
۱. قبل از شروع
تایپ کردن کد راهی عالی برای تقویت حافظه و تعمیق درک شما از مطالب است. در حالی که کپی-پیست کردن میتواند در زمان صرفهجویی کند، سرمایهگذاری روی این تمرین میتواند در درازمدت منجر به کارایی بیشتر و مهارتهای کدنویسی قویتر شود.
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه یک برنامه اندروید بسازید که با استفاده از رانتایم جدید گوگل برای TensorFlow Lite، LiteRT، قطعهبندی تصویر را به صورت بلادرنگ روی یک دوربین زنده انجام دهد. شما یک برنامه اندروید مبتدی را انتخاب کرده و قابلیتهای قطعهبندی تصویر را به آن اضافه خواهید کرد. همچنین مراحل پیشپردازش، استنتاج و پسپردازش را نیز بررسی خواهیم کرد. شما:
- یک برنامه اندروید بسازید که تصاویر را به صورت بلادرنگ (real-time) قطعهبندی کند.
- یک مدل قطعهبندی تصویر LiteRT از پیش آموزشدیده را ادغام کنید.
- تصویر ورودی برای مدل را پیشپردازش کنید.
- از LiteRT runtime برای شتابدهی CPU و GPU استفاده کنید.
- نحوه پردازش خروجی مدل برای نمایش ماسک تقسیمبندی را درک کنید.
- نحوه تنظیم دوربین جلو را یاد بگیرید.
در نهایت، چیزی شبیه به تصویر زیر ایجاد خواهید کرد:

پیشنیازها
این آزمایشگاه کد برای توسعهدهندگان باتجربه موبایل که میخواهند در زمینه یادگیری ماشین تجربه کسب کنند، طراحی شده است. شما باید با موارد زیر آشنا باشید:
- توسعه اندروید با استفاده از کاتلین و اندروید استودیو
- مفاهیم اولیه پردازش تصویر
آنچه یاد خواهید گرفت
- نحوه ادغام و استفاده از LiteRT runtime در یک برنامه اندروید.
- نحوه انجام قطعهبندی تصویر با استفاده از یک مدل LiteRT از پیش آموزشدیده.
- نحوه پیشپردازش تصویر ورودی برای مدل.
- نحوه اجرای استنتاج برای مدل.
- نحوه پردازش خروجی یک مدل قطعهبندی برای تجسم نتایج.
- نحوه استفاده از CameraX برای پردازش فید دوربین در لحظه.
آنچه نیاز دارید
- نسخه جدیدی از اندروید استودیو (آزمایش شده روی نسخه ۲۰۲۵.۱.۱).
- یک دستگاه اندروید فیزیکی. بهتر است روی دستگاههای گلکسی و پیکسل آزمایش شود.
- کد نمونه (از گیتهاب).
- آشنایی اولیه با توسعه اندروید با زبان کاتلین
۲. قطعهبندی تصویر
تقسیمبندی تصویر یک وظیفه بینایی کامپیوتر است که شامل تقسیم یک تصویر به چندین بخش یا ناحیه میشود. برخلاف تشخیص شیء که یک کادر مرزی در اطراف یک شیء رسم میکند، تقسیمبندی تصویر یک کلاس یا برچسب خاص را به هر پیکسل در تصویر اختصاص میدهد. این امر درک بسیار دقیقتر و جزئیتری از محتوای تصویر را فراهم میکند و به شما امکان میدهد شکل و مرز دقیق هر شیء را بدانید.
برای مثال، به جای اینکه فقط بدانید یک «شخص» در یک جعبه قرار دارد، میتوانید دقیقاً بدانید کدام پیکسلها متعلق به آن شخص هستند. این آموزش نحوه انجام قطعهبندی تصویر در زمان واقعی را در یک دستگاه اندروید با استفاده از یک مدل یادگیری ماشین از پیش آموزش دیده نشان میدهد.

LiteRT: پیشروی در یادگیری ماشین روی دستگاه
یک فناوری کلیدی که امکان تقسیمبندی با دقت بالا و بلادرنگ را در دستگاههای تلفن همراه فراهم میکند، LiteRT است. LiteRT به عنوان نسل بعدی و با عملکرد بالای زمان اجرای گوگل برای TensorFlow Lite، به گونهای مهندسی شده است که بهترین عملکرد مطلق را از سختافزار اصلی دریافت کند.
این امر از طریق استفاده هوشمندانه و بهینه از شتابدهندههای سختافزاری مانند GPU (واحد پردازش گرافیکی) و NPU (واحد پردازش عصبی) محقق میشود. LiteRT با انتقال حجم کار محاسباتی شدید مدل قطعهبندی از CPU عمومی به این پردازندههای تخصصی، زمان استنتاج را به طرز چشمگیری کاهش میدهد. این شتاب همان چیزی است که اجرای روان مدلهای پیچیده را بر روی یک تصویر زنده دوربین امکانپذیر میکند و مرز آنچه را که میتوانیم با یادگیری ماشینی مستقیماً بر روی تلفن خود به دست آوریم، گسترش میدهد. بدون این سطح از عملکرد، قطعهبندی در زمان واقعی برای یک تجربه کاربری خوب بسیار کند و ناهموار خواهد بود.
۳. آماده شوید
مخزن را کلون کنید
ابتدا، مخزن LiteRT را کلون کنید:
git clone https://github.com/google-ai-edge/litert-samples.git
litert-samples/compiled_model_api/image_segmentation دایرکتوری است که تمام منابع مورد نیاز شما را در خود جای داده است. برای این آزمایشگاه کد، فقط به پروژه kotlin_cpu_gpu/android_starter نیاز دارید. اگر در پروژهای به مشکل برخوردید، میتوانید پروژه نهایی را بررسی کنید: kotlin_cpu_gpu/android
نکتهای در مورد مسیرهای فایل
این آموزش مسیر فایلها را در قالب لینوکس/مک مشخص میکند. اگر از ویندوز استفاده میکنید، باید مسیرها را متناسب با آن تنظیم کنید.
همچنین توجه به تمایز بین نمای پروژه اندروید استودیو و نمای استاندارد سیستم فایل مهم است. نمای پروژه اندروید استودیو نمایشی ساختاریافته از فایلهای پروژه شماست که برای توسعه اندروید سازماندهی شده است. مسیرهای فایل در این آموزش به مسیرهای سیستم فایل اشاره دارند، نه مسیرهای موجود در نمای پروژه اندروید استودیو.
برنامه شروع کننده را وارد کنید
بیایید با وارد کردن برنامه اولیه به اندروید استودیو شروع کنیم.
- اندروید استودیو را باز کنید و گزینه Open را انتخاب کنید.
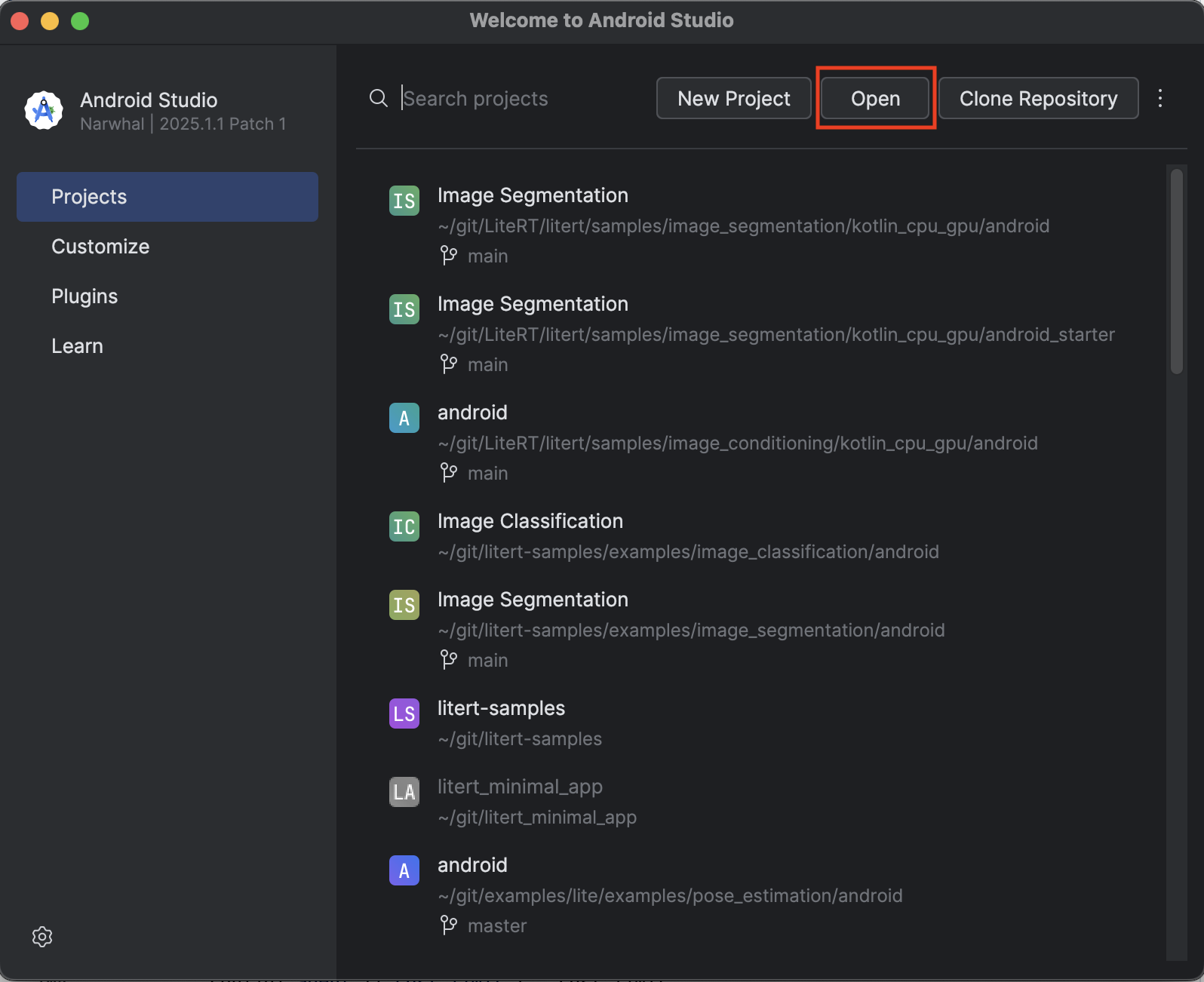
- به پوشهی
kotlin_cpu_gpu/android_starterبروید و آن را باز کنید.
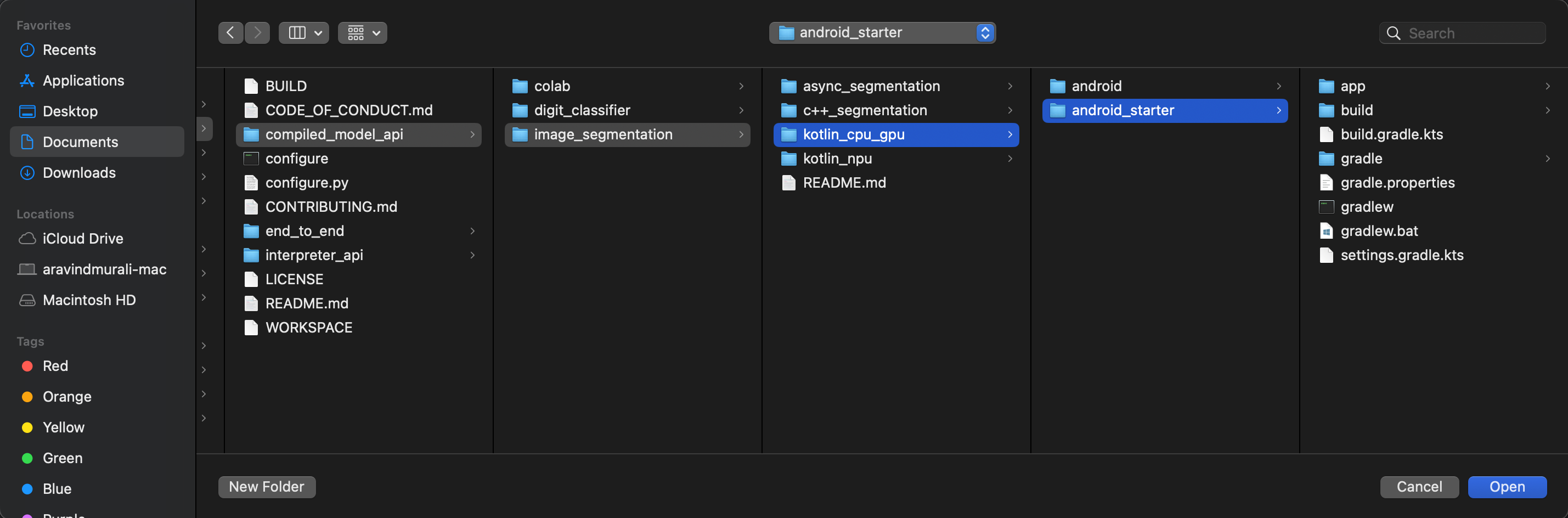
برای اطمینان از اینکه همه وابستگیها برای برنامه شما در دسترس هستند، باید پس از اتمام فرآیند وارد کردن، پروژه خود را با فایلهای gradle همگامسازی کنید.
- از نوار ابزار اندروید استودیو، گزینهی «همگامسازی پروژه با فایلهای گرادل» (Sync Project with Gradle Files) را انتخاب کنید.
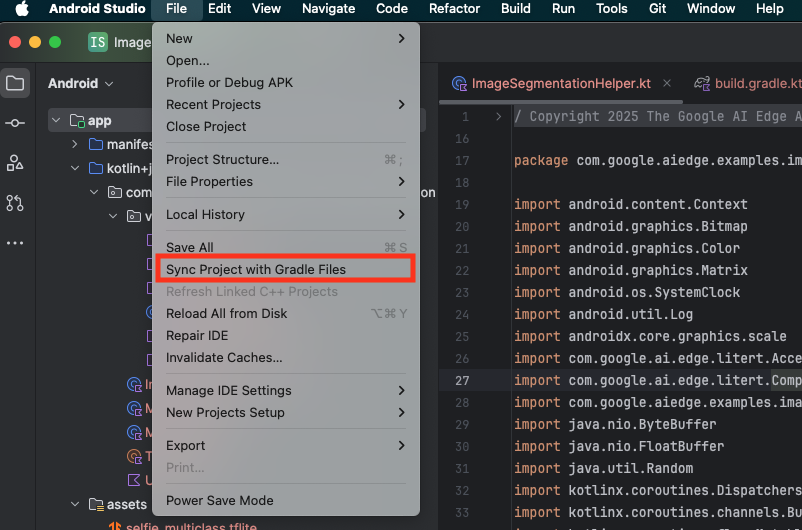
- لطفاً این مرحله را نادیده نگیرید - اگر این مرحله کار نکند، بقیه آموزش بیمعنی خواهد بود.
برنامه شروع کننده را اجرا کنید
حالا که پروژه را به اندروید استودیو وارد کردهاید، آمادهاید تا برای اولین بار برنامه را اجرا کنید.
دستگاه اندروید خود را از طریق USB به رایانه متصل کنید و در نوار ابزار اندروید استودیو روی Run کلیک کنید.
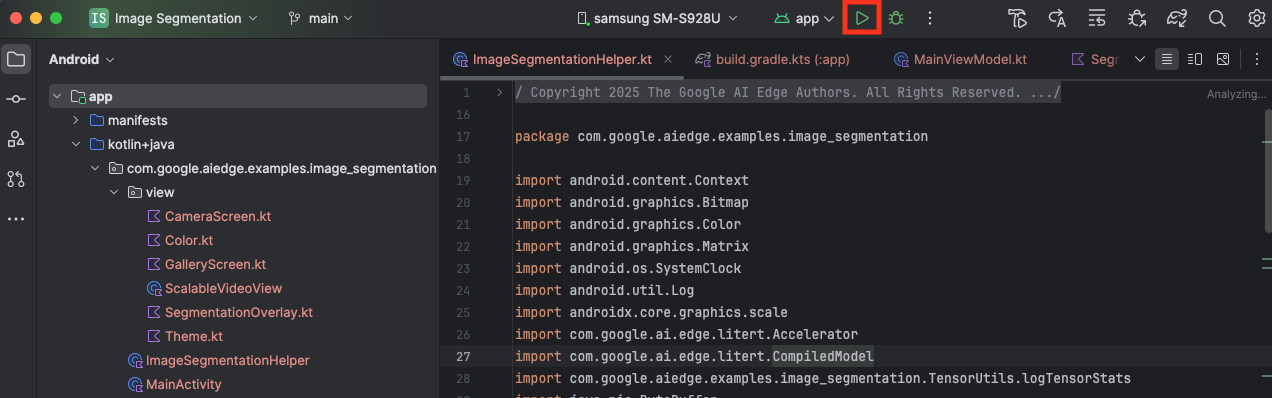
برنامه باید روی دستگاه شما اجرا شود. شما یک فید دوربین زنده را خواهید دید، اما هنوز هیچ تقسیمبندیای انجام نخواهد شد. تمام ویرایشهای فایلی که در این آموزش انجام خواهید داد، در دایرکتوری litert-samples/compiled_model_api/image_segmentation/kotlin_cpu_gpu/android_starter/app/src/main/java/com/google/ai/edge/examples/image_segmentation قرار خواهند گرفت (حالا میدانید که چرا اندروید استودیو این را بازسازی میکند 😃).
همچنین میتوانید کامنتهای TODO را در فایلهای ImageSegmentationHelper.kt ، MainViewModel.kt و view/SegmentationOverlay.kt مشاهده کنید. در مراحل بعدی، با پر کردن این TODO ها، قابلیت تقسیمبندی تصویر را پیادهسازی خواهید کرد.
۴. اپلیکیشن اولیه را درک کنید
برنامهی آغازین از قبل یک رابط کاربری اولیه و منطق کار با دوربین دارد. در اینجا مروری سریع بر فایلهای کلیدی داریم:
-
app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainActivity.kt: این نقطه ورودی اصلی برنامه است. رابط کاربری را با استفاده از Jetpack Compose تنظیم میکند و مجوزهای دوربین را مدیریت میکند. -
app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainViewModel.kt: این ViewModel وضعیت رابط کاربری را مدیریت کرده و فرآیند قطعهبندی تصویر را هماهنگ میکند. -
app/src/main/java/com/google/ai/edge/examples/image_segmentation/ImageSegmentationHelper.kt: اینجا جایی است که منطق اصلی برای قطعهبندی تصویر را اضافه خواهیم کرد. این فایل، بارگذاری مدل، پردازش فریمهای دوربین و اجرای استنتاج را مدیریت خواهد کرد. -
app/src/main/java/com/google/ai/edge/examples/image_segmentation/view/CameraScreen.kt: این تابع Composable پیشنمایش دوربین و پوشش تقسیمبندی را نمایش میدهد. -
app/download_model.gradle: این اسکریپتselfie_multiclass.tfliteرا دانلود میکند. این مدل قطعهبندی تصویر TensorFlow Lite از پیش آموزشدیده است که ما از آن استفاده خواهیم کرد.
۵. درک LiteRT و افزودن وابستگیها
حالا، بیایید قابلیت تقسیمبندی تصویر را به برنامهی اولیه اضافه کنیم.
۱. وابستگی LiteRT را اضافه کنید
ابتدا باید کتابخانه LiteRT را به پروژه خود اضافه کنید. این اولین قدم حیاتی برای فعال کردن یادگیری ماشینی روی دستگاه با زمان اجرای بهینه شده گوگل است.
فایل app/build.gradle.kts را باز کنید و خط زیر را به بلوک dependencies اضافه کنید:
// LiteRT for on-device ML
implementation(libs.litert)
پس از افزودن وابستگی، با کلیک روی دکمه Sync Now که در گوشه بالا سمت راست اندروید استودیو ظاهر میشود، پروژه خود را با فایلهای Gradle همگامسازی کنید.

۲. درک API های کلیدی LiteRT
ImageSegmentationHelper.kt را باز کنید
قبل از نوشتن کد پیادهسازی، درک اجزای اصلی LiteRT API که استفاده خواهید کرد، مهم است. مطمئن شوید که از بسته com.google.ai.edge.litert وارد میکنید، importهای زیر را به بالای ImageSegmentationHelper.kt اضافه کنید:
import com.google.ai.edge.litert.Accelerator
import com.google.ai.edge.litert.CompiledModel
-
CompiledModel: این کلاس مرکزی برای تعامل با مدل TFLite شماست. این کلاس، مدلی را نشان میدهد که از قبل کامپایل شده و برای یک شتابدهنده سختافزاری خاص (مانند CPU یا GPU) بهینه شده است. این پیشکامپایل، یکی از ویژگیهای کلیدی LiteRT است که منجر به استنتاج سریعتر و کارآمدتر میشود. -
CompiledModel.Options: شما از این کلاس سازنده برای پیکربندیCompiledModelاستفاده میکنید. مهمترین تنظیم، مشخص کردن شتابدهنده سختافزاری است که میخواهید برای اجرای مدل خود استفاده کنید. -
Accelerator: این enum به شما امکان میدهد سختافزار مورد نیاز برای استنتاج را انتخاب کنید. پروژه اولیه از قبل برای مدیریت این گزینهها پیکربندی شده است:-
Accelerator.CPU: برای اجرای مدل روی CPU دستگاه. این گزینه سازگارترین گزینه برای همه است. -
Accelerator.GPU: برای اجرای مدل روی GPU دستگاه. این اغلب برای مدلهای مبتنی بر تصویر به طور قابل توجهی سریعتر از CPU است.
-
- بافرهای ورودی و خروجی (
TensorBuffer) : LiteRT ازTensorBufferبرای ورودیها و خروجیهای مدل استفاده میکند. این به شما کنترل دقیقی بر حافظه میدهد و از کپیهای غیرضروری دادهها جلوگیری میکند. شما این بافرها را مستقیماً از نمونهCompiledModelخود با استفاده ازmodel.createInputBuffers()وmodel.createOutputBuffers()دریافت خواهید کرد و سپس دادههای ورودی خود را در آنها مینویسید و نتایج را از آنها میخوانید. -
model.run(): این تابعی است که استنتاج را اجرا میکند. شما بافرهای ورودی و خروجی را به آن ارسال میکنید و LiteRT وظیفه پیچیده اجرای مدل روی شتابدهنده سختافزاری انتخاب شده را بر عهده میگیرد.
۶. پیادهسازی اولیهی ImageSegmentationHelper را تکمیل کنید
حالا وقت نوشتن کد است. شما پیادهسازی اولیهی ImageSegmentationHelper.kt را تکمیل خواهید کرد. این شامل راهاندازی کلاس خصوصی Segmenter برای نگهداری مدل LiteRT و پیادهسازی تابع cleanup() برای آزادسازی صحیح آن است.
- تکمیل کلاس
Segmenterو تابعcleanup(): در فایلImageSegmentationHelper.kt، اسکلتی برای یک کلاس خصوصی به نامSegmenterو تابعی به نامcleanup()خواهید یافت. ابتدا، کلاسSegmenterرا با تعریف سازنده آن برای نگهداری مدل، ایجاد ویژگیهایی برای بافرهای ورودی/خروجی و افزودن یک متدclose()برای آزادسازی مدل، تکمیل کنید. سپس، تابعcleanup()را برای فراخوانی این متدclose()جدید پیادهسازی کنید. کلاسSegmenterو تابعcleanup()موجود را با کد زیر جایگزین کنید: (~خط 83)private class Segmenter( // Add this argument private val model: CompiledModel, private val coloredLabels: List<ColoredLabel>, ) { // Add these private vals private val inputBuffers = model.createInputBuffers() private val outputBuffers = model.createOutputBuffers() fun cleanup() { // cleanup buffers inputBuffers.forEach { it.close() } outputBuffers.forEach { it.close() } // cleanup model model.close() } } - متد toAccelerator را تعریف کنید : این متد enumهای شتابدهنده تعریفشده از منوی شتابدهنده را به enumهای شتابدهنده مختص ماژولهای LiteRT واردشده نگاشت میکند (~خط ۲۲۵):
fun toAccelerator(acceleratorEnum: AcceleratorEnum): Accelerator { return when (acceleratorEnum) { AcceleratorEnum.CPU -> Accelerator.CPU AcceleratorEnum.GPU -> Accelerator.GPU } } - مقداردهی اولیه
CompiledModel: اکنون تابعinitSegmenterرا پیدا کنید. در اینجا نمونهCompiledModelرا ایجاد کرده و از آن برای نمونهسازی کلاسSegmenterکه اکنون تعریف کردهاید استفاده خواهید کرد. این کد مدل را با شتابدهنده مشخصشده (CPU یا GPU) تنظیم کرده و آن را برای استنتاج آماده میکند.TODOدرinitSegmenterبا پیادهسازی زیر جایگزین کنید (Cmd/Ctrl+f 'initSegmenter` یا ~line 62):cleanup() try { withContext(singleThreadDispatcher) { val model = CompiledModel.create( context.assets, "selfie_multiclass.tflite", CompiledModel.Options(toAccelerator(acceleratorEnum)), null, ) segmenter = Segmenter(model, coloredLabels) Log.d(TAG, "Created an image segmenter") } } catch (e: Exception) { Log.i(TAG, "Create LiteRT from selfie_multiclass is failed: ${e.message}") _error.emit(e) }
۷. شروع قطعهبندی و پیشپردازش
حالا که یک مدل داریم، باید فرآیند قطعهبندی را آغاز کنیم و دادههای ورودی را برای مدل آماده کنیم.
تقسیمبندی تریگر
فرآیند قطعهبندی در MainViewModel.kt آغاز میشود که فریمها را از دوربین دریافت میکند.
MainViewModel.kt را باز کنید .
- فعالسازی قطعهبندی از فریمهای دوربین : توابع
segmentدرMainViewModelنقطه ورود برای وظیفه قطعهبندی ما هستند. این توابع هر زمان که تصویر جدیدی از دوربین در دسترس باشد یا از گالری انتخاب شود، فراخوانی میشوند. سپس این توابع، متدsegmentرا درImageSegmentationHelperما فراخوانی میکنند.TODOهای هر دو تابعsegmentرا با موارد زیر جایگزین کنید (خط ~107):// For ImageProxy (from CameraX) fun segment(imageProxy: ImageProxy) { segmentJob = viewModelScope.launch { imageSegmentationHelper.segment(imageProxy.toBitmap(), imageProxy.imageInfo.rotationDegrees) imageProxy.close() } } // For Bitmaps (from gallery) fun segment(bitmap: Bitmap, rotationDegrees: Int) { segmentJob = viewModelScope.launch { val argbBitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true) imageSegmentationHelper.segment(argbBitmap, rotationDegrees) } }
پیشپردازش تصویر
حالا بیایید به ImageSegmentationHelper.kt برگردیم تا پیشپردازش تصویر را مدیریت کنیم.
ImageSegmentationHelper.kt را باز کنید
- پیادهسازی تابع
segmentعمومی : این تابع به عنوان یک پوشش عمل میکند که تابعsegmentخصوصی را درون کلاسSegmenterفراخوانی میکند.TODOبا (~خط ۹۵) جایگزین کنید:try { withContext(singleThreadDispatcher) { segmenter?.segment(bitmap, rotationDegrees)?.let { if (isActive) _segmentation.emit(it) } } } catch (e: Exception) { Log.i(TAG, "Image segment error occurred: ${e.message}") _error.emit(e) } - پیادهسازی پیشپردازش : تابع private
segmentدرون کلاسSegmenterجایی است که ما تبدیلهای لازم را روی تصویر ورودی انجام میدهیم تا آن را برای مدل آماده کنیم. این شامل مقیاسبندی، چرخش و نرمالسازی تصویر میشود. سپس این تابع یک تابع privatesegmentدیگر را برای انجام استنتاج فراخوانی میکند.TODOرا درsegment(bitmap: Bitmap, ...)با (~خط 121) جایگزین کنید:val totalStartTime = SystemClock.uptimeMillis() val rotation = -rotationDegrees / 90 val (h, w) = Pair(256, 256) // Preprocessing val preprocessStartTime = SystemClock.uptimeMillis() var image = bitmap.scale(w, h, true) image = rot90Clockwise(image, rotation) val inputFloatArray = normalize(image, 127.5f, 127.5f) Log.d(TAG, "Preprocessing time: ${SystemClock.uptimeMillis() - preprocessStartTime} ms") // Inference val inferenceStartTime = SystemClock.uptimeMillis() val segmentResult = segment(inputFloatArray) Log.d(TAG, "Inference time: ${SystemClock.uptimeMillis() - inferenceStartTime} ms") Log.d(TAG, "Total segmentation time: ${SystemClock.uptimeMillis() - totalStartTime} ms") return SegmentationResult(segmentResult, SystemClock.uptimeMillis() - inferenceStartTime)
۸. استنتاج اولیه با LiteRT
با پیشپردازش دادههای ورودی، اکنون میتوانیم استنتاج اصلی را با استفاده از LiteRT اجرا کنیم.
ImageSegmentationHelper.kt را باز کنید
- پیادهسازی اجرای مدل : تابع private
segment(inputFloatArray: FloatArray)جایی است که ما مستقیماً با متد LiteRTrun()تعامل داریم. ما دادههای پیشپردازششده خود را در بافر ورودی مینویسیم، مدل را اجرا میکنیم و نتایج را از بافر خروجی میخوانیم.TODOرا در این تابع با (~خط 188) جایگزین کنید:val (h, w, c) = Triple(256, 256, 6) // MODEL EXECUTION PHASE val modelExecStartTime = SystemClock.uptimeMillis() // Write input data - measure time val bufferWriteStartTime = SystemClock.uptimeMillis() inputBuffers[0].writeFloat(inputFloatArray) val bufferWriteTime = SystemClock.uptimeMillis() - bufferWriteStartTime Log.d(TAG, "Buffer write time: $bufferWriteTime ms") // Optional tensor inspection logTensorStats("Input tensor", inputFloatArray) // Run model inference - measure time val modelRunStartTime = SystemClock.uptimeMillis() model.run(inputBuffers, outputBuffers) val modelRunTime = SystemClock.uptimeMillis() - modelRunStartTime Log.d(TAG, "Model.run() time: $modelRunTime ms") // Read output data - measure time val bufferReadStartTime = SystemClock.uptimeMillis() val outputFloatArray = outputBuffers[0].readFloat() val outputBuffer = FloatBuffer.wrap(outputFloatArray) val bufferReadTime = SystemClock.uptimeMillis() - bufferReadStartTime Log.d(TAG, "Buffer read time: $bufferReadTime ms") val modelExecTime = SystemClock.uptimeMillis() - modelExecStartTime Log.d(TAG, "Total model execution time: $modelExecTime ms") // Optional tensor inspection logTensorStats("Output tensor", outputFloatArray) // POSTPROCESSING PHASE val postprocessStartTime = SystemClock.uptimeMillis() // Process mask from model output val inferenceData = InferenceData(width = w, height = h, channels = c, buffer = outputBuffer) val mask = processImage(inferenceData) val postprocessTime = SystemClock.uptimeMillis() - postprocessStartTime Log.d(TAG, "Postprocessing time (mask creation): $postprocessTime ms") return Segmentation( listOf(Mask(mask, inferenceData.width, inferenceData.height)), coloredLabels, )
۹. پسپردازش و نمایش لایه رویی
پس از اجرای استنتاج، یک خروجی خام از مدل دریافت میکنیم. باید این خروجی را پردازش کنیم تا یک ماسک تقسیمبندی بصری ایجاد کنیم و سپس آن را روی صفحه نمایش دهیم.
ImageSegmentationHelper.kt را باز کنید
- پیادهسازی پردازش خروجی : تابع
processImageخروجی خام ممیز شناور از مدل را به یکByteBufferتبدیل میکند که نشاندهنده ماسک تقسیمبندی است. این کار را با یافتن کلاسی با بالاترین احتمال برای هر پیکسل انجام میدهد.TODOآن را با (~خط ۲۳۸) جایگزین کنید:val mask = ByteBuffer.allocateDirect(inferenceData.width * inferenceData.height) for (i in 0 until inferenceData.height) { for (j in 0 until inferenceData.width) { val offset = inferenceData.channels * (i * inferenceData.width + j) var maxIndex = 0 var maxValue = inferenceData.buffer.get(offset) for (index in 1 until inferenceData.channels) { if (inferenceData.buffer.get(offset + index) > maxValue) { maxValue = inferenceData.buffer.get(offset + index) maxIndex = index } } mask.put(i * inferenceData.width + j, maxIndex.toByte()) } } return mask
MainViewModel.kt را باز کنید .
- جمعآوری و پردازش نتایج تقسیمبندی : اکنون به
MainViewModelبرمیگردیم تا نتایج تقسیمبندی را ازImageSegmentationHelperپردازش کنیم.segmentationUiShareFlowSegmentationResultجمعآوری میکند، ماسک را به یکBitmapرنگارنگ تبدیل میکند و آن را در اختیار رابط کاربری قرار میدهد.TODOدر ویژگیsegmentationUiShareFlowبا (~خط ۶۳) جایگزین کنید - کد موجود در آنجا را جایگزین نکنید، فقط بدنه را پر کنید:viewModelScope.launch { imageSegmentationHelper.segmentation .filter { it.segmentation.masks.isNotEmpty() } .map { val segmentation = it.segmentation val mask = segmentation.masks[0] val maskArray = mask.data val width = mask.width val height = mask.height val pixelSize = width * height val pixels = IntArray(pixelSize) val colorLabels = segmentation.coloredLabels.mapIndexed { index, coloredLabel -> ColorLabel(index, coloredLabel.label, coloredLabel.argb) } // Set color for pixels for (i in 0 until pixelSize) { val colorLabel = colorLabels[maskArray[i].toInt()] val color = colorLabel.getColor() pixels[i] = color } // Get image info val overlayInfo = OverlayInfo(pixels = pixels, width = width, height = height) val inferenceTime = it.inferenceTime Pair(overlayInfo, inferenceTime) } .collect { flow.emit(it) } }
نمای باز view/SegmentationOverlay.kt
بخش آخر، جهتدهی صحیح پوشش تقسیمبندی هنگام چرخش کاربر به سمت دوربین جلو است. تصویر دوربین به طور طبیعی برای دوربین جلو نیز منعکس میشود، بنابراین باید همان چرخش افقی را روی پوشش Bitmap خود اعمال کنیم تا مطمئن شویم که به درستی با پیشنمایش دوربین همتراز میشود.
- مدیریت جهت قرارگیری لایه :
TODOرا در فایلSegmentationOverlay.ktپیدا کنید و آن را با کد زیر جایگزین کنید. این کد بررسی میکند که آیا دوربین جلو فعال است یا خیر و در این صورت، قبل از ترسیم لایهBitmapرویCanvas، یک چرخش افقی به آن اعمال میکند. (~خط ۴۲):val orientedBitmap = if (lensFacing == CameraSelector.LENS_FACING_FRONT) { // Create a matrix for horizontal flipping val matrix = Matrix().apply { preScale(-1f, 1f) } Bitmap.createBitmap(image, 0, 0, image.width, image.height, matrix, false).also { image.recycle() } } else { image }
۱۰. اجرا و استفاده از برنامه نهایی
اکنون تمام تغییرات لازم در کد را انجام دادهاید. وقت آن است که برنامه را اجرا کنید و نتیجه کار خود را در عمل ببینید!
- اجرای برنامه : دستگاه اندروید خود را متصل کنید و در نوار ابزار اندروید استودیو روی Run کلیک کنید.
- ویژگیها را آزمایش کنید : به محض اجرای برنامه، باید تصویر زنده دوربین را با یک پوشش رنگی از تقسیمبندیها مشاهده کنید.
- تغییر دوربین : برای تغییر بین دوربین جلو و عقب، روی آیکون چرخش دوربین در بالا ضربه بزنید. توجه کنید که چگونه لایه رویی به درستی جهت گیری میکند.
- تغییر شتابدهنده : برای تغییر شتابدهنده سختافزاری، روی دکمه «CPU» یا «GPU» در پایین صفحه ضربه بزنید. تغییر زمان استنتاج نمایش داده شده در پایین صفحه را مشاهده کنید. پردازنده گرافیکی (GPU) باید به طور قابل توجهی سریعتر باشد.
- استفاده از تصویر گالری : برای انتخاب تصویر از گالری عکس دستگاه خود، روی زبانه «گالری» در بالا ضربه بزنید. برنامه، تقسیمبندی را روی تصویر ثابت انتخاب شده اجرا خواهد کرد.

اکنون شما یک برنامهی قطعهبندی تصویر کاملاً کاربردی و بلادرنگ دارید که توسط LiteRT پشتیبانی میشود!
۱۱. پیشرفته (اختیاری): استفاده از NPU
این مخزن همچنین شامل نسخهای از برنامه است که برای واحدهای پردازش عصبی (NPU) بهینه شده است. نسخه NPU میتواند افزایش عملکرد قابل توجهی را در دستگاههایی که دارای NPU سازگار هستند، ارائه دهد.
برای امتحان کردن نسخه NPU، پروژه kotlin_npu/android را در اندروید استودیو باز کنید. کد بسیار شبیه به نسخه CPU/GPU است و برای استفاده از نماینده NPU پیکربندی شده است.
برای استفاده از نماینده NPU، باید در برنامه دسترسی زودهنگام ثبت نام کنید.
۱۲. تبریک میگویم!
شما با موفقیت یک برنامه اندروید ساختید که با استفاده از LiteRT، قطعهبندی تصویر را به صورت بلادرنگ انجام میدهد. شما یاد گرفتهاید که چگونه:
- ادغام زمان اجرای LiteRT در یک برنامه اندروید.
- یک مدل تقسیمبندی تصویر TFLite را بارگذاری و اجرا کنید.
- ورودی مدل را پیشپردازش کنید.
- خروجی مدل را برای ایجاد یک ماسک تقسیمبندی پردازش کنید.
- برای یک برنامه دوربین در لحظه از CameraX استفاده کنید.
مراحل بعدی
- یک مدل تقسیمبندی تصویر متفاوت را امتحان کنید.
- با نمایندگان مختلف LiteRT (CPU، GPU، NPU) آزمایش کنید.