
1. Zanim zaczniesz
Wpisywanie kodu to świetny sposób na wyrobienie pamięci mięśniowej i pogłębienie wiedzy. Kopiowanie i wklejanie może oszczędzić czas, ale inwestowanie w tę praktykę może w dłuższej perspektywie zwiększyć wydajność i poprawić umiejętności kodowania.
Z tego samouczka dowiesz się, jak utworzyć aplikację na Androida, która wykonuje segmentację obrazu w czasie rzeczywistym na podstawie obrazu z kamery na żywo za pomocą nowego środowiska wykonawczego Google dla TensorFlow Lite, czyli LiteRT. Zaczniesz od aplikacji na Androida i dodasz do niej funkcje segmentacji obrazu. Omówimy też kroki wstępnego przetwarzania, wnioskowania i przetwarzania końcowego. W ramach ćwiczenia:
- Utwórz aplikację na Androida, która segmentuje obrazy w czasie rzeczywistym.
- Zintegruj wytrenowany model segmentacji obrazów LiteRT.
- Wstępnie przetwórz obraz wejściowy na potrzeby modelu.
- Używaj środowiska wykonawczego LiteRT do przyspieszania działania na CPU i GPU.
- Dowiedz się, jak przetwarzać dane wyjściowe modelu, aby wyświetlać maskę segmentacji.
- Dowiedz się, jak dostosować ustawienia przedniego aparatu.
Ostatecznie uzyskasz efekt podobny do tego na obrazie poniżej:

Wymagania wstępne
Te ćwiczenia z programowania są przeznaczone dla doświadczonych programistów aplikacji mobilnych, którzy chcą zdobyć doświadczenie w zakresie uczenia maszynowego. Musisz znać:
- Tworzenie aplikacji na Androida w Kotlinie i Android Studio
- Podstawowe pojęcia dotyczące przetwarzania obrazów
Czego się nauczysz
- Jak zintegrować i używać środowiska wykonawczego LiteRT w aplikacji na Androida.
- Jak przeprowadzić segmentację obrazu za pomocą wytrenowanego modelu LiteRT.
- Jak wstępnie przetworzyć obraz wejściowy na potrzeby modelu.
- Jak przeprowadzić wnioskowanie na podstawie modelu.
- Jak przetwarzać dane wyjściowe modelu segmentacji, aby wizualizować wyniki.
- Jak używać CameraX do przetwarzania obrazu z aparatu w czasie rzeczywistym.
Czego potrzebujesz
- Najnowsza wersja Androida Studio (testowana na wersji 2025.1.1).
- fizyczne urządzenie z Androidem, Najlepiej przetestować ją na urządzeniach Galaxy i Pixel.
- przykładowy kod (z GitHuba);
- Podstawowa wiedza na temat tworzenia aplikacji na Androida w języku Kotlin.
2. Segmentacja obrazu
Segmentacja obrazu to zadanie z zakresu widzenia komputerowego, które polega na podzieleniu obrazu na wiele segmentów lub regionów. W przeciwieństwie do wykrywania obiektów, które rysuje ramkę ograniczającą wokół obiektu, segmentacja obrazu przypisuje określoną klasę lub etykietę do każdego piksela na obrazie. Dzięki temu uzyskasz znacznie bardziej szczegółowe i dokładne informacje o zawartości obrazu, co pozwoli Ci poznać dokładny kształt i granice każdego obiektu.
Na przykład zamiast tylko wiedzieć, że w ramce znajduje się „osoba”, możesz dokładnie określić, które piksele do niej należą. Z tego samouczka dowiesz się, jak przeprowadzić segmentację obrazu w czasie rzeczywistym na urządzeniu z Androidem za pomocą wstępnie wytrenowanego modelu uczenia maszynowego.

LiteRT: przesuwanie granic uczenia maszynowego na urządzeniu
Kluczową technologią umożliwiającą segmentację w czasie rzeczywistym i wysokiej jakości na urządzeniach mobilnych jest LiteRT. LiteRT to środowisko wykonawcze TensorFlow Lite nowej generacji o wysokiej wydajności. Zostało zaprojektowane tak, aby w pełni wykorzystywać możliwości sprzętu.
Osiąga to dzięki inteligentnemu i zoptymalizowanemu wykorzystaniu akceleratorów sprzętowych, takich jak GPU (procesor graficzny) i NPU (procesor sieci neuronowej). Przenosząc intensywne obliczenia modelu segmentacji z procesora ogólnego przeznaczenia na te wyspecjalizowane procesory, LiteRT znacznie skraca czas wnioskowania. Dzięki temu złożone modele mogą działać płynnie na żywo w aplikacji Aparat, co poszerza możliwości uczenia maszynowego bezpośrednio na telefonie. Bez takiej wydajności segmentacja w czasie rzeczywistym byłaby zbyt wolna i niestabilna, aby zapewnić użytkownikom dobre wrażenia.
3. Konfiguracja
Klonowanie repozytorium
Najpierw sklonuj repozytorium LiteRT:
git clone https://github.com/google-ai-edge/litert-samples.git
litert-samples/compiled_model_api/image_segmentation to katalog ze wszystkimi potrzebnymi zasobami. W tym ćwiczeniu potrzebny będzie tylko projekt kotlin_cpu_gpu/android_starter. Jeśli utkniesz, możesz sprawdzić gotowy projekt: kotlin_cpu_gpu/android
Uwaga dotycząca ścieżek do plików
W tym samouczku ścieżki plików są podane w formacie Linux/macOS. Jeśli korzystasz z systemu Windows, musisz odpowiednio dostosować ścieżki.
Warto też zwrócić uwagę na różnicę między widokiem projektu w Android Studio a standardowym widokiem systemu plików. Widok projektu w Android Studio to uporządkowana reprezentacja plików projektu, zorganizowana pod kątem tworzenia aplikacji na Androida. Ścieżki plików w tym samouczku odnoszą się do ścieżek w systemie plików, a nie do ścieżek w widoku projektu w Android Studio.
Importowanie aplikacji startowej
Zacznijmy od zaimportowania aplikacji początkowej do Android Studio.
- Otwórz Android Studio i kliknij Otwórz.
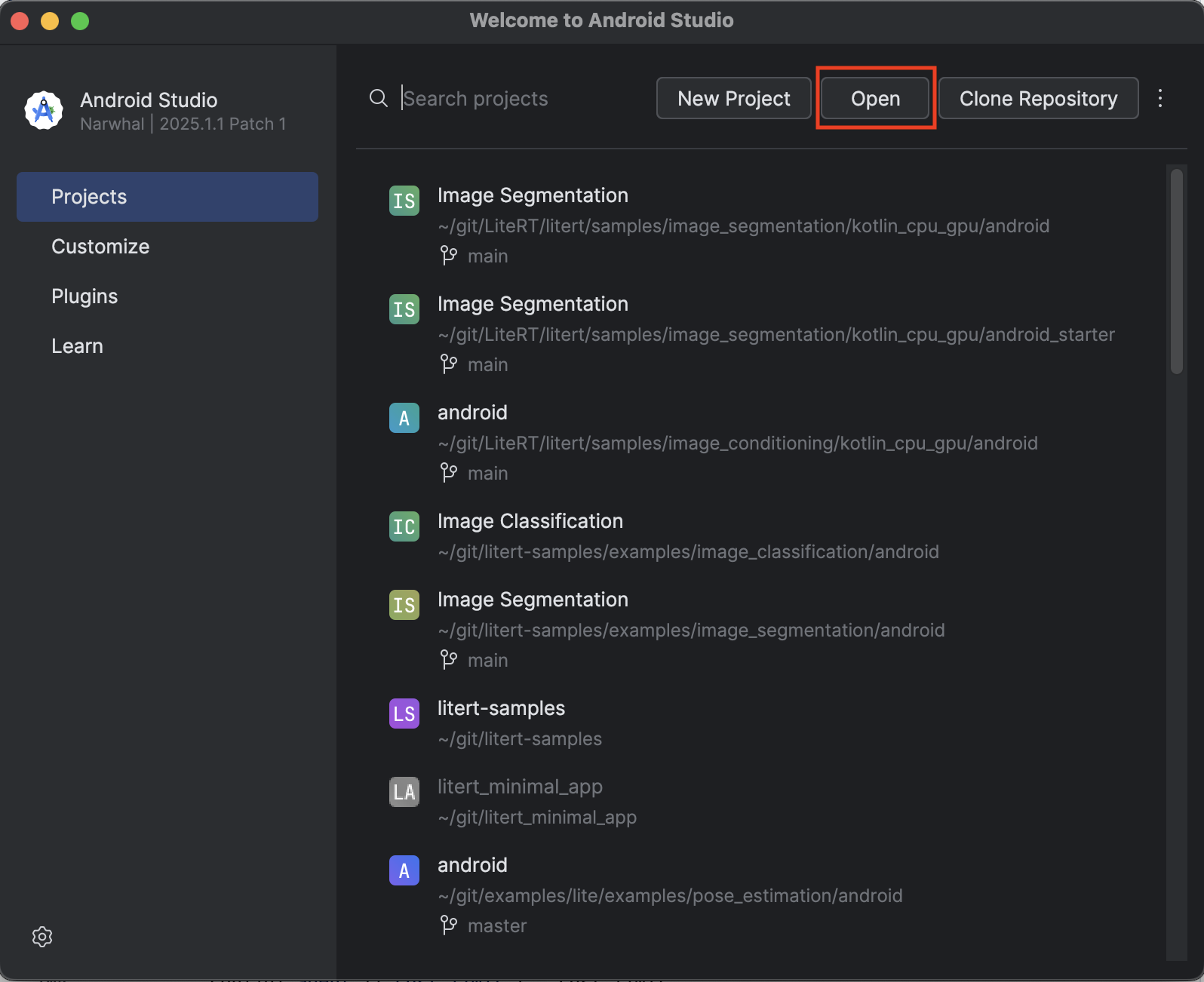
- Przejdź do katalogu
kotlin_cpu_gpu/android_starteri otwórz go.
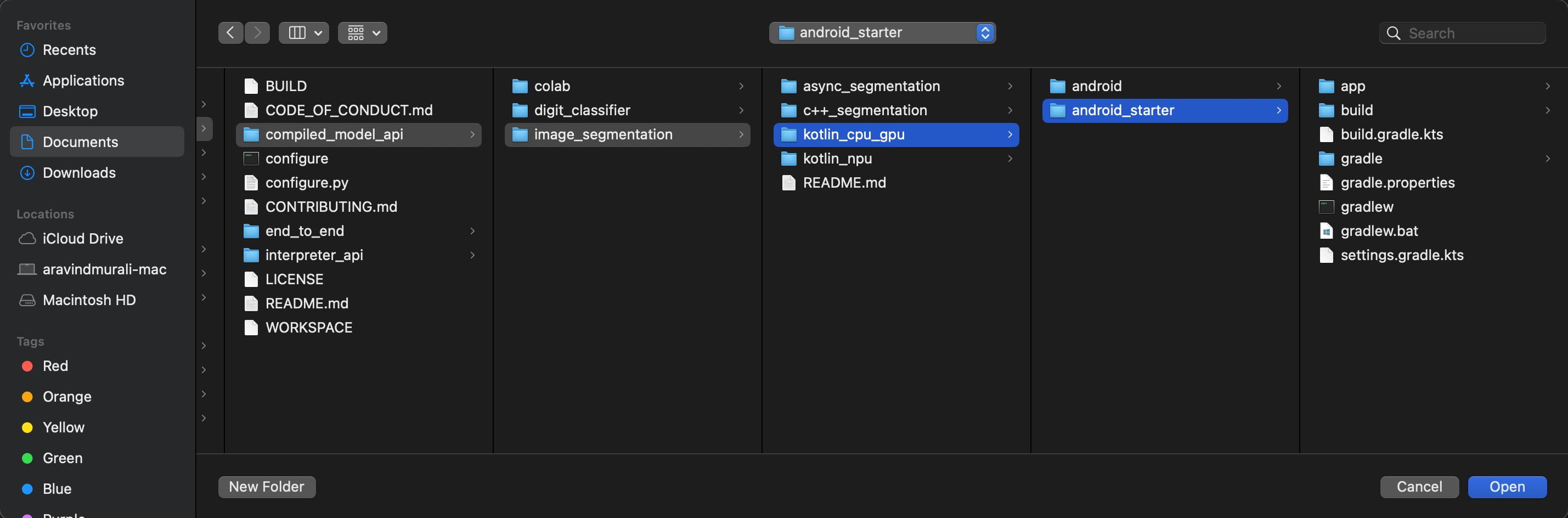
Aby mieć pewność, że wszystkie zależności są dostępne dla aplikacji, po zakończeniu procesu importowania zsynchronizuj projekt z plikami Gradle.
- Na pasku narzędzi Android Studio wybierz Synchronizuj projekt z plikami Gradle.
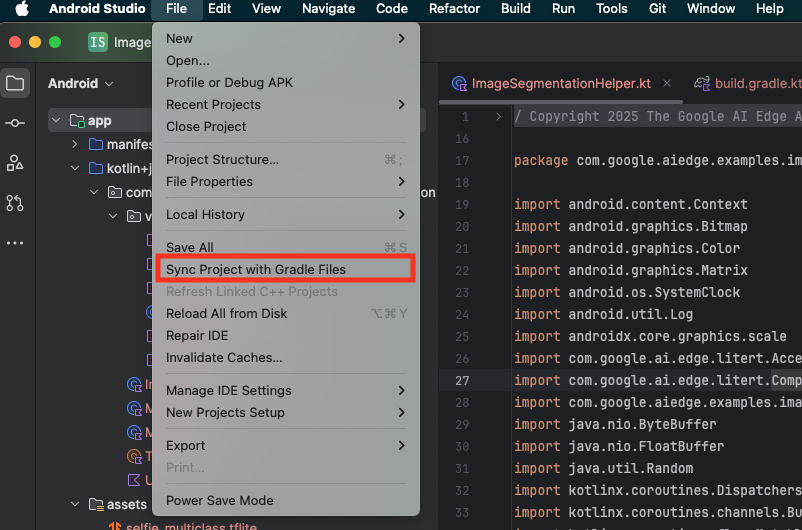
- Nie pomijaj tego kroku – jeśli nie zadziała, reszta samouczka nie będzie miała sensu.
Uruchom aplikację startową
Po zaimportowaniu projektu do Android Studio możesz po raz pierwszy uruchomić aplikację.
Podłącz urządzenie z Androidem do komputera przez USB i na pasku narzędzi Android Studio kliknij Uruchom.
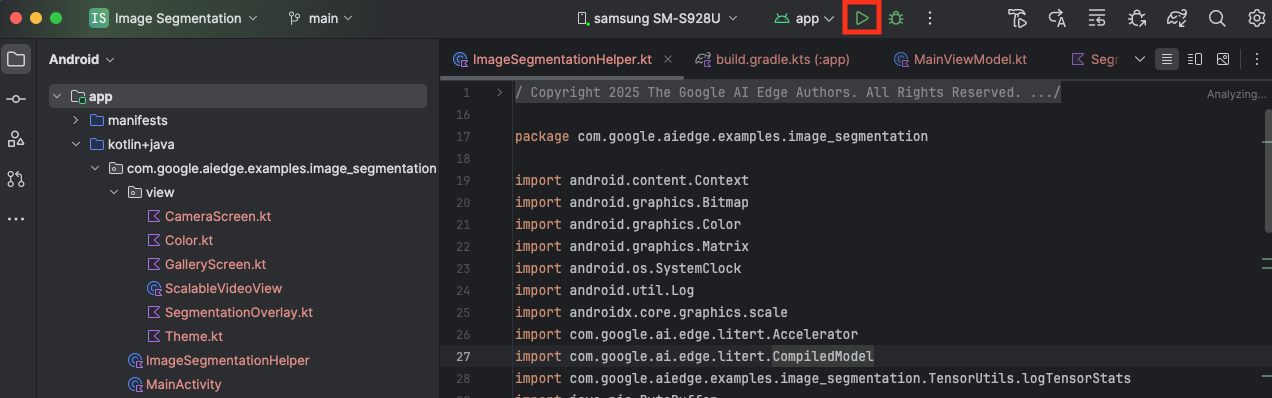
Aplikacja powinna się uruchomić na urządzeniu. Zobaczysz transmisję na żywo z kamery, ale segmentacja nie będzie jeszcze działać. Wszystkie zmiany w plikach, które wprowadzisz w tym samouczku, będą dotyczyć katalogu litert-samples/compiled_model_api/image_segmentation/kotlin_cpu_gpu/android_starter/app/src/main/java/com/google/ai/edge/examples/image_segmentation (teraz już wiesz, dlaczego Android Studio zmienia jego strukturę 😃).
Zobaczysz też TODO komentarze w plikach ImageSegmentationHelper.kt, MainViewModel.kt i view/SegmentationOverlay.kt. W kolejnych krokach wdrożysz funkcję segmentacji obrazu, wypełniając te pola TODO.
4. Informacje o aplikacji startowej
Aplikacja startowa ma już podstawowy interfejs i logikę obsługi aparatu. Oto krótkie omówienie najważniejszych plików:
app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainActivity.kt: to główny punkt wejścia do aplikacji. Konfiguruje interfejs za pomocą Jetpack Compose i zarządza uprawnieniami dostępu do aparatu.app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainViewModel.kt: ten ViewModel zarządza stanem interfejsu i koordynuje proces segmentacji obrazu.app/src/main/java/com/google/ai/edge/examples/image_segmentation/ImageSegmentationHelper.kt: w tym miejscu dodamy podstawową logikę segmentacji obrazu. Zajmie się wczytywaniem modelu, przetwarzaniem klatek z kamery i przeprowadzaniem wnioskowania.app/src/main/java/com/google/ai/edge/examples/image_segmentation/view/CameraScreen.kt: ta funkcja Composable wyświetla podgląd z kamery i nakładkę segmentacji.app/download_model.gradle: ten skrypt pobieraselfie_multiclass.tflite. Jest to wstępnie wytrenowany model segmentacji obrazów TensorFlow Lite, którego będziemy używać.
5. Informacje o LiteRT i dodawanie zależności
Teraz dodajmy do aplikacji startowej funkcję segmentacji obrazu.
1. Dodaj zależność LiteRT
Najpierw musisz dodać bibliotekę LiteRT do projektu. Jest to kluczowy pierwszy krok, który umożliwia uczenie maszynowe na urządzeniu z optymalizowanym środowiskiem wykonawczym Google.
Otwórz plik app/build.gradle.kts i dodaj ten wiersz do bloku dependencies:
// LiteRT for on-device ML
implementation(libs.litert)
Po dodaniu zależności zsynchronizuj projekt z plikami Gradle, klikając przycisk Synchronizuj teraz, który pojawi się w prawym górnym rogu Android Studio.

2. Poznaj najważniejsze interfejsy API LiteRT
OtwórzImageSegmentationHelper.kt
Zanim napiszesz kod implementacji, musisz poznać podstawowe komponenty interfejsu LiteRT API, których będziesz używać. Upewnij się, że importujesz z pakietu com.google.ai.edge.litert. Dodaj te importy na początku pliku ImageSegmentationHelper.kt:
import com.google.ai.edge.litert.Accelerator
import com.google.ai.edge.litert.CompiledModel
CompiledModel: jest to główna klasa do interakcji z modelem TFLite. Jest to model, który został wstępnie skompilowany i zoptymalizowany pod kątem konkretnego akceleratora sprzętowego (np. procesora lub GPU). Wstępna kompilacja to kluczowa funkcja LiteRT, która zapewnia szybsze i wydajniejsze wnioskowanie.CompiledModel.Options: za pomocą tej klasy kreatora możesz skonfigurowaćCompiledModel. Najważniejsze ustawienie to określenie akceleratora sprzętowego, którego chcesz używać do uruchamiania modelu.Accelerator: ten wyliczeniowy typ danych umożliwia wybór sprzętu do wnioskowania. Projekt startowy jest już skonfigurowany do obsługi tych opcji:Accelerator.CPU: do uruchamiania modelu na procesorze urządzenia. Jest to najbardziej uniwersalna opcja.Accelerator.GPU: do uruchamiania modelu na procesorze graficznym urządzenia. W przypadku modeli opartych na obrazach jest to często znacznie szybsze niż w przypadku procesora.
- Bufory wejściowe i wyjściowe (
TensorBuffer): LiteRT używaTensorBufferdo danych wejściowych i wyjściowych modelu. Dzięki temu masz szczegółową kontrolę nad pamięcią i unikasz niepotrzebnych kopii danych. Te bufory uzyskasz bezpośrednio z instancjiCompiledModelza pomocą funkcjimodel.createInputBuffers()imodel.createOutputBuffers(), a następnie zapiszesz w nich dane wejściowe i odczytasz wyniki. model.run(): ta funkcja wykonuje wnioskowanie. Przekazujesz do niego bufory wejściowe i wyjściowe, a LiteRT zajmuje się złożonym zadaniem uruchomienia modelu na wybranym akceleratorze sprzętowym.
6. Kończenie wstępnej implementacji ImageSegmentationHelper
Teraz czas napisać kod. Przeprowadzisz wstępną implementację ImageSegmentationHelper.kt. Obejmuje to skonfigurowanie Segmenter klasy prywatnej do przechowywania modelu LiteRT i wdrożenie funkcji cleanup(), która umożliwia jego prawidłowe zwalnianie.
- Ukończ
Segmenterklasę icleanup()funkcję: w plikuImageSegmentationHelper.ktznajdziesz szkielet klasy prywatnej o nazwieSegmenteri funkcji o nazwiecleanup(). Najpierw uzupełnij klasęSegmenter, definiując jej konstruktor do przechowywania modelu, tworząc właściwości buforów wejściowych i wyjściowych oraz dodając metodęclose()do zwalniania modelu. Następnie zaimplementuj funkcjęcleanup(), aby wywołać nową metodęclose().Zastąp istniejącą klasęSegmenteri funkcjęcleanup()tym kodem: (~wiersz 83)private class Segmenter( // Add this argument private val model: CompiledModel, private val coloredLabels: List<ColoredLabel>, ) { // Add these private vals private val inputBuffers = model.createInputBuffers() private val outputBuffers = model.createOutputBuffers() fun cleanup() { // cleanup buffers inputBuffers.forEach { it.close() } outputBuffers.forEach { it.close() } // cleanup model model.close() } } - Zdefiniuj metodę toAccelerator: ta metoda mapuje zdefiniowane wyliczenia akceleratora z menu akceleratora na wyliczenia akceleratora specyficzne dla zaimportowanych modułów LiteRT (około wiersza 225):
fun toAccelerator(acceleratorEnum: AcceleratorEnum): Accelerator { return when (acceleratorEnum) { AcceleratorEnum.CPU -> Accelerator.CPU AcceleratorEnum.GPU -> Accelerator.GPU } } - Zainicjuj
CompiledModel: znajdź teraz funkcjęinitSegmenter. W tym miejscu utworzysz instancjęCompiledModeli użyjesz jej do utworzenia instancji zdefiniowanej klasySegmenter. Ten kod konfiguruje model z określonym akceleratorem (CPU lub GPU) i przygotowuje go do wnioskowania. Zastąp znakTODOwinitSegmentertym kodem (naciśnij Cmd/Ctrl+f i wpisz „initSegmenter” lub przejdź do wiersza 62):cleanup() try { withContext(singleThreadDispatcher) { val model = CompiledModel.create( context.assets, "selfie_multiclass.tflite", CompiledModel.Options(toAccelerator(acceleratorEnum)), null, ) segmenter = Segmenter(model, coloredLabels) Log.d(TAG, "Created an image segmenter") } } catch (e: Exception) { Log.i(TAG, "Create LiteRT from selfie_multiclass is failed: ${e.message}") _error.emit(e) }
7. Rozpocznij segmentację i przetwarzanie wstępne
Teraz, gdy mamy już model, musimy uruchomić proces segmentacji i przygotować dane wejściowe dla modelu.
Aktywowanie segmentacji
Proces segmentacji rozpoczyna się w MainViewModel.kt, które otrzymuje klatki z kamery.
OtwórzMainViewModel.kt
- Wywoływanie segmentacji z klatek kamery: funkcje
segmentwMainViewModelsą punktem wejścia dla naszego zadania segmentacji. Są one wywoływane, gdy z aparatu jest dostępne nowe zdjęcie lub gdy zostanie ono wybrane z galerii. Te funkcje wywołują następnie metodęsegmentw naszymImageSegmentationHelper. Zastąp symboleTODOw obu funkcjachsegmenttymi wartościami (wiersz 107):// For ImageProxy (from CameraX) fun segment(imageProxy: ImageProxy) { segmentJob = viewModelScope.launch { imageSegmentationHelper.segment(imageProxy.toBitmap(), imageProxy.imageInfo.rotationDegrees) imageProxy.close() } } // For Bitmaps (from gallery) fun segment(bitmap: Bitmap, rotationDegrees: Int) { segmentJob = viewModelScope.launch { val argbBitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true) imageSegmentationHelper.segment(argbBitmap, rotationDegrees) } }
Wstępne przetwarzanie obrazu
Wróćmy teraz do ImageSegmentationHelper.kt, aby zająć się wstępnym przetwarzaniem obrazu.
OtwórzImageSegmentationHelper.kt
- Wdróż funkcję Public
segment: ta funkcja służy jako otoka, która wywołuje prywatną funkcjęsegmentw klasieSegmenter. ZastąpTODOtym kodem (około wiersza 95):try { withContext(singleThreadDispatcher) { segmenter?.segment(bitmap, rotationDegrees)?.let { if (isActive) _segmentation.emit(it) } } } catch (e: Exception) { Log.i(TAG, "Image segment error occurred: ${e.message}") _error.emit(e) } - Wdrożenie wstępnego przetwarzania: prywatna
segmentfunkcja w klasieSegmenterto miejsce, w którym przeprowadzimy niezbędne przekształcenia obrazu wejściowego, aby przygotować go do modelu. Obejmuje to skalowanie, obracanie i normalizowanie obrazu. Ta funkcja wywoła następnie inną prywatną funkcjęsegment, aby przeprowadzić wnioskowanie. ZastąpTODOw funkcjisegment(bitmap: Bitmap, ...)tym ciągiem (~line 121):val totalStartTime = SystemClock.uptimeMillis() val rotation = -rotationDegrees / 90 val (h, w) = Pair(256, 256) // Preprocessing val preprocessStartTime = SystemClock.uptimeMillis() var image = bitmap.scale(w, h, true) image = rot90Clockwise(image, rotation) val inputFloatArray = normalize(image, 127.5f, 127.5f) Log.d(TAG, "Preprocessing time: ${SystemClock.uptimeMillis() - preprocessStartTime} ms") // Inference val inferenceStartTime = SystemClock.uptimeMillis() val segmentResult = segment(inputFloatArray) Log.d(TAG, "Inference time: ${SystemClock.uptimeMillis() - inferenceStartTime} ms") Log.d(TAG, "Total segmentation time: ${SystemClock.uptimeMillis() - totalStartTime} ms") return SegmentationResult(segmentResult, SystemClock.uptimeMillis() - inferenceStartTime)
8. Podstawowe wnioskowanie z użyciem LiteRT
Po wstępnym przetworzeniu danych wejściowych możemy przeprowadzić wnioskowanie podstawowe za pomocą LiteRT.
OtwórzImageSegmentationHelper.kt
- Wdrażanie wykonywania modelu: prywatna funkcja
segment(inputFloatArray: FloatArray)to miejsce, w którym bezpośrednio wchodzimy w interakcję z metodą LiteRTrun(). Zapisujemy wstępnie przetworzone dane w buforze wejściowym, uruchamiamy model i odczytujemy wyniki z bufora wyjściowego. ZastąpTODOw tej funkcji tym kodem (~wiersz 188):val (h, w, c) = Triple(256, 256, 6) // MODEL EXECUTION PHASE val modelExecStartTime = SystemClock.uptimeMillis() // Write input data - measure time val bufferWriteStartTime = SystemClock.uptimeMillis() inputBuffers[0].writeFloat(inputFloatArray) val bufferWriteTime = SystemClock.uptimeMillis() - bufferWriteStartTime Log.d(TAG, "Buffer write time: $bufferWriteTime ms") // Optional tensor inspection logTensorStats("Input tensor", inputFloatArray) // Run model inference - measure time val modelRunStartTime = SystemClock.uptimeMillis() model.run(inputBuffers, outputBuffers) val modelRunTime = SystemClock.uptimeMillis() - modelRunStartTime Log.d(TAG, "Model.run() time: $modelRunTime ms") // Read output data - measure time val bufferReadStartTime = SystemClock.uptimeMillis() val outputFloatArray = outputBuffers[0].readFloat() val outputBuffer = FloatBuffer.wrap(outputFloatArray) val bufferReadTime = SystemClock.uptimeMillis() - bufferReadStartTime Log.d(TAG, "Buffer read time: $bufferReadTime ms") val modelExecTime = SystemClock.uptimeMillis() - modelExecStartTime Log.d(TAG, "Total model execution time: $modelExecTime ms") // Optional tensor inspection logTensorStats("Output tensor", outputFloatArray) // POSTPROCESSING PHASE val postprocessStartTime = SystemClock.uptimeMillis() // Process mask from model output val inferenceData = InferenceData(width = w, height = h, channels = c, buffer = outputBuffer) val mask = processImage(inferenceData) val postprocessTime = SystemClock.uptimeMillis() - postprocessStartTime Log.d(TAG, "Postprocessing time (mask creation): $postprocessTime ms") return Segmentation( listOf(Mask(mask, inferenceData.width, inferenceData.height)), coloredLabels, )
9. Przetwarzanie końcowe i wyświetlanie nakładki
Po przeprowadzeniu wnioskowania otrzymujemy surowe dane wyjściowe z modelu. Musimy przetworzyć te dane wyjściowe, aby utworzyć wizualną maskę segmentacji, a następnie wyświetlić ją na ekranie.
OtwórzImageSegmentationHelper.kt
- Wdrożenie przetwarzania danych wyjściowych: funkcja
processImagekonwertuje surowe dane wyjściowe zmiennoprzecinkowe z modelu na wartośćByteBuffer, która reprezentuje maskę segmentacji. W tym celu wyszukuje klasę o najwyższym prawdopodobieństwie dla każdego piksela. Zastąp jegoTODOtym kodem (~wiersz 238):val mask = ByteBuffer.allocateDirect(inferenceData.width * inferenceData.height) for (i in 0 until inferenceData.height) { for (j in 0 until inferenceData.width) { val offset = inferenceData.channels * (i * inferenceData.width + j) var maxIndex = 0 var maxValue = inferenceData.buffer.get(offset) for (index in 1 until inferenceData.channels) { if (inferenceData.buffer.get(offset + index) > maxValue) { maxValue = inferenceData.buffer.get(offset + index) maxIndex = index } } mask.put(i * inferenceData.width + j, maxIndex.toByte()) } } return mask
OtwórzMainViewModel.kt
- Zbieranie i przetwarzanie wyników segmentacji: wracamy teraz do
MainViewModel, aby przetworzyć wyniki segmentacji zImageSegmentationHelper.segmentationUiShareFlowzbieraSegmentationResult, przekształca maskę w kolorowąBitmapi przekazuje ją do interfejsu. ZastąpTODOw właściwościsegmentationUiShareFlowciągiem (~line 63) – nie zastępuj kodu, który już tam jest, tylko wypełnij treść:viewModelScope.launch { imageSegmentationHelper.segmentation .filter { it.segmentation.masks.isNotEmpty() } .map { val segmentation = it.segmentation val mask = segmentation.masks[0] val maskArray = mask.data val width = mask.width val height = mask.height val pixelSize = width * height val pixels = IntArray(pixelSize) val colorLabels = segmentation.coloredLabels.mapIndexed { index, coloredLabel -> ColorLabel(index, coloredLabel.label, coloredLabel.argb) } // Set color for pixels for (i in 0 until pixelSize) { val colorLabel = colorLabels[maskArray[i].toInt()] val color = colorLabel.getColor() pixels[i] = color } // Get image info val overlayInfo = OverlayInfo(pixels = pixels, width = width, height = height) val inferenceTime = it.inferenceTime Pair(overlayInfo, inferenceTime) } .collect { flow.emit(it) } }
Otwórzview/SegmentationOverlay.kt
Ostatnim elementem jest prawidłowe zorientowanie nakładki segmentacji, gdy użytkownik przełączy się na przedni aparat. Obraz z przedniego aparatu jest naturalnie odbity lustrzanie, więc musimy zastosować to samo odbicie poziome do naszej nakładki Bitmap, aby zapewnić jej prawidłowe dopasowanie do podglądu z aparatu.
- Obsługa orientacji nakładki: znajdź
TODOw plikuSegmentationOverlay.kti zastąp go tym kodem. Ten kod sprawdza, czy przedni aparat jest aktywny, a jeśli tak, stosuje do nakładkiBitmappoziome odwrócenie, zanim zostanie ona narysowana naCanvas. (~line 42):val orientedBitmap = if (lensFacing == CameraSelector.LENS_FACING_FRONT) { // Create a matrix for horizontal flipping val matrix = Matrix().apply { preScale(-1f, 1f) } Bitmap.createBitmap(image, 0, 0, image.width, image.height, matrix, false).also { image.recycle() } } else { image }
10. Uruchamianie i używanie gotowej aplikacji
Wszystkie niezbędne zmiany w kodzie zostały wprowadzone. Czas uruchomić aplikację i zobaczyć efekty swojej pracy.
- Uruchom aplikację: podłącz urządzenie z Androidem i kliknij Uruchom na pasku narzędzi Android Studio.
- Przetestuj funkcje: po uruchomieniu aplikacji powinien pojawić się obraz z kamery na żywo z kolorową nakładką segmentacji.
- Przełączanie aparatów: kliknij ikonę zmiany aparatu u góry, aby przełączać się między przednim a tylnym aparatem. Zwróć uwagę, jak nakładka prawidłowo się orientuje.
- Zmień akcelerator: kliknij przycisk „CPU” lub „GPU” u dołu, aby przełączyć akcelerator sprzętowy. Obserwuj zmianę czasu wnioskowania wyświetlanego u dołu ekranu. GPU powinien być znacznie szybszy.
- Użyj obrazu z galerii: u góry kliknij kartę „Galeria”, aby wybrać obraz z galerii zdjęć na urządzeniu. Aplikacja przeprowadzi segmentację wybranego obrazu statycznego.

Masz teraz w pełni funkcjonalną aplikację do segmentacji obrazu w czasie rzeczywistym opartą na LiteRT.
11. Zaawansowane (opcjonalnie): korzystanie z NPU
To repozytorium zawiera też wersję aplikacji zoptymalizowaną pod kątem jednostek przetwarzania neuronowego (NPU). Wersja NPU może znacznie zwiększyć wydajność na urządzeniach z kompatybilnym procesorem NPU.
Aby wypróbować wersję NPU, otwórz kotlin_npu/android projekt w Android Studio. Kod jest bardzo podobny do wersji na CPU/GPU i jest skonfigurowany do używania delegata NPU.
Aby korzystać z delegata NPU, musisz zarejestrować się w programie wcześniejszego dostępu.
12. Gratulacje!
Udało Ci się utworzyć aplikację na Androida, która wykonuje segmentację obrazu w czasie rzeczywistym za pomocą biblioteki LiteRT. Wiesz już, jak:
- Zintegruj środowisko wykonawcze LiteRT z aplikacją na Androida.
- Wczytywanie i uruchamianie modelu segmentacji obrazów TFLite.
- przetworzyć wstępnie dane wejściowe modelu;
- Przetwórz dane wyjściowe modelu, aby utworzyć maskę segmentacji.
- Użyj CameraX w aplikacji aparatu działającej w czasie rzeczywistym.
Następne kroki
- Spróbuj użyć innego modelu segmentacji obrazu.
- Eksperymentuj z różnymi delegatami LiteRT (CPU, GPU, NPU).