
El SDK de conector y la API de Cloud Search permiten crear colas de indexación de Cloud Search. Usa estas colas para lo siguiente:
- Mantener el estado por documento (estado, hashes, etc.) para mantener el índice sincronizado
- Mantener una lista de elementos para indexar descubiertos durante el proceso transversal
- Priorizar elementos según su estado
- Mantener información de estado, como puntos de control y tokens de cambio
Una cola es una etiqueta asignada a un elemento indexado (p.ej., "predeterminada").
Estado y prioridad
La prioridad de un documento depende de su
ItemStatus
código. Los códigos posibles, en orden de prioridad (de mayor a menor), son los siguientes:
ERROR: El elemento encontró un error asíncrono y debe volver a indexarse.MODIFIED: El elemento ya se indexó, pero cambió en el repositorio.NEW_ITEM: El elemento aún no está indexado.ACCEPTED: El elemento ya se indexó y no cambió.
En el caso de los elementos con el mismo estado, la prioridad más alta se otorga a aquellos que han estado en la cola durante más tiempo.
Indexa un elemento nuevo o modificado
En la figura 1, se muestran los pasos para indexar un elemento nuevo o modificado con una cola de indexación. Estos pasos reflejan las llamadas a la API de REST. Para ver los equivalentes del SDK, consulta Operaciones de cola (SDK de conector).
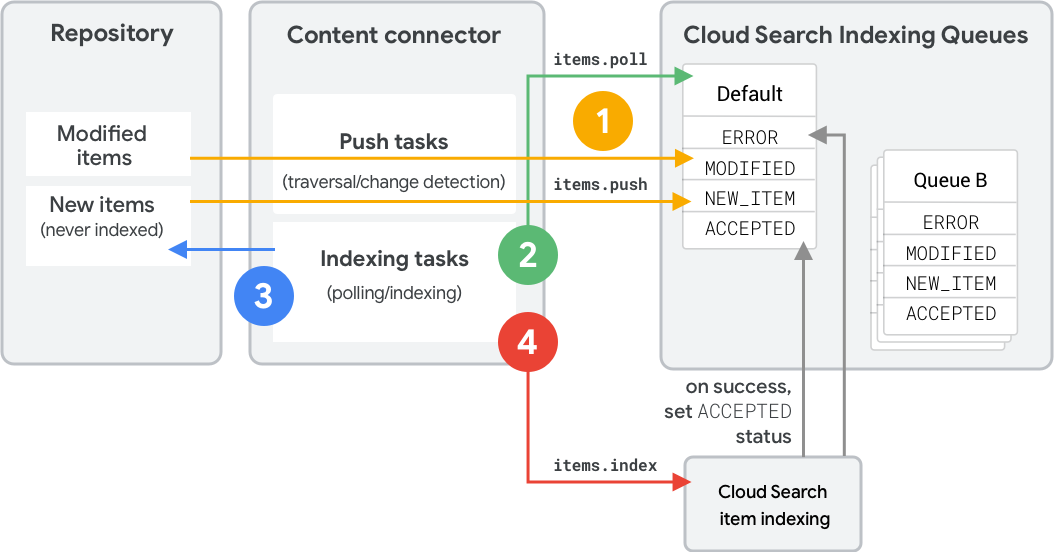
- El conector de contenido usa
items.pushpara enviar metadatos y hashes a una cola.- Si el conector incluye un envío
typeocontentHash, Cloud Search determina el estado. - Los elementos desconocidos reciben el estado
NEW_ITEM. - Los elementos existentes con hashes coincidentes permanecen
ACCEPTED. - Los elementos existentes con hashes diferentes se convierten en
MODIFIED.
- Si el conector incluye un envío
- El conector usa
items.pollpara determinar qué elementos indexar. Cloud Search muestra los elementos en orden de prioridad. - El conector recupera elementos del repositorio y compila solicitudes de la API de Index.
- El conector usa
items.indexpara indexar los elementos. Un elemento ingresa al estadoACCEPTEDdespués de un procesamiento exitoso.
Borra un elemento
La estrategia de recorrido completo usa dos colas para indexar elementos y detectar eliminaciones. En la figura 2, se muestra el segundo recorrido de esta estrategia.
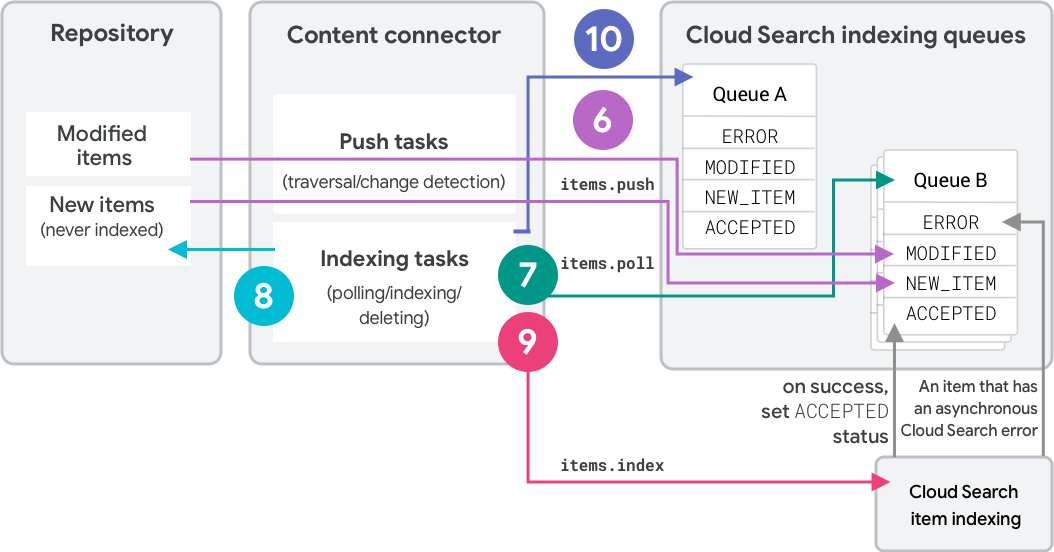
- En el recorrido inicial, el conector envía elementos a la "cola A" como
NEW_ITEM. Cada elemento recibe la etiqueta "A". - El conector consulta la cola A y, luego, indexa los elementos.
- En el segundo recorrido completo, el conector envía elementos a la "cola B".
- Los elementos desconocidos reciben la etiqueta "B" y el estado
NEW_ITEM. - Los elementos existentes con hashes coincidentes cambian su etiqueta a "B" y permanecen
ACCEPTED. - Los elementos existentes con hashes diferentes cambian su etiqueta a "B" y se convierten en
MODIFIED.
- Los elementos desconocidos reciben la etiqueta "B" y el estado
- El conector consulta la cola B y, luego, indexa los elementos.
- Por último, el conector llama a
deleteQueueItemsen la cola A. Esto borra todos los elementos indexados anteriormente que aún tienen la etiqueta "A". - Los recorridos posteriores intercambian los roles de las dos colas.
Operaciones de cola (SDK de conector)
Usa el
pushItems
compilador para enviar elementos. El SDK extrae automáticamente elementos de la cola en
orden de prioridad con el método
getDoc
de la clase Repository.
Operaciones de cola (API de REST)
- Para enviar, usa
Items.push. - Para consultar, usa
Items.poll.
También puedes usar
Items.index
para enviar elementos durante la indexación. Estos elementos reciben el estado ACCEPTED automáticamente.
Items.push
Este método agrega IDs a la cola. El
type
determina el resultado. El envío de un ID nuevo agrega una entrada con el estado NEW_ITEM.
La carga útil opcional se muestra durante la consulta.
Los elementos consultados están reservados y no se pueden mostrar con otras llamadas de consulta. El uso de Items.push con type establecido en NOT_MODIFIED, REPOSITORY_ERROR o REQUEUE anula la reserva de las entradas.
Items.push con hash
Especifica metadatos o hashes de contenido en la solicitud de envío.
Cloud Search los compara con los valores almacenados. Si no coinciden, la entrada se convierte en MODIFIED. Los IDs no coincidentes que no existen se convierten en NEW_ITEM.
Items.poll
Este método recupera entradas de alta prioridad. Cada entrada que se muestra se reserva hasta que se agota el tiempo de espera, se vuelve a indexar o se anula la reserva con Items.push.