
1. 시작하기 전에
이 Codelab에서는 최초에 블로그 스팸 댓글 데이터 세트로 빌드한 텍스트 분류 모델을 직접 수집한 댓글로 업데이트하여 내 데이터에 잘 맞도록 모델을 개선하는 방법을 알아봅니다.
기본 요건
이 Codelab은 Flutter 앱에서 텍스트 분류 시작하기 개발자 과정의 일부입니다. 이 개발자 과정의 Codelab은 순차적입니다. 이전 Codelab을 진행하면서 작업할 앱과 모델을 미리 빌드해야 합니다. 이전 활동을 아직 완료하지 않았다면 여기에서 멈추고 이전 활동을 진행하시기 바랍니다.
학습할 내용
- TensorFlow Lite Model Maker로 댓글 스팸 감지 모델 학습 Codelab에서 빌드한 텍스트 분류 모델을 업데이트하는 방법
- 앱에서 가장 흔한 스팸을 차단하도록 모델을 맞춤설정하는 방법
필요한 항목
- 이전 활동에서 살펴보고 빌드한 Flutter 앱 및 스팸 필터 모델
2. 텍스트 분류 향상
- 이 코드를 가져오려면 이 저장소를 클론하고
tfserving-flutter/codelab2/finished폴더에서 앱을 로드합니다. - TensorFlow Serving Docker 이미지를 시작한 후 빌드한 앱에서
buy my book to learn online trading을 입력하고 gRPC > Classify를 클릭합니다.
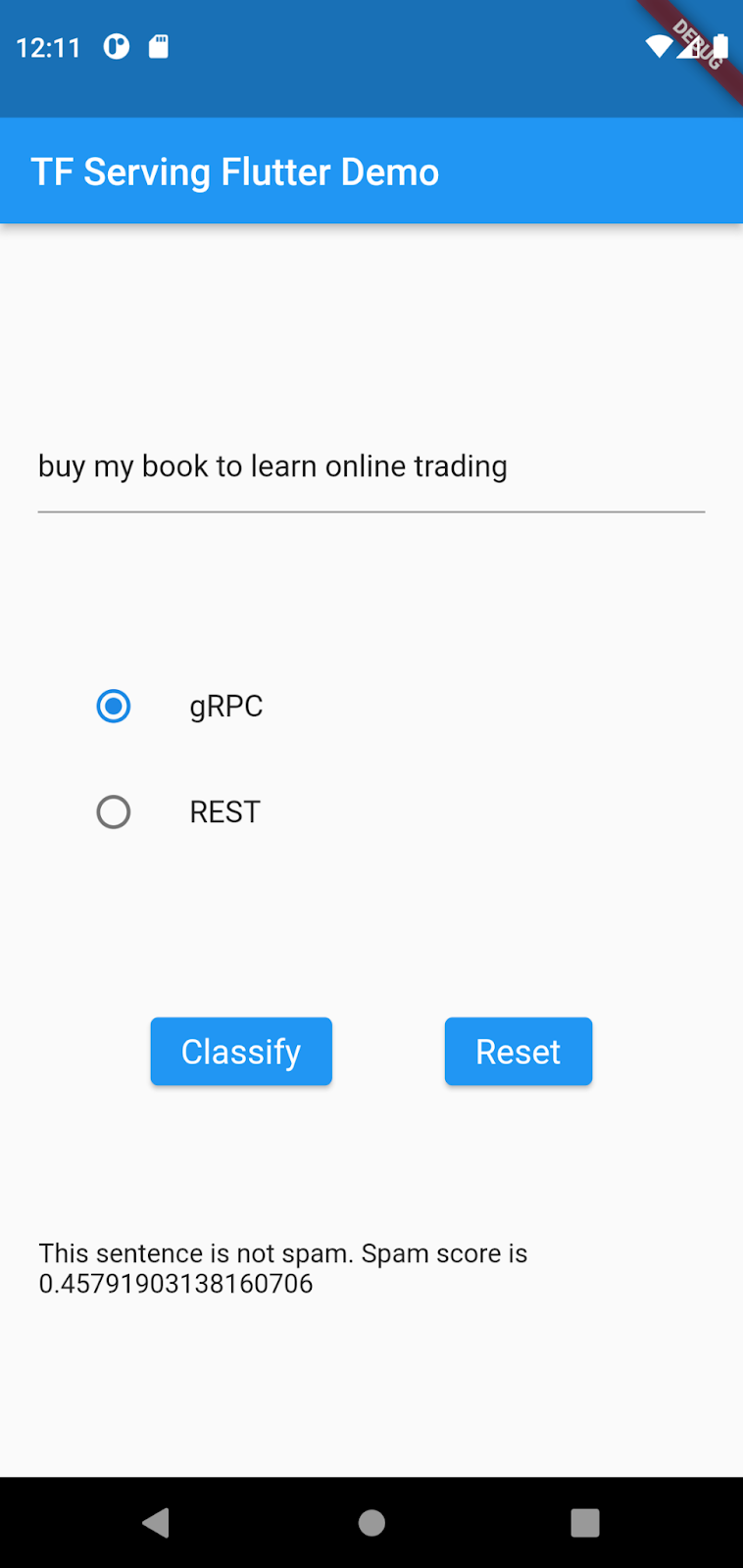
최초의 데이터 세트에서는 온라인 거래가 많이 발생하지 않아서 이 내용이 스팸임을 모델이 학습하지 않았으므로 앱이 생성하는 스팸 점수가 낮습니다. 이 Codelab에서는 모델이 해당 문장을 스팸으로 식별할 수 있도록 새 데이터로 모델을 업데이트합니다.
3. CSV 파일 수정
최초 모델을 학습시키기 위해 스팸 여부를 나타내는 라벨이 지정된 거의 1,000개의 댓글을 포함하는 CSV(lmblog_comments.csv)로 데이터 세트를 생성했습니다. 텍스트 편집기에서 CSV를 열면 파일을 살펴볼 수 있습니다.
CSV 파일의 구조를 보면 첫 번째 행이 열을 설명하며, 각각 commenttext 및 spam 라벨이 지정되어 있습니다. 모든 후속 행이 같은 형식을 따릅니다.

오른쪽 라벨에는 스팸인 경우 true 값이, 스팸이 아닌 경우 false 값이 할당됩니다. 예를 들어 세 번째 줄은 스팸으로 간주됩니다.
웹사이트에 온라인 거래와 관련된 스팸 메시지가 들어오는 경우 웹사이트 하단에 스팸 댓글의 예시를 추가할 수 있습니다. 예:
online trading can be highly highly effective,true online trading can be highly effective,true online trading now,true online trading here,true online trading for the win,true
- 새 모델을 학습시킬 때 사용할 수 있도록
lmblog_comments.csv등의 새 이름으로 파일을 저장합니다.
이 Codelab의 나머지 부분에서는 온라인 거래 업데이트와 관련하여 Cloud Storage에서 제공, 수정, 호스팅된 예시를 사용합니다. 자체 데이터 세트를 사용하려면 코드에서 URL을 변경하면 됩니다.
4. 새 데이터로 모델 다시 학습시키기
모델을 다시 학습시키려면 SpamCommentsModelMaker.ipynb의 코드를 재사용하면서 lmblog_comments_extras.csv라는 새 CSV 데이터 세트를 가리키기만 하면 됩니다. 업데이트된 콘텐츠가 포함된 전체 노트북은 SpamCommentsUpdateModelMaker.ipynb.로 제공됩니다.
Colaboratory에 액세스할 수 있는 경우 직접 실행할 수 있습니다. 그렇지 않은 경우 저장소에서 코드를 가져온 다음 원하는 노트북 환경에서 실행합니다.
업데이트된 코드는 다음 코드 스니펫과 같습니다.
training_data = tf.keras.utils.get_file(fname='comments-spam-extras.csv',
origin='https://storage.googleapis.com/laurencemoroney-blog.appspot.com/
lmblog_comments_extras.csv',
extract=False)
학습할 때 모델의 학습 정확도가 여전히 높은 것을 확인할 수 있습니다.

/mm_update_spam_savedmodel 폴더 전체를 압축하고 생성된 mm_update_spam_savedmodel.zip 파일을 다운로드합니다.
# Rename the SavedModel subfolder to a version number
!mv /mm_update_spam_savedmodel/saved_model /mm_update_spam_savedmodel/123
!zip -r mm_update_spam_savedmodel.zip /mm_update_spam_savedmodel/
5. Docker 시작 및 Flutter 앱 업데이트
- 다운로드한
mm_update_spam_savedmodel.zip파일의 압축을 폴더에 풀고 이전 Codelab의 Docker 컨테이너 인스턴스를 중지한 후 다시 시작합니다. 이때PATH/TO/UPDATE/SAVEDMODEL자리표시자를 다운로드한 파일을 호스팅하는 폴더의 절대 경로로 바꿉니다.
docker run -it --rm -p 8500:8500 -p 8501:8501 -v "PATH/TO/UPDATE/SAVEDMODEL:/models/spam-detection" -e MODEL_NAME=spam-detection tensorflow/serving
- 원하는 코드 편집기로
lib/main.dart파일을 열고inputTensorName및outTensorName변수를 정의하는 부분을 찾습니다.
const inputTensorName = 'input_3';
const outputTensorName = 'dense_5';
inputTensorName변수를 'input_1'값으로,outputTensorName변수를'dense_1'값으로 다시 할당합니다.
const inputTensorName = 'input_1';
const outputTensorName = 'dense_1';
- 다운로드한
vocab.txt파일을lib/assets/폴더에 복사하여 기존 파일을 대체합니다. - Android Emulator에서 Text Classification Flutter 앱을 수동으로 삭제합니다.
- 터미널에서
'flutter run'명령어를 실행하여 앱을 실행합니다. - 앱에서
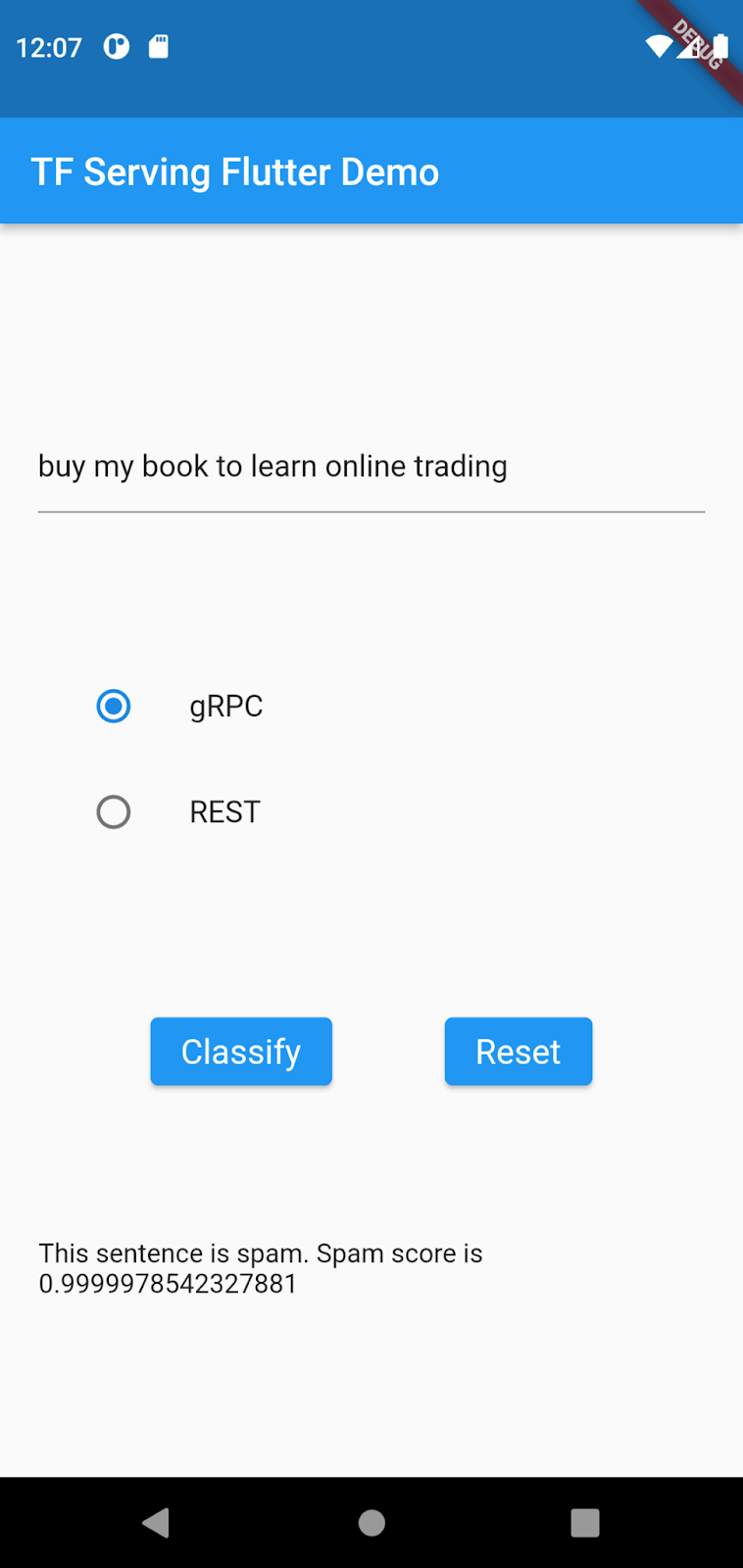
buy my book to learn online trading을 입력하고 gRPC > Classify를 클릭합니다.
이제 모델이 개선되어 buy my book to online trading을 스팸으로 감지합니다.
6. 수고하셨습니다.
새로운 데이터로 모델을 다시 학습시키고 Flutter 앱과 통합했으며 새로운 스팸 문장을 감지하도록 기능을 업데이트했습니다.