
1. 事前準備
在本程式碼研究室中,您將瞭解如何更新從原始部落格垃圾內容留言資料集建構的文字分類模型,但會加入您自己的留言,以便建立適用於您資料的模型。
必要條件
這個程式碼研究室是「在 Flutter 應用程式中開始使用文字分類功能」學習路徑的一部分。本課程中的程式碼研究室是循序進行。您要使用的應用程式和模型應已在先前的程式碼研究室中建構完成。如果尚未完成先前的活動,請先停止並完成:
課程內容
- 如何更新在「使用 TensorFlow Lite Model Maker 訓練留言垃圾內容偵測模型」程式碼研究室中建構的文字分類模型。
- 如何自訂模型,封鎖應用程式中最常見的垃圾內容。
軟硬體需求
- 您在先前活動中觀察及建構的 Flutter 應用程式和垃圾內容篩選模型。
2. 提升文字分類效果
- 如要取得這個程式碼的程式碼,請複製這個存放區,然後從
tfserving-flutter/codelab2/finished資料夾載入應用程式。 - 啟動 TensorFlow Serving Docker 映像檔後,在您建構的應用程式中輸入
buy my book to learn online trading,然後按一下「gRPC」>「Classify」。
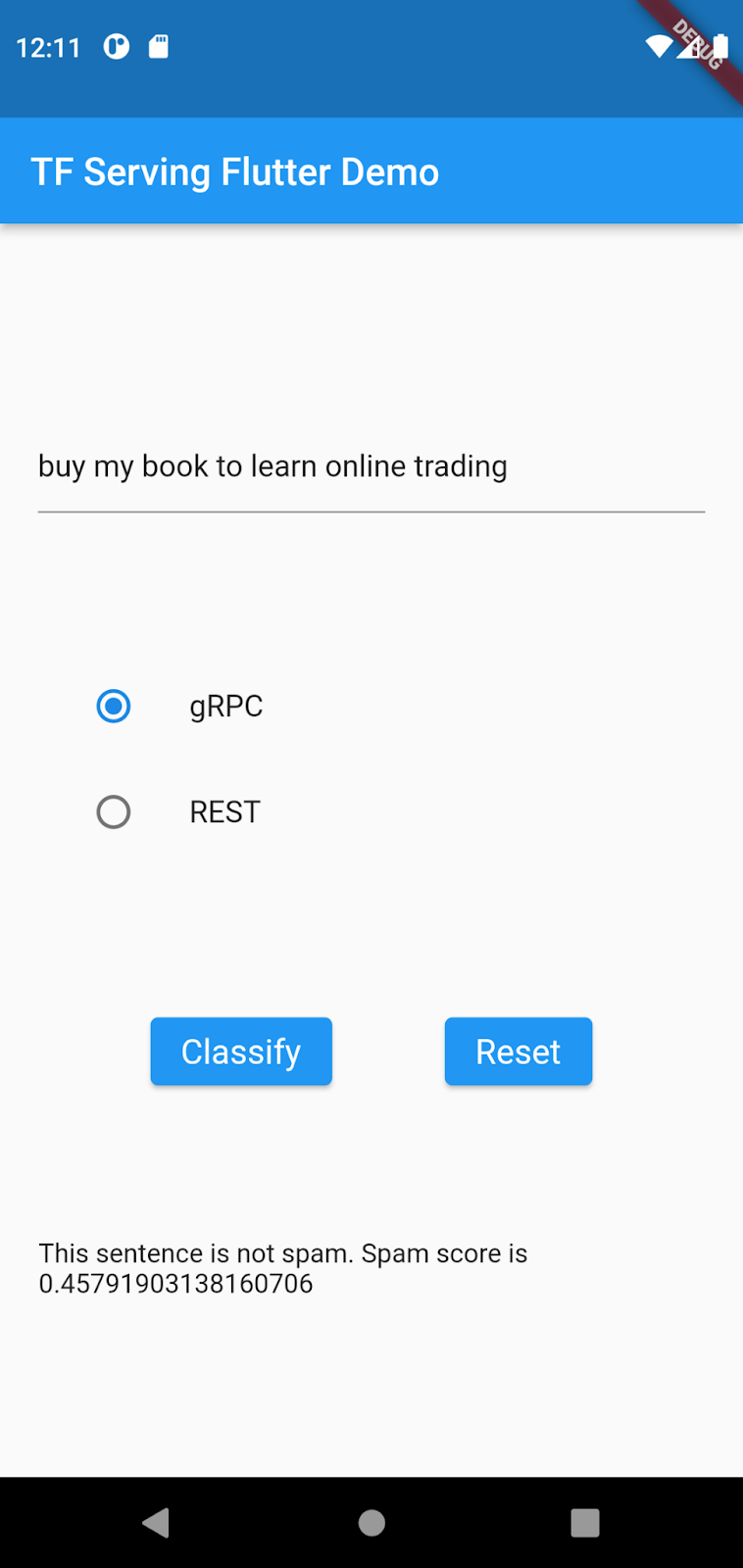
由於原始資料集中沒有太多線上交易的例子,模型尚未學會這是垃圾內容,因此應用程式產生的垃圾內容分數偏低。在本程式碼研究室中,您會使用新資料更新模型,讓模型將同一句話識別為垃圾內容!
3. 編輯 CSV 檔案
為訓練原始模型,我們建立了一個 CSV 格式的資料集 (lmblog_comments.csv),其中包含近千則留言,並標示為垃圾內容或非垃圾內容。(如要檢查 CSV 檔案,請在文字編輯器中開啟該檔案)。
CSV 檔案的第一列應說明資料欄,並標示為 commenttext 和 spam。後續每列都採用這個格式:

右側的標籤會分別指派垃圾內容的 true 值和非垃圾內容的 false 值。舉例來說,第三行會被視為垃圾內容。
如果有人在您的網站上發布有關線上交易的垃圾訊息,您可以在網站底部新增垃圾留言範例。例如:
online trading can be highly highly effective,true online trading can be highly effective,true online trading now,true online trading here,true online trading for the win,true
- 以新名稱儲存檔案,例如
lmblog_comments.csv,以便用於訓練新模型。
在本程式碼研究室的其餘部分,您將使用範例,並編輯範例,然後將範例託管在 Cloud Storage,並提供線上交易更新。如要使用自有資料集,可以變更程式碼中的網址。
4. 使用新資料重新訓練模型
如要重新訓練模型,只要重複使用 (SpamCommentsModelMaker.ipynb) 中的程式碼,但將其指向名為 lmblog_comments_extras.csv 的新 CSV 資料集即可。如要取得更新內容的完整記事本,請前往 SpamCommentsUpdateModelMaker.ipynb.
如果您有 Colaboratory 的存取權,可以直接啟動。否則,請從存放區取得程式碼,然後在所選的筆記本環境中執行。
更新後的程式碼片段如下所示:
training_data = tf.keras.utils.get_file(fname='comments-spam-extras.csv',
origin='https://storage.googleapis.com/laurencemoroney-blog.appspot.com/
lmblog_comments_extras.csv',
extract=False)
訓練時,您應該會發現模型仍可訓練至高準確率:

壓縮整個 /mm_update_spam_savedmodel 資料夾,然後下載產生的 mm_update_spam_savedmodel.zip 檔案。
# Rename the SavedModel subfolder to a version number
!mv /mm_update_spam_savedmodel/saved_model /mm_update_spam_savedmodel/123
!zip -r mm_update_spam_savedmodel.zip /mm_update_spam_savedmodel/
5. 啟動 Docker 並更新 Flutter 應用程式
- 將下載的
mm_update_spam_savedmodel.zip檔案解壓縮到資料夾中,然後停止上一個程式碼研究室的 Docker 容器執行個體,並重新啟動,但請將PATH/TO/UPDATE/SAVEDMODEL預留位置替換為下載檔案所在資料夾的絕對路徑:
docker run -it --rm -p 8500:8500 -p 8501:8501 -v "PATH/TO/UPDATE/SAVEDMODEL:/models/spam-detection" -e MODEL_NAME=spam-detection tensorflow/serving
- 使用慣用的程式碼編輯器開啟
lib/main.dart檔案,然後找出定義inputTensorName和outTensorName變數的部分:
const inputTensorName = 'input_3';
const outputTensorName = 'dense_5';
- 將
inputTensorName變數重新指派為「input_1'值,並將outputTensorName變數重新指派為'dense_1'值:
const inputTensorName = 'input_1';
const outputTensorName = 'dense_1';
- 將下載的
vocab.txt檔案複製到lib/assets/資料夾,取代現有檔案。 - 從 Android 模擬器手動移除 Text Classification Flutter 應用程式。
- 在終端機中執行
'flutter run'指令,啟動應用程式。 - 在應用程式中輸入
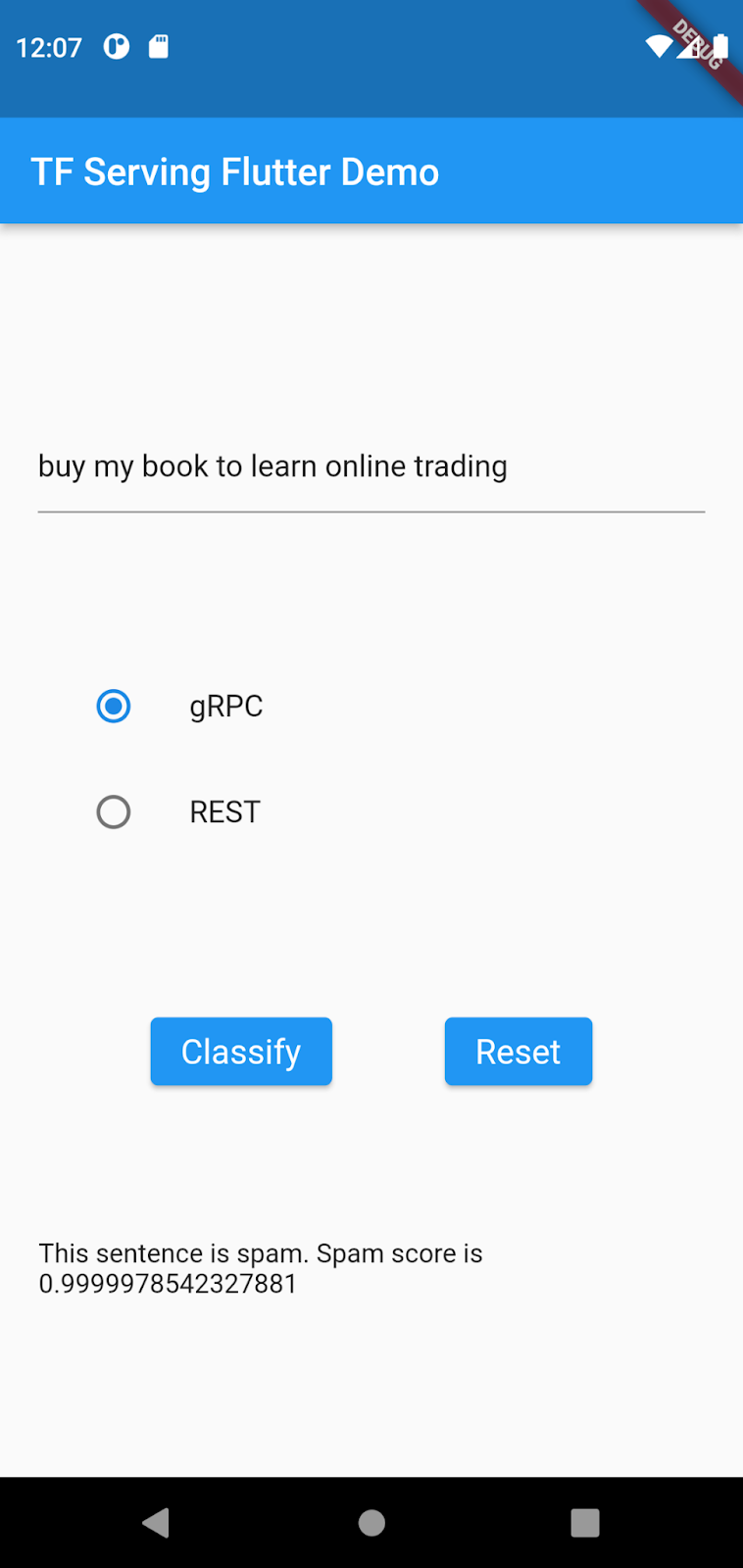
buy my book to learn online trading,然後依序點選「gRPC」>「Classify」。
現在模型已改良,可將買我的書來進行線上交易偵測為垃圾內容。
6. 恭喜
您已使用新資料重新訓練模型、將模型與 Flutter 應用程式整合,並更新功能來偵測新的垃圾內容句子!