
1. قبل البدء
كتابة الرموز البرمجية هي طريقة رائعة لتعزيز الذاكرة العضلية وتعميق فهمك للمادة. على الرغم من أنّ عملية النسخ واللصق يمكن أن توفّر الوقت، إلا أنّ الاستثمار في هذه الممارسة يمكن أن يؤدي إلى زيادة الكفاءة وتعزيز مهارات الترميز على المدى الطويل.
في هذا الدرس العملي، ستتعرّف على كيفية إنشاء تطبيق Android ينفّذ تقسيم الصور في الوقت الفعلي على خلاصة كاميرا مباشرة باستخدام وقت التشغيل الجديد من Google لـ TensorFlow Lite، وهو LiteRT. ستستخدم تطبيق Android أوليًا وتضيف إليه إمكانات تقسيم الصور. سنتناول أيضًا خطوات المعالجة المسبقة والاستدلال والمعالجة اللاحقة. عليك إجراء ما يلي:
- إنشاء تطبيق Android يقسّم الصور في الوقت الفعلي
- دمج نموذج LiteRT مُدرَّب مسبقًا لتقسيم الصور
- معالجة صورة الإدخال مسبقًا للنموذج
- استخدِم بيئة التشغيل LiteRT لتسريع وحدة المعالجة المركزية ووحدة معالجة الرسومات.
- تعرَّف على كيفية معالجة نتائج النموذج لعرض قناع التقسيم الدلالي.
- تعرَّف على كيفية ضبط الكاميرا الأمامية.
في النهاية، ستنشئ شيئًا مشابهًا للصورة أدناه:

المتطلبات الأساسية
تم تصميم هذا الدرس التطبيقي حول الترميز للمطوّرين المتمرّسين في تطوير تطبيقات الأجهزة الجوّالة الذين يريدون اكتساب خبرة في تعلُّم الآلة. يجب أن تكون على دراية بما يلي:
- تطوير تطبيقات Android باستخدام Kotlin و"استوديو Android"
- المفاهيم الأساسية لمعالجة الصور
ما ستتعلمه
- كيفية دمج واستخدام وقت تشغيل LiteRT في تطبيق Android
- كيفية تنفيذ تقسيم الصور باستخدام نموذج LiteRT مُدرَّب مسبقًا
- كيفية المعالجة المسبقة لصورة الإدخال للنموذج
- كيفية تنفيذ الاستدلال للنموذج
- كيفية معالجة ناتج نموذج تقسيم البيانات لعرض النتائج
- كيفية استخدام CameraX لمعالجة خلاصة الكاميرا في الوقت الفعلي
المتطلبات
- إصدار حديث من "استوديو Android" (تم اختباره على الإصدار 2025.1.1)
- جهاز Android فعلي من الأفضل اختبارها على أجهزة Galaxy وPixel.
- التعليمات البرمجية النموذجية (من GitHub)
- معرفة أساسية بتطوير تطبيقات Android باستخدام لغة Kotlin
2. تقسيم الصور
تقسيم الصور هو مهمة متعلقة برؤية الكمبيوتر تتضمّن تقسيم الصورة إلى عدّة أجزاء أو مناطق. على عكس رصد العناصر الذي يرسم مربّعًا محيطًا حول أحد العناصر، يحدّد تقسيم الصور فئة أو تصنيفًا معيّنًا لكل بكسل في الصورة. يوفّر ذلك فهمًا أكثر تفصيلاً ودقة لمحتوى الصورة، ما يتيح لك معرفة الشكل والحدود الدقيقة لكل عنصر.
على سبيل المثال، بدلاً من معرفة أنّ هناك "شخصًا" في مربّع، يمكنك معرفة وحدات البكسل التي تخصّ هذا الشخص تحديدًا. يوضّح هذا البرنامج التعليمي كيفية إجراء تقسيم الصور في الوقت الفعلي على جهاز Android باستخدام نموذج تعلُّم آلي مُدرَّب مسبقًا.

LiteRT: تعزيز إمكانات تعلُّم الآلة على الجهاز
LiteRT هي إحدى التقنيات الرئيسية التي تتيح تقسيم الصور بدقة عالية وفي الوقت الفعلي على الأجهزة الجوّالة. LiteRT هو وقت تشغيل عالي الأداء من الجيل التالي من Google لـ TensorFlow Lite، وهو مصمّم لتحقيق أفضل أداء ممكن من الأجهزة الأساسية.
ويتم تحقيق ذلك من خلال الاستخدام الذكي والمحسّن لمسرّعات الأجهزة، مثل وحدة معالجة الرسومات (GPU) ووحدة المعالجة العصبية (NPU). من خلال نقل عبء العمل الحسابي المكثّف لنموذج التقسيم من وحدة المعالجة المركزية للأغراض العامة إلى هذه المعالِجات المتخصّصة، يقلّل LiteRT بشكل كبير من وقت الاستدلال. هذا التسريع هو ما يتيح تشغيل النماذج المعقّدة بسلاسة على خلاصة الكاميرا المباشرة، ما يوسّع حدود ما يمكننا تحقيقه باستخدام تعلُّم الآلة مباشرةً على هاتفك. وبدون هذا المستوى من الأداء، سيكون تقسيم المحتوى في الوقت الفعلي بطيئًا جدًا ومتقطعًا، ما يؤدي إلى تجربة مستخدم سيئة.
3. طريقة الإعداد
إنشاء نسخة طبق الأصل من المستودع
أولاً، أنشئ نسخة طبق الأصل من مستودع LiteRT:
git clone https://github.com/google-ai-edge/litert-samples.git
litert-samples/compiled_model_api/image_segmentation هو الدليل الذي يتضمّن جميع الموارد التي ستحتاج إليها. في هذا الدرس التطبيقي، لن تحتاج إلا إلى مشروع kotlin_cpu_gpu/android_starter. يمكنك مراجعة المشروع المكتمل إذا واجهتك مشكلة: kotlin_cpu_gpu/android
ملاحظة حول مسارات الملفات
يحدّد هذا الدليل التوجيهي مسارات الملفات بتنسيق Linux/macOS. إذا كنت تستخدم نظام التشغيل Windows، عليك تعديل المسارات وفقًا لذلك.
من المهم أيضًا ملاحظة الفرق بين طريقة عرض المشروع في "استوديو Android" وطريقة عرض نظام الملفات العادية. طريقة عرض المشروع في "استوديو Android" هي تمثيل منظَّم لملفات مشروعك، ويتم ترتيبها لتطوير تطبيقات Android. تشير مسارات الملفات في هذا البرنامج التعليمي إلى مسارات نظام الملفات، وليس إلى المسارات في طريقة عرض المشروع في "استوديو Android".
استيراد تطبيق البداية
لنبدأ باستيراد تطبيق البداية إلى Android Studio.
- افتح "استوديو Android" وانقر على فتح.
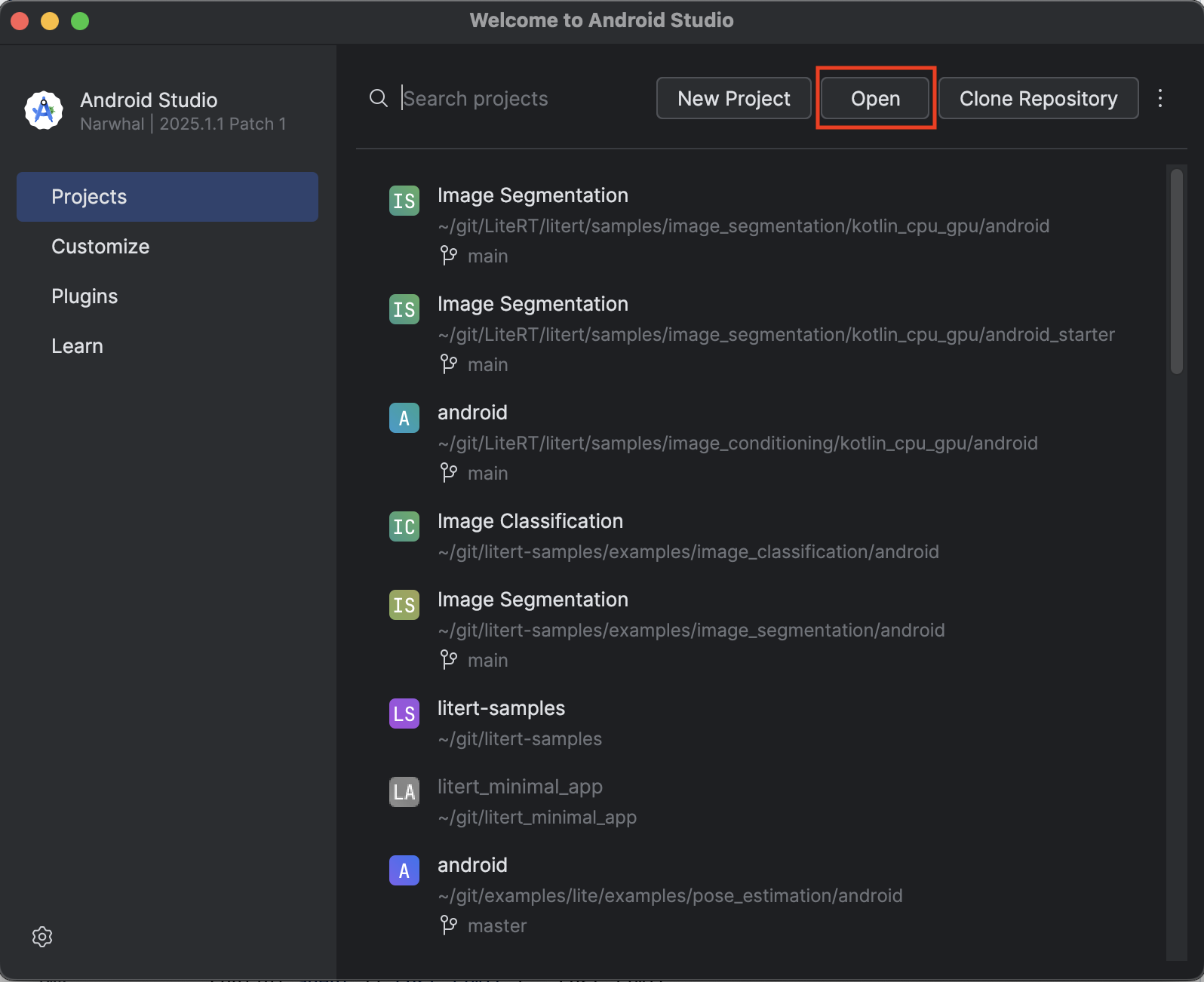
- انتقِل إلى الدليل
kotlin_cpu_gpu/android_starterوافتحه.
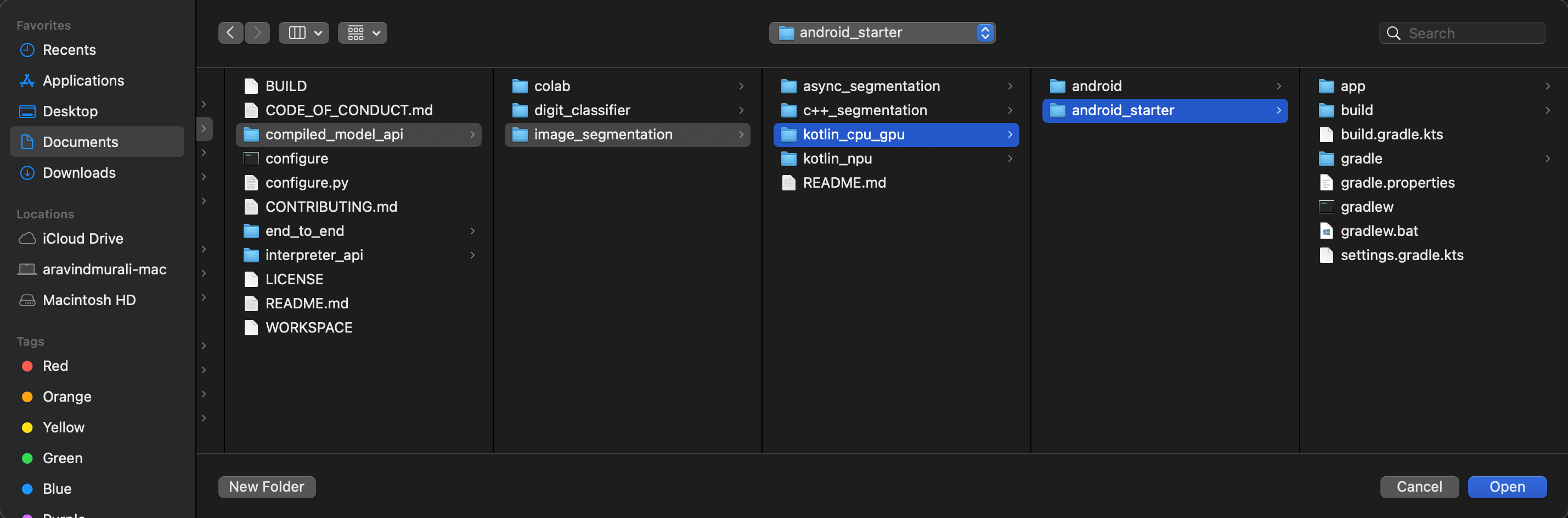
للتأكّد من توفّر جميع العناصر التابعة لتطبيقك، عليك مزامنة مشروعك مع ملفات Gradle عند انتهاء عملية الاستيراد.
- انقر على مزامنة المشروع مع ملفات Gradle من شريط أدوات "استوديو Android".
- يُرجى عدم تخطّي هذه الخطوة، لأنّ بقية البرنامج التعليمي لن تكون مفهومة إذا لم تنجح هذه الخطوة.
تشغيل تطبيق المبتدئين
بعد استيراد المشروع إلى "استوديو Android"، يمكنك الآن تشغيل التطبيق للمرة الأولى.
وصِّل جهاز Android بالكمبيوتر باستخدام كابل USB وانقر على تشغيل في شريط أدوات Android Studio.
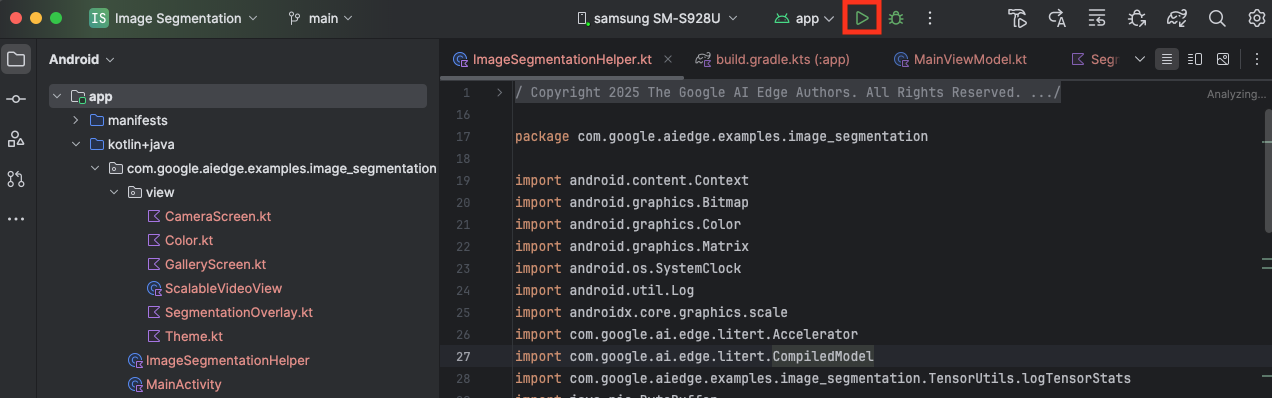
من المفترض أن يتم تشغيل التطبيق على جهازك. ستظهر لك خلاصة مباشرة من الكاميرا، ولكن لن يتم تقسيم الصورة بعد. ستكون جميع تعديلات الملفات التي ستجريها في هذا البرنامج التعليمي ضمن الدليل litert-samples/compiled_model_api/image_segmentation/kotlin_cpu_gpu/android_starter/app/src/main/java/com/google/ai/edge/examples/image_segmentation (أنت تعرف الآن سبب إعادة "استوديو Android" هيكلة هذا الدليل 😃).
ستظهر لك أيضًا تعليقات TODO في ملفات ImageSegmentationHelper.kt وMainViewModel.kt وview/SegmentationOverlay.kt. في الخطوات التالية، ستنفّذ وظيفة تقسيم الصور عن طريق ملء TODOs هذه.
4. التعرّف على التطبيق التجريبي
يحتوي تطبيق البداية على واجهة مستخدم أساسية ومنطق معالجة الكاميرا. في ما يلي نظرة عامة سريعة على الملفات الرئيسية:
-
app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainActivity.kt: هذه هي نقطة الدخول الرئيسية للتطبيق. ويعمل على إعداد واجهة المستخدم باستخدام Jetpack Compose ويتعامل مع أذونات الكاميرا. -
app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainViewModel.kt: تدير هذه الفئة ViewModel حالة واجهة المستخدم وتنسّق عملية تقسيم الصور. app/src/main/java/com/google/ai/edge/examples/image_segmentation/ImageSegmentationHelper.kt: هنا سنضيف المنطق الأساسي لتقسيم الصور. سيتولّى هذا الرمز تحميل النموذج ومعالجة لقطات الكاميرا وتنفيذ الاستدلال.-
app/src/main/java/com/google/ai/edge/examples/image_segmentation/view/CameraScreen.kt: تعرض هذه الدالة القابلة للإنشاء معاينة الكاميرا وتراكب التقسيم. app/download_model.gradle: ينزّل هذا النص البرمجيselfie_multiclass.tflite. هذا هو نموذج تقسيم الصور TensorFlow Lite المُدرَّب مسبقًا الذي سنستخدمه.
5. التعرّف على LiteRT وإضافة التبعيات
لنبدأ الآن بإضافة وظيفة تقسيم الصور إلى تطبيق المبتدئين.
1. إضافة تبعية LiteRT
عليك أولاً إضافة مكتبة LiteRT إلى مشروعك. هذه هي الخطوة الأولى المهمة لتفعيل ميزة "تعلُّم الآلة على الجهاز" باستخدام وقت التشغيل المحسّن من Google.
افتح ملف app/build.gradle.kts وأضِف السطر التالي إلى كتلة dependencies:
// LiteRT for on-device ML
implementation(libs.litert)
بعد إضافة التبعية، زامِن مشروعك مع ملفات Gradle من خلال النقر على الزر مزامنة الآن الذي يظهر في أعلى يسار "استوديو Android".

2. التعرّف على واجهات برمجة التطبيقات الرئيسية في LiteRT
فتح ImageSegmentationHelper.kt
قبل كتابة رمز التنفيذ، من المهم فهم المكوّنات الأساسية لواجهة برمجة التطبيقات LiteRT التي ستستخدمها. تأكَّد من أنّك تستورد من الحزمة com.google.ai.edge.litert، وأضِف عمليات الاستيراد التالية إلى أعلى ImageSegmentationHelper.kt:
import com.google.ai.edge.litert.Accelerator
import com.google.ai.edge.litert.CompiledModel
-
CompiledModel: هذه هي الفئة المركزية للتفاعل مع نموذج TFLite. يمثّل هذا النوع نموذجًا تم تجميعه مسبقًا وتحسينه ليتوافق مع مسرِّع أجهزة معيّن (مثل وحدة المعالجة المركزية أو وحدة معالجة الرسومات). وتُعد عملية التجميع المُسبَق هذه إحدى الميزات الرئيسية في LiteRT التي تؤدي إلى استنتاج أسرع وأكثر كفاءة. CompiledModel.Options: يمكنك استخدام فئة أداة الإنشاء هذه لإعدادCompiledModel. أهم إعداد هو تحديد أداة تسريع الأجهزة التي تريد استخدامها لتشغيل النموذج.-
Accelerator: يتيح لك هذا النوع من التعداد اختيار الجهاز للاستدلال. تمّ إعداد المشروع المبدئي مسبقًا للتعامل مع الخيارات التالية:-
Accelerator.CPU: لتشغيل النموذج على وحدة المعالجة المركزية (CPU) للجهاز هذا هو الخيار الأكثر توافقًا مع جميع الأجهزة. -
Accelerator.GPU: لتشغيل النموذج على وحدة معالجة الرسومات (GPU) في الجهاز ويكون ذلك غالبًا أسرع بكثير من وحدة المعالجة المركزية بالنسبة إلى النماذج المستندة إلى الصور.
-
- مخازن الإدخال والإخراج المؤقتة (
TensorBuffer): تستخدم LiteRTTensorBufferلإدخال النماذج وإخراجها. يتيح لك ذلك التحكّم بشكل دقيق في الذاكرة وتجنُّب نُسخ البيانات غير الضرورية. ستحصل على هذه المخازن المؤقتة مباشرةً من مثيلCompiledModelباستخدامmodel.createInputBuffers()وmodel.createOutputBuffers()، ثم ستكتب بيانات الإدخال فيها وتقرأ النتائج منها. -
model.run(): هذه هي الدالة التي تنفّذ الاستنتاج. يمكنك تمرير مخزّنَي الإدخال والإخراج المؤقتَين إليه، ويتولّى LiteRT المهمة المعقّدة المتمثّلة في تشغيل النموذج على أداة تسريع الأجهزة المحدّدة.
6. إكمال عملية التنفيذ الأولية لـ ImageSegmentationHelper
حان الوقت الآن لكتابة بعض التعليمات البرمجية. ستكمل عملية التنفيذ الأوّلي لـ ImageSegmentationHelper.kt. يتضمّن ذلك إعداد الفئة الخاصة Segmenter لاحتواء نموذج LiteRT وتنفيذ الدالة cleanup() لإصداره بشكلٍ صحيح.
- إنهاء الفئة
Segmenterوالدالةcleanup(): في ملفImageSegmentationHelper.kt، ستجد هيكلاً لفئة خاصة باسمSegmenterودالة باسمcleanup(). أولاً، أكمل فئةSegmenterمن خلال تحديد الدالة الإنشائية الخاصة بها لاحتواء النموذج، وإنشاء خصائص لمخازن الإدخال/الإخراج المؤقتة، وإضافة طريقةclose()لإصدار النموذج. بعد ذلك، نفِّذ الدالةcleanup()لاستدعاء طريقةclose()الجديدة هذه.استبدِل الفئةSegmenterوالدالةcleanup()الحالية بما يلي: (~line 83)private class Segmenter( // Add this argument private val model: CompiledModel, private val coloredLabels: List<ColoredLabel>, ) { // Add these private vals private val inputBuffers = model.createInputBuffers() private val outputBuffers = model.createOutputBuffers() fun cleanup() { // cleanup buffers inputBuffers.forEach { it.close() } outputBuffers.forEach { it.close() } // cleanup model model.close() } } - تحديد طريقة toAccelerator: تربط هذه الطريقة تعدادات المسرّعات المحدّدة من قائمة المسرّعات بتعدادات المسرّعات الخاصة بوحدات LiteRT التي تم استيرادها (حوالي السطر 225):
fun toAccelerator(acceleratorEnum: AcceleratorEnum): Accelerator { return when (acceleratorEnum) { AcceleratorEnum.CPU -> Accelerator.CPU AcceleratorEnum.GPU -> Accelerator.GPU } } - بدء
CompiledModel: ابحث الآن عن الدالةinitSegmenter. هذا هو المكان الذي ستنشئ فيه مثيلCompiledModelوتستخدمه لإنشاء مثيل لفئةSegmenterالتي تم تحديدها الآن. يُعدّ هذا الرمز النموذج باستخدام أداة التسريع المحدّدة (وحدة المعالجة المركزية أو وحدة معالجة الرسومات) ويجهّزه للاستدلال. استبدِلTODOفيinitSegmenterبالتنفيذ التالي (Cmd/Ctrl+f `initSegmenter` أو السطر 62 تقريبًا):cleanup() try { withContext(singleThreadDispatcher) { val model = CompiledModel.create( context.assets, "selfie_multiclass.tflite", CompiledModel.Options(toAccelerator(acceleratorEnum)), null, ) segmenter = Segmenter(model, coloredLabels) Log.d(TAG, "Created an image segmenter") } } catch (e: Exception) { Log.i(TAG, "Create LiteRT from selfie_multiclass is failed: ${e.message}") _error.emit(e) }
7. بدء التقسيم المسبق والمعالجة المسبقة
بعد أن أصبح لدينا نموذج، علينا بدء عملية التقسيم وتجهيز البيانات المُدخَلة للنموذج.
تقسيم المشغّلات
تبدأ عملية التقسيم في MainViewModel.kt، الذي يتلقّى اللقطات من الكاميرا.
فتح MainViewModel.kt
- بدء تقسيم الصور من إطارات الكاميرا: تشكّل الدوال
segmentفيMainViewModelنقطة الدخول لمهمة تقسيم الصور. يتم استدعاؤها عندما تتوفّر صورة جديدة من الكاميرا أو يتم اختيارها من المعرض. تستدعي هذه الدوال بعد ذلك طريقةsegmentفيImageSegmentationHelper. استبدِلTODOفي كلتا الدالتَينsegmentبما يلي (السطر 107 تقريبًا):// For ImageProxy (from CameraX) fun segment(imageProxy: ImageProxy) { segmentJob = viewModelScope.launch { imageSegmentationHelper.segment(imageProxy.toBitmap(), imageProxy.imageInfo.rotationDegrees) imageProxy.close() } } // For Bitmaps (from gallery) fun segment(bitmap: Bitmap, rotationDegrees: Int) { segmentJob = viewModelScope.launch { val argbBitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true) imageSegmentationHelper.segment(argbBitmap, rotationDegrees) } }
المعالجة المُسبقة للصورة
لنرجع الآن إلى ImageSegmentationHelper.kt لمعالجة الصورة مسبقًا.
فتح ImageSegmentationHelper.kt
- تنفيذ الدالة Public
segment: تعمل هذه الدالة كبرنامج تضمين يستدعي الدالة الخاصةsegmentضمن الفئةSegmenter. استبدِلTODOبما يلي (~السطر 95):try { withContext(singleThreadDispatcher) { segmenter?.segment(bitmap, rotationDegrees)?.let { if (isActive) _segmentation.emit(it) } } } catch (e: Exception) { Log.i(TAG, "Image segment error occurred: ${e.message}") _error.emit(e) } - تنفيذ المعالجة المسبقة: الدالة الخاصة
segmentداخل الفئةSegmenterهي المكان الذي سنُجري فيه عمليات التحويل اللازمة على الصورة المدخلة لتجهيزها للنموذج. ويشمل ذلك تغيير حجم الصورة وتدويرها وتسويتها. ستستدعي هذه الدالة بعد ذلك دالةsegmentخاصة أخرى لإجراء الاستنتاج. استبدِلTODOفي الدالةsegment(bitmap: Bitmap, ...)بما يلي (~line 121):val totalStartTime = SystemClock.uptimeMillis() val rotation = -rotationDegrees / 90 val (h, w) = Pair(256, 256) // Preprocessing val preprocessStartTime = SystemClock.uptimeMillis() var image = bitmap.scale(w, h, true) image = rot90Clockwise(image, rotation) val inputFloatArray = normalize(image, 127.5f, 127.5f) Log.d(TAG, "Preprocessing time: ${SystemClock.uptimeMillis() - preprocessStartTime} ms") // Inference val inferenceStartTime = SystemClock.uptimeMillis() val segmentResult = segment(inputFloatArray) Log.d(TAG, "Inference time: ${SystemClock.uptimeMillis() - inferenceStartTime} ms") Log.d(TAG, "Total segmentation time: ${SystemClock.uptimeMillis() - totalStartTime} ms") return SegmentationResult(segmentResult, SystemClock.uptimeMillis() - inferenceStartTime)
8. الاستدلال الأساسي باستخدام LiteRT
بعد المعالجة المُسبقة لبيانات الإدخال، يمكننا الآن تشغيل الاستدلال الأساسي باستخدام LiteRT.
فتح ImageSegmentationHelper.kt
- تنفيذ النموذج: الدالة الخاصة
segment(inputFloatArray: FloatArray)هي المكان الذي نتفاعل فيه مباشرةً مع طريقةrun()في LiteRT. نكتب البيانات التي تمت معالجتها مسبقًا في مخزن الإدخال المؤقت، ونشغّل النموذج، ونقرأ النتائج من مخزن الإخراج المؤقت. استبدِلTODOفي هذه الدالة بما يلي (~السطر 188):val (h, w, c) = Triple(256, 256, 6) // MODEL EXECUTION PHASE val modelExecStartTime = SystemClock.uptimeMillis() // Write input data - measure time val bufferWriteStartTime = SystemClock.uptimeMillis() inputBuffers[0].writeFloat(inputFloatArray) val bufferWriteTime = SystemClock.uptimeMillis() - bufferWriteStartTime Log.d(TAG, "Buffer write time: $bufferWriteTime ms") // Optional tensor inspection logTensorStats("Input tensor", inputFloatArray) // Run model inference - measure time val modelRunStartTime = SystemClock.uptimeMillis() model.run(inputBuffers, outputBuffers) val modelRunTime = SystemClock.uptimeMillis() - modelRunStartTime Log.d(TAG, "Model.run() time: $modelRunTime ms") // Read output data - measure time val bufferReadStartTime = SystemClock.uptimeMillis() val outputFloatArray = outputBuffers[0].readFloat() val outputBuffer = FloatBuffer.wrap(outputFloatArray) val bufferReadTime = SystemClock.uptimeMillis() - bufferReadStartTime Log.d(TAG, "Buffer read time: $bufferReadTime ms") val modelExecTime = SystemClock.uptimeMillis() - modelExecStartTime Log.d(TAG, "Total model execution time: $modelExecTime ms") // Optional tensor inspection logTensorStats("Output tensor", outputFloatArray) // POSTPROCESSING PHASE val postprocessStartTime = SystemClock.uptimeMillis() // Process mask from model output val inferenceData = InferenceData(width = w, height = h, channels = c, buffer = outputBuffer) val mask = processImage(inferenceData) val postprocessTime = SystemClock.uptimeMillis() - postprocessStartTime Log.d(TAG, "Postprocessing time (mask creation): $postprocessTime ms") return Segmentation( listOf(Mask(mask, inferenceData.width, inferenceData.height)), coloredLabels, )
9- المعالجة اللاحقة وعرض التراكب
بعد تنفيذ الاستدلال، نحصل على ناتج أولي من النموذج. علينا معالجة هذه النتائج لإنشاء قناع تجزئة مرئي ثم عرضه على الشاشة.
فتح ImageSegmentationHelper.kt
- تنفيذ معالجة الإخراج: تحوّل الدالة
processImageالناتج الأولي للفاصلة العائمة من النموذج إلىByteBufferيمثّل قناع التقسيم. ويتم ذلك من خلال العثور على الفئة التي لديها أعلى احتمال لكل بكسل. استبدِلTODOبما يلي (~line 238):val mask = ByteBuffer.allocateDirect(inferenceData.width * inferenceData.height) for (i in 0 until inferenceData.height) { for (j in 0 until inferenceData.width) { val offset = inferenceData.channels * (i * inferenceData.width + j) var maxIndex = 0 var maxValue = inferenceData.buffer.get(offset) for (index in 1 until inferenceData.channels) { if (inferenceData.buffer.get(offset + index) > maxValue) { maxValue = inferenceData.buffer.get(offset + index) maxIndex = index } } mask.put(i * inferenceData.width + j, maxIndex.toByte()) } } return mask
فتح MainViewModel.kt
- جمع نتائج التقسيم ومعالجتها: نعود الآن إلى
MainViewModelلمعالجة نتائج التقسيم منImageSegmentationHelper. تجمعsegmentationUiShareFlowSegmentationResultوتحوّل القناع إلىBitmapملون، ثم توفّره لواجهة المستخدم. استبدِلTODOفي السمةsegmentationUiShareFlowبـ (~line 63)، ولا تستبدِل الرمز البرمجي المتوفّر، بل املأ النص فقط:viewModelScope.launch { imageSegmentationHelper.segmentation .filter { it.segmentation.masks.isNotEmpty() } .map { val segmentation = it.segmentation val mask = segmentation.masks[0] val maskArray = mask.data val width = mask.width val height = mask.height val pixelSize = width * height val pixels = IntArray(pixelSize) val colorLabels = segmentation.coloredLabels.mapIndexed { index, coloredLabel -> ColorLabel(index, coloredLabel.label, coloredLabel.argb) } // Set color for pixels for (i in 0 until pixelSize) { val colorLabel = colorLabels[maskArray[i].toInt()] val color = colorLabel.getColor() pixels[i] = color } // Get image info val overlayInfo = OverlayInfo(pixels = pixels, width = width, height = height) val inferenceTime = it.inferenceTime Pair(overlayInfo, inferenceTime) } .collect { flow.emit(it) } }
فتح view/SegmentationOverlay.kt
أما الخطوة الأخيرة، فهي توجيه طبقة التجزئة بشكل صحيح عندما ينتقل المستخدم إلى الكاميرا الأمامية. يتم عكس خلاصة الكاميرا تلقائيًا للكاميرا الأمامية، لذا علينا تطبيق عملية القلب الأفقي نفسها على التراكب Bitmap لضمان محاذاته بشكل صحيح مع معاينة الكاميرا.
- التعامل مع اتجاه التراكب: ابحث عن
TODOفي ملفSegmentationOverlay.ktواستبدِله بالرمز التالي. يتحقّق هذا الرمز مما إذا كانت الكاميرا الأمامية نشطة، وإذا كان الأمر كذلك، يتم تطبيق قلب أفقي على التراكبBitmapقبل رسمه علىCanvas. (~line 42):val orientedBitmap = if (lensFacing == CameraSelector.LENS_FACING_FRONT) { // Create a matrix for horizontal flipping val matrix = Matrix().apply { preScale(-1f, 1f) } Bitmap.createBitmap(image, 0, 0, image.width, image.height, matrix, false).also { image.recycle() } } else { image }
10. تشغيل التطبيق النهائي واستخدامه
لقد أكملت الآن جميع التغييرات اللازمة على الرموز البرمجية. حان الوقت لتشغيل التطبيق ومشاهدة عملك على أرض الواقع.
- تشغيل التطبيق: وصِّل جهاز Android وانقر على تشغيل في شريط أدوات "استوديو Android".
- اختبار الميزات: بعد تشغيل التطبيق، من المفترض أن يظهر لك بث مباشر من الكاميرا مع تراكب تجزئة ملوّن.
- تبديل الكاميرات: انقر على رمز قلب العدسة في أعلى الشاشة للتبديل بين الكاميرا الأمامية والكاميرا الخلفية. لاحظ كيف يتم توجيه التراكب بشكل صحيح.
- تغيير المسرِّع: انقر على الزر "وحدة المعالجة المركزية" أو "وحدة معالجة الرسومات" في أسفل الشاشة لتبديل مسرِّع الأجهزة. لاحظ التغيير في وقت الاستنتاج المعروض في أسفل الشاشة. يجب أن تكون وحدة معالجة الرسومات أسرع بكثير.
- استخدام صورة من "معرض الصور": انقر على علامة التبويب "معرض الصور" في أعلى الشاشة لاختيار صورة من معرض الصور في جهازك. سيُجري التطبيق عملية تقسيم على الصورة الثابتة المحدّدة.

أصبح لديك الآن تطبيق كامل الميزات لتصنيف الصور في الوقت الفعلي يستند إلى LiteRT.
11. الإعدادات المتقدّمة (اختيارية): استخدام وحدة المعالجة العصبية
يحتوي هذا المستودع أيضًا على إصدار من التطبيق تم تحسينه لوحدات المعالجة العصبية (NPU). يمكن أن يوفّر إصدار NPU تحسينًا كبيرًا في الأداء على الأجهزة التي تتضمّن وحدة معالجة عصبية متوافقة.
لتجربة إصدار NPU، افتح مشروع kotlin_npu/android في "استوديو Android". الرمز البرمجي مشابه جدًا لرمز وحدة المعالجة المركزية/وحدة معالجة الرسومات، وتم إعداده لاستخدام وكيل وحدة المعالجة العصبية.
لاستخدام مفوّض NPU، عليك التسجيل في برنامج استخدام المنتج قبل إطلاقه.
12. تهانينا!
لقد أنشأت بنجاح تطبيق Android يتيح تقسيم الصور في الوقت الفعلي باستخدام LiteRT. لقد تعلّمت كيفية:
- دمج وقت تشغيل LiteRT في تطبيق Android
- تحميل نموذج تقسيم الصور في TFLite وتشغيله
- معالجة مُدخلات النموذج مسبقًا
- معالجة ناتج النموذج لإنشاء قناع تقسيم دلالي
- استخدِم CameraX لإنشاء تطبيق كاميرا يعمل في الوقت الفعلي.
الخطوات التالية
- جرِّب نموذجًا مختلفًا لتقسيم الصور.
- جرِّب استخدام مفوّضين مختلفين في LiteRT (وحدة المعالجة المركزية ووحدة معالجة الرسومات ووحدة المعالجة العصبية).