
1. Prima di iniziare
Digitare il codice è un ottimo modo per sviluppare la memoria muscolare e approfondire la comprensione del materiale. Sebbene il copia e incolla possa farti risparmiare tempo, investire in questa pratica può portare a una maggiore efficienza e a competenze di programmazione più solide nel lungo periodo.
In questo codelab imparerai a creare un'applicazione per Android che esegue la segmentazione delle immagini in tempo reale su un feed della videocamera live utilizzando il nuovo runtime di Google per TensorFlow Lite, LiteRT. Prenderai un'applicazione Android iniziale e aggiungerai funzionalità di segmentazione delle immagini. Esamineremo anche i passaggi di pre-elaborazione, inferenza e post-elaborazione. Imparerai a:
- Crea un'app per Android che segmenta le immagini in tempo reale.
- Integra un modello di segmentazione delle immagini LiteRT preaddestrato.
- Preelabora l'immagine di input per il modello.
- Utilizza il runtime LiteRT per l'accelerazione di CPU e GPU.
- Scopri come elaborare l'output del modello per visualizzare la maschera di segmentazione.
- Scopri come regolare la fotocamera anteriore.
Alla fine, creerai qualcosa di simile all'immagine qui sotto:

Prerequisiti
Questo codelab è stato progettato per sviluppatori mobile esperti che vogliono acquisire esperienza con il machine learning. Devi avere familiarità con:
- Sviluppo per Android utilizzando Kotlin e Android Studio
- Concetti di base dell'elaborazione delle immagini
Cosa imparerai a fare
- Come integrare e utilizzare il runtime LiteRT in un'applicazione Android.
- Come eseguire la segmentazione delle immagini utilizzando un modello LiteRT preaddestrato.
- Come pre-elaborare l'immagine di input per il modello.
- Come eseguire l'inferenza per il modello.
- Come elaborare l'output di un modello di segmentazione per visualizzare i risultati.
- Come utilizzare CameraX per l'elaborazione del feed della videocamera in tempo reale.
Che cosa ti serve
- Una versione recente di Android Studio (testata sulla versione 2025.1.1).
- Un dispositivo Android fisico. È stato testato al meglio su dispositivi Galaxy e Pixel.
- Il codice campione (da GitHub).
- Conoscenza di base dello sviluppo Android in Kotlin.
2. Segmentazione dell'immagine
La segmentazione delle immagini è un'attività di computer vision che prevede la suddivisione di un'immagine in più segmenti o regioni. A differenza del rilevamento di oggetti, che disegna un riquadro di delimitazione intorno a un oggetto, la segmentazione delle immagini assegna una classe o un'etichetta specifica a ogni singolo pixel dell'immagine. In questo modo, puoi ottenere una comprensione molto più dettagliata e granulare dei contenuti dell'immagine, in modo da conoscere la forma e il confine esatti di ogni oggetto.
Ad esempio, invece di sapere solo che una "persona" si trova in un riquadro, puoi sapere esattamente a quali pixel appartiene. Questo tutorial mostra come eseguire la segmentazione delle immagini in tempo reale su un dispositivo Android utilizzando un modello di machine learning preaddestrato.

LiteRT: spingere i limiti del ML on-device
Una tecnologia chiave che consente la segmentazione in tempo reale e ad alta fedeltà sui dispositivi mobili è LiteRT. LiteRT è il runtime di nuova generazione ad alte prestazioni di Google per TensorFlow Lite, progettato per ottenere le migliori prestazioni possibili dall'hardware sottostante.
Ciò avviene tramite l'utilizzo intelligente e ottimizzato di acceleratori hardware come la GPU (Graphics Processing Unit) e la NPU (Neural Processing Unit). Scaricando l'intenso carico di lavoro computazionale del modello di segmentazione dalla CPU per uso generico a questi processori specializzati, LiteRT riduce drasticamente il tempo di inferenza. Questa accelerazione consente di eseguire senza problemi modelli complessi su un feed videocamera in diretta, ampliando i limiti di ciò che possiamo ottenere con il machine learning direttamente sul tuo smartphone. Senza questo livello di prestazioni, la segmentazione in tempo reale sarebbe troppo lenta e instabile per garantire una buona esperienza utente.
3. Configurazione
Clona il repository
Innanzitutto, clona il repository per LiteRT:
git clone https://github.com/google-ai-edge/litert-samples.git
litert-samples/compiled_model_api/image_segmentation è la directory con tutte le risorse di cui avrai bisogno. Per questo codelab, ti servirà solo il progetto kotlin_cpu_gpu/android_starter. Se hai difficoltà, ti consigliamo di rivedere il progetto finito: kotlin_cpu_gpu/android
Una nota sui percorsi dei file
Questo tutorial specifica i percorsi dei file nel formato Linux/macOS. Se utilizzi Windows, dovrai modificare i percorsi di conseguenza.
È anche importante notare la distinzione tra la visualizzazione del progetto Android Studio e una visualizzazione standard del file system. La visualizzazione del progetto Android Studio è una rappresentazione strutturata dei file del progetto, organizzati per lo sviluppo Android. I percorsi dei file in questo tutorial si riferiscono ai percorsi del file system, non ai percorsi nella visualizzazione del progetto Android Studio.
Importare l'app iniziale
Iniziamo importando l'app iniziale in Android Studio.
- Apri Android Studio e seleziona Apri.
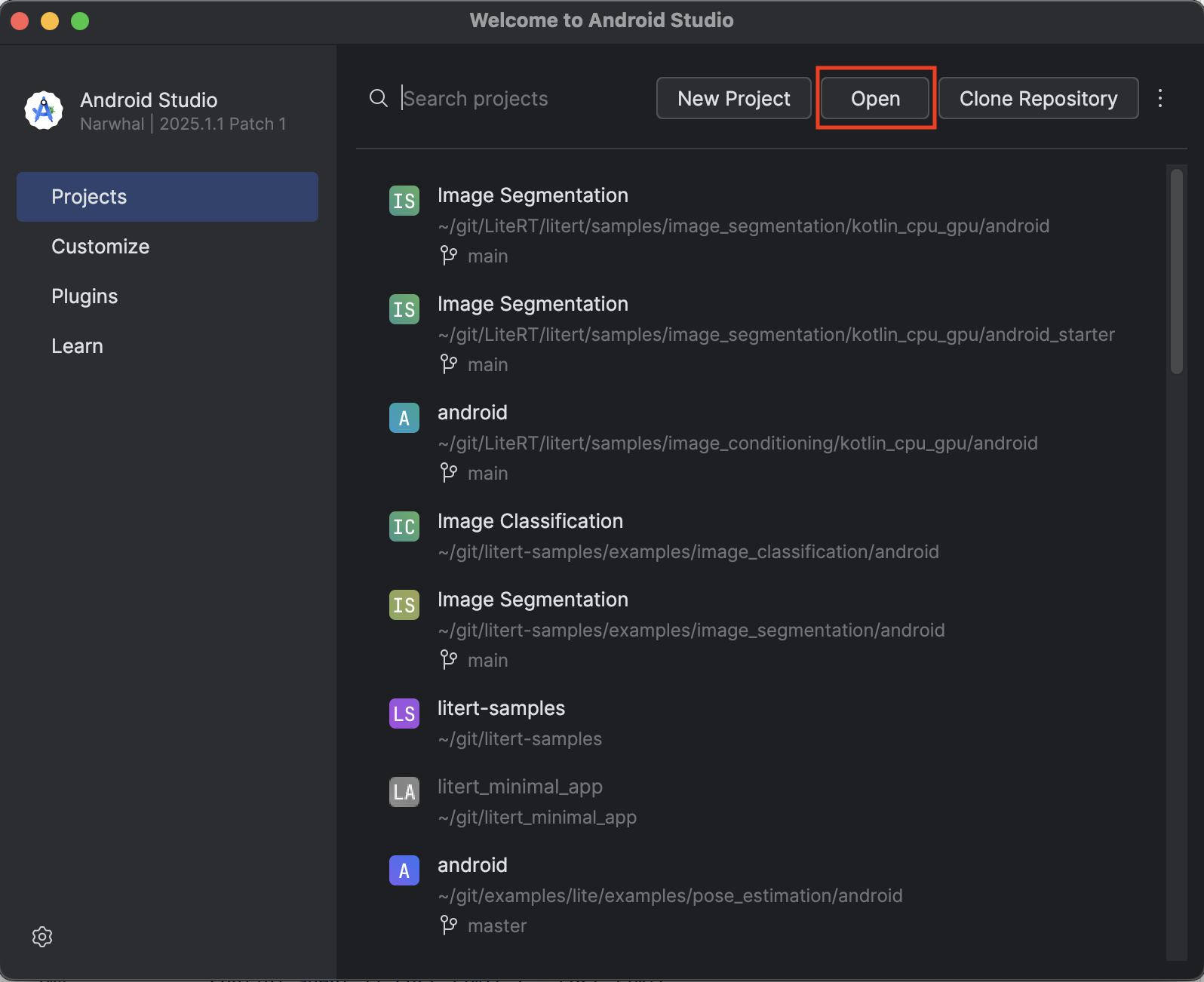
- Vai alla directory
kotlin_cpu_gpu/android_startere aprila.
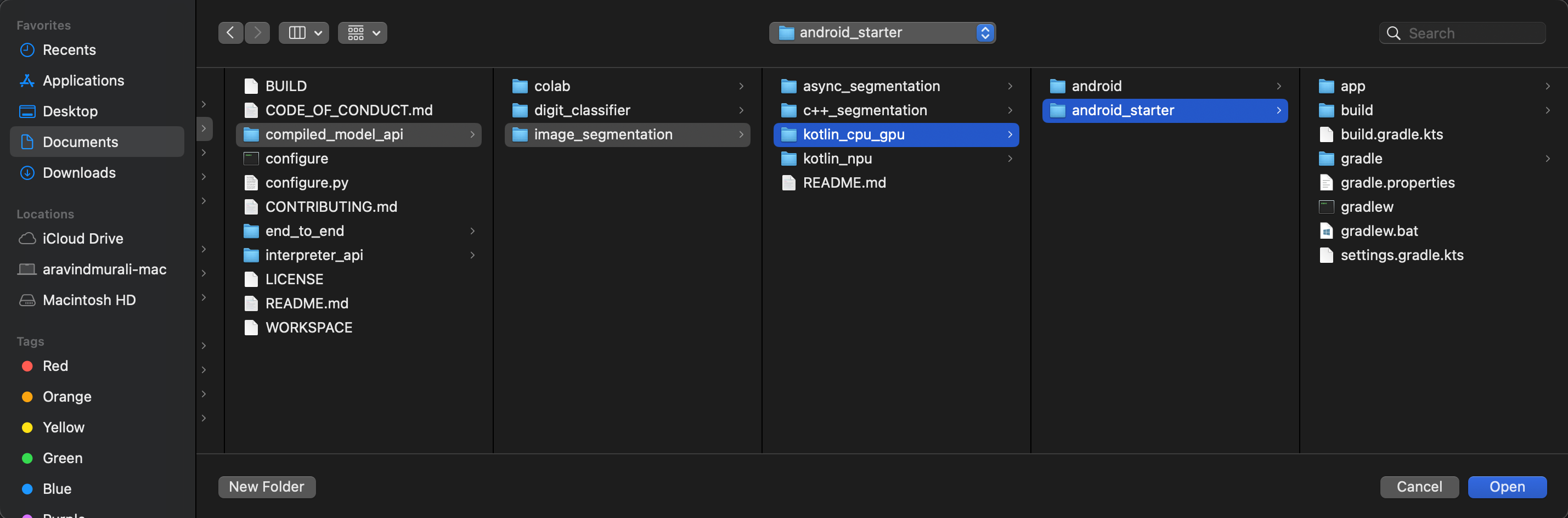
Per assicurarti che tutte le dipendenze siano disponibili per la tua app, devi sincronizzare il progetto con i file Gradle al termine del processo di importazione.
- Seleziona Sincronizza progetto con i file Gradle dalla barra degli strumenti di Android Studio.
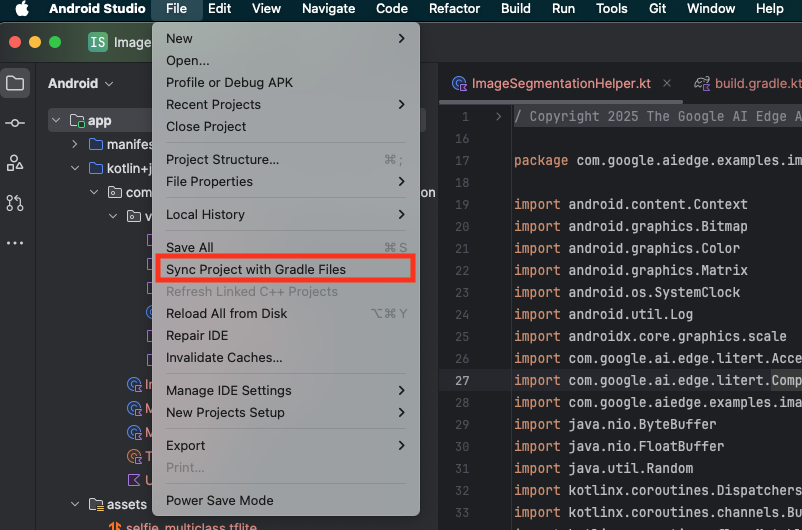
- Non saltare questo passaggio, altrimenti il resto del tutorial non avrà senso.
Esegui l'app iniziale
Ora che hai importato il progetto in Android Studio, puoi eseguire l'app per la prima volta.
Collega il dispositivo Android al computer tramite USB e fai clic su Esegui nella barra degli strumenti di Android Studio.
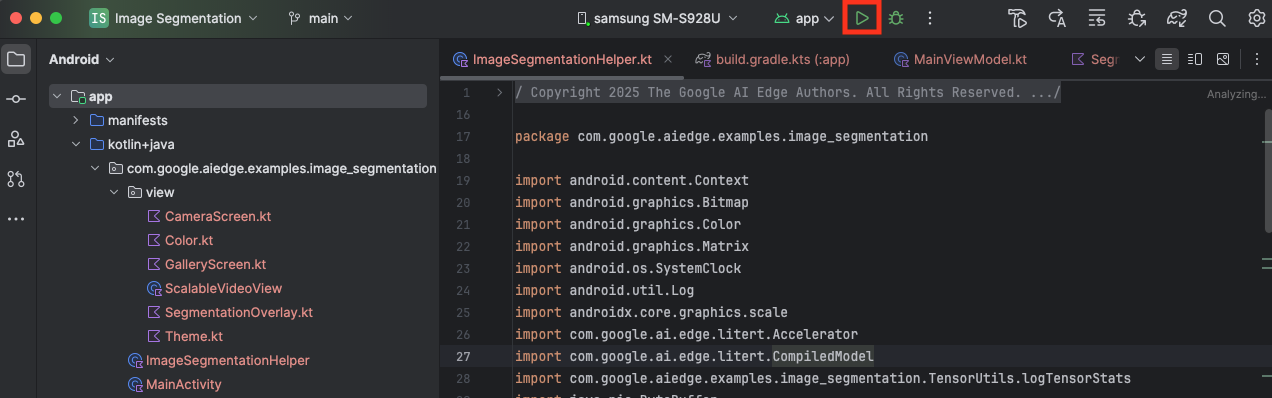
L'app dovrebbe avviarsi sul dispositivo. Vedrai un feed della videocamera in diretta, ma non verrà ancora eseguita alcuna segmentazione. Tutte le modifiche ai file che apporterai in questo tutorial si troveranno nella directory litert-samples/compiled_model_api/image_segmentation/kotlin_cpu_gpu/android_starter/app/src/main/java/com/google/ai/edge/examples/image_segmentation (ora sai perché Android Studio la ristruttura 😃).
Vedrai anche i commenti TODO nei file ImageSegmentationHelper.kt, MainViewModel.kt e view/SegmentationOverlay.kt. Nei passaggi successivi, implementerai la funzionalità di segmentazione delle immagini compilando questi TODO.
4. Informazioni sull'app iniziale
L'app iniziale ha già un'interfaccia utente di base e una logica di gestione della videocamera. Ecco una rapida panoramica dei file chiave:
app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainActivity.kt: questo è l'entry point principale dell'applicazione. Configura la UI utilizzando Jetpack Compose e gestisce le autorizzazioni della fotocamera.app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainViewModel.kt: questo ViewModel gestisce lo stato dell'interfaccia utente e coordina il processo di segmentazione delle immagini.app/src/main/java/com/google/ai/edge/examples/image_segmentation/ImageSegmentationHelper.kt: qui aggiungeremo la logica di base per la segmentazione delle immagini. Si occuperà di caricare il modello, elaborare i fotogrammi della videocamera ed eseguire l'inferenza.app/src/main/java/com/google/ai/edge/examples/image_segmentation/view/CameraScreen.kt: questa funzione componibile mostra l'anteprima della videocamera e la sovrapposizione della segmentazione.app/download_model.gradle: questo script scaricaselfie_multiclass.tflite. Questo è il modello di segmentazione delle immagini TensorFlow Lite preaddestrato che utilizzeremo.
5. Informazioni su LiteRT e aggiunta di dipendenze
Ora aggiungiamo la funzionalità di segmentazione delle immagini all'app iniziale.
1. Aggiungi la dipendenza LiteRT
Innanzitutto, devi aggiungere la libreria LiteRT al tuo progetto. Questo è il primo passo fondamentale per attivare il machine learning on-device con il runtime ottimizzato di Google.
Apri il file app/build.gradle.kts e aggiungi la seguente riga al blocco dependencies:
// LiteRT for on-device ML
implementation(libs.litert)
Dopo aver aggiunto la dipendenza, sincronizza il progetto con i file Gradle facendo clic sul pulsante Sincronizza ora visualizzato nell'angolo in alto a destra di Android Studio.

2. Informazioni sulle API Key LiteRT
Apri ImageSegmentationHelper.kt
Prima di scrivere il codice di implementazione, è importante comprendere i componenti principali dell'API LiteRT che utilizzerai. Assicurati di importare dal pacchetto com.google.ai.edge.litert, aggiungi le seguenti importazioni nella parte superiore di ImageSegmentationHelper.kt:
import com.google.ai.edge.litert.Accelerator
import com.google.ai.edge.litert.CompiledModel
CompiledModel: questa è la classe centrale per interagire con il modello TFLite. Rappresenta un modello precompilato e ottimizzato per un acceleratore hardware specifico (come la CPU o la GPU). Questa precompilazione è una funzionalità chiave di LiteRT che consente un'inferenza più rapida ed efficiente.CompiledModel.Options: utilizzi questa classe di builder per configurareCompiledModel. L'impostazione più importante è la specifica dell'acceleratore hardware che vuoi utilizzare per l'esecuzione del modello.Accelerator: questa enumerazione ti consente di scegliere l'hardware per l'inferenza. Il progetto iniziale è già configurato per gestire queste opzioni:Accelerator.CPU: per l'esecuzione del modello sulla CPU del dispositivo. Questa è l'opzione più compatibile a livello universale.Accelerator.GPU: per l'esecuzione del modello sulla GPU del dispositivo. Spesso è molto più veloce della CPU per i modelli basati su immagini.
- Buffer di input e output (
TensorBuffer): LiteRT utilizzaTensorBufferper gli input e gli output del modello. In questo modo, hai un controllo granulare sulla memoria ed eviti copie di dati non necessarie. Riceverai questi buffer direttamente dalla tua istanzaCompiledModelutilizzandomodel.createInputBuffers()emodel.createOutputBuffers(), quindi scriverai i dati di input e leggerai i risultati. model.run(): questa è la funzione che esegue l'inferenza. Passi i buffer di input e output e LiteRT gestisce il complesso compito di eseguire il modello sull'acceleratore hardware selezionato.
6. Completa l'implementazione iniziale di ImageSegmentationHelper
Ora è il momento di scrivere un po' di codice. Completerai l'implementazione iniziale di ImageSegmentationHelper.kt. Ciò comporta la configurazione della classe privata Segmenter per contenere il modello LiteRT e l'implementazione della funzione cleanup() per rilasciarlo correttamente.
- Completa la classe
Segmentere la funzionecleanup(): nel fileImageSegmentationHelper.kttroverai lo scheletro di una classe privata denominataSegmentere una funzione denominatacleanup(). Per prima cosa, completa la classeSegmenterdefinendo il relativo costruttore per contenere il modello, creando proprietà per i buffer di input/output e aggiungendo un metodoclose()per rilasciare il modello. Quindi, implementa la funzionecleanup()per chiamare questo nuovo metodoclose().Sostituisci la classeSegmentere la funzionecleanup()esistenti con quanto segue: (~riga 83)private class Segmenter( // Add this argument private val model: CompiledModel, private val coloredLabels: List<ColoredLabel>, ) { // Add these private vals private val inputBuffers = model.createInputBuffers() private val outputBuffers = model.createOutputBuffers() fun cleanup() { // cleanup buffers inputBuffers.forEach { it.close() } outputBuffers.forEach { it.close() } // cleanup model model.close() } } - Definisci il metodo toAccelerator: questo metodo mappa gli enum dell'acceleratore definiti dal menu dell'acceleratore agli enum dell'acceleratore specifici dei moduli LiteRT importati (~riga 225):
fun toAccelerator(acceleratorEnum: AcceleratorEnum): Accelerator { return when (acceleratorEnum) { AcceleratorEnum.CPU -> Accelerator.CPU AcceleratorEnum.GPU -> Accelerator.GPU } } - Inizializza
CompiledModel: ora trova la funzioneinitSegmenter. Qui creerai l'istanzaCompiledModele la utilizzerai per creare un'istanza della classeSegmenterora definita. Questo codice configura il modello con l'acceleratore specificato (CPU o GPU) e lo prepara per l'inferenza. SostituisciTODOininitSegmentercon la seguente implementazione (Cmd/Ctrl+f "initSegmenter" o riga 62 circa):cleanup() try { withContext(singleThreadDispatcher) { val model = CompiledModel.create( context.assets, "selfie_multiclass.tflite", CompiledModel.Options(toAccelerator(acceleratorEnum)), null, ) segmenter = Segmenter(model, coloredLabels) Log.d(TAG, "Created an image segmenter") } } catch (e: Exception) { Log.i(TAG, "Create LiteRT from selfie_multiclass is failed: ${e.message}") _error.emit(e) }
7. Avvia la segmentazione e il pre-elaborazione
Ora che abbiamo un modello, dobbiamo attivare il processo di segmentazione e preparare i dati di input per il modello.
Segmentazione basata sui trigger
Il processo di segmentazione inizia in MainViewModel.kt, che riceve i frame dalla videocamera.
Apri MainViewModel.kt
- Trigger Segmentation from Camera Frames (Attiva la segmentazione dai frame della videocamera): le funzioni
segmentinMainViewModelsono il punto di ingresso per la nostra attività di segmentazione. Vengono chiamati ogni volta che una nuova immagine è disponibile dalla fotocamera o selezionata dalla galleria. Queste funzioni chiamano quindi il metodosegmentnel nostroImageSegmentationHelper. Sostituisci iTODOin entrambe le funzionisegmentcon quanto segue (riga 107 circa):// For ImageProxy (from CameraX) fun segment(imageProxy: ImageProxy) { segmentJob = viewModelScope.launch { imageSegmentationHelper.segment(imageProxy.toBitmap(), imageProxy.imageInfo.rotationDegrees) imageProxy.close() } } // For Bitmaps (from gallery) fun segment(bitmap: Bitmap, rotationDegrees: Int) { segmentJob = viewModelScope.launch { val argbBitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true) imageSegmentationHelper.segment(argbBitmap, rotationDegrees) } }
Pre-elaborare l'immagine
Ora torniamo a ImageSegmentationHelper.kt per gestire il pre-elaborazione delle immagini.
Apri ImageSegmentationHelper.kt
- Implementa la funzione Public
segment: questa funzione funge da wrapper che chiama la funzione privatasegmentall'interno della classeSegmenter. SostituisciTODOcon (~linea 95):try { withContext(singleThreadDispatcher) { segmenter?.segment(bitmap, rotationDegrees)?.let { if (isActive) _segmentation.emit(it) } } } catch (e: Exception) { Log.i(TAG, "Image segment error occurred: ${e.message}") _error.emit(e) } - Implementa il pre-elaborazione: la funzione privata
segmentall'interno della classeSegmenterè il punto in cui eseguiremo le trasformazioni necessarie sull'immagine di input per prepararla per il modello. Sono inclusi il ridimensionamento, la rotazione e la normalizzazione dell'immagine. Questa funzione chiamerà quindi un'altra funzione privatasegmentper eseguire l'inferenza. SostituisciTODOnella funzionesegment(bitmap: Bitmap, ...)con (~linea 121):val totalStartTime = SystemClock.uptimeMillis() val rotation = -rotationDegrees / 90 val (h, w) = Pair(256, 256) // Preprocessing val preprocessStartTime = SystemClock.uptimeMillis() var image = bitmap.scale(w, h, true) image = rot90Clockwise(image, rotation) val inputFloatArray = normalize(image, 127.5f, 127.5f) Log.d(TAG, "Preprocessing time: ${SystemClock.uptimeMillis() - preprocessStartTime} ms") // Inference val inferenceStartTime = SystemClock.uptimeMillis() val segmentResult = segment(inputFloatArray) Log.d(TAG, "Inference time: ${SystemClock.uptimeMillis() - inferenceStartTime} ms") Log.d(TAG, "Total segmentation time: ${SystemClock.uptimeMillis() - totalStartTime} ms") return SegmentationResult(segmentResult, SystemClock.uptimeMillis() - inferenceStartTime)
8. Inferenza primaria con LiteRT
Con i dati di input pre-elaborati, ora possiamo eseguire l'inferenza principale utilizzando LiteRT.
Apri ImageSegmentationHelper.kt
- Implementa l'esecuzione del modello: la funzione privata
segment(inputFloatArray: FloatArray)è il punto in cui interagiamo direttamente con il metodo LiteRTrun(). Scriviamo i dati preelaborati nel buffer di input, eseguiamo il modello e leggiamo i risultati dal buffer di output. SostituisciTODOin questa funzione con (~riga 188):val (h, w, c) = Triple(256, 256, 6) // MODEL EXECUTION PHASE val modelExecStartTime = SystemClock.uptimeMillis() // Write input data - measure time val bufferWriteStartTime = SystemClock.uptimeMillis() inputBuffers[0].writeFloat(inputFloatArray) val bufferWriteTime = SystemClock.uptimeMillis() - bufferWriteStartTime Log.d(TAG, "Buffer write time: $bufferWriteTime ms") // Optional tensor inspection logTensorStats("Input tensor", inputFloatArray) // Run model inference - measure time val modelRunStartTime = SystemClock.uptimeMillis() model.run(inputBuffers, outputBuffers) val modelRunTime = SystemClock.uptimeMillis() - modelRunStartTime Log.d(TAG, "Model.run() time: $modelRunTime ms") // Read output data - measure time val bufferReadStartTime = SystemClock.uptimeMillis() val outputFloatArray = outputBuffers[0].readFloat() val outputBuffer = FloatBuffer.wrap(outputFloatArray) val bufferReadTime = SystemClock.uptimeMillis() - bufferReadStartTime Log.d(TAG, "Buffer read time: $bufferReadTime ms") val modelExecTime = SystemClock.uptimeMillis() - modelExecStartTime Log.d(TAG, "Total model execution time: $modelExecTime ms") // Optional tensor inspection logTensorStats("Output tensor", outputFloatArray) // POSTPROCESSING PHASE val postprocessStartTime = SystemClock.uptimeMillis() // Process mask from model output val inferenceData = InferenceData(width = w, height = h, channels = c, buffer = outputBuffer) val mask = processImage(inferenceData) val postprocessTime = SystemClock.uptimeMillis() - postprocessStartTime Log.d(TAG, "Postprocessing time (mask creation): $postprocessTime ms") return Segmentation( listOf(Mask(mask, inferenceData.width, inferenceData.height)), coloredLabels, )
9. Post-elaborazione e visualizzazione dell'overlay
Dopo aver eseguito l'inferenza, otteniamo un output non elaborato dal modello. Dobbiamo elaborare questo output per creare una maschera di segmentazione visiva e poi visualizzarla sullo schermo.
Apri ImageSegmentationHelper.kt
- Implementa l'elaborazione dell'output: la funzione
processImageconverte l'output grezzo in virgola mobile del modello in unByteBufferche rappresenta la maschera di segmentazione. A questo scopo, trova la classe con la probabilità più alta per ogni pixel. Sostituisci il relativoTODOcon (~linea 238):val mask = ByteBuffer.allocateDirect(inferenceData.width * inferenceData.height) for (i in 0 until inferenceData.height) { for (j in 0 until inferenceData.width) { val offset = inferenceData.channels * (i * inferenceData.width + j) var maxIndex = 0 var maxValue = inferenceData.buffer.get(offset) for (index in 1 until inferenceData.channels) { if (inferenceData.buffer.get(offset + index) > maxValue) { maxValue = inferenceData.buffer.get(offset + index) maxIndex = index } } mask.put(i * inferenceData.width + j, maxIndex.toByte()) } } return mask
Apri MainViewModel.kt
- Raccogli ed elabora i risultati della segmentazione: ora torniamo a
MainViewModelper elaborare i risultati della segmentazione diImageSegmentationHelper.segmentationUiShareFlowraccoglieSegmentationResult, converte la maschera in unBitmapcolorato e lo fornisce all'UI. SostituisciTODOnella proprietàsegmentationUiShareFlowcon (~riga 63). Non sostituire il codice già presente, ma compila solo il corpo:viewModelScope.launch { imageSegmentationHelper.segmentation .filter { it.segmentation.masks.isNotEmpty() } .map { val segmentation = it.segmentation val mask = segmentation.masks[0] val maskArray = mask.data val width = mask.width val height = mask.height val pixelSize = width * height val pixels = IntArray(pixelSize) val colorLabels = segmentation.coloredLabels.mapIndexed { index, coloredLabel -> ColorLabel(index, coloredLabel.label, coloredLabel.argb) } // Set color for pixels for (i in 0 until pixelSize) { val colorLabel = colorLabels[maskArray[i].toInt()] val color = colorLabel.getColor() pixels[i] = color } // Get image info val overlayInfo = OverlayInfo(pixels = pixels, width = width, height = height) val inferenceTime = it.inferenceTime Pair(overlayInfo, inferenceTime) } .collect { flow.emit(it) } }
Apri view/SegmentationOverlay.kt
L'ultimo passaggio consiste nell'orientare correttamente l'overlay di segmentazione quando l'utente passa alla fotocamera anteriore. Il feed della videocamera viene sottoposto a mirroring naturale per la videocamera anteriore, quindi dobbiamo applicare lo stesso ribaltamento orizzontale alla sovrapposizione Bitmap per assicurarci che sia allineata correttamente all'anteprima della videocamera.
- Handle Overlay Orientation: trova
TODOnel fileSegmentationOverlay.kte sostituiscilo con il seguente codice. Questo codice controlla se la fotocamera frontale è attiva e, in caso affermativo, applica un'inversione orizzontale alla sovrapposizioneBitmapprima che venga disegnata sulCanvas. (~line 42):val orientedBitmap = if (lensFacing == CameraSelector.LENS_FACING_FRONT) { // Create a matrix for horizontal flipping val matrix = Matrix().apply { preScale(-1f, 1f) } Bitmap.createBitmap(image, 0, 0, image.width, image.height, matrix, false).also { image.recycle() } } else { image }
10. Eseguire e utilizzare l'app finale
Ora hai completato tutte le modifiche al codice necessarie. È ora di eseguire l'app e vedere il tuo lavoro in azione.
- Esegui l'app: collega il tuo dispositivo Android e fai clic su Esegui nella barra degli strumenti di Android Studio.
- Prova le funzionalità: una volta avviata l'app, dovresti vedere il feed della videocamera in diretta con una segmentazione colorata in overlay.
- Cambia fotocamera: tocca l'icona di inversione della fotocamera in alto per passare dalla fotocamera anteriore a quella posteriore e viceversa. Nota come l'overlay si orienta correttamente.
- Cambia acceleratore: tocca il pulsante "CPU" o "GPU" in basso per cambiare l'acceleratore hardware. Osserva la modifica del Tempo di inferenza visualizzato nella parte inferiore dello schermo. La GPU dovrebbe essere molto più veloce.
- Utilizzare un'immagine della galleria: tocca la scheda "Galleria" in alto per selezionare un'immagine dalla galleria fotografica del tuo dispositivo. L'app eseguirà la segmentazione sull'immagine statica selezionata.

Ora hai un'app di segmentazione delle immagini in tempo reale e completamente funzionale basata su LiteRT.
11. (Facoltativo) Avanzato: utilizzo della NPU
Questo repository contiene anche una versione dell'app ottimizzata per le unità di elaborazione neurale (NPU). La versione NPU può fornire un aumento significativo delle prestazioni sui dispositivi che dispongono di una NPU compatibile.
Per provare la versione NPU, apri il progetto kotlin_npu/android in Android Studio. Il codice è molto simile alla versione CPU/GPU ed è configurato per utilizzare il delegato NPU.
Per utilizzare il delegato NPU, devi registrarti all'Early Access Program.
12. Complimenti!
Hai creato correttamente un'app per Android che esegue la segmentazione delle immagini in tempo reale utilizzando LiteRT. Hai imparato a:
- Integra il runtime LiteRT in un'app per Android.
- Carica ed esegui un modello di segmentazione delle immagini TFLite.
- Preelabora l'input del modello.
- Elabora l'output del modello per creare una maschera di segmentazione.
- Utilizza CameraX per un'app fotocamera in tempo reale.
Passaggi successivi
- Prova un altro modello di segmentazione delle immagini.
- Sperimenta con diversi delegati LiteRT (CPU, GPU, NPU).