
1. 始める前に
この Codelab では、ML の基本である「Hello, World」を学習します。Java や C++ などの言語で明示的なルールをプログラミングする代わりに、データでトレーニングされたシステムを構築して、数値間の関係を判定するルールを推測します。
たとえば、次のような問題が考えられます。フィットネス トラッキング用のアクティビティ認識を行うシステムを構築しています。人が歩いている速さにアクセスできる場合や、条件を使用してその速度に基づいてアクティビティを推測しようとすることがあります。

if(speed<4){
status=WALKING;
}
これを別の条件で実行するように拡張することもできます。

if(speed<4){
status=WALKING;
} else {
status=RUNNING;
}
最後の条件として、同じようにサイクリングを検出できます。

if(speed<4){
status=WALKING;
} else if(speed<12){
status=RUNNING;
} else {
status=BIKING;
}
ここで、ゴルフなどのアクティビティを含める場合はどうなるかを考えてみましょう。アクティビティを決定するルールを作成する方法はあまり明確ではありません。

// Now what?
ゴルフ活動を認識できるプログラムを作成するのは非常に難しいので、何をすればよいでしょうか。ML は問題の解決に役立ちます。
前提条件
この Codelab を試す前に、以下の準備を行ってください。
- Python に関する確かな知識
- 基本的なプログラミング スキル
ラボの内容
- 機械学習の基礎
作成するアプリの概要
- 初めての機械学習モデル
必要なもの
TensorFlow を使用して ML モデルを作成したことがない場合は、必要なすべての依存関係を含むブラウザベースの環境である Colaboratory を使用できます。Colab で実行する Codelab の残りの部分のコードを確認できます。
別の IDE を使用している場合は、Python がインストールされていることを確認してください。TensorFlow と NumPy ライブラリも必要です。TensorFlow の詳細については、こちらをご覧ください。ここで NumPy をインストールします。
2. ML とは
次の図に示すように、アプリを構築する従来の方法を考えてみましょう。

ルールはプログラミング言語で記述します。これらはデータに基づいて動作し、プログラムは答えを提供します**。** アクティビティ検出の場合、ルール(アクティビティ タイプを定義するために記述したコード)がデータ(人物の移動速度)に基づいて作用し、ユーザーのアクティビティ ステータス(ウォーキング、ランニング、サイクリング、その他何かの操作を行ったか)を調べるための戻り値を返します。
ML を使用してアクティビティのステータスを検出するプロセスはよく似ていますが、軸だけが異なります。

ルールを定義してプログラミング言語で表現しようとする代わりに、データとともに解答(通常はラベルと呼びます)を提供すると、マシンが解答とデータの関係を決定するルールを推測します。たとえば、ML のコンテキストにおけるアクティビティ検出のシナリオは次のようになります。
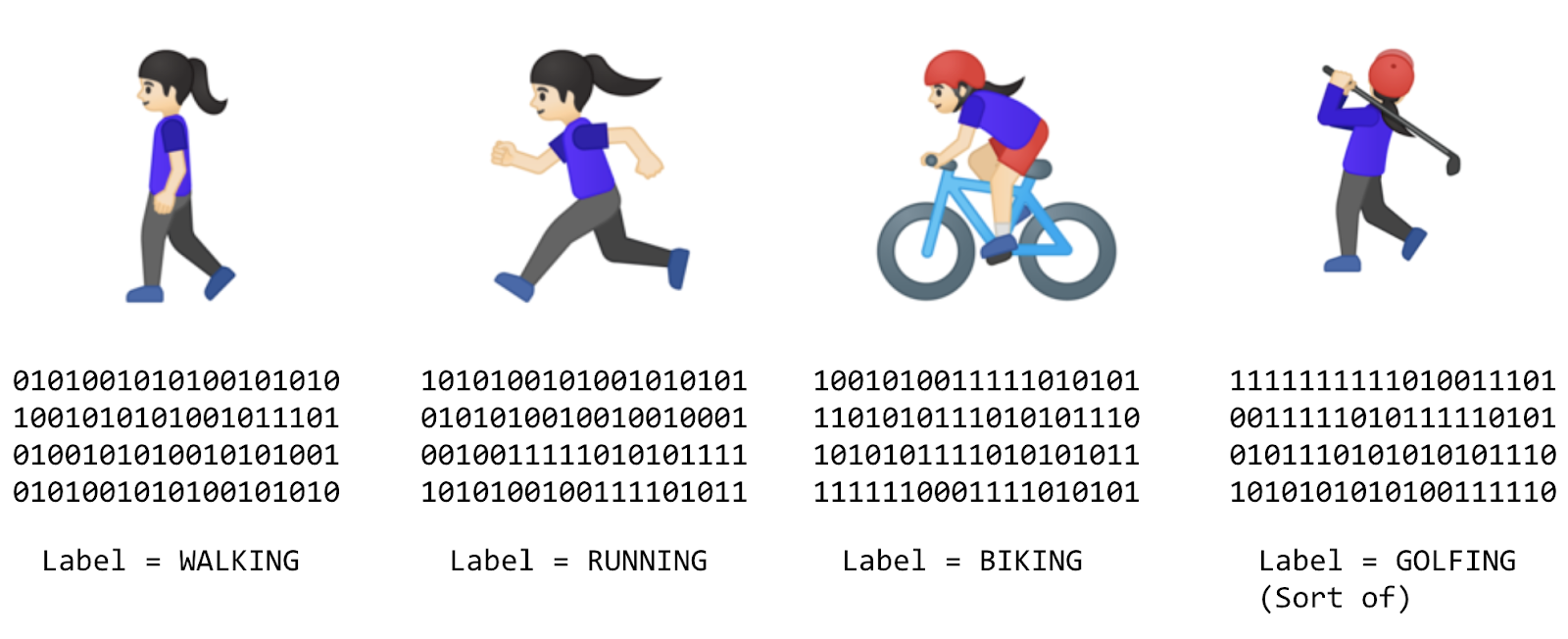
膨大なデータを収集し、「ウォーキング」や「ランニング」などのデータを効果的にラベル付けします。するとコンピュータは、特定のアクティビティを表す個別のパターンをデータから特定するルールを推定できます。
このアプローチは、このシナリオをプログラミングする代替方法であるだけでなく、ルールベースの従来のプログラミングアプローチでは不可能なゴルフのシナリオなど、新しいシナリオをオープンにすることもできます。
従来のプログラミングでは、コードはバイナリにコンパイルされ、通常はプログラムと呼ばれます。ML では、データとラベルから作成する項目をモデルと呼びます。
したがって、この図に戻ると、次のようになります。

その結果をモデルとみなします。これは実行時に次のように使用されます。

モデルにデータを渡すと、モデルはトレーニングから推測されたルールを使用して、「そのデータはウォーキング」や「自転車」のように予測します。
3. 最初の ML モデルを作成する
次の数字セットについて考えてみましょう。お客様との関係を確認することはできますか?
X: | -1 | 0 | 1 | 2 回 | 3 | 4 |
Y: | -2 | 1 | 4 | 7 | 10 | 13 |
これらの指標を見ると、左から右に読むと X の値が 1 増加し、Y の値が 3 増加していることがわかります。Y は 3 のプラスマイナスに等しいと考えるでしょう。すると、おそらく X の 0 を見て、Y が 1 になり、Y=3X+1 の関係が得られます。
これは、データを使用してパターンを見つけるためにモデルをトレーニングする場合とほぼ同じです。
実際のコードを見てみましょう。
同等の作業を行うために、ニューラル ネットワークをどのようにトレーニングしますか。データの使用一連の X と Y のセットを供給することで、それらの間の関係を把握できます。
インポート
まずはインポートを行います。ここでは、使いやすいように TensorFlow をインポートして tf という名前を付けています。
次に、numpy というライブラリをインポートします。このライブラリを使用すると、データをリストとして簡単かつ迅速に表すことができます。
ニューラル ネットワークを連続する一連のレイヤとして定義するためのフレームワークは keras と呼ばれるため、それもインポートします。
import tensorflow as tf
import numpy as np
from tensorflow import keras
ニューラル ネットワークを定義してコンパイルする
次に、できるだけシンプルなニューラル ネットワークを作成します。レイヤは 1 つあり、そのレイヤには 1 つのニューロンがあり、レイヤへの入力シェイプは 1 つの値のみです。
model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])
次に、ニューラル ネットワークをコンパイルするコードを記述します。その際は、loss と optimizer の 2 つの関数を指定する必要があります。
この例では、数値の関係は Y=3X+1 であるとわかります。
コンピュータがその言語を学習しようとしているときは、Y=10X+10 のように推測します。loss 関数は、既知の正解に対して推測された回答を測定し、どの程度的確な結果であったかを測定します。
次に、モデルは optimizer 関数を使用して別の推測を行います。損失関数の結果に基づいて、損失を最小限に抑えようとします。この時点で、Y=5X+5 のような形になるでしょう。それでも十分に悪い結果ですが、正しい結果に近づいています(損失は減少しています)。
このモデルは、エポック数に対して繰り返されます。この数はすぐにわかります。
まず、損失に mean_squared_error を使用し、オプティマイザーに確率的勾配降下法(sgd)を使用するように指示する方法です。数学についてはまだ理解できなくても理解できますが、
時間の経過とともに、さまざまなシナリオに適したさまざまな損失関数およびオプティマイザー機能について学習します。
model.compile(optimizer='sgd', loss='mean_squared_error')
データを提供する
次に、データをフィードします。ここでは、前の例の 6 つの X 変数と 6 つの Y 変数を使用します。これらの式の関係は、Y=3X+1 となるので、X は -1、Y は -2 となることがわかります。
NumPy と呼ばれる Python ライブラリには、これを実現するために多数の配列型のデータ構造が用意されています。np.array[] を使用して、NumPy で配列として値を指定します。
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-2.0, 1.0, 4.0, 7.0, 10.0, 13.0], dtype=float)
これで、ニューラル ネットワークを定義するために必要なコードがすべて揃いました。次のステップでは、これらの数値間のパターンを推測して、モデルの作成に使用できるかどうかを確認します。
4. ニューラル ネットワークのトレーニング
model.fit の呼び出しでは、X と Y の関係を学習するニューラル ネットワークのトレーニング プロセスを行います。そこでループを経て、推測が行われます。また、損失の程度(損失)を測定するか、オプティマイザを使用して別の推測を行います。これは、指定したエポックの数で行われます。このコードを実行すると、エポックごとに損失が出力されます。
model.fit(xs, ys, epochs=500)
たとえば、最初の数エポックでは、損失値は非常に大きいことがわかりますが、各ステップで損失値は小さくなっています。

トレーニングが進むにつれて、すぐに損失はわずかになります。

トレーニングが終了するまでに、損失は非常に小さく、モデルはこのモデル間の数値関係を推測するのに優れています。

おそらく 500 エポックをすべて必要とせず、さまざまな量のテストもできます。この例からわかるように、50 エポック後の損失はごくわずかであるため、これで十分かもしれません。
5. モデルの使用
X と Y の関係を学習するようにトレーニングされたモデルがあるとします。model.predict メソッドを使用して、未知の X の Y を調べることができます。たとえば、X が 10 の場合、Y はいくつになるでしょうか。次のコードを実行する前に、推測してみてください。
print(model.predict([10.0]))
31 は思ったかもしれませんが、結局少し終わりました。なぜでしょう。
ニューラル ネットワークは確率を処理するため、X と Y の関係は Y=3X+1 と非常に高い確率で計算されましたが、6 つのデータポイントではそのことはわかりません。結果は 31 に非常に近いものの、31 であるとは限りません。
ニューラル ネットワークを操作すると、そのパターンが繰り返されます。ほとんどの場合、確実性ではなく確率に対処し、確率に基づいて結果を特定するため、特に分類に関しては、少しコーディングを行います。
6. 完了
信じられないかもしれませんが、ML で扱う概念のほとんどは、かなり複雑なシナリオでも使用できます。ネットワークを定義して、2 つの数値セットの関係を特定するニューラル ネットワークをトレーニングする方法を学びました。ニューロンを含むレイヤのセット(この場合は 1 つのみ)を定義し、ここでは損失関数とオプティマイザーを使用してコンパイルしました。
ネットワーク、損失関数、オプティマイザーのコレクションにより、数値間の関係を推測し、それらがどの程度良好に機能しているかを測定してから、新しい推測のための新しいパラメータを生成するプロセスを処理します。詳細は TensorFlow.org をご覧ください。
詳細
ML と TensorFlow がコンピュータ ビジョン モデルにどのように役立つかについては、TensorFlow を使用したコンピュータ ビジョン モデルの構築をご覧ください。