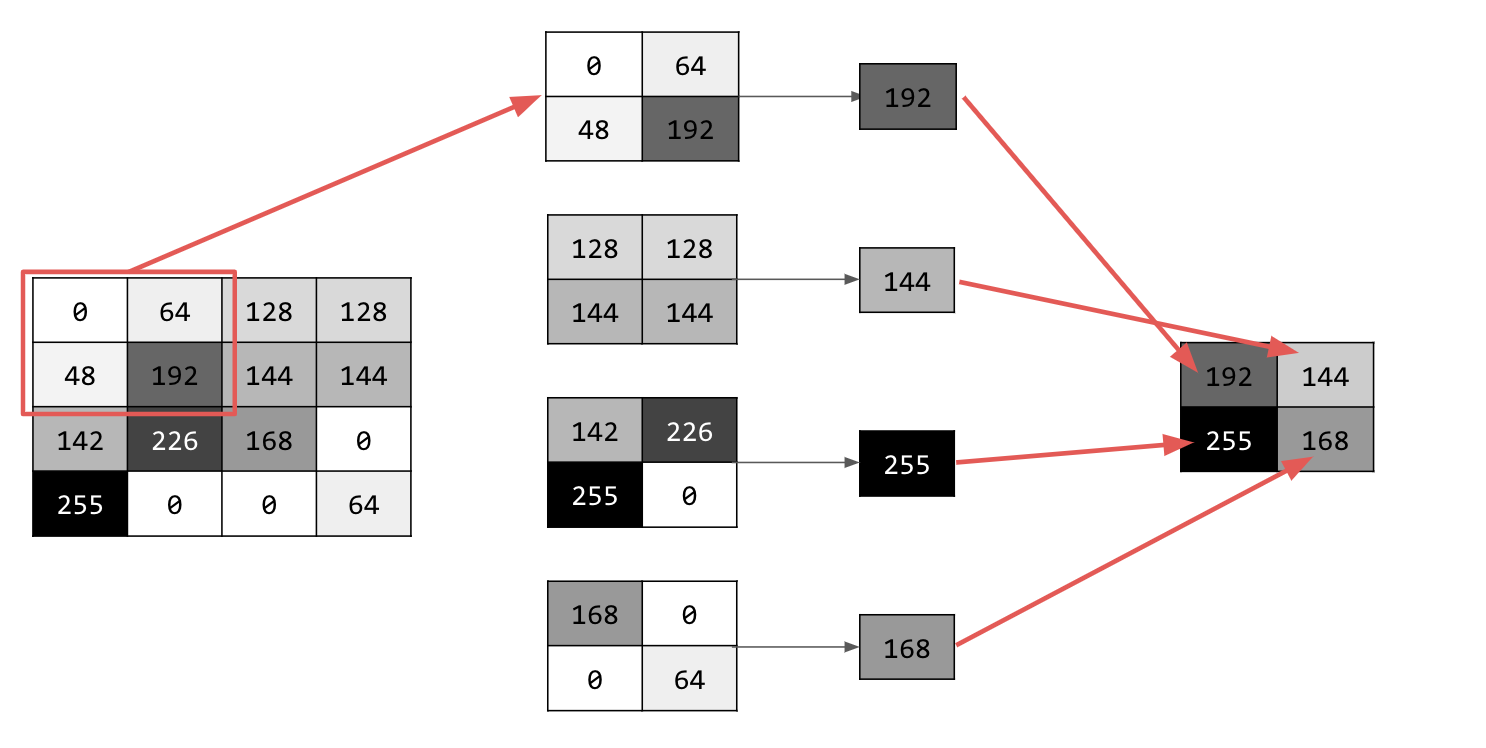
7. プーリングのコードを記述する
次のコードは、(2, 2)プーリングを示しています。実行して出力を確認します。
画像は元のサイズの 4 分の 1 になっていますが、すべての特徴が保持されていることがわかります。
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

そのプロットの軸に注目してください。画像は元のサイズの 4 分の 1 の 256x256 になりましたが、画像内のデータが少なくなったにもかかわらず、検出された特徴が強化されています。
8. 完了
これで、最初のコンピュータ ビジョン モデルが構築されました。コンピュータ ビジョン モデルをさらに強化する方法については、畳み込みニューラル ネットワーク(CNN)を構築してコンピュータ ビジョンを強化するに進んでください。