
1. 始める前に
コードを入力することは、筋肉の記憶を構築し、教材の理解を深めるのに最適な方法です。コピー&ペーストは時間を節約できますが、この方法に投資することで、長期的には効率が向上し、コーディング スキルが向上します。
この Codelab では、TensorFlow Lite の新しいランタイムである LiteRT を使用して、ライブカメラ フィードでリアルタイム画像セグメンテーションを実行する Android アプリケーションを作成する方法を学びます。スターター Android アプリケーションを使用して、画像セグメンテーション機能を追加します。前処理、推論、後処理の手順についても説明します。次のことを行います。
- 画像をリアルタイムでセグメント化する Android アプリをビルドします。
- 事前トレーニング済みの LiteRT 画像セグメンテーション モデルを統合します。
- モデルの入力画像を前処理します。
- CPU と GPU の高速化には LiteRT ランタイムを使用します。
- モデルの出力を処理してセグメンテーション マスクを表示する方法を理解する。
- 前面カメラの調整方法について説明します。
最終的には、次の画像のようなものが作成されます。

前提条件
この Codelab は、機械学習の経験を積みたいモバイル デベロッパーを対象としています。以下について把握しておく必要があります。
- Kotlin と Android Studio を使用した Android 開発
- 画像処理の基本コンセプト
学習内容
- Android アプリケーションで LiteRT ランタイムを統合して使用する方法。
- 事前トレーニング済みの LiteRT モデルを使用して画像セグメンテーションを行う方法。
- モデルの入力画像を前処理する方法。
- モデルの推論を実行する方法。
- セグメンテーション モデルの出力を処理して結果を可視化する方法。
- リアルタイムのカメラフィード処理に CameraX を使用する方法。
必要なもの
- 最新バージョンの Android Studio(v2025.1.1 でテスト済み)。
- 物理 Android デバイス。Galaxy デバイスと Google Pixel デバイスでテストするのが最適です。
- サンプルコード(GitHub から)。
- Kotlin での Android 開発に関する基本的な知識。
2. 画像セグメンテーション
画像セグメンテーションは、画像を複数のセグメントまたはリージョンに分割するコンピュータ ビジョン タスクです。オブジェクトの周囲に境界ボックスを描画するオブジェクト検出とは異なり、画像セグメンテーションでは、画像内のすべてのピクセルに特定のクラスまたはラベルが割り当てられます。これにより、画像のコンテンツをより詳細かつ粒度細かく把握し、各オブジェクトの正確な形状と境界を把握できます。
たとえば、単に「人物」がボックス内にいることを知るだけでなく、その人物に属するピクセルを正確に把握できます。このチュートリアルでは、事前トレーニング済みの ML モデルを使用して Android デバイスでリアルタイム画像セグメンテーションを行う方法を説明します。

LiteRT: オンデバイス ML のエッジを押し広げる
モバイル デバイスでリアルタイムかつ高精度のセグメンテーションを実現する重要なテクノロジーが LiteRT です。TensorFlow Lite の次世代高性能ランタイムである LiteRT は、基盤となるハードウェアから最高のパフォーマンスを引き出すように設計されています。
これは、GPU(グラフィック プロセッシング ユニット)や NPU(ニューラル プロセッシング ユニット)などのハードウェア アクセラレータをインテリジェントかつ最適化して使用することで実現されます。セグメンテーション モデルの計算負荷の高いワークロードを汎用 CPU からこれらの専用プロセッサにオフロードすることで、LiteRT は推論時間を大幅に短縮します。この高速化により、複雑なモデルをライブ カメラフィードでスムーズに実行できるようになり、スマートフォンで直接機械学習を活用できる範囲が広がります。このレベルのパフォーマンスがなければ、リアルタイム セグメンテーションは遅すぎて、ユーザー エクスペリエンスが低下します。
3. セットアップする
リポジトリのクローンを作成します。
まず、LiteRT のリポジトリのクローンを作成します。
git clone https://github.com/google-ai-edge/litert-samples.git
litert-samples/compiled_model_api/image_segmentation は、必要なすべてのリソースを含むディレクトリです。この Codelab では、kotlin_cpu_gpu/android_starter プロジェクトのみが必要です。行き詰まった場合は、完成したプロジェクトを確認してください。kotlin_cpu_gpu/android
ファイルパスに関する注意事項
このチュートリアルでは、Linux/macOS 形式でファイルパスを指定します。Windows を使用している場合は、パスを適宜調整する必要があります。
Android Studio のプロジェクト ビューと標準のファイル システム ビューの違いに注意することも重要です。Android Studio のプロジェクト ビューは、Android 開発用に整理されたプロジェクト ファイルの構造化された表現です。このチュートリアルのファイルパスは、Android Studio プロジェクト ビューのパスではなく、ファイル システムのパスを指します。
スターター アプリをインポートする
まず、スターター アプリを Android Studio にインポートしましょう。
- Android Studio を開き、[Open] を選択します。
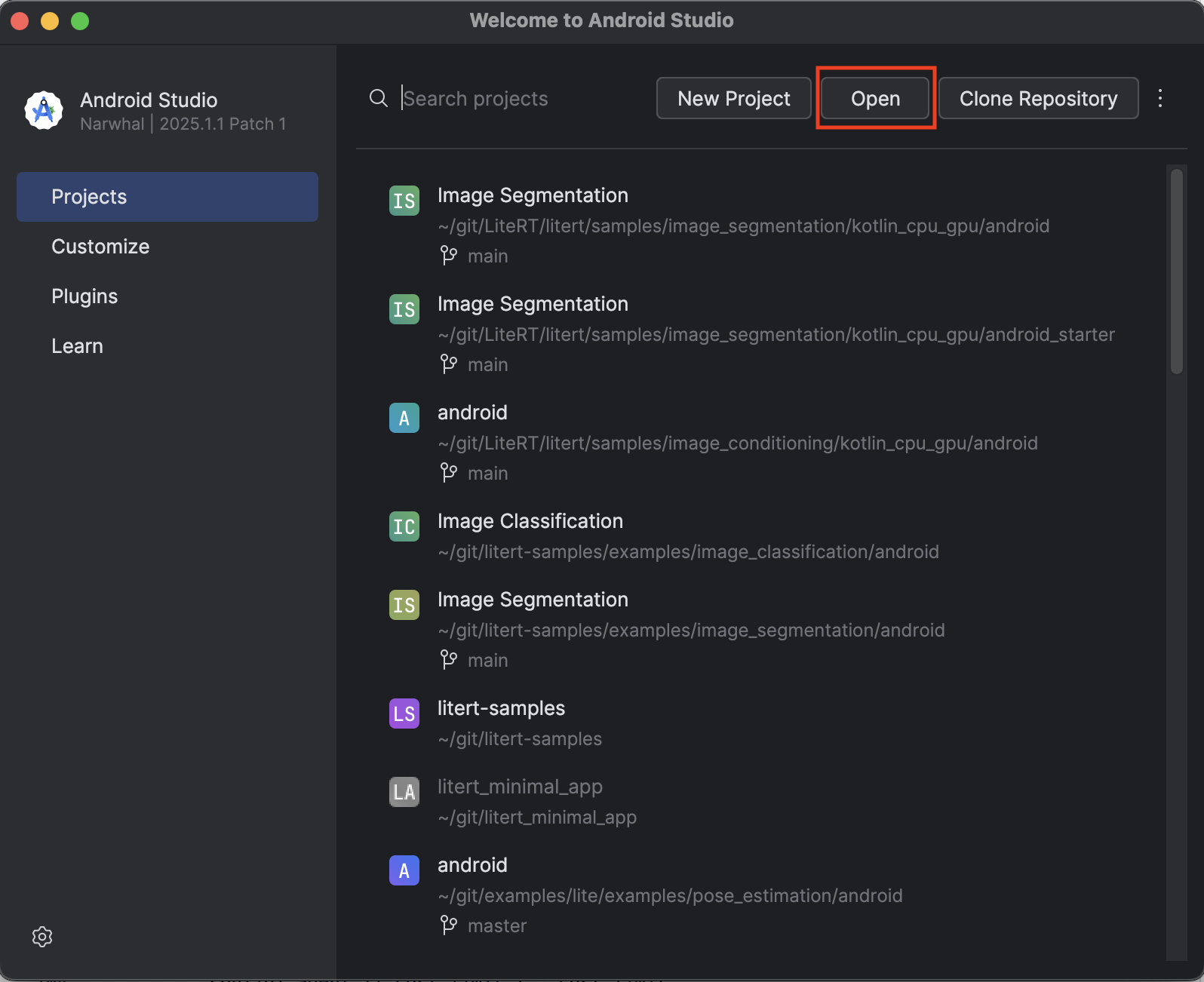
kotlin_cpu_gpu/android_starterディレクトリに移動して開きます。
アプリで必要な依存関係がすべて利用可能であることを確認するには、インポート プロセスが完了したら、プロジェクトを Gradle ファイルと同期する必要があります。
- Android Studio のツールバーから [Sync Project with Gradle Files] を選択します。
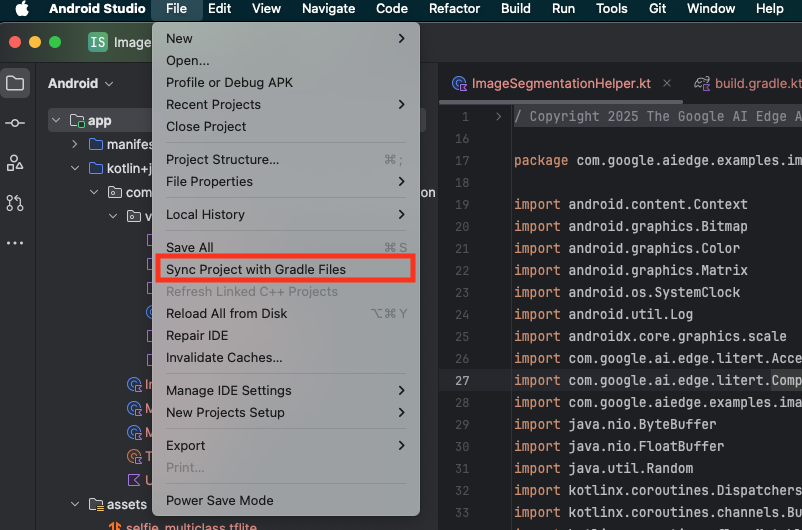
- この手順はスキップしないでください。この手順が機能しない場合、チュートリアルの残りの部分が意味をなさなくなります。
スターター アプリを実行する
Android Studio にプロジェクトをインポートしたので、アプリを初めて実行する準備ができました。
Android デバイスを USB 経由でパソコンに接続し、Android Studio のツールバーで [実行] をクリックします。
デバイスでアプリが起動するはずです。カメラのライブフィードが表示されますが、セグメンテーションはまだ行われていません。このチュートリアルで行うファイル編集はすべて litert-samples/compiled_model_api/image_segmentation/kotlin_cpu_gpu/android_starter/app/src/main/java/com/google/ai/edge/examples/image_segmentation ディレクトリの下で行います(Android Studio がこのディレクトリを再構築する理由がわかりましたね 😃)。
また、ImageSegmentationHelper.kt、MainViewModel.kt、view/SegmentationOverlay.kt の各ファイルに TODO コメントが表示されます。次の手順では、これらの TODO を入力して画像セグメンテーション機能を実装します。
4. スターター アプリについて理解する
スターター アプリには、基本的な UI とカメラ処理ロジックがすでに含まれています。主なファイルの概要は次のとおりです。
app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainActivity.kt: アプリケーションのメイン エントリ ポイントです。Jetpack Compose を使用して UI を設定し、カメラの権限を処理します。app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainViewModel.kt: この ViewModel は UI の状態を管理し、画像セグメンテーション プロセスを調整します。app/src/main/java/com/google/ai/edge/examples/image_segmentation/ImageSegmentationHelper.kt: ここに画像セグメンテーションのコアロジックを追加します。モデルの読み込み、カメラフレームの処理、推論の実行を処理します。app/src/main/java/com/google/ai/edge/examples/image_segmentation/view/CameraScreen.kt: このコンポーザブル関数は、カメラのプレビューとセグメンテーションのオーバーレイを表示します。app/download_model.gradle: このスクリプトはselfie_multiclass.tfliteをダウンロードします。これは、使用する事前トレーニング済みの TensorFlow Lite 画像セグメンテーション モデルです。
5. LiteRT の理解と依存関係の追加
次に、画像セグメンテーション機能をスターター アプリに追加しましょう。
1. LiteRT の依存関係を追加する
まず、LiteRT ライブラリをプロジェクトに追加する必要があります。これは、Google の最適化されたランタイムでオンデバイス ML を有効にするための重要な第一歩です。
app/build.gradle.kts ファイルを開き、次の行を dependencies ブロックに追加します。
// LiteRT for on-device ML
implementation(libs.litert)
依存関係を追加したら、Android Studio の右上隅に表示される [Sync Now] ボタンをクリックして、プロジェクトを Gradle ファイルと同期します。

2. Key LiteRT API について
開く ImageSegmentationHelper.kt
実装コードを記述する前に、使用する LiteRT API のコア コンポーネントを理解しておくことが重要です。com.google.ai.edge.litert パッケージからインポートしていることを確認し、次のインポートを ImageSegmentationHelper.kt の先頭に追加します。
import com.google.ai.edge.litert.Accelerator
import com.google.ai.edge.litert.CompiledModel
CompiledModel: これは、TFLite モデルとやり取りするための中心となるクラスです。これは、特定のハードウェア アクセラレータ(CPU や GPU など)用に事前コンパイルされ、最適化されたモデルを表します。この事前コンパイルは、推論の高速化と効率化につながる LiteRT の重要な機能です。CompiledModel.Options: このビルダークラスを使用してCompiledModelを構成します。最も重要な設定は、モデルの実行に使用するハードウェア アクセラレータを指定することです。Accelerator: この列挙型を使用すると、推論用のハードウェアを選択できます。スターター プロジェクトは、これらのオプションを処理するようにすでに構成されています。Accelerator.CPU: デバイスの CPU でモデルを実行する場合。これは最も普遍的に互換性のあるオプションです。Accelerator.GPU: デバイスの GPU でモデルを実行する場合。画像ベースのモデルの場合、多くの場合、CPU よりも大幅に高速です。
- 入力バッファと出力バッファ(
TensorBuffer): LiteRT はモデルの入力と出力にTensorBufferを使用します。これにより、メモリをきめ細かく制御し、不要なデータコピーを回避できます。これらのバッファは、model.createInputBuffers()とmodel.createOutputBuffers()を使用してCompiledModelインスタンスから直接取得し、入力データを書き込んで結果を読み取ります。 model.run(): 推論を実行する関数です。入力バッファと出力バッファを渡すと、LiteRT が選択したハードウェア アクセラレータでモデルを実行する複雑なタスクを処理します。
6. ImageSegmentationHelper の初期実装を完了する
それでは、コードを記述してみましょう。ImageSegmentationHelper.kt の初期実装を完了します。これには、LiteRT モデルを保持する Segmenter プライベート クラスを設定し、それを適切に解放する cleanup() 関数を実装することが含まれます。
Segmenterクラスとcleanup()関数を完成させる:ImageSegmentationHelper.ktファイルには、Segmenterという名前のプライベート クラスとcleanup()という名前の関数のスケルトンがあります。まず、モデルを保持するコンストラクタを定義し、入出力バッファのプロパティを作成し、モデルを解放するclose()メソッドを追加して、Segmenterクラスを完成させます。次に、この新しいclose()メソッドを呼び出すcleanup()関数を実装します。既存のSegmenterクラスとcleanup()関数を次のように置き換えます(83 行目付近)。private class Segmenter( // Add this argument private val model: CompiledModel, private val coloredLabels: List<ColoredLabel>, ) { // Add these private vals private val inputBuffers = model.createInputBuffers() private val outputBuffers = model.createOutputBuffers() fun cleanup() { // cleanup buffers inputBuffers.forEach { it.close() } outputBuffers.forEach { it.close() } // cleanup model model.close() } }- toAccelerator メソッドを定義する: このメソッドは、アクセラレータ メニューで定義されたアクセラレータ列挙型を、インポートされた LiteRT モジュールに固有のアクセラレータ列挙型にマッピングします(225 行目付近)。
fun toAccelerator(acceleratorEnum: AcceleratorEnum): Accelerator { return when (acceleratorEnum) { AcceleratorEnum.CPU -> Accelerator.CPU AcceleratorEnum.GPU -> Accelerator.GPU } } CompiledModelを初期化する:initSegmenter関数を見つけます。ここでCompiledModelインスタンスを作成し、それを使用して定義したSegmenterクラスをインスタンス化します。このコードは、指定されたアクセラレータ(CPU または GPU)を使用してモデルを設定し、推論の準備をします。initSegmenterのTODOを次の実装に置き換えます(Cmd/Ctrl+f で「initSegmenter」または 62 行目付近を検索)。cleanup() try { withContext(singleThreadDispatcher) { val model = CompiledModel.create( context.assets, "selfie_multiclass.tflite", CompiledModel.Options(toAccelerator(acceleratorEnum)), null, ) segmenter = Segmenter(model, coloredLabels) Log.d(TAG, "Created an image segmenter") } } catch (e: Exception) { Log.i(TAG, "Create LiteRT from selfie_multiclass is failed: ${e.message}") _error.emit(e) }
7. セグメンテーションと前処理を開始します。
モデルが完成したので、セグメンテーション プロセスをトリガーして、モデルの入力データを準備する必要があります。
トリガー セグメンテーション
セグメンテーション プロセスは、カメラからフレームを受け取る MainViewModel.kt で開始されます。
開く MainViewModel.kt
- カメラ フレームからセグメンテーションをトリガーする:
MainViewModelのsegment関数は、セグメンテーション タスクのエントリ ポイントです。これらは、カメラから新しい画像が利用可能になったとき、またはギャラリーから画像が選択されたときに呼び出されます。これらの関数は、ImageSegmentationHelperのsegmentメソッドを呼び出します。両方のsegment関数のTODOを次のように置き換えます(107 行目付近)。// For ImageProxy (from CameraX) fun segment(imageProxy: ImageProxy) { segmentJob = viewModelScope.launch { imageSegmentationHelper.segment(imageProxy.toBitmap(), imageProxy.imageInfo.rotationDegrees) imageProxy.close() } } // For Bitmaps (from gallery) fun segment(bitmap: Bitmap, rotationDegrees: Int) { segmentJob = viewModelScope.launch { val argbBitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true) imageSegmentationHelper.segment(argbBitmap, rotationDegrees) } }
画像を前処理する
ImageSegmentationHelper.kt に戻って、画像の前処理を処理しましょう。
開く ImageSegmentationHelper.kt
- 公開
segment関数を実装する: この関数は、Segmenterクラス内の非公開segment関数を呼び出すラッパーとして機能します。TODOを次のように置き換えます(95 行目付近)。try { withContext(singleThreadDispatcher) { segmenter?.segment(bitmap, rotationDegrees)?.let { if (isActive) _segmentation.emit(it) } } } catch (e: Exception) { Log.i(TAG, "Image segment error occurred: ${e.message}") _error.emit(e) } - 前処理を実装する:
Segmenterクラス内の非公開segment関数で、入力画像に必要な変換を行い、モデルの準備をします。これには、画像の拡大縮小、回転、正規化が含まれます。この関数は、別のプライベートsegment関数を呼び出して推論を実行します。segment(bitmap: Bitmap, ...)関数のTODOを次の内容に置き換えます(121 行目付近)。val totalStartTime = SystemClock.uptimeMillis() val rotation = -rotationDegrees / 90 val (h, w) = Pair(256, 256) // Preprocessing val preprocessStartTime = SystemClock.uptimeMillis() var image = bitmap.scale(w, h, true) image = rot90Clockwise(image, rotation) val inputFloatArray = normalize(image, 127.5f, 127.5f) Log.d(TAG, "Preprocessing time: ${SystemClock.uptimeMillis() - preprocessStartTime} ms") // Inference val inferenceStartTime = SystemClock.uptimeMillis() val segmentResult = segment(inputFloatArray) Log.d(TAG, "Inference time: ${SystemClock.uptimeMillis() - inferenceStartTime} ms") Log.d(TAG, "Total segmentation time: ${SystemClock.uptimeMillis() - totalStartTime} ms") return SegmentationResult(segmentResult, SystemClock.uptimeMillis() - inferenceStartTime)
8. LiteRT を使用したプライマリ推論
入力データを前処理したので、LiteRT を使用してコア推論を実行できます。
開く ImageSegmentationHelper.kt
- モデル実行を実装する: プライベート
segment(inputFloatArray: FloatArray)関数は、LiteRTrun()メソッドと直接やり取りする場所です。前処理されたデータを入力バッファに書き込み、モデルを実行して、出力バッファから結果を読み取ります。この関数のTODOを次のように置き換えます(188 行目付近)。val (h, w, c) = Triple(256, 256, 6) // MODEL EXECUTION PHASE val modelExecStartTime = SystemClock.uptimeMillis() // Write input data - measure time val bufferWriteStartTime = SystemClock.uptimeMillis() inputBuffers[0].writeFloat(inputFloatArray) val bufferWriteTime = SystemClock.uptimeMillis() - bufferWriteStartTime Log.d(TAG, "Buffer write time: $bufferWriteTime ms") // Optional tensor inspection logTensorStats("Input tensor", inputFloatArray) // Run model inference - measure time val modelRunStartTime = SystemClock.uptimeMillis() model.run(inputBuffers, outputBuffers) val modelRunTime = SystemClock.uptimeMillis() - modelRunStartTime Log.d(TAG, "Model.run() time: $modelRunTime ms") // Read output data - measure time val bufferReadStartTime = SystemClock.uptimeMillis() val outputFloatArray = outputBuffers[0].readFloat() val outputBuffer = FloatBuffer.wrap(outputFloatArray) val bufferReadTime = SystemClock.uptimeMillis() - bufferReadStartTime Log.d(TAG, "Buffer read time: $bufferReadTime ms") val modelExecTime = SystemClock.uptimeMillis() - modelExecStartTime Log.d(TAG, "Total model execution time: $modelExecTime ms") // Optional tensor inspection logTensorStats("Output tensor", outputFloatArray) // POSTPROCESSING PHASE val postprocessStartTime = SystemClock.uptimeMillis() // Process mask from model output val inferenceData = InferenceData(width = w, height = h, channels = c, buffer = outputBuffer) val mask = processImage(inferenceData) val postprocessTime = SystemClock.uptimeMillis() - postprocessStartTime Log.d(TAG, "Postprocessing time (mask creation): $postprocessTime ms") return Segmentation( listOf(Mask(mask, inferenceData.width, inferenceData.height)), coloredLabels, )
9. 後処理とオーバーレイの表示
推論を実行すると、モデルから未加工の出力が得られます。この出力を処理して視覚的なセグメンテーション マスクを作成し、画面に表示する必要があります。
開く ImageSegmentationHelper.kt
- 出力処理を実装する:
processImage関数は、モデルからの未加工の浮動小数点出力をセグメンテーション マスクを表すByteBufferに変換します。これは、各ピクセルの確率が最も高いクラスを見つけることで行われます。そのTODOを次のように置き換えます(~238 行目)。val mask = ByteBuffer.allocateDirect(inferenceData.width * inferenceData.height) for (i in 0 until inferenceData.height) { for (j in 0 until inferenceData.width) { val offset = inferenceData.channels * (i * inferenceData.width + j) var maxIndex = 0 var maxValue = inferenceData.buffer.get(offset) for (index in 1 until inferenceData.channels) { if (inferenceData.buffer.get(offset + index) > maxValue) { maxValue = inferenceData.buffer.get(offset + index) maxIndex = index } } mask.put(i * inferenceData.width + j, maxIndex.toByte()) } } return mask
開く MainViewModel.kt
- セグメンテーション結果を収集して処理する:
MainViewModelに戻り、ImageSegmentationHelperからのセグメンテーション結果を処理します。segmentationUiShareFlowはSegmentationResultを収集し、マスクをカラフルなBitmapに変換して、UI に提供します。segmentationUiShareFlowプロパティのTODOを(63 行目付近)に置き換えます。すでに存在するコードは置き換えず、本文を埋めるだけです。viewModelScope.launch { imageSegmentationHelper.segmentation .filter { it.segmentation.masks.isNotEmpty() } .map { val segmentation = it.segmentation val mask = segmentation.masks[0] val maskArray = mask.data val width = mask.width val height = mask.height val pixelSize = width * height val pixels = IntArray(pixelSize) val colorLabels = segmentation.coloredLabels.mapIndexed { index, coloredLabel -> ColorLabel(index, coloredLabel.label, coloredLabel.argb) } // Set color for pixels for (i in 0 until pixelSize) { val colorLabel = colorLabels[maskArray[i].toInt()] val color = colorLabel.getColor() pixels[i] = color } // Get image info val overlayInfo = OverlayInfo(pixels = pixels, width = width, height = height) val inferenceTime = it.inferenceTime Pair(overlayInfo, inferenceTime) } .collect { flow.emit(it) } }
開く view/SegmentationOverlay.kt
最後の仕上げとして、ユーザーが前面カメラに切り替えたときにセグメンテーション オーバーレイの向きを正しく調整します。前面カメラのカメラフィードは自然にミラーリングされるため、オーバーレイ Bitmap に同じ水平方向の反転を適用して、カメラ プレビューと正しく揃うようにする必要があります。
- オーバーレイの向きを処理:
SegmentationOverlay.ktファイルでTODOを見つけ、次のコードに置き換えます。このコードは、前面カメラがアクティブかどうかを確認し、アクティブな場合は、オーバーレイBitmapがCanvasに描画される前に、水平方向に反転させます。(~line 42):val orientedBitmap = if (lensFacing == CameraSelector.LENS_FACING_FRONT) { // Create a matrix for horizontal flipping val matrix = Matrix().apply { preScale(-1f, 1f) } Bitmap.createBitmap(image, 0, 0, image.width, image.height, matrix, false).also { image.recycle() } } else { image }
10. 最終版アプリを実行して使用する
これで、必要なコード変更はすべて完了しました。アプリを実行して、動作を確認しましょう。
- アプリを実行する: Android デバイスを接続し、Android Studio のツールバーで [実行] をクリックします。
- 機能をテストする: アプリを起動すると、カラフルなセグメンテーション オーバーレイが表示されたカメラのライブフィードが表示されます。
- カメラの切り替え: 上部のカメラ切り替えアイコンをタップすると、前面カメラと背面カメラを切り替えることができます。オーバーレイが正しく向きを変えていることに注目してください。
- アクセラレータを変更: 下部の [CPU] または [GPU] ボタンをタップして、ハードウェア アクセラレータを切り替えます。画面の下部に表示される [推論時間] の変化を確認します。GPU は大幅に高速化されます。
- ギャラリーの画像を使用する: 上部の [ギャラリー] タブをタップして、デバイスのフォト ギャラリーから画像を選択します。選択した静止画像に対してセグメンテーションが実行されます。

これで、LiteRT を活用した、完全に機能するリアルタイム画像セグメンテーション アプリが完成しました。
11. 高度な使用方法(省略可): NPU の使用
このリポジトリには、ニューラル プロセッシング ユニット(NPU)向けに最適化されたアプリのバージョンも含まれています。NPU バージョンは、互換性のある NPU を搭載したデバイスでパフォーマンスを大幅に向上させることができます。
NPU バージョンを試すには、Android Studio で kotlin_npu/android プロジェクトを開きます。このコードは CPU/GPU バージョンと非常によく似ており、NPU デリゲートを使用するように構成されています。
NPU デリゲートを使用するには、早期アクセス プログラムに登録する必要があります。
12. 完了
LiteRT を使用してリアルタイムで画像セグメンテーションを行う Android アプリが正常に作成されました。ここでは、以下の方法を学びました。
- LiteRT ランタイムを Android アプリに統合します。
- TFLite 画像セグメンテーション モデルを読み込んで実行します。
- モデルの入力を前処理します。
- モデルの出力を処理してセグメンテーション マスクを作成します。
- リアルタイムのカメラアプリには CameraX を使用します。
次のステップ
- 別の画像セグメンテーション モデルを試す。
- さまざまな LiteRT デリゲート(CPU、GPU、NPU)を試す。