
1. Hinweis
Wenn Sie Code eingeben, können Sie Ihr Wissen festigen und das Material besser verstehen. Auch wenn das Kopieren und Einfügen von Code Zeit sparen kann, kann sich die Investition in diese Praxis langfristig in Form von höherer Effizienz und besseren Programmierkenntnissen auszahlen.
In diesem Codelab erfahren Sie, wie Sie eine Android-Anwendung erstellen, die mit dem neuen Laufzeitmodul für TensorFlow Lite, LiteRT, von Google eine Echtzeit-Bildsegmentierung für einen Live-Kamerafeed durchführt. Sie nehmen eine Android-Starteranwendung und fügen ihr Funktionen zur Bildsegmentierung hinzu. Wir werden auch die Schritte für die Vorverarbeitung, Inferenz und Nachbearbeitung durchgehen. Sie werden Folgendes tun:
- Eine Android-App erstellen, die Bilder in Echtzeit segmentiert
- Ein vortrainiertes LiteRT-Modell zur Bildsegmentierung einbinden.
- Verarbeiten Sie das Eingabebild für das Modell vor.
- Verwenden Sie die LiteRT-Laufzeit für die CPU- und GPU-Beschleunigung.
- Informationen zum Verarbeiten der Modellausgabe zum Anzeigen der Segmentierungsmaske.
- Informationen zum Anpassen der Einstellungen für die Frontkamera
Am Ende haben Sie etwas Ähnliches wie in der Abbildung unten erstellt:

Voraussetzungen
Dieses Codelab wurde für erfahrene mobile Entwickler entwickelt, die sich mit Machine Learning vertraut machen möchten. Sie sollten mit Folgendem vertraut sein:
- Android-Entwicklung mit Kotlin und Android Studio
- Grundlegende Konzepte der Bildverarbeitung
Lerninhalte
- So integrieren und verwenden Sie die LiteRT-Laufzeit in einer Android-Anwendung.
- So führen Sie die Bildsegmentierung mit einem vortrainierten LiteRT-Modell durch.
- So verarbeiten Sie das Eingabebild für das Modell vor.
- So führen Sie die Inferenz für das Modell aus.
- So verarbeiten Sie die Ausgabe eines Segmentierungsmodells, um die Ergebnisse zu visualisieren.
- Verwendung von CameraX für die Verarbeitung von Kamerafeeds in Echtzeit.
Voraussetzungen
- Eine aktuelle Version von Android Studio (getestet mit Version 2025.1.1).
- Ein physisches Android-Gerät. Die Funktion wurde am besten auf Galaxy- und Pixel-Geräten getestet.
- Der Beispielcode (von GitHub).
- Grundkenntnisse in der Android-Entwicklung mit Kotlin.
2. Bildsegmentierung
Die Bildsegmentierung ist eine Aufgabe im Bereich Computer Vision, bei der ein Bild in mehrere Segmente oder Regionen unterteilt wird. Im Gegensatz zur Objekterkennung, bei der ein Begrenzungsrahmen um ein Objekt gezeichnet wird, wird bei der Bildsegmentierung jedem einzelnen Pixel im Bild eine bestimmte Klasse oder ein bestimmtes Label zugewiesen. So erhalten Sie ein viel detaillierteres und genaueres Verständnis der Bildinhalte und können die genaue Form und Grenze jedes Objekts erkennen.
So können Sie beispielsweise nicht nur erkennen, dass sich eine Person in einem Rechteck befindet, sondern auch genau, welche Pixel zu dieser Person gehören. In dieser Anleitung wird gezeigt, wie Sie mit einem vortrainierten Modell für maschinelles Lernen eine Echtzeit-Bildsegmentierung auf einem Android-Gerät durchführen.

LiteRT: On-Device-ML auf dem neuesten Stand
Eine Schlüsseltechnologie, die eine hochgenaue Echtzeitsegmentierung auf Mobilgeräten ermöglicht, ist LiteRT. LiteRT ist die leistungsstarke Laufzeit der nächsten Generation von Google für TensorFlow Lite und wurde entwickelt, um die bestmögliche Leistung aus der zugrunde liegenden Hardware herauszuholen.
Das wird durch die intelligente und optimierte Nutzung von Hardwarebeschleunigern wie GPU (Graphics Processing Unit) und NPU (Neural Processing Unit) erreicht. Durch die Auslagerung der rechenintensiven Arbeitslast des Segmentierungsmodells von der Allzweck-CPU auf diese Spezialprozessoren wird die Inferenzzeit mit LiteRT erheblich verkürzt. Durch diese Beschleunigung können komplexe Modelle reibungslos auf einem Live-Kamerafeed ausgeführt werden. So können wir mit maschinellem Lernen direkt auf Ihrem Smartphone noch mehr erreichen. Ohne diese Leistung wäre die Echtzeitsegmentierung zu langsam und ruckartig, um ein gutes Nutzererlebnis zu bieten.
3. Einrichten
Repository klonen
Klonen Sie zuerst das Repository für LiteRT:
git clone https://github.com/google-ai-edge/litert-samples.git
litert-samples/compiled_model_api/image_segmentation ist das Verzeichnis mit allen benötigten Ressourcen. Für dieses Codelab benötigen Sie nur das kotlin_cpu_gpu/android_starter-Projekt. Wenn Sie nicht weiterkommen, können Sie sich das fertige Projekt ansehen: kotlin_cpu_gpu/android
Hinweis zu Dateipfaden
In dieser Anleitung werden Dateipfade im Linux-/macOS-Format angegeben. Wenn Sie Windows verwenden, müssen Sie die Pfade entsprechend anpassen.
Außerdem ist es wichtig, den Unterschied zwischen der Android Studio-Projektansicht und einer Standarddateisystemansicht zu beachten. Die Android Studio-Projektansicht ist eine strukturierte Darstellung der Dateien Ihres Projekts, die für die Android-Entwicklung organisiert sind. Die Dateipfade in diesem Tutorial beziehen sich auf die Dateisystempfade und nicht auf die Pfade in der Android Studio-Projektansicht.
Start-App importieren
Importieren wir zuerst die Starter-App in Android Studio.
- Öffnen Sie Android Studio und wählen Sie Open (Öffnen) aus.
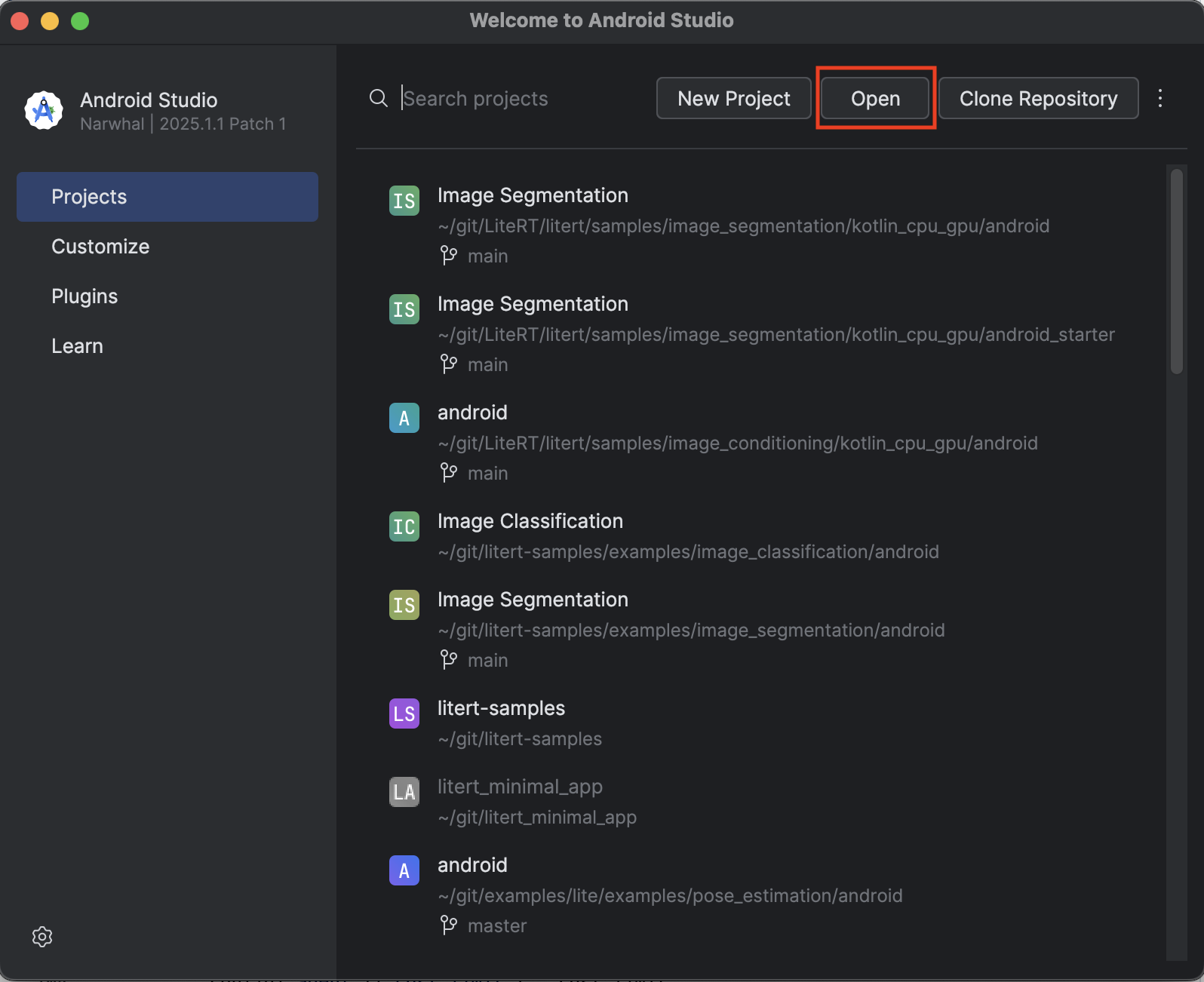
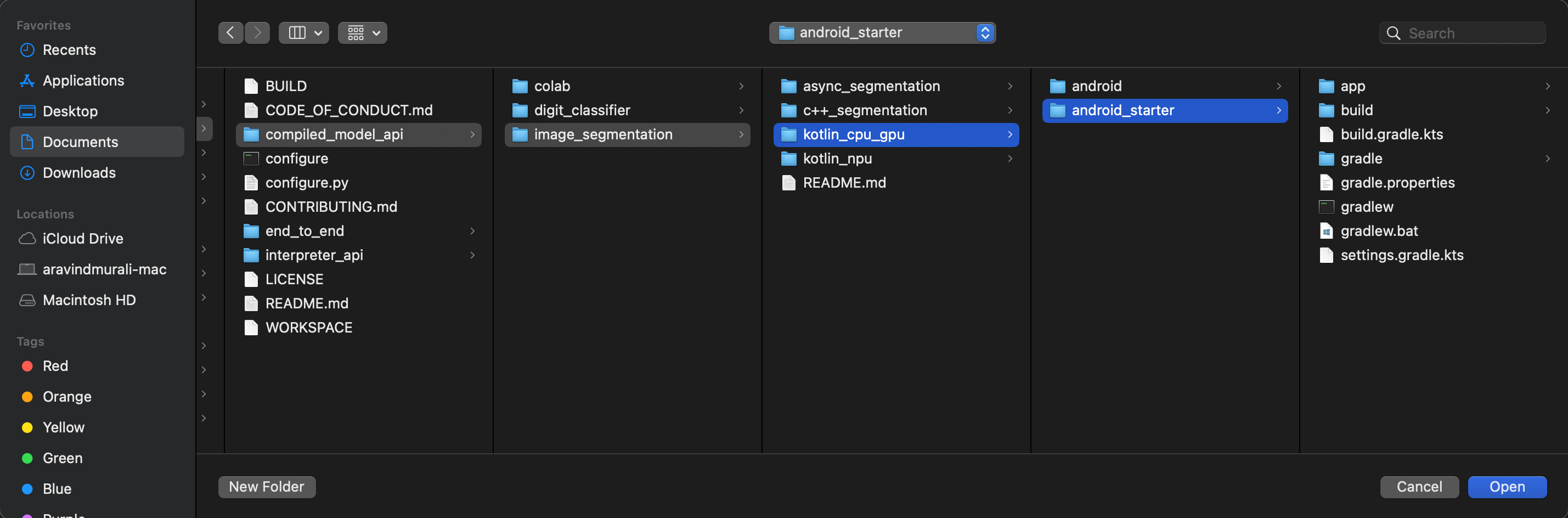
- Rufen Sie das Verzeichnis
kotlin_cpu_gpu/android_starterauf und öffnen Sie es.
Damit alle Abhängigkeiten für Ihre App verfügbar sind, sollten Sie Ihr Projekt nach Abschluss des Importvorgangs mit Gradle-Dateien synchronisieren.
- Wählen Sie in der Android Studio-Symbolleiste Projekt mit Gradle-Dateien synchronisieren aus.
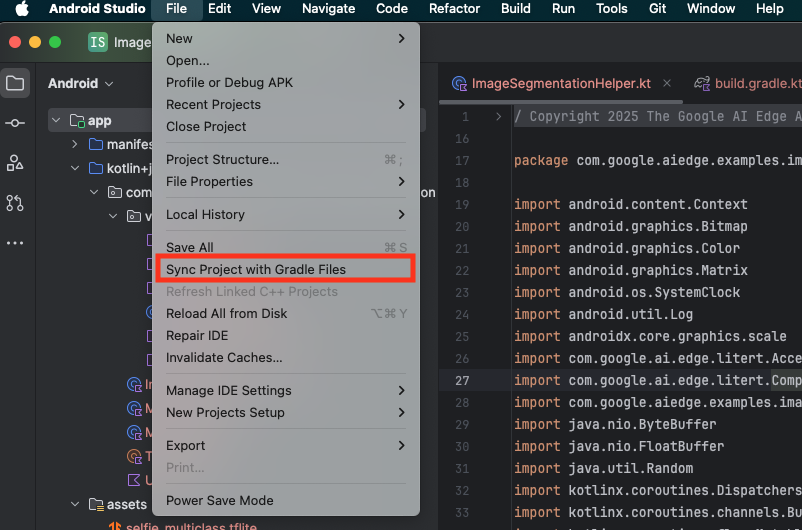
- Überspringen Sie diesen Schritt nicht. Wenn er nicht funktioniert, ist der Rest der Anleitung nicht sinnvoll.
Start-App ausführen
Nachdem Sie das Projekt in Android Studio importiert haben, können Sie die App zum ersten Mal ausführen.
Verbinden Sie Ihr Android-Gerät über USB mit Ihrem Computer und klicken Sie in der Android Studio-Symbolleiste auf Run (Ausführen).
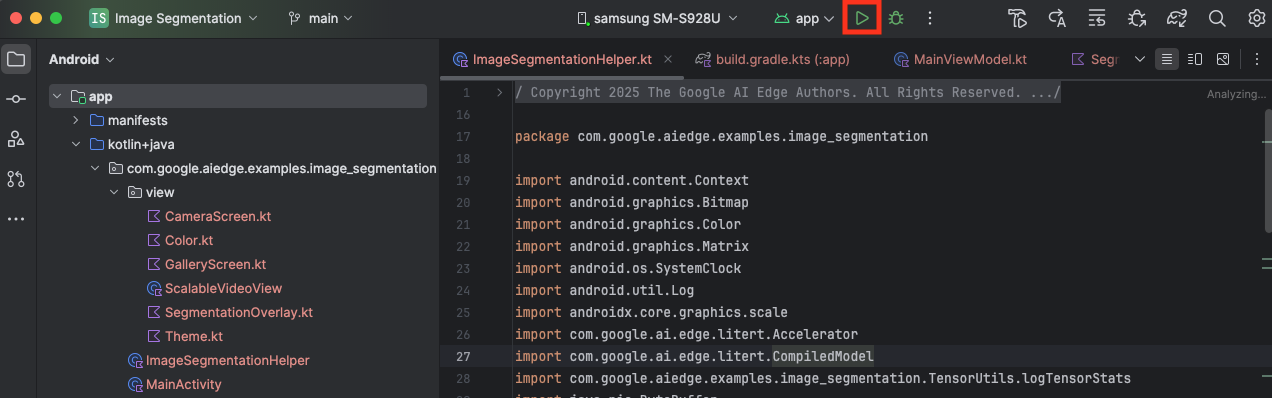
Die App sollte auf Ihrem Gerät gestartet werden. Sie sehen einen Live-Kamerafeed, aber es erfolgt noch keine Segmentierung. Alle Dateiänderungen, die Sie in diesem Tutorial vornehmen, werden im Verzeichnis litert-samples/compiled_model_api/image_segmentation/kotlin_cpu_gpu/android_starter/app/src/main/java/com/google/ai/edge/examples/image_segmentation vorgenommen. Jetzt wissen Sie auch, warum Android Studio dieses Verzeichnis umstrukturiert 😃.
Außerdem sehen Sie TODO-Kommentare in den Dateien ImageSegmentationHelper.kt, MainViewModel.kt und view/SegmentationOverlay.kt. In den folgenden Schritten implementieren Sie die Bildsegmentierungsfunktion, indem Sie diese TODO ausfüllen.
4. Informationen zur Start-App
Die Starter-App enthält bereits eine grundlegende Benutzeroberfläche und Logik für die Kamera. Hier ein kurzer Überblick über die wichtigsten Dateien:
app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainActivity.kt: Dies ist der Haupteinstiegspunkt der Anwendung. Sie richtet die Benutzeroberfläche mit Jetpack Compose ein und verwaltet die Kameraberechtigungen.app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainViewModel.kt: Dieses ViewModel verwaltet den UI-Zustand und orchestriert den Bildsegmentierungsprozess.app/src/main/java/com/google/ai/edge/examples/image_segmentation/ImageSegmentationHelper.kt: Hier fügen wir die Kernlogik für die Bildsegmentierung hinzu. Es kümmert sich um das Laden des Modells, die Verarbeitung der Kamera-Frames und die Ausführung der Inferenz.app/src/main/java/com/google/ai/edge/examples/image_segmentation/view/CameraScreen.kt: Diese zusammensetzbare Funktion zeigt die Kameravorschau und das Segmentierungs-Overlay an.app/download_model.gradle: Mit diesem Skript wirdselfie_multiclass.tfliteheruntergeladen. Dies ist das vortrainierte TensorFlow Lite-Modell für die Bildsegmentierung, das wir verwenden werden.
5. LiteRT verstehen und Abhängigkeiten hinzufügen
Fügen wir nun der Starter-App die Bildsegmentierungsfunktion hinzu.
1. LiteRT-Abhängigkeit hinzufügen
Zuerst müssen Sie die LiteRT-Bibliothek Ihrem Projekt hinzufügen. Das ist der erste wichtige Schritt, um On-Device-Machine-Learning mit der optimierten Laufzeit von Google zu ermöglichen.
Öffnen Sie die Datei app/build.gradle.kts und fügen Sie dem Block dependencies die folgende Zeile hinzu:
// LiteRT for on-device ML
implementation(libs.litert)
Nachdem Sie die Abhängigkeit hinzugefügt haben, synchronisieren Sie Ihr Projekt mit den Gradle-Dateien. Klicken Sie dazu oben rechts in Android Studio auf die Schaltfläche Jetzt synchronisieren.

2. Wichtige LiteRT-APIs
ImageSegmentationHelper.kt öffnen
Bevor Sie den Implementierungscode schreiben, sollten Sie die wichtigsten Komponenten der LiteRT API kennen, die Sie verwenden werden. Achten Sie darauf, dass Sie das com.google.ai.edge.litert-Paket importieren, und fügen Sie die folgenden Importe oben in ImageSegmentationHelper.kt ein:
import com.google.ai.edge.litert.Accelerator
import com.google.ai.edge.litert.CompiledModel
CompiledModel: Dies ist die zentrale Klasse für die Interaktion mit Ihrem TFLite-Modell. Es stellt ein Modell dar, das für einen bestimmten Hardwarebeschleuniger (z. B. die CPU oder GPU) vorkompiliert und optimiert wurde. Diese Vorabkompilierung ist ein wichtiges Feature von LiteRT, das zu einer schnelleren und effizienteren Inferenz führt.CompiledModel.Options: Mit dieser Builder-Klasse konfigurieren Sie dieCompiledModel. Die wichtigste Einstellung ist die Angabe des Hardwarebeschleunigers, den Sie zum Ausführen Ihres Modells verwenden möchten.Accelerator: Mit dieser Aufzählung können Sie die Hardware für die Inferenz auswählen. Das Starterprojekt ist bereits für die Verarbeitung dieser Optionen konfiguriert:Accelerator.CPU: Zum Ausführen des Modells auf der CPU des Geräts. Dies ist die universellste Option.Accelerator.GPU: Zum Ausführen des Modells auf der GPU des Geräts. Das ist oft deutlich schneller als die CPU für bildbasierte Modelle.
- Ein- und Ausgabepuffer (
TensorBuffer): LiteRT verwendetTensorBufferfür Modelleingaben und -ausgaben. So haben Sie eine detaillierte Kontrolle über den Speicher und vermeiden unnötige Datenkopien. Sie rufen diese Puffer direkt aus IhrerCompiledModel-Instanz mitmodel.createInputBuffers()undmodel.createOutputBuffers()ab, schreiben Ihre Eingabedaten in sie und lesen die Ergebnisse daraus. model.run(): Diese Funktion führt die Inferenz aus. Sie übergeben die Ein- und Ausgabepuffer und LiteRT übernimmt die komplexe Aufgabe, das Modell auf dem ausgewählten Hardwarebeschleuniger auszuführen.
6. Erste Implementierung von ImageSegmentationHelper abschließen
Jetzt ist es an der Zeit, etwas Code zu schreiben. Sie führen die Erstimplementierung von ImageSegmentationHelper.kt durch. Dazu müssen Sie die private Klasse Segmenter einrichten, um das LiteRT-Modell zu speichern, und die Funktion cleanup() implementieren, um es ordnungsgemäß freizugeben.
Segmenter-Klasse undcleanup()-Funktion fertigstellen: In der DateiImageSegmentationHelper.ktfinden Sie ein Gerüst für eine private Klasse namensSegmenterund eine Funktion namenscleanup(). Vervollständigen Sie zuerst die KlasseSegmenter, indem Sie ihren Konstruktor zum Speichern des Modells definieren, Attribute für die Ein-/Ausgabepuffer erstellen und eineclose()-Methode zum Freigeben des Modells hinzufügen. Implementieren Sie dann die Funktioncleanup(), um diese neueclose()-Methode aufzurufen.Ersetzen Sie die vorhandeneSegmenter-Klasse und die Funktioncleanup()durch Folgendes: (~Zeile 83)private class Segmenter( // Add this argument private val model: CompiledModel, private val coloredLabels: List<ColoredLabel>, ) { // Add these private vals private val inputBuffers = model.createInputBuffers() private val outputBuffers = model.createOutputBuffers() fun cleanup() { // cleanup buffers inputBuffers.forEach { it.close() } outputBuffers.forEach { it.close() } // cleanup model model.close() } }- toAccelerator-Methode definieren: Diese Methode ordnet die definierten Beschleuniger-Enums aus dem Beschleunigermenü den Beschleuniger-Enums zu, die für die importierten LiteRT-Module spezifisch sind (~Zeile 225):
fun toAccelerator(acceleratorEnum: AcceleratorEnum): Accelerator { return when (acceleratorEnum) { AcceleratorEnum.CPU -> Accelerator.CPU AcceleratorEnum.GPU -> Accelerator.GPU } } CompiledModelinitialisieren: Suchen Sie nun die FunktioninitSegmenter. Hier erstellen Sie dieCompiledModel-Instanz und verwenden sie, um die jetzt definierteSegmenter-Klasse zu instanziieren. Mit diesem Code wird das Modell mit dem angegebenen Beschleuniger (CPU oder GPU) eingerichtet und für die Inferenz vorbereitet. Ersetzen SieTODOininitSegmenterdurch die folgende Implementierung (Cmd/Strg+f „initSegmenter“ oder Zeile 62):cleanup() try { withContext(singleThreadDispatcher) { val model = CompiledModel.create( context.assets, "selfie_multiclass.tflite", CompiledModel.Options(toAccelerator(acceleratorEnum)), null, ) segmenter = Segmenter(model, coloredLabels) Log.d(TAG, "Created an image segmenter") } } catch (e: Exception) { Log.i(TAG, "Create LiteRT from selfie_multiclass is failed: ${e.message}") _error.emit(e) }
7. Segmentierung und Vorverarbeitung starten
Nachdem wir ein Modell haben, müssen wir den Segmentierungsprozess auslösen und die Eingabedaten für das Modell vorbereiten.
Trigger-Segmentierung
Die Segmentierung beginnt in MainViewModel.kt, das Frames von der Kamera empfängt.
MainViewModel.kt öffnen
- Segmentierung über Kamera-Frames auslösen: Die
segment-Funktionen inMainViewModelsind der Einstiegspunkt für unsere Segmentierungsaufgabe. Sie werden aufgerufen, wenn ein neues Bild von der Kamera verfügbar ist oder aus der Galerie ausgewählt wird. Diese Funktionen rufen dann die Methodesegmentin unseremImageSegmentationHelperauf. Ersetzen Sie dieTODOs in beidensegment-Funktionen durch Folgendes (Zeile ~107):// For ImageProxy (from CameraX) fun segment(imageProxy: ImageProxy) { segmentJob = viewModelScope.launch { imageSegmentationHelper.segment(imageProxy.toBitmap(), imageProxy.imageInfo.rotationDegrees) imageProxy.close() } } // For Bitmaps (from gallery) fun segment(bitmap: Bitmap, rotationDegrees: Int) { segmentJob = viewModelScope.launch { val argbBitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true) imageSegmentationHelper.segment(argbBitmap, rotationDegrees) } }
Bild vorverarbeiten
Kehren wir nun zu ImageSegmentationHelper.kt zurück, um die Bildvorverarbeitung zu übernehmen.
ImageSegmentationHelper.kt öffnen
- Implementieren Sie die öffentliche
segment-Funktion: Diese Funktion dient als Wrapper, der die privatesegment-Funktion in derSegmenter-Klasse aufruft. Ersetzen SieTODOdurch (~Zeile 95):try { withContext(singleThreadDispatcher) { segmenter?.segment(bitmap, rotationDegrees)?.let { if (isActive) _segmentation.emit(it) } } } catch (e: Exception) { Log.i(TAG, "Image segment error occurred: ${e.message}") _error.emit(e) } - Vorverarbeitung implementieren: In der privaten Funktion
segmentin der KlasseSegmenterführen wir die erforderlichen Transformationen für das Eingabebild durch, um es für das Modell vorzubereiten. Dazu gehören das Skalieren, Drehen und Normalisieren des Bildes. Diese Funktion ruft dann eine weitere privatesegment-Funktion auf, um die Inferenz durchzuführen. Ersetzen SieTODOin der Funktionsegment(bitmap: Bitmap, ...)durch (~Zeile 121):val totalStartTime = SystemClock.uptimeMillis() val rotation = -rotationDegrees / 90 val (h, w) = Pair(256, 256) // Preprocessing val preprocessStartTime = SystemClock.uptimeMillis() var image = bitmap.scale(w, h, true) image = rot90Clockwise(image, rotation) val inputFloatArray = normalize(image, 127.5f, 127.5f) Log.d(TAG, "Preprocessing time: ${SystemClock.uptimeMillis() - preprocessStartTime} ms") // Inference val inferenceStartTime = SystemClock.uptimeMillis() val segmentResult = segment(inputFloatArray) Log.d(TAG, "Inference time: ${SystemClock.uptimeMillis() - inferenceStartTime} ms") Log.d(TAG, "Total segmentation time: ${SystemClock.uptimeMillis() - totalStartTime} ms") return SegmentationResult(segmentResult, SystemClock.uptimeMillis() - inferenceStartTime)
8. Primäre Inferenz mit LiteRT
Nachdem die Eingabedaten vorverarbeitet wurden, können wir jetzt die Kerninferenz mit LiteRT ausführen.
ImageSegmentationHelper.kt öffnen
- Modellausführung implementieren: In der privaten Funktion
segment(inputFloatArray: FloatArray)interagieren wir direkt mit der LiteRT-Methoderun(). Wir schreiben unsere vorverarbeiteten Daten in den Eingabepuffer, führen das Modell aus und lesen die Ergebnisse aus dem Ausgabepuffer. Ersetzen SieTODOin dieser Funktion durch (~Zeile 188):val (h, w, c) = Triple(256, 256, 6) // MODEL EXECUTION PHASE val modelExecStartTime = SystemClock.uptimeMillis() // Write input data - measure time val bufferWriteStartTime = SystemClock.uptimeMillis() inputBuffers[0].writeFloat(inputFloatArray) val bufferWriteTime = SystemClock.uptimeMillis() - bufferWriteStartTime Log.d(TAG, "Buffer write time: $bufferWriteTime ms") // Optional tensor inspection logTensorStats("Input tensor", inputFloatArray) // Run model inference - measure time val modelRunStartTime = SystemClock.uptimeMillis() model.run(inputBuffers, outputBuffers) val modelRunTime = SystemClock.uptimeMillis() - modelRunStartTime Log.d(TAG, "Model.run() time: $modelRunTime ms") // Read output data - measure time val bufferReadStartTime = SystemClock.uptimeMillis() val outputFloatArray = outputBuffers[0].readFloat() val outputBuffer = FloatBuffer.wrap(outputFloatArray) val bufferReadTime = SystemClock.uptimeMillis() - bufferReadStartTime Log.d(TAG, "Buffer read time: $bufferReadTime ms") val modelExecTime = SystemClock.uptimeMillis() - modelExecStartTime Log.d(TAG, "Total model execution time: $modelExecTime ms") // Optional tensor inspection logTensorStats("Output tensor", outputFloatArray) // POSTPROCESSING PHASE val postprocessStartTime = SystemClock.uptimeMillis() // Process mask from model output val inferenceData = InferenceData(width = w, height = h, channels = c, buffer = outputBuffer) val mask = processImage(inferenceData) val postprocessTime = SystemClock.uptimeMillis() - postprocessStartTime Log.d(TAG, "Postprocessing time (mask creation): $postprocessTime ms") return Segmentation( listOf(Mask(mask, inferenceData.width, inferenceData.height)), coloredLabels, )
9. Nachbearbeitung und Anzeige des Overlays
Nach der Ausführung der Inferenz erhalten wir eine Rohausgabe vom Modell. Wir müssen diese Ausgabe verarbeiten, um eine visuelle Segmentierungsmaske zu erstellen und sie dann auf dem Bildschirm anzuzeigen.
ImageSegmentationHelper.kt öffnen
- Ausgabeverarbeitung implementieren: Die Funktion
processImagekonvertiert die Rohausgabe des Modells in Gleitkommazahlen in einByteBuffer, das die Segmentierungsmaske darstellt. Dazu wird für jedes Pixel die Klasse mit der höchsten Wahrscheinlichkeit ermittelt. Ersetzen SieTODOdurch (~Zeile 238):val mask = ByteBuffer.allocateDirect(inferenceData.width * inferenceData.height) for (i in 0 until inferenceData.height) { for (j in 0 until inferenceData.width) { val offset = inferenceData.channels * (i * inferenceData.width + j) var maxIndex = 0 var maxValue = inferenceData.buffer.get(offset) for (index in 1 until inferenceData.channels) { if (inferenceData.buffer.get(offset + index) > maxValue) { maxValue = inferenceData.buffer.get(offset + index) maxIndex = index } } mask.put(i * inferenceData.width + j, maxIndex.toByte()) } } return mask
MainViewModel.kt öffnen
- Segmentierungsergebnisse erfassen und verarbeiten: Jetzt kehren wir zur
MainViewModelzurück, um die Segmentierungsergebnisse aus derImageSegmentationHelperzu verarbeiten. DersegmentationUiShareFlowerfasst dieSegmentationResult, wandelt die Maske in ein farbigesBitmapum und stellt sie der Benutzeroberfläche zur Verfügung. Ersetzen SieTODOin dersegmentationUiShareFlow-Eigenschaft durch (~Zeile 63). Ersetzen Sie nicht den bereits vorhandenen Code, sondern füllen Sie nur den Textkörper aus:viewModelScope.launch { imageSegmentationHelper.segmentation .filter { it.segmentation.masks.isNotEmpty() } .map { val segmentation = it.segmentation val mask = segmentation.masks[0] val maskArray = mask.data val width = mask.width val height = mask.height val pixelSize = width * height val pixels = IntArray(pixelSize) val colorLabels = segmentation.coloredLabels.mapIndexed { index, coloredLabel -> ColorLabel(index, coloredLabel.label, coloredLabel.argb) } // Set color for pixels for (i in 0 until pixelSize) { val colorLabel = colorLabels[maskArray[i].toInt()] val color = colorLabel.getColor() pixels[i] = color } // Get image info val overlayInfo = OverlayInfo(pixels = pixels, width = width, height = height) val inferenceTime = it.inferenceTime Pair(overlayInfo, inferenceTime) } .collect { flow.emit(it) } }
view/SegmentationOverlay.kt öffnen
Schließlich muss das Segmentierungs-Overlay richtig ausgerichtet werden, wenn der Nutzer zur Frontkamera wechselt. Das Kamerabild wird für die Frontkamera gespiegelt. Daher müssen wir das Overlay Bitmap horizontal spiegeln, damit es richtig mit der Kameravorschau übereinstimmt.
- Handle Overlay Orientation (Overlay-Ausrichtung verarbeiten): Suchen Sie in der Datei
SegmentationOverlay.ktnachTODOund ersetzen Sie den Ausdruck durch den folgenden Code. Dieser Code prüft, ob die Frontkamera aktiv ist. Wenn ja, wird das OverlayBitmaphorizontal gespiegelt, bevor es auf demCanvasgezeichnet wird. (~Zeile 42):val orientedBitmap = if (lensFacing == CameraSelector.LENS_FACING_FRONT) { // Create a matrix for horizontal flipping val matrix = Matrix().apply { preScale(-1f, 1f) } Bitmap.createBitmap(image, 0, 0, image.width, image.height, matrix, false).also { image.recycle() } } else { image }
10. Finale App ausführen und verwenden
Sie haben jetzt alle erforderlichen Codeänderungen vorgenommen. Jetzt ist es an der Zeit, die App auszuführen und sich das Ergebnis anzusehen.
- App ausführen: Verbinden Sie Ihr Android-Gerät und klicken Sie in der Android Studio-Symbolleiste auf Ausführen.
- Funktionen testen: Nach dem Start der App sollte der Live-Kamerafeed mit einem farbigen Segmentierungs-Overlay angezeigt werden.
- Kameras wechseln: Tippen Sie oben auf das Symbol zum Wechseln der Kamera, um zwischen der Front- und der Rückkamera zu wechseln. Das Overlay wird richtig ausgerichtet.
- Beschleuniger ändern: Tippen Sie unten auf die Schaltfläche „CPU“ oder „GPU“, um den Hardwarebeschleuniger zu wechseln. Beachten Sie die Änderung der Inference Time (Schlussfolgerungszeit), die unten auf dem Bildschirm angezeigt wird. Die GPU sollte deutlich schneller sein.
- Galeriebild verwenden: Tippen Sie oben auf den Tab „Galerie“, um ein Bild aus der Fotogalerie Ihres Geräts auszuwählen. Die App führt die Segmentierung für das ausgewählte statische Bild aus.

Sie haben jetzt eine voll funktionsfähige Echtzeit-Bildsegmentierungs-App, die auf LiteRT basiert.
11. Erweitert (optional): NPU verwenden
Dieses Repository enthält auch eine Version der App, die für Neural Processing Units (NPUs) optimiert ist. Die NPU-Version kann auf Geräten mit einer kompatiblen NPU eine erhebliche Leistungssteigerung ermöglichen.
Wenn Sie die NPU-Version ausprobieren möchten, öffnen Sie das kotlin_npu/android-Projekt in Android Studio. Der Code ist der CPU-/GPU-Version sehr ähnlich und für die Verwendung des NPU-Delegaten konfiguriert.
Wenn Sie den NPU-Delegate verwenden möchten, müssen Sie sich für das Early-Access-Programm registrieren.
12. Glückwunsch!
Sie haben erfolgreich eine Android-App entwickelt, die mit LiteRT eine Echtzeit-Bildsegmentierung durchführt. Sie haben Folgendes gelernt:
- LiteRT-Laufzeit in eine Android-App einbinden
- TFLite-Modell für die Bildsegmentierung laden und ausführen
- Verarbeiten Sie die Eingabe des Modells vor.
- Verarbeiten Sie die Ausgabe des Modells, um eine Segmentierungsmaske zu erstellen.
- Verwenden Sie CameraX für eine Echtzeit-Kamera-App.
Nächste Schritte
- Versuchen Sie es mit einem anderen Bildsegmentierungsmodell.
- Mit verschiedenen LiteRT-Delegaten (CPU, GPU, NPU) experimentieren.