
1. Avant de commencer
Dans cet atelier de programmation, vous allez apprendre à exécuter une inférence de régression à partir d'une application iOS à l'aide de TensorFlow Serving avec REST et gRPC.
Prérequis
- Connaissances de base en développement iOS avec Swift
- Des connaissances de base en machine learning avec TensorFlow, telles que l'entraînement et le déploiement
- Connaissances de base de Colaboratory
- Connaissances de base des terminaux, de Python et de Docker
Points abordés
- Entraînement d'un modèle de régression avec TensorFlow.
- Créer une application iOS simple et effectuer des prédictions à l'aide du modèle entraîné avec TensorFlow Serving (REST et gRPC)
- Comment afficher le résultat dans l'UI
Prérequis
- Accès à Colab
- La dernière version de Xcode
- CocoaPods
- Docker
- Bash
- Compilateur de tampon de protocole (requis uniquement si vous souhaitez générer à nouveau vous-même le bouchon gRPC)
- Plug-in gRPC de générateur de code gRPC (nécessaire uniquement pour générer vous-même le bouchon gRPC)
2. Configuration
Pour télécharger le code de cet atelier de programmation:
- Accédez au dépôt GitHub de cet atelier de programmation.
- Cliquez sur Code > Télécharger le fichier ZIP pour télécharger l'ensemble du code de cet atelier de programmation.
- Décompressez le fichier ZIP téléchargé pour décompresser un dossier racine
codelabscontenant toutes les ressources dont vous avez besoin.
Pour cet atelier de programmation, vous n'avez besoin que des fichiers du sous-répertoire TFServing/RegressioniOS dans le dépôt, qui contient deux dossiers:
- Le dossier
startercontient le code de démarrage sur lequel s'appuie cet atelier de programmation. - Le dossier
finishedcontient le code final de l'exemple d'application.
3. Télécharger les dépendances pour le projet
Télécharger les pods requis
- Dans le dossier
starter/iOS, exécutez la commande suivante:
pod install
CocoaPods installera toutes les bibliothèques nécessaires et générera un fichier regression.xcworkspace.
4. Exécuter l'application de démarrage
- Double-cliquez sur le fichier
regression.xcworkspacepour ouvrir Xcode.
Exécuter et explorer l'application
- Définissez la cible de l'appareil sur n'importe quel iPhone, par exemple iPhone 13.

- Cliquez sur
 'Run' (Exécuter), puis attendez que Xcode compile le projet et démarre l'application de départ du simulateur.
'Run' (Exécuter), puis attendez que Xcode compile le projet et démarre l'application de départ du simulateur.
L'interface utilisateur est assez simple. Il existe une zone de texte dans laquelle vous pouvez saisir un nombre, qui est envoyé au backend de TensorFlow Serving avec REST ou gRPC. Le backend effectue une régression sur la valeur d'entrée et renvoie la valeur prédite à l'application cliente, qui affiche à nouveau le résultat dans l'interface utilisateur.

Si vous saisissez un nombre et cliquez sur Déduire, rien ne se produit, car l'application ne peut pas encore communiquer avec le backend.
5. Entraîner un modèle de régression simple avec TensorFlow
La régression est l'une des tâches de ML les plus courantes. Son objectif est de prédire une quantité continue unique en fonction de l'entrée. Par exemple, en fonction de la météo, annoncez la température la plus élevée demain.
Entraîner un modèle de régression
- Ouvrez ce lien dans votre navigateur.
Colab charge le notebook Python.
- Dans le notebook Python, importez la commande suivante :
TensorFlowetNumPyEnsuite, créez six paires de données d'entraînement avecxsen entrée etysen tant que libellés.
Si vous représentez ces points de données sur un graphique, ils se trouvent en fait sur une ligne droite, car ils sont générés à partir de l'équation y = 2x -1.

- Utilisez l'API Keras pour créer un réseau de neurones à deux couches simple afin de prédire la valeur
yen fonction de l'entréex, puis compiler et ajuster le modèle.
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=10, input_shape=[1]),
tf.keras.layers.Dense(units=1),
])
model.compile(optimizer='sgd',
loss='mean_squared_error')
history = model.fit(xs, ys, epochs=500, verbose=0)
print("Finished training the model")
print(model.predict([10.0]))
L'entraînement du modèle prend quelques secondes. Vous pouvez voir que la valeur prédite pour l'entrée 10 est 18.999996, ce qui est une bonne prédiction, car la vérité terrain est 2 * 10 -1 = 19.
- Exporter le modèle:
model_dir = './regression/'
version = 123
export_path = os.path.join(model_dir, str(version))
model.save(export_path, save_format="tf")
print('\nexport_path = {}'.format(export_path))
!ls -l {export_path}
- Compressez le modèle SavedModel exporté dans un seul fichier
regression.zip:
!zip -r regression.zip ./regression
- Dans le menu de navigation, cliquez sur Runtime > Run all (Exécuter > Tout exécuter) pour exécuter le notebook, puis attendez que l'exécution se termine.
- Cliquez sur
 Fichiers, puis téléchargez le fichier
Fichiers, puis téléchargez le fichier regression.zip.
6. Déployer un modèle de régression avec TensorFlow Serving
- Pour déployer le modèle avec TensorFlow Serving, décompressez le fichier
regression.ziptéléchargé avec un outil de décompression comme 7-Zip.
La structure de dossiers doit se présenter comme suit:

Vous pouvez désigner le dossier regression comme le dossier SavedModel. 123 est un exemple de numéro de version. Si vous le souhaitez, vous pouvez en choisir un autre.
Lancer TensorFlow Serving
- Dans votre terminal, démarrez TensorFlow Serving avec Docker, mais remplacez l'espace réservé
PATH/TO/SAVEDMODELpar le chemin absolu du dossierregressionsur votre ordinateur.
docker pull tensorflow/serving docker run -it --rm -p 8500:8500 -p 8501:8501 -v "PATH/TO/SAVEDMODEL:/models/regression" -e MODEL_NAME=regression tensorflow/serving
Docker télécharge d'abord l'image TensorFlow Serving, ce qui prend une minute. Ensuite, le service TensorFlow Serving doit commencer. Le journal doit ressembler à l'extrait de code suivant:
2022-02-25 06:01:12.513231: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2022-02-25 06:01:12.585012: I external/org_tensorflow/tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 3000000000 Hz
2022-02-25 06:01:13.395083: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: /models/ssd_mobilenet_v2_2/123
2022-02-25 06:01:13.837562: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 1928700 microseconds.
2022-02-25 06:01:13.877848: I tensorflow_serving/servables/tensorflow/saved_model_warmup_util.cc:59] No warmup data file found at /models/ssd_mobilenet_v2_2/123/assets.extra/tf_serving_warmup_requests
2022-02-25 06:01:13.929844: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: regression version: 123}
2022-02-25 06:01:13.985848: I tensorflow_serving/model_servers/server_core.cc:486] Finished adding/updating models
2022-02-25 06:01:13.985987: I tensorflow_serving/model_servers/server.cc:367] Profiler service is enabled
2022-02-25 06:01:13.988994: I tensorflow_serving/model_servers/server.cc:393] Running gRPC ModelServer at 0.0.0.0:8500 ...
[warn] getaddrinfo: address family for nodename not supported
2022-02-25 06:01:14.033872: I tensorflow_serving/model_servers/server.cc:414] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 245] NET_LOG: Entering the event loop ...
7. Connecter l'application iOS à TensorFlow Serving par REST
Le backend est prêt. Vous pouvez donc envoyer des requêtes client à TensorFlow Serving pour effectuer des prédictions. Il existe deux façons d'envoyer des requêtes à TensorFlow Serving:
- REST
- gRPC
Envoyer des requêtes et recevoir des réponses avec REST
Il vous suffit de suivre ces trois étapes simples:
- Créez la requête REST.
- Envoyez la requête REST à TensorFlow Serving.
- Extrayez le résultat prédit de la réponse REST et affichez l'interface utilisateur.
Vous devez suivre ces étapes dans le fichier iOS/regression/ViewController.swift.
Créer la requête REST
- Pour le moment, la fonction
doInference()n'envoie pas la requête REST à TensorFlow Serving. Vous devez implémenter cette branche REST pour créer une requête REST:
if (connectionMode[picker.selectedRow(inComponent: 0)] == "REST") {
print("Using REST")
// TODO: Add code to send a REST request to TensorFlow Serving.
}
TensorFlow Serving attend une requête POST contenant une seule valeur. Vous devez donc intégrer la valeur d'entrée dans un fichier JSON, qui est la charge utile de la requête.
- Ajoutez ce code à la branche REST:
//Create the REST request.
let json: [String: Any] = ["signature_name" : "serving_default", "instances" : [[value]]]
let jsonData = try? JSONSerialization.data(withJSONObject: json)
let url = URL(string: "http://localhost:8501/v1/models/regression:predict")!
var request = URLRequest(url: url)
request.httpMethod = "POST"
// Insert JSON data into the request.
request.httpBody = jsonData
Envoyer la requête REST à TensorFlow Serving
- Ajoutez ce code juste après le code de la branche REST:
// Send the REST request.
let task = URLSession.shared.dataTask(with: request) { data, response, error in
guard let data = data, error == nil else {
print(error?.localizedDescription ?? "No data")
return
}
// TODO: Add code to process the response.
}
task.resume()
Traitez la réponse REST à partir de TensorFlow Serving.
- Ajoutez ce code à l'extrait de code précédent juste après le commentaire
TODO: Add code to process the response.:
// Process the REST response.
let results: RESTResults = try! JSONDecoder().decode(RESTResults.self, from: data)
DispatchQueue.main.async{
self.txtOutput.text = String(results.predictions[0][0])
}
La fonction de post-traitement extrait les valeurs prédites de la réponse et affiche le résultat dans l'interface utilisateur.
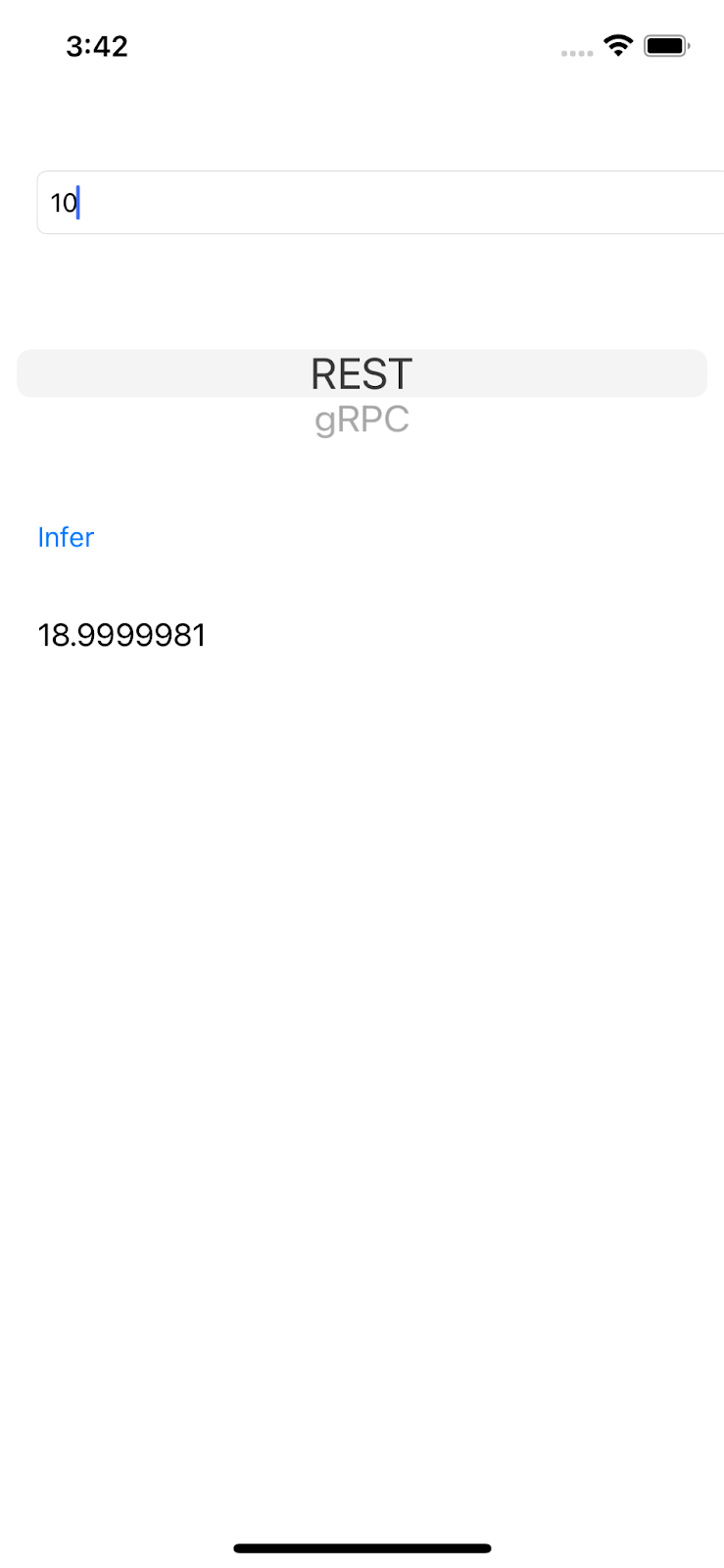
Exécuter le code
- Cliquez sur Run (Exécuter), puis attendez que Xcode lance l'application dans le simulateur.
- Saisissez un nombre dans la zone de texte, puis cliquez sur Décaler.
Une valeur prédite s'affiche dans l'UI.
8. Connecter l'application iOS à TensorFlow Serving via gRPC
Outre REST, TensorFlow Serving est également compatible avec gRPC.
gRPC est un framework d'appel de procédure à distance (RPC) moderne et Open Source qui peut être exécuté dans n'importe quel environnement. Grâce à cette solution, les services peuvent être connectés efficacement aux services de centres de données, et ils sont compatibles avec l'équilibrage de charge, le traçage, la vérification de l'état et l'authentification. En pratique, gRPC a été plus performant que REST en pratique.
Envoyer des requêtes et recevoir des réponses avec gRPC
Il existe quatre étapes simples:
- Facultatif: Générez le code du bouchon pour le client gRPC.
- Créez la requête gRPC.
- Envoyez la requête gRPC à TensorFlow Serving.
- Extrayez le résultat prédit de la réponse gRPC, puis affichez l'interface utilisateur.
Vous devez suivre ces étapes dans le fichier iOS/regression/ViewController.swift.
Facultatif: Générer le code du bouchon pour le client gRPC
Pour utiliser gRPC avec TensorFlow Serving, vous devez suivre le workflow gRPC. Pour en savoir plus, consultez la documentation gRPC.
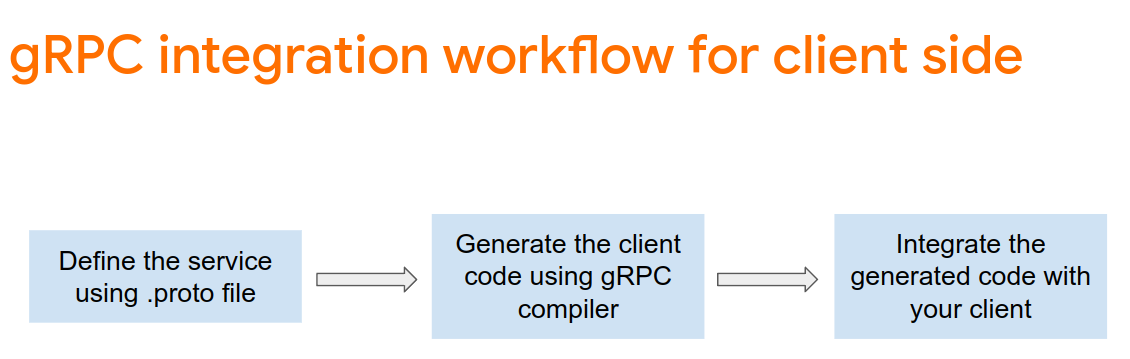
TensorFlow Serving et TensorFlow définissent les fichiers .proto pour vous. À partir de TensorFlow et de TensorFlow Serving 2.8, ces fichiers .proto sont nécessaires:
tensorflow/core/example/example.proto
tensorflow/core/example/feature.proto
tensorflow/core/protobuf/struct.proto
tensorflow/core/protobuf/saved_object_graph.proto
tensorflow/core/protobuf/saver.proto
tensorflow/core/protobuf/trackable_object_graph.proto
tensorflow/core/protobuf/meta_graph.proto
tensorflow/core/framework/node_def.proto
tensorflow/core/framework/attr_value.proto
tensorflow/core/framework/function.proto
tensorflow/core/framework/types.proto
tensorflow/core/framework/tensor_shape.proto
tensorflow/core/framework/full_type.proto
tensorflow/core/framework/versions.proto
tensorflow/core/framework/op_def.proto
tensorflow/core/framework/graph.proto
tensorflow/core/framework/tensor.proto
tensorflow/core/framework/resource_handle.proto
tensorflow/core/framework/variable.proto
tensorflow_serving/apis/inference.proto
tensorflow_serving/apis/classification.proto
tensorflow_serving/apis/predict.proto
tensorflow_serving/apis/regression.proto
tensorflow_serving/apis/get_model_metadata.proto
tensorflow_serving/apis/input.proto
tensorflow_serving/apis/prediction_service.proto
tensorflow_serving/apis/model.proto
Pour générer le code du bouchon, procédez comme suit:
- Dans votre terminal, accédez au dossier
starter/src/proto/, puis générez la simulation:
bash generate_grpc_stub_swift.sh
Un certain nombre de fichiers .swift sont générés dans le dossier starter/src/proto/generated/import.
- S'ils ne sont pas encore copiés dans votre projet, faites glisser tous les fichiers
.swiftgénérés dans votre projet dans Xcode.

Créer la requête gRPC
Comme pour la requête REST, vous créez la requête gRPC dans la branche gRPC.
if (connectionMode[picker.selectedRow(inComponent: 0)] == "REST") {
}
else {
print("Using gRPC")
// TODO: add code to send a gRPC request to TF Serving
}
- Pour créer la requête gRPC, ajoutez ce code à la branche gRPC:
//Create the gRPC request.
let group = MultiThreadedEventLoopGroup(numberOfThreads: 1)
let channel = ClientConnection.insecure(group: group).connect(host: "localhost", port: 8500)
let stub = Tensorflow_Serving_PredictionServiceClient(channel: channel)
var modelSpec = Tensorflow_Serving_ModelSpec()
modelSpec.name = "regression"
modelSpec.signatureName = "serving_default"
// Prepare the input tensor.
var batchDim = Tensorflow_TensorShapeProto.Dim()
batchDim.size = 1
var inputDim = Tensorflow_TensorShapeProto.Dim()
inputDim.size = 1
var inputTensorShape = Tensorflow_TensorShapeProto()
inputTensorShape.dim = [batchDim, inputDim]
var inputTensor = Tensorflow_TensorProto()
inputTensor.dtype = Tensorflow_DataType.dtFloat
inputTensor.tensorShape = inputTensorShape
inputTensor.floatVal = [Float(value)]
var request = Tensorflow_Serving_PredictRequest()
request.modelSpec = modelSpec
request.inputs = ["dense_input" : inputTensor]
let callOptions = CallOptions(timeLimit: .timeout(.seconds(15)))
Envoyer la requête gRPC à TensorFlow Serving
- Ajoutez ce code à la branche gRPC immédiatement après le code de l'extrait de code précédent:
// Send the gRPC request.
let call = stub.predict(request, callOptions: callOptions)
Traiter la réponse gRPC de TensorFlow Serving
- Ajoutez ce code juste après le code dans l'extrait de code précédent:
// Process the response.
call.response.whenSuccess { response in
let result = response.outputs["dense_1"]?.floatVal[0]
DispatchQueue.main.async{
self.txtOutput.text = String(describing: result!)
}
}
call.response.whenFailure { error in
print("Call failed with error\n\(error)")
}
La fonction de post-traitement extrait les valeurs prédites de la réponse et affiche le résultat dans l'interface utilisateur.
Exécuter le code
- Dans le menu de navigation, cliquez sur Run (Exécuter), puis attendez que Xcode lance l'application dans le simulateur.
- Saisissez un nombre dans la zone de texte, puis cliquez sur Décaler.
Une valeur prédite s'affiche dans l'UI.
9. Félicitations
Vous avez utilisé TensorFlow Serving pour ajouter des fonctionnalités de régression à votre application.